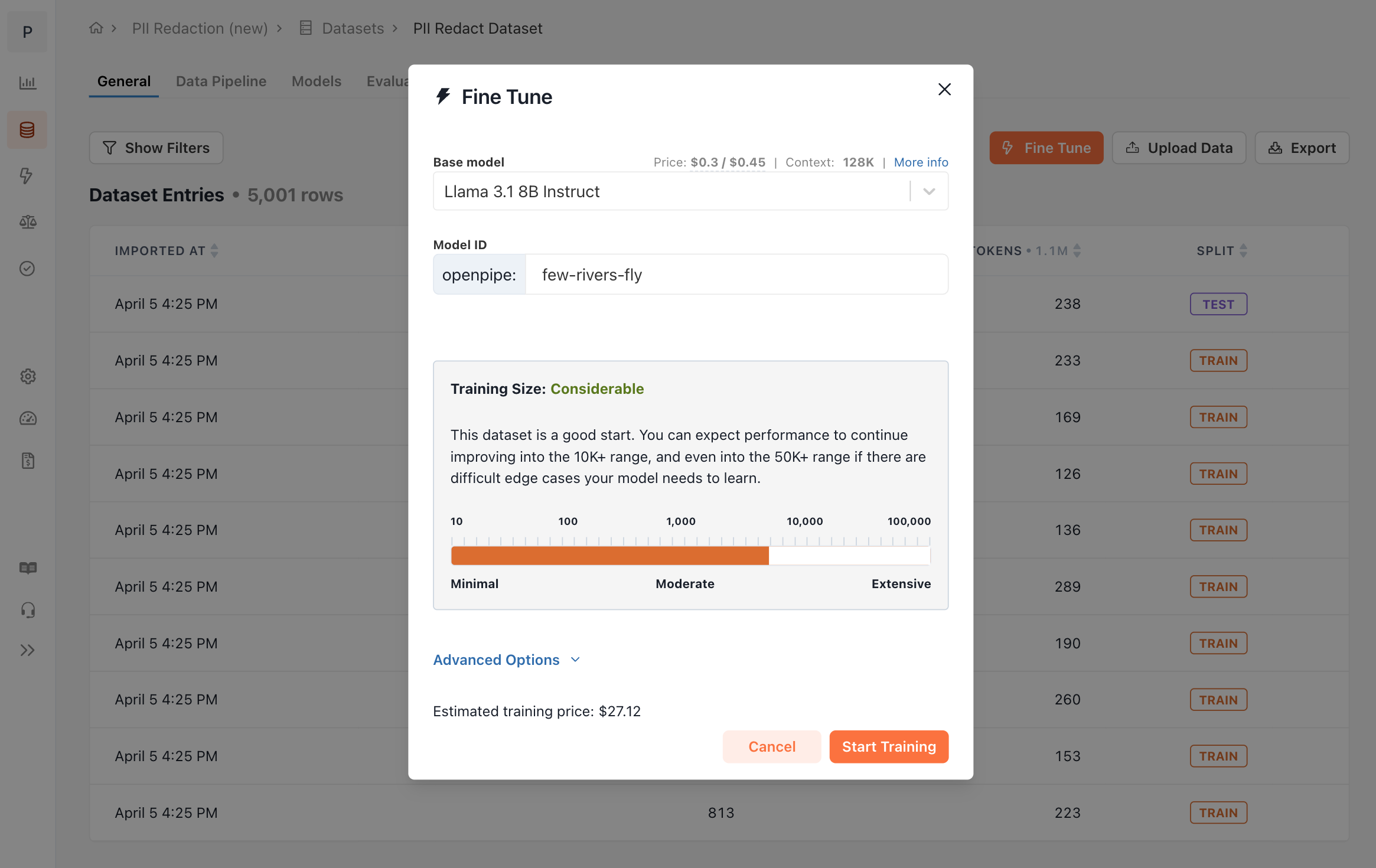
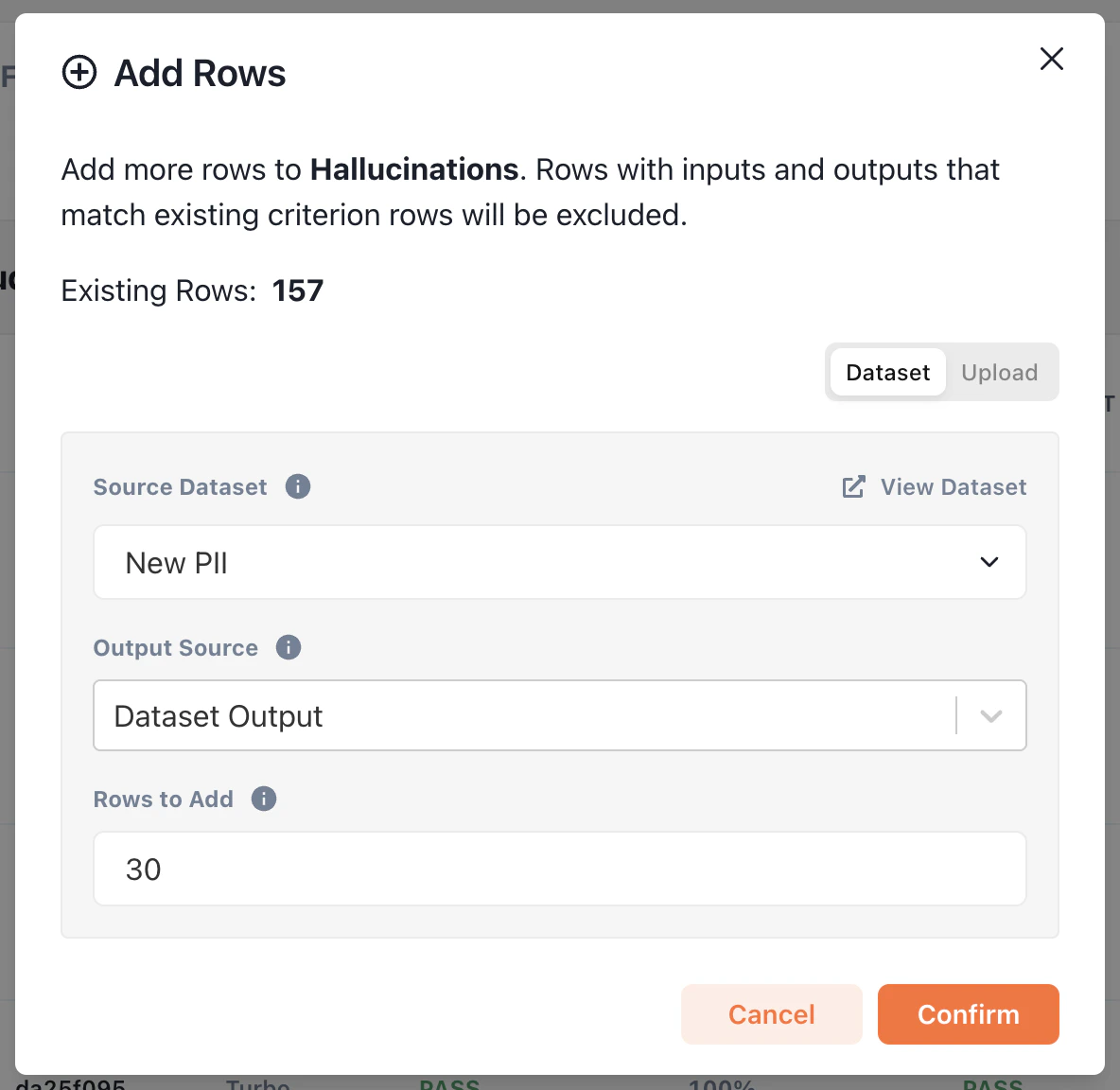
 ### Importing from a Dataset
When importing from a dataset, you select a number of rows to be randomly sampled from the dataset of your choice to imported into the criterion alignment set. The inputs of each of these rows will be copied directly from the rows in the dataset without any changes. By default, the outputs will also be copied from the original dataset. However, if you set **Output Source** to be an LLM model, the outputs will be generated by the LLM model based on the dataset inputs.
### Importing from a Dataset
When importing from a dataset, you select a number of rows to be randomly sampled from the dataset of your choice to imported into the criterion alignment set. The inputs of each of these rows will be copied directly from the rows in the dataset without any changes. By default, the outputs will also be copied from the original dataset. However, if you set **Output Source** to be an LLM model, the outputs will be generated by the LLM model based on the dataset inputs.
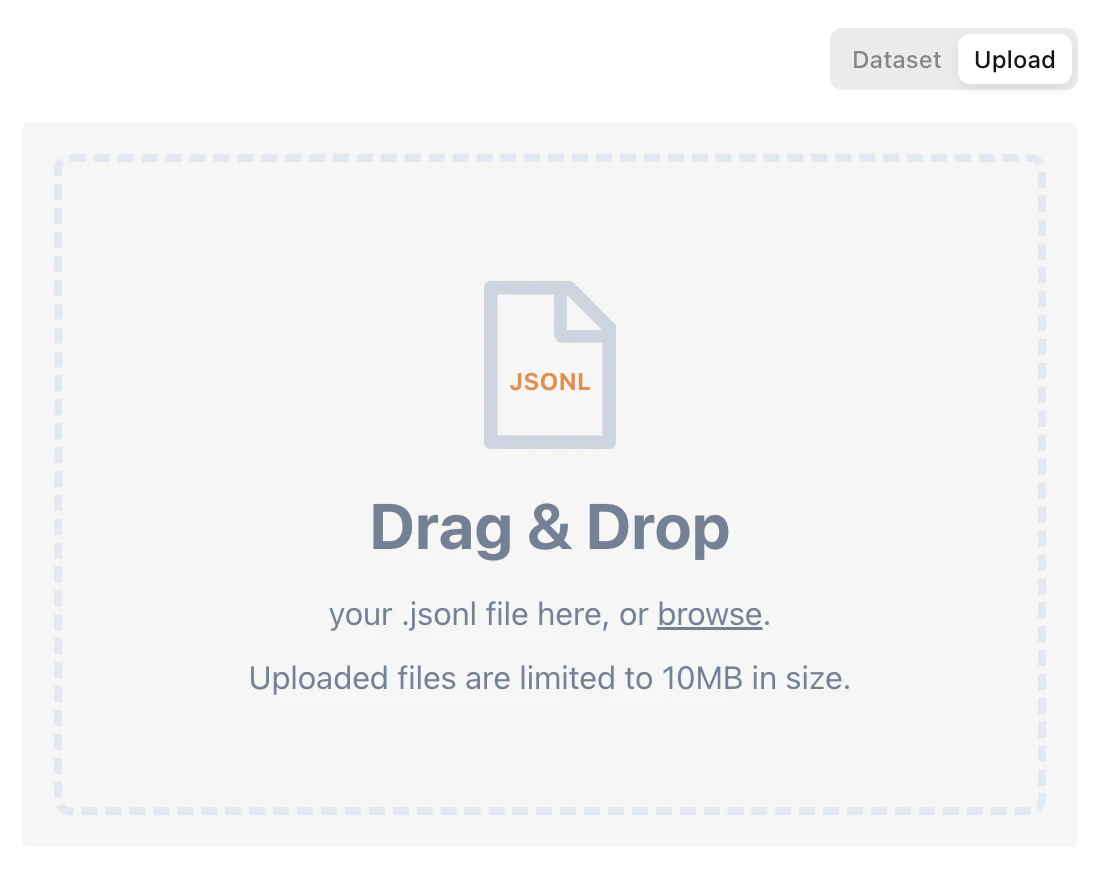
 ### Importing from a JSONL File
You can also import an alignment set from a JSONL file. Uploads are limited to 10MB in size,
which should be plenty for an alignment set.
### Importing from a JSONL File
You can also import an alignment set from a JSONL file. Uploads are limited to 10MB in size,
which should be plenty for an alignment set.
 The schema of the JSONL file is exactly the same as an OpenAI-compatible [JSONL fine-tuning file](/features/datasets/uploading-data#openai-fields), but also supports an optional `judgement` field for each row. `judgement` can be either `PASS` or `FAIL`, depending on whether the row should pass or fail the criterion.
#### Example
```jsonl theme={null}
...
{"judgement": "PASS", "messages":[{"role":"system","content":"You are a helpful assistant"},{"role":"user","content":"What is the capital of Tasmania?"},{"role":"assistant","content":null,"tool_calls":[{"id":"","type":"function","function":{"name":"identify_capital","arguments":"{\"capital\":\"Hobart\"}"}}]}],"tools":[{"type":"function","function":{"name":"identify_capital","parameters":{"type":"object","properties":{"capital":{"type":"string"}}}}}]}
{"judgement": "FAIL", "messages":[{"role":"system","content":"You are a helpful assistant"},{"role":"user","content":"What is the capital of Sweden?"},{"role":"assistant","content":null,"tool_calls":[{"id":"","type":"function","function":{"name":"identify_capital","arguments":"{\"capital\":\"Beijing\"}"}}]}],"tools":[{"type":"function","function":{"name":"identify_capital","parameters":{"type":"object","properties":{"capital":{"type":"string"}}}}}]}
{"messages":[{"role":"system","content":"You are a helpful assistant"},{"role":"user","content":"What is the capital of Sweden?"},{"role":"assistant","content":null,"tool_calls":[{"id":"","type":"function","function":{"name":"identify_capital","arguments":"{\"capital\":\"Stockholm\"}"}}]}],"tools":[{"type":"function","function":{"name":"identify_capital","parameters":{"type":"object","properties":{"capital":{"type":"string"}}}}}]}
...
```
## Alignment Stats
Alignment stats are a simple way to understand how well your criterion is performing.
As you refine your criterion prompt, you're alignment stats will improve as well.
The schema of the JSONL file is exactly the same as an OpenAI-compatible [JSONL fine-tuning file](/features/datasets/uploading-data#openai-fields), but also supports an optional `judgement` field for each row. `judgement` can be either `PASS` or `FAIL`, depending on whether the row should pass or fail the criterion.
#### Example
```jsonl theme={null}
...
{"judgement": "PASS", "messages":[{"role":"system","content":"You are a helpful assistant"},{"role":"user","content":"What is the capital of Tasmania?"},{"role":"assistant","content":null,"tool_calls":[{"id":"","type":"function","function":{"name":"identify_capital","arguments":"{\"capital\":\"Hobart\"}"}}]}],"tools":[{"type":"function","function":{"name":"identify_capital","parameters":{"type":"object","properties":{"capital":{"type":"string"}}}}}]}
{"judgement": "FAIL", "messages":[{"role":"system","content":"You are a helpful assistant"},{"role":"user","content":"What is the capital of Sweden?"},{"role":"assistant","content":null,"tool_calls":[{"id":"","type":"function","function":{"name":"identify_capital","arguments":"{\"capital\":\"Beijing\"}"}}]}],"tools":[{"type":"function","function":{"name":"identify_capital","parameters":{"type":"object","properties":{"capital":{"type":"string"}}}}}]}
{"messages":[{"role":"system","content":"You are a helpful assistant"},{"role":"user","content":"What is the capital of Sweden?"},{"role":"assistant","content":null,"tool_calls":[{"id":"","type":"function","function":{"name":"identify_capital","arguments":"{\"capital\":\"Stockholm\"}"}}]}],"tools":[{"type":"function","function":{"name":"identify_capital","parameters":{"type":"object","properties":{"capital":{"type":"string"}}}}}]}
...
```
## Alignment Stats
Alignment stats are a simple way to understand how well your criterion is performing.
As you refine your criterion prompt, you're alignment stats will improve as well.
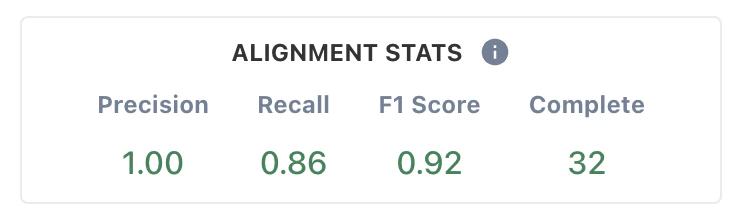 * **Precision** indicates the fraction of rows that the LLM judge labeled as failing that a human judge also labeled as failing. It's an indicator of how reliable the LLM judge's FAIL label is.
* **Recall** indicates the fraction of rows that a human judge labeled as failing that the LLM judge also labeled as failing. It's an indicator of how reliable the LLM judge's PASS label is.
* **F1 Score** is the harmonic mean of precision and recall. As either score improves, the F1 score will also improve.
To ensure your alignment stats are meaningful, we recommend labeling at least 30 rows,
but in some cases you may need to label more in order to get a reliable statistic.
---
# Source: https://docs.openpipe.ai/features/chat-completions/anthropic.md
> ## Documentation Index
> Fetch the complete documentation index at: https://docs.openpipe.ai/llms.txt
> Use this file to discover all available pages before exploring further.
# Anthropic Proxy
If you'd like to make chat completion requests to Anthropic models without modifying your prompt schema, you can proxy OpenAI-compatible requests through OpenPipe, and we'll handle
the translation for you.
To proxy requests to Anthropic models, first add your Anthropic API Key to your project settings. Then, adjust the **model** parameter of your requests to be the name of the model you
wish to query, prepended with the string `anthropic:`. For example, to make a request to `claude-3-5-sonnet-20241022`, use the following code:
* **Precision** indicates the fraction of rows that the LLM judge labeled as failing that a human judge also labeled as failing. It's an indicator of how reliable the LLM judge's FAIL label is.
* **Recall** indicates the fraction of rows that a human judge labeled as failing that the LLM judge also labeled as failing. It's an indicator of how reliable the LLM judge's PASS label is.
* **F1 Score** is the harmonic mean of precision and recall. As either score improves, the F1 score will also improve.
To ensure your alignment stats are meaningful, we recommend labeling at least 30 rows,
but in some cases you may need to label more in order to get a reliable statistic.
---
# Source: https://docs.openpipe.ai/features/chat-completions/anthropic.md
> ## Documentation Index
> Fetch the complete documentation index at: https://docs.openpipe.ai/llms.txt
> Use this file to discover all available pages before exploring further.
# Anthropic Proxy
If you'd like to make chat completion requests to Anthropic models without modifying your prompt schema, you can proxy OpenAI-compatible requests through OpenPipe, and we'll handle
the translation for you.
To proxy requests to Anthropic models, first add your Anthropic API Key to your project settings. Then, adjust the **model** parameter of your requests to be the name of the model you
wish to query, prepended with the string `anthropic:`. For example, to make a request to `claude-3-5-sonnet-20241022`, use the following code:
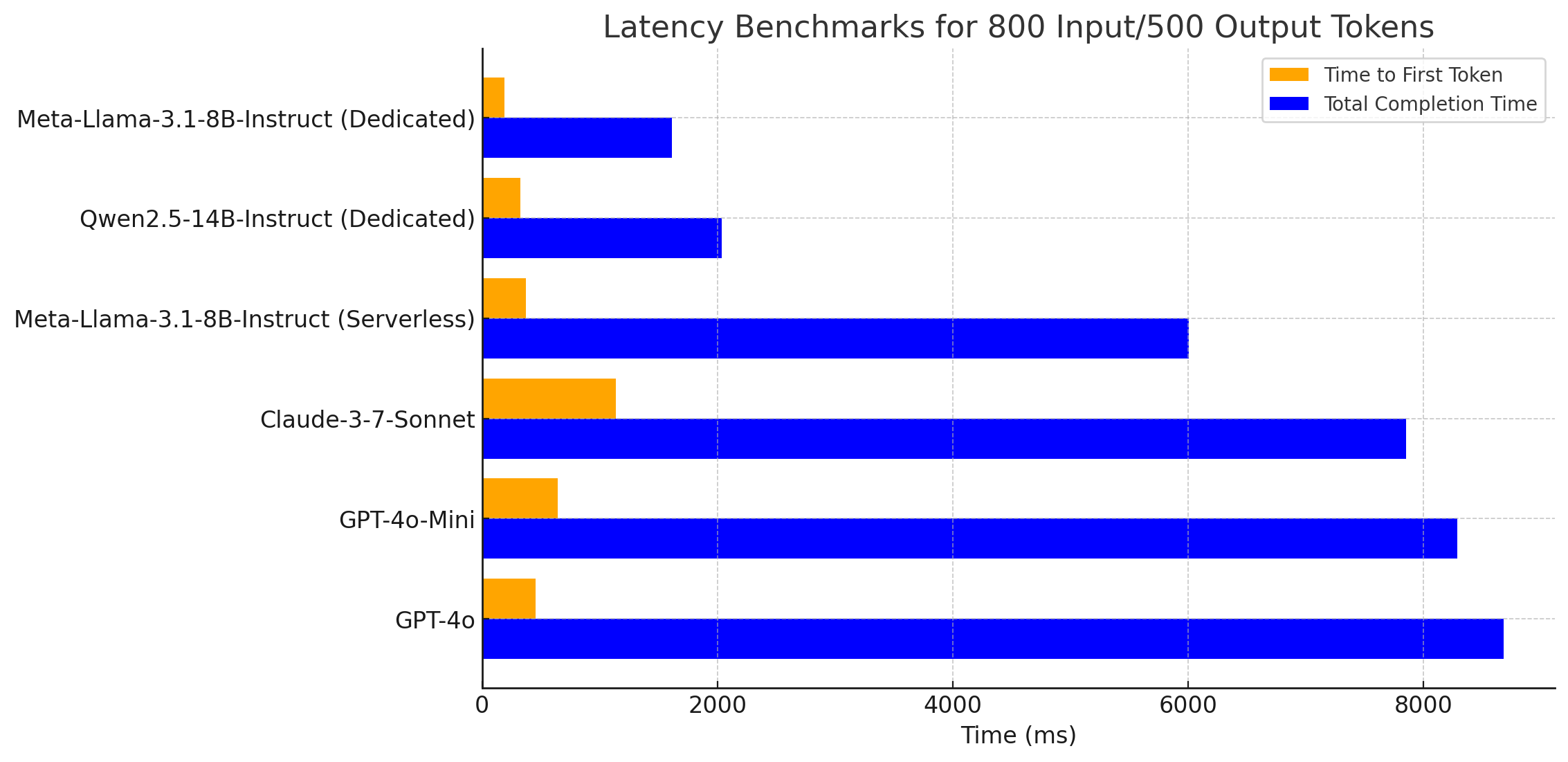 As shown in the chart above, the models hosted on dedicated deployments are able to provide much faster response times than the serverless deployment or closed models, with a dedicated Qwen 2.5 14B Instruct deployment outperforming Llama 3.1 8B Instruct despite being almost twice as large.
If you have questions about any of these deployment types or would like to trial one of your models on a dedicated deployment, please reach out to [hello@openpipe.ai](mailto:hello@openpipe.ai). Happy training!
---
# Source: https://docs.openpipe.ai/features/datasets/exporting-data.md
> ## Documentation Index
> Fetch the complete documentation index at: https://docs.openpipe.ai/llms.txt
> Use this file to discover all available pages before exploring further.
# Exporting Data
> Export your past requests as a JSONL file in their raw form.
## Dataset export
After you've collected, filtered, and transformed your dataset entries for fine-tuning, you can export them as a JSONL file.
As shown in the chart above, the models hosted on dedicated deployments are able to provide much faster response times than the serverless deployment or closed models, with a dedicated Qwen 2.5 14B Instruct deployment outperforming Llama 3.1 8B Instruct despite being almost twice as large.
If you have questions about any of these deployment types or would like to trial one of your models on a dedicated deployment, please reach out to [hello@openpipe.ai](mailto:hello@openpipe.ai). Happy training!
---
# Source: https://docs.openpipe.ai/features/datasets/exporting-data.md
> ## Documentation Index
> Fetch the complete documentation index at: https://docs.openpipe.ai/llms.txt
> Use this file to discover all available pages before exploring further.
# Exporting Data
> Export your past requests as a JSONL file in their raw form.
## Dataset export
After you've collected, filtered, and transformed your dataset entries for fine-tuning, you can export them as a JSONL file.
 ### Fields
* **`messages`:** The complete chat history.
* **`tools`:** The tools provided to the model.
* **`tool_choice`:** The tool required for the model to use.
* **`split`:** The train/test split to which the entry belongs.
### Example
```jsonl theme={null}
{"messages":[{"role":"system","content":"You are a helpful assistant"},{"role":"user","content":"What is the capital of Tasmania?"},{"role":"assistant","content":null,"tool_calls":[{"id":"","type":"function","function":{"name":"identify_capital","arguments":"{\"capital\":\"Hobart\"}"}}]}],"tools":[{"type":"function","function":{"name":"identify_capital","parameters":{"type":"object","properties":{"capital":{"type":"string"}}}}}]}
{"messages":[{"role":"system","content":"You are a helpful assistant"},{"role":"user","content":"What is the capital of Sweden?"},{"role":"assistant","content":null,"tool_calls":[{"id":"","type":"function","function":{"name":"identify_capital","arguments":"{\"capital\":\"Stockholm\"}"}}]}],"tools":[{"type":"function","function":{"name":"identify_capital","parameters":{"type":"object","properties":{"capital":{"type":"string"}}}}}]}
```
---
# Source: https://docs.openpipe.ai/features/request-logs/exporting-logs.md
> ## Documentation Index
> Fetch the complete documentation index at: https://docs.openpipe.ai/llms.txt
> Use this file to discover all available pages before exploring further.
# Exporting Logs
> Export your past requests as a JSONL file in their raw form.
## Request logs export
Once your request logs are recorded, you can export them at any time. The exported jsonl contains all the data that we've collected from your logged calls, including tags and errors.
### Fields
* **`messages`:** The complete chat history.
* **`tools`:** The tools provided to the model.
* **`tool_choice`:** The tool required for the model to use.
* **`split`:** The train/test split to which the entry belongs.
### Example
```jsonl theme={null}
{"messages":[{"role":"system","content":"You are a helpful assistant"},{"role":"user","content":"What is the capital of Tasmania?"},{"role":"assistant","content":null,"tool_calls":[{"id":"","type":"function","function":{"name":"identify_capital","arguments":"{\"capital\":\"Hobart\"}"}}]}],"tools":[{"type":"function","function":{"name":"identify_capital","parameters":{"type":"object","properties":{"capital":{"type":"string"}}}}}]}
{"messages":[{"role":"system","content":"You are a helpful assistant"},{"role":"user","content":"What is the capital of Sweden?"},{"role":"assistant","content":null,"tool_calls":[{"id":"","type":"function","function":{"name":"identify_capital","arguments":"{\"capital\":\"Stockholm\"}"}}]}],"tools":[{"type":"function","function":{"name":"identify_capital","parameters":{"type":"object","properties":{"capital":{"type":"string"}}}}}]}
```
---
# Source: https://docs.openpipe.ai/features/request-logs/exporting-logs.md
> ## Documentation Index
> Fetch the complete documentation index at: https://docs.openpipe.ai/llms.txt
> Use this file to discover all available pages before exploring further.
# Exporting Logs
> Export your past requests as a JSONL file in their raw form.
## Request logs export
Once your request logs are recorded, you can export them at any time. The exported jsonl contains all the data that we've collected from your logged calls, including tags and errors.
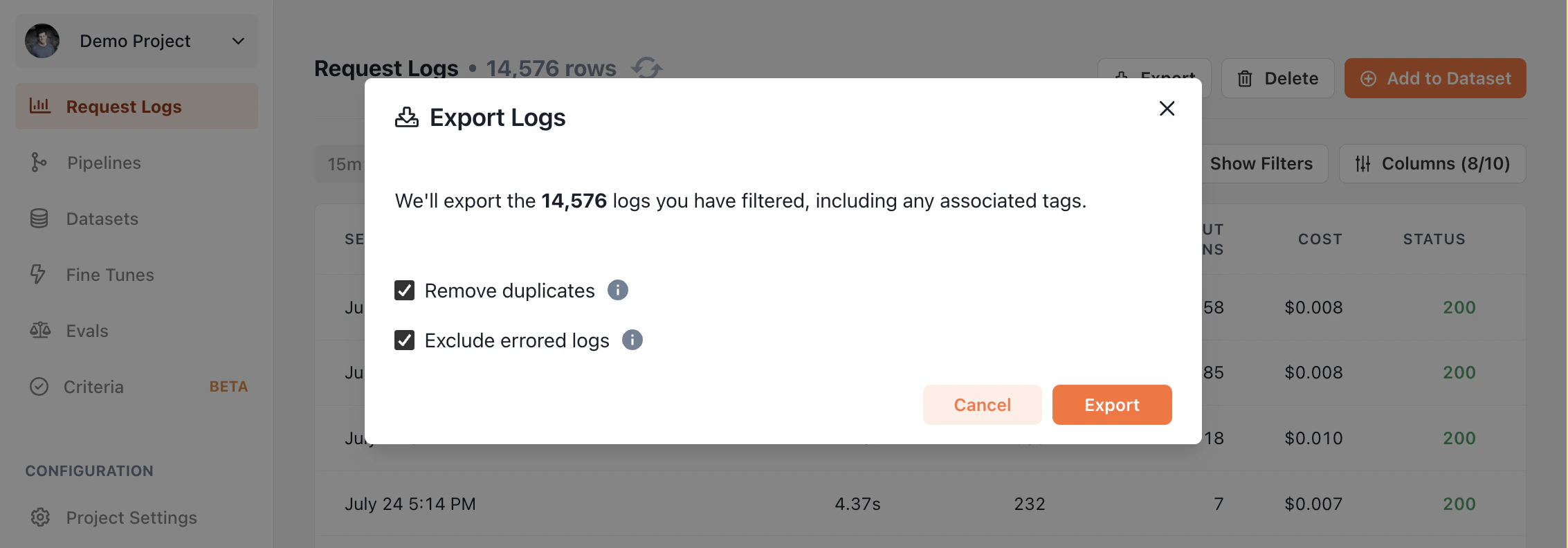 ### Fields
* **`Input`:** The complete chat creation request.
* **`Output`:** Whatever output was generated, including errors.
* **`Tags`:** Any metadata tags that you included when making the request.
### Example
```jsonl theme={null}
{"input":{"model":"openpipe:test-tool-calls-ft","tools":[{"type":"function","function":{"name":"get_current_weather","parameters":{"type":"object","required":["location"],"properties":{"unit":{"enum":["celsius","fahrenheit"],"type":"string"},"location":{"type":"string","description":"The city and state, e.g. San Francisco, CA"}}},"description":"Get the current weather in a given location"}}],"messages":[{"role":"system","content":"tell me the weather in SF and Orlando"}]},"output":{"id":"c7670af0d71648b0bd829fa1901ac6c5","model":"openpipe:test-tool-calls-ft","usage":{"total_tokens":106,"prompt_tokens":47,"completion_tokens":59},"object":"chat.completion","choices":[{"index":0,"message":{"role":"assistant","content":null,"tool_calls":[{"id":"","type":"function","function":{"name":"get_current_weather","arguments":"{\"location\": \"San Francisco, CA\", \"unit\": \"celsius\"}"}},{"id":"","type":"function","function":{"name":"get_current_weather","arguments":"{\"location\": \"Orlando, FL\", \"unit\": \"celsius\"}"}}]},"finish_reason":"stop"}],"created":1702666185703},"tags":{"prompt_id":"test_sync_tool_calls_ft","$sdk":"python","$sdk.version":"4.1.0"}}
{"input":{"model":"openpipe:test-content-ft","messages":[{"role":"system","content":"count to 3"}]},"output":{"id":"47116eaa9dad4238bf12e32135f9c147","model":"openpipe:test-content-ft","usage":{"total_tokens":38,"prompt_tokens":29,"completion_tokens":9},"object":"chat.completion","choices":[{"index":0,"message":{"role":"assistant","content":"1, 2, 3"},"finish_reason":"stop"}],"created":1702666036923},"tags":{"prompt_id":"test_sync_content_ft","$sdk":"python","$sdk.version":"4.1.0"}}
```
If you'd like to see how it works, try exporting some logs from our [public demo](https://app.openpipe.ai/p/BRZFEx50Pf/request-logs).
---
# Source: https://docs.openpipe.ai/features/external-models.md
# Source: https://docs.openpipe.ai/features/chat-completions/external-models.md
> ## Documentation Index
> Fetch the complete documentation index at: https://docs.openpipe.ai/llms.txt
> Use this file to discover all available pages before exploring further.
# Proxying to External Models
### Fields
* **`Input`:** The complete chat creation request.
* **`Output`:** Whatever output was generated, including errors.
* **`Tags`:** Any metadata tags that you included when making the request.
### Example
```jsonl theme={null}
{"input":{"model":"openpipe:test-tool-calls-ft","tools":[{"type":"function","function":{"name":"get_current_weather","parameters":{"type":"object","required":["location"],"properties":{"unit":{"enum":["celsius","fahrenheit"],"type":"string"},"location":{"type":"string","description":"The city and state, e.g. San Francisco, CA"}}},"description":"Get the current weather in a given location"}}],"messages":[{"role":"system","content":"tell me the weather in SF and Orlando"}]},"output":{"id":"c7670af0d71648b0bd829fa1901ac6c5","model":"openpipe:test-tool-calls-ft","usage":{"total_tokens":106,"prompt_tokens":47,"completion_tokens":59},"object":"chat.completion","choices":[{"index":0,"message":{"role":"assistant","content":null,"tool_calls":[{"id":"","type":"function","function":{"name":"get_current_weather","arguments":"{\"location\": \"San Francisco, CA\", \"unit\": \"celsius\"}"}},{"id":"","type":"function","function":{"name":"get_current_weather","arguments":"{\"location\": \"Orlando, FL\", \"unit\": \"celsius\"}"}}]},"finish_reason":"stop"}],"created":1702666185703},"tags":{"prompt_id":"test_sync_tool_calls_ft","$sdk":"python","$sdk.version":"4.1.0"}}
{"input":{"model":"openpipe:test-content-ft","messages":[{"role":"system","content":"count to 3"}]},"output":{"id":"47116eaa9dad4238bf12e32135f9c147","model":"openpipe:test-content-ft","usage":{"total_tokens":38,"prompt_tokens":29,"completion_tokens":9},"object":"chat.completion","choices":[{"index":0,"message":{"role":"assistant","content":"1, 2, 3"},"finish_reason":"stop"}],"created":1702666036923},"tags":{"prompt_id":"test_sync_content_ft","$sdk":"python","$sdk.version":"4.1.0"}}
```
If you'd like to see how it works, try exporting some logs from our [public demo](https://app.openpipe.ai/p/BRZFEx50Pf/request-logs).
---
# Source: https://docs.openpipe.ai/features/external-models.md
# Source: https://docs.openpipe.ai/features/chat-completions/external-models.md
> ## Documentation Index
> Fetch the complete documentation index at: https://docs.openpipe.ai/llms.txt
> Use this file to discover all available pages before exploring further.
# Proxying to External Models
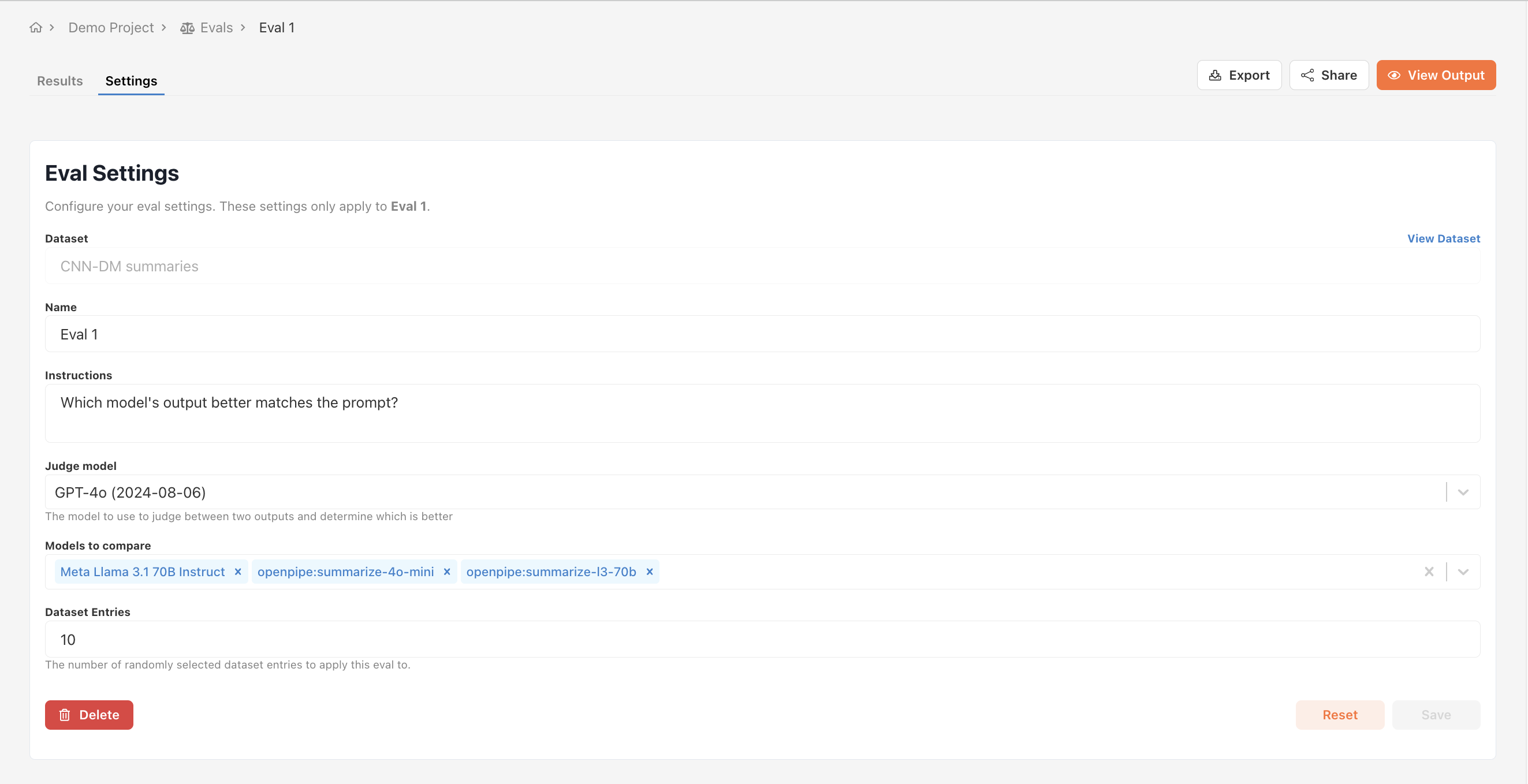

In addition to the results table, you can also view results in a matrix format. This is useful for visualizing how specific models perform against one another.
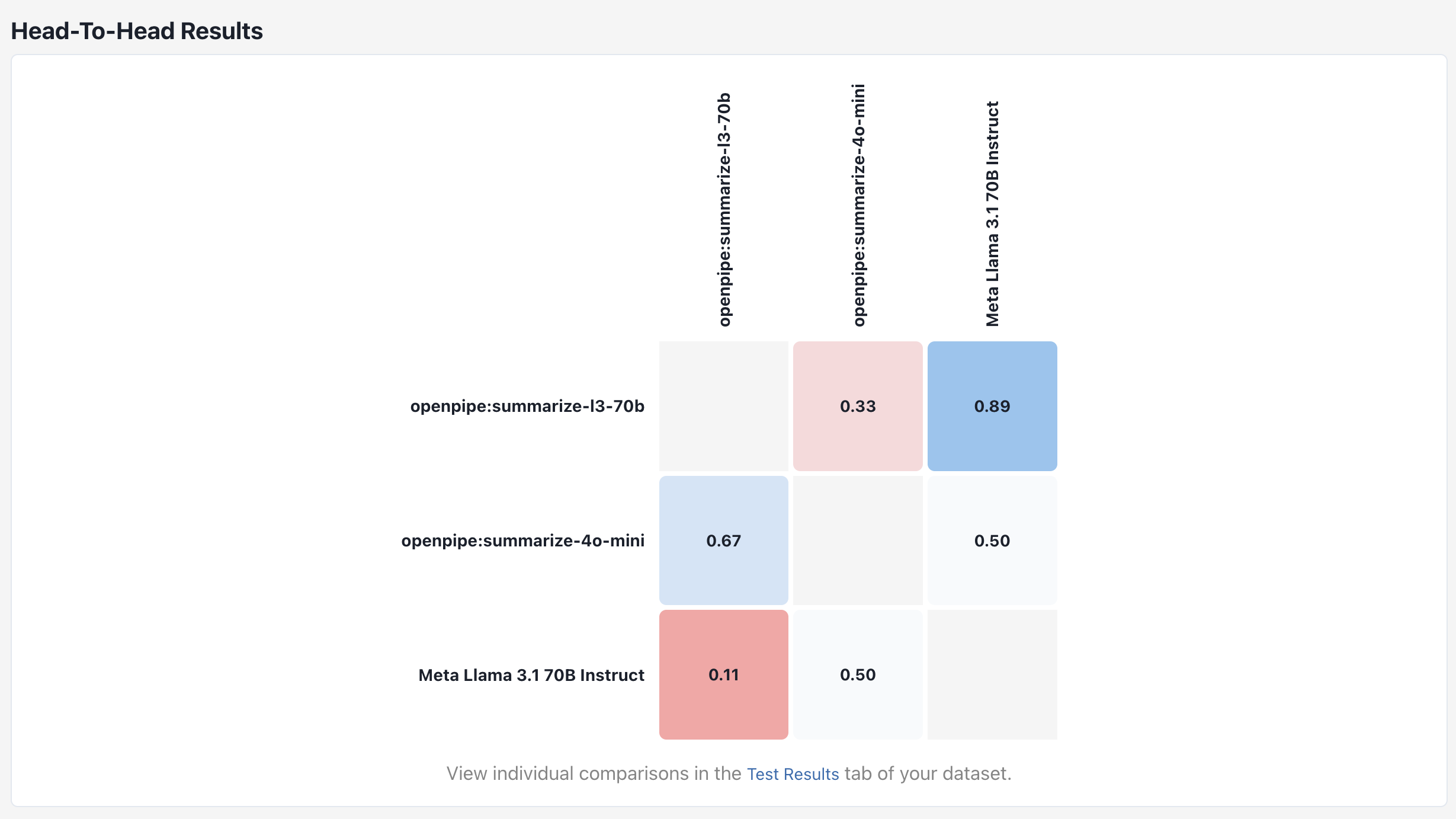
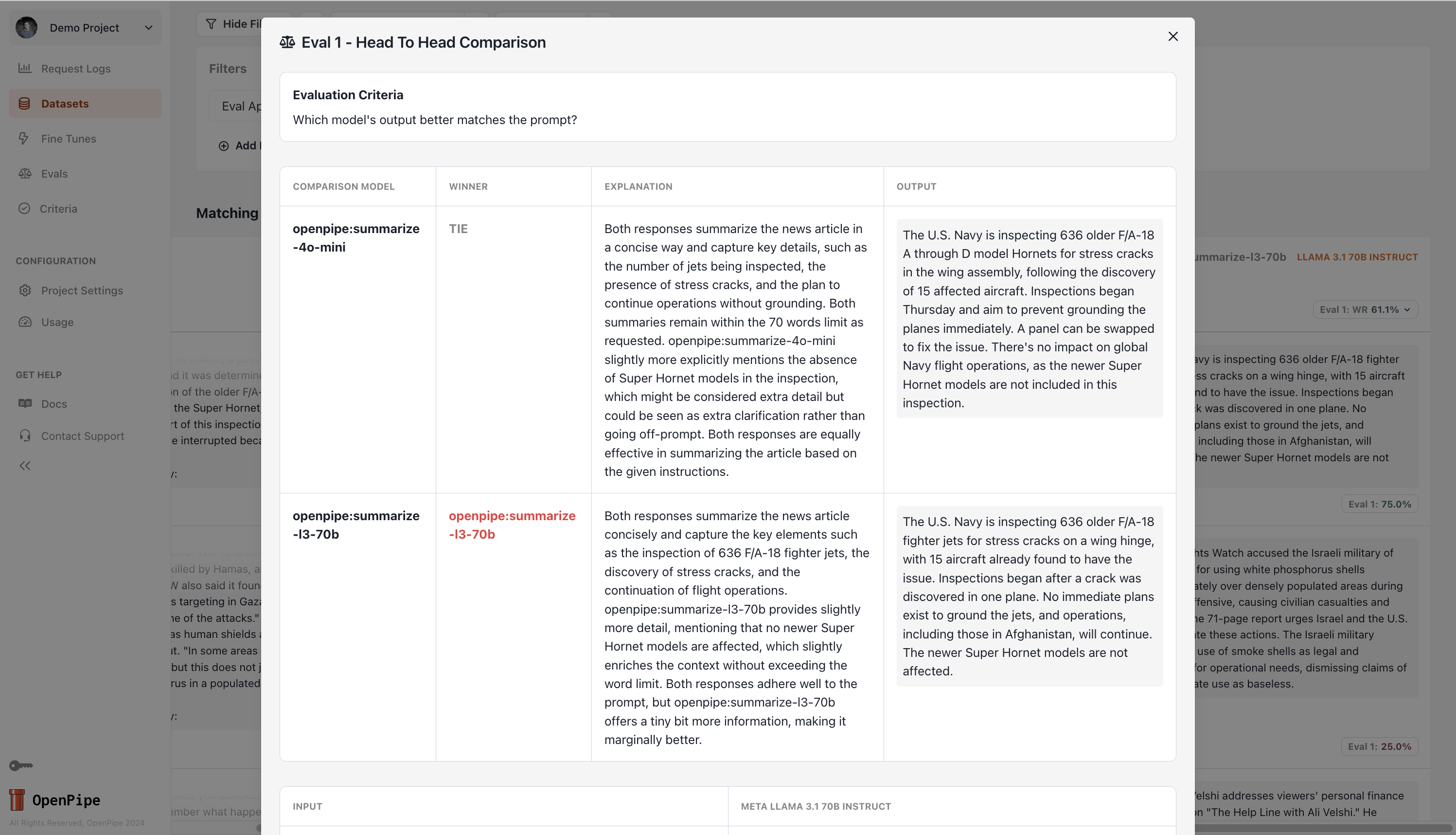
To see why one model might be outperforming another, you can navigate back to the [evaluation table](https://app.openpipe.ai/p/BRZFEx50Pf/datasets/3e7e82c1-b066-476c-9f17-17fd85a2169b/evaluate) and click on a result pill to see the evaluation judge's reasoning.
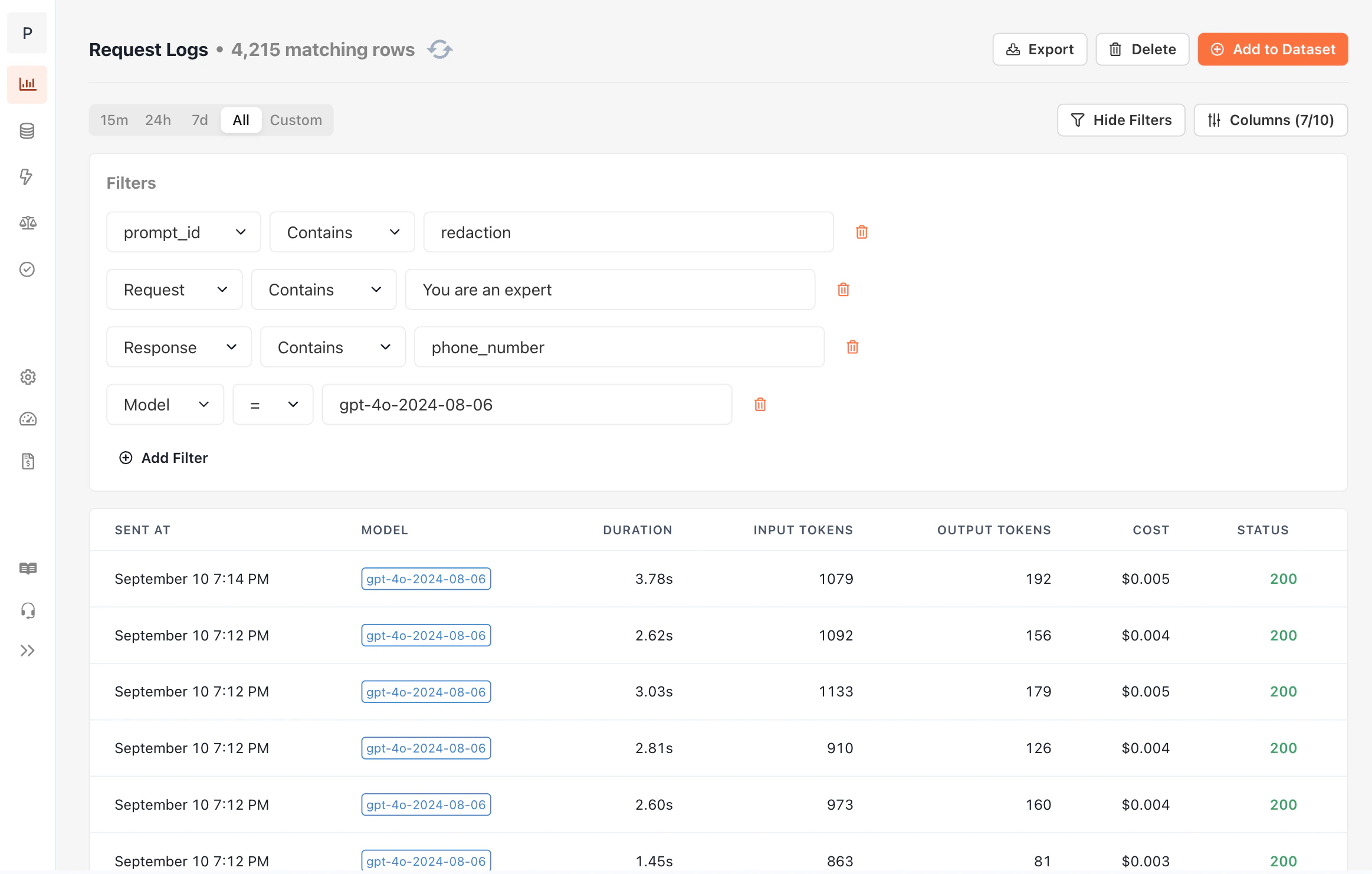
While head-to-head evaluations are convenient, they can quickly become expensive to run, and provide limited insight into how well a model performs. For more precise metrics, consider [criterion](/features/evaluations/criterion) or [code](/features/evaluations/code) evaluations. --- # Source: https://docs.openpipe.ai/features/datasets/importing-logs.md > ## Documentation Index > Fetch the complete documentation index at: https://docs.openpipe.ai/llms.txt > Use this file to discover all available pages before exploring further. # Importing Request Logs > Search and filter your past LLM requests to inspect your responses and build a training dataset. Logged requests will be visible on your project's [Request Logs](https://app.openpipe.ai/p/BRZFEx50Pf/request-logs?filterData=%7B%22shown%22%3Atrue%2C%22filters%22%3A%5B%7B%22id%22%3A%221706912835890%22%2C%22field%22%3A%22request%22%2C%22comparator%22%3A%22CONTAINS%22%2C%22value%22%3A%22You+are+an+expert%22%7D%2C%7B%22id%22%3A%221706912850914%22%2C%22field%22%3A%22response%22%2C%22comparator%22%3A%22NOT_CONTAINS%22%2C%22value%22%3A%22As+an+AI+language+model%22%7D%2C%7B%22id%22%3A%221706912861496%22%2C%22field%22%3A%22model%22%2C%22comparator%22%3A%22%3D%22%2C%22value%22%3A%22gpt-4-0613%22%7D%2C%7B%22id%22%3A%221706912870230%22%2C%22field%22%3A%22tags.prompt_id%22%2C%22comparator%22%3A%22CONTAINS%22%2C%22value%22%3A%22redaction%22%7D%5D%7D) page. You can filter your logs by completionId, model, custom tags, and more to narrow down your results.
 Once you've found a set of data that you'd like to train on, import those logs into the dataset of your choice.
Once you've found a set of data that you'd like to train on, import those logs into the dataset of your choice.
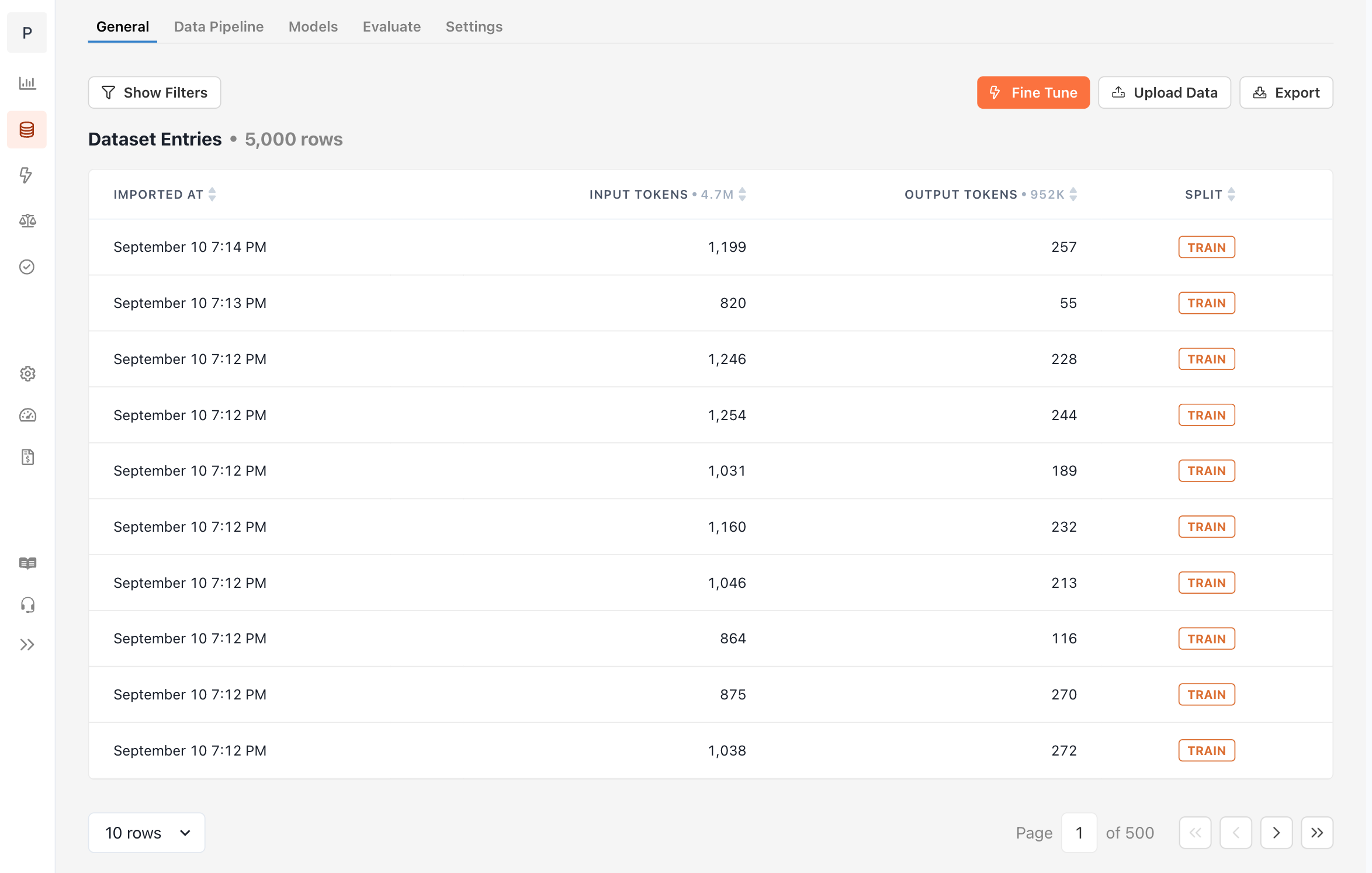
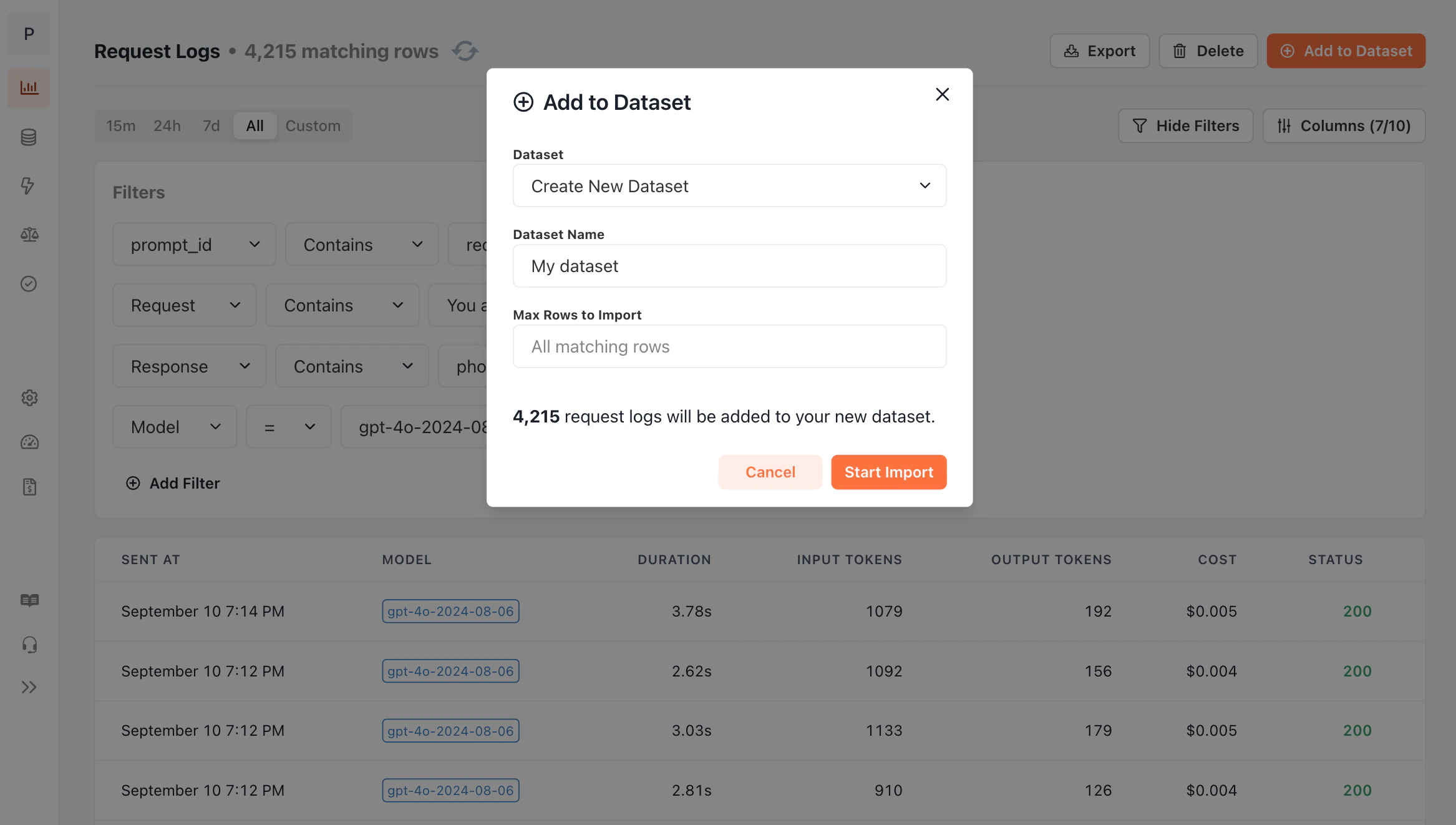 After your data has been saved to your dataset, [kicking off a training job](/features/fine-tuning) is straightforward.
---
# Source: https://docs.openpipe.ai/introduction.md
> ## Documentation Index
> Fetch the complete documentation index at: https://docs.openpipe.ai/llms.txt
> Use this file to discover all available pages before exploring further.
# OpenPipe Documentation
> Software engineers and data scientists use OpenPipe's intuitive fine-tuning and monitoring services to decrease the cost and latency of their LLM operations. You can use OpenPipe to collect and analyze LLM logs, create fine-tuned models, and compare output from multiple models given the same input.
After your data has been saved to your dataset, [kicking off a training job](/features/fine-tuning) is straightforward.
---
# Source: https://docs.openpipe.ai/introduction.md
> ## Documentation Index
> Fetch the complete documentation index at: https://docs.openpipe.ai/llms.txt
> Use this file to discover all available pages before exploring further.
# OpenPipe Documentation
> Software engineers and data scientists use OpenPipe's intuitive fine-tuning and monitoring services to decrease the cost and latency of their LLM operations. You can use OpenPipe to collect and analyze LLM logs, create fine-tuned models, and compare output from multiple models given the same input.
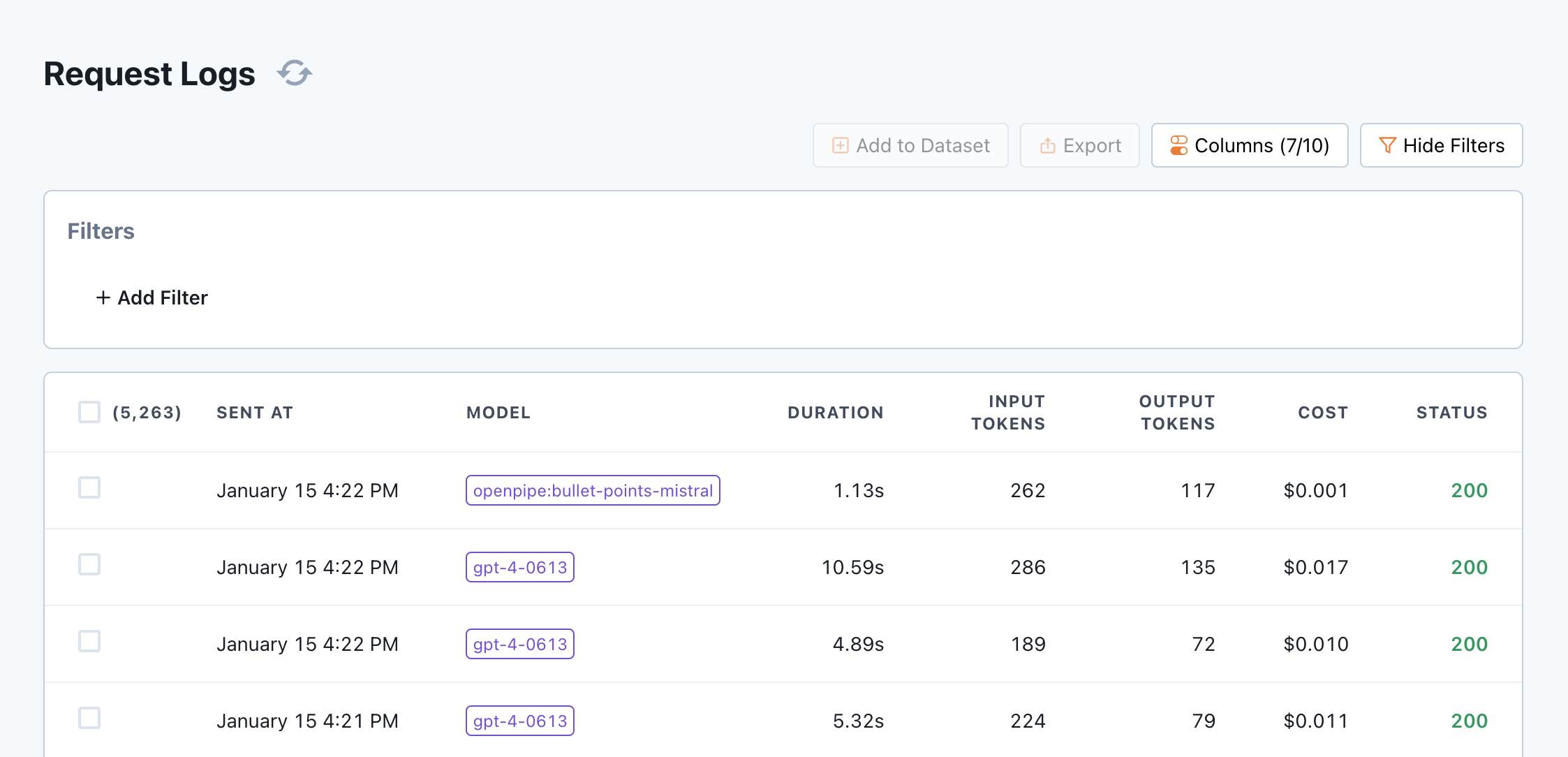 Feel free to run some sample inference on the [PII Redaction model](https://app.openpipe.ai/p/BRZFEx50Pf/fine-tunes/efb0d474-97b6-4735-a0af-55643b50600a/general) in our public project.
---
# Source: https://docs.openpipe.ai/api-reference/post-chatcompletions.md
> ## Documentation Index
> Fetch the complete documentation index at: https://docs.openpipe.ai/llms.txt
> Use this file to discover all available pages before exploring further.
# Chat Completions
> OpenAI-compatible route for generating inference and optionally logging the request.
## OpenAPI
````yaml post /chat/completions
openapi: 3.0.3
info:
title: OpenPipe API
description: The public API for reporting API calls to OpenPipe
version: 0.1.1
servers:
- url: https://api.openpipe.ai/api/v1
security: []
paths:
/chat/completions:
post:
description: >-
OpenAI-compatible route for generating inference and optionally logging
the request.
operationId: createChatCompletion
parameters: []
requestBody:
required: true
content:
application/json:
schema:
type: object
properties:
messages:
type: array
items:
anyOf:
- type: object
properties:
role:
type: string
enum:
- system
content:
anyOf:
- type: string
- type: array
items:
type: object
properties:
type:
type: string
enum:
- text
text:
type: string
required:
- type
- text
additionalProperties: false
default: ''
name:
type: string
required:
- role
additionalProperties: false
- type: object
properties:
role:
type: string
enum:
- user
content:
anyOf:
- type: string
- type: array
items:
anyOf:
- type: object
properties:
type:
type: string
enum:
- text
text:
type: string
required:
- type
- text
additionalProperties: false
- type: object
properties:
type:
type: string
enum:
- image_url
image_url:
type: object
properties:
detail:
anyOf:
- type: string
enum:
- auto
- type: string
enum:
- low
- type: string
enum:
- high
url:
type: string
required:
- url
additionalProperties: false
required:
- type
- image_url
additionalProperties: false
- type: object
properties:
type:
type: string
enum:
- input_audio
input_audio:
type: object
properties:
data:
type: string
format:
type: string
enum:
- wav
- mp3
required:
- data
- format
additionalProperties: false
required:
- type
- input_audio
additionalProperties: false
default: ''
name:
type: string
required:
- role
additionalProperties: false
- type: object
properties:
role:
type: string
enum:
- assistant
audio:
type: object
properties:
id:
type: string
required:
- id
additionalProperties: false
nullable: true
content:
anyOf:
- type: string
- type: array
items:
anyOf:
- type: object
properties:
type:
type: string
enum:
- text
text:
type: string
required:
- type
- text
additionalProperties: false
- type: object
properties:
type:
type: string
enum:
- refusal
refusal:
type: string
required:
- type
- refusal
additionalProperties: false
- enum:
- 'null'
nullable: true
default: null
function_call:
type: object
properties:
name:
type: string
default: ''
arguments:
type: string
default: ''
additionalProperties: false
nullable: true
tool_calls:
type: array
items:
type: object
properties:
id:
type: string
function:
type: object
properties:
name:
type: string
arguments:
type: string
required:
- name
- arguments
additionalProperties: false
type:
type: string
enum:
- function
required:
- id
- function
- type
additionalProperties: false
nullable: true
name:
type: string
refusal:
type: string
nullable: true
annotations:
type: array
items:
type: object
properties:
type:
type: string
enum:
- url_citation
url_citation:
type: object
properties:
start_index:
type: number
end_index:
type: number
title:
type: string
url:
type: string
required:
- start_index
- end_index
- title
- url
additionalProperties: false
required:
- type
- url_citation
additionalProperties: false
required:
- role
additionalProperties: false
- type: object
properties:
role:
type: string
enum:
- developer
content:
anyOf:
- type: string
- type: array
items:
type: object
properties:
type:
type: string
enum:
- text
text:
type: string
required:
- type
- text
additionalProperties: false
default: ''
name:
type: string
required:
- role
additionalProperties: false
- type: object
properties:
role:
type: string
enum:
- tool
content:
anyOf:
- type: string
- type: array
items:
type: object
properties:
type:
type: string
enum:
- text
text:
type: string
required:
- type
- text
additionalProperties: false
default: ''
tool_call_id:
type: string
required:
- role
- tool_call_id
additionalProperties: false
- type: object
properties:
role:
type: string
enum:
- function
name:
type: string
content:
anyOf:
- type: string
- enum:
- 'null'
nullable: true
required:
- role
- name
- content
additionalProperties: false
model:
type: string
audio:
type: object
properties:
format:
type: string
enum:
- wav
- mp3
- flac
- opus
- pcm16
voice:
type: string
enum:
- alloy
- ash
- ballad
- coral
- echo
- sage
- shimmer
- verse
required:
- format
- voice
additionalProperties: false
nullable: true
function_call:
anyOf:
- type: string
enum:
- none
- type: string
enum:
- auto
- type: object
properties:
name:
type: string
required:
- name
additionalProperties: false
functions:
type: array
items:
type: object
properties:
name:
type: string
parameters:
type: object
additionalProperties: {}
description:
type: string
strict:
type: boolean
nullable: true
required:
- name
additionalProperties: false
tool_choice:
anyOf:
- type: string
enum:
- none
- type: string
enum:
- auto
- type: string
enum:
- required
- type: object
properties:
type:
type: string
enum:
- function
default: function
function:
type: object
properties:
name:
type: string
required:
- name
additionalProperties: false
default:
name: ''
additionalProperties: false
tools:
type: array
items:
type: object
properties:
function:
type: object
properties:
name:
type: string
parameters:
type: object
additionalProperties: {}
description:
type: string
strict:
type: boolean
nullable: true
required:
- name
additionalProperties: false
type:
type: string
enum:
- function
required:
- function
- type
additionalProperties: false
'n':
type: number
max_tokens:
type: number
nullable: true
max_completion_tokens:
type: number
nullable: true
temperature:
type: number
top_p:
type: number
nullable: true
presence_penalty:
type: number
nullable: true
frequency_penalty:
type: number
nullable: true
stop:
anyOf:
- type: string
- type: array
items:
type: string
nullable: true
response_format:
anyOf:
- type: object
properties:
type:
type: string
enum:
- text
required:
- type
additionalProperties: false
- type: object
properties:
type:
type: string
enum:
- json_object
required:
- type
additionalProperties: false
- type: object
properties:
type:
type: string
enum:
- json_schema
json_schema:
type: object
properties:
name:
type: string
description:
type: string
schema:
type: object
additionalProperties: {}
strict:
type: boolean
nullable: true
required:
- name
additionalProperties: false
required:
- type
- json_schema
additionalProperties: false
logprobs:
type: boolean
top_logprobs:
type: number
nullable: true
stream_options:
type: object
properties:
include_usage:
type: boolean
required:
- include_usage
additionalProperties: false
store:
type: boolean
metadata:
type: object
additionalProperties:
type: string
nullable: true
stream:
type: boolean
default: false
required:
- messages
- model
additionalProperties: true
responses:
'200':
description: Successful response
content:
application/json:
schema:
anyOf:
- type: object
properties:
id:
type: string
object:
type: string
enum:
- chat.completion
created:
type: number
model:
type: string
choices:
type: array
items:
type: object
properties:
finish_reason:
anyOf:
- type: string
enum:
- length
- type: string
enum:
- function_call
- type: string
enum:
- tool_calls
- type: string
enum:
- stop
- type: string
enum:
- content_filter
index:
type: number
message:
type: object
properties:
reasoning_content:
type: string
nullable: true
content:
type: string
nullable: true
default: null
refusal:
type: string
nullable: true
role:
type: string
enum:
- assistant
function_call:
type: object
properties:
name:
type: string
default: ''
arguments:
type: string
default: ''
additionalProperties: false
nullable: true
tool_calls:
type: array
items:
type: object
properties:
id:
type: string
function:
type: object
properties:
name:
type: string
arguments:
type: string
required:
- name
- arguments
additionalProperties: false
type:
type: string
enum:
- function
required:
- id
- function
- type
additionalProperties: false
nullable: true
required:
- role
additionalProperties: false
logprobs:
type: object
properties:
content:
type: array
items:
type: object
properties:
token:
type: string
bytes:
type: array
items:
type: number
nullable: true
logprob:
type: number
top_logprobs:
type: array
items:
type: object
properties:
token:
type: string
bytes:
type: array
items:
type: number
nullable: true
logprob:
type: number
required:
- token
- bytes
- logprob
additionalProperties: false
required:
- token
- bytes
- logprob
- top_logprobs
additionalProperties: false
nullable: true
default: null
refusal:
type: array
items:
type: object
properties:
token:
type: string
bytes:
type: array
items:
type: number
nullable: true
logprob:
type: number
top_logprobs:
type: array
items:
type: object
properties:
token:
type: string
bytes:
type: array
items:
type: number
nullable: true
logprob:
type: number
required:
- token
- bytes
- logprob
additionalProperties: false
required:
- token
- bytes
- logprob
- top_logprobs
additionalProperties: false
nullable: true
default: null
additionalProperties: false
nullable: true
default: null
content_filter_results:
type: object
properties: {}
additionalProperties: true
criteria_results:
type: object
additionalProperties:
anyOf:
- type: object
properties:
status:
type: string
enum:
- success
score:
type: number
explanation:
type: string
errorCode:
type: number
errorMessage:
type: string
required:
- status
- score
additionalProperties: false
- type: object
properties:
status:
type: string
enum:
- error
score:
type: number
explanation:
type: string
errorCode:
type: number
errorMessage:
type: string
required:
- status
- errorCode
- errorMessage
additionalProperties: false
required:
- finish_reason
- index
- message
additionalProperties: false
usage:
type: object
properties:
prompt_tokens:
type: number
completion_tokens:
type: number
total_tokens:
type: number
prompt_cache_hit_tokens:
type: number
prompt_cache_miss_tokens:
type: number
completion_tokens_details:
type: object
properties:
reasoning_tokens:
type: number
nullable: true
audio_tokens:
type: number
nullable: true
text_tokens:
type: number
nullable: true
accepted_prediction_tokens:
type: number
nullable: true
rejected_prediction_tokens:
type: number
nullable: true
additionalProperties: false
nullable: true
prompt_tokens_details:
type: object
properties:
cached_tokens:
type: number
nullable: true
audio_tokens:
type: number
nullable: true
additionalProperties: false
nullable: true
criteria:
type: object
additionalProperties:
type: object
properties:
total_tokens:
type: number
description: >-
The total number of tokens used to generate
the criterion judgement. Only returned for
OpenPipe-trained reward models currently.
required:
- total_tokens
additionalProperties: false
required:
- prompt_tokens
- completion_tokens
- total_tokens
additionalProperties: false
required:
- id
- object
- created
- model
- choices
additionalProperties: false
nullable: true
- {}
default:
$ref: '#/components/responses/error'
security:
- Authorization: []
components:
responses:
error:
description: Error response
content:
application/json:
schema:
type: object
properties:
message:
type: string
code:
type: string
issues:
type: array
items:
type: object
properties:
message:
type: string
required:
- message
additionalProperties: false
required:
- message
- code
additionalProperties: false
securitySchemes:
Authorization:
type: http
scheme: bearer
````
---
# Source: https://docs.openpipe.ai/api-reference/post-createDataset.md
> ## Documentation Index
> Fetch the complete documentation index at: https://docs.openpipe.ai/llms.txt
> Use this file to discover all available pages before exploring further.
# Create Dataset
> Create a new dataset.
## OpenAPI
````yaml post /datasets
openapi: 3.0.3
info:
title: OpenPipe API
description: The public API for reporting API calls to OpenPipe
version: 0.1.1
servers:
- url: https://api.openpipe.ai/api/v1
security: []
paths:
/datasets:
post:
description: Create a new dataset.
operationId: createDataset
parameters: []
requestBody:
required: true
content:
application/json:
schema:
type: object
properties:
name:
type: string
required:
- name
additionalProperties: false
responses:
'200':
description: Successful response
content:
application/json:
schema:
type: object
properties:
object:
type: string
enum:
- dataset
id:
type: string
name:
type: string
created:
type: string
updated:
type: string
dataset_entry_count:
type: number
fine_tune_count:
type: number
required:
- object
- id
- name
- created
- updated
- dataset_entry_count
- fine_tune_count
additionalProperties: false
default:
$ref: '#/components/responses/error'
security:
- Authorization: []
components:
responses:
error:
description: Error response
content:
application/json:
schema:
type: object
properties:
message:
type: string
code:
type: string
issues:
type: array
items:
type: object
properties:
message:
type: string
required:
- message
additionalProperties: false
required:
- message
- code
additionalProperties: false
securitySchemes:
Authorization:
type: http
scheme: bearer
````
---
# Source: https://docs.openpipe.ai/api-reference/post-createDatasetEntries.md
> ## Documentation Index
> Fetch the complete documentation index at: https://docs.openpipe.ai/llms.txt
> Use this file to discover all available pages before exploring further.
# Add Entries to Dataset
> Add new dataset entries.
## OpenAPI
````yaml post /datasets/{datasetId}/entries
openapi: 3.0.3
info:
title: OpenPipe API
description: The public API for reporting API calls to OpenPipe
version: 0.1.1
servers:
- url: https://api.openpipe.ai/api/v1
security: []
paths:
/datasets/{datasetId}/entries:
post:
description: Add new dataset entries.
operationId: createDatasetEntries
parameters:
- name: datasetId
in: path
required: true
schema:
type: string
requestBody:
required: true
content:
application/json:
schema:
type: object
properties:
entries:
type: array
items:
type: object
properties:
messages:
type: array
items:
anyOf:
- type: object
properties:
role:
type: string
enum:
- system
content:
anyOf:
- type: string
- type: array
items:
type: object
properties:
type:
type: string
enum:
- text
text:
type: string
required:
- type
- text
additionalProperties: false
default: ''
name:
type: string
required:
- role
additionalProperties: false
- type: object
properties:
role:
type: string
enum:
- user
content:
anyOf:
- type: string
- type: array
items:
anyOf:
- type: object
properties:
type:
type: string
enum:
- text
text:
type: string
required:
- type
- text
additionalProperties: false
- type: object
properties:
type:
type: string
enum:
- image_url
image_url:
type: object
properties:
detail:
anyOf:
- type: string
enum:
- auto
- type: string
enum:
- low
- type: string
enum:
- high
url:
type: string
required:
- url
additionalProperties: false
required:
- type
- image_url
additionalProperties: false
- type: object
properties:
type:
type: string
enum:
- input_audio
input_audio:
type: object
properties:
data:
type: string
format:
type: string
enum:
- wav
- mp3
required:
- data
- format
additionalProperties: false
required:
- type
- input_audio
additionalProperties: false
default: ''
name:
type: string
required:
- role
additionalProperties: false
- type: object
properties:
role:
type: string
enum:
- assistant
audio:
type: object
properties:
id:
type: string
required:
- id
additionalProperties: false
nullable: true
content:
anyOf:
- type: string
- type: array
items:
anyOf:
- type: object
properties:
type:
type: string
enum:
- text
text:
type: string
required:
- type
- text
additionalProperties: false
- type: object
properties:
type:
type: string
enum:
- refusal
refusal:
type: string
required:
- type
- refusal
additionalProperties: false
- enum:
- 'null'
nullable: true
default: null
function_call:
type: object
properties:
name:
type: string
default: ''
arguments:
type: string
default: ''
additionalProperties: false
nullable: true
tool_calls:
type: array
items:
type: object
properties:
id:
type: string
function:
type: object
properties:
name:
type: string
arguments:
type: string
required:
- name
- arguments
additionalProperties: false
type:
type: string
enum:
- function
required:
- id
- function
- type
additionalProperties: false
nullable: true
name:
type: string
refusal:
type: string
nullable: true
annotations:
type: array
items:
type: object
properties:
type:
type: string
enum:
- url_citation
url_citation:
type: object
properties:
start_index:
type: number
end_index:
type: number
title:
type: string
url:
type: string
required:
- start_index
- end_index
- title
- url
additionalProperties: false
required:
- type
- url_citation
additionalProperties: false
required:
- role
additionalProperties: false
- type: object
properties:
role:
type: string
enum:
- developer
content:
anyOf:
- type: string
- type: array
items:
type: object
properties:
type:
type: string
enum:
- text
text:
type: string
required:
- type
- text
additionalProperties: false
default: ''
name:
type: string
required:
- role
additionalProperties: false
- type: object
properties:
role:
type: string
enum:
- tool
content:
anyOf:
- type: string
- type: array
items:
type: object
properties:
type:
type: string
enum:
- text
text:
type: string
required:
- type
- text
additionalProperties: false
default: ''
tool_call_id:
type: string
required:
- role
- tool_call_id
additionalProperties: false
- type: object
properties:
role:
type: string
enum:
- function
name:
type: string
content:
anyOf:
- type: string
- enum:
- 'null'
nullable: true
required:
- role
- name
- content
additionalProperties: false
rejected_message:
type: object
properties:
reasoning_content:
type: string
nullable: true
content:
type: string
nullable: true
default: null
refusal:
type: string
nullable: true
role:
type: string
enum:
- assistant
function_call:
type: object
properties:
name:
type: string
default: ''
arguments:
type: string
default: ''
additionalProperties: false
nullable: true
tool_calls:
type: array
items:
type: object
properties:
id:
type: string
function:
type: object
properties:
name:
type: string
arguments:
type: string
required:
- name
- arguments
additionalProperties: false
type:
type: string
enum:
- function
required:
- id
- function
- type
additionalProperties: false
nullable: true
required:
- role
additionalProperties: false
tool_choice:
anyOf:
- type: string
enum:
- none
- type: string
enum:
- auto
- type: string
enum:
- required
- type: object
properties:
type:
type: string
enum:
- function
default: function
function:
type: object
properties:
name:
type: string
required:
- name
additionalProperties: false
default:
name: ''
additionalProperties: false
tools:
type: array
items:
type: object
properties:
function:
type: object
properties:
name:
type: string
parameters:
type: object
additionalProperties: {}
description:
type: string
strict:
type: boolean
nullable: true
required:
- name
additionalProperties: false
type:
type: string
enum:
- function
required:
- function
- type
additionalProperties: false
response_format:
anyOf:
- type: object
properties:
type:
type: string
enum:
- text
required:
- type
additionalProperties: false
- type: object
properties:
type:
type: string
enum:
- json_object
required:
- type
additionalProperties: false
- type: object
properties:
type:
type: string
enum:
- json_schema
json_schema:
type: object
properties:
name:
type: string
description:
type: string
schema:
type: object
additionalProperties: {}
strict:
type: boolean
nullable: true
required:
- name
additionalProperties: false
required:
- type
- json_schema
additionalProperties: false
split:
type: string
enum:
- TRAIN
- TEST
metadata:
type: object
additionalProperties:
type: string
required:
- messages
additionalProperties: false
minItems: 1
maxItems: 100
required:
- entries
additionalProperties: false
responses:
'200':
description: Successful response
content:
application/json:
schema:
type: object
properties:
object:
type: string
enum:
- dataset.entries.creation
entries_created:
type: number
errors:
type: object
properties:
object:
type: string
enum:
- list
data:
type: array
items:
type: object
properties:
object:
type: string
enum:
- dataset.entries.creation.error
entry_index:
type: number
message:
type: string
required:
- object
- entry_index
- message
additionalProperties: false
required:
- object
- data
additionalProperties: false
required:
- object
- entries_created
- errors
additionalProperties: false
default:
$ref: '#/components/responses/error'
security:
- Authorization: []
components:
responses:
error:
description: Error response
content:
application/json:
schema:
type: object
properties:
message:
type: string
code:
type: string
issues:
type: array
items:
type: object
properties:
message:
type: string
required:
- message
additionalProperties: false
required:
- message
- code
additionalProperties: false
securitySchemes:
Authorization:
type: http
scheme: bearer
````
---
# Source: https://docs.openpipe.ai/api-reference/post-createModel.md
> ## Documentation Index
> Fetch the complete documentation index at: https://docs.openpipe.ai/llms.txt
> Use this file to discover all available pages before exploring further.
# Create Model
> Train a new model.
## OpenAPI
````yaml post /models
openapi: 3.0.3
info:
title: OpenPipe API
description: The public API for reporting API calls to OpenPipe
version: 0.1.1
servers:
- url: https://api.openpipe.ai/api/v1
security: []
paths:
/models:
post:
description: Train a new model.
operationId: createModel
parameters: []
requestBody:
required: true
content:
application/json:
schema:
type: object
properties:
datasetId:
type: string
slug:
type: string
pruningRuleIds:
type: array
items:
type: string
default: []
trainingConfig:
anyOf:
- type: object
properties:
provider:
type: string
enum:
- openpipe
baseModel:
type: string
description: >-
The base model to train from. This could be a base
model name or the slug of a previously trained
model. Supported base models include:
`meta-llama/Meta-Llama-3.1-8B-Instruct`,
`meta-llama/Meta-Llama-3.1-70B-Instruct`,
`meta-llama/Llama-3.3-70B-Instruct`,
`meta-llama/Llama-3.1-8B`,
`meta-llama/Llama-3.1-70B`,
`Qwen/Qwen2.5-72B-Instruct`,
`Qwen/Qwen2.5-Coder-7B-Instruct`,
`Qwen/Qwen2.5-Coder-32B-Instruct`,
`Qwen/Qwen2.5-1.5B-Instruct`,
`Qwen/Qwen2.5-7B-Instruct`,
`Qwen/Qwen2-VL-7B-Instruct`,
`Qwen/Qwen2.5-14B-Instruct`, `Qwen/Qwen3-8B`,
`Qwen/Qwen3-14B`,
`mistralai/Mistral-Nemo-Base-2407`,
`mistralai/Mistral-Small-24B-Base-2501`,
`meta-llama/Llama-3.2-1B-Instruct`,
`meta-llama/Llama-3.2-3B-Instruct`,
`google/gemma-3-1b-it`, `google/gemma-3-4b-it`,
`google/gemma-3-12b-it`, `google/gemma-3-27b-it`
enable_sft:
type: boolean
default: true
description: >-
Whether to enable SFT training. If true, the model
will be trained using SFT. Can be used in
conjunction with DPO training.
enable_preference_tuning:
type: boolean
description: >-
Whether to enable DPO training. If true, the model
will be trained using DPO. Can be used in
conjunction with SFT training.
default: false
sft_hyperparameters:
type: object
properties:
batch_size:
anyOf:
- type: string
enum:
- auto
- type: number
learning_rate_multiplier:
type: number
num_epochs:
type: number
additionalProperties: false
default: {}
description: >-
Hyperparameters for SFT training job. Ensure
`enable_sft` is true. If no SFT hyperparameters are
provided, default values will be used.
preference_hyperparameters:
type: object
properties:
variant:
anyOf:
- type: string
enum:
- DPO
- type: string
enum:
- APO Zero
learning_rate_multiplier:
type: number
num_epochs:
type: number
training_beta:
type: number
adapter_weight:
type: number
additionalProperties: false
default: {}
description: >-
Hyperparameters for DPO training job. Ensure
`enable_preference_tuning` is true. If no preference
hyperparameters are provided, default values will be
used.
hyperparameters:
type: object
properties:
is_sft_enabled:
type: boolean
default: true
batch_size:
anyOf:
- type: string
enum:
- auto
- type: number
learning_rate_multiplier:
type: number
num_epochs:
type: number
is_preference_tuning_enabled:
type: boolean
preference_tuning_variant:
anyOf:
- type: string
enum:
- DPO
- type: string
enum:
- APO Zero
preference_tuning_learning_rate_multiplier:
type: number
preference_tuning_num_epochs:
type: number
preference_tuning_training_beta:
type: number
preference_tuning_adapter_weight:
type: number
additionalProperties: false
description: >-
DEPRECATED: Use the `sft_hyperparameters` and
`preference_hyperparameters` fields instead.
required:
- provider
- baseModel
additionalProperties: false
- type: object
properties:
provider:
type: string
enum:
- openpipeReward
baseModel:
type: string
description: >-
The base model to train from. This could be a base
model name or the slug of a previously trained
model. Supported base models include:
`meta-llama/Llama-3.2-1B-Instruct`,
`meta-llama/Llama-3.2-3B-Instruct`,
`meta-llama/Meta-Llama-3.1-8B-Instruct`,
`Qwen/Qwen2.5-0.5B-Instruct`,
`Qwen/Qwen2.5-1.5B-Instruct`,
`Qwen/Qwen2.5-3B-Instruct`,
`Qwen/Qwen2.5-7B-Instruct`, `Qwen/Qwen3-8B`
hyperparameters:
type: object
properties:
batch_size:
anyOf:
- type: string
enum:
- auto
- type: number
learning_rate_multiplier:
type: number
num_epochs:
type: number
additionalProperties: false
default: {}
required:
- provider
- baseModel
additionalProperties: false
- type: object
properties:
provider:
type: string
enum:
- openai
baseModel:
type: string
enum:
- gpt-4.1-2025-04-14
- gpt-4.1-mini-2025-04-14
- gpt-4o-mini-2024-07-18
- gpt-4o-2024-08-06
- gpt-3.5-turbo-0125
enable_sft:
type: boolean
default: true
description: >-
Whether to enable SFT training. If true, the model
will be trained using SFT. Can be used in
conjunction with DPO training.
enable_preference_tuning:
type: boolean
description: >-
Whether to enable DPO training. If true, the model
will be trained using DPO. Can be used in
conjunction with SFT training.
default: false
sft_hyperparameters:
type: object
properties:
batch_size:
type: number
learning_rate_multiplier:
type: number
n_epochs:
type: number
additionalProperties: false
default: {}
description: >-
Hyperparameters for SFT training job. Ensure
`enable_sft` is true. If no SFT hyperparameters are
provided, default values will be used.
preference_hyperparameters:
type: object
properties:
beta:
type: number
batch_size:
type: number
learning_rate_multiplier:
type: number
n_epochs:
type: number
additionalProperties: false
default: {}
description: >-
Hyperparameters for DPO training job. Ensure
`enable_preference_tuning` is true. If no preference
hyperparameters are provided, default values will be
used.
hyperparameters:
type: object
properties:
is_sft_enabled:
type: boolean
default: true
batch_size:
type: number
learning_rate_multiplier:
type: number
n_epochs:
type: number
is_preference_tuning_enabled:
type: boolean
preference_tuning_beta:
type: number
preference_tuning_batch_size:
type: number
preference_tuning_learning_rate_multiplier:
type: number
preference_tuning_n_epochs:
type: number
additionalProperties: false
description: >-
DEPRECATED: Use the `sft_hyperparameters` and
`preference_hyperparameters` fields instead.
required:
- provider
- baseModel
additionalProperties: false
- type: object
properties:
provider:
type: string
enum:
- gemini
baseModel:
type: string
enum:
- models/gemini-1.0-pro-001
- models/gemini-1.5-flash-001-tuning
sft_hyperparameters:
type: object
properties:
epochs:
type: number
batch_size:
type: number
learning_rate:
type: number
learning_rate_multiplier:
type: number
additionalProperties: false
default: {}
description: >-
Hyperparameters for SFT training job. If no SFT
hyperparameters are provided, default values will be
used.
hyperparameters:
type: object
properties:
epochs:
type: number
batch_size:
type: number
learning_rate:
type: number
learning_rate_multiplier:
type: number
additionalProperties: false
description: >-
DEPRECATED: Use the `sft_hyperparameters` field
instead.
required:
- provider
- baseModel
additionalProperties: false
defaultTemperature:
type: number
required:
- datasetId
- slug
- trainingConfig
additionalProperties: false
responses:
'200':
description: Successful response
content:
application/json:
schema:
type: object
properties:
id:
type: string
name:
type: string
object:
type: string
enum:
- model
description:
type: string
nullable: true
created:
type: string
updated:
type: string
openpipe:
type: object
properties:
baseModel:
type: string
hyperparameters:
type: object
additionalProperties: {}
nullable: true
status:
type: string
enum:
- PENDING
- TRAINING
- DEPLOYED
- ERROR
- DEPRECATED
- PENDING_DEPRECATION
- QUEUED
- PROVISIONING
datasetId:
type: string
errorMessage:
type: string
nullable: true
required:
- baseModel
- hyperparameters
- status
- datasetId
- errorMessage
additionalProperties: false
contextWindow:
type: number
maxCompletionTokens:
type: number
capabilities:
type: array
items:
type: string
enum:
- chat
- tools
- json
pricing:
type: object
properties:
chatIn:
type: number
description: $/million tokens
chatOut:
type: number
description: $/million tokens
required:
- chatIn
- chatOut
additionalProperties: false
owned_by:
type: string
required:
- id
- name
- object
- description
- created
- updated
- openpipe
- contextWindow
- maxCompletionTokens
- capabilities
- pricing
- owned_by
additionalProperties: false
default:
$ref: '#/components/responses/error'
security:
- Authorization: []
components:
responses:
error:
description: Error response
content:
application/json:
schema:
type: object
properties:
message:
type: string
code:
type: string
issues:
type: array
items:
type: object
properties:
message:
type: string
required:
- message
additionalProperties: false
required:
- message
- code
additionalProperties: false
securitySchemes:
Authorization:
type: http
scheme: bearer
````
---
# Source: https://docs.openpipe.ai/api-reference/post-criteriajudge.md
> ## Documentation Index
> Fetch the complete documentation index at: https://docs.openpipe.ai/llms.txt
> Use this file to discover all available pages before exploring further.
# Judge Criteria
> Get a judgement of a completion against the specified criterion
## OpenAPI
````yaml post /criteria/judge
openapi: 3.0.3
info:
title: OpenPipe API
description: The public API for reporting API calls to OpenPipe
version: 0.1.1
servers:
- url: https://api.openpipe.ai/api/v1
security: []
paths:
/criteria/judge:
post:
description: Get a judgement of a completion against the specified criterion
operationId: getCriterionJudgement
parameters: []
requestBody:
required: true
content:
application/json:
schema:
type: object
properties:
criterion_id:
type: string
description: The ID of the criterion to judge.
input:
type: object
properties:
messages:
type: array
items:
anyOf:
- type: object
properties:
role:
type: string
enum:
- system
content:
anyOf:
- type: string
- type: array
items:
type: object
properties:
type:
type: string
enum:
- text
text:
type: string
required:
- type
- text
additionalProperties: false
default: ''
name:
type: string
required:
- role
additionalProperties: false
- type: object
properties:
role:
type: string
enum:
- user
content:
anyOf:
- type: string
- type: array
items:
anyOf:
- type: object
properties:
type:
type: string
enum:
- text
text:
type: string
required:
- type
- text
additionalProperties: false
- type: object
properties:
type:
type: string
enum:
- image_url
image_url:
type: object
properties:
detail:
anyOf:
- type: string
enum:
- auto
- type: string
enum:
- low
- type: string
enum:
- high
url:
type: string
required:
- url
additionalProperties: false
required:
- type
- image_url
additionalProperties: false
- type: object
properties:
type:
type: string
enum:
- input_audio
input_audio:
type: object
properties:
data:
type: string
format:
type: string
enum:
- wav
- mp3
required:
- data
- format
additionalProperties: false
required:
- type
- input_audio
additionalProperties: false
default: ''
name:
type: string
required:
- role
additionalProperties: false
- type: object
properties:
role:
type: string
enum:
- assistant
audio:
type: object
properties:
id:
type: string
required:
- id
additionalProperties: false
nullable: true
content:
anyOf:
- type: string
- type: array
items:
anyOf:
- type: object
properties:
type:
type: string
enum:
- text
text:
type: string
required:
- type
- text
additionalProperties: false
- type: object
properties:
type:
type: string
enum:
- refusal
refusal:
type: string
required:
- type
- refusal
additionalProperties: false
- enum:
- 'null'
nullable: true
default: null
function_call:
type: object
properties:
name:
type: string
default: ''
arguments:
type: string
default: ''
additionalProperties: false
nullable: true
tool_calls:
type: array
items:
type: object
properties:
id:
type: string
function:
type: object
properties:
name:
type: string
arguments:
type: string
required:
- name
- arguments
additionalProperties: false
type:
type: string
enum:
- function
required:
- id
- function
- type
additionalProperties: false
nullable: true
name:
type: string
refusal:
type: string
nullable: true
annotations:
type: array
items:
type: object
properties:
type:
type: string
enum:
- url_citation
url_citation:
type: object
properties:
start_index:
type: number
end_index:
type: number
title:
type: string
url:
type: string
required:
- start_index
- end_index
- title
- url
additionalProperties: false
required:
- type
- url_citation
additionalProperties: false
required:
- role
additionalProperties: false
- type: object
properties:
role:
type: string
enum:
- developer
content:
anyOf:
- type: string
- type: array
items:
type: object
properties:
type:
type: string
enum:
- text
text:
type: string
required:
- type
- text
additionalProperties: false
default: ''
name:
type: string
required:
- role
additionalProperties: false
- type: object
properties:
role:
type: string
enum:
- tool
content:
anyOf:
- type: string
- type: array
items:
type: object
properties:
type:
type: string
enum:
- text
text:
type: string
required:
- type
- text
additionalProperties: false
default: ''
tool_call_id:
type: string
required:
- role
- tool_call_id
additionalProperties: false
- type: object
properties:
role:
type: string
enum:
- function
name:
type: string
content:
anyOf:
- type: string
- enum:
- 'null'
nullable: true
required:
- role
- name
- content
additionalProperties: false
description: >-
All messages sent to the model when generating the
output.
tool_choice:
anyOf:
- type: string
enum:
- none
- type: string
enum:
- auto
- type: string
enum:
- required
- type: object
properties:
type:
type: string
enum:
- function
default: function
function:
type: object
properties:
name:
type: string
required:
- name
additionalProperties: false
default:
name: ''
additionalProperties: false
description: >-
The tool choice to use when generating the output, if
any.
tools:
type: array
items:
type: object
properties:
function:
type: object
properties:
name:
type: string
parameters:
type: object
additionalProperties: {}
description:
type: string
strict:
type: boolean
nullable: true
required:
- name
additionalProperties: false
type:
type: string
enum:
- function
required:
- function
- type
additionalProperties: false
description: >-
The tools available to the model when generating the
output, if any.
required:
- messages
additionalProperties: false
output:
type: object
properties:
reasoning_content:
type: string
nullable: true
content:
type: string
nullable: true
default: null
refusal:
type: string
nullable: true
role:
type: string
enum:
- assistant
function_call:
type: object
properties:
name:
type: string
default: ''
arguments:
type: string
default: ''
additionalProperties: false
nullable: true
tool_calls:
type: array
items:
type: object
properties:
id:
type: string
function:
type: object
properties:
name:
type: string
arguments:
type: string
required:
- name
- arguments
additionalProperties: false
type:
type: string
enum:
- function
required:
- id
- function
- type
additionalProperties: false
nullable: true
required:
- role
additionalProperties: false
description: The completion message of the model.
required:
- criterion_id
- output
additionalProperties: false
responses:
'200':
description: Successful response
content:
application/json:
schema:
type: object
properties:
score:
type: number
description: >-
A score of 0 means the output failed this completion, and
a score of 1 means it passed. A criteria may also return a
decimal scores between 0 and 1, indicating the model's
confidence or 'likelihood' that the criteria passed.
explanation:
type: string
description: >-
An explanation of the score including the model's
reasoning, if applicable.
usage:
type: object
properties:
total_tokens:
type: number
description: >-
The total number of tokens used to generate the
criterion judgement. Only returned for
OpenPipe-trained reward models currently.
required:
- total_tokens
additionalProperties: false
required:
- score
additionalProperties: false
default:
$ref: '#/components/responses/error'
security:
- Authorization: []
components:
responses:
error:
description: Error response
content:
application/json:
schema:
type: object
properties:
message:
type: string
code:
type: string
issues:
type: array
items:
type: object
properties:
message:
type: string
required:
- message
additionalProperties: false
required:
- message
- code
additionalProperties: false
securitySchemes:
Authorization:
type: http
scheme: bearer
````
---
# Source: https://docs.openpipe.ai/api-reference/post-report-anthropic.md
> ## Documentation Index
> Fetch the complete documentation index at: https://docs.openpipe.ai/llms.txt
> Use this file to discover all available pages before exploring further.
# Report Anthropic
> Record request logs from Anthropic models
## OpenAPI
````yaml post /report-anthropic
openapi: 3.0.3
info:
title: OpenPipe API
description: The public API for reporting API calls to OpenPipe
version: 0.1.1
servers:
- url: https://api.openpipe.ai/api/v1
security: []
paths:
/report-anthropic:
post:
description: Record request logs from Anthropic models
operationId: reportAnthropic
parameters: []
requestBody:
required: true
content:
application/json:
schema:
type: object
properties:
requestedAt:
type: number
description: Unix timestamp in milliseconds
receivedAt:
type: number
description: Unix timestamp in milliseconds
reqPayload:
anyOf:
- type: object
properties:
max_tokens:
type: number
messages:
type: array
items:
type: object
properties:
content:
anyOf:
- type: string
- type: array
items:
anyOf:
- type: object
properties:
text:
type: string
type:
type: string
enum:
- text
cache_control:
anyOf:
- type: object
properties:
type:
type: string
enum:
- ephemeral
required:
- type
additionalProperties: false
- enum:
- 'null'
nullable: true
citations:
type: array
items:
anyOf:
- type: object
properties:
cited_text:
type: string
document_index:
type: number
document_title:
type: string
nullable: true
end_char_index:
type: number
start_char_index:
type: number
type:
type: string
enum:
- char_location
required:
- cited_text
- document_index
- document_title
- end_char_index
- start_char_index
- type
additionalProperties: false
- type: object
properties:
cited_text:
type: string
document_index:
type: number
document_title:
type: string
nullable: true
end_page_number:
type: number
start_page_number:
type: number
type:
type: string
enum:
- page_location
required:
- cited_text
- document_index
- document_title
- end_page_number
- start_page_number
- type
additionalProperties: false
- type: object
properties:
cited_text:
type: string
document_index:
type: number
document_title:
type: string
nullable: true
end_block_index:
type: number
start_block_index:
type: number
type:
type: string
enum:
- content_block_location
required:
- cited_text
- document_index
- document_title
- end_block_index
- start_block_index
- type
additionalProperties: false
nullable: true
required:
- text
- type
additionalProperties: false
- type: object
properties:
source:
type: object
properties:
data:
type: string
media_type:
anyOf:
- type: string
enum:
- image/jpeg
- type: string
enum:
- image/png
- type: string
enum:
- image/gif
- type: string
enum:
- image/webp
type:
type: string
enum:
- base64
required:
- data
- media_type
- type
additionalProperties: false
type:
type: string
enum:
- image
cache_control:
anyOf:
- type: object
properties:
type:
type: string
enum:
- ephemeral
required:
- type
additionalProperties: false
- enum:
- 'null'
nullable: true
required:
- source
- type
additionalProperties: false
- type: object
properties:
id:
type: string
input: {}
name:
type: string
type:
type: string
enum:
- tool_use
cache_control:
anyOf:
- type: object
properties:
type:
type: string
enum:
- ephemeral
required:
- type
additionalProperties: false
- enum:
- 'null'
nullable: true
required:
- id
- name
- type
additionalProperties: false
- type: object
properties:
tool_use_id:
type: string
type:
type: string
enum:
- tool_result
content:
anyOf:
- type: string
- type: array
items:
anyOf:
- type: object
properties:
text:
type: string
type:
type: string
enum:
- text
cache_control:
anyOf:
- type: object
properties:
type:
type: string
enum:
- ephemeral
required:
- type
additionalProperties: false
- enum:
- 'null'
nullable: true
citations:
type: array
items:
anyOf:
- type: object
properties:
cited_text:
type: {}
document_index:
type: {}
document_title:
type: {}
nullable: {}
end_char_index:
type: {}
start_char_index:
type: {}
type:
type: {}
enum: {}
required:
- cited_text
- document_index
- document_title
- end_char_index
- start_char_index
- type
additionalProperties: false
- type: object
properties:
cited_text:
type: {}
document_index:
type: {}
document_title:
type: {}
nullable: {}
end_page_number:
type: {}
start_page_number:
type: {}
type:
type: {}
enum: {}
required:
- cited_text
- document_index
- document_title
- end_page_number
- start_page_number
- type
additionalProperties: false
- type: object
properties:
cited_text:
type: {}
document_index:
type: {}
document_title:
type: {}
nullable: {}
end_block_index:
type: {}
start_block_index:
type: {}
type:
type: {}
enum: {}
required:
- cited_text
- document_index
- document_title
- end_block_index
- start_block_index
- type
additionalProperties: false
nullable: true
required:
- text
- type
additionalProperties: false
- type: object
properties:
source:
type: object
properties:
data:
type: string
media_type:
anyOf:
- type: string
enum:
- image/jpeg
- type: string
enum:
- image/png
- type: string
enum:
- image/gif
- type: string
enum:
- image/webp
type:
type: string
enum:
- base64
required:
- data
- media_type
- type
additionalProperties: false
type:
type: string
enum:
- image
cache_control:
anyOf:
- type: object
properties:
type:
type: string
enum:
- ephemeral
required:
- type
additionalProperties: false
- enum:
- 'null'
nullable: true
required:
- source
- type
additionalProperties: false
is_error:
type: boolean
cache_control:
anyOf:
- type: object
properties:
type:
type: string
enum:
- ephemeral
required:
- type
additionalProperties: false
- enum:
- 'null'
nullable: true
required:
- tool_use_id
- type
additionalProperties: false
- type: object
properties:
source:
anyOf:
- type: object
properties:
data:
type: string
media_type:
type: string
enum:
- application/pdf
type:
type: string
enum:
- base64
required:
- data
- media_type
- type
additionalProperties: false
- type: object
properties:
data:
type: string
media_type:
type: string
enum:
- text/plain
type:
type: string
enum:
- text
required:
- data
- media_type
- type
additionalProperties: false
- type: object
properties:
content:
anyOf:
- type: string
- type: array
items:
anyOf:
- type: object
properties:
text:
type: string
type:
type: string
enum:
- text
cache_control:
anyOf:
- {}
- {}
citations:
type: array
items:
anyOf: {}
nullable: true
required:
- text
- type
additionalProperties: false
- type: object
properties:
source:
type: object
properties:
data: {}
media_type: {}
type: {}
required:
- data
- media_type
- type
additionalProperties: false
type:
type: string
enum:
- image
cache_control:
anyOf:
- {}
- {}
required:
- source
- type
additionalProperties: false
type:
type: string
enum:
- content
required:
- content
- type
additionalProperties: false
- type: object
properties:
type:
type: string
enum:
- url
url:
type: string
required:
- type
- url
additionalProperties: false
type:
type: string
enum:
- document
cache_control:
anyOf:
- type: object
properties:
type:
type: string
enum:
- ephemeral
required:
- type
additionalProperties: false
- enum:
- 'null'
nullable: true
citations:
type: object
properties:
enabled:
type: boolean
additionalProperties: false
context:
anyOf:
- type: string
- enum:
- 'null'
nullable: true
title:
anyOf:
- type: string
- enum:
- 'null'
nullable: true
required:
- source
- type
additionalProperties: false
- type: object
properties:
thinking:
type: string
signature:
type: string
type:
type: string
enum:
- thinking
required:
- thinking
- signature
- type
additionalProperties: false
- type: object
properties:
data:
type: string
type:
type: string
enum:
- redacted_thinking
required:
- data
- type
additionalProperties: false
role:
anyOf:
- type: string
enum:
- user
- type: string
enum:
- assistant
required:
- content
- role
additionalProperties: false
model:
type: string
metadata:
type: object
properties:
user_id:
anyOf:
- type: string
- enum:
- 'null'
nullable: true
additionalProperties: false
stop_sequences:
type: array
items:
type: string
stream:
type: boolean
enum:
- true
system:
anyOf:
- type: string
- type: array
items:
type: object
properties:
text:
type: string
type:
type: string
enum:
- text
cache_control:
anyOf:
- type: object
properties:
type:
type: string
enum:
- ephemeral
required:
- type
additionalProperties: false
- enum:
- 'null'
nullable: true
citations:
type: array
items:
anyOf:
- type: object
properties:
cited_text:
type: string
document_index:
type: number
document_title:
type: string
nullable: true
end_char_index:
type: number
start_char_index:
type: number
type:
type: string
enum:
- char_location
required:
- cited_text
- document_index
- document_title
- end_char_index
- start_char_index
- type
additionalProperties: false
- type: object
properties:
cited_text:
type: string
document_index:
type: number
document_title:
type: string
nullable: true
end_page_number:
type: number
start_page_number:
type: number
type:
type: string
enum:
- page_location
required:
- cited_text
- document_index
- document_title
- end_page_number
- start_page_number
- type
additionalProperties: false
- type: object
properties:
cited_text:
type: string
document_index:
type: number
document_title:
type: string
nullable: true
end_block_index:
type: number
start_block_index:
type: number
type:
type: string
enum:
- content_block_location
required:
- cited_text
- document_index
- document_title
- end_block_index
- start_block_index
- type
additionalProperties: false
nullable: true
required:
- text
- type
additionalProperties: false
temperature:
type: number
top_k:
type: number
top_p:
type: number
thinking:
anyOf:
- type: object
properties:
budget_tokens:
type: number
type:
type: string
enum:
- enabled
required:
- budget_tokens
- type
additionalProperties: false
- type: object
properties:
type:
type: string
enum:
- disabled
required:
- type
additionalProperties: false
tool_choice:
anyOf:
- type: object
properties:
type:
type: string
enum:
- auto
disable_parallel_tool_use:
type: boolean
required:
- type
additionalProperties: false
- type: object
properties:
type:
type: string
enum:
- any
disable_parallel_tool_use:
type: boolean
required:
- type
additionalProperties: false
- type: object
properties:
type:
type: string
enum:
- tool
name:
type: string
disable_parallel_tool_use:
type: boolean
required:
- type
- name
additionalProperties: false
- type: object
properties:
type:
type: string
enum:
- none
required:
- type
additionalProperties: false
tools:
type: array
items:
anyOf:
- type: object
properties:
name:
type: string
input_schema:
type: object
properties:
type:
type: string
enum:
- object
properties: {}
required:
- type
additionalProperties: true
description:
type: string
cache_control:
anyOf:
- type: object
properties:
type:
type: string
enum:
- ephemeral
required:
- type
additionalProperties: false
- enum:
- 'null'
nullable: true
required:
- name
- input_schema
additionalProperties: false
- type: object
properties:
name:
type: string
enum:
- bash
type:
type: string
enum:
- bash_20250124
cache_control:
anyOf:
- type: object
properties:
type:
type: string
enum:
- ephemeral
required:
- type
additionalProperties: false
- enum:
- 'null'
nullable: true
required:
- name
- type
additionalProperties: false
- type: object
properties:
name:
type: string
enum:
- str_replace_editor
type:
type: string
enum:
- text_editor_20250124
cache_control:
anyOf:
- type: object
properties:
type:
type: string
enum:
- ephemeral
required:
- type
additionalProperties: false
- enum:
- 'null'
nullable: true
required:
- name
- type
additionalProperties: false
required:
- max_tokens
- messages
- model
- stream
additionalProperties: true
- type: object
properties:
max_tokens:
type: number
messages:
type: array
items:
type: object
properties:
content:
anyOf:
- type: string
- type: array
items:
anyOf:
- type: object
properties:
text:
type: string
type:
type: string
enum:
- text
cache_control:
anyOf:
- type: object
properties:
type:
type: string
enum:
- ephemeral
required:
- type
additionalProperties: false
- enum:
- 'null'
nullable: true
citations:
type: array
items:
anyOf:
- type: object
properties:
cited_text:
type: string
document_index:
type: number
document_title:
type: string
nullable: true
end_char_index:
type: number
start_char_index:
type: number
type:
type: string
enum:
- char_location
required:
- cited_text
- document_index
- document_title
- end_char_index
- start_char_index
- type
additionalProperties: false
- type: object
properties:
cited_text:
type: string
document_index:
type: number
document_title:
type: string
nullable: true
end_page_number:
type: number
start_page_number:
type: number
type:
type: string
enum:
- page_location
required:
- cited_text
- document_index
- document_title
- end_page_number
- start_page_number
- type
additionalProperties: false
- type: object
properties:
cited_text:
type: string
document_index:
type: number
document_title:
type: string
nullable: true
end_block_index:
type: number
start_block_index:
type: number
type:
type: string
enum:
- content_block_location
required:
- cited_text
- document_index
- document_title
- end_block_index
- start_block_index
- type
additionalProperties: false
nullable: true
required:
- text
- type
additionalProperties: false
- type: object
properties:
source:
type: object
properties:
data:
type: string
media_type:
anyOf:
- type: string
enum:
- image/jpeg
- type: string
enum:
- image/png
- type: string
enum:
- image/gif
- type: string
enum:
- image/webp
type:
type: string
enum:
- base64
required:
- data
- media_type
- type
additionalProperties: false
type:
type: string
enum:
- image
cache_control:
anyOf:
- type: object
properties:
type:
type: string
enum:
- ephemeral
required:
- type
additionalProperties: false
- enum:
- 'null'
nullable: true
required:
- source
- type
additionalProperties: false
- type: object
properties:
id:
type: string
input: {}
name:
type: string
type:
type: string
enum:
- tool_use
cache_control:
anyOf:
- type: object
properties:
type:
type: string
enum:
- ephemeral
required:
- type
additionalProperties: false
- enum:
- 'null'
nullable: true
required:
- id
- name
- type
additionalProperties: false
- type: object
properties:
tool_use_id:
type: string
type:
type: string
enum:
- tool_result
content:
anyOf:
- type: string
- type: array
items:
anyOf:
- type: object
properties:
text:
type: string
type:
type: string
enum:
- text
cache_control:
anyOf:
- type: object
properties:
type:
type: string
enum:
- ephemeral
required:
- type
additionalProperties: false
- enum:
- 'null'
nullable: true
citations:
type: array
items:
anyOf:
- type: object
properties:
cited_text:
type: {}
document_index:
type: {}
document_title:
type: {}
nullable: {}
end_char_index:
type: {}
start_char_index:
type: {}
type:
type: {}
enum: {}
required:
- cited_text
- document_index
- document_title
- end_char_index
- start_char_index
- type
additionalProperties: false
- type: object
properties:
cited_text:
type: {}
document_index:
type: {}
document_title:
type: {}
nullable: {}
end_page_number:
type: {}
start_page_number:
type: {}
type:
type: {}
enum: {}
required:
- cited_text
- document_index
- document_title
- end_page_number
- start_page_number
- type
additionalProperties: false
- type: object
properties:
cited_text:
type: {}
document_index:
type: {}
document_title:
type: {}
nullable: {}
end_block_index:
type: {}
start_block_index:
type: {}
type:
type: {}
enum: {}
required:
- cited_text
- document_index
- document_title
- end_block_index
- start_block_index
- type
additionalProperties: false
nullable: true
required:
- text
- type
additionalProperties: false
- type: object
properties:
source:
type: object
properties:
data:
type: string
media_type:
anyOf:
- type: string
enum:
- image/jpeg
- type: string
enum:
- image/png
- type: string
enum:
- image/gif
- type: string
enum:
- image/webp
type:
type: string
enum:
- base64
required:
- data
- media_type
- type
additionalProperties: false
type:
type: string
enum:
- image
cache_control:
anyOf:
- type: object
properties:
type:
type: string
enum:
- ephemeral
required:
- type
additionalProperties: false
- enum:
- 'null'
nullable: true
required:
- source
- type
additionalProperties: false
is_error:
type: boolean
cache_control:
anyOf:
- type: object
properties:
type:
type: string
enum:
- ephemeral
required:
- type
additionalProperties: false
- enum:
- 'null'
nullable: true
required:
- tool_use_id
- type
additionalProperties: false
- type: object
properties:
source:
anyOf:
- type: object
properties:
data:
type: string
media_type:
type: string
enum:
- application/pdf
type:
type: string
enum:
- base64
required:
- data
- media_type
- type
additionalProperties: false
- type: object
properties:
data:
type: string
media_type:
type: string
enum:
- text/plain
type:
type: string
enum:
- text
required:
- data
- media_type
- type
additionalProperties: false
- type: object
properties:
content:
anyOf:
- type: string
- type: array
items:
anyOf:
- type: object
properties:
text:
type: string
type:
type: string
enum:
- text
cache_control:
anyOf:
- {}
- {}
citations:
type: array
items:
anyOf: {}
nullable: true
required:
- text
- type
additionalProperties: false
- type: object
properties:
source:
type: object
properties:
data: {}
media_type: {}
type: {}
required:
- data
- media_type
- type
additionalProperties: false
type:
type: string
enum:
- image
cache_control:
anyOf:
- {}
- {}
required:
- source
- type
additionalProperties: false
type:
type: string
enum:
- content
required:
- content
- type
additionalProperties: false
- type: object
properties:
type:
type: string
enum:
- url
url:
type: string
required:
- type
- url
additionalProperties: false
type:
type: string
enum:
- document
cache_control:
anyOf:
- type: object
properties:
type:
type: string
enum:
- ephemeral
required:
- type
additionalProperties: false
- enum:
- 'null'
nullable: true
citations:
type: object
properties:
enabled:
type: boolean
additionalProperties: false
context:
anyOf:
- type: string
- enum:
- 'null'
nullable: true
title:
anyOf:
- type: string
- enum:
- 'null'
nullable: true
required:
- source
- type
additionalProperties: false
- type: object
properties:
thinking:
type: string
signature:
type: string
type:
type: string
enum:
- thinking
required:
- thinking
- signature
- type
additionalProperties: false
- type: object
properties:
data:
type: string
type:
type: string
enum:
- redacted_thinking
required:
- data
- type
additionalProperties: false
role:
anyOf:
- type: string
enum:
- user
- type: string
enum:
- assistant
required:
- content
- role
additionalProperties: false
model:
type: string
metadata:
type: object
properties:
user_id:
anyOf:
- type: string
- enum:
- 'null'
nullable: true
additionalProperties: false
stop_sequences:
type: array
items:
type: string
stream:
type: boolean
enum:
- false
default: false
system:
anyOf:
- type: string
- type: array
items:
type: object
properties:
text:
type: string
type:
type: string
enum:
- text
cache_control:
anyOf:
- type: object
properties:
type:
type: string
enum:
- ephemeral
required:
- type
additionalProperties: false
- enum:
- 'null'
nullable: true
citations:
type: array
items:
anyOf:
- type: object
properties:
cited_text:
type: string
document_index:
type: number
document_title:
type: string
nullable: true
end_char_index:
type: number
start_char_index:
type: number
type:
type: string
enum:
- char_location
required:
- cited_text
- document_index
- document_title
- end_char_index
- start_char_index
- type
additionalProperties: false
- type: object
properties:
cited_text:
type: string
document_index:
type: number
document_title:
type: string
nullable: true
end_page_number:
type: number
start_page_number:
type: number
type:
type: string
enum:
- page_location
required:
- cited_text
- document_index
- document_title
- end_page_number
- start_page_number
- type
additionalProperties: false
- type: object
properties:
cited_text:
type: string
document_index:
type: number
document_title:
type: string
nullable: true
end_block_index:
type: number
start_block_index:
type: number
type:
type: string
enum:
- content_block_location
required:
- cited_text
- document_index
- document_title
- end_block_index
- start_block_index
- type
additionalProperties: false
nullable: true
required:
- text
- type
additionalProperties: false
temperature:
type: number
top_k:
type: number
top_p:
type: number
thinking:
anyOf:
- type: object
properties:
budget_tokens:
type: number
type:
type: string
enum:
- enabled
required:
- budget_tokens
- type
additionalProperties: false
- type: object
properties:
type:
type: string
enum:
- disabled
required:
- type
additionalProperties: false
tool_choice:
anyOf:
- type: object
properties:
type:
type: string
enum:
- auto
disable_parallel_tool_use:
type: boolean
required:
- type
additionalProperties: false
- type: object
properties:
type:
type: string
enum:
- any
disable_parallel_tool_use:
type: boolean
required:
- type
additionalProperties: false
- type: object
properties:
type:
type: string
enum:
- tool
name:
type: string
disable_parallel_tool_use:
type: boolean
required:
- type
- name
additionalProperties: false
- type: object
properties:
type:
type: string
enum:
- none
required:
- type
additionalProperties: false
tools:
type: array
items:
anyOf:
- type: object
properties:
name:
type: string
input_schema:
type: object
properties:
type:
type: string
enum:
- object
properties: {}
required:
- type
additionalProperties: true
description:
type: string
cache_control:
anyOf:
- type: object
properties:
type:
type: string
enum:
- ephemeral
required:
- type
additionalProperties: false
- enum:
- 'null'
nullable: true
required:
- name
- input_schema
additionalProperties: false
- type: object
properties:
name:
type: string
enum:
- bash
type:
type: string
enum:
- bash_20250124
cache_control:
anyOf:
- type: object
properties:
type:
type: string
enum:
- ephemeral
required:
- type
additionalProperties: false
- enum:
- 'null'
nullable: true
required:
- name
- type
additionalProperties: false
- type: object
properties:
name:
type: string
enum:
- str_replace_editor
type:
type: string
enum:
- text_editor_20250124
cache_control:
anyOf:
- type: object
properties:
type:
type: string
enum:
- ephemeral
required:
- type
additionalProperties: false
- enum:
- 'null'
nullable: true
required:
- name
- type
additionalProperties: false
required:
- max_tokens
- messages
- model
additionalProperties: true
description: JSON-encoded request payload
respPayload:
type: object
properties:
id:
type: string
content:
type: array
items:
anyOf:
- type: object
properties:
text:
type: string
type:
type: string
enum:
- text
citations:
type: array
items:
anyOf:
- type: object
properties:
cited_text:
type: string
document_index:
type: number
document_title:
type: string
nullable: true
end_char_index:
type: number
start_char_index:
type: number
type:
type: string
enum:
- char_location
required:
- cited_text
- document_index
- document_title
- end_char_index
- start_char_index
- type
additionalProperties: false
- type: object
properties:
cited_text:
type: string
document_index:
type: number
document_title:
type: string
nullable: true
end_page_number:
type: number
start_page_number:
type: number
type:
type: string
enum:
- page_location
required:
- cited_text
- document_index
- document_title
- end_page_number
- start_page_number
- type
additionalProperties: false
- type: object
properties:
cited_text:
type: string
document_index:
type: number
document_title:
type: string
nullable: true
end_block_index:
type: number
start_block_index:
type: number
type:
type: string
enum:
- content_block_location
required:
- cited_text
- document_index
- document_title
- end_block_index
- start_block_index
- type
additionalProperties: false
nullable: true
default: null
required:
- text
- type
additionalProperties: false
- type: object
properties:
id:
type: string
name:
type: string
type:
type: string
enum:
- tool_use
input: {}
required:
- id
- name
- type
additionalProperties: false
- type: object
properties:
thinking:
type: string
signature:
type: string
type:
type: string
enum:
- thinking
required:
- thinking
- signature
- type
additionalProperties: false
- type: object
properties:
data:
type: string
type:
type: string
enum:
- redacted_thinking
required:
- data
- type
additionalProperties: false
model:
type: string
role:
type: string
enum:
- assistant
stop_reason:
anyOf:
- type: string
enum:
- end_turn
- type: string
enum:
- max_tokens
- type: string
enum:
- stop_sequence
- type: string
enum:
- tool_use
- enum:
- 'null'
nullable: true
stop_sequence:
anyOf:
- type: string
- enum:
- 'null'
nullable: true
type:
type: string
enum:
- message
usage:
type: object
properties:
input_tokens:
type: number
output_tokens:
type: number
cache_creation_input_tokens:
type: number
nullable: true
cache_read_input_tokens:
type: number
nullable: true
required:
- input_tokens
- output_tokens
- cache_creation_input_tokens
- cache_read_input_tokens
additionalProperties: false
required:
- id
- content
- model
- role
- stop_reason
- stop_sequence
- type
- usage
additionalProperties: false
description: JSON-encoded response payload
statusCode:
type: number
description: HTTP status code of response
errorMessage:
type: string
description: User-friendly error message
metadata:
type: object
additionalProperties:
type: string
description: >-
Extra metadata tags to attach to the call for filtering. Eg
{ "userId": "123", "prompt_id": "populate-title" }
default: {}
tags:
type: object
additionalProperties:
anyOf:
- type: string
- type: number
- type: boolean
- enum:
- 'null'
nullable: true
description: 'Deprecated: use "metadata" instead'
default: {}
additionalProperties: false
responses:
'200':
description: Successful response
content:
application/json:
schema:
type: object
properties:
status:
anyOf:
- type: string
enum:
- ok
- type: string
enum:
- error
required:
- status
additionalProperties: false
default:
$ref: '#/components/responses/error'
security:
- Authorization: []
components:
responses:
error:
description: Error response
content:
application/json:
schema:
type: object
properties:
message:
type: string
code:
type: string
issues:
type: array
items:
type: object
properties:
message:
type: string
required:
- message
additionalProperties: false
required:
- message
- code
additionalProperties: false
securitySchemes:
Authorization:
type: http
scheme: bearer
````
---
# Source: https://docs.openpipe.ai/api-reference/post-report.md
> ## Documentation Index
> Fetch the complete documentation index at: https://docs.openpipe.ai/llms.txt
> Use this file to discover all available pages before exploring further.
# Report
> Record request logs from OpenAI models
## OpenAPI
````yaml post /report
openapi: 3.0.3
info:
title: OpenPipe API
description: The public API for reporting API calls to OpenPipe
version: 0.1.1
servers:
- url: https://api.openpipe.ai/api/v1
security: []
paths:
/report:
post:
description: Record request logs from OpenAI models
operationId: report
parameters: []
requestBody:
required: true
content:
application/json:
schema:
type: object
properties:
requestedAt:
type: number
description: Unix timestamp in milliseconds
receivedAt:
type: number
description: Unix timestamp in milliseconds
reqPayload:
description: JSON-encoded request payload
respPayload:
description: JSON-encoded response payload
statusCode:
type: number
description: HTTP status code of response
errorMessage:
type: string
description: User-friendly error message
tags:
type: object
additionalProperties:
anyOf:
- type: string
- type: number
- type: boolean
- enum:
- 'null'
nullable: true
description: >-
DEPRECATED: use "reqPayload.metadata" to attach extra
metadata tags to the call for filtering. Eg { "userId":
"123", "prompt_id": "populate-title" }
default: {}
additionalProperties: false
responses:
'200':
description: Successful response
content:
application/json:
schema:
type: object
properties:
status:
anyOf:
- type: string
enum:
- ok
- type: string
enum:
- error
required:
- status
additionalProperties: false
default:
$ref: '#/components/responses/error'
security:
- Authorization: []
components:
responses:
error:
description: Error response
content:
application/json:
schema:
type: object
properties:
message:
type: string
code:
type: string
issues:
type: array
items:
type: object
properties:
message:
type: string
required:
- message
additionalProperties: false
required:
- message
- code
additionalProperties: false
securitySchemes:
Authorization:
type: http
scheme: bearer
````
---
# Source: https://docs.openpipe.ai/api-reference/post-updatemetadata.md
> ## Documentation Index
> Fetch the complete documentation index at: https://docs.openpipe.ai/llms.txt
> Use this file to discover all available pages before exploring further.
# Update Metadata
> Update tags metadata for logged calls matching the provided filters.
## OpenAPI
````yaml post /logs/update-metadata
openapi: 3.0.3
info:
title: OpenPipe API
description: The public API for reporting API calls to OpenPipe
version: 0.1.1
servers:
- url: https://api.openpipe.ai/api/v1
security: []
paths:
/logs/update-metadata:
post:
description: Update tags metadata for logged calls matching the provided filters.
operationId: updateLogMetadata
parameters: []
requestBody:
required: true
content:
application/json:
schema:
type: object
properties:
filters:
type: array
items:
type: object
properties:
field:
type: string
description: >-
The field to filter on. Possible fields include:
`model`, `completionId`, and `metadata.your_tag_name`.
equals:
anyOf:
- type: string
- type: number
- type: boolean
required:
- field
- equals
additionalProperties: false
metadata:
type: object
additionalProperties:
anyOf:
- type: string
- enum:
- 'null'
nullable: true
description: >-
Extra metadata to attach to the call for filtering. Eg {
"userId": "123", "prompt_id": "populate-title" }
required:
- filters
- metadata
additionalProperties: false
responses:
'200':
description: Successful response
content:
application/json:
schema:
type: object
properties:
matchedLogs:
type: number
required:
- matchedLogs
additionalProperties: false
default:
$ref: '#/components/responses/error'
security:
- Authorization: []
components:
responses:
error:
description: Error response
content:
application/json:
schema:
type: object
properties:
message:
type: string
code:
type: string
issues:
type: array
items:
type: object
properties:
message:
type: string
required:
- message
additionalProperties: false
required:
- message
- code
additionalProperties: false
securitySchemes:
Authorization:
type: http
scheme: bearer
````
---
# Source: https://docs.openpipe.ai/pricing/pricing.md
> ## Documentation Index
> Fetch the complete documentation index at: https://docs.openpipe.ai/llms.txt
> Use this file to discover all available pages before exploring further.
# Pricing Overview
## Training
We charge for training based on the size of the model and the number of tokens in the dataset.
| Model Category | Cost per 1M tokens |
| ------------------ | ------------------ |
| **8B and smaller** | \$0.48 |
| **14B models** | \$1.50 |
| **32B models** | \$1.90 |
| **70B+ models** | \$2.90 |
## Hosted Inference
Choose between two billing models for running models on our infrastructure:
### 1. Per-Token Pricing
Available for our most popular, high-volume models. You only pay for the tokens you process, with no minimum commitment and automatic infrastructure scaling.
| Model | Input (per 1M tokens) | Output (per 1M tokens) |
| -------------------------- | --------------------- | ---------------------- |
| **Llama 3.1 8B Instruct** | \$0.30 | \$0.45 |
| **Qwen 2.5 14B Instruct** | \$1.00 | \$1.50 |
| **Llama 3.1 70B Instruct** | \$1.80 | \$2.00 |
### 2. Hourly Compute Units
Designed for experimental and lower-volume models. A Compute Unit (CU) can handle up to 24 simultaneous requests per second. Billing is precise down to the second, with automatic scaling when traffic exceeds capacity. Compute units remain active for 60 seconds after traffic spikes.
| Model | Rate per CU Hour |
| ---------------------- | ---------------- |
| **Llama 3.1 8B** | \$1.50 |
| **Mistral Nemo 12B** | \$1.50 |
| **Qwen 2.5 32B Coder** | \$6.00 |
| **Qwen 2.5 72B** | \$12.00 |
| **Llama 3.1 70B** | \$12.00 |
## Third-Party Models (OpenAI, Gemini, etc.)
Third-party models fine-tuned through OpenPipe like OpenAI's GPT series or Google's Gemini, we provide direct API integration without any additional markup. You will be billed directly by the respective provider (OpenAI, Google, etc.) at their standard rates. We simply pass through the API calls and responses.
## Enterprise Plans
For organizations requiring custom solutions, we offer enterprise plans that include:
* Volume discounts
* On-premises deployment options
* Dedicated support
* Custom SLAs
* Advanced security features
* Increased data storage
Contact our team at [hello@openpipe.ai](mailto:hello@openpipe.ai) to discuss enterprise pricing and requirements.
---
# Source: https://docs.openpipe.ai/features/pruning-rules.md
> ## Documentation Index
> Fetch the complete documentation index at: https://docs.openpipe.ai/llms.txt
> Use this file to discover all available pages before exploring further.
# Pruning Rules
> Decrease input token counts by pruning out chunks of static text.
Some prompts have large chunks of unchanging text, like system messages which don't change from one request to the next. By removing this static text and fine-tuning a model on the compacted data, we can reduce the size of incoming requests and save you money on inference.
Add pruning rules to your dataset in the Settings tab, as shown below and in our [demo dataset](https://app.openpipe.ai/p/BRZFEx50Pf/datasets/0aa75f72-3fe5-4294-a94e-94c9236befa6/settings).
Feel free to run some sample inference on the [PII Redaction model](https://app.openpipe.ai/p/BRZFEx50Pf/fine-tunes/efb0d474-97b6-4735-a0af-55643b50600a/general) in our public project.
---
# Source: https://docs.openpipe.ai/api-reference/post-chatcompletions.md
> ## Documentation Index
> Fetch the complete documentation index at: https://docs.openpipe.ai/llms.txt
> Use this file to discover all available pages before exploring further.
# Chat Completions
> OpenAI-compatible route for generating inference and optionally logging the request.
## OpenAPI
````yaml post /chat/completions
openapi: 3.0.3
info:
title: OpenPipe API
description: The public API for reporting API calls to OpenPipe
version: 0.1.1
servers:
- url: https://api.openpipe.ai/api/v1
security: []
paths:
/chat/completions:
post:
description: >-
OpenAI-compatible route for generating inference and optionally logging
the request.
operationId: createChatCompletion
parameters: []
requestBody:
required: true
content:
application/json:
schema:
type: object
properties:
messages:
type: array
items:
anyOf:
- type: object
properties:
role:
type: string
enum:
- system
content:
anyOf:
- type: string
- type: array
items:
type: object
properties:
type:
type: string
enum:
- text
text:
type: string
required:
- type
- text
additionalProperties: false
default: ''
name:
type: string
required:
- role
additionalProperties: false
- type: object
properties:
role:
type: string
enum:
- user
content:
anyOf:
- type: string
- type: array
items:
anyOf:
- type: object
properties:
type:
type: string
enum:
- text
text:
type: string
required:
- type
- text
additionalProperties: false
- type: object
properties:
type:
type: string
enum:
- image_url
image_url:
type: object
properties:
detail:
anyOf:
- type: string
enum:
- auto
- type: string
enum:
- low
- type: string
enum:
- high
url:
type: string
required:
- url
additionalProperties: false
required:
- type
- image_url
additionalProperties: false
- type: object
properties:
type:
type: string
enum:
- input_audio
input_audio:
type: object
properties:
data:
type: string
format:
type: string
enum:
- wav
- mp3
required:
- data
- format
additionalProperties: false
required:
- type
- input_audio
additionalProperties: false
default: ''
name:
type: string
required:
- role
additionalProperties: false
- type: object
properties:
role:
type: string
enum:
- assistant
audio:
type: object
properties:
id:
type: string
required:
- id
additionalProperties: false
nullable: true
content:
anyOf:
- type: string
- type: array
items:
anyOf:
- type: object
properties:
type:
type: string
enum:
- text
text:
type: string
required:
- type
- text
additionalProperties: false
- type: object
properties:
type:
type: string
enum:
- refusal
refusal:
type: string
required:
- type
- refusal
additionalProperties: false
- enum:
- 'null'
nullable: true
default: null
function_call:
type: object
properties:
name:
type: string
default: ''
arguments:
type: string
default: ''
additionalProperties: false
nullable: true
tool_calls:
type: array
items:
type: object
properties:
id:
type: string
function:
type: object
properties:
name:
type: string
arguments:
type: string
required:
- name
- arguments
additionalProperties: false
type:
type: string
enum:
- function
required:
- id
- function
- type
additionalProperties: false
nullable: true
name:
type: string
refusal:
type: string
nullable: true
annotations:
type: array
items:
type: object
properties:
type:
type: string
enum:
- url_citation
url_citation:
type: object
properties:
start_index:
type: number
end_index:
type: number
title:
type: string
url:
type: string
required:
- start_index
- end_index
- title
- url
additionalProperties: false
required:
- type
- url_citation
additionalProperties: false
required:
- role
additionalProperties: false
- type: object
properties:
role:
type: string
enum:
- developer
content:
anyOf:
- type: string
- type: array
items:
type: object
properties:
type:
type: string
enum:
- text
text:
type: string
required:
- type
- text
additionalProperties: false
default: ''
name:
type: string
required:
- role
additionalProperties: false
- type: object
properties:
role:
type: string
enum:
- tool
content:
anyOf:
- type: string
- type: array
items:
type: object
properties:
type:
type: string
enum:
- text
text:
type: string
required:
- type
- text
additionalProperties: false
default: ''
tool_call_id:
type: string
required:
- role
- tool_call_id
additionalProperties: false
- type: object
properties:
role:
type: string
enum:
- function
name:
type: string
content:
anyOf:
- type: string
- enum:
- 'null'
nullable: true
required:
- role
- name
- content
additionalProperties: false
model:
type: string
audio:
type: object
properties:
format:
type: string
enum:
- wav
- mp3
- flac
- opus
- pcm16
voice:
type: string
enum:
- alloy
- ash
- ballad
- coral
- echo
- sage
- shimmer
- verse
required:
- format
- voice
additionalProperties: false
nullable: true
function_call:
anyOf:
- type: string
enum:
- none
- type: string
enum:
- auto
- type: object
properties:
name:
type: string
required:
- name
additionalProperties: false
functions:
type: array
items:
type: object
properties:
name:
type: string
parameters:
type: object
additionalProperties: {}
description:
type: string
strict:
type: boolean
nullable: true
required:
- name
additionalProperties: false
tool_choice:
anyOf:
- type: string
enum:
- none
- type: string
enum:
- auto
- type: string
enum:
- required
- type: object
properties:
type:
type: string
enum:
- function
default: function
function:
type: object
properties:
name:
type: string
required:
- name
additionalProperties: false
default:
name: ''
additionalProperties: false
tools:
type: array
items:
type: object
properties:
function:
type: object
properties:
name:
type: string
parameters:
type: object
additionalProperties: {}
description:
type: string
strict:
type: boolean
nullable: true
required:
- name
additionalProperties: false
type:
type: string
enum:
- function
required:
- function
- type
additionalProperties: false
'n':
type: number
max_tokens:
type: number
nullable: true
max_completion_tokens:
type: number
nullable: true
temperature:
type: number
top_p:
type: number
nullable: true
presence_penalty:
type: number
nullable: true
frequency_penalty:
type: number
nullable: true
stop:
anyOf:
- type: string
- type: array
items:
type: string
nullable: true
response_format:
anyOf:
- type: object
properties:
type:
type: string
enum:
- text
required:
- type
additionalProperties: false
- type: object
properties:
type:
type: string
enum:
- json_object
required:
- type
additionalProperties: false
- type: object
properties:
type:
type: string
enum:
- json_schema
json_schema:
type: object
properties:
name:
type: string
description:
type: string
schema:
type: object
additionalProperties: {}
strict:
type: boolean
nullable: true
required:
- name
additionalProperties: false
required:
- type
- json_schema
additionalProperties: false
logprobs:
type: boolean
top_logprobs:
type: number
nullable: true
stream_options:
type: object
properties:
include_usage:
type: boolean
required:
- include_usage
additionalProperties: false
store:
type: boolean
metadata:
type: object
additionalProperties:
type: string
nullable: true
stream:
type: boolean
default: false
required:
- messages
- model
additionalProperties: true
responses:
'200':
description: Successful response
content:
application/json:
schema:
anyOf:
- type: object
properties:
id:
type: string
object:
type: string
enum:
- chat.completion
created:
type: number
model:
type: string
choices:
type: array
items:
type: object
properties:
finish_reason:
anyOf:
- type: string
enum:
- length
- type: string
enum:
- function_call
- type: string
enum:
- tool_calls
- type: string
enum:
- stop
- type: string
enum:
- content_filter
index:
type: number
message:
type: object
properties:
reasoning_content:
type: string
nullable: true
content:
type: string
nullable: true
default: null
refusal:
type: string
nullable: true
role:
type: string
enum:
- assistant
function_call:
type: object
properties:
name:
type: string
default: ''
arguments:
type: string
default: ''
additionalProperties: false
nullable: true
tool_calls:
type: array
items:
type: object
properties:
id:
type: string
function:
type: object
properties:
name:
type: string
arguments:
type: string
required:
- name
- arguments
additionalProperties: false
type:
type: string
enum:
- function
required:
- id
- function
- type
additionalProperties: false
nullable: true
required:
- role
additionalProperties: false
logprobs:
type: object
properties:
content:
type: array
items:
type: object
properties:
token:
type: string
bytes:
type: array
items:
type: number
nullable: true
logprob:
type: number
top_logprobs:
type: array
items:
type: object
properties:
token:
type: string
bytes:
type: array
items:
type: number
nullable: true
logprob:
type: number
required:
- token
- bytes
- logprob
additionalProperties: false
required:
- token
- bytes
- logprob
- top_logprobs
additionalProperties: false
nullable: true
default: null
refusal:
type: array
items:
type: object
properties:
token:
type: string
bytes:
type: array
items:
type: number
nullable: true
logprob:
type: number
top_logprobs:
type: array
items:
type: object
properties:
token:
type: string
bytes:
type: array
items:
type: number
nullable: true
logprob:
type: number
required:
- token
- bytes
- logprob
additionalProperties: false
required:
- token
- bytes
- logprob
- top_logprobs
additionalProperties: false
nullable: true
default: null
additionalProperties: false
nullable: true
default: null
content_filter_results:
type: object
properties: {}
additionalProperties: true
criteria_results:
type: object
additionalProperties:
anyOf:
- type: object
properties:
status:
type: string
enum:
- success
score:
type: number
explanation:
type: string
errorCode:
type: number
errorMessage:
type: string
required:
- status
- score
additionalProperties: false
- type: object
properties:
status:
type: string
enum:
- error
score:
type: number
explanation:
type: string
errorCode:
type: number
errorMessage:
type: string
required:
- status
- errorCode
- errorMessage
additionalProperties: false
required:
- finish_reason
- index
- message
additionalProperties: false
usage:
type: object
properties:
prompt_tokens:
type: number
completion_tokens:
type: number
total_tokens:
type: number
prompt_cache_hit_tokens:
type: number
prompt_cache_miss_tokens:
type: number
completion_tokens_details:
type: object
properties:
reasoning_tokens:
type: number
nullable: true
audio_tokens:
type: number
nullable: true
text_tokens:
type: number
nullable: true
accepted_prediction_tokens:
type: number
nullable: true
rejected_prediction_tokens:
type: number
nullable: true
additionalProperties: false
nullable: true
prompt_tokens_details:
type: object
properties:
cached_tokens:
type: number
nullable: true
audio_tokens:
type: number
nullable: true
additionalProperties: false
nullable: true
criteria:
type: object
additionalProperties:
type: object
properties:
total_tokens:
type: number
description: >-
The total number of tokens used to generate
the criterion judgement. Only returned for
OpenPipe-trained reward models currently.
required:
- total_tokens
additionalProperties: false
required:
- prompt_tokens
- completion_tokens
- total_tokens
additionalProperties: false
required:
- id
- object
- created
- model
- choices
additionalProperties: false
nullable: true
- {}
default:
$ref: '#/components/responses/error'
security:
- Authorization: []
components:
responses:
error:
description: Error response
content:
application/json:
schema:
type: object
properties:
message:
type: string
code:
type: string
issues:
type: array
items:
type: object
properties:
message:
type: string
required:
- message
additionalProperties: false
required:
- message
- code
additionalProperties: false
securitySchemes:
Authorization:
type: http
scheme: bearer
````
---
# Source: https://docs.openpipe.ai/api-reference/post-createDataset.md
> ## Documentation Index
> Fetch the complete documentation index at: https://docs.openpipe.ai/llms.txt
> Use this file to discover all available pages before exploring further.
# Create Dataset
> Create a new dataset.
## OpenAPI
````yaml post /datasets
openapi: 3.0.3
info:
title: OpenPipe API
description: The public API for reporting API calls to OpenPipe
version: 0.1.1
servers:
- url: https://api.openpipe.ai/api/v1
security: []
paths:
/datasets:
post:
description: Create a new dataset.
operationId: createDataset
parameters: []
requestBody:
required: true
content:
application/json:
schema:
type: object
properties:
name:
type: string
required:
- name
additionalProperties: false
responses:
'200':
description: Successful response
content:
application/json:
schema:
type: object
properties:
object:
type: string
enum:
- dataset
id:
type: string
name:
type: string
created:
type: string
updated:
type: string
dataset_entry_count:
type: number
fine_tune_count:
type: number
required:
- object
- id
- name
- created
- updated
- dataset_entry_count
- fine_tune_count
additionalProperties: false
default:
$ref: '#/components/responses/error'
security:
- Authorization: []
components:
responses:
error:
description: Error response
content:
application/json:
schema:
type: object
properties:
message:
type: string
code:
type: string
issues:
type: array
items:
type: object
properties:
message:
type: string
required:
- message
additionalProperties: false
required:
- message
- code
additionalProperties: false
securitySchemes:
Authorization:
type: http
scheme: bearer
````
---
# Source: https://docs.openpipe.ai/api-reference/post-createDatasetEntries.md
> ## Documentation Index
> Fetch the complete documentation index at: https://docs.openpipe.ai/llms.txt
> Use this file to discover all available pages before exploring further.
# Add Entries to Dataset
> Add new dataset entries.
## OpenAPI
````yaml post /datasets/{datasetId}/entries
openapi: 3.0.3
info:
title: OpenPipe API
description: The public API for reporting API calls to OpenPipe
version: 0.1.1
servers:
- url: https://api.openpipe.ai/api/v1
security: []
paths:
/datasets/{datasetId}/entries:
post:
description: Add new dataset entries.
operationId: createDatasetEntries
parameters:
- name: datasetId
in: path
required: true
schema:
type: string
requestBody:
required: true
content:
application/json:
schema:
type: object
properties:
entries:
type: array
items:
type: object
properties:
messages:
type: array
items:
anyOf:
- type: object
properties:
role:
type: string
enum:
- system
content:
anyOf:
- type: string
- type: array
items:
type: object
properties:
type:
type: string
enum:
- text
text:
type: string
required:
- type
- text
additionalProperties: false
default: ''
name:
type: string
required:
- role
additionalProperties: false
- type: object
properties:
role:
type: string
enum:
- user
content:
anyOf:
- type: string
- type: array
items:
anyOf:
- type: object
properties:
type:
type: string
enum:
- text
text:
type: string
required:
- type
- text
additionalProperties: false
- type: object
properties:
type:
type: string
enum:
- image_url
image_url:
type: object
properties:
detail:
anyOf:
- type: string
enum:
- auto
- type: string
enum:
- low
- type: string
enum:
- high
url:
type: string
required:
- url
additionalProperties: false
required:
- type
- image_url
additionalProperties: false
- type: object
properties:
type:
type: string
enum:
- input_audio
input_audio:
type: object
properties:
data:
type: string
format:
type: string
enum:
- wav
- mp3
required:
- data
- format
additionalProperties: false
required:
- type
- input_audio
additionalProperties: false
default: ''
name:
type: string
required:
- role
additionalProperties: false
- type: object
properties:
role:
type: string
enum:
- assistant
audio:
type: object
properties:
id:
type: string
required:
- id
additionalProperties: false
nullable: true
content:
anyOf:
- type: string
- type: array
items:
anyOf:
- type: object
properties:
type:
type: string
enum:
- text
text:
type: string
required:
- type
- text
additionalProperties: false
- type: object
properties:
type:
type: string
enum:
- refusal
refusal:
type: string
required:
- type
- refusal
additionalProperties: false
- enum:
- 'null'
nullable: true
default: null
function_call:
type: object
properties:
name:
type: string
default: ''
arguments:
type: string
default: ''
additionalProperties: false
nullable: true
tool_calls:
type: array
items:
type: object
properties:
id:
type: string
function:
type: object
properties:
name:
type: string
arguments:
type: string
required:
- name
- arguments
additionalProperties: false
type:
type: string
enum:
- function
required:
- id
- function
- type
additionalProperties: false
nullable: true
name:
type: string
refusal:
type: string
nullable: true
annotations:
type: array
items:
type: object
properties:
type:
type: string
enum:
- url_citation
url_citation:
type: object
properties:
start_index:
type: number
end_index:
type: number
title:
type: string
url:
type: string
required:
- start_index
- end_index
- title
- url
additionalProperties: false
required:
- type
- url_citation
additionalProperties: false
required:
- role
additionalProperties: false
- type: object
properties:
role:
type: string
enum:
- developer
content:
anyOf:
- type: string
- type: array
items:
type: object
properties:
type:
type: string
enum:
- text
text:
type: string
required:
- type
- text
additionalProperties: false
default: ''
name:
type: string
required:
- role
additionalProperties: false
- type: object
properties:
role:
type: string
enum:
- tool
content:
anyOf:
- type: string
- type: array
items:
type: object
properties:
type:
type: string
enum:
- text
text:
type: string
required:
- type
- text
additionalProperties: false
default: ''
tool_call_id:
type: string
required:
- role
- tool_call_id
additionalProperties: false
- type: object
properties:
role:
type: string
enum:
- function
name:
type: string
content:
anyOf:
- type: string
- enum:
- 'null'
nullable: true
required:
- role
- name
- content
additionalProperties: false
rejected_message:
type: object
properties:
reasoning_content:
type: string
nullable: true
content:
type: string
nullable: true
default: null
refusal:
type: string
nullable: true
role:
type: string
enum:
- assistant
function_call:
type: object
properties:
name:
type: string
default: ''
arguments:
type: string
default: ''
additionalProperties: false
nullable: true
tool_calls:
type: array
items:
type: object
properties:
id:
type: string
function:
type: object
properties:
name:
type: string
arguments:
type: string
required:
- name
- arguments
additionalProperties: false
type:
type: string
enum:
- function
required:
- id
- function
- type
additionalProperties: false
nullable: true
required:
- role
additionalProperties: false
tool_choice:
anyOf:
- type: string
enum:
- none
- type: string
enum:
- auto
- type: string
enum:
- required
- type: object
properties:
type:
type: string
enum:
- function
default: function
function:
type: object
properties:
name:
type: string
required:
- name
additionalProperties: false
default:
name: ''
additionalProperties: false
tools:
type: array
items:
type: object
properties:
function:
type: object
properties:
name:
type: string
parameters:
type: object
additionalProperties: {}
description:
type: string
strict:
type: boolean
nullable: true
required:
- name
additionalProperties: false
type:
type: string
enum:
- function
required:
- function
- type
additionalProperties: false
response_format:
anyOf:
- type: object
properties:
type:
type: string
enum:
- text
required:
- type
additionalProperties: false
- type: object
properties:
type:
type: string
enum:
- json_object
required:
- type
additionalProperties: false
- type: object
properties:
type:
type: string
enum:
- json_schema
json_schema:
type: object
properties:
name:
type: string
description:
type: string
schema:
type: object
additionalProperties: {}
strict:
type: boolean
nullable: true
required:
- name
additionalProperties: false
required:
- type
- json_schema
additionalProperties: false
split:
type: string
enum:
- TRAIN
- TEST
metadata:
type: object
additionalProperties:
type: string
required:
- messages
additionalProperties: false
minItems: 1
maxItems: 100
required:
- entries
additionalProperties: false
responses:
'200':
description: Successful response
content:
application/json:
schema:
type: object
properties:
object:
type: string
enum:
- dataset.entries.creation
entries_created:
type: number
errors:
type: object
properties:
object:
type: string
enum:
- list
data:
type: array
items:
type: object
properties:
object:
type: string
enum:
- dataset.entries.creation.error
entry_index:
type: number
message:
type: string
required:
- object
- entry_index
- message
additionalProperties: false
required:
- object
- data
additionalProperties: false
required:
- object
- entries_created
- errors
additionalProperties: false
default:
$ref: '#/components/responses/error'
security:
- Authorization: []
components:
responses:
error:
description: Error response
content:
application/json:
schema:
type: object
properties:
message:
type: string
code:
type: string
issues:
type: array
items:
type: object
properties:
message:
type: string
required:
- message
additionalProperties: false
required:
- message
- code
additionalProperties: false
securitySchemes:
Authorization:
type: http
scheme: bearer
````
---
# Source: https://docs.openpipe.ai/api-reference/post-createModel.md
> ## Documentation Index
> Fetch the complete documentation index at: https://docs.openpipe.ai/llms.txt
> Use this file to discover all available pages before exploring further.
# Create Model
> Train a new model.
## OpenAPI
````yaml post /models
openapi: 3.0.3
info:
title: OpenPipe API
description: The public API for reporting API calls to OpenPipe
version: 0.1.1
servers:
- url: https://api.openpipe.ai/api/v1
security: []
paths:
/models:
post:
description: Train a new model.
operationId: createModel
parameters: []
requestBody:
required: true
content:
application/json:
schema:
type: object
properties:
datasetId:
type: string
slug:
type: string
pruningRuleIds:
type: array
items:
type: string
default: []
trainingConfig:
anyOf:
- type: object
properties:
provider:
type: string
enum:
- openpipe
baseModel:
type: string
description: >-
The base model to train from. This could be a base
model name or the slug of a previously trained
model. Supported base models include:
`meta-llama/Meta-Llama-3.1-8B-Instruct`,
`meta-llama/Meta-Llama-3.1-70B-Instruct`,
`meta-llama/Llama-3.3-70B-Instruct`,
`meta-llama/Llama-3.1-8B`,
`meta-llama/Llama-3.1-70B`,
`Qwen/Qwen2.5-72B-Instruct`,
`Qwen/Qwen2.5-Coder-7B-Instruct`,
`Qwen/Qwen2.5-Coder-32B-Instruct`,
`Qwen/Qwen2.5-1.5B-Instruct`,
`Qwen/Qwen2.5-7B-Instruct`,
`Qwen/Qwen2-VL-7B-Instruct`,
`Qwen/Qwen2.5-14B-Instruct`, `Qwen/Qwen3-8B`,
`Qwen/Qwen3-14B`,
`mistralai/Mistral-Nemo-Base-2407`,
`mistralai/Mistral-Small-24B-Base-2501`,
`meta-llama/Llama-3.2-1B-Instruct`,
`meta-llama/Llama-3.2-3B-Instruct`,
`google/gemma-3-1b-it`, `google/gemma-3-4b-it`,
`google/gemma-3-12b-it`, `google/gemma-3-27b-it`
enable_sft:
type: boolean
default: true
description: >-
Whether to enable SFT training. If true, the model
will be trained using SFT. Can be used in
conjunction with DPO training.
enable_preference_tuning:
type: boolean
description: >-
Whether to enable DPO training. If true, the model
will be trained using DPO. Can be used in
conjunction with SFT training.
default: false
sft_hyperparameters:
type: object
properties:
batch_size:
anyOf:
- type: string
enum:
- auto
- type: number
learning_rate_multiplier:
type: number
num_epochs:
type: number
additionalProperties: false
default: {}
description: >-
Hyperparameters for SFT training job. Ensure
`enable_sft` is true. If no SFT hyperparameters are
provided, default values will be used.
preference_hyperparameters:
type: object
properties:
variant:
anyOf:
- type: string
enum:
- DPO
- type: string
enum:
- APO Zero
learning_rate_multiplier:
type: number
num_epochs:
type: number
training_beta:
type: number
adapter_weight:
type: number
additionalProperties: false
default: {}
description: >-
Hyperparameters for DPO training job. Ensure
`enable_preference_tuning` is true. If no preference
hyperparameters are provided, default values will be
used.
hyperparameters:
type: object
properties:
is_sft_enabled:
type: boolean
default: true
batch_size:
anyOf:
- type: string
enum:
- auto
- type: number
learning_rate_multiplier:
type: number
num_epochs:
type: number
is_preference_tuning_enabled:
type: boolean
preference_tuning_variant:
anyOf:
- type: string
enum:
- DPO
- type: string
enum:
- APO Zero
preference_tuning_learning_rate_multiplier:
type: number
preference_tuning_num_epochs:
type: number
preference_tuning_training_beta:
type: number
preference_tuning_adapter_weight:
type: number
additionalProperties: false
description: >-
DEPRECATED: Use the `sft_hyperparameters` and
`preference_hyperparameters` fields instead.
required:
- provider
- baseModel
additionalProperties: false
- type: object
properties:
provider:
type: string
enum:
- openpipeReward
baseModel:
type: string
description: >-
The base model to train from. This could be a base
model name or the slug of a previously trained
model. Supported base models include:
`meta-llama/Llama-3.2-1B-Instruct`,
`meta-llama/Llama-3.2-3B-Instruct`,
`meta-llama/Meta-Llama-3.1-8B-Instruct`,
`Qwen/Qwen2.5-0.5B-Instruct`,
`Qwen/Qwen2.5-1.5B-Instruct`,
`Qwen/Qwen2.5-3B-Instruct`,
`Qwen/Qwen2.5-7B-Instruct`, `Qwen/Qwen3-8B`
hyperparameters:
type: object
properties:
batch_size:
anyOf:
- type: string
enum:
- auto
- type: number
learning_rate_multiplier:
type: number
num_epochs:
type: number
additionalProperties: false
default: {}
required:
- provider
- baseModel
additionalProperties: false
- type: object
properties:
provider:
type: string
enum:
- openai
baseModel:
type: string
enum:
- gpt-4.1-2025-04-14
- gpt-4.1-mini-2025-04-14
- gpt-4o-mini-2024-07-18
- gpt-4o-2024-08-06
- gpt-3.5-turbo-0125
enable_sft:
type: boolean
default: true
description: >-
Whether to enable SFT training. If true, the model
will be trained using SFT. Can be used in
conjunction with DPO training.
enable_preference_tuning:
type: boolean
description: >-
Whether to enable DPO training. If true, the model
will be trained using DPO. Can be used in
conjunction with SFT training.
default: false
sft_hyperparameters:
type: object
properties:
batch_size:
type: number
learning_rate_multiplier:
type: number
n_epochs:
type: number
additionalProperties: false
default: {}
description: >-
Hyperparameters for SFT training job. Ensure
`enable_sft` is true. If no SFT hyperparameters are
provided, default values will be used.
preference_hyperparameters:
type: object
properties:
beta:
type: number
batch_size:
type: number
learning_rate_multiplier:
type: number
n_epochs:
type: number
additionalProperties: false
default: {}
description: >-
Hyperparameters for DPO training job. Ensure
`enable_preference_tuning` is true. If no preference
hyperparameters are provided, default values will be
used.
hyperparameters:
type: object
properties:
is_sft_enabled:
type: boolean
default: true
batch_size:
type: number
learning_rate_multiplier:
type: number
n_epochs:
type: number
is_preference_tuning_enabled:
type: boolean
preference_tuning_beta:
type: number
preference_tuning_batch_size:
type: number
preference_tuning_learning_rate_multiplier:
type: number
preference_tuning_n_epochs:
type: number
additionalProperties: false
description: >-
DEPRECATED: Use the `sft_hyperparameters` and
`preference_hyperparameters` fields instead.
required:
- provider
- baseModel
additionalProperties: false
- type: object
properties:
provider:
type: string
enum:
- gemini
baseModel:
type: string
enum:
- models/gemini-1.0-pro-001
- models/gemini-1.5-flash-001-tuning
sft_hyperparameters:
type: object
properties:
epochs:
type: number
batch_size:
type: number
learning_rate:
type: number
learning_rate_multiplier:
type: number
additionalProperties: false
default: {}
description: >-
Hyperparameters for SFT training job. If no SFT
hyperparameters are provided, default values will be
used.
hyperparameters:
type: object
properties:
epochs:
type: number
batch_size:
type: number
learning_rate:
type: number
learning_rate_multiplier:
type: number
additionalProperties: false
description: >-
DEPRECATED: Use the `sft_hyperparameters` field
instead.
required:
- provider
- baseModel
additionalProperties: false
defaultTemperature:
type: number
required:
- datasetId
- slug
- trainingConfig
additionalProperties: false
responses:
'200':
description: Successful response
content:
application/json:
schema:
type: object
properties:
id:
type: string
name:
type: string
object:
type: string
enum:
- model
description:
type: string
nullable: true
created:
type: string
updated:
type: string
openpipe:
type: object
properties:
baseModel:
type: string
hyperparameters:
type: object
additionalProperties: {}
nullable: true
status:
type: string
enum:
- PENDING
- TRAINING
- DEPLOYED
- ERROR
- DEPRECATED
- PENDING_DEPRECATION
- QUEUED
- PROVISIONING
datasetId:
type: string
errorMessage:
type: string
nullable: true
required:
- baseModel
- hyperparameters
- status
- datasetId
- errorMessage
additionalProperties: false
contextWindow:
type: number
maxCompletionTokens:
type: number
capabilities:
type: array
items:
type: string
enum:
- chat
- tools
- json
pricing:
type: object
properties:
chatIn:
type: number
description: $/million tokens
chatOut:
type: number
description: $/million tokens
required:
- chatIn
- chatOut
additionalProperties: false
owned_by:
type: string
required:
- id
- name
- object
- description
- created
- updated
- openpipe
- contextWindow
- maxCompletionTokens
- capabilities
- pricing
- owned_by
additionalProperties: false
default:
$ref: '#/components/responses/error'
security:
- Authorization: []
components:
responses:
error:
description: Error response
content:
application/json:
schema:
type: object
properties:
message:
type: string
code:
type: string
issues:
type: array
items:
type: object
properties:
message:
type: string
required:
- message
additionalProperties: false
required:
- message
- code
additionalProperties: false
securitySchemes:
Authorization:
type: http
scheme: bearer
````
---
# Source: https://docs.openpipe.ai/api-reference/post-criteriajudge.md
> ## Documentation Index
> Fetch the complete documentation index at: https://docs.openpipe.ai/llms.txt
> Use this file to discover all available pages before exploring further.
# Judge Criteria
> Get a judgement of a completion against the specified criterion
## OpenAPI
````yaml post /criteria/judge
openapi: 3.0.3
info:
title: OpenPipe API
description: The public API for reporting API calls to OpenPipe
version: 0.1.1
servers:
- url: https://api.openpipe.ai/api/v1
security: []
paths:
/criteria/judge:
post:
description: Get a judgement of a completion against the specified criterion
operationId: getCriterionJudgement
parameters: []
requestBody:
required: true
content:
application/json:
schema:
type: object
properties:
criterion_id:
type: string
description: The ID of the criterion to judge.
input:
type: object
properties:
messages:
type: array
items:
anyOf:
- type: object
properties:
role:
type: string
enum:
- system
content:
anyOf:
- type: string
- type: array
items:
type: object
properties:
type:
type: string
enum:
- text
text:
type: string
required:
- type
- text
additionalProperties: false
default: ''
name:
type: string
required:
- role
additionalProperties: false
- type: object
properties:
role:
type: string
enum:
- user
content:
anyOf:
- type: string
- type: array
items:
anyOf:
- type: object
properties:
type:
type: string
enum:
- text
text:
type: string
required:
- type
- text
additionalProperties: false
- type: object
properties:
type:
type: string
enum:
- image_url
image_url:
type: object
properties:
detail:
anyOf:
- type: string
enum:
- auto
- type: string
enum:
- low
- type: string
enum:
- high
url:
type: string
required:
- url
additionalProperties: false
required:
- type
- image_url
additionalProperties: false
- type: object
properties:
type:
type: string
enum:
- input_audio
input_audio:
type: object
properties:
data:
type: string
format:
type: string
enum:
- wav
- mp3
required:
- data
- format
additionalProperties: false
required:
- type
- input_audio
additionalProperties: false
default: ''
name:
type: string
required:
- role
additionalProperties: false
- type: object
properties:
role:
type: string
enum:
- assistant
audio:
type: object
properties:
id:
type: string
required:
- id
additionalProperties: false
nullable: true
content:
anyOf:
- type: string
- type: array
items:
anyOf:
- type: object
properties:
type:
type: string
enum:
- text
text:
type: string
required:
- type
- text
additionalProperties: false
- type: object
properties:
type:
type: string
enum:
- refusal
refusal:
type: string
required:
- type
- refusal
additionalProperties: false
- enum:
- 'null'
nullable: true
default: null
function_call:
type: object
properties:
name:
type: string
default: ''
arguments:
type: string
default: ''
additionalProperties: false
nullable: true
tool_calls:
type: array
items:
type: object
properties:
id:
type: string
function:
type: object
properties:
name:
type: string
arguments:
type: string
required:
- name
- arguments
additionalProperties: false
type:
type: string
enum:
- function
required:
- id
- function
- type
additionalProperties: false
nullable: true
name:
type: string
refusal:
type: string
nullable: true
annotations:
type: array
items:
type: object
properties:
type:
type: string
enum:
- url_citation
url_citation:
type: object
properties:
start_index:
type: number
end_index:
type: number
title:
type: string
url:
type: string
required:
- start_index
- end_index
- title
- url
additionalProperties: false
required:
- type
- url_citation
additionalProperties: false
required:
- role
additionalProperties: false
- type: object
properties:
role:
type: string
enum:
- developer
content:
anyOf:
- type: string
- type: array
items:
type: object
properties:
type:
type: string
enum:
- text
text:
type: string
required:
- type
- text
additionalProperties: false
default: ''
name:
type: string
required:
- role
additionalProperties: false
- type: object
properties:
role:
type: string
enum:
- tool
content:
anyOf:
- type: string
- type: array
items:
type: object
properties:
type:
type: string
enum:
- text
text:
type: string
required:
- type
- text
additionalProperties: false
default: ''
tool_call_id:
type: string
required:
- role
- tool_call_id
additionalProperties: false
- type: object
properties:
role:
type: string
enum:
- function
name:
type: string
content:
anyOf:
- type: string
- enum:
- 'null'
nullable: true
required:
- role
- name
- content
additionalProperties: false
description: >-
All messages sent to the model when generating the
output.
tool_choice:
anyOf:
- type: string
enum:
- none
- type: string
enum:
- auto
- type: string
enum:
- required
- type: object
properties:
type:
type: string
enum:
- function
default: function
function:
type: object
properties:
name:
type: string
required:
- name
additionalProperties: false
default:
name: ''
additionalProperties: false
description: >-
The tool choice to use when generating the output, if
any.
tools:
type: array
items:
type: object
properties:
function:
type: object
properties:
name:
type: string
parameters:
type: object
additionalProperties: {}
description:
type: string
strict:
type: boolean
nullable: true
required:
- name
additionalProperties: false
type:
type: string
enum:
- function
required:
- function
- type
additionalProperties: false
description: >-
The tools available to the model when generating the
output, if any.
required:
- messages
additionalProperties: false
output:
type: object
properties:
reasoning_content:
type: string
nullable: true
content:
type: string
nullable: true
default: null
refusal:
type: string
nullable: true
role:
type: string
enum:
- assistant
function_call:
type: object
properties:
name:
type: string
default: ''
arguments:
type: string
default: ''
additionalProperties: false
nullable: true
tool_calls:
type: array
items:
type: object
properties:
id:
type: string
function:
type: object
properties:
name:
type: string
arguments:
type: string
required:
- name
- arguments
additionalProperties: false
type:
type: string
enum:
- function
required:
- id
- function
- type
additionalProperties: false
nullable: true
required:
- role
additionalProperties: false
description: The completion message of the model.
required:
- criterion_id
- output
additionalProperties: false
responses:
'200':
description: Successful response
content:
application/json:
schema:
type: object
properties:
score:
type: number
description: >-
A score of 0 means the output failed this completion, and
a score of 1 means it passed. A criteria may also return a
decimal scores between 0 and 1, indicating the model's
confidence or 'likelihood' that the criteria passed.
explanation:
type: string
description: >-
An explanation of the score including the model's
reasoning, if applicable.
usage:
type: object
properties:
total_tokens:
type: number
description: >-
The total number of tokens used to generate the
criterion judgement. Only returned for
OpenPipe-trained reward models currently.
required:
- total_tokens
additionalProperties: false
required:
- score
additionalProperties: false
default:
$ref: '#/components/responses/error'
security:
- Authorization: []
components:
responses:
error:
description: Error response
content:
application/json:
schema:
type: object
properties:
message:
type: string
code:
type: string
issues:
type: array
items:
type: object
properties:
message:
type: string
required:
- message
additionalProperties: false
required:
- message
- code
additionalProperties: false
securitySchemes:
Authorization:
type: http
scheme: bearer
````
---
# Source: https://docs.openpipe.ai/api-reference/post-report-anthropic.md
> ## Documentation Index
> Fetch the complete documentation index at: https://docs.openpipe.ai/llms.txt
> Use this file to discover all available pages before exploring further.
# Report Anthropic
> Record request logs from Anthropic models
## OpenAPI
````yaml post /report-anthropic
openapi: 3.0.3
info:
title: OpenPipe API
description: The public API for reporting API calls to OpenPipe
version: 0.1.1
servers:
- url: https://api.openpipe.ai/api/v1
security: []
paths:
/report-anthropic:
post:
description: Record request logs from Anthropic models
operationId: reportAnthropic
parameters: []
requestBody:
required: true
content:
application/json:
schema:
type: object
properties:
requestedAt:
type: number
description: Unix timestamp in milliseconds
receivedAt:
type: number
description: Unix timestamp in milliseconds
reqPayload:
anyOf:
- type: object
properties:
max_tokens:
type: number
messages:
type: array
items:
type: object
properties:
content:
anyOf:
- type: string
- type: array
items:
anyOf:
- type: object
properties:
text:
type: string
type:
type: string
enum:
- text
cache_control:
anyOf:
- type: object
properties:
type:
type: string
enum:
- ephemeral
required:
- type
additionalProperties: false
- enum:
- 'null'
nullable: true
citations:
type: array
items:
anyOf:
- type: object
properties:
cited_text:
type: string
document_index:
type: number
document_title:
type: string
nullable: true
end_char_index:
type: number
start_char_index:
type: number
type:
type: string
enum:
- char_location
required:
- cited_text
- document_index
- document_title
- end_char_index
- start_char_index
- type
additionalProperties: false
- type: object
properties:
cited_text:
type: string
document_index:
type: number
document_title:
type: string
nullable: true
end_page_number:
type: number
start_page_number:
type: number
type:
type: string
enum:
- page_location
required:
- cited_text
- document_index
- document_title
- end_page_number
- start_page_number
- type
additionalProperties: false
- type: object
properties:
cited_text:
type: string
document_index:
type: number
document_title:
type: string
nullable: true
end_block_index:
type: number
start_block_index:
type: number
type:
type: string
enum:
- content_block_location
required:
- cited_text
- document_index
- document_title
- end_block_index
- start_block_index
- type
additionalProperties: false
nullable: true
required:
- text
- type
additionalProperties: false
- type: object
properties:
source:
type: object
properties:
data:
type: string
media_type:
anyOf:
- type: string
enum:
- image/jpeg
- type: string
enum:
- image/png
- type: string
enum:
- image/gif
- type: string
enum:
- image/webp
type:
type: string
enum:
- base64
required:
- data
- media_type
- type
additionalProperties: false
type:
type: string
enum:
- image
cache_control:
anyOf:
- type: object
properties:
type:
type: string
enum:
- ephemeral
required:
- type
additionalProperties: false
- enum:
- 'null'
nullable: true
required:
- source
- type
additionalProperties: false
- type: object
properties:
id:
type: string
input: {}
name:
type: string
type:
type: string
enum:
- tool_use
cache_control:
anyOf:
- type: object
properties:
type:
type: string
enum:
- ephemeral
required:
- type
additionalProperties: false
- enum:
- 'null'
nullable: true
required:
- id
- name
- type
additionalProperties: false
- type: object
properties:
tool_use_id:
type: string
type:
type: string
enum:
- tool_result
content:
anyOf:
- type: string
- type: array
items:
anyOf:
- type: object
properties:
text:
type: string
type:
type: string
enum:
- text
cache_control:
anyOf:
- type: object
properties:
type:
type: string
enum:
- ephemeral
required:
- type
additionalProperties: false
- enum:
- 'null'
nullable: true
citations:
type: array
items:
anyOf:
- type: object
properties:
cited_text:
type: {}
document_index:
type: {}
document_title:
type: {}
nullable: {}
end_char_index:
type: {}
start_char_index:
type: {}
type:
type: {}
enum: {}
required:
- cited_text
- document_index
- document_title
- end_char_index
- start_char_index
- type
additionalProperties: false
- type: object
properties:
cited_text:
type: {}
document_index:
type: {}
document_title:
type: {}
nullable: {}
end_page_number:
type: {}
start_page_number:
type: {}
type:
type: {}
enum: {}
required:
- cited_text
- document_index
- document_title
- end_page_number
- start_page_number
- type
additionalProperties: false
- type: object
properties:
cited_text:
type: {}
document_index:
type: {}
document_title:
type: {}
nullable: {}
end_block_index:
type: {}
start_block_index:
type: {}
type:
type: {}
enum: {}
required:
- cited_text
- document_index
- document_title
- end_block_index
- start_block_index
- type
additionalProperties: false
nullable: true
required:
- text
- type
additionalProperties: false
- type: object
properties:
source:
type: object
properties:
data:
type: string
media_type:
anyOf:
- type: string
enum:
- image/jpeg
- type: string
enum:
- image/png
- type: string
enum:
- image/gif
- type: string
enum:
- image/webp
type:
type: string
enum:
- base64
required:
- data
- media_type
- type
additionalProperties: false
type:
type: string
enum:
- image
cache_control:
anyOf:
- type: object
properties:
type:
type: string
enum:
- ephemeral
required:
- type
additionalProperties: false
- enum:
- 'null'
nullable: true
required:
- source
- type
additionalProperties: false
is_error:
type: boolean
cache_control:
anyOf:
- type: object
properties:
type:
type: string
enum:
- ephemeral
required:
- type
additionalProperties: false
- enum:
- 'null'
nullable: true
required:
- tool_use_id
- type
additionalProperties: false
- type: object
properties:
source:
anyOf:
- type: object
properties:
data:
type: string
media_type:
type: string
enum:
- application/pdf
type:
type: string
enum:
- base64
required:
- data
- media_type
- type
additionalProperties: false
- type: object
properties:
data:
type: string
media_type:
type: string
enum:
- text/plain
type:
type: string
enum:
- text
required:
- data
- media_type
- type
additionalProperties: false
- type: object
properties:
content:
anyOf:
- type: string
- type: array
items:
anyOf:
- type: object
properties:
text:
type: string
type:
type: string
enum:
- text
cache_control:
anyOf:
- {}
- {}
citations:
type: array
items:
anyOf: {}
nullable: true
required:
- text
- type
additionalProperties: false
- type: object
properties:
source:
type: object
properties:
data: {}
media_type: {}
type: {}
required:
- data
- media_type
- type
additionalProperties: false
type:
type: string
enum:
- image
cache_control:
anyOf:
- {}
- {}
required:
- source
- type
additionalProperties: false
type:
type: string
enum:
- content
required:
- content
- type
additionalProperties: false
- type: object
properties:
type:
type: string
enum:
- url
url:
type: string
required:
- type
- url
additionalProperties: false
type:
type: string
enum:
- document
cache_control:
anyOf:
- type: object
properties:
type:
type: string
enum:
- ephemeral
required:
- type
additionalProperties: false
- enum:
- 'null'
nullable: true
citations:
type: object
properties:
enabled:
type: boolean
additionalProperties: false
context:
anyOf:
- type: string
- enum:
- 'null'
nullable: true
title:
anyOf:
- type: string
- enum:
- 'null'
nullable: true
required:
- source
- type
additionalProperties: false
- type: object
properties:
thinking:
type: string
signature:
type: string
type:
type: string
enum:
- thinking
required:
- thinking
- signature
- type
additionalProperties: false
- type: object
properties:
data:
type: string
type:
type: string
enum:
- redacted_thinking
required:
- data
- type
additionalProperties: false
role:
anyOf:
- type: string
enum:
- user
- type: string
enum:
- assistant
required:
- content
- role
additionalProperties: false
model:
type: string
metadata:
type: object
properties:
user_id:
anyOf:
- type: string
- enum:
- 'null'
nullable: true
additionalProperties: false
stop_sequences:
type: array
items:
type: string
stream:
type: boolean
enum:
- true
system:
anyOf:
- type: string
- type: array
items:
type: object
properties:
text:
type: string
type:
type: string
enum:
- text
cache_control:
anyOf:
- type: object
properties:
type:
type: string
enum:
- ephemeral
required:
- type
additionalProperties: false
- enum:
- 'null'
nullable: true
citations:
type: array
items:
anyOf:
- type: object
properties:
cited_text:
type: string
document_index:
type: number
document_title:
type: string
nullable: true
end_char_index:
type: number
start_char_index:
type: number
type:
type: string
enum:
- char_location
required:
- cited_text
- document_index
- document_title
- end_char_index
- start_char_index
- type
additionalProperties: false
- type: object
properties:
cited_text:
type: string
document_index:
type: number
document_title:
type: string
nullable: true
end_page_number:
type: number
start_page_number:
type: number
type:
type: string
enum:
- page_location
required:
- cited_text
- document_index
- document_title
- end_page_number
- start_page_number
- type
additionalProperties: false
- type: object
properties:
cited_text:
type: string
document_index:
type: number
document_title:
type: string
nullable: true
end_block_index:
type: number
start_block_index:
type: number
type:
type: string
enum:
- content_block_location
required:
- cited_text
- document_index
- document_title
- end_block_index
- start_block_index
- type
additionalProperties: false
nullable: true
required:
- text
- type
additionalProperties: false
temperature:
type: number
top_k:
type: number
top_p:
type: number
thinking:
anyOf:
- type: object
properties:
budget_tokens:
type: number
type:
type: string
enum:
- enabled
required:
- budget_tokens
- type
additionalProperties: false
- type: object
properties:
type:
type: string
enum:
- disabled
required:
- type
additionalProperties: false
tool_choice:
anyOf:
- type: object
properties:
type:
type: string
enum:
- auto
disable_parallel_tool_use:
type: boolean
required:
- type
additionalProperties: false
- type: object
properties:
type:
type: string
enum:
- any
disable_parallel_tool_use:
type: boolean
required:
- type
additionalProperties: false
- type: object
properties:
type:
type: string
enum:
- tool
name:
type: string
disable_parallel_tool_use:
type: boolean
required:
- type
- name
additionalProperties: false
- type: object
properties:
type:
type: string
enum:
- none
required:
- type
additionalProperties: false
tools:
type: array
items:
anyOf:
- type: object
properties:
name:
type: string
input_schema:
type: object
properties:
type:
type: string
enum:
- object
properties: {}
required:
- type
additionalProperties: true
description:
type: string
cache_control:
anyOf:
- type: object
properties:
type:
type: string
enum:
- ephemeral
required:
- type
additionalProperties: false
- enum:
- 'null'
nullable: true
required:
- name
- input_schema
additionalProperties: false
- type: object
properties:
name:
type: string
enum:
- bash
type:
type: string
enum:
- bash_20250124
cache_control:
anyOf:
- type: object
properties:
type:
type: string
enum:
- ephemeral
required:
- type
additionalProperties: false
- enum:
- 'null'
nullable: true
required:
- name
- type
additionalProperties: false
- type: object
properties:
name:
type: string
enum:
- str_replace_editor
type:
type: string
enum:
- text_editor_20250124
cache_control:
anyOf:
- type: object
properties:
type:
type: string
enum:
- ephemeral
required:
- type
additionalProperties: false
- enum:
- 'null'
nullable: true
required:
- name
- type
additionalProperties: false
required:
- max_tokens
- messages
- model
- stream
additionalProperties: true
- type: object
properties:
max_tokens:
type: number
messages:
type: array
items:
type: object
properties:
content:
anyOf:
- type: string
- type: array
items:
anyOf:
- type: object
properties:
text:
type: string
type:
type: string
enum:
- text
cache_control:
anyOf:
- type: object
properties:
type:
type: string
enum:
- ephemeral
required:
- type
additionalProperties: false
- enum:
- 'null'
nullable: true
citations:
type: array
items:
anyOf:
- type: object
properties:
cited_text:
type: string
document_index:
type: number
document_title:
type: string
nullable: true
end_char_index:
type: number
start_char_index:
type: number
type:
type: string
enum:
- char_location
required:
- cited_text
- document_index
- document_title
- end_char_index
- start_char_index
- type
additionalProperties: false
- type: object
properties:
cited_text:
type: string
document_index:
type: number
document_title:
type: string
nullable: true
end_page_number:
type: number
start_page_number:
type: number
type:
type: string
enum:
- page_location
required:
- cited_text
- document_index
- document_title
- end_page_number
- start_page_number
- type
additionalProperties: false
- type: object
properties:
cited_text:
type: string
document_index:
type: number
document_title:
type: string
nullable: true
end_block_index:
type: number
start_block_index:
type: number
type:
type: string
enum:
- content_block_location
required:
- cited_text
- document_index
- document_title
- end_block_index
- start_block_index
- type
additionalProperties: false
nullable: true
required:
- text
- type
additionalProperties: false
- type: object
properties:
source:
type: object
properties:
data:
type: string
media_type:
anyOf:
- type: string
enum:
- image/jpeg
- type: string
enum:
- image/png
- type: string
enum:
- image/gif
- type: string
enum:
- image/webp
type:
type: string
enum:
- base64
required:
- data
- media_type
- type
additionalProperties: false
type:
type: string
enum:
- image
cache_control:
anyOf:
- type: object
properties:
type:
type: string
enum:
- ephemeral
required:
- type
additionalProperties: false
- enum:
- 'null'
nullable: true
required:
- source
- type
additionalProperties: false
- type: object
properties:
id:
type: string
input: {}
name:
type: string
type:
type: string
enum:
- tool_use
cache_control:
anyOf:
- type: object
properties:
type:
type: string
enum:
- ephemeral
required:
- type
additionalProperties: false
- enum:
- 'null'
nullable: true
required:
- id
- name
- type
additionalProperties: false
- type: object
properties:
tool_use_id:
type: string
type:
type: string
enum:
- tool_result
content:
anyOf:
- type: string
- type: array
items:
anyOf:
- type: object
properties:
text:
type: string
type:
type: string
enum:
- text
cache_control:
anyOf:
- type: object
properties:
type:
type: string
enum:
- ephemeral
required:
- type
additionalProperties: false
- enum:
- 'null'
nullable: true
citations:
type: array
items:
anyOf:
- type: object
properties:
cited_text:
type: {}
document_index:
type: {}
document_title:
type: {}
nullable: {}
end_char_index:
type: {}
start_char_index:
type: {}
type:
type: {}
enum: {}
required:
- cited_text
- document_index
- document_title
- end_char_index
- start_char_index
- type
additionalProperties: false
- type: object
properties:
cited_text:
type: {}
document_index:
type: {}
document_title:
type: {}
nullable: {}
end_page_number:
type: {}
start_page_number:
type: {}
type:
type: {}
enum: {}
required:
- cited_text
- document_index
- document_title
- end_page_number
- start_page_number
- type
additionalProperties: false
- type: object
properties:
cited_text:
type: {}
document_index:
type: {}
document_title:
type: {}
nullable: {}
end_block_index:
type: {}
start_block_index:
type: {}
type:
type: {}
enum: {}
required:
- cited_text
- document_index
- document_title
- end_block_index
- start_block_index
- type
additionalProperties: false
nullable: true
required:
- text
- type
additionalProperties: false
- type: object
properties:
source:
type: object
properties:
data:
type: string
media_type:
anyOf:
- type: string
enum:
- image/jpeg
- type: string
enum:
- image/png
- type: string
enum:
- image/gif
- type: string
enum:
- image/webp
type:
type: string
enum:
- base64
required:
- data
- media_type
- type
additionalProperties: false
type:
type: string
enum:
- image
cache_control:
anyOf:
- type: object
properties:
type:
type: string
enum:
- ephemeral
required:
- type
additionalProperties: false
- enum:
- 'null'
nullable: true
required:
- source
- type
additionalProperties: false
is_error:
type: boolean
cache_control:
anyOf:
- type: object
properties:
type:
type: string
enum:
- ephemeral
required:
- type
additionalProperties: false
- enum:
- 'null'
nullable: true
required:
- tool_use_id
- type
additionalProperties: false
- type: object
properties:
source:
anyOf:
- type: object
properties:
data:
type: string
media_type:
type: string
enum:
- application/pdf
type:
type: string
enum:
- base64
required:
- data
- media_type
- type
additionalProperties: false
- type: object
properties:
data:
type: string
media_type:
type: string
enum:
- text/plain
type:
type: string
enum:
- text
required:
- data
- media_type
- type
additionalProperties: false
- type: object
properties:
content:
anyOf:
- type: string
- type: array
items:
anyOf:
- type: object
properties:
text:
type: string
type:
type: string
enum:
- text
cache_control:
anyOf:
- {}
- {}
citations:
type: array
items:
anyOf: {}
nullable: true
required:
- text
- type
additionalProperties: false
- type: object
properties:
source:
type: object
properties:
data: {}
media_type: {}
type: {}
required:
- data
- media_type
- type
additionalProperties: false
type:
type: string
enum:
- image
cache_control:
anyOf:
- {}
- {}
required:
- source
- type
additionalProperties: false
type:
type: string
enum:
- content
required:
- content
- type
additionalProperties: false
- type: object
properties:
type:
type: string
enum:
- url
url:
type: string
required:
- type
- url
additionalProperties: false
type:
type: string
enum:
- document
cache_control:
anyOf:
- type: object
properties:
type:
type: string
enum:
- ephemeral
required:
- type
additionalProperties: false
- enum:
- 'null'
nullable: true
citations:
type: object
properties:
enabled:
type: boolean
additionalProperties: false
context:
anyOf:
- type: string
- enum:
- 'null'
nullable: true
title:
anyOf:
- type: string
- enum:
- 'null'
nullable: true
required:
- source
- type
additionalProperties: false
- type: object
properties:
thinking:
type: string
signature:
type: string
type:
type: string
enum:
- thinking
required:
- thinking
- signature
- type
additionalProperties: false
- type: object
properties:
data:
type: string
type:
type: string
enum:
- redacted_thinking
required:
- data
- type
additionalProperties: false
role:
anyOf:
- type: string
enum:
- user
- type: string
enum:
- assistant
required:
- content
- role
additionalProperties: false
model:
type: string
metadata:
type: object
properties:
user_id:
anyOf:
- type: string
- enum:
- 'null'
nullable: true
additionalProperties: false
stop_sequences:
type: array
items:
type: string
stream:
type: boolean
enum:
- false
default: false
system:
anyOf:
- type: string
- type: array
items:
type: object
properties:
text:
type: string
type:
type: string
enum:
- text
cache_control:
anyOf:
- type: object
properties:
type:
type: string
enum:
- ephemeral
required:
- type
additionalProperties: false
- enum:
- 'null'
nullable: true
citations:
type: array
items:
anyOf:
- type: object
properties:
cited_text:
type: string
document_index:
type: number
document_title:
type: string
nullable: true
end_char_index:
type: number
start_char_index:
type: number
type:
type: string
enum:
- char_location
required:
- cited_text
- document_index
- document_title
- end_char_index
- start_char_index
- type
additionalProperties: false
- type: object
properties:
cited_text:
type: string
document_index:
type: number
document_title:
type: string
nullable: true
end_page_number:
type: number
start_page_number:
type: number
type:
type: string
enum:
- page_location
required:
- cited_text
- document_index
- document_title
- end_page_number
- start_page_number
- type
additionalProperties: false
- type: object
properties:
cited_text:
type: string
document_index:
type: number
document_title:
type: string
nullable: true
end_block_index:
type: number
start_block_index:
type: number
type:
type: string
enum:
- content_block_location
required:
- cited_text
- document_index
- document_title
- end_block_index
- start_block_index
- type
additionalProperties: false
nullable: true
required:
- text
- type
additionalProperties: false
temperature:
type: number
top_k:
type: number
top_p:
type: number
thinking:
anyOf:
- type: object
properties:
budget_tokens:
type: number
type:
type: string
enum:
- enabled
required:
- budget_tokens
- type
additionalProperties: false
- type: object
properties:
type:
type: string
enum:
- disabled
required:
- type
additionalProperties: false
tool_choice:
anyOf:
- type: object
properties:
type:
type: string
enum:
- auto
disable_parallel_tool_use:
type: boolean
required:
- type
additionalProperties: false
- type: object
properties:
type:
type: string
enum:
- any
disable_parallel_tool_use:
type: boolean
required:
- type
additionalProperties: false
- type: object
properties:
type:
type: string
enum:
- tool
name:
type: string
disable_parallel_tool_use:
type: boolean
required:
- type
- name
additionalProperties: false
- type: object
properties:
type:
type: string
enum:
- none
required:
- type
additionalProperties: false
tools:
type: array
items:
anyOf:
- type: object
properties:
name:
type: string
input_schema:
type: object
properties:
type:
type: string
enum:
- object
properties: {}
required:
- type
additionalProperties: true
description:
type: string
cache_control:
anyOf:
- type: object
properties:
type:
type: string
enum:
- ephemeral
required:
- type
additionalProperties: false
- enum:
- 'null'
nullable: true
required:
- name
- input_schema
additionalProperties: false
- type: object
properties:
name:
type: string
enum:
- bash
type:
type: string
enum:
- bash_20250124
cache_control:
anyOf:
- type: object
properties:
type:
type: string
enum:
- ephemeral
required:
- type
additionalProperties: false
- enum:
- 'null'
nullable: true
required:
- name
- type
additionalProperties: false
- type: object
properties:
name:
type: string
enum:
- str_replace_editor
type:
type: string
enum:
- text_editor_20250124
cache_control:
anyOf:
- type: object
properties:
type:
type: string
enum:
- ephemeral
required:
- type
additionalProperties: false
- enum:
- 'null'
nullable: true
required:
- name
- type
additionalProperties: false
required:
- max_tokens
- messages
- model
additionalProperties: true
description: JSON-encoded request payload
respPayload:
type: object
properties:
id:
type: string
content:
type: array
items:
anyOf:
- type: object
properties:
text:
type: string
type:
type: string
enum:
- text
citations:
type: array
items:
anyOf:
- type: object
properties:
cited_text:
type: string
document_index:
type: number
document_title:
type: string
nullable: true
end_char_index:
type: number
start_char_index:
type: number
type:
type: string
enum:
- char_location
required:
- cited_text
- document_index
- document_title
- end_char_index
- start_char_index
- type
additionalProperties: false
- type: object
properties:
cited_text:
type: string
document_index:
type: number
document_title:
type: string
nullable: true
end_page_number:
type: number
start_page_number:
type: number
type:
type: string
enum:
- page_location
required:
- cited_text
- document_index
- document_title
- end_page_number
- start_page_number
- type
additionalProperties: false
- type: object
properties:
cited_text:
type: string
document_index:
type: number
document_title:
type: string
nullable: true
end_block_index:
type: number
start_block_index:
type: number
type:
type: string
enum:
- content_block_location
required:
- cited_text
- document_index
- document_title
- end_block_index
- start_block_index
- type
additionalProperties: false
nullable: true
default: null
required:
- text
- type
additionalProperties: false
- type: object
properties:
id:
type: string
name:
type: string
type:
type: string
enum:
- tool_use
input: {}
required:
- id
- name
- type
additionalProperties: false
- type: object
properties:
thinking:
type: string
signature:
type: string
type:
type: string
enum:
- thinking
required:
- thinking
- signature
- type
additionalProperties: false
- type: object
properties:
data:
type: string
type:
type: string
enum:
- redacted_thinking
required:
- data
- type
additionalProperties: false
model:
type: string
role:
type: string
enum:
- assistant
stop_reason:
anyOf:
- type: string
enum:
- end_turn
- type: string
enum:
- max_tokens
- type: string
enum:
- stop_sequence
- type: string
enum:
- tool_use
- enum:
- 'null'
nullable: true
stop_sequence:
anyOf:
- type: string
- enum:
- 'null'
nullable: true
type:
type: string
enum:
- message
usage:
type: object
properties:
input_tokens:
type: number
output_tokens:
type: number
cache_creation_input_tokens:
type: number
nullable: true
cache_read_input_tokens:
type: number
nullable: true
required:
- input_tokens
- output_tokens
- cache_creation_input_tokens
- cache_read_input_tokens
additionalProperties: false
required:
- id
- content
- model
- role
- stop_reason
- stop_sequence
- type
- usage
additionalProperties: false
description: JSON-encoded response payload
statusCode:
type: number
description: HTTP status code of response
errorMessage:
type: string
description: User-friendly error message
metadata:
type: object
additionalProperties:
type: string
description: >-
Extra metadata tags to attach to the call for filtering. Eg
{ "userId": "123", "prompt_id": "populate-title" }
default: {}
tags:
type: object
additionalProperties:
anyOf:
- type: string
- type: number
- type: boolean
- enum:
- 'null'
nullable: true
description: 'Deprecated: use "metadata" instead'
default: {}
additionalProperties: false
responses:
'200':
description: Successful response
content:
application/json:
schema:
type: object
properties:
status:
anyOf:
- type: string
enum:
- ok
- type: string
enum:
- error
required:
- status
additionalProperties: false
default:
$ref: '#/components/responses/error'
security:
- Authorization: []
components:
responses:
error:
description: Error response
content:
application/json:
schema:
type: object
properties:
message:
type: string
code:
type: string
issues:
type: array
items:
type: object
properties:
message:
type: string
required:
- message
additionalProperties: false
required:
- message
- code
additionalProperties: false
securitySchemes:
Authorization:
type: http
scheme: bearer
````
---
# Source: https://docs.openpipe.ai/api-reference/post-report.md
> ## Documentation Index
> Fetch the complete documentation index at: https://docs.openpipe.ai/llms.txt
> Use this file to discover all available pages before exploring further.
# Report
> Record request logs from OpenAI models
## OpenAPI
````yaml post /report
openapi: 3.0.3
info:
title: OpenPipe API
description: The public API for reporting API calls to OpenPipe
version: 0.1.1
servers:
- url: https://api.openpipe.ai/api/v1
security: []
paths:
/report:
post:
description: Record request logs from OpenAI models
operationId: report
parameters: []
requestBody:
required: true
content:
application/json:
schema:
type: object
properties:
requestedAt:
type: number
description: Unix timestamp in milliseconds
receivedAt:
type: number
description: Unix timestamp in milliseconds
reqPayload:
description: JSON-encoded request payload
respPayload:
description: JSON-encoded response payload
statusCode:
type: number
description: HTTP status code of response
errorMessage:
type: string
description: User-friendly error message
tags:
type: object
additionalProperties:
anyOf:
- type: string
- type: number
- type: boolean
- enum:
- 'null'
nullable: true
description: >-
DEPRECATED: use "reqPayload.metadata" to attach extra
metadata tags to the call for filtering. Eg { "userId":
"123", "prompt_id": "populate-title" }
default: {}
additionalProperties: false
responses:
'200':
description: Successful response
content:
application/json:
schema:
type: object
properties:
status:
anyOf:
- type: string
enum:
- ok
- type: string
enum:
- error
required:
- status
additionalProperties: false
default:
$ref: '#/components/responses/error'
security:
- Authorization: []
components:
responses:
error:
description: Error response
content:
application/json:
schema:
type: object
properties:
message:
type: string
code:
type: string
issues:
type: array
items:
type: object
properties:
message:
type: string
required:
- message
additionalProperties: false
required:
- message
- code
additionalProperties: false
securitySchemes:
Authorization:
type: http
scheme: bearer
````
---
# Source: https://docs.openpipe.ai/api-reference/post-updatemetadata.md
> ## Documentation Index
> Fetch the complete documentation index at: https://docs.openpipe.ai/llms.txt
> Use this file to discover all available pages before exploring further.
# Update Metadata
> Update tags metadata for logged calls matching the provided filters.
## OpenAPI
````yaml post /logs/update-metadata
openapi: 3.0.3
info:
title: OpenPipe API
description: The public API for reporting API calls to OpenPipe
version: 0.1.1
servers:
- url: https://api.openpipe.ai/api/v1
security: []
paths:
/logs/update-metadata:
post:
description: Update tags metadata for logged calls matching the provided filters.
operationId: updateLogMetadata
parameters: []
requestBody:
required: true
content:
application/json:
schema:
type: object
properties:
filters:
type: array
items:
type: object
properties:
field:
type: string
description: >-
The field to filter on. Possible fields include:
`model`, `completionId`, and `metadata.your_tag_name`.
equals:
anyOf:
- type: string
- type: number
- type: boolean
required:
- field
- equals
additionalProperties: false
metadata:
type: object
additionalProperties:
anyOf:
- type: string
- enum:
- 'null'
nullable: true
description: >-
Extra metadata to attach to the call for filtering. Eg {
"userId": "123", "prompt_id": "populate-title" }
required:
- filters
- metadata
additionalProperties: false
responses:
'200':
description: Successful response
content:
application/json:
schema:
type: object
properties:
matchedLogs:
type: number
required:
- matchedLogs
additionalProperties: false
default:
$ref: '#/components/responses/error'
security:
- Authorization: []
components:
responses:
error:
description: Error response
content:
application/json:
schema:
type: object
properties:
message:
type: string
code:
type: string
issues:
type: array
items:
type: object
properties:
message:
type: string
required:
- message
additionalProperties: false
required:
- message
- code
additionalProperties: false
securitySchemes:
Authorization:
type: http
scheme: bearer
````
---
# Source: https://docs.openpipe.ai/pricing/pricing.md
> ## Documentation Index
> Fetch the complete documentation index at: https://docs.openpipe.ai/llms.txt
> Use this file to discover all available pages before exploring further.
# Pricing Overview
## Training
We charge for training based on the size of the model and the number of tokens in the dataset.
| Model Category | Cost per 1M tokens |
| ------------------ | ------------------ |
| **8B and smaller** | \$0.48 |
| **14B models** | \$1.50 |
| **32B models** | \$1.90 |
| **70B+ models** | \$2.90 |
## Hosted Inference
Choose between two billing models for running models on our infrastructure:
### 1. Per-Token Pricing
Available for our most popular, high-volume models. You only pay for the tokens you process, with no minimum commitment and automatic infrastructure scaling.
| Model | Input (per 1M tokens) | Output (per 1M tokens) |
| -------------------------- | --------------------- | ---------------------- |
| **Llama 3.1 8B Instruct** | \$0.30 | \$0.45 |
| **Qwen 2.5 14B Instruct** | \$1.00 | \$1.50 |
| **Llama 3.1 70B Instruct** | \$1.80 | \$2.00 |
### 2. Hourly Compute Units
Designed for experimental and lower-volume models. A Compute Unit (CU) can handle up to 24 simultaneous requests per second. Billing is precise down to the second, with automatic scaling when traffic exceeds capacity. Compute units remain active for 60 seconds after traffic spikes.
| Model | Rate per CU Hour |
| ---------------------- | ---------------- |
| **Llama 3.1 8B** | \$1.50 |
| **Mistral Nemo 12B** | \$1.50 |
| **Qwen 2.5 32B Coder** | \$6.00 |
| **Qwen 2.5 72B** | \$12.00 |
| **Llama 3.1 70B** | \$12.00 |
## Third-Party Models (OpenAI, Gemini, etc.)
Third-party models fine-tuned through OpenPipe like OpenAI's GPT series or Google's Gemini, we provide direct API integration without any additional markup. You will be billed directly by the respective provider (OpenAI, Google, etc.) at their standard rates. We simply pass through the API calls and responses.
## Enterprise Plans
For organizations requiring custom solutions, we offer enterprise plans that include:
* Volume discounts
* On-premises deployment options
* Dedicated support
* Custom SLAs
* Advanced security features
* Increased data storage
Contact our team at [hello@openpipe.ai](mailto:hello@openpipe.ai) to discuss enterprise pricing and requirements.
---
# Source: https://docs.openpipe.ai/features/pruning-rules.md
> ## Documentation Index
> Fetch the complete documentation index at: https://docs.openpipe.ai/llms.txt
> Use this file to discover all available pages before exploring further.
# Pruning Rules
> Decrease input token counts by pruning out chunks of static text.
Some prompts have large chunks of unchanging text, like system messages which don't change from one request to the next. By removing this static text and fine-tuning a model on the compacted data, we can reduce the size of incoming requests and save you money on inference.
Add pruning rules to your dataset in the Settings tab, as shown below and in our [demo dataset](https://app.openpipe.ai/p/BRZFEx50Pf/datasets/0aa75f72-3fe5-4294-a94e-94c9236befa6/settings).
 To see the effect your pruning rules had on an individual training entry's input messages, open the Dataset Entry drawer:
To see the effect your pruning rules had on an individual training entry's input messages, open the Dataset Entry drawer:
 By default, fine-tuned models inherit pruning rules applied to the dataset on which they were trained (see [demo model](https://app.openpipe.ai/p/BRZFEx50Pf/fine-tunes/5a2af605-03d3-412c-a7d3-611bdf6e1dcf/general)). These rules will automatically prune matching text from any incoming requests sent to that model. New pruning rules will not be associated with previously trained models, so you don't need to worry about backwards compatibility when adding new rules to your dataset. Before training a new model, you can choose to disable any inherited pruning rules.
By default, fine-tuned models inherit pruning rules applied to the dataset on which they were trained (see [demo model](https://app.openpipe.ai/p/BRZFEx50Pf/fine-tunes/5a2af605-03d3-412c-a7d3-611bdf6e1dcf/general)). These rules will automatically prune matching text from any incoming requests sent to that model. New pruning rules will not be associated with previously trained models, so you don't need to worry about backwards compatibility when adding new rules to your dataset. Before training a new model, you can choose to disable any inherited pruning rules.
 ## Warning: can affect quality!
We’ve found that while pruning rules always decrease latency and costs, they can also negatively affect response quality, especially with smaller datasets. We recommend enabling pruning rules on datasets with 10K+ training examples, as smaller datasets may not provide enough guidance for the model to fully learn the task.
---
# Source: https://docs.openpipe.ai/getting-started/quick-start.md
# Source: https://docs.openpipe.ai/features/fine-tuning/quick-start.md
# Source: https://docs.openpipe.ai/features/evaluations/quick-start.md
# Source: https://docs.openpipe.ai/features/dpo/quick-start.md
# Source: https://docs.openpipe.ai/features/datasets/quick-start.md
# Source: https://docs.openpipe.ai/features/criteria/quick-start.md
> ## Documentation Index
> Fetch the complete documentation index at: https://docs.openpipe.ai/llms.txt
> Use this file to discover all available pages before exploring further.
# Criteria Quick Start
> Create and align your first criterion.
Criteria are a reliable way to detect and correct mistakes in LLM output. Criteria can be used when defining LLM evaluations, improving data quality, and for [runtime evaluation](/features/criteria/api#runtime-evaluation) when generating **best of N** samples.
This tutorial will walk you through creating and aligning your first criterion.
## Warning: can affect quality!
We’ve found that while pruning rules always decrease latency and costs, they can also negatively affect response quality, especially with smaller datasets. We recommend enabling pruning rules on datasets with 10K+ training examples, as smaller datasets may not provide enough guidance for the model to fully learn the task.
---
# Source: https://docs.openpipe.ai/getting-started/quick-start.md
# Source: https://docs.openpipe.ai/features/fine-tuning/quick-start.md
# Source: https://docs.openpipe.ai/features/evaluations/quick-start.md
# Source: https://docs.openpipe.ai/features/dpo/quick-start.md
# Source: https://docs.openpipe.ai/features/datasets/quick-start.md
# Source: https://docs.openpipe.ai/features/criteria/quick-start.md
> ## Documentation Index
> Fetch the complete documentation index at: https://docs.openpipe.ai/llms.txt
> Use this file to discover all available pages before exploring further.
# Criteria Quick Start
> Create and align your first criterion.
Criteria are a reliable way to detect and correct mistakes in LLM output. Criteria can be used when defining LLM evaluations, improving data quality, and for [runtime evaluation](/features/criteria/api#runtime-evaluation) when generating **best of N** samples.
This tutorial will walk you through creating and aligning your first criterion.
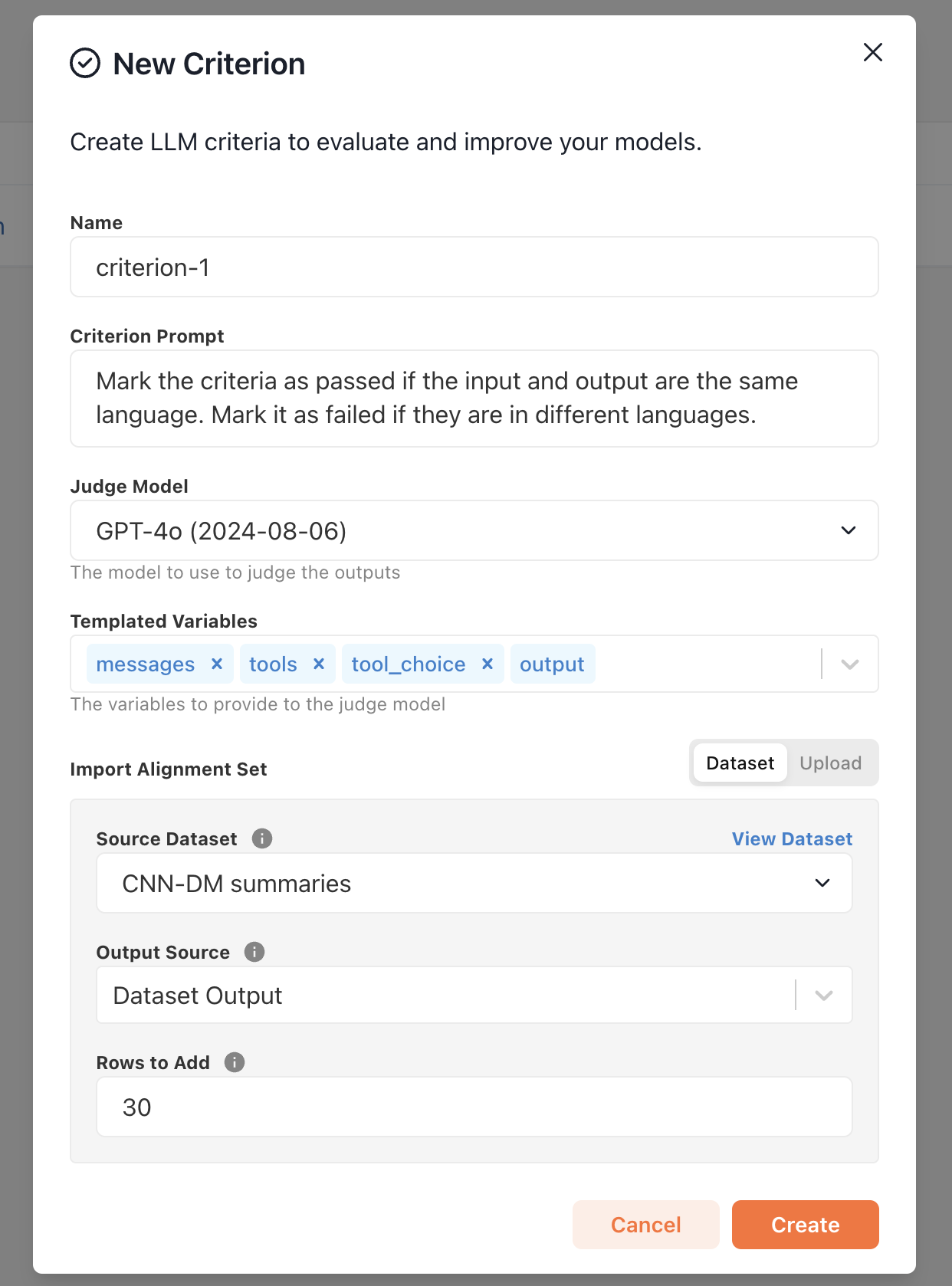 By default, each of the following fields will be templated into the criterion's prompt when assigning a judgement to an output:
* `messages` *(optional):* The messages used to generate the output
* `tools` *(optional):* The tools used to generate the output
* `tool_choice` *(optional):* The tool choice used to generate the output
* `output` *(required):* The chat completion object to be judged
Many criteria do not require all of the input fields, and some may judge based soley on the `output`. You can exclude fields by removing them from the **Templated Variables** section.
By default, each of the following fields will be templated into the criterion's prompt when assigning a judgement to an output:
* `messages` *(optional):* The messages used to generate the output
* `tools` *(optional):* The tools used to generate the output
* `tool_choice` *(optional):* The tool choice used to generate the output
* `output` *(required):* The chat completion object to be judged
Many criteria do not require all of the input fields, and some may judge based soley on the `output`. You can exclude fields by removing them from the **Templated Variables** section.
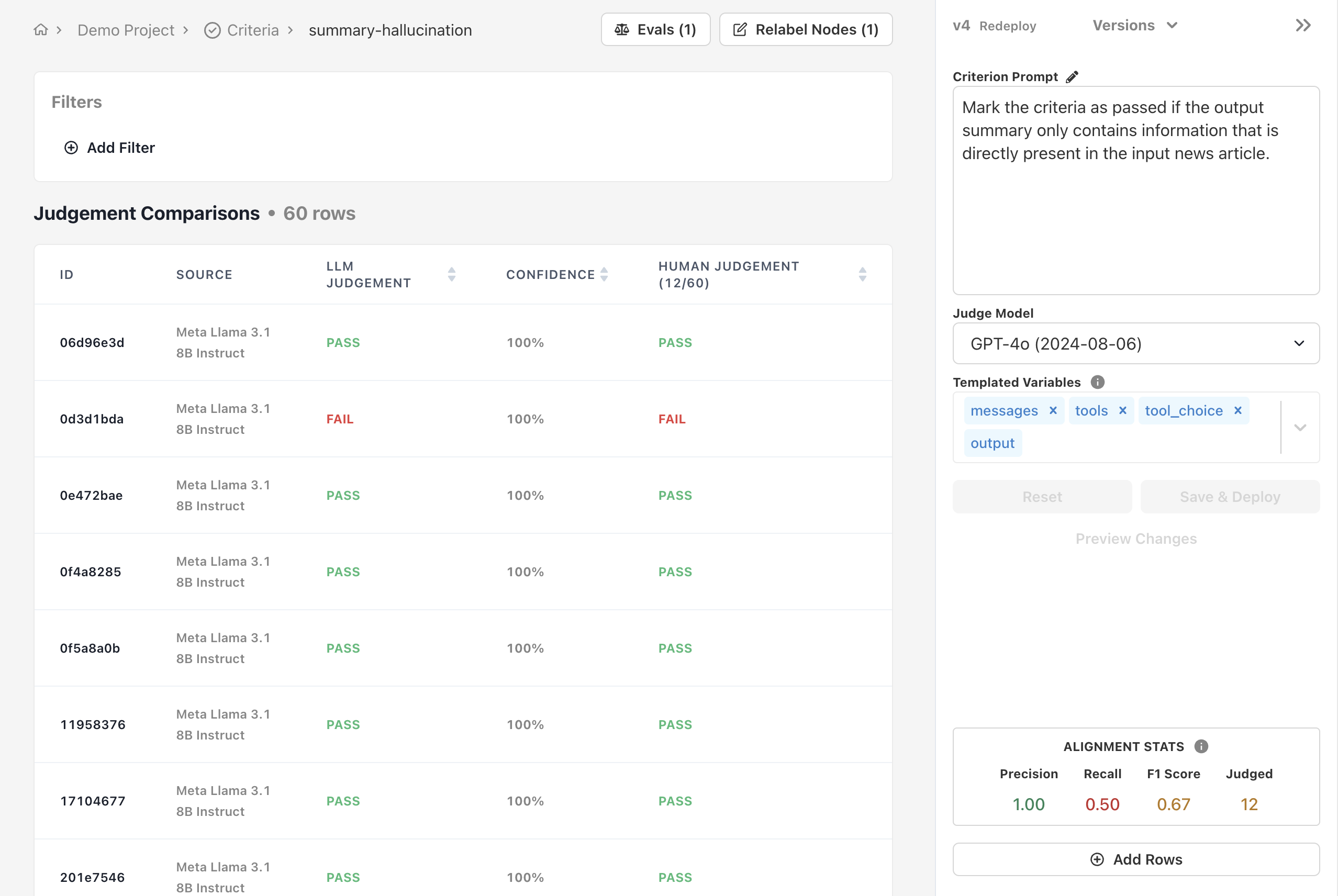
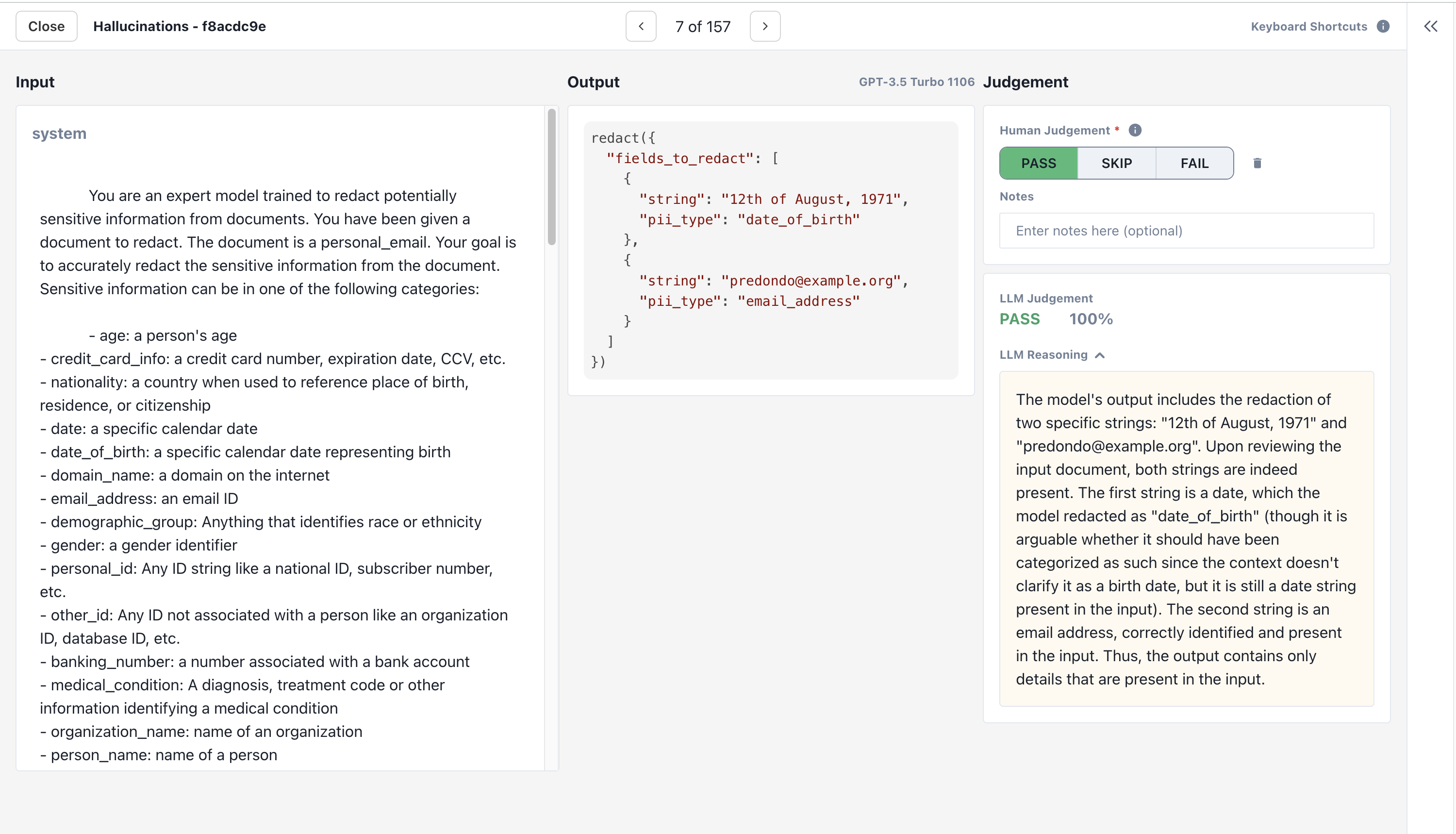 Try to label at least 30 rows to provide a reliable estimate of the LLM's precision and recall.
Try to label at least 30 rows to provide a reliable estimate of the LLM's precision and recall.
 Investing time in a good prompt and selecting the best judge model pays dividends.
High-quality LLM judgements help you quickly identify rows that fail the criterion, speeding up the process of manually labeling rows.
Investing time in a good prompt and selecting the best judge model pays dividends.
High-quality LLM judgements help you quickly identify rows that fail the criterion, speeding up the process of manually labeling rows.
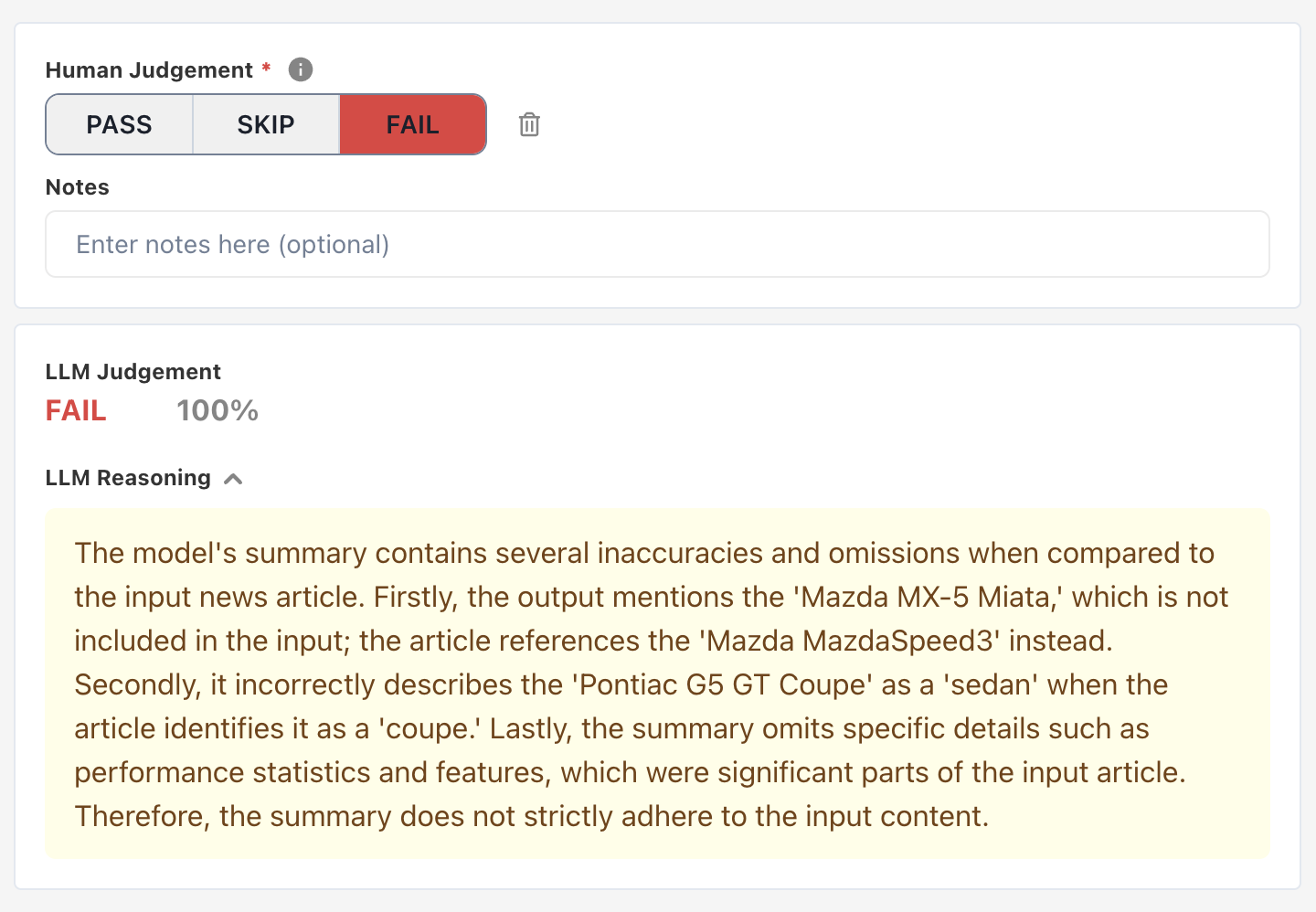 As you improve your criterion prompt, you'll notice your [alignment stats](/features/criteria/alignment-set#alignment-stats) improving.
Once you've labeled at least 30 rows and are satisfied with the precision and recall of your LLM judge, the criterion is ready to be deployed!
As you improve your criterion prompt, you'll notice your [alignment stats](/features/criteria/alignment-set#alignment-stats) improving.
Once you've labeled at least 30 rows and are satisfied with the precision and recall of your LLM judge, the criterion is ready to be deployed!
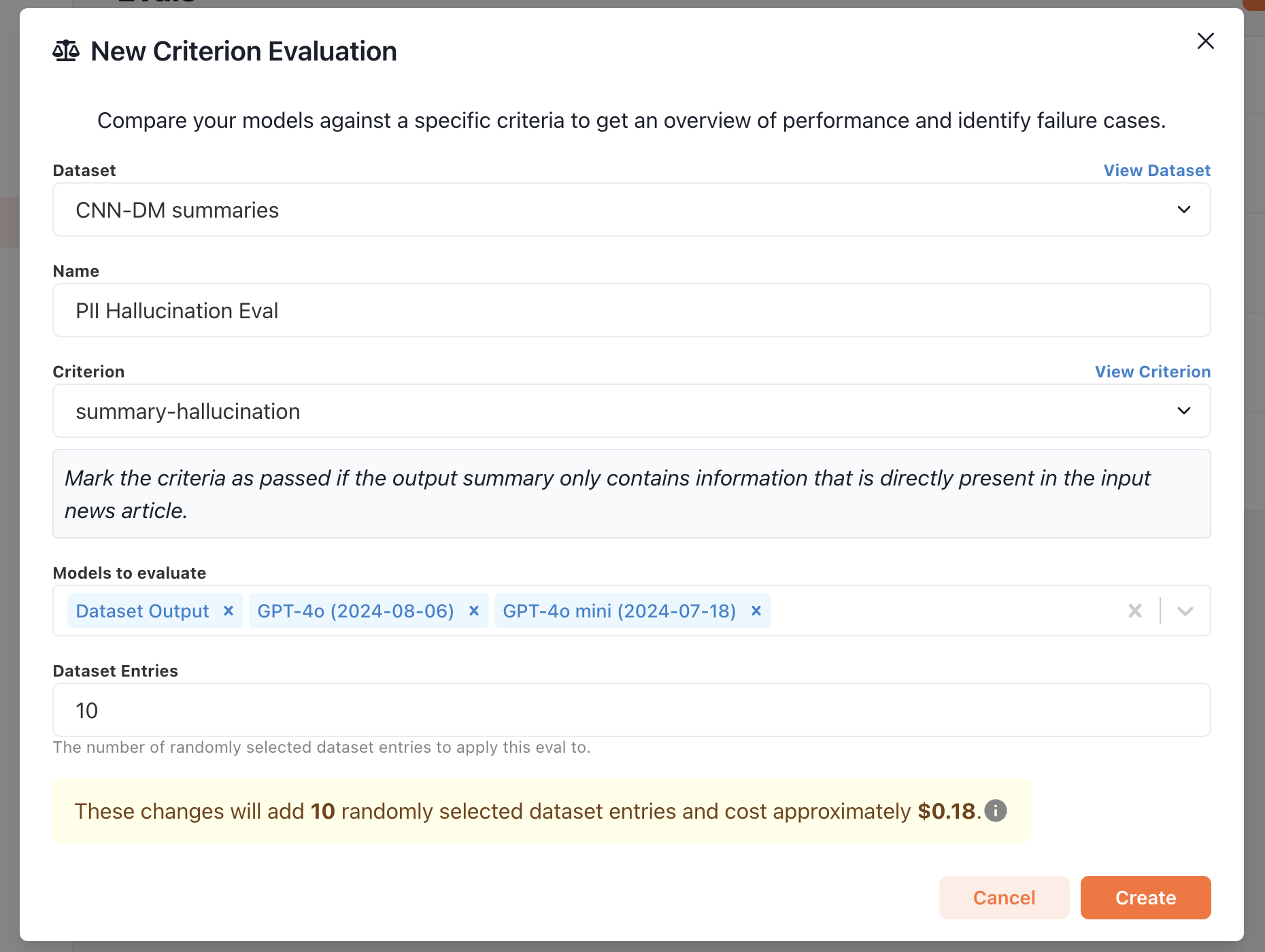 Finally, click **Create** to run the evaluation. Just like that, you're be able to view evaluation results based on aligned LLM judgements!
Finally, click **Create** to run the evaluation. Just like that, you're be able to view evaluation results based on aligned LLM judgements!
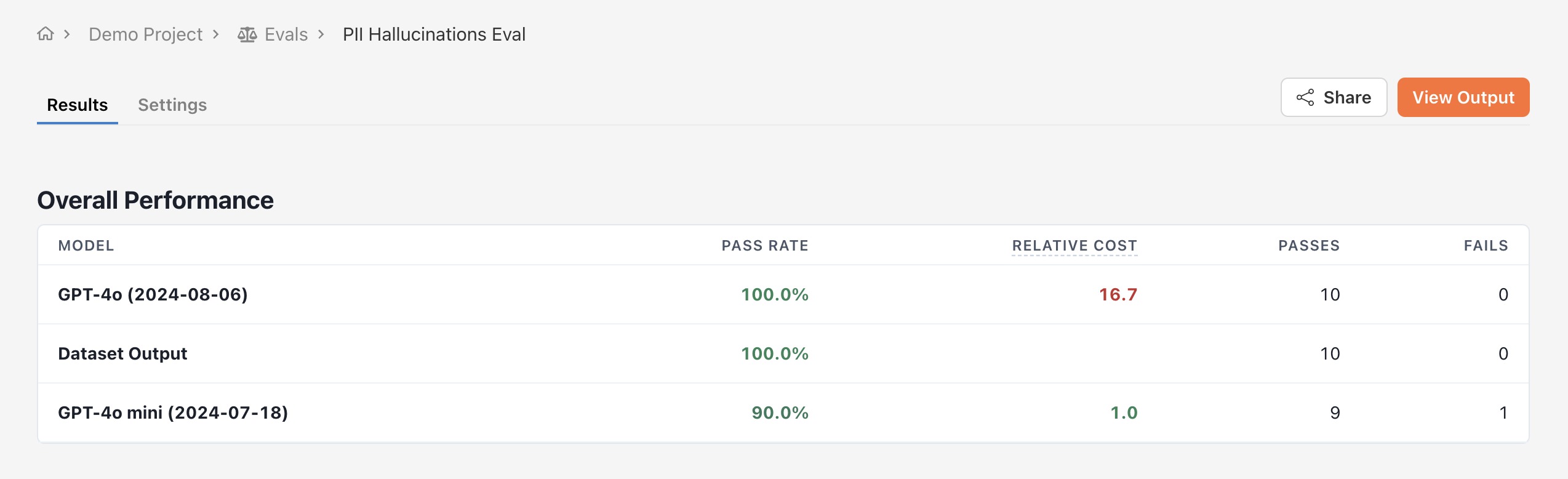 ---
# Source: https://docs.openpipe.ai/features/datasets/relabeling-data.md
> ## Documentation Index
> Fetch the complete documentation index at: https://docs.openpipe.ai/llms.txt
> Use this file to discover all available pages before exploring further.
# Relabeling Data
> Use powerful models to generate new outputs for your data before training.
After importing rows from request logs or uploading a JSONL file, you can optionally relabel
each row by sending its messages, tools, and other input parameters to a more powerful model,
which will generate an output to replace your row's existing output. If time or cost constraints prevent
you from using the most powerful model available in production, relabeling offers an opportunity to
optimize the quality of your training data before kicking off a job.
---
# Source: https://docs.openpipe.ai/features/datasets/relabeling-data.md
> ## Documentation Index
> Fetch the complete documentation index at: https://docs.openpipe.ai/llms.txt
> Use this file to discover all available pages before exploring further.
# Relabeling Data
> Use powerful models to generate new outputs for your data before training.
After importing rows from request logs or uploading a JSONL file, you can optionally relabel
each row by sending its messages, tools, and other input parameters to a more powerful model,
which will generate an output to replace your row's existing output. If time or cost constraints prevent
you from using the most powerful model available in production, relabeling offers an opportunity to
optimize the quality of your training data before kicking off a job.
 We provide a number of built-in relabeling options.
Anthropic:
* `claude-3-opus-20240229`
* `claude-sonnet-3-7-20250219`
* `claude-sonnet-3-5-20241022`
OpenAI:
* `gpt-4-5-preview-02-27`
* `o1-2024-12-17`
* `o3-mini-2025-01-31`
* `gpt-4o-2024-08-06`
* `gpt-4o-2024-11-20`
* `gpt-4-turbo-2024-04-09`
* `gpt-4-0125-preview`
* `gpt-4-1106-preview`
* `gpt-4-0613`
Gemini:
* `gemini-2-0-flash`
* `gemini-2-0-pro-exp-02-05`
Meta:
* `meta-llama-3-1-405b-instruct`
DeepSeek:
* `deepseek-v3`
* `deepseek-r1`
---
# Source: https://docs.openpipe.ai/features/request-logs/reporting-anthropic.md
> ## Documentation Index
> Fetch the complete documentation index at: https://docs.openpipe.ai/llms.txt
> Use this file to discover all available pages before exploring further.
# Logging Anthropic Requests
Anthropic's language models have a different API structure than those of OpenAI.
To record requests made to Anthropic's models, follow the examples below:
We provide a number of built-in relabeling options.
Anthropic:
* `claude-3-opus-20240229`
* `claude-sonnet-3-7-20250219`
* `claude-sonnet-3-5-20241022`
OpenAI:
* `gpt-4-5-preview-02-27`
* `o1-2024-12-17`
* `o3-mini-2025-01-31`
* `gpt-4o-2024-08-06`
* `gpt-4o-2024-11-20`
* `gpt-4-turbo-2024-04-09`
* `gpt-4-0125-preview`
* `gpt-4-1106-preview`
* `gpt-4-0613`
Gemini:
* `gemini-2-0-flash`
* `gemini-2-0-pro-exp-02-05`
Meta:
* `meta-llama-3-1-405b-instruct`
DeepSeek:
* `deepseek-v3`
* `deepseek-r1`
---
# Source: https://docs.openpipe.ai/features/request-logs/reporting-anthropic.md
> ## Documentation Index
> Fetch the complete documentation index at: https://docs.openpipe.ai/llms.txt
> Use this file to discover all available pages before exploring further.
# Logging Anthropic Requests
Anthropic's language models have a different API structure than those of OpenAI.
To record requests made to Anthropic's models, follow the examples below:
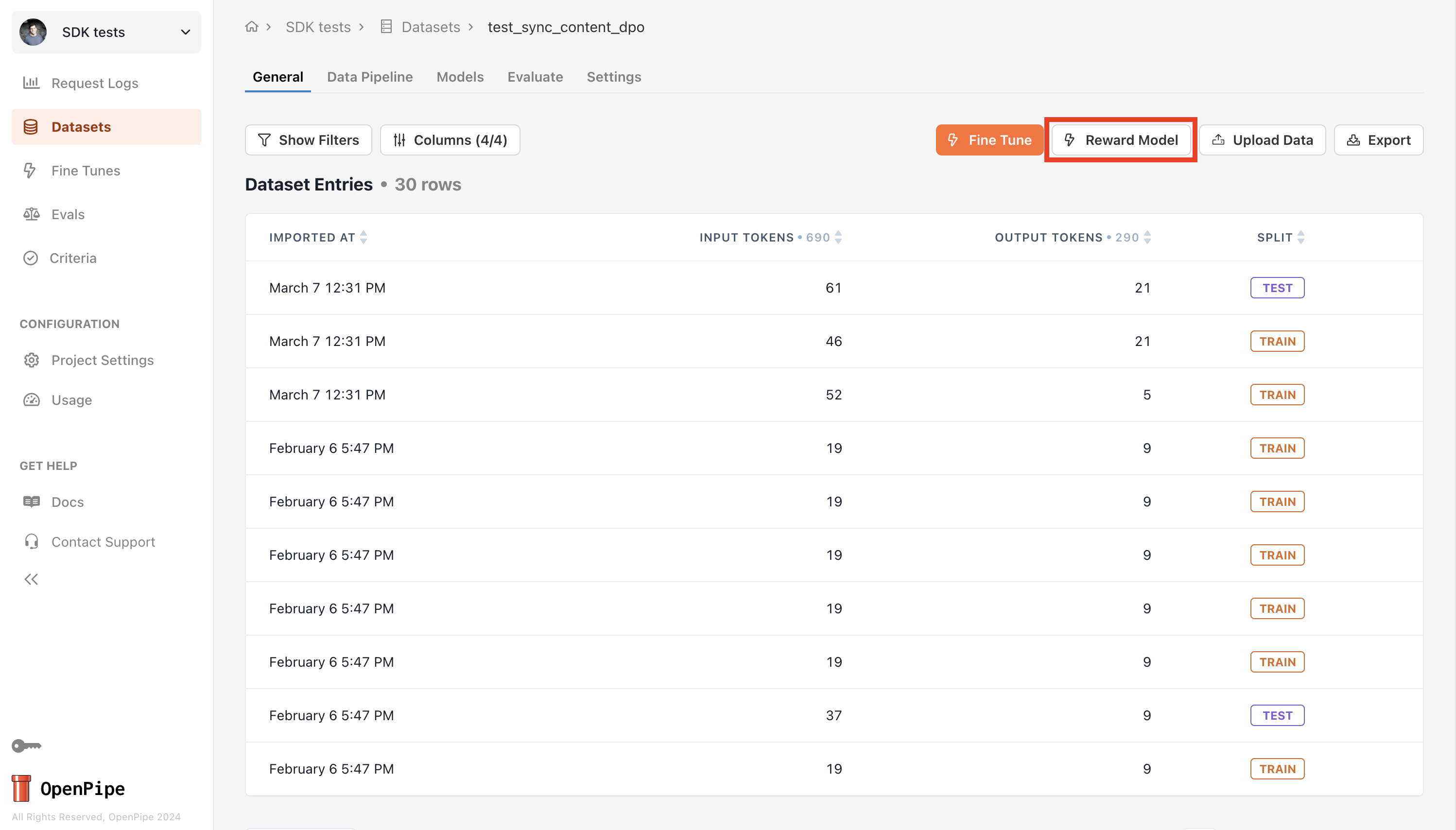 Select a base model and optionally configure hyperparameters, then click "Start Training".
Select a base model and optionally configure hyperparameters, then click "Start Training".
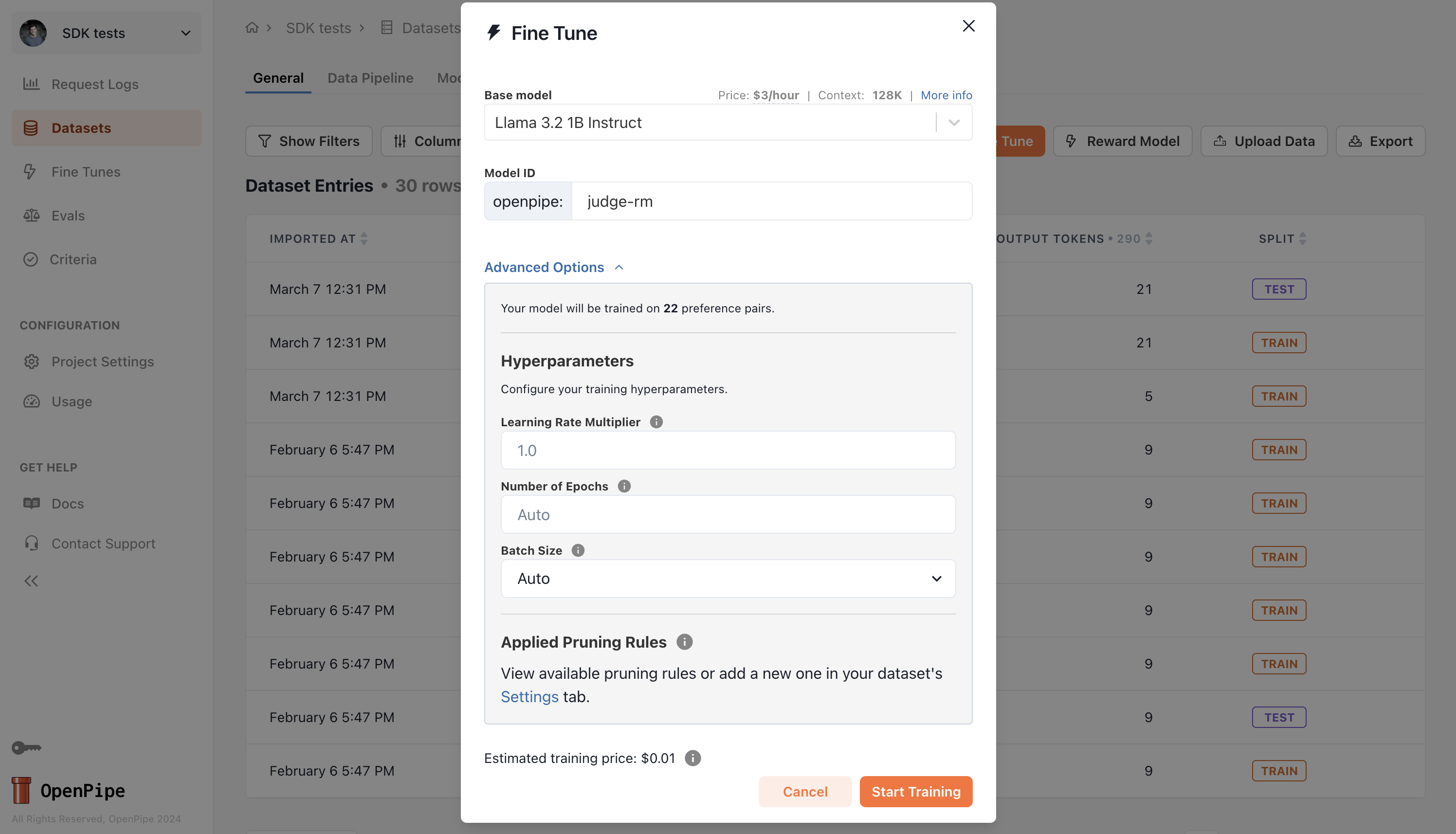 Your reward model will be trained in the background. You can check the status of your model by navigating to the Fine Tunes page and selecting your model.
Your reward model will be trained in the background. You can check the status of your model by navigating to the Fine Tunes page and selecting your model.
 ### Using a reward model
Like criteria, reward models can be used for best of N sampling and offline evaluation. Reward model slugs can be specified independently or in conjunction with criteria, as shown below:
```bash theme={null}
curl --request POST \
--url https://app.openpipe.ai/api/v1/chat/completions \
--header "Authorization: Bearer $OPENPIPE_API_KEY" \
--header 'Content-Type: application/json' \
--header 'op-criteria: ["
### Using a reward model
Like criteria, reward models can be used for best of N sampling and offline evaluation. Reward model slugs can be specified independently or in conjunction with criteria, as shown below:
```bash theme={null}
curl --request POST \
--url https://app.openpipe.ai/api/v1/chat/completions \
--header "Authorization: Bearer $OPENPIPE_API_KEY" \
--header 'Content-Type: application/json' \
--header 'op-criteria: [" Each line of the file should be compatible with the OpenAI [chat format](https://platform.openai.com/docs/api-reference/chat/object), with additional optional fields.
### OpenAI Fields
* **`messages`: Required** - Formatted as a list of OpenAI [chat completion messages](https://platform.openai.com/docs/guides/gpt/chat-completions-api). The list should end with an assistant message.
* **`tools`: Optional** - An array of tools (functions) available for the model to call. For more information read OpenAI's [function calling docs](https://platform.openai.com/docs/guides/function-calling).
* **`tool_choice`: Optional** - You can set this to indicate that the model should be required to call the given tool. For more information read OpenAI's [function calling docs](https://platform.openai.com/docs/guides/function-calling).
#### Deprecated
* **`functions`: Deprecated | Optional** - An array of functions available for the model to call.
* **`function_call`: Deprecated | Optional** - You can set this to indicate that the model should be required to call the given function.
You can include other parameters from the OpenAI chat completion input format (eg. temperature), but they will be ignored since they aren't relevant for training.
### Additional Fields
* **`split`: Optional** - One of "TRAIN" or "TEST". If you don't set this field we'll automatically divide your inputs into train and test splits with a target ratio of 90:10.
* **`rejected_message`: Optional** - Add a rejected output for entries on which you want to perform direct preference optimization (DPO). You can find more information about that here: [Direct Preference Optimization](/features/dpo/overview)
* **`metadata`: Optional** - A string=>string dictionary of any additional information you want to associate with an entry. This can be useful for tracking information like prompt IDs.
### Example
```jsonl theme={null}
...
{"messages":[{"role":"system","content":"You are a helpful assistant"},{"role":"user","content":"What is the capital of Tasmania?"},{"role":"assistant","content":"Hobart"}], "rejected_message":{"role": "assistant", "content": "Paris"}, "split": "TRAIN", "metadata": {"prompt_id": "capital_cities", "any_key": "any_value"}}
{"messages":[{"role":"system","content":"You are a helpful assistant"},{"role":"user","content":"What is the capital of Sweden?"},{"role":"assistant","content":"Stockholm"}], "rejected_message":{"role": "assistant", "content": "London"}, "split": "TEST", "metadata": {"prompt_id": "capital_cities", "any_key": "any_value"}}
...
```
---
# Source: https://docs.openpipe.ai/features/fine-tuning/webapp.md
> ## Documentation Index
> Fetch the complete documentation index at: https://docs.openpipe.ai/llms.txt
> Use this file to discover all available pages before exploring further.
# Fine Tuning via Webapp
> Fine tune your models on filtered logs or uploaded datasets. Filter by prompt id and exclude requests with an undesirable output.
OpenPipe allows you to train, evaluate, and deploy your models all in the same place. We recommend training your models
through the webapp, which provides more flexibility and a smoother experience than the API. To fine-tune a new model, follow these steps:
1. Create a new dataset or navigate to an existing one.
2. Click "Fine Tune" in the top right.
3. Select a base model.
4. (Optional) Set custom hyperparameters and configure [pruning rules](/features/pruning-rules).
5. Click "Start Training" to kick off the job.
Once started, your model's training job will take at least a few minutes and potentially several hours, depending on the size of the
model and the amount of data. You can check your model's status by navigating to the Fine Tunes page and selecting your model.
For an example of how an OpenPipe model looks once it's trained, see our public [PII Redaction](https://app.openpipe.ai/p/BRZFEx50Pf/fine-tunes/6076ad69-cce5-4892-ae54-e0549bbe107f/general) model. Feel free to hit it with some sample queries!
Each line of the file should be compatible with the OpenAI [chat format](https://platform.openai.com/docs/api-reference/chat/object), with additional optional fields.
### OpenAI Fields
* **`messages`: Required** - Formatted as a list of OpenAI [chat completion messages](https://platform.openai.com/docs/guides/gpt/chat-completions-api). The list should end with an assistant message.
* **`tools`: Optional** - An array of tools (functions) available for the model to call. For more information read OpenAI's [function calling docs](https://platform.openai.com/docs/guides/function-calling).
* **`tool_choice`: Optional** - You can set this to indicate that the model should be required to call the given tool. For more information read OpenAI's [function calling docs](https://platform.openai.com/docs/guides/function-calling).
#### Deprecated
* **`functions`: Deprecated | Optional** - An array of functions available for the model to call.
* **`function_call`: Deprecated | Optional** - You can set this to indicate that the model should be required to call the given function.
You can include other parameters from the OpenAI chat completion input format (eg. temperature), but they will be ignored since they aren't relevant for training.
### Additional Fields
* **`split`: Optional** - One of "TRAIN" or "TEST". If you don't set this field we'll automatically divide your inputs into train and test splits with a target ratio of 90:10.
* **`rejected_message`: Optional** - Add a rejected output for entries on which you want to perform direct preference optimization (DPO). You can find more information about that here: [Direct Preference Optimization](/features/dpo/overview)
* **`metadata`: Optional** - A string=>string dictionary of any additional information you want to associate with an entry. This can be useful for tracking information like prompt IDs.
### Example
```jsonl theme={null}
...
{"messages":[{"role":"system","content":"You are a helpful assistant"},{"role":"user","content":"What is the capital of Tasmania?"},{"role":"assistant","content":"Hobart"}], "rejected_message":{"role": "assistant", "content": "Paris"}, "split": "TRAIN", "metadata": {"prompt_id": "capital_cities", "any_key": "any_value"}}
{"messages":[{"role":"system","content":"You are a helpful assistant"},{"role":"user","content":"What is the capital of Sweden?"},{"role":"assistant","content":"Stockholm"}], "rejected_message":{"role": "assistant", "content": "London"}, "split": "TEST", "metadata": {"prompt_id": "capital_cities", "any_key": "any_value"}}
...
```
---
# Source: https://docs.openpipe.ai/features/fine-tuning/webapp.md
> ## Documentation Index
> Fetch the complete documentation index at: https://docs.openpipe.ai/llms.txt
> Use this file to discover all available pages before exploring further.
# Fine Tuning via Webapp
> Fine tune your models on filtered logs or uploaded datasets. Filter by prompt id and exclude requests with an undesirable output.
OpenPipe allows you to train, evaluate, and deploy your models all in the same place. We recommend training your models
through the webapp, which provides more flexibility and a smoother experience than the API. To fine-tune a new model, follow these steps:
1. Create a new dataset or navigate to an existing one.
2. Click "Fine Tune" in the top right.
3. Select a base model.
4. (Optional) Set custom hyperparameters and configure [pruning rules](/features/pruning-rules).
5. Click "Start Training" to kick off the job.
Once started, your model's training job will take at least a few minutes and potentially several hours, depending on the size of the
model and the amount of data. You can check your model's status by navigating to the Fine Tunes page and selecting your model.
For an example of how an OpenPipe model looks once it's trained, see our public [PII Redaction](https://app.openpipe.ai/p/BRZFEx50Pf/fine-tunes/6076ad69-cce5-4892-ae54-e0549bbe107f/general) model. Feel free to hit it with some sample queries!