 ---
# Source: https://docs.venice.ai/api-reference/api-spec.md
# Introduction
> Reference documentation for the Venice API
The Venice API offers HTTP-based REST and streaming interfaces for building AI applications with uncensored models and private inference. You can create with text generation, image creation, embeddings, and more, all without restrictive content policies. Integration examples and SDKs are available in the [documentation](/overview/getting-started).
## Authentication
The Venice API uses API keys for authentication. Create and manage your API keys in your [API settings](https://venice.ai/settings/api).
All API requests require HTTP Bearer authentication:
```
Authorization: Bearer VENICE_API_KEY
```
---
# Source: https://docs.venice.ai/api-reference/api-spec.md
# Introduction
> Reference documentation for the Venice API
The Venice API offers HTTP-based REST and streaming interfaces for building AI applications with uncensored models and private inference. You can create with text generation, image creation, embeddings, and more, all without restrictive content policies. Integration examples and SDKs are available in the [documentation](/overview/getting-started).
## Authentication
The Venice API uses API keys for authentication. Create and manage your API keys in your [API settings](https://venice.ai/settings/api).
All API requests require HTTP Bearer authentication:
```
Authorization: Bearer VENICE_API_KEY
```
Additional usage-based pricing applies, see [pricing](/overview/pricing#web-search-and-scraping). | `off` | | `enable_web_scraping` | boolean | Enable web scraping of URLs detected in the user message. Scraped content augments responses and bypasses web search
Additional usage-based pricing applies, see [pricing](/overview/pricing#web-search-and-scraping). | `false` | | `enable_web_citations` | boolean | When web search is enabled, request that the LLM cite its sources using `[REF]0[/REF]` format | `false` | | `include_search_results_in_stream` | boolean | Experimental: Include search results in the stream as the first emitted chunk | `false` | | `return_search_results_as_documents` | boolean | Surface search results in an OpenAI-compatible tool call named `venice_web_search_documents` for LangChain integration | `false` | | `include_venice_system_prompt` | boolean | Whether to include Venice's default system prompts alongside specified system prompts | `true` |
Loading models...
***
## Available Voices
Kokoro TTS supports 60+ multilingual and stylistic voices:
| Voice ID | Description |
| ------------ | ------------------------ |
| `af_nova` | Female, American English |
| `am_liam` | Male, American English |
| `bf_emma` | Female, British English |
| `zf_xiaobei` | Female, Chinese |
| `jm_kumo` | Male, Japanese |
Loading models...
***
 When the transaction is complete, you will see the VVV tokens exit the wallet and sVVV tokens returned to your wallet. This indicates a successful stake.
When the transaction is complete, you will see the VVV tokens exit the wallet and sVVV tokens returned to your wallet. This indicates a successful stake.
Loading models...
***
## Model Types
* **Generation:** Create images from text prompts
* **Upscale:** Enhance image resolution and quality
* **Edit:** Modify existing images with inpainting
Loading models...
---
> To find navigation and other pages in this documentation, fetch the llms.txt file at: https://docs.venice.ai/llms.txt
---
# Source: https://docs.venice.ai/api-reference/endpoint/api_keys/generate_web3_key/post.md
# Generate API Key with Web3 Wallet
> Authenticates a wallet holding sVVV and creates an API key.
## OpenAPI
````yaml POST /api_keys/generate_web3_key
paths:
path: /api_keys/generate_web3_key
method: post
servers:
- url: https://api.venice.ai/api/v1
request:
security: []
parameters:
path: {}
query: {}
header: {}
cookie: {}
body:
application/json:
schemaArray:
- type: object
properties:
apiKeyType:
allOf:
- type: string
enum:
- INFERENCE
- ADMIN
description: >-
The API Key type. Admin keys have full access to the API
while inference keys are only able to call inference
endpoints.
example: ADMIN
consumptionLimit:
allOf:
- type: object
properties:
usd:
anyOf:
- type: number
minimum: 0
- nullable: true
title: 'null'
- nullable: true
title: 'null'
description: USD limit
example: 50
diem:
anyOf:
- type: number
minimum: 0
- nullable: true
title: 'null'
- nullable: true
title: 'null'
description: Diem limit
example: 10
vcu:
anyOf:
- type: number
minimum: 0
- nullable: true
title: 'null'
- nullable: true
title: 'null'
description: VCU limit (deprecated - use Diem instead)
deprecated: true
example: 100
description: The API Key consumption limits for each epoch.
example:
usd: 50
diem: 10
vcu: 30
description:
allOf:
- type: string
default: Web3 API Key
description: The API Key description
example: Web3 API Key
expiresAt:
allOf:
- anyOf:
- type: string
enum:
- ''
- type: string
pattern: ^\d{4}-\d{2}-\d{2}$
- type: string
pattern: ^\d{4}-\d{2}-\d{2}T\d{2}:\d{2}:\d{2}(\.\d{3})?Z$
description: >-
The API Key expiration date. If not provided, the key will
not expire.
example: '2023-10-01T12:00:00.000Z'
address:
allOf:
- type: string
description: The wallet's address
example: '0x45B73055F3aDcC4577Bb709db10B19d11b5c94eE'
signature:
allOf:
- type: string
description: The token, signed with the wallet's private key
example: >-
0xbb5ff2e177f3a97fa553057864ad892eb64120f3eaf9356b4742a10f9a068d42725de895b5e45160b679cbe6961dc4cb552ba10dc97bdd8258d9154810785c451c
token:
allOf:
- type: string
description: >-
The token obtained from
https://api.venice.ai/api/v1/api_keys/generate_web3_key
example: >-
eyJhbGciOiJIUzI1NiIsInR5cCI6IkpXVCJ9.eyJzdWIiOiIxMjM0NTY3ODkwIiwibmFtZSI6IkpvaG4gRG9lIiwiaWF0IjoxNTE2MjM5MDIyfQ.SflKxwRJSMeKKF2QT4fwpMeJf36POk6yJV_adQssw5c
requiredProperties:
- apiKeyType
- address
- signature
- token
additionalProperties: false
examples:
example:
value:
apiKeyType: ADMIN
consumptionLimit:
usd: 50
diem: 10
vcu: 30
description: Web3 API Key
expiresAt: '2023-10-01T12:00:00.000Z'
address: '0x45B73055F3aDcC4577Bb709db10B19d11b5c94eE'
signature: >-
0xbb5ff2e177f3a97fa553057864ad892eb64120f3eaf9356b4742a10f9a068d42725de895b5e45160b679cbe6961dc4cb552ba10dc97bdd8258d9154810785c451c
token: >-
eyJhbGciOiJIUzI1NiIsInR5cCI6IkpXVCJ9.eyJzdWIiOiIxMjM0NTY3ODkwIiwibmFtZSI6IkpvaG4gRG9lIiwiaWF0IjoxNTE2MjM5MDIyfQ.SflKxwRJSMeKKF2QT4fwpMeJf36POk6yJV_adQssw5c
response:
'200':
application/json:
schemaArray:
- type: object
properties:
data:
allOf:
- type: object
properties:
apiKey:
type: string
description: >-
The API Key. This is only shown once, so make sure to
save it somewhere safe.
apiKeyType:
type: string
enum:
- INFERENCE
- ADMIN
description: The API Key type
example: ADMIN
consumptionLimit:
type: object
properties:
usd:
anyOf:
- type: number
minimum: 0
- nullable: true
title: 'null'
- nullable: true
title: 'null'
description: USD limit
example: 50
diem:
anyOf:
- type: number
minimum: 0
- nullable: true
title: 'null'
- nullable: true
title: 'null'
description: Diem limit
example: 10
vcu:
anyOf:
- type: number
minimum: 0
- nullable: true
title: 'null'
- nullable: true
title: 'null'
description: VCU limit (deprecated - use Diem instead)
deprecated: true
example: 100
description: The API Key consumption limits for each epoch.
example:
usd: 50
diem: 10
vcu: 30
description:
type: string
description: The API Key description
example: Example API Key
expiresAt:
type: string
nullable: true
description: The API Key expiration date
example: '2023-10-01T12:00:00.000Z'
id:
type: string
description: The API Key ID
example: e28e82dc-9df2-4b47-b726-d0a222ef2ab5
required:
- apiKey
- apiKeyType
- consumptionLimit
- expiresAt
- id
additionalProperties: false
success:
allOf:
- type: boolean
requiredProperties:
- data
- success
additionalProperties: false
examples:
example:
value:
data:
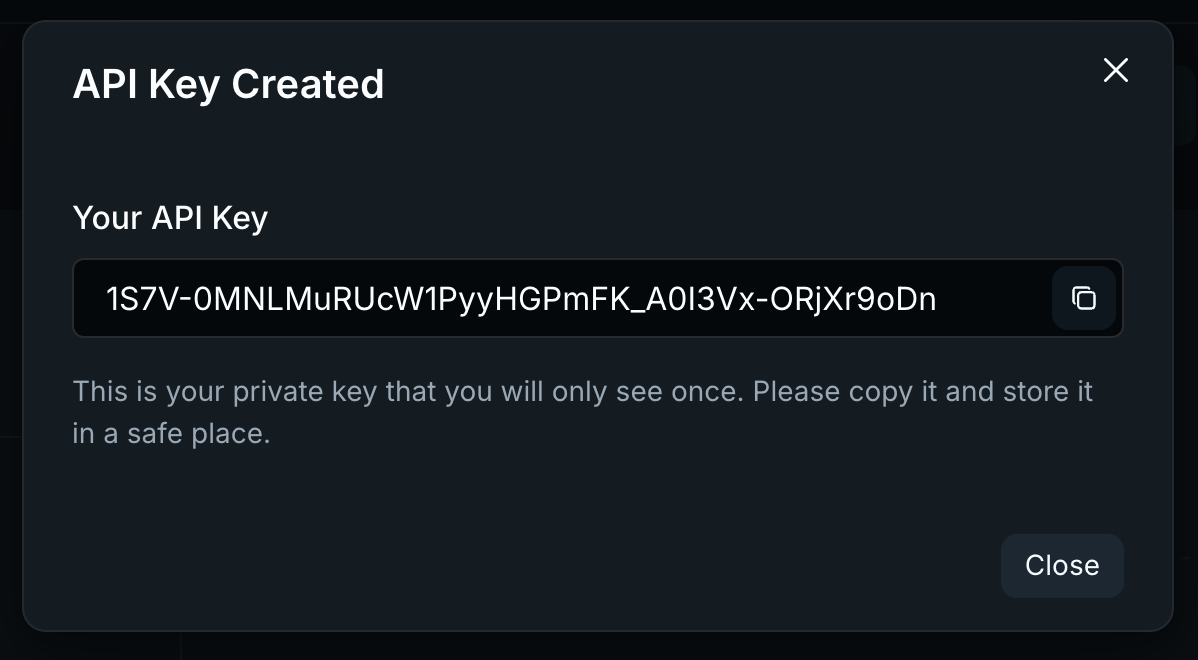
apiKey:  ---
# Source: https://docs.venice.ai/api-reference/endpoint/video/queue.md
# Queue Video Generation
> Queue a new video generation request.
Call `/video/quote` to get a price estimate, then poll `/video/retrieve` with the returned `queue_id` until complete.
***
## OpenAPI
````yaml POST /video/queue
openapi: 3.0.0
info:
description: The Venice.ai API.
termsOfService: https://venice.ai/legal/tos
title: Venice.ai API
version: '20251230.213343'
servers:
- url: https://api.venice.ai/api/v1
security:
- BearerAuth: []
tags:
- description: >-
Given a list of messages comprising a conversation, the model will return
a response. Supports multimodal inputs including text, images, audio
(input_audio), and video (video_url) for compatible models.
name: Chat
- description: List and describe the various models available in the API.
name: Models
- description: Generate and manipulate images using AI models.
name: Image
- description: Generate videos using AI models.
name: Video
- description: List and retrieve character information for use in completions.
name: Characters
externalDocs:
description: Venice.ai API documentation
url: https://docs.venice.ai
paths:
/video/queue:
post:
tags:
- Video
summary: /api/v1/video/queue
description: Queue a new video generation request.
operationId: queueVideo
requestBody:
content:
application/json:
schema:
$ref: '#/components/schemas/QueueVideoRequest'
responses:
'200':
description: Video generation request queued successfully
content:
application/json:
schema:
type: object
properties:
model:
type: string
description: The ID of the model used for video generation.
example: video-model-123
queue_id:
type: string
description: The ID of the video generation request.
example: 123e4567-e89b-12d3-a456-426614174000
required:
- model
- queue_id
additionalProperties: false
'400':
description: Invalid request parameters
content:
application/json:
schema:
$ref: '#/components/schemas/DetailedError'
'401':
description: Authentication failed
content:
application/json:
schema:
$ref: '#/components/schemas/StandardError'
'402':
description: Insufficient USD or Diem balance to complete request
content:
application/json:
schema:
$ref: '#/components/schemas/StandardError'
'413':
description: >-
The request payload is too large. Please reduce the size of your
request.
content:
application/json:
schema:
$ref: '#/components/schemas/StandardError'
'422':
description: >-
Your prompt violates the content policy of Venice.ai or the model
provider
content:
application/json:
schema:
$ref: '#/components/schemas/StandardError'
'500':
description: Inference processing failed
content:
application/json:
schema:
$ref: '#/components/schemas/StandardError'
components:
schemas:
QueueVideoRequest:
type: object
properties:
model:
type: string
description: The model to use for image generation.
example: wan-2.5-preview-image-to-video
prompt:
type: string
minLength: 1
maxLength: 2500
description: >-
The prompt to use for video generation. The maximum length is 2500
characters.
example: Commerce being conducted in the city of Venice, Italy.
negative_prompt:
type: string
maxLength: 2500
default: low resolution, error, worst quality, low quality, defects
description: >-
The negative prompt to use for video generation. The maximum length
is 2500 characters.
example: low resolution, error, worst quality, low quality, defects
duration:
type: string
enum:
- 5s
- 10s
description: The duration of the video to generate.
example: 5s
aspect_ratio:
description: The aspect ratio of the video to generate.
example: '16:9'
resolution:
type: string
enum:
- 1080p
- 720p
- 480p
default: 720p
description: The resolution of the video to generate.
example: 720p
audio:
description: >-
For models which support audio generation and configuration,
indicates if audio should be generated. Defaults to true.
example: true
image_url:
type: string
description: >-
For image to video models, the reference image to use for video
generation. Must be either a URL (starting with "http://" or
"https://") or a data URL (starting with "data:").
example: data:image/png;base64,iVBORw0K...
audio_url:
type: string
description: >-
For models that support audio input, the audio file to use as
background music. Must be either a URL or a data URL. Supported
formats: WAV, MP3. Max duration: 30s. Max size: 15MB.
example: data:audio/mpeg;base64,SUQzBAA...
video_url:
description: >-
For models that support video input, the video file to use as a
reference. Must be either a URL or a data URL. Supported formats:
MP4, MOV, WebM.
example: data:video/mp4;base64,AAAAFGZ0eXA...
required:
- model
- prompt
- duration
- image_url
additionalProperties: false
DetailedError:
type: object
properties:
details:
type: object
properties: {}
description: Details about the incorrect input
example:
_errors: []
field:
_errors:
- Field is required
error:
type: string
description: A description of the error
required:
- error
StandardError:
type: object
properties:
error:
type: string
description: A description of the error
required:
- error
securitySchemes:
BearerAuth:
bearerFormat: JWT
scheme: bearer
type: http
````
---
> To find navigation and other pages in this documentation, fetch the llms.txt file at: https://docs.venice.ai/llms.txt
---
# Source: https://docs.venice.ai/api-reference/endpoint/video/quote.md
# Quote Video Generation
> Quote a video generation request. Utilizes the same parameters as the queue API and will return the price in USD for the request.
***
## OpenAPI
````yaml POST /video/quote
openapi: 3.0.0
info:
description: The Venice.ai API.
termsOfService: https://venice.ai/legal/tos
title: Venice.ai API
version: '20251230.213343'
servers:
- url: https://api.venice.ai/api/v1
security:
- BearerAuth: []
tags:
- description: >-
Given a list of messages comprising a conversation, the model will return
a response. Supports multimodal inputs including text, images, audio
(input_audio), and video (video_url) for compatible models.
name: Chat
- description: List and describe the various models available in the API.
name: Models
- description: Generate and manipulate images using AI models.
name: Image
- description: Generate videos using AI models.
name: Video
- description: List and retrieve character information for use in completions.
name: Characters
externalDocs:
description: Venice.ai API documentation
url: https://docs.venice.ai
paths:
/video/quote:
post:
tags:
- Video
summary: /api/v1/video/quote
description: >-
Quote a video generation request. Utilizes the same parameters as the
queue API and will return the price in USD for the request.
operationId: quoteVideo
requestBody:
content:
application/json:
schema:
$ref: '#/components/schemas/QueueVideoRequest'
responses:
'200':
description: Video generation price quote
content:
application/json:
schema:
type: object
properties:
quote:
type: number
required:
- quote
'400':
description: Invalid request parameters
content:
application/json:
schema:
$ref: '#/components/schemas/DetailedError'
components:
schemas:
QueueVideoRequest:
type: object
properties:
model:
type: string
description: The model to use for image generation.
example: wan-2.5-preview-image-to-video
prompt:
type: string
minLength: 1
maxLength: 2500
description: >-
The prompt to use for video generation. The maximum length is 2500
characters.
example: Commerce being conducted in the city of Venice, Italy.
negative_prompt:
type: string
maxLength: 2500
default: low resolution, error, worst quality, low quality, defects
description: >-
The negative prompt to use for video generation. The maximum length
is 2500 characters.
example: low resolution, error, worst quality, low quality, defects
duration:
type: string
enum:
- 5s
- 10s
description: The duration of the video to generate.
example: 5s
aspect_ratio:
description: The aspect ratio of the video to generate.
example: '16:9'
resolution:
type: string
enum:
- 1080p
- 720p
- 480p
default: 720p
description: The resolution of the video to generate.
example: 720p
audio:
description: >-
For models which support audio generation and configuration,
indicates if audio should be generated. Defaults to true.
example: true
image_url:
type: string
description: >-
For image to video models, the reference image to use for video
generation. Must be either a URL (starting with "http://" or
"https://") or a data URL (starting with "data:").
example: data:image/png;base64,iVBORw0K...
audio_url:
type: string
description: >-
For models that support audio input, the audio file to use as
background music. Must be either a URL or a data URL. Supported
formats: WAV, MP3. Max duration: 30s. Max size: 15MB.
example: data:audio/mpeg;base64,SUQzBAA...
video_url:
description: >-
For models that support video input, the video file to use as a
reference. Must be either a URL or a data URL. Supported formats:
MP4, MOV, WebM.
example: data:video/mp4;base64,AAAAFGZ0eXA...
required:
- model
- prompt
- duration
- image_url
additionalProperties: false
DetailedError:
type: object
properties:
details:
type: object
properties: {}
description: Details about the incorrect input
example:
_errors: []
field:
_errors:
- Field is required
error:
type: string
description: A description of the error
required:
- error
securitySchemes:
BearerAuth:
bearerFormat: JWT
scheme: bearer
type: http
````
---
> To find navigation and other pages in this documentation, fetch the llms.txt file at: https://docs.venice.ai/llms.txt
---
# Source: https://docs.venice.ai/api-reference/rate-limiting.md
# Rate Limits
> This page describes the request and token rate limits for the Venice API.
## Failed Request Rate Limits
Failed requests including 500 errors, 503 capacity errors, 429 rate limit errors are should be retried with exponential back off.
For 429 rate limit errors, please use `x-ratelimit-reset-requests` and `x-ratelimit-remaining-requests` to determine when to next retry.
To protect our infrastructure from abuse, if an user generates more than 20 failed requests in a 30 second window, the API will return a 429 error indicating the error rate limit has been reached:
```
Too many failed attempts (> 20) resulting in a non-success status code. Please wait 30s and try again. See https://docs.venice.ai/api-reference/rate-limiting for more information.
```
## Paid Tier Rate Limits
Rate limits apply to users who have purchased API credits or staked VVV to gain Diem.
Helpful links:
* [Real time rate limits](https://docs.venice.ai/api-reference/endpoint/api_keys/rate_limits?playground=open)
* [Rate limit logs](https://docs.venice.ai/api-reference/endpoint/api_keys/rate_limit_logs?playground=open) - View requests that have hit the rate limiter
---
# Source: https://docs.venice.ai/api-reference/endpoint/video/queue.md
# Queue Video Generation
> Queue a new video generation request.
Call `/video/quote` to get a price estimate, then poll `/video/retrieve` with the returned `queue_id` until complete.
***
## OpenAPI
````yaml POST /video/queue
openapi: 3.0.0
info:
description: The Venice.ai API.
termsOfService: https://venice.ai/legal/tos
title: Venice.ai API
version: '20251230.213343'
servers:
- url: https://api.venice.ai/api/v1
security:
- BearerAuth: []
tags:
- description: >-
Given a list of messages comprising a conversation, the model will return
a response. Supports multimodal inputs including text, images, audio
(input_audio), and video (video_url) for compatible models.
name: Chat
- description: List and describe the various models available in the API.
name: Models
- description: Generate and manipulate images using AI models.
name: Image
- description: Generate videos using AI models.
name: Video
- description: List and retrieve character information for use in completions.
name: Characters
externalDocs:
description: Venice.ai API documentation
url: https://docs.venice.ai
paths:
/video/queue:
post:
tags:
- Video
summary: /api/v1/video/queue
description: Queue a new video generation request.
operationId: queueVideo
requestBody:
content:
application/json:
schema:
$ref: '#/components/schemas/QueueVideoRequest'
responses:
'200':
description: Video generation request queued successfully
content:
application/json:
schema:
type: object
properties:
model:
type: string
description: The ID of the model used for video generation.
example: video-model-123
queue_id:
type: string
description: The ID of the video generation request.
example: 123e4567-e89b-12d3-a456-426614174000
required:
- model
- queue_id
additionalProperties: false
'400':
description: Invalid request parameters
content:
application/json:
schema:
$ref: '#/components/schemas/DetailedError'
'401':
description: Authentication failed
content:
application/json:
schema:
$ref: '#/components/schemas/StandardError'
'402':
description: Insufficient USD or Diem balance to complete request
content:
application/json:
schema:
$ref: '#/components/schemas/StandardError'
'413':
description: >-
The request payload is too large. Please reduce the size of your
request.
content:
application/json:
schema:
$ref: '#/components/schemas/StandardError'
'422':
description: >-
Your prompt violates the content policy of Venice.ai or the model
provider
content:
application/json:
schema:
$ref: '#/components/schemas/StandardError'
'500':
description: Inference processing failed
content:
application/json:
schema:
$ref: '#/components/schemas/StandardError'
components:
schemas:
QueueVideoRequest:
type: object
properties:
model:
type: string
description: The model to use for image generation.
example: wan-2.5-preview-image-to-video
prompt:
type: string
minLength: 1
maxLength: 2500
description: >-
The prompt to use for video generation. The maximum length is 2500
characters.
example: Commerce being conducted in the city of Venice, Italy.
negative_prompt:
type: string
maxLength: 2500
default: low resolution, error, worst quality, low quality, defects
description: >-
The negative prompt to use for video generation. The maximum length
is 2500 characters.
example: low resolution, error, worst quality, low quality, defects
duration:
type: string
enum:
- 5s
- 10s
description: The duration of the video to generate.
example: 5s
aspect_ratio:
description: The aspect ratio of the video to generate.
example: '16:9'
resolution:
type: string
enum:
- 1080p
- 720p
- 480p
default: 720p
description: The resolution of the video to generate.
example: 720p
audio:
description: >-
For models which support audio generation and configuration,
indicates if audio should be generated. Defaults to true.
example: true
image_url:
type: string
description: >-
For image to video models, the reference image to use for video
generation. Must be either a URL (starting with "http://" or
"https://") or a data URL (starting with "data:").
example: data:image/png;base64,iVBORw0K...
audio_url:
type: string
description: >-
For models that support audio input, the audio file to use as
background music. Must be either a URL or a data URL. Supported
formats: WAV, MP3. Max duration: 30s. Max size: 15MB.
example: data:audio/mpeg;base64,SUQzBAA...
video_url:
description: >-
For models that support video input, the video file to use as a
reference. Must be either a URL or a data URL. Supported formats:
MP4, MOV, WebM.
example: data:video/mp4;base64,AAAAFGZ0eXA...
required:
- model
- prompt
- duration
- image_url
additionalProperties: false
DetailedError:
type: object
properties:
details:
type: object
properties: {}
description: Details about the incorrect input
example:
_errors: []
field:
_errors:
- Field is required
error:
type: string
description: A description of the error
required:
- error
StandardError:
type: object
properties:
error:
type: string
description: A description of the error
required:
- error
securitySchemes:
BearerAuth:
bearerFormat: JWT
scheme: bearer
type: http
````
---
> To find navigation and other pages in this documentation, fetch the llms.txt file at: https://docs.venice.ai/llms.txt
---
# Source: https://docs.venice.ai/api-reference/endpoint/video/quote.md
# Quote Video Generation
> Quote a video generation request. Utilizes the same parameters as the queue API and will return the price in USD for the request.
***
## OpenAPI
````yaml POST /video/quote
openapi: 3.0.0
info:
description: The Venice.ai API.
termsOfService: https://venice.ai/legal/tos
title: Venice.ai API
version: '20251230.213343'
servers:
- url: https://api.venice.ai/api/v1
security:
- BearerAuth: []
tags:
- description: >-
Given a list of messages comprising a conversation, the model will return
a response. Supports multimodal inputs including text, images, audio
(input_audio), and video (video_url) for compatible models.
name: Chat
- description: List and describe the various models available in the API.
name: Models
- description: Generate and manipulate images using AI models.
name: Image
- description: Generate videos using AI models.
name: Video
- description: List and retrieve character information for use in completions.
name: Characters
externalDocs:
description: Venice.ai API documentation
url: https://docs.venice.ai
paths:
/video/quote:
post:
tags:
- Video
summary: /api/v1/video/quote
description: >-
Quote a video generation request. Utilizes the same parameters as the
queue API and will return the price in USD for the request.
operationId: quoteVideo
requestBody:
content:
application/json:
schema:
$ref: '#/components/schemas/QueueVideoRequest'
responses:
'200':
description: Video generation price quote
content:
application/json:
schema:
type: object
properties:
quote:
type: number
required:
- quote
'400':
description: Invalid request parameters
content:
application/json:
schema:
$ref: '#/components/schemas/DetailedError'
components:
schemas:
QueueVideoRequest:
type: object
properties:
model:
type: string
description: The model to use for image generation.
example: wan-2.5-preview-image-to-video
prompt:
type: string
minLength: 1
maxLength: 2500
description: >-
The prompt to use for video generation. The maximum length is 2500
characters.
example: Commerce being conducted in the city of Venice, Italy.
negative_prompt:
type: string
maxLength: 2500
default: low resolution, error, worst quality, low quality, defects
description: >-
The negative prompt to use for video generation. The maximum length
is 2500 characters.
example: low resolution, error, worst quality, low quality, defects
duration:
type: string
enum:
- 5s
- 10s
description: The duration of the video to generate.
example: 5s
aspect_ratio:
description: The aspect ratio of the video to generate.
example: '16:9'
resolution:
type: string
enum:
- 1080p
- 720p
- 480p
default: 720p
description: The resolution of the video to generate.
example: 720p
audio:
description: >-
For models which support audio generation and configuration,
indicates if audio should be generated. Defaults to true.
example: true
image_url:
type: string
description: >-
For image to video models, the reference image to use for video
generation. Must be either a URL (starting with "http://" or
"https://") or a data URL (starting with "data:").
example: data:image/png;base64,iVBORw0K...
audio_url:
type: string
description: >-
For models that support audio input, the audio file to use as
background music. Must be either a URL or a data URL. Supported
formats: WAV, MP3. Max duration: 30s. Max size: 15MB.
example: data:audio/mpeg;base64,SUQzBAA...
video_url:
description: >-
For models that support video input, the video file to use as a
reference. Must be either a URL or a data URL. Supported formats:
MP4, MOV, WebM.
example: data:video/mp4;base64,AAAAFGZ0eXA...
required:
- model
- prompt
- duration
- image_url
additionalProperties: false
DetailedError:
type: object
properties:
details:
type: object
properties: {}
description: Details about the incorrect input
example:
_errors: []
field:
_errors:
- Field is required
error:
type: string
description: A description of the error
required:
- error
securitySchemes:
BearerAuth:
bearerFormat: JWT
scheme: bearer
type: http
````
---
> To find navigation and other pages in this documentation, fetch the llms.txt file at: https://docs.venice.ai/llms.txt
---
# Source: https://docs.venice.ai/api-reference/rate-limiting.md
# Rate Limits
> This page describes the request and token rate limits for the Venice API.
## Failed Request Rate Limits
Failed requests including 500 errors, 503 capacity errors, 429 rate limit errors are should be retried with exponential back off.
For 429 rate limit errors, please use `x-ratelimit-reset-requests` and `x-ratelimit-remaining-requests` to determine when to next retry.
To protect our infrastructure from abuse, if an user generates more than 20 failed requests in a 30 second window, the API will return a 429 error indicating the error rate limit has been reached:
```
Too many failed attempts (> 20) resulting in a non-success status code. Please wait 30s and try again. See https://docs.venice.ai/api-reference/rate-limiting for more information.
```
## Paid Tier Rate Limits
Rate limits apply to users who have purchased API credits or staked VVV to gain Diem.
Helpful links:
* [Real time rate limits](https://docs.venice.ai/api-reference/endpoint/api_keys/rate_limits?playground=open)
* [Rate limit logs](https://docs.venice.ai/api-reference/endpoint/api_keys/rate_limit_logs?playground=open) - View requests that have hit the rate limiter
| Header | Description |
| ---------------------------------------------------------------------------- | --------------------------------------------------------------------------------------- |
|
---
# Source: https://docs.venice.ai/api-reference/endpoint/api_keys/rate_limit_logs.md
# Rate Limit Logs
> Returns the last 50 rate limits that the account exceeded.
## OpenAPI
````yaml GET /api_keys/rate_limits/log
paths:
path: /api_keys/rate_limits/log
method: get
servers:
- url: https://api.venice.ai/api/v1
request:
security:
- title: BearerAuth
parameters:
query: {}
header:
Authorization:
type: http
scheme: bearer
cookie: {}
parameters:
path: {}
query: {}
header: {}
cookie: {}
body: {}
response:
'200':
application/json:
schemaArray:
- type: object
properties:
data:
allOf:
- type: array
items:
type: object
properties:
apiKeyId:
type: string
description: The ID of the API key that exceeded the limit.
modelId:
type: string
default: zai-org-glm-4.6
description: >-
The ID of the model that was used when the rate
limit was exceeded.
rateLimitTier:
type: string
description: The API tier of the rate limit.
example: paid
rateLimitType:
type: string
description: The type of rate limit that was exceeded.
example: RPM
timestamp:
type: string
description: The timestamp when the rate limit was exceeded.
example: '2023-10-01T12:00:00.000Z'
required:
- apiKeyId
- modelId
- rateLimitTier
- rateLimitType
- timestamp
additionalProperties: false
description: The last 50 rate limit logs for the account.
object:
allOf:
- type: string
enum:
- list
requiredProperties:
- data
- object
additionalProperties: false
examples:
example:
value:
data:
- apiKeyId: **x-ratelimit-limit-requests**
| The number of requests you've made in the current evaluation period. |
| **x-ratelimit-remaining-requests**
| The remaining requests you can make in the current evaluation period. |
| **x-ratelimit-reset-requests**
| The unix time stamp when the rate limit will reset. |
| **x-ratelimit-limit-tokens**
| The number of total (prompt + completion) tokens used within a 1 minute sliding window. |
| **x-ratelimit-remaining-tokens**
| The remaining number of total tokens that can be used during the evaluation period. |
| **x-ratelimit-reset-tokens**
| The duration of time in seconds until the token rate limit resets. |
| **x-venice-balance-diem**
| The user's Diem balance before the request has been processed. |
| **x-venice-balance-usd**
| The user's USD balance before the request has been processed. |
Loading models...
***
## Capabilities
* **Function Calling:** Let the model invoke tools and external APIs
* **Reasoning:** Extended thinking for complex problem-solving
* **Vision:** Analyze images alongside text prompts
* **Code:** Optimized for code generation and understanding
Loading models...
## Model Types
**Text to Video:** Generate videos from text prompts
**Image to Video:** Animate static images into video clips