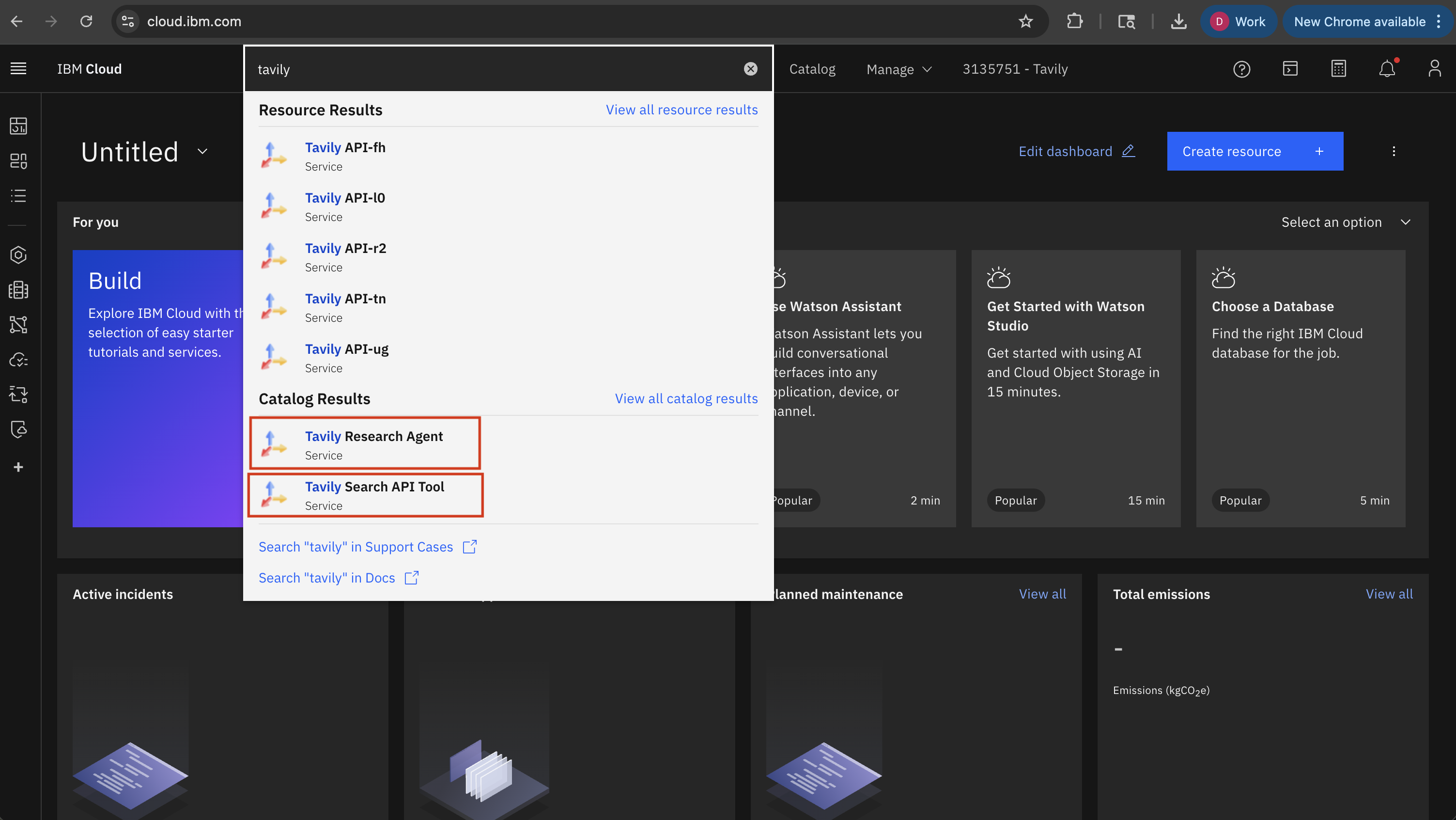
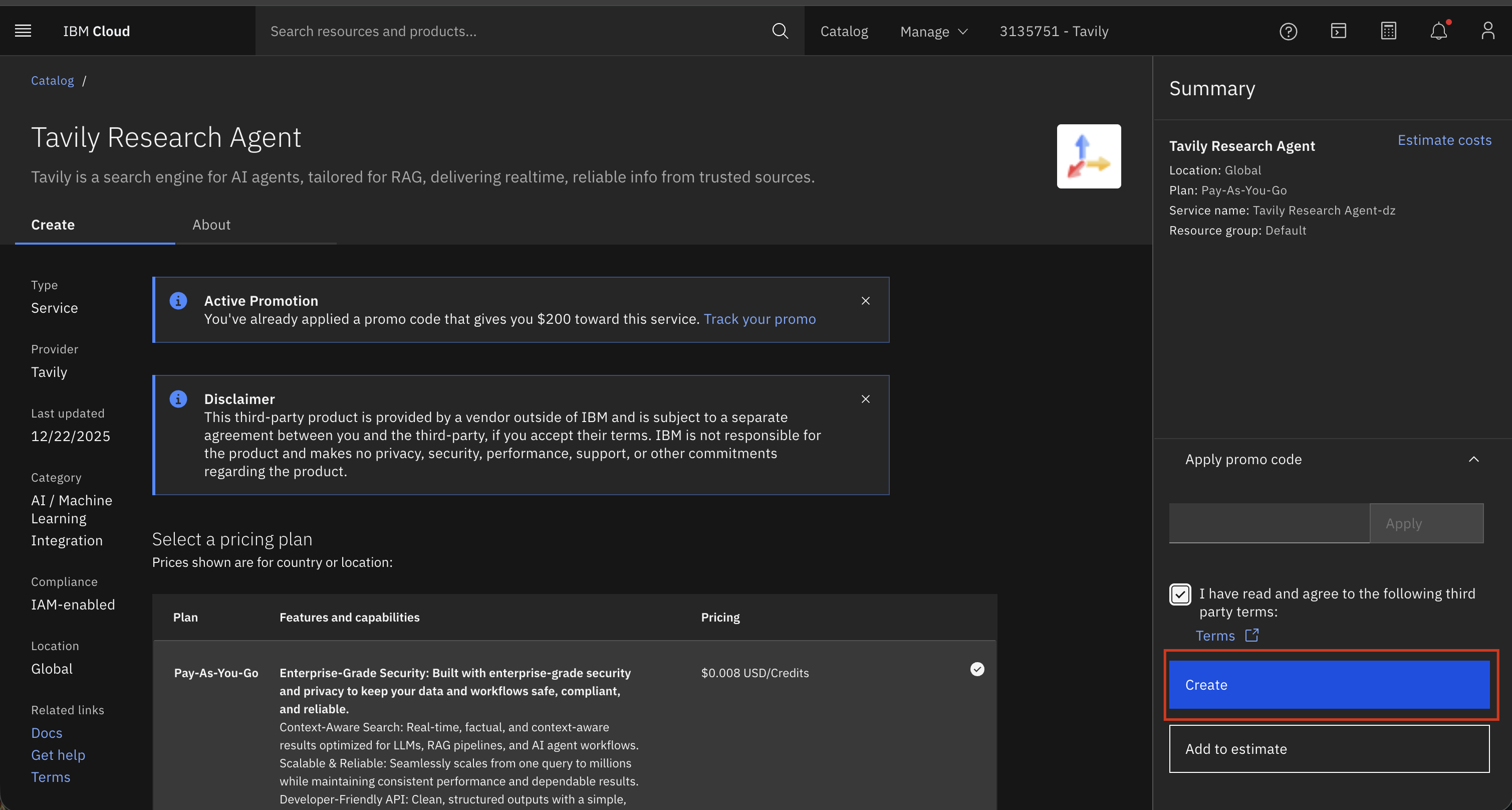
 3. Select either **Tavily Search API** or **Tavily Research Agent** depending on your needs
4. Click **Create** to provision a new instance
3. Select either **Tavily Search API** or **Tavily Research Agent** depending on your needs
4. Click **Create** to provision a new instance
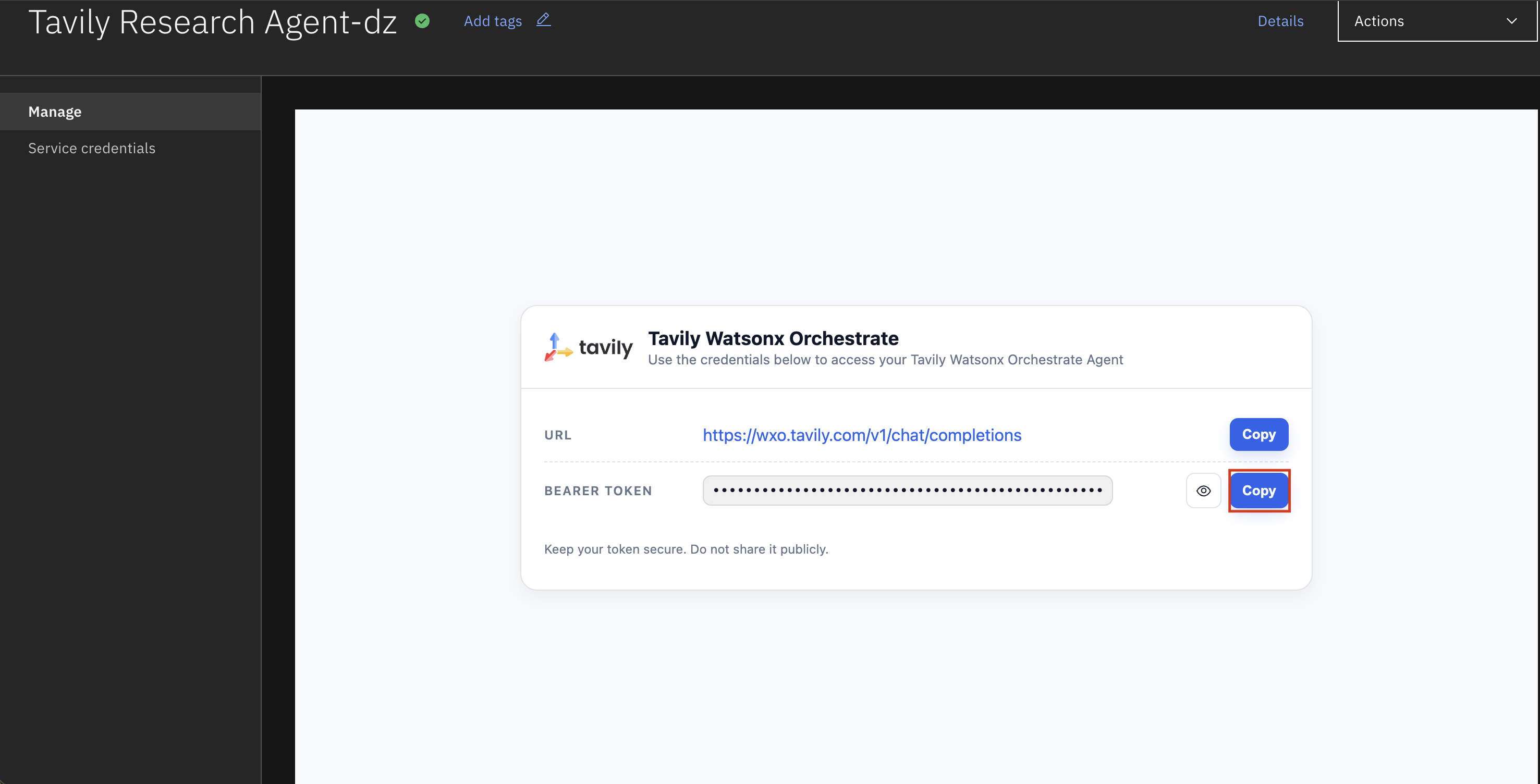
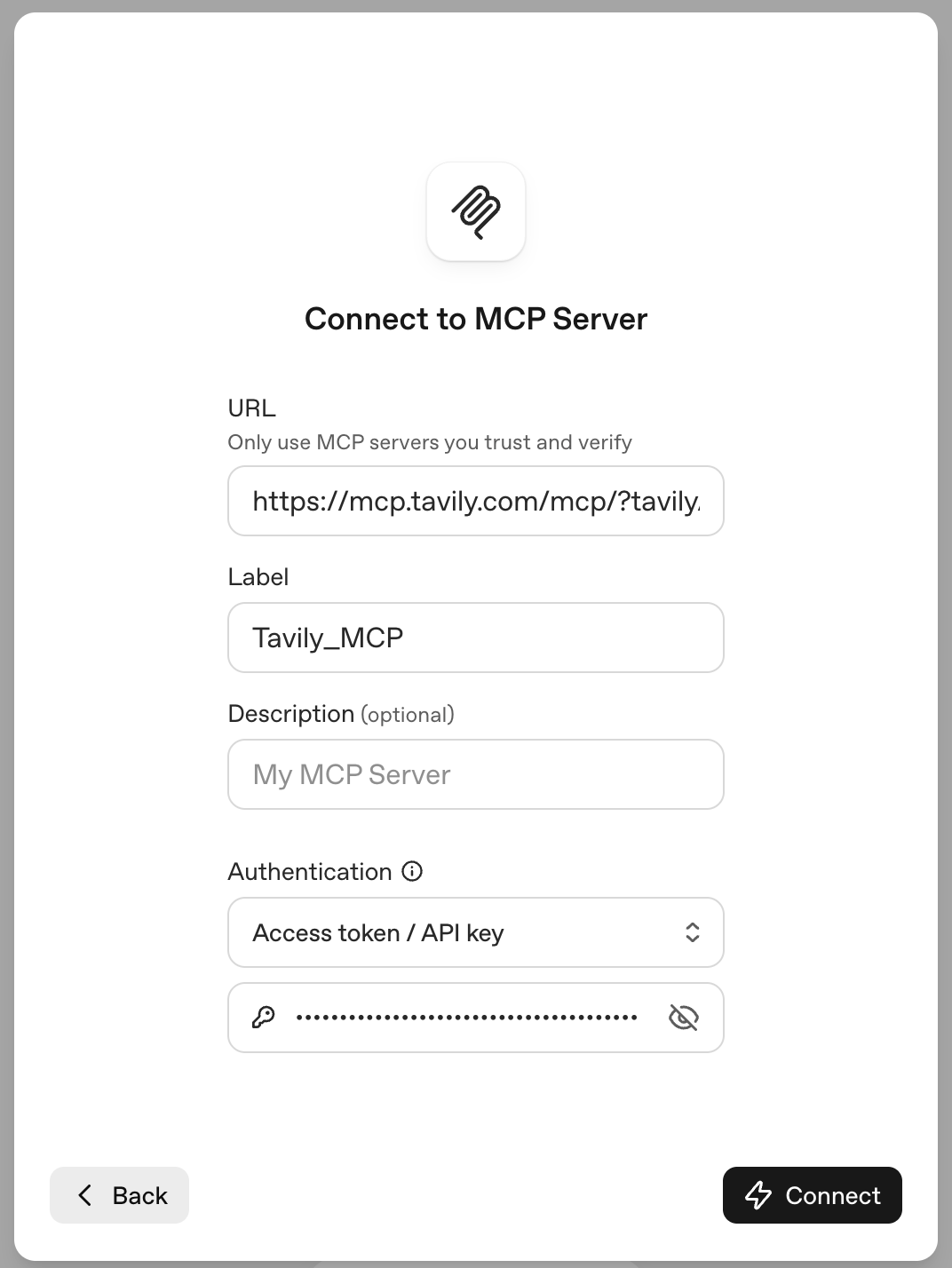
 ### Step 2: Copy Your Bearer Token
Once your instance is created, copy the bearer token from the credentials section. You'll need this to connect the agent in watsonx Orchestrate.
### Step 2: Copy Your Bearer Token
Once your instance is created, copy the bearer token from the credentials section. You'll need this to connect the agent in watsonx Orchestrate.
 ### Step 3: Add Tavily to watsonx Orchestrate
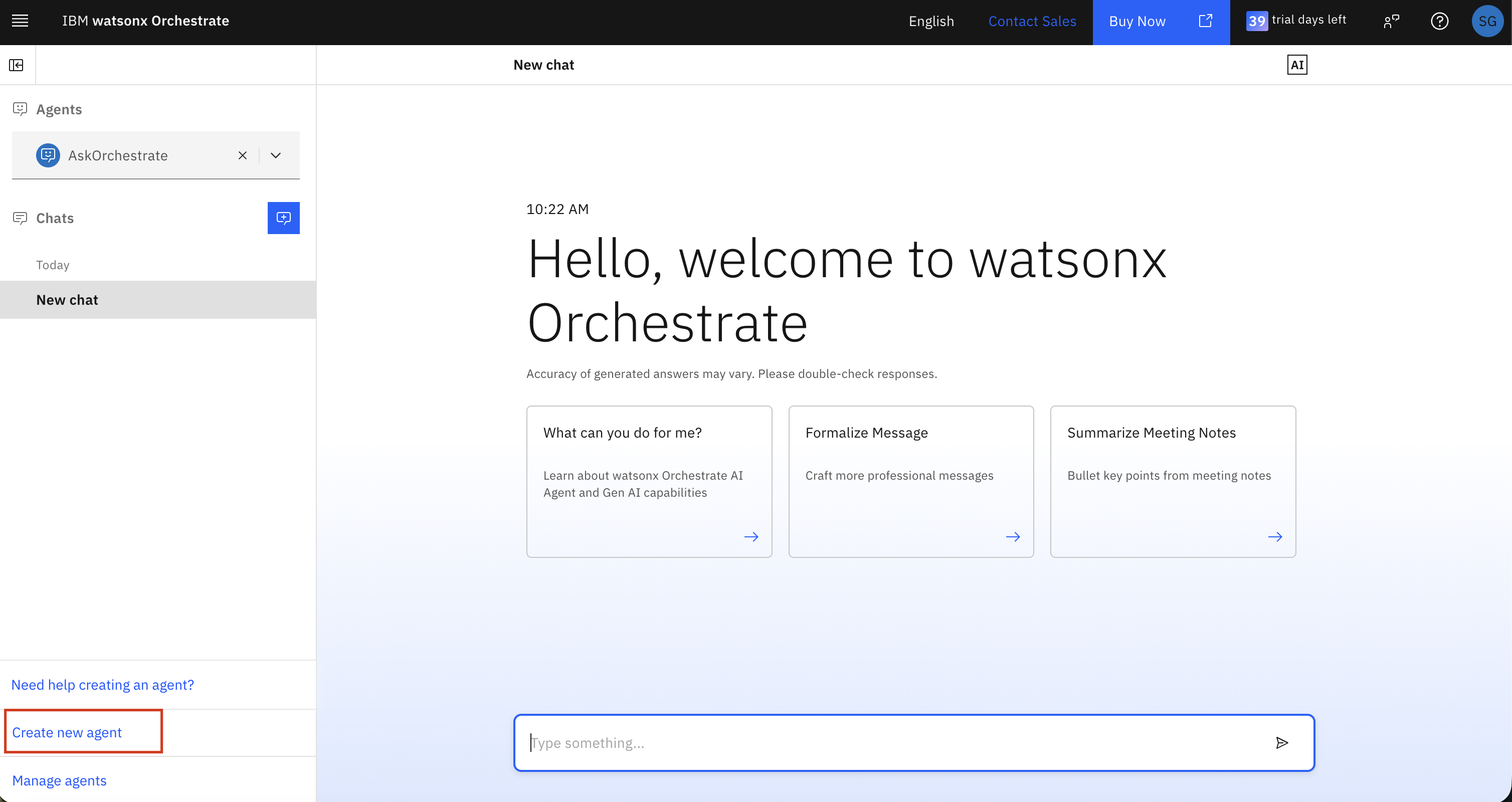
1. Navigate to [watsonx Orchestrate](https://dl.watson-orchestrate.ibm.com/chat)
2. Create a new agent
### Step 3: Add Tavily to watsonx Orchestrate
1. Navigate to [watsonx Orchestrate](https://dl.watson-orchestrate.ibm.com/chat)
2. Create a new agent
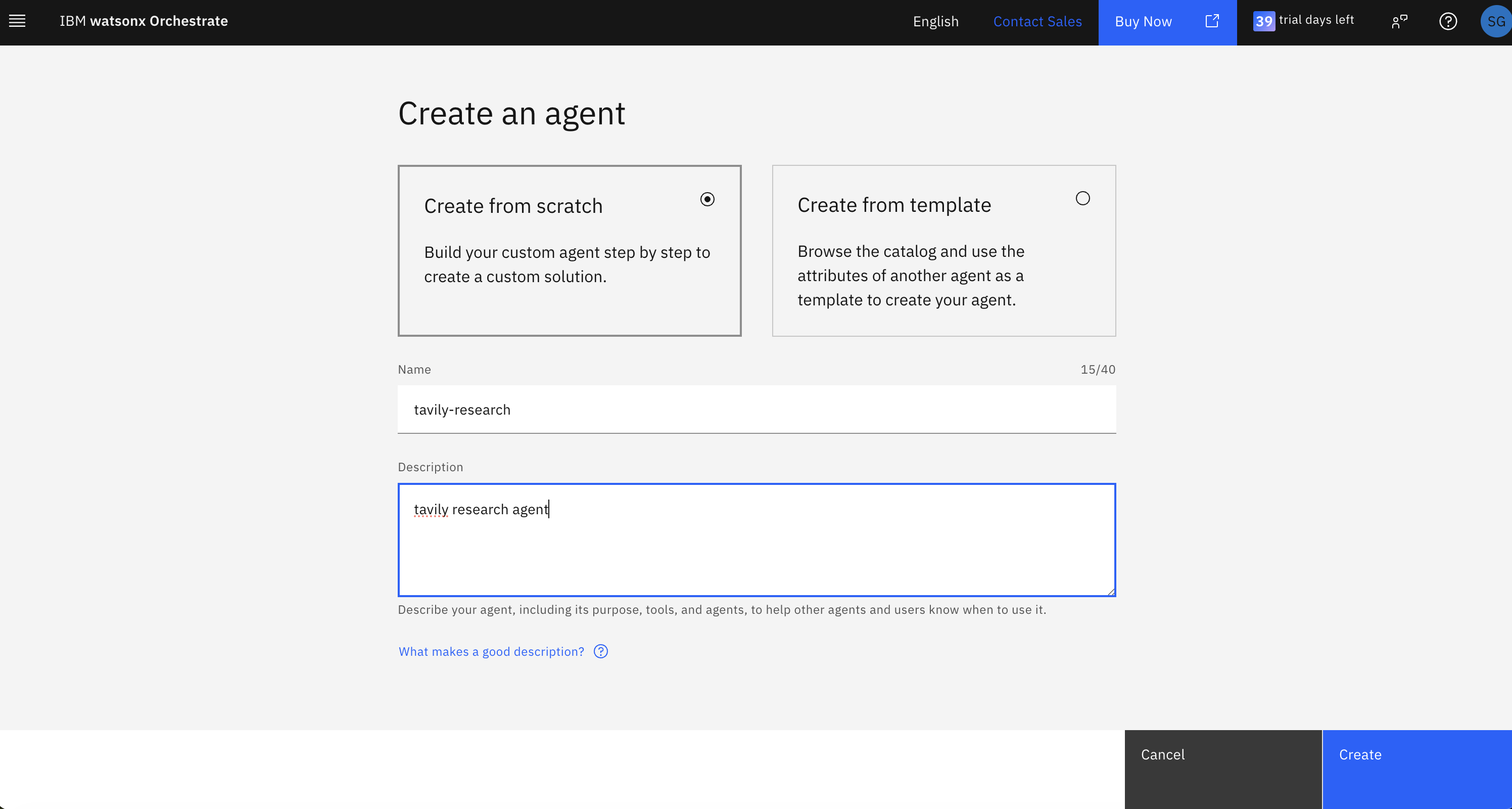
 3. Name your agent
3. Name your agent
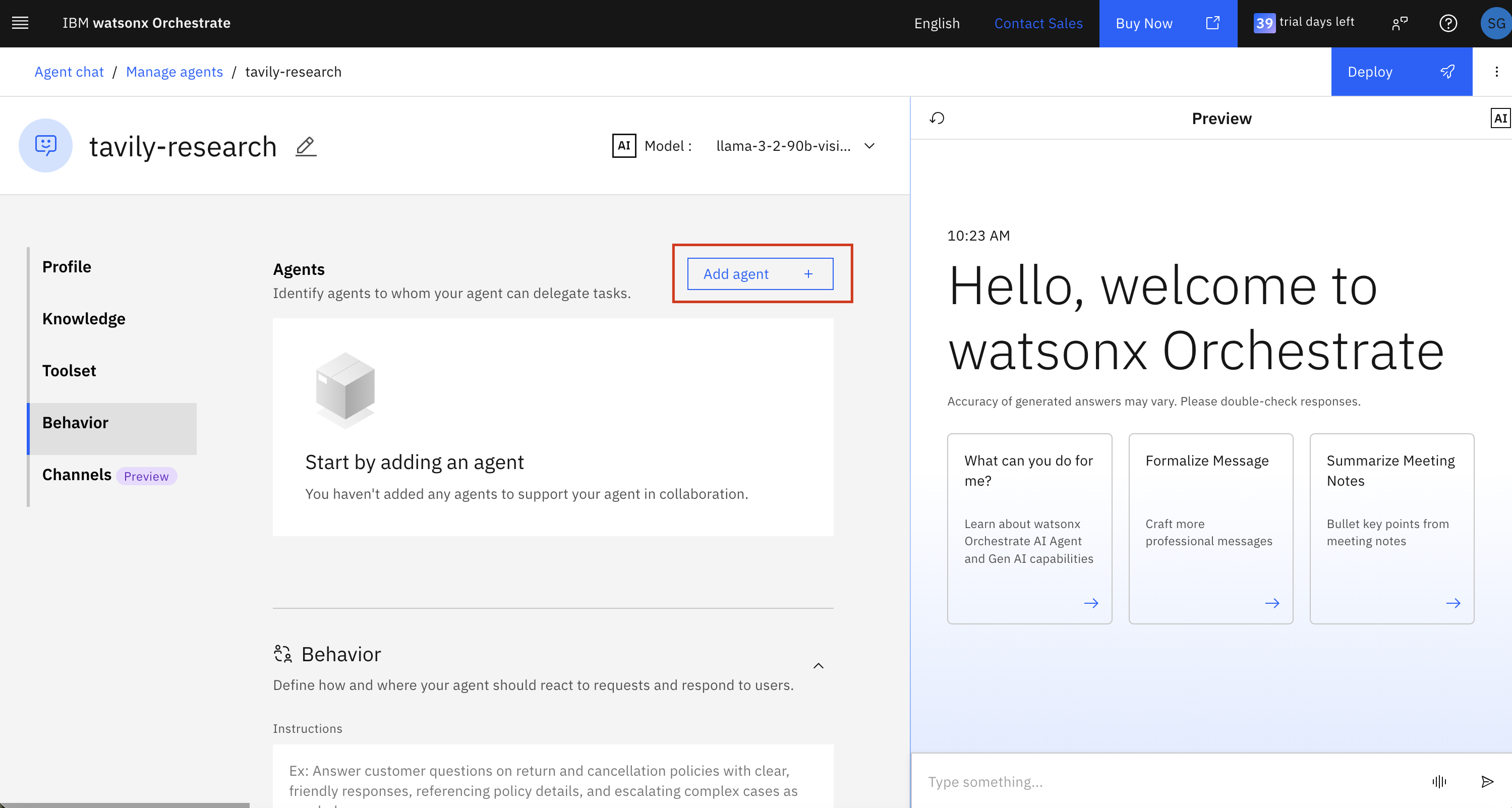
 4. Add a collaborator agent
4. Add a collaborator agent
 5. Select **Tavily Research Agent** from the partner agents list
5. Select **Tavily Research Agent** from the partner agents list
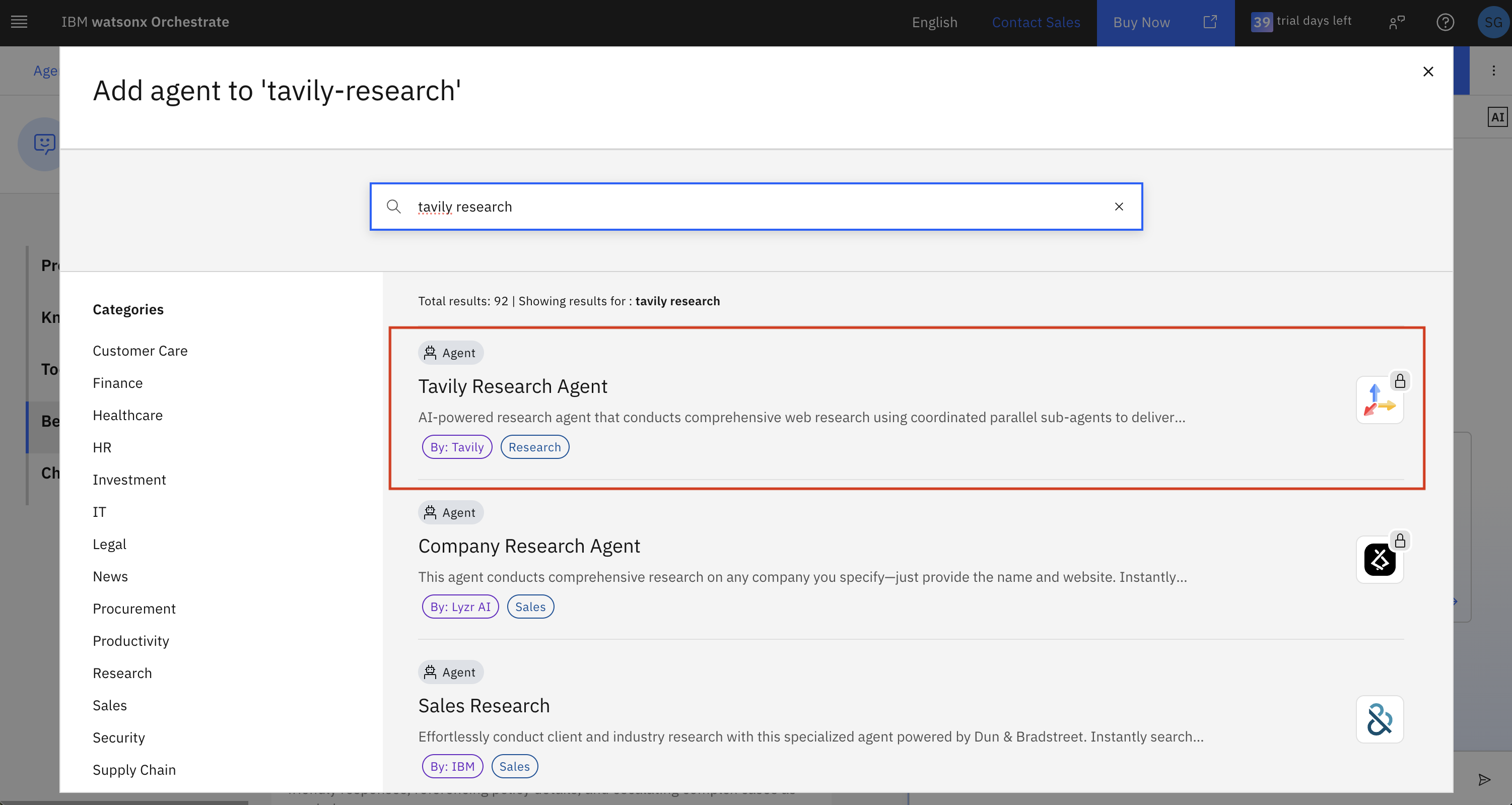 6. Review the agent details and click **Add as collaborator**
6. Review the agent details and click **Add as collaborator**
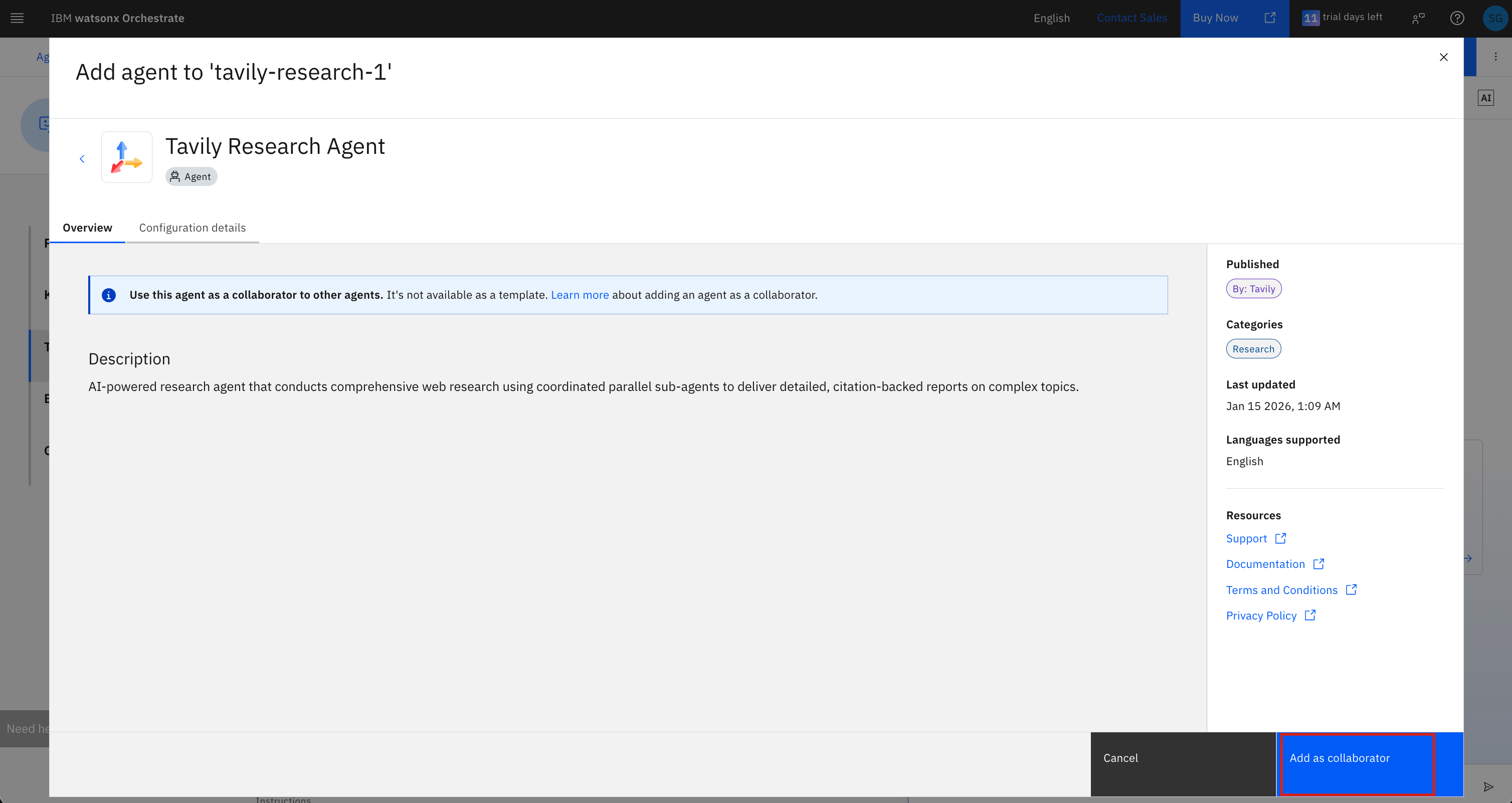 7. Enter your bearer token (from Step 2) in the **Bearer token** field and click **Register and add**
7. Enter your bearer token (from Step 2) in the **Bearer token** field and click **Register and add**
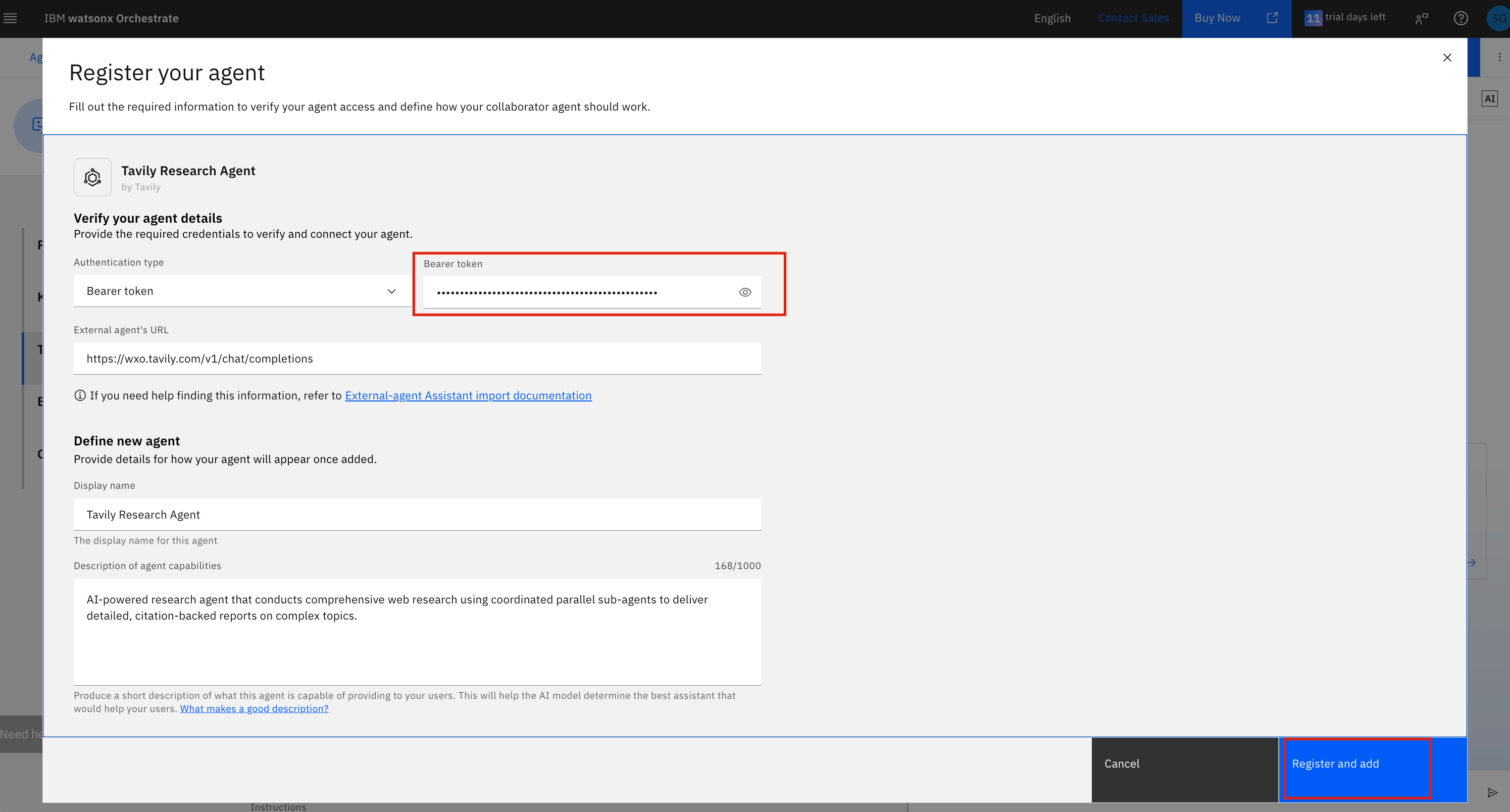 8. The Tavily Research Agent will now appear in your agent's **Toolset** under the Agents section
8. The Tavily Research Agent will now appear in your agent's **Toolset** under the Agents section
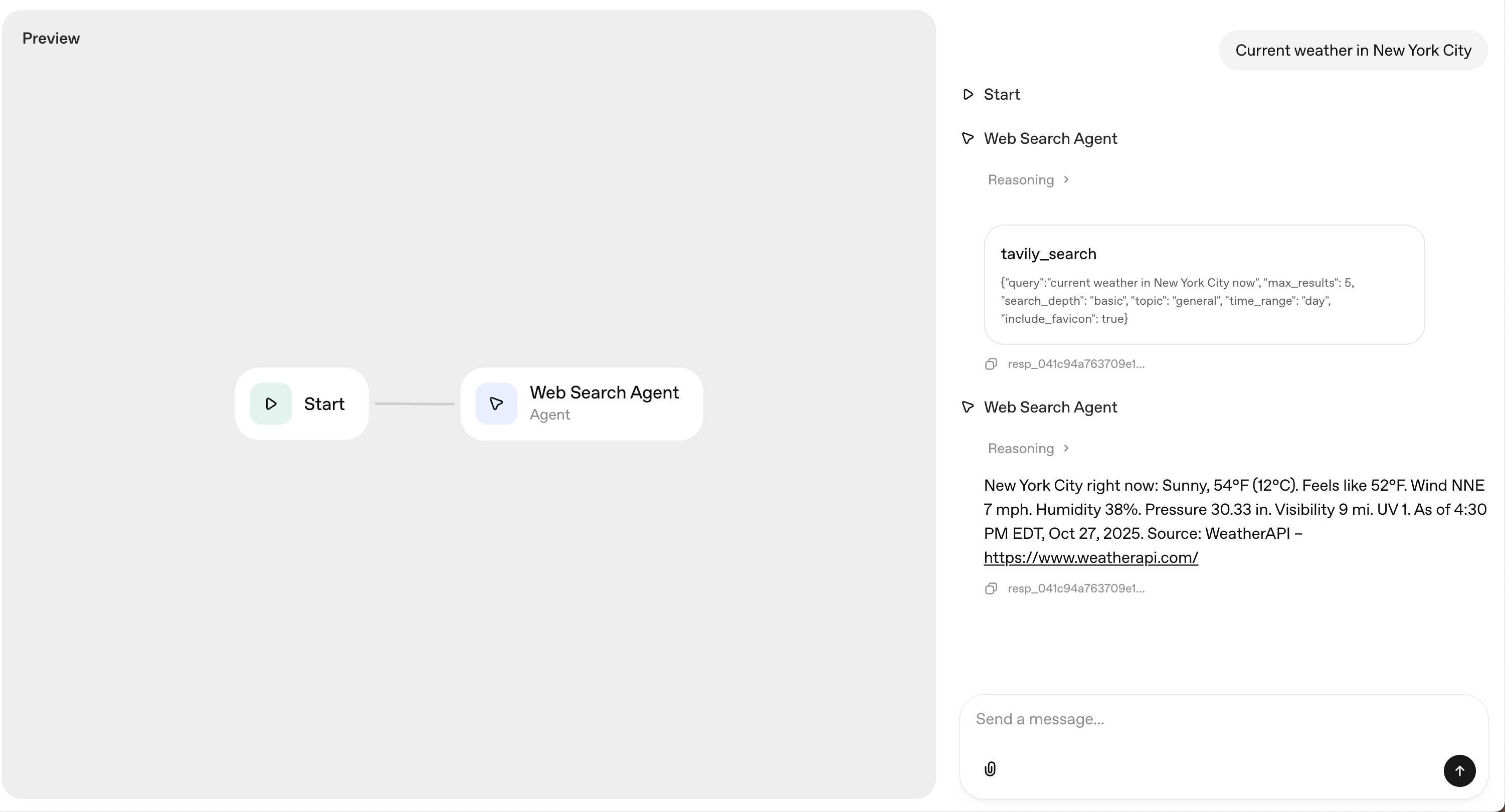
 ### Step 4: Try It Out
Ask a question in the chat that requires real-time web research, and watsonx Orchestrate will automatically hand off to the Tavily Research Agent.
### Step 4: Try It Out
Ask a question in the chat that requires real-time web research, and watsonx Orchestrate will automatically hand off to the Tavily Research Agent.
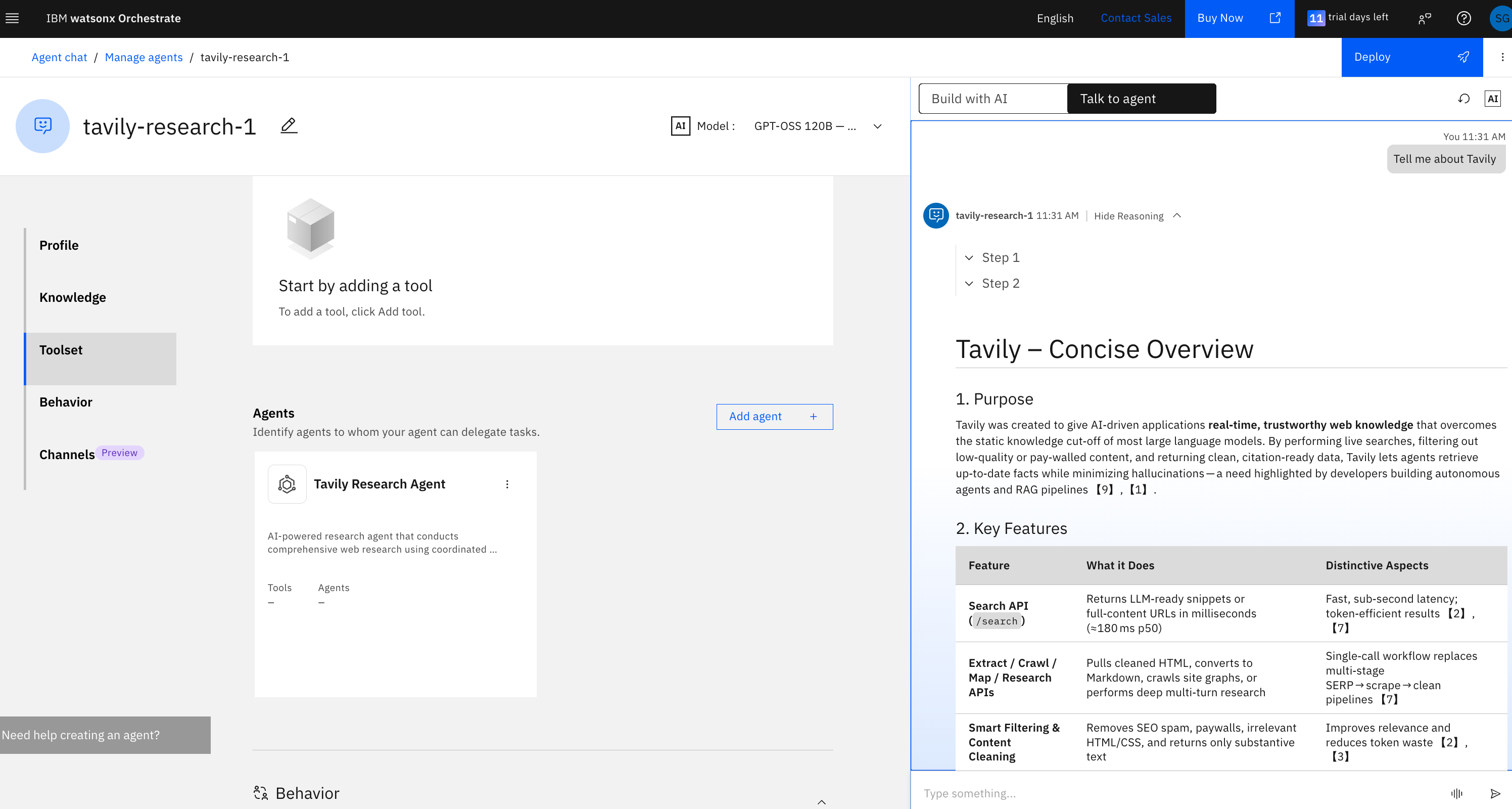 Your Tavily Research Agent is now ready to use within watsonx Orchestrate.
## Resources
* [IBM watsonx Orchestrate Documentation](https://www.ibm.com/docs/en/watsonx/watson-orchestrate/base?topic=agents-adding-orchestration#adding-a-collaborator-agent)
* [Partner Agents Catalog](https://www.ibm.com/docs/en/watsonx/watson-orchestrate/base?topic=catalog-partner-agents)
---
# Source: https://docs.tavily.com/documentation/about.md
> ## Documentation Index
> Fetch the complete documentation index at: https://docs.tavily.com/llms.txt
> Use this file to discover all available pages before exploring further.
# About
> Welcome to Tavily!
Your Tavily Research Agent is now ready to use within watsonx Orchestrate.
## Resources
* [IBM watsonx Orchestrate Documentation](https://www.ibm.com/docs/en/watsonx/watson-orchestrate/base?topic=agents-adding-orchestration#adding-a-collaborator-agent)
* [Partner Agents Catalog](https://www.ibm.com/docs/en/watsonx/watson-orchestrate/base?topic=catalog-partner-agents)
---
# Source: https://docs.tavily.com/documentation/about.md
> ## Documentation Index
> Fetch the complete documentation index at: https://docs.tavily.com/llms.txt
> Use this file to discover all available pages before exploring further.
# About
> Welcome to Tavily!
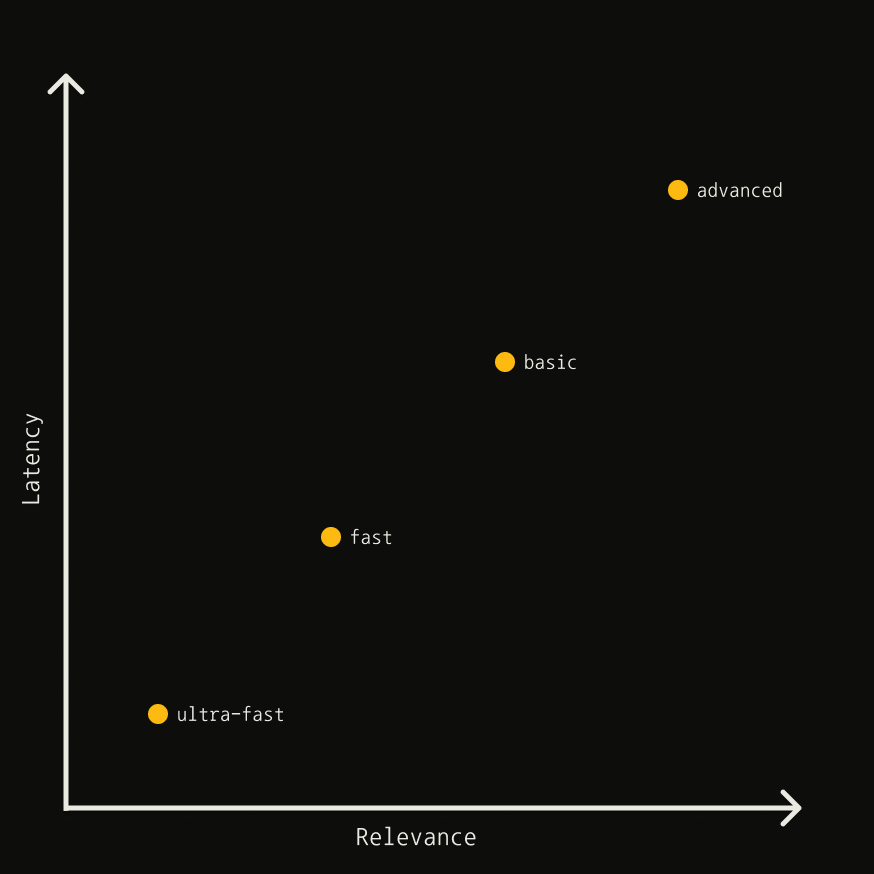 *This chart is a heuristic and is not to scale.*
*This chart is a heuristic and is not to scale.*
X-Project-ID headerX-Project-ID: your-project-id to any API request
project\_id="your-project-id" when instantiating the client, or set the TAVILY\_PROJECT environment variable
projectId: "your-project-id" when instantiating the client, or set the TAVILY\_PROJECT environment variable
search\_depth parameter - New options: fast and ultra-fastfast (BETA)ultra-fast (BETA)query and chunks\_per\_source parameters for Extract and Crawlquery (Extract)stringchunks\_per\_source (Extract & Crawl)integerchunks\_per\_source to define the maximum number of relevant chunks returned per source and to control the raw\_content length.raw\_content field as: \ \[...] \ \[...] \ .query is provided (Extract) or instructions are provided (Crawl).include\_usage parameterinclude\_usage parameter to true to receive credit usage information in the API response.
boolean
false
usage object with credits information, making it easy to track API credit consumption for each request.
@tavily/ai-sdk package that provides pre-built AI SDK tools for Vercel's AI SDK v5.
tavilySearch, tavilyExtract, tavilyCrawl, and tavilyMap
timeout parameter for Crawl and timeout parameter for Mapfloat
timeout parameternumber (float)
extract\_depth: 10 seconds for basic extraction and 30 seconds for advanced extraction.
start\_date parameter,end\_date parameterstart\_date and end\_date parameters in the Search endpoints.
start\_date will return all results after the specified start date. Required to be written in the format YYYY-MM-DD.
end\_date will return all results before the specified end date. Required to be written in the format YYYY-MM-DD.
start\_date to 2025-01-01 and end\_date to 2025-04-01 to reiceive results strictly from this time range.
include\_favicon parameterinclude\_favicon parameter to true to receive the favicon URL (if available) for each result in the API response.
auto\_parametersfalseauto\_parameters is enabled, Tavily automatically configures search parameters based on your query's content and intent. You can still set other parameters manually, and your explicit values will override the automatic ones.include\_answer, include\_raw\_content, and max\_results must always be set manually, as they directly affect response size.search\_depth may be automatically set to advanced when it's likely to improve results. This uses 2 API credits per request. To avoid the extra cost, you can explicitly set search\_depth to basic./usage endpointGET [https://api.tavily.com/usage](https://api.tavily.com/usage) with your API key to monitor your account in real time.
country parameterBoost search results from a specific country.
topic is general.
Integrate Tavily with n8n to enhance your workflows with real-time web search and content extraction—without writing code. With Tavily's powerful search and extraction capabilities, you can seamlessly integrate up-to-date online information into your n8n automations.
With Tavily's powerful search and content extraction capabilities, you can seamlessly integrate real-time online information into your Make workflows and automations.
format parameter
enum\markdownmarkdown returns content in markdown format. text returns plain text and may increase latency.markdown, textsearch\_depth and chunks\_per\_sourceparameters
search\_depthenum\basicadvanced search is tailored to retrieve the most relevant sources and content snippets for your query, while basic search provides generic content snippets from each source.basic search costs 1 API Credit, while an advanced search costs 2 API Credits.basic, advancedchunks\_per\_sourcechunks\_per\_source to define the maximum number of relevant chunks returned per source and to control the content length.\ \[...] \ \[...] \ .search\_depth is advanced.1 \< x \< 3 ## Try Our Chatbot
### Step 1: Get Your API Key
## Try Our Chatbot
### Step 1: Get Your API Key
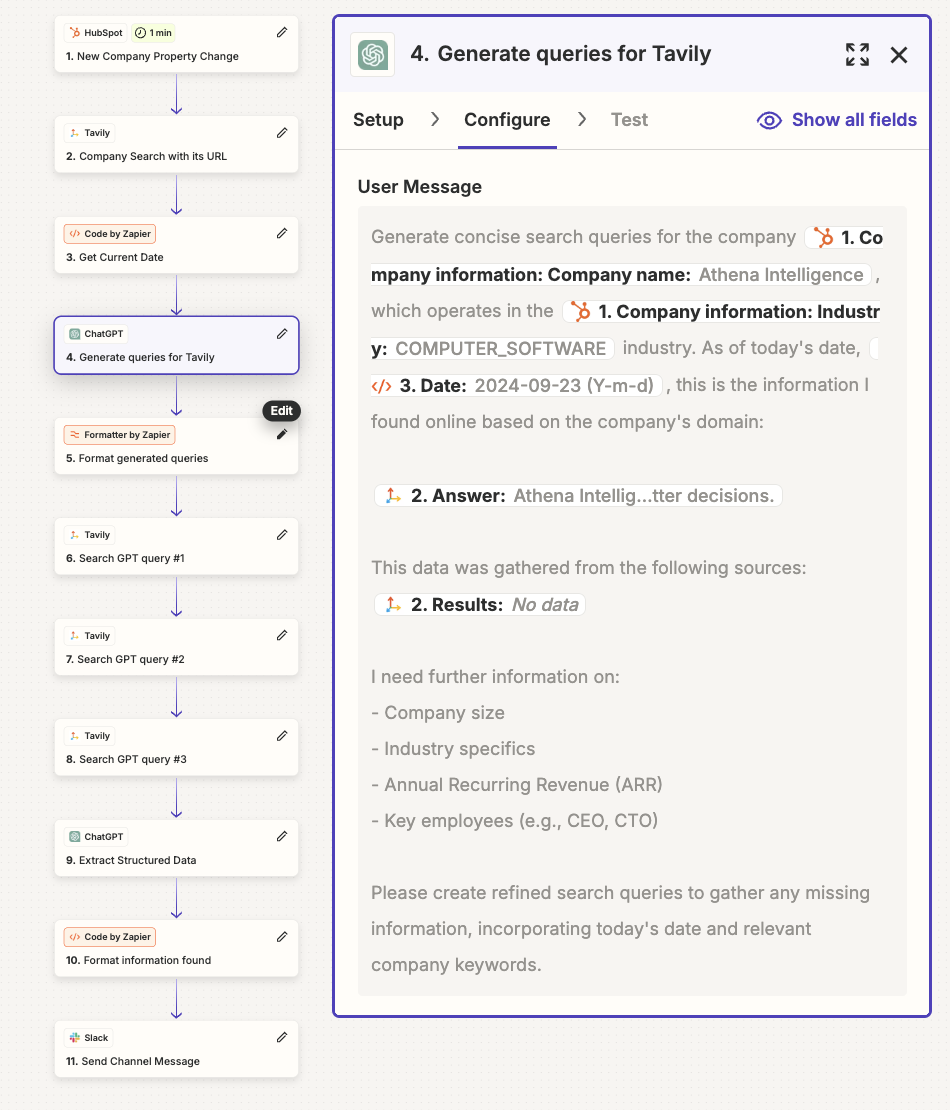
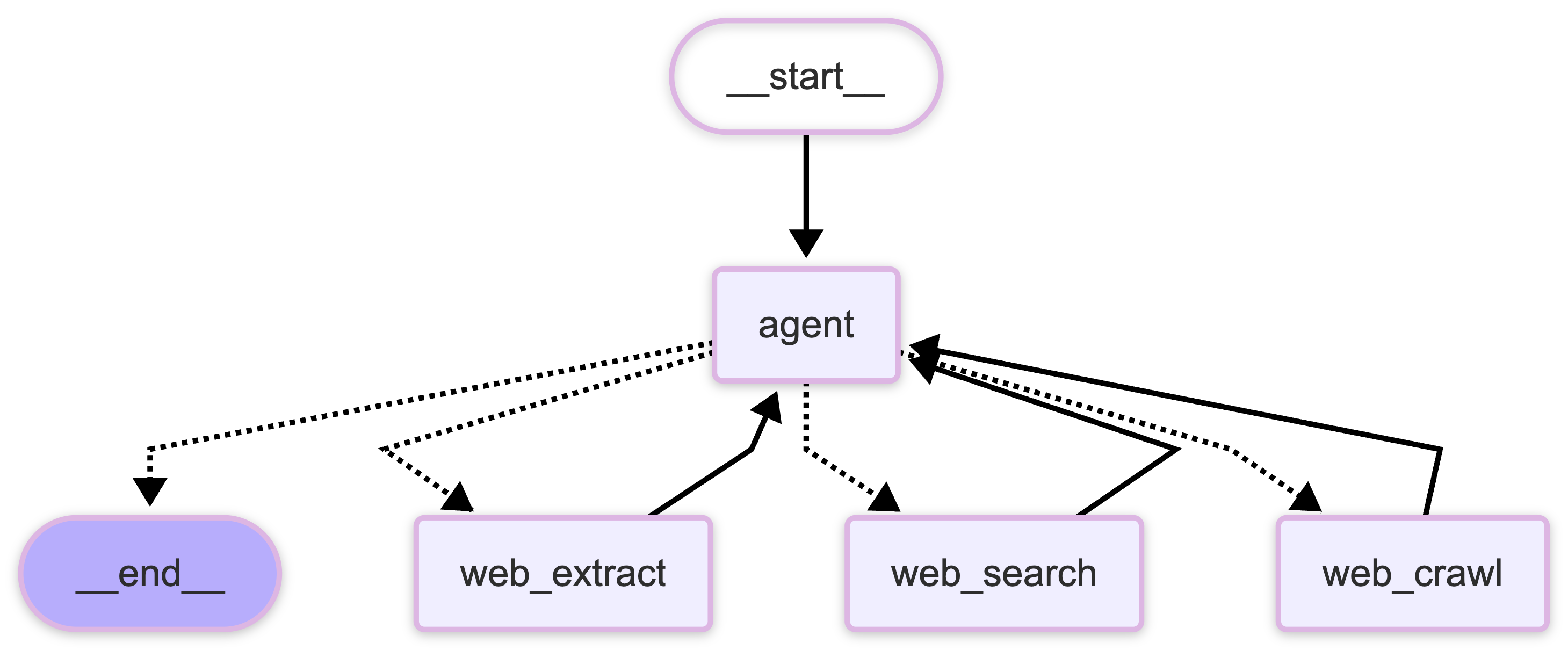 The workflow consists of several key components:
The workflow consists of several key components:
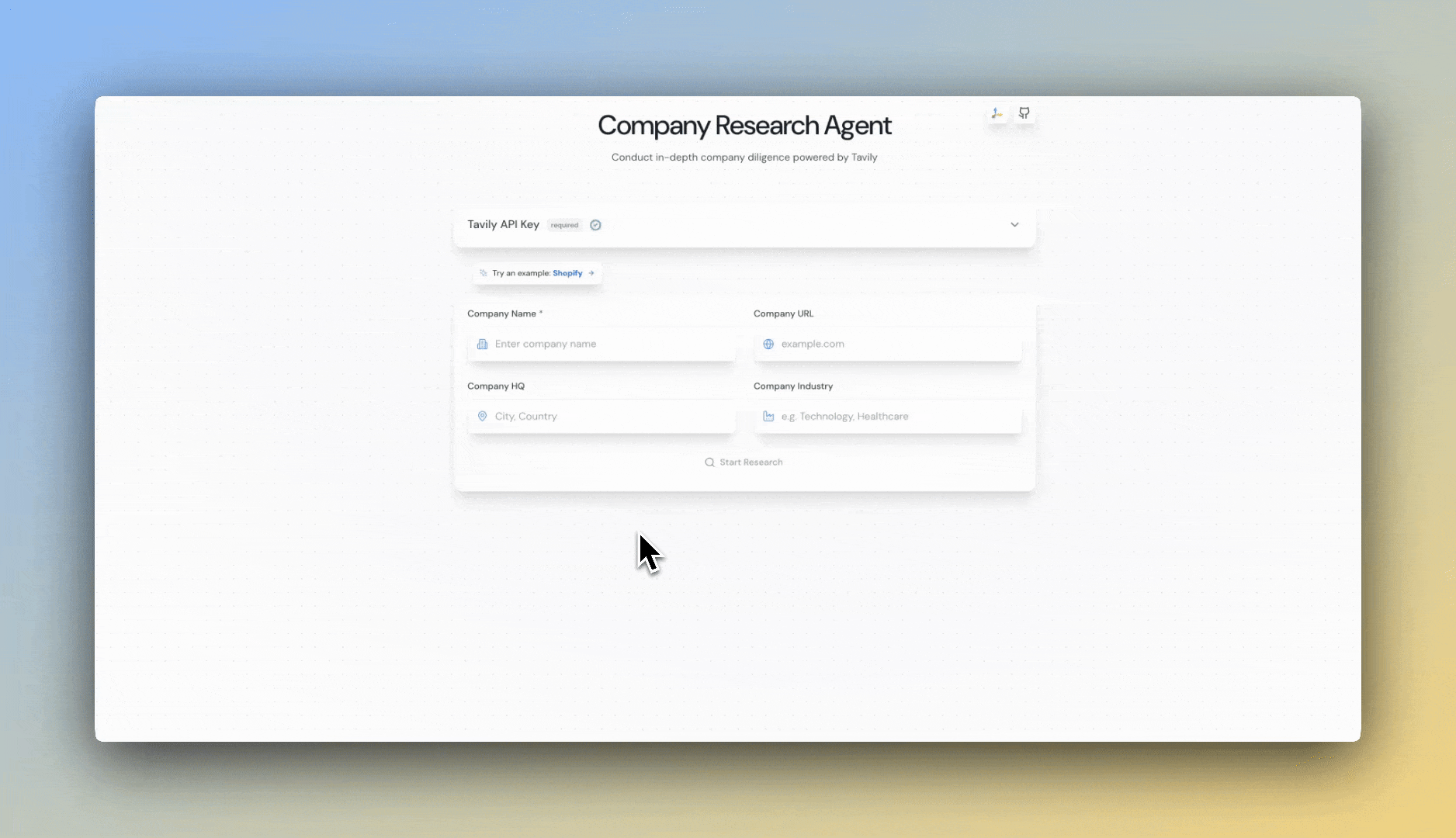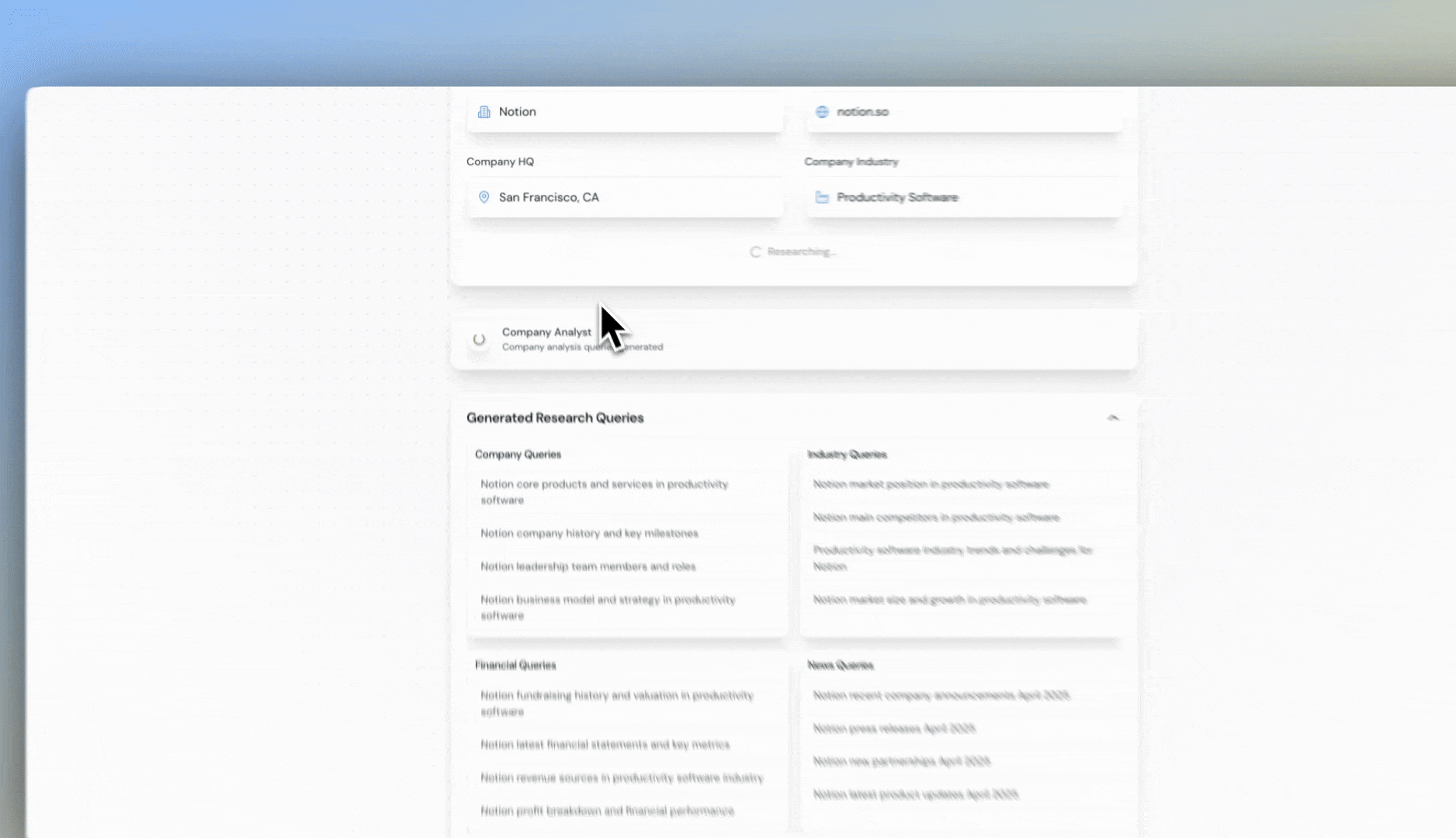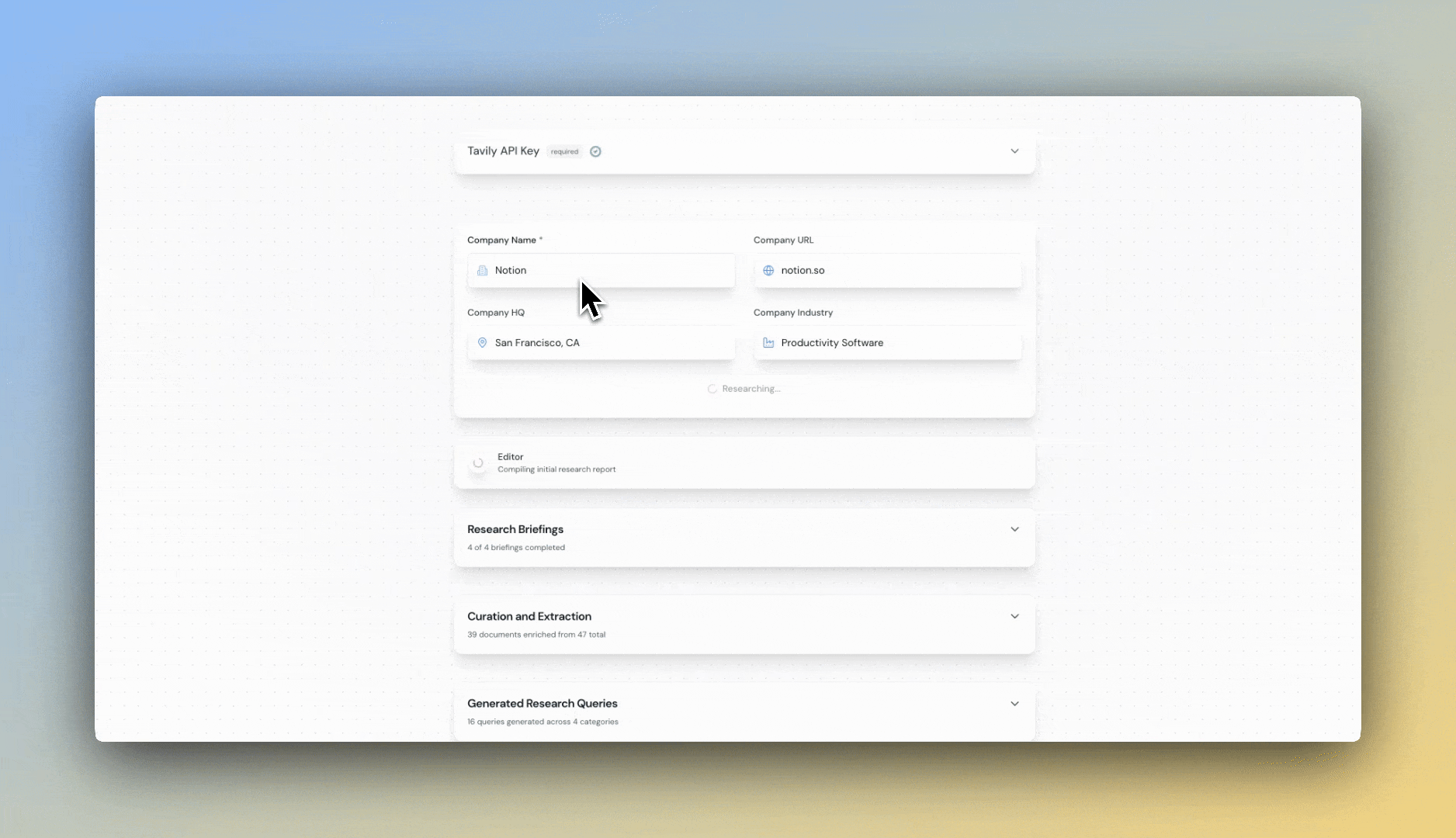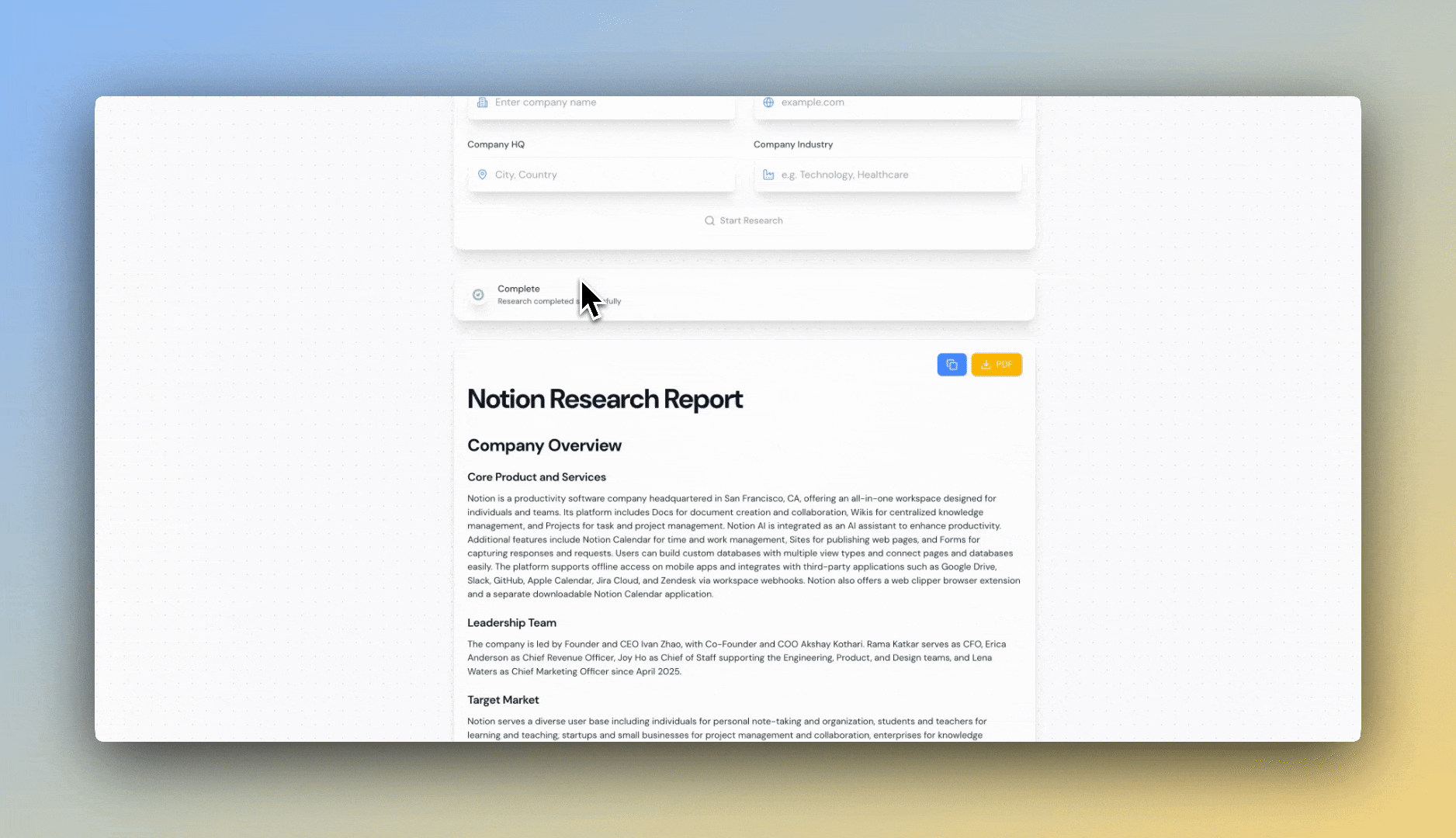 ## Try Our Company Researcher
### Step 1: Get Your API Key
## Try Our Company Researcher
### Step 1: Get Your API Key
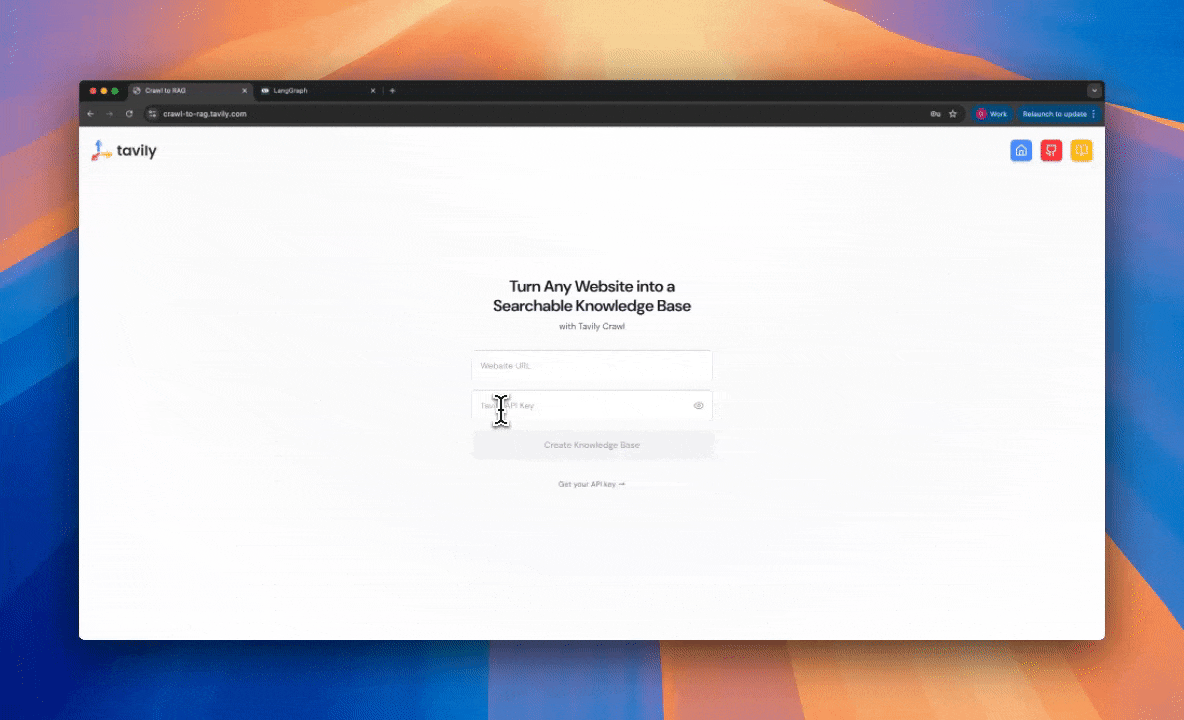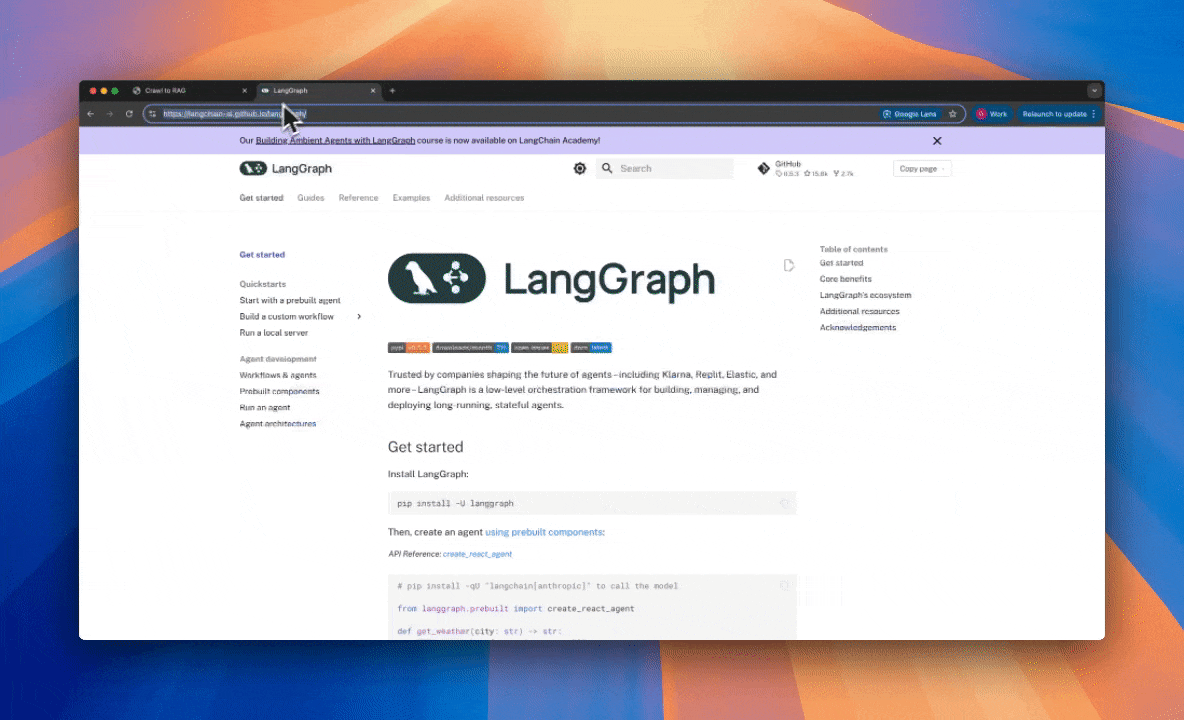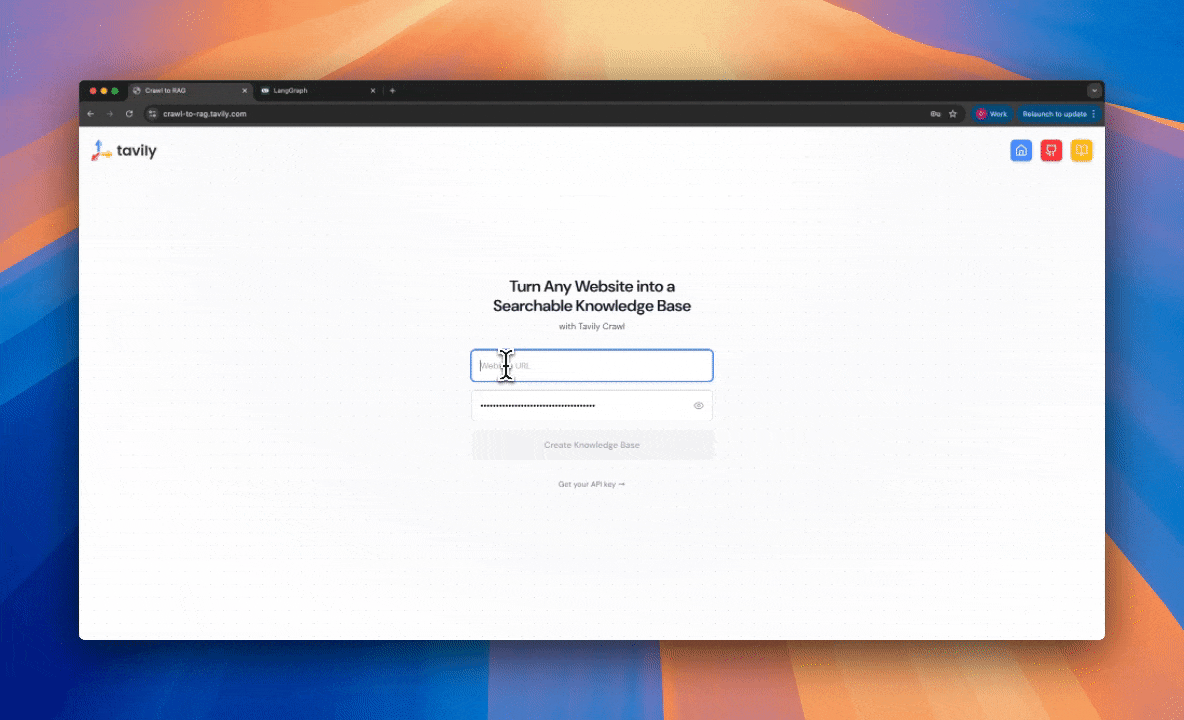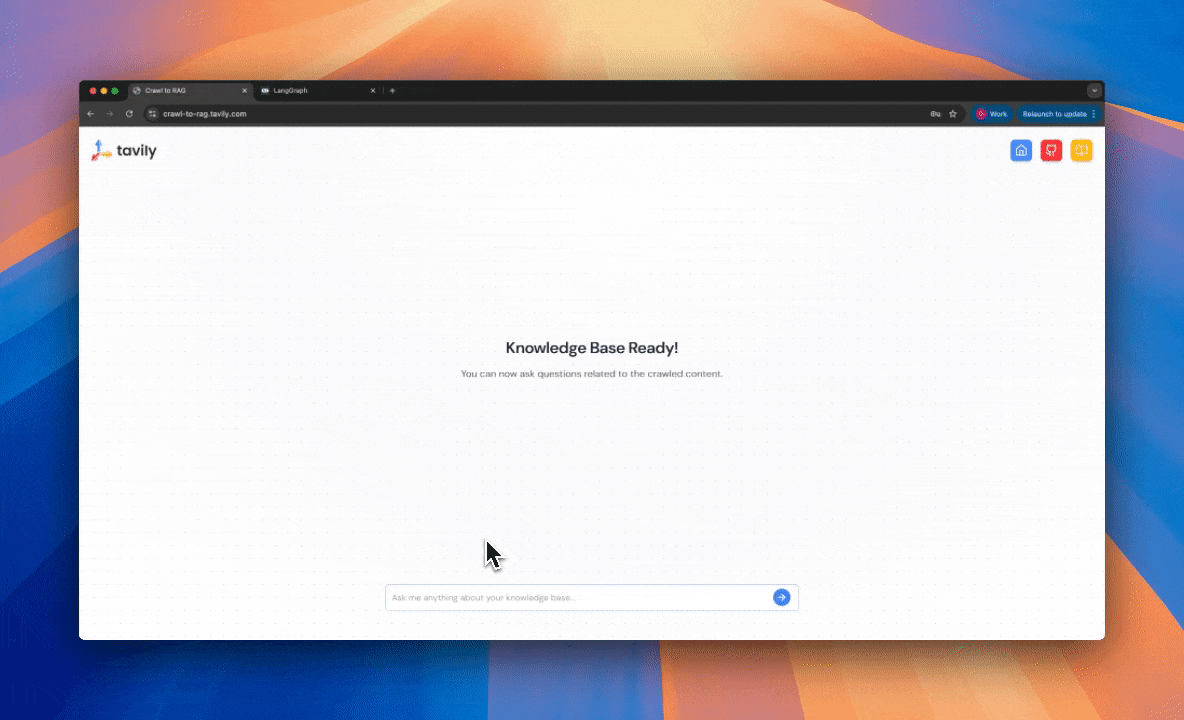 ### 2. Intelligent Q\&A Interface:
Query your crawled data through a conversational agent that provides citation-backed answers while maintaining conversation history and context. The agent intelligently distinguishes between informational questions (requiring vector search) and conversational queries (using general knowledge).
### 2. Intelligent Q\&A Interface:
Query your crawled data through a conversational agent that provides citation-backed answers while maintaining conversation history and context. The agent intelligently distinguishes between informational questions (requiring vector search) and conversational queries (using general knowledge).
 ## Try Our Crawl to RAG Use Case
### Step 1: Get Your API Key
## Try Our Crawl to RAG Use Case
### Step 1: Get Your API Key
 #### Enrich your spreadsheet
#### Enrich your spreadsheet
 #### Export as CSV
#### Export as CSV
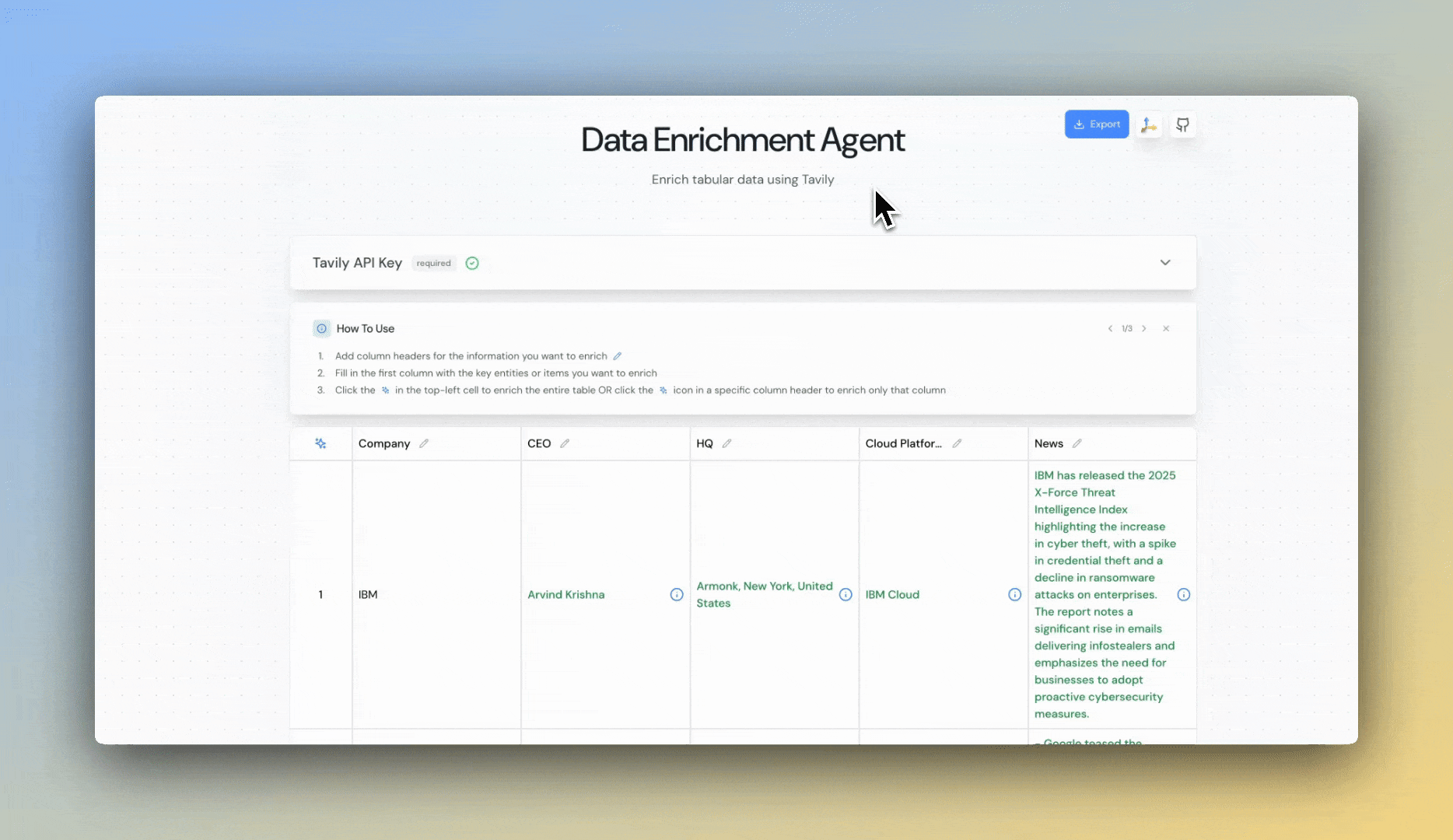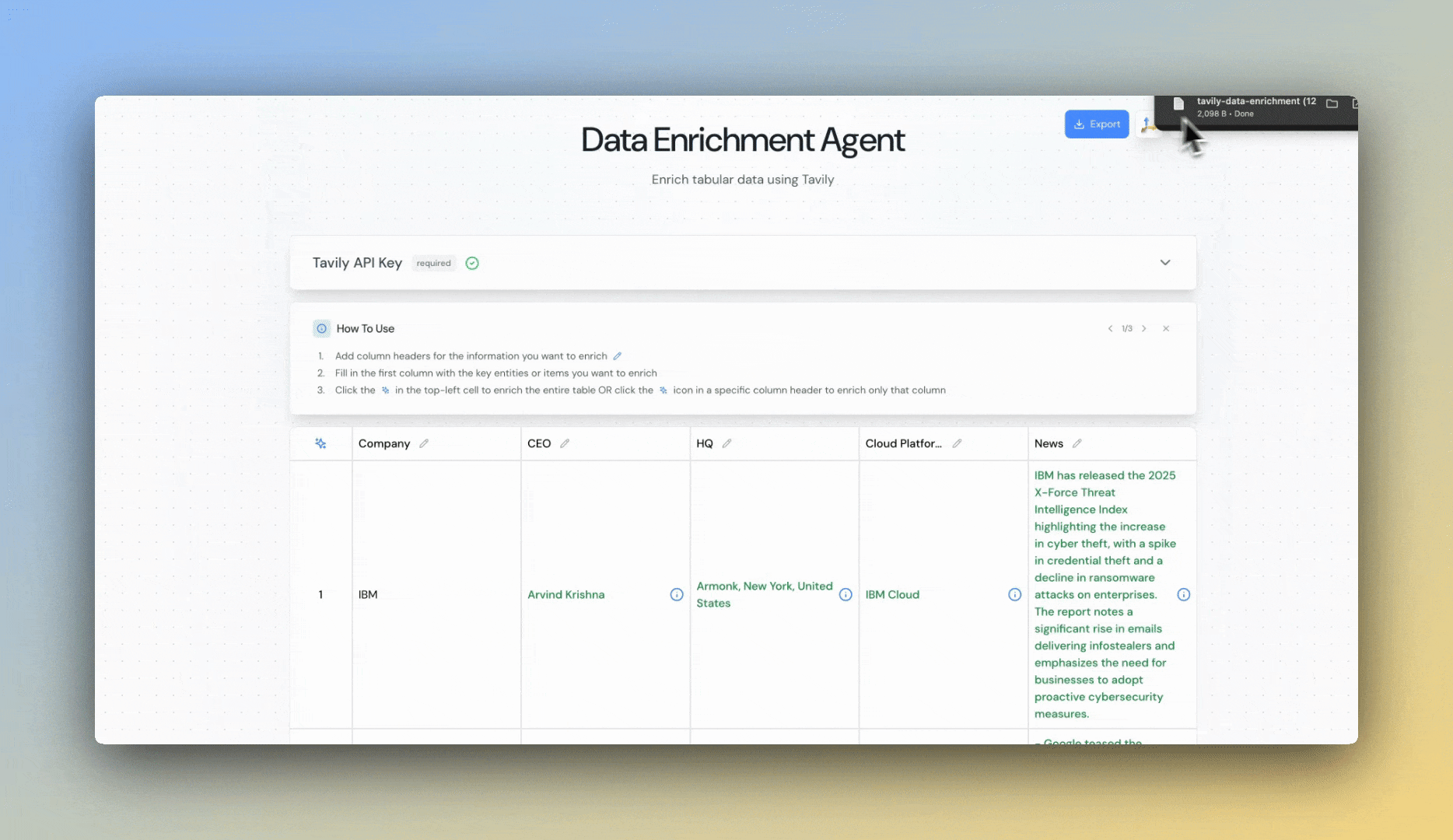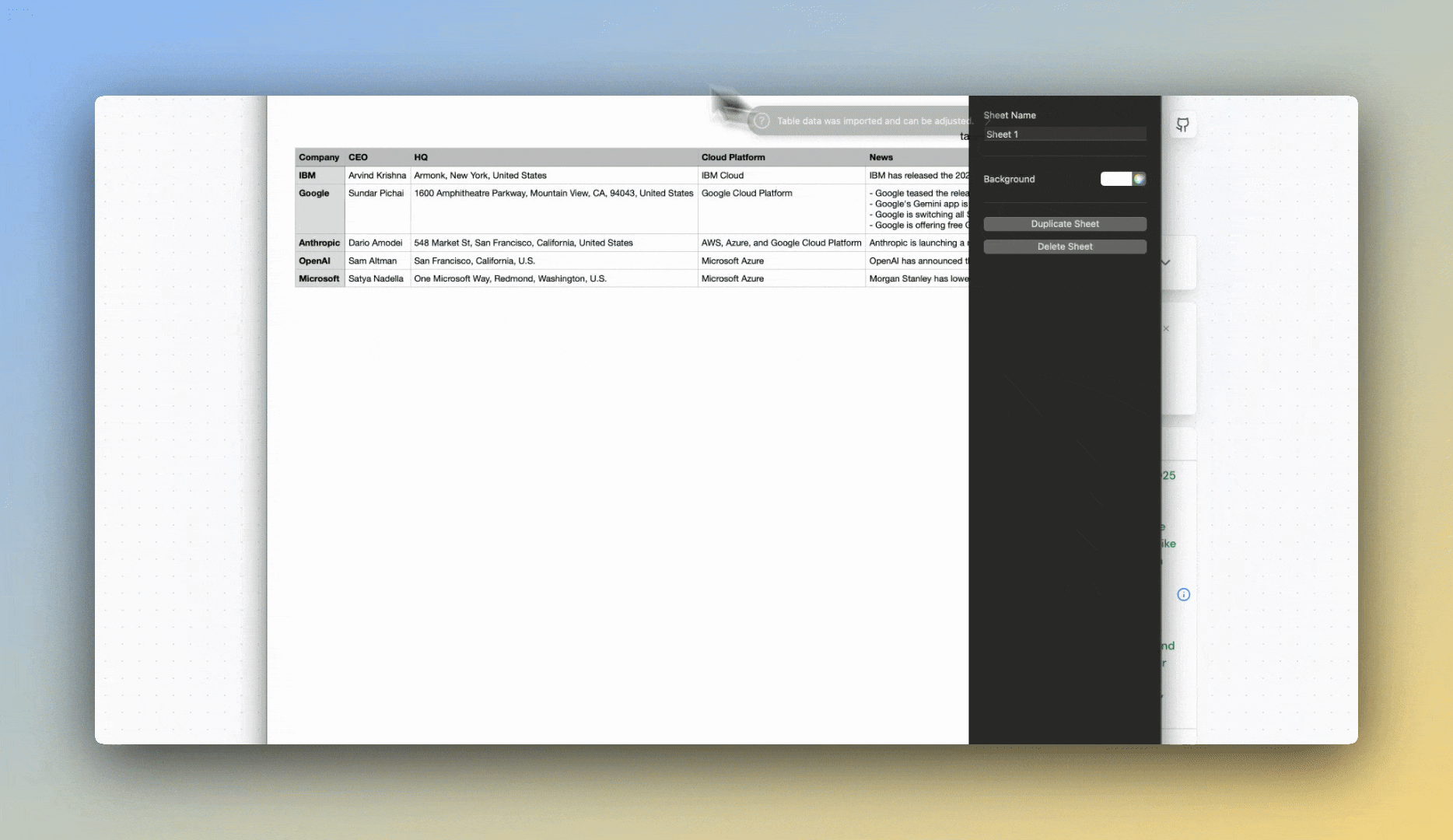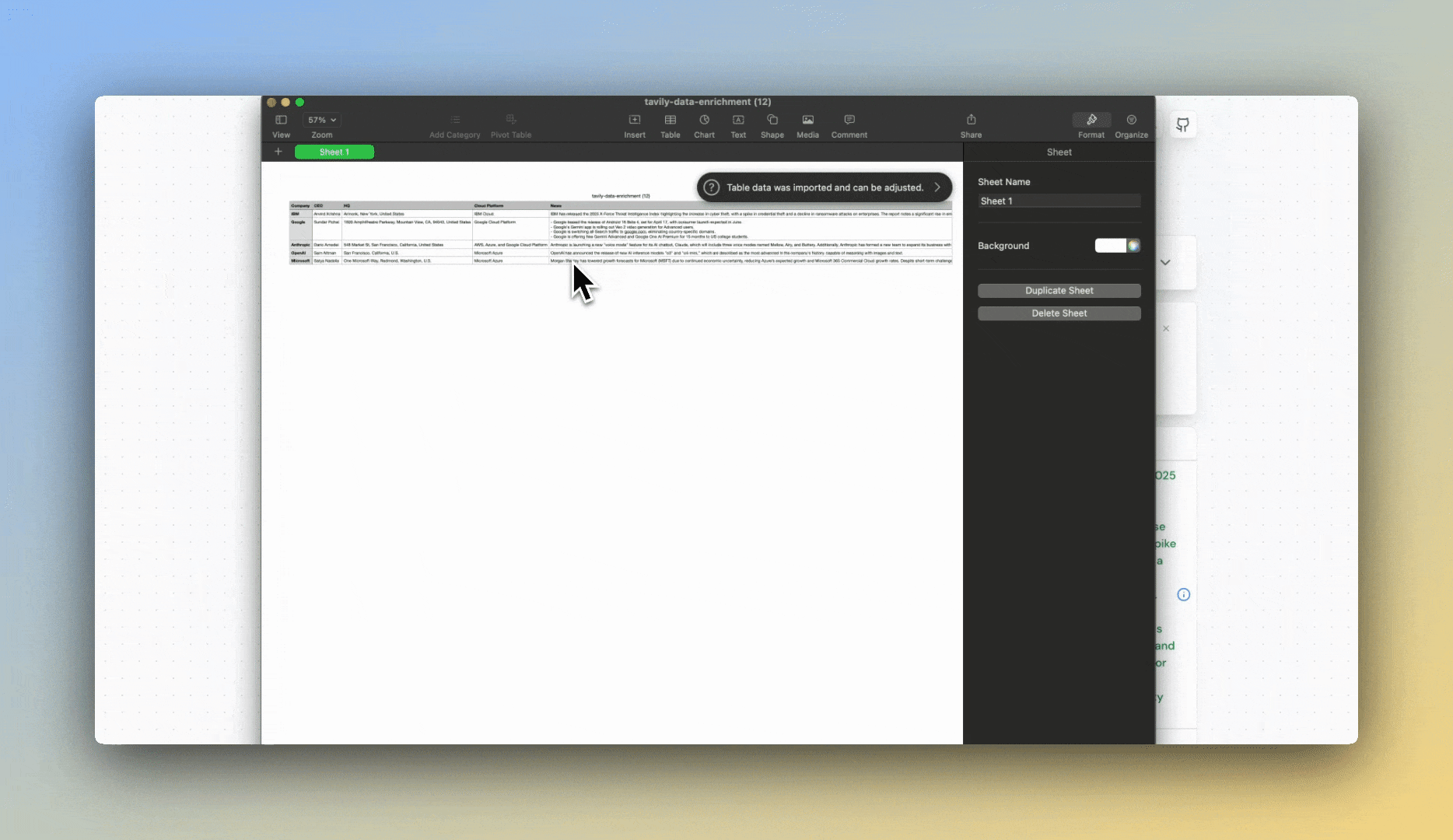 ## Try Our Data Enrichment Agent
### Step 1: Get Your API Key
## Try Our Data Enrichment Agent
### Step 1: Get Your API Key
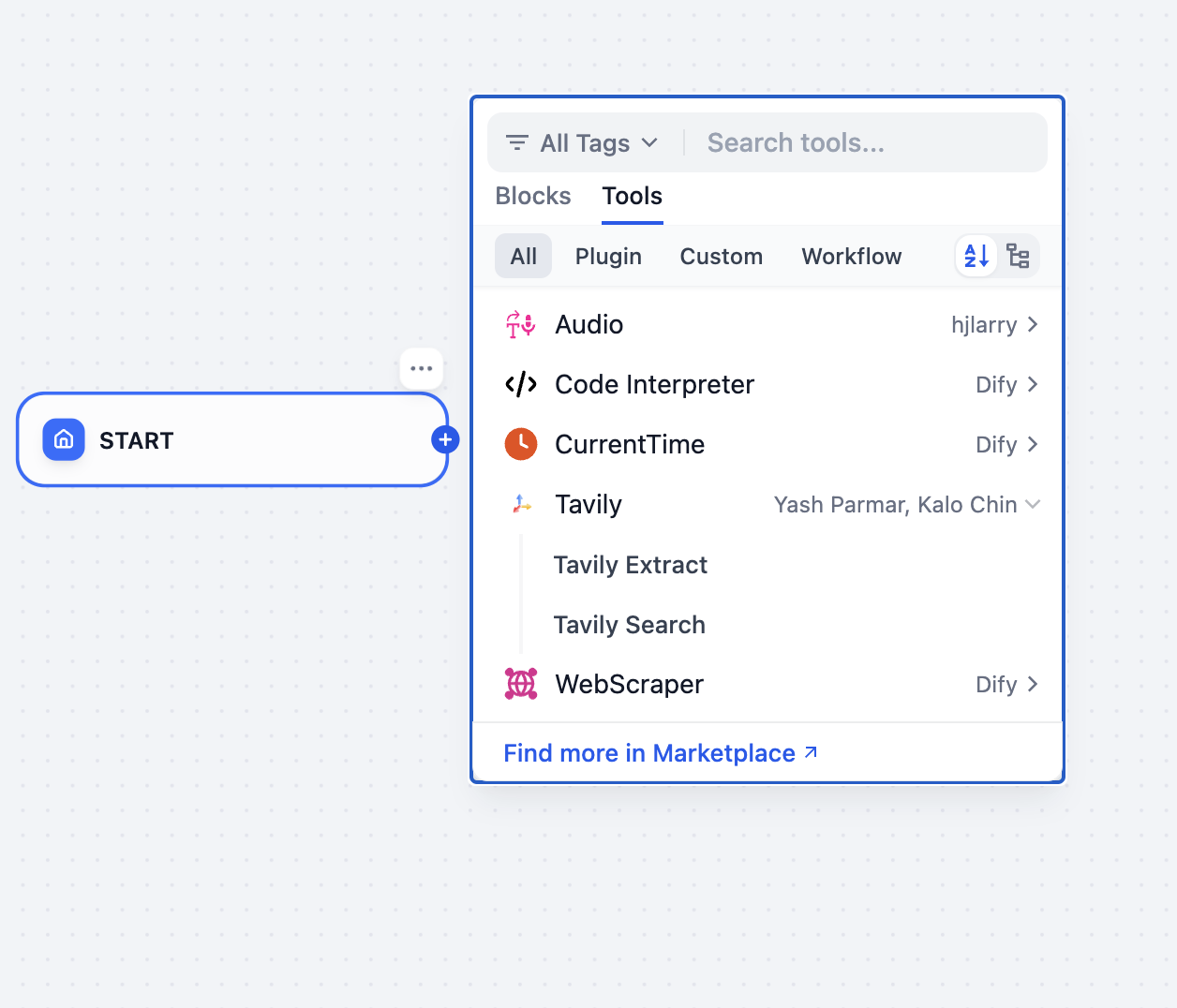 ## Example use case: automated deep research
Use **Tavily Search API** within **Dify** to conduct automated, multi-step searches, iterating through multiple queries to gather, refine, and summarize insights for comprehensive reports.
For a detailed walkthrough, check out this blog post:
[DeepResearch: Building a Research Automation App with Dify](https://dify.ai/blog/deepresearch-building-a-research-automation-app-with-dify)
## Best practices for using Tavily in Dify
* **Design Concise Queries** – Use focused queries to maximize the relevance of search results.
* **Utilize Domain Filtering** – Use the `include_domains` parameter to narrow search results to specific domains.
* **Enable an Agentic Workflow** – Leverage an LLM to dynamically generate and refine queries for Tavily.
***
---
# Source: https://docs.tavily.com/documentation/api-reference/endpoint/extract.md
> ## Documentation Index
> Fetch the complete documentation index at: https://docs.tavily.com/llms.txt
> Use this file to discover all available pages before exploring further.
# Tavily Extract
> Extract web page content from one or more specified URLs using Tavily Extract.
## OpenAPI
````yaml POST /extract
openapi: 3.0.3
info:
title: Tavily Search and Extract API
description: >-
Our REST API provides seamless access to Tavily Search, a powerful search
engine for LLM agents, and Tavily Extract, an advanced web scraping solution
optimized for LLMs.
version: 1.0.0
servers:
- url: https://api.tavily.com/
security: []
tags:
- name: Search
- name: Extract
- name: Crawl
- name: Map
- name: Research
- name: Usage
paths:
/extract:
post:
summary: Retrieve raw web content from specified URLs
description: >-
Extract web page content from one or more specified URLs using Tavily
Extract.
requestBody:
description: Parameters for the Tavily Extract request.
required: true
content:
application/json:
schema:
type: object
properties:
urls:
oneOf:
- type: string
description: The URL to extract content from.
example: https://en.wikipedia.org/wiki/Artificial_intelligence
- type: array
items:
type: string
description: A list of URLs to extract content from.
example:
- https://en.wikipedia.org/wiki/Artificial_intelligence
- https://en.wikipedia.org/wiki/Machine_learning
- https://en.wikipedia.org/wiki/Data_science
query:
type: string
description: >-
User intent for reranking extracted content chunks. When
provided, chunks are reranked based on relevance to this
query.
chunks_per_source:
type: integer
description: >-
Chunks are short content snippets (maximum 500 characters
each) pulled directly from the source. Use
`chunks_per_source` to define the maximum number of relevant
chunks returned per source and to control the `raw_content`
length. Chunks will appear in the `raw_content` field as:
`
## Example use case: automated deep research
Use **Tavily Search API** within **Dify** to conduct automated, multi-step searches, iterating through multiple queries to gather, refine, and summarize insights for comprehensive reports.
For a detailed walkthrough, check out this blog post:
[DeepResearch: Building a Research Automation App with Dify](https://dify.ai/blog/deepresearch-building-a-research-automation-app-with-dify)
## Best practices for using Tavily in Dify
* **Design Concise Queries** – Use focused queries to maximize the relevance of search results.
* **Utilize Domain Filtering** – Use the `include_domains` parameter to narrow search results to specific domains.
* **Enable an Agentic Workflow** – Leverage an LLM to dynamically generate and refine queries for Tavily.
***
---
# Source: https://docs.tavily.com/documentation/api-reference/endpoint/extract.md
> ## Documentation Index
> Fetch the complete documentation index at: https://docs.tavily.com/llms.txt
> Use this file to discover all available pages before exploring further.
# Tavily Extract
> Extract web page content from one or more specified URLs using Tavily Extract.
## OpenAPI
````yaml POST /extract
openapi: 3.0.3
info:
title: Tavily Search and Extract API
description: >-
Our REST API provides seamless access to Tavily Search, a powerful search
engine for LLM agents, and Tavily Extract, an advanced web scraping solution
optimized for LLMs.
version: 1.0.0
servers:
- url: https://api.tavily.com/
security: []
tags:
- name: Search
- name: Extract
- name: Crawl
- name: Map
- name: Research
- name: Usage
paths:
/extract:
post:
summary: Retrieve raw web content from specified URLs
description: >-
Extract web page content from one or more specified URLs using Tavily
Extract.
requestBody:
description: Parameters for the Tavily Extract request.
required: true
content:
application/json:
schema:
type: object
properties:
urls:
oneOf:
- type: string
description: The URL to extract content from.
example: https://en.wikipedia.org/wiki/Artificial_intelligence
- type: array
items:
type: string
description: A list of URLs to extract content from.
example:
- https://en.wikipedia.org/wiki/Artificial_intelligence
- https://en.wikipedia.org/wiki/Machine_learning
- https://en.wikipedia.org/wiki/Data_science
query:
type: string
description: >-
User intent for reranking extracted content chunks. When
provided, chunks are reranked based on relevance to this
query.
chunks_per_source:
type: integer
description: >-
Chunks are short content snippets (maximum 500 characters
each) pulled directly from the source. Use
`chunks_per_source` to define the maximum number of relevant
chunks returned per source and to control the `raw_content`
length. Chunks will appear in the `raw_content` field as:
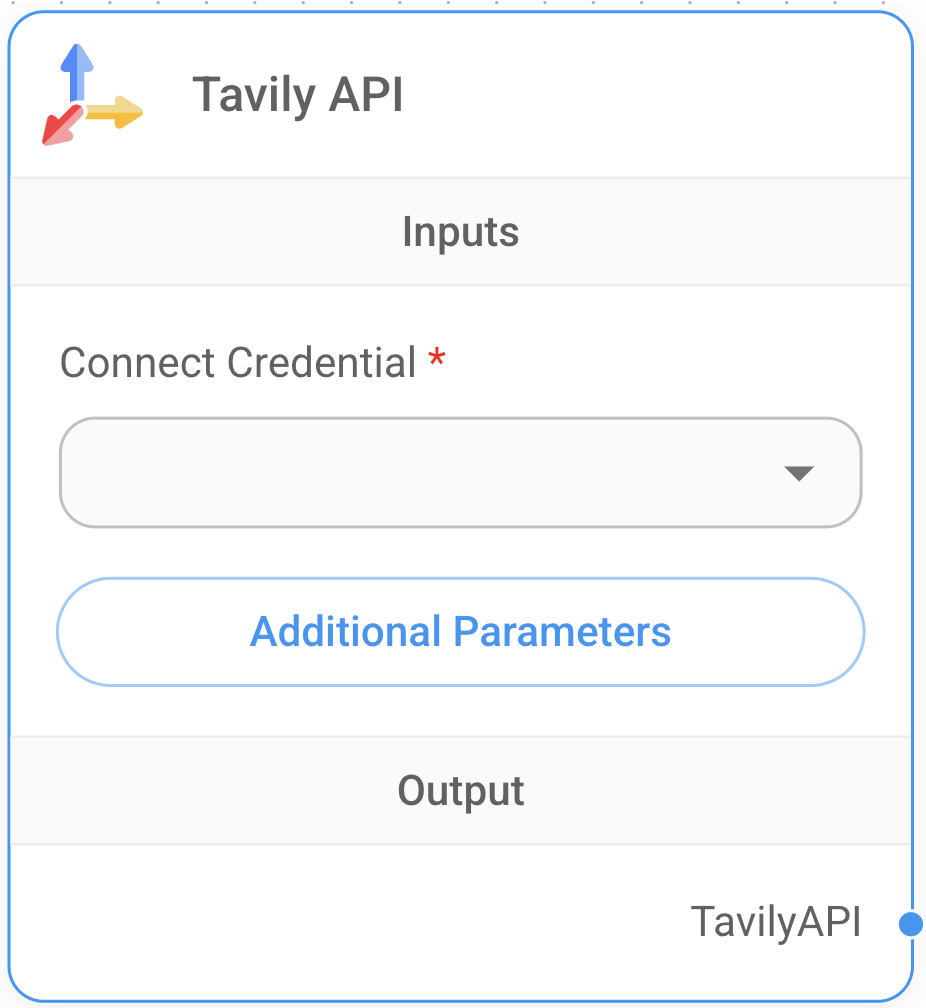
`Create a new flow in Flowise:
Add the Tavily node to your flow:
For Chat Flow:
For Agent Flow:
Configure the Tavily node with your credentials and parameters:
Connect the Tavily node to other nodes in your flow:
 ---
# Source: https://docs.tavily.com/documentation/integrations/google-adk.md
> ## Documentation Index
> Fetch the complete documentation index at: https://docs.tavily.com/llms.txt
> Use this file to discover all available pages before exploring further.
# Google ADK
> Connect your Google ADK agent to Tavily's AI-focused search, extraction, and crawling platform for real-time web intelligence.
## Introduction
The Tavily MCP Server connects your ADK agent to Tavily's AI-focused search, extraction, and crawling platform. This gives your agent the ability to perform real-time web searches, intelligently extract specific data from web pages, and crawl or create structured maps of websites.
## Prerequisites
Before you begin, make sure you have:
* Python 3.9 or later
* pip for installing packages
* A [Tavily API key](https://app.tavily.com/home) (sign up for free if you don't have one)
* A [Gemini API key](https://aistudio.google.com/app/apikey) for Google AI Studio
## Installation
Install ADK by running:
```bash theme={null}
pip install google-adk mcp
```
## Building Your Agent
### Step 1: Create an Agent Project
Run the `adk create` command to start a new agent project:
```bash theme={null}
adk create my_agent
```
This creates a new directory with the following structure:
```
my_agent/
agent.py # main agent code
.env # API keys or project IDs
__init__.py
```
### Step 2: Update Your Agent Code
Edit the `my_agent/agent.py` file to integrate Tavily. Choose either **Remote MCP Server** or **Local MCP Server**:
---
# Source: https://docs.tavily.com/documentation/integrations/google-adk.md
> ## Documentation Index
> Fetch the complete documentation index at: https://docs.tavily.com/llms.txt
> Use this file to discover all available pages before exploring further.
# Google ADK
> Connect your Google ADK agent to Tavily's AI-focused search, extraction, and crawling platform for real-time web intelligence.
## Introduction
The Tavily MCP Server connects your ADK agent to Tavily's AI-focused search, extraction, and crawling platform. This gives your agent the ability to perform real-time web searches, intelligently extract specific data from web pages, and crawl or create structured maps of websites.
## Prerequisites
Before you begin, make sure you have:
* Python 3.9 or later
* pip for installing packages
* A [Tavily API key](https://app.tavily.com/home) (sign up for free if you don't have one)
* A [Gemini API key](https://aistudio.google.com/app/apikey) for Google AI Studio
## Installation
Install ADK by running:
```bash theme={null}
pip install google-adk mcp
```
## Building Your Agent
### Step 1: Create an Agent Project
Run the `adk create` command to start a new agent project:
```bash theme={null}
adk create my_agent
```
This creates a new directory with the following structure:
```
my_agent/
agent.py # main agent code
.env # API keys or project IDs
__init__.py
```
### Step 2: Update Your Agent Code
Edit the `my_agent/agent.py` file to integrate Tavily. Choose either **Remote MCP Server** or **Local MCP Server**:
 ## Available Tools
Once connected, your agent gains access to Tavily's powerful web intelligence tools:
### tavily-search
Execute a search query to find relevant information across the web.
### tavily-extract
Extract structured data from any web page. Extract text, links, and images from single pages or batch process multiple URLs efficiently.
### tavily-map
Traverses websites like a graph and can explore hundreds of paths in parallel with intelligent discovery to generate comprehensive site maps.
### tavily-crawl
Traversal tool that can explore hundreds of paths in parallel with built-in extraction and intelligent discovery.
---
# Source: https://docs.tavily.com/examples/open-sources/gpt-researcher.md
# GPT Researcher
## Multi Agent Frameworks
We are strong advocates for the future of AI agents, envisioning a world where autonomous agents communicate and collaborate as a cohesive team to undertake and complete complex tasks.
We hold the belief that research is a pivotal element in successfully tackling these complex tasks, ensuring superior outcomes.
Consider the scenario of developing a coding agent responsible for coding tasks using the latest API documentation and best practices. It would be wise to integrate an agent specializing in research to curate the most recent and relevant documentation, before crafting a technical design that would subsequently be handed off to the coding assistant tasked with generating the code. This approach is applicable across various sectors, including finance, business analysis, healthcare, marketing, and legal, among others.
One multi-agent framework that we're excited about is [LangGraph](https://langchain-ai.github.io/langgraph/), built by the team at [Langchain](https://www.langchain.com/). LangGraph is a Python library for building stateful, multi-actor applications with LLMs. It extends the [LangChain Expression Language](https://python.langchain.com/docs/concepts/lcel/) with the ability to coordinate multiple chains (or actors) across multiple steps of computation.
What's great about LangGraph is that it follows a DAG architecture, enabling each specialized agent to communicate with one another, and subsequently trigger actions among other agents within the graph.
We've added an example for leveraging [GPT Researcher with LangGraph](https://github.com/assafelovic/gpt-researcher/tree/master/multi_agents) which can be found in `/multi_agents`.
The example demonstrates a generic use case for an editorial agent team that works together to complete a research report on a given task.
### The Multi Agent Team
The research team is made up of 7 AI agents:
1. Chief Editor - Oversees the research process and manages the team. This is the "master" agent that coordinates the other agents using Langgraph.
2. Researcher (gpt-researcher) - A specialized autonomous agent that conducts in depth research on a given topic.
3. Editor - Responsible for planning the research outline and structure.
4. Reviewer - Validates the correctness of the research results given a set of criteria.
5. Revisor - Revises the research results based on the feedback from the reviewer.
6. Writer - Responsible for compiling and writing the final report.
7. Publisher - Responsible for publishing the final report in various formats.
### How it works
Generally, the process is based on the following stages:
1. Planning stage
2. Data collection and analysis
3. Writing and submission
4. Review and revision
5. Publication
### Architecture
## Available Tools
Once connected, your agent gains access to Tavily's powerful web intelligence tools:
### tavily-search
Execute a search query to find relevant information across the web.
### tavily-extract
Extract structured data from any web page. Extract text, links, and images from single pages or batch process multiple URLs efficiently.
### tavily-map
Traverses websites like a graph and can explore hundreds of paths in parallel with intelligent discovery to generate comprehensive site maps.
### tavily-crawl
Traversal tool that can explore hundreds of paths in parallel with built-in extraction and intelligent discovery.
---
# Source: https://docs.tavily.com/examples/open-sources/gpt-researcher.md
# GPT Researcher
## Multi Agent Frameworks
We are strong advocates for the future of AI agents, envisioning a world where autonomous agents communicate and collaborate as a cohesive team to undertake and complete complex tasks.
We hold the belief that research is a pivotal element in successfully tackling these complex tasks, ensuring superior outcomes.
Consider the scenario of developing a coding agent responsible for coding tasks using the latest API documentation and best practices. It would be wise to integrate an agent specializing in research to curate the most recent and relevant documentation, before crafting a technical design that would subsequently be handed off to the coding assistant tasked with generating the code. This approach is applicable across various sectors, including finance, business analysis, healthcare, marketing, and legal, among others.
One multi-agent framework that we're excited about is [LangGraph](https://langchain-ai.github.io/langgraph/), built by the team at [Langchain](https://www.langchain.com/). LangGraph is a Python library for building stateful, multi-actor applications with LLMs. It extends the [LangChain Expression Language](https://python.langchain.com/docs/concepts/lcel/) with the ability to coordinate multiple chains (or actors) across multiple steps of computation.
What's great about LangGraph is that it follows a DAG architecture, enabling each specialized agent to communicate with one another, and subsequently trigger actions among other agents within the graph.
We've added an example for leveraging [GPT Researcher with LangGraph](https://github.com/assafelovic/gpt-researcher/tree/master/multi_agents) which can be found in `/multi_agents`.
The example demonstrates a generic use case for an editorial agent team that works together to complete a research report on a given task.
### The Multi Agent Team
The research team is made up of 7 AI agents:
1. Chief Editor - Oversees the research process and manages the team. This is the "master" agent that coordinates the other agents using Langgraph.
2. Researcher (gpt-researcher) - A specialized autonomous agent that conducts in depth research on a given topic.
3. Editor - Responsible for planning the research outline and structure.
4. Reviewer - Validates the correctness of the research results given a set of criteria.
5. Revisor - Revises the research results based on the feedback from the reviewer.
6. Writer - Responsible for compiling and writing the final report.
7. Publisher - Responsible for publishing the final report in various formats.
### How it works
Generally, the process is based on the following stages:
1. Planning stage
2. Data collection and analysis
3. Writing and submission
4. Review and revision
5. Publication
### Architecture
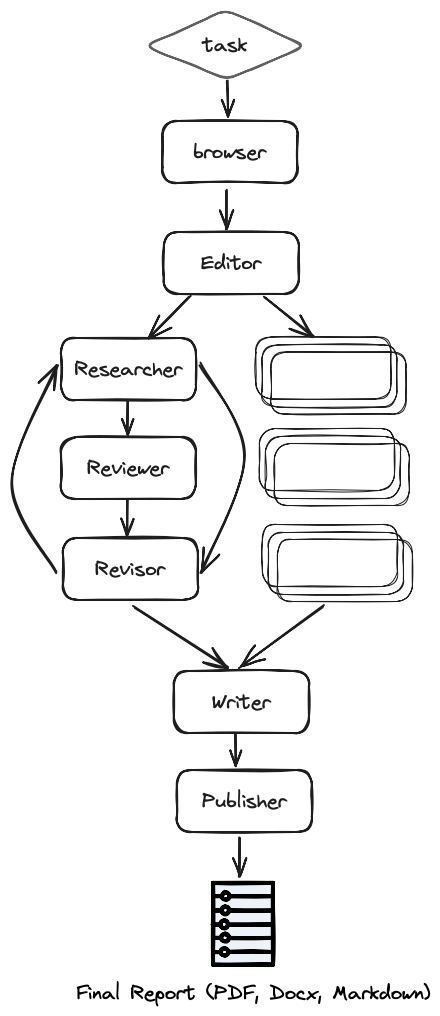 ### Steps
More specifically (as seen in the architecture diagram) the process is as follows:
1. Browser (gpt-researcher) - Browses the internet for initial research based on the given research task.
2. Editor - Plans the report outline and structure based on the initial research.
3. For each outline topic (in parallel):
4. Researcher (gpt-researcher) - Runs an in depth research on the subtopics and writes a draft.
5. Reviewer - Validates the correctness of the draft given a set of criteria and provides feedback.
6. Revisor - Revises the draft until it is satisfactory based on the reviewer feedback.
7. Writer - Compiles and writes the final report including an introduction, conclusion and references section from the given research findings.
8. Publisher - Publishes the final report to multi formats such as PDF, Docx, Markdown, etc.
### How to run
1. Install required packages:
```python theme={null}
pip install -r requirements.txt
```
2. Run the application:
```python theme={null}
python main.py
```
### Usage
To change the research query and customize the report, edit the `task.json` file in the main directory.
## Customization
The config.py enables you to customize GPT Researcher to your specific needs and preferences.
Thanks to our amazing community and contributions, GPT Researcher supports multiple LLMs and Retrievers. In addition, GPT Researcher can be tailored to various report formats (such as APA), word count, research iterations depth, etc.
GPT Researcher defaults to our recommended suite of integrations: [OpenAI](https://platform.openai.com/docs/overview) for LLM calls and [Tavily API](https://app.tavily.com/home) for retrieving realtime online information.
As seen below, OpenAI still stands as the superior LLM. We assume it will stay this way for some time, and that prices will only continue to decrease, while performance and speed increase over time.
It may not come as a surprise that our default search engine is Tavily. We're aimed at building our search engine to tailor the exact needs of searching and aggregating for the most factual and unbiased information for research tasks. We highly recommend using it with GPT Researcher, and more generally with LLM applications that are built with RAG.
Here is an example of the default config.py file found in `/gpt_researcher/config/`:
```python theme={null}
def __init__(self, config_file: str = None):
self.config_file = config_file
self.retriever = "tavily"
self.llm_provider = "openai"
self.fast_llm_model = "gpt-3.5-turbo"
self.smart_llm_model = "gpt-4o"
self.fast_token_limit = 2000
self.smart_token_limit = 4000
self.browse_chunk_max_length = 8192
self.summary_token_limit = 700
self.temperature = 0.6
self.user_agent = "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko)" \
" Chrome/119.0.0.0 Safari/537.36 Edg/119.0.0.0"
self.memory_backend = "local"
self.total_words = 1000
self.report_format = "apa"
self.max_iterations = 1
self.load_config_file()
```
Please note that you can also include your own external JSON file by adding the path in the config\_file param.
To learn more about additional LLM support you can check out the [Langchain supported LLMs documentation](https://python.langchain.com/docs/integrations/llms/). Simply pass different provider names in the `llm_provider` config param.
You can also change the search engine by modifying the retriever param to others such as `duckduckgo`, `googleAPI`, `googleSerp`, `searx` and more.
Please note that you might need to sign up and obtain an API key for any of the other supported retrievers and LLM providers.
## Agent Example
If you're interested in using GPT Researcher as a standalone agent, you can easily import it into any existing Python project. Below, is an example of calling the agent to generate a research report:
```python theme={null}
from gpt_researcher import GPTResearcher
import asyncio
# It is best to define global constants at the top of your script
QUERY = "What happened in the latest burning man floods?"
REPORT_TYPE = "research_report"
async def fetch_report(query, report_type):
"""
Fetch a research report based on the provided query and report type.
"""
researcher = GPTResearcher(query=query, report_type=report_type, config_path=None)
await researcher.conduct_research()
report = await researcher.write_report()
return report
async def generate_research_report():
"""
This is a sample script that executes an async main function to run a research report.
"""
report = await fetch_report(QUERY, REPORT_TYPE)
print(report)
if __name__ == "__main__":
asyncio.run(generate_research_report())
```
You can further enhance this example to use the returned report as context for generating valuable content such as news article, marketing content, email templates, newsletters, etc.
You can also use GPT Researcher to gather information about code documentation, business analysis, financial information and more. All of which can be used to complete much more complex tasks that require factual and high quality realtime information.
## Getting Started
**Step 0** - Install Python 3.11 or later. [See here](https://www.tutorialsteacher.com/python/install-python) for a step-by-step guide.
**Step 1** - Download the project and navigate to its directory
```python theme={null}
$ git clone https://github.com/assafelovic/gpt-researcher.git
$ cd gpt-researcher
```
**Step 2** - Set up API keys using two methods: exporting them directly or storing them in a `.env` file.
For Linux/Temporary Windows Setup, use the export method:
```python theme={null}
export OPENAI_API_KEY={Your OpenAI API Key here}
export TAVILY_API_KEY={Your Tavily API Key here}
```
For a more permanent setup, create a `.env` file in the current gpt-researcher folder and input the keys as follows:
```python theme={null}
OPENAI_API_KEY={Your OpenAI API Key here}
TAVILY_API_KEY={Your Tavily API Key here}
```
For LLM, we recommend [OpenAI GPT](https://platform.openai.com/docs/guides/text-generation), but you can use any other LLM model (including open sources), simply change the llm model and provider in config/config.py.
For search engine, we recommend [Tavily Search API](https://app.tavily.com/home), but you can also refer to other search engines of your choice by changing the search provider in config/config.py to `duckduckgo`, `googleAPI`, `googleSerp`, `searx`, or `bing`. Then add the corresponding env API key as seen in the config.py file.
### Quickstart
**Step 1** - Install dependencies
```python theme={null}
$ pip install -r requirements.txt
```
**Step 2** - Run the agent with FastAPI
```python theme={null}
$ uvicorn main:app --reload
```
**Step 3** - Go to [http://localhost:8000](http://localhost:8000) on any browser and enjoy researching!
### Using Virtual Environment or Poetry
Select either based on your familiarity with each:
### Virtual Environment
Establishing the Virtual Environment with Activate/Deactivate configuration
Create a virtual environment using the `venv` package with the environment name `
### Steps
More specifically (as seen in the architecture diagram) the process is as follows:
1. Browser (gpt-researcher) - Browses the internet for initial research based on the given research task.
2. Editor - Plans the report outline and structure based on the initial research.
3. For each outline topic (in parallel):
4. Researcher (gpt-researcher) - Runs an in depth research on the subtopics and writes a draft.
5. Reviewer - Validates the correctness of the draft given a set of criteria and provides feedback.
6. Revisor - Revises the draft until it is satisfactory based on the reviewer feedback.
7. Writer - Compiles and writes the final report including an introduction, conclusion and references section from the given research findings.
8. Publisher - Publishes the final report to multi formats such as PDF, Docx, Markdown, etc.
### How to run
1. Install required packages:
```python theme={null}
pip install -r requirements.txt
```
2. Run the application:
```python theme={null}
python main.py
```
### Usage
To change the research query and customize the report, edit the `task.json` file in the main directory.
## Customization
The config.py enables you to customize GPT Researcher to your specific needs and preferences.
Thanks to our amazing community and contributions, GPT Researcher supports multiple LLMs and Retrievers. In addition, GPT Researcher can be tailored to various report formats (such as APA), word count, research iterations depth, etc.
GPT Researcher defaults to our recommended suite of integrations: [OpenAI](https://platform.openai.com/docs/overview) for LLM calls and [Tavily API](https://app.tavily.com/home) for retrieving realtime online information.
As seen below, OpenAI still stands as the superior LLM. We assume it will stay this way for some time, and that prices will only continue to decrease, while performance and speed increase over time.
It may not come as a surprise that our default search engine is Tavily. We're aimed at building our search engine to tailor the exact needs of searching and aggregating for the most factual and unbiased information for research tasks. We highly recommend using it with GPT Researcher, and more generally with LLM applications that are built with RAG.
Here is an example of the default config.py file found in `/gpt_researcher/config/`:
```python theme={null}
def __init__(self, config_file: str = None):
self.config_file = config_file
self.retriever = "tavily"
self.llm_provider = "openai"
self.fast_llm_model = "gpt-3.5-turbo"
self.smart_llm_model = "gpt-4o"
self.fast_token_limit = 2000
self.smart_token_limit = 4000
self.browse_chunk_max_length = 8192
self.summary_token_limit = 700
self.temperature = 0.6
self.user_agent = "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko)" \
" Chrome/119.0.0.0 Safari/537.36 Edg/119.0.0.0"
self.memory_backend = "local"
self.total_words = 1000
self.report_format = "apa"
self.max_iterations = 1
self.load_config_file()
```
Please note that you can also include your own external JSON file by adding the path in the config\_file param.
To learn more about additional LLM support you can check out the [Langchain supported LLMs documentation](https://python.langchain.com/docs/integrations/llms/). Simply pass different provider names in the `llm_provider` config param.
You can also change the search engine by modifying the retriever param to others such as `duckduckgo`, `googleAPI`, `googleSerp`, `searx` and more.
Please note that you might need to sign up and obtain an API key for any of the other supported retrievers and LLM providers.
## Agent Example
If you're interested in using GPT Researcher as a standalone agent, you can easily import it into any existing Python project. Below, is an example of calling the agent to generate a research report:
```python theme={null}
from gpt_researcher import GPTResearcher
import asyncio
# It is best to define global constants at the top of your script
QUERY = "What happened in the latest burning man floods?"
REPORT_TYPE = "research_report"
async def fetch_report(query, report_type):
"""
Fetch a research report based on the provided query and report type.
"""
researcher = GPTResearcher(query=query, report_type=report_type, config_path=None)
await researcher.conduct_research()
report = await researcher.write_report()
return report
async def generate_research_report():
"""
This is a sample script that executes an async main function to run a research report.
"""
report = await fetch_report(QUERY, REPORT_TYPE)
print(report)
if __name__ == "__main__":
asyncio.run(generate_research_report())
```
You can further enhance this example to use the returned report as context for generating valuable content such as news article, marketing content, email templates, newsletters, etc.
You can also use GPT Researcher to gather information about code documentation, business analysis, financial information and more. All of which can be used to complete much more complex tasks that require factual and high quality realtime information.
## Getting Started
**Step 0** - Install Python 3.11 or later. [See here](https://www.tutorialsteacher.com/python/install-python) for a step-by-step guide.
**Step 1** - Download the project and navigate to its directory
```python theme={null}
$ git clone https://github.com/assafelovic/gpt-researcher.git
$ cd gpt-researcher
```
**Step 2** - Set up API keys using two methods: exporting them directly or storing them in a `.env` file.
For Linux/Temporary Windows Setup, use the export method:
```python theme={null}
export OPENAI_API_KEY={Your OpenAI API Key here}
export TAVILY_API_KEY={Your Tavily API Key here}
```
For a more permanent setup, create a `.env` file in the current gpt-researcher folder and input the keys as follows:
```python theme={null}
OPENAI_API_KEY={Your OpenAI API Key here}
TAVILY_API_KEY={Your Tavily API Key here}
```
For LLM, we recommend [OpenAI GPT](https://platform.openai.com/docs/guides/text-generation), but you can use any other LLM model (including open sources), simply change the llm model and provider in config/config.py.
For search engine, we recommend [Tavily Search API](https://app.tavily.com/home), but you can also refer to other search engines of your choice by changing the search provider in config/config.py to `duckduckgo`, `googleAPI`, `googleSerp`, `searx`, or `bing`. Then add the corresponding env API key as seen in the config.py file.
### Quickstart
**Step 1** - Install dependencies
```python theme={null}
$ pip install -r requirements.txt
```
**Step 2** - Run the agent with FastAPI
```python theme={null}
$ uvicorn main:app --reload
```
**Step 3** - Go to [http://localhost:8000](http://localhost:8000) on any browser and enjoy researching!
### Using Virtual Environment or Poetry
Select either based on your familiarity with each:
### Virtual Environment
Establishing the Virtual Environment with Activate/Deactivate configuration
Create a virtual environment using the `venv` package with the environment name `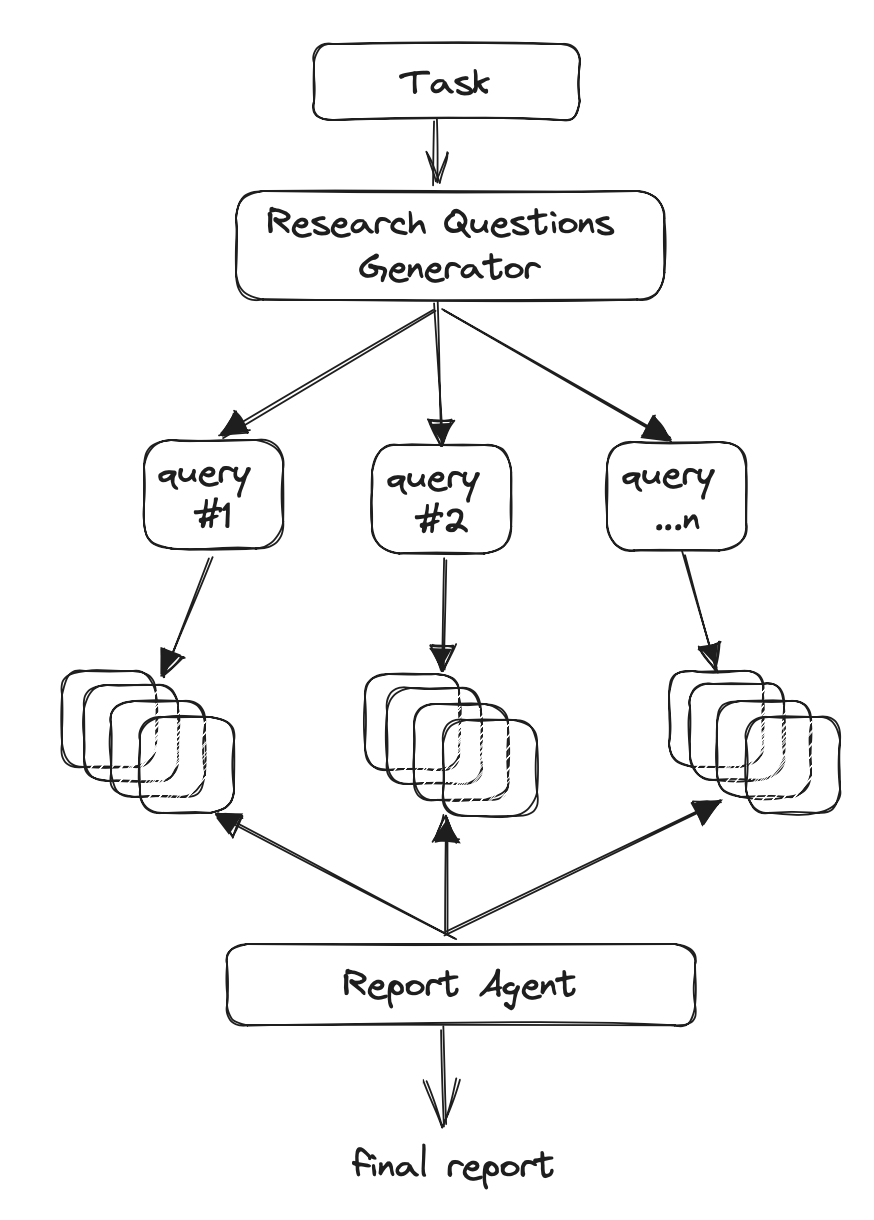 More specifically:
1. Create a domain specific agent based on research query or task.
2. Generate a set of research questions that together form an objective opinion on any given task.
3. For each research question, trigger a crawler agent that scrapes online resources for information relevant to the given task.
4. For each scraped resources, summarize based on relevant information and keep track of its sources.
5. Finally, filter and aggregate all summarized sources and generate a final research report.
### Demo
### Tutorials
1. [How it Works](https://medium.com/better-programming/how-i-built-an-autonomous-ai-agent-for-online-research-93435a97c6c)
2. [How to Install](https://www.loom.com/share/04ebffb6ed2a4520a27c3e3addcdde20?sid=da1848e8-b1f1-42d1-93c3-5b0b9c3b24ea)
3. [Live Demo](https://www.loom.com/share/6a3385db4e8747a1913dd85a7834846f?sid=a740fd5b-2aa3-457e-8fb7-86976f59f9b8)
4. [Home Page](https://gptr.dev/)
### Features
1. 📝 Generate research, outlines, resources and lessons reports
2. 📜 Can generate long and detailed research reports (over 2K words)
3. 🌐 Aggregates over 20 web sources per research to form objective and factual conclusions
4. 🖥️ Includes an easy-to-use web interface (HTML/CSS/JS)
5. 🔍 Scrapes web sources with javascript support
6. 📂 Keeps track and context of visited and used web sources
7. 📄 Export research reports to PDF, Word and more...
### Disclaimer
This project, GPT Researcher, is an experimental application and is provided "as-is" without any warranty, express or implied. We are sharing codes for academic purposes under the MIT license. Nothing herein is academic advice, and NOT a recommendation to use in academic or research papers.
Our view on unbiased research claims:
The whole point of our scraping system is to reduce incorrect fact. How? The more sites we scrape the less chances of incorrect data. We are scraping 20 per research, the chances that they are all wrong is extremely low.
We do not aim to eliminate biases; we aim to reduce it as much as possible. We are here as a community to figure out the most effective human/llm interactions.
In research, people also tend towards biases as most have already opinions on the topics they research about. This tool scrapes many opinions and will evenly explain diverse views that a biased person would never have read.
Please note that the use of the GPT-4 language model can be expensive due to its token usage. By utilizing this project, you acknowledge that you are responsible for monitoring and managing your own token usage and the associated costs. It is highly recommended to check your OpenAI API usage regularly and set up any necessary limits or alerts to prevent unexpected charges.
## PIP Package
🌟 Exciting News! Now, you can integrate gpt-researcher with your apps seamlessly!
### Steps to Install GPT Researcher 🛠️
Follow these easy steps to get started:
0. Pre-requisite: Ensure Python 3.10+ is installed on your machine 💻
1. Install gpt-researcher: Grab the official package from [PyPi](https://pypi.org/project/gpt-researcher/).
```python theme={null}
pip install gpt-researcher
```
2. Environment Variables: Create a .env file with your OpenAI API key or simply export it
```python theme={null}
export OPENAI_API_KEY={Your OpenAI API Key here}
export TAVILY_API_KEY={Your Tavily API Key here}
```
3. Start using GPT Researcher in your own codebase
### Example Usage 📝
```python theme={null}
from gpt_researcher import GPTResearcher
import asyncio
from gpt_researcher import GPTResearcher
import asyncio
async def get_report(query: str, report_type: str) -> str:
researcher = GPTResearcher(query, report_type)
research_result = await researcher.conduct_research()
report = await researcher.write_report()
return report
if __name__ == "__main__":
query = "what team may win the NBA finals?"
report_type = "research_report"
report = asyncio.run(get_report(query, report_type))
print(report)
```
### Specific Examples 🌐
Example 1: Research Report 📚
```python theme={null}
query = "Latest developments in renewable energy technologies"
report_type = "research_report"
```
Example 2: Resource Report 📋
```python theme={null}
query = "List of top AI conferences in 2023"
report_type = "resource_report"
```
Example 3: Outline Report 📝
```python theme={null}
query = "Outline for an article on the impact of AI in education"
report_type = "outline_report"
```
### Integration with Web Frameworks 🌍
FastAPI Example:
```python theme={null}
from fastapi import FastAPI
from gpt_researcher import GPTResearcher
import asyncio
app = FastAPI()
@app.get("/report/{report_type}")
async def get_report(query: str, report_type: str) -> dict:
researcher = GPTResearcher(query, report_type)
research_result = await researcher.conduct_research()
report = await researcher.write_report()
return {"report": report}
# Run the server
# uvicorn main:app --reload
```
Flask Example
Pre-requisite: Install flask with the async extra.
```python theme={null}
pip install 'flask[async]'
```
```python theme={null}
from flask import Flask, request
from gpt_researcher import GPTResearcher
app = Flask(__name__)
@app.route('/report/
More specifically:
1. Create a domain specific agent based on research query or task.
2. Generate a set of research questions that together form an objective opinion on any given task.
3. For each research question, trigger a crawler agent that scrapes online resources for information relevant to the given task.
4. For each scraped resources, summarize based on relevant information and keep track of its sources.
5. Finally, filter and aggregate all summarized sources and generate a final research report.
### Demo
### Tutorials
1. [How it Works](https://medium.com/better-programming/how-i-built-an-autonomous-ai-agent-for-online-research-93435a97c6c)
2. [How to Install](https://www.loom.com/share/04ebffb6ed2a4520a27c3e3addcdde20?sid=da1848e8-b1f1-42d1-93c3-5b0b9c3b24ea)
3. [Live Demo](https://www.loom.com/share/6a3385db4e8747a1913dd85a7834846f?sid=a740fd5b-2aa3-457e-8fb7-86976f59f9b8)
4. [Home Page](https://gptr.dev/)
### Features
1. 📝 Generate research, outlines, resources and lessons reports
2. 📜 Can generate long and detailed research reports (over 2K words)
3. 🌐 Aggregates over 20 web sources per research to form objective and factual conclusions
4. 🖥️ Includes an easy-to-use web interface (HTML/CSS/JS)
5. 🔍 Scrapes web sources with javascript support
6. 📂 Keeps track and context of visited and used web sources
7. 📄 Export research reports to PDF, Word and more...
### Disclaimer
This project, GPT Researcher, is an experimental application and is provided "as-is" without any warranty, express or implied. We are sharing codes for academic purposes under the MIT license. Nothing herein is academic advice, and NOT a recommendation to use in academic or research papers.
Our view on unbiased research claims:
The whole point of our scraping system is to reduce incorrect fact. How? The more sites we scrape the less chances of incorrect data. We are scraping 20 per research, the chances that they are all wrong is extremely low.
We do not aim to eliminate biases; we aim to reduce it as much as possible. We are here as a community to figure out the most effective human/llm interactions.
In research, people also tend towards biases as most have already opinions on the topics they research about. This tool scrapes many opinions and will evenly explain diverse views that a biased person would never have read.
Please note that the use of the GPT-4 language model can be expensive due to its token usage. By utilizing this project, you acknowledge that you are responsible for monitoring and managing your own token usage and the associated costs. It is highly recommended to check your OpenAI API usage regularly and set up any necessary limits or alerts to prevent unexpected charges.
## PIP Package
🌟 Exciting News! Now, you can integrate gpt-researcher with your apps seamlessly!
### Steps to Install GPT Researcher 🛠️
Follow these easy steps to get started:
0. Pre-requisite: Ensure Python 3.10+ is installed on your machine 💻
1. Install gpt-researcher: Grab the official package from [PyPi](https://pypi.org/project/gpt-researcher/).
```python theme={null}
pip install gpt-researcher
```
2. Environment Variables: Create a .env file with your OpenAI API key or simply export it
```python theme={null}
export OPENAI_API_KEY={Your OpenAI API Key here}
export TAVILY_API_KEY={Your Tavily API Key here}
```
3. Start using GPT Researcher in your own codebase
### Example Usage 📝
```python theme={null}
from gpt_researcher import GPTResearcher
import asyncio
from gpt_researcher import GPTResearcher
import asyncio
async def get_report(query: str, report_type: str) -> str:
researcher = GPTResearcher(query, report_type)
research_result = await researcher.conduct_research()
report = await researcher.write_report()
return report
if __name__ == "__main__":
query = "what team may win the NBA finals?"
report_type = "research_report"
report = asyncio.run(get_report(query, report_type))
print(report)
```
### Specific Examples 🌐
Example 1: Research Report 📚
```python theme={null}
query = "Latest developments in renewable energy technologies"
report_type = "research_report"
```
Example 2: Resource Report 📋
```python theme={null}
query = "List of top AI conferences in 2023"
report_type = "resource_report"
```
Example 3: Outline Report 📝
```python theme={null}
query = "Outline for an article on the impact of AI in education"
report_type = "outline_report"
```
### Integration with Web Frameworks 🌍
FastAPI Example:
```python theme={null}
from fastapi import FastAPI
from gpt_researcher import GPTResearcher
import asyncio
app = FastAPI()
@app.get("/report/{report_type}")
async def get_report(query: str, report_type: str) -> dict:
researcher = GPTResearcher(query, report_type)
research_result = await researcher.conduct_research()
report = await researcher.write_report()
return {"report": report}
# Run the server
# uvicorn main:app --reload
```
Flask Example
Pre-requisite: Install flask with the async extra.
```python theme={null}
pip install 'flask[async]'
```
```python theme={null}
from flask import Flask, request
from gpt_researcher import GPTResearcher
app = Flask(__name__)
@app.route('/report/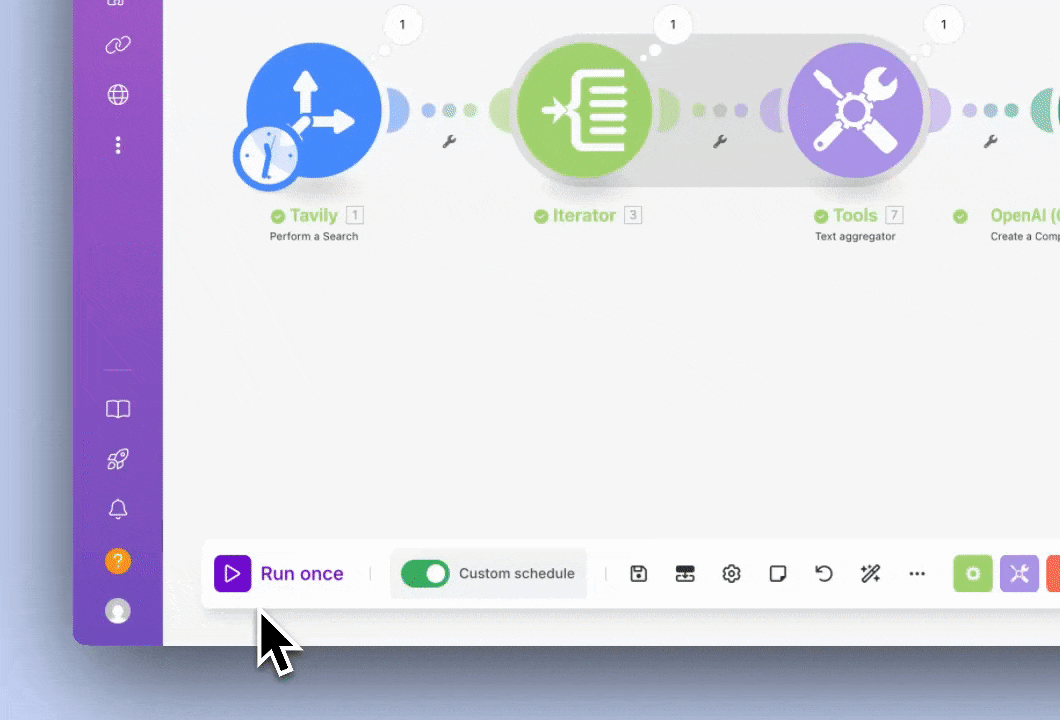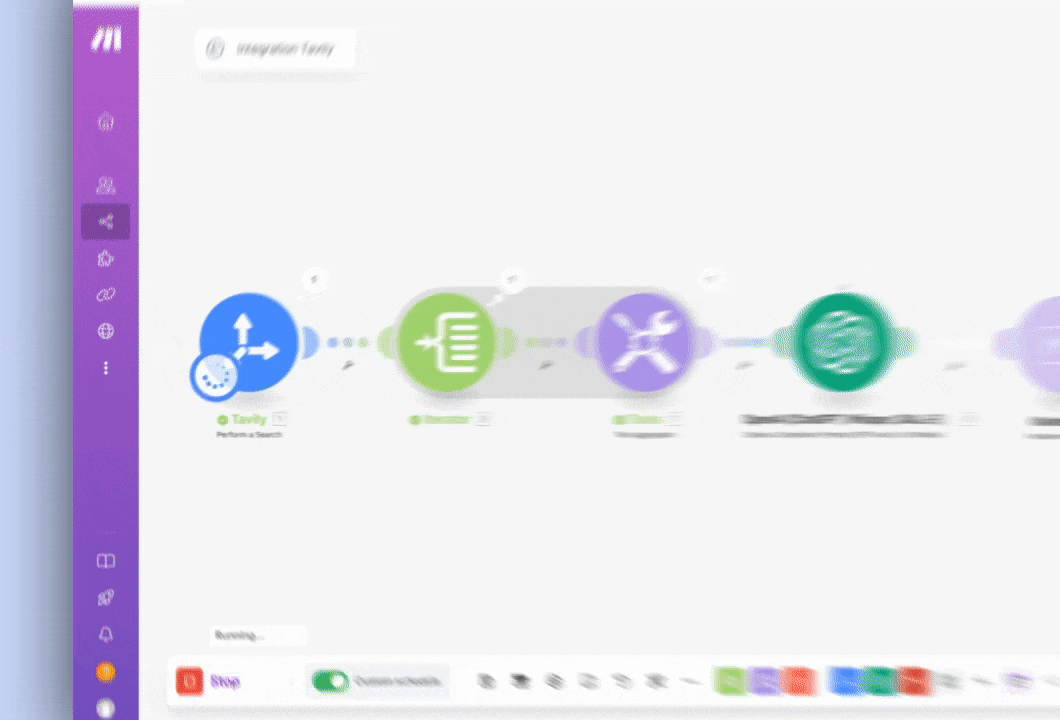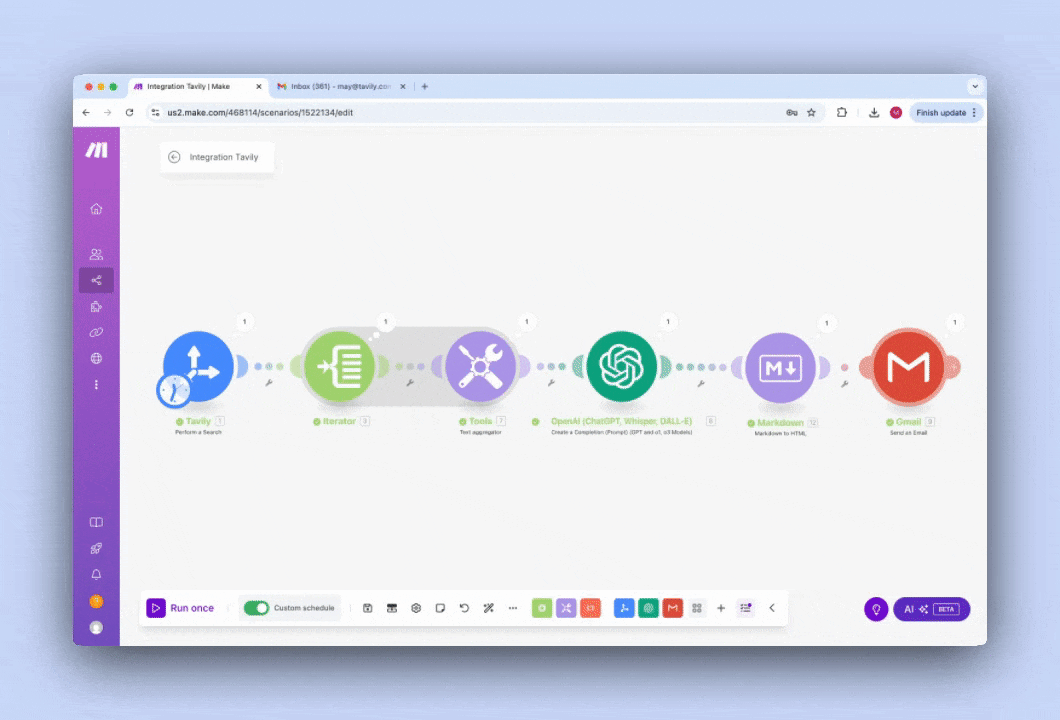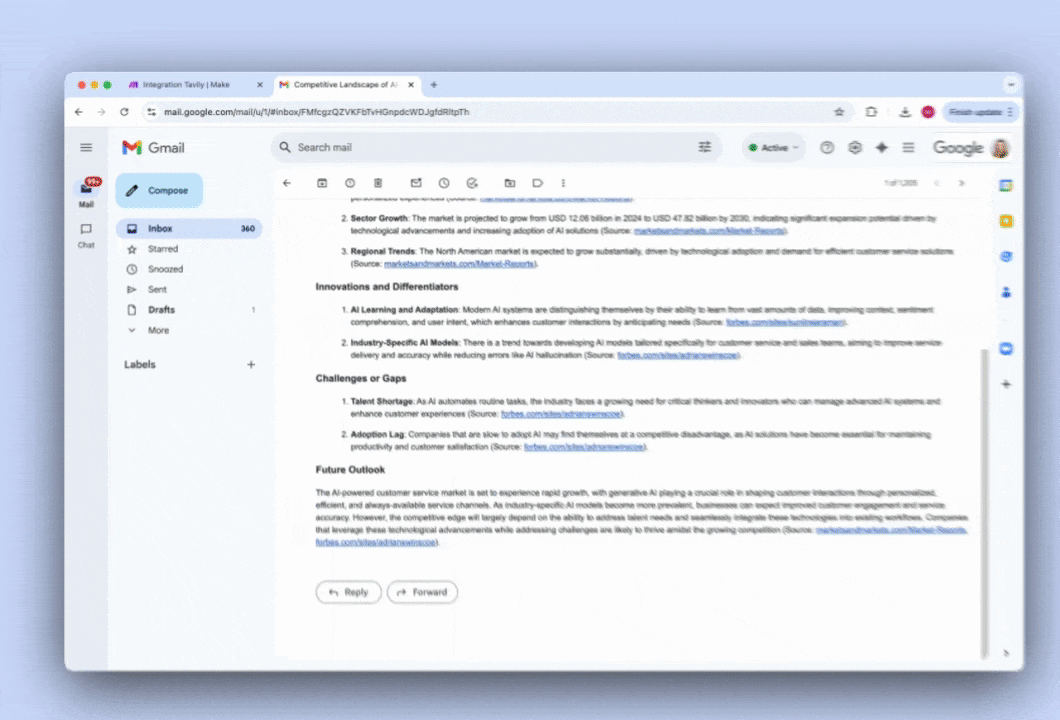 ## How to set up Tavily with Make
## How to set up Tavily with Make
Log in to your Make account.
Create a new scenario and select a trigger module that will start your workflow.
Add Tavily as an action module in your scenario and choose between **Perform a Search** or **Extract Raw Content**:
Connection: Connect your Tavily account by entering your [Tavily API key](https://app.tavily.com/home).
Configuration: Set up your parameters:
For Search:
For Extract:
Test: Run a test to verify your configuration.
Utilize the search results in your workflow:
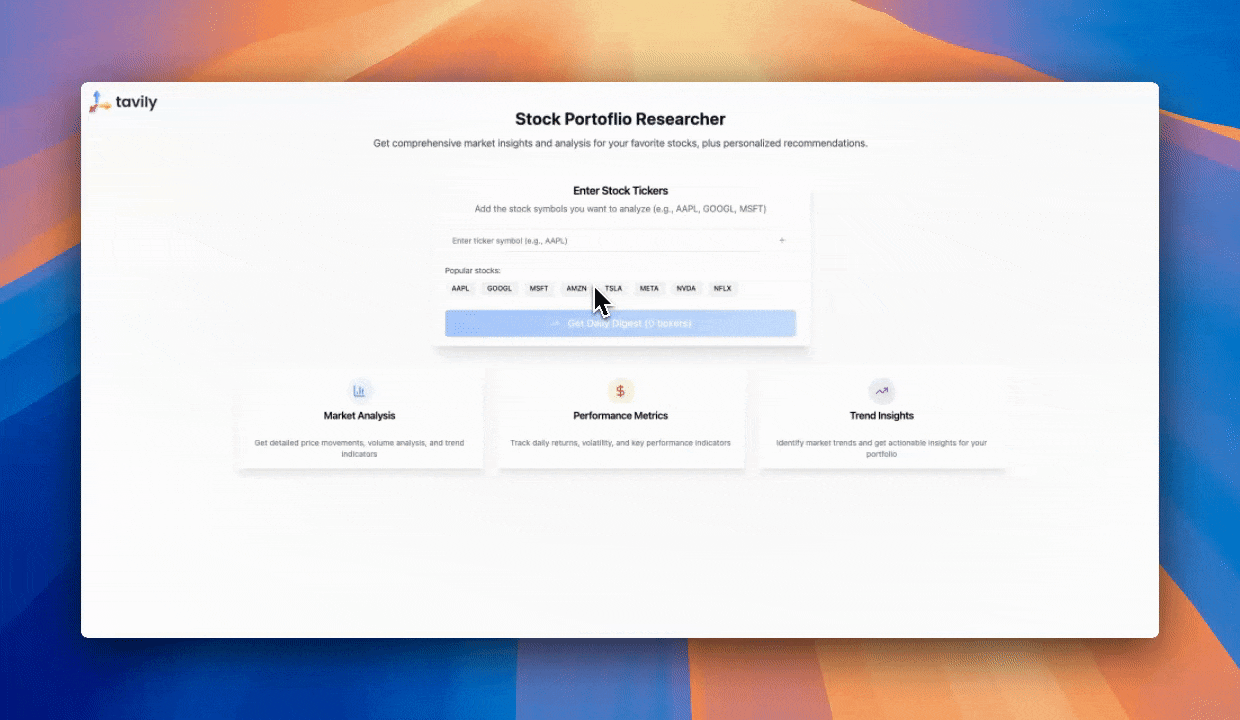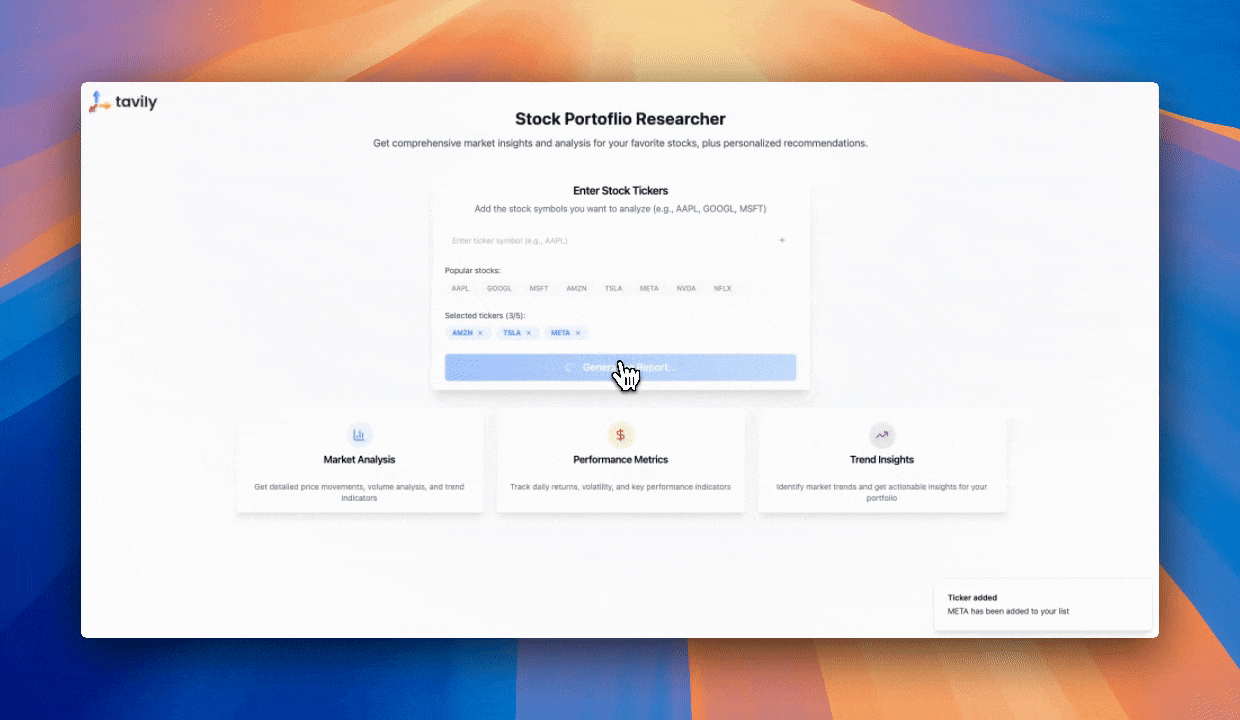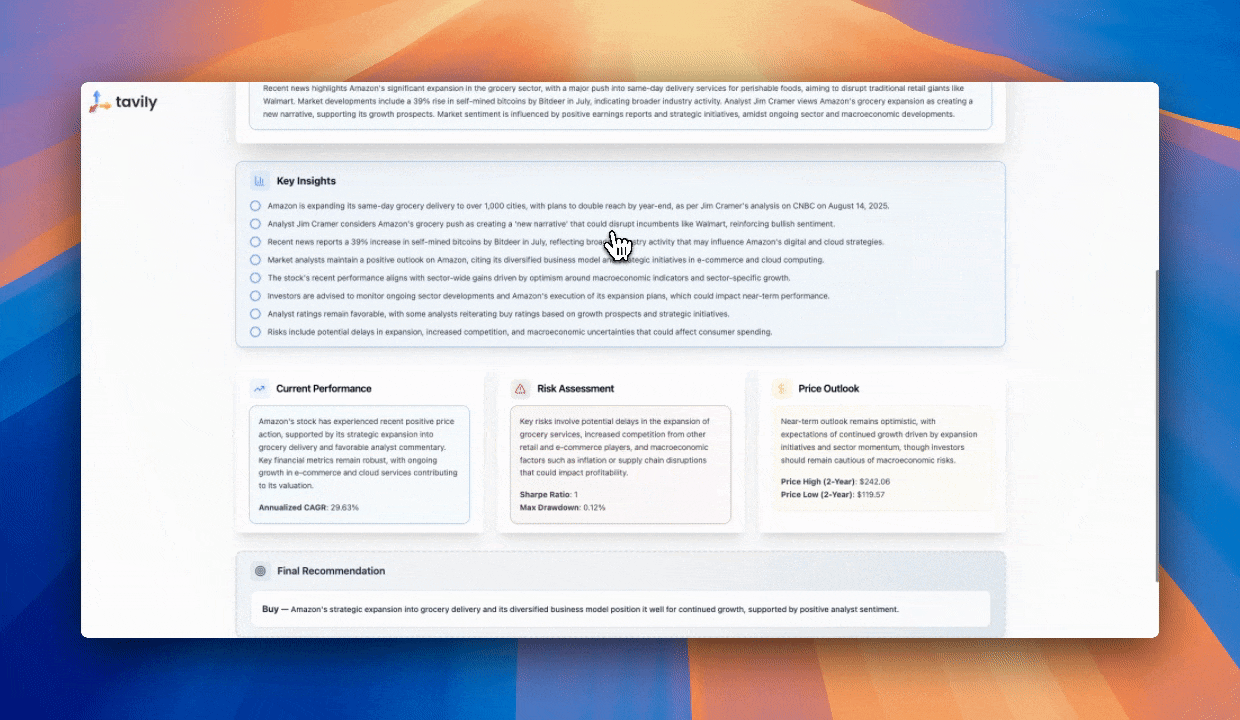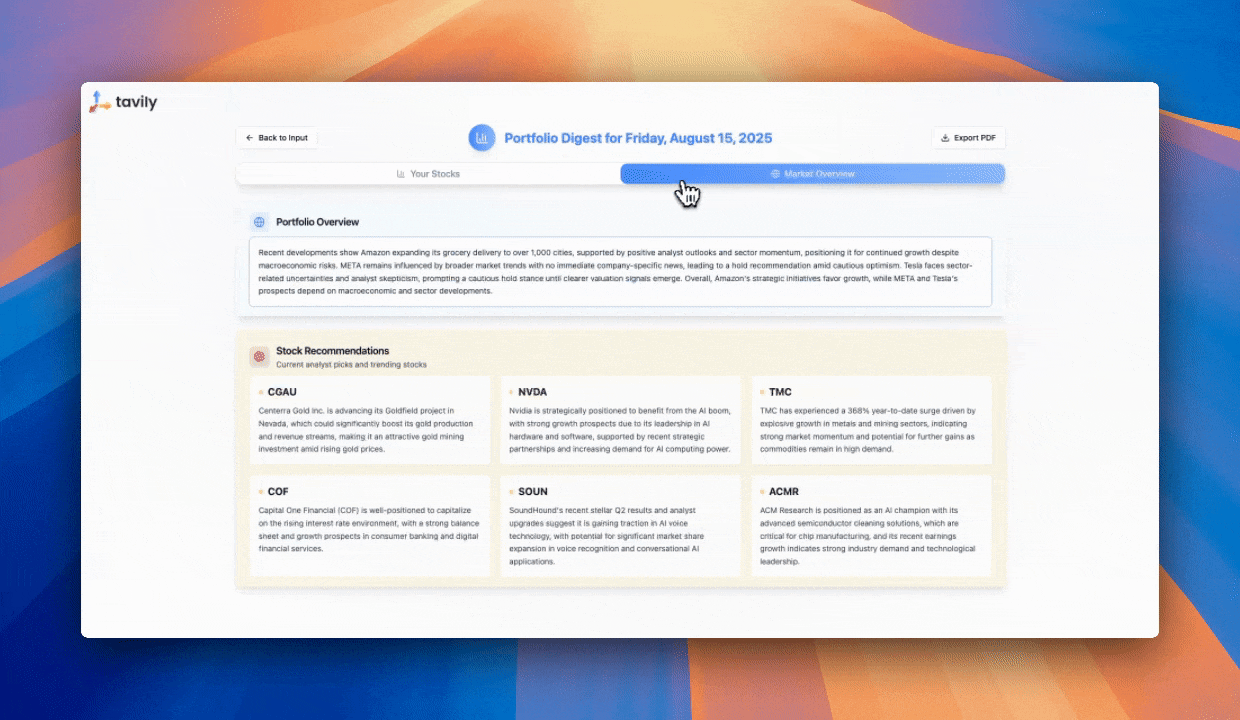 ## Try Our Market Researcher
### Step 1: Get Your API Key
## Try Our Market Researcher
### Step 1: Get Your API Key


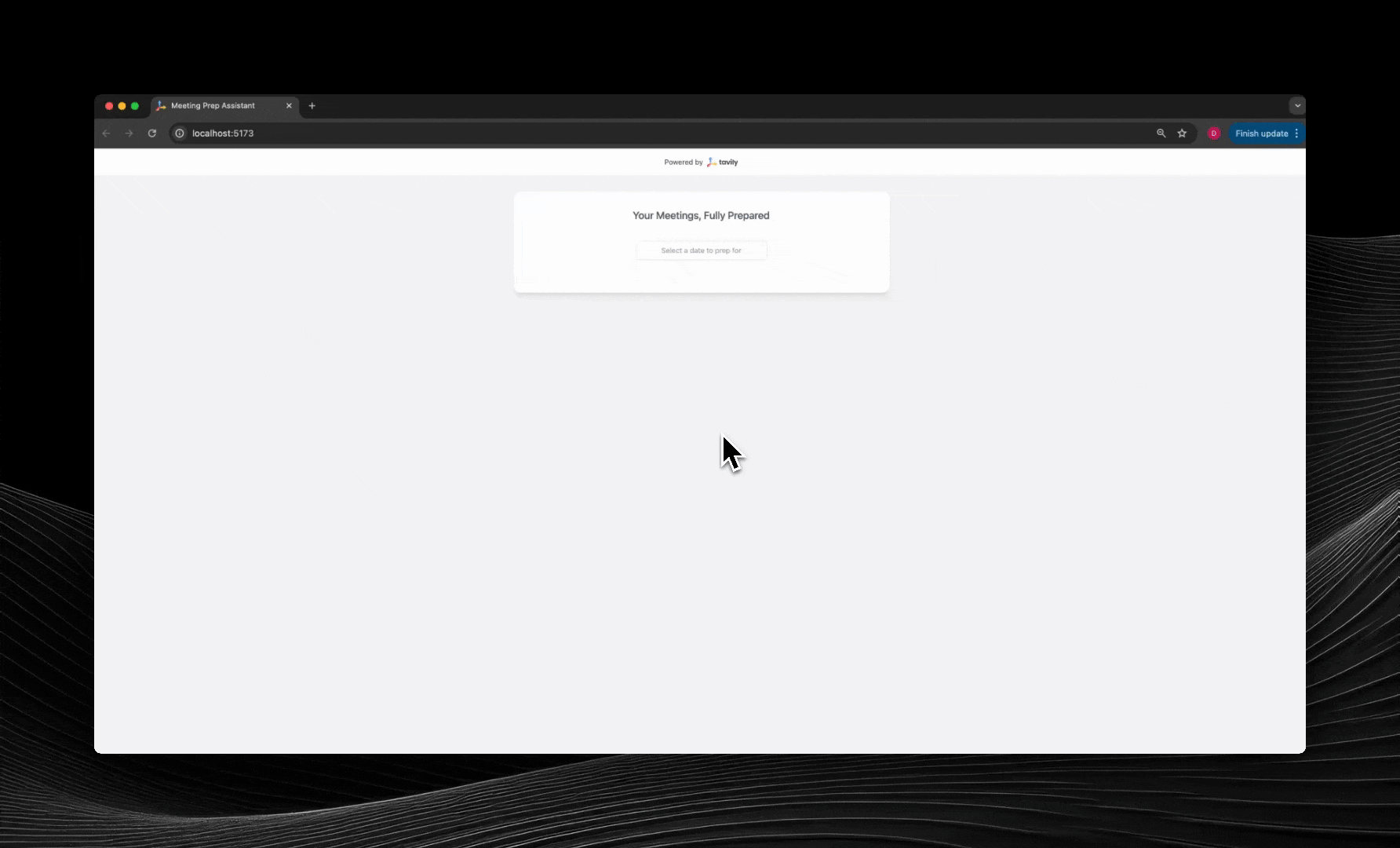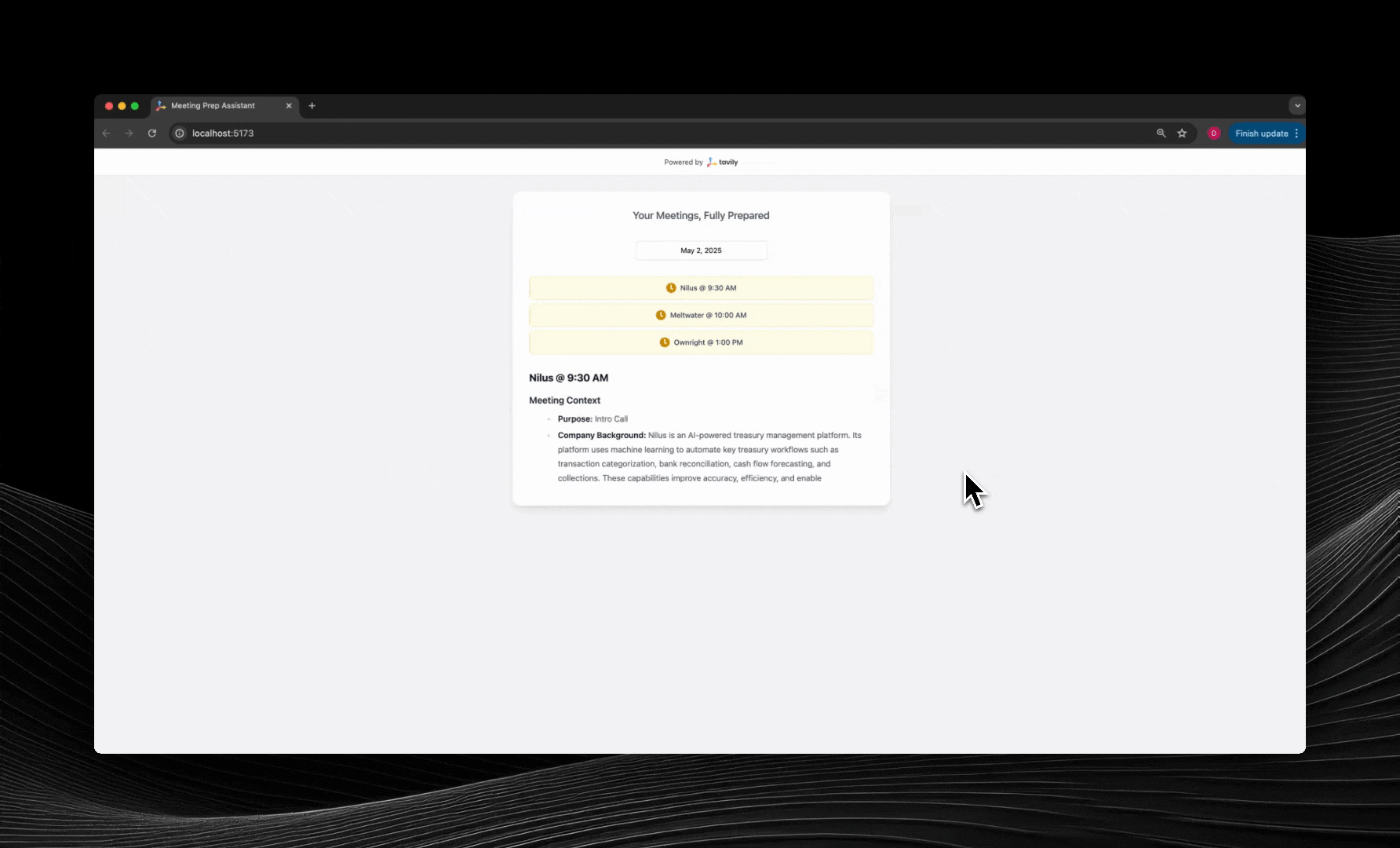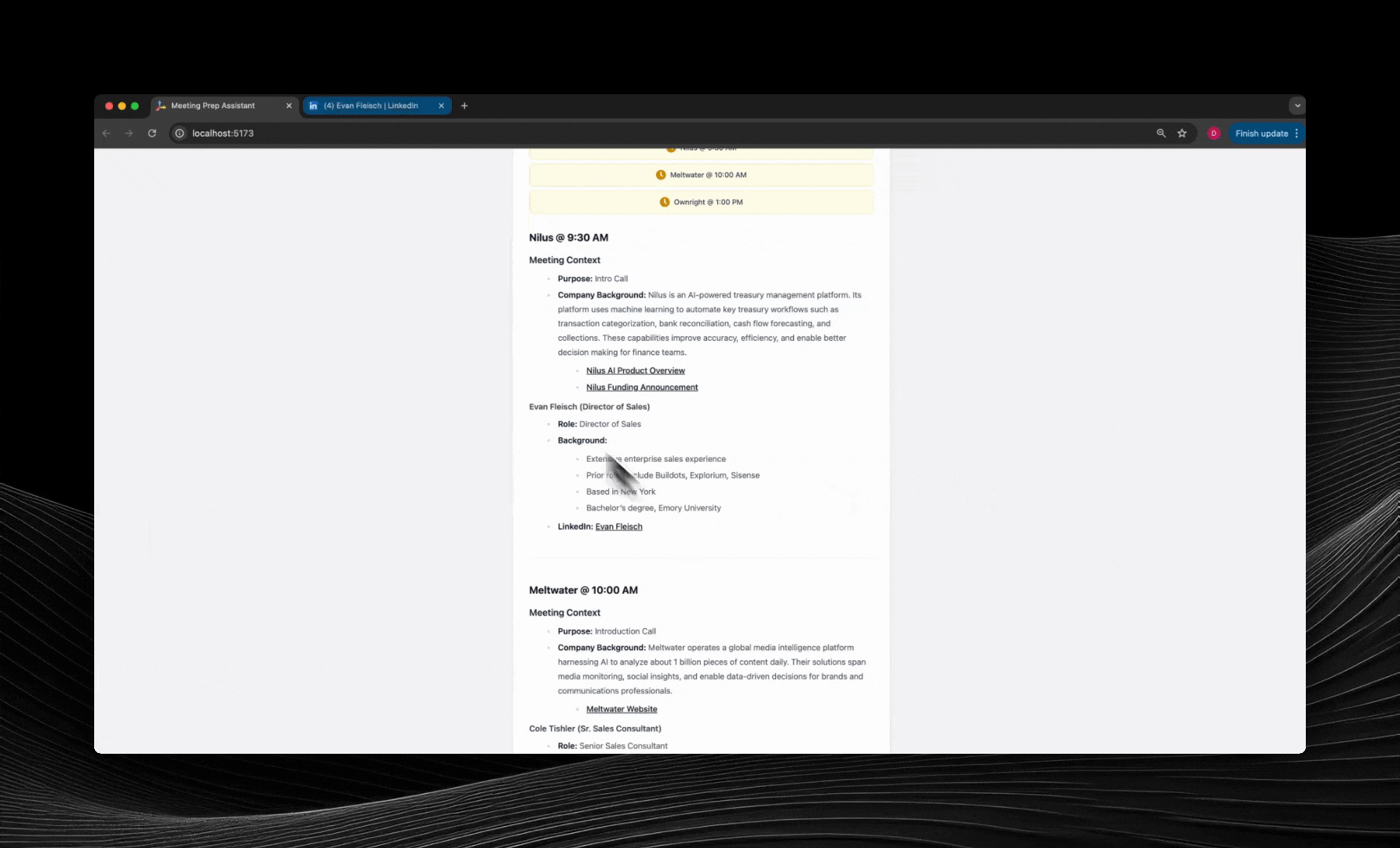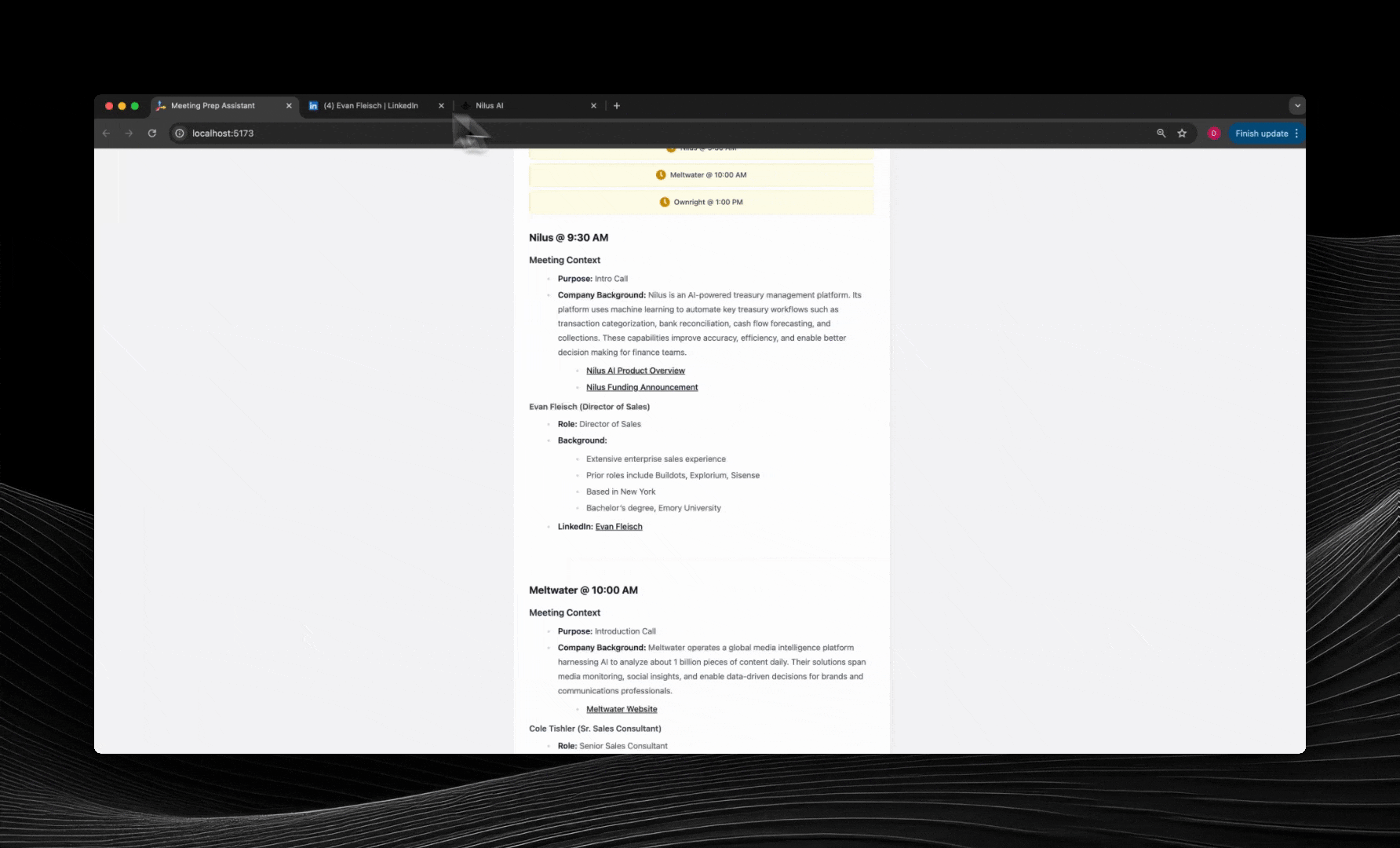 ## Try Our Meeting Prep Agent
### Step 1: Get Your API Key
## Try Our Meeting Prep Agent
### Step 1: Get Your API Key
 ## Features
1. **Real-time Web Search**: Instantly fetches up-to-date information using Tavily's search API.
2. **Agentic Reasoning**: Combines MCP and ReAct agent flows for smarter, context-aware responses.
3. **Streaming Substeps**: See agentic reasoning and substeps streamed live for transparency.
4. **Citations**: All web search results are cited for easy verification.
5. **Google Calendar Integration**: (via mcp-use) Access and analyze your meeting data.
6. **Async FastAPI Backend**: High-performance, async-ready backend for fast responses.
7. **Modern React Frontend**: Interactive UI for dynamic user interactions.
---
# Source: https://docs.tavily.com/documentation/integrations/n8n.md
> ## Documentation Index
> Fetch the complete documentation index at: https://docs.tavily.com/llms.txt
> Use this file to discover all available pages before exploring further.
# n8n
> Tavily is now available for no-code integration through n8n.
## Introduction
Integrate Tavily with n8n to enhance your workflows with real-time web search and content extraction—without writing code. With Tavily's powerful search and extraction capabilities, you can seamlessly integrate up-to-date online information into your n8n automations.
## Features
1. **Real-time Web Search**: Instantly fetches up-to-date information using Tavily's search API.
2. **Agentic Reasoning**: Combines MCP and ReAct agent flows for smarter, context-aware responses.
3. **Streaming Substeps**: See agentic reasoning and substeps streamed live for transparency.
4. **Citations**: All web search results are cited for easy verification.
5. **Google Calendar Integration**: (via mcp-use) Access and analyze your meeting data.
6. **Async FastAPI Backend**: High-performance, async-ready backend for fast responses.
7. **Modern React Frontend**: Interactive UI for dynamic user interactions.
---
# Source: https://docs.tavily.com/documentation/integrations/n8n.md
> ## Documentation Index
> Fetch the complete documentation index at: https://docs.tavily.com/llms.txt
> Use this file to discover all available pages before exploring further.
# n8n
> Tavily is now available for no-code integration through n8n.
## Introduction
Integrate Tavily with n8n to enhance your workflows with real-time web search and content extraction—without writing code. With Tavily's powerful search and extraction capabilities, you can seamlessly integrate up-to-date online information into your n8n automations.
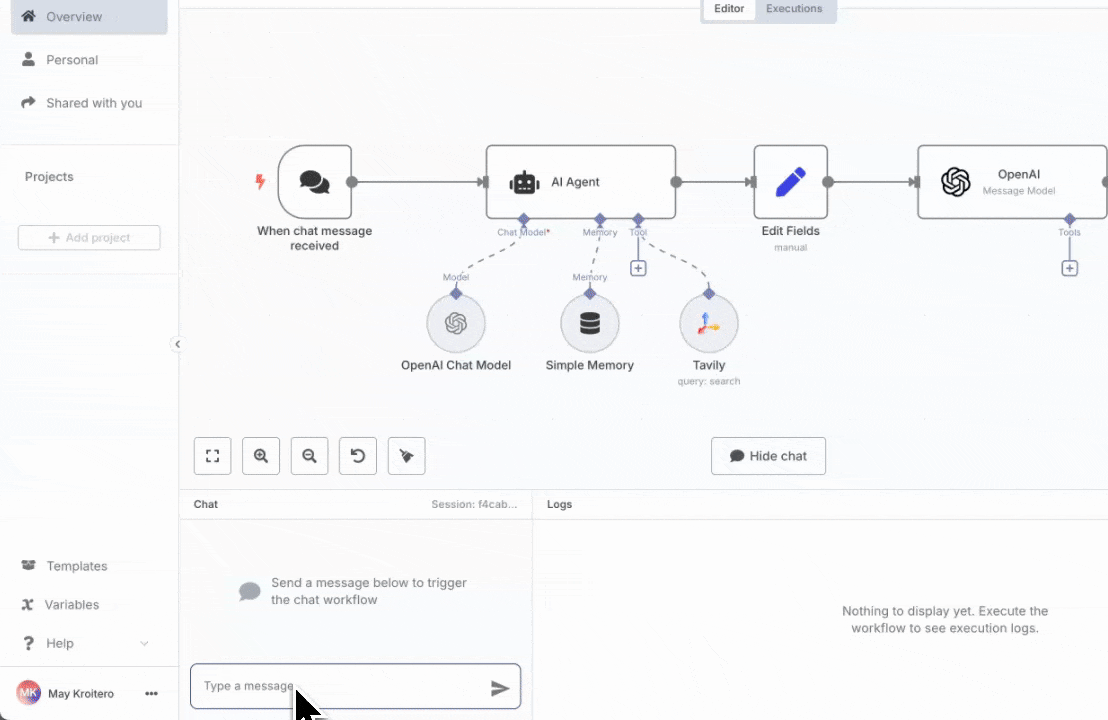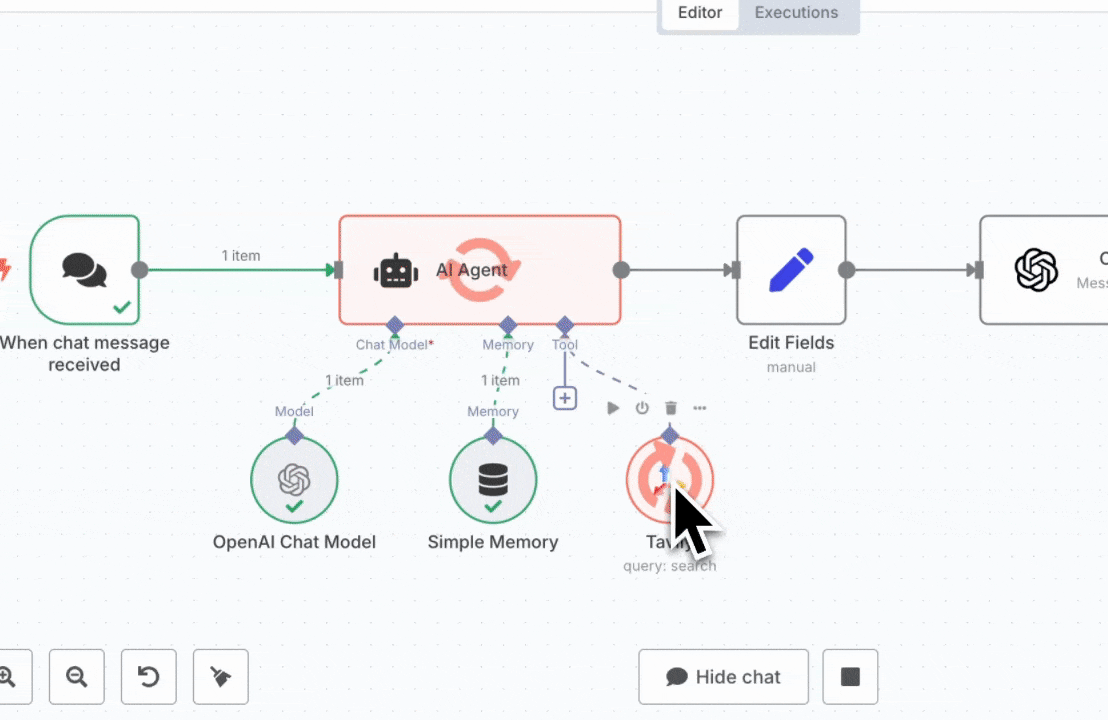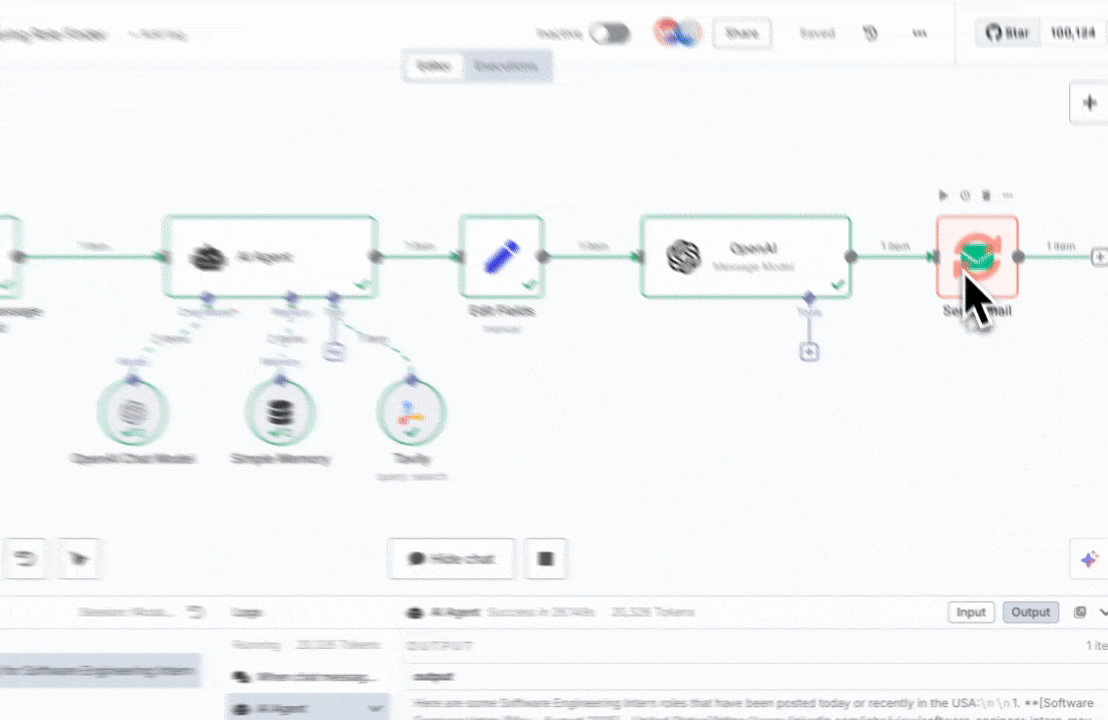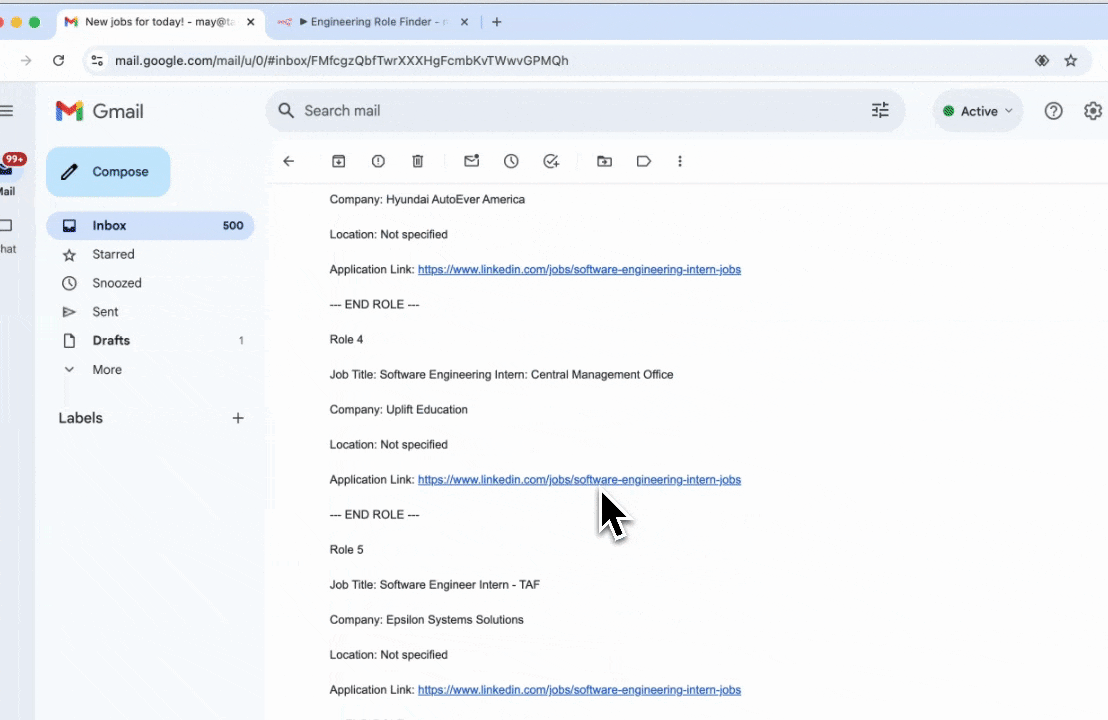 ## How to set up Tavily with n8n
## How to set up Tavily with n8n
Log in to your n8n account or self-hosted instance.
Create a new workflow and select a trigger node to start your automation.
Option 1: Add Tavily as a Node
In the node library, search for Tavily. Add it to your workflow and choose between Search or Extract actions.
Option 2: Add Tavily as a Tool to an AI Agent
If you are building an AI agent workflow, you can add Tavily as a tool to your agent. This allows your agent to use Tavily for web search or content extraction as part of its reasoning process.
Connection: Connect your Tavily account by entering your Tavily API key.
Configuration: Set up your parameters:
For Search:
query (can be manually entered or populated from another node's output)topic ("general" or "news")For Extract:
Test: Run a test to verify your configuration.
Utilize the search or extraction results in your workflow:
Repository data unavailable
View on GitHub →{repoData.owner}/ {repoData.name}
{repoData.description || 'No description available'}
Unable to load repository data. Please try again later.
Browse projects on GitHub →

| Environment | Requests per minute (RPM) |
|---|---|
Development |
100 |
Production |
1,000 |
| Environment | Requests per minute (RPM) |
|---|---|
Development |
100 |
Production |
100 |
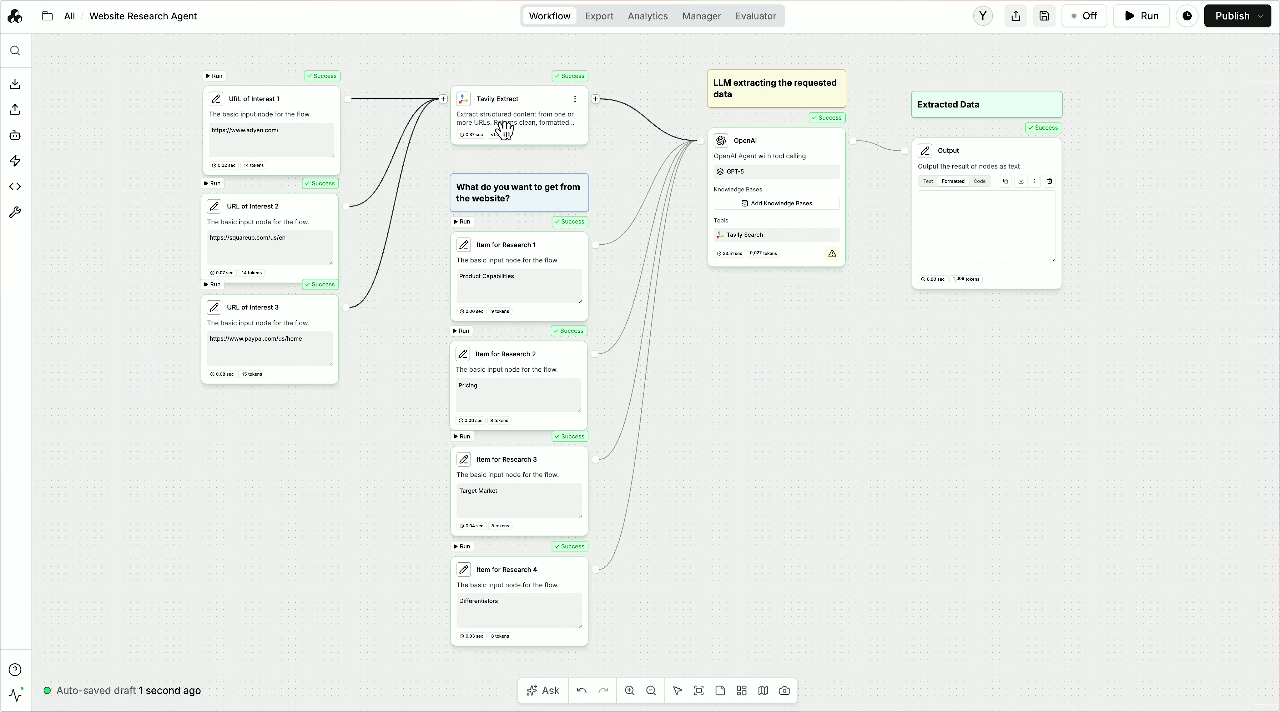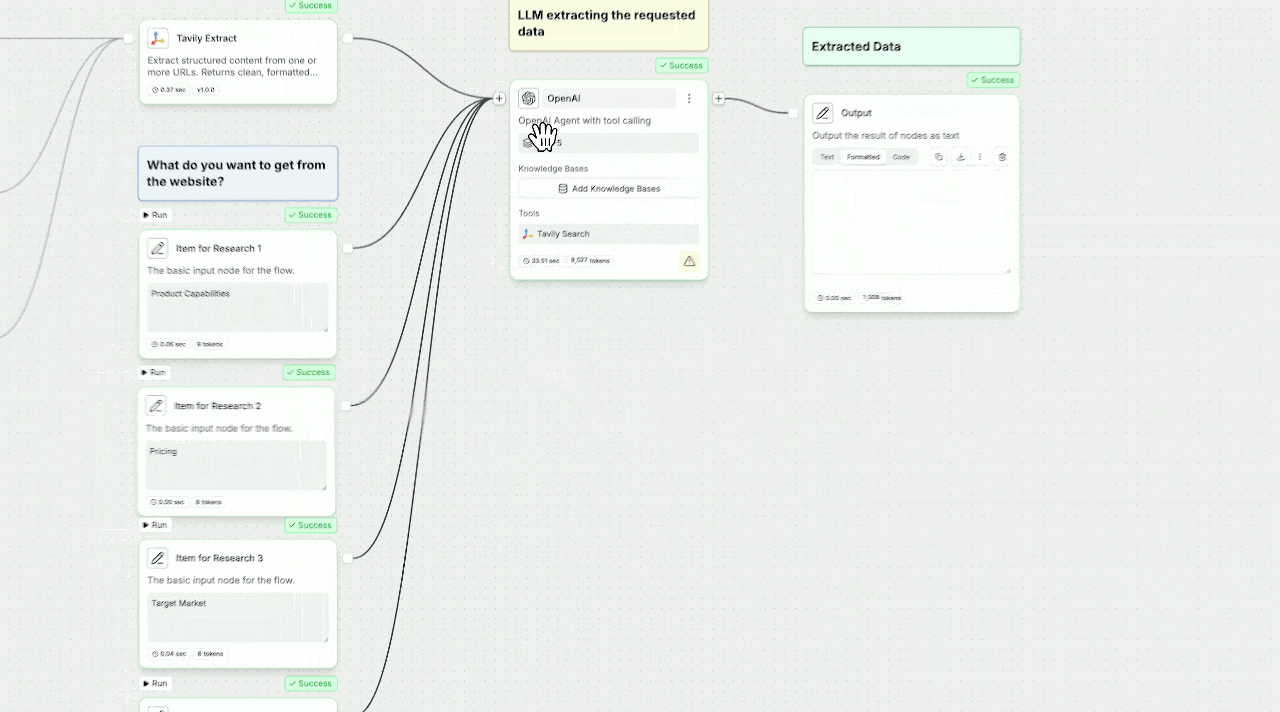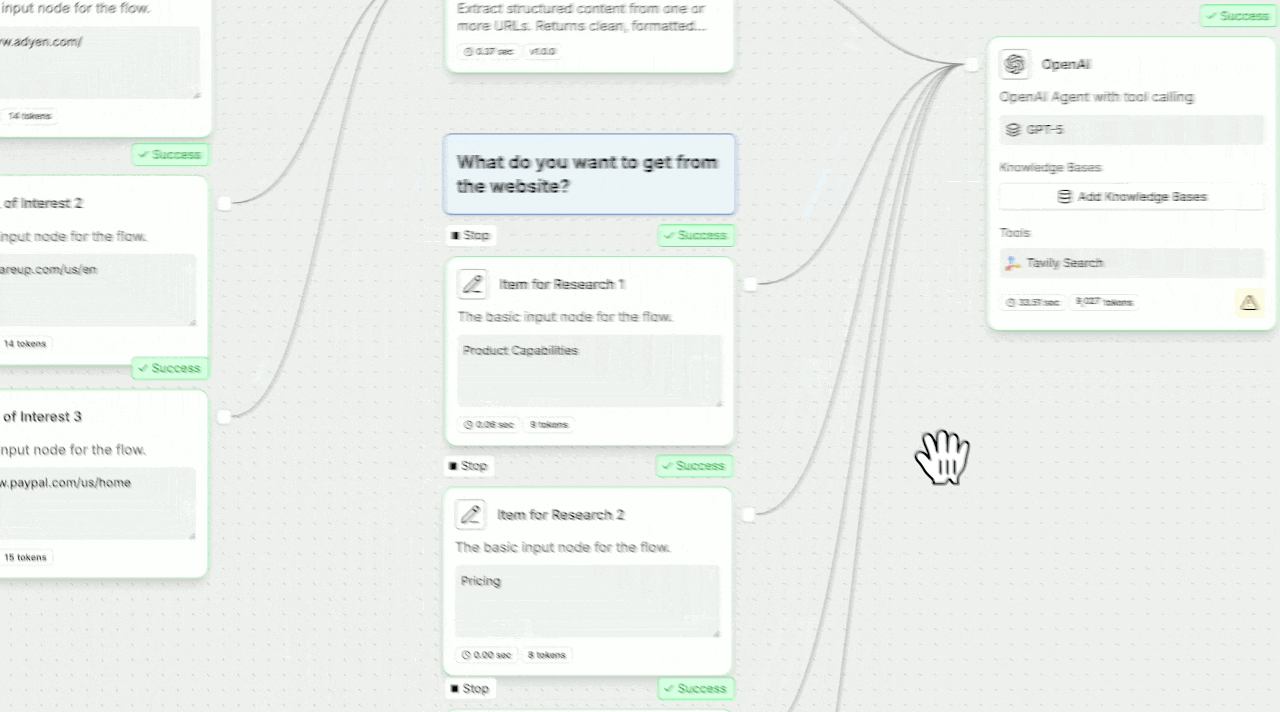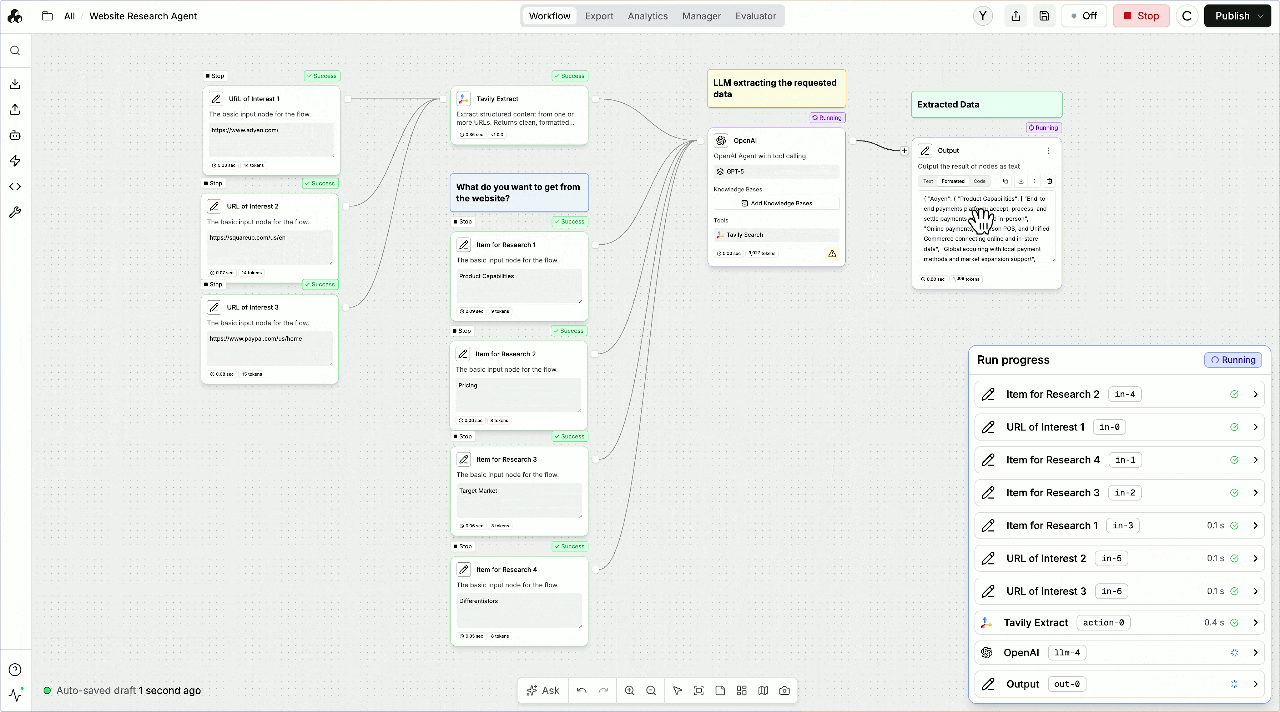 ## How to set up Tavily with StackAI
## How to set up Tavily with StackAI
Log in to your StackAI account or self-hosted instance.
Create a new workflow or choose one of the available templates.
**Option 1: Add Tavily as a Node**
**Option 2: Add Tavily as a Tool to an AI Agent**
**For Search:**
query (can be manually entered or
populated from another node's output)
topic ("general" or "news")
**For Extract:**
**For Crawl:**
**For Map:**
**Test:** Run the node to verify your configuration.
Utilize the search, crawl, extract, or map results in your workflow:
Log in to your Tines account.
Create a new story or open an existing one where you want to add Tavily.
Follow these steps to add a Tavily action to your story:
Use Tines built-in actions to process Tavily's response:
Enrich a company when it is added to an Airtable database. Receive a webhook notification when a new record is added and fill out the remaining fields with web searches powered by Tavily.
See the full story on Tines' library.
Search the internet using Tavily in response to a Slack slash command. Summarize the results and post them in a Slack thread, including source links. Users can click on the links to access more detailed information from the original sources.
See the full story on Tines' library.
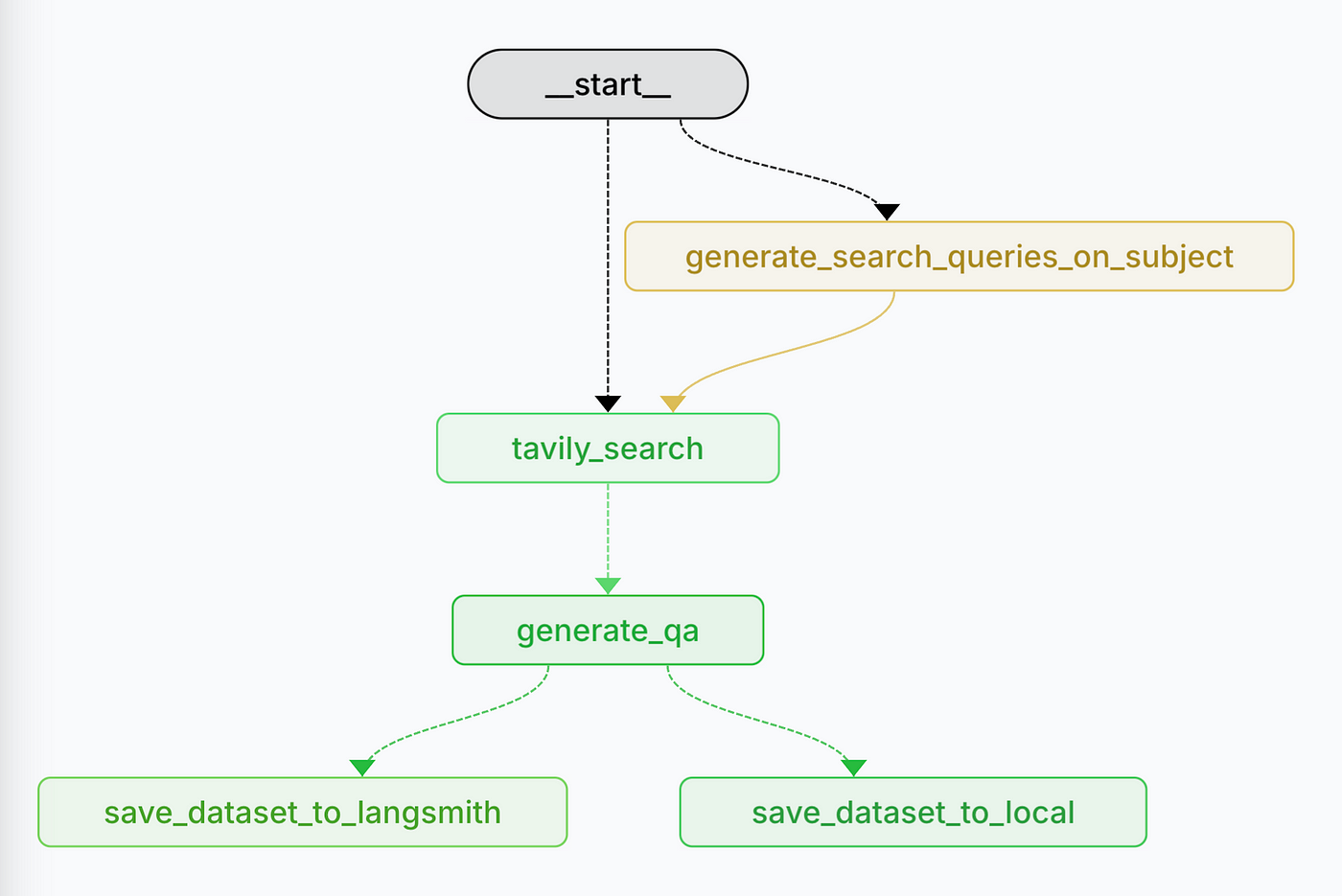 The Real-Time Dataset Generator follows a systematic workflow to create high-quality evaluation datasets:
The Real-Time Dataset Generator follows a systematic workflow to create high-quality evaluation datasets:

Your journey to state-of-the-art web search starts right here.
Log in to your Zapier account.
Create a new Zap and select a trigger event that will start your workflow.
Add an action step with Tavily in your workflow:
Use the `results` and optionally the `answer` generated by Tavily in the rest of your workflow, such as: