>>")
# 2. Create an index configured for use with a particular model
index_config = pc.create_index_for_model(
name="my-model-index",
cloud=CloudProvider.AWS,
region=AwsRegion.US_EAST_1,
embed=IndexEmbed(
model=EmbedModel.Multilingual_E5_Large,
field_map={"text": "my_text_field"}
)
)
# 3. Instantiate an Index client
idx = pc.Index(host=index_config.host)
# 4. Upsert records
idx.upsert_records(
namespace="my-namespace",
records=[
{
"_id": "test1",
"my_text_field": "Apple is a popular fruit known for its sweetness and crisp texture.",
},
{
"_id": "test2",
"my_text_field": "The tech company Apple is known for its innovative products like the iPhone.",
},
{
"_id": "test3",
"my_text_field": "Many people enjoy eating apples as a healthy snack.",
},
{
"_id": "test4",
"my_text_field": "Apple Inc. has revolutionized the tech industry with its sleek designs and user-friendly interfaces.",
},
{
"_id": "test5",
"my_text_field": "An apple a day keeps the doctor away, as the saying goes.",
},
{
"_id": "test6",
"my_text_field": "Apple Computer Company was founded on April 1, 1976, by Steve Jobs, Steve Wozniak, and Ronald Wayne as a partnership.",
},
],
)
# 5. Search for similar records
from pinecone import SearchQuery, SearchRerank, RerankModel
response = index.search_records(
namespace="my-namespace",
query=SearchQuery(
inputs={
"text": "Apple corporation",
},
top_k=3
),
rerank=SearchRerank(
model=RerankModel.Bge_Reranker_V2_M3,
rank_fields=["my_text_field"],
top_n=3,
),
)
```
## Issues & Bugs
If you notice bugs or have feedback, please [file an issue](https://github.com/pinecone-io/pinecone-python-client/issues).
You can also get help in the [Pinecone Community Forum](https://community.pinecone.io/).
---
# Source: https://docs.pinecone.io/troubleshooting/remove-metadata-field.md
> ## Documentation Index
> Fetch the complete documentation index at: https://docs.pinecone.io/llms.txt
> Use this file to discover all available pages before exploring further.
# Remove a metadata field from a record
You must perform an [`upsert`](/reference/api/2024-10/data-plane/upsert) operation to remove existing metadata fields from a record.
You will need to provide the existing ID and values of the vector. The metadata you provide in the upsert operation will replace any existing metadata, thus clearing the fields you seek to drop.
Metadata fields cannot be removed using the `update` operation.
---
# Source: https://docs.pinecone.io/guides/search/rerank-results.md
> ## Documentation Index
> Fetch the complete documentation index at: https://docs.pinecone.io/llms.txt
> Use this file to discover all available pages before exploring further.
# Rerank results
> Improve the quality of results with reranking.
Reranking is used as part of a two-stage vector retrieval process to improve the quality of results. You first query an index for a given number of relevant results, and then you send the query and results to a reranking model. The reranking model scores the results based on their semantic relevance to the query and returns a new, more accurate ranking. This approach is one of the simplest methods for improving quality in retrieval augmented generation (RAG) pipelines.
Pinecone provides [hosted reranking models](#reranking-models) so it's easy to manage two-stage vector retrieval on a single platform. You can use a hosted model to rerank results as an integrated part of a query, or you can use a hosted model or external model to rerank results as a standalone operation.
## Integrated reranking
To rerank initial results as an integrated part of a query, without any extra steps, use the [`search`](/reference/api/latest/data-plane/search_records) operation with the `rerank` parameter, including the [hosted reranking model](#reranking-models) you want to use, the number of reranked results to return, and the fields to use for reranking, if different than the main query.
For example, the following code searches for the 3 records most semantically related to a query text and uses the `hosted bge-reranker-v2-m3` model to rerank the results and return only the 2 most relevant documents:
```python Python theme={null}
from pinecone import Pinecone
pc = Pinecone(api_key="YOUR_API_KEY")
# To get the unique host for an index,
# see https://docs.pinecone.io/guides/manage-data/target-an-index
index = pc.Index(host="INDEX_HOST")
ranked_results = index.search(
namespace="example-namespace",
query={
"inputs": {"text": "Disease prevention"},
"top_k": 4
},
rerank={
"model": "bge-reranker-v2-m3",
"top_n": 2,
"rank_fields": ["chunk_text"]
},
fields=["category", "chunk_text"]
)
print(ranked_results)
```
```javascript JavaScript theme={null}
import { Pinecone } from '@pinecone-database/pinecone'
const pc = new Pinecone({ apiKey: "YOUR_API_KEY" })
// To get the unique host for an index,
// see https://docs.pinecone.io/guides/manage-data/target-an-index
const namespace = pc.index("INDEX_NAME", "INDEX_HOST").namespace("example-namespace");
const response = await namespace.searchRecords({
query: {
topK: 2,
inputs: { text: 'Disease prevention' },
},
fields: ['chunk_text', 'category'],
rerank: {
model: 'bge-reranker-v2-m3',
rankFields: ['chunk_text'],
topN: 2,
},
});
console.log(response);
```
```java Java theme={null}
import io.pinecone.clients.Index;
import io.pinecone.configs.PineconeConfig;
import io.pinecone.configs.PineconeConnection;
import org.openapitools.db_data.client.ApiException;
import org.openapitools.db_data.client.model.SearchRecordsRequestRerank;
import org.openapitools.db_data.client.model.SearchRecordsResponse;
import java.util.*;
public class SearchText {
public static void main(String[] args) throws ApiException {
PineconeConfig config = new PineconeConfig("YOUR_API_KEY");
// To get the unique host for an index,
// see https://docs.pinecone.io/guides/manage-data/target-an-index
config.setHost("INDEX_HOST");
PineconeConnection connection = new PineconeConnection(config);
Index index = new Index(config, connection, "integrated-dense-java");
String query = "Disease prevention";
List fields = new ArrayList<>();
fields.add("category");
fields.add("chunk_text");
ListrankFields = new ArrayList<>();
rankFields.add("chunk_text");
SearchRecordsRequestRerank rerank = new SearchRecordsRequestRerank()
.query(query)
.model("bge-reranker-v2-m3")
.topN(2)
.rankFields(rankFields);
SearchRecordsResponse recordsResponseReranked = index.searchRecordsByText(query, "example-namespace", fields,4, null, rerank);
System.out.println(recordsResponseReranked);
}
}
```
```go Go theme={null}
package main
import (
"context"
"encoding/json"
"fmt"
"log"
"github.com/pinecone-io/go-pinecone/v4/pinecone"
)
func prettifyStruct(obj interface{}) string {
bytes, _ := json.MarshalIndent(obj, "", " ")
return string(bytes)
}
func main() {
ctx := context.Background()
pc, err := pinecone.NewClient(pinecone.NewClientParams{
ApiKey: "YOUR_API_KEY",
})
if err != nil {
log.Fatalf("Failed to create Client: %v", err)
}
// To get the unique host for an index,
// see https://docs.pinecone.io/guides/manage-data/target-an-index
idxConnection, err := pc.Index(pinecone.NewIndexConnParams{Host: "INDEX_HOST", Namespace: "example-namespace"})
if err != nil {
log.Fatalf("Failed to create IndexConnection for Host: %v", err)
}
topN := int32(2)
res, err := idxConnection.SearchRecords(ctx, &pinecone.SearchRecordsRequest{
Query: pinecone.SearchRecordsQuery{
TopK: 3,
Inputs: &map[string]interface{}{
"text": "Disease prevention",
},
},
Rerank: &pinecone.SearchRecordsRerank{
Model: "bge-reranker-v2-m3",
TopN: &topN,
RankFields: []string{"chunk_text"},
},
Fields: &[]string{"chunk_text", "category"},
})
if err != nil {
log.Fatalf("Failed to search records: %v", err)
}
fmt.Printf(prettifyStruct(res))
}
```
```csharp C# theme={null}
using Pinecone;
var pinecone = new PineconeClient("YOUR_API_KEY");
// To get the unique host for an index,
// see https://docs.pinecone.io/guides/manage-data/target-an-index
var index = pinecone.Index(host: "INDEX_HOST");
var response = await index.SearchRecordsAsync(
"example-namespace",
new SearchRecordsRequest
{
Query = new SearchRecordsRequestQuery
{
TopK = 4,
Inputs = new Dictionary { { "text", "Disease prevention" } },
},
Fields = ["category", "chunk_text"],
Rerank = new SearchRecordsRequestRerank
{
Model = "bge-reranker-v2-m3",
TopN = 2,
RankFields = ["chunk_text"],
}
}
);
Console.WriteLine(response);
```
```shell curl theme={null}
INDEX_HOST="INDEX_HOST"
NAMESPACE="YOUR_NAMESPACE"
PINECONE_API_KEY="YOUR_API_KEY"
curl "https://$INDEX_HOST/records/namespaces/$NAMESPACE/search" \
-H "Accept: application/json" \
-H "Content-Type: application/json" \
-H "Api-Key: $PINECONE_API_KEY" \
-H "X-Pinecone-Api-Version: unstable" \
-d '{
"query": {
"inputs": {"text": "Disease prevention"},
"top_k": 4
},
"rerank": {
"model": "bge-reranker-v2-m3",
"top_n": 2,
"rank_fields": ["chunk_text"]
},
"fields": ["category", "chunk_text"]
}'
```
The response looks as follows. For each hit, the `_score` represents the relevance of a document to the query, normalized between 0 and 1, with scores closer to 1 indicating higher relevance.
```python Python theme={null}
{'result': {'hits': [{'_id': 'rec3',
'_score': 0.004399413242936134,
'fields': {'category': 'immune system',
'chunk_text': 'Rich in vitamin C and other '
'antioxidants, apples '
'contribute to immune health '
'and may reduce the risk of '
'chronic diseases.'}},
{'_id': 'rec4',
'_score': 0.0029235430993139744,
'fields': {'category': 'endocrine system',
'chunk_text': 'The high fiber content in '
'apples can also help regulate '
'blood sugar levels, making '
'them a favorable snack for '
'people with diabetes.'}}]},
'usage': {'embed_total_tokens': 8, 'read_units': 6, 'rerank_units': 1}}
```
```javascript JavaScript theme={null}
{
result: {
hits: [
{
_id: 'rec3',
_score: 0.004399413242936134,
fields: {
category: 'immune system',
chunk_text: 'Rich in vitamin C and other antioxidants, apples contribute to immune health and may reduce the risk of chronic diseases.'
}
},
{
_id: 'rec4',
_score: 0.0029235430993139744,
fields: {
category: 'endocrine system',
chunk_text: 'The high fiber content in apples can also help regulate blood sugar levels, making them a favorable snack for people with diabetes.'
}
}
]
},
usage: {
readUnits: 6,
embedTotalTokens: 8,
rerankUnits: 1
}
}
```
```java Java theme={null}
class SearchRecordsResponse {
result: class SearchRecordsResponseResult {
hits: [class Hit {
id: rec3
score: 0.004399413242936134
fields: {category=immune system, chunk_text=Rich in vitamin C and other antioxidants, apples contribute to immune health and may reduce the risk of chronic diseases.}
additionalProperties: null
}, class Hit {
id: rec4
score: 0.0029235430993139744
fields: {category=endocrine system, chunk_text=The high fiber content in apples can also help regulate blood sugar levels, making them a favorable snack for people with diabetes.}
additionalProperties: null
}]
additionalProperties: null
}
usage: class SearchUsage {
readUnits: 6
embedTotalTokens: 13
rerankUnits: 1
additionalProperties: null
}
additionalProperties: null
}
```
```go Go theme={null}
{
"result": {
"hits": [
{
"_id": "rec3",
"_score": 0.13683891,
"fields": {
"category": "immune system",
"chunk_text": "Rich in vitamin C and other antioxidants, apples contribute to immune health and may reduce the risk of chronic diseases."
}
},
{
"_id": "rec4",
"_score": 0.0029235430993139744,
"fields": {
"category": "endocrine system",
"chunk_text": "The high fiber content in apples can also help regulate blood sugar levels, making them a favorable snack for people with diabetes."
}
}
]
},
"usage": {
"read_units": 6,
"embed_total_tokens": 8,
"rerank_units": 1
}
}
```
```csharp C# theme={null}
{
"result": {
"hits": [
{
"_id": "rec3",
"_score": 0.004399413242936134,
"fields": {
"category": "immune system",
"chunk_text": "Rich in vitamin C and other antioxidants, apples contribute to immune health and may reduce the risk of chronic diseases."
}
},
{
"_id": "rec4",
"_score": 0.0029121784027665854,
"fields": {
"category": "endocrine system",
"chunk_text": "The high fiber content in apples can also help regulate blood sugar levels, making them a favorable snack for people with diabetes."
}
}
]
},
"usage": {
"read_units": 6,
"embed_total_tokens": 8,
"rerank_units": 1
}
}
```
```json curl theme={null}
{
"result": {
"hits": [
{
"_id": "rec3",
"_score": 0.004433765076100826,
"fields": {
"category": "immune system",
"chunk_text": "Rich in vitamin C and other antioxidants, apples contribute to immune health and may reduce the risk of chronic diseases."
}
},
{
"_id": "rec4",
"_score": 0.0029121784027665854,
"fields": {
"category": "endocrine system",
"chunk_text": "The high fiber content in apples can also help regulate blood sugar levels, making them a favorable snack for people with diabetes."
}
}
]
},
"usage": {
"embed_total_tokens": 8,
"read_units": 6,
"rerank_units": 1
}
}
```
## Standalone reranking
To rerank initial results as a standalone operation, use the [`rerank`](/reference/api/latest/inference/rerank) operation with the [hosted reranking model](#reranking-models) you want to use, the query results and the query, the number of ranked results to return, the field to use for reranking, and any other model-specific parameters.
For example, the following code uses the hosted `bge-reranker-v2-m3` model to rerank the values of the `documents.chunk_text` fields based on their relevance to the query and return only the 2 most relevant documents, along with their score:
```python Python theme={null}
from pinecone import Pinecone
pc = Pinecone(api_key="YOUR_API_KEY")
ranked_results = pc.inference.rerank(
model="bge-reranker-v2-m3",
query="What is AAPL's outlook, considering both product launches and market conditions?",
documents=[
{"id": "vec2", "chunk_text": "Analysts suggest that AAPL'\''s upcoming Q4 product launch event might solidify its position in the premium smartphone market."},
{"id": "vec3", "chunk_text": "AAPL'\''s strategic Q3 partnerships with semiconductor suppliers could mitigate component risks and stabilize iPhone production."},
{"id": "vec1", "chunk_text": "AAPL reported a year-over-year revenue increase, expecting stronger Q3 demand for its flagship phones."},
],
top_n=2,
rank_fields=["chunk_text"],
return_documents=True,
parameters={
"truncate": "END"
}
)
print(ranked_results)
```
```javascript JavaScript theme={null}
import { Pinecone } from '@pinecone-database/pinecone';
const pc = new Pinecone({ apiKey: 'YOUR_API_KEY' });
const rerankingModel = 'bge-reranker-v2-m3';
const query = "What is AAPL's outlook, considering both product launches and market conditions?";
const documents = [
{ id: 'vec2', chunk_text: "Analysts suggest that AAPL's upcoming Q4 product launch event might solidify its position in the premium smartphone market." },
{ id: 'vec3', chunk_text: "AAPL's strategic Q3 partnerships with semiconductor suppliers could mitigate component risks and stabilize iPhone production." },
{ id: 'vec1', chunk_text: "AAPL reported a year-over-year revenue increase, expecting stronger Q3 demand for its flagship phones." },
];
const rerankOptions = {
topN: 2,
rankFields: ['chunk_text'],
returnDocuments: true,
parameters: {
truncate: 'END'
},
};
const rankedResults = await pc.inference.rerank(
rerankingModel,
query,
documents,
rerankOptions
);
console.log(rankedResults);
```
```java Java theme={null}
import io.pinecone.clients.Inference;
import io.pinecone.clients.Pinecone;
import org.openapitools.inference.client.model.RerankResult;
import org.openapitools.inference.client.ApiException;
import java.util.*;
public class RerankExample {
public static void main(String[] args) throws ApiException {
Pinecone pc = new Pinecone.Builder("YOUR_API_KEY").build();
Inference inference = pc.getInferenceClient();
// The model to use for reranking
String model = "bge-reranker-v2-m3";
// The query to rerank documents against
String query = "What is AAPL's outlook, considering both product launches and market conditions?";
// Add the documents to rerank
List> documents = new ArrayList<>();
Map doc1 = new HashMap<>();
doc1.put("id", "vec2");
doc1.put("chunk_text", "Analysts suggest that AAPL's upcoming Q4 product launch event might solidify its position in the premium smartphone market.");
documents.add(doc1);
Map doc2 = new HashMap<>();
doc2.put("id", "vec3");
doc2.put("chunk_text", "AAPL's strategic Q3 partnerships with semiconductor suppliers could mitigate component risks and stabilize iPhone production");
documents.add(doc2);
Map doc3 = new HashMap<>();
doc3.put("id", "vec1");
doc3.put("chunk_text", "AAPL reported a year-over-year revenue increase, expecting stronger Q3 demand for its flagship phones.");
documents.add(doc3);
// The fields to rank the documents by. If not provided, the default is "text"
List rankFields = Arrays.asList("chunk_text");
// The number of results to return sorted by relevance. Defaults to the number of inputs
int topN = 2;
// Whether to return the documents in the response
boolean returnDocuments = true;
// Additional model-specific parameters for the reranker
Map parameters = new HashMap<>();
parameters.put("truncate", "END");
// Send ranking request
RerankResult result = inference.rerank(model, query, documents, rankFields, topN, returnDocuments, parameters);
// Get ranked data
System.out.println(result.getData());
}
}
```
```go Go theme={null}
package main
import (
"context"
"encoding/json"
"fmt"
"log"
"github.com/pinecone-io/go-pinecone/v4/pinecone"
)
func prettifyStruct(obj interface{}) string {
bytes, _ := json.MarshalIndent(obj, "", " ")
return string(bytes)
}
func main() {
ctx := context.Background()
pc, err := pinecone.NewClient(pinecone.NewClientParams{
ApiKey: "YOUR_API_KEY",
})
if err != nil {
log.Fatalf("Failed to create Client: %v", err)
}
rerankModel := "bge-reranker-v2-m3"
topN := 2
returnDocuments := true
documents := []pinecone.Document{
{"id": "vec2", "chunk_text": "Analysts suggest that AAPL's upcoming Q4 product launch event might solidify its position in the premium smartphone market."},
{"id": "vec3", "chunk_text": "AAPL's strategic Q3 partnerships with semiconductor suppliers could mitigate component risks and stabilize iPhone production."},
{"id": "vec1", "chunk_text": "AAPL reported a year-over-year revenue increase, expecting stronger Q3 demand for its flagship phones."},
}
ranking, err := pc.Inference.Rerank(ctx, &pinecone.RerankRequest{
Model: rerankModel,
Query: "What is AAPL's outlook, considering both product launches and market conditions?",
ReturnDocuments: &returnDocuments,
TopN: &topN,
RankFields: &[]string{"chunk_text"},
Documents: documents,
})
if err != nil {
log.Fatalf("Failed to rerank: %v", err)
}
fmt.Printf(prettifyStruct(ranking))
}
```
```csharp C# theme={null}
using Pinecone;
var pinecone = new PineconeClient("YOUR_API_KEY");
// Add the documents to rerank
var documents = new List>
{
new()
{
["id"] = "vec2",
["chunk_text"] = "Analysts suggest that AAPL's upcoming Q4 product launch event might solidify its position in the premium smartphone market."
},
new()
{
["id"] = "vec3",
["chunk_text"] = "AAPL's strategic Q3 partnerships with semiconductor suppliers could mitigate component risks and stabilize iPhone production."
},
new()
{
["id"] = "vec1",
["chunk_text"] = "AAPL reported a year-over-year revenue increase, expecting stronger Q3 demand for its flagship phones."
}
};
// The fields to rank the documents by. If not provided, the default is "text"
var rankFields = new List { "chunk_text" };
// Additional model-specific parameters for the reranker
var parameters = new Dictionary
{
["truncate"] = "END"
};
// Send ranking request
var result = await pinecone.Inference.RerankAsync(
new RerankRequest
{
Model = "bge-reranker-v2-m3",
Query = "What is AAPL's outlook, considering both product launches and market conditions?",
Documents = documents,
RankFields = rankFields,
TopN = 2,
ReturnDocuments = true,
Parameters = parameters
});
Console.WriteLine(result);
```
```shell curl theme={null}
PINECONE_API_KEY="YOUR_API_KEY"
curl https://api.pinecone.io/rerank \
-H "Content-Type: application/json" \
-H "Accept: application/json" \
-H "X-Pinecone-Api-Version: 2025-10" \
-H "Api-Key: $PINECONE_API_KEY" \
-d '{
"model": "bge-reranker-v2-m3",
"query": "What is AAPL'\''s outlook, considering both product launches and market conditions?",
"documents": [
{"id": "vec2", "chunk_text": "Analysts suggest that AAPL'\''s upcoming Q4 product launch event might solidify its position in the premium smartphone market."},
{"id": "vec3", "chunk_text": "AAPL'\''s strategic Q3 partnerships with semiconductor suppliers could mitigate component risks and stabilize iPhone production."},
{"id": "vec1", "chunk_text": "AAPL reported a year-over-year revenue increase, expecting stronger Q3 demand for its flagship phones."}
],
"top_n": 2,
"rank_fields": ["chunk_text"],
"return_documents": true,
"parameters": {
"truncate": "END"
}
}'
```
The response looks as follows. For each hit, the \_score represents the relevance of a document to the query, normalized between 0 and 1, with scores closer to 1 indicating higher relevance.
```python Python theme={null}
RerankResult(
model='bge-reranker-v2-m3',
data=[{
index=0,
score=0.004166256,
document={
id='vec2',
chunk_text="Analysts suggest that AAPL'''s upcoming Q4 product launch event might solidify its position in the premium smartphone market."
}
},{
index=2,
score=0.0011513996,
document={
id='vec1',
chunk_text='AAPL reported a year-over-year revenue increase, expecting stronger Q3 demand for its flagship phones.'
}
}],
usage={'rerank_units': 1}
)
```
```javascript JavaScript theme={null}
{
model: 'bge-reranker-v2-m3',
data: [
{ index: 0, score: 0.004166256, document: [id: 'vec2', chunk_text: "Analysts suggest that AAPL'''s upcoming Q4 product launch event might solidify its position in the premium smartphone market."] },
{ index: 2, score: 0.0011513996, document: [id: 'vec1', chunk_text: 'AAPL reported a year-over-year revenue increase, expecting stronger Q3 demand for its flagship phones.'] }
],
usage: { rerankUnits: 1 }
}
```
```java Java theme={null}
[class RankedDocument {
index: 0
score: 0.0063143647
document: {id=vec2, chunk_text=Analysts suggest that AAPL's upcoming Q4 product launch event might solidify its position in the premium smartphone market.}
additionalProperties: null
}, class RankedDocument {
index: 2
score: 0.0011513996
document: {id=vec1, chunk_text=AAPL reported a year-over-year revenue increase, expecting stronger Q3 demand for its flagship phones.}
additionalProperties: null
}]
```
```go Go theme={null}
{
"data": [
{
"document": {
"id": "vec2",
"chunk_text": "Analysts suggest that AAPL's upcoming Q4 product launch event might solidify its position in the premium smartphone market."
},
"index": 0,
"score": 0.0063143647
},
{
"document": {
"id": "vec1",
"chunk_text": "AAPL reported a year-over-year revenue increase, expecting stronger Q3 demand for its flagship phones."
},
"index": 2,
"score": 0.0011513996
}
],
"model": "bge-reranker-v2-m3",
"usage": {
"rerank_units": 1
}
}
```
```csharp C# theme={null}
{
"model": "bge-reranker-v2-m3",
"data": [
{
"index": 0,
"score": 0.006289902,
"document": {
"chunk_text": "Analysts suggest that AAPL\u0027s upcoming Q4 product launch event might solidify its position in the premium smartphone market.",
"id": "vec2"
}
},
{
"index": 3,
"score": 0.0011513996,
"document": {
"chunk_text": "AAPL reported a year-over-year revenue increase, expecting stronger Q3 demand for its flagship phones.",
"id": "vec1"
}
}
],
"usage": {
"rerank_units": 1
}
}
```
```json curl theme={null}
{
"model": "bge-reranker-v2-m3",
"data": [
{
"index": 0,
"document": {
"chunk_text": "Analysts suggest that AAPL's upcoming Q4 product launch event might solidify its position in the premium smartphone market.",
"id": "vec2"
},
"score": 0.007606672
},
{
"index": 3,
"document": {
"chunk_text": "AAPL reported a year-over-year revenue increase, expecting stronger Q3 demand for its flagship phones.",
"id": "vec1"
},
"score": 0.0013406205
}
],
"usage": {
"rerank_units": 1
}
}
```
## Reranking models
Pinecone hosts several reranking models so it's easy to manage two-stage vector retrieval on a single platform. You can use a hosted model to rerank results as an integrated part of a query, or you can use a hosted model to rerank results as a standalone operation.
The following reranking models are hosted by Pinecone.
To understand how cost is calculated for reranking, see [Reranking cost](/guides/manage-cost/understanding-cost#reranking). To get model details via the API, see [List models](/reference/api/latest/inference/list_models) and [Describe a model](/reference/api/latest/inference/describe_model).
[`cohere-rerank-3.5`](/models/cohere-rerank-3.5) is Cohere's leading reranking model, balancing performance and latency for a wide range of enterprise search applications.
**Details**
* Modality: Text
* Max tokens per query and document pair: 40,000
* Max documents: 200
For rate limits, see [Rerank requests per minute](/reference/api/database-limits#rerank-requests-per-minute-per-model) and [Rerank request per month](/reference/api/database-limits#rerank-requests-per-month-per-model).
**Parameters**
The `cohere-rerank-3.5` model supports the following parameters:
| Parameter | Type | Required/Optional | Description | |
| :------------------- | :--------------- | :---------------- | :-------------------------------------------------------------------------------------------------------------------------------------- | ---------- |
| `max_chunks_per_doc` | integer | Optional | Long documents will be automatically truncated to the specified number of chunks. Accepted range: `1 - 3072`. | |
| `rank_fields` | array of strings | Optional | The fields to use for reranking. The model reranks based on the order of the fields specified (e.g., `["field1", "field2", "field3"]`). | `["text"]` |
[`bge-reranker-v2-m3`](/models/bge-reranker-v2-m3) is a high-performance, multilingual reranking model that works well on messy data and short queries expected to return medium-length passages of text (1-2 paragraphs).
**Details**
* Modality: Text
* Max tokens per query and document pair: 1024
* Max documents: 100
For rate limits, see [Rerank requests per minute](/reference/api/database-limits#rerank-requests-per-minute-per-model) and [Rerank request per month](/reference/api/database-limits#rerank-requests-per-month-per-model).
**Parameters**
The `bge-reranker-v2-m3` model supports the following parameters:
| Parameter | Type | Required/Optional | Description | Default |
| :------------ | :--------------- | :---------------- | :--------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- | :--------- |
| `truncate` | string | Optional | How to handle inputs longer than those supported by the model. Accepted values: `END` or `NONE`.
`END` truncates the input sequence at the input token limit. `NONE` returns an error when the input exceeds the input token limit. | `NONE` |
| `rank_fields` | array of strings | Optional | The field to use for reranking. The model supports only a single rerank field. | `["text"]` |
[`pinecone-rerank-v0`](/models/pinecone-rerank-v0) is a state of the art reranking model that out-performs competitors on widely accepted benchmarks. It can handle chunks up to 512 tokens (1-2 paragraphs).
**Details**
* Modality: Text
* Max tokens per query and document pair: 512
* Max documents: 100
For rate limits, see [Rerank requests per minute](/reference/api/database-limits#rerank-requests-per-minute-per-model) and [Rerank request per month](/reference/api/database-limits#rerank-requests-per-month-per-model).
**Parameters**
The `pinecone-rerank-v0` model supports the following parameters:
| Parameter | Type | Required/Optional | Description | Default |
| :------------ | :--------------- | :---------------- | :--------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- | :--------- |
| `truncate` | string | Optional | How to handle inputs longer than those supported by the model. Accepted values: `END` or `NONE`.
`END` truncates the input sequence at the input token limit. `NONE` returns an error when the input exceeds the input token limit. | `END` |
| `rank_fields` | array of strings | Optional | The field to use for reranking. The model supports only a single rerank field. | `["text"]` |
---
# Source: https://docs.pinecone.io/reference/api/2025-10/inference/rerank.md
> ## Documentation Index
> Fetch the complete documentation index at: https://docs.pinecone.io/llms.txt
> Use this file to discover all available pages before exploring further.
# Rerank results
> Rerank results according to their relevance to a query.
For guidance and examples, see [Rerank results](https://docs.pinecone.io/guides/search/rerank-results).
```shell curl theme={null}
PINECONE_API_KEY="YOUR_API_KEY"
curl https://api.pinecone.io/rerank \
-H "Content-Type: application/json" \
-H "Accept: application/json" \
-H "X-Pinecone-Api-Version: 2025-10" \
-H "Api-Key: $PINECONE_API_KEY" \
-d '{
"model": "bge-reranker-v2-m3",
"query": "The tech company Apple is known for its innovative products like the iPhone.",
"return_documents": true,
"top_n": 4,
"documents": [
{"id": "vec1", "text": "Apple is a popular fruit known for its sweetness and crisp texture."},
{"id": "vec2", "text": "Many people enjoy eating apples as a healthy snack."},
{"id": "vec3", "text": "Apple Inc. has revolutionized the tech industry with its sleek designs and user-friendly interfaces."},
{"id": "vec4", "text": "An apple a day keeps the doctor away, as the saying goes."}
],
"parameters": {
"truncate": "END"
}
}'
```
```JSON curl theme={null}
{
"data":[
{
"index":2,
"document":{
"id":"vec3",
"text":"Apple Inc. has revolutionized the tech industry with its sleek designs and user-friendly interfaces."
},
"score":0.47654688
},
{
"index":0,
"document":{
"id":"vec1",
"text":"Apple is a popular fruit known for its sweetness and crisp texture."
},
"score":0.047963805
},
{
"index":3,
"document":{
"id":"vec4",
"text":"An apple a day keeps the doctor away, as the saying goes."
},
"score":0.007587992
},
{
"index":1,
"document":{
"id":"vec2",
"text":"Many people enjoy eating apples as a healthy snack."
},
"score":0.0006491712
}
],
"usage":{
"rerank_units":1
}
}
```
## OpenAPI
````yaml https://raw.githubusercontent.com/pinecone-io/pinecone-api/refs/heads/main/2025-10/inference_2025-10.oas.yaml post /rerank
openapi: 3.0.3
info:
title: Pinecone Inference API
description: >-
Pinecone is a vector database that makes it easy to search and retrieve
billions of high-dimensional vectors.
contact:
name: Pinecone Support
url: https://support.pinecone.io
email: support@pinecone.io
license:
name: Apache 2.0
url: https://www.apache.org/licenses/LICENSE-2.0
version: 2025-10
servers:
- url: https://api.pinecone.io
description: Production API endpoints
security:
- ApiKeyAuth: []
tags:
- name: Inference
description: Model inference
externalDocs:
description: More Pinecone.io API docs
url: https://docs.pinecone.io/introduction
paths:
/rerank:
post:
tags:
- Inference
summary: Rerank results
description: >-
Rerank results according to their relevance to a query.
For guidance and examples, see [Rerank
results](https://docs.pinecone.io/guides/search/rerank-results).
operationId: rerank
parameters:
- in: header
name: X-Pinecone-Api-Version
description: Required date-based version header
required: true
schema:
default: 2025-10
type: string
style: simple
requestBody:
description: Rerank documents for the given query
content:
application/json:
schema:
$ref: '#/components/schemas/RerankRequest'
responses:
'200':
description: OK
content:
application/json:
schema:
$ref: '#/components/schemas/RerankResult'
'400':
description: Bad request. The request body included invalid request parameters.
content:
application/json:
schema:
$ref: '#/components/schemas/ErrorResponse'
examples:
index-metric-validation-error:
summary: Validation error
value:
error:
code: INVALID_ARGUMENT
message: >-
Bad request. The request body included invalid request
parameters.
status: 400
'401':
description: 'Unauthorized. Possible causes: Invalid API key.'
content:
application/json:
schema:
$ref: '#/components/schemas/ErrorResponse'
examples:
unauthorized:
summary: Unauthorized
value:
error:
code: UNAUTHENTICATED
message: Invalid API key.
status: 401
'500':
description: Internal server error.
content:
application/json:
schema:
$ref: '#/components/schemas/ErrorResponse'
examples:
internal-server-error:
summary: Internal server error
value:
error:
code: UNKNOWN
message: Internal server error
status: 500
components:
schemas:
RerankRequest:
type: object
properties:
model:
example: bge-reranker-v2-m3
description: >-
The
[model](https://docs.pinecone.io/guides/search/rerank-results#reranking-models)
to use for reranking.
type: string
query:
example: What is the capital of France?
description: The query to rerank documents against.
type: string
top_n:
example: 5
description: >-
The number of results to return sorted by relevance. Defaults to the
number of inputs.
type: integer
return_documents:
example: true
description: Whether to return the documents in the response.
default: true
type: boolean
rank_fields:
description: >
The field(s) to consider for reranking. If not provided, the default
is `["text"]`.
The number of fields supported is
[model-specific](https://docs.pinecone.io/guides/search/rerank-results#reranking-models).
default:
- text
type: array
items:
type: string
documents:
description: The documents to rerank.
type: array
items:
$ref: '#/components/schemas/Document'
parameters:
example:
truncate: END
description: >-
Additional model-specific parameters. Refer to the [model
guide](https://docs.pinecone.io/guides/search/rerank-results#reranking-models)
for available model parameters.
type: object
additionalProperties: true
required:
- model
- documents
- query
RerankResult:
description: The result of a reranking request.
type: object
properties:
model:
example: bge-reranker-v2-m3
description: The model used to rerank documents.
type: string
data:
description: The reranked documents.
type: array
items:
$ref: '#/components/schemas/RankedDocument'
usage:
description: Usage statistics for the model inference.
type: object
properties:
rerank_units:
example: 1
description: The number of rerank units consumed by this operation.
type: integer
format: int32
minimum: 0
required:
- model
- data
- usage
ErrorResponse:
example:
error:
code: QUOTA_EXCEEDED
message: >-
The index exceeds the project quota of 5 pods by 2 pods. Upgrade
your account or change the project settings to increase the quota.
status: 429
description: The response shape used for all error responses.
type: object
properties:
status:
example: 500
description: The HTTP status code of the error.
type: integer
error:
example:
code: INVALID_ARGUMENT
message: >-
Index name must contain only lowercase alphanumeric characters or
hyphens, and must not begin or end with a hyphen.
description: Detailed information about the error that occurred.
type: object
properties:
code:
description: >-
The error code.
Possible values: `OK`, `UNKNOWN`, `INVALID_ARGUMENT`,
`DEADLINE_EXCEEDED`, `QUOTA_EXCEEDED`, `NOT_FOUND`,
`ALREADY_EXISTS`, `PERMISSION_DENIED`, `UNAUTHENTICATED`,
`RESOURCE_EXHAUSTED`, `FAILED_PRECONDITION`, `ABORTED`,
`OUT_OF_RANGE`, `UNIMPLEMENTED`, `INTERNAL`, `UNAVAILABLE`,
`DATA_LOSS`, or `FORBIDDEN`.
x-enum:
- OK
- UNKNOWN
- INVALID_ARGUMENT
- DEADLINE_EXCEEDED
- QUOTA_EXCEEDED
- NOT_FOUND
- ALREADY_EXISTS
- PERMISSION_DENIED
- UNAUTHENTICATED
- RESOURCE_EXHAUSTED
- FAILED_PRECONDITION
- ABORTED
- OUT_OF_RANGE
- UNIMPLEMENTED
- INTERNAL
- UNAVAILABLE
- DATA_LOSS
- FORBIDDEN
type: string
message:
example: >-
Index name must contain only lowercase alphanumeric characters
or hyphens, and must not begin or end with a hyphen.
description: A human-readable error message describing the error.
type: string
details:
description: >-
Additional information about the error. This field is not
guaranteed to be present.
type: object
required:
- code
- message
required:
- status
- error
Document:
example:
id: '1'
text: Paris is the capital of France.
title: France
url: https://example.com
description: Document for reranking
type: object
additionalProperties: true
RankedDocument:
description: A ranked document with a relevance score and an index position.
type: object
properties:
index:
description: The index position of the document from the original request.
type: integer
score:
example: 0.5
description: >-
The relevance of the document to the query, normalized between 0 and
1, with scores closer to 1 indicating higher relevance.
type: number
document:
$ref: '#/components/schemas/Document'
required:
- index
- score
securitySchemes:
ApiKeyAuth:
type: apiKey
in: header
name: Api-Key
description: >-
An API Key is required to call Pinecone APIs. Get yours from the
[console](https://app.pinecone.io/).
````
---
# Source: https://docs.pinecone.io/guides/indexes/pods/restore-a-pod-based-index.md
> ## Documentation Index
> Fetch the complete documentation index at: https://docs.pinecone.io/llms.txt
> Use this file to discover all available pages before exploring further.
# Restore a pod-based index
> Restore pod-based indexes from collections
Customers who sign up for a Standard or Enterprise plan on or after August 18, 2025 cannot create pod-based indexes. Instead, create [serverless indexes](/guides/index-data/create-an-index), and consider using [dedicated read nodes](/guides/index-data/dedicated-read-nodes) for large workloads (millions of records or more, and moderate or high query rates).
You can restore a pod-based index by creating a new index from a [collection](/guides/indexes/pods/understanding-collections).
## Create a pod-based index from a collection
To create a pod-based index from a [collection](/guides/manage-data/back-up-an-index#pod-based-index-backups-using-collections), use the [`create_index`](/reference/api/latest/control-plane/create_index) endpoint and provide a [`source_collection`](/reference/api/latest/control-plane/create_index#!path=source%5Fcollection\&t=request) parameter containing the name of the collection from which you wish to create an index. The new index can differ from the original source index: the new index can have a different name, number of pods, or pod type. The new index is queryable and writable.
```Python Python theme={null}
from pinecone.grpc import PineconeGRPC as Pinecone, PodSpec
pc = Pinecone(api_key="YOUR_API_KEY")
pc.create_index(
name="docs-example",
dimension=128,
metric="cosine",
spec=PodSpec(
environment="us-west-1-gcp",
pod_type="p1.x1",
pods=1,
source_collection="example-collection"
)
)
```
```JavaScript JavaScript theme={null}
import { Pinecone } from '@pinecone-database/pinecone'
const pc = new Pinecone({
apiKey: 'YOUR_API_KEY'
});
await pc.createIndex({
name: 'docs-example',
dimension: 128,
metric: 'cosine',
spec: {
pod: {
environment: 'us-west-1-gcp',
podType: 'p1.x1',
pods: 1,
sourceCollection: 'example-collection'
}
}
});
```
```java Java theme={null}
import io.pinecone.clients.Pinecone;
import org.openapitools.db_control.client.model.IndexModel;
import org.openapitools.db_control.client.model.DeletionProtection;
public class CreateIndexFromCollectionExample {
public static void main(String[] args) {
Pinecone pc = new Pinecone.Builder("YOUR_API_KEY").build();
pc.createPodsIndex("docs-example", 1536, "us-west1-gcp",
"p1.x1", "cosine", "example-collection", DeletionProtection.DISABLED);
}
}
```
```go Go theme={null}
package main
import (
"context"
"fmt"
"log"
"github.com/pinecone-io/go-pinecone/v4/pinecone"
)
func main() {
ctx := context.Background()
pc, err := pinecone.NewClient(pinecone.NewClientParams{
ApiKey: "YOUR_API_KEY",
})
if err != nil {
log.Fatalf("Failed to create Client: %v", err)
}
indexName := "docs-example"
metric := pinecone.Dotproduct
deletionProtection := pinecone.DeletionProtectionDisabled
idx, err := pc.CreatePodIndex(ctx, &pinecone.CreatePodIndexRequest{
Name: indexName,
Metric: &metric,
Dimension: 1536,
Environment: "us-east1-gcp",
PodType: "p1.x1",
SourceCollection: "example-collection",
DeletionProtection: &deletionProtection,
})
if err != nil {
log.Fatalf("Failed to create pod-based index: %v", idx.Name)
} else {
fmt.Printf("Successfully created pod-based index: %v", idx.Name)
}
}
```
```csharp C# theme={null}
using Pinecone;
var pinecone = new PineconeClient("YOUR_API_KEY");
var createIndexRequest = await pinecone.CreateIndexAsync(new CreateIndexRequest
{
Name = "docs-example",
Dimension = 1538,
Metric = MetricType.Cosine,
Spec = new PodIndexSpec
{
Pod = new PodSpec
{
Environment = "us-east1-gcp",
PodType = "p1.x1",
Pods = 1,
Replicas = 1,
Shards = 1,
SourceCollection = "example-collection",
}
},
DeletionProtection = DeletionProtection.Enabled,
});
```
```bash curl theme={null}
PINECONE_API_KEY="YOUR_API_KEY"
curl -s "https://api.pinecone.io/indexes" \
-H "Accept: application/json" \
-H "Content-Type: application/json" \
-H "Api-Key: $PINECONE_API_KEY" \
-H "X-Pinecone-Api-Version: 2025-10" \
-d '{
"name": "docs-example",
"dimension": 128,
"metric": "cosine",
"spec": {
"pod": {
"environment": "us-west-1-gcp",
"pod_type": "p1.x1",
"pods": 1,
"source_collection": "example-collection"
}
}
}'
```
---
# Source: https://docs.pinecone.io/guides/manage-data/restore-an-index.md
> ## Documentation Index
> Fetch the complete documentation index at: https://docs.pinecone.io/llms.txt
> Use this file to discover all available pages before exploring further.
# Restore an index
> Restore serverless indexes from backup snapshots.
## Create a serverless index from a backup
When restoring a serverless index from backup, you can change the index name, tags, and deletion protection setting. All other properties of the restored index will remain identical to the source index, including cloud and region, dimension and similarity metric, and associated embedding model when restoring an index with [integrated embedding](/guides/index-data/indexing-overview#integrated-embedding).
To [create a serverless index from a backup](/reference/api/latest/control-plane/create_index_from_backup), provide the ID of the backup, the name of the new index, and, optionally, changes to the index tags and deletion protection settings:
```python Python theme={null}
from pinecone import Pinecone
pc = Pinecone(api_key="YOUR_API_KEY")
pc.create_index_from_backup(
backup_id="a65ff585-d987-4da5-a622-72e19a6ed5f4",
name="restored-index",
tags={
"tag0": "val0",
"tag1": "val1"
},
deletion_protection="enabled"
)
```
```javascript JavaScript theme={null}
import { Pinecone } from '@pinecone-database/pinecone';
const pc = new Pinecone({ apiKey: 'YOUR_API_KEY' })
const response = await pc.createIndexFromBackup({
backupId: 'a65ff585-d987-4da5-a622-72e19a6ed5f4',
name: 'restored-index',
tags: {
tag0: 'val0',
tag1: 'val1'
},
deletionProtection: 'enabled'
});
console.log(response);
```
```java Java theme={null}
import io.pinecone.clients.Pinecone;
import org.openapitools.db_control.client.ApiException;
import org.openapitools.db_control.client.model.*;
public class CreateIndexFromBackup {
public static void main(String[] args) throws ApiException {
Pinecone pc = new Pinecone.Builder("YOUR_API_KEY").build();
String backupID = "a65ff585-d987-4da5-a622-72e19a6ed5f4";
String indexName = "restored-index";
CreateIndexFromBackupResponse backupResponse = pc.createIndexFromBackup(backupID, indexName);
System.out.println(backupResponse);
}
}
```
```go Go theme={null}
package main
import (
"context"
"encoding/json"
"fmt"
"log"
"time"
"github.com/pinecone-io/go-pinecone/v4/pinecone"
)
func prettifyStruct(obj interface{}) string {
bytes, _ := json.MarshalIndent(obj, "", " ")
return string(bytes)
}
func main() {
ctx := context.Background()
pc, err := pinecone.NewClient(pinecone.NewClientParams{
ApiKey: "YOUR_API_KEY",
})
if err != nil {
log.Fatalf("Failed to create Client: %v", err)
}
indexName := "restored-index"
restoredIndexTags := pinecone.IndexTags{"restored_on": time.Now().Format("2006-01-02 15:04")}
createIndexFromBackupResp, err := pc.CreateIndexFromBackup(ctx, &pinecone.CreateIndexFromBackupParams{
BackupId: "e12269b0-a29b-4af0-9729-c7771dec03e3",
Name: indexName,
Tags: &restoredIndexTags,
})
fmt.Printf(prettifyStruct(createIndexFromBackupResp))
}
```
```csharp C# theme={null}
using Pinecone;
var pinecone = new PineconeClient("YOUR_API_KEY");
var response = await pinecone.Backups.CreateIndexFromBackupAsync(
"a65ff585-d987-4da5-a622-72e19a6ed5f4",
new CreateIndexFromBackupRequest
{
Name = "restored-index",
Tags = new Dictionary
{
{ "tag0", "val0" },
{ "tag1", "val1" }
},
DeletionProtection = DeletionProtection.Enabled
}
);
Console.WriteLine(response);
```
```bash curl theme={null}
PINECONE_API_KEY="YOUR_API_KEY"
BACKUP_ID="a65ff585-d987-4da5-a622-72e19a6ed5f4"
curl "https://api.pinecone.io/backups/$BACKUP_ID/create-index" \
-H "Api-Key: $PINECONE_API_KEY" \
-H "X-Pinecone-Api-Version: 2025-10" \
-H 'Content-Type: application/json' \
-d '{
"name": "restored-index",
"tags": {
"tag0": "val0",
"tag1": "val1"
},
"deletion_protection": "enabled"
}'
```
The example returns a response like the following:
```python Python theme={null}
{'deletion_protection': 'enabled',
'dimension': 1024,
'embed': {'dimension': 1024,
'field_map': {'text': 'chunk_text'},
'metric': 'cosine',
'model': 'multilingual-e5-large',
'read_parameters': {'input_type': 'query', 'truncate': 'END'},
'vector_type': 'dense',
'write_parameters': {'input_type': 'passage', 'truncate': 'END'}},
'host': 'example-dense-index-python3-govk0nt.svc.aped-4627-b74a.pinecone.io',
'metric': 'cosine',
'name': 'example-dense-index-python3',
'spec': {'serverless': {'cloud': 'aws', 'region': 'us-east-1'}},
'status': {'ready': True, 'state': 'Ready'},
'tags': {'tag0': 'val0', 'tag1': 'val1'},
'vector_type': 'dense'}
```
```javascript JavaScript theme={null}
{
restoreJobId: 'e9ba8ff8-7948-4cfa-ba43-34227f6d30d4',
indexId: '025117b3-e683-423c-b2d1-6d30fbe5027f'
}
```
```java Java theme={null}
class CreateIndexFromBackupResponse {
restoreJobId: e9ba8ff8-7948-4cfa-ba43-34227f6d30d4
indexId: 025117b3-e683-423c-b2d1-6d30fbe5027f
additionalProperties: null
}
```
```go Go theme={null}
{
"index_id": "025117b3-e683-423c-b2d1-6d30fbe5027f",
"restore_job_id": "e9ba8ff8-7948-4cfa-ba43-34227f6d30d4"
}
```
```csharp C# theme={null}
{
"restore_job_id":"e9ba8ff8-7948-4cfa-ba43-34227f6d30d4",
"index_id":"025117b3-e683-423c-b2d1-6d30fbe5027f"
}
```
```json curl theme={null}
{
"restore_job_id":"e9ba8ff8-7948-4cfa-ba43-34227f6d30d4",
"index_id":"025117b3-e683-423c-b2d1-6d30fbe5027f"
}
```
You can create a serverless index from a backup using the [Pinecone console](https://app.pinecone.io/organizations/-/projects).
## List restore jobs
You can [list all restore jobs](/reference/api/latest/control-plane/list_restore_jobs) as follows.
Up to 100 restore jobs are returned at a time by default, in sorted order (bitwise “C” collation). If the `limit` parameter is set, up to that number of restore jobs are returned instead. Whenever there are additional restore jobs to return, the response also includes a `pagination_token` that you can use to get the next batch of jobs. When the response does not include a `pagination_token`, there are no more restore jobs to return.
```python Python theme={null}
from pinecone import Pinecone
pc = Pinecone(api_key="YOUR_API_KEY")
restore_jobs = pc.list_restore_jobs()
print(restore_jobs)
```
```javascript JavaScript theme={null}
import { Pinecone } from '@pinecone-database/pinecone';
const pc = new Pinecone({ apiKey: 'YOUR_API_KEY' })
const restoreJobs = await pc.listRestoreJobs();
console.log(restoreJobs);
```
```java Java theme={null}
import io.pinecone.clients.Pinecone;
import org.openapitools.db_control.client.ApiException;
import org.openapitools.db_control.client.model.*;
public class CreateIndexFromBackup {
public static void main(String[] args) throws ApiException {
Pinecone pc = new Pinecone.Builder("YOUR_API-KEY").build();
// List all restore jobs with default pagination limit
RestoreJobList restoreJobList = pc.listRestoreJobs(null, null);
// List all restore jobs with pagination limit of 5
RestoreJobList restoreJobListWithLimit = pc.listRestoreJobs(5);
// List all restore jobs with pagination limit and token
RestoreJobList restoreJobListPaginated = pc.listRestoreJobs(5, "eyJza2lwX3Bhc3QiOiIxMDEwMy0=");
System.out.println(restoreJobList);
System.out.println(restoreJobListWithLimit);
System.out.println(restoreJobListPaginated);
}
}
```
```go Go theme={null}
package main
import (
"context"
"encoding/json"
"fmt"
"log"
"github.com/pinecone-io/go-pinecone/v4/pinecone"
)
func prettifyStruct(obj interface{}) string {
bytes, _ := json.MarshalIndent(obj, "", " ")
return string(bytes)
}
func main() {
ctx := context.Background()
pc, err := pinecone.NewClient(pinecone.NewClientParams{
ApiKey: "YOUR_API_KEY",
})
if err != nil {
log.Fatalf("Failed to create Client: %v", err)
}
limit := 2
restoreJobs, err := pc.ListRestoreJobs(ctx, &pinecone.ListRestoreJobsParams{
Limit: &limit,
})
if err != nil {
log.Fatalf("Failed to list restore jobs: %v", err)
}
fmt.Printf(prettifyStruct(restoreJobs))
}
```
```csharp C# theme={null}
using Pinecone;
var pinecone = new PineconeClient("YOUR_API_KEY");
var jobs = await pinecone.RestoreJobs.ListAsync(new ListRestoreJobsRequest());
Console.WriteLine(jobs);
```
```bash curl theme={null}
PINECONE_API_KEY="YOUR_API_KEY"
curl "https://api.pinecone.io/restore-jobs" \
-H "X-Pinecone-Api-Version: 2025-10" \
-H "Api-Key: $PINECONE_API_KEY"
```
The example returns a response like the following:
```python Python theme={null}
[{
"restore_job_id": "06b08366-a0a9-404d-96c2-e791c71743e5",
"backup_id": "95707edb-e482-49cf-b5a5-312219a51a97",
"target_index_name": "restored-index",
"target_index_id": "027aff93-de40-4f48-a573-6dbcd654f961",
"status": "Completed",
"created_at": "2025-05-15T13:59:51.439479+00:00",
"completed_at": "2025-05-15T14:00:09.222998+00:00",
"percent_complete": 100.0
}, {
"restore_job_id": "4902f735-b876-4e53-a05c-bc01d99251cb",
"backup_id": "8c85e612-ed1c-4f97-9f8c-8194e07bcf71",
"target_index_name": "restored-index2",
"target_index_id": "027aff93-de40-4f48-a573-6dbcd654f961",
"status": "Completed",
"created_at": "2025-05-15T21:06:19.906074+00:00",
"completed_at": "2025-05-15T21:06:39.360509+00:00",
"percent_complete": 100.0
}]
```
```javascript JavaScript theme={null}
{
data: [
{
restoreJobId: '69acc1d0-9105-4fcb-b1db-ebf97b285c5e',
backupId: '8c85e612-ed1c-4f97-9f8c-8194e07bcf71',
targetIndexName: 'restored-index2',
targetIndexId: 'e6c0387f-33db-4227-9e91-32181106e56b',
status: 'Completed',
createdAt: 2025-05-14T17:25:59.378Z,
completedAt: 2025-05-14T17:26:23.997Z,
percentComplete: 100
},
{
restoreJobId: '9857add2-99d4-4399-870e-aa7f15d8d326',
backupId: '94a63aeb-efae-4f7a-b059-75d32c27ca57',
targetIndexName: 'restored-index',
targetIndexId: '0d8aed24-adf8-4b77-8e10-fd674309dc85',
status: 'Completed',
createdAt: 2025-04-25T18:14:05.227Z,
completedAt: 2025-04-25T18:14:11.074Z,
percentComplete: 100
}
],
pagination: undefined
}
```
```java Java theme={null}
class RestoreJobList {
data: [class RestoreJobModel {
restoreJobId: cf597d76-4484-4b6c-b07c-2bfcac3388aa
backupId: 0d75b99f-be61-4a93-905e-77201286c02e
targetIndexName: restored-index
targetIndexId: 8a810881-1505-46c0-b906-947c048b15f5
status: Completed
createdAt: 2025-05-16T20:09:18.700631Z
completedAt: 2025-05-16T20:11:30.673296Z
percentComplete: 100.0
additionalProperties: null
}, class RestoreJobModel {
restoreJobId: 4902f735-b876-4e53-a05c-bc01d99251cb
backupId: 8c85e612-ed1c-4f97-9f8c-8194e07bcf71
targetIndexName: restored-index2
targetIndexId: 710cb6e6-bfb4-4bf5-a425-9754e5bbc832
status: Completed
createdAt: 2025-05-15T21:06:19.906074Z
completedAt: 2025-05-15T21:06:39.360509Z
percentComplete: 100.0
additionalProperties: null
}]
pagination: class PaginationResponse {
next: eyJsaW1pdCI6Miwib2Zmc2V0IjoyfQ==
additionalProperties: null
}
additionalProperties: null
}
```
```go Go theme={null}
{
"data": [
{
"backup_id": "8c85e612-ed1c-4f97-9f8c-8194e07bcf71",
"completed_at": "2025-05-16T20:11:30.673296Z",
"created_at": "2025-05-16T20:09:18.700631Z",
"percent_complete": 100,
"restore_job_id": "e9ba8ff8-7948-4cfa-ba43-34227f6d30d4",
"status": "Completed",
"target_index_id": "025117b3-e683-423c-b2d1-6d30fbe5027f",
"target_index_name": "restored-index"
},
{
"backup_id": "95707edb-e482-49cf-b5a5-312219a51a97",
"completed_at": "2025-05-15T21:04:34.2463Z",
"created_at": "2025-05-15T21:04:15.949067Z",
"percent_complete": 100,
"restore_job_id": "eee4f8b8-cd3e-45fe-9ed5-93c28e237f24",
"status": "Completed",
"target_index_id": "5a0d555f-7ccd-422a-a3a6-78f7b73350c0",
"target_index_name": "restored-index2"
}
],
"pagination": {
"next": "eyJsaW1pdCI6MTAsIm9mZnNldCI6MTB9"
}
}
```
```csharp C# theme={null}
{
"data": [
{
"restore_job_id": "9857add2-99d4-4399-870e-aa7f15d8d326",
"backup_id": "94a63aeb-efae-4f7a-b059-75d32c27ca57",
"target_index_name": "restored-index",
"target_index_id": "0d8aed24-adf8-4b77-8e10-fd674309dc85",
"status": "Completed",
"created_at": "2025-04-25T18:14:05.227526Z",
"completed_at": "2025-04-25T18:14:11.074618Z",
"percent_complete": 100
},
{
"restore_job_id": "69acc1d0-9105-4fcb-b1db-ebf97b285c5e",
"backup_id": "8c85e612-ed1c-4f97-9f8c-8194e07bcf71",
"target_index_name": "restored-index2",
"target_index_id": "e6c0387f-33db-4227-9e91-32181106e56b",
"status": "Completed",
"created_at": "2025-05-14T17:25:59.378989Z",
"completed_at": "2025-05-14T17:26:23.997284Z",
"percent_complete": 100
}
]
}
```
```json curl theme={null}
{
"data": [
{
"restore_job_id": "9857add2-99d4-4399-870e-aa7f15d8d326",
"backup_id": "94a63aeb-efae-4f7a-b059-75d32c27ca57",
"target_index_name": "restored-index",
"target_index_id": "0d8aed24-adf8-4b77-8e10-fd674309dc85",
"status": "Completed",
"created_at": "2025-04-25T18:14:05.227526Z",
"completed_at": "2025-04-25T18:14:11.074618Z",
"percent_complete": 100
},
{
"restore_job_id": "69acc1d0-9105-4fcb-b1db-ebf97b285c5e",
"backup_id": "8c85e612-ed1c-4f97-9f8c-8194e07bcf71",
"target_index_name": "restored-index2",
"target_index_id": "e6c0387f-33db-4227-9e91-32181106e56b",
"status": "Completed",
"created_at": "2025-05-14T17:25:59.378989Z",
"completed_at": "2025-05-14T17:26:23.997284Z",
"percent_complete": 100
}
],
"pagination": null
}
```
## View restore job details
You can [view the details of a specific restore job](/reference/api/latest/control-plane/describe_restore_job), as in the following example:
```python Python theme={null}
from pinecone import Pinecone
pc = Pinecone(api_key="YOUR_API_KEY")
restore_job = pc.describe_restore_job(job_id="9857add2-99d4-4399-870e-aa7f15d8d326")
print(restore_job)
```
```javascript JavaScript theme={null}
import { Pinecone } from '@pinecone-database/pinecone';
const pc = new Pinecone({ apiKey: 'YOUR_API_KEY' })
const restoreJob = await pc.describeRestoreJob('9857add2-99d4-4399-870e-aa7f15d8d326');
console.log(restoreJob);
```
```java Java theme={null}
import io.pinecone.clients.Pinecone;
import org.openapitools.db_control.client.ApiException;
import org.openapitools.db_control.client.model.*;
public class CreateIndexFromBackup {
public static void main(String[] args) throws ApiException {
Pinecone pc = new Pinecone.Builder("YOUR_API-KEY").build();
RestoreJobModel restoreJob = pc.describeRestoreJob("9857add2-99d4-4399-870e-aa7f15d8d326");
System.out.println(restoreJob);
}
}
```
```go Go theme={null}
package main
import (
"context"
"encoding/json"
"fmt"
"log"
"github.com/pinecone-io/go-pinecone/v4/pinecone"
)
func prettifyStruct(obj interface{}) string {
bytes, _ := json.MarshalIndent(obj, "", " ")
return string(bytes)
}
func main() {
ctx := context.Background()
pc, err := pinecone.NewClient(pinecone.NewClientParams{
ApiKey: "YOUR_API_KEY",
})
if err != nil {
log.Fatalf("Failed to create Client: %v", err)
}
restoreJob, err := pc.DescribeRestoreJob(ctx, "e9ba8ff8-7948-4cfa-ba43-34227f6d30d4")
if err != nil {
log.Fatalf("Failed to describe restore job: %v", err)
}
fmt.Printf(prettifyStruct(restoreJob))
}
```
```csharp C# theme={null}
using Pinecone;
var pinecone = new PineconeClient("YOUR_API_KEY");
var job = await pinecone.RestoreJobs.GetAsync("9857add2-99d4-4399-870e-aa7f15d8d326");
Console.WriteLine(job);
```
```bash curl theme={null}
PINECONE_API_KEY="YOUR_API_KEY"
JOB_ID="9857add2-99d4-4399-870e-aa7f15d8d326"
curl "https://api.pinecone.io/restore-jobs/$JOB_ID" \
-H "X-Pinecone-Api-Version: 2025-10" \
-H "Api-Key: $PINECONE_API_KEY" \
-H 'accept: application/json'
```
The example returns a response like the following:
```python Python theme={null}
{'backup_id': '94a63aeb-efae-4f7a-b059-75d32c27ca57',
'completed_at': datetime.datetime(2025, 4, 25, 18, 14, 11, 74618, tzinfo=tzutc()),
'created_at': datetime.datetime(2025, 4, 25, 18, 14, 5, 227526, tzinfo=tzutc()),
'percent_complete': 100.0,
'restore_job_id': '9857add2-99d4-4399-870e-aa7f15d8d326',
'status': 'Completed',
'target_index_id': '0d8aed24-adf8-4b77-8e10-fd674309dc85',
'target_index_name': 'restored-index'}
```
```javascript JavaScript theme={null}
{
restoreJobId: '9857add2-99d4-4399-870e-aa7f15d8d326',
backupId: '94a63aeb-efae-4f7a-b059-75d32c27ca57',
targetIndexName: 'restored-index',
targetIndexId: '0d8aed24-adf8-4b77-8e10-fd674309dc85',
status: 'Completed',
createdAt: 2025-04-25T18:14:05.227Z,
completedAt: 2025-04-25T18:14:11.074Z,
percentComplete: 100
}
```
```java Java theme={null}
class RestoreJobModel {
restoreJobId: cf597d76-4484-4b6c-b07c-2bfcac3388aa
backupId: 0d75b99f-be61-4a93-905e-77201286c02e
targetIndexName: restored-index
targetIndexId: 0d8aed24-adf8-4b77-8e10-fd674309dc85
status: Completed
createdAt: 2025-05-16T20:09:18.700631Z
completedAt: 2025-05-16T20:11:30.673296Z
percentComplete: 100.0
additionalProperties: null
}
```
```go Go theme={null}
{
"backup_id": "8c85e612-ed1c-4f97-9f8c-8194e07bcf71",
"completed_at": "2025-05-16T20:11:30.673296Z",
"created_at": "2025-05-16T20:09:18.700631Z",
"percent_complete": 100,
"restore_job_id": "e9ba8ff8-7948-4cfa-ba43-34227f6d30d4",
"status": "Completed",
"target_index_id": "025117b3-e683-423c-b2d1-6d30fbe5027f",
"target_index_name": "restored-index"
}
```
```csharp C# theme={null}
{
"restore_job_id": "9857add2-99d4-4399-870e-aa7f15d8d326",
"backup_id": "94a63aeb-efae-4f7a-b059-75d32c27ca57",
"target_index_name": "restored-index",
"target_index_id": "0d8aed24-adf8-4b77-8e10-fd674309dc85",
"status": "Completed",
"created_at": "2025-04-25T18:14:05.227526Z",
"completed_at": "2025-04-25T18:14:11.074618Z",
"percent_complete": 100
}
```
```json curl theme={null}
{
"restore_job_id": "9857add2-99d4-4399-870e-aa7f15d8d326",
"backup_id": "94a63aeb-efae-4f7a-b059-75d32c27ca57",
"target_index_name": "restored-index",
"target_index_id": "0d8aed24-adf8-4b77-8e10-fd674309dc85",
"status": "Completed",
"created_at": "2025-04-25T18:14:05.227526Z",
"completed_at": "2025-04-25T18:14:11.074618Z",
"percent_complete": 100
}
```
---
# Source: https://docs.pinecone.io/troubleshooting/restrictions-on-index-names.md
> ## Documentation Index
> Fetch the complete documentation index at: https://docs.pinecone.io/llms.txt
> Use this file to discover all available pages before exploring further.
# Restrictions on index names
There are two main restrictions on index names in Pinecone: **character restrictions** and a **maximum length**.
## Character restrictions
Index names can only use UTF-8 lowercase alphanumeric Latin characters and dashes. Non-Latin characters (such as Chinese or Cyrillic) and emojis are not supported. Additionally, they cannot contain dots, as these are used to separate hosts and subnets in DNS, which Pinecone uses to route requests and queries.
## Maximum length
The maximum length of your index name is a factor of limits imposed by the infrastructure Pinecone uses behind the scenes. The combination of your index name and project ID (normally a seven-character, alphanumeric string) cannot exceed 52 characters, plus a dash to separate them. Your project ID is different from your project name, which is often longer than seven characters. You can identify your project ID by the hostname used to connect to your index; it's the last set of characters after the final `-`. For example, if your index is `foo` and your project ID is `abc1234` in the `us-east1-gcp` environment, your index's hostname would be `foo-abc1234.svc.us-east1-gcp.pinecone.io`, and its length would be 11 characters (3 for the index name, 1 for the dash, 7 for the project ID).
---
# Source: https://docs.pinecone.io/guides/assistant/retrieve-context-snippets.md
> ## Documentation Index
> Fetch the complete documentation index at: https://docs.pinecone.io/llms.txt
> Use this file to discover all available pages before exploring further.
# Retrieve context snippets
> Access relevant context and citations from Pinecone Assistant.
This page shows you how to [retrieve context snippets](/guides/assistant/context-snippets-overview).
To try this in your browser, use the [Pinecone Assistant - Context colab notebook](https://colab.research.google.com/drive/1AD4QWsXBG1FQRwq-ModlaggR7Cx7NJCz).
## Retrieve context snippets from an assistant
You can [retrieve context snippets](/reference/api/latest/assistant/context_assistant) from an assistant, as in the following example:
```python Python theme={null}
# To use the Python SDK, install the plugin:
# pip install --upgrade pinecone pinecone-plugin-assistant
from pinecone import Pinecone
pc = Pinecone(api_key="YOUR_API_KEY")
assistant = pc.assistant.Assistant(assistant_name="example-assistant")
response = assistant.context(query="Who is the CFO of Netflix?")
for snippet in response.snippets:
print(snippet)
```
```javascript JavaScript theme={null}
import { Pinecone } from '@pinecone-database/pinecone'
const pc = new Pinecone({ apiKey: 'YOUR_API_KEY' });
const assistantName = 'example-assistant';
const assistant = pc.Assistant(assistantName);
const response = await assistant.context({
query: 'Who is the CFO of Netflix?',
});
console.log(response);
```
```bash curl theme={null}
PINECONE_API_KEY="YOUR_API_KEY"
ASSISTANT_NAME="example-assistant"
curl "https://prod-1-data.ke.pinecone.io/assistant/chat/$ASSISTANT_NAME/context" \
-H "Api-Key: $PINECONE_API_KEY" \
-H "accept: application/json" \
-H "Content-Type: application/json" \
-H "X-Pinecone-Api-Version: 2025-10" \
-d '{
"query": "Who is the CFO of Netflix?"
}'
```
The example above returns a JSON object like the following:
```json JSON theme={null}
{
"snippets":
[
{
"type":"text",
"content":"EXHIBIT 31.3\nCERTIFICATION OF CHIEF FINANCIAL OFFICER\nPURSUANT TO SECTION 302 OF THE SARBANES-OXLEY ACT OF 2002\nI, Spencer Neumann, certify that: ..."
"score":0.9960699,
"reference":
{
"type":"pdf",
"file":
{
"status":"Available",
"id":"e6034e51-0bb9-4926-84c6-70597dbd07a7",
"name":"Netflix-10-K-01262024.pdf",
"size":1073470,
"metadata":null,
"updated_on":"2024-11-21T22:59:10.426001030Z",
"created_on":"2024-11-21T22:58:35.879120257Z",
"percent_done":1.0,
"signed_url":"https://storage.googleapis.com...",
"error_message":null
},
"pages":[78]
}
},
{
"type":"text",
"content":"EXHIBIT 32.1\n..."
...
```
[`signed_url`](https://cloud.google.com/storage/docs/access-control/signed-urls) provides temporary, read-only access to the relevant file. Anyone with the link can access the file, so treat it as sensitive data. Expires in one hour.
## Control the snippets retrieved
This is available in API versions `2025-04` and later.
You can limit [token usage](/guides/assistant/pricing-and-limits#token-usage) by tuning `top_k * snippet_size`:
* `snippet_size`: Controls the max size of a snippet (default is 2048 tokens). Note that snippet size can vary and, in rare cases, may be bigger than the set `snippet_size`. Snippet size controls the amount of context given for each chunk of text.
* `top_k`: Controls the max number of context snippets retrieved (default is 16). `top_k` controls the diversity of information received in the returned snippets.
While additional tokens will be used for other parameters, adjusting the `top_k` and `snippet_size` can help manage token consumption.
```python Python theme={null}
# To use the Python SDK, install the plugin:
# pip install --upgrade pinecone pinecone-plugin-assistant
from pinecone import Pinecone
pc = Pinecone(api_key="YOUR_API_KEY")
assistant = pc.assistant.Assistant(assistant_name="example-assistant")
response = assistant.context(query="Who is the CFO of Netflix?", top_k=10, snippet_size=2500)
for snippet in response.snippets:
print(snippet)
```
```bash curl theme={null}
PINECONE_API_KEY="YOUR_API_KEY"
ASSISTANT_NAME="example-assistant"
curl "https://prod-1-data.ke.pinecone.io/assistant/chat/$ASSISTANT_NAME/context" \
-H "Api-Key: $PINECONE_API_KEY" \
-H "accept: application/json" \
-H "Content-Type: application/json" \
-H "X-Pinecone-Api-Version: 2025-10" \
-d '{
"query": "Who is the CFO of Netflix?",
"top_k": 10,
"snippet_size": 2500
}'
```
---
# Source: https://docs.pinecone.io/troubleshooting/return-all-vectors-in-an-index.md
> ## Documentation Index
> Fetch the complete documentation index at: https://docs.pinecone.io/llms.txt
> Use this file to discover all available pages before exploring further.
# Return all vectors in an index
Pinecone is designed to find vectors that are similar to a given set of conditions, either by comparing a new vector to the ones in the index or by comparing a vector in the index to all of the others using the [query by ID feature](/reference/api/2024-10/data-plane/query). Because the Pinecone query function relies on performing this similarity search, there isn't a way to return all of the vectors currently stored in the index with a single query.
There isn't a guaranteed workaround for this type of query today but providing the ability to query all or export the entire index is on our roadmap for the future.
---
# Source: https://docs.pinecone.io/reference/rust-sdk.md
# Rust SDK
The Rust SDK is in "alpha" and is under active development. The SDK should be considered unstable and should not be used in production. Before a 1.0 release, there are no guarantees of backward compatibility between minor versions. See the [Rust SDK README](https://github.com/pinecone-io/pinecone-rust-client/blob/main/README.md) for full installation instructions and usage examples.
To make a feature request or report an issue, please [file an issue](https://github.com/pinecone-io/pinecone-rust-client/issues).
## Install
To install the latest version of the [Rust SDK](https://github.com/pinecone-io/pinecone-rust-client), add a dependency to the current project:
```shell theme={null}
cargo add pinecone-sdk
```
## Initialize
Once installed, you can import the SDK and then use an [API key](/guides/production/security-overview#api-keys) to initialize a client instance:
```rust Rust theme={null}
use pinecone_sdk::pinecone::PineconeClientConfig;
use pinecone_sdk::utils::errors::PineconeError;
#[tokio::main]
async fn main() -> Result<(), PineconeError> {
let config = PineconeClientConfig {
api_key: Some("YOUR_API_KEY".to_string()),
..Default::default()
};
let pinecone = config.client()?;
let indexes = pinecone.list_indexes().await?;
println!("Indexes: {:?}", indexes);
Ok(())
}
```
---
# Source: https://docs.pinecone.io/examples/sample-apps.md
> ## Documentation Index
> Fetch the complete documentation index at: https://docs.pinecone.io/llms.txt
> Use this file to discover all available pages before exploring further.
# Sample apps
export const Tag = ({text, icon}) => {
return
{icon &&  }
{text}
;
};
export const UtilityExampleCard = ({title, text, link}) => {
return
}
{text}
;
};
export const UtilityExampleCard = ({title, text, link}) => {
return
{title}
{text}
;
};
export const ExampleCard = ({title, text, link, children, arrow, vectors, namespaces}) => {
return
{title}
{text}
{children && {children}
}
{arrow && }
{(vectors || namespaces) &&
{vectors && {vectors} vectors}
{namespaces && {namespaces} namespaces}
}
;
};
---
# Source: https://docs.pinecone.io/guides/indexes/pods/scale-pod-based-indexes.md
> ## Documentation Index
> Fetch the complete documentation index at: https://docs.pinecone.io/llms.txt
> Use this file to discover all available pages before exploring further.
# Scale pod-based indexes
> Scale indexes vertically or horizontally as needed
Customers who sign up for a Standard or Enterprise plan on or after August 18, 2025 cannot create pod-based indexes. Instead, create [serverless indexes](/guides/index-data/create-an-index), and consider using [dedicated read nodes](/guides/index-data/dedicated-read-nodes) for large workloads (millions of records or more, and moderate or high query rates).
While your index can still serve queries, new upserts may fail as the capacity becomes exhausted. If you need to scale your environment to accommodate more vectors, you can modify your existing index and scale it vertically or create a new index and scale horizontally.
This page explains how you can scale your [pod-based indexes](/guides/index-data/indexing-overview#pod-based-indexes) horizontally and vertically.
## Vertical vs. horizontal scaling
If you need to scale your environment to accommodate more vectors, you can modify your existing index to scale it vertically or create a new index and scale horizontally. This article will describe both methods and how to scale your index effectively.
## Vertical scaling
[Vertical scaling](https://www.pinecone.io/learn/testing-p2-collections-scaling/#vertical-scaling-on-p1-and-s1) is fast and involves no downtime. This is a good choice when you can't pause upserts and must continue serving traffic. It also allows you to double your capacity instantly. However, there are some factors to consider.
### Increase pod size
The default [pod size](/guides/index-data/indexing-overview#pod-size-and-performance) is `x1`. You can increase the size to `x2`, `x4`, or `x8`. Moving up to the next size effectively doubles the capacity of the index. If you need to scale by smaller increments, then consider horizontal scaling.
Increasing the pod size of your index does not result in downtime. Reads and writes continue uninterrupted during the scaling process, which completes in about 10 minutes. You cannot reduce the pod size of your indexes.
The number of base pods you specify when you initially create the index is static and cannot be changed. For example, if you start with 10 pods of `p1.x1` and vertically scale to `p1.x2`, this equates to 20 pods worth of usage. Pod types (performance versus storage pods) also cannot be changed with vertical scaling. If you want to change your pod type while scaling, then horizontal scaling is the better option.
#### When to increase pod size
If your index is at around 90% fullness, we recommend increasing its size. This helps ensure optimal performance and prevents upserts from failing due to capacity constraints.
#### How to increase pod size
You can increase the pod size in the Pinecone console or using the API.
1. Open the [Pinecone console](https://app.pinecone.io/organizations/-/projects).
2. Select the project containing the index you want to configure.
3. Go to **Database > Indexes**.
4. Select the index.
5. Click the **...** button.
6. Select **Configure**.
7. In the dropdown, choose the pod size to use.
8. Click **Confirm**.
Use the [`configure_index`](/reference/api/latest/control-plane/configure_index) operation and append the new size to the `pod_type` parameter, separated by a period (.).
**Example**
The following example assumes that `docs-example` has size `x1` and increases the size to `x2`.
```Python Python theme={null}
from pinecone.grpc import PineconeGRPC as Pinecone
pc = Pinecone(api_key="YOUR_API_KEY")
pc.configure_index("docs-example", pod_type="s1.x2")
```
```JavaScript JavaScript theme={null}
import { Pinecone } from '@pinecone-database/pinecone'
const pinecone = new Pinecone({
apiKey: 'YOUR_API_KEY'
});
await pc.configureIndex('docs-example', {
spec: {
pod: {
podType: 's1.x2',
},
},
});
```
```java Java theme={null}
import io.pinecone.clients.Pinecone;
public class ConfigureIndexExample {
public static void main(String[] args) {
Pinecone pc = new Pinecone.Builder("PINECONE_API_KEY").build();
pc.configurePodsIndex("docs-example", "s1.x2");
}
}
```
```go Go theme={null}
package main
import (
"context"
"fmt"
"log"
"github.com/pinecone-io/go-pinecone/v4/pinecone"
)
func main() {
ctx := context.Background()
pc, err := pinecone.NewClient(pinecone.NewClientParams{
ApiKey: "YOUR_API_KEY",
})
if err != nil {
log.Fatalf("Failed to create Client: %v", err)
}
idx, err := pc.ConfigureIndex(ctx, "docs-example", pinecone.ConfigureIndexParams{PodType: "s1.x2"})
if err != nil {
log.Fatalf("Failed to configure index \"%v\": %v", idx.Name, err)
} else {
fmt.Printf("Successfully configured index \"%v\"", idx.Name)
}
}
```
```csharp C# theme={null}
using Pinecone;
var pinecone = new PineconeClient("YOUR_API_KEY");
var indexMetadata = await pinecone.ConfigureIndexAsync("docs-example", new ConfigureIndexRequest
{
Spec = new ConfigureIndexRequestSpec
{
Pod = new ConfigureIndexRequestSpecPod {
PodType = "s1.x2",
}
}
});
```
```bash curl theme={null}
PINECONE_API_KEY="YOUR_API_KEY"
curl -s -X PATCH "https://api.pinecone.io/indexes/docs-example-curl" \
-H "Content-Type: application/json" \
-H "Api-Key: $PINECONE_API_KEY" \
-H "X-Pinecone-Api-Version: 2025-10" \
-d '{
"pod_type": "s1.x2"
}'
```
The size change can take up to 15 minutes to complete.
### Decrease pod size
After creating an index, you cannot vertically downscale the index/pod size. Instead, you must [create a collection](/guides/indexes/pods/back-up-a-pod-based-index) and then [create a new index from your collection](/guides/indexes/pods/restore-a-pod-based-index) and specify your desired pod size.
### Check the status of a pod size change
To check the status of a pod size change, use the [`describe_index`](/reference/api/latest/control-plane/describe_index/) endpoint. The `status` field in the results contains the key-value pair `"state":"ScalingUp"` or `"state":"ScalingDown"` during the resizing process and the key-value pair `"state":"Ready"` after the process is complete.
The index fullness metric provided by [`describe_index_stats`](/reference/api/latest/data-plane/describeindexstats) may be inaccurate until the resizing process is complete.
**Example**
The following example uses `describe_index` to get the index status of the index `docs-example`. The `status` field contains the key-value pair `"state":"ScalingUp"`, indicating that the resizing process is still ongoing.
```Python Python theme={null}
from pinecone.grpc import PineconeGRPC as Pinecone
pc = Pinecone(api_key="YOUR_API_KEY")
pc.describe_index(name="docs-example")
```
```JavaScript JavaScript theme={null}
import { Pinecone } from '@pinecone-database/pinecone'
const pc = new Pinecone({
apiKey: 'YOUR_API_KEY'
});
await pc.describeIndex({
name: "docs-example",
});
```
```java Java theme={null}
import io.pinecone.clients.Pinecone;
import org.openapitools.db_control.client.model.*;
public class DescribeIndexExample {
public static void main(String[] args) {
Pinecone pc = new Pinecone.Builder("YOUR_API_KEY").build();
IndexModel indexModel = pc.describeIndex("docs-example");
}
}
```
```go Go theme={null}
package main
import (
"context"
"fmt"
"log"
"github.com/pinecone-io/go-pinecone/v4/pinecone"
)
func main() {
ctx := context.Background()
pc, err := pinecone.NewClient(pinecone.NewClientParams{
ApiKey: "YOUR_API_KEY",
})
if err != nil {
log.Fatalf("Failed to create Client: %v", err)
}
idx, err := pc.DescribeIndex(ctx, "docs-example")
if err != nil {
log.Fatalf("Failed to describe index %v: %v", idx.Name, err)
} else {
fmt.Printf("Successfully found index: %v", idx.Name)
}
}
```
```csharp C# theme={null}
using Pinecone;
var pinecone = new PineconeClient("YOUR_API_KEY");
var indexModel = await pinecone.DescribeIndexAsync("docs-example");
Console.WriteLine(indexModel);
```
```bash curl theme={null}
PINECONE_API_KEY="YOUR_API_KEY"
curl -s -X GET "https://api.pinecone.io/indexes/docs-example-curl" \
-H "Api-Key: $PINECONE_API_KEY" \
-H "X-Pinecone-Api-Version: 2025-10"
```
## Horizontal scaling
There are two approaches to horizontal scaling in Pinecone: adding pods and adding replicas. Adding pods increases all resources but requires a pause in upserts; adding replicas only increases throughput and requires no pause in upserts.
### Add pods
Adding additional pods to a running index is not supported directly. However, you can increase the number of pods by using our [collections](/guides/indexes/pods/understanding-collections) feature to create a new index with more pods.
A collection is an immutable snapshot of your index in time: a collection stores the data but not the original index configuration. When you [create an index from a collection](/guides/indexes/pods/create-a-pod-based-index#create-a-pod-index-from-a-collection), you define the new index configuration. This allows you to scale the base pod count horizontally without scaling vertically.
The main advantage of this approach is that you can scale incrementally instead of doubling capacity as with vertical scaling. Also, you can redefine pod types if you are experimenting or if you need to use a different pod type, such as performance-optimized pods or storage-optimized pods. Another advantage of this method is that you can change your [metadata configuration](/guides/indexes/pods/manage-pod-based-indexes#selective-metadata-indexing) to redefine metadata fields as indexed or stored-only. This is important when tuning your index for the best throughput.
Here are the general steps to make a copy of your index and create a new index while changing the pod type, pod count, metadata configuration, replicas, and all typical parameters when creating a new collection:
1. Pause upserts.
2. Create a collection from the current index.
3. Create an index from the collection with new parameters.
4. Continue upserts to the newly created index. Note: the URL has likely changed.
5. Delete the old index if desired.
For detailed steps on creating the collection, see [backup indexes](/guides/manage-data/back-up-an-index#create-a-backup-using-a-collection). For steps on creating an index from a collection, see [Create an index from a collection](/guides/indexes/pods/create-a-pod-based-index#create-a-pod-index-from-a-collection).
### Add replicas
Each replica duplicates the resources and data in an index. This means that adding additional replicas increases the throughput of the index but not its capacity. However, adding replicas does not require downtime.
Throughput in terms of queries per second (QPS) scales linearly with the number of replicas per index.
#### When to add replicas
There are two primary scenarios where adding replicas is beneficial:
**Increase QPS**: The primary reason to add replicas is to increase your index's queries per second (QPS). Each new replica adds another pod for reading from your index and, generally speaking, will increase your QPS by an equal amount as a single pod. For example, if you consistently get 25 QPS for a single pod, each replica will result in 25 more QPS.
If you don't see an increase in QPS after adding replicas, add multiprocessing to your application to ensure you are running parallel operations. You can use the [Pinecone gRPC SDK](/guides/index-data/upsert-data#grpc-python-sdk), or your multiprocessing library of choice.
**Provide data redundancy**: When you add a replica to your index, the Pinecone controller will choose a zone in the same region that does not currently have a replica, up to a maximum of three zones (your fourth and subsequent replicas will be hosted in zones with existing replicas). If your application requires multizone redundancy, this is our recommended approach to achieve that.
#### How to add replicas
To add replicas, use the `configure_index` endpoint to increase the number of replicas for your index:
```Python Python theme={null}
from pinecone.grpc import PineconeGRPC as Pinecone
pc = Pinecone(api_key="YOUR_API_KEY")
pc.configure_index("docs-example", replicas=4)
```
```JavaScript JavaScript theme={null}
import { Pinecone } from '@pinecone-database/pinecone'
const pc = new Pinecone({
apiKey: 'YOUR_API_KEY'
});
await pc.configureIndex('docs-example', {
spec: {
pod: {
replicas: 4,
},
},
});
```
```java Java theme={null}
import io.pinecone.clients.Pinecone;
public class ConfigureIndexExample {
public static void main(String[] args) {
Pinecone pc = new Pinecone.Builder("PINECONE_API_KEY").build();
pc.configurePodsIndex("docs-example", 4, DeletionProtection.DISABLED);
}
}
```
```go Go theme={null}
package main
import (
"context"
"fmt"
"log"
"github.com/pinecone-io/go-pinecone/v4/pinecone"
)
func main() {
ctx := context.Background()
pc, err := pinecone.NewClient(pinecone.NewClientParams{
ApiKey: "YOUR_API_KEY",
})
if err != nil {
log.Fatalf("Failed to create Client: %v", err)
}
idx, err := pc.ConfigureIndex(ctx, "docs-example", pinecone.ConfigureIndexParams{Replicas: 4})
if err != nil {
log.Fatalf("Failed to configure index \"%v\": %v", idx.Name, err)
} else {
fmt.Printf("Successfully configured index \"%v\"", idx.Name)
}
}
```
```csharp C# theme={null}
using Pinecone;
var pinecone = new PineconeClient("YOUR_API_KEY");
var configureIndexRequest = await pinecone.ConfigureIndexAsync("docs-example", new ConfigureIndexRequest
{
Spec = new ConfigureIndexRequestSpec
{
Pod = new ConfigureIndexRequestSpecPod {
Replicas = 4,
}
}
});
```
```bash curl theme={null}
PINECONE_API_KEY="YOUR_API_KEY"
curl -s -X PATCH "https://api.pinecone.io/indexes/docs-example-curl" \
-H "Content-Type: application/json" \
-H "Api-Key: $PINECONE_API_KEY" \
-H "X-Pinecone-Api-Version: 2025-10" \
-d '{
"replicas": 4
}'
```
## Next steps
* See our learning center for more information on [vertical scaling](https://www.pinecone.io/learn/testing-p2-collections-scaling/#vertical-scaling-on-p1-and-s1).
* Learn more about [collections](/guides/indexes/pods/understanding-collections).
---
# Source: https://docs.pinecone.io/guides/assistant/quickstart/sdk-quickstart.md
> ## Documentation Index
> Fetch the complete documentation index at: https://docs.pinecone.io/llms.txt
> Use this file to discover all available pages before exploring further.
# Pinecone Assistant: SDK quickstart
> Use a Pinecone SDK to create an assistant, upload documents, and chat with the assistant.
Use a Pinecone SDK to create an assistant, upload documents, and chat with the assistant.
To get started in your browser, use the [Assistant Quickstart colab notebook](https://colab.research.google.com/github/pinecone-io/examples/blob/master/docs/assistant-quickstart.ipynb).
## 1. Install an SDK
The Pinecone [Python SDK](/reference/sdks/python/overview) and [Node.js SDK](/reference/sdks/node/overview) provide convenient programmatic access to the [Assistant API](/reference/api/latest/assistant/).
```shell Python theme={null}
pip install pinecone
pip install pinecone-plugin-assistant
```
```shell JavaScript theme={null}
npm install @pinecone-database/pinecone
```
## 2. Get an API key
You need an API key to make calls to your assistant.
Create a new API key in the [Pinecone console](https://app.pinecone.io/organizations/-/keys), or use the widget below to generate a key. If you don't have a Pinecone account, the widget will sign you up for the free [Starter plan](https://www.pinecone.io/pricing/).
Your generated API key:
```shell theme={null}
"{{YOUR_API_KEY}}"
```
## 3. Create an assistant
[Create an assistant](/reference/api/latest/assistant/create_assistant), as in the following example:
```python Python theme={null}
from pinecone import Pinecone
pc = Pinecone(api_key="{{YOUR_API_KEY}}")
assistant = pc.assistant.create_assistant(
assistant_name="example-assistant",
instructions="Use American English for spelling and grammar.", # Description or directive for the assistant to apply to all responses.
region="us", # Region to deploy assistant. Options: "us" (default) or "eu".
timeout=30 # Maximum seconds to wait for assistant status to become "Ready" before timing out.
)
```
```javascript JavaScript theme={null}
import { Pinecone } from '@pinecone-database/pinecone'
const pc = new Pinecone({ apiKey: "{{YOUR_API_KEY}}" });
const assistant = await pc.createAssistant({
name: 'example-assistant',
instructions: 'Use American English for spelling and grammar.', // Description or directive for the assistant to apply to all responses.
region: 'us'
});
```
## 4. Upload a file to the assistant
With Pinecone Assistant, you can upload documents, ask questions, and receive responses that reference your documents. This is known as retrieval-augmented generation (RAG).
For this quickstart, [download a sample 10-k filing file](https://s22.q4cdn.com/959853165/files/doc_financials/2023/ar/Netflix-10-K-01262024.pdf) to your local device.
Next, [upload the file](/reference/api/latest/assistant/upload_file) to your assistant:
```python Python theme={null}
# Get the assistant.
assistant = pc.assistant.Assistant(
assistant_name="example-assistant",
)
# Upload a file.
response = assistant.upload_file(
file_path="/path/to/file/Netflix-10-K-01262024.pdf",
metadata={"company": "netflix", "document_type": "form 10k"},
timeout=None
)
```
```javascript JavaScript theme={null}
const assistantName = 'example-assistant';
const assistant = pc.Assistant(assistantName);
await assistant.uploadFile({
path: '/Users/jdoe/Downloads/example_file.txt'
});
```
## 5. Chat with the assistant
With the sample file uploaded, you can now [chat with the assistant](/reference/api/latest/assistant/chat_assistant). Ask the assistant questions about your document. It returns either a JSON object or a text stream.
For faster chat responses, use GPT models (`gpt-4o`, `gpt-4.1`, `gpt-5`, or `o4-mini`). You can also enable streaming to improve perceived latency by showing content as it's generated.
The following example requests a default response to the message, "Who is the CFO of Netflix?":
```python Python theme={null}
from pinecone_plugins.assistant.models.chat import Message
msg = Message(role="user", content="Who is the CFO of Netflix?")
resp = assistant.chat(messages=[msg])
print(resp)
```
```javascript JavaScript theme={null}
const chatResp = await assistant.chat({
messages: [{ role: 'user', content: 'Who is the CFO of Netflix?' }],
model: 'gpt-4o'
});
console.log(chatResp);
```
The example above returns a response like the following:
```
{
'id': '0000000000000000163008a05b317b7b',
'model': 'gpt-4o-2024-05-13',
'usage': {
'prompt_tokens': 9259,
'completion_tokens': 30,
'total_tokens': 9289
},
'message': {
'content': 'The Chief Financial Officer (CFO) of Netflix is Spencer Neumann.',
'role': '"assistant"'
},
'finish_reason': 'stop',
'citations': [
{
'position': 63,
'references': [
{
'pages': [78, 72, 79],
'file': {
'name': 'Netflix-10-K-01262024.pdf',
'id': '76a11dd1...',
'metadata': {
'company': 'netflix',
'document_type': 'form 10k'
},
'created_on': '2024-12-06T01:29:07.369208590Z',
'updated_on': '2024-12-06T01:29:50.923493799Z',
'status': 'Available',
'percent_done': 1.0,
'signed_url': 'https://storage.googleapis.com/...',
"error_message": null,
'size': 1073470.0
}
}
]
}
]
}
```
[`signed_url`](https://cloud.google.com/storage/docs/access-control/signed-urls) provides temporary, read-only access to the relevant file. Anyone with the link can access the file, so treat it as sensitive data. Expires in one hour.
## 6. Clean up
When you no longer need the `example-assistant`, [delete the assistant](/reference/api/latest/assistant/delete_assistant):
Deleting an assistant also deletes all files uploaded to the assistant.
```python Python theme={null}
pc.assistant.delete_assistant(
assistant_name="example-assistant",
)
```
```javascript JavaScript theme={null}
await pc.deleteAssistant('example-assistant');
```
## Next steps
* Learn more about [Pinecone Assistant](/guides/assistant/overview)
* Learn about [additional assistant features](https://www.pinecone.io/learn/assistant-api-deep-dive/)
* [Evaluate](/guides/assistant/evaluate-answers) the assistant's responses
* View a [sample app](/examples/sample-apps/pinecone-assistant) that uses Pinecone Assistant
---
# Source: https://docs.pinecone.io/guides/search/search-overview.md
> ## Documentation Index
> Fetch the complete documentation index at: https://docs.pinecone.io/llms.txt
> Use this file to discover all available pages before exploring further.
# Search overview
> Explore semantic, lexical, and hybrid search options.
## Search types
* [Semantic search](/guides/search/semantic-search)
* [Lexical search](/guides/search/lexical-search)
* [Hybrid search](/guides/search/hybrid-search)
## Optimization
* [Filter by metadata](/guides/search/filter-by-metadata)
* [Rerank results](/guides/search/rerank-results)
* [Parallel queries](/guides/search/semantic-search#parallel-queries)
## Limits
| Metric | Limit |
| :---------------- | :----- |
| Max `top_k` value | 10,000 |
| Max result size | 4MB |
The query result size is affected by the dimension of the dense vectors and whether or not dense vector values and metadata are included in the result.
If a query fails due to exceeding the 4MB result size limit, choose a lower `top_k` value, or use `include_metadata=False` or `include_values=False` to exclude metadata or values from the result. For better performance, especially with higher `top_k` values, avoid including vector values unless you need them.
## Cost
* To understand how cost is calculated for queries, see [Understanding cost](/guides/manage-cost/understanding-cost#query).
* For up-to-date pricing information, see [Pricing](https://www.pinecone.io/pricing/).
## Data freshness
Pinecone is eventually consistent, so there can be a slight delay before new or changed records are visible to queries. You can view index stats to [check data freshness](/guides/index-data/check-data-freshness).
---
# Source: https://docs.pinecone.io/reference/api/2025-10/data-plane/search_records.md
> ## Documentation Index
> Fetch the complete documentation index at: https://docs.pinecone.io/llms.txt
> Use this file to discover all available pages before exploring further.
# Search with text
> Search a namespace with a query text, query vector, or record ID and return the most similar records, along with their similarity scores. Optionally, rerank the initial results based on their relevance to the query.
Searching with text is supported only for indexes with [integrated embedding](https://docs.pinecone.io/guides/index-data/indexing-overview#vector-embedding). Searching with a query vector or record ID is supported for all indexes.
For guidance and examples, see [Search](https://docs.pinecone.io/guides/search/search-overview).
```shell curl theme={null}
INDEX_HOST="INDEX_HOST"
NAMESPACE="YOUR_NAMESPACE"
PINECONE_API_KEY="YOUR_API_KEY"
# Search with a query text and rerank the results
# Supported only for indexes with integrated embedding
curl "https://$INDEX_HOST/records/namespaces/$NAMESPACE/search" \
-H "Accept: application/json" \
-H "Content-Type: application/json" \
-H "Api-Key: $PINECONE_API_KEY" \
-H "X-Pinecone-Api-Version: 2025-10" \
-d '{
"query": {
"inputs": {"text": "Disease prevention"},
"top_k": 4,
},
"fields": ["category", "chunk_text"]
"rerank": {
"model": "bge-reranker-v2-m3",
"top_n": 2,
"rank_fields": ["chunk_text"] # Specified field must also be included in 'fields'
}
}'
# Search with a query vector and rerank the results
curl "https://$INDEX_HOST/records/namespaces/$NAMESPACE/search" \
-H "Accept: application/json" \
-H "Content-Type: application/json" \
-H "Api-Key: $PINECONE_API_KEY" \
-H "X-Pinecone-Api-Version: 2025-10" \
-d '{
"query": {
"vector": {
"values": [0.3, 0.3, 0.3, 0.3, 0.3, 0.3, 0.3, 0.3]
},
"top_k": 4,
},
"fields": ["category", "chunk_text"]
"rerank": {
"query": "Disease prevention",
"model": "bge-reranker-v2-m3",
"top_n": 2,
"rank_fields": ["chunk_text"] # Specified field must also be included in 'fields'
}
}'
# Search with a record ID and rerank the results
# Supported only for indexes with integrated embedding
curl "https://$INDEX_HOST/records/namespaces/$NAMESPACE/search" \
-H "Accept: application/json" \
-H "Content-Type: application/json" \
-H "Api-Key: $PINECONE_API_KEY" \
-H "X-Pinecone-Api-Version: 2025-10" \
-d '{
"query": {
"id": "rec1",
"top_k": 4,
},
"fields": ["category", "chunk_text"]
"rerank": {
"query": "Disease prevention",
"model": "bge-reranker-v2-m3",
"top_n": 2,
"rank_fields": ["chunk_text"]
}
}'
```
```json curl theme={null}
{
"result": {
"hits": [
{
"_id": "rec3",
"_score": 0.004433765076100826,
"fields": {
"category": "immune system",
"chunk_text": "Rich in vitamin C and other antioxidants, apples contribute to immune health and may reduce the risk of chronic diseases."
}
},
{
"_id": "rec4",
"_score": 0.0029121784027665854,
"fields": {
"category": "endocrine system",
"chunk_text": "The high fiber content in apples can also help regulate blood sugar levels, making them a favorable snack for people with diabetes."
}
}
]
},
"usage": {
"embed_total_tokens": 8,
"read_units": 6,
"rerank_units": 1
}
}
```
## OpenAPI
````yaml https://raw.githubusercontent.com/pinecone-io/pinecone-api/refs/heads/main/2025-10/db_data_2025-10.oas.yaml post /records/namespaces/{namespace}/search
openapi: 3.0.3
info:
title: Pinecone Data Plane API
description: >-
Pinecone is a vector database that makes it easy to search and retrieve
billions of high-dimensional vectors.
contact:
name: Pinecone Support
url: https://support.pinecone.io
email: support@pinecone.io
license:
name: Apache 2.0
url: https://www.apache.org/licenses/LICENSE-2.0
version: 2025-10
servers:
- url: https://{index_host}
variables:
index_host:
default: unknown
description: host of the index
security:
- ApiKeyAuth: []
tags:
- name: Vector Operations
- name: Bulk Operations
- name: Namespace Operations
externalDocs:
description: More Pinecone.io API docs
url: https://docs.pinecone.io/introduction
paths:
/records/namespaces/{namespace}/search:
post:
tags:
- Vector Operations
summary: Search with text
description: >-
Search a namespace with a query text, query vector, or record ID and
return the most similar records, along with their similarity scores.
Optionally, rerank the initial results based on their relevance to the
query.
Searching with text is supported only for indexes with [integrated
embedding](https://docs.pinecone.io/guides/index-data/indexing-overview#vector-embedding).
Searching with a query vector or record ID is supported for all
indexes.
For guidance and examples, see
[Search](https://docs.pinecone.io/guides/search/search-overview).
operationId: searchRecordsNamespace
parameters:
- in: header
name: X-Pinecone-Api-Version
description: Required date-based version header
required: true
schema:
default: 2025-10
type: string
style: simple
- in: path
name: namespace
description: The namespace to search.
required: true
schema:
type: string
style: simple
requestBody:
content:
application/json:
schema:
$ref: '#/components/schemas/SearchRecordsRequest'
required: true
responses:
'200':
description: A successful search namespace response.
content:
application/json:
schema:
$ref: '#/components/schemas/SearchRecordsResponse'
'400':
description: Bad request. The request body included invalid request parameters.
content:
application/json:
schema:
$ref: '#/components/schemas/rpcStatus'
4XX:
description: An unexpected error response.
content:
application/json:
schema:
$ref: '#/components/schemas/rpcStatus'
5XX:
description: An unexpected error response.
content:
application/json:
schema:
$ref: '#/components/schemas/rpcStatus'
components:
schemas:
SearchRecordsRequest:
example:
fields:
- chunk_text
query:
inputs:
text: your query text
top_k: 10
description: A search request for records in a specific namespace.
type: object
properties:
query:
description: .
type: object
properties:
top_k:
example: 10
description: The number of similar records to return.
type: integer
format: int32
filter:
description: >-
The filter to apply. You can use vector metadata to limit your
search. See [Understanding
metadata](https://docs.pinecone.io/guides/index-data/indexing-overview#metadata).
type: object
inputs:
$ref: '#/components/schemas/EmbedInputs'
vector:
$ref: '#/components/schemas/SearchRecordsVector'
id:
example: example-vector-1
description: The unique ID of the vector to be used as a query vector.
type: string
maxLength: 512
match_terms:
$ref: '#/components/schemas/SearchMatchTerms'
required:
- top_k
fields:
example:
- chunk_text
description: >-
The fields to return in the search results. If not specified, the
response will include all fields.
type: array
items:
type: string
maxLength: 100
rerank:
description: Parameters for reranking the initial search results.
type: object
properties:
model:
example: bge-reranker-v2-m3
description: >-
The name of the [reranking
model](https://docs.pinecone.io/guides/search/rerank-results#reranking-models)
to use.
type: string
rank_fields:
example:
- chunk_text
- title
description: >
The field(s) to consider for reranking. If not provided, the
default is `["text"]`.
The number of fields supported is
[model-specific](https://docs.pinecone.io/guides/search/rerank-results#reranking-models).
type: array
items:
type: string
top_n:
example: 5
description: >-
The number of top results to return after reranking. Defaults to
top_k.
type: integer
format: int32
parameters:
example:
truncate: END
description: >-
Additional model-specific parameters. Refer to the [model
guide](https://docs.pinecone.io/guides/search/rerank-results#reranking-models)
for available model parameters.
type: object
additionalProperties: true
query:
example: What is the capital of France?
description: >-
The query to rerank documents against. If a specific rerank
query is specified, it overwrites the query input that was
provided at the top level.
type: string
required:
- model
- rank_fields
required:
- query
SearchRecordsResponse:
example:
result:
hits:
- _id: example-record-1
_score: 0.9281134605407715
fields:
data: your example text
usage:
embed_total_tokens: 10
read_units: 5
description: The records search response.
type: object
properties:
result:
type: object
properties:
hits:
description: The hits for the search document request.
type: array
items:
$ref: '#/components/schemas/Hit'
required:
- hits
usage:
$ref: '#/components/schemas/SearchUsage'
required:
- usage
- result
rpcStatus:
type: object
properties:
code:
type: integer
format: int32
message:
type: string
details:
type: array
items:
$ref: '#/components/schemas/protobufAny'
EmbedInputs:
example:
text: chunk_text
type: object
SearchRecordsVector:
type: object
properties:
values:
$ref: '#/components/schemas/VectorValues'
sparse_values:
example:
- 0.1
- 0.2
- 0.3
description: The sparse embedding values.
type: array
items:
type: number
format: float
sparse_indices:
example:
- 10
- 3
- 156
description: The sparse embedding indices.
type: array
items:
type: integer
format: int32
minimum: 0
SearchMatchTerms:
example:
strategy: all
terms:
- animal
- CHARACTER
- donald Duck
description: >-
Specifies which terms must be present in the text of each search hit
based on the specified strategy. The match is performed
against the text field specified in the integrated index `field_map`
configuration.
Terms are normalized and tokenized into single tokens before matching,
and order does not matter.
Example:
`"match_terms": {"terms": ["animal", "CHARACTER", "donald Duck"], "strategy": "all"}` will tokenize
to `["animal", "character", "donald", "duck"]`, and would match
`"Donald F. Duck is a funny animal character"` but would not match `"A duck is a funny animal"`.
Match terms filtering is supported only for sparse indexes with
[integrated
embedding](https://docs.pinecone.io/guides/index-data/indexing-overview#vector-embedding)
configured to use the
[pinecone-sparse-english-v0](https://docs.pinecone.io/models/pinecone-sparse-english-v0)
model.
type: object
properties:
strategy:
description: >-
The strategy for matching terms in the text. Currently, only `all`
is supported, which means all specified terms must be present.
x-enum:
- all
type: string
terms:
description: >-
A list of terms that must be present in the text of each search hit
based on the specified strategy.
type: array
items:
type: string
Hit:
example:
_id: example-record-1
_score: 0.9281134605407715
fields:
data: your example text
more_data:
text: your example text
description: A record whose vector values are similar to the provided search query.
type: object
properties:
_id:
description: The record id of the search hit.
type: string
_score:
description: The similarity score of the returned record.
type: number
format: float
fields:
description: The selected record fields associated with the search hit.
type: object
required:
- _id
- _score
- fields
SearchUsage:
type: object
properties:
read_units:
example: 5
description: The number of read units consumed by this operation.
type: integer
format: int32
minimum: 0
embed_total_tokens:
example: 2
description: The number of embedding tokens consumed by this operation.
type: integer
format: int32
minimum: 0
rerank_units:
example: 1
description: The number of rerank units consumed by this operation.
type: integer
format: int32
minimum: 0
required:
- read_units
protobufAny:
type: object
properties:
typeUrl:
type: string
value:
type: string
format: byte
VectorValues:
description: This is the vector data included in the request.
type: array
items:
type: number
format: float
minLength: 1
maxLength: 20000
securitySchemes:
ApiKeyAuth:
type: apiKey
in: header
name: Api-Key
description: >-
An API Key is required to call Pinecone APIs. Get yours from the
[console](https://app.pinecone.io/).
````
---
# Source: https://docs.pinecone.io/guides/production/security-overview.md
# Source: https://docs.pinecone.io/guides/assistant/admin/security-overview.md
> ## Documentation Index
> Fetch the complete documentation index at: https://docs.pinecone.io/llms.txt
> Use this file to discover all available pages before exploring further.
# Security overview
> Understand Pinecone's security features, including authentication, encryption, and audit logs.
This page describes Pinecone's security protocols, practices, and features.
## Access management
### API keys
Each Pinecone [project](/guides/assistant/admin/projects-overview) has one or more [API keys](/guides/assistant/admin/manage-api-keys). In order to make calls to the Pinecone API, a user must provide a valid API key for the relevant Pinecone project.
You can [manage API key permissions](/guides/assistant/admin/manage-api-keys) in the [Pinecone console](https://app.pinecone.io/organizations/-/projects/-/keys). The available permission roles are as follows:
#### General permissions
| Role | Permissions |
| :--- | :---------------------------------------------- |
| All | Permissions to read and write all project data. |
| Role | Permissions |
| :-------------- | :----------------------------------------------- |
| `ProjectEditor` | Permissions to read and write all project data. |
| `ProjectViewer` | Permissions to read all project data. |
#### Control plane permissions
| Role | Permissions |
| :-------- | :---------------------------------------------------------------------------------------------------------- |
| ReadWrite | Permissions to list, describe, create, delete, and configure indexes, backups, collections, and assistants. |
| ReadOnly | Permissions to list and describe indexes, backups, collections, and assistants. |
| None | No control plane permissions. |
| Role | Permissions |
| :------------------- | :---------------------------------------------------------------------------------------------------------- |
| `ControlPlaneEditor` | Permissions to list, describe, create, delete, and configure indexes, backups, collections, and assistants. |
| `ControlPlaneViewer` | Permissions to list and describe indexes, backups, collections, and assistants. |
| None | No control plane permissions. |
#### Data plane permissions
| Role | Permissions |
| :-------- | :--------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- |
| ReadWrite | - Indexes: Permissions to query, import, fetch, add, update, and delete index data.
- Pinecone Assistant: Permissions to add, list, view, and delete files; chat with an assistant, and evaluate responses.
- Pinecone Inference: Permissions to generate embeddings and rerank documents.
|
| ReadOnly | - Indexes: Permissions to query, fetch, list ID, and view stats.
- Pinecone Assistant: Permissions to list and view files, chat with an assistant, and evaluate responses.
- Pinecone Inference: Permissions to generate embeddings and rerank documents.
|
| None | No data plane permissions. |
| Role | Permissions |
| :---------------- | :--------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- |
| `DataPlaneEditor` | - Indexes: Permissions to query, import, fetch, add, update, and delete index data.
- Pinecone Assistant: Permissions to add, list, view, and delete files; chat with an assistant, and evaluate responses.
- Pinecone Inference: Permissions to generate embeddings and rerank documents.
|
| `DataPlaneViewer` | - Indexes: Permissions to query, fetch, list ID, and view stats.
- Pinecone Assistant: Permissions to list and view files, chat with an assistant, and evaluate responses.
- Pinecone Inference: Permissions to generate embeddings and rerank documents.
|
| None | No data plane permissions. |
### Organization single sign-on (SSO)
SSO allows organizations to manage their teams' access to Pinecone through their identity management solution. Once your integration is configured, you can require that users from your domain sign in through SSO, and you can specify a default role for teammates when they sign up. SSO is available on Standard and Enterprise plans.
For more information, see [configure single sign on](/guides/assistant/admin/configure-sso-with-okta).
### Role-based access controls (RBAC)
Pinecone uses role-based access controls (RBAC) to manage access to resources.
Service accounts, API keys, and users are all *principals*. A principal's access is determined by the *roles* assigned to it. Roles are assigned to a principal for a *resource*, either a project or an organization. The roles available to be assigned depend on the type of principal and resource.
#### Service account roles
A service account can be assigned roles for the organization it belongs to, and any projects within that organization. A user can be assigned roles for each organization they belong to, and any projects within that organization. For more information, see [Organization roles](/guides/assistant/admin/organizations-overview#organization-roles) and [Project roles](/guides/assistant/admin/projects-overview#project-roles).
#### API key roles
An API key can only be assigned permissions for the projects it belongs to. For more information, see [API keys](#api-keys).
#### User roles
A user can be assigned roles for each organization they belong to, and any projects within that organization. For more information, see [Organization roles](/guides/assistant/admin/organizations-overview#organization-roles) and [Project roles](/guides/assistant/admin/projects-overview#project-roles).
## Compliance
To learn more about data privacy and compliance at Pinecone, visit the [Pinecone Trust and Security Center](https://security.pinecone.io/).
### Audit logs
[Audit logs](/guides/assistant/admin/configure-audit-logs) provide a detailed record of user and API actions that occur within Pinecone.
Events are captured every 30 minutes and each log batch will be saved into its own file as a JSON blob, keyed by the time of the log to be written. Only logs since the integration was created and enabled will be saved.
Audit log events adhere to a standard JSON schema and include the following fields:
```json JSON theme={null}
{
"id": "00000000-0000-0000-0000-000000000000",
"organization_id": "AA1bbbbCCdd2EEEe3FF",
"organization_name": "example-org",
"client": {
"userAgent": "rawUserAgent"
},
"actor": {
"principal_id": "00000000-0000-0000-0000-000000000000",
"principal_name": "example@pinecone.io",
"principal_type": "user", // user, api_key, service_account
"display_name": "Example Person" // Only in case of user
},
"event": {
"time": "2024-10-21T20:51:53.697Z",
"action": "create",
"resource_type": "index",
"resource_id": "uuid",
"resource_name": "docs-example",
"outcome": {
"result": "success",
"reason": "", // Only displays for "result": "failure"
"error_code": "", // Only displays for "result": "failure"
},
"parameters": { // Varies based on event
}
}
}
```
The following events are captured in the audit logs:
* [Organization events](#organization-events)
* [Project events](#project-events)
* [Index events](#index-events)
* [User and API key events](#user-and-api-key-events)
* [Security and governance events](#security-and-governance-events)
#### Organization events
| Action | Query parameters |
| ----------------- | -------------------------------------------------------------------------------------------------------------- |
| Rename org | `event.action: update`, `event.resource_type: organization`, `event.resource_id: NEW_ORG_NAME` |
| Delete org | `event.action: delete`, `event.resource_type: organization`, `event.resource_id: DELETED_ORG_NAME` |
| Create org member | `event.action: create`, `event.resource_type: user`, `event.resource_id: [ARRAY_OF_USER_EMAILS]` |
| Update org member | `event.action: update`, `event.resource_type: user`, `event.resource_id: { user: USER_EMAIL, role: NEW_ROLE }` |
| Delete org member | `event.action: delete`, `event.resource_type: user`, `event.resource_id: USER_EMAIL` |
#### Project events
| Action | Query parameters |
| -------------------------- | ------------------------------------------------------------------------------------------------------------------ |
| Create project | `event.action: create`, `event.resource_type: project`, `event.resouce_id: PROJ_NAME` |
| Update project | `event.action: update`, `event.resource_type: project`, `event.resource_id: PROJECT_NAME` |
| Delete project | `event.action: delete`, `event.resource_type: project`, `event.resource_id: PROJECT_NAME` |
| Invite project member | `event.action: create`, `event.resource_type: user`, `event.resource_id: [ARRAY_OF_USER_EMAILS]` |
| Update project member role | `event.action: update`, `event.resource_type: user`, `event.resource_id: { user: USER_EMAIL, role: NEW_ROLE }` |
| Delete project member | `event.action: delete`, `event.resource_type: user`, `event.resource_id: { user: USER_EMAIL, project: PROJ_NAME }` |
#### Index events
| Action | Query parameters |
| ------------- | --------------------------------------------------------------------------------------- |
| Create index | `event.action: create`, `event.resource_type: index`, `event.resouce_id: INDEX_NAME` |
| Update index | `event.action: update`, `event.resource_type: index`, `event.resource_id: INDEX_NAME` |
| Delete index | `event.action: delete`, `event.resource_type: index`, `event.resource_id: INDEX_NAME` |
| Create backup | `event.action: create`, `event.resource_type: backup`, `event.resource_id: BACKUP_NAME` |
| Delete backup | `event.action: delete`, `event.resource_type: backup`, `event.resource_id: BACKUP_NAME` |
#### User and API key events
| Action | Query parameters |
| -------------- | --------------------------------------------------------------------------------------- |
| User login | `event.action: login`, `event.resource_type: user`, `event.resouce_id: USERNAME` |
| Create API key | `event.action: create`, `event.resource_type: api-key`, `event.resource_id: API_KEY_ID` |
| Delete API key | `event.action: delete`, `event.resource_type: api-key`, `event.resource_id: API_KEY_ID` |
#### Security and governance events
| Action | Query parameters |
| ----------------------- | ---------------------------------------------------------------------------------------------------------- |
| Create Private Endpoint | `event.action: create`, `event.resource_type: private-endpoints`, `event.resource_id: PRIVATE_ENDPOINT_ID` |
| Delete Private Endpoint | `event.action: delete`, `event.resource_type: private-endpoints`, `event.resource_id: PRIVATE_ENDPOINT_ID` |
## Data protection
### Encryption at rest
Pinecone encrypts stored data using the 256-bit Advanced Encryption Standard (AES-256) encryption algorithm.
### Encryption in transit
Pinecone uses standard protocols to encrypt user data in transit. Clients open HTTPS or gRPC connections to the Pinecone API; the Pinecone API gateway uses gRPC connections to user deployments in the cloud. These HTTPS and gRPC connections use the TLS 1.2 protocol with 256-bit Advanced Encryption Standard (AES-256) encryption.
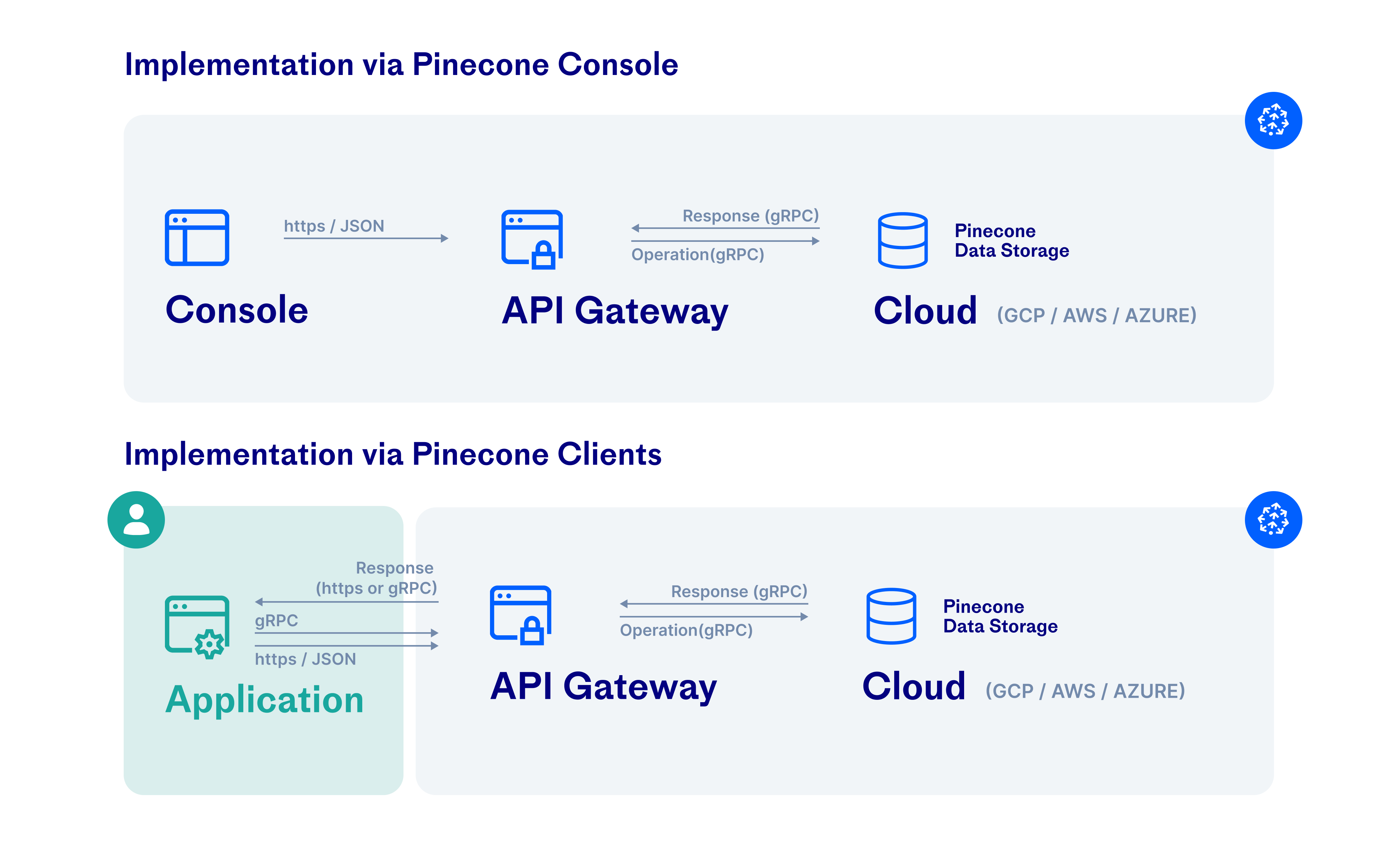 Traffic is also encrypted in transit between the Pinecone backend and cloud infrastructure services, such as S3 and GCS. For more information, see [Google Cloud Platform](https://cloud.google.com/docs/security/encryption-in-transit) and [AWS security documentation](https://docs.aws.amazon.com/AmazonS3/userguide/UsingEncryption.html).
## Network security
### Proxies
The following Pinecone SDKs support the use of proxies:
* [Python SDK](/reference/sdks/python/overview#proxy-configuration)
* [Node.js SDK](/reference/sdks/node/overview#proxy-configuration)
---
# Source: https://docs.pinecone.io/guides/search/semantic-search.md
> ## Documentation Index
> Fetch the complete documentation index at: https://docs.pinecone.io/llms.txt
> Use this file to discover all available pages before exploring further.
# Semantic search
> Find semantically similar records using dense vectors.
This page shows you how to search a [dense index](/guides/index-data/indexing-overview#dense-indexes) for records that are most similar in meaning and context to a query. This is often called semantic search, nearest neighbor search, similarity search, or just vector search.
Semantic search uses [dense vectors](https://www.pinecone.io/learn/vector-embeddings/). Each number in a dense vector corresponds to a point in a multidimensional space. Vectors that are closer together in that space are semantically similar.
## Search with text
Searching with text is supported only for [indexes with integrated embedding](/guides/index-data/indexing-overview#integrated-embedding).
To search a dense index with a query text, use the [`search_records`](/reference/api/latest/data-plane/search_records) operation with the following parameters:
* The `namespace` to query. To use the default namespace, set the namespace to `"__default__"`.
* The `query.inputs.text` parameter with the query text. Pinecone uses the embedding model integrated with the index to convert the text to a dense vector automatically.
* The `query.top_k` parameter with the number of similar records to return.
* Optionally, you can specify the `fields` to return in the response. If not specified, the response will include all fields.
For example, the following code searches for the 2 records most semantically related to a query text:
```python Python theme={null}
from pinecone import Pinecone
pc = Pinecone(api_key="YOUR_API_KEY")
# To get the unique host for an index,
# see https://docs.pinecone.io/guides/manage-data/target-an-index
index = pc.Index(host="INDEX_HOST")
results = index.search(
namespace="example-namespace",
query={
"inputs": {"text": "Disease prevention"},
"top_k": 2
},
fields=["category", "chunk_text"]
)
print(results)
```
```javascript JavaScript theme={null}
import { Pinecone } from '@pinecone-database/pinecone'
const pc = new Pinecone({ apiKey: "YOUR_API_KEY" })
// To get the unique host for an index,
// see https://docs.pinecone.io/guides/manage-data/target-an-index
const namespace = pc.index("INDEX_NAME", "INDEX_HOST").namespace("example-namespace");
const response = await namespace.searchRecords({
query: {
topK: 2,
inputs: { text: 'Disease prevention' },
},
fields: ['chunk_text', 'category'],
});
console.log(response);
```
```java Java theme={null}
import io.pinecone.clients.Index;
import io.pinecone.configs.PineconeConfig;
import io.pinecone.configs.PineconeConnection;
import org.openapitools.db_data.client.ApiException;
import org.openapitools.db_data.client.model.SearchRecordsResponse;
import java.util.*;
public class SearchText {
public static void main(String[] args) throws ApiException {
PineconeConfig config = new PineconeConfig("YOUR_API_KEY");
// To get the unique host for an index,
// see https://docs.pinecone.io/guides/manage-data/target-an-index
config.setHost("INDEX_HOST");
PineconeConnection connection = new PineconeConnection(config);
Index index = new Index(config, connection, "integrated-dense-java");
String query = "Disease prevention";
List fields = new ArrayList<>();
fields.add("category");
fields.add("chunk_text");
// Search the dense index
SearchRecordsResponse recordsResponse = index.searchRecordsByText(query, "example-namespace", fields, 2, null, null);
// Print the results
System.out.println(recordsResponse);
}
}
```
```go Go theme={null}
package main
import (
"context"
"encoding/json"
"fmt"
"log"
"github.com/pinecone-io/go-pinecone/v4/pinecone"
)
func prettifyStruct(obj interface{}) string {
bytes, _ := json.MarshalIndent(obj, "", " ")
return string(bytes)
}
func main() {
ctx := context.Background()
pc, err := pinecone.NewClient(pinecone.NewClientParams{
ApiKey: "YOUR_API_KEY",
})
if err != nil {
log.Fatalf("Failed to create Client: %v", err)
}
// To get the unique host for an index,
// see https://docs.pinecone.io/guides/manage-data/target-an-index
idxConnection, err := pc.Index(pinecone.NewIndexConnParams{Host: "INDEX_HOST", Namespace: "example-namespace"})
if err != nil {
log.Fatalf("Failed to create IndexConnection for Host: %v", err)
}
res, err := idxConnection.SearchRecords(ctx, &pinecone.SearchRecordsRequest{
Query: pinecone.SearchRecordsQuery{
TopK: 2,
Inputs: &map[string]interface{}{
"text": "Disease prevention",
},
},
Fields: &[]string{"chunk_text", "category"},
})
if err != nil {
log.Fatalf("Failed to search records: %v", err)
}
fmt.Printf(prettifyStruct(res))
}
```
```csharp C# theme={null}
using Pinecone;
var pinecone = new PineconeClient("YOUR_API_KEY");
// To get the unique host for an index,
// see https://docs.pinecone.io/guides/manage-data/target-an-index
var index = pinecone.Index(host: "INDEX_HOST");
var response = await index.SearchRecordsAsync(
"example-namespace",
new SearchRecordsRequest
{
Query = new SearchRecordsRequestQuery
{
TopK = 4,
Inputs = new Dictionary { { "text", "Disease prevention" } },
},
Fields = ["category", "chunk_text"],
}
);
Console.WriteLine(response);
```
```shell curl theme={null}
INDEX_HOST="INDEX_HOST"
NAMESPACE="YOUR_NAMESPACE"
PINECONE_API_KEY="YOUR_API_KEY"
curl "https://$INDEX_HOST/records/namespaces/$NAMESPACE/search" \
-H "Accept: application/json" \
-H "Content-Type: application/json" \
-H "Api-Key: $PINECONE_API_KEY" \
-H "X-Pinecone-Api-Version: unstable" \
-d '{
"query": {
"inputs": {"text": "Disease prevention"},
"top_k": 2
},
"fields": ["category", "chunk_text"]
}'
```
The response will look as follows. Each record is returned with a similarity score that represents its distance to the query vector, calculated according to the [similarity metric](/guides/index-data/create-an-index#similarity-metrics) for the index.
```python Python theme={null}
{'result': {'hits': [{'_id': 'rec3',
'_score': 0.8204272389411926,
'fields': {'category': 'immune system',
'chunk_text': 'Rich in vitamin C and other '
'antioxidants, apples '
'contribute to immune health '
'and may reduce the risk of '
'chronic diseases.'}},
{'_id': 'rec1',
'_score': 0.7931625843048096,
'fields': {'category': 'digestive system',
'chunk_text': 'Apples are a great source of '
'dietary fiber, which supports '
'digestion and helps maintain a '
'healthy gut.'}}]},
'usage': {'embed_total_tokens': 8, 'read_units': 6}}
```
```javascript JavaScript theme={null}
{
result: {
hits: [
{
_id: 'rec3',
_score: 0.82042724,
fields: {
category: 'immune system',
chunk_text: 'Rich in vitamin C and other antioxidants, apples contribute to immune health and may reduce the risk of chronic diseases.'
}
},
{
_id: 'rec1',
_score: 0.7931626,
fields: {
category: 'digestive system',
chunk_text: 'Apples are a great source of dietary fiber, which supports digestion and helps maintain a healthy gut.'
}
}
]
},
usage: {
readUnits: 6,
embedTotalTokens: 8
}
}
```
```java Java theme={null}
class SearchRecordsResponse {
result: class SearchRecordsResponseResult {
hits: [class Hit {
id: rec3
score: 0.8204272389411926
fields: {category=immune system, chunk_text=Rich in vitamin C and other antioxidants, apples contribute to immune health and may reduce the risk of chronic diseases.}
additionalProperties: null
}, class Hit {
id: rec1
score: 0.7931625843048096
fields: {category=endocrine system, chunk_text=Apples are a great source of dietary fiber, which supports digestion and helps maintain a healthy gut.}
additionalProperties: null
}]
additionalProperties: null
}
usage: class SearchUsage {
readUnits: 6
embedTotalTokens: 13
}
additionalProperties: null
}
```
```go Go theme={null}
{
"result": {
"hits": [
{
"_id": "rec3",
"_score": 0.82042724,
"fields": {
"category": "immune system",
"chunk_text": "Rich in vitamin C and other antioxidants, apples contribute to immune health and may reduce the risk of chronic diseases."
}
},
{
"_id": "rec1",
"_score": 0.7931626,
"fields": {
"category": "digestive system",
"chunk_text": "Apples are a great source of dietary fiber, which supports digestion and helps maintain a healthy gut."
}
}
]
},
"usage": {
"read_units": 6,
"embed_total_tokens": 8
}
}
```
```csharp C# theme={null}
{
"result": {
"hits": [
{
"_id": "rec3",
"_score": 0.13741668,
"fields": {
"category": "immune system",
"chunk_text": "Rich in vitamin C and other antioxidants, apples contribute to immune health and may reduce the risk of chronic diseases."
}
},
{
"_id": "rec1",
"_score": 0.0023413408,
"fields": {
"category": "digestive system",
"chunk_text": "Apples are a great source of dietary fiber, which supports digestion and helps maintain a healthy gut."
}
}
]
},
"usage": {
"read_units": 6,
"embed_total_tokens": 5,
"rerank_units": 1
}
}
```
```json curl theme={null}
{
"result": {
"hits": [
{
"_id": "rec3",
"_score": 0.82042724,
"fields": {
"category": "immune system",
"chunk_text": "Rich in vitamin C and other antioxidants, apples contribute to immune health and may reduce the risk of chronic diseases."
}
},
{
"_id": "rec1",
"_score": 0.7931626,
"fields": {
"category": "digestive system",
"chunk_text": "Apples are a great source of dietary fiber, which supports digestion and helps maintain a healthy gut."
}
}
]
},
"usage": {
"embed_total_tokens": 8,
"read_units": 6
}
}
```
## Search with a dense vector
To search a dense index with a dense vector representation of a query, use the [`query`](/reference/api/latest/data-plane/query) operation with the following parameters:
* The `namespace` to query. To use the default namespace, set the namespace to `"__default__"`.
* The `vector` parameter with the dense vector values representing your query.
* The `top_k` parameter with the number of results to return.
* Optionally, you can set `include_values` and/or `include_metadata` to `true` to include the vector values and/or metadata of the matching records in the response. For better performance, especially with higher `top_k` values, avoid including vector values unless you need them. See [Decrease latency](/guides/optimize/decrease-latency#avoid-including-vector-values-when-not-needed) for more details.
For example, the following code uses a dense vector representation of the query “Disease prevention” to search for the 3 most semantically similar records in the `example-namespaces` namespace:
```Python Python theme={null}
from pinecone.grpc import PineconeGRPC as Pinecone
pc = Pinecone(api_key="YOUR_API_KEY")
# To get the unique host for an index,
# see https://docs.pinecone.io/guides/manage-data/target-an-index
index = pc.Index(host="INDEX_HOST")
index.query(
namespace="example-namespace",
vector=[0.0236663818359375,-0.032989501953125, ..., -0.01041412353515625,0.0086669921875],
top_k=3,
include_metadata=True,
include_values=False
)
```
```JavaScript JavaScript theme={null}
import { Pinecone } from '@pinecone-database/pinecone'
const pc = new Pinecone({ apiKey: "YOUR_API_KEY" })
// To get the unique host for an index,
// see https://docs.pinecone.io/guides/manage-data/target-an-index
const index = pc.index("INDEX_NAME", "INDEX_HOST")
const queryResponse = await index.namespace('example-namespace').query({
vector: [0.0236663818359375,-0.032989501953125,...,-0.01041412353515625,0.0086669921875],
topK: 3,
includeValues: false,
includeMetadata: true,
});
```
```java Java theme={null}
import io.pinecone.clients.Index;
import io.pinecone.configs.PineconeConfig;
import io.pinecone.configs.PineconeConnection;
import io.pinecone.unsigned_indices_model.QueryResponseWithUnsignedIndices;
import java.util.Arrays;
import java.util.List;
public class QueryExample {
public static void main(String[] args) {
PineconeConfig config = new PineconeConfig("YOUR_API_KEY");
// To get the unique host for an index,
// see https://docs.pinecone.io/guides/manage-data/target-an-index
config.setHost("INDEX_HOST");
PineconeConnection connection = new PineconeConnection(config);
Index index = new Index(connection, "INDEX_NAME");
List query = Arrays.asList(0.0236663818359375f, -0.032989501953125f, ..., -0.01041412353515625f, 0.0086669921875f);
QueryResponseWithUnsignedIndices queryResponse = index.query(3, query, null, null, null, "example-namespace", null, false, true);
System.out.println(queryResponse);
}
}
```
```go Go theme={null}
package main
import (
"context"
"encoding/json"
"fmt"
"log"
"github.com/pinecone-io/go-pinecone/v4/pinecone"
)
func prettifyStruct(obj interface{}) string {
bytes, _ := json.MarshalIndent(obj, "", " ")
return string(bytes)
}
func main() {
ctx := context.Background()
pc, err := pinecone.NewClient(pinecone.NewClientParams{
ApiKey: "YOUR_API_KEY",
})
if err != nil {
log.Fatalf("Failed to create Client: %v", err)
}
// To get the unique host for an index,
// see https://docs.pinecone.io/guides/manage-data/target-an-index
idxConnection, err := pc.Index(pinecone.NewIndexConnParams{Host: "INDEX_HOST", Namespace: "example-namespace"})
if err != nil {
log.Fatalf("Failed to create IndexConnection for Host: %v", err)
}
queryVector := []float32{0.0236663818359375,-0.032989501953125,...,-0.01041412353515625,0.0086669921875}
res, err := idxConnection.QueryByVectorValues(ctx, &pinecone.QueryByVectorValuesRequest{
Vector: queryVector,
TopK: 3,
IncludeValues: false,
includeMetadata: true,
})
if err != nil {
log.Fatalf("Error encountered when querying by vector: %v", err)
} else {
fmt.Printf(prettifyStruct(res))
}
}
```
```csharp C# theme={null}
using Pinecone;
var pinecone = new PineconeClient("YOUR_API_KEY");
// To get the unique host for an index,
// see https://docs.pinecone.io/guides/manage-data/target-an-index
var index = pinecone.Index(host: "INDEX_HOST");
var queryResponse = await index.QueryAsync(new QueryRequest {
Vector = new[] { 0.0236663818359375f ,-0.032989501953125f, ..., -0.01041412353515625f, 0.0086669921875f },
Namespace = "example-namespace",
TopK = 3,
IncludeMetadata = true,
});
Console.WriteLine(queryResponse);
```
```bash curl theme={null}
# To get the unique host for an index,
# see https://docs.pinecone.io/guides/manage-data/target-an-index
PINECONE_API_KEY="YOUR_API_KEY"
INDEX_HOST="INDEX_HOST"
curl "https://$INDEX_HOST/query" \
-H "Api-Key: $PINECONE_API_KEY" \
-H 'Content-Type: application/json' \
-H "X-Pinecone-Api-Version: 2025-10" \
-d '{
"vector": [0.0236663818359375,-0.032989501953125,...,-0.01041412353515625,0.0086669921875],
"namespace": "example-namespace",
"topK": 3,
"includeMetadata": true,
"includeValues": false
}'
```
The response will look as follows. Each record is returned with a similarity score that represents its distance to the query vector, calculated according to the [similarity metric](/guides/index-data/create-an-index#similarity-metrics) for the index.
```python Python theme={null}
{'matches': [{'id': 'rec3',
'metadata': {'category': 'immune system',
'chunk_text': 'Rich in vitamin C and other '
'antioxidants, apples contribute to '
'immune health and may reduce the '
'risk of chronic diseases.'},
'score': 0.82026422,
'values': []},
{'id': 'rec1',
'metadata': {'category': 'digestive system',
'chunk_text': 'Apples are a great source of '
'dietary fiber, which supports '
'digestion and helps maintain a '
'healthy gut.'},
'score': 0.793068111,
'values': []},
{'id': 'rec4',
'metadata': {'category': 'endocrine system',
'chunk_text': 'The high fiber content in apples '
'can also help regulate blood sugar '
'levels, making them a favorable '
'snack for people with diabetes.'},
'score': 0.780169606,
'values': []}],
'namespace': 'example-namespace',
'usage': {'read_units': 6}}
```
```JavaScript JavaScript theme={null}
{
matches: [
{
id: 'rec3',
score: 0.819709897,
values: [],
sparseValues: undefined,
metadata: [Object]
},
{
id: 'rec1',
score: 0.792900264,
values: [],
sparseValues: undefined,
metadata: [Object]
},
{
id: 'rec4',
score: 0.780068815,
values: [],
sparseValues: undefined,
metadata: [Object]
}
],
namespace: 'example-namespace',
usage: { readUnits: 6 }
}
```
```java Java theme={null}
class QueryResponseWithUnsignedIndices {
matches: [ScoredVectorWithUnsignedIndices {
score: 0.8197099
id: rec3
values: []
metadata: fields {
key: "category"
value {
string_value: "immune system"
}
}
fields {
key: "chunk_text"
value {
string_value: "Rich in vitamin C and other antioxidants, apples contribute to immune health and may reduce the risk of chronic diseases."
}
}
sparseValuesWithUnsignedIndices: SparseValuesWithUnsignedIndices {
indicesWithUnsigned32Int: []
values: []
}
}, ScoredVectorWithUnsignedIndices {
score: 0.79290026
id: rec1
values: []
metadata: fields {
key: "category"
value {
string_value: "digestive system"
}
}
fields {
key: "chunk_text"
value {
string_value: "Apples are a great source of dietary fiber, which supports digestion and helps maintain a healthy gut."
}
}
sparseValuesWithUnsignedIndices: SparseValuesWithUnsignedIndices {
indicesWithUnsigned32Int: []
values: []
}
}, ScoredVectorWithUnsignedIndices {
score: 0.7800688
id: rec4
values: []
metadata: fields {
key: "category"
value {
string_value: "endocrine system"
}
}
fields {
key: "chunk_text"
value {
string_value: "The high fiber content in apples can also help regulate blood sugar levels, making them a favorable snack for people with diabetes."
}
}
sparseValuesWithUnsignedIndices: SparseValuesWithUnsignedIndices {
indicesWithUnsigned32Int: []
values: []
}
}]
namespace: example-namespace
usage: read_units: 6
}
```
```go Go theme={null}
{
"matches": [
{
"vector": {
"id": "rec3",
"metadata": {
"category": "immune system",
"chunk_text": "Rich in vitamin C and other antioxidants, apples contribute to immune health and may reduce the risk of chronic diseases."
}
},
"score": 0.8197099
},
{
"vector": {
"id": "rec1",
"metadata": {
"category": "digestive system",
"chunk_text": "Apples are a great source of dietary fiber, which supports digestion and helps maintain a healthy gut."
}
},
"score": 0.79290026
},
{
"vector": {
"id": "rec4",
"metadata": {
"category": "endocrine system",
"chunk_text": "The high fiber content in apples can also help regulate blood sugar levels, making them a favorable snack for people with diabetes."
}
},
"score": 0.7800688
}
],
"usage": {
"read_units": 6
},
"namespace": "example-namespace"
}
```
```csharp C# theme={null}
{
"results": [],
"matches": [
{
"id": "rec3",
"score": 0.8197099,
"values": [],
"metadata": {
"category": "immune system",
"chunk_text": "Rich in vitamin C and other antioxidants, apples contribute to immune health and may reduce the risk of chronic diseases."
}
},
{
"id": "rec1",
"score": 0.79290026,
"values": [],
"metadata": {
"category": "digestive system",
"chunk_text": "Apples are a great source of dietary fiber, which supports digestion and helps maintain a healthy gut."
}
},
{
"id": "rec4",
"score": 0.7800688,
"values": [],
"metadata": {
"category": "endocrine system",
"chunk_text": "The high fiber content in apples can also help regulate blood sugar levels, making them a favorable snack for people with diabetes."
}
}
],
"namespace": "example-namespace",
"usage": {
"readUnits": 6
}
}
```
```json curl theme={null}
{
"results": [],
"matches": [
{
"id": "rec3",
"score": 0.820593238,
"values": [],
"metadata": {
"category": "immune system",
"chunk_text": "Rich in vitamin C and other antioxidants, apples contribute to immune health and may reduce the risk of chronic diseases."
}
},
{
"id": "rec1",
"score": 0.792266726,
"values": [],
"metadata": {
"category": "digestive system",
"chunk_text": "Apples are a great source of dietary fiber, which supports digestion and helps maintain a healthy gut."
}
},
{
"id": "rec4",
"score": 0.780045748,
"values": [],
"metadata": {
"category": "endocrine system",
"chunk_text": "The high fiber content in apples can also help regulate blood sugar levels, making them a favorable snack for people with diabetes."
}
}
],
"namespace": "example-namespace",
"usage": {
"readUnits": 6
}
}
```
## Search with a record ID
When you search with a record ID, Pinecone uses the dense vector associated with the record as the query. To search a dense index with a record ID, use the [`query`](/reference/api/latest/data-plane/query) operation with the following parameters:
* The `namespace` to query. To use the default namespace, set the namespace to `"__default__"`.
* The `id` parameter with the unique record ID containing the vector to use as the query.
* The `top_k` parameter with the number of results to return.
* Optionally, you can set `include_values` and/or `include_metadata` to `true` to include the vector values and/or metadata of the matching records in the response. For better performance, especially with higher `top_k` values, avoid including vector values unless you need them. See [Decrease latency](/guides/optimize/decrease-latency#avoid-including-vector-values-when-not-needed) for more details.
For example, the following code uses an ID to search for the 3 records in the `example-namespace` namespace that are most semantically similar to the dense vector in the record:
```Python Python theme={null}
from pinecone.grpc import PineconeGRPC as Pinecone
pc = Pinecone(api_key="YOUR_API_KEY")
# To get the unique host for an index,
# see https://docs.pinecone.io/guides/manage-data/target-an-index
index = pc.Index(host="INDEX_HOST")
index.query(
namespace="example-namespace",
id="rec2",
top_k=3,
include_metadata=True,
include_values=False
)
```
```JavaScript JavaScript theme={null}
import { Pinecone } from '@pinecone-database/pinecone'
const pc = new Pinecone({ apiKey: "YOUR_API_KEY" })
// To get the unique host for an index,
// see https://docs.pinecone.io/guides/manage-data/target-an-index
const index = pc.index("INDEX_NAME", "INDEX_HOST")
const queryResponse = await index.namespace('example-namespace').query({
id: 'rec2',
topK: 3,
includeValues: false,
includeMetadata: true,
});
```
```java Java theme={null}
import io.pinecone.clients.Index;
import io.pinecone.configs.PineconeConfig;
import io.pinecone.configs.PineconeConnection;
import io.pinecone.unsigned_indices_model.QueryResponseWithUnsignedIndices;
public class QueryExample {
public static void main(String[] args) {
PineconeConfig config = new PineconeConfig("YOUR_API_KEY");
// To get the unique host for an index,
// see https://docs.pinecone.io/guides/manage-data/target-an-index
config.setHost("INDEX_HOST");
PineconeConnection connection = new PineconeConnection(config);
Index index = new Index(connection, "INDEX_NAME");
QueryResponseWithUnsignedIndices queryRespone = index.queryByVectorId(3, "rec2", "example-namespace", null, false, true);
System.out.println(queryResponse);
}
}
```
```go Go theme={null}
package main
import (
"context"
"encoding/json"
"fmt"
"log"
"github.com/pinecone-io/go-pinecone/v4/pinecone"
)
func prettifyStruct(obj interface{}) string {
bytes, _ := json.MarshalIndent(obj, "", " ")
return string(bytes)
}
func main() {
ctx := context.Background()
pc, err := pinecone.NewClient(pinecone.NewClientParams{
ApiKey: "YOUR_API_KEY",
})
if err != nil {
log.Fatalf("Failed to create Client: %v", err)
}
// To get the unique host for an index,
// see https://docs.pinecone.io/guides/manage-data/target-an-index
idxConnection, err := pc.Index(pinecone.NewIndexConnParams{Host: "INDEX_HOST", Namespace: "example-namespace"})
if err != nil {
log.Fatalf("Failed to create IndexConnection for Host: %v", err)
}
vectorId := "rec2"
res, err := idxConnection.QueryByVectorId(ctx, &pinecone.QueryByVectorIdRequest{
VectorId: vectorId,
TopK: 3,
IncludeValues: false,
IncludeMetadata: true,
})
if err != nil {
log.Fatalf("Error encountered when querying by vector ID `%v`: %v", vectorId, err)
} else {
fmt.Printf(prettifyStruct(res.Matches))
}
}
```
```csharp C# theme={null}
using Pinecone;
var pinecone = new PineconeClient("YOUR_API_KEY");
// To get the unique host for an index,
// see https://docs.pinecone.io/guides/manage-data/target-an-index
var index = pinecone.Index(host: "INDEX_HOST");
var queryResponse = await index.QueryAsync(new QueryRequest {
Id = "rec2",
Namespace = "example-namespace",
TopK = 3,
IncludeValues = false,
IncludeMetadata = true
});
Console.WriteLine(queryResponse);
```
```bash curl theme={null}
# To get the unique host for an index,
# see https://docs.pinecone.io/guides/manage-data/target-an-index
PINECONE_API_KEY="YOUR_API_KEY"
INDEX_HOST="INDEX_HOST"
curl "https://$INDEX_HOST/query" \
-H "Api-Key: $PINECONE_API_KEY" \
-H 'Content-Type: application/json' \
-H "X-Pinecone-Api-Version: 2025-10" \
-d '{
"id": "rec2",
"namespace": "example-namespace",
"topK": 3,
"includeMetadata": true,
"includeValues": false
}'
```
## Parallel queries
Python SDK v6.0.0 and later provide `async` methods for use with [asyncio](https://docs.python.org/3/library/asyncio.html). Async support makes it possible to use Pinecone with modern async web frameworks such as FastAPI, Quart, and Sanic, and can significantly increase the efficiency of running queries in parallel. For more details, see the [Async requests](/reference/sdks/python/overview#async-requests).
---
# Source: https://docs.pinecone.io/troubleshooting/serverless-index-connection-errors.md
> ## Documentation Index
> Fetch the complete documentation index at: https://docs.pinecone.io/llms.txt
> Use this file to discover all available pages before exploring further.
# Serverless index connection errors
## Problem
To connect to a serverless index, you must use an updated Pinecone client. Trying to connect to a serverless index with an outdated client will raise errors similar to one of the following:
```console console theme={null}
Failed to resolve 'controller.us-west-2.pinecone.io'
controller.us-west-2-aws.pinecone.io not found
Request failed to reach Pinecone while calling https://controller.us-west-2.pinecone.io/actions/whoami
```
## Solution
Upgrade to the latest [Python](https://github.com/pinecone-io/pinecone-python-client) or [Node.js](https://sdk.pinecone.io/typescript/) client and try again:
```python Python theme={null}
pip install "pinecone[grpc]" --upgrade
```
```js JavaScript theme={null}
npm install @pinecone-database/pinecone@latest
```
---
# Source: https://docs.pinecone.io/integrations/snowflake.md
> ## Documentation Index
> Fetch the complete documentation index at: https://docs.pinecone.io/llms.txt
> Use this file to discover all available pages before exploring further.
# Snowflake
export const PrimarySecondaryCTA = ({primaryLabel, primaryHref, primaryTarget, secondaryLabel, secondaryHref, secondaryTarget}) =>
Traffic is also encrypted in transit between the Pinecone backend and cloud infrastructure services, such as S3 and GCS. For more information, see [Google Cloud Platform](https://cloud.google.com/docs/security/encryption-in-transit) and [AWS security documentation](https://docs.aws.amazon.com/AmazonS3/userguide/UsingEncryption.html).
## Network security
### Proxies
The following Pinecone SDKs support the use of proxies:
* [Python SDK](/reference/sdks/python/overview#proxy-configuration)
* [Node.js SDK](/reference/sdks/node/overview#proxy-configuration)
---
# Source: https://docs.pinecone.io/guides/search/semantic-search.md
> ## Documentation Index
> Fetch the complete documentation index at: https://docs.pinecone.io/llms.txt
> Use this file to discover all available pages before exploring further.
# Semantic search
> Find semantically similar records using dense vectors.
This page shows you how to search a [dense index](/guides/index-data/indexing-overview#dense-indexes) for records that are most similar in meaning and context to a query. This is often called semantic search, nearest neighbor search, similarity search, or just vector search.
Semantic search uses [dense vectors](https://www.pinecone.io/learn/vector-embeddings/). Each number in a dense vector corresponds to a point in a multidimensional space. Vectors that are closer together in that space are semantically similar.
## Search with text
Searching with text is supported only for [indexes with integrated embedding](/guides/index-data/indexing-overview#integrated-embedding).
To search a dense index with a query text, use the [`search_records`](/reference/api/latest/data-plane/search_records) operation with the following parameters:
* The `namespace` to query. To use the default namespace, set the namespace to `"__default__"`.
* The `query.inputs.text` parameter with the query text. Pinecone uses the embedding model integrated with the index to convert the text to a dense vector automatically.
* The `query.top_k` parameter with the number of similar records to return.
* Optionally, you can specify the `fields` to return in the response. If not specified, the response will include all fields.
For example, the following code searches for the 2 records most semantically related to a query text:
```python Python theme={null}
from pinecone import Pinecone
pc = Pinecone(api_key="YOUR_API_KEY")
# To get the unique host for an index,
# see https://docs.pinecone.io/guides/manage-data/target-an-index
index = pc.Index(host="INDEX_HOST")
results = index.search(
namespace="example-namespace",
query={
"inputs": {"text": "Disease prevention"},
"top_k": 2
},
fields=["category", "chunk_text"]
)
print(results)
```
```javascript JavaScript theme={null}
import { Pinecone } from '@pinecone-database/pinecone'
const pc = new Pinecone({ apiKey: "YOUR_API_KEY" })
// To get the unique host for an index,
// see https://docs.pinecone.io/guides/manage-data/target-an-index
const namespace = pc.index("INDEX_NAME", "INDEX_HOST").namespace("example-namespace");
const response = await namespace.searchRecords({
query: {
topK: 2,
inputs: { text: 'Disease prevention' },
},
fields: ['chunk_text', 'category'],
});
console.log(response);
```
```java Java theme={null}
import io.pinecone.clients.Index;
import io.pinecone.configs.PineconeConfig;
import io.pinecone.configs.PineconeConnection;
import org.openapitools.db_data.client.ApiException;
import org.openapitools.db_data.client.model.SearchRecordsResponse;
import java.util.*;
public class SearchText {
public static void main(String[] args) throws ApiException {
PineconeConfig config = new PineconeConfig("YOUR_API_KEY");
// To get the unique host for an index,
// see https://docs.pinecone.io/guides/manage-data/target-an-index
config.setHost("INDEX_HOST");
PineconeConnection connection = new PineconeConnection(config);
Index index = new Index(config, connection, "integrated-dense-java");
String query = "Disease prevention";
List fields = new ArrayList<>();
fields.add("category");
fields.add("chunk_text");
// Search the dense index
SearchRecordsResponse recordsResponse = index.searchRecordsByText(query, "example-namespace", fields, 2, null, null);
// Print the results
System.out.println(recordsResponse);
}
}
```
```go Go theme={null}
package main
import (
"context"
"encoding/json"
"fmt"
"log"
"github.com/pinecone-io/go-pinecone/v4/pinecone"
)
func prettifyStruct(obj interface{}) string {
bytes, _ := json.MarshalIndent(obj, "", " ")
return string(bytes)
}
func main() {
ctx := context.Background()
pc, err := pinecone.NewClient(pinecone.NewClientParams{
ApiKey: "YOUR_API_KEY",
})
if err != nil {
log.Fatalf("Failed to create Client: %v", err)
}
// To get the unique host for an index,
// see https://docs.pinecone.io/guides/manage-data/target-an-index
idxConnection, err := pc.Index(pinecone.NewIndexConnParams{Host: "INDEX_HOST", Namespace: "example-namespace"})
if err != nil {
log.Fatalf("Failed to create IndexConnection for Host: %v", err)
}
res, err := idxConnection.SearchRecords(ctx, &pinecone.SearchRecordsRequest{
Query: pinecone.SearchRecordsQuery{
TopK: 2,
Inputs: &map[string]interface{}{
"text": "Disease prevention",
},
},
Fields: &[]string{"chunk_text", "category"},
})
if err != nil {
log.Fatalf("Failed to search records: %v", err)
}
fmt.Printf(prettifyStruct(res))
}
```
```csharp C# theme={null}
using Pinecone;
var pinecone = new PineconeClient("YOUR_API_KEY");
// To get the unique host for an index,
// see https://docs.pinecone.io/guides/manage-data/target-an-index
var index = pinecone.Index(host: "INDEX_HOST");
var response = await index.SearchRecordsAsync(
"example-namespace",
new SearchRecordsRequest
{
Query = new SearchRecordsRequestQuery
{
TopK = 4,
Inputs = new Dictionary { { "text", "Disease prevention" } },
},
Fields = ["category", "chunk_text"],
}
);
Console.WriteLine(response);
```
```shell curl theme={null}
INDEX_HOST="INDEX_HOST"
NAMESPACE="YOUR_NAMESPACE"
PINECONE_API_KEY="YOUR_API_KEY"
curl "https://$INDEX_HOST/records/namespaces/$NAMESPACE/search" \
-H "Accept: application/json" \
-H "Content-Type: application/json" \
-H "Api-Key: $PINECONE_API_KEY" \
-H "X-Pinecone-Api-Version: unstable" \
-d '{
"query": {
"inputs": {"text": "Disease prevention"},
"top_k": 2
},
"fields": ["category", "chunk_text"]
}'
```
The response will look as follows. Each record is returned with a similarity score that represents its distance to the query vector, calculated according to the [similarity metric](/guides/index-data/create-an-index#similarity-metrics) for the index.
```python Python theme={null}
{'result': {'hits': [{'_id': 'rec3',
'_score': 0.8204272389411926,
'fields': {'category': 'immune system',
'chunk_text': 'Rich in vitamin C and other '
'antioxidants, apples '
'contribute to immune health '
'and may reduce the risk of '
'chronic diseases.'}},
{'_id': 'rec1',
'_score': 0.7931625843048096,
'fields': {'category': 'digestive system',
'chunk_text': 'Apples are a great source of '
'dietary fiber, which supports '
'digestion and helps maintain a '
'healthy gut.'}}]},
'usage': {'embed_total_tokens': 8, 'read_units': 6}}
```
```javascript JavaScript theme={null}
{
result: {
hits: [
{
_id: 'rec3',
_score: 0.82042724,
fields: {
category: 'immune system',
chunk_text: 'Rich in vitamin C and other antioxidants, apples contribute to immune health and may reduce the risk of chronic diseases.'
}
},
{
_id: 'rec1',
_score: 0.7931626,
fields: {
category: 'digestive system',
chunk_text: 'Apples are a great source of dietary fiber, which supports digestion and helps maintain a healthy gut.'
}
}
]
},
usage: {
readUnits: 6,
embedTotalTokens: 8
}
}
```
```java Java theme={null}
class SearchRecordsResponse {
result: class SearchRecordsResponseResult {
hits: [class Hit {
id: rec3
score: 0.8204272389411926
fields: {category=immune system, chunk_text=Rich in vitamin C and other antioxidants, apples contribute to immune health and may reduce the risk of chronic diseases.}
additionalProperties: null
}, class Hit {
id: rec1
score: 0.7931625843048096
fields: {category=endocrine system, chunk_text=Apples are a great source of dietary fiber, which supports digestion and helps maintain a healthy gut.}
additionalProperties: null
}]
additionalProperties: null
}
usage: class SearchUsage {
readUnits: 6
embedTotalTokens: 13
}
additionalProperties: null
}
```
```go Go theme={null}
{
"result": {
"hits": [
{
"_id": "rec3",
"_score": 0.82042724,
"fields": {
"category": "immune system",
"chunk_text": "Rich in vitamin C and other antioxidants, apples contribute to immune health and may reduce the risk of chronic diseases."
}
},
{
"_id": "rec1",
"_score": 0.7931626,
"fields": {
"category": "digestive system",
"chunk_text": "Apples are a great source of dietary fiber, which supports digestion and helps maintain a healthy gut."
}
}
]
},
"usage": {
"read_units": 6,
"embed_total_tokens": 8
}
}
```
```csharp C# theme={null}
{
"result": {
"hits": [
{
"_id": "rec3",
"_score": 0.13741668,
"fields": {
"category": "immune system",
"chunk_text": "Rich in vitamin C and other antioxidants, apples contribute to immune health and may reduce the risk of chronic diseases."
}
},
{
"_id": "rec1",
"_score": 0.0023413408,
"fields": {
"category": "digestive system",
"chunk_text": "Apples are a great source of dietary fiber, which supports digestion and helps maintain a healthy gut."
}
}
]
},
"usage": {
"read_units": 6,
"embed_total_tokens": 5,
"rerank_units": 1
}
}
```
```json curl theme={null}
{
"result": {
"hits": [
{
"_id": "rec3",
"_score": 0.82042724,
"fields": {
"category": "immune system",
"chunk_text": "Rich in vitamin C and other antioxidants, apples contribute to immune health and may reduce the risk of chronic diseases."
}
},
{
"_id": "rec1",
"_score": 0.7931626,
"fields": {
"category": "digestive system",
"chunk_text": "Apples are a great source of dietary fiber, which supports digestion and helps maintain a healthy gut."
}
}
]
},
"usage": {
"embed_total_tokens": 8,
"read_units": 6
}
}
```
## Search with a dense vector
To search a dense index with a dense vector representation of a query, use the [`query`](/reference/api/latest/data-plane/query) operation with the following parameters:
* The `namespace` to query. To use the default namespace, set the namespace to `"__default__"`.
* The `vector` parameter with the dense vector values representing your query.
* The `top_k` parameter with the number of results to return.
* Optionally, you can set `include_values` and/or `include_metadata` to `true` to include the vector values and/or metadata of the matching records in the response. For better performance, especially with higher `top_k` values, avoid including vector values unless you need them. See [Decrease latency](/guides/optimize/decrease-latency#avoid-including-vector-values-when-not-needed) for more details.
For example, the following code uses a dense vector representation of the query “Disease prevention” to search for the 3 most semantically similar records in the `example-namespaces` namespace:
```Python Python theme={null}
from pinecone.grpc import PineconeGRPC as Pinecone
pc = Pinecone(api_key="YOUR_API_KEY")
# To get the unique host for an index,
# see https://docs.pinecone.io/guides/manage-data/target-an-index
index = pc.Index(host="INDEX_HOST")
index.query(
namespace="example-namespace",
vector=[0.0236663818359375,-0.032989501953125, ..., -0.01041412353515625,0.0086669921875],
top_k=3,
include_metadata=True,
include_values=False
)
```
```JavaScript JavaScript theme={null}
import { Pinecone } from '@pinecone-database/pinecone'
const pc = new Pinecone({ apiKey: "YOUR_API_KEY" })
// To get the unique host for an index,
// see https://docs.pinecone.io/guides/manage-data/target-an-index
const index = pc.index("INDEX_NAME", "INDEX_HOST")
const queryResponse = await index.namespace('example-namespace').query({
vector: [0.0236663818359375,-0.032989501953125,...,-0.01041412353515625,0.0086669921875],
topK: 3,
includeValues: false,
includeMetadata: true,
});
```
```java Java theme={null}
import io.pinecone.clients.Index;
import io.pinecone.configs.PineconeConfig;
import io.pinecone.configs.PineconeConnection;
import io.pinecone.unsigned_indices_model.QueryResponseWithUnsignedIndices;
import java.util.Arrays;
import java.util.List;
public class QueryExample {
public static void main(String[] args) {
PineconeConfig config = new PineconeConfig("YOUR_API_KEY");
// To get the unique host for an index,
// see https://docs.pinecone.io/guides/manage-data/target-an-index
config.setHost("INDEX_HOST");
PineconeConnection connection = new PineconeConnection(config);
Index index = new Index(connection, "INDEX_NAME");
List query = Arrays.asList(0.0236663818359375f, -0.032989501953125f, ..., -0.01041412353515625f, 0.0086669921875f);
QueryResponseWithUnsignedIndices queryResponse = index.query(3, query, null, null, null, "example-namespace", null, false, true);
System.out.println(queryResponse);
}
}
```
```go Go theme={null}
package main
import (
"context"
"encoding/json"
"fmt"
"log"
"github.com/pinecone-io/go-pinecone/v4/pinecone"
)
func prettifyStruct(obj interface{}) string {
bytes, _ := json.MarshalIndent(obj, "", " ")
return string(bytes)
}
func main() {
ctx := context.Background()
pc, err := pinecone.NewClient(pinecone.NewClientParams{
ApiKey: "YOUR_API_KEY",
})
if err != nil {
log.Fatalf("Failed to create Client: %v", err)
}
// To get the unique host for an index,
// see https://docs.pinecone.io/guides/manage-data/target-an-index
idxConnection, err := pc.Index(pinecone.NewIndexConnParams{Host: "INDEX_HOST", Namespace: "example-namespace"})
if err != nil {
log.Fatalf("Failed to create IndexConnection for Host: %v", err)
}
queryVector := []float32{0.0236663818359375,-0.032989501953125,...,-0.01041412353515625,0.0086669921875}
res, err := idxConnection.QueryByVectorValues(ctx, &pinecone.QueryByVectorValuesRequest{
Vector: queryVector,
TopK: 3,
IncludeValues: false,
includeMetadata: true,
})
if err != nil {
log.Fatalf("Error encountered when querying by vector: %v", err)
} else {
fmt.Printf(prettifyStruct(res))
}
}
```
```csharp C# theme={null}
using Pinecone;
var pinecone = new PineconeClient("YOUR_API_KEY");
// To get the unique host for an index,
// see https://docs.pinecone.io/guides/manage-data/target-an-index
var index = pinecone.Index(host: "INDEX_HOST");
var queryResponse = await index.QueryAsync(new QueryRequest {
Vector = new[] { 0.0236663818359375f ,-0.032989501953125f, ..., -0.01041412353515625f, 0.0086669921875f },
Namespace = "example-namespace",
TopK = 3,
IncludeMetadata = true,
});
Console.WriteLine(queryResponse);
```
```bash curl theme={null}
# To get the unique host for an index,
# see https://docs.pinecone.io/guides/manage-data/target-an-index
PINECONE_API_KEY="YOUR_API_KEY"
INDEX_HOST="INDEX_HOST"
curl "https://$INDEX_HOST/query" \
-H "Api-Key: $PINECONE_API_KEY" \
-H 'Content-Type: application/json' \
-H "X-Pinecone-Api-Version: 2025-10" \
-d '{
"vector": [0.0236663818359375,-0.032989501953125,...,-0.01041412353515625,0.0086669921875],
"namespace": "example-namespace",
"topK": 3,
"includeMetadata": true,
"includeValues": false
}'
```
The response will look as follows. Each record is returned with a similarity score that represents its distance to the query vector, calculated according to the [similarity metric](/guides/index-data/create-an-index#similarity-metrics) for the index.
```python Python theme={null}
{'matches': [{'id': 'rec3',
'metadata': {'category': 'immune system',
'chunk_text': 'Rich in vitamin C and other '
'antioxidants, apples contribute to '
'immune health and may reduce the '
'risk of chronic diseases.'},
'score': 0.82026422,
'values': []},
{'id': 'rec1',
'metadata': {'category': 'digestive system',
'chunk_text': 'Apples are a great source of '
'dietary fiber, which supports '
'digestion and helps maintain a '
'healthy gut.'},
'score': 0.793068111,
'values': []},
{'id': 'rec4',
'metadata': {'category': 'endocrine system',
'chunk_text': 'The high fiber content in apples '
'can also help regulate blood sugar '
'levels, making them a favorable '
'snack for people with diabetes.'},
'score': 0.780169606,
'values': []}],
'namespace': 'example-namespace',
'usage': {'read_units': 6}}
```
```JavaScript JavaScript theme={null}
{
matches: [
{
id: 'rec3',
score: 0.819709897,
values: [],
sparseValues: undefined,
metadata: [Object]
},
{
id: 'rec1',
score: 0.792900264,
values: [],
sparseValues: undefined,
metadata: [Object]
},
{
id: 'rec4',
score: 0.780068815,
values: [],
sparseValues: undefined,
metadata: [Object]
}
],
namespace: 'example-namespace',
usage: { readUnits: 6 }
}
```
```java Java theme={null}
class QueryResponseWithUnsignedIndices {
matches: [ScoredVectorWithUnsignedIndices {
score: 0.8197099
id: rec3
values: []
metadata: fields {
key: "category"
value {
string_value: "immune system"
}
}
fields {
key: "chunk_text"
value {
string_value: "Rich in vitamin C and other antioxidants, apples contribute to immune health and may reduce the risk of chronic diseases."
}
}
sparseValuesWithUnsignedIndices: SparseValuesWithUnsignedIndices {
indicesWithUnsigned32Int: []
values: []
}
}, ScoredVectorWithUnsignedIndices {
score: 0.79290026
id: rec1
values: []
metadata: fields {
key: "category"
value {
string_value: "digestive system"
}
}
fields {
key: "chunk_text"
value {
string_value: "Apples are a great source of dietary fiber, which supports digestion and helps maintain a healthy gut."
}
}
sparseValuesWithUnsignedIndices: SparseValuesWithUnsignedIndices {
indicesWithUnsigned32Int: []
values: []
}
}, ScoredVectorWithUnsignedIndices {
score: 0.7800688
id: rec4
values: []
metadata: fields {
key: "category"
value {
string_value: "endocrine system"
}
}
fields {
key: "chunk_text"
value {
string_value: "The high fiber content in apples can also help regulate blood sugar levels, making them a favorable snack for people with diabetes."
}
}
sparseValuesWithUnsignedIndices: SparseValuesWithUnsignedIndices {
indicesWithUnsigned32Int: []
values: []
}
}]
namespace: example-namespace
usage: read_units: 6
}
```
```go Go theme={null}
{
"matches": [
{
"vector": {
"id": "rec3",
"metadata": {
"category": "immune system",
"chunk_text": "Rich in vitamin C and other antioxidants, apples contribute to immune health and may reduce the risk of chronic diseases."
}
},
"score": 0.8197099
},
{
"vector": {
"id": "rec1",
"metadata": {
"category": "digestive system",
"chunk_text": "Apples are a great source of dietary fiber, which supports digestion and helps maintain a healthy gut."
}
},
"score": 0.79290026
},
{
"vector": {
"id": "rec4",
"metadata": {
"category": "endocrine system",
"chunk_text": "The high fiber content in apples can also help regulate blood sugar levels, making them a favorable snack for people with diabetes."
}
},
"score": 0.7800688
}
],
"usage": {
"read_units": 6
},
"namespace": "example-namespace"
}
```
```csharp C# theme={null}
{
"results": [],
"matches": [
{
"id": "rec3",
"score": 0.8197099,
"values": [],
"metadata": {
"category": "immune system",
"chunk_text": "Rich in vitamin C and other antioxidants, apples contribute to immune health and may reduce the risk of chronic diseases."
}
},
{
"id": "rec1",
"score": 0.79290026,
"values": [],
"metadata": {
"category": "digestive system",
"chunk_text": "Apples are a great source of dietary fiber, which supports digestion and helps maintain a healthy gut."
}
},
{
"id": "rec4",
"score": 0.7800688,
"values": [],
"metadata": {
"category": "endocrine system",
"chunk_text": "The high fiber content in apples can also help regulate blood sugar levels, making them a favorable snack for people with diabetes."
}
}
],
"namespace": "example-namespace",
"usage": {
"readUnits": 6
}
}
```
```json curl theme={null}
{
"results": [],
"matches": [
{
"id": "rec3",
"score": 0.820593238,
"values": [],
"metadata": {
"category": "immune system",
"chunk_text": "Rich in vitamin C and other antioxidants, apples contribute to immune health and may reduce the risk of chronic diseases."
}
},
{
"id": "rec1",
"score": 0.792266726,
"values": [],
"metadata": {
"category": "digestive system",
"chunk_text": "Apples are a great source of dietary fiber, which supports digestion and helps maintain a healthy gut."
}
},
{
"id": "rec4",
"score": 0.780045748,
"values": [],
"metadata": {
"category": "endocrine system",
"chunk_text": "The high fiber content in apples can also help regulate blood sugar levels, making them a favorable snack for people with diabetes."
}
}
],
"namespace": "example-namespace",
"usage": {
"readUnits": 6
}
}
```
## Search with a record ID
When you search with a record ID, Pinecone uses the dense vector associated with the record as the query. To search a dense index with a record ID, use the [`query`](/reference/api/latest/data-plane/query) operation with the following parameters:
* The `namespace` to query. To use the default namespace, set the namespace to `"__default__"`.
* The `id` parameter with the unique record ID containing the vector to use as the query.
* The `top_k` parameter with the number of results to return.
* Optionally, you can set `include_values` and/or `include_metadata` to `true` to include the vector values and/or metadata of the matching records in the response. For better performance, especially with higher `top_k` values, avoid including vector values unless you need them. See [Decrease latency](/guides/optimize/decrease-latency#avoid-including-vector-values-when-not-needed) for more details.
For example, the following code uses an ID to search for the 3 records in the `example-namespace` namespace that are most semantically similar to the dense vector in the record:
```Python Python theme={null}
from pinecone.grpc import PineconeGRPC as Pinecone
pc = Pinecone(api_key="YOUR_API_KEY")
# To get the unique host for an index,
# see https://docs.pinecone.io/guides/manage-data/target-an-index
index = pc.Index(host="INDEX_HOST")
index.query(
namespace="example-namespace",
id="rec2",
top_k=3,
include_metadata=True,
include_values=False
)
```
```JavaScript JavaScript theme={null}
import { Pinecone } from '@pinecone-database/pinecone'
const pc = new Pinecone({ apiKey: "YOUR_API_KEY" })
// To get the unique host for an index,
// see https://docs.pinecone.io/guides/manage-data/target-an-index
const index = pc.index("INDEX_NAME", "INDEX_HOST")
const queryResponse = await index.namespace('example-namespace').query({
id: 'rec2',
topK: 3,
includeValues: false,
includeMetadata: true,
});
```
```java Java theme={null}
import io.pinecone.clients.Index;
import io.pinecone.configs.PineconeConfig;
import io.pinecone.configs.PineconeConnection;
import io.pinecone.unsigned_indices_model.QueryResponseWithUnsignedIndices;
public class QueryExample {
public static void main(String[] args) {
PineconeConfig config = new PineconeConfig("YOUR_API_KEY");
// To get the unique host for an index,
// see https://docs.pinecone.io/guides/manage-data/target-an-index
config.setHost("INDEX_HOST");
PineconeConnection connection = new PineconeConnection(config);
Index index = new Index(connection, "INDEX_NAME");
QueryResponseWithUnsignedIndices queryRespone = index.queryByVectorId(3, "rec2", "example-namespace", null, false, true);
System.out.println(queryResponse);
}
}
```
```go Go theme={null}
package main
import (
"context"
"encoding/json"
"fmt"
"log"
"github.com/pinecone-io/go-pinecone/v4/pinecone"
)
func prettifyStruct(obj interface{}) string {
bytes, _ := json.MarshalIndent(obj, "", " ")
return string(bytes)
}
func main() {
ctx := context.Background()
pc, err := pinecone.NewClient(pinecone.NewClientParams{
ApiKey: "YOUR_API_KEY",
})
if err != nil {
log.Fatalf("Failed to create Client: %v", err)
}
// To get the unique host for an index,
// see https://docs.pinecone.io/guides/manage-data/target-an-index
idxConnection, err := pc.Index(pinecone.NewIndexConnParams{Host: "INDEX_HOST", Namespace: "example-namespace"})
if err != nil {
log.Fatalf("Failed to create IndexConnection for Host: %v", err)
}
vectorId := "rec2"
res, err := idxConnection.QueryByVectorId(ctx, &pinecone.QueryByVectorIdRequest{
VectorId: vectorId,
TopK: 3,
IncludeValues: false,
IncludeMetadata: true,
})
if err != nil {
log.Fatalf("Error encountered when querying by vector ID `%v`: %v", vectorId, err)
} else {
fmt.Printf(prettifyStruct(res.Matches))
}
}
```
```csharp C# theme={null}
using Pinecone;
var pinecone = new PineconeClient("YOUR_API_KEY");
// To get the unique host for an index,
// see https://docs.pinecone.io/guides/manage-data/target-an-index
var index = pinecone.Index(host: "INDEX_HOST");
var queryResponse = await index.QueryAsync(new QueryRequest {
Id = "rec2",
Namespace = "example-namespace",
TopK = 3,
IncludeValues = false,
IncludeMetadata = true
});
Console.WriteLine(queryResponse);
```
```bash curl theme={null}
# To get the unique host for an index,
# see https://docs.pinecone.io/guides/manage-data/target-an-index
PINECONE_API_KEY="YOUR_API_KEY"
INDEX_HOST="INDEX_HOST"
curl "https://$INDEX_HOST/query" \
-H "Api-Key: $PINECONE_API_KEY" \
-H 'Content-Type: application/json' \
-H "X-Pinecone-Api-Version: 2025-10" \
-d '{
"id": "rec2",
"namespace": "example-namespace",
"topK": 3,
"includeMetadata": true,
"includeValues": false
}'
```
## Parallel queries
Python SDK v6.0.0 and later provide `async` methods for use with [asyncio](https://docs.python.org/3/library/asyncio.html). Async support makes it possible to use Pinecone with modern async web frameworks such as FastAPI, Quart, and Sanic, and can significantly increase the efficiency of running queries in parallel. For more details, see the [Async requests](/reference/sdks/python/overview#async-requests).
---
# Source: https://docs.pinecone.io/troubleshooting/serverless-index-connection-errors.md
> ## Documentation Index
> Fetch the complete documentation index at: https://docs.pinecone.io/llms.txt
> Use this file to discover all available pages before exploring further.
# Serverless index connection errors
## Problem
To connect to a serverless index, you must use an updated Pinecone client. Trying to connect to a serverless index with an outdated client will raise errors similar to one of the following:
```console console theme={null}
Failed to resolve 'controller.us-west-2.pinecone.io'
controller.us-west-2-aws.pinecone.io not found
Request failed to reach Pinecone while calling https://controller.us-west-2.pinecone.io/actions/whoami
```
## Solution
Upgrade to the latest [Python](https://github.com/pinecone-io/pinecone-python-client) or [Node.js](https://sdk.pinecone.io/typescript/) client and try again:
```python Python theme={null}
pip install "pinecone[grpc]" --upgrade
```
```js JavaScript theme={null}
npm install @pinecone-database/pinecone@latest
```
---
# Source: https://docs.pinecone.io/integrations/snowflake.md
> ## Documentation Index
> Fetch the complete documentation index at: https://docs.pinecone.io/llms.txt
> Use this file to discover all available pages before exploring further.
# Snowflake
export const PrimarySecondaryCTA = ({primaryLabel, primaryHref, primaryTarget, secondaryLabel, secondaryHref, secondaryTarget}) =>
{primaryLabel && primaryHref &&
}
{secondaryLabel && secondaryHref &&
}
{primaryLabel && primaryHref &&
}
{secondaryLabel && secondaryHref &&
}
{primaryLabel && primaryHref &&
}
{secondaryLabel && secondaryHref &&
}
{primaryLabel && primaryHref &&
}
{secondaryLabel && secondaryHref &&
}
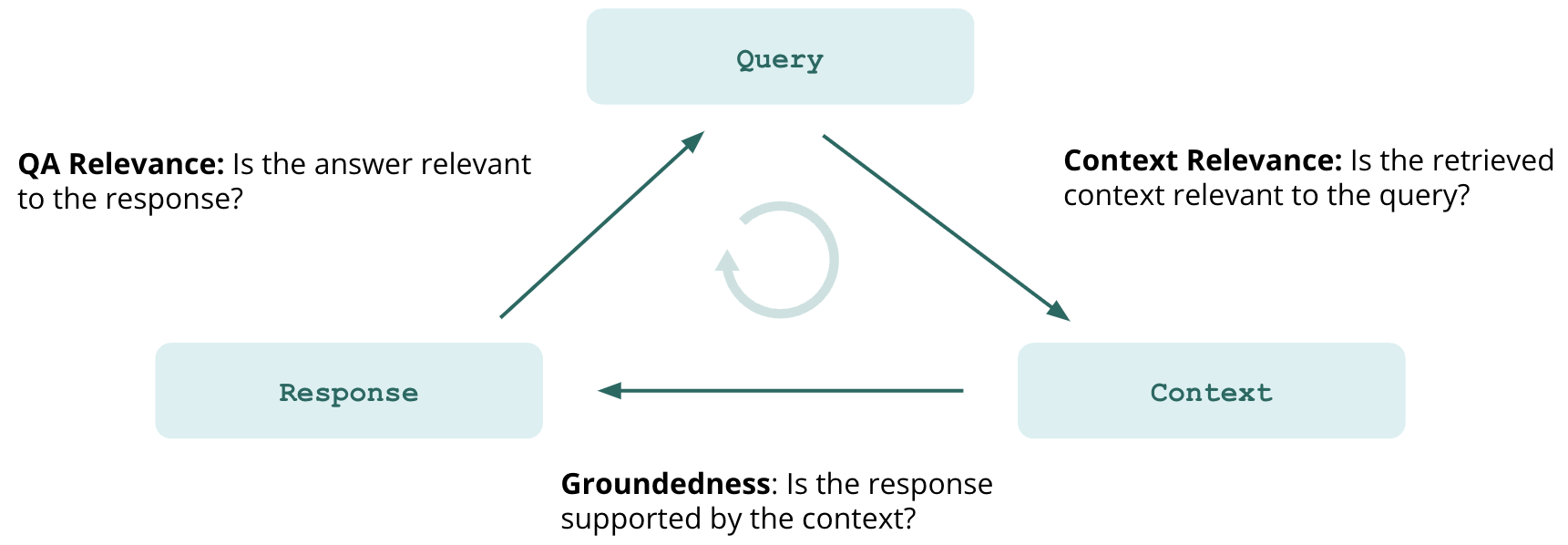 In addition to the above, feedback functions also support the evaluation of ground truth agreement, sentiment, model agreement, language match, toxicity, and a full suite of moderation evaluations, including hate, violence and more. TruLens implements feedback functions as an extensible framework that can evaluate your custom needs as well.
During the development cycle, TruLens supports the iterative development of a wide range of LLM applications by wrapping your application to log cost, latency, key metadata and evaluations of each application run. This allows you to track and identify failure modes, pinpoint their root cause, and measure improvement across experiments.
In addition to the above, feedback functions also support the evaluation of ground truth agreement, sentiment, model agreement, language match, toxicity, and a full suite of moderation evaluations, including hate, violence and more. TruLens implements feedback functions as an extensible framework that can evaluate your custom needs as well.
During the development cycle, TruLens supports the iterative development of a wide range of LLM applications by wrapping your application to log cost, latency, key metadata and evaluations of each application run. This allows you to track and identify failure modes, pinpoint their root cause, and measure improvement across experiments.
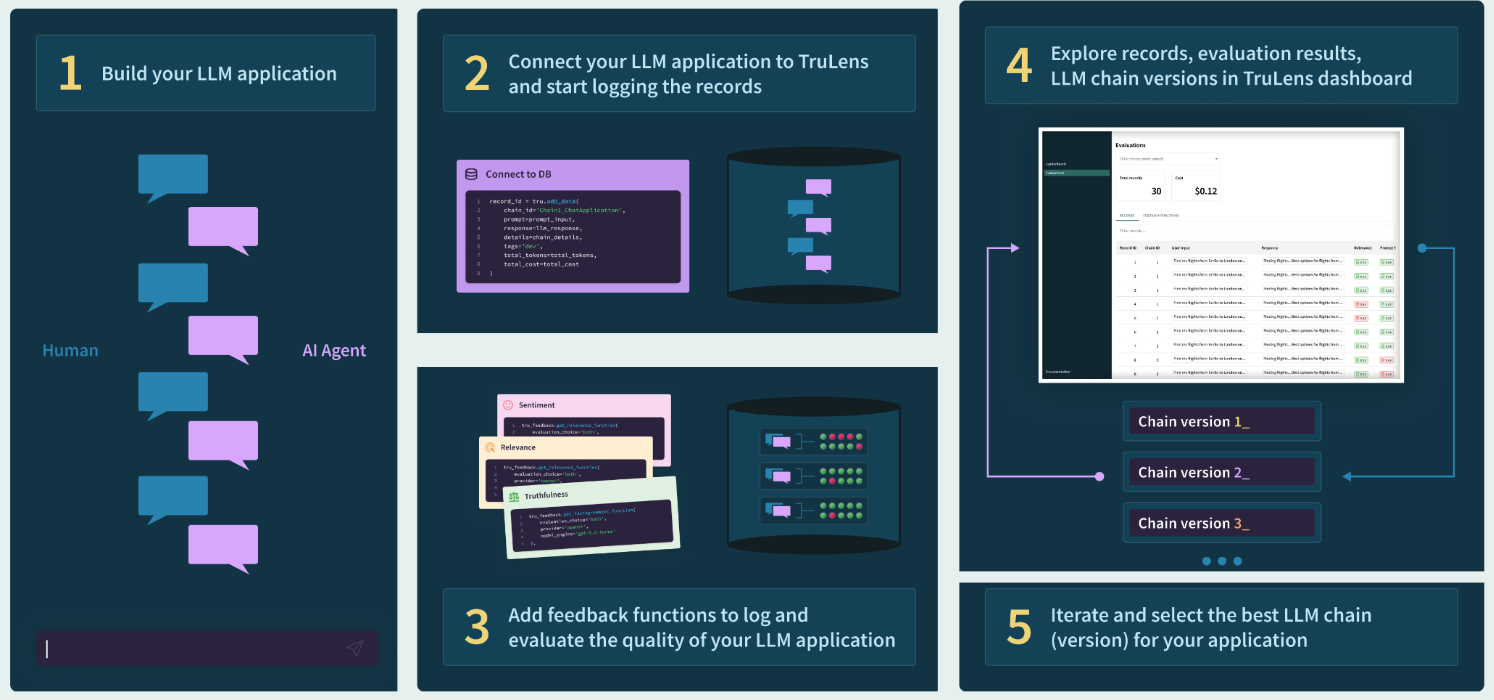 ### Why Pinecone?
Large language models alone have a hallucination problem. Several decades of machine learning research have optimized models, including modern LLMs, for generalization, while actively penalizing memorization. However, many of today's applications require factual, grounded answers. LLMs are also expensive to train, and provided by third party APIs. This means the knowledge of an LLM is fixed. Retrieval-augmented generation (RAG) is a way to reliably ensure models are grounded, with Pinecone as the curated source of real world information, long term memory, application domain knowledge, or whitelisted data.
In the RAG paradigm, rather than just passing a user question directly to a language model, the system retrieves any documents that could be relevant in answering the question from the knowledge base, and then passes those documents (along with the original question) to the language model to generate the final response. The most popular method for RAG involves chaining together LLMs with vector databases, such as the widely used Pinecone vector DB.
In this process, a numerical vector (an embedding) is calculated for all documents, and those vectors are then stored in a database optimized for storing and querying vectors. Incoming queries are vectorized as well, typically using an encoder LLM to convert the query into an embedding. The query embedding is then matched via embedding similarity against the document embeddings in the vector database to retrieve the documents that are relevant to the query.
### Why Pinecone?
Large language models alone have a hallucination problem. Several decades of machine learning research have optimized models, including modern LLMs, for generalization, while actively penalizing memorization. However, many of today's applications require factual, grounded answers. LLMs are also expensive to train, and provided by third party APIs. This means the knowledge of an LLM is fixed. Retrieval-augmented generation (RAG) is a way to reliably ensure models are grounded, with Pinecone as the curated source of real world information, long term memory, application domain knowledge, or whitelisted data.
In the RAG paradigm, rather than just passing a user question directly to a language model, the system retrieves any documents that could be relevant in answering the question from the knowledge base, and then passes those documents (along with the original question) to the language model to generate the final response. The most popular method for RAG involves chaining together LLMs with vector databases, such as the widely used Pinecone vector DB.
In this process, a numerical vector (an embedding) is calculated for all documents, and those vectors are then stored in a database optimized for storing and querying vectors. Incoming queries are vectorized as well, typically using an encoder LLM to convert the query into an embedding. The query embedding is then matched via embedding similarity against the document embeddings in the vector database to retrieve the documents that are relevant to the query.
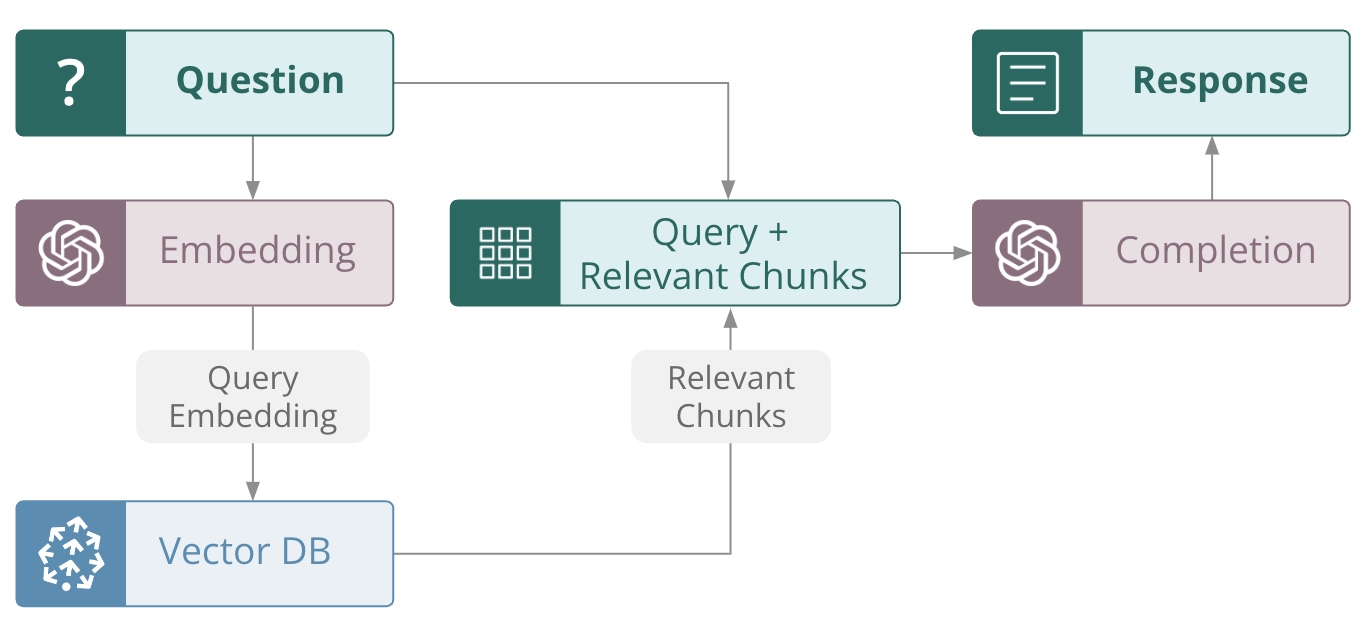 Pinecone makes it easy to build high-performance vector search applications, including retrieval-augmented question answering. Pinecone can easily handle very large scales of hundreds of millions and even billions of vector embeddings. Pinecone's large scale allows it to handle long term memory or a large corpus of rich external and domain-appropriate data so that the LLM component of RAG application can focus on tasks like summarization, inference and planning. This setup is optimal for developing a non-hallucinatory application.\
In addition, Pinecone is fully managed, so it is easy to change configurations and components. Combined with the tracking and evaluation with TruLens, this is a powerful combination that enables fast iteration of your application.
### Using Pinecone and TruLens to improve LLM performance and reduce hallucination
To build an effective RAG-style LLM application, it is important to experiment with various configuration choices while setting up the vector database, and study their impact on performance metrics.
In this example, we explore the downstream impact of some of these configuration choices on response quality, cost and latency with a sample LLM application built with Pinecone as the vector DB. The evaluation and experiment tracking is done with the [TruLens](https://www.trulens.org/) open source library. TruLens offers an extensible set of [feedback functions](https://truera.com/ai-quality-education/generative-ai-and-llms/whats-missing-to-evaluate-foundation-models-at-scale/) to evaluate LLM apps and enables developers to easily track their LLM app experiments.
In each component of this application, different configuration choices can be made that can impact downstream performance. Some of these choices include the following:
**Constructing the Vector DB**
* Data preprocessing and selection
* Chunk Size and Chunk Overlap
* Index distance metric
* Selection of embeddings
**Retrieval**
* Amount of context retrieved (top k)
* Query planning
**LLM**
* Prompting
* Model choice
* Model parameters (size, temperature, frequency penalty, model retries, etc.)
These configuration choices are useful to keep in mind when constructing your app. In general, there is no optimal choice for all use cases. Rather, we recommend that you experiment with and evaluate a variety of configurations to find the optimal selection as you are building your application.
#### Creating the index in Pinecone
Here we'll download a pre-embedded dataset from the `pinecone-datasets` library allowing us to skip the embedding and preprocessing steps.
```Python Python theme={null}
import pinecone_datasets
dataset = pinecone_datasets.load_dataset('wikipedia-simple-text-embedding-ada-002-100K')
dataset.head()
```
After downloading the data, we can initialize our pinecone environment and create our first index. Here, we have our first potentially important choice, by selecting the **distance metric** used for our index.
```Python Python theme={null}
pinecone.create_index(
name=index_name_v1,
metric='cosine', # We'll try each distance metric here.
dimension=1536 # 1536 dim of text-embedding-ada-002.
)
```
Then, we can upsert our documents into the index in batches.
```Python Python theme={null}
for batch in dataset.iter_documents(batch_size=100):
index.upsert(batch)
```
#### Build the vector store
Now that we've built our index, we can start using LangChain to initialize our vector store.
```Python Python theme={null}
embed = OpenAIEmbeddings(
model='text-embedding-ada-002',
openai_api_key=OPENAI_API_KEY
)
from langchain.vectorstores import Pinecone
text_field = "text"
# Switch back to a normal index for LangChain.
index = pinecone.Index(index_name_v1)
vectorstore = Pinecone(
index, embed.embed_query, text_field
)
```
In RAG, we take the query as a question that is to be answered by an LLM, but the LLM must answer the question based on the information it receives from the `vectorstore`.
#### Initialize our RAG application
To do this, we initialize a `RetrievalQA` as our app:
```Python Python theme={null}
from langchain.chat_models import ChatOpenAI
from langchain.chains import RetrievalQA
# completion llm
llm = ChatOpenAI(
model_name='gpt-3.5-turbo',
temperature=0.0
)
qa = RetrievalQA.from_chain_type(
llm=llm,
chain_type="stuff",
retriever=vectorstore.as_retriever()
)
```
#### TruLens for evaluation and tracking of LLM experiments
Once we've set up our app, we should put together our [feedback functions](https://truera.com/ai-quality-education/generative-ai-and-llms/whats-missing-to-evaluate-foundation-models-at-scale/). As a reminder, feedback functions are an extensible method for evaluating LLMs. Here we'll set up two feedback functions: `qs_relevance` and `qa_relevance`. They're defined as follows:
*QS Relevance: query-statement relevance is the average of relevance (0 to 1) for each context chunk returned by the semantic search.*
*QA Relevance: question-answer relevance is the relevance (again, 0 to 1) of the final answer to the original question.*
```Python Python theme={null}
# Imports main tools for eval
from trulens_eval import TruChain, Feedback, Tru, feedback, Select
import numpy as np
tru = Tru()
# OpenAI as feedback provider
openai = feedback.OpenAI()
# Question/answer relevance between overall question and answer.
qa_relevance = Feedback(openai.relevance).on_input_output()
# Question/statement relevance between question and each context chunk.
qs_relevance =
Feedback(openai.qs_relevance).
on_input()
# See explanation below
.on(Select.Record.app.combine_documents_chain._call.args.inputs.input_documents[:].page_content)
.aggregate(np.mean)
```
Our use of selectors here also requires an explanation.
QA Relevance is the simpler of the two. Here, we are using `.on_input_output()` to specify that the feedback function should be applied on both the input and output of the application.
For QS Relevance, we use TruLens selectors to locate the context chunks retrieved by our application. Let's break it down into simple parts:
1. Argument Specification – The `on_input` which appears first is a convenient shorthand and states that the first argument to `qs_relevance` (the question) is to be the main input of the app.
2. Argument Specification – The `on(Select...)` line specifies where the statement argument to the implementation comes from. We want to evaluate the context chunks, which are an intermediate step of the LLM app. This form references the langchain app object call chain, which can be viewed from `tru.run_dashboard()`. This flexibility allows you to apply a feedback function to any intermediate step of your LLM app. Below is an example where TruLens displays how to select each piece of the context.
Pinecone makes it easy to build high-performance vector search applications, including retrieval-augmented question answering. Pinecone can easily handle very large scales of hundreds of millions and even billions of vector embeddings. Pinecone's large scale allows it to handle long term memory or a large corpus of rich external and domain-appropriate data so that the LLM component of RAG application can focus on tasks like summarization, inference and planning. This setup is optimal for developing a non-hallucinatory application.\
In addition, Pinecone is fully managed, so it is easy to change configurations and components. Combined with the tracking and evaluation with TruLens, this is a powerful combination that enables fast iteration of your application.
### Using Pinecone and TruLens to improve LLM performance and reduce hallucination
To build an effective RAG-style LLM application, it is important to experiment with various configuration choices while setting up the vector database, and study their impact on performance metrics.
In this example, we explore the downstream impact of some of these configuration choices on response quality, cost and latency with a sample LLM application built with Pinecone as the vector DB. The evaluation and experiment tracking is done with the [TruLens](https://www.trulens.org/) open source library. TruLens offers an extensible set of [feedback functions](https://truera.com/ai-quality-education/generative-ai-and-llms/whats-missing-to-evaluate-foundation-models-at-scale/) to evaluate LLM apps and enables developers to easily track their LLM app experiments.
In each component of this application, different configuration choices can be made that can impact downstream performance. Some of these choices include the following:
**Constructing the Vector DB**
* Data preprocessing and selection
* Chunk Size and Chunk Overlap
* Index distance metric
* Selection of embeddings
**Retrieval**
* Amount of context retrieved (top k)
* Query planning
**LLM**
* Prompting
* Model choice
* Model parameters (size, temperature, frequency penalty, model retries, etc.)
These configuration choices are useful to keep in mind when constructing your app. In general, there is no optimal choice for all use cases. Rather, we recommend that you experiment with and evaluate a variety of configurations to find the optimal selection as you are building your application.
#### Creating the index in Pinecone
Here we'll download a pre-embedded dataset from the `pinecone-datasets` library allowing us to skip the embedding and preprocessing steps.
```Python Python theme={null}
import pinecone_datasets
dataset = pinecone_datasets.load_dataset('wikipedia-simple-text-embedding-ada-002-100K')
dataset.head()
```
After downloading the data, we can initialize our pinecone environment and create our first index. Here, we have our first potentially important choice, by selecting the **distance metric** used for our index.
```Python Python theme={null}
pinecone.create_index(
name=index_name_v1,
metric='cosine', # We'll try each distance metric here.
dimension=1536 # 1536 dim of text-embedding-ada-002.
)
```
Then, we can upsert our documents into the index in batches.
```Python Python theme={null}
for batch in dataset.iter_documents(batch_size=100):
index.upsert(batch)
```
#### Build the vector store
Now that we've built our index, we can start using LangChain to initialize our vector store.
```Python Python theme={null}
embed = OpenAIEmbeddings(
model='text-embedding-ada-002',
openai_api_key=OPENAI_API_KEY
)
from langchain.vectorstores import Pinecone
text_field = "text"
# Switch back to a normal index for LangChain.
index = pinecone.Index(index_name_v1)
vectorstore = Pinecone(
index, embed.embed_query, text_field
)
```
In RAG, we take the query as a question that is to be answered by an LLM, but the LLM must answer the question based on the information it receives from the `vectorstore`.
#### Initialize our RAG application
To do this, we initialize a `RetrievalQA` as our app:
```Python Python theme={null}
from langchain.chat_models import ChatOpenAI
from langchain.chains import RetrievalQA
# completion llm
llm = ChatOpenAI(
model_name='gpt-3.5-turbo',
temperature=0.0
)
qa = RetrievalQA.from_chain_type(
llm=llm,
chain_type="stuff",
retriever=vectorstore.as_retriever()
)
```
#### TruLens for evaluation and tracking of LLM experiments
Once we've set up our app, we should put together our [feedback functions](https://truera.com/ai-quality-education/generative-ai-and-llms/whats-missing-to-evaluate-foundation-models-at-scale/). As a reminder, feedback functions are an extensible method for evaluating LLMs. Here we'll set up two feedback functions: `qs_relevance` and `qa_relevance`. They're defined as follows:
*QS Relevance: query-statement relevance is the average of relevance (0 to 1) for each context chunk returned by the semantic search.*
*QA Relevance: question-answer relevance is the relevance (again, 0 to 1) of the final answer to the original question.*
```Python Python theme={null}
# Imports main tools for eval
from trulens_eval import TruChain, Feedback, Tru, feedback, Select
import numpy as np
tru = Tru()
# OpenAI as feedback provider
openai = feedback.OpenAI()
# Question/answer relevance between overall question and answer.
qa_relevance = Feedback(openai.relevance).on_input_output()
# Question/statement relevance between question and each context chunk.
qs_relevance =
Feedback(openai.qs_relevance).
on_input()
# See explanation below
.on(Select.Record.app.combine_documents_chain._call.args.inputs.input_documents[:].page_content)
.aggregate(np.mean)
```
Our use of selectors here also requires an explanation.
QA Relevance is the simpler of the two. Here, we are using `.on_input_output()` to specify that the feedback function should be applied on both the input and output of the application.
For QS Relevance, we use TruLens selectors to locate the context chunks retrieved by our application. Let's break it down into simple parts:
1. Argument Specification – The `on_input` which appears first is a convenient shorthand and states that the first argument to `qs_relevance` (the question) is to be the main input of the app.
2. Argument Specification – The `on(Select...)` line specifies where the statement argument to the implementation comes from. We want to evaluate the context chunks, which are an intermediate step of the LLM app. This form references the langchain app object call chain, which can be viewed from `tru.run_dashboard()`. This flexibility allows you to apply a feedback function to any intermediate step of your LLM app. Below is an example where TruLens displays how to select each piece of the context.
 3. Aggregation specification -- The last line aggregate (`np.mean`) specifies how feedback outputs are to be aggregated. This only applies to cases where the argument specification names more than one value for an input or output.
The result of these lines is that `f_qs_relevance` can be now be run on apps/records and will automatically select the specified components of those apps/records
To finish up, we just wrap our Retrieval QA app with TruLens along with a list of the feedback functions we will use for eval.
```Python Python theme={null}
# wrap with TruLens
truchain = TruChain(qa,
app_id='Chain1_WikipediaQA',
feedbacks=[qa_relevance, qs_relevance])
truchain(“Which state is Washington D.C. in?”)
```
After submitting a number of queries to our application, we can track our experiment and evaluations with the TruLens dashboard.
```Python Python theme={null}
tru.run_dashboard()
```
Here is a view of our first experiment:
3. Aggregation specification -- The last line aggregate (`np.mean`) specifies how feedback outputs are to be aggregated. This only applies to cases where the argument specification names more than one value for an input or output.
The result of these lines is that `f_qs_relevance` can be now be run on apps/records and will automatically select the specified components of those apps/records
To finish up, we just wrap our Retrieval QA app with TruLens along with a list of the feedback functions we will use for eval.
```Python Python theme={null}
# wrap with TruLens
truchain = TruChain(qa,
app_id='Chain1_WikipediaQA',
feedbacks=[qa_relevance, qs_relevance])
truchain(“Which state is Washington D.C. in?”)
```
After submitting a number of queries to our application, we can track our experiment and evaluations with the TruLens dashboard.
```Python Python theme={null}
tru.run_dashboard()
```
Here is a view of our first experiment:
 #### Experiment with distance metrics
Now that we've walked through the process of building our tracked RAG application using cosine as the distance metric, all we have to do for the next two experiments is to rebuild the index with `euclidean` or `dotproduct` as the metric and follow the rest of the steps above as is.
Because we are using OpenAI embeddings, which are normalized to length 1, dot product and cosine distance are equivalent - and Euclidean will also yield the same ranking. See the OpenAI docs for more information. With the same document ranking, we should not expect a difference in response quality, but computation latency may vary across the metrics. Indeed, OpenAI advises that dot product computation may be a bit faster than cosine. We will be able to confirm this expected latency difference with TruLens.
```Python Python theme={null}
index_name_v2 = 'langchain-rag-euclidean'
pinecone.create_index(
name=index_name_v2,
metric='euclidean', # metric='dotproduct',
dimension=1536, # 1536 dim of text-embedding-ada-002
)
```
After doing so, we can view our evaluations for all three LLM apps sitting on top of the different indexes. All three apps are struggling with query-statement relevance. In other words, the context retrieved is only somewhat relevant to the original query.
**We can also see that both the Euclidean and dot-product metrics performed at a lower latency than cosine at roughly the same evaluation quality.**
#### Experiment with distance metrics
Now that we've walked through the process of building our tracked RAG application using cosine as the distance metric, all we have to do for the next two experiments is to rebuild the index with `euclidean` or `dotproduct` as the metric and follow the rest of the steps above as is.
Because we are using OpenAI embeddings, which are normalized to length 1, dot product and cosine distance are equivalent - and Euclidean will also yield the same ranking. See the OpenAI docs for more information. With the same document ranking, we should not expect a difference in response quality, but computation latency may vary across the metrics. Indeed, OpenAI advises that dot product computation may be a bit faster than cosine. We will be able to confirm this expected latency difference with TruLens.
```Python Python theme={null}
index_name_v2 = 'langchain-rag-euclidean'
pinecone.create_index(
name=index_name_v2,
metric='euclidean', # metric='dotproduct',
dimension=1536, # 1536 dim of text-embedding-ada-002
)
```
After doing so, we can view our evaluations for all three LLM apps sitting on top of the different indexes. All three apps are struggling with query-statement relevance. In other words, the context retrieved is only somewhat relevant to the original query.
**We can also see that both the Euclidean and dot-product metrics performed at a lower latency than cosine at roughly the same evaluation quality.**
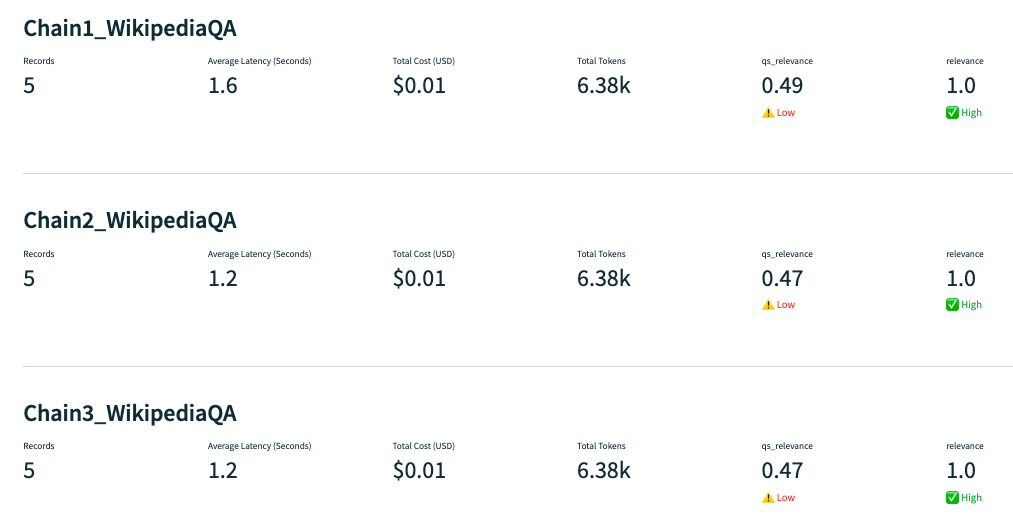 ### Problem: hallucination
Digging deeper into the Query Statement Relevance, we notice one problem in particular with a question about famous dental floss brands. The app responds correctly, but is not backed up by the context retrieved, which does not mention any specific brands.
### Problem: hallucination
Digging deeper into the Query Statement Relevance, we notice one problem in particular with a question about famous dental floss brands. The app responds correctly, but is not backed up by the context retrieved, which does not mention any specific brands.
 #### Quickly evaluate app components with LangChain and TruLens
Using a less powerful model is a common way to reduce hallucination for some applications. We'll evaluate ada-001 in our next experiment for this purpose.
#### Quickly evaluate app components with LangChain and TruLens
Using a less powerful model is a common way to reduce hallucination for some applications. We'll evaluate ada-001 in our next experiment for this purpose.
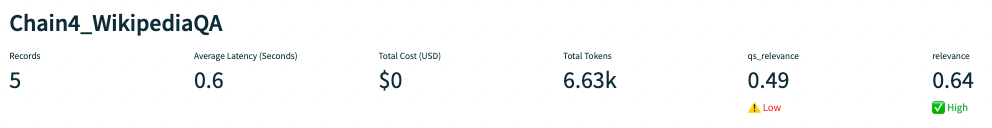 Changing different components of apps built with frameworks like LangChain is really easy. In this case we just need to call `text-ada-001` from the LangChain LLM store. Adding in easy evaluation with TruLens allows us to quickly iterate through different components to find our optimal app configuration.
```Python Python theme={null}
# completion llm
from langchain.llms import OpenAI
llm = OpenAI(
model_name='text-ada-001',
temperature=0
)
from langchain.chains import RetrievalQAWithSourcesChain
qa_with_sources = RetrievalQA.from_chain_type(
llm=llm,
chain_type="stuff",
retriever=vectorstore.as_retriever()
)
# wrap with TruLens
truchain = TruChain(qa_with_sources,
app_id='Chain4_WikipediaQA',
feedbacks=[qa_relevance, qs_relevance])
```
**However, this configuration with a less powerful model struggles to return a relevant answer given the context provided.**
Changing different components of apps built with frameworks like LangChain is really easy. In this case we just need to call `text-ada-001` from the LangChain LLM store. Adding in easy evaluation with TruLens allows us to quickly iterate through different components to find our optimal app configuration.
```Python Python theme={null}
# completion llm
from langchain.llms import OpenAI
llm = OpenAI(
model_name='text-ada-001',
temperature=0
)
from langchain.chains import RetrievalQAWithSourcesChain
qa_with_sources = RetrievalQA.from_chain_type(
llm=llm,
chain_type="stuff",
retriever=vectorstore.as_retriever()
)
# wrap with TruLens
truchain = TruChain(qa_with_sources,
app_id='Chain4_WikipediaQA',
feedbacks=[qa_relevance, qs_relevance])
```
**However, this configuration with a less powerful model struggles to return a relevant answer given the context provided.**
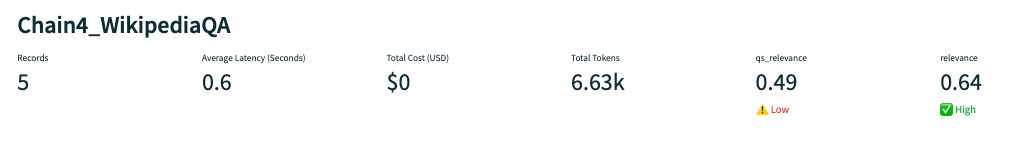 For example, when asked “Which year was Hawaii's state song written?”, the app retrieves context that contains the correct answer but fails to respond with that answer, instead simply responding with the name of the song.
For example, when asked “Which year was Hawaii's state song written?”, the app retrieves context that contains the correct answer but fails to respond with that answer, instead simply responding with the name of the song.
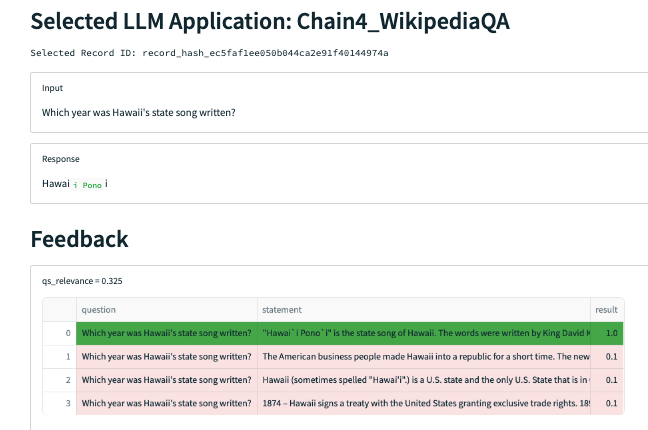 While our relevance function is not doing a great job here in differentiating which context chunks are relevant, we can manually see that only the one (the 4th chunk) mentions the year the song was written. Narrowing our `top_k`, or the number of context chunks retrieved by the semantic search, may help.
We can do so as follows:
```Python Python theme={null}
qa = RetrievalQA.from_chain_type(
llm=llm,
chain_type="stuff",
retriever=vectorstore.as_retriever(top_k = 1)
)
```
The way the `top_k` is implemented in LangChain's RetrievalQA is that the documents are still retrieved by semantic search and only the `top_k` are passed to the LLM. Therefore, TruLens also captures all of the context chunks that are being retrieved. In order to calculate an accurate QS Relevance metric that matches what's being passed to the LLM, we only calculate the relevance of the top context chunk retrieved by slicing the `input_documents` passed into the TruLens Select function:
```Python Python theme={null}
qs_relevance = Feedback(openai.qs_relevance).on_input().on(
Select.Record.app.combine_documents_chain._call.args.inputs.input_documents[:1].page_content
).aggregate(np.mean)
```
Once we've done so, our final application has much improved `qs_relevance`, `qa_relevance` and latency!
While our relevance function is not doing a great job here in differentiating which context chunks are relevant, we can manually see that only the one (the 4th chunk) mentions the year the song was written. Narrowing our `top_k`, or the number of context chunks retrieved by the semantic search, may help.
We can do so as follows:
```Python Python theme={null}
qa = RetrievalQA.from_chain_type(
llm=llm,
chain_type="stuff",
retriever=vectorstore.as_retriever(top_k = 1)
)
```
The way the `top_k` is implemented in LangChain's RetrievalQA is that the documents are still retrieved by semantic search and only the `top_k` are passed to the LLM. Therefore, TruLens also captures all of the context chunks that are being retrieved. In order to calculate an accurate QS Relevance metric that matches what's being passed to the LLM, we only calculate the relevance of the top context chunk retrieved by slicing the `input_documents` passed into the TruLens Select function:
```Python Python theme={null}
qs_relevance = Feedback(openai.qs_relevance).on_input().on(
Select.Record.app.combine_documents_chain._call.args.inputs.input_documents[:1].page_content
).aggregate(np.mean)
```
Once we've done so, our final application has much improved `qs_relevance`, `qa_relevance` and latency!
 With that change, our application is successfully retrieving the one piece of context it needs, and successfully forming an answer from that context.
With that change, our application is successfully retrieving the one piece of context it needs, and successfully forming an answer from that context.
 Even better, the application now knows what it doesn't know:
Even better, the application now knows what it doesn't know:
 ### Summary
In conclusion, we note that exploring the downstream impact of some Pinecone configuration choices on response quality, cost and latency is an important part of the LLM app development process, ensuring that we make the choices that lead to the app performing the best. Overall, TruLens and Pinecone are the perfect combination for building reliable RAG-style applications. Pinecone provides a way to efficiently store and retrieve context used by LLM apps, and TruLens provides a way to track and evaluate each iteration of your application.
---
# Source: https://docs.pinecone.io/integrations/twelve-labs.md
> ## Documentation Index
> Fetch the complete documentation index at: https://docs.pinecone.io/llms.txt
> Use this file to discover all available pages before exploring further.
# Twelve Labs
export const PrimarySecondaryCTA = ({primaryLabel, primaryHref, primaryTarget, secondaryLabel, secondaryHref, secondaryTarget}) =>
### Summary
In conclusion, we note that exploring the downstream impact of some Pinecone configuration choices on response quality, cost and latency is an important part of the LLM app development process, ensuring that we make the choices that lead to the app performing the best. Overall, TruLens and Pinecone are the perfect combination for building reliable RAG-style applications. Pinecone provides a way to efficiently store and retrieve context used by LLM apps, and TruLens provides a way to track and evaluate each iteration of your application.
---
# Source: https://docs.pinecone.io/integrations/twelve-labs.md
> ## Documentation Index
> Fetch the complete documentation index at: https://docs.pinecone.io/llms.txt
> Use this file to discover all available pages before exploring further.
# Twelve Labs
export const PrimarySecondaryCTA = ({primaryLabel, primaryHref, primaryTarget, secondaryLabel, secondaryHref, secondaryTarget}) =>
{primaryLabel && primaryHref &&
}
{secondaryLabel && secondaryHref &&
}
A [dense index](/guides/index-data/indexing-overview#dense-indexes) contains records with one dense vector each.
Dense index records can also contain sparse vectors (when the index metric is set to `dotproduct`), which can be useful for [hybrid search](/guides/search/hybrid-search#use-a-single-hybrid-index). To learn how to calculate the size of a hybrid index, see [Hybrid index](#hybrid-index).
**Calculate dense index size (assuming no sparse vectors)**
```
Index size = Number of records × (
ID size +
Metadata size +
Dense vector dimensions × 4 bytes
)
```
Where:
* `ID size` and `Metadata size` are measured in bytes, averaged across all records.
* Each `Dense vector dimension` uses 4 bytes.
**Example dense index calculations**
These examples assume 8-byte IDs:
| Records | Dense vector dimensions | Avg metadata size | Index size |
| :--------- | :---------------------- | :---------------- | :--------- |
| 500,000 | 768 | 500 bytes | 1.79 GB |
| 1,000,000 | 1536 | 1,000 bytes | 7.15 GB |
| 5,000,000 | 1024 | 15,000 bytes | 95.5 GB |
| 10,000,000 | 1536 | 1,000 bytes | 71.5 GB |
Example: 500,000 records × (8-byte ID + (768 dense vector dimensions × 4 bytes) + 500 bytes of metadata) = 1.79 GB
A [sparse index](/guides/index-data/indexing-overview#sparse-indexes) contains records with one sparse vector each.
**Calculate sparse index size**
```
Index size = Number of records × (
ID size +
Metadata size +
Number of non-zero sparse values × 8 bytes
)
```
Where:
* `ID size` and `Metadata size` are measured in bytes, averaged across all records.
* `Number of non-zero sparse values`: Average number across all records. To find the count for a single record, check the length of the sparse vector's `indices` or `values` array. Each non-zero value uses 8 bytes.
**Example sparse index calculations**
These examples assume 8-byte IDs:
| Records | Avg number of non-zero sparse values | Avg metadata size | Index size |
| :--------- | :----------------------------------- | :---------------- | :--------- |
| 500,000 | 10 | 500 bytes | 0.29 GB |
| 1,000,000 | 50 | 1,000 bytes | 1.41 GB |
| 5,000,000 | 100 | 15,000 bytes | 79.0 GB |
| 10,000,000 | 50 | 1,000 bytes | 14.1 GB |
Example: 500,000 records × (8-byte ID + (10 non-zero sparse values × 8 bytes) + 500 bytes of metadata) = 0.29 GB
A [hybrid index](/guides/search/hybrid-search#use-a-single-hybrid-index) contains records that each have one dense vector and an optional sparse vector.
**Calculate hybrid index size**
```
Index size = Number of records × (
ID size +
Metadata size +
Dense vector dimensions × 4 bytes +
Number of non-zero sparse values × 8 bytes
)
```
Where:
* `ID size` and `Metadata size` are measured in bytes, averaged across all records.
* Each `Dense vector dimension` uses 4 bytes.
* `Number of non-zero sparse values`: Average number across all records, including those without sparse vectors. To find the count for a single record, check the length of the sparse vector's `indices` or `values` array. Each non-zero value uses 8 bytes.
**Example hybrid index calculations**
These examples assume 8-byte IDs:
| Records | Dense vector dimensions | Avg number of non-zero sparse values | Avg metadata size | Index size |
| :--------- | :---------------------- | :----------------------------------- | :---------------- | :--------- |
| 500,000 | 768 | 10 | 500 bytes | 1.83 GB |
| 1,000,000 | 1536 | 50 | 1,000 bytes | 7.54 GB |
| 5,000,000 | 1024 | 100 | 15,000 bytes | 99.5 GB |
| 10,000,000 | 1536 | 50 | 1,000 bytes | 75.4 GB |
Example: 500,000 records × (8-byte ID + (768 dense vector dimensions × 4 bytes) + (10 non-zero sparse values × 8 bytes) + 500 bytes of metadata) = 1.83 GB
## Imports
[Importing from object storage](/guides/index-data/import-data) is the most efficient and cost-effective method to load large numbers of records into an index. The cost of an import is based on the size of the records read, whether the records were imported successfully or not.
If the import operation fails (e.g., after encountering a vector of the wrong dimension in an import with `on_error="abort"`), you will still be charged for the records read. However, if the import fails because of an internal system error, you will not incur charges. In this case, the import will return the error message `"We were unable to process your request. If the problem persists, please contact us at https://support.pinecone.io"`.
For the latest import pricing rates, see [Pricing](https://www.pinecone.io/pricing/).
## Backups and restores
A [backup](/guides/manage-data/backups-overview) is a static copy of a serverless index. Both the cost of storing a backup and [restoring an index](/guides/manage-data/restore-an-index) from a backup is based on the size of the index. For the latest backup and restore pricing rates, see [Pricing](https://www.pinecone.io/pricing/).
## Embedding
Pinecone hosts several [embedding models](/guides/index-data/create-an-index#embedding-models) so it's easy to manage your vector storage and search process on a single platform. You can use a hosted model to embed your data as an integrated part of upserting and querying, or you can use a hosted model to embed your data as a standalone operation.
Embedding costs are determined by how many [tokens](https://www.pinecone.io/learn/tokenization/) are in a request. In general, the more words contained in your passage or query, the more tokens you generate.
For example, if you generate embeddings for the query, "What is the maximum diameter of a red pine?", Pinecone Inference generates 10 tokens, then converts them into an embedding. If the price per token for your billing plan is \$.08 per million tokens, then this API call costs \$.00001.
To learn more about tokenization, see [Choosing an embedding model](https://www.pinecone.io/learn/series/rag/embedding-models-rundown/). For the latest embed pricing rates, see [Pricing](https://www.pinecone.io/pricing/).
Embedding requests returns the total tokens generated. You can use this information to [monitor and manage embedding costs](/guides/manage-cost/monitor-usage-and-costs#embedding-tokens).
## Reranking
Pinecone hosts several [reranking models](/guides/search/rerank-results#reranking-models) so it's easy to manage two-stage vector retrieval on a single platform. You can use a hosted model to rerank results as an integrated part of a query, or you can use a hosted model to rerank results as a standalone operation.
Reranking costs are determined by the number of requests to the reranking model. For the latest rerank pricing rates, see [Pricing](https://www.pinecone.io/pricing/).
## Assistant
For details on how costs are incurred in Pinecone Assistant, see [Assistant pricing](/guides/assistant/pricing-and-limits).
## See also
* [Manage cost](/guides/manage-cost/manage-cost)
* [Monitor usage](/guides/manage-cost/monitor-usage-and-costs)
* [Pricing](https://www.pinecone.io/pricing/)
---
# Source: https://docs.pinecone.io/guides/organizations/understanding-organizations.md
> ## Documentation Index
> Fetch the complete documentation index at: https://docs.pinecone.io/llms.txt
> Use this file to discover all available pages before exploring further.
# Understanding organizations
> Understand organization structure, projects, and billing.
A Pinecone organization is a set of [projects](/guides/projects/understanding-projects) that use the same billing. Organizations allow one or more users to control billing and project permissions for all of the projects belonging to the organization. Each project belongs to an organization.
While an email address can be associated with multiple organizations, it cannot be used to create more than one organization. For information about managing organization members, see [Manage organization members](/guides/organizations/manage-organization-members).
## Projects in an organization
Each organization contains one or more projects that share the same organization owners and billing settings. Each project belongs to exactly one organization. If you need to move a project from one organization to another, [contact Support](https://app.pinecone.io/organizations/-/settings/support/ticket).
## Billing settings
All of the projects in an organization share the same billing method and settings. The billing settings for the organization are controlled by the organization owners.
Organization owners can update the billing contact information, update the payment method, and view and download invoices using the [Pinecone console](https://app.pinecone.io/organizations/-/settings/billing).
## Organization roles
Organization owners can manage access to their organizations and projects by assigning roles to organization members and service accounts. The role determines the entity's permissions within Pinecone. The organization roles are as follows:
* **Organization owner**: Organization owners have global permissions across the organization. This includes managing billing details, organization members, and all projects. Organization owners are automatically [project owners](/guides/projects/understanding-projects#project-roles) and, therefore, have all project owner permissions as well.
* **Organization user**: Organization users have restricted organization-level permissions. When inviting organization users, you also choose the projects they belong to and the project role they should have.
* **Billing admin**: Billing admins have permissions to view and update billing details, but they cannot manage organization members. Billing admins cannot manage projects unless they are also [project owners](/guides/projects/understanding-projects#project-roles).
The following table summarizes the permissions for each organization role:
| Permission | Org Owner | Org User | Billing Admin |
| ------------------------------------ | --------- | -------- | ------------- |
| View account details | ✓ | ✓ | ✓ |
| Update organization name | ✓ | | |
| Delete the organization | ✓ | | |
| View billing details | ✓ | | ✓ |
| Update billing details | ✓ | | ✓ |
| View usage details | ✓ | | ✓ |
| View support plans | ✓ | | ✓ |
| Invite members to the organization | ✓ | | |
| Delete pending member invites | ✓ | | |
| Remove members from the organization | ✓ | | |
| Update organization member roles | ✓ | | |
| Create projects | ✓ | ✓ | |
## Organization single sign-on (SSO)
SSO allows organizations to manage their teams' access to Pinecone through their identity management solution. Once your integration is configured, you can specify a default role for teammates when they sign up.
For more information, see [Configure single sign-on](/guides/production/configure-single-sign-on/okta).
SSO is available on Standard and Enterprise plans.
## Service accounts
This feature is in [public preview](/release-notes/feature-availability) and available only on [Enterprise plans](https://www.pinecone.io/pricing/).
[Service accounts](/guides/organizations/manage-service-accounts) enable programmatic access to Pinecone's Admin API, which can be used to create and manage projects and API keys.
Use service accounts to automate infrastructure management and integrate Pinecone into your deployment workflows, rather than through manual actions in the Pinecone console. Service accounts use the [organization roles](/guides/organizations/understanding-organizations#organization-roles) and [project role](/guides/projects/understanding-projects#project-roles) for permissioning, and provide a secure and auditable way to handle programmatic access.
## See also
* [Manage organization members](/guides/organizations/manage-organization-members)
* [Manage project members](/guides/projects/manage-project-members)
---
# Source: https://docs.pinecone.io/guides/indexes/pods/understanding-pod-based-indexes.md
> ## Documentation Index
> Fetch the complete documentation index at: https://docs.pinecone.io/llms.txt
> Use this file to discover all available pages before exploring further.
# Understanding pod-based indexes
> Learn about pod-based index architecture and types
Customers who sign up for a Standard or Enterprise plan on or after August 18, 2025 cannot create pod-based indexes. Instead, create [serverless indexes](/guides/index-data/create-an-index), and consider using [dedicated read nodes](/guides/index-data/dedicated-read-nodes) for large workloads (millions of records or more, and moderate or high query rates).
With pod-based indexes, you choose one or more pre-configured units of hardware (pods). Depending on the pod type, pod size, and number of pods used, you get different amounts of storage and higher or lower latency and throughput. Be sure to [choose an appropriate pod type and size](/guides/indexes/pods/choose-a-pod-type-and-size) for your dataset and workload.
## Pod types
Different pod types are priced differently. See [Understanding cost](/guides/manage-cost/understanding-cost) for more details.
Once a pod-based index is created, you cannot change its pod type. However, you can create a collection from an index and then [create a new index with a different pod type](/guides/indexes/pods/create-a-pod-based-index#create-a-pod-index-from-a-collection) from the collection.
### s1 pods
These storage-optimized pods provide large storage capacity and lower overall costs with slightly higher query latencies than p1 pods. They are ideal for very large indexes with moderate or relaxed latency requirements.
Each s1 pod has enough capacity for around 5M vectors of 768 dimensions.
### p1 pods
These performance-optimized pods provide very low query latencies, but hold fewer vectors per pod than s1 pods. They are ideal for applications with low latency requirements (\<100ms).
Each p1 pod has enough capacity for around 1M vectors of 768 dimensions.
### p2 pods
The p2 pod type provides greater query throughput with lower latency. For vectors with fewer than 128 dimension and queries where `topK` is less than 50, p2 pods support up to 200 QPS per replica and return queries in less than 10ms. This means that query throughput and latency are better than s1 and p1.
Each p2 pod has enough capacity for around 1M vectors of 768 dimensions. However, capacity may vary with dimensionality.
The data ingestion rate for p2 pods is significantly slower than for p1 pods; this rate decreases as the number of dimensions increases. For example, a p2 pod containing vectors with 128 dimensions can upsert up to 300 updates per second; a p2 pod containing vectors with 768 dimensions or more supports upsert of 50 updates per second. Because query latency and throughput for p2 pods vary from p1 pods, test p2 pod performance with your dataset.
The p2 pod type does not support sparse vector values.
## Pod size and performance
Each pod type supports four pod sizes: `x1`, `x2`, `x4`, and `x8`. Your index storage and compute capacity doubles for each size step. The default pod size is `x1`. You can increase the size of a pod after index creation.
To learn about changing the pod size of an index, see [Configure an index](/guides/indexes/pods/scale-pod-based-indexes#increase-pod-size).
## Pod environments
When creating a pod-based index, you must choose the cloud environment where you want the index to be hosted. The project environment can affect your [pricing](https://pinecone.io/pricing). The following table lists the available cloud regions and the corresponding values of the `environment` parameter for the [`create_index`](/guides/index-data/create-an-index#create-a-pod-based-index) endpoint:
| Cloud | Region | Environment |
| ----- | ---------------------------- | ----------------------------- |
| GCP | us-west-1 (N. California) | `us-west1-gcp` |
| GCP | us-central-1 (Iowa) | `us-central1-gcp` |
| GCP | us-west-4 (Las Vegas) | `us-west4-gcp` |
| GCP | us-east-4 (Virginia) | `us-east4-gcp` |
| GCP | northamerica-northeast-1 | `northamerica-northeast1-gcp` |
| GCP | asia-northeast-1 (Japan) | `asia-northeast1-gcp` |
| GCP | asia-southeast-1 (Singapore) | `asia-southeast1-gcp` |
| GCP | us-east-1 (South Carolina) | `us-east1-gcp` |
| GCP | eu-west-1 (Belgium) | `eu-west1-gcp` |
| GCP | eu-west-4 (Netherlands) | `eu-west4-gcp` |
| AWS | us-east-1 (Virginia) | `us-east-1-aws` |
| Azure | eastus (Virginia) | `eastus-azure` |
[Contact us](http://www.pinecone.io/contact/) if you need a dedicated deployment in other regions.
The environment cannot be changed after the index is created.
## Pod costs
For each pod-based index, billing is determined by the per-minute price per pod and the number of pods the index uses, regardless of index activity. The per-minute price varies by pod type, pod size, account plan, and cloud region. For the latest pod-based index pricing rates, see [Pricing](https://www.pinecone.io/pricing/pods).
Total cost depends on a combination of factors:
* **Pod type.** Each pod type has different per-minute pricing.
* **Number of pods.** This includes replicas, which duplicate pods.
* **Pod size.** Larger pod sizes have proportionally higher costs per minute.
* **Total pod-minutes.** This includes the total time each pod is running, starting at pod creation and rounded up to 15-minute increments.
* **Cloud provider.** The cost per pod-type and pod-minute varies depending on the cloud provider you choose for your project.
* **Collection storage.** Collections incur costs per GB of data per minute in storage, rounded up to 15-minute increments.
* **Plan.** The free plan incurs no costs; the Standard or Enterprise plans incur different costs per pod-type, pod-minute, cloud provider, and collection storage.
The following equation calculates the total costs accrued over time:
```
(Number of pods) * (pod size) * (number of replicas) * (minutes pod exists) * (pod price per minute)
+ (collection storage in GB) * (collection storage time in minutes) * (collection storage price per GB per minute)
```
To see a calculation of your current usage and costs, go to [**Settings > Usage**](https://app.pinecone.io/organizations/-/settings/usage) in the Pinecone console.
While our pricing page lists rates on an hourly basis for ease of comparison, this example lists prices per minute, as this is how Pinecone calculates billing.
An example application has the following requirements:
* 1,000,000 vectors with 1536 dimensions
* 150 queries per second with `top_k` = 10
* Deployment in an EU region
* Ability to store 1GB of inactive vectors
[Based on these requirements](/guides/indexes/pods/choose-a-pod-type-and-size), the organization chooses to configure the project to use the Standard billing plan to host one `p1.x2` pod with three replicas and a collection containing 1 GB of data. This project runs continuously for the month of January on the Standard plan. The components of the total cost for this example are given in Table 1 below:
**Table 1: Example billing components**
| Billing component | Value |
| ----------------------------- | ------------ |
| Number of pods | 1 |
| Number of replicas | 3 |
| Pod size | x2 |
| Total pod count | 6 |
| Minutes in January | 44,640 |
| Pod-minutes (pods \* minutes) | 267,840 |
| Pod price per minute | \$0.0012 |
| Collection storage | 1 GB |
| Collection storage minutes | 44,640 |
| Price per storage minute | \$0.00000056 |
The invoice for this example is given in Table 2 below:
**Table 2: Example invoice**
| Product | Quantity | Price per unit | Charge |
| ------------- | -------- | -------------- | -------- |
| Collections | 44,640 | \$0.00000056 | \$0.025 |
| P2 Pods (AWS) | 0 | | \$0.00 |
| P2 Pods (GCP) | 0 | | \$0.00 |
| S1 Pods | 0 | | \$0.00 |
| P1 Pods | 267,840 | \$0.0012 | \$514.29 |
Amount due \$514.54
## Known limitations
* [Pod storage capacity](#pod-types)
* Each **p1** pod has enough capacity for 1M vectors with 768 dimensions.
* Each **s1** pod has enough capacity for 5M vectors with 768 dimensions.
* [Metadata](/guides/index-data/indexing-overview#metadata)
* Metadata with high cardinality, such as a unique value for every vector in a large index, uses more memory than expected and can cause the pods to become full.
* [Collections](/guides/manage-data/back-up-an-index#pod-based-index-backups-using-collections)
* You cannot query or write to a collection after its creation. For this reason, a collection only incurs storage costs.
* You can only perform operations on collections in the current Pinecone project.
* [Sparse-dense vectors](/guides/search/hybrid-search#use-a-single-hybrid-index)
* Only `s1` and `p1` [pod-based indexes](/guides/indexes/pods/understanding-pod-based-indexes#pod-types) using the dotproduct distance metric support sparse-dense vectors.
---
# Source: https://docs.pinecone.io/guides/projects/understanding-projects.md
> ## Documentation Index
> Fetch the complete documentation index at: https://docs.pinecone.io/llms.txt
> Use this file to discover all available pages before exploring further.
# Understanding projects
> Learn about projects, environments, and member roles.
A Pinecone project belongs to an [organization](/guides/organizations/understanding-organizations) and contains a number of [indexes](/guides/index-data/indexing-overview) and users. Only a user who belongs to the project can access the indexes in that project. Each project also has at least one project owner.
## Project environments
You choose a cloud environment for each index in a project. This makes it easy to manage related resources across environments and use the same API key to access them.
## Project roles
If you are an [organization owner](/guides/organizations/understanding-organizations#organization-roles) or project owner, you can manage members in your project. Project members are assigned a role, which determines their permissions within the project. The project roles are as follows:
* **Project owner**: Project owners have global permissions across projects they own.
* **Project user**: Project users have restricted permissions for the specific projects they are invited to.
The following table summarizes the permissions for each project role:
| Permission | Owner | User |
| :-------------------------- | ----- | ---- |
| Update project names | ✓ | |
| Delete projects | ✓ | |
| View project members | ✓ | ✓ |
| Update project member roles | ✓ | |
| Delete project members | ✓ | |
| View API keys | ✓ | ✓ |
| Create API keys | ✓ | |
| Delete API keys | ✓ | |
| View indexes | ✓ | ✓ |
| Create indexes | ✓ | ✓ |
| Delete indexes | ✓ | ✓ |
| Upsert vectors | ✓ | ✓ |
| Query vectors | ✓ | ✓ |
| Fetch vectors | ✓ | ✓ |
| Update a vector | ✓ | ✓ |
| Delete a vector | ✓ | ✓ |
| List vector IDs | ✓ | ✓ |
| Get index stats | ✓ | ✓ |
Specific to pod-based indexes:
Customers who sign up for a Standard or Enterprise plan on or after August 18, 2025 cannot create pod-based indexes. Instead, create [serverless indexes](/guides/index-data/create-an-index), and consider using [dedicated read nodes](/guides/index-data/dedicated-read-nodes) for large workloads (millions of records or more, and moderate or high query rates).
| Permission | Owner | User |
| :------------------------ | ----- | ---- |
| Update project pod limits | ✓ | |
| View project pod limits | ✓ | ✓ |
| Update index size | ✓ | ✓ |
## API keys
Each Pinecone [project](/guides/projects/understanding-projects) has one or more API keys. In order to [make calls to the Pinecone API](/guides/get-started/quickstart), you must provide a valid API key for the relevant Pinecone project.
For more information, see [Manage API keys](/guides/projects/manage-api-keys).
## Project IDs
Each Pinecone project has a unique product ID.
To find the ID of a project, go to the project list in the [Pinecone console](https://app.pinecone.io/organizations/-/projects).
## See also
* [Understanding organizations](guides/organizations/understanding-organizations)
* [Manage organization members](guides/organizations/manage-organization-members)
---
# Source: https://docs.pinecone.io/integrations/unstructured.md
> ## Documentation Index
> Fetch the complete documentation index at: https://docs.pinecone.io/llms.txt
> Use this file to discover all available pages before exploring further.
# Unstructured
export const PrimarySecondaryCTA = ({primaryLabel, primaryHref, primaryTarget, secondaryLabel, secondaryHref, secondaryTarget}) =>
{primaryLabel && primaryHref &&
}
{secondaryLabel && secondaryHref &&
}
96 records with text |
| Max metadata size per record | 40 KB |
| Max length for a record ID | 512 characters |
| Max dimensionality for dense vectors | 20,000 |
| Max non-zero values for sparse vectors | 2048 |
| Max dimensionality for sparse vectors | 4.2 billion |
---
# Source: https://docs.pinecone.io/reference/api/2025-10/data-plane/upsert.md
> ## Documentation Index
> Fetch the complete documentation index at: https://docs.pinecone.io/llms.txt
> Use this file to discover all available pages before exploring further.
# Upsert vectors
> Upsert vectors into a namespace. If a new value is upserted for an existing vector ID, it will overwrite the previous value.
For guidance, examples, and limits, see [Upsert data](https://docs.pinecone.io/guides/index-data/upsert-data).
To control costs when ingesting large datasets (10,000,000+ records), use [import](/guides/index-data/import-data) instead of upsert.
```shell curl theme={null}
# To get the unique host for an index,
# see https://docs.pinecone.io/guides/manage-data/target-an-index
PINECONE_API_KEY="YOUR_API_KEY"
INDEX_HOST="INDEX_HOST"
curl "https://$INDEX_HOST/vectors/upsert" \
-H "Api-Key: $PINECONE_API_KEY" \
-H 'Content-Type: application/json' \
-H "X-Pinecone-Api-Version: 2025-10" \
-d '{
"vectors": [
{
"id": "vec1",
"values": [0.1, 0.1, 0.1, 0.1, 0.1, 0.1, 0.1, 0.1],
"metadata": {"genre": "comedy", "year": 2020}
},
{
"id": "vec2",
"values": [0.2, 0.2, 0.2, 0.2, 0.2, 0.2, 0.2, 0.2],
"metadata": {"genre": "documentary", "year": 2019}
}
],
"namespace": "example-namespace"
}'
```
```
```
## OpenAPI
````yaml https://raw.githubusercontent.com/pinecone-io/pinecone-api/refs/heads/main/2025-10/db_data_2025-10.oas.yaml post /vectors/upsert
openapi: 3.0.3
info:
title: Pinecone Data Plane API
description: >-
Pinecone is a vector database that makes it easy to search and retrieve
billions of high-dimensional vectors.
contact:
name: Pinecone Support
url: https://support.pinecone.io
email: support@pinecone.io
license:
name: Apache 2.0
url: https://www.apache.org/licenses/LICENSE-2.0
version: 2025-10
servers:
- url: https://{index_host}
variables:
index_host:
default: unknown
description: host of the index
security:
- ApiKeyAuth: []
tags:
- name: Vector Operations
- name: Bulk Operations
- name: Namespace Operations
externalDocs:
description: More Pinecone.io API docs
url: https://docs.pinecone.io/introduction
paths:
/vectors/upsert:
post:
tags:
- Vector Operations
summary: Upsert vectors
description: >-
Upsert vectors into a namespace. If a new value is upserted for an
existing vector ID, it will overwrite the previous value.
For guidance, examples, and limits, see [Upsert
data](https://docs.pinecone.io/guides/index-data/upsert-data).
operationId: upsertVectors
parameters:
- in: header
name: X-Pinecone-Api-Version
description: Required date-based version header
required: true
schema:
default: 2025-10
type: string
style: simple
requestBody:
content:
application/json:
schema:
$ref: '#/components/schemas/UpsertRequest'
required: true
responses:
'200':
description: A successful response.
content:
application/json:
schema:
$ref: '#/components/schemas/UpsertResponse'
'400':
description: Bad request. The request body included invalid request parameters.
content:
application/json:
schema:
$ref: '#/components/schemas/rpcStatus'
4XX:
description: An unexpected error response.
content:
application/json:
schema:
$ref: '#/components/schemas/rpcStatus'
5XX:
description: An unexpected error response.
content:
application/json:
schema:
$ref: '#/components/schemas/rpcStatus'
components:
schemas:
UpsertRequest:
description: The request for the `upsert` operation.
type: object
properties:
vectors:
description: >-
An array containing the vectors to upsert. Recommended batch limit
is up to 1000 vectors.
type: array
items:
$ref: '#/components/schemas/Vector'
minLength: 1
maxLength: 1000
namespace:
example: example-namespace
description: The namespace where you upsert vectors.
type: string
required:
- vectors
UpsertResponse:
description: The response for the `upsert` operation.
type: object
properties:
upsertedCount:
example: 2
description: The number of vectors upserted.
type: integer
format: int64
rpcStatus:
type: object
properties:
code:
type: integer
format: int32
message:
type: string
details:
type: array
items:
$ref: '#/components/schemas/protobufAny'
Vector:
type: object
properties:
id:
example: example-vector-1
description: This is the vector's unique id.
type: string
required:
- id
minLength: 1
maxLength: 512
values:
example:
- 0.1
- 0.2
- 0.3
- 0.4
- 0.5
- 0.6
- 0.7
- 0.8
description: This is the vector data included in the request.
type: array
required:
- values
items:
type: number
format: float
minLength: 1
maxLength: 20000
sparseValues:
$ref: '#/components/schemas/SparseValues'
metadata:
example:
genre: documentary
year: 2019
description: This is the metadata included in the request.
type: object
required:
- id
protobufAny:
type: object
properties:
typeUrl:
type: string
value:
type: string
format: byte
SparseValues:
description: >-
Vector sparse data. Represented as a list of indices and a list of
corresponded values, which must be with the same length.
type: object
properties:
indices:
example:
- 1
- 312
- 822
- 14
- 980
description: The indices of the sparse data.
type: array
required:
- indices
items:
type: integer
format: int64
minLength: 1
maxLength: 1000
values:
example:
- 0.1
- 0.2
- 0.3
- 0.4
- 0.5
description: >-
The corresponding values of the sparse data, which must be with the
same length as the indices.
type: array
required:
- values
items:
type: number
format: float
minLength: 1
maxLength: 1000
required:
- indices
- values
securitySchemes:
ApiKeyAuth:
type: apiKey
in: header
name: Api-Key
description: >-
An API Key is required to call Pinecone APIs. Get yours from the
[console](https://app.pinecone.io/).
````
---
# Source: https://docs.pinecone.io/reference/api/2025-10/data-plane/upsert_records.md
> ## Documentation Index
> Fetch the complete documentation index at: https://docs.pinecone.io/llms.txt
> Use this file to discover all available pages before exploring further.
# Upsert text
> Upsert text into a namespace. Pinecone converts the text to vectors automatically using the hosted embedding model associated with the index.
Upserting text is supported only for [indexes with integrated embedding](https://docs.pinecone.io/reference/api/2025-01/control-plane/create_for_model).
For guidance, examples, and limits, see [Upsert data](https://docs.pinecone.io/guides/index-data/upsert-data).
```shell curl theme={null}
# To get the unique host for an index,
# see https://docs.pinecone.io/guides/manage-data/target-an-index
INDEX_HOST="INDEX_HOST"
NAMESPACE="YOUR_NAMESPACE"
PINECONE_API_KEY="YOUR_API_KEY"
# Upsert records into a namespace
# `chunk_text` fields are converted to dense vectors
# `category` fields are stored as metadata
curl "https://$INDEX_HOST/records/namespaces/$NAMESPACE/upsert" \
-H "Content-Type: application/x-ndjson" \
-H "Api-Key: $PINECONE_API_KEY" \
-H "X-Pinecone-Api-Version: 2025-10" \
-d '{"_id": "rec1", "chunk_text": "Apples are a great source of dietary fiber, which supports digestion and helps maintain a healthy gut.", "category": "digestive system"}
{"_id": "rec2", "chunk_text": "Apples originated in Central Asia and have been cultivated for thousands of years, with over 7,500 varieties available today.", "category": "cultivation"}
{"_id": "rec3", "chunk_text": "Rich in vitamin C and other antioxidants, apples contribute to immune health and may reduce the risk of chronic diseases.", "category": "immune system"}
{"_id": "rec4", "chunk_text": "The high fiber content in apples can also help regulate blood sugar levels, making them a favorable snack for people with diabetes.", "category": "endocrine system"}'
```
## OpenAPI
````yaml https://raw.githubusercontent.com/pinecone-io/pinecone-api/refs/heads/main/2025-10/db_data_2025-10.oas.yaml post /records/namespaces/{namespace}/upsert
openapi: 3.0.3
info:
title: Pinecone Data Plane API
description: >-
Pinecone is a vector database that makes it easy to search and retrieve
billions of high-dimensional vectors.
contact:
name: Pinecone Support
url: https://support.pinecone.io
email: support@pinecone.io
license:
name: Apache 2.0
url: https://www.apache.org/licenses/LICENSE-2.0
version: 2025-10
servers:
- url: https://{index_host}
variables:
index_host:
default: unknown
description: host of the index
security:
- ApiKeyAuth: []
tags:
- name: Vector Operations
- name: Bulk Operations
- name: Namespace Operations
externalDocs:
description: More Pinecone.io API docs
url: https://docs.pinecone.io/introduction
paths:
/records/namespaces/{namespace}/upsert:
post:
tags:
- Vector Operations
summary: Upsert text
description: >-
Upsert text into a namespace. Pinecone converts the text to vectors
automatically using the hosted embedding model associated with the
index.
Upserting text is supported only for [indexes with integrated
embedding](https://docs.pinecone.io/reference/api/2025-01/control-plane/create_for_model).
For guidance, examples, and limits, see [Upsert
data](https://docs.pinecone.io/guides/index-data/upsert-data).
operationId: upsertRecordsNamespace
parameters:
- in: header
name: X-Pinecone-Api-Version
description: Required date-based version header
required: true
schema:
default: 2025-10
type: string
style: simple
- in: path
name: namespace
description: The namespace to upsert records into.
required: true
schema:
type: string
style: simple
requestBody:
description: >
Each record in the request body must include an `_id` field and a
field that matches your index's `field_map` configuration (such as
`chunk_text` or `data`). All other fields are stored as metadata.
content:
application/x-ndjson:
schema:
type: array
items:
$ref: '#/components/schemas/UpsertRecord'
required: true
responses:
'201':
description: A successful response.
'400':
description: Bad request. The request body included invalid request parameters.
content:
application/json:
schema:
$ref: '#/components/schemas/rpcStatus'
4XX:
description: An unexpected error response.
content:
application/json:
schema:
$ref: '#/components/schemas/rpcStatus'
5XX:
description: An unexpected error response.
content:
application/json:
schema:
$ref: '#/components/schemas/rpcStatus'
components:
schemas:
UpsertRecord:
example:
_id: example-record-1
description: The request for the `upsert` operation.
type: object
properties:
_id:
description: >-
The unique ID of the record to upsert. Note that `id` can be used as
an alias for `_id`.
type: string
required:
- _id
rpcStatus:
type: object
properties:
code:
type: integer
format: int32
message:
type: string
details:
type: array
items:
$ref: '#/components/schemas/protobufAny'
protobufAny:
type: object
properties:
typeUrl:
type: string
value:
type: string
format: byte
securitySchemes:
ApiKeyAuth:
type: apiKey
in: header
name: Api-Key
description: >-
An API Key is required to call Pinecone APIs. Get yours from the
[console](https://app.pinecone.io/).
````
---
# Source: https://docs.pinecone.io/integrations/vercel.md
> ## Documentation Index
> Fetch the complete documentation index at: https://docs.pinecone.io/llms.txt
> Use this file to discover all available pages before exploring further.
# Vercel
export const PrimarySecondaryCTA = ({primaryLabel, primaryHref, primaryTarget, secondaryLabel, secondaryHref, secondaryTarget}) =>
{primaryLabel && primaryHref &&
}
{secondaryLabel && secondaryHref &&
}
 ## Specify an API version
When using the API directly, it is important to specify an API version in your requests. If you don't, requests default to the oldest supported stable version. Once support for that version ends, your requests will default to the next oldest stable version, which could include breaking changes that require you to update your integration.
To specify an API version, set the `X-Pinecone-Api-Version` header to the version name.
For example, based on the version support diagram above, if it is currently October 2025 and you want to use the latest stable version to describe an index, you would set `"X-Pinecone-Api-Version: 2025-10"`:
```shell curl theme={null}
PINECONE_API_KEY="YOUR_API_KEY"
curl -i -X GET "https://api.pinecone.io/indexes/movie-recommendations" \
-H "Api-Key: $PINECONE_API_KEY" \
-H "X-Pinecone-Api-Version: 2025-10"
```
To use an older version, specify that version instead.
## SDK versions
Official [Pinecone SDKs](/reference/pinecone-sdks) provide convenient access to Pinecone APIs. SDK versions are pinned to specific API versions. When a new API version is released, a new version of the SDK is also released.
For the mapping between SDK and API versions, see [SDK versions](/reference/pinecone-sdks#sdk-versions).
## Breaking changes
Breaking changes are changes that can potentially break your integration with a Pinecone API. Breaking changes include:
* Removing an entire operation
* Removing or renaming a parameter
* Removing or renaming a response field
* Adding a new required parameter
* Making a previously optional parameter required
* Changing the type of a parameter or response field
* Removing enum values
* Adding a new validation rule to an existing parameter
* Changing authentication or authorization requirements
## Non-breaking changes
Non-breaking changes are additive and should not break your integration. Additive changes include:
* Adding an operation
* Adding an optional parameter
* Adding an optional request header
* Adding a response field
* Adding a response header
* Adding enum values
## Get updates
To ensure you always know about upcoming API changes, follow the [Release notes](/release-notes/).
---
# Source: https://docs.pinecone.io/integrations/voltagent.md
> ## Documentation Index
> Fetch the complete documentation index at: https://docs.pinecone.io/llms.txt
> Use this file to discover all available pages before exploring further.
# VoltAgent
export const PrimarySecondaryCTA = ({primaryLabel, primaryHref, primaryTarget, secondaryLabel, secondaryHref, secondaryTarget}) =>
## Specify an API version
When using the API directly, it is important to specify an API version in your requests. If you don't, requests default to the oldest supported stable version. Once support for that version ends, your requests will default to the next oldest stable version, which could include breaking changes that require you to update your integration.
To specify an API version, set the `X-Pinecone-Api-Version` header to the version name.
For example, based on the version support diagram above, if it is currently October 2025 and you want to use the latest stable version to describe an index, you would set `"X-Pinecone-Api-Version: 2025-10"`:
```shell curl theme={null}
PINECONE_API_KEY="YOUR_API_KEY"
curl -i -X GET "https://api.pinecone.io/indexes/movie-recommendations" \
-H "Api-Key: $PINECONE_API_KEY" \
-H "X-Pinecone-Api-Version: 2025-10"
```
To use an older version, specify that version instead.
## SDK versions
Official [Pinecone SDKs](/reference/pinecone-sdks) provide convenient access to Pinecone APIs. SDK versions are pinned to specific API versions. When a new API version is released, a new version of the SDK is also released.
For the mapping between SDK and API versions, see [SDK versions](/reference/pinecone-sdks#sdk-versions).
## Breaking changes
Breaking changes are changes that can potentially break your integration with a Pinecone API. Breaking changes include:
* Removing an entire operation
* Removing or renaming a parameter
* Removing or renaming a response field
* Adding a new required parameter
* Making a previously optional parameter required
* Changing the type of a parameter or response field
* Removing enum values
* Adding a new validation rule to an existing parameter
* Changing authentication or authorization requirements
## Non-breaking changes
Non-breaking changes are additive and should not break your integration. Additive changes include:
* Adding an operation
* Adding an optional parameter
* Adding an optional request header
* Adding a response field
* Adding a response header
* Adding enum values
## Get updates
To ensure you always know about upcoming API changes, follow the [Release notes](/release-notes/).
---
# Source: https://docs.pinecone.io/integrations/voltagent.md
> ## Documentation Index
> Fetch the complete documentation index at: https://docs.pinecone.io/llms.txt
> Use this file to discover all available pages before exploring further.
# VoltAgent
export const PrimarySecondaryCTA = ({primaryLabel, primaryHref, primaryTarget, secondaryLabel, secondaryHref, secondaryTarget}) =>
{primaryLabel && primaryHref &&
}
{secondaryLabel && secondaryHref &&
}
{primaryLabel && primaryHref &&
}
{secondaryLabel && secondaryHref &&
}
{primaryLabel && primaryHref &&
}
{secondaryLabel && secondaryHref &&
}
 ### Launch week: Pinecone Local
Pinecone now offers Pinecone Local, an in-memory database emulator available as a Docker image. You can use Pinecone Local to [develop your applications locally](/guides/operations/local-development), or to [test your applications in CI/CD](/guides/production/automated-testing), without connecting to your Pinecone account, affecting production data, or incurring any usage or storage fees. Pinecone Local is in [public preview](/release-notes/feature-availability).
### Launch week: Pinecone Local
Pinecone now offers Pinecone Local, an in-memory database emulator available as a Docker image. You can use Pinecone Local to [develop your applications locally](/guides/operations/local-development), or to [test your applications in CI/CD](/guides/production/automated-testing), without connecting to your Pinecone account, affecting production data, or incurring any usage or storage fees. Pinecone Local is in [public preview](/release-notes/feature-availability).
 ### Launch week: Dark mode
Dark mode is now out for Pinecone's website, docs, and console. You can change your theme at the top right of each site.
### Launch week: Dark mode
Dark mode is now out for Pinecone's website, docs, and console. You can change your theme at the top right of each site.
 Pinecone Assistant is generally available (GA) for all users.
[Read more](https://www.pinecone.io/blog/pinecone-assistant-generally-available) about the release on our blog.
Pinecone Assistant is generally available (GA) for all users.
[Read more](https://www.pinecone.io/blog/pinecone-assistant-generally-available) about the release on our blog.
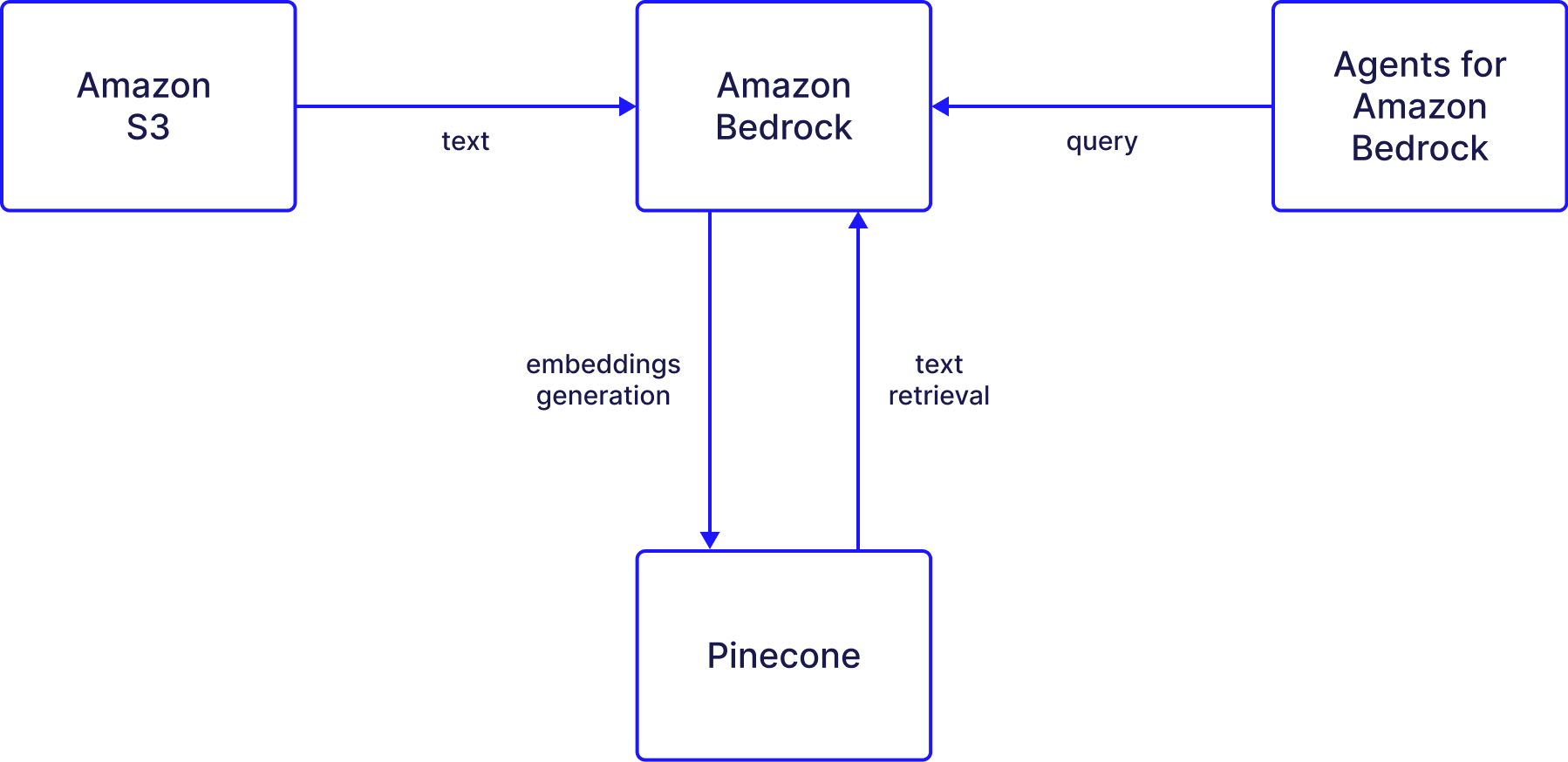 ## Setup guide
The process of using a Bedrock knowledge base with Pinecone works as follows:
## Setup guide
The process of using a Bedrock knowledge base with Pinecone works as follows:
 3. Click **Next**.
4. Enter a **Secret name** and **Description**.
5. Click **Next** to save your key.
6. On the **Configure rotation** page, select all the default options in the next screen, and click **Next**.
7. Click **Store**.
8. Click on the new secret you created and save the secret ARN for a later step.
#### Set up S3
The knowledge base is going to draw on data saved in S3. For this example, we use a [sample of research papers](https://huggingface.co/datasets/jamescalam/ai-arxiv2-semantic-chunks) obtained from a dataset. This data will be embedded and then saved in Pinecone.
1. Create a new general purpose bucket in [Amazon S3](https://console.aws.amazon.com/s3/home).
2. Once the bucket is created, upload a CSV file.
3. Click **Next**.
4. Enter a **Secret name** and **Description**.
5. Click **Next** to save your key.
6. On the **Configure rotation** page, select all the default options in the next screen, and click **Next**.
7. Click **Store**.
8. Click on the new secret you created and save the secret ARN for a later step.
#### Set up S3
The knowledge base is going to draw on data saved in S3. For this example, we use a [sample of research papers](https://huggingface.co/datasets/jamescalam/ai-arxiv2-semantic-chunks) obtained from a dataset. This data will be embedded and then saved in Pinecone.
1. Create a new general purpose bucket in [Amazon S3](https://console.aws.amazon.com/s3/home).
2. Once the bucket is created, upload a CSV file.
 By inspecting the trace, we can see what chunks were used by the Agent and diagnose issues with responses.
By inspecting the trace, we can see what chunks were used by the Agent and diagnose issues with responses.
 ## Related articles
* [Pinecone as a Knowledge Base for Amazon Bedrock](https://www.pinecone.io/blog/amazon-bedrock-integration/)
---
# Source: https://docs.pinecone.io/integrations/amazon-sagemaker.md
> ## Documentation Index
> Fetch the complete documentation index at: https://docs.pinecone.io/llms.txt
> Use this file to discover all available pages before exploring further.
# Amazon SageMaker
export const PrimarySecondaryCTA = ({primaryLabel, primaryHref, primaryTarget, secondaryLabel, secondaryHref, secondaryTarget}) =>
## Related articles
* [Pinecone as a Knowledge Base for Amazon Bedrock](https://www.pinecone.io/blog/amazon-bedrock-integration/)
---
# Source: https://docs.pinecone.io/integrations/amazon-sagemaker.md
> ## Documentation Index
> Fetch the complete documentation index at: https://docs.pinecone.io/llms.txt
> Use this file to discover all available pages before exploring further.
# Amazon SageMaker
export const PrimarySecondaryCTA = ({primaryLabel, primaryHref, primaryTarget, secondaryLabel, secondaryHref, secondaryTarget}) => 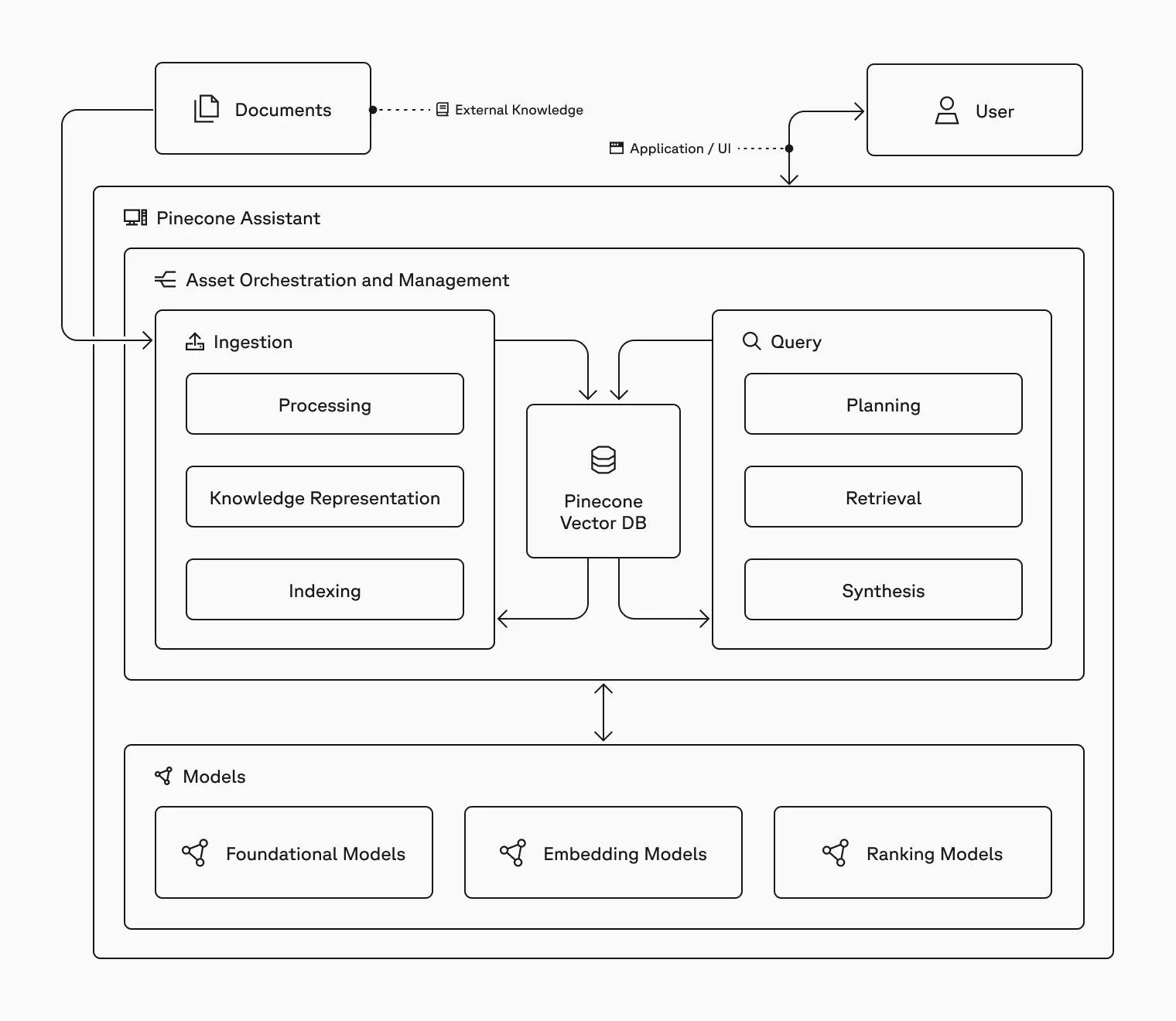
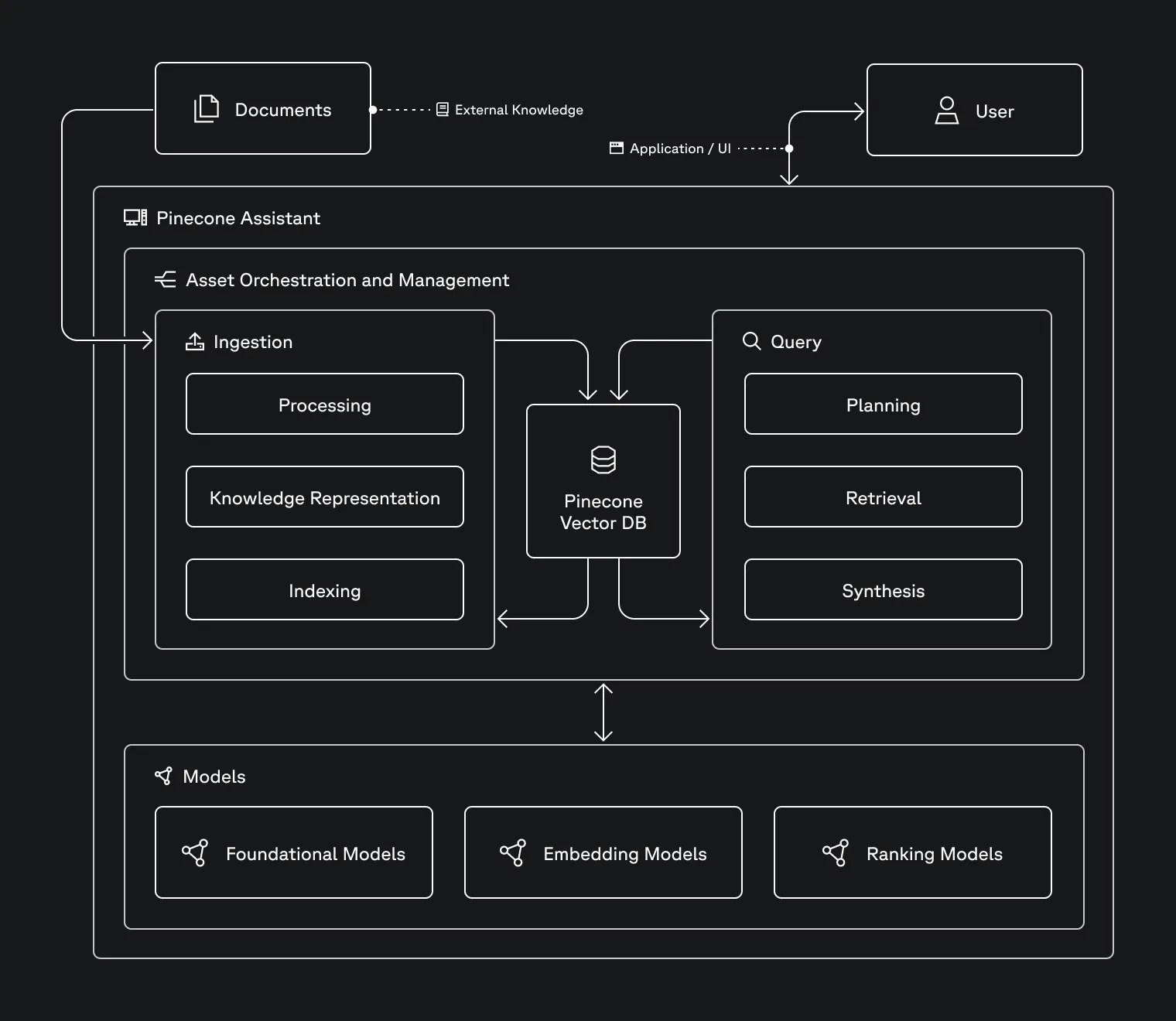 ## Data ingestion
When a [document is uploaded](/guides/assistant/manage-files), the assistant processes the content by chunking it into smaller parts and generating [vector embeddings](https://www.pinecone.io/learn/vector-embeddings-for-developers/) for each chunk. These embeddings are stored in an [index](/guides/index-data/indexing-overview), making them ready for retrieval.
## Data retrieval
During a [chat](/guides/assistant/chat-with-assistant), the assistant processes the message to formulate relevant search queries, which are used to query the index and identify the most relevant chunks from the uploaded content.
## Response generation
After retrieving these chunks, the assistant performs a ranking step to determine which information is most relevant. This [context](/guides/assistant/context-snippets-overview), along with the chat history and [assistant instructions](/guides/assistant/manage-assistants#add-instructions-to-an-assistant), is then used by a large language model (LLM) to generate responses that are informed by your documents.
---
# Source: https://docs.pinecone.io/reference/api/assistant/assistant-limits.md
> ## Documentation Index
> Fetch the complete documentation index at: https://docs.pinecone.io/llms.txt
> Use this file to discover all available pages before exploring further.
# Pinecone Assistant limits
Pinecone Assistant limits vary based on [subscription plan](https://www.pinecone.io/pricing/).
### Object limits
Object limits are restrictions on the number or size of assistant-related objects.
| Metric | Starter plan | Standard plan | Enterprise plan |
| :----------------------------------- | :------------ | :------------ | :-------------- |
| Assistants per project | 5 | Unlimited | Unlimited |
| File storage per project | 1 GB | Unlimited | Unlimited |
| Chat input tokens per project | 1,500,000 | Unlimited | Unlimited |
| Chat output tokens per project | 200,000 | Unlimited | Unlimited |
| Context retrieval tokens per project | 500,000 | Unlimited | Unlimited |
| Evaluation input tokens per project | Not available | 150,000 | 500,000 |
| Files per assistant | 100 | 10,000 | 10,000 |
| File size (.docx, .json, .md, .txt) | 10 MB | 10 MB | 10 MB |
| File size (.pdf) | 10 MB | 100 MB | 100 MB |
| Metadata size per file | 16 KB | 16 KB | 16 KB |
Additionally, the following limits apply to [multimodal PDFs](/guides/assistant/multimodal) (currently in [public preview](/release-notes/feature-availability)):
| Metric | Starter plan | Standard plan | Enterprise plan |
| :---------------------------- | :----------- | :------------ | :-------------- |
| Max file size | 10 MB | 50 MB | 50 MB |
| Page limit | 100 | 100 | 100 |
| Multimodal PDFs per assistant | 10 | 20 | 20 |
### Rate limits
Rate limits help protect your applications from misuse and maintain the health of our shared infrastructure. These limits are designed to support typical production workloads while ensuring reliable performance for all users.
**Most rate limits can be adjusted upon request.** If you need higher limits to scale your application, [contact Support](https://app.pinecone.io/organizations/-/settings/support/ticket) with details about your use case.
Requests that exceed a rate limit fail and return a `429 - TOO_MANY_REQUESTS` status.
## Data ingestion
When a [document is uploaded](/guides/assistant/manage-files), the assistant processes the content by chunking it into smaller parts and generating [vector embeddings](https://www.pinecone.io/learn/vector-embeddings-for-developers/) for each chunk. These embeddings are stored in an [index](/guides/index-data/indexing-overview), making them ready for retrieval.
## Data retrieval
During a [chat](/guides/assistant/chat-with-assistant), the assistant processes the message to formulate relevant search queries, which are used to query the index and identify the most relevant chunks from the uploaded content.
## Response generation
After retrieving these chunks, the assistant performs a ranking step to determine which information is most relevant. This [context](/guides/assistant/context-snippets-overview), along with the chat history and [assistant instructions](/guides/assistant/manage-assistants#add-instructions-to-an-assistant), is then used by a large language model (LLM) to generate responses that are informed by your documents.
---
# Source: https://docs.pinecone.io/reference/api/assistant/assistant-limits.md
> ## Documentation Index
> Fetch the complete documentation index at: https://docs.pinecone.io/llms.txt
> Use this file to discover all available pages before exploring further.
# Pinecone Assistant limits
Pinecone Assistant limits vary based on [subscription plan](https://www.pinecone.io/pricing/).
### Object limits
Object limits are restrictions on the number or size of assistant-related objects.
| Metric | Starter plan | Standard plan | Enterprise plan |
| :----------------------------------- | :------------ | :------------ | :-------------- |
| Assistants per project | 5 | Unlimited | Unlimited |
| File storage per project | 1 GB | Unlimited | Unlimited |
| Chat input tokens per project | 1,500,000 | Unlimited | Unlimited |
| Chat output tokens per project | 200,000 | Unlimited | Unlimited |
| Context retrieval tokens per project | 500,000 | Unlimited | Unlimited |
| Evaluation input tokens per project | Not available | 150,000 | 500,000 |
| Files per assistant | 100 | 10,000 | 10,000 |
| File size (.docx, .json, .md, .txt) | 10 MB | 10 MB | 10 MB |
| File size (.pdf) | 10 MB | 100 MB | 100 MB |
| Metadata size per file | 16 KB | 16 KB | 16 KB |
Additionally, the following limits apply to [multimodal PDFs](/guides/assistant/multimodal) (currently in [public preview](/release-notes/feature-availability)):
| Metric | Starter plan | Standard plan | Enterprise plan |
| :---------------------------- | :----------- | :------------ | :-------------- |
| Max file size | 10 MB | 50 MB | 50 MB |
| Page limit | 100 | 100 | 100 |
| Multimodal PDFs per assistant | 10 | 20 | 20 |
### Rate limits
Rate limits help protect your applications from misuse and maintain the health of our shared infrastructure. These limits are designed to support typical production workloads while ensuring reliable performance for all users.
**Most rate limits can be adjusted upon request.** If you need higher limits to scale your application, [contact Support](https://app.pinecone.io/organizations/-/settings/support/ticket) with details about your use case.
Requests that exceed a rate limit fail and return a `429 - TOO_MANY_REQUESTS` status.
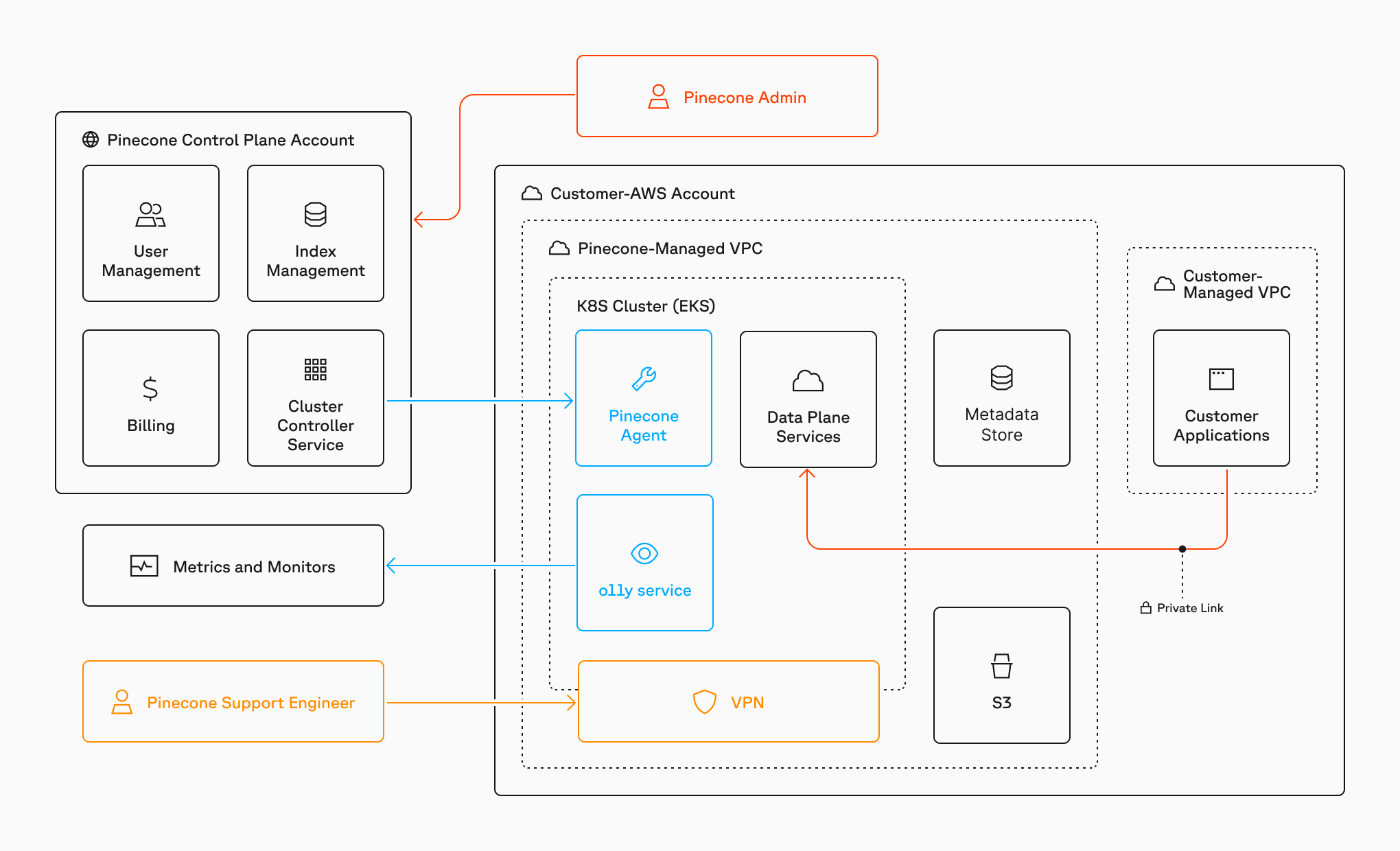
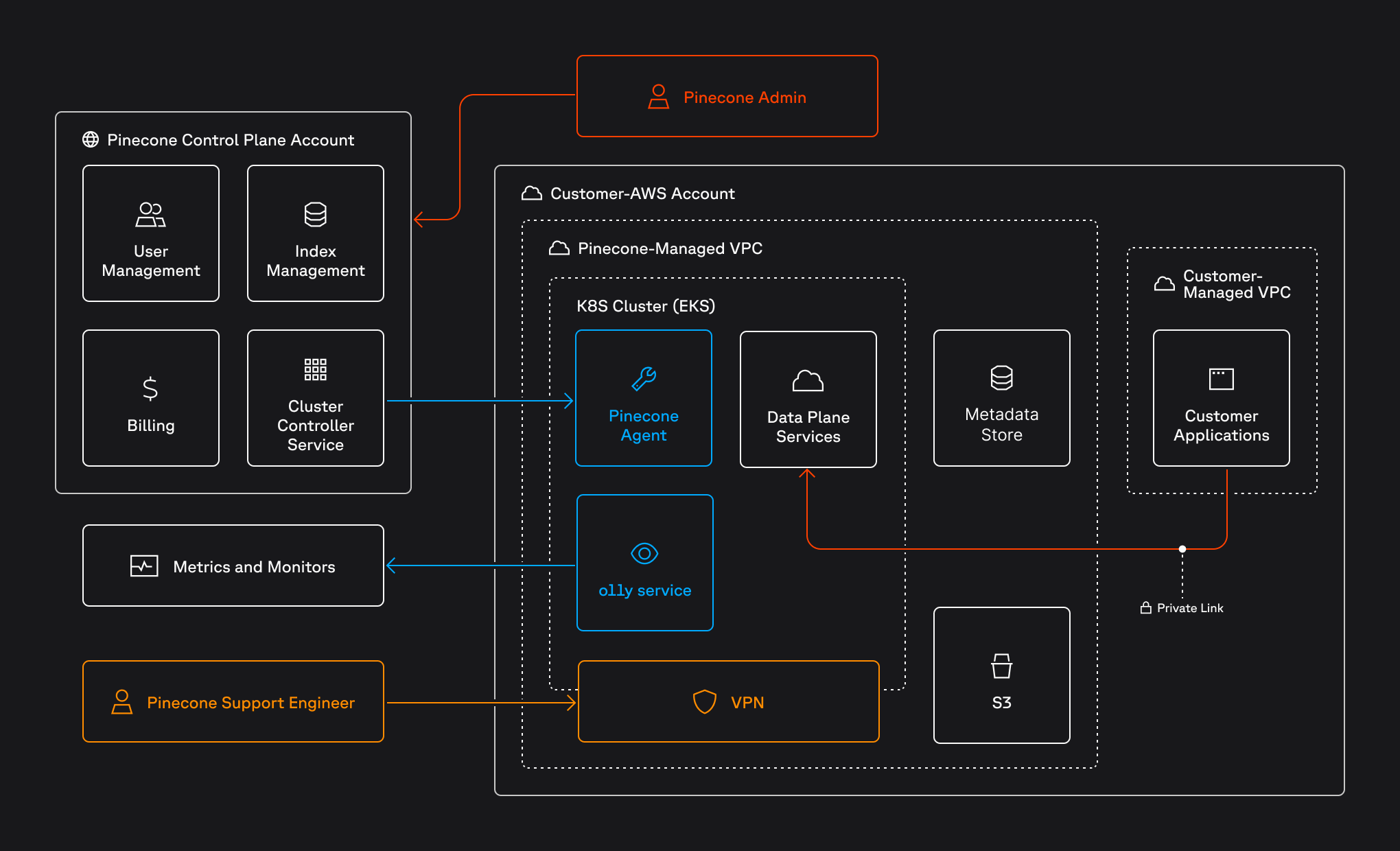 The BYOC architecture employs a split model:
* **Data plane**: The data plane is responsible for storing and processing your records, executing queries, and interacting with object storage for index data. In a BYOC deployment, the data plane is hosted in your own AWS or GCP account within a dedicated VPC, ensuring that all data is stored and processed locally and does not leave your organizational boundaries. You use a [private endpoint](#configure-a-private-endpoint) (AWS PrivateLink or GCP Private Service Connect) as an additional measure to secure requests to your indexes.
* **Control plane**: The control plane is responsible for managing the index lifecycle as well as region-agnostic services such as user management, authentication, and billing. The control plane does not hold or process any records. In a BYOC deployment, the control plane is managed by Pinecone and hosted globally. Communication between the data plane and control plane is encrypted using TLS and employs role-based access control (RBAC) with minimal IAM permissions.
## Onboarding
The onboarding process for BYOC in AWS or GCP involves the following general stages:
The BYOC architecture employs a split model:
* **Data plane**: The data plane is responsible for storing and processing your records, executing queries, and interacting with object storage for index data. In a BYOC deployment, the data plane is hosted in your own AWS or GCP account within a dedicated VPC, ensuring that all data is stored and processed locally and does not leave your organizational boundaries. You use a [private endpoint](#configure-a-private-endpoint) (AWS PrivateLink or GCP Private Service Connect) as an additional measure to secure requests to your indexes.
* **Control plane**: The control plane is responsible for managing the index lifecycle as well as region-agnostic services such as user management, authentication, and billing. The control plane does not hold or process any records. In a BYOC deployment, the control plane is managed by Pinecone and hosted globally. Communication between the data plane and control plane is encrypted using TLS and employs role-based access control (RBAC) with minimal IAM permissions.
## Onboarding
The onboarding process for BYOC in AWS or GCP involves the following general stages:
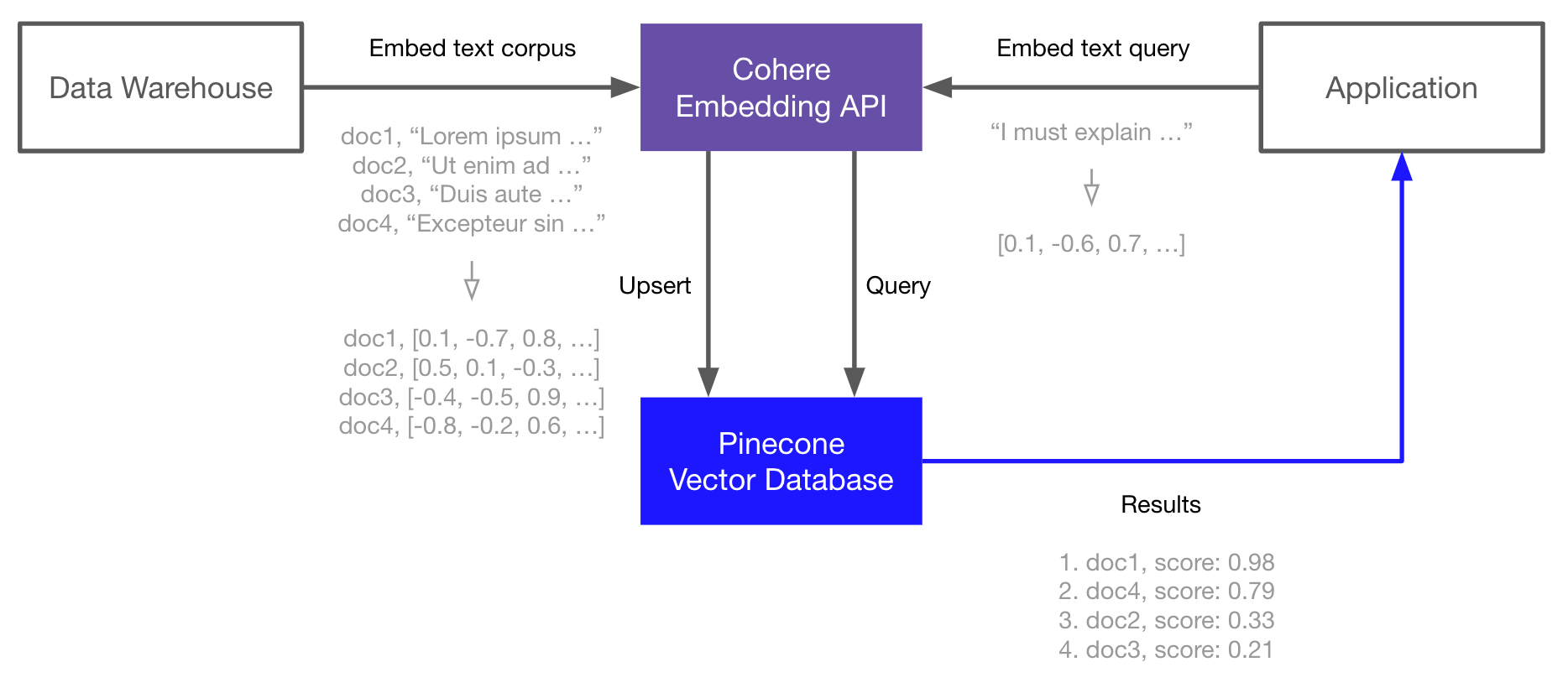 ### Set up the environment
Start by installing the Cohere and Pinecone clients and HuggingFace *Datasets* for downloading the TREC dataset used in this guide:
```shell Shell theme={null}
pip install -U cohere pinecone datasets
```
### Create embeddings
Sign up for an API key at [Cohere](https://dashboard.cohere.com/api-keys) and then use it to initialize your connection.
```Python Python theme={null}
import cohere
co = cohere.Client("
### Set up the environment
Start by installing the Cohere and Pinecone clients and HuggingFace *Datasets* for downloading the TREC dataset used in this guide:
```shell Shell theme={null}
pip install -U cohere pinecone datasets
```
### Create embeddings
Sign up for an API key at [Cohere](https://dashboard.cohere.com/api-keys) and then use it to initialize your connection.
```Python Python theme={null}
import cohere
co = cohere.Client("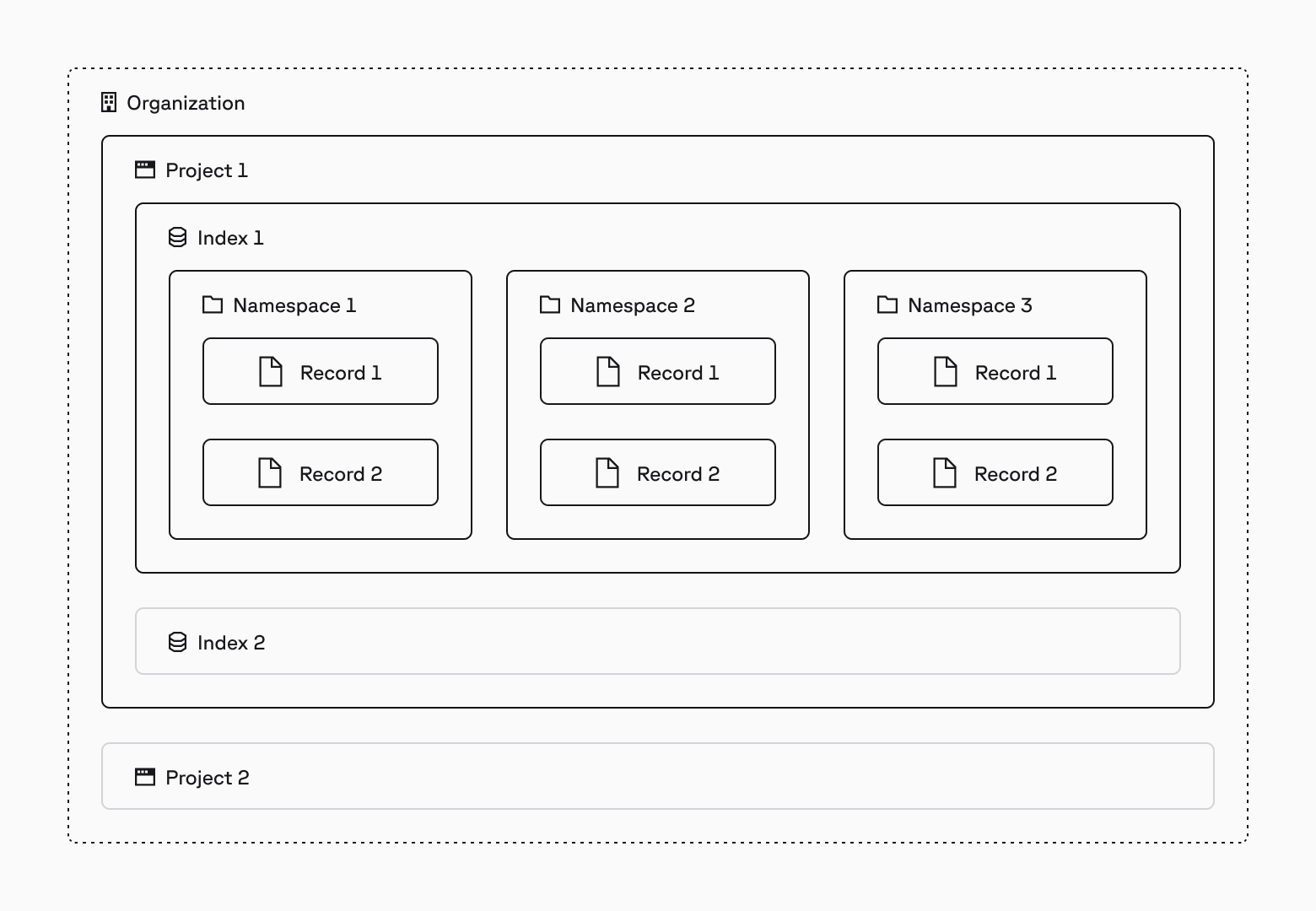
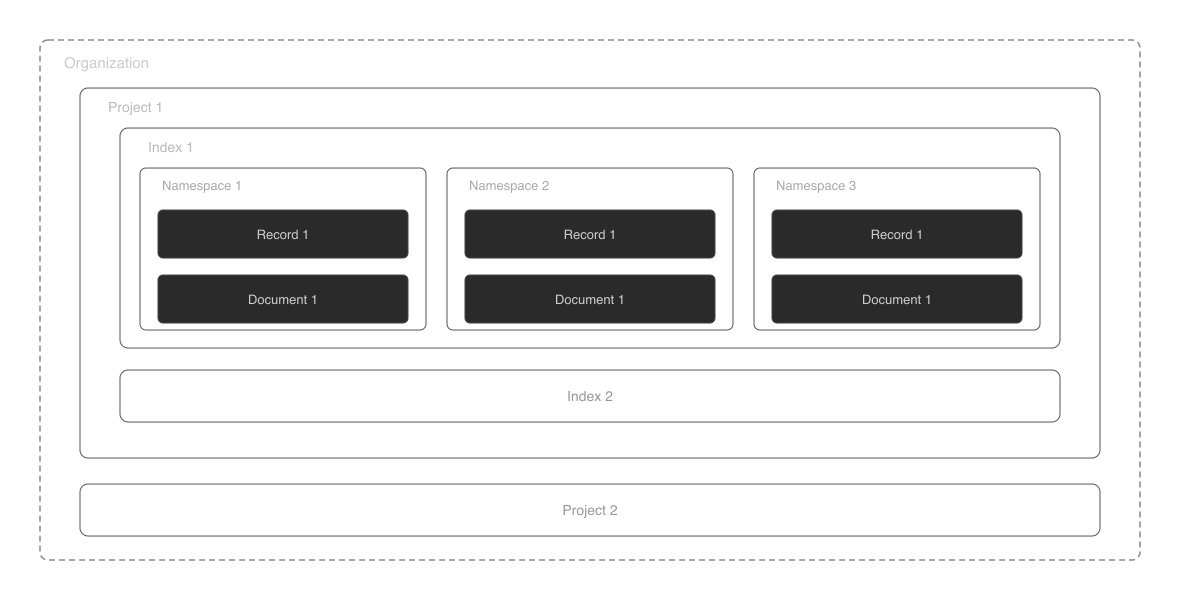 ## Organization
An organization is a group of one or more [projects](#project) that use the same billing. Organizations allow one or more [users](#user) to control billing and permissions for all of the projects belonging to the organization.
For more information, see [Understanding organizations](/guides/organizations/understanding-organizations).
## Project
A project belongs to an [organization](#organization) and contains one or more [indexes](#index). Each project belongs to exactly one organization, but only [users](#user) who belong to the project can access the indexes in that project. [API keys](#api-key) and [Assistants](#assistant) are project-specific.
For more information, see [Understanding projects](/guides/projects/understanding-projects).
## Index
There are two types of [serverless indexes](/guides/index-data/indexing-overview), dense and sparse.
### Dense index
Dense indexes store records that have one [dense vector](#dense-vector) each.
## Organization
An organization is a group of one or more [projects](#project) that use the same billing. Organizations allow one or more [users](#user) to control billing and permissions for all of the projects belonging to the organization.
For more information, see [Understanding organizations](/guides/organizations/understanding-organizations).
## Project
A project belongs to an [organization](#organization) and contains one or more [indexes](#index). Each project belongs to exactly one organization, but only [users](#user) who belong to the project can access the indexes in that project. [API keys](#api-key) and [Assistants](#assistant) are project-specific.
For more information, see [Understanding projects](/guides/projects/understanding-projects).
## Index
There are two types of [serverless indexes](/guides/index-data/indexing-overview), dense and sparse.
### Dense index
Dense indexes store records that have one [dense vector](#dense-vector) each.
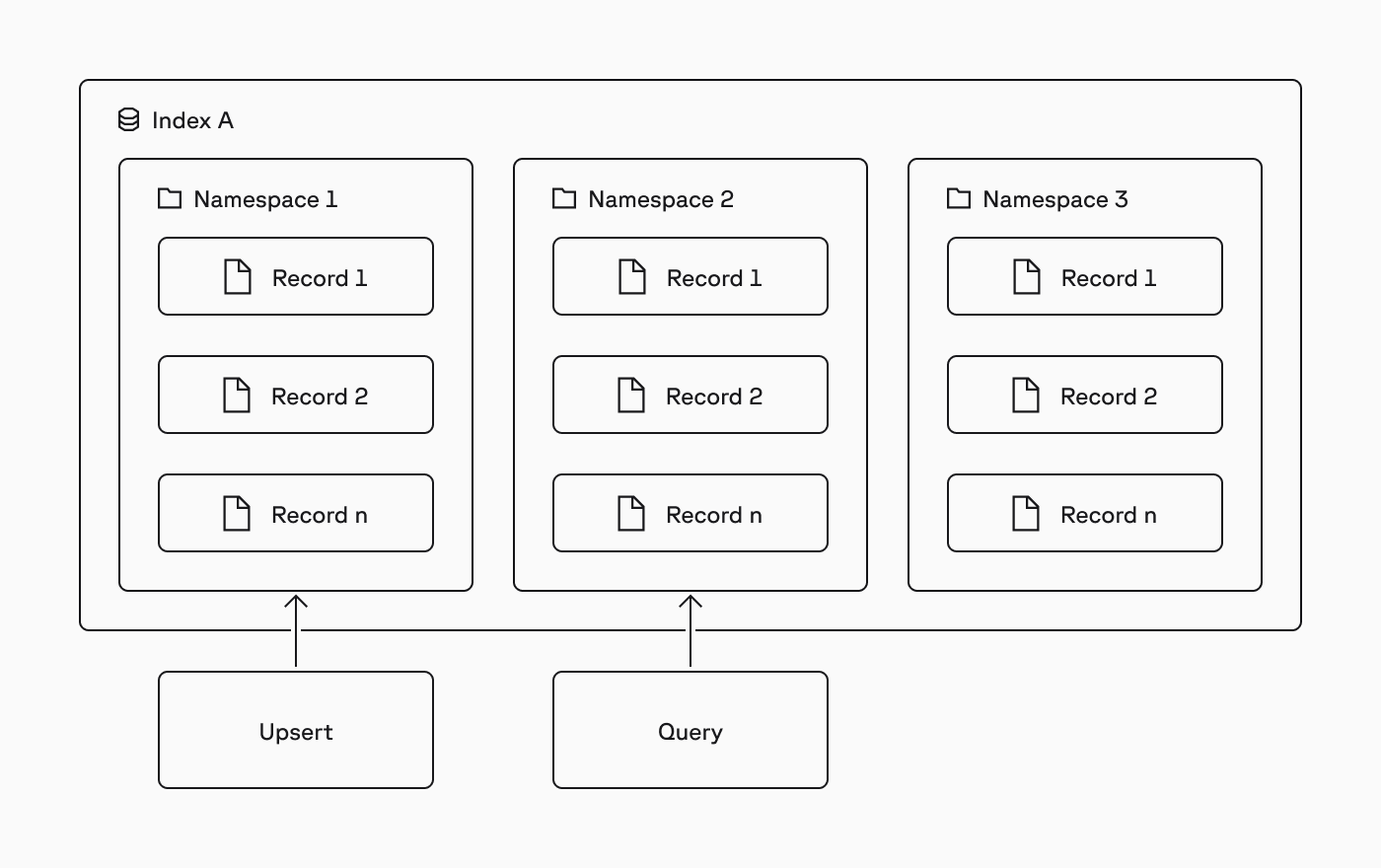
 For more information, see [Use namespaces](/guides/index-data/indexing-overview#namespaces).
## Record
A record is a basic unit of data and consists of a [record ID](#record-id), a [dense vector](#dense-vector) or a [sparse vector](#sparse-vector) (depending on the type of index), and optional [metadata](#metadata).
For more information, see [Upsert data](/guides/index-data/upsert-data).
### Record ID
A record ID is a record's unique ID. [Use ID prefixes](/guides/index-data/data-modeling#use-structured-ids) that reflect the type of data you're storing.
### Dense vector
A dense vector, also referred to as a vector embedding or simply a vector, is a series of numbers that represent the meaning and relationships of data. Each number in a dense vector corresponds to a point in a multidimensional space. Vectors that are closer together in that space are semantically similar.
Dense vectors are stored in [dense indexes](#dense-index).
You use a dense embedding model to convert data to dense vectors. The embedding model can be external to Pinecone or [hosted on Pinecone infrastructure](/guides/index-data/create-an-index#embedding-models) and integrated with an index.
For more information about dense vectors, see [What are vector embeddings?](https://www.pinecone.io/learn/vector-embeddings/).
### Sparse vector
Sparse vectors are often used to represent documents or queries in a way that captures keyword information. Each dimension in a sparse vector typically represents a word from a dictionary, and the non-zero values represent the importance of these words in the document.
Sparse vectors have a large number of dimensions, but a small number of those values are non-zero. Because most values are zero, Pinecone stores sparse vectors efficiently by keeping only the non-zero values along with their corresponding indices.
Sparse vectors are stored in [sparse indexes](#sparse-index) and [hybrid indexes](/guides/search/hybrid-search#use-a-single-hybrid-index). To convert data to sparse vectors, use a sparse embedding model. The embedding model can be external to Pinecone or [hosted on Pinecone infrastructure](/guides/index-data/create-an-index#embedding-models) and integrated with an index.
For more information about sparse vectors, see [Sparse retrieval](https://www.pinecone.io/learn/sparse-retrieval/).
### Metadata
Metadata is additional information included in a record to provide more context and enable additional [filtering capabilities](/guides/index-data/indexing-overview#metadata). For example, the original text that was embedded can be stored in the metadata.
## Other concepts
Although not represented in the diagram above, Pinecone also contains the following concepts:
* [API key](#api-key)
* [User](#user)
* [Backup or collection](#backup-or-collection)
* [Pinecone Inference](#pinecone-inference)
### API key
An API key is a unique token that [authenticates](/reference/api/authentication) and authorizes access to the [Pinecone APIs](/reference/api/introduction). API keys are project-specific.
### User
A user is a member of organizations and projects. Users are assigned specific roles at the organization and project levels that determine the user's permissions in the [Pinecone console](https://app.pinecone.io).
For more information, see [Manage organization members](/guides/organizations/manage-organization-members) and [Manage project members](/guides/projects/manage-project-members).
### Backup or collection
A backup is a static copy of a serverless index.
Backups only consume storage. They are non-queryable representations of a set of records. You can create a backup from an index, and you can create a new index from that backup. The new index configuration can differ from the original source index: for example, it can have a different name. However, it must have the same number of dimensions and similarity metric as the source index.
For more information, see [Understanding backups](/guides/manage-data/backups-overview).
### Pinecone Inference
Pinecone Inference is an API service that provides access to [embedding models](/guides/index-data/create-an-index#embedding-models) and [reranking models](/guides/search/rerank-results#reranking-models) hosted on Pinecone's infrastructure.
## Learn more
* [Vector database](https://www.pinecone.io/learn/vector-database/)
* [Pinecone APIs](/reference/api/introduction)
* [Approximate nearest neighbor (ANN) algorithms](https://www.pinecone.io/learn/a-developers-guide-to-ann-algorithms/)
* [Retrieval augmented generation (RAG)](https://www.pinecone.io/learn/retrieval-augmented-generation/)
* [Image search](https://www.pinecone.io/learn/series/image-search/)
* [Tokenization](https://www.pinecone.io/learn/tokenization/)
---
# Source: https://docs.pinecone.io/guides/production/configure-audit-logs.md
# Source: https://docs.pinecone.io/guides/assistant/admin/configure-audit-logs.md
> ## Documentation Index
> Fetch the complete documentation index at: https://docs.pinecone.io/llms.txt
> Use this file to discover all available pages before exploring further.
# Configure audit logs
> Track user and API actions with audit log configuration.
This page describes how to configure audit logs in Pinecone. Audit logs provide a detailed record of user, service account, and API actions that occur on the management and [control plane](/guides/get-started/database-architecture#control-plane) within Pinecone. Pinecone supports Amazon S3 as a destination for audit logs.
For more information, see [Use namespaces](/guides/index-data/indexing-overview#namespaces).
## Record
A record is a basic unit of data and consists of a [record ID](#record-id), a [dense vector](#dense-vector) or a [sparse vector](#sparse-vector) (depending on the type of index), and optional [metadata](#metadata).
For more information, see [Upsert data](/guides/index-data/upsert-data).
### Record ID
A record ID is a record's unique ID. [Use ID prefixes](/guides/index-data/data-modeling#use-structured-ids) that reflect the type of data you're storing.
### Dense vector
A dense vector, also referred to as a vector embedding or simply a vector, is a series of numbers that represent the meaning and relationships of data. Each number in a dense vector corresponds to a point in a multidimensional space. Vectors that are closer together in that space are semantically similar.
Dense vectors are stored in [dense indexes](#dense-index).
You use a dense embedding model to convert data to dense vectors. The embedding model can be external to Pinecone or [hosted on Pinecone infrastructure](/guides/index-data/create-an-index#embedding-models) and integrated with an index.
For more information about dense vectors, see [What are vector embeddings?](https://www.pinecone.io/learn/vector-embeddings/).
### Sparse vector
Sparse vectors are often used to represent documents or queries in a way that captures keyword information. Each dimension in a sparse vector typically represents a word from a dictionary, and the non-zero values represent the importance of these words in the document.
Sparse vectors have a large number of dimensions, but a small number of those values are non-zero. Because most values are zero, Pinecone stores sparse vectors efficiently by keeping only the non-zero values along with their corresponding indices.
Sparse vectors are stored in [sparse indexes](#sparse-index) and [hybrid indexes](/guides/search/hybrid-search#use-a-single-hybrid-index). To convert data to sparse vectors, use a sparse embedding model. The embedding model can be external to Pinecone or [hosted on Pinecone infrastructure](/guides/index-data/create-an-index#embedding-models) and integrated with an index.
For more information about sparse vectors, see [Sparse retrieval](https://www.pinecone.io/learn/sparse-retrieval/).
### Metadata
Metadata is additional information included in a record to provide more context and enable additional [filtering capabilities](/guides/index-data/indexing-overview#metadata). For example, the original text that was embedded can be stored in the metadata.
## Other concepts
Although not represented in the diagram above, Pinecone also contains the following concepts:
* [API key](#api-key)
* [User](#user)
* [Backup or collection](#backup-or-collection)
* [Pinecone Inference](#pinecone-inference)
### API key
An API key is a unique token that [authenticates](/reference/api/authentication) and authorizes access to the [Pinecone APIs](/reference/api/introduction). API keys are project-specific.
### User
A user is a member of organizations and projects. Users are assigned specific roles at the organization and project levels that determine the user's permissions in the [Pinecone console](https://app.pinecone.io).
For more information, see [Manage organization members](/guides/organizations/manage-organization-members) and [Manage project members](/guides/projects/manage-project-members).
### Backup or collection
A backup is a static copy of a serverless index.
Backups only consume storage. They are non-queryable representations of a set of records. You can create a backup from an index, and you can create a new index from that backup. The new index configuration can differ from the original source index: for example, it can have a different name. However, it must have the same number of dimensions and similarity metric as the source index.
For more information, see [Understanding backups](/guides/manage-data/backups-overview).
### Pinecone Inference
Pinecone Inference is an API service that provides access to [embedding models](/guides/index-data/create-an-index#embedding-models) and [reranking models](/guides/search/rerank-results#reranking-models) hosted on Pinecone's infrastructure.
## Learn more
* [Vector database](https://www.pinecone.io/learn/vector-database/)
* [Pinecone APIs](/reference/api/introduction)
* [Approximate nearest neighbor (ANN) algorithms](https://www.pinecone.io/learn/a-developers-guide-to-ann-algorithms/)
* [Retrieval augmented generation (RAG)](https://www.pinecone.io/learn/retrieval-augmented-generation/)
* [Image search](https://www.pinecone.io/learn/series/image-search/)
* [Tokenization](https://www.pinecone.io/learn/tokenization/)
---
# Source: https://docs.pinecone.io/guides/production/configure-audit-logs.md
# Source: https://docs.pinecone.io/guides/assistant/admin/configure-audit-logs.md
> ## Documentation Index
> Fetch the complete documentation index at: https://docs.pinecone.io/llms.txt
> Use this file to discover all available pages before exploring further.
# Configure audit logs
> Track user and API actions with audit log configuration.
This page describes how to configure audit logs in Pinecone. Audit logs provide a detailed record of user, service account, and API actions that occur on the management and [control plane](/guides/get-started/database-architecture#control-plane) within Pinecone. Pinecone supports Amazon S3 as a destination for audit logs.
 The `ConnectPopup` function can be called with either the JavaScript library or script. The JavaScript library is the most commonly used method, but the script can be used in instances where you cannot build and use a custom library, like within the constraints of a content management system (CMS).
The function includes the following **required** configuration option:
* `integrationId`: The slug assigned to the integration. If `integrationId` is not passed, the widget will not render.
The `ConnectPopup` function can be called with either the JavaScript library or script. The JavaScript library is the most commonly used method, but the script can be used in instances where you cannot build and use a custom library, like within the constraints of a content management system (CMS).
The function includes the following **required** configuration option:
* `integrationId`: The slug assigned to the integration. If `integrationId` is not passed, the widget will not render.
 [Once you have created your `integrationId`](#create-an-integration-id), you can embed the **Connect** widget multiple ways:
* [JavaScript](#javascript) library (`@pinecone-database/connect`) or script: Renders the widget in apps and websites.
* [Colab](#colab) (`pinecone-notebooks`): Renders the widget in Colab notebooks using Python.
Once you have created your integration, be sure to [attribute usage to your integration](/integrations/build-integration/attribute-usage-to-your-integration).
### JavaScript
To embed the **Connect to Pinecone** widget in your app or website using the [`@pinecone-database/connect` library](https://www.npmjs.com/package/@pinecone-database/connect), install the necessary dependencies:
```shell Shell theme={null}
# Install dependencies
npm i -S @pinecone-database/connect
```
You can use the JavaScript library to render the **Connect to Pinecone** widget and obtain the API key with the [`connectToPinecone` function](#connecttopinecone-function). It displays the widget and calls the provided callback function with the Pinecone API key, once the user completes the flow.
The function includes the following **required** configuration options:
* `integrationId`: The slug assigned to the integration. If `integrationId` is not passed, the widget will not render.
[Once you have created your `integrationId`](#create-an-integration-id), you can embed the **Connect** widget multiple ways:
* [JavaScript](#javascript) library (`@pinecone-database/connect`) or script: Renders the widget in apps and websites.
* [Colab](#colab) (`pinecone-notebooks`): Renders the widget in Colab notebooks using Python.
Once you have created your integration, be sure to [attribute usage to your integration](/integrations/build-integration/attribute-usage-to-your-integration).
### JavaScript
To embed the **Connect to Pinecone** widget in your app or website using the [`@pinecone-database/connect` library](https://www.npmjs.com/package/@pinecone-database/connect), install the necessary dependencies:
```shell Shell theme={null}
# Install dependencies
npm i -S @pinecone-database/connect
```
You can use the JavaScript library to render the **Connect to Pinecone** widget and obtain the API key with the [`connectToPinecone` function](#connecttopinecone-function). It displays the widget and calls the provided callback function with the Pinecone API key, once the user completes the flow.
The function includes the following **required** configuration options:
* `integrationId`: The slug assigned to the integration. If `integrationId` is not passed, the widget will not render.

 ### API gateway
Every request to Pinecone includes an [API key](/guides/projects/manage-api-keys) that's assigned to a specific [project](/guides/projects/understanding-projects). The API gateway first validates your API key to make sure you have permission to access the project. Once validated, it routes your request to either the global control plane (for managing projects and indexes) or a regional data plane (for reading and writing data), depending on what you're trying to do.
### Control plane
The global control plane manages your organizational resources like projects and indexes. It uses a dedicated database to keep track of all these objects. The control plane also handles billing, user management, and coordinates operations across different regions.
### Data plane
The data plane handles all requests to write and read records in [indexes](/guides/index-data/indexing-overview) within a specific [cloud region](/guides/index-data/create-an-index#cloud-regions). Each index is divided into one or more logical [namespaces](/guides/index-data/indexing-overview#namespaces), and all your read and write requests target a specific namespace.
Pinecone separates write and read operations into different paths, with each scaling independently based on demand. This separation ensures that your queries never slow down your writes, and your writes never slow down your queries.
### Object storage
For each namespace in a serverless index, Pinecone organizes records into immutable files called slabs. These slabs are [optimized for fast querying](#index-builder) and stored in distributed object storage that provides virtually unlimited scalability and high availability.
## Write path
### API gateway
Every request to Pinecone includes an [API key](/guides/projects/manage-api-keys) that's assigned to a specific [project](/guides/projects/understanding-projects). The API gateway first validates your API key to make sure you have permission to access the project. Once validated, it routes your request to either the global control plane (for managing projects and indexes) or a regional data plane (for reading and writing data), depending on what you're trying to do.
### Control plane
The global control plane manages your organizational resources like projects and indexes. It uses a dedicated database to keep track of all these objects. The control plane also handles billing, user management, and coordinates operations across different regions.
### Data plane
The data plane handles all requests to write and read records in [indexes](/guides/index-data/indexing-overview) within a specific [cloud region](/guides/index-data/create-an-index#cloud-regions). Each index is divided into one or more logical [namespaces](/guides/index-data/indexing-overview#namespaces), and all your read and write requests target a specific namespace.
Pinecone separates write and read operations into different paths, with each scaling independently based on demand. This separation ensures that your queries never slow down your writes, and your writes never slow down your queries.
### Object storage
For each namespace in a serverless index, Pinecone organizes records into immutable files called slabs. These slabs are [optimized for fast querying](#index-builder) and stored in distributed object storage that provides virtually unlimited scalability and high availability.
## Write path

 ### Request log
When you send a write request (to add, update, or delete records), the [data plane](#data-plane) first logs the request details with a unique sequence number (LSN). This ensures all operations happen in the correct order and provides a way to track the state of the index.
Pinecone immediately returns a `200 OK` response, guaranteeing that your write is durable and won't be lost. The system then processes your write in the background.
### Index builder
The index builder stores your write data in an in-memory structure called a memtable. This includes your vector data, any metadata you've attached, and the sequence number. If you're updating or deleting a record, the system also tracks how to handle the old version during queries.
Periodically, the index builder moves data from the memtable to permanent storage. In [object storage](#object-storage), your data is organized into immutable files called slabs. These slabs are optimized for query performance. Smaller slabs use fast indexing techniques that provide good performance with minimal resource requirements. As slabs grow, the system merges them into larger slabs that use more sophisticated methods that provide better performance at scale. This adaptive process both optimizes query performance for each slab and amortizes the cost of more expensive indexing through the lifetime of the namespace.
### Request log
When you send a write request (to add, update, or delete records), the [data plane](#data-plane) first logs the request details with a unique sequence number (LSN). This ensures all operations happen in the correct order and provides a way to track the state of the index.
Pinecone immediately returns a `200 OK` response, guaranteeing that your write is durable and won't be lost. The system then processes your write in the background.
### Index builder
The index builder stores your write data in an in-memory structure called a memtable. This includes your vector data, any metadata you've attached, and the sequence number. If you're updating or deleting a record, the system also tracks how to handle the old version during queries.
Periodically, the index builder moves data from the memtable to permanent storage. In [object storage](#object-storage), your data is organized into immutable files called slabs. These slabs are optimized for query performance. Smaller slabs use fast indexing techniques that provide good performance with minimal resource requirements. As slabs grow, the system merges them into larger slabs that use more sophisticated methods that provide better performance at scale. This adaptive process both optimizes query performance for each slab and amortizes the cost of more expensive indexing through the lifetime of the namespace.

 ### Query routers
When you send a search query, the [data plane](#data-plane) first validates your request and checks that it meets system limits like [rate and object limits](/reference/api/database-limits.mdx). The query router then identifies which slabs contain relevant data and routes your query to the appropriate executors. It also searches the memtable for any recent data that hasn't been moved to permanent storage yet.
### Query executors
Each query executor searches through its assigned slabs and returns the most relevant candidates to the query router. If your query includes metadata filters, the executors exclude records that don't match your criteria before finding the best matches.
Most of the time, the slabs are cached in memory or on local SSD, which provides very fast query performance. If a slab isn't cached (which happens when it's accessed for the first time or hasn't been used recently), the executor fetches it from object storage and caches it for future queries.
The query router then combines results from all executors, removes duplicates, merges them with results from the memtable, and returns the final set of best matches to you.
---
# Source: https://docs.pinecone.io/reference/api/database-limits.md
> ## Documentation Index
> Fetch the complete documentation index at: https://docs.pinecone.io/llms.txt
> Use this file to discover all available pages before exploring further.
# Pinecone Database limits
This page describes different types of limits for Pinecone Database.
## Rate limits
Rate limits help protect your applications from misuse and maintain the health of our shared serverless infrastructure. These limits are designed to support typical production workloads while ensuring reliable performance for all users.
**Most rate limits can be adjusted upon request.** If you need higher limits to scale your application, [contact Support](https://app.pinecone.io/organizations/-/settings/support/ticket) with details about your use case. Pinecone is committed to supporting your growth and can often accommodate higher throughput requirements.
Rate limits vary based on [pricing plan](https://www.pinecone.io/pricing/) and apply to [serverless indexes](/guides/index-data/indexing-overview) only.
### Query routers
When you send a search query, the [data plane](#data-plane) first validates your request and checks that it meets system limits like [rate and object limits](/reference/api/database-limits.mdx). The query router then identifies which slabs contain relevant data and routes your query to the appropriate executors. It also searches the memtable for any recent data that hasn't been moved to permanent storage yet.
### Query executors
Each query executor searches through its assigned slabs and returns the most relevant candidates to the query router. If your query includes metadata filters, the executors exclude records that don't match your criteria before finding the best matches.
Most of the time, the slabs are cached in memory or on local SSD, which provides very fast query performance. If a slab isn't cached (which happens when it's accessed for the first time or hasn't been used recently), the executor fetches it from object storage and caches it for future queries.
The query router then combines results from all executors, removes duplicates, merges them with results from the memtable, and returns the final set of best matches to you.
---
# Source: https://docs.pinecone.io/reference/api/database-limits.md
> ## Documentation Index
> Fetch the complete documentation index at: https://docs.pinecone.io/llms.txt
> Use this file to discover all available pages before exploring further.
# Pinecone Database limits
This page describes different types of limits for Pinecone Database.
## Rate limits
Rate limits help protect your applications from misuse and maintain the health of our shared serverless infrastructure. These limits are designed to support typical production workloads while ensuring reliable performance for all users.
**Most rate limits can be adjusted upon request.** If you need higher limits to scale your application, [contact Support](https://app.pinecone.io/organizations/-/settings/support/ticket) with details about your use case. Pinecone is committed to supporting your growth and can often accommodate higher throughput requirements.
Rate limits vary based on [pricing plan](https://www.pinecone.io/pricing/) and apply to [serverless indexes](/guides/index-data/indexing-overview) only.
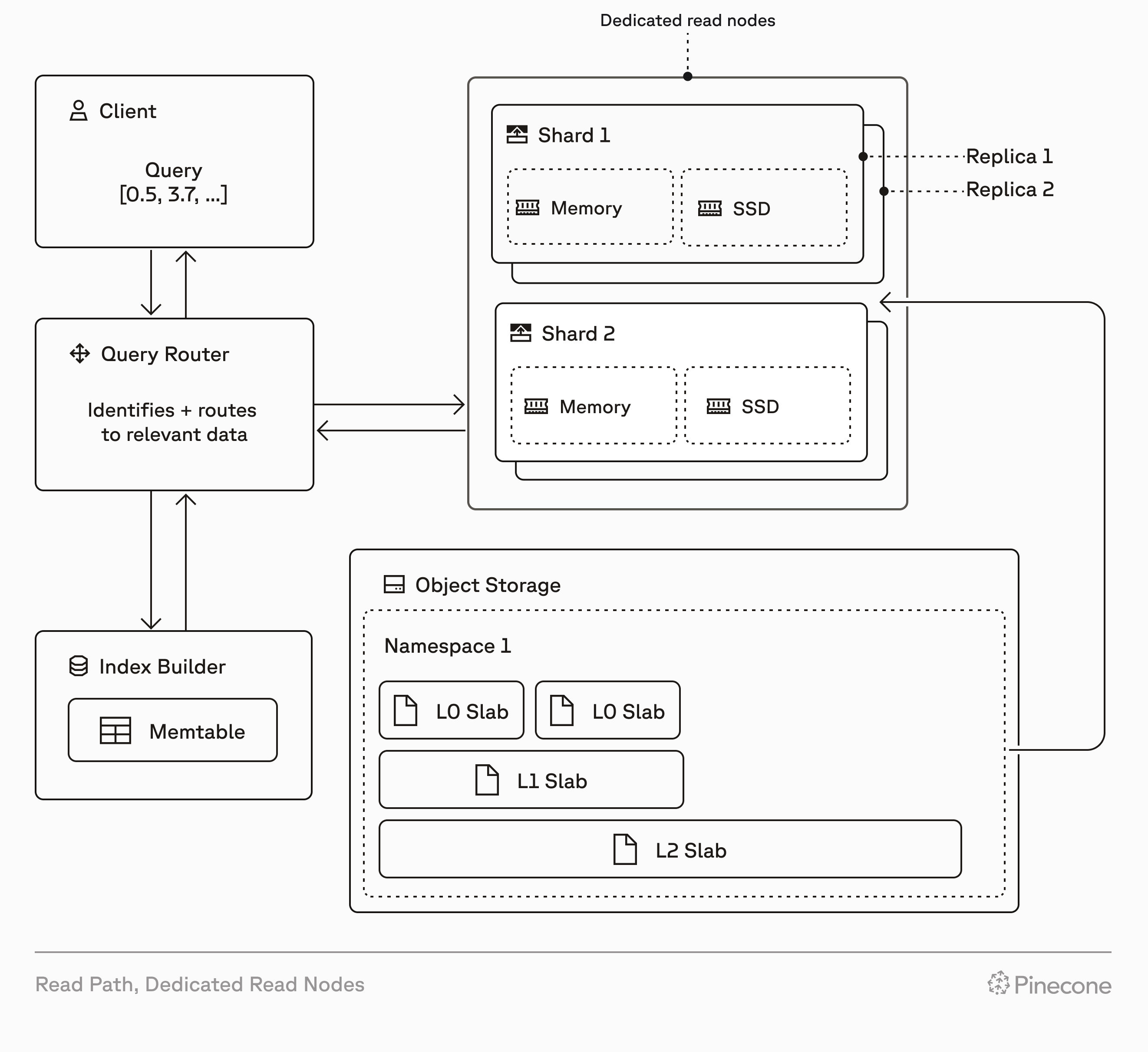
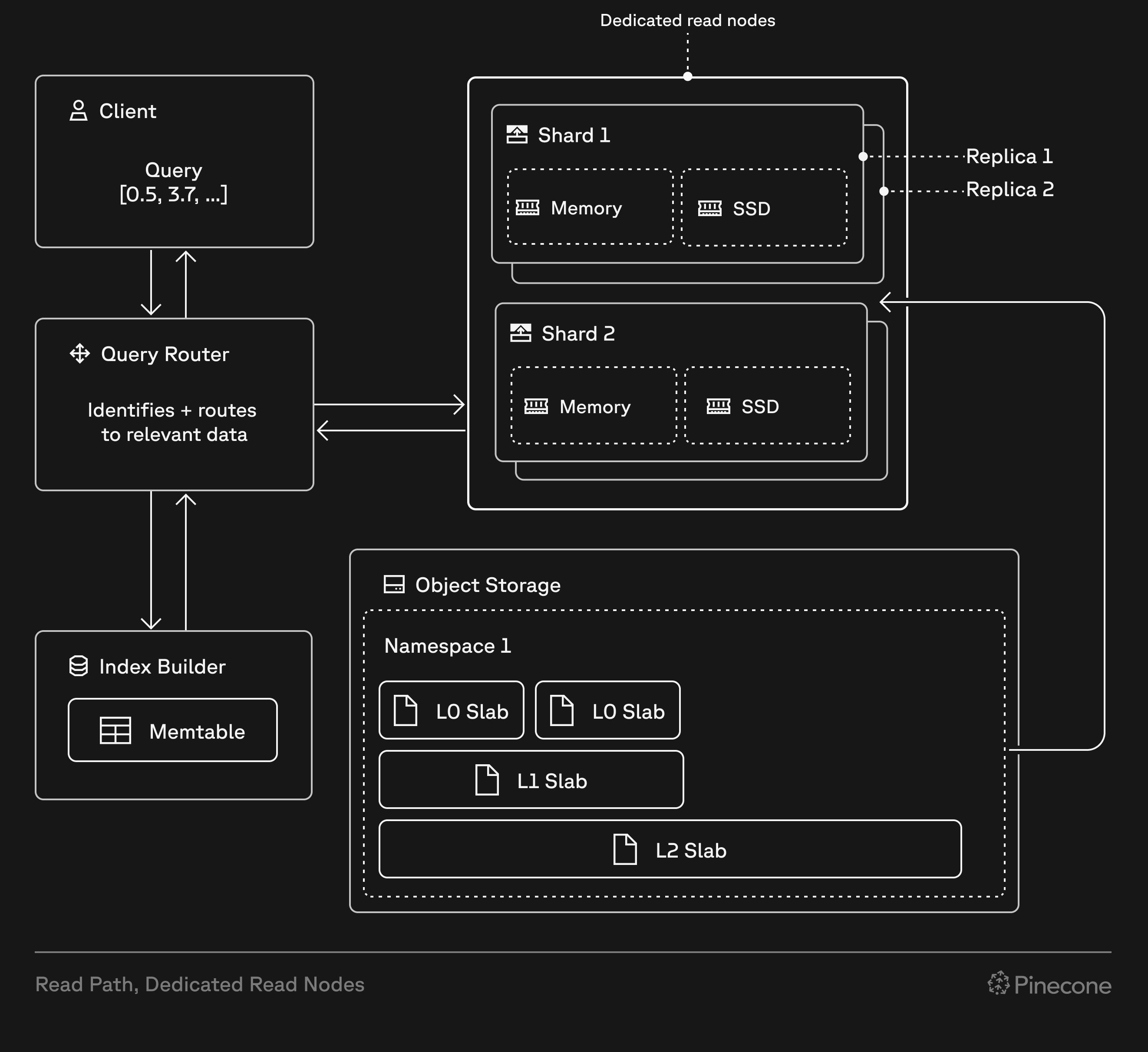 ## On-demand vs dedicated
On-demand indexes and dedicated read nodes are both built on Pinecone's serverless infrastructure. They use the same write path, storage layer, and data operations API.
However, every dedicated read nodes index has isolated hardware for read operations (query, fetch, list), allowing these operations to run on dedicated query executors. This affects performance, cost, and how you scale:
| Feature | On-demand | Dedicated read nodes |
| :---------------------- | :--------------------------------------------------------------------------------------------------------------------------------------------- | :----------------------------------------------------------------------------------------------------------------------------------------------------------------- |
| **Read infrastructure** | Multi-tenant compute resources shared across customers | Isolated, provisioned query executors dedicated to your index |
| **Read costs** | Pay per [read unit](/guides/manage-cost/understanding-cost#serverless-indexes) (1 RU per 1 GB of namespace size per query, minimum 0.25 RU) | Fixed hourly rate for read capacity based on node type, shards, and replicas |
| **Other costs** | [Storage](/guides/manage-cost/understanding-cost#storage) and [write](/guides/manage-cost/understanding-cost#write-units) costs based on usage | [Storage](/guides/manage-cost/understanding-cost#storage) and [write](/guides/manage-cost/understanding-cost#write-units) costs based on usage (same as on-demand) |
| **Caching** | Best-effort; frequently accessed data is cached, but cold queries fetch from object storage | Guaranteed; all index data always warm in memory and on local SSDs |
| **Read rate limits** | [2,000 RUs/second per index (adjustable)](/reference/api/database-limits#rate-limits) | No read rate limits (only bounded by CPU capacity) |
| **Scaling** | Automatic; Pinecone handles capacity | Manual; add [shards](#shards) for storage, add [replicas](#replicas) for throughput |
| **Best for** | Variable workloads, multi-tenant applications with many namespaces, low to moderate query rates | Sustained high query rates, large single-namespace workloads, predictable performance and cost |
## When to use dedicated read nodes
Dedicated read nodes are ideal for workloads with millions to billions of records and predictable query rates. They provide performance and cost benefits compared to on-demand for high-throughput workloads, and may be required when your workload exceeds on-demand rate limits.
There's no universal formula for choosing between on-demand and dedicated read nodes—performance and cost vary by workload (vector dimensionality, metadata filtering, and query patterns). Consider the following factors when making your decision:
## On-demand vs dedicated
On-demand indexes and dedicated read nodes are both built on Pinecone's serverless infrastructure. They use the same write path, storage layer, and data operations API.
However, every dedicated read nodes index has isolated hardware for read operations (query, fetch, list), allowing these operations to run on dedicated query executors. This affects performance, cost, and how you scale:
| Feature | On-demand | Dedicated read nodes |
| :---------------------- | :--------------------------------------------------------------------------------------------------------------------------------------------- | :----------------------------------------------------------------------------------------------------------------------------------------------------------------- |
| **Read infrastructure** | Multi-tenant compute resources shared across customers | Isolated, provisioned query executors dedicated to your index |
| **Read costs** | Pay per [read unit](/guides/manage-cost/understanding-cost#serverless-indexes) (1 RU per 1 GB of namespace size per query, minimum 0.25 RU) | Fixed hourly rate for read capacity based on node type, shards, and replicas |
| **Other costs** | [Storage](/guides/manage-cost/understanding-cost#storage) and [write](/guides/manage-cost/understanding-cost#write-units) costs based on usage | [Storage](/guides/manage-cost/understanding-cost#storage) and [write](/guides/manage-cost/understanding-cost#write-units) costs based on usage (same as on-demand) |
| **Caching** | Best-effort; frequently accessed data is cached, but cold queries fetch from object storage | Guaranteed; all index data always warm in memory and on local SSDs |
| **Read rate limits** | [2,000 RUs/second per index (adjustable)](/reference/api/database-limits#rate-limits) | No read rate limits (only bounded by CPU capacity) |
| **Scaling** | Automatic; Pinecone handles capacity | Manual; add [shards](#shards) for storage, add [replicas](#replicas) for throughput |
| **Best for** | Variable workloads, multi-tenant applications with many namespaces, low to moderate query rates | Sustained high query rates, large single-namespace workloads, predictable performance and cost |
## When to use dedicated read nodes
Dedicated read nodes are ideal for workloads with millions to billions of records and predictable query rates. They provide performance and cost benefits compared to on-demand for high-throughput workloads, and may be required when your workload exceeds on-demand rate limits.
There's no universal formula for choosing between on-demand and dedicated read nodes—performance and cost vary by workload (vector dimensionality, metadata filtering, and query patterns). Consider the following factors when making your decision:
 ---
# Source: https://docs.pinecone.io/troubleshooting/error-cannot-import-name-pinecone.md
> ## Documentation Index
> Fetch the complete documentation index at: https://docs.pinecone.io/llms.txt
> Use this file to discover all available pages before exploring further.
# Error: Cannot import name 'Pinecone' from 'pinecone'
## Problem
When using an older version of the [Python SDK](https://github.com/pinecone-io/pinecone-python-client) (earlier than 3.0.0), trying to import the `Pinecone` class raises the following error:
```console console theme={null}
ImportError: cannot import name 'Pinecone' from 'pinecone'
```
## Solution
Upgrade the SDK version and try again:
```Shell Shell theme={null}
# If you're interacting with Pinecone via HTTP requests, use:
pip install pinecone --upgrade
```
```Shell Shell theme={null}
# If you're interacting with Pinecone via gRPC, use:
pip install "pinecone[grpc]" --upgrade
```
---
# Source: https://docs.pinecone.io/guides/production/error-handling.md
> ## Documentation Index
> Fetch the complete documentation index at: https://docs.pinecone.io/llms.txt
> Use this file to discover all available pages before exploring further.
# Error handling
> Handle errors with retry logic and best practices.
## Understand error types
Pinecone uses [conventional HTTP response codes](/reference/api/errors) to indicate the success or failure of API requests:
* **2xx codes** indicate success
* **4xx codes** indicate client errors (issues with your request)
* **5xx codes** indicate server errors (issues with Pinecone's servers)
### Client errors (4xx)
Client errors indicate problems with your request. These errors typically require changes to your code or configuration:
* **400 - Invalid Argument**: Your request contains invalid parameters. Check your request format and parameters.
* **401 - Unauthenticated**: Your API key is missing or invalid. Verify your [API key](/guides/projects/manage-api-keys).
* **402 - Payment Required**: Your account has a payment issue. Check your billing status in the [console](https://app.pinecone.io).
* **403 - Forbidden**: You've exceeded a [quota](/reference/api/database-limits#object-limits) or hit [deletion protection](/guides/manage-data/manage-indexes#configure-deletion-protection).
* **404 - Not Found**: The requested resource doesn't exist. Verify the resource name and that it hasn't been deleted.
* **409 - Already Exists**: You're trying to create a resource that already exists.
* **429 - Too Many Requests**: You're being [rate-limited](/reference/api/database-limits#rate-limits). Implement [backoff and retry logic](#implement-retry-logic).
### Server errors (5xx)
Server errors indicate temporary issues with Pinecone's infrastructure:
* **500 - Unknown**: An internal server error occurred.
* **502 - Bad Gateway**: The API gateway received an invalid response from a backend service.
* **503 - Unavailable**: The service is currently unavailable.
* **504 - Gateway Timeout**: The API gateway did not receive a timely response from the backend server. This can occur due to slow requests or backend processing delays.
**Best practice for 5xx errors**: [Implement retry logic with exponential backoff](/guides/production/error-handling#implement-retry-logic). These errors are typically transient.
## Capture errors
Each SDK provides error handling mechanisms specific to the language:
### Python SDK
The Python SDK raises exceptions that you can catch and handle:
```python theme={null}
from pinecone import Pinecone
from pinecone.exceptions import PineconeException
pc = Pinecone(api_key="YOUR_API_KEY")
index = pc.Index("your-index")
try:
index.upsert(
vectors=[
{"id": "vec1", "values": [0.1, 0.2, 0.3]}
]
)
except PineconeException as e:
# Handle Pinecone-specific errors
print(f"Pinecone error: {e}")
except Exception as e:
# Handle other errors
print(f"Unexpected error: {e}")
```
See the [Python SDK documentation](https://sdk.pinecone.io/python/) for more details on exception handling.
### Node.js SDK
The Node.js SDK uses standard JavaScript error handling:
```javascript theme={null}
const { Pinecone } = require('@pinecone-database/pinecone');
const pc = new Pinecone({ apiKey: 'YOUR_API_KEY' });
try {
const index = pc.index('your-index');
await index.upsert([
{ id: 'vec1', values: [0.1, 0.2, 0.3] }
]);
} catch (error) {
console.error('Error upserting data:', error);
// Handle the error appropriately
}
```
See the [Node.js SDK documentation](https://sdk.pinecone.io/typescript/) for more information.
### Other SDKs
For SDK-specific error handling patterns, see the documentation for your language:
* [Go SDK](/reference/sdks/go/overview)
* [Java SDK](/reference/sdks/java/overview)
* [.NET SDK](/reference/sdks/dotnet/overview)
## Implement retry logic
For transient errors (5xx codes and 429 rate limiting), implement retry logic. Start with basic retries for simple use cases, or use exponential backoff for production systems.
### Basic retry logic
For simple use cases, start with a basic retry loop with fixed delays:
```python theme={null}
import time
from pinecone.exceptions import PineconeException
def simple_retry(func, max_retries=3, delay=2):
"""
Retry a function with a fixed delay between attempts.
Args:
func: Function to retry
max_retries: Maximum number of retry attempts
delay: Delay in seconds between retries
"""
for attempt in range(max_retries):
try:
return func()
except PineconeException as e:
if attempt == max_retries - 1:
raise # Last attempt, re-raise the exception
print(f"Attempt {attempt + 1} failed, retrying in {delay}s...")
time.sleep(delay)
# Usage
try:
simple_retry(lambda: index.upsert(vectors))
except Exception as e:
print(f"Failed after {max_retries} attempts: {e}")
```
This basic approach works well for occasional transient errors, but for production systems with higher traffic, use exponential backoff instead.
### Exponential backoff
Exponential backoff progressively increases the wait time between retries to avoid overwhelming the service:
```python theme={null}
import time
import random
def exponential_backoff_retry(func, max_retries=5, base_delay=1, max_delay=60):
"""
Retry a function with exponential backoff.
Args:
func: Function to retry
max_retries: Maximum number of retry attempts
base_delay: Initial delay in seconds
max_delay: Maximum delay between retries
"""
for attempt in range(max_retries):
try:
return func()
except PineconeException as e:
if attempt == max_retries - 1:
raise # Last attempt, re-raise the exception
# Get status code if available
status_code = getattr(e, 'status', None)
# Only retry on 5xx errors or 429 (rate limiting)
if status_code and (status_code >= 500 or status_code == 429):
# Calculate delay with exponential backoff and jitter
delay = min(base_delay * (2 ** attempt), max_delay)
jitter = random.uniform(0, delay * 0.1) # Add 10% jitter
wait_time = delay + jitter
print(f"Retry attempt {attempt + 1}/{max_retries} after {wait_time:.2f}s")
time.sleep(wait_time)
else:
# Don't retry client errors (4xx except 429)
raise
# Usage
try:
exponential_backoff_retry(lambda: index.upsert(vectors))
except Exception as e:
print(f"Failed after retries: {e}")
```
### Key retry principles
1. **Add jitter**: Random variation in retry timing helps avoid thundering herd problems.
2. **Set max retries**: Prevent infinite retry loops.
3. **Cap delay time**: Don't wait indefinitely between retries.
4. **Don't retry client errors**: 4xx errors (except 429) won't resolve with retries.
5. **Log retry attempts**: Track retry behavior for monitoring and debugging.
## Handle rate limits (429)
When you receive a 429 error, you're being rate-limited. See [Rate limits](/reference/api/database-limits#rate-limits) for current limits.
Rate limits help protect your applications and maintain the health of the serverless infrastructure. **Most limits can be adjusted upon request**—if you need higher limits to scale, [contact Support](https://app.pinecone.io/organizations/-/settings/support/ticket) with details about your use case.
---
# Source: https://docs.pinecone.io/troubleshooting/error-cannot-import-name-pinecone.md
> ## Documentation Index
> Fetch the complete documentation index at: https://docs.pinecone.io/llms.txt
> Use this file to discover all available pages before exploring further.
# Error: Cannot import name 'Pinecone' from 'pinecone'
## Problem
When using an older version of the [Python SDK](https://github.com/pinecone-io/pinecone-python-client) (earlier than 3.0.0), trying to import the `Pinecone` class raises the following error:
```console console theme={null}
ImportError: cannot import name 'Pinecone' from 'pinecone'
```
## Solution
Upgrade the SDK version and try again:
```Shell Shell theme={null}
# If you're interacting with Pinecone via HTTP requests, use:
pip install pinecone --upgrade
```
```Shell Shell theme={null}
# If you're interacting with Pinecone via gRPC, use:
pip install "pinecone[grpc]" --upgrade
```
---
# Source: https://docs.pinecone.io/guides/production/error-handling.md
> ## Documentation Index
> Fetch the complete documentation index at: https://docs.pinecone.io/llms.txt
> Use this file to discover all available pages before exploring further.
# Error handling
> Handle errors with retry logic and best practices.
## Understand error types
Pinecone uses [conventional HTTP response codes](/reference/api/errors) to indicate the success or failure of API requests:
* **2xx codes** indicate success
* **4xx codes** indicate client errors (issues with your request)
* **5xx codes** indicate server errors (issues with Pinecone's servers)
### Client errors (4xx)
Client errors indicate problems with your request. These errors typically require changes to your code or configuration:
* **400 - Invalid Argument**: Your request contains invalid parameters. Check your request format and parameters.
* **401 - Unauthenticated**: Your API key is missing or invalid. Verify your [API key](/guides/projects/manage-api-keys).
* **402 - Payment Required**: Your account has a payment issue. Check your billing status in the [console](https://app.pinecone.io).
* **403 - Forbidden**: You've exceeded a [quota](/reference/api/database-limits#object-limits) or hit [deletion protection](/guides/manage-data/manage-indexes#configure-deletion-protection).
* **404 - Not Found**: The requested resource doesn't exist. Verify the resource name and that it hasn't been deleted.
* **409 - Already Exists**: You're trying to create a resource that already exists.
* **429 - Too Many Requests**: You're being [rate-limited](/reference/api/database-limits#rate-limits). Implement [backoff and retry logic](#implement-retry-logic).
### Server errors (5xx)
Server errors indicate temporary issues with Pinecone's infrastructure:
* **500 - Unknown**: An internal server error occurred.
* **502 - Bad Gateway**: The API gateway received an invalid response from a backend service.
* **503 - Unavailable**: The service is currently unavailable.
* **504 - Gateway Timeout**: The API gateway did not receive a timely response from the backend server. This can occur due to slow requests or backend processing delays.
**Best practice for 5xx errors**: [Implement retry logic with exponential backoff](/guides/production/error-handling#implement-retry-logic). These errors are typically transient.
## Capture errors
Each SDK provides error handling mechanisms specific to the language:
### Python SDK
The Python SDK raises exceptions that you can catch and handle:
```python theme={null}
from pinecone import Pinecone
from pinecone.exceptions import PineconeException
pc = Pinecone(api_key="YOUR_API_KEY")
index = pc.Index("your-index")
try:
index.upsert(
vectors=[
{"id": "vec1", "values": [0.1, 0.2, 0.3]}
]
)
except PineconeException as e:
# Handle Pinecone-specific errors
print(f"Pinecone error: {e}")
except Exception as e:
# Handle other errors
print(f"Unexpected error: {e}")
```
See the [Python SDK documentation](https://sdk.pinecone.io/python/) for more details on exception handling.
### Node.js SDK
The Node.js SDK uses standard JavaScript error handling:
```javascript theme={null}
const { Pinecone } = require('@pinecone-database/pinecone');
const pc = new Pinecone({ apiKey: 'YOUR_API_KEY' });
try {
const index = pc.index('your-index');
await index.upsert([
{ id: 'vec1', values: [0.1, 0.2, 0.3] }
]);
} catch (error) {
console.error('Error upserting data:', error);
// Handle the error appropriately
}
```
See the [Node.js SDK documentation](https://sdk.pinecone.io/typescript/) for more information.
### Other SDKs
For SDK-specific error handling patterns, see the documentation for your language:
* [Go SDK](/reference/sdks/go/overview)
* [Java SDK](/reference/sdks/java/overview)
* [.NET SDK](/reference/sdks/dotnet/overview)
## Implement retry logic
For transient errors (5xx codes and 429 rate limiting), implement retry logic. Start with basic retries for simple use cases, or use exponential backoff for production systems.
### Basic retry logic
For simple use cases, start with a basic retry loop with fixed delays:
```python theme={null}
import time
from pinecone.exceptions import PineconeException
def simple_retry(func, max_retries=3, delay=2):
"""
Retry a function with a fixed delay between attempts.
Args:
func: Function to retry
max_retries: Maximum number of retry attempts
delay: Delay in seconds between retries
"""
for attempt in range(max_retries):
try:
return func()
except PineconeException as e:
if attempt == max_retries - 1:
raise # Last attempt, re-raise the exception
print(f"Attempt {attempt + 1} failed, retrying in {delay}s...")
time.sleep(delay)
# Usage
try:
simple_retry(lambda: index.upsert(vectors))
except Exception as e:
print(f"Failed after {max_retries} attempts: {e}")
```
This basic approach works well for occasional transient errors, but for production systems with higher traffic, use exponential backoff instead.
### Exponential backoff
Exponential backoff progressively increases the wait time between retries to avoid overwhelming the service:
```python theme={null}
import time
import random
def exponential_backoff_retry(func, max_retries=5, base_delay=1, max_delay=60):
"""
Retry a function with exponential backoff.
Args:
func: Function to retry
max_retries: Maximum number of retry attempts
base_delay: Initial delay in seconds
max_delay: Maximum delay between retries
"""
for attempt in range(max_retries):
try:
return func()
except PineconeException as e:
if attempt == max_retries - 1:
raise # Last attempt, re-raise the exception
# Get status code if available
status_code = getattr(e, 'status', None)
# Only retry on 5xx errors or 429 (rate limiting)
if status_code and (status_code >= 500 or status_code == 429):
# Calculate delay with exponential backoff and jitter
delay = min(base_delay * (2 ** attempt), max_delay)
jitter = random.uniform(0, delay * 0.1) # Add 10% jitter
wait_time = delay + jitter
print(f"Retry attempt {attempt + 1}/{max_retries} after {wait_time:.2f}s")
time.sleep(wait_time)
else:
# Don't retry client errors (4xx except 429)
raise
# Usage
try:
exponential_backoff_retry(lambda: index.upsert(vectors))
except Exception as e:
print(f"Failed after retries: {e}")
```
### Key retry principles
1. **Add jitter**: Random variation in retry timing helps avoid thundering herd problems.
2. **Set max retries**: Prevent infinite retry loops.
3. **Cap delay time**: Don't wait indefinitely between retries.
4. **Don't retry client errors**: 4xx errors (except 429) won't resolve with retries.
5. **Log retry attempts**: Track retry behavior for monitoring and debugging.
## Handle rate limits (429)
When you receive a 429 error, you're being rate-limited. See [Rate limits](/reference/api/database-limits#rate-limits) for current limits.
Rate limits help protect your applications and maintain the health of the serverless infrastructure. **Most limits can be adjusted upon request**—if you need higher limits to scale, [contact Support](https://app.pinecone.io/organizations/-/settings/support/ticket) with details about your use case.
 We click on **Create new endpoint**, choose a model repository (eg name of the model), endpoint name (this can be anything), and select a cloud environment. Before moving on it is *very important* that we set the **Task** to **Sentence Embeddings** (found within the *Advanced configuration* settings).
We click on **Create new endpoint**, choose a model repository (eg name of the model), endpoint name (this can be anything), and select a cloud environment. Before moving on it is *very important* that we set the **Task** to **Sentence Embeddings** (found within the *Advanced configuration* settings).
 Other important options include the *Instance Type*, by default this uses CPU which is cheaper but also slower. For faster processing we need a GPU instance. And finally, we set our privacy setting near the end of the page.
After setting our options we can click **Create Endpoint** at the bottom of the page. This action should take use to the next page where we will see the current status of our endpoint.
Other important options include the *Instance Type*, by default this uses CPU which is cheaper but also slower. For faster processing we need a GPU instance. And finally, we set our privacy setting near the end of the page.
After setting our options we can click **Create Endpoint** at the bottom of the page. This action should take use to the next page where we will see the current status of our endpoint.
 Once the status has moved from **Building** to **Running** (this can take some time), we're ready to begin creating embeddings with it.
## Create embeddings
Each endpoint is given an **Endpoint URL**, it can be found on the endpoint **Overview** page. We need to assign this endpoint URL to the `endpoint_url` variable.
Once the status has moved from **Building** to **Running** (this can take some time), we're ready to begin creating embeddings with it.
## Create embeddings
Each endpoint is given an **Endpoint URL**, it can be found on the endpoint **Overview** page. We need to assign this endpoint URL to the `endpoint_url` variable.
 ```Python Python theme={null}
endpoint = "
```Python Python theme={null}
endpoint = " ```Python Python theme={null}
api_org = "
```Python Python theme={null}
api_org = "
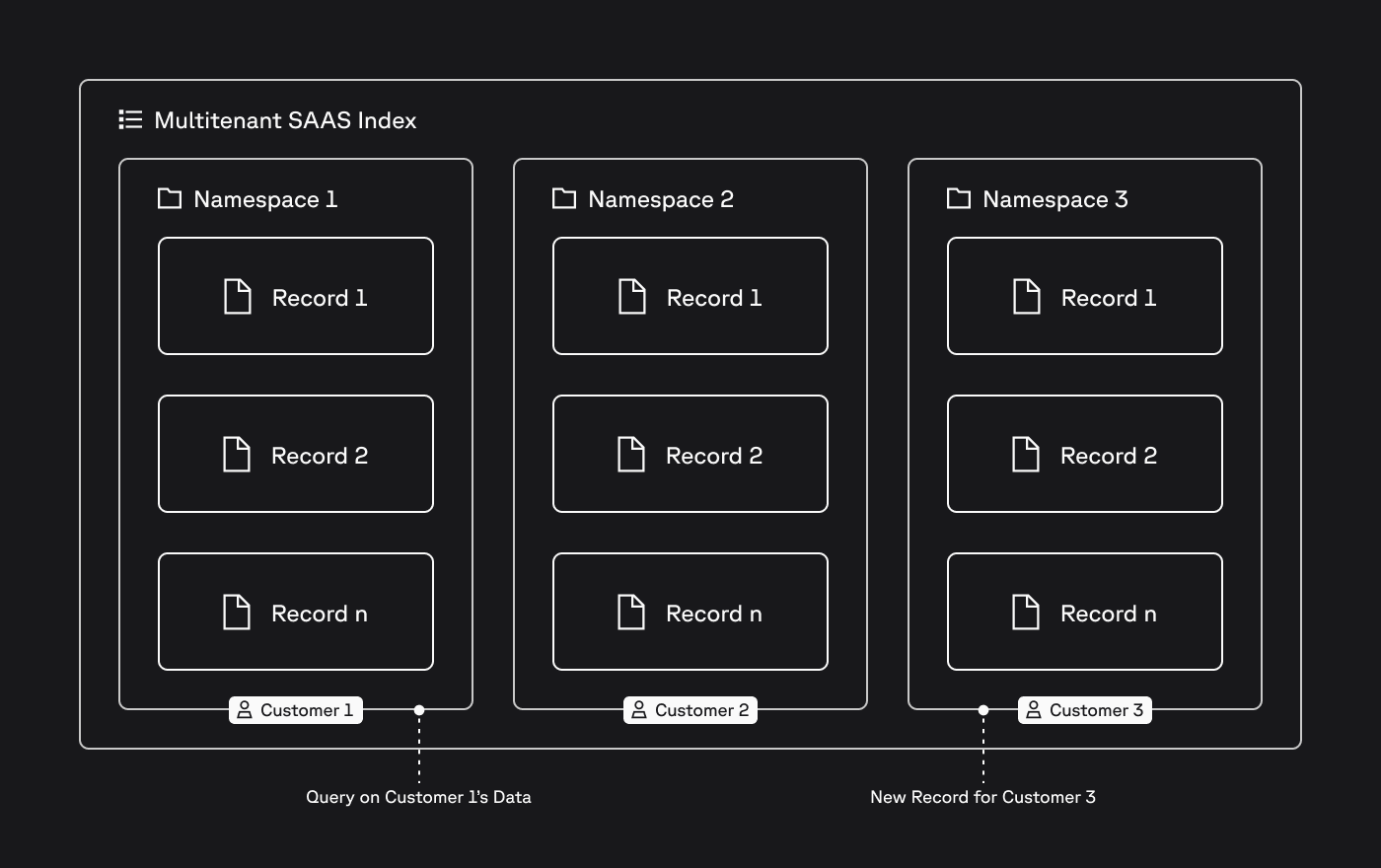 In Pinecone, an [index](/guides/index-data/indexing-overview) is the highest-level organizational unit of data, where you define the dimension of vectors to be stored in the index and the measure of similarity to be used when querying the index.
Within an index, records are stored in [namespaces](/guides/index-data/indexing-overview#namespaces), and all [upserts](/guides/index-data/upsert-data), [queries](/guides/search/search-overview), and other [data plane operations](/reference/api/latest/data-plane) always target one namespace.
This structure makes it easy to implement multitenancy. For example, for an AI-powered SaaS application where you need to isolate the data of each customer, you would assign each customer to a namespace and target their writes and queries to that namespace (diagram above).
In cases where you have different workload patterns (e.g., RAG and semantic search), you would use a different index for each workload, with one namespace per customer in each index:
In Pinecone, an [index](/guides/index-data/indexing-overview) is the highest-level organizational unit of data, where you define the dimension of vectors to be stored in the index and the measure of similarity to be used when querying the index.
Within an index, records are stored in [namespaces](/guides/index-data/indexing-overview#namespaces), and all [upserts](/guides/index-data/upsert-data), [queries](/guides/search/search-overview), and other [data plane operations](/reference/api/latest/data-plane) always target one namespace.
This structure makes it easy to implement multitenancy. For example, for an AI-powered SaaS application where you need to isolate the data of each customer, you would assign each customer to a namespace and target their writes and queries to that namespace (diagram above).
In cases where you have different workload patterns (e.g., RAG and semantic search), you would use a different index for each workload, with one namespace per customer in each index:
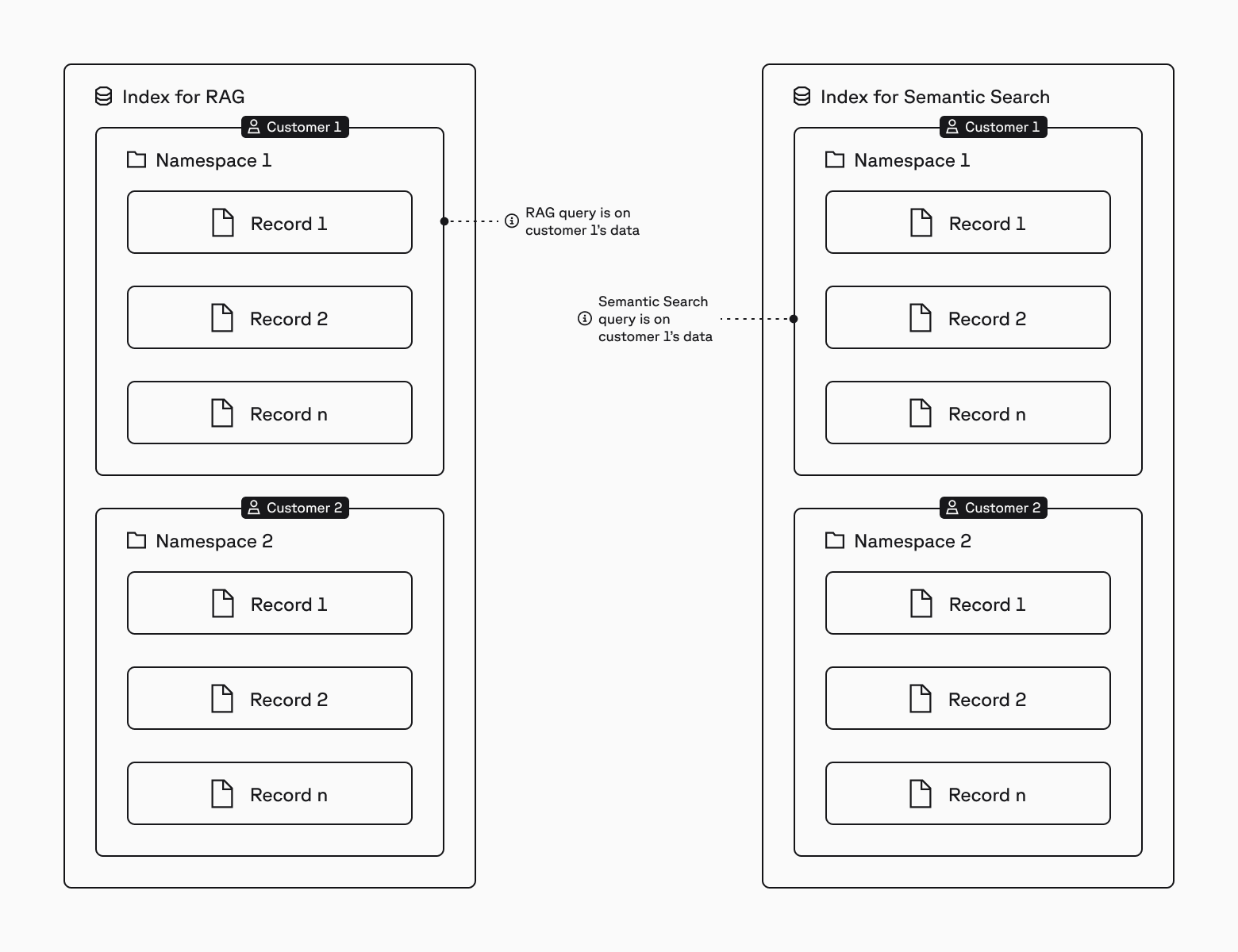
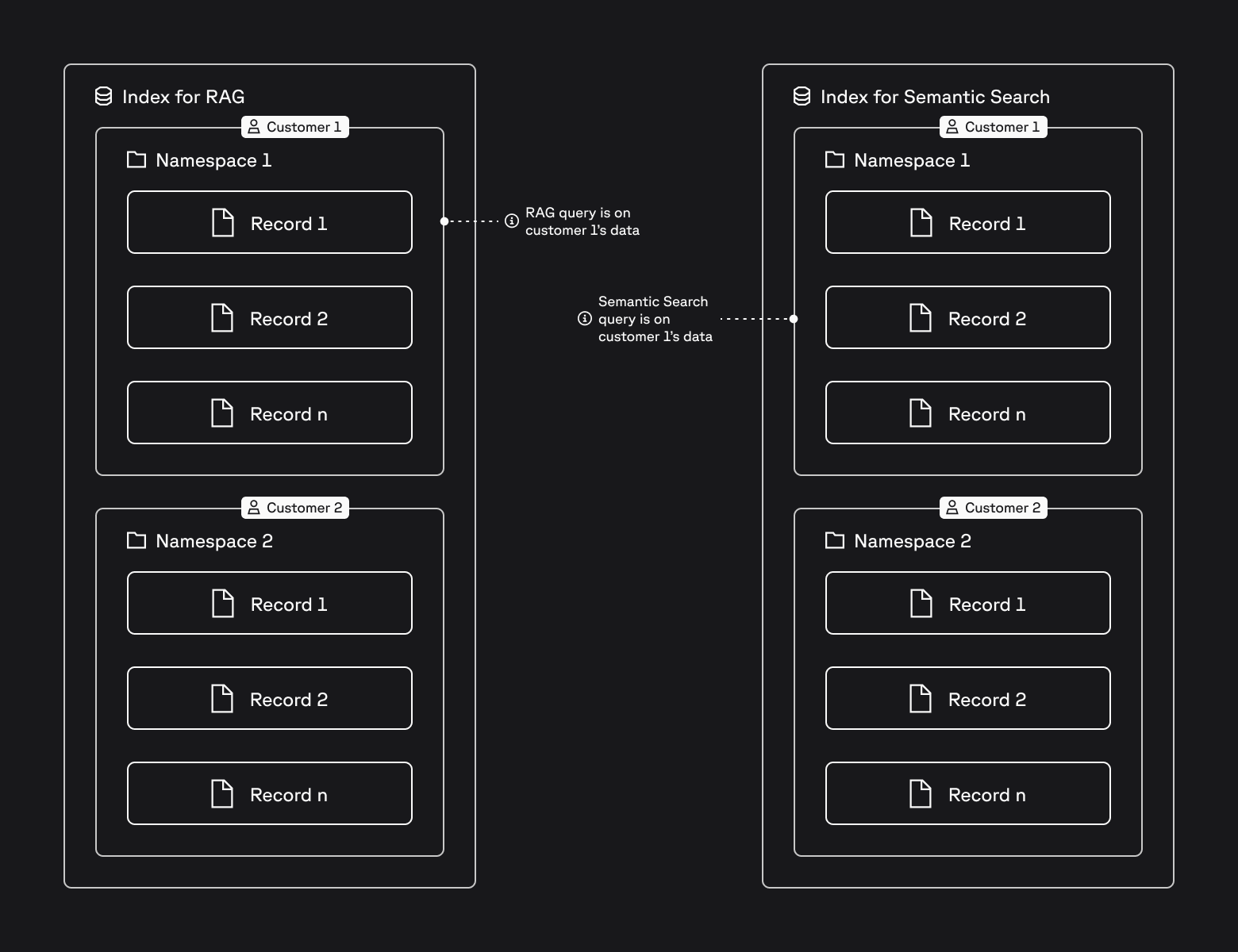
 When the new serverless index is ready, the status will change to green:
When the new serverless index is ready, the status will change to green:
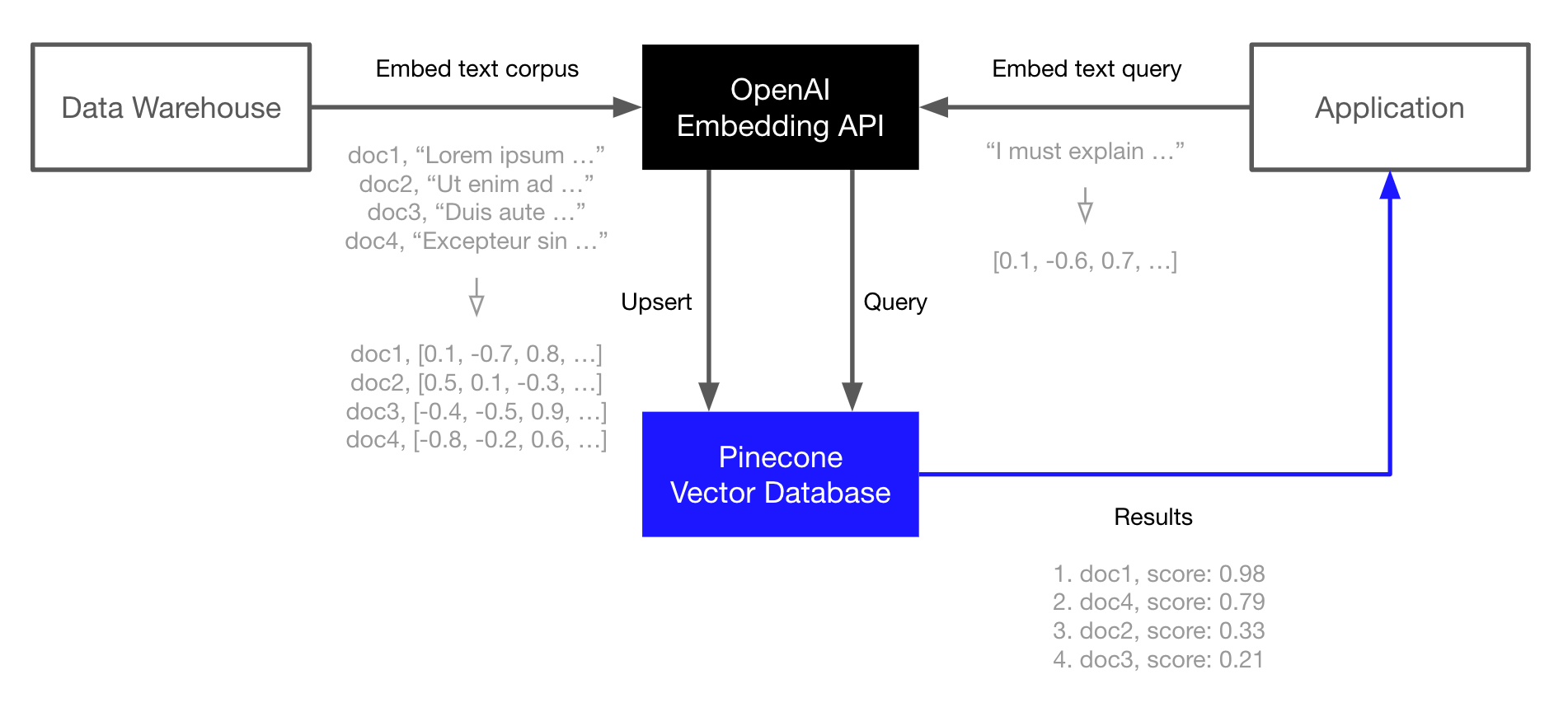 Let's get started...
### Environment Setup
We start by installing the OpenAI and Pinecone clients, we will also need HuggingFace *Datasets* for downloading the TREC dataset that we will use in this guide.
```Bash Bash theme={null}
!pip install -qU \
pinecone[grpc]==7.3.0 \
openai==1.93.0 \
datasets==3.6.0
```
#### Creating Embeddings
To create embeddings we must first initialize our connection to OpenAI Embeddings, we sign up for an API key at [OpenAI](https://beta.openai.com/signup).
```Python Python theme={null}
from openai import OpenAI
client = OpenAI(
api_key="OPENAI_API_KEY"
) # get API key from platform.openai.com
```
We can now create embeddings with the OpenAI v3 small embedding model like so:
```Python Python theme={null}
MODEL = "text-embedding-3-small"
res = client.embeddings.create(
input=[
"Sample document text goes here",
"there will be several phrases in each batch"
], model=MODEL
)
```
In `res` we should find a JSON-like object containing two 1536-dimensional embeddings, these are the vector representations of the two inputs provided above. To access the embeddings directly we can write:
```Python Python theme={null}
# we can extract embeddings to a list
embeds = [record.embedding for record in res.data]
len(embeds)
```
We will use this logic when creating our embeddings for the **T**ext **RE**trieval **C**onference (TREC) question classification dataset later.
#### Initializing a Pinecone Index
Next, we initialize an index to store the vector embeddings. For this we need a Pinecone API key, [sign up for one here](https://app.pinecone.io).
```Python Python theme={null}
import time
from pinecone.grpc import PineconeGRPC as Pinecone
from pinecone import ServerlessSpec
pc = Pinecone(api_key="...")
spec = ServerlessSpec(cloud="aws", region="us-east-1")
index_name = 'semantic-search-openai'
# check if index already exists (it shouldn't if this is your first run)
if index_name not in pc.list_indexes().names():
# if does not exist, create index
pc.create_index(
index_name,
dimension=len(embeds[0]), # dimensionality of text-embed-3-small
metric='dotproduct',
spec=spec
)
# connect to index
index = pc.Index(index_name)
time.sleep(1)
# view index stats
index.describe_index_stats()
```
#### Populating the Index
With both OpenAI and Pinecone connections initialized, we can move onto populating the index. For this, we need the TREC dataset.
```Python Python theme={null}
from datasets import load_dataset
# load the first 1K rows of the TREC dataset
trec = load_dataset('trec', split='train[:1000]')
```
Then we create a vector embedding for each question using OpenAI (as demonstrated earlier), and `upsert` the ID, vector embedding, and original text for each phrase to Pinecone.
Let's get started...
### Environment Setup
We start by installing the OpenAI and Pinecone clients, we will also need HuggingFace *Datasets* for downloading the TREC dataset that we will use in this guide.
```Bash Bash theme={null}
!pip install -qU \
pinecone[grpc]==7.3.0 \
openai==1.93.0 \
datasets==3.6.0
```
#### Creating Embeddings
To create embeddings we must first initialize our connection to OpenAI Embeddings, we sign up for an API key at [OpenAI](https://beta.openai.com/signup).
```Python Python theme={null}
from openai import OpenAI
client = OpenAI(
api_key="OPENAI_API_KEY"
) # get API key from platform.openai.com
```
We can now create embeddings with the OpenAI v3 small embedding model like so:
```Python Python theme={null}
MODEL = "text-embedding-3-small"
res = client.embeddings.create(
input=[
"Sample document text goes here",
"there will be several phrases in each batch"
], model=MODEL
)
```
In `res` we should find a JSON-like object containing two 1536-dimensional embeddings, these are the vector representations of the two inputs provided above. To access the embeddings directly we can write:
```Python Python theme={null}
# we can extract embeddings to a list
embeds = [record.embedding for record in res.data]
len(embeds)
```
We will use this logic when creating our embeddings for the **T**ext **RE**trieval **C**onference (TREC) question classification dataset later.
#### Initializing a Pinecone Index
Next, we initialize an index to store the vector embeddings. For this we need a Pinecone API key, [sign up for one here](https://app.pinecone.io).
```Python Python theme={null}
import time
from pinecone.grpc import PineconeGRPC as Pinecone
from pinecone import ServerlessSpec
pc = Pinecone(api_key="...")
spec = ServerlessSpec(cloud="aws", region="us-east-1")
index_name = 'semantic-search-openai'
# check if index already exists (it shouldn't if this is your first run)
if index_name not in pc.list_indexes().names():
# if does not exist, create index
pc.create_index(
index_name,
dimension=len(embeds[0]), # dimensionality of text-embed-3-small
metric='dotproduct',
spec=spec
)
# connect to index
index = pc.Index(index_name)
time.sleep(1)
# view index stats
index.describe_index_stats()
```
#### Populating the Index
With both OpenAI and Pinecone connections initialized, we can move onto populating the index. For this, we need the TREC dataset.
```Python Python theme={null}
from datasets import load_dataset
# load the first 1K rows of the TREC dataset
trec = load_dataset('trec', split='train[:1000]')
```
Then we create a vector embedding for each question using OpenAI (as demonstrated earlier), and `upsert` the ID, vector embedding, and original text for each phrase to Pinecone.