 ## Using an official base image
Pipecat Cloud provides a series of base images that we recommend for most use-cases. Base images provide:
* Simplified development and deployment
* Optimizations for performance and security
* Pre-installed system dependencies for most multi-modal agent use-cases
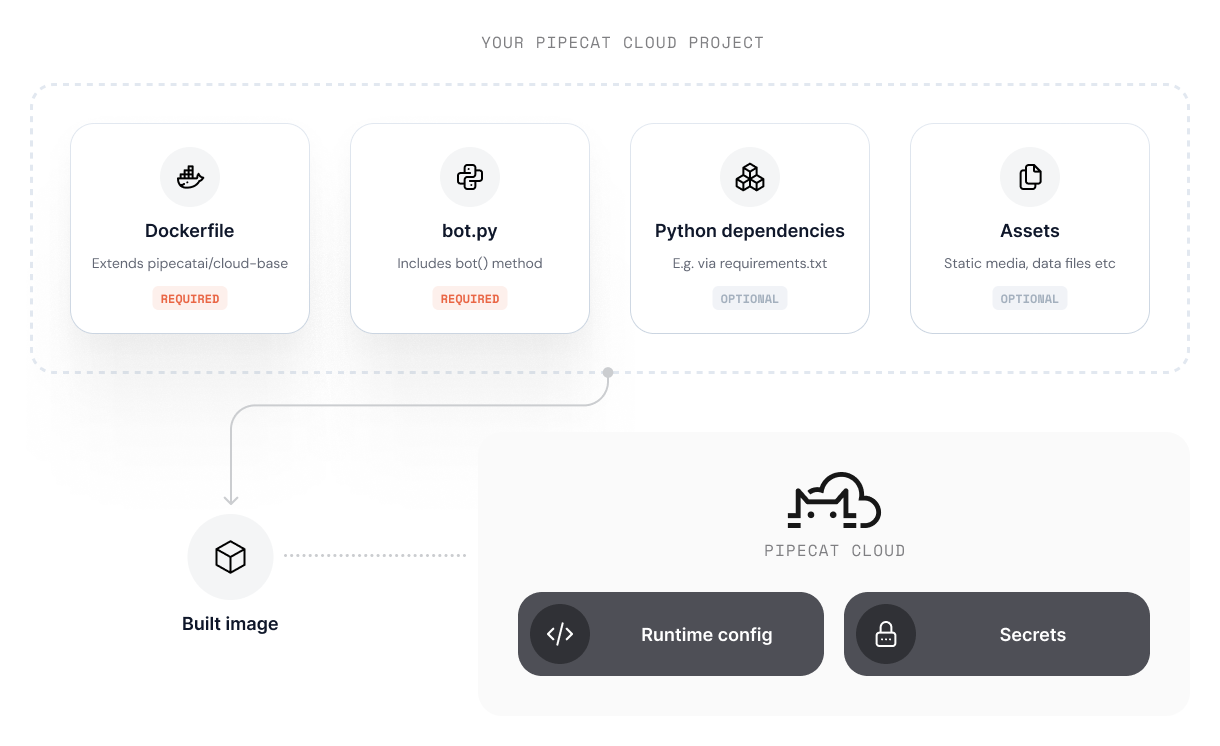
Using a base image reduces complexity in your project but requires you to adhere to a specific project structure.
* Your project must contain a `bot.py` file that defines the agent pipeline
* The `bot.py` must contain a `bot()` method that is the entry point for your agent pipeline
* The `bot()` method must be asynchronous, e.g. `async def bot():`
You do not need to specify a `CMD` as part of your Dockerfile - the base image is configured to run your `bot.py` module.
You can browse available base images in the [Pipecat Cloud Docker Hub
## Using an official base image
Pipecat Cloud provides a series of base images that we recommend for most use-cases. Base images provide:
* Simplified development and deployment
* Optimizations for performance and security
* Pre-installed system dependencies for most multi-modal agent use-cases
Using a base image reduces complexity in your project but requires you to adhere to a specific project structure.
* Your project must contain a `bot.py` file that defines the agent pipeline
* The `bot.py` must contain a `bot()` method that is the entry point for your agent pipeline
* The `bot()` method must be asynchronous, e.g. `async def bot():`
You do not need to specify a `CMD` as part of your Dockerfile - the base image is configured to run your `bot.py` module.
You can browse available base images in the [Pipecat Cloud Docker Hub | {header} | )}||||||
|---|---|---|---|---|---|---|
| {entry.name}() {entry.deprecated ? "⚠️ DEPRECATED" : ""} | {entry.dt || "❌"} | {entry.swrtc || "❌"} | {entry.rn || "❌"} | {entry.ws || "❌"} | {entry.oai || "❌"} | {entry.gem || "❌"} |
| {header} | )}||||||
|---|---|---|---|---|---|---|
| {entry.name}() {entry.deprecated ? "⚠️ DEPRECATED" : ""} | {entry.dt || "❌"} | {entry.swrtc || "❌"} | {entry.rn || "❌"} | {entry.ws || "❌"} | {entry.oai || "❌"} | {entry.gem || "❌"} |