COPY table\_name FROM 'cloud\_storage\_file\_path' WITH (option);COPY table\_name FROM 'cloud\_storage\_file\_path' WITH (option);COPY table\_name (column\_name) TO `{'file_path' | STDOUT}` WITH (option, ...);- **Delimiter**: For CSV format, the default delimiter is a comma (,)
- By default, the `COPY TO` command overwrites the CSV file if it already exists.
- Please ensure that the directory where you save the file has a write permissions.
- By default, the `COPY TO` command overwrites the CSV file if it already exists.
- Please ensure that the directory where you save the file has the necessary write permissions.
Invalid `postgresql_port` is an exception to the degraded state. Without it being properly set, even liveness condidtion is not met.
- **Temporary Degradation**: Nodes temporarily degraded are assumed to recover and are not considered in query planning. | | Query Execution | The `SHOW NODES` query requires the cluster to be ready and the scheduling node to not be degraded. It allows you to check the degradation status of each node in the cluster. A non-degraded leader collects data on every connected node, including degraded ones. | --- # Source: https://docs.oxla.com/sql-reference/sql-mutations/delete.md > ## Documentation Index > Fetch the complete documentation index at: https://docs.oxla.com/llms.txt > Use this file to discover all available pages before exploring further. # DELETE ## Overview The `DELETE` mutation deletes one or more records from a table based on specified conditions. This support has limitations: * Only one data mutation (DELETE or UPDATE) at a given moment is possible, trying to run another one will fail. * Data mutations rewrite all files containing the data from the UPDATE/DELETE condition. Running `DELETE from the table` without any condition is possible, but it will be much slower than the `DROP TABLE table`. * The syntax is simplified in comparison to Postgres. For example, the `SET column=
 ## EXCEPT ALL
### Overview
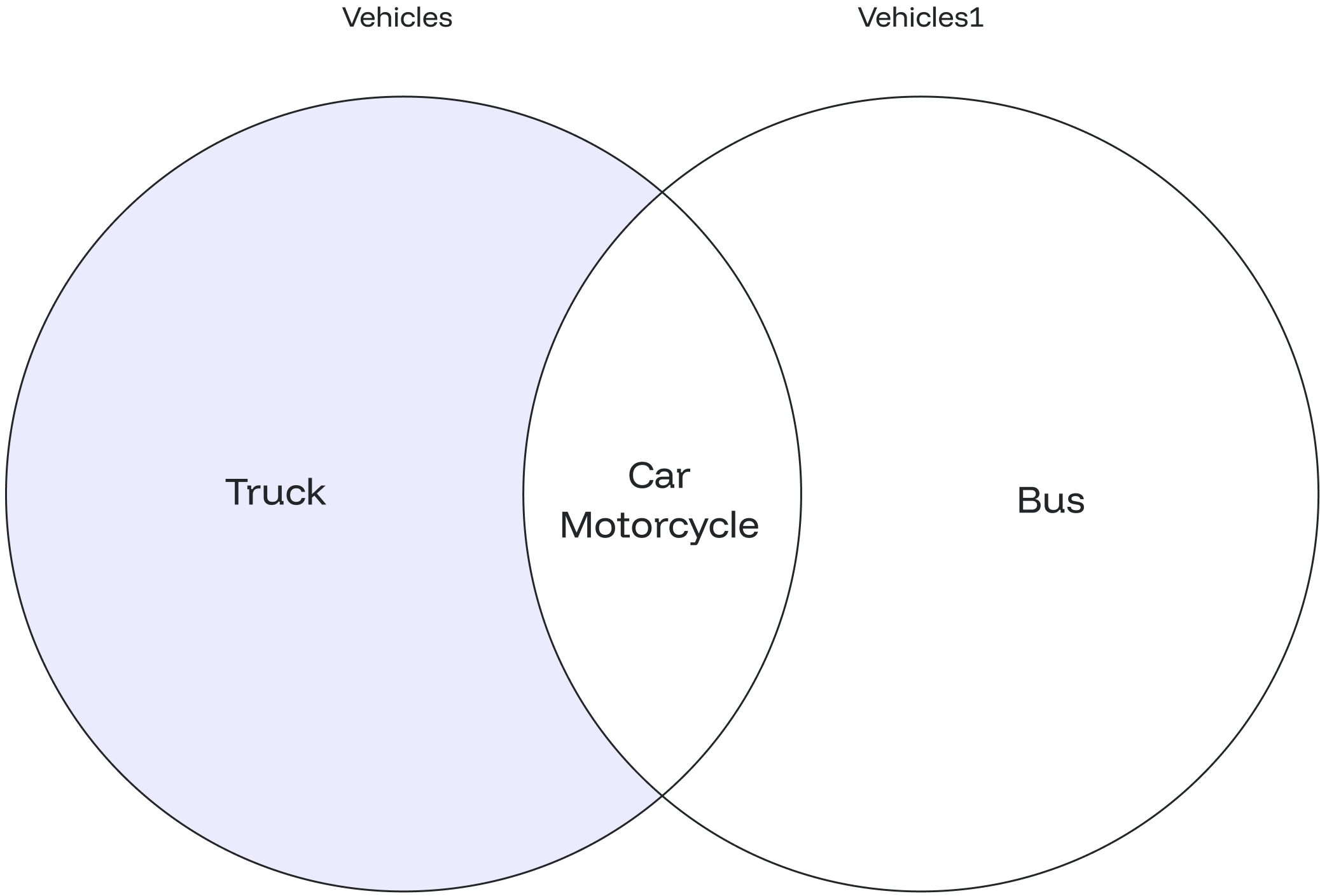
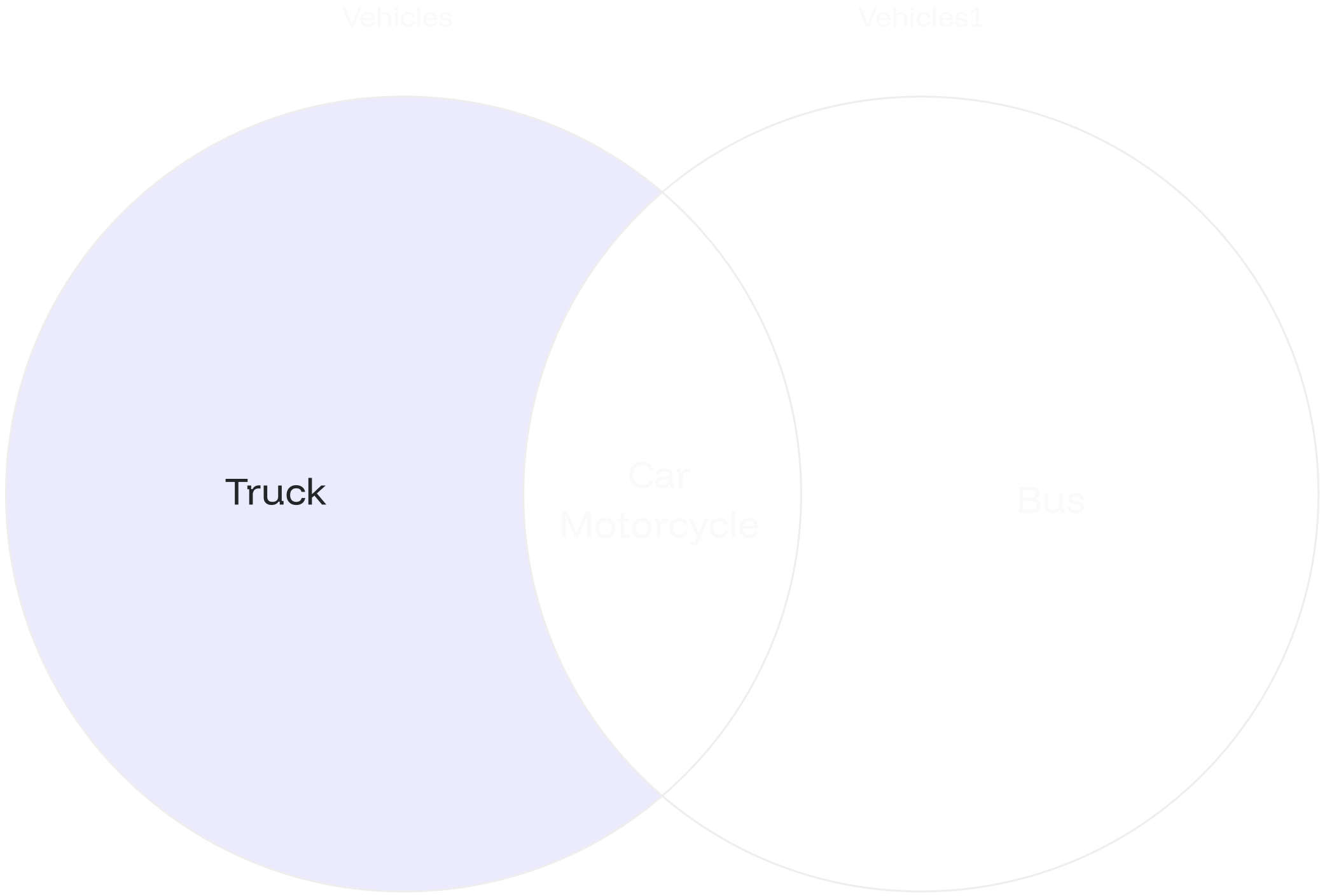
The `EXCEPT ALL` allows you to find rows specific to the first `SELECT` statement while preserving duplicate entries.
### Syntax
The syntax for the `EXCEPT ALL` is similar to `EXCEPT`:
```sql theme={null}
SELECT value1, value2, ... value_n
FROM table1
EXCEPT ALL
SELECT value1, value2, ... value_n
FROM table2;
```
The parameters from the syntax are explained below:
* `value1, value2, ... value_n`: The columns you want to retrieve.
* `table1, table2`: The tables from which you wish to retrieve records.
## EXCEPT ALL
### Overview
The `EXCEPT ALL` allows you to find rows specific to the first `SELECT` statement while preserving duplicate entries.
### Syntax
The syntax for the `EXCEPT ALL` is similar to `EXCEPT`:
```sql theme={null}
SELECT value1, value2, ... value_n
FROM table1
EXCEPT ALL
SELECT value1, value2, ... value_n
FROM table2;
```
The parameters from the syntax are explained below:
* `value1, value2, ... value_n`: The columns you want to retrieve.
* `table1, table2`: The tables from which you wish to retrieve records.
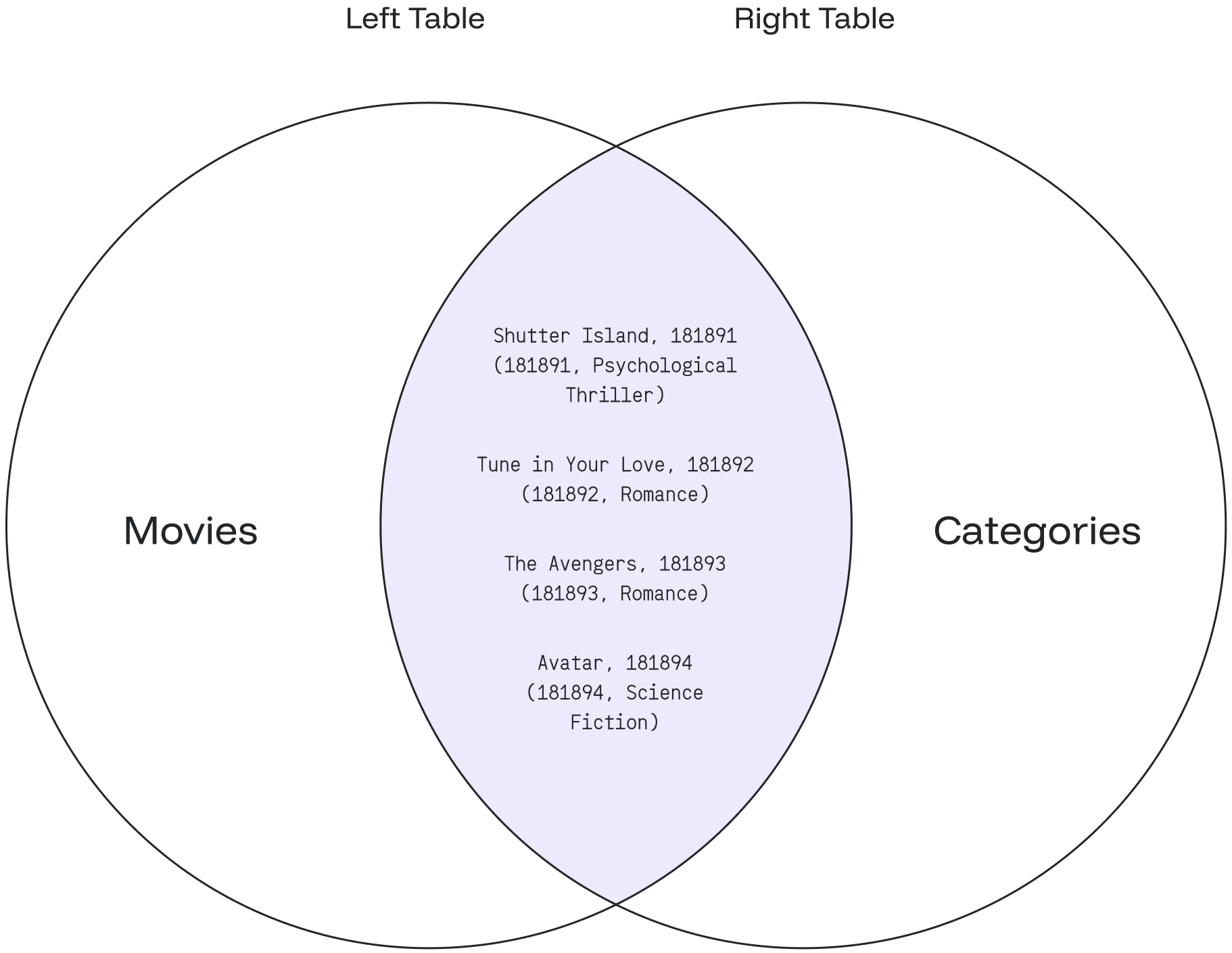
 ### Example #2
Let’s create two tables, `left_array_values` and `right_array_values`, to hold sets of values.
```sql theme={null}
CREATE TABLE left_array_values (
value INT
);
CREATE TABLE right_array_values (
value INT
);
INSERT INTO left_array_values VALUES (1), (1), (3);
INSERT INTO right_array_values VALUES (1), (2);
```
View the contents of the two arrays before performing the comparison.
```sql theme={null}
SELECT * FROM left_array_values;
SELECT * FROM right_array_values;
```
Upon execution, the tables will appear as follows:
```sql theme={null}
value
-------
1
1
3
value
-------
1
2
```
We will now use the `EXCEPT ALL` operation to compare the values within the arrays, focusing on unique elements while retaining duplicate entries.
```sql theme={null}
SELECT value
FROM left_array_values
EXCEPT ALL
SELECT value
FROM right_array_values;
```
The `EXCEPT ALL` operation processes each element individually from both inputs at a time. The comparison occurs element-wise, leading to the inclusion of both 1 and 3 in the final result.
```sql theme={null}
value
-------
3
1
```
---
# Source: https://docs.oxla.com/sql-reference/sql-functions/math-functions/exp.md
> ## Documentation Index
> Fetch the complete documentation index at: https://docs.oxla.com/llms.txt
> Use this file to discover all available pages before exploring further.
# EXP
## Overview
The `EXP()` function returns the exponential value of a number specified in the argument.
## Syntax
The syntax for the `EXP()` is:
```sql theme={null}
EXP(number);
```
Where:
* `number`: The number for which you want to calculate the exponential value. Equivalent to the formula `e^number`.
## Examples
Let's explore examples to see how the `EXP()` function works.
### Case #1: Basic Usage
In this case, we use the `EXP()` function with positive and negative values.
```sql theme={null}
SELECT EXP(0) AS "EXP of 0",
EXP(1) AS "EXP of 1",
EXP(2) AS "EXP of 2",
EXP(-1) AS "EXP of -1",
EXP(-2) AS "EXP of -2";
```
You will get the following result:
```sql theme={null}
EXP of 0 | EXP of 1 | EXP of 2 | EXP of -1 | EXP of -2
----------+-------------------+------------------+---------------------+--------------------
1 | 2.718281828459045 | 7.38905609893065 | 0.36787944117144233 | 0.1353352832366127
```
### Case #2: Using `EXP()` with Fractions
This case uses the `EXP()` function with a fractional argument.
```sql theme={null}
SELECT EXP(3.2);
```
Here is the result:
```sql theme={null}
exp
--------------------
24.532531366911574
```
### Case #3: Using `EXP()` with Expressions
Here, we use the `EXP()` function with expressions.
```sql theme={null}
SELECT EXP(5 * 5);
```
See the result below:
```sql theme={null}
exp
-------------------
72004899337.38588
```
---
# Source: https://docs.oxla.com/sql-reference/sql-functions/timestamp-functions/extract.md
> ## Documentation Index
> Fetch the complete documentation index at: https://docs.oxla.com/llms.txt
> Use this file to discover all available pages before exploring further.
# EXTRACT
## Overview
The `EXTRACT()` function retrieves a specified part (field) from a given date/time or interval value.
It is commonly used to obtain components such as year, month, day, hour, etc., from timestamps or dates.
## Syntax
```sql theme={null}
EXTRACT (field FROM source)
```
## Parameters
* `field`: string or identifier specifying the part of the date / time to extract
* `source`: date / time value from which to extract the specifed field
The table below shows the supported input and corresponding return types for the `EXTRACT()` function:
| Input Type: `source` | Supported `field` values | Return Type |
| -------------------- | -------------------------------------------------- | ------------------ |
| `TIMESTAMP` | `YEAR`, `MONTH`, `DAY`, `HOUR`, `MINUTE`, `SECOND` | `DOUBLE PRECISION` |
| `TIMESTAMPTZ` | `YEAR`, `MONTH`, `DAY`, `HOUR`, `MINUTE`, `SECOND` | `DOUBLE PRECISION` |
| `DATE` | `YEAR`, `MONTH`, `DAY` | `INTEGER` |
### Example #2
Let’s create two tables, `left_array_values` and `right_array_values`, to hold sets of values.
```sql theme={null}
CREATE TABLE left_array_values (
value INT
);
CREATE TABLE right_array_values (
value INT
);
INSERT INTO left_array_values VALUES (1), (1), (3);
INSERT INTO right_array_values VALUES (1), (2);
```
View the contents of the two arrays before performing the comparison.
```sql theme={null}
SELECT * FROM left_array_values;
SELECT * FROM right_array_values;
```
Upon execution, the tables will appear as follows:
```sql theme={null}
value
-------
1
1
3
value
-------
1
2
```
We will now use the `EXCEPT ALL` operation to compare the values within the arrays, focusing on unique elements while retaining duplicate entries.
```sql theme={null}
SELECT value
FROM left_array_values
EXCEPT ALL
SELECT value
FROM right_array_values;
```
The `EXCEPT ALL` operation processes each element individually from both inputs at a time. The comparison occurs element-wise, leading to the inclusion of both 1 and 3 in the final result.
```sql theme={null}
value
-------
3
1
```
---
# Source: https://docs.oxla.com/sql-reference/sql-functions/math-functions/exp.md
> ## Documentation Index
> Fetch the complete documentation index at: https://docs.oxla.com/llms.txt
> Use this file to discover all available pages before exploring further.
# EXP
## Overview
The `EXP()` function returns the exponential value of a number specified in the argument.
## Syntax
The syntax for the `EXP()` is:
```sql theme={null}
EXP(number);
```
Where:
* `number`: The number for which you want to calculate the exponential value. Equivalent to the formula `e^number`.
## Examples
Let's explore examples to see how the `EXP()` function works.
### Case #1: Basic Usage
In this case, we use the `EXP()` function with positive and negative values.
```sql theme={null}
SELECT EXP(0) AS "EXP of 0",
EXP(1) AS "EXP of 1",
EXP(2) AS "EXP of 2",
EXP(-1) AS "EXP of -1",
EXP(-2) AS "EXP of -2";
```
You will get the following result:
```sql theme={null}
EXP of 0 | EXP of 1 | EXP of 2 | EXP of -1 | EXP of -2
----------+-------------------+------------------+---------------------+--------------------
1 | 2.718281828459045 | 7.38905609893065 | 0.36787944117144233 | 0.1353352832366127
```
### Case #2: Using `EXP()` with Fractions
This case uses the `EXP()` function with a fractional argument.
```sql theme={null}
SELECT EXP(3.2);
```
Here is the result:
```sql theme={null}
exp
--------------------
24.532531366911574
```
### Case #3: Using `EXP()` with Expressions
Here, we use the `EXP()` function with expressions.
```sql theme={null}
SELECT EXP(5 * 5);
```
See the result below:
```sql theme={null}
exp
-------------------
72004899337.38588
```
---
# Source: https://docs.oxla.com/sql-reference/sql-functions/timestamp-functions/extract.md
> ## Documentation Index
> Fetch the complete documentation index at: https://docs.oxla.com/llms.txt
> Use this file to discover all available pages before exploring further.
# EXTRACT
## Overview
The `EXTRACT()` function retrieves a specified part (field) from a given date/time or interval value.
It is commonly used to obtain components such as year, month, day, hour, etc., from timestamps or dates.
## Syntax
```sql theme={null}
EXTRACT (field FROM source)
```
## Parameters
* `field`: string or identifier specifying the part of the date / time to extract
* `source`: date / time value from which to extract the specifed field
The table below shows the supported input and corresponding return types for the `EXTRACT()` function:
| Input Type: `source` | Supported `field` values | Return Type |
| -------------------- | -------------------------------------------------- | ------------------ |
| `TIMESTAMP` | `YEAR`, `MONTH`, `DAY`, `HOUR`, `MINUTE`, `SECOND` | `DOUBLE PRECISION` |
| `TIMESTAMPTZ` | `YEAR`, `MONTH`, `DAY`, `HOUR`, `MINUTE`, `SECOND` | `DOUBLE PRECISION` |
| `DATE` | `YEAR`, `MONTH`, `DAY` | `INTEGER` |
-`NULL` values within the expressions are ignored.
- The result will be `NULL` if all expressions evaluate to `NULL`.

 ## INTERSECT ALL
### Overview
The `INTERSECT ALL` retrieves all common rows between two or more tables, including duplicates.
This means that if a row appears multiple times in any of the `SELECT` statements, it will be included in the final result set multiple times.
### Syntax
The syntax for `INTERSECT ALL` is similar to `INTERSECT`:
```sql theme={null}
SELECT value1, value2, ... value_n
FROM tables
INTERSECT ALL
SELECT value1, value2, ... value_n
FROM tables;
```
The parameters from the syntax are explained below:
* `value1, value2, ... value_n`: The columns you wish to retrieve. You can also retrieve all the values using the `SELECT * FROM` query.
* `table1, table2`: The tables from which you want to retrieve records.
## INTERSECT ALL
### Overview
The `INTERSECT ALL` retrieves all common rows between two or more tables, including duplicates.
This means that if a row appears multiple times in any of the `SELECT` statements, it will be included in the final result set multiple times.
### Syntax
The syntax for `INTERSECT ALL` is similar to `INTERSECT`:
```sql theme={null}
SELECT value1, value2, ... value_n
FROM tables
INTERSECT ALL
SELECT value1, value2, ... value_n
FROM tables;
```
The parameters from the syntax are explained below:
* `value1, value2, ... value_n`: The columns you wish to retrieve. You can also retrieve all the values using the `SELECT * FROM` query.
* `table1, table2`: The tables from which you want to retrieve records.

 ---
# Source: https://docs.oxla.com/sql-reference/sql-data-types/interval.md
> ## Documentation Index
> Fetch the complete documentation index at: https://docs.oxla.com/llms.txt
> Use this file to discover all available pages before exploring further.
# Interval
## Overview
The Interval data type represents periods between dates or times, which can be precisely calculated and expressed through various units. Those can be combined and include additional options for different interval calculations.
In this doc, you'll find more about the **interval syntax**, learn what are **supported units and abbreviations**, browse through **examples** and finally find out how to **extract data from intervals**.
## Syntax
The syntax for specifying an interval is as follows:
```sql theme={null}
SELECT INTERVAL 'quantity unit [quantity unit...] [direction]' [OPTION]
```
**Parameters Description**
| **Parameter** | **Description** |
| ------------- | ---------------------------------------------------------------------------------------------------------------------------------------------------------------------------- |
| `quantity` | The value representing the number of units |
| `unit` | - Year, month, day, hour, minute, etc.
---
# Source: https://docs.oxla.com/sql-reference/sql-data-types/interval.md
> ## Documentation Index
> Fetch the complete documentation index at: https://docs.oxla.com/llms.txt
> Use this file to discover all available pages before exploring further.
# Interval
## Overview
The Interval data type represents periods between dates or times, which can be precisely calculated and expressed through various units. Those can be combined and include additional options for different interval calculations.
In this doc, you'll find more about the **interval syntax**, learn what are **supported units and abbreviations**, browse through **examples** and finally find out how to **extract data from intervals**.
## Syntax
The syntax for specifying an interval is as follows:
```sql theme={null}
SELECT INTERVAL 'quantity unit [quantity unit...] [direction]' [OPTION]
```
**Parameters Description**
| **Parameter** | **Description** |
| ------------- | ---------------------------------------------------------------------------------------------------------------------------------------------------------------------------- |
| `quantity` | The value representing the number of units |
| `unit` | - Year, month, day, hour, minute, etc. - Abbreviations, short forms and dash format is supported
- Plural forms are also acceptable (e.g. months, days, weeks) | | `direction` | An optional parameter: **ago** or **empty string** | | `OPTION` | Additional options when parsing interval | ## Supported Units and Abbreviations | **Unit** | **Abbreviations** | | ----------- | ------------------ | | Millennium | - | | Century | - | | Decade | - | | Year | `y`, `yr`, `yrs` | | Month | - | | Week | - | | Day | `d` | | Hour | `h`, `hr`, `hrs` | | Minute | `min`, `mins`, `m` | | Second | `s`, `sec`, `secs` | | Millisecond | `ms` | | Microsecond | - | ## Options for Interval Parsing * `YEAR`, `MONTH`, `DAY`, `HOUR`, `MINUTE`, `SECOND` * `YEAR TO MONTH`, `DAY TO HOUR`, `DAY TO MINUTE`, `DAY TO SECOND`, `HOUR TO MINUTE`, `HOUR TO SECOND`, `MINUTE TO SECOND` ## Examples #### Select Interval With Multiple Units In this example, we'll calculate the interval by combining multiple units of time. ```sql theme={null} SELECT INTERVAL '5 years 4 months 2 weeks 3 days 5 hours 10 minutes 25 seconds' as "Interval"; ``` ```sql theme={null} Interval --------------------------------- 5 years 4 mons 17 days 05:10:25 (1 row) ``` #### Using Abbreviations This example shows how to use abbreviated units for time intervals. ```sql theme={null} SELECT INTERVAL '10 yr 8 months 2 weeks 6 days 5 hrs 10 min 20 s as "Interval"; ``` ```sql theme={null} Interval ---------------------------------- 10 years 8 mons 20 days 05:10:20 (1 row) ``` #### Using Dash Format Here you'll find out how to use the dash format for specifying intervals. ```sql theme={null} SELECT INTERVAL '1-2 3 DAYS 04:05:06.070809' as "Interval"; ``` ```sql theme={null} Interval -------------------------------------- 1 year 2 mons 3 days 04:05:06.070809 (1 row) ``` #### Parsing Intervals Using Specific Units By running the code below, the output will show everything up to minutes and ignore seconds and miliseconds. ```sql theme={null} SELECT INTERVAL '1-2 5 DAYS 07:08:06.040809' MINUTE as "Interval"; ``` ```sql theme={null} Interval ------------------------------- 1 year 2 mons 5 days 07:08:00 (1 row) ``` #### Displaying Specific Range Only Executing the query below will result only years and months being displayed excluding days, hours, minutes, and seconds from the input. ```sql theme={null} SELECT INTERVAL '2-4 5 DAYS 04:05:06.070809' YEAR TO MONTH as "Interval"; ``` ```sql theme={null} Interval ---------------- 2 years 4 mons (1 row) ``` #### Extracting Data From Interval In order to extract the interval numbers from the timestamp, you can use the **EXTRACT()** function the following way: ```sql theme={null} SELECT EXTRACT (field FROM interval) ``` * `field`: supports time units, such as `YEAR`, `MONTH`, `DAY`, `HOUR`, etc. * `interval`: specified timestamp. ```sql theme={null} SELECT EXTRACT (MINUTE FROM INTERVAL '2 hours 30 minutes'); ``` As the output of the above query, only the minutes part will be returned. ```sql theme={null} extract ------------ 30 (1 row) ```
 ---
# Source: https://docs.oxla.com/sql-reference/sql-functions/json-functions/json-array-extract.md
> ## Documentation Index
> Fetch the complete documentation index at: https://docs.oxla.com/llms.txt
> Use this file to discover all available pages before exploring further.
# JSON_ARRAY_EXTRACT
## **Overview**
The `JSON_ARRAY_EXTRACT()` function returns the JSON array as a set of JSON values.
## **Syntax**
The `JSON_ARRAY_EXTRACT()` has the basic syntax as seen below.
```sql theme={null}
JSON_ARRAY_EXTRACT('json_array'::JSON,id);
```
`JSON_ARRAY_EXTRACT()` requires the following parameters:
* `json_array`: the array to be extracted.
* `::JSON`: argument indicating that the query is of type JSON.
* `id`: ID of the element that we want to extract. It is read in an array format that starts with 0.
### Another Option
`JSON_ARRAY_EXTRACT` can also be achieved with the `->` operator, as shown in the syntax below:
```sql theme={null}
SELECT 'from_json'::JSON -> path;
```
* `from_json`: the JSON value from which to extract.
* `::JSON`: a symbol that casts the string literal to a JSON type.
* `path`: key of the field that we want to extract.
## Examples
### Case #1: Basic JSON\_ARRAY\_EXTRACT() function
1. In the below example, we will extract a JSON array as a JSON set.
```sql theme={null}
SELECT JSON_ARRAY_EXTRACT('["Bougenvile", 2, 12, "Lily"]'::JSON,3);
```
**or**
```sql theme={null}
SELECT ('["Bougenvile", 2, 12, "Lily"]'::JSON -> 3);
```
2. The extracted array will look like the following.
```sql theme={null}
+------------+
| f |
+------------+
| "Lily" |
+------------+
```
### Case #2: Extract element of JSON array as text
1. In this case, we will extract the element of the JSON array as text with the `->>` operator.
```sql theme={null}
SELECT ('["Bougenvile", 2, 12, "Lily"]'::JSON ->> 1);
```
2. You will get the final output as follows:
```sql theme={null}
+------------+
| f |
+------------+
| 2.000000 |
+------------+
```
---
# Source: https://docs.oxla.com/sql-reference/sql-functions/json-functions/json-array-length.md
> ## Documentation Index
> Fetch the complete documentation index at: https://docs.oxla.com/llms.txt
> Use this file to discover all available pages before exploring further.
# JSON_ARRAY_LENGTH
## Overview
The `JSON_ARRAY_LENGTH()` function returns the length of a specified JSON array.
## Syntax
This function has the following basic syntax.
```sql theme={null}
JSON_ARRAY_LENGTH(arrayval JSON)
```
The required argument for this function is `arrayval`. It represents the JSON array which we will count the length.
## Examples
### Case #1: Get a JSON array length with a JSON value
The following example returns the number of elements in the array:
```sql theme={null}
SELECT JSON_ARRAY_LENGTH('[4, 7, 10, 11, 14, {"vegetables":"spinach","fruits":"melon"}, {"a":"b"}]');
```
The function above will return the following result:
```sql theme={null}
+-------+
| f |
+-------+
| 7 |
+-------+
```
### Case #2: Get a JSON array length with a number
The following example returns the number of elements in the array.
```sql theme={null}
SELECT JSON_ARRAY_LENGTH('[1, 2, [3, 4]]');
```
You will get the final result as follows:
```sql theme={null}
+-------+
| f |
+-------+
| 3 |
+-------+
```
### Case #3: JSON array length where the array is NULL or empty
This example shows that an empty JSON array will return 0.
```sql theme={null}
SELECT JSON_ARRAY_LENGTH('[]');
```
An empty array will return 0 in the final output:
```sql theme={null}
+-------+
| f |
+-------+
| 0 |
+-------+
```
---
# Source: https://docs.oxla.com/sql-reference/sql-functions/json-functions/json-extract-path-text.md
> ## Documentation Index
> Fetch the complete documentation index at: https://docs.oxla.com/llms.txt
> Use this file to discover all available pages before exploring further.
# JSON_EXTRACT_PATH_TEXT
## Overview
The `JSON_EXTRACT_PATH_TEXT()` function extracts JSON nested value from a specified JSON value according to the defined path.
---
# Source: https://docs.oxla.com/sql-reference/sql-functions/json-functions/json-array-extract.md
> ## Documentation Index
> Fetch the complete documentation index at: https://docs.oxla.com/llms.txt
> Use this file to discover all available pages before exploring further.
# JSON_ARRAY_EXTRACT
## **Overview**
The `JSON_ARRAY_EXTRACT()` function returns the JSON array as a set of JSON values.
## **Syntax**
The `JSON_ARRAY_EXTRACT()` has the basic syntax as seen below.
```sql theme={null}
JSON_ARRAY_EXTRACT('json_array'::JSON,id);
```
`JSON_ARRAY_EXTRACT()` requires the following parameters:
* `json_array`: the array to be extracted.
* `::JSON`: argument indicating that the query is of type JSON.
* `id`: ID of the element that we want to extract. It is read in an array format that starts with 0.
### Another Option
`JSON_ARRAY_EXTRACT` can also be achieved with the `->` operator, as shown in the syntax below:
```sql theme={null}
SELECT 'from_json'::JSON -> path;
```
* `from_json`: the JSON value from which to extract.
* `::JSON`: a symbol that casts the string literal to a JSON type.
* `path`: key of the field that we want to extract.
## Examples
### Case #1: Basic JSON\_ARRAY\_EXTRACT() function
1. In the below example, we will extract a JSON array as a JSON set.
```sql theme={null}
SELECT JSON_ARRAY_EXTRACT('["Bougenvile", 2, 12, "Lily"]'::JSON,3);
```
**or**
```sql theme={null}
SELECT ('["Bougenvile", 2, 12, "Lily"]'::JSON -> 3);
```
2. The extracted array will look like the following.
```sql theme={null}
+------------+
| f |
+------------+
| "Lily" |
+------------+
```
### Case #2: Extract element of JSON array as text
1. In this case, we will extract the element of the JSON array as text with the `->>` operator.
```sql theme={null}
SELECT ('["Bougenvile", 2, 12, "Lily"]'::JSON ->> 1);
```
2. You will get the final output as follows:
```sql theme={null}
+------------+
| f |
+------------+
| 2.000000 |
+------------+
```
---
# Source: https://docs.oxla.com/sql-reference/sql-functions/json-functions/json-array-length.md
> ## Documentation Index
> Fetch the complete documentation index at: https://docs.oxla.com/llms.txt
> Use this file to discover all available pages before exploring further.
# JSON_ARRAY_LENGTH
## Overview
The `JSON_ARRAY_LENGTH()` function returns the length of a specified JSON array.
## Syntax
This function has the following basic syntax.
```sql theme={null}
JSON_ARRAY_LENGTH(arrayval JSON)
```
The required argument for this function is `arrayval`. It represents the JSON array which we will count the length.
## Examples
### Case #1: Get a JSON array length with a JSON value
The following example returns the number of elements in the array:
```sql theme={null}
SELECT JSON_ARRAY_LENGTH('[4, 7, 10, 11, 14, {"vegetables":"spinach","fruits":"melon"}, {"a":"b"}]');
```
The function above will return the following result:
```sql theme={null}
+-------+
| f |
+-------+
| 7 |
+-------+
```
### Case #2: Get a JSON array length with a number
The following example returns the number of elements in the array.
```sql theme={null}
SELECT JSON_ARRAY_LENGTH('[1, 2, [3, 4]]');
```
You will get the final result as follows:
```sql theme={null}
+-------+
| f |
+-------+
| 3 |
+-------+
```
### Case #3: JSON array length where the array is NULL or empty
This example shows that an empty JSON array will return 0.
```sql theme={null}
SELECT JSON_ARRAY_LENGTH('[]');
```
An empty array will return 0 in the final output:
```sql theme={null}
+-------+
| f |
+-------+
| 0 |
+-------+
```
---
# Source: https://docs.oxla.com/sql-reference/sql-functions/json-functions/json-extract-path-text.md
> ## Documentation Index
> Fetch the complete documentation index at: https://docs.oxla.com/llms.txt
> Use this file to discover all available pages before exploring further.
# JSON_EXTRACT_PATH_TEXT
## Overview
The `JSON_EXTRACT_PATH_TEXT()` function extracts JSON nested value from a specified JSON value according to the defined path.
Keyword
| Oxla Status
|
| --------------------------------- | :---------------------------------------- |
| ABSOLUTE | non-reserved |
| ACTION | non-reserved |
| ADD | non-reserved |
| AFTER | non-reserved |
| AGGREGATE | non-reserved |
| ALL | reserved |
| ALLOCATE | reserved |
| ALTER | non-reserved |
| ANALYSE | reserved |
| ANALYZE | reserved |
| AND | reserved |
| ANY | reserved |
| ANY\_VALUE | non-reserved |
| ARE | reserved |
| ARRAY | reserved, requires AS |
| ARRAY\_MAX\_CARDINALITY | non-reserved |
| AS | reserved, requires AS |
| ASC | reserved |
| ASENSITIVE | non-reserved |
| ASSERTION | non-reserved |
| ASSIGNMENT | non-reserved |
| ASYMMETRIC | reserved |
| AT | non-reserved |
| ATOMIC | non-reserved |
| AUTHORIZATION | reserved (can be function or type) |
| AVG | non-reserved |
| BEFORE | non-reserved |
| BEGIN | non-reserved |
| BEGIN\_FRAME | non-reserved |
| BEGIN\_PARTITION | non-reserved |
| BETWEEN | non-reserved (cannot be function or type) |
| BIGINT | non-reserved (cannot be function or type) |
| BIT | non-reserved (cannot be function or type) |
| BIT\_LENGTH | reserved |
| BLOB | non-reserved |
| BOOL | non-reserved |
| BOOLEAN | non-reserved (cannot be function or type) |
| BOTH | reserved |
| BY | non-reserved |
| CACHE | non-reserved |
| CALL | reserved |
| CALLED | reserved |
| CARDINALITY | non-reserved |
| CASCADE | reserved |
| CASCADED | reserved |
| CASE | reserved |
| CAST | reserved |
| CATALOG | non-reserved |
| CEILING | non-reserved |
| CHAR | non-reserved |
| CHAR\_LENGTH | non-reserved |
| CHARACTER | non-reserved |
| CHARACTER\_LENGTH | non-reserved |
| CHECK | reserved |
| CLASSIFIER | non-reserved |
| CLOB | non-reserved |
| CLOSE | reserved |
| COALESCE | reserved |
| COLLATE | reserved |
| COLLATION | reserved |
| COLLECT | non-reserved |
| COLUMN | reserved |
| COLUMNS | non-reserved |
| COMMIT | reserved |
| CONDITION | reserved |
| CONNECT | reserved |
| CONNECTION | reserved |
| CONSTRAINT | reserved |
| CONSTRAINTS | non-reserved |
| CONTAINS | non-reserved |
| CONTINUE | reserved |
| CONTROL | non-reserved |
| CONVERT | non-reserved |
| COPY | non-reserved |
| CORR | non-reserved |
| CORRESPONDING | reserved |
| COVAR\_POP | non-reserved |
| COVAR\_SAMP | non-reserved |
| CREATE | reserved |
| CROSS | reserved |
| CUBE | reserved |
| CUME\_DIST | non-reserved |
| CURRENT | reserved |
| CURRENT\_USER | reserved |
| CURRENT\_ROLE | reserved |
| CURSOR | reserved |
| CYCLE | reserved |
| DATABASE | non-reserved |
| DATABASES | non-reserved |
| DATALINK | non-reserved |
| DATE | non-reserved |
| DATETIME | non-reserved |
| DAY | non-reserved |
| DEALLOCATE | reserved |
| DEC | non-reserved |
| DECFLOAT | non-reserved |
| DECIMAL | non-reserved |
| DECLARE | reserved |
| DEFAULT | reserved |
| DEFERRABLE | reserved |
| DEFERRED | reserved |
| DEFINE | non-reserved |
| DELETE | reserved |
| DELTA | non-reserved |
| DENSE\_RANK | non-reserved |
| DEREF | non-reserved |
| DESC | reserved |
| DESCRIBE | reserved |
| DESCRIPTOR | reserved |
| DETERMINISTIC | reserved |
| DIAGNOSTICS | reserved |
| DIRECT | non-reserved |
| DISCONNECT | reserved |
| DISTINCT | reserved |
| DLNEWCOPY | non-reserved |
| DLPREVIOUSCOPY | non-reserved |
| DLURLCOMPLETE | non-reserved |
| DLURLCOMPLETEONLY | non-reserved |
| DLURLCOMPLETEWRITE | non-reserved |
| DLURLPATH | non-reserved |
| DLURLPATHONLY | non-reserved |
| DLURLPATHWRITE | non-reserved |
| DLURLSCHEME | non-reserved |
| DLURLSERVER | non-reserved |
| DLVALUE | non-reserved |
| DO | reserved |
| DOMAIN | non-reserved |
| DOUBLE | non-reserved |
| DROP | reserved |
| DYNAMIC | non-reserved |
| EACH | reserved |
| ELEMENT | non-reserved |
| ELSE | reserved |
| EMPTY | non-reserved |
| END | reserved |
| END\_FRAME | non-reserved |
| END\_PARTITION | non-reserved |
| EQUALS | non-reserved |
| ESCAPE | reserved |
| EVERY | reserved |
| EXCEPT | reserved |
| EXCEPTION | reserved |
| EXEC | reserved |
| EXECUTE | reserved |
| EXISTS | reserved |
| EXP | non-reserved |
| EXPLAIN | reserved |
| EXTERNAL | reserved |
| EXTRACT | reserved |
| FALSE | reserved |
| FETCH | reserved |
| FILE | non-reserved |
| FILTER | reserved |
| FIRST | reserved |
| FIRST\_VALUE | non-reserved |
| FLOAT | non-reserved |
| FLOOR | non-reserved |
| FOR | reserved |
| FOREIGN | reserved |
| FORMAT | non-reserved |
| FOUND | non-reserved |
| FRAME\_ROW | non-reserved |
| FREE | non-reserved |
| FROM | reserved |
| FULL | reserved |
| FUNCTION | reserved |
| FUSION | non-reserved |
| GET | non-reserved |
| GLOBAL | reserved |
| GO | non-reserved |
| GOTO | non-reserved |
| GRANT | reserved |
| GROUP | reserved |
| GROUPING | reserved |
| GROUPS | non-reserved |
| HASH | non-reserved |
| HAVING | reserved |
| HINT | non-reserved |
| HOLD | non-reserved |
| HOUR | non-reserved |
| IDENTITY | reserved |
| IF | reserved |
| ILIKE | non-reserved |
| IMMEDIATE | reserved |
| IMPORT | non-reserved |
| IN | reserved |
| INDEX | reserved |
| INDICATOR | reserved |
| INITIAL | reserved |
| INITIALLY | reserved |
| INNER | reserved |
| INOUT | reserved |
| INPUT | reserved |
| INSENSITIVE | reserved |
| INSERT | reserved |
| INT | non-reserved |
| INTEGER | non-reserved |
| INTERSECT | reserved |
| INTERSECTION | non-reserved |
| INTERVAL | reserved |
| INTO | reserved |
| IS | reserved |
| ISNULL | non-reserved |
| ISOLATION | reserved |
| JOIN | reserved |
| JSON | non-reserved |
| JSON\_ARRAY | non-reserved |
| JSON\_ARRAYAGG | non-reserved |
| JSON\_EXISTS | non-reserved |
| JSON\_OBJECT | non-reserved |
| JSON\_OBJECTAGG | non-reserved |
| JSON\_QUERY | non-reserved |
| JSON\_TABLE | non-reserved |
| JSON\_TABLE\_PRIMITIVE | non-reserved |
| JSON\_VALUE | non-reserved |
| JSONB | non-reserved |
| KEY | non-reserved |
| LAG | non-reserved |
| LANGUAGE | reserved |
| LARGE | non-reserved |
| LAST | reserved |
| LAST\_VALUE | non-reserved |
| LATERAL | reserved |
| LEAD | non-reserved |
| LEADING | reserved |
| LEFT | reserved |
| LEVEL | non-reserved |
| LIKE | reserved |
| LIKE\_REGEX | non-reserved |
| LIMIT | reserved |
| LISTAGG | non-reserved |
| LN | non-reserved |
| LOAD | non-reserved |
| LOCAL | reserved |
| LOCALTIME | reserved |
| LOCALTIMESTAMP | reserved |
| LONG | non-reserved |
| MEASURES | non-reserved |
| MEMBER | non-reserved |
| MERGE | reserved |
| METHOD | non-reserved |
| MINUS | reserved |
| MINUTE | non-reserved |
| MODIFIES | reserved |
| MODULE | non-reserved |
| MONTH | non-reserved |
| MULTISET | non-reserved |
| NAMES | non-reserved |
| NATIONAL | non-reserved |
| NATURAL | reserved |
| NCHAR | non-reserved |
| NCLOB | non-reserved |
| NEW | reserved |
| NEXT | non-reserved |
| NO | reserved |
| NONE | non-reserved |
| NOT | reserved |
| NTILE | non-reserved |
| NULL | reserved |
| NULLIF | reserved |
| NULLS | reserved |
| NVARCHAR | non-reserved |
| OCCURRENCES\_REGEX | non-reserved |
| OCTET\_LENGTH | non-reserved |
| OF | reserved |
| OFF | non-reserved |
| OFFSET | reserved |
| OLD | reserved |
| OMIT | non-reserved |
| ON | reserved |
| ONE | non-reserved |
| ONLY | reserved |
| OPEN | reserved |
| OPTION | reserved |
| OR | reserved |
| ORDER | reserved |
| OUT | reserved |
| OUTER | reserved |
| OUTPUT | reserved |
| OVER | reserved |
| OVERLAPS | reserved |
| OVERLAY | non-reserved |
| PAD | non-reserved |
| PARAMETER | reserved |
| PARAMETERS | non-reserved |
| PARTIAL | reserved |
| PARTITION | reserved |
| PATTERN | non-reserved |
| PER | non-reserved |
| PERCENT | non-reserved |
| PERCENT\_RANK | non-reserved |
| PERCENTILE\_CONT | non-reserved |
| PERCENTILE\_DISC | non-reserved |
| PERIOD | reserved |
| PERMUTE | non-reserved |
| PLACING | non-reserved |
| PLAN | non-reserved |
| PORTION | non-reserved |
| PRECEDES | non-reserved |
| PRECISION | reserved |
| PREPARE | reserved |
| PRESERVE | reserved |
| PRIMARY | reserved |
| PRIOR | reserved |
| PRIVILEGES | non-reserved |
| PROCEDURE | reserved |
| PTF | non-reserved |
| PUBLIC | reserved |
| RANGE | reserved |
| READ | reserved |
| READS | reserved |
| REAL | non-reserved |
| RECURSIVE | reserved |
| REF | reserved |
| REFERENCES | reserved |
| REFERENCING | reserved |
| REGR\_AVGX | non-reserved |
| REGR\_AVGY | non-reserved |
| REGR\_COUNT | non-reserved |
| REGR\_INTERCEPT | non-reserved |
| REGR\_R2 | non-reserved |
| REGR\_SLOPE | non-reserved |
| REGR\_SXX | non-reserved |
| REGR\_SXY | non-reserved |
| REGR\_SYY | non-reserved |
| RELATIVE | non-reserved |
| RELEASE | reserved |
| RENAME | reserved |
| RESTRICT | reserved |
| RESULT | reserved |
| RETURN | reserved |
| RETURNS | reserved |
| REVOKE | reserved |
| RIGHT | reserved |
| ROLLBACK | reserved |
| ROLLUP | reserved |
| ROW | reserved |
| ROW\_NUMBER | non-reserved |
| ROWS | reserved |
| RUNNING | non-reserved |
| SAVEPOINT | reserved |
| SCHEMA | reserved |
| SCHEMAS | non-reserved |
| SCOPE | reserved |
| SCROLL | reserved |
| SEARCH | non-reserved |
| SECOND | non-reserved |
| SECTION | non-reserved |
| SEEK | non-reserved |
| SELECT | reserved |
| SENSITIVE | reserved |
| SESSION | reserved |
| SESSION\_USER | reserved |
| SET | reserved |
| SHOW | non-reserved |
| SIMILAR | non-reserved |
| SIZE | non-reserved |
| SKIP | non-reserved |
| SMALLINT | non-reserved |
| SOME | reserved |
| SORTED | non-reserved |
| SPACE | non-reserved |
| SPATIAL | non-reserved |
| SPECIFIC | reserved |
| SPECIFICTYPE | non-reserved |
| SQL | reserved |
| SQLCODE | non-reserved |
| SQLERROR | non-reserved |
| SQLEXCEPTION | non-reserved |
| SQLSTATE | non-reserved |
| SQLWARNING | non-reserved |
| START | reserved |
| STATIC | reserved |
| STDDEV\_POP | non-reserved |
| STDDEV\_SAMP | non-reserved |
| STRING | non-reserved |
| SUBMULTISET | non-reserved |
| SUBSET | non-reserved |
| SUCCEEDS | non-reserved |
| SYMMETRIC | reserved |
| SYSTEM | reserved |
| SYSTEM\_TIME | non-reserved |
| SYSTEM\_USER | reserved |
| TABLE | reserved |
| TABLES | non-reserved |
| TABLESAMPLE | reserved |
| TEMPORARY | reserved |
| TEXT | non-reserved |
| THEN | reserved |
| TIME | non-reserved |
| TIMESTAMP | non-reserved |
| TIMESTAMP\_TRUNC | non-reserved |
| TO | reserved |
| TOP | non-reserved |
| TRAILING | reserved |
| TRANSACTION | reserved |
| TRANSLATE | reserved |
| TRANSLATE\_REGEX | non-reserved |
| TRANSLATION | non-reserved |
| TREAT | reserved |
| TRIGGER | reserved |
| TRUE | reserved |
| TRUNCATE | reserved |
| UESCAPE | reserved |
| UNION | reserved |
| UNIQUE | reserved |
| UNKNOWN | reserved |
| UNLOAD | non-reserved |
| UNMATCHED | non-reserved |
| UNNEST | non-reserved |
| UPDATE | reserved |
| UPPER | non-reserved |
| USAGE | reserved |
| USER | non-reserved |
| USING | reserved |
| VALUES | reserved |
| VAR\_POP | non-reserved |
| VAR\_SAMP | non-reserved |
| VARBINARY | non-reserved |
| VARCHAR | non-reserved |
| VARIADIC | reserved |
| VARYING | reserved |
| VERSIONING | non-reserved |
| VIEW | reserved |
| VIRTUAL | non-reserved |
| WHEN | reserved |
| WHENEVER | reserved |
| WHERE | reserved |
| WIDTH\_BUCKET | non-reserved |
| WINDOW | reserved |
| WITH | reserved |
| WITHIN | reserved |
| WITHOUT | reserved |
| WORK | reserved |
| WRITE | non-reserved |
| XML | non-reserved |
| XMLAGG | non-reserved |
| XMLATTRIBUTES | non-reserved |
| XMLBINARY | non-reserved |
| XMLCAST | non-reserved |
| XMLCOMMENT | non-reserved |
| XMLCONCAT | non-reserved |
| XMLDOCUMENT | non-reserved |
| XMLELEMENT | non-reserved |
| XMLEXISTS | non-reserved |
| XMLFOREST | non-reserved |
| XMLITERATE | non-reserved |
| XMLNAMESPACES | non-reserved |
| XMLPARSE | non-reserved |
| XMLPI | non-reserved |
| XMLQUERY | non-reserved |
| XMLSERIALIZE | non-reserved |
| XMLTABLE | non-reserved |
| XMLTEXT | non-reserved |
| XMLVALIDATE | non-reserved |
| YEAR | non-reserved |
| ZONE | non-reserved |
---
# Source: https://docs.oxla.com/sql-reference/sql-functions/window-functions/lag.md
> ## Documentation Index
> Fetch the complete documentation index at: https://docs.oxla.com/llms.txt
> Use this file to discover all available pages before exploring further.
# LAG()
## Overview
The `LAG()` window function returns the values from specific rows based on the offset argument (previous to the current row in the partition). It can be used with all [data types supported by Oxla](/sql-reference/sql-data-types/overview)
## Syntax
The syntax for this function is as follows:
```sql theme={null}
LAG (expression, offset, default)
OVER (
[PARTITION BY partition_expression, ... ]
ORDER BY sort_expression [ASC | DESC], ...
)
```
The output's data type for this function is the same as the input's one. If there is no row that meets the offset criteria, it returns a default value (that must be of a type compatible with the expression value)
## Parameters
* `expression`: column, which will be referenced
* `offset`: numeric indicator of the previous row to access, that is relative to the current row (optional, if not specified 1 will be returned)
* `default`: value that wil be returned if the `offset` is out of range (optional, if not specified `NULL` will be returned)
## Examples
For the needs of this section, we will create the `winsales` table that stores details about some sales transactions:
```sql theme={null}
CREATE TABLE winsales(
salesid int,
dateid date,
sellerid int,
buyerid text,
qty int,
qty_shipped int);
INSERT INTO winsales VALUES
(30001, '8/2/2003', 3, 'b', 10, 10),
(10001, '12/24/2003', 1, 'c', 10, 10),
(10005, '12/24/2003', 1, 'a', 30, null),
(40001, '1/9/2004', 4, 'a', 40, null),
(10006, '1/18/2004', 1, 'c', 10, null),
(20001, '2/12/2004', 2, 'b', 20, 20),
(40005, '2/12/2004', 4, 'a', 10, 10),
(20002, '2/16/2004', 2, 'c', 20, 20),
(30003, '4/18/2004', 3, 'b', 15, null),
(30004, '4/18/2004', 3, 'b', 20, null),
(30007, '9/7/2004', 3, 'c', 30, null);
```
### LAG(expression, offset)
In this example, we will focus on executing the `LAG()` function with expression and offset parameters' values specified:
```sql theme={null}
SELECT buyerid, dateid, qty
LAG(qty,1) OVER (ORDER BY buyerid, dateid) AS prev_qty
FROM winsales WHERE buyerid = 'c'
ORDER BY buyerid, dateid;
```
When executing the query above, it returns the buyer ID, date ID, quantity and previous quantity for all rows with buyer ID equal to `c`:
```sql theme={null}
buyerid | dateid | qty | prev_qty
---------+------------+-----+----------
c | 2003-12-24 | 10 |
c | 2004-01-18 | 10 | 10
c | 2004-02-16 | 20 | 10
c | 2004-09-07 | 30 | 20
(4 rows)
```
### LAG(expression, offset, default)
In this example, we will focus on executing the `LAG()` function with expression, offset and default parameters' values specified:
```sql theme={null}
SELECT buyerid, dateid, qty
LAG(buyerid,1,'unknown') OVER (ORDER BY dateid) AS prev_buyerid
FROM winsales
ORDER BY dateid;
```
The query above returns the buyer ID, date ID, quantity and previous buyer ID for all rows:
```sql theme={null}
buyerid | dateid | qty | prev_buyerid
---------+------------+-----+--------------
b | 2003-08-02 | 10 | unknown
c | 2003-12-24 | 10 | b
a | 2003-12-24 | 30 | c
a | 2004-01-09 | 40 | a
c | 2004-01-18 | 10 | a
b | 2004-02-12 | 20 | c
a | 2004-02-12 | 10 | b
c | 2004-02-16 | 20 | a
b | 2004-04-18 | 15 | c
b | 2004-04-18 | 20 | b
c | 2004-09-07 | 30 | b
(11 rows)
```
### Time Series: LAG() to Compare Daily Sales Quantities
In this example, we will use LAG() to compare each day's sales quantity (`qty`) with the previous day's quantity, ordered by `dateid`:
```sql theme={null}
SELECT dateid, qty,
LAG(qty) OVER (ORDER BY dateid) AS prev_day_qty,
qty - LAG(qty) OVER (ORDER BY dateid) AS qty_change
FROM winsales
ORDER BY dateid;
```
By executing the query above, we will get the following output:
```sql theme={null}
dateid | qty | prev_day_qty | qty_change
------------+-----+--------------+------------
2003-08-02 | 10 | |
2003-12-24 | 10 | 10 | 0
2003-12-24 | 30 | 10 | 20
2004-01-09 | 40 | 30 | 10
2004-01-18 | 10 | 40 | -30
2004-02-12 | 20 | 10 | 10
2004-02-12 | 10 | 20 | -10
2004-02-16 | 20 | 10 | 10
2004-04-18 | 15 | 20 | -5
2004-04-18 | 20 | 15 | 5
2004-09-07 | 30 | 20 | 10
(11 rows)
```
---
# Source: https://docs.oxla.com/sql-reference/sql-functions/window-functions/last-value.md
> ## Documentation Index
> Fetch the complete documentation index at: https://docs.oxla.com/llms.txt
> Use this file to discover all available pages before exploring further.
# LAST_VALUE()
## Overview
The `LAST_VALUE()` is a window function that retrieves the last value in an ordered set of values within a specified partition.
## Syntax
The syntax for this function is as follows:
```sql theme={null}
LAST_VALUE(expression) OVER (
[PARTITION BY partition_expression]
ORDER BY sort_expression
RANGE BETWEEN start_value AND end_value
)
```
## Parameters
* `expression`: input's column or expression values that returns a single value. It represents the value you want to retrieve from the first row of the sorted partition
* `PARTITION BY`: optional clause, which divides the result set into partitions to which the `LAST_VALUE()` function is applied (if omitted, the entire result set is treated as a single partition)
* `ORDER BY`: order of rows in each partition to which the function is applied
* `RANGE BETWEEN `: range-based window frame relative to the current row
## Example
For the needs of this section, we will use a simplified version of the `film` table from the Pagila database, containing only the `title`, `length` and `rating` columns. The complete schema for the `film` table can be found on the
Pagila website.
```sql theme={null}
DROP TABLE IF EXISTS film;
CREATE TABLE film (
title text NOT NULL,
length int,
rating text
);
INSERT INTO film(title, length, rating) VALUES
('ATTRACTION NEWTON', 83, 'PG-13'),
('CHRISTMAS MOONSHINE', 150, 'NC-17'),
('DANGEROUS UPTOWN', 121, 'PG'),
('KILL BROTHERHOOD', 54, 'G'),
('HALLOWEEN NUTS', 47, 'PG-13'),
('HOURS RAGE', 122, 'NC-17'),
('PIANIST OUTFIELD', 136, 'NC-17'),
('PICKUP DRIVING', 77, 'G'),
('INDEPENDENCE HOTEL', 157, 'NC-17'),
('PRIVATE DROP', 106, 'PG'),
('SAINTS BRIDE', 125, 'G'),
('FOREVER CANDIDATE', 131, 'NC-17'),
('MILLION ACE', 142, 'PG-13'),
('SLEEPY JAPANESE', 137, 'PG'),
('WRATH MILE', 176, 'NC-17'),
('YOUTH KICK', 179, 'NC-17'),
('CLOCKWORK PARADISE', 143, 'PG-13');
```
The query below uses the `LAST_VALUE()` function to retrieve the title of the film with the longest duration, partitioning results by rating and ordering by length.
```sql theme={null}
SELECT
title,
length,
rating,
LAST_VALUE(title) OVER (
PARTITION BY rating
ORDER BY
length ASC ROWS BETWEEN UNBOUNDED PRECEDING AND UNBOUNDED FOLLOWING
) AS shortest_film_in_rating
FROM film;
```
By running the code above, we will get the following output:
```bash theme={null}
| title | length | rating | longest_film_in_rating |
|---------------------|--------|--------|------------------------|
| KILL BROTHERHOOD | 54 | G | SAINTS BRIDE |
| PICKUP DRIVING | 77 | G | SAINTS BRIDE |
| SAINTS BRIDE | 125 | G | SAINTS BRIDE |
| HOURS RAGE | 122 | NC-17 | YOUTH KICK |
| FOREVER CANDIDATE | 131 | NC-17 | YOUTH KICK |
| PIANIST OUTFIELD | 136 | NC-17 | YOUTH KICK |
| CHRISTMAS MOONSHINE | 150 | NC-17 | YOUTH KICK |
| INDEPENDENCE HOTEL | 157 | NC-17 | YOUTH KICK |
| WRATH MILE | 176 | NC-17 | YOUTH KICK |
| YOUTH KICK | 179 | NC-17 | YOUTH KICK |
| DANGEROUS UPTOWN | 121 | PG | SLEEPY JAPANESE |
| SLEEPY JAPANESE | 137 | PG | SLEEPY JAPANESE |
| HALLOWEEN NUTS | 47 | PG-13 | CLOCKWORK PARADISE |
| ATTRACTION NEWTON | 83 | PG-13 | CLOCKWORK PARADISE |
| MILLION ACE | 142 | PG-13 | CLOCKWORK PARADISE |
| CLOCKWORK PARADISE | 143 | PG-13 | CLOCKWORK PARADISE |
```
---
# Source: https://docs.oxla.com/sql-reference/sql-functions/window-functions/lead.md
> ## Documentation Index
> Fetch the complete documentation index at: https://docs.oxla.com/llms.txt
> Use this file to discover all available pages before exploring further.
# LEAD()
## Overview
The `LEAD()` window function takes a column and an integer offset as arguments and returns the value of the cell in that column that is located at the specified number of rows after the current row. It can be used with all [data types supported by Oxla](/sql-reference/sql-data-types/overview.)
## Syntax
The syntax for this function is as follows:
```sql theme={null}
LEAD (expression, offset, default)
OVER (
[PARTITION BY partition_expression, ... ]
ORDER BY sort_expression [ASC | DESC], ...
)
```
The output's type for this function is the same as the input's one. If there is no row and value that meets the offset criteria, it returns the specified default value, which must be of a type compatible with the input value.
## Parameters
* `expression`: column, which will be referenced
* `offset`: numeric indicator of the row that is relative to the current one (optional, if not specified 1 will be returned)
* `default`: value that wil be returned if the `offset` is out of range (optional, if not specified `NULL` will be returned)
## Examples
In this example, we will use the `winsales` table that stores details about some sales transactions:
```sql theme={null}
CREATE TABLE winsales(
salesid int,
dateid date,
sellerid int,
buyerid text,
qty int,
qty_shipped int);
INSERT INTO winsales VALUES
(30001, '8/2/2003', 3, 'b', 10, 10),
(10001, '12/24/2003', 1, 'c', 10, 10),
(10005, '12/24/2003', 1, 'a', 30, null),
(40001, '1/9/2004', 4, 'a', 40, null),
(10006, '1/18/2004', 1, 'c', 10, null),
(20001, '2/12/2004', 2, 'b', 20, 20),
(40005, '2/12/2004', 4, 'a', 10, 10),
(20002, '2/16/2004', 2, 'c', 20, 20),
(30003, '4/18/2004', 3, 'b', 15, null),
(30004, '4/18/2004', 3, 'b', 20, null),
(30007, '9/7/2004', 3, 'c', 30, null);
```
### LEAD(expression, offset)
In this example, we will focus on executing the `LEAD()` function with expression and offset parameters' values specified:
```sql theme={null}
SELECT buyerid, dateid, qty
LEAD(qty,1) OVER (ORDER BY buyerid, dateid) AS next_qty
FROM winsales WHERE buyerid = 'c'
ORDER BY buyerid, dateid;
```
The following query returns the buyer ID, date ID, quantity and previous quantity for all rows with buyer ID equal to `c`:
```sql theme={null}
buyerid | dateid | qty | next_qty
---------+------------+-----+----------
c | 2003-12-24 | 10 | 10
c | 2004-01-18 | 10 | 20
c | 2004-02-16 | 20 | 30
c | 2004-09-07 | 30 |
(4 rows)
```
### Expression, Offset And Default Specified
In this example, we will focus on executing the `LEAD()` function with expression, offset and default parameters' values specified:
```sql theme={null}
SELECT buyerid, dateid, qty
LEAD(buyerid,1,'unknown') OVER (ORDER BY dateid) AS next_buyerid
FROM winsales
ORDER BY dateid;
```
The above query returns the buyer ID, date ID, quantity and following buyer ID for all rows:
```sql theme={null}
buyerid | dateid | qty | next_buyerid
---------+------------+-----+--------------
b | 2003-08-02 | 10 | c
c | 2003-12-24 | 10 | a
a | 2003-12-24 | 30 | a
a | 2004-01-09 | 40 | c
c | 2004-01-18 | 10 | b
b | 2004-02-12 | 20 | a
a | 2004-02-12 | 10 | c
c | 2004-02-16 | 20 | b
b | 2004-04-18 | 15 | b
b | 2004-04-18 | 20 | c
c | 2004-09-07 | 30 | unknown
(11 rows)
```
### Time Series: LEAD() to Compare Next Day’s Sales Quantity
In this example, we will use LEAD() to compare each day's sales quantity (`qty`) with the next day's quantity, ordered by `dateid`:
```sql theme={null}
SELECT dateid, qty,
LEAD(qty) OVER (ORDER BY dateid) AS next_day_qty,
LEAD(qty) OVER (ORDER BY dateid) - qty AS qty_change
FROM winsales
ORDER BY dateid;
```
By executing the query above, we will get the following output:
```sql theme={null}
dateid | qty | next_day_qty | qty_change
------------+-----+--------------+------------
2003-08-02 | 10 | 10 | 0
2003-12-24 | 10 | 30 | 20
2003-12-24 | 30 | 40 | 10
2004-01-09 | 40 | 10 | -30
2004-01-18 | 10 | 20 | 10
2004-02-12 | 20 | 10 | -10
2004-02-12 | 10 | 20 | 10
2004-02-16 | 20 | 15 | -5
2004-04-18 | 15 | 20 | 5
2004-04-18 | 20 | 30 | 10
2004-09-07 | 30 | |
(11 rows)
```
---
# Source: https://docs.oxla.com/sql-reference/sql-functions/math-functions/least.md
> ## Documentation Index
> Fetch the complete documentation index at: https://docs.oxla.com/llms.txt
> Use this file to discover all available pages before exploring further.
# LEAST
## Overview
The `LEAST()` function returns the least or smallest value in a list of values. It needs at least one argument to work with, and if you mix different types, like a text and a number, it will return an error.
For example, comparing the greatest value among 4, "two", and 9 would result in an error.
## Syntax
The syntax for the `LEAST()` function is as follows:
```sql theme={null}
LEAST(value_1, [value_n])
```
Where:
* `value_1`: Represents the first value.
* `value_n`: Represents one or more additional values, separated by commas.
-`NULL` values in the list will be ignored.
- The result will be `NULL` if all the expressions evaluate to `NULL`.

 ---
# Source: https://docs.oxla.com/sql-reference/sql-functions/string-functions/length.md
> ## Documentation Index
> Fetch the complete documentation index at: https://docs.oxla.com/llms.txt
> Use this file to discover all available pages before exploring further.
# LENGTH
## Overview
The `LENGTH()` function is used to find the length of a string, i.e., the number of characters in a given string. It accepts a string as a parameter. Syntax of the length function is illustrated below:
```sql theme={null}
LENGTH(string)
```
The input type is a string, and the return type is int, as it returns the number of characters.
**Special cases:**
* If a null value is passed in the function, i.e., `LENGTH(NULL)`, it will return `NULL`.
* If the parameter is an empty string `LENGTH(")`, it will return 0.
* If the parameter is a space character `LENGTH('')`, not empty or null, it will return 1 as it is not empty anymore.
## Examples
### #Case 1: Basic `LENGTH()` function
The below example uses the `LENGTH()` function to find out the length of a string text:
```sql theme={null}
SELECT LENGTH ('Oxla PostgreSQL Tutorial');
```
The final output will be as follows:
```sql theme={null}
+------------+
| length |
+------------+
| 24 |
+------------+
```
### #Case 2: `LENGTH()` function using columns
Let's see how the `LENGTH()` function works on the **personal\_details** table containing the employee's **id**, **first\_name**, **last\_name**, and **gender** of a retail store as columns.
```sql theme={null}
CREATE TABLE personal_details (
id int,
first_name text,
last_name text,
gender text
);
INSERT INTO personal_details
(id, first_name, last_name, gender)
VALUES
(1,'Mark','Wheeler','M'),
(2,'Tom','Hanks','M'),
(3,'Jane','Hopper','F'),
(4,'Emily','Byers','F'),
(5,'Lucas','Sinclair','M');
```
```sql theme={null}
SELECT * FROM personal_details;
```
The above query will show the following table:
```sql theme={null}
+-----+-------------+-------------+----------+
| id | first_name | last_name | gender |
+-----+-------------+-------------+----------+
| 1 | Mark | Wheeler | M |
| 2 | Tom | Hanks | M |
| 3 | Jane | Hopper | F |
| 4 | Emily | Byers | F |
| 5 | Lucas | Sinclair | M |
+-----+-------------+-------------+----------+
```
The following query returns the last name and the length of the last name from the personal\_details table, where the length of the last\_name is greater than 5.
```sql theme={null}
SELECT last_name,length(last_name)
AS "Length of Last Name"
FROM personal_details
WHERE LENGTH(last_name) > 5;
```
The output displays all those items in the last\_name column with a length of more than 5 characters.
```sql theme={null}
+---------------+-----------------------+
| last_name | Length of Last Name |
+---------------+-----------------------+
| Wheeler | 7 |
| Hopper | 6 |
| Sinclair | 8 |
+---------------+-----------------------+
```
---
# Source: https://docs.oxla.com/sql-reference/sql-clauses/limit.md
> ## Documentation Index
> Fetch the complete documentation index at: https://docs.oxla.com/llms.txt
> Use this file to discover all available pages before exploring further.
# LIMIT
## Overview
`LIMIT` is an optional clause that can be combined with `SELECT` statements used for retrieving records from one or more tables. It basically specifies the number of records a query should return after filtering the data.
## Syntax
There are two versions available for the `LIMIT` clause syntax:
---
# Source: https://docs.oxla.com/sql-reference/sql-functions/string-functions/length.md
> ## Documentation Index
> Fetch the complete documentation index at: https://docs.oxla.com/llms.txt
> Use this file to discover all available pages before exploring further.
# LENGTH
## Overview
The `LENGTH()` function is used to find the length of a string, i.e., the number of characters in a given string. It accepts a string as a parameter. Syntax of the length function is illustrated below:
```sql theme={null}
LENGTH(string)
```
The input type is a string, and the return type is int, as it returns the number of characters.
**Special cases:**
* If a null value is passed in the function, i.e., `LENGTH(NULL)`, it will return `NULL`.
* If the parameter is an empty string `LENGTH(")`, it will return 0.
* If the parameter is a space character `LENGTH('')`, not empty or null, it will return 1 as it is not empty anymore.
## Examples
### #Case 1: Basic `LENGTH()` function
The below example uses the `LENGTH()` function to find out the length of a string text:
```sql theme={null}
SELECT LENGTH ('Oxla PostgreSQL Tutorial');
```
The final output will be as follows:
```sql theme={null}
+------------+
| length |
+------------+
| 24 |
+------------+
```
### #Case 2: `LENGTH()` function using columns
Let's see how the `LENGTH()` function works on the **personal\_details** table containing the employee's **id**, **first\_name**, **last\_name**, and **gender** of a retail store as columns.
```sql theme={null}
CREATE TABLE personal_details (
id int,
first_name text,
last_name text,
gender text
);
INSERT INTO personal_details
(id, first_name, last_name, gender)
VALUES
(1,'Mark','Wheeler','M'),
(2,'Tom','Hanks','M'),
(3,'Jane','Hopper','F'),
(4,'Emily','Byers','F'),
(5,'Lucas','Sinclair','M');
```
```sql theme={null}
SELECT * FROM personal_details;
```
The above query will show the following table:
```sql theme={null}
+-----+-------------+-------------+----------+
| id | first_name | last_name | gender |
+-----+-------------+-------------+----------+
| 1 | Mark | Wheeler | M |
| 2 | Tom | Hanks | M |
| 3 | Jane | Hopper | F |
| 4 | Emily | Byers | F |
| 5 | Lucas | Sinclair | M |
+-----+-------------+-------------+----------+
```
The following query returns the last name and the length of the last name from the personal\_details table, where the length of the last\_name is greater than 5.
```sql theme={null}
SELECT last_name,length(last_name)
AS "Length of Last Name"
FROM personal_details
WHERE LENGTH(last_name) > 5;
```
The output displays all those items in the last\_name column with a length of more than 5 characters.
```sql theme={null}
+---------------+-----------------------+
| last_name | Length of Last Name |
+---------------+-----------------------+
| Wheeler | 7 |
| Hopper | 6 |
| Sinclair | 8 |
+---------------+-----------------------+
```
---
# Source: https://docs.oxla.com/sql-reference/sql-clauses/limit.md
> ## Documentation Index
> Fetch the complete documentation index at: https://docs.oxla.com/llms.txt
> Use this file to discover all available pages before exploring further.
# LIMIT
## Overview
`LIMIT` is an optional clause that can be combined with `SELECT` statements used for retrieving records from one or more tables. It basically specifies the number of records a query should return after filtering the data.
## Syntax
There are two versions available for the `LIMIT` clause syntax:
The logarithm doesn’t take negative numbers or 0.
If the first argument matches the second argument, the `NULLIF()` function returns **NULL**. Otherwise, it returns the first argument as-is.
obj\_description (object\_oid, catalog\_name) → NULLThe Microsoft Excel and Microsoft SQL Server's Analysis Services are also using OLAP features!
 ***
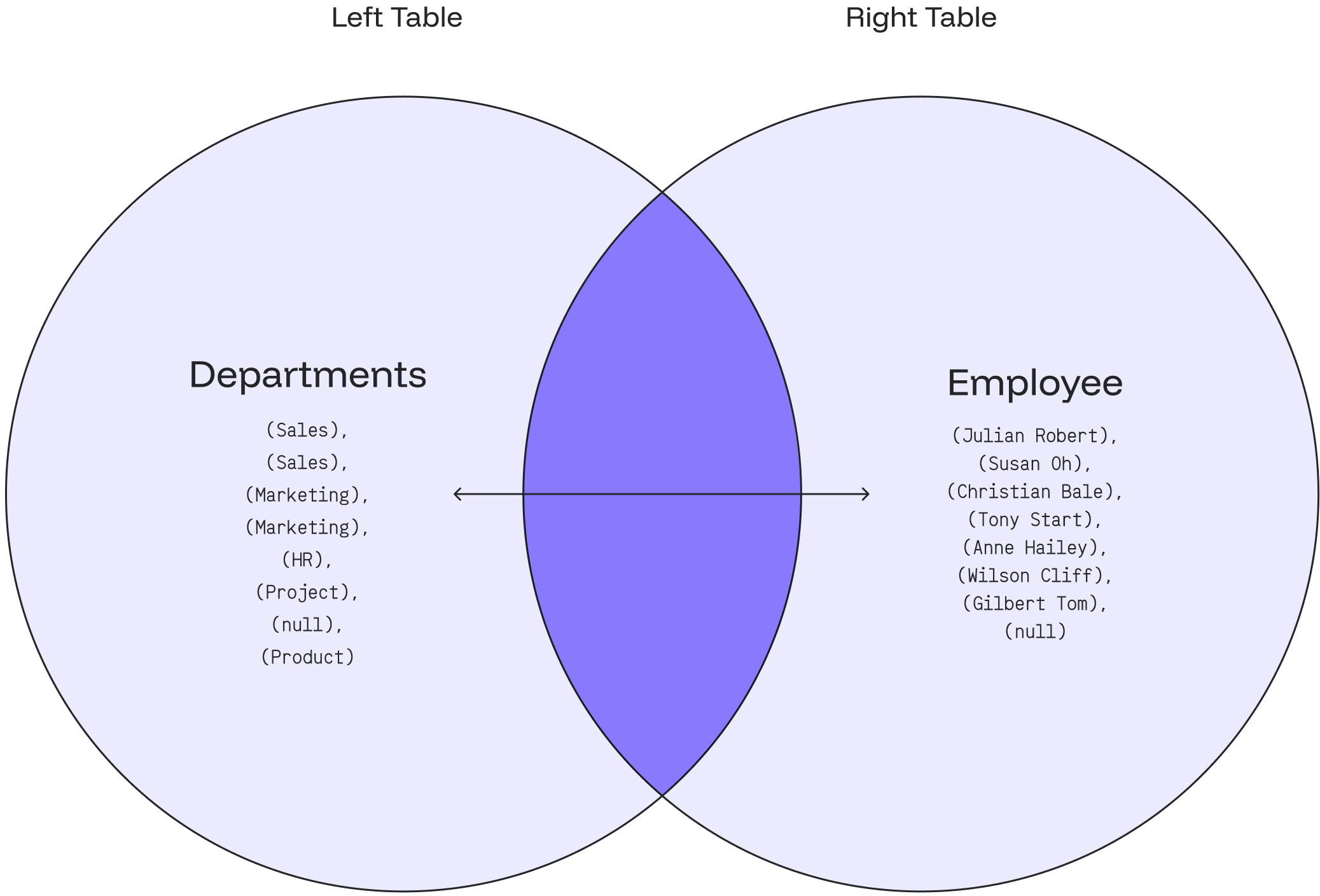
### Case 2: `FULL OUTER JOIN` with `WHERE` Clause
**a) Employee**
1. We can look up the department that does not have any employees by adding a `WHERE` clause and `NULL` as the following query:
```sql theme={null}
SELECT employee_name, department_name
FROM departments
FULL OUTER JOIN employee
ON departments.department_id = employee.dept_id
WHERE employee_name IS NULL;
```
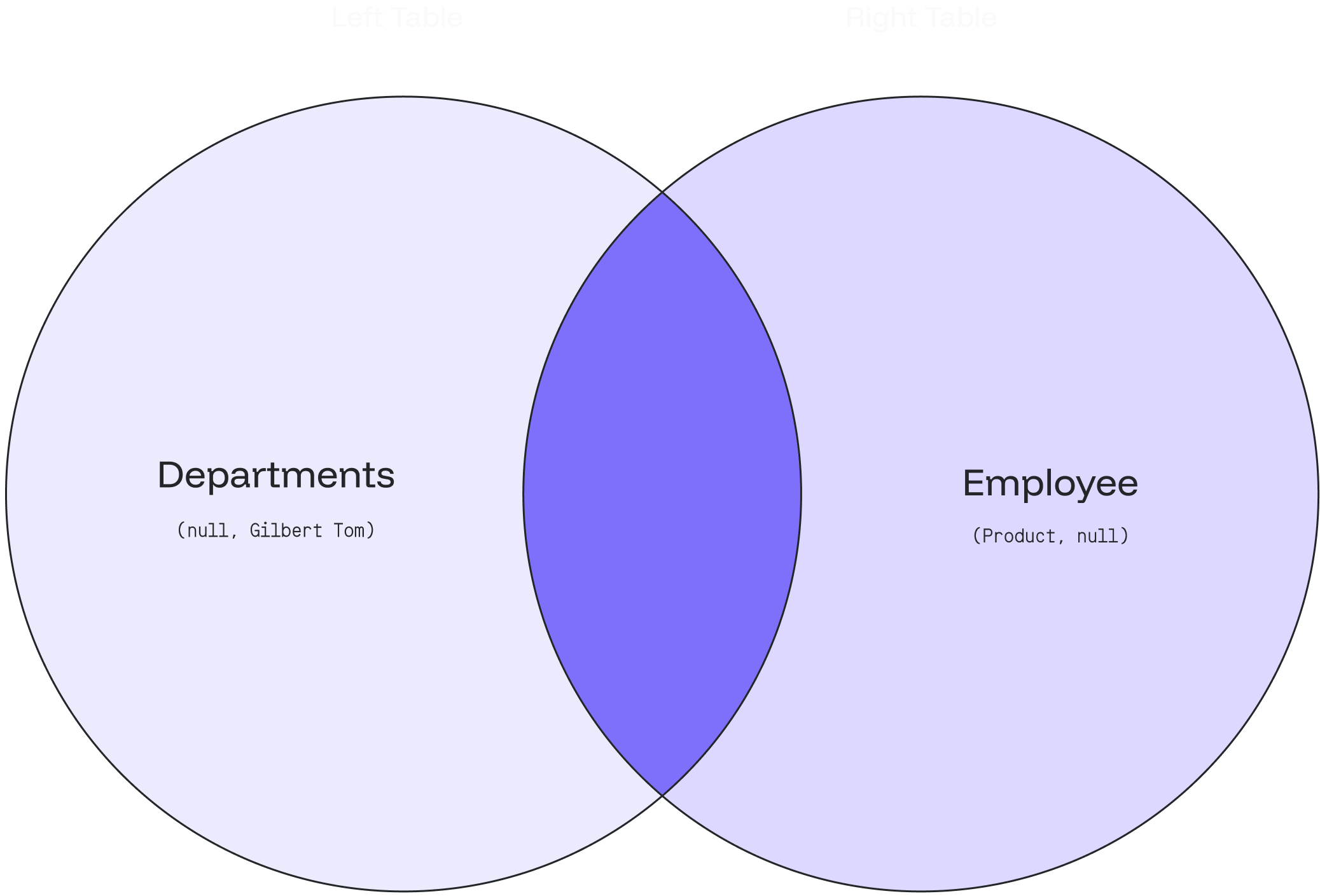
2. The result will indicate that the **Product** department doesn’t have any employees 👨🏻💼
```sql theme={null}
+------------------+--------------------+
| employee_name | department_name |
+------------------+--------------------+
| null | Product |
+------------------+--------------------+
```
**b) Department**
1\) Let’s find out the employee who doesn’t belong to any department by adding a WHERE clause and NULL as the following query:
```sql theme={null}
SELECT employee_name, department_name
FROM employee
FULL OUTER JOIN departments
ON employee.dept_id = departments.department_id
WHERE department_name IS NULL;
```
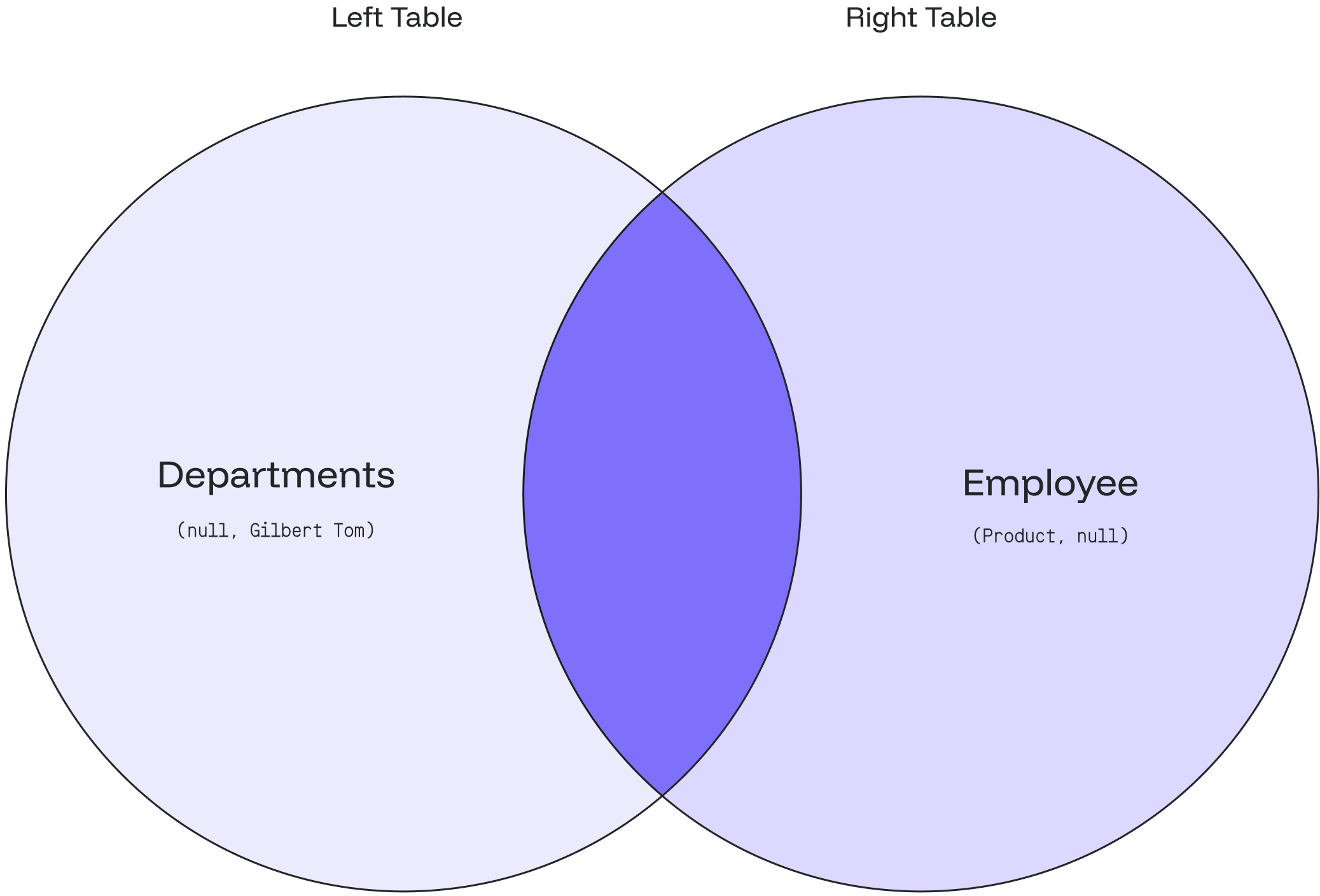
2\) The result will show that **Gilbert Tom** doesn’t belong to any department 👨🏻💼
```sql theme={null}
+------------------+--------------------+
| employee_name | department_name |
+------------------+--------------------+
| Gilbert Tom | null |
+------------------+--------------------+
```
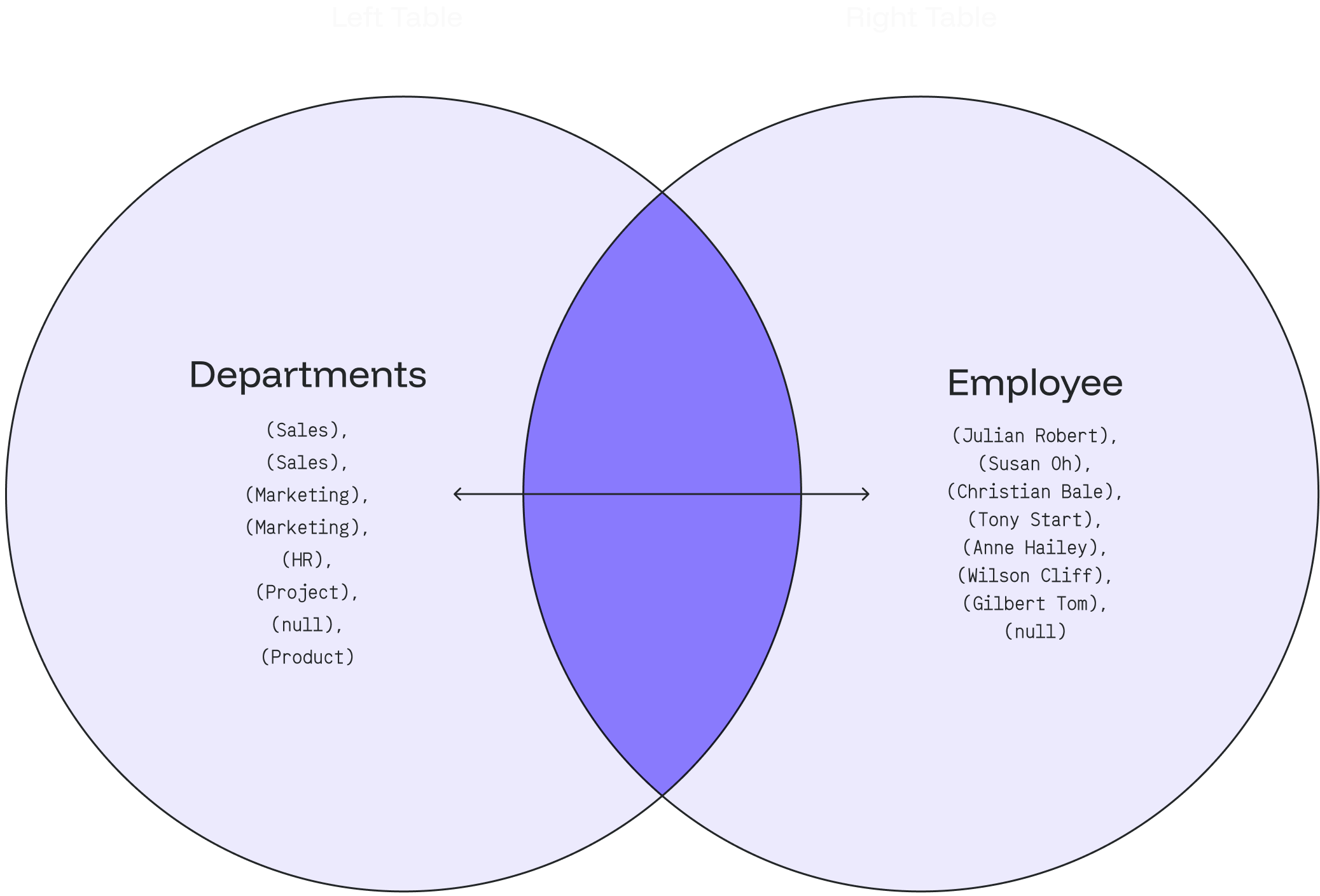
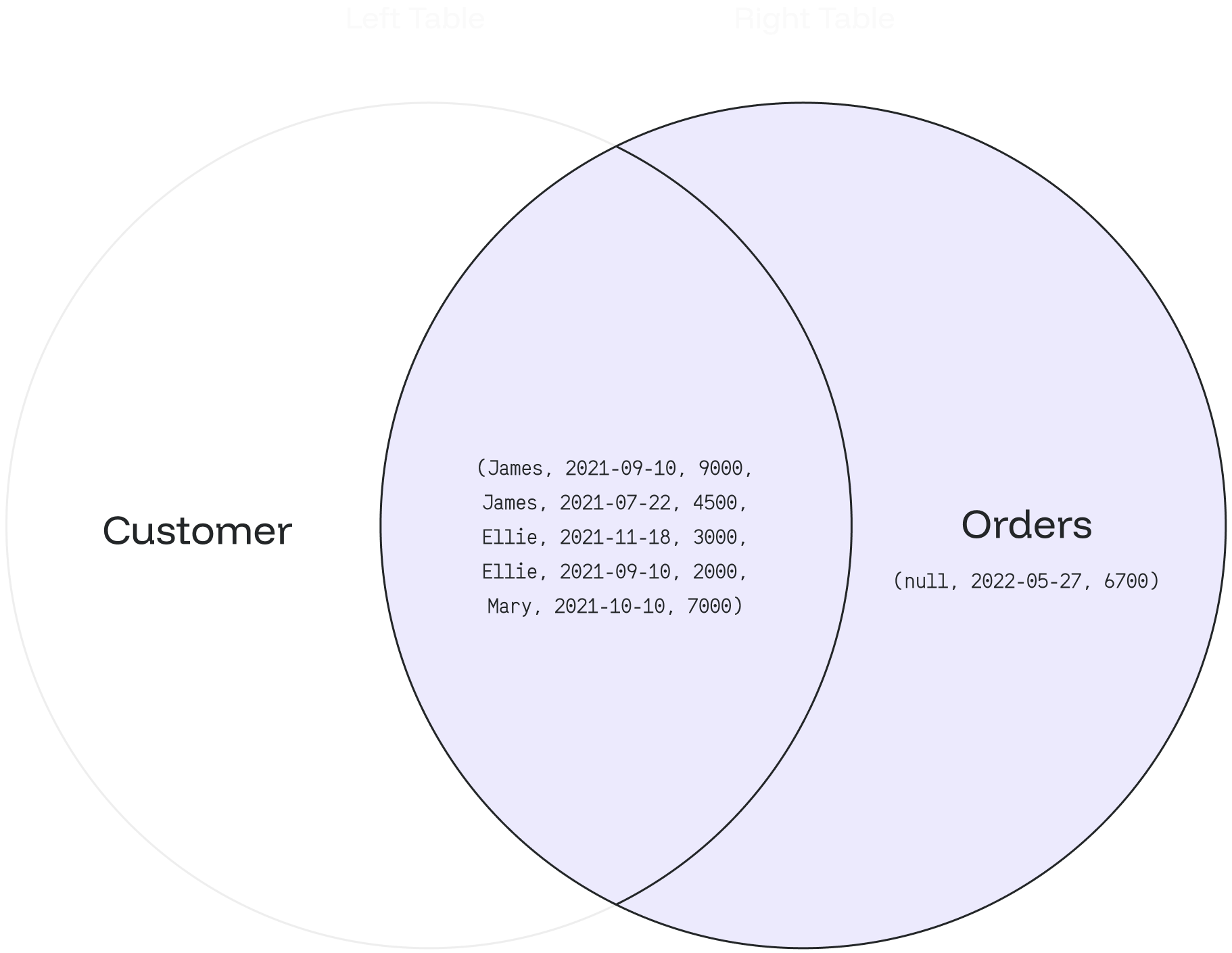
The following Venn diagram illustrates how the FULL OUTER JOIN works for the department and employee with a null value:
***
### Case 2: `FULL OUTER JOIN` with `WHERE` Clause
**a) Employee**
1. We can look up the department that does not have any employees by adding a `WHERE` clause and `NULL` as the following query:
```sql theme={null}
SELECT employee_name, department_name
FROM departments
FULL OUTER JOIN employee
ON departments.department_id = employee.dept_id
WHERE employee_name IS NULL;
```
2. The result will indicate that the **Product** department doesn’t have any employees 👨🏻💼
```sql theme={null}
+------------------+--------------------+
| employee_name | department_name |
+------------------+--------------------+
| null | Product |
+------------------+--------------------+
```
**b) Department**
1\) Let’s find out the employee who doesn’t belong to any department by adding a WHERE clause and NULL as the following query:
```sql theme={null}
SELECT employee_name, department_name
FROM employee
FULL OUTER JOIN departments
ON employee.dept_id = departments.department_id
WHERE department_name IS NULL;
```
2\) The result will show that **Gilbert Tom** doesn’t belong to any department 👨🏻💼
```sql theme={null}
+------------------+--------------------+
| employee_name | department_name |
+------------------+--------------------+
| Gilbert Tom | null |
+------------------+--------------------+
```
The following Venn diagram illustrates how the FULL OUTER JOIN works for the department and employee with a null value:
 ---
# Source: https://docs.oxla.com/sql-reference/sql-clauses/over-window.md
> ## Documentation Index
> Fetch the complete documentation index at: https://docs.oxla.com/llms.txt
> Use this file to discover all available pages before exploring further.
# OVER / WINDOW
## Overview
All window functions utilise a set of clauses specific for them, some of which are mandatory while others are optional.
## OVER Clause
When it comes to required ones, there is the `OVER` clause, which defines a window or user-specified set of rows within a query result set. It is a mandatory element of window functions, defining the window specification and differentiating them from other SQL functions.
### Syntax
The syntax for this clause looks as follows:
```sql theme={null}
OVER (PARTITION BY rows1 ORDER BY rows2)
```
where, the `PARTITION BY` clause is a list of `expressions` interpreted in much the same fashion as the elements of a `GROUP BY` clause, with major exception that they are always simple expressions and never the name or number of an output column. Another difference is that these expressions can contain aggregate function calls, which are not allowed in a regular `GROUP BY` clause (they are allowed here because windowing occurs after grouping and aggregation)
`[ PARTITION BY expression [, ...] ]` (optional window partition)
The `ORDER BY` clause used in the `OVER` clause above is a list of `expressions` interpreted in much the same fashion as the elements of a statement-level `ORDER BY` clause, except that the expressions are always taken as simple expressions and never the name or number of an output column.
`[ ORDER BY expression [ ASC | DESC | USING operator ] [ NULLS { FIRST | LAST } ] [, ...] ]` (optional window ordering)
## WINDOW Clause
In terms of window functions' optional clauses, there is the `WINDOW` clause that defines one or more named window specification, as a `window_name` and `window_definition` pair.
### Syntax
The syntax for this clause looks as follows:
```sql theme={null}
WINDOW window_name AS (window_definition) [, ...]
```
where `window_name` is a name that can be referenced from the `OVER` clauses or subsequent `window definition`. There are a few important things to keep in mind here:
* The `window_definition` may use an `existing_window_name` to refer to a previous `window_definition` in the `WINDOW` clause, but the previous `window_definition` must not specify a `frame` clause
* The `window_definition` copies the `PARTITION BY` clause and `ORDER BY` clause from previous `window_definition`, but it cannot specify its own `PARTION BY` clause, and can specify an `ORDER BY` clause if the previous `window_definition` does not have one.
`[ existing_window_name ] [ PARTITION BY clause ] [ ORDER BY clause ] [ frame clause ]` (all arguments are optional)
---
# Source: https://docs.oxla.com/sql-reference/sql-clauses/over-window.md
> ## Documentation Index
> Fetch the complete documentation index at: https://docs.oxla.com/llms.txt
> Use this file to discover all available pages before exploring further.
# OVER / WINDOW
## Overview
All window functions utilise a set of clauses specific for them, some of which are mandatory while others are optional.
## OVER Clause
When it comes to required ones, there is the `OVER` clause, which defines a window or user-specified set of rows within a query result set. It is a mandatory element of window functions, defining the window specification and differentiating them from other SQL functions.
### Syntax
The syntax for this clause looks as follows:
```sql theme={null}
OVER (PARTITION BY rows1 ORDER BY rows2)
```
where, the `PARTITION BY` clause is a list of `expressions` interpreted in much the same fashion as the elements of a `GROUP BY` clause, with major exception that they are always simple expressions and never the name or number of an output column. Another difference is that these expressions can contain aggregate function calls, which are not allowed in a regular `GROUP BY` clause (they are allowed here because windowing occurs after grouping and aggregation)
`[ PARTITION BY expression [, ...] ]` (optional window partition)
The `ORDER BY` clause used in the `OVER` clause above is a list of `expressions` interpreted in much the same fashion as the elements of a statement-level `ORDER BY` clause, except that the expressions are always taken as simple expressions and never the name or number of an output column.
`[ ORDER BY expression [ ASC | DESC | USING operator ] [ NULLS { FIRST | LAST } ] [, ...] ]` (optional window ordering)
## WINDOW Clause
In terms of window functions' optional clauses, there is the `WINDOW` clause that defines one or more named window specification, as a `window_name` and `window_definition` pair.
### Syntax
The syntax for this clause looks as follows:
```sql theme={null}
WINDOW window_name AS (window_definition) [, ...]
```
where `window_name` is a name that can be referenced from the `OVER` clauses or subsequent `window definition`. There are a few important things to keep in mind here:
* The `window_definition` may use an `existing_window_name` to refer to a previous `window_definition` in the `WINDOW` clause, but the previous `window_definition` must not specify a `frame` clause
* The `window_definition` copies the `PARTITION BY` clause and `ORDER BY` clause from previous `window_definition`, but it cannot specify its own `PARTION BY` clause, and can specify an `ORDER BY` clause if the previous `window_definition` does not have one.
`[ existing_window_name ] [ PARTITION BY clause ] [ ORDER BY clause ] [ frame clause ]` (all arguments are optional)
Syntax
The syntax for this function is as follows:
```sql theme={null}
PERCENTILE_CONT(fraction) WITHIN GROUP (ORDER BY order_list)
```
Parameters
- `fraction`: decimal value between 0 and 1 representing the desired percentile (e.g. 0.25 for the 25th percentile)
```sql theme={null}
PERCENTILE_CONT(fractions) WITHIN GROUP (ORDER BY order_list)
```
Parameters
- `fractions`: array of decimal values between 0 and 1 representing the desired percentiles (e.g. `ARRAY[0.25, 0.50, 0.75, 0.90]`)
Syntax
The syntax for this function is as follows:
```sql theme={null}
PERCENTILE_DISC(fraction) WITHIN GROUP (ORDER BY order_list)
```
Parameters
- `fraction`: decimal value between 0 and 1 representing the desired percentile (e.g. 0.25 for the 25th percentile)
```sql theme={null}
PERCENTILE_DISC(fractions) WITHIN GROUP (ORDER BY order_list)
```
Parameters
- `fractions`: array of decimal values between 0 and 1 representing the desired percentiles (e.g. `ARRAY[0.25, 0.50, 0.75, 0.90]`)
pg\_get\_constraintdef (constraint\_oid \[, pretty\_bool]) → NULLpg\_get\_statisticsobjdef\_columns() → NULLpg\_relation\_is\_publishable(table\_name\_or\_oid)pg\_table\_is\_visible(table\_or\_index\_oid)`sslmode=verify-full;sslrootcert=\{path to ssl cert from SaaS\}` to the first parameter of PDO to ensure full SSL endpoint verification and encryption. 
 ---
# Source: https://docs.oxla.com/security/roles.md
> ## Documentation Index
> Fetch the complete documentation index at: https://docs.oxla.com/llms.txt
> Use this file to discover all available pages before exploring further.
# Roles
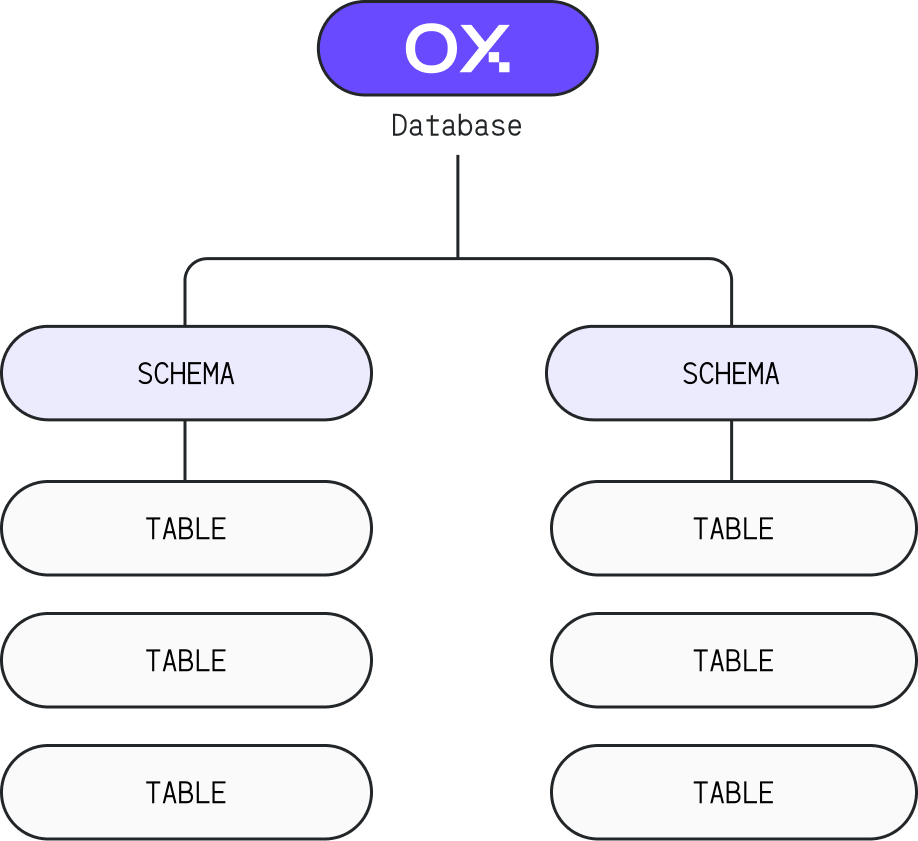
Roles in Oxla can be used to manage access to the following objects:
* Database
* Schema
* Table
---
# Source: https://docs.oxla.com/security/roles.md
> ## Documentation Index
> Fetch the complete documentation index at: https://docs.oxla.com/llms.txt
> Use this file to discover all available pages before exploring further.
# Roles
Roles in Oxla can be used to manage access to the following objects:
* Database
* Schema
* Table
 ## Default Schema in Oxla
By default, the `public` schema is used in Oxla. When unqualified `table_name` is used, that `table_name` is equivalent to `public.table_name`. It also applies to `CREATE`, `DROP`, and `SELECT TABLE` statements.
## Default Schema in Oxla
By default, the `public` schema is used in Oxla. When unqualified `table_name` is used, that `table_name` is equivalent to `public.table_name`. It also applies to `CREATE`, `DROP`, and `SELECT TABLE` statements.
shobj\_description (object\_oid, catalog\_name) → NULLIf the index is less than or equal to 0, no characters are returned.
Once it exceeds 0, characters from the string are yielded, starting from the first one. | ### Length The `length` is used to determine the number of characters to be extracted\*. \*It can be one or more characters. | **Input** | **Return** | | ------------------------- | ---------------------------------------------------------------------------------------------------------- | | `length` = 0 | Returns an empty substring. | | `length` is not set | The function will start from the specified `start_position` and end at the last character of the `string`. | | `length` = negative value | Returns an error. | ## Examples ### Case 1: `SUBSTR()` function with specified `start_position` & `length` In this example, we will set the `start_position` with the first six characters and have five characters extracted: ```sql theme={null} SELECT substr('Watermelon',6,5) AS "Fruit"; ``` The updated table is shown below: ```sql theme={null} Fruit ------- melon ``` ### Case 2: `SUBSTR()` function with `length` = 0 The following query will extract a string with `length` = 0: ```sql theme={null} SELECT substr('Watermelon',6,0) AS "Fruit"; ``` It will display an empty output as there is no `length` specified: ```sql theme={null} Fruit ------- ``` ### Case 3: `SUBSTR()` function with `length` = negative value Here we will check if the `length` is specified with a negative value: ```sql theme={null} SELECT substr('Watermelon',6,-2) AS "Fruit"; ``` Instead of extracting the string from the last characters, it will return an error as seen below: ```sql theme={null} ERROR: Length of substring cannot be negative ``` ### Case 4: `SUBSTR()` function with `start_position` > `string` We know that **Watermelon** only has ten characters, but this time, we will figure out if the specified `start_position` is larger than the string’s characters: ```sql theme={null} SELECT substr('Watermelon',20,2) AS "Fruit"; ``` It will display an empty output as shown below: ```sql theme={null} Fruit ------- ``` ### Case 5: `SUBSTR()` Function with 2 Arguments In this example, we will set the `start_position` with the first six characters and have five characters extracted. ```sql theme={null} SELECT substr('database', 6) AS "Result"; ``` It will display the substring from position 6 output as shown below: ```sql theme={null} Result -------- ase ``` --- # Source: https://docs.oxla.com/sql-reference/sql-functions/string-functions/substring.md > ## Documentation Index > Fetch the complete documentation index at: https://docs.oxla.com/llms.txt > Use this file to discover all available pages before exploring further. # SUBSTRING
Keep in mind that all user sessions have a local timezone associated with them, affecting how timestamps `with time zone` values are displayed.
The timezone information **is not stored in the database**. Consequently, every time a user requests a value of this type, Oxla converts from UTC to the user's local timezone before displaying it.
Oxla relies on timezone information served by host machine operating system. It must be up-to-date in order to ensure correct timestamp conversions, date calculations, and compliance with regional time changes such as daylight saving adjustments.
- 0001 is 1
- 1 is 1 | | `MM` | Month number (1–12) | - Up to 2 digits
- 01 is 1
- 1 is 1 | | `DD` | Day of month (1–31) | - Up to 2 digits
- 01 is 1
- 1 is 1 | | `HH` | Hour of day (1–12) | - Up to 2 digits
- 01 is 1
- 1 is 1 | | `HH12` | Hour of day (1–12) | - Up to 2 digits
- 01 is 1
- 1 is 1 | | `HH24` | Hour of day (0–23) | - Up to 2 digits
- 01 is 1
- 1 is 1 | | `MI` | Minute (0–59) | - Up to 2 digits
- 01 is 1
- 1 is 1 | | `SS` | Second (0–59) | - Up to 2 digits
- 01 is 1
- 1 is 1 | | `MS` | Millisecond (0–999) | - Up to 3 digits
- 001 is 1 millisecond
- 1 is 100 milliseconds | | `US` | Microsecond (0–999999) | - Up to 6 digits
- 000001 is 1 microsecond
- 1 is 100000 milliseconds | | `AM`, `am`, `PM` or `pm` | Meridiem indicator | Without periods | | `A.M.`, `a.m.`, `P.M.` or `p.m.` | Meridiem indicator | With periods | ## Examples ### Case #1: Timestamp into YYYY-MM-DD HH24:MI The `TO_TIMESTAMP()` function converts the provided string into a timestamp with the format `YYYY-MM-DD HH24:MI`. ```sql theme={null} select TO_TIMESTAMP('2020-03-04 14:30', 'YYYY-MM-DD HH24:MI'); ``` The final output will be a timestamp with a timezone. ```sql theme={null} to_timestamp ------------------------------- 2020-03-04 14:30:00.000000+00 ``` ### Case #2: Timestamp into MM-DD HH12:MI The `TO_TIMESTAMP()` function converts the provided string into a timestamp with the format `MM-DD HH12:MI`. ```sql theme={null} select TO_TIMESTAMP('3-04 02:30', 'MM-DD HH12:MI'); ``` The final output will be a timestamp with a timezone. ```sql theme={null} to_timestamp ---------------------------- 1-03-04 02:30:00.000000+00 ``` ### Case #3: Timestamp into YYYY-MM HH12:MI(AM/PM) The `TO_TIMESTAMP()`\` function converts the provided string into a timestamp with the format `YYYY-MM HH12:MI` with meridiem indicator (AM/PM). **Request 1** ```sql theme={null} select TO_TIMESTAMP('2020-02 12:30AM', 'YYYY-MM HH12:MIPM'); ``` **Request 2** ```sql theme={null} select TO_TIMESTAMP('2020-02 12:30AM', 'YYYY-MM HH:MIAM'); ``` The final output of both requests will have the same result. It changes the time into a 12-hour format, resulting in **12:30** being adjusted to **00:30**. ```sql theme={null} to_timestamp ------------------------------- 2020-02-01 00:30:00.000000+00 ``` ### Case #4: Timestamp into YYYY-MM-DD HH24:MI:SS.MS.US The `TO_TIMESTAMP()` function converts the provided string into a timestamp with `YYYY-MM-DD HH24:MI:SS.MS.US` format. ```sql theme={null} select TO_TIMESTAMP('1960-01-31 15:12:02.020.001230', 'YYYY-MM-DD HH24:MI:SS.MS.US'); ``` The final output will be a timestamp with milliseconds and microseconds. ```sql theme={null} to_timestamp ------------------------------- 1960-01-31 15:12:02.021230+00 ``` ### Case #5: Timestamp into YYYY-MM-DD HH24:MI:SS.MS The `TO_TIMESTAMP()` function converts the provided string into a timestamp with `YYYY-MM-DD HH24:MI:SS.MS` format. ```sql theme={null} select TO_TIMESTAMP('1960-01-31 15:12:02.02', 'YYYY-MM-DD HH24:MI:SS.MS'); ``` The final output will be a timestamp with milliseconds. ```sql theme={null} to_timestamp ------------------------------- 1960-01-31 15:12:02.020000+00 ``` --- # Source: https://docs.oxla.com/sql-reference/transactions.md > ## Documentation Index > Fetch the complete documentation index at: https://docs.oxla.com/llms.txt > Use this file to discover all available pages before exploring further. # Transactions ## Overview The transactions are supported only on the syntax level to allow integration with tools that requires it. While the syntax is accepted, all the queries are executed immediately and with no transactional guarantees. ## Commands These commands are used to manage transactions: ### BEGIN Initiates a new transaction by calling one of the syntax below.
Call one of the syntax below.
1. The data types of corresponding columns in the `SELECT` queries must be compatible.
2. The order of columns is flexible as long as the columns in consecutive places are pairwise compatible. For example, you can do `SELECT col1, col2 FROM table1 UNION SELECT col2, col1 FROM table2`.
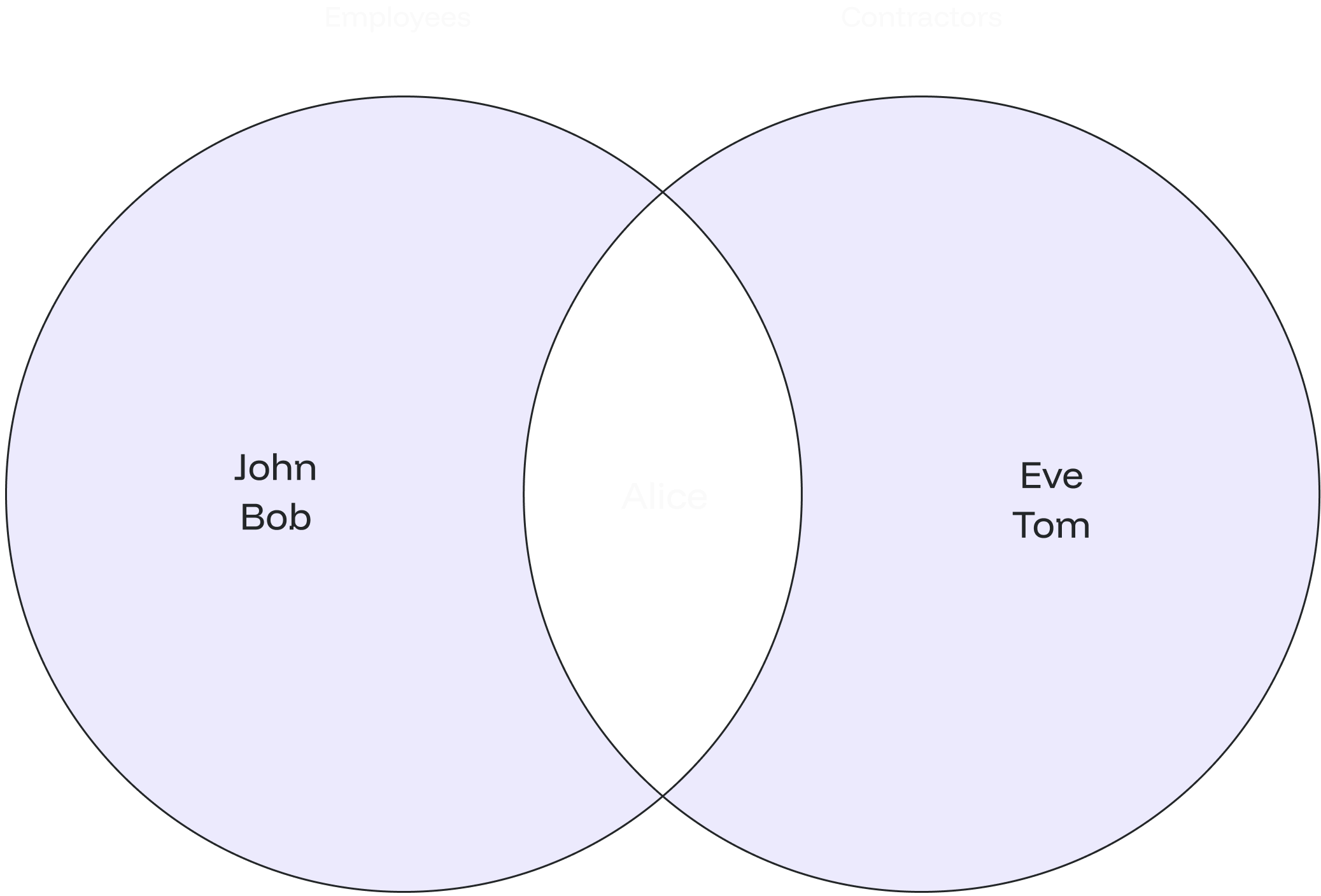 ## UNION ALL
### Overview
The `UNION ALL` combines the result sets of 2 or more select statements, returning all rows from the query and not removing duplicate rows between the tables.
### Syntax
Below is the syntax of the `UNION ALL`:
```sql theme={null}
SELECT value1, value2, ... value_n
FROM tables
UNION ALL
SELECT value1, value2, ... value_n
FROM tables;
```
The parameters from the syntax are explained below:
* `value1, value2, ... value_n`: The columns you wish to retrieve. You can also retrieve all the values using the `SELECT * FROM` query.
* `table1, table2`: The tables that you wish to retrieve records from.
## UNION ALL
### Overview
The `UNION ALL` combines the result sets of 2 or more select statements, returning all rows from the query and not removing duplicate rows between the tables.
### Syntax
Below is the syntax of the `UNION ALL`:
```sql theme={null}
SELECT value1, value2, ... value_n
FROM tables
UNION ALL
SELECT value1, value2, ... value_n
FROM tables;
```
The parameters from the syntax are explained below:
* `value1, value2, ... value_n`: The columns you wish to retrieve. You can also retrieve all the values using the `SELECT * FROM` query.
* `table1, table2`: The tables that you wish to retrieve records from.
1. The data types of corresponding columns in the `SELECT` queries must be compatible.
2. The order of columns is flexible as long as the columns in consecutive places are pairwise compatible.

 ---
# Source: https://docs.oxla.com/sql-reference/sql-functions/timestamp-functions/unix-macros.md
> ## Documentation Index
> Fetch the complete documentation index at: https://docs.oxla.com/llms.txt
> Use this file to discover all available pages before exploring further.
# UNIX_MICROS
## Overview
The `UNIX_MICROS()` function returns a given timestamp into a UNIX timestamp in microseconds, from 1970-01-01 00:00:00-00 (can be negative). Its syntax is illustrated below:
```sql theme={null}
SELECT UNIX_MICRO(TIMESTAMP)
```
Its input type is a TIMESTAMP expression, and the return data type is `BIGINT` representing time in microseconds.
## Examples
### Case #1: Basic `UNIX_MICROS()` function
The below example uses the `UNIX_MICROS()` function to convert a given timestamp into a UNIX timestamp in microseconds:
```sql theme={null}
SELECT UNIX_MICRO(TIMESTAMP "2022-12-25 13:30:00+00") AS unix_microsvalues;
```
The final output will be as follows:
```sql theme={null}
+-----------------------------+
| unix_microsvalues |
+-----------------------------+
| 1671975000000000.000000 |
+-----------------------------+
```
### Case #2: `UNIX_MICROS()` function using columns
Let’s suppose we have a table named **time\_example** with the following timestamp values:
```sql theme={null}
CREATE TABLE time_example (
time_stamp timestamp
);
INSERT INTO time_example VALUES
('2022-12-25 13:30:00'),
('2021-10-02 06:30:00'),
('2020-09-25 07:25:00');
```
```sql theme={null}
SELECT * FROM time_example;
```
The above query will show the following table:
```sql theme={null}
+-------------------------+
| time_example |
+-------------------------+
| 2022-12-25 13:30:00 |
| 2021-10-02 06:30:00 |
| 2020-09-25 07:25:00 |
+-------------------------+
```
We want to convert all timestamp values into UNIX timestamp values in microseconds. To do that, we have to run the following query:
```sql theme={null}
SELECT time_stamp, UNIX_MICROS(time_stamp)
AS time_micros
FROM time_example;
```
The output displays all the timestamp entries in the **time\_stamp** column and the converted UNIX timestamps in microseconds in the column **time\_micros**.
```sql theme={null}
+-------------------------+--------------------------+
| time_stamp | time_micros |
+-------------------------+--------------------------+
| 2022-12-25 13:30:00 | 1671975000000000.000000 |
| 2021-10-02 06:30:00 | 1633156200000000.000000 |
| 2020-09-25 07:25:00 | 1601018700000000.000000 |
+-------------------------+--------------------------+
```
---
# Source: https://docs.oxla.com/sql-reference/sql-functions/timestamp-functions/unix-micros.md
> ## Documentation Index
> Fetch the complete documentation index at: https://docs.oxla.com/llms.txt
> Use this file to discover all available pages before exploring further.
# UNIX_MICROS
## Overview
The `UNIX_MICROS()` function returns a given timestamp into a UNIX timestamp in microseconds, from 1970-01-01 00:00:00-00 (can be negative). Its syntax is illustrated below:
```sql theme={null}
SELECT UNIX_MICRO(TIMESTAMP)
```
Its input type is a TIMESTAMP expression, and the return data type is `int64` representing time in microseconds.
## Examples
### Case #1: Basic `UNIX_MICROS()` function
The below example uses the `UNIX_MICROS()` function to convert a given timestamp into a UNIX timestamp in microseconds:
```sql theme={null}
SELECT UNIX_MICRO(TIMESTAMP "2022-12-25 13:30:00+00") AS unix_microsvalues;
```
The final output will be as follows:
```sql theme={null}
+-----------------------------+
| unix_microsvalues |
+-----------------------------+
| 1671975000000000.000000 |
+-----------------------------+
```
### Case #2: `UNIX_MICROS()` function using columns
Let’s suppose we have a table named **time\_example** with the following timestamp values:
```sql theme={null}
CREATE TABLE time_example (
time_stamp timestamp
);
INSERT INTO time_example VALUES
('2022-12-25 13:30:00'),
('2021-10-02 06:30:00'),
('2020-09-25 07:25:00');
```
```sql theme={null}
SELECT * FROM time_example;
```
The above query will show the following table:
```sql theme={null}
+-------------------------+
| time_example |
+-------------------------+
| 2022-12-25 13:30:00 |
| 2021-10-02 06:30:00 |
| 2020-09-25 07:25:00 |
+-------------------------+
```
We want to convert all timestamp values into UNIX timestamp values in microseconds. To do that, we have to run the following query:
```sql theme={null}
SELECT time_stamp, UNIX_MICROS(time_stamp)
AS time_micros
FROM time_example;
```
The output displays all the timestamp entries in the **time\_stamp** column and the converted UNIX timestamps in microseconds in the column **time\_micros**.
```sql theme={null}
+-------------------------+--------------------------+
| time_stamp | time_micros |
+-------------------------+--------------------------+
| 2022-12-25 13:30:00 | 1671975000000000.000000 |
| 2021-10-02 06:30:00 | 1633156200000000.000000 |
| 2020-09-25 07:25:00 | 1601018700000000.000000 |
+-------------------------+--------------------------+
```
---
# Source: https://docs.oxla.com/sql-reference/sql-functions/timestamp-functions/unix-millis.md
> ## Documentation Index
> Fetch the complete documentation index at: https://docs.oxla.com/llms.txt
> Use this file to discover all available pages before exploring further.
# UNIX_MILLIS
## Overview
The `UNIX_MILLIS()` function returns a given timestamp to a UNIX timestamp in milliseconds from 1970-01-01 00:00:00-00 (can be negative). Its syntax is illustrated below:
```sql theme={null}
SELECT UNIX_MILLIS(TIMESTAMP)
```
Its input type is a TIMESTAMP expression, and the return data type is `BIGINT` representing time in milliseconds.
## Examples
### Case #1: Basic `UNIX_MILLIS()` function
The below example uses the `UNIX_MILLIS()` function to convert a given timestamp into a UNIX timestamp in milliseconds:
```sql theme={null}
SELECT UNIX_MILLIS(TIMESTAMP "1996-5-02 7:15:00+00") AS unix_millisvalues;
```
The final output will be as follows:
```sql theme={null}
+-----------------------------+
| unix_millisvalues |
+-----------------------------+
| 831021300000.000000 |
+-----------------------------+
```
### Case #2: `UNIX_MILLIS()` function using columns
Let’s suppose we have a table named **time\_example **with the following timestamp values in the** time\_stamp** column:
```sql theme={null}
CREATE TABLE time_example (
time_stamp timestamp
);
INSERT INTO time_example VALUES
('2004-07-23 11:30:00+00'),
('2011-02-12 04:45:00+00'),
('1975-08-03 07:50:00+00');
```
```sql theme={null}
SELECT * FROM time_example;
```
The above query will show the following table:
```sql theme={null}
+-------------------------+
| time_example |
+-------------------------+
| 2004-07-23 11:30:00 |
| 2011-02-12 04:45:00 |
| 1975-08-03 07:50:00 |
+-------------------------+
```
We want to convert all timestamp values into UNIX timestamp values in milliseconds. To do that, we have to run the following query:
```sql theme={null}
SELECT time_stamp, UNIX_MILLIS(time_stamp) AS time_millis FROM time_example;
```
The output displays all the timestamp entries of the table in the \*\*time\_stamp \*\*column and the converted UNIX milliseconds timestamp entries in the column **time\_millis**.
```sql theme={null}
+-------------------------+-----------------------+
| time_stamp | time_millis |
+-------------------------+-----------------------+
| 2004-07-23 11:30:00 | 1090582200000.000000 |
| 2011-02-12 04:45:00 | 1297485900000.000000 |
| 1975-08-03 07:50:00 | 176284200000.000000 |
+-------------------------+-----------------------+
```
---
# Source: https://docs.oxla.com/sql-reference/sql-functions/timestamp-functions/unix-seconds.md
> ## Documentation Index
> Fetch the complete documentation index at: https://docs.oxla.com/llms.txt
> Use this file to discover all available pages before exploring further.
# UNIX_SECONDS
## Overview
The `UNIX_SECONDS()` function returns a given timestamp to a UNIX timestamp in seconds, from 1970-01-01 00:00:00-00. Its syntax is illustrated below:
```sql theme={null}
SELECT UNIX_SECONDS(TIMESTAMP)
```
Its input type is a TIMESTAMP expression, and the return data type is `BIGINT` representing time in seconds.
## Examples
### Case #1: Basic `UNIX_SECONDS()` function
The below example uses the `UNIX_SECONDS()` function to convert a given timestamp into a UNIX timestamp in seconds:
```sql theme={null}
SELECT UNIX_SECONDS(TIMESTAMP "2008-12-25 15:30:00+00") AS unix_secondsvalues;
```
The final output will be as follows:
```sql theme={null}
+-----------------------------+
| unix_secondsvalues |
+-----------------------------+
| 1230219000.000000 |
+-----------------------------+
```
### Case #2: `UNIX_SECONDS()` function using columns
Let’s suppose we have a table named \*\*time\_example \*\*with the following timestamp values in the **time\_stampvalues** column:
```sql theme={null}
CREATE TABLE time_example (
time_stampvalues timestamp
);
INSERT INTO time_example VALUES
('2022-12-25 13:30:00'),
('2020-09-25 07:25:00'),
('2008-12-25 15:30:00'),
('2021-10-02 06:30:00');
```
```sql theme={null}
SELECT * FROM time_example;
```
The above query will return the following table:
```sql theme={null}
+-------------------------+
| time_stampvalues |
+-------------------------+
| 2022-12-25 13:30:00 |
| 2020-09-25 07:25:00 |
| 2008-12-25 15:30:00 |
| 2021-10-02 06:30:00 |
+-------------------------+
```
1. We want to convert all timestamp values into UNIX timestamp values in seconds. To do that, we have to run the following query:
```sql theme={null}
SELECT time_stampvalues, UNIX_SECONDS(time_stampvalues)
AS time_secondsvalues
FROM time_example;
```
2. The output displays all the timestamp entries of the table in the **time\_stampvalues** column and the converted UNIX seconds timestamp entries in the column **time\_secondsvalues**.
```sql theme={null}
+-------------------------+-----------------------+
| time_stampvalues | time_secondsvalues |
+-------------------------+-----------------------+
| 2022-12-25 13:30:00 | 1671975000.000000 |
| 2020-09-25 07:25:00 | 1601018700.000000 |
| 2008-12-25 15:30:00 | 1230219000.000000 |
| 2021-10-02 06:30:00 | 1633156200.000000 |
+-------------------------+-----------------------+
```
---
# Source: https://docs.oxla.com/sql-reference/sql-mutations/update.md
> ## Documentation Index
> Fetch the complete documentation index at: https://docs.oxla.com/llms.txt
> Use this file to discover all available pages before exploring further.
# UPDATE
## **Overview**
The `UPDATE` mutation is used to modify the existing records in a table. This support has limitations:
* Only **one data mutation (DELETE or UPDATE)** at given moment is possible, trying to run another one will result in failure.
* Data mutations rewrite all files containing the data from the UPDATE/DELETE condition. Please note that running `DELETE from table` without any condition is possible, but it will be much slower than just `DROP TABLE table`.
* The syntax is simplified in comparison to Postgres. For example, the `SET column=
---
# Source: https://docs.oxla.com/sql-reference/sql-functions/timestamp-functions/unix-macros.md
> ## Documentation Index
> Fetch the complete documentation index at: https://docs.oxla.com/llms.txt
> Use this file to discover all available pages before exploring further.
# UNIX_MICROS
## Overview
The `UNIX_MICROS()` function returns a given timestamp into a UNIX timestamp in microseconds, from 1970-01-01 00:00:00-00 (can be negative). Its syntax is illustrated below:
```sql theme={null}
SELECT UNIX_MICRO(TIMESTAMP)
```
Its input type is a TIMESTAMP expression, and the return data type is `BIGINT` representing time in microseconds.
## Examples
### Case #1: Basic `UNIX_MICROS()` function
The below example uses the `UNIX_MICROS()` function to convert a given timestamp into a UNIX timestamp in microseconds:
```sql theme={null}
SELECT UNIX_MICRO(TIMESTAMP "2022-12-25 13:30:00+00") AS unix_microsvalues;
```
The final output will be as follows:
```sql theme={null}
+-----------------------------+
| unix_microsvalues |
+-----------------------------+
| 1671975000000000.000000 |
+-----------------------------+
```
### Case #2: `UNIX_MICROS()` function using columns
Let’s suppose we have a table named **time\_example** with the following timestamp values:
```sql theme={null}
CREATE TABLE time_example (
time_stamp timestamp
);
INSERT INTO time_example VALUES
('2022-12-25 13:30:00'),
('2021-10-02 06:30:00'),
('2020-09-25 07:25:00');
```
```sql theme={null}
SELECT * FROM time_example;
```
The above query will show the following table:
```sql theme={null}
+-------------------------+
| time_example |
+-------------------------+
| 2022-12-25 13:30:00 |
| 2021-10-02 06:30:00 |
| 2020-09-25 07:25:00 |
+-------------------------+
```
We want to convert all timestamp values into UNIX timestamp values in microseconds. To do that, we have to run the following query:
```sql theme={null}
SELECT time_stamp, UNIX_MICROS(time_stamp)
AS time_micros
FROM time_example;
```
The output displays all the timestamp entries in the **time\_stamp** column and the converted UNIX timestamps in microseconds in the column **time\_micros**.
```sql theme={null}
+-------------------------+--------------------------+
| time_stamp | time_micros |
+-------------------------+--------------------------+
| 2022-12-25 13:30:00 | 1671975000000000.000000 |
| 2021-10-02 06:30:00 | 1633156200000000.000000 |
| 2020-09-25 07:25:00 | 1601018700000000.000000 |
+-------------------------+--------------------------+
```
---
# Source: https://docs.oxla.com/sql-reference/sql-functions/timestamp-functions/unix-micros.md
> ## Documentation Index
> Fetch the complete documentation index at: https://docs.oxla.com/llms.txt
> Use this file to discover all available pages before exploring further.
# UNIX_MICROS
## Overview
The `UNIX_MICROS()` function returns a given timestamp into a UNIX timestamp in microseconds, from 1970-01-01 00:00:00-00 (can be negative). Its syntax is illustrated below:
```sql theme={null}
SELECT UNIX_MICRO(TIMESTAMP)
```
Its input type is a TIMESTAMP expression, and the return data type is `int64` representing time in microseconds.
## Examples
### Case #1: Basic `UNIX_MICROS()` function
The below example uses the `UNIX_MICROS()` function to convert a given timestamp into a UNIX timestamp in microseconds:
```sql theme={null}
SELECT UNIX_MICRO(TIMESTAMP "2022-12-25 13:30:00+00") AS unix_microsvalues;
```
The final output will be as follows:
```sql theme={null}
+-----------------------------+
| unix_microsvalues |
+-----------------------------+
| 1671975000000000.000000 |
+-----------------------------+
```
### Case #2: `UNIX_MICROS()` function using columns
Let’s suppose we have a table named **time\_example** with the following timestamp values:
```sql theme={null}
CREATE TABLE time_example (
time_stamp timestamp
);
INSERT INTO time_example VALUES
('2022-12-25 13:30:00'),
('2021-10-02 06:30:00'),
('2020-09-25 07:25:00');
```
```sql theme={null}
SELECT * FROM time_example;
```
The above query will show the following table:
```sql theme={null}
+-------------------------+
| time_example |
+-------------------------+
| 2022-12-25 13:30:00 |
| 2021-10-02 06:30:00 |
| 2020-09-25 07:25:00 |
+-------------------------+
```
We want to convert all timestamp values into UNIX timestamp values in microseconds. To do that, we have to run the following query:
```sql theme={null}
SELECT time_stamp, UNIX_MICROS(time_stamp)
AS time_micros
FROM time_example;
```
The output displays all the timestamp entries in the **time\_stamp** column and the converted UNIX timestamps in microseconds in the column **time\_micros**.
```sql theme={null}
+-------------------------+--------------------------+
| time_stamp | time_micros |
+-------------------------+--------------------------+
| 2022-12-25 13:30:00 | 1671975000000000.000000 |
| 2021-10-02 06:30:00 | 1633156200000000.000000 |
| 2020-09-25 07:25:00 | 1601018700000000.000000 |
+-------------------------+--------------------------+
```
---
# Source: https://docs.oxla.com/sql-reference/sql-functions/timestamp-functions/unix-millis.md
> ## Documentation Index
> Fetch the complete documentation index at: https://docs.oxla.com/llms.txt
> Use this file to discover all available pages before exploring further.
# UNIX_MILLIS
## Overview
The `UNIX_MILLIS()` function returns a given timestamp to a UNIX timestamp in milliseconds from 1970-01-01 00:00:00-00 (can be negative). Its syntax is illustrated below:
```sql theme={null}
SELECT UNIX_MILLIS(TIMESTAMP)
```
Its input type is a TIMESTAMP expression, and the return data type is `BIGINT` representing time in milliseconds.
## Examples
### Case #1: Basic `UNIX_MILLIS()` function
The below example uses the `UNIX_MILLIS()` function to convert a given timestamp into a UNIX timestamp in milliseconds:
```sql theme={null}
SELECT UNIX_MILLIS(TIMESTAMP "1996-5-02 7:15:00+00") AS unix_millisvalues;
```
The final output will be as follows:
```sql theme={null}
+-----------------------------+
| unix_millisvalues |
+-----------------------------+
| 831021300000.000000 |
+-----------------------------+
```
### Case #2: `UNIX_MILLIS()` function using columns
Let’s suppose we have a table named **time\_example **with the following timestamp values in the** time\_stamp** column:
```sql theme={null}
CREATE TABLE time_example (
time_stamp timestamp
);
INSERT INTO time_example VALUES
('2004-07-23 11:30:00+00'),
('2011-02-12 04:45:00+00'),
('1975-08-03 07:50:00+00');
```
```sql theme={null}
SELECT * FROM time_example;
```
The above query will show the following table:
```sql theme={null}
+-------------------------+
| time_example |
+-------------------------+
| 2004-07-23 11:30:00 |
| 2011-02-12 04:45:00 |
| 1975-08-03 07:50:00 |
+-------------------------+
```
We want to convert all timestamp values into UNIX timestamp values in milliseconds. To do that, we have to run the following query:
```sql theme={null}
SELECT time_stamp, UNIX_MILLIS(time_stamp) AS time_millis FROM time_example;
```
The output displays all the timestamp entries of the table in the \*\*time\_stamp \*\*column and the converted UNIX milliseconds timestamp entries in the column **time\_millis**.
```sql theme={null}
+-------------------------+-----------------------+
| time_stamp | time_millis |
+-------------------------+-----------------------+
| 2004-07-23 11:30:00 | 1090582200000.000000 |
| 2011-02-12 04:45:00 | 1297485900000.000000 |
| 1975-08-03 07:50:00 | 176284200000.000000 |
+-------------------------+-----------------------+
```
---
# Source: https://docs.oxla.com/sql-reference/sql-functions/timestamp-functions/unix-seconds.md
> ## Documentation Index
> Fetch the complete documentation index at: https://docs.oxla.com/llms.txt
> Use this file to discover all available pages before exploring further.
# UNIX_SECONDS
## Overview
The `UNIX_SECONDS()` function returns a given timestamp to a UNIX timestamp in seconds, from 1970-01-01 00:00:00-00. Its syntax is illustrated below:
```sql theme={null}
SELECT UNIX_SECONDS(TIMESTAMP)
```
Its input type is a TIMESTAMP expression, and the return data type is `BIGINT` representing time in seconds.
## Examples
### Case #1: Basic `UNIX_SECONDS()` function
The below example uses the `UNIX_SECONDS()` function to convert a given timestamp into a UNIX timestamp in seconds:
```sql theme={null}
SELECT UNIX_SECONDS(TIMESTAMP "2008-12-25 15:30:00+00") AS unix_secondsvalues;
```
The final output will be as follows:
```sql theme={null}
+-----------------------------+
| unix_secondsvalues |
+-----------------------------+
| 1230219000.000000 |
+-----------------------------+
```
### Case #2: `UNIX_SECONDS()` function using columns
Let’s suppose we have a table named \*\*time\_example \*\*with the following timestamp values in the **time\_stampvalues** column:
```sql theme={null}
CREATE TABLE time_example (
time_stampvalues timestamp
);
INSERT INTO time_example VALUES
('2022-12-25 13:30:00'),
('2020-09-25 07:25:00'),
('2008-12-25 15:30:00'),
('2021-10-02 06:30:00');
```
```sql theme={null}
SELECT * FROM time_example;
```
The above query will return the following table:
```sql theme={null}
+-------------------------+
| time_stampvalues |
+-------------------------+
| 2022-12-25 13:30:00 |
| 2020-09-25 07:25:00 |
| 2008-12-25 15:30:00 |
| 2021-10-02 06:30:00 |
+-------------------------+
```
1. We want to convert all timestamp values into UNIX timestamp values in seconds. To do that, we have to run the following query:
```sql theme={null}
SELECT time_stampvalues, UNIX_SECONDS(time_stampvalues)
AS time_secondsvalues
FROM time_example;
```
2. The output displays all the timestamp entries of the table in the **time\_stampvalues** column and the converted UNIX seconds timestamp entries in the column **time\_secondsvalues**.
```sql theme={null}
+-------------------------+-----------------------+
| time_stampvalues | time_secondsvalues |
+-------------------------+-----------------------+
| 2022-12-25 13:30:00 | 1671975000.000000 |
| 2020-09-25 07:25:00 | 1601018700.000000 |
| 2008-12-25 15:30:00 | 1230219000.000000 |
| 2021-10-02 06:30:00 | 1633156200.000000 |
+-------------------------+-----------------------+
```
---
# Source: https://docs.oxla.com/sql-reference/sql-mutations/update.md
> ## Documentation Index
> Fetch the complete documentation index at: https://docs.oxla.com/llms.txt
> Use this file to discover all available pages before exploring further.
# UPDATE
## **Overview**
The `UPDATE` mutation is used to modify the existing records in a table. This support has limitations:
* Only **one data mutation (DELETE or UPDATE)** at given moment is possible, trying to run another one will result in failure.
* Data mutations rewrite all files containing the data from the UPDATE/DELETE condition. Please note that running `DELETE from table` without any condition is possible, but it will be much slower than just `DROP TABLE table`.
* The syntax is simplified in comparison to Postgres. For example, the `SET column=This marks the initial release of our new Mutation feature, providing you with the ability to update data. The Mutations involve rewriting entire files which take several minutes and could generate infrastructure costs. We are aiming to enhance and optimize this feature in future updates!

