

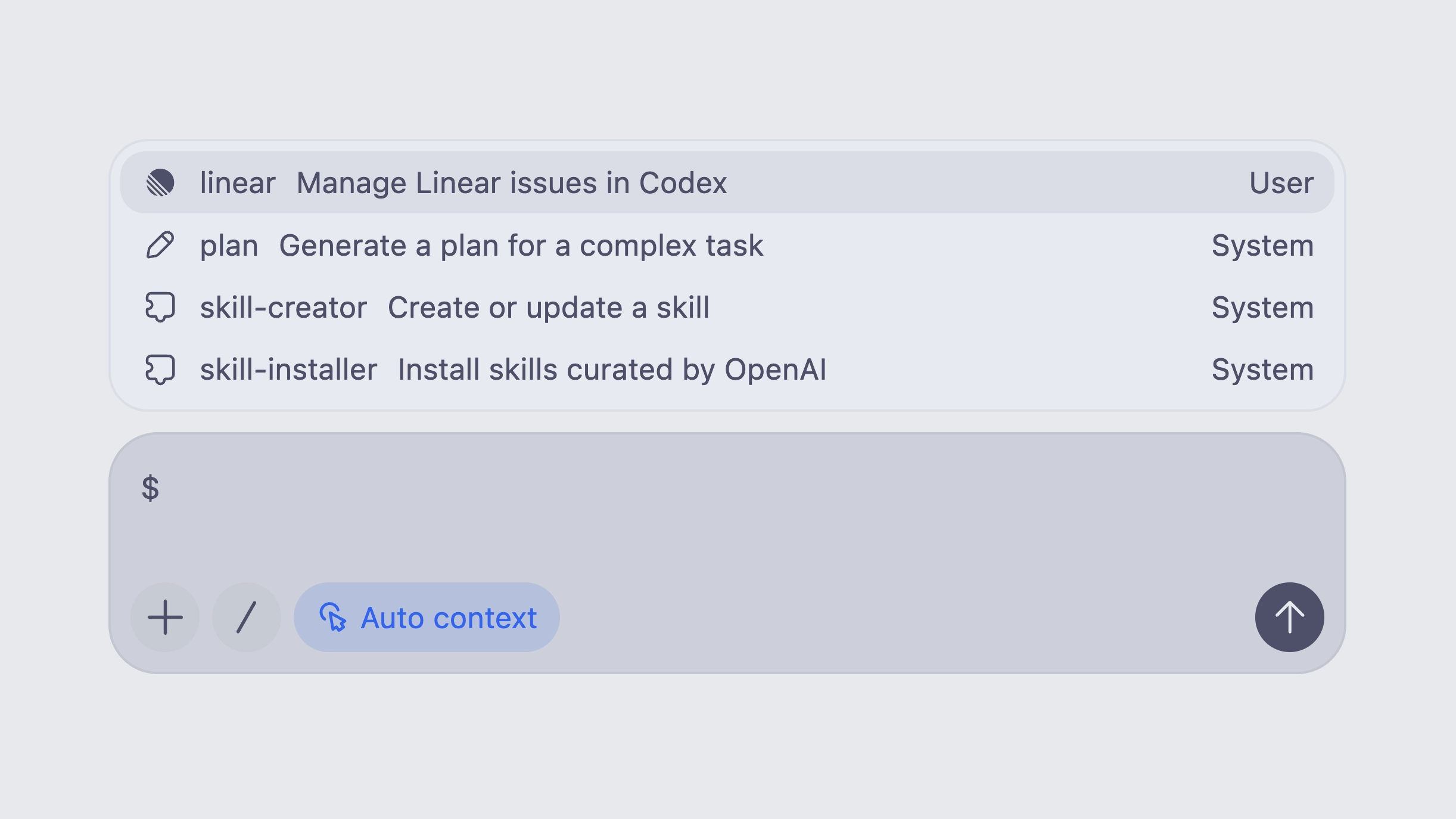
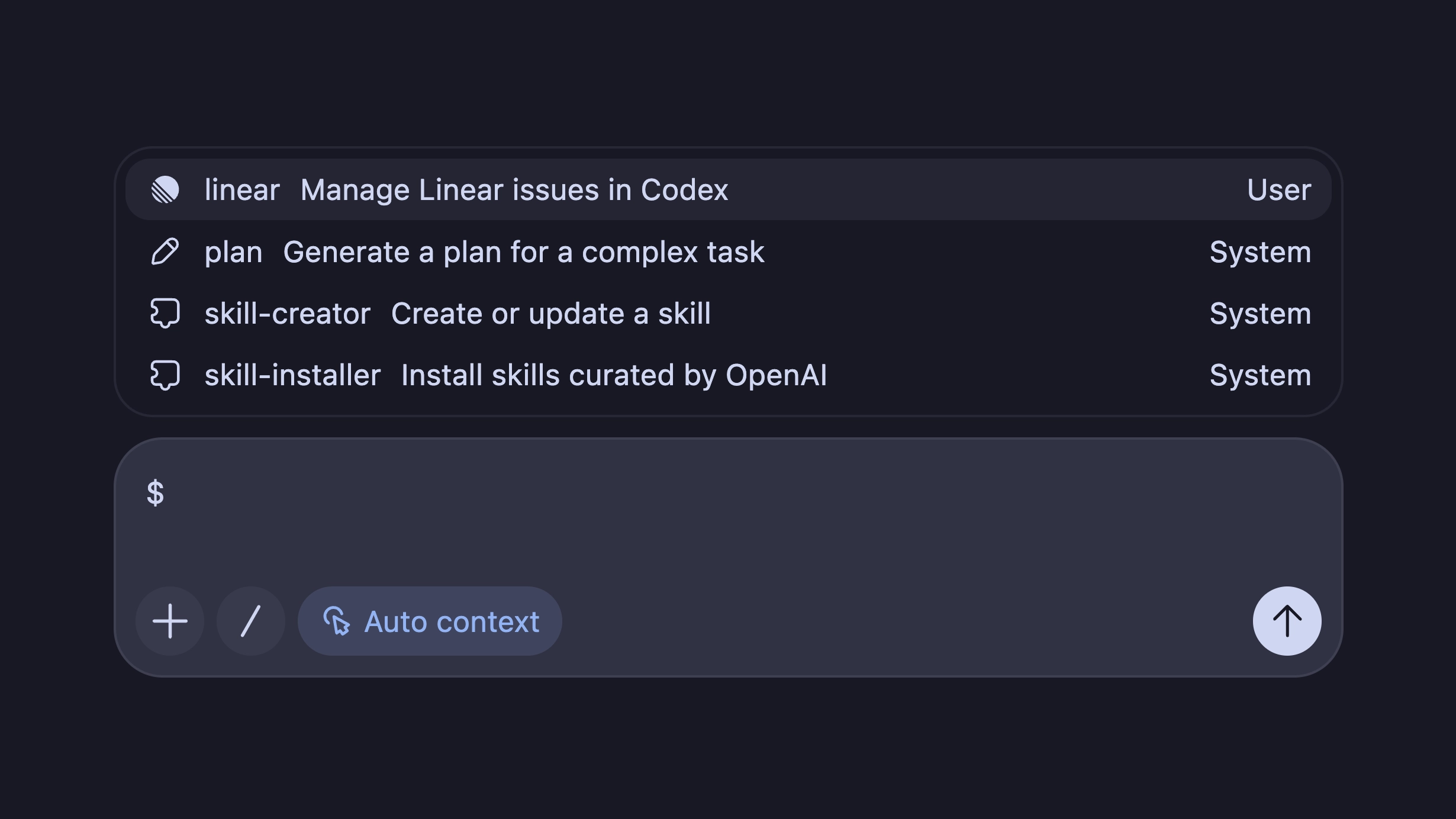
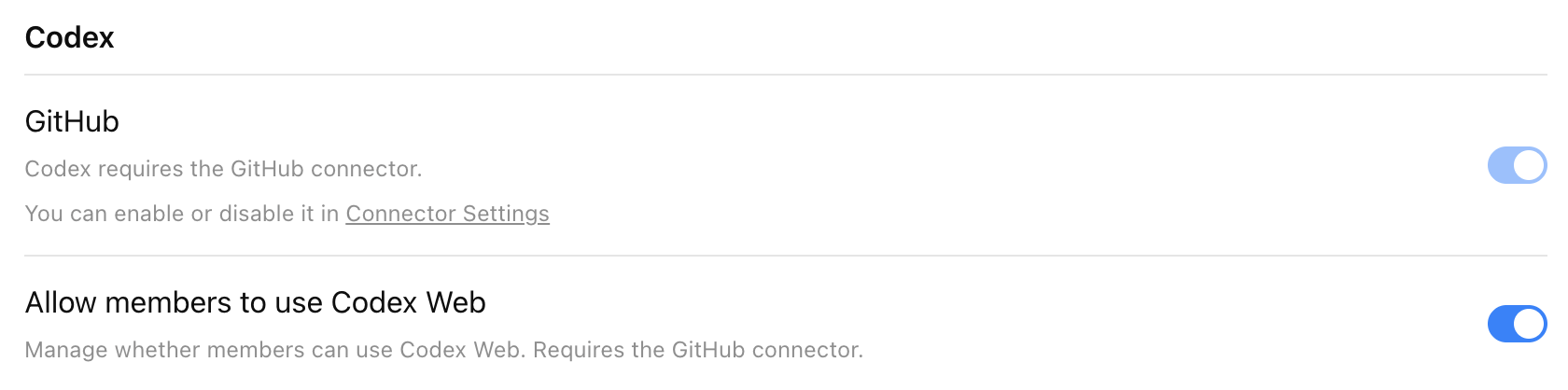

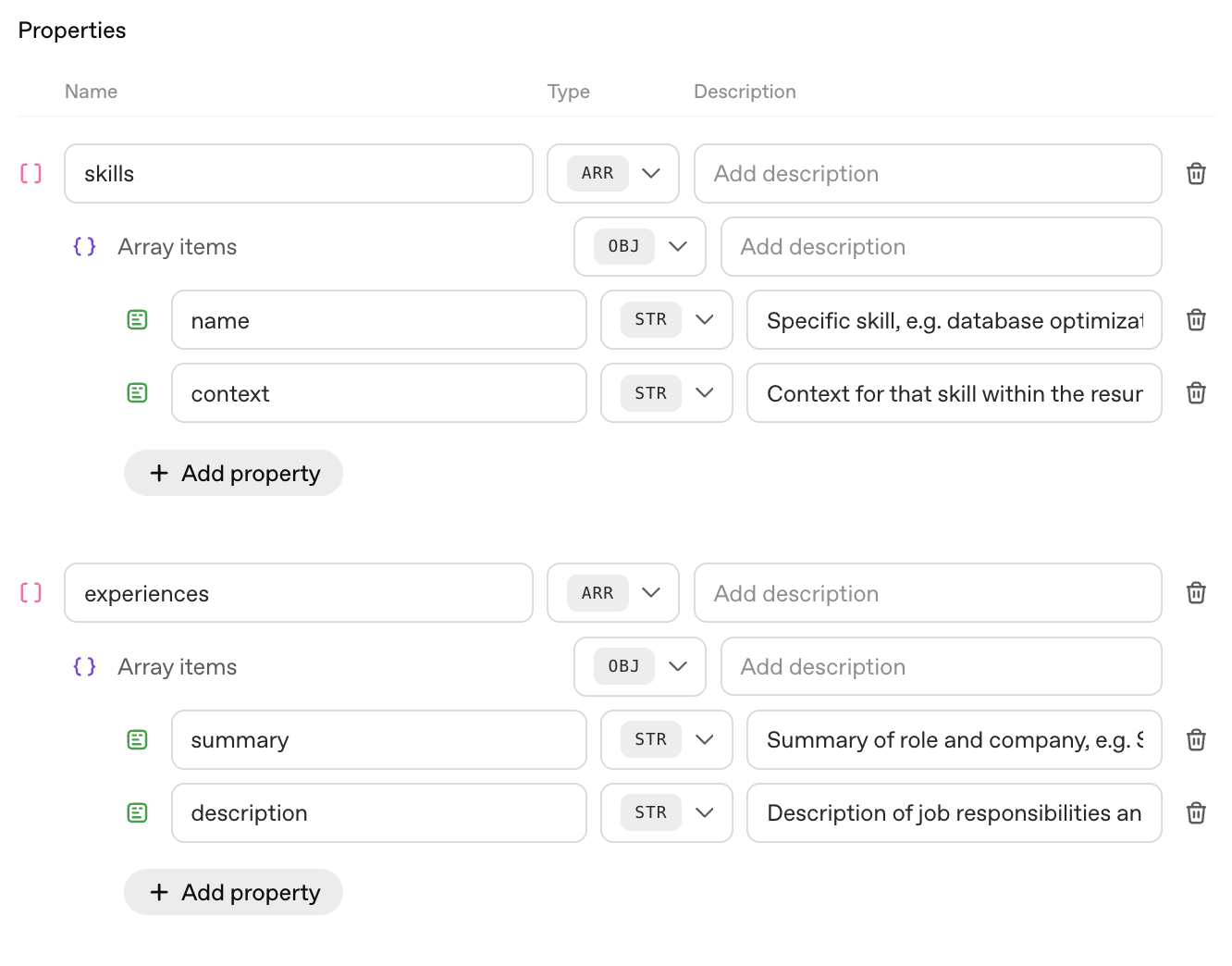
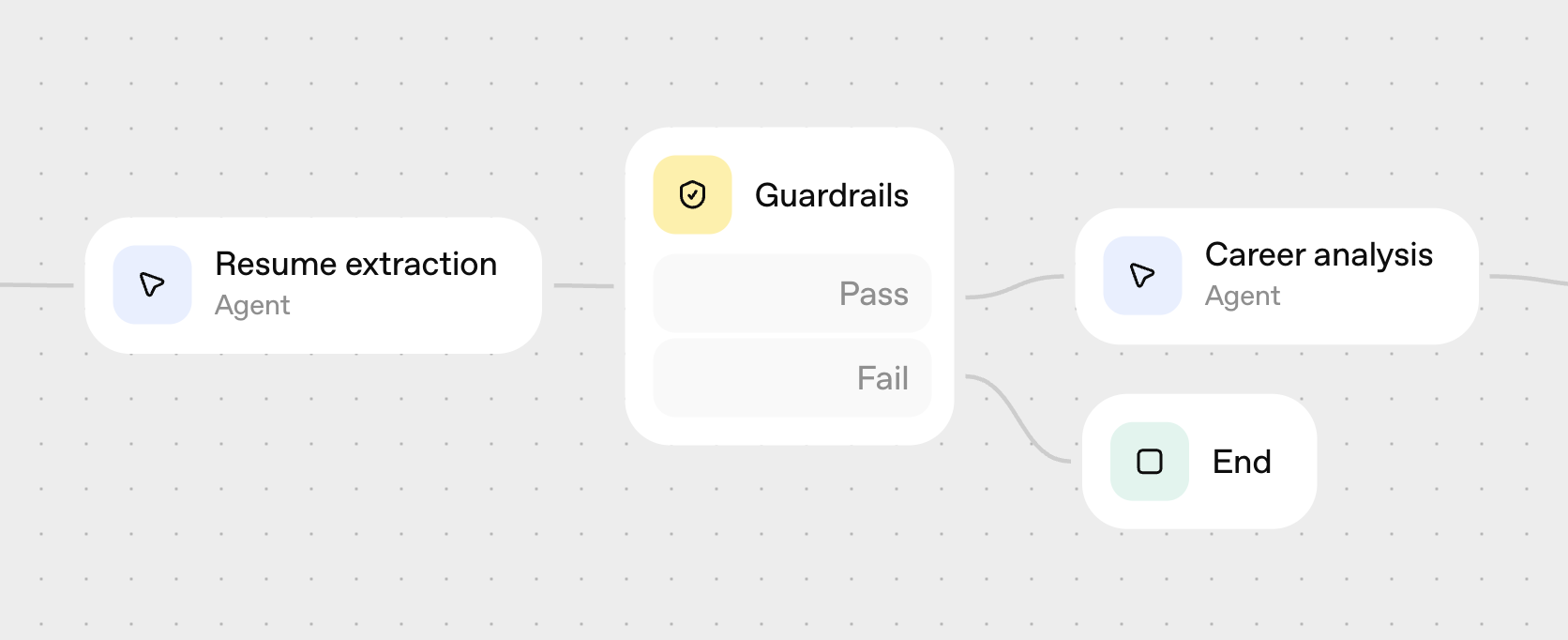
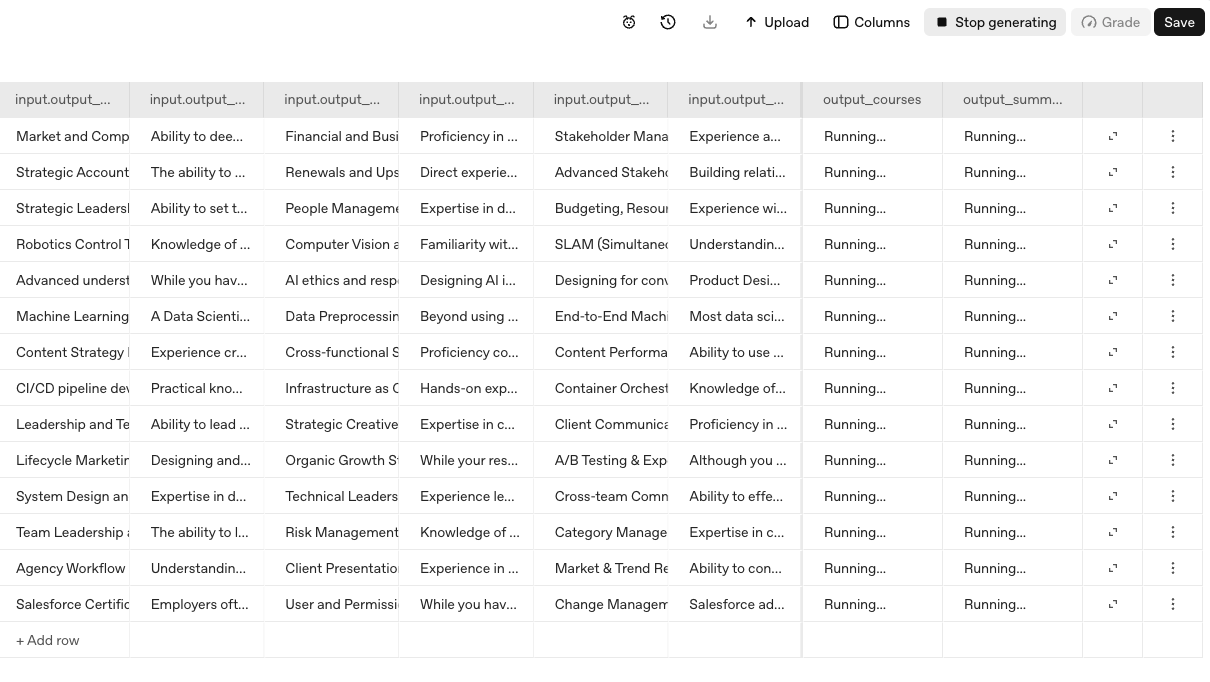
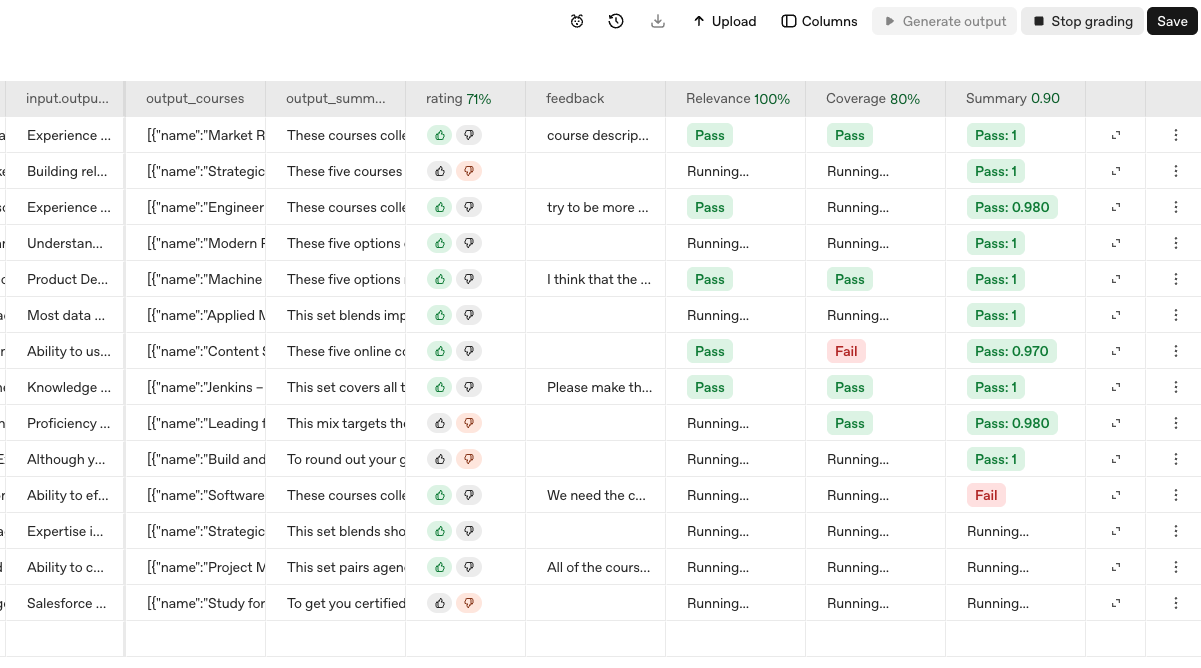
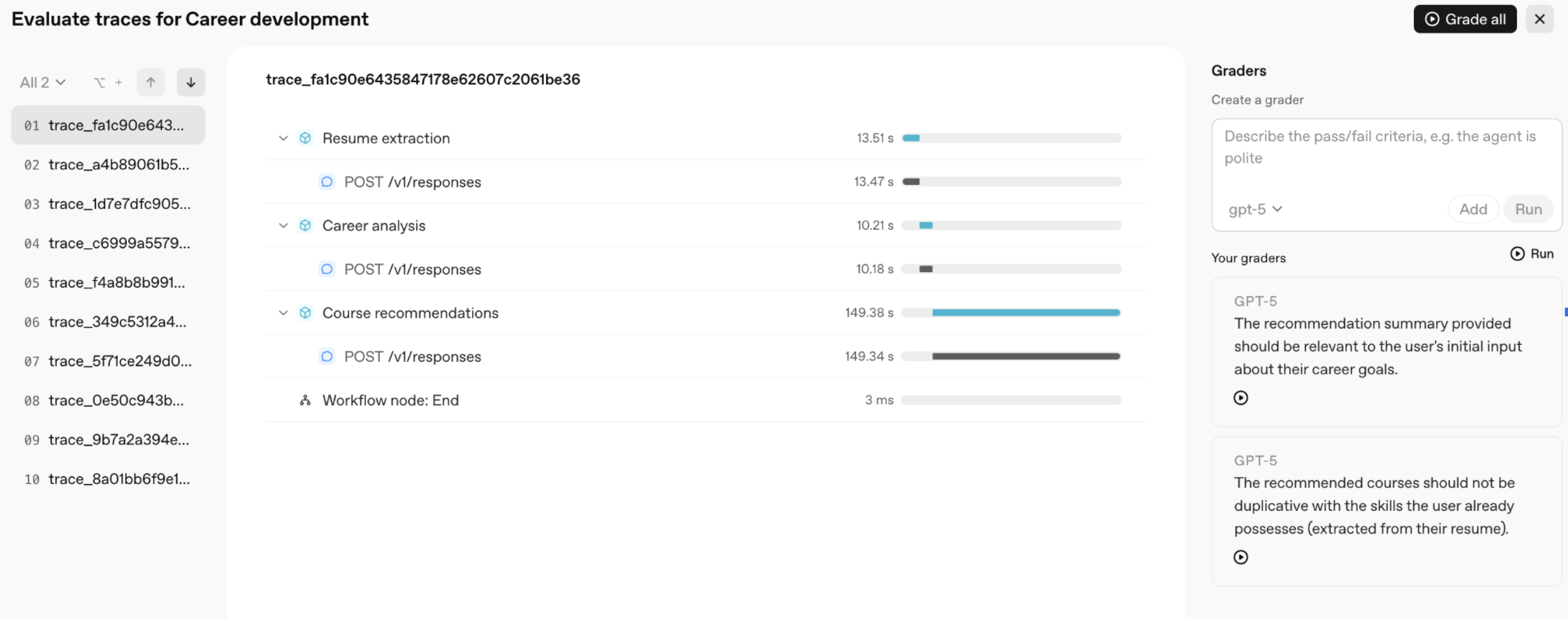
 ## Prerequisites
- A GitHub Repo with Actions workflows
- You’ll need to create `OPENAI_API_KEY` as an environment variable in GitHub settings under https://github.com/{org-name}/{repo-name}/settings/secrets/actions. You can also set this at org level(for sharing secrets across multiple repos)
- Codex requires python as a prerequisite to use `codex login`
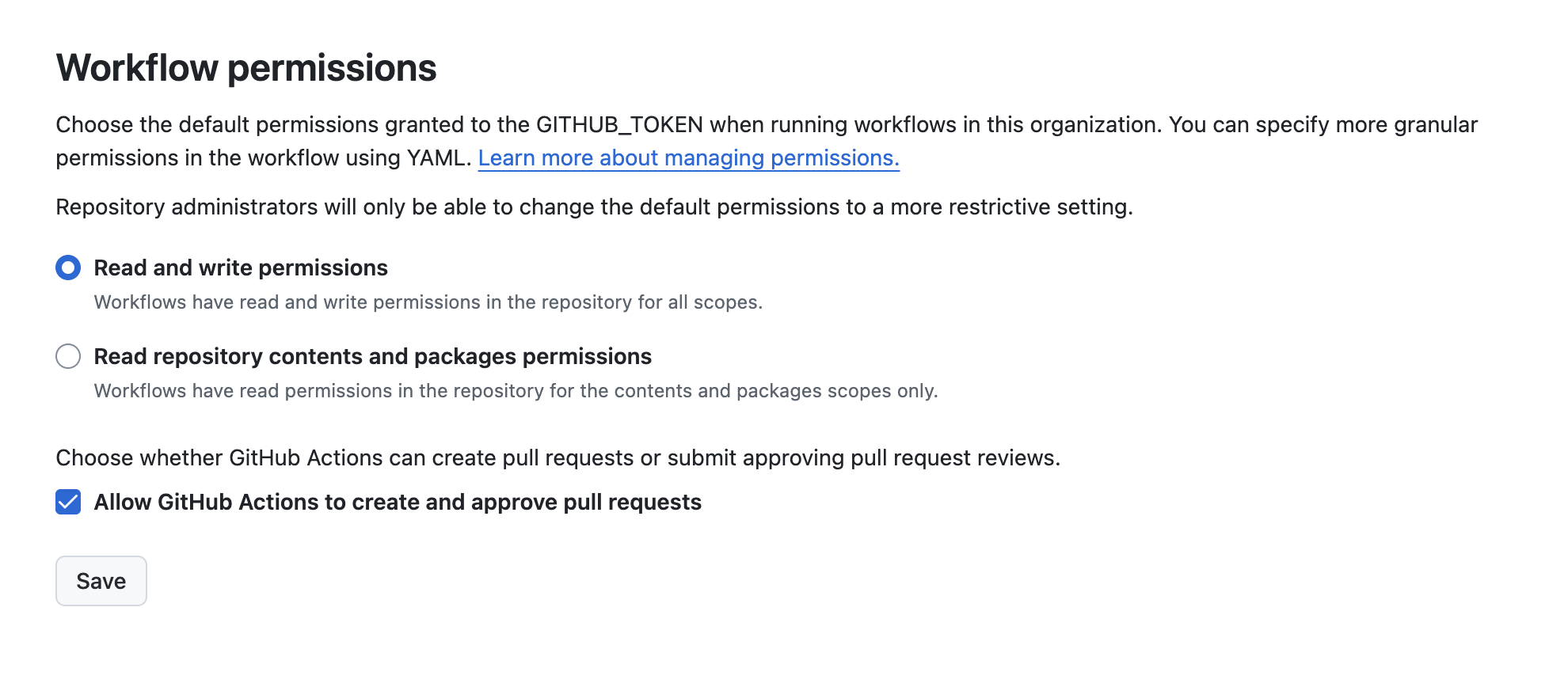
- You’ll need to check the setting to enable actions to create PRs on your repo, and also in your organization:
## Prerequisites
- A GitHub Repo with Actions workflows
- You’ll need to create `OPENAI_API_KEY` as an environment variable in GitHub settings under https://github.com/{org-name}/{repo-name}/settings/secrets/actions. You can also set this at org level(for sharing secrets across multiple repos)
- Codex requires python as a prerequisite to use `codex login`
- You’ll need to check the setting to enable actions to create PRs on your repo, and also in your organization:
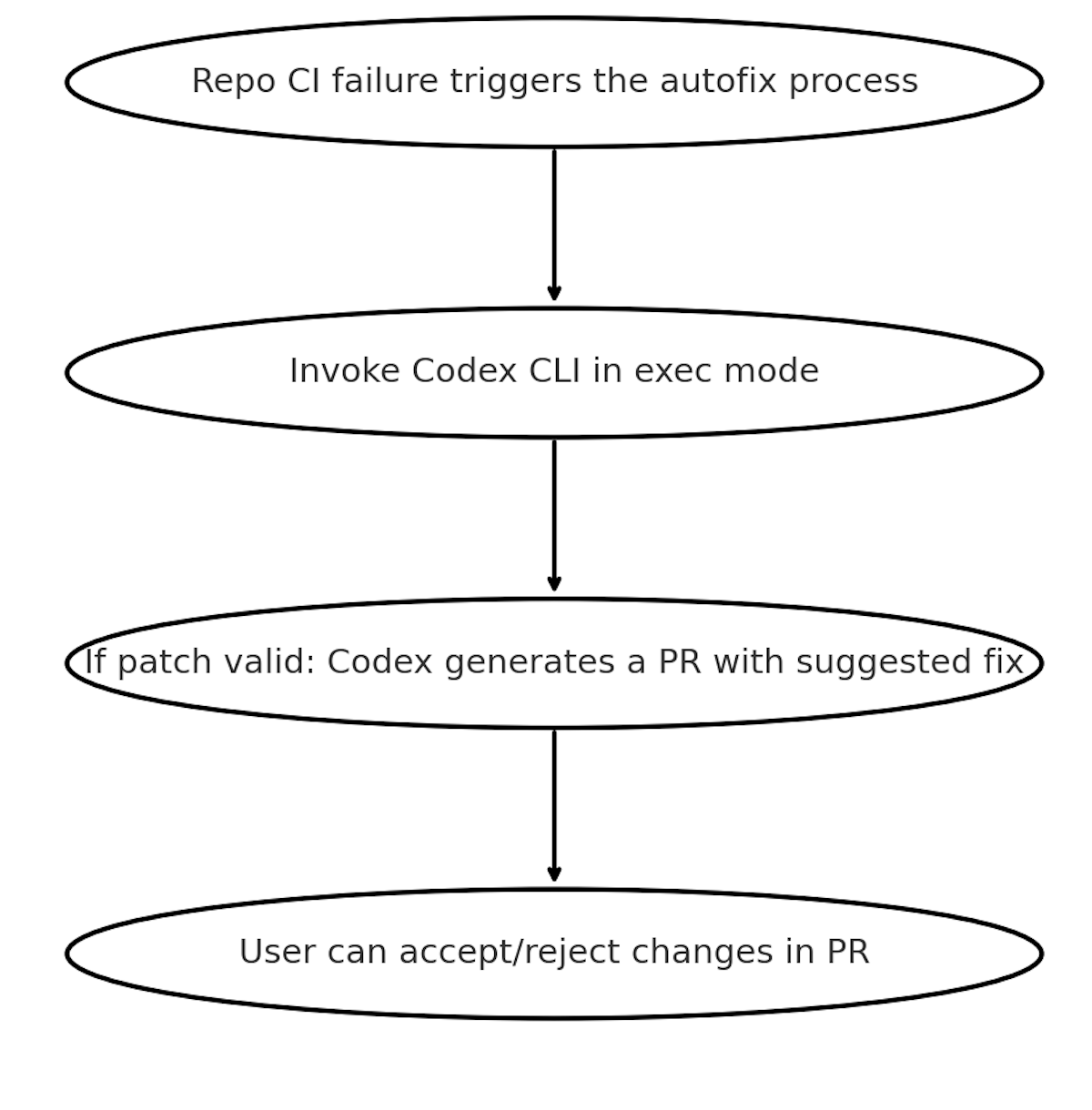
 ## Step 1: Add the Github Action to your CI Pipeline
The following YAML shows a GitHub action that auto triggers when CI fails, installs Codex, uses codex exec and then makes a PR on the failing branch with the fix. Replace "CI" with the name of the workflow you want to monitor.
```yaml
name: Codex Auto-Fix on Failure
on:
workflow_run:
# Trigger this job after any run of the primary CI workflow completes
workflows: ["CI"]
types: [completed]
permissions:
contents: write
pull-requests: write
jobs:
auto-fix:
# Only run when the referenced workflow concluded with a failure
if: ${{ github.event.workflow_run.conclusion == 'failure' }}
runs-on: ubuntu-latest
env:
OPENAI_API_KEY: ${{ secrets.OPENAI_API_KEY }}
FAILED_WORKFLOW_NAME: ${{ github.event.workflow_run.name }}
FAILED_RUN_URL: ${{ github.event.workflow_run.html_url }}
FAILED_HEAD_BRANCH: ${{ github.event.workflow_run.head_branch }}
FAILED_HEAD_SHA: ${{ github.event.workflow_run.head_sha }}
steps:
- name: Check OpenAI API Key Set
run: |
if [ -z "$OPENAI_API_KEY" ]; then
echo "OPENAI_API_KEY secret is not set. Skipping auto-fix." >&2
exit 1
fi
- name: Checkout Failing Ref
uses: actions/checkout@v4
with:
ref: ${{ env.FAILED_HEAD_SHA }}
fetch-depth: 0
- name: Setup Node.js
uses: actions/setup-node@v4
with:
node-version: '20'
cache: 'npm'
- name: Install dependencies
run: |
if [ -f package-lock.json ]; then npm ci; else npm i; fi
- name: Run Codex
uses: openai/codex-action@main
id: codex
with:
openai_api_key: ${{ secrets.OPENAI_API_KEY }}
prompt: "You are working in a Node.js monorepo with Jest tests and GitHub Actions. Read the repository, run the test suite, identify the minimal change needed to make all tests pass, implement only that change, and stop. Do not refactor unrelated code or files. Keep changes small and surgical."
codex_args: '["--config","sandbox_mode=\"workspace-write\""]'
- name: Verify tests
run: npm test --silent
- name: Create pull request with fixes
if: success()
uses: peter-evans/create-pull-request@v6
with:
commit-message: "fix(ci): auto-fix failing tests via Codex"
branch: codex/auto-fix-${{ github.event.workflow_run.run_id }}
base: ${{ env.FAILED_HEAD_BRANCH }}
title: "Auto-fix failing CI via Codex"
body: |
Codex automatically generated this PR in response to a CI failure on workflow `${{ env.FAILED_WORKFLOW_NAME }}`.
Failed run: ${{ env.FAILED_RUN_URL }}
Head branch: `${{ env.FAILED_HEAD_BRANCH }}`
This PR contains minimal changes intended solely to make the CI pass.
```
## Step 2: Actions Workflow kicked off
You can navigate to the Actions tab under Repo to view the failing jobs in your Actions workflow.
## Step 1: Add the Github Action to your CI Pipeline
The following YAML shows a GitHub action that auto triggers when CI fails, installs Codex, uses codex exec and then makes a PR on the failing branch with the fix. Replace "CI" with the name of the workflow you want to monitor.
```yaml
name: Codex Auto-Fix on Failure
on:
workflow_run:
# Trigger this job after any run of the primary CI workflow completes
workflows: ["CI"]
types: [completed]
permissions:
contents: write
pull-requests: write
jobs:
auto-fix:
# Only run when the referenced workflow concluded with a failure
if: ${{ github.event.workflow_run.conclusion == 'failure' }}
runs-on: ubuntu-latest
env:
OPENAI_API_KEY: ${{ secrets.OPENAI_API_KEY }}
FAILED_WORKFLOW_NAME: ${{ github.event.workflow_run.name }}
FAILED_RUN_URL: ${{ github.event.workflow_run.html_url }}
FAILED_HEAD_BRANCH: ${{ github.event.workflow_run.head_branch }}
FAILED_HEAD_SHA: ${{ github.event.workflow_run.head_sha }}
steps:
- name: Check OpenAI API Key Set
run: |
if [ -z "$OPENAI_API_KEY" ]; then
echo "OPENAI_API_KEY secret is not set. Skipping auto-fix." >&2
exit 1
fi
- name: Checkout Failing Ref
uses: actions/checkout@v4
with:
ref: ${{ env.FAILED_HEAD_SHA }}
fetch-depth: 0
- name: Setup Node.js
uses: actions/setup-node@v4
with:
node-version: '20'
cache: 'npm'
- name: Install dependencies
run: |
if [ -f package-lock.json ]; then npm ci; else npm i; fi
- name: Run Codex
uses: openai/codex-action@main
id: codex
with:
openai_api_key: ${{ secrets.OPENAI_API_KEY }}
prompt: "You are working in a Node.js monorepo with Jest tests and GitHub Actions. Read the repository, run the test suite, identify the minimal change needed to make all tests pass, implement only that change, and stop. Do not refactor unrelated code or files. Keep changes small and surgical."
codex_args: '["--config","sandbox_mode=\"workspace-write\""]'
- name: Verify tests
run: npm test --silent
- name: Create pull request with fixes
if: success()
uses: peter-evans/create-pull-request@v6
with:
commit-message: "fix(ci): auto-fix failing tests via Codex"
branch: codex/auto-fix-${{ github.event.workflow_run.run_id }}
base: ${{ env.FAILED_HEAD_BRANCH }}
title: "Auto-fix failing CI via Codex"
body: |
Codex automatically generated this PR in response to a CI failure on workflow `${{ env.FAILED_WORKFLOW_NAME }}`.
Failed run: ${{ env.FAILED_RUN_URL }}
Head branch: `${{ env.FAILED_HEAD_BRANCH }}`
This PR contains minimal changes intended solely to make the CI pass.
```
## Step 2: Actions Workflow kicked off
You can navigate to the Actions tab under Repo to view the failing jobs in your Actions workflow.
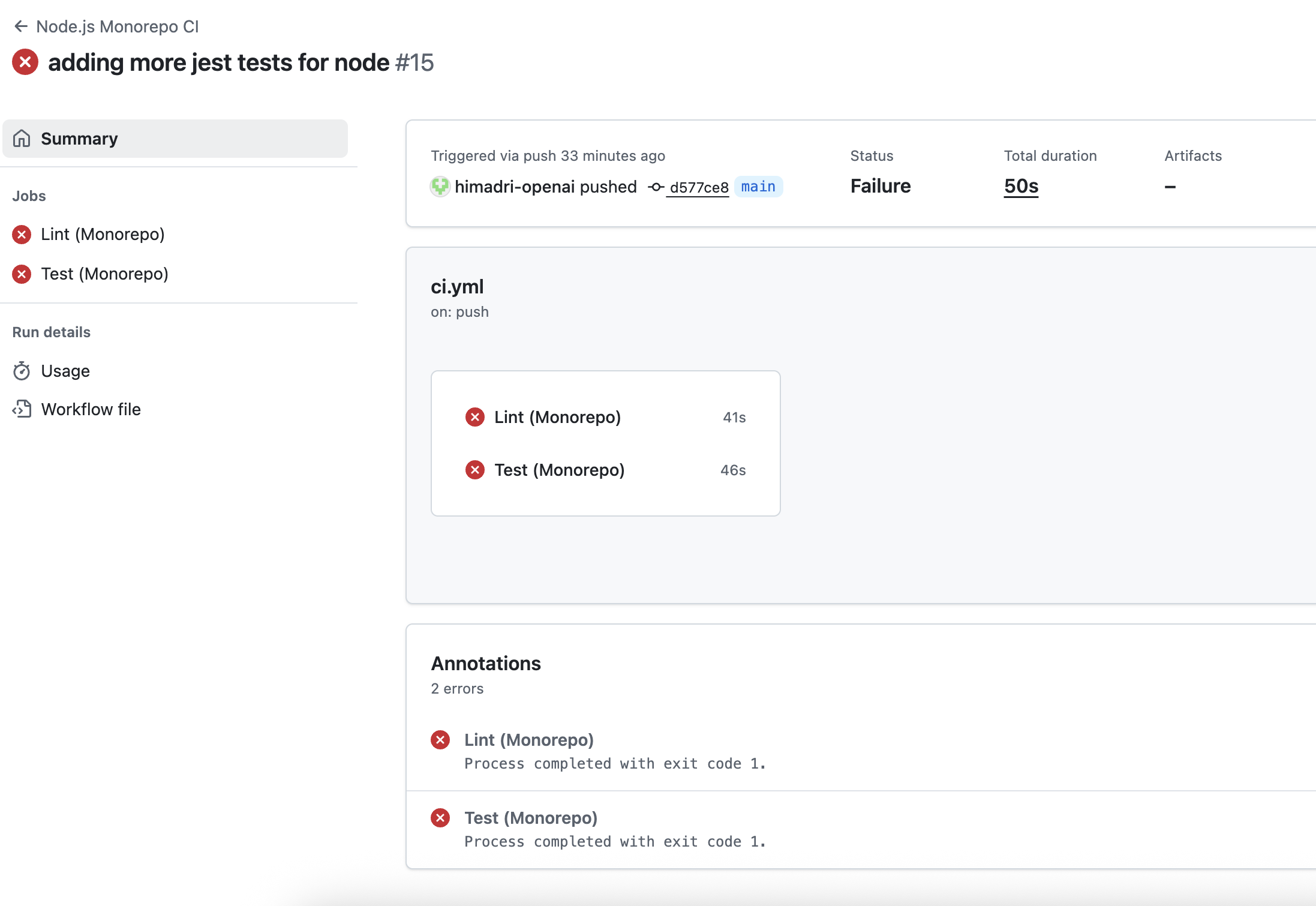 The Codex workflow should be triggered upon completion of the failed workflow.
The Codex workflow should be triggered upon completion of the failed workflow.
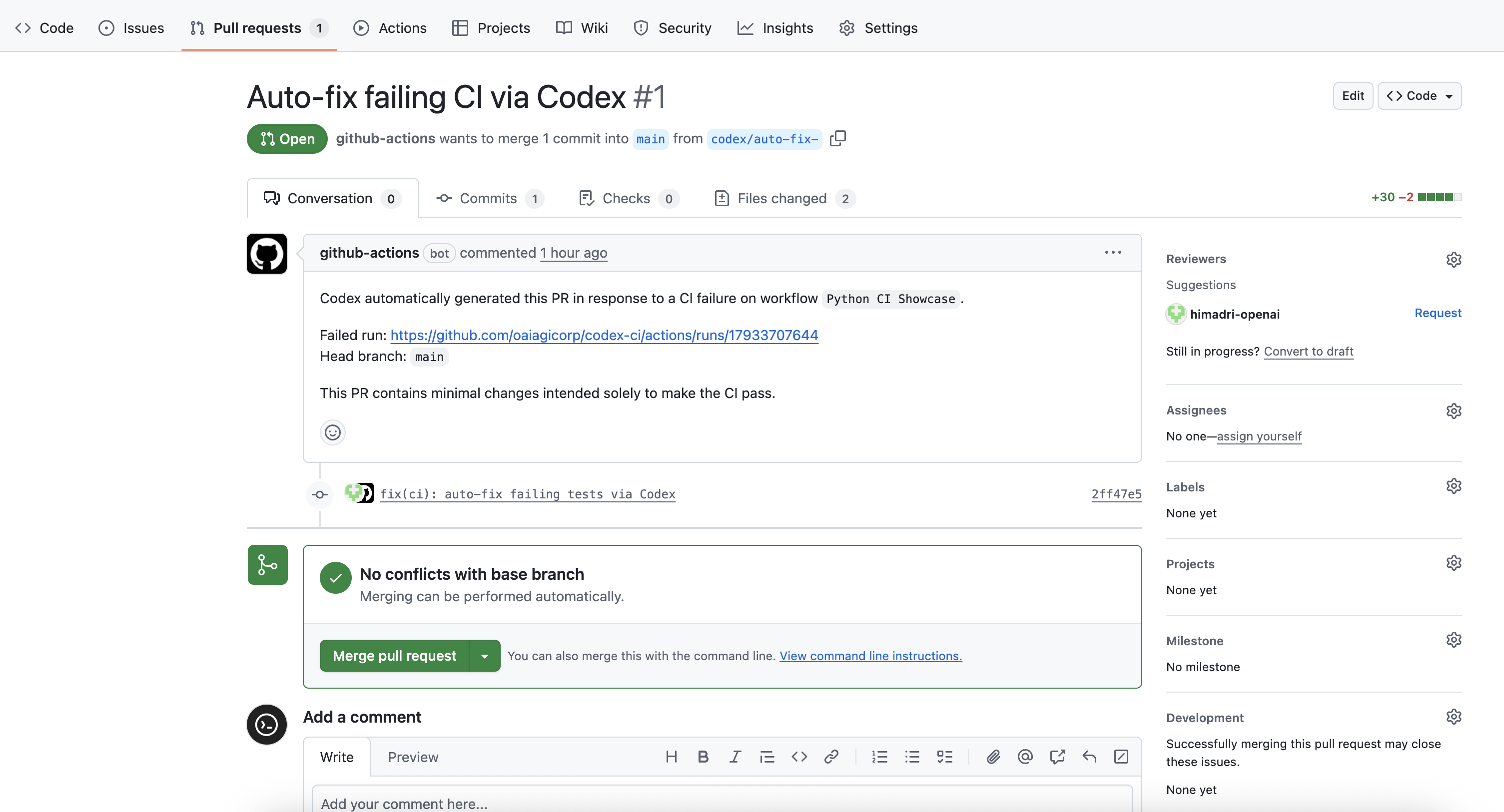
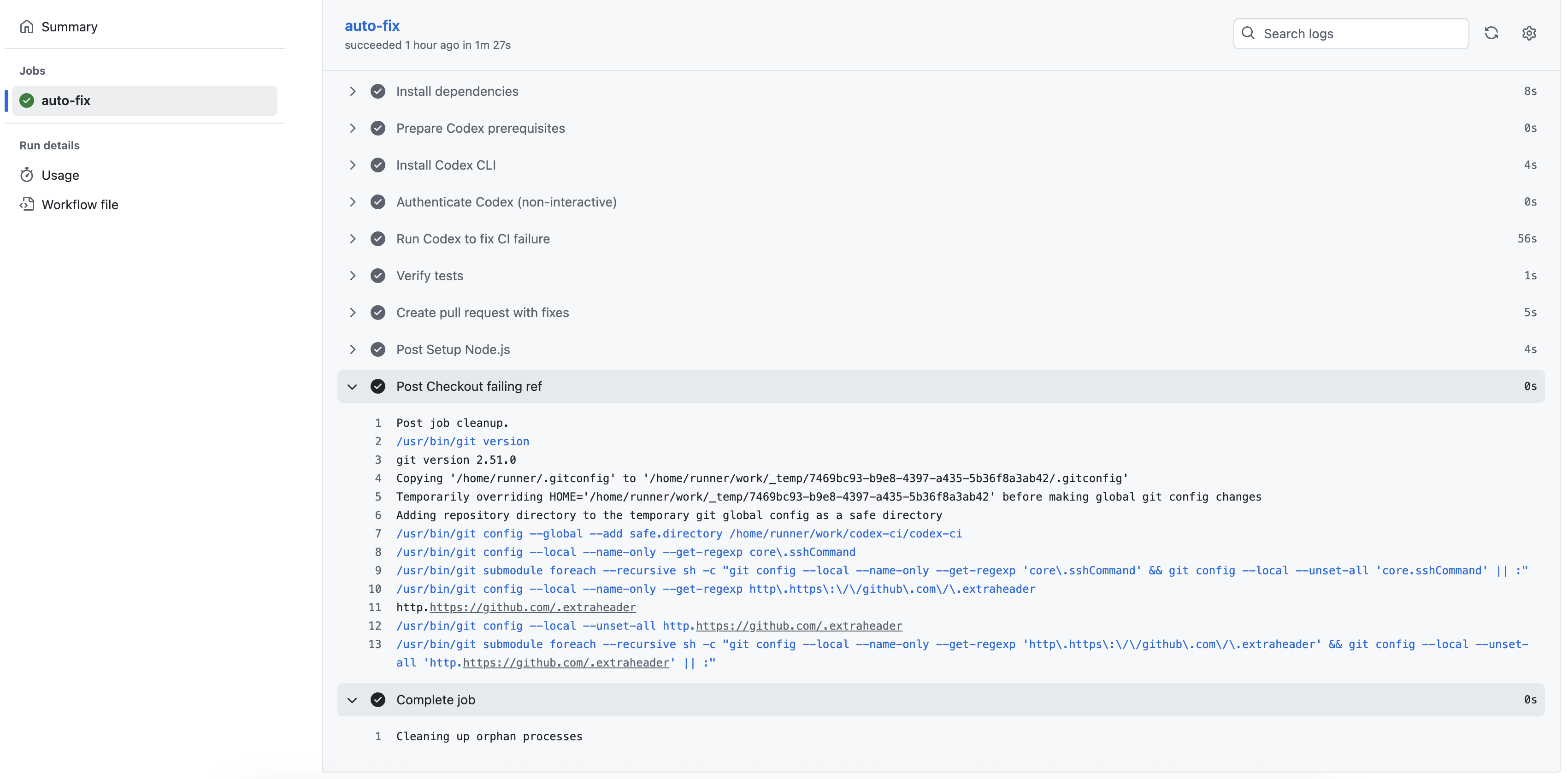 ## Step 3: Verify that Codex Created a PR for Review
And after the Codex workflow completes execution, it should open a pull request from the feature branch codex/auto-fix. Check to see if everything looks good and then merge it.
## Step 3: Verify that Codex Created a PR for Review
And after the Codex workflow completes execution, it should open a pull request from the feature branch codex/auto-fix. Check to see if everything looks good and then merge it.
 ## Conclusion
This automation seamlessly integrates OpenAI Codex CLI with GitHub Actions to automatically propose fixes for failing CI runs.
By leveraging Codex, you can reduce manual intervention, accelerate code reviews, and keep your main branch healthy. The workflow ensures that test failures are addressed quickly and efficiently, letting developers focus on higher-value tasks. Explore more about codex-cli and its capabilities [here](https://github.com/openai/codex/).
---
# Source: https://developers.openai.com/codex/app/automations.md
# Automations
## Conclusion
This automation seamlessly integrates OpenAI Codex CLI with GitHub Actions to automatically propose fixes for failing CI runs.
By leveraging Codex, you can reduce manual intervention, accelerate code reviews, and keep your main branch healthy. The workflow ensures that test failures are addressed quickly and efficiently, letting developers focus on higher-value tasks. Explore more about codex-cli and its capabilities [here](https://github.com/openai/codex/).
---
# Source: https://developers.openai.com/codex/app/automations.md
# Automations



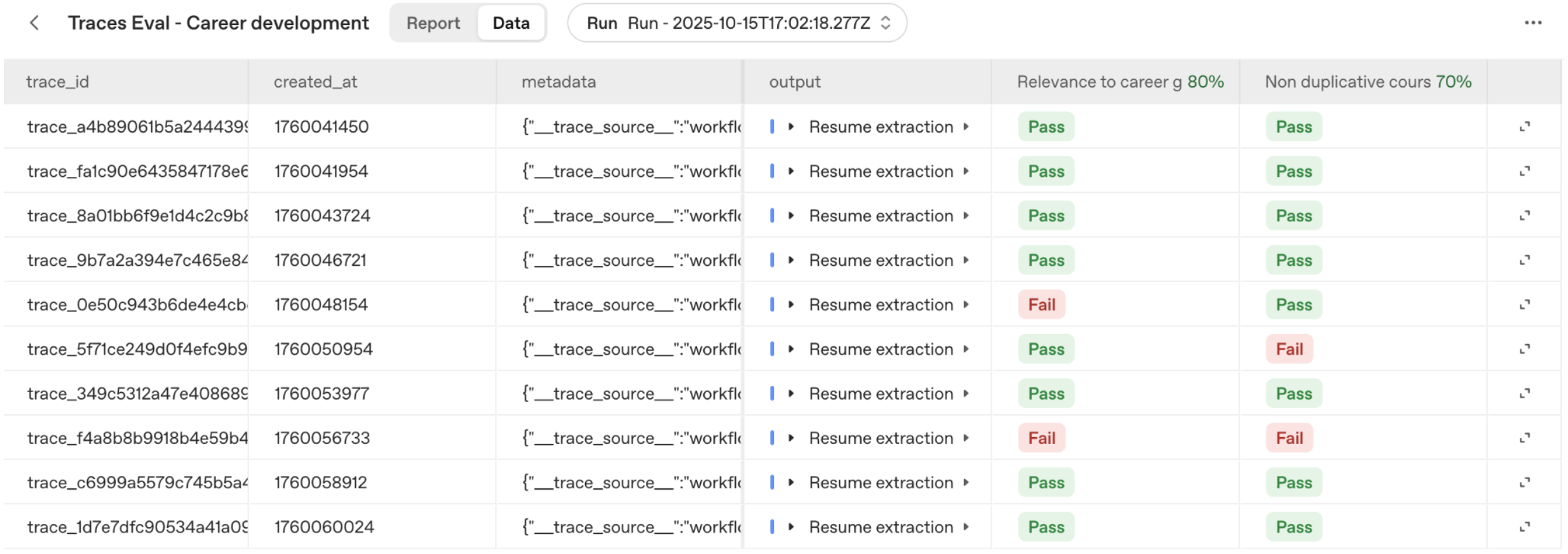
| Poster_Link | Series_Title | Released_Year | Certificate | Runtime | Genre | IMDB_Rating | Overview | Meta_score | Director | Star1 | Star2 | Star3 | Star4 | No_of_Votes | Gross | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | https://m.media-amazon.com/images/M/MV5BMDFkYT... | The Shawshank Redemption | 1994 | A | 142 min | Drama | 9.3 | Two imprisoned men bond over a number of years... | 80.0 | Frank Darabont | Tim Robbins | Morgan Freeman | Bob Gunton | William Sadler | 2343110 | 28,341,469 |
| 1 | https://m.media-amazon.com/images/M/MV5BM2MyNj... | The Godfather | 1972 | A | 175 min | Crime, Drama | 9.2 | An organized crime dynasty's aging patriarch t... | 100.0 | Francis Ford Coppola | Marlon Brando | Al Pacino | James Caan | Diane Keaton | 1620367 | 134,966,411 |
| 2 | https://m.media-amazon.com/images/M/MV5BMTMxNT... | The Dark Knight | 2008 | UA | 152 min | Action, Crime, Drama | 9.0 | When the menace known as the Joker wreaks havo... | 84.0 | Christopher Nolan | Christian Bale | Heath Ledger | Aaron Eckhart | Michael Caine | 2303232 | 534,858,444 |
| 3 | https://m.media-amazon.com/images/M/MV5BMWMwMG... | The Godfather: Part II | 1974 | A | 202 min | Crime, Drama | 9.0 | The early life and career of Vito Corleone in ... | 90.0 | Francis Ford Coppola | Al Pacino | Robert De Niro | Robert Duvall | Diane Keaton | 1129952 | 57,300,000 |
| 4 | https://m.media-amazon.com/images/M/MV5BMWU4N2... | 12 Angry Men | 1957 | U | 96 min | Crime, Drama | 9.0 | A jury holdout attempts to prevent a miscarria... | 96.0 | Sidney Lumet | Henry Fonda | Lee J. Cobb | Martin Balsam | John Fiedler | 689845 | 4,360,000 |
| asin | url | title | brand | price | availability | categories | primary_image | images | upc | ... | color | material | style | important_information | product_overview | about_item | description | specifications | uniq_id | scraped_at | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | B0CJHKVG6P | https://www.amazon.com/dp/B0CJHKVG6P | GOYMFK 1pc Free Standing Shoe Rack, Multi-laye... | GOYMFK | $24.99 | Only 13 left in stock - order soon. | ['Home & Kitchen', 'Storage & Organization', '... | https://m.media-amazon.com/images/I/416WaLx10j... | ['https://m.media-amazon.com/images/I/416WaLx1... | NaN | ... | White | Metal | Modern | [] | [{'Brand': ' GOYMFK '}, {'Color': ' White '}, ... | ['Multiple layers: Provides ample storage spac... | multiple shoes, coats, hats, and other items E... | ['Brand: GOYMFK', 'Color: White', 'Material: M... | 02593e81-5c09-5069-8516-b0b29f439ded | 2024-02-02 15:15:08 |
| 1 | B0B66QHB23 | https://www.amazon.com/dp/B0B66QHB23 | subrtex Leather ding Room, Dining Chairs Set o... | subrtex | NaN | NaN | ['Home & Kitchen', 'Furniture', 'Dining Room F... | https://m.media-amazon.com/images/I/31SejUEWY7... | ['https://m.media-amazon.com/images/I/31SejUEW... | NaN | ... | Black | Sponge | Black Rubber Wood | [] | NaN | ['【Easy Assembly】: Set of 2 dining room chairs... | subrtex Dining chairs Set of 2 | ['Brand: subrtex', 'Color: Black', 'Product Di... | 5938d217-b8c5-5d3e-b1cf-e28e340f292e | 2024-02-02 15:15:09 |
| 2 | B0BXRTWLYK | https://www.amazon.com/dp/B0BXRTWLYK | Plant Repotting Mat MUYETOL Waterproof Transpl... | MUYETOL | $5.98 | In Stock | ['Patio, Lawn & Garden', 'Outdoor Décor', 'Doo... | https://m.media-amazon.com/images/I/41RgefVq70... | ['https://m.media-amazon.com/images/I/41RgefVq... | NaN | ... | Green | Polyethylene | Modern | [] | [{'Brand': ' MUYETOL '}, {'Size': ' 26.8*26.8 ... | ['PLANT REPOTTING MAT SIZE: 26.8" x 26.8", squ... | NaN | ['Brand: MUYETOL', 'Size: 26.8*26.8', 'Item We... | b2ede786-3f51-5a45-9a5b-bcf856958cd8 | 2024-02-02 15:15:09 |
| 3 | B0C1MRB2M8 | https://www.amazon.com/dp/B0C1MRB2M8 | Pickleball Doormat, Welcome Doormat Absorbent ... | VEWETOL | $13.99 | Only 10 left in stock - order soon. | ['Patio, Lawn & Garden', 'Outdoor Décor', 'Doo... | https://m.media-amazon.com/images/I/61vz1Igler... | ['https://m.media-amazon.com/images/I/61vz1Igl... | NaN | ... | A5589 | Rubber | Modern | [] | [{'Brand': ' VEWETOL '}, {'Size': ' 16*24INCH ... | ['Specifications: 16x24 Inch ', " High-Quality... | The decorative doormat features a subtle textu... | ['Brand: VEWETOL', 'Size: 16*24INCH', 'Materia... | 8fd9377b-cfa6-5f10-835c-6b8eca2816b5 | 2024-02-02 15:15:10 |
| 4 | B0CG1N9QRC | https://www.amazon.com/dp/B0CG1N9QRC | JOIN IRON Foldable TV Trays for Eating Set of ... | JOIN IRON Store | $89.99 | Usually ships within 5 to 6 weeks | ['Home & Kitchen', 'Furniture', 'Game & Recrea... | https://m.media-amazon.com/images/I/41p4d4VJnN... | ['https://m.media-amazon.com/images/I/41p4d4VJ... | NaN | ... | Grey Set of 4 | Iron | X Classic Style | [] | NaN | ['Includes 4 Folding Tv Tray Tables And one Co... | Set of Four Folding Trays With Matching Storag... | ['Brand: JOIN IRON', 'Shape: Rectangular', 'In... | bdc9aa30-9439-50dc-8e89-213ea211d66a | 2024-02-02 15:15:11 |
5 rows × 25 columns
 ```text
CAPTION: A stylish white free-standing shoe rack featuring multiple layers and eight double hooks, perfect for organizing shoes and accessories in living rooms, bathrooms, or hallways.
```
```text
CAPTION: A stylish white free-standing shoe rack featuring multiple layers and eight double hooks, perfect for organizing shoes and accessories in living rooms, bathrooms, or hallways.
```
 ```text
CAPTION: Set of 2 black leather dining chairs featuring a sleek design with vertical stitching and sturdy wooden legs.
```
```text
CAPTION: Set of 2 black leather dining chairs featuring a sleek design with vertical stitching and sturdy wooden legs.
```
 ```text
CAPTION: The MUYETOL Plant Repotting Mat is a waterproof, portable, and foldable gardening work mat measuring 26.8" x 26.8", designed for easy soil changing and indoor transplanting.
```
```text
CAPTION: The MUYETOL Plant Repotting Mat is a waterproof, portable, and foldable gardening work mat measuring 26.8" x 26.8", designed for easy soil changing and indoor transplanting.
```
 ```text
CAPTION: Absorbent non-slip doormat featuring the phrase "It's a good day to play PICKLEBALL" with paddle graphics, measuring 16x24 inches.
```
```text
CAPTION: Absorbent non-slip doormat featuring the phrase "It's a good day to play PICKLEBALL" with paddle graphics, measuring 16x24 inches.
```
 ```text
CAPTION: Set of 4 foldable TV trays in grey, featuring a compact design with a stand for easy storage, perfect for small spaces.
```
### Creating the batch job
As with the first example, we will create an array of json tasks to generate a `jsonl` file and use it to create the batch job.
```python
# Creating an array of json tasks
tasks = []
for index, row in df.iterrows():
title = row['title']
img_url = row['primary_image']
task = {
"custom_id": f"task-{index}",
"method": "POST",
"url": "/v1/chat/completions",
"body": {
# This is what you would have in your Chat Completions API call
"model": "gpt-4o-mini",
"temperature": 0.2,
"max_tokens": 300,
"messages": [
{
"role": "system",
"content": caption_system_prompt
},
{
"role": "user",
"content": [
{
"type": "text",
"text": title
},
{
"type": "image_url",
"image_url": {
"url": img_url
}
},
],
}
]
}
}
tasks.append(task)
```
```python
# Creating the file
file_name = "data/batch_tasks_furniture.jsonl"
with open(file_name, 'w') as file:
for obj in tasks:
file.write(json.dumps(obj) + '\n')
```
```python
# Uploading the file
batch_file = client.files.create(
file=open(file_name, "rb"),
purpose="batch"
)
```
```python
# Creating the job
batch_job = client.batches.create(
input_file_id=batch_file.id,
endpoint="/v1/chat/completions",
completion_window="24h"
)
```
```python
batch_job = client.batches.retrieve(batch_job.id)
print(batch_job)
```
### Getting results
As with the first example, we can retrieve results once the batch job is done.
Reminder: the results are not in the same order as in the input file.
Make sure to check the custom_id to match the results against the input requests
```python
# Retrieving result file
result_file_id = batch_job.output_file_id
result = client.files.content(result_file_id).content
```
```python
result_file_name = "data/batch_job_results_furniture.jsonl"
with open(result_file_name, 'wb') as file:
file.write(result)
```
```python
# Loading data from saved file
results = []
with open(result_file_name, 'r') as file:
for line in file:
# Parsing the JSON string into a dict and appending to the list of results
json_object = json.loads(line.strip())
results.append(json_object)
```
```python
# Reading only the first results
for res in results[:5]:
task_id = res['custom_id']
# Getting index from task id
index = task_id.split('-')[-1]
result = res['response']['body']['choices'][0]['message']['content']
item = df.iloc[int(index)]
img_url = item['primary_image']
img = Image(url=img_url)
display(img)
print(f"CAPTION: {result}\n\n")
```
```text
CAPTION: Set of 4 foldable TV trays in grey, featuring a compact design with a stand for easy storage, perfect for small spaces.
```
### Creating the batch job
As with the first example, we will create an array of json tasks to generate a `jsonl` file and use it to create the batch job.
```python
# Creating an array of json tasks
tasks = []
for index, row in df.iterrows():
title = row['title']
img_url = row['primary_image']
task = {
"custom_id": f"task-{index}",
"method": "POST",
"url": "/v1/chat/completions",
"body": {
# This is what you would have in your Chat Completions API call
"model": "gpt-4o-mini",
"temperature": 0.2,
"max_tokens": 300,
"messages": [
{
"role": "system",
"content": caption_system_prompt
},
{
"role": "user",
"content": [
{
"type": "text",
"text": title
},
{
"type": "image_url",
"image_url": {
"url": img_url
}
},
],
}
]
}
}
tasks.append(task)
```
```python
# Creating the file
file_name = "data/batch_tasks_furniture.jsonl"
with open(file_name, 'w') as file:
for obj in tasks:
file.write(json.dumps(obj) + '\n')
```
```python
# Uploading the file
batch_file = client.files.create(
file=open(file_name, "rb"),
purpose="batch"
)
```
```python
# Creating the job
batch_job = client.batches.create(
input_file_id=batch_file.id,
endpoint="/v1/chat/completions",
completion_window="24h"
)
```
```python
batch_job = client.batches.retrieve(batch_job.id)
print(batch_job)
```
### Getting results
As with the first example, we can retrieve results once the batch job is done.
Reminder: the results are not in the same order as in the input file.
Make sure to check the custom_id to match the results against the input requests
```python
# Retrieving result file
result_file_id = batch_job.output_file_id
result = client.files.content(result_file_id).content
```
```python
result_file_name = "data/batch_job_results_furniture.jsonl"
with open(result_file_name, 'wb') as file:
file.write(result)
```
```python
# Loading data from saved file
results = []
with open(result_file_name, 'r') as file:
for line in file:
# Parsing the JSON string into a dict and appending to the list of results
json_object = json.loads(line.strip())
results.append(json_object)
```
```python
# Reading only the first results
for res in results[:5]:
task_id = res['custom_id']
# Getting index from task id
index = task_id.split('-')[-1]
result = res['response']['body']['choices'][0]['message']['content']
item = df.iloc[int(index)]
img_url = item['primary_image']
img = Image(url=img_url)
display(img)
print(f"CAPTION: {result}\n\n")
```
 ```text
CAPTION: Brushed brass pedestal towel rack with a sleek, modern design, featuring multiple bars for hanging towels, measuring 25.75 x 14.44 x 32 inches.
```
```text
CAPTION: Brushed brass pedestal towel rack with a sleek, modern design, featuring multiple bars for hanging towels, measuring 25.75 x 14.44 x 32 inches.
```
 ```text
CAPTION: Black round end table featuring a tempered glass top and a metal frame, with a lower shelf for additional storage.
```
```text
CAPTION: Black round end table featuring a tempered glass top and a metal frame, with a lower shelf for additional storage.
```
 ```text
CAPTION: Black collapsible and height-adjustable telescoping stool, portable and designed for makeup artists and hairstylists, shown in various stages of folding for easy transport.
```
```text
CAPTION: Black collapsible and height-adjustable telescoping stool, portable and designed for makeup artists and hairstylists, shown in various stages of folding for easy transport.
```
 ```text
CAPTION: Ergonomic pink gaming chair featuring breathable fabric, adjustable height, lumbar support, a footrest, and a swivel recliner function.
```
```text
CAPTION: Ergonomic pink gaming chair featuring breathable fabric, adjustable height, lumbar support, a footrest, and a swivel recliner function.
```
 ```text
CAPTION: A set of two Glitzhome adjustable bar stools featuring a mid-century modern design with swivel seats, PU leather upholstery, and wooden backrests.
```
## Wrapping up
In this cookbook, we have seen two examples of how to use the new Batch API, but keep in mind that the Batch API works the same way as the Chat Completions endpoint, supporting the same parameters and most of the recent models (gpt-4o, gpt-4o-mini, gpt-4-turbo, gpt-3.5-turbo...).
By using this API, you can significantly reduce costs, so we recommend switching every workload that can happen async to a batch job with this new API.
---
# Source: https://developers.openai.com/codex/guides/build-ai-native-engineering-team.md
# Building an AI-Native Engineering Team
## Introduction
AI models are rapidly expanding the range of tasks they can perform, with significant implications for engineering. Frontier systems now sustain multi-hour reasoning: as of August 2025, METR found that leading models could complete **2 hours and 17 minutes** of continuous work with roughly **50% confidence** of producing a correct answer.
This capability is improving quickly, with task length doubling about every seven months. Only a few years ago, models could manage about 30 seconds of reasoning – enough for small code suggestions. Today, as models sustain longer chains of reasoning, the entire software development lifecycle is potentially in scope for AI assistance, enabling coding agents to contribute effectively to planning, design, development, testing, code reviews, and deployment.
![][image1]In this guide, we’ll share real examples that outline how AI agents are contributing to the software development lifecycle with practical guidance on what engineering leaders can do today to start building AI-native teams and processes.
## AI Coding: From Autocomplete to Agents
AI coding tools have progressed far beyond their origins as autocomplete assistants. Early tools handled quick tasks such as suggesting the next line of code or filling in function templates. As models gained stronger reasoning abilities, developers began interacting with agents through chat interfaces in IDEs for pair programming and code exploration.
Today’s coding agents can generate entire files, scaffold new projects, and translate designs into code. They can reason through multi-step problems such as debugging or refactoring, with agent execution also now shifting from an individual developer’s machine to cloud-based, multi-agent environments. This is changing how developers work, allowing them to spend less time generating code with the agent inside the IDE and more time delegating entire workflows.
| Capability | What It Enables |
| :--------------------------------- | :--------------------------------------------------------------------------------------------------------------------------------------------------------------------- |
| **Unified context across systems** | A single model can read code, configuration, and telemetry, providing consistent reasoning across layers that previously required separate tooling. |
| **Structured tool execution** | Models can now call compilers, test runners, and scanners directly, producing verifiable results rather than static suggestions. |
| **Persistent project memory** | Long context windows and techniques like compaction allow models to follow a feature from proposal to deployment, remembering previous design choices and constraints. |
| **Evaluation loops** | Model outputs can be tested automatically against benchmarks—unit tests, latency targets, or style guides—so improvements are grounded in measurable quality. |
At OpenAI, we have witnessed this firsthand. Development cycles have accelerated, with work that once required weeks now being delivered in days. Teams move more easily across domains, onboard faster to unfamiliar projects, and operate with greater agility and autonomy across the organization. Many routine and time-consuming tasks, from documenting new code and surfacing relevant tests, maintaining dependencies and cleaning up feature flags are now delegated to Codex entirely.
However, some aspects of engineering remain unchanged. True ownership of code—especially for new or ambiguous problems—still rests with engineers, and certain challenges exceed the capabilities of current models. But with coding agents like Codex, engineers can now spend more time on complex and novel challenges, focusing on design, architecture, and system-level reasoning rather than debugging or rote implementation.
In the following sections, we break down how each phase of the SDLC changes with coding agents — and outline the concrete steps your team can take to start operating as an AI-native engineering org.
## 1. Plan
Teams across an organization often depend on engineers to determine whether a feature is feasible, how long it will take to build, and which systems or teams will be involved. While anyone can draft a specification, forming an accurate plan typically requires deep codebase awareness and multiple rounds of iteration with engineering to uncover requirements, clarify edge cases, and align on what is technically realistic.
### How coding agents help
AI coding agents give teams immediate, code-aware insights during planning and scoping. For example, teams may build workflows that connect coding agents to their issue-tracking systems to read a feature specification, cross-reference it against the codebase, and then flag ambiguities, break the work into subcomponents, or estimate difficulty.
Coding agents can also instantly trace code paths to show which services are involved in a feature — work that previously required hours or days of manual digging through a large codebase.
### What engineers do instead
Teams spend more time on core feature work because agents surface the context that previously required meetings for product alignment and scoping. Key implementation details, dependencies, and edge cases are identified up front, enabling faster decisions with fewer meetings.
| Delegate | Review | Own |
| --------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- | -------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- | ------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------ |
| AI agents can take the first pass at feasibility and architectural analysis. They read a specification, map it to the codebase, identify dependencies, and surface ambiguities or edge cases that need clarification. | Teams review the agent’s findings to validate accuracy, assess completeness, and ensure estimates reflect real technical constraints. Story point assignment, effort sizing, and identifying non-obvious risks still require human judgment. | Strategic decisions — such as prioritization, long-term direction, sequencing, and tradeoffs — remain human-led. Teams may ask the agent for options or next steps, but final responsibility for planning and product direction stays with the organization. |
### Getting started checklist
- Identify common processes that require alignment between features and source code. Common areas include feature scoping and ticket creation.
- Begin by implementing basic workflows, for example tagging and deduplicating issues or feature requests.
- Consider more advanced workflows, like adding sub-tasks to a ticket based on an initial feature description. Or kick off an agent run when a ticket reaches a specific stage to supplement the description with more details.
```text
CAPTION: A set of two Glitzhome adjustable bar stools featuring a mid-century modern design with swivel seats, PU leather upholstery, and wooden backrests.
```
## Wrapping up
In this cookbook, we have seen two examples of how to use the new Batch API, but keep in mind that the Batch API works the same way as the Chat Completions endpoint, supporting the same parameters and most of the recent models (gpt-4o, gpt-4o-mini, gpt-4-turbo, gpt-3.5-turbo...).
By using this API, you can significantly reduce costs, so we recommend switching every workload that can happen async to a batch job with this new API.
---
# Source: https://developers.openai.com/codex/guides/build-ai-native-engineering-team.md
# Building an AI-Native Engineering Team
## Introduction
AI models are rapidly expanding the range of tasks they can perform, with significant implications for engineering. Frontier systems now sustain multi-hour reasoning: as of August 2025, METR found that leading models could complete **2 hours and 17 minutes** of continuous work with roughly **50% confidence** of producing a correct answer.
This capability is improving quickly, with task length doubling about every seven months. Only a few years ago, models could manage about 30 seconds of reasoning – enough for small code suggestions. Today, as models sustain longer chains of reasoning, the entire software development lifecycle is potentially in scope for AI assistance, enabling coding agents to contribute effectively to planning, design, development, testing, code reviews, and deployment.
![][image1]In this guide, we’ll share real examples that outline how AI agents are contributing to the software development lifecycle with practical guidance on what engineering leaders can do today to start building AI-native teams and processes.
## AI Coding: From Autocomplete to Agents
AI coding tools have progressed far beyond their origins as autocomplete assistants. Early tools handled quick tasks such as suggesting the next line of code or filling in function templates. As models gained stronger reasoning abilities, developers began interacting with agents through chat interfaces in IDEs for pair programming and code exploration.
Today’s coding agents can generate entire files, scaffold new projects, and translate designs into code. They can reason through multi-step problems such as debugging or refactoring, with agent execution also now shifting from an individual developer’s machine to cloud-based, multi-agent environments. This is changing how developers work, allowing them to spend less time generating code with the agent inside the IDE and more time delegating entire workflows.
| Capability | What It Enables |
| :--------------------------------- | :--------------------------------------------------------------------------------------------------------------------------------------------------------------------- |
| **Unified context across systems** | A single model can read code, configuration, and telemetry, providing consistent reasoning across layers that previously required separate tooling. |
| **Structured tool execution** | Models can now call compilers, test runners, and scanners directly, producing verifiable results rather than static suggestions. |
| **Persistent project memory** | Long context windows and techniques like compaction allow models to follow a feature from proposal to deployment, remembering previous design choices and constraints. |
| **Evaluation loops** | Model outputs can be tested automatically against benchmarks—unit tests, latency targets, or style guides—so improvements are grounded in measurable quality. |
At OpenAI, we have witnessed this firsthand. Development cycles have accelerated, with work that once required weeks now being delivered in days. Teams move more easily across domains, onboard faster to unfamiliar projects, and operate with greater agility and autonomy across the organization. Many routine and time-consuming tasks, from documenting new code and surfacing relevant tests, maintaining dependencies and cleaning up feature flags are now delegated to Codex entirely.
However, some aspects of engineering remain unchanged. True ownership of code—especially for new or ambiguous problems—still rests with engineers, and certain challenges exceed the capabilities of current models. But with coding agents like Codex, engineers can now spend more time on complex and novel challenges, focusing on design, architecture, and system-level reasoning rather than debugging or rote implementation.
In the following sections, we break down how each phase of the SDLC changes with coding agents — and outline the concrete steps your team can take to start operating as an AI-native engineering org.
## 1. Plan
Teams across an organization often depend on engineers to determine whether a feature is feasible, how long it will take to build, and which systems or teams will be involved. While anyone can draft a specification, forming an accurate plan typically requires deep codebase awareness and multiple rounds of iteration with engineering to uncover requirements, clarify edge cases, and align on what is technically realistic.
### How coding agents help
AI coding agents give teams immediate, code-aware insights during planning and scoping. For example, teams may build workflows that connect coding agents to their issue-tracking systems to read a feature specification, cross-reference it against the codebase, and then flag ambiguities, break the work into subcomponents, or estimate difficulty.
Coding agents can also instantly trace code paths to show which services are involved in a feature — work that previously required hours or days of manual digging through a large codebase.
### What engineers do instead
Teams spend more time on core feature work because agents surface the context that previously required meetings for product alignment and scoping. Key implementation details, dependencies, and edge cases are identified up front, enabling faster decisions with fewer meetings.
| Delegate | Review | Own |
| --------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- | -------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- | ------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------ |
| AI agents can take the first pass at feasibility and architectural analysis. They read a specification, map it to the codebase, identify dependencies, and surface ambiguities or edge cases that need clarification. | Teams review the agent’s findings to validate accuracy, assess completeness, and ensure estimates reflect real technical constraints. Story point assignment, effort sizing, and identifying non-obvious risks still require human judgment. | Strategic decisions — such as prioritization, long-term direction, sequencing, and tradeoffs — remain human-led. Teams may ask the agent for options or next steps, but final responsibility for planning and product direction stays with the organization. |
### Getting started checklist
- Identify common processes that require alignment between features and source code. Common areas include feature scoping and ticket creation.
- Begin by implementing basic workflows, for example tagging and deduplicating issues or feature requests.
- Consider more advanced workflows, like adding sub-tasks to a ticket based on an initial feature description. Or kick off an agent run when a ticket reaches a specific stage to supplement the description with more details.
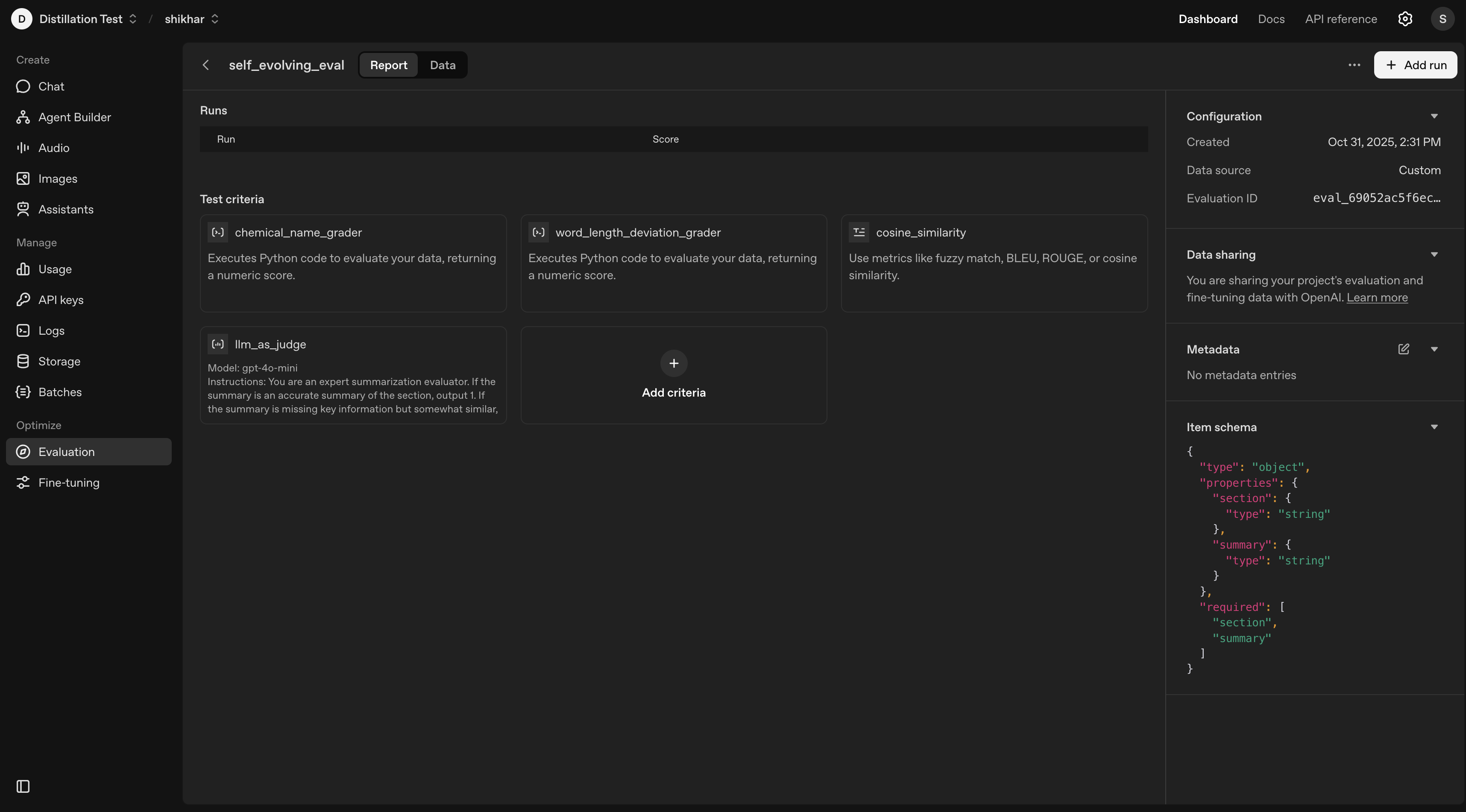
 ## The Code Review Prompt
GPT-5.2-Codex has received specific training to improve its code review abilities. You can steer GPT-5.2-Codex to conduct a code review with the following prompt:
```
You are acting as a reviewer for a proposed code change made by another engineer.
Focus on issues that impact correctness, performance, security, maintainability, or developer experience.
Flag only actionable issues introduced by the pull request.
When you flag an issue, provide a short, direct explanation and cite the affected file and line range.
Prioritize severe issues and avoid nit-level comments unless they block understanding of the diff.
After listing findings, produce an overall correctness verdict (\"patch is correct\" or \"patch is incorrect\") with a concise justification and a confidence score between 0 and 1.
Ensure that file citations and line numbers are exactly correct using the tools available; if they are incorrect your comments will be rejected.
```
## Codex Structured Outputs
In order to make comments on code ranges in our pull request, we need to receive Codex's response in a specific format. To do that we can create a file called `codex-output-schema.json` that conforms to OpenAI's [structured outputs](https://platform.openai.com/docs/guides/structured-outputs) format.
To use this file in our workflow YAML, we can call Codex with the `output-schema-file` argument like this:
```yaml
- name: Run Codex structured review
id: run-codex
uses: openai/codex-action@main
with:
openai-api-key: ${{ secrets.OPENAI_API_KEY }}
prompt-file: codex-prompt.md
sandbox: read-only
model: ${{ env.CODEX_MODEL }}
output-schema-file: codex-output-schema.json # <-- Our schema file
output-file: codex-output.json
```
You can also pass a similar argument to `codex exec` for example:
```bash
codex exec "Review my pull request!" --output-schema codex-output-schema.json
```
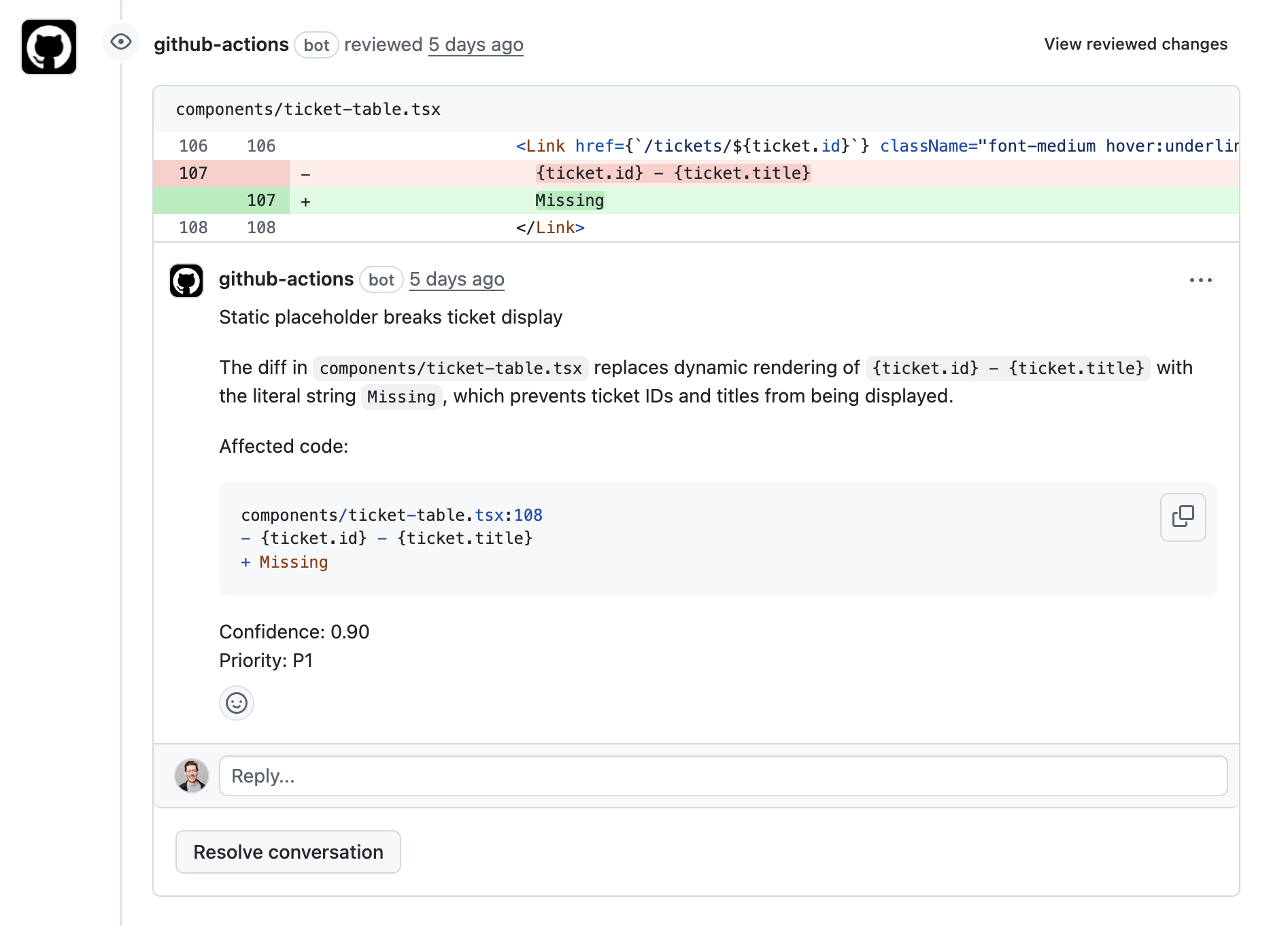
## GitHub Actions Example
Let's put it all together. If you're using GitHub Actions in an on-prem environment, you can tailor this example to your specific workflow. Inline comments highlight the key steps.
```yaml
name: Codex Code Review
# Determine when the review action should be run:
on:
pull_request:
types:
- opened
- reopened
- synchronize
- ready_for_review
concurrency:
group: codex-structured-review-${{ github.event.pull_request.number }}
cancel-in-progress: true
jobs:
codex-structured-review:
name: Run Codex structured review
runs-on: ubuntu-latest
permissions:
contents: read
pull-requests: write
env:
OPENAI_API_KEY: ${{ secrets.OPENAI_API_KEY }}
GITHUB_TOKEN: ${{ github.token }}
CODEX_MODEL: ${{ vars.CODEX_MODEL || 'o4-mini' }}
PR_NUMBER: ${{ github.event.pull_request.number }}
HEAD_SHA: ${{ github.event.pull_request.head.sha }}
BASE_SHA: ${{ github.event.pull_request.base.sha }}
REPOSITORY: ${{ github.repository }}
outputs:
codex-output: ${{ steps.run-codex.outputs.final-message }}
steps:
- name: Checkout pull request merge commit
uses: actions/checkout@v5
with:
ref: refs/pull/${{ github.event.pull_request.number }}/merge
- name: Fetch base and head refs
run: |
set -euxo pipefail
git fetch --no-tags origin \
"${{ github.event.pull_request.base.ref }}" \
+refs/pull/${{ github.event.pull_request.number }}/head
shell: bash
# The structured output schema ensures that codex produces comments
# with filepaths, line numbers, title, body, etc.
- name: Generate structured output schema
run: |
set -euo pipefail
cat <<'JSON' > codex-output-schema.json
{
"type": "object",
"properties": {
"findings": {
"type": "array",
"items": {
"type": "object",
"properties": {
"title": {
"type": "string",
"maxLength": 80
},
"body": {
"type": "string",
"minLength": 1
},
"confidence_score": {
"type": "number",
"minimum": 0,
"maximum": 1
},
"priority": {
"type": "integer",
"minimum": 0,
"maximum": 3
},
"code_location": {
"type": "object",
"properties": {
"absolute_file_path": {
"type": "string",
"minLength": 1
},
"line_range": {
"type": "object",
"properties": {
"start": {
"type": "integer",
"minimum": 1
},
"end": {
"type": "integer",
"minimum": 1
}
},
"required": [
"start",
"end"
],
"additionalProperties": false
}
},
"required": [
"absolute_file_path",
"line_range"
],
"additionalProperties": false
}
},
"required": [
"title",
"body",
"confidence_score",
"priority",
"code_location"
],
"additionalProperties": false
}
},
"overall_correctness": {
"type": "string",
"enum": [
"patch is correct",
"patch is incorrect"
]
},
"overall_explanation": {
"type": "string",
"minLength": 1
},
"overall_confidence_score": {
"type": "number",
"minimum": 0,
"maximum": 1
}
},
"required": [
"findings",
"overall_correctness",
"overall_explanation",
"overall_confidence_score"
],
"additionalProperties": false
}
JSON
shell: bash
# This section generates our prompt:
- name: Build Codex review prompt
env:
REVIEW_PROMPT_PATH: ${{ vars.CODEX_PROMPT_PATH || 'review_prompt.md' }}
run: |
set -euo pipefail
PROMPT_PATH="codex-prompt.md"
TEMPLATE_PATH="${REVIEW_PROMPT_PATH}"
if [ -n "$TEMPLATE_PATH" ] && [ -f "$TEMPLATE_PATH" ]; then
cat "$TEMPLATE_PATH" > "$PROMPT_PATH"
else
{
printf '%s\n' "You are acting as a reviewer for a proposed code change made by another engineer."
printf '%s\n' "Focus on issues that impact correctness, performance, security, maintainability, or developer experience."
printf '%s\n' "Flag only actionable issues introduced by the pull request."
printf '%s\n' "When you flag an issue, provide a short, direct explanation and cite the affected file and line range."
printf '%s\n' "Prioritize severe issues and avoid nit-level comments unless they block understanding of the diff."
printf '%s\n' "After listing findings, produce an overall correctness verdict (\"patch is correct\" or \"patch is incorrect\") with a concise justification and a confidence score between 0 and 1."
printf '%s\n' "Ensure that file citations and line numbers are exactly correct using the tools available; if they are incorrect your comments will be rejected."
} > "$PROMPT_PATH"
fi
{
echo ""
echo "Repository: ${REPOSITORY}"
echo "Pull Request #: ${PR_NUMBER}"
echo "Base ref: ${{ github.event.pull_request.base.ref }}"
echo "Head ref: ${{ github.event.pull_request.head.ref }}"
echo "Base SHA: ${BASE_SHA}"
echo "Head SHA: ${HEAD_SHA}"
echo "Changed files:"
git --no-pager diff --name-status "${BASE_SHA}" "${HEAD_SHA}"
echo ""
echo "Unified diff (context=5):"
git --no-pager diff --unified=5 --stat=200 "${BASE_SHA}" "${HEAD_SHA}" > /tmp/diffstat.txt
git --no-pager diff --unified=5 "${BASE_SHA}" "${HEAD_SHA}" > /tmp/full.diff
cat /tmp/diffstat.txt
echo ""
cat /tmp/full.diff
} >> "$PROMPT_PATH"
shell: bash
# Putting it all together: we run the codex action with our code review prompt,
# structured output, and output file:
- name: Run Codex structured review
id: run-codex
uses: openai/codex-action@main
with:
openai-api-key: ${{ secrets.OPENAI_API_KEY }}
prompt-file: codex-prompt.md
output-schema-file: codex-output-schema.json
output-file: codex-output.json
sandbox: read-only
model: ${{ env.CODEX_MODEL }}
- name: Inspect structured Codex output
if: ${{ always() }}
run: |
if [ -s codex-output.json ]; then
jq '.' codex-output.json || true
else
echo "Codex output file missing"
fi
shell: bash
# This step produces in-line code review comments on specific line
# ranges of code.
- name: Publish inline review comments
if: ${{ always() }}
env:
REVIEW_JSON: codex-output.json
run: |
set -euo pipefail
if [ ! -s "$REVIEW_JSON" ]; then
echo "No Codex output file present; skipping comment publishing."
exit 0
fi
findings_count=$(jq '.findings | length' "$REVIEW_JSON")
if [ "$findings_count" -eq 0 ]; then
echo "Codex returned no findings; skipping inline comments."
exit 0
fi
jq -c --arg commit "$HEAD_SHA" '.findings[] | {
body: (.title + "\n\n" + .body + "\n\nConfidence: " + (.confidence_score | tostring) + (if has("priority") then "\nPriority: P" + (.priority | tostring) else "" end)),
commit_id: $commit,
path: .code_location.absolute_file_path,
line: .code_location.line_range.end,
side: "RIGHT",
start_line: (if .code_location.line_range.start != .code_location.line_range.end then .code_location.line_range.start else null end),
start_side: (if .code_location.line_range.start != .code_location.line_range.end then "RIGHT" else null end)
} | with_entries(select(.value != null))' "$REVIEW_JSON" > findings.jsonl
while IFS= read -r payload; do
echo "Posting review comment payload:" && echo "$payload" | jq '.'
curl -sS \
-X POST \
-H "Accept: application/vnd.github+json" \
-H "Authorization: Bearer ${GITHUB_TOKEN}" \
-H "X-GitHub-Api-Version: 2022-11-28" \
"https://api.github.com/repos/${REPOSITORY}/pulls/${PR_NUMBER}/comments" \
-d "$payload"
done < findings.jsonl
shell: bash
# This section creates a single comment summarizing the review.
- name: Publish overall summary comment
if: ${{ always() }}
env:
REVIEW_JSON: codex-output.json
run: |
set -euo pipefail
if [ ! -s "$REVIEW_JSON" ]; then
echo "Codex output missing; skipping summary."
exit 0
fi
overall_state=$(jq -r '.overall_correctness' "$REVIEW_JSON")
overall_body=$(jq -r '.overall_explanation' "$REVIEW_JSON")
confidence=$(jq -r '.overall_confidence_score' "$REVIEW_JSON")
msg="**Codex automated review**\n\nVerdict: ${overall_state}\nConfidence: ${confidence}\n\n${overall_body}"
curl -sS \
-X POST \
-H "Accept: application/vnd.github+json" \
-H "Authorization: Bearer ${GITHUB_TOKEN}" \
-H "X-GitHub-Api-Version: 2022-11-28" \
"https://api.github.com/repos/${REPOSITORY}/issues/${PR_NUMBER}/comments" \
-d "$(jq -n --arg body "$msg" '{body: $body}')"
shell: bash
```
## Gitlab Example
GitLab doesn’t have a direct equivalent to the GitHub Action, but you can run codex exec inside GitLab CI/CD to perform automated code reviews.
However, the GitHub Action includes an important [safety strategy](https://github.com/openai/codex-action?tab=readme-ov-file#safety-strategy): it drops sudo permissions so Codex cannot access its own OpenAI API key. This isolation is critical—especially for public repositories where sensitive secrets (like your OpenAI API key) may be present—because it prevents Codex from reading or exfiltrating credentials during execution.
Before running this job, configure your GitLab project:
1. Go to **Project → Settings → CI/CD**.
2. Expand the **Variables** section.
3. Add these variables:
- `OPENAI_API_KEY`
- `GITLAB_TOKEN`
4. Mark them as masked/protected as appropriate.
5. Add the following GitLab example job to your `.gitlab-ci.yml` file at the root of your repository so it runs during merge request pipelines.
Please be mindful with your API key on public repositories.
```yaml
stages:
- review
codex-structured-review:
stage: review
image: ubuntu:22.04
rules:
- if: '$CI_PIPELINE_SOURCE == "merge_request_event"'
variables:
PR_NUMBER: $CI_MERGE_REQUEST_IID
REPOSITORY: "$CI_PROJECT_PATH"
BASE_SHA: "$CI_MERGE_REQUEST_DIFF_BASE_SHA"
HEAD_SHA: "$CI_COMMIT_SHA"
before_script:
- apt-get update -y
- apt-get install -y git curl jq
- |
if ! command -v codex >/dev/null 2>&1; then
ARCH="$(uname -m)"
case "$ARCH" in
x86_64) CODEX_PLATFORM="x86_64-unknown-linux-musl" ;;
aarch64|arm64) CODEX_PLATFORM="aarch64-unknown-linux-musl" ;;
*)
echo "Unsupported architecture: $ARCH"
exit 1
;;
esac
CODEX_VERSION="${CODEX_VERSION:-latest}"
if [ -n "${CODEX_DOWNLOAD_URL:-}" ]; then
CODEX_URL="$CODEX_DOWNLOAD_URL"
elif [ "$CODEX_VERSION" = "latest" ]; then
CODEX_URL="https://github.com/openai/codex/releases/latest/download/codex-${CODEX_PLATFORM}.tar.gz"
else
CODEX_URL="https://github.com/openai/codex/releases/download/${CODEX_VERSION}/codex-${CODEX_PLATFORM}.tar.gz"
fi
TMP_DIR="$(mktemp -d)"
curl -fsSL "$CODEX_URL" -o "$TMP_DIR/codex.tar.gz"
tar -xzf "$TMP_DIR/codex.tar.gz" -C "$TMP_DIR"
install -m 0755 "$TMP_DIR"/codex-* /usr/local/bin/codex
rm -rf "$TMP_DIR"
fi
- git fetch origin $CI_MERGE_REQUEST_TARGET_BRANCH_NAME
- git fetch origin $CI_MERGE_REQUEST_SOURCE_BRANCH_NAME
- git checkout $CI_MERGE_REQUEST_SOURCE_BRANCH_NAME
script:
- echo "Running Codex structured review for MR !${PR_NUMBER}"
# Generate structured output schema
- |
cat <<'JSON' > codex-output-schema.json
{
"$schema": "http://json-schema.org/draft-07/schema#",
"title": "Codex Structured Review",
"type": "object",
"additionalProperties": false,
"required": [
"overall_correctness",
"overall_explanation",
"overall_confidence_score",
"findings"
],
"properties": {
"overall_correctness": {
"type": "string",
"description": "Overall verdict for the merge request."
},
"overall_explanation": {
"type": "string",
"description": "Explanation backing up the verdict."
},
"overall_confidence_score": {
"type": "number",
"minimum": 0,
"maximum": 1,
"description": "Confidence level for the verdict."
},
"findings": {
"type": "array",
"description": "Collection of actionable review findings.",
"items": {
"type": "object",
"additionalProperties": false,
"required": [
"title",
"body",
"confidence_score",
"code_location"
],
"properties": {
"title": {
"type": "string"
},
"body": {
"type": "string"
},
"confidence_score": {
"type": "number",
"minimum": 0,
"maximum": 1
},
"code_location": {
"type": "object",
"additionalProperties": false,
"required": [
"absolute_file_path",
"relative_file_path",
"line_range"
],
"properties": {
"absolute_file_path": {
"type": "string"
},
"relative_file_path": {
"type": "string"
},
"line_range": {
"type": "object",
"additionalProperties": false,
"required": [
"start",
"end"
],
"properties": {
"start": {
"type": "integer",
"minimum": 1
},
"end": {
"type": "integer",
"minimum": 1
}
}
}
}
}
}
},
"default": []
}
}
}
JSON
# Build Codex review prompt
- |
PROMPT_PATH="codex-prompt.md"
TEMPLATE_PATH="${REVIEW_PROMPT_PATH:-review_prompt.md}"
if [ -n "$TEMPLATE_PATH" ] && [ -f "$TEMPLATE_PATH" ]; then
cat "$TEMPLATE_PATH" > "$PROMPT_PATH"
else
{
printf '%s\n' "You are acting as a reviewer for a proposed code change..."
printf '%s\n' "Focus on issues that impact correctness, performance, security..."
printf '%s\n' "Flag only actionable issues introduced by this merge request..."
printf '%s\n' "Provide an overall correctness verdict..."
} > "$PROMPT_PATH"
fi
{
echo ""
echo "Repository: ${REPOSITORY}"
echo "Merge Request #: ${PR_NUMBER}"
echo "Base SHA: ${BASE_SHA}"
echo "Head SHA: ${HEAD_SHA}"
echo ""
echo "Changed files:"
git --no-pager diff --name-status "${BASE_SHA}" "${HEAD_SHA}"
echo ""
echo "Unified diff (context=5):"
git --no-pager diff --unified=5 "${BASE_SHA}" "${HEAD_SHA}"
} >> "$PROMPT_PATH"
# Run Codex exec CLI
- |
printenv OPENAI_API_KEY | codex login --with-api-key && \
codex exec --output-schema codex-output-schema.json \
--output-last-message codex-output.json \
--sandbox read-only \
- < codex-prompt.md
# Inspect structured Codex output
- |
if [ -s codex-output.json ]; then
jq '.' codex-output.json || true
else
echo "Codex output file missing"; exit 1
fi
# Publish inline comments to GitLab MR
- |
findings_count=$(jq '.findings | length' codex-output.json)
if [ "$findings_count" -eq 0 ]; then
echo "No findings from Codex; skipping comments."
exit 0
fi
jq -c \
--arg base "$BASE_SHA" \
--arg start "$BASE_SHA" \
--arg head "$HEAD_SHA" '
.findings[] | {
body: (.title + "\n\n" + .body + "\n\nConfidence: " + (.confidence_score | tostring)),
position: {
position_type: "text",
base_sha: $base,
start_sha: $start,
head_sha: $head,
new_path: (.code_location.relative_file_path // .code_location.absolute_file_path),
new_line: .code_location.line_range.end
}
}
' codex-output.json > findings.jsonl
while IFS= read -r payload; do
curl -sS --request POST \
--header "PRIVATE-TOKEN: $GITLAB_TOKEN" \
--header "Content-Type: application/json" \
--data "$payload" \
"https://gitlab.com/api/v4/projects/${CI_PROJECT_ID}/merge_requests/${PR_NUMBER}/discussions"
done < findings.jsonl
# Publish overall summary comment
- |
overall_state=$(jq -r '.overall_correctness' codex-output.json)
overall_body=$(jq -r '.overall_explanation' codex-output.json)
confidence=$(jq -r '.overall_confidence_score' codex-output.json)
summary="**Codex automated review**\n\nVerdict: ${overall_state}\nConfidence: ${confidence}\n\n${overall_body}"
curl -sS --request POST \
--header "PRIVATE-TOKEN: $GITLAB_TOKEN" \
--header "Content-Type: application/json" \
--data "$(jq -n --arg body "$summary" '{body: $body}')" \
"https://gitlab.com/api/v4/projects/${CI_PROJECT_ID}/merge_requests/${PR_NUMBER}/notes"
artifacts:
when: always
paths:
- codex-output.json
- codex-prompt.md
```
## Jenkins Example
We can use the same approach to scripting a job with Jenkins. Once again, comments highlight key stages of the workflow:
```groovy
pipeline {
agent any
options {
timestamps()
ansiColor('xterm')
// Prevent overlapping runs on the same PR. Newer builds will cancel older ones after passing the milestone.
disableConcurrentBuilds()
}
environment {
// Default model like your GHA (can be overridden at job/env level)
CODEX_MODEL = "${env.CODEX_MODEL ?: 'o4-mini'}"
// Filled in during Init
PR_NUMBER = ''
HEAD_SHA = ''
BASE_SHA = ''
REPOSITORY = '' // org/repo
}
stages {
stage('Init (PR context, repo, SHAs)') {
steps {
checkout scm
// Compute PR context and SHAs similar to the GitHub Action
sh '''
set -euo pipefail
# Derive PR number from Jenkins env when building PRs via GitHub Branch Source
PR_NUMBER="${CHANGE_ID:-}"
if [ -z "$PR_NUMBER" ]; then
echo "Not a PR build (CHANGE_ID missing). Exiting."
exit 1
fi
echo "PR_NUMBER=$PR_NUMBER" >> $WORKSPACE/jenkins.env
# Discover owner/repo (normalize SSH/HTTPS forms)
ORIGIN_URL="$(git config --get remote.origin.url)"
if echo "$ORIGIN_URL" | grep -qE '^git@github.com:'; then
REPO_PATH="${ORIGIN_URL#git@github.com:}"
REPO_PATH="${REPO_PATH%.git}"
else
# e.g. https://github.com/owner/repo.git
REPO_PATH="${ORIGIN_URL#https://github.com/}"
REPO_PATH="${REPO_PATH%.git}"
fi
echo "REPOSITORY=$REPO_PATH" >> $WORKSPACE/jenkins.env
# Ensure we have all refs we need
git fetch --no-tags origin \
"+refs/heads/*:refs/remotes/origin/*" \
"+refs/pull/${PR_NUMBER}/head:refs/remotes/origin/PR-${PR_NUMBER}-head" \
"+refs/pull/${PR_NUMBER}/merge:refs/remotes/origin/PR-${PR_NUMBER}-merge"
# HEAD (PR head) and BASE (target branch tip)
CHANGE_TARGET="${CHANGE_TARGET:-main}"
HEAD_SHA="$(git rev-parse refs/remotes/origin/PR-${PR_NUMBER}-head)"
BASE_SHA="$(git rev-parse refs/remotes/origin/${CHANGE_TARGET})"
echo "HEAD_SHA=$HEAD_SHA" >> $WORKSPACE/jenkins.env
echo "BASE_SHA=$BASE_SHA" >> $WORKSPACE/jenkins.env
echo "Resolved:"
echo " REPOSITORY=$REPO_PATH"
echo " PR_NUMBER=$PR_NUMBER"
echo " CHANGE_TARGET=$CHANGE_TARGET"
echo " HEAD_SHA=$HEAD_SHA"
echo " BASE_SHA=$BASE_SHA"
'''
script {
def envMap = readProperties file: 'jenkins.env'
env.PR_NUMBER = envMap['PR_NUMBER']
env.REPOSITORY = envMap['REPOSITORY']
env.HEAD_SHA = envMap['HEAD_SHA']
env.BASE_SHA = envMap['BASE_SHA']
}
// Ensure only latest build for this PR proceeds; older in-flight builds will be aborted here
milestone 1
}
}
stage('Generate structured output schema') {
steps {
sh '''
set -euo pipefail
cat > codex-output-schema.json <<'JSON'
{
"type": "object",
"properties": {
"findings": {
"type": "array",
"items": {
"type": "object",
"properties": {
"title": { "type": "string", "maxLength": 80 },
"body": { "type": "string", "minLength": 1 },
"confidence_score": { "type": "number", "minimum": 0, "maximum": 1 },
"priority": { "type": "integer", "minimum": 0, "maximum": 3 },
"code_location": {
"type": "object",
"properties": {
"absolute_file_path": { "type": "string", "minLength": 1 },
"line_range": {
"type": "object",
"properties": {
"start": { "type": "integer", "minimum": 1 },
"end": { "type": "integer", "minimum": 1 }
},
"required": ["start","end"],
"additionalProperties": false
}
},
"required": ["absolute_file_path","line_range"],
"additionalProperties": false
}
},
"required": ["title","body","confidence_score","priority","code_location"],
"additionalProperties": false
}
},
"overall_correctness": { "type": "string", "enum": ["patch is correct","patch is incorrect"] },
"overall_explanation": { "type": "string", "minLength": 1 },
"overall_confidence_score": { "type": "number", "minimum": 0, "maximum": 1 }
},
"required": ["findings","overall_correctness","overall_explanation","overall_confidence_score"],
"additionalProperties": false
}
JSON
'''
}
}
stage('Build Codex review prompt') {
environment {
REVIEW_PROMPT_PATH = "${env.CODEX_PROMPT_PATH ?: 'review_prompt.md'}"
}
steps {
sh '''
set -euo pipefail
PROMPT_PATH="codex-prompt.md"
TEMPLATE_PATH="${REVIEW_PROMPT_PATH}"
if [ -n "$TEMPLATE_PATH" ] && [ -f "$TEMPLATE_PATH" ]; then
cat "$TEMPLATE_PATH" > "$PROMPT_PATH"
else
{
printf '%s\n' "You are acting as a reviewer for a proposed code change made by another engineer."
printf '%s\n' "Focus on issues that impact correctness, performance, security, maintainability, or developer experience."
printf '%s\n' "Flag only actionable issues introduced by the pull request."
printf '%s\n' "When you flag an issue, provide a short, direct explanation and cite the affected file and line range."
printf '%s\n' "Prioritize severe issues and avoid nit-level comments unless they block understanding of the diff."
printf '%s\n' "After listing findings, produce an overall correctness verdict (\\\"patch is correct\\\" or \\\"patch is incorrect\\\") with a concise justification and a confidence score between 0 and 1."
printf '%s\n' "Ensure that file citations and line numbers are exactly correct using the tools available; if they are incorrect your comments will be rejected."
} > "$PROMPT_PATH"
fi
{
echo ""
echo "Repository: ${REPOSITORY}"
echo "Pull Request #: ${PR_NUMBER}"
echo "Base ref: ${CHANGE_TARGET}"
echo "Head ref: ${CHANGE_BRANCH:-PR-${PR_NUMBER}-head}"
echo "Base SHA: ${BASE_SHA}"
echo "Head SHA: ${HEAD_SHA}"
echo "Changed files:"
git --no-pager diff --name-status "${BASE_SHA}" "${HEAD_SHA}"
echo ""
echo "Unified diff (context=5):"
git --no-pager diff --unified=5 --stat=200 "${BASE_SHA}" "${HEAD_SHA}" > /tmp/diffstat.txt
git --no-pager diff --unified=5 "${BASE_SHA}" "${HEAD_SHA}" > /tmp/full.diff
cat /tmp/diffstat.txt
echo ""
cat /tmp/full.diff
} >> "$PROMPT_PATH"
'''
}
}
stage('Run Codex structured review') {
environment {
REVIEW_PROMPT = 'codex-prompt.md'
REVIEW_SCHEMA = 'codex-output-schema.json'
REVIEW_OUTPUT = 'codex-output.json'
}
steps {
withCredentials([
string(credentialsId: 'openai-api-key', variable: 'OPENAI_API_KEY')
]) {
// Option A: If you have the OpenAI CLI installed on the Jenkins agent
sh '''
set -euo pipefail
if command -v openai >/dev/null 2>&1; then
# Use the Responses API with a JSON schema tool spec
# Produces codex-output.json with the structured result.
openai responses.create \
--model "${CODEX_MODEL}" \
--input-file "${REVIEW_PROMPT}" \
--response-format "json_object" \
--output-schema "${RESPONSE_FORMAT}" \
--tool-choice "auto" \
> raw_response.json || true
# Fallback if CLI doesn’t support your exact flags:
# Keep demo resilient: If raw_response.json is empty, create a minimal stub so later steps don’t fail.
if [ ! -s raw_response.json ]; then
echo '{"findings":[],"overall_correctness":"patch is correct","overall_explanation":"No issues detected.","overall_confidence_score":0.5}' > "${REVIEW_OUTPUT}"
else
# If your CLI/format returns a JSON object with the structured content in .output or similar, map it here.
# Adjust jq path to match your CLI output shape.
jq -r '.output // .' raw_response.json > "${REVIEW_OUTPUT}" || cp raw_response.json "${REVIEW_OUTPUT}"
fi
else
echo "openai CLI not found; creating a stub output for demo continuity."
echo '{"findings":[],"overall_correctness":"patch is correct","overall_explanation":"(CLI not available on agent)","overall_confidence_score":0.4}' > "${REVIEW_OUTPUT}"
fi
'''
}
}
}
stage('Inspect structured Codex output') {
steps {
sh '''
if [ -s codex-output.json ]; then
jq '.' codex-output.json || true
else
echo "Codex output file missing"
fi
'''
}
}
stage('Publish inline review comments') {
when { expression { true } }
steps {
withCredentials([string(credentialsId: 'github-token', variable: 'GITHUB_TOKEN')]) {
sh '''
set -euo pipefail
REVIEW_JSON="codex-output.json"
if [ ! -s "$REVIEW_JSON" ]; then
echo "No Codex output file present; skipping comment publishing."
exit 0
fi
findings_count=$(jq '.findings | length' "$REVIEW_JSON")
if [ "$findings_count" -eq 0 ]; then
echo "Codex returned no findings; skipping inline comments."
exit 0
fi
jq -c --arg commit "$HEAD_SHA" '.findings[] | {
body: (.title + "\\n\\n" + .body + "\\n\\nConfidence: " + (.confidence_score | tostring) + (if has("priority") then "\\nPriority: P" + (.priority | tostring) else "" end)),
commit_id: $commit,
path: .code_location.absolute_file_path,
line: .code_location.line_range.end,
side: "RIGHT",
start_line: (if .code_location.line_range.start != .code_location.line_range.end then .code_location.line_range.start else null end),
start_side: (if .code_location.line_range.start != .code_location.line_range.end then "RIGHT" else null end)
} | with_entries(select(.value != null))' "$REVIEW_JSON" > findings.jsonl
while IFS= read -r payload; do
echo "Posting review comment payload:" && echo "$payload" | jq '.'
curl -sS \
-X POST \
-H "Accept: application/vnd.github+json" \
-H "Authorization: Bearer ${GITHUB_TOKEN}" \
-H "X-GitHub-Api-Version: 2022-11-28" \
"https://api.github.com/repos/${REPOSITORY}/pulls/${PR_NUMBER}/comments" \
-d "$payload"
done < findings.jsonl
'''
}
}
}
stage('Publish overall summary comment') {
steps {
withCredentials([string(credentialsId: 'github-token', variable: 'GITHUB_TOKEN')]) {
sh '''
set -euo pipefail
REVIEW_JSON="codex-output.json"
if [ ! -s "$REVIEW_JSON" ]; then
echo "Codex output missing; skipping summary."
exit 0
fi
overall_state=$(jq -r '.overall_correctness' "$REVIEW_JSON")
overall_body=$(jq -r '.overall_explanation' "$REVIEW_JSON")
confidence=$(jq -r '.overall_confidence_score' "$REVIEW_JSON")
msg="**Codex automated review**\\n\\nVerdict: ${overall_state}\\nConfidence: ${confidence}\\n\\n${overall_body}"
jq -n --arg body "$msg" '{body: $body}' > /tmp/summary.json
curl -sS \
-X POST \
-H "Accept: application/vnd.github+json" \
-H "Authorization: Bearer ${GITHUB_TOKEN}" \
-H "X-GitHub-Api-Version: 2022-11-28" \
"https://api.github.com/repos/${REPOSITORY}/issues/${PR_NUMBER}/comments" \
-d @/tmp/summary.json
'''
}
}
}
}
post {
always {
archiveArtifacts artifacts: 'codex-*.json, *.md, /tmp/diff*.txt', allowEmptyArchive: true
}
}
}
```
# Wrap Up
With the Codex SDK, you can build your own GitHub Code Review in on-prem environments. However, the pattern of triggering Codex with a prompt, receiving a structured output, and then acting on that output with an API call extends far beyond Code Review. For example, we could use this pattern to trigger a root-cause analysis when an incident is created and post a structured report into a Slack channel. Or we could create a code quality report on each PR and post results into a dashboard.
---
# Source: https://developers.openai.com/resources/guide/building-agents-guide.md
# Building agents guide
> Official guide to building agents using the OpenAI platform.
- Type: Guide
- Tags: agents
- URL: https://platform.openai.com/docs/guides/agents
- Created: 2025-07-18
- Updated: 2025-08-13
## Summary
This guide describes how to create and manage agents. — Agents SDK, agentic, tool calling
## Details
Walks through agent architecture and best practices.
---
# Source: https://developers.openai.com/resources/video/building-with-open-models-video.md
# Building with Open Models
> Talk covering how developers customize and deploy OpenAI’s open models.
- Type: Video
- Tags: fine-tuning
- URL: https://www.youtube.com/watch?v=1HL2YHRj270
- Created: 2025-10-22
- Updated: 2025-10-22
## Summary
Explains strategies for adapting open models to specific products and workflows. — open models, customization
## Details
Walks through real examples of preparing data, fine-tuning, and evaluating open models so they can power production-ready experiences.
---
# Source: https://developers.openai.com/cookbook/examples/codex/codex_mcp_agents_sdk/building_consistent_workflows_codex_cli_agents_sdk.md
# Building Consistent Workflows with Codex CLI & Agents SDK
### Ensuring Repeatable, Traceable, and Scaleable Agentic Development
## Introduction
Developers strive for consistency in everything they do. With Codex CLI and the Agents SDK, that consistency can now scale like never before. Whether you’re refactoring a large codebase, rolling out new features, or introducing a new testing framework, Codex integrates seamlessly into CLI, IDE, and cloud workflows to automate and enforce repeatable development patterns.
In this track, we’ll build both single and multi-agent systems using the Agents SDK, with Codex CLI exposed as an MCP Server. This enables:
- **Consistency and Repeatability** by providing each agent a scoped context.
- **Scalable Orchestration** to coordinate single and multi-agent systems.
- **Observability & Auditability** by reviewing the full agentic stack trace.
## What We’ll Cover
- Initializing Codex CLI as an MCP Server: How to run Codex as a long-running MCP process.
- Building Single-Agent Systems: Using Codex MCP for scoped tasks.
- Orchestrating Multi-Agent Workflows: Coordinating multiple specialized agents.
- Tracing Agentic Behavior: Leveraging agent traces for visibility and evaluation.
## Prerequisites & Setup
Before starting this track, ensure you have the following:
- Basic coding familiarity: You should be comfortable with Python and JavaScript.
- Developer environment: You’ll need an IDE, like VS Code or Cursor.
- OpenAI API key: Create or find your API key in the OpenAI Dashboard.
## Environment Setup
1. create a `.env` folder in your directory and add your `OPENAI_API_KEY` Key
2. Install dependencies
```python
%pip install openai-agents openai ## install dependencies
```
## Initializing Codex CLI as an MCP Server
Here run Codex CLI as an MCP Server inside the Agents SDK. We provide the initialization parameters of `codex mcp`. This command starts Codex CLI as an MCP server and exposes two Codex tools available on the MCP server — `codex()` and `codex-reply()`. These are the underlying tools that the Agents SDK will call when it needs to invoke Codex.
- `codex()` is used for creating a conversation.
- `codex-reply()` is for continuing a conversation.
```python
import asyncio
from agents import Agent, Runner
from agents.mcp import MCPServerStdio
async def main() -> None:
async with MCPServerStdio(
name="Codex CLI",
params={
"command": "npx",
"args": ["-y", "codex", "mcp-server"],
},
client_session_timeout_seconds=360000,
) as codex_mcp_server:
print("Codex MCP server started.")
# We will add more code here in the next section
return
```
Also note that we are extending the MCP Server timeout to allow Codex CLI enough time to execute and complete the given task.
---
## Building Single Agent Systems
Let’s start with a simple example to use our Codex MCP Server. We define two agents:
1. **Designer Agent** – brainstorms and creates a small brief for a game.
2. **Developer Agent** – implements a simple game according to the Designer’s spec.
```python
developer_agent = Agent(
name="Game Developer",
instructions=(
"You are an expert in building simple games using basic html + css + javascript with no dependencies. "
"Save your work in a file called index.html in the current directory."
"Always call codex with \"approval-policy\": \"never\" and \"sandbox\": \"workspace-write\""
),
mcp_servers=[codex_mcp_server],
)
designer_agent = Agent(
name="Game Designer",
instructions=(
"You are an indie game connoisseur. Come up with an idea for a single page html + css + javascript game that a developer could build in about 50 lines of code. "
"Format your request as a 3 sentence design brief for a game developer and call the Game Developer coder with your idea."
),
model="gpt-5",
handoffs=[developer_agent],
)
result = await Runner.run(designer_agent, "Implement a fun new game!")
```
Notice that we are providing the Developer agent with the ability to write files to the project directory without asking the user for permissions.
Now run the code and you’ll see an `index.html` file generated. Go ahead and open the file and start playing the game!
Here’s a few screenshots of the game my agentic system created. Yours will be different!
| Example gameplay | Game Over Score |
| :---: | :---: |
|
## The Code Review Prompt
GPT-5.2-Codex has received specific training to improve its code review abilities. You can steer GPT-5.2-Codex to conduct a code review with the following prompt:
```
You are acting as a reviewer for a proposed code change made by another engineer.
Focus on issues that impact correctness, performance, security, maintainability, or developer experience.
Flag only actionable issues introduced by the pull request.
When you flag an issue, provide a short, direct explanation and cite the affected file and line range.
Prioritize severe issues and avoid nit-level comments unless they block understanding of the diff.
After listing findings, produce an overall correctness verdict (\"patch is correct\" or \"patch is incorrect\") with a concise justification and a confidence score between 0 and 1.
Ensure that file citations and line numbers are exactly correct using the tools available; if they are incorrect your comments will be rejected.
```
## Codex Structured Outputs
In order to make comments on code ranges in our pull request, we need to receive Codex's response in a specific format. To do that we can create a file called `codex-output-schema.json` that conforms to OpenAI's [structured outputs](https://platform.openai.com/docs/guides/structured-outputs) format.
To use this file in our workflow YAML, we can call Codex with the `output-schema-file` argument like this:
```yaml
- name: Run Codex structured review
id: run-codex
uses: openai/codex-action@main
with:
openai-api-key: ${{ secrets.OPENAI_API_KEY }}
prompt-file: codex-prompt.md
sandbox: read-only
model: ${{ env.CODEX_MODEL }}
output-schema-file: codex-output-schema.json # <-- Our schema file
output-file: codex-output.json
```
You can also pass a similar argument to `codex exec` for example:
```bash
codex exec "Review my pull request!" --output-schema codex-output-schema.json
```
## GitHub Actions Example
Let's put it all together. If you're using GitHub Actions in an on-prem environment, you can tailor this example to your specific workflow. Inline comments highlight the key steps.
```yaml
name: Codex Code Review
# Determine when the review action should be run:
on:
pull_request:
types:
- opened
- reopened
- synchronize
- ready_for_review
concurrency:
group: codex-structured-review-${{ github.event.pull_request.number }}
cancel-in-progress: true
jobs:
codex-structured-review:
name: Run Codex structured review
runs-on: ubuntu-latest
permissions:
contents: read
pull-requests: write
env:
OPENAI_API_KEY: ${{ secrets.OPENAI_API_KEY }}
GITHUB_TOKEN: ${{ github.token }}
CODEX_MODEL: ${{ vars.CODEX_MODEL || 'o4-mini' }}
PR_NUMBER: ${{ github.event.pull_request.number }}
HEAD_SHA: ${{ github.event.pull_request.head.sha }}
BASE_SHA: ${{ github.event.pull_request.base.sha }}
REPOSITORY: ${{ github.repository }}
outputs:
codex-output: ${{ steps.run-codex.outputs.final-message }}
steps:
- name: Checkout pull request merge commit
uses: actions/checkout@v5
with:
ref: refs/pull/${{ github.event.pull_request.number }}/merge
- name: Fetch base and head refs
run: |
set -euxo pipefail
git fetch --no-tags origin \
"${{ github.event.pull_request.base.ref }}" \
+refs/pull/${{ github.event.pull_request.number }}/head
shell: bash
# The structured output schema ensures that codex produces comments
# with filepaths, line numbers, title, body, etc.
- name: Generate structured output schema
run: |
set -euo pipefail
cat <<'JSON' > codex-output-schema.json
{
"type": "object",
"properties": {
"findings": {
"type": "array",
"items": {
"type": "object",
"properties": {
"title": {
"type": "string",
"maxLength": 80
},
"body": {
"type": "string",
"minLength": 1
},
"confidence_score": {
"type": "number",
"minimum": 0,
"maximum": 1
},
"priority": {
"type": "integer",
"minimum": 0,
"maximum": 3
},
"code_location": {
"type": "object",
"properties": {
"absolute_file_path": {
"type": "string",
"minLength": 1
},
"line_range": {
"type": "object",
"properties": {
"start": {
"type": "integer",
"minimum": 1
},
"end": {
"type": "integer",
"minimum": 1
}
},
"required": [
"start",
"end"
],
"additionalProperties": false
}
},
"required": [
"absolute_file_path",
"line_range"
],
"additionalProperties": false
}
},
"required": [
"title",
"body",
"confidence_score",
"priority",
"code_location"
],
"additionalProperties": false
}
},
"overall_correctness": {
"type": "string",
"enum": [
"patch is correct",
"patch is incorrect"
]
},
"overall_explanation": {
"type": "string",
"minLength": 1
},
"overall_confidence_score": {
"type": "number",
"minimum": 0,
"maximum": 1
}
},
"required": [
"findings",
"overall_correctness",
"overall_explanation",
"overall_confidence_score"
],
"additionalProperties": false
}
JSON
shell: bash
# This section generates our prompt:
- name: Build Codex review prompt
env:
REVIEW_PROMPT_PATH: ${{ vars.CODEX_PROMPT_PATH || 'review_prompt.md' }}
run: |
set -euo pipefail
PROMPT_PATH="codex-prompt.md"
TEMPLATE_PATH="${REVIEW_PROMPT_PATH}"
if [ -n "$TEMPLATE_PATH" ] && [ -f "$TEMPLATE_PATH" ]; then
cat "$TEMPLATE_PATH" > "$PROMPT_PATH"
else
{
printf '%s\n' "You are acting as a reviewer for a proposed code change made by another engineer."
printf '%s\n' "Focus on issues that impact correctness, performance, security, maintainability, or developer experience."
printf '%s\n' "Flag only actionable issues introduced by the pull request."
printf '%s\n' "When you flag an issue, provide a short, direct explanation and cite the affected file and line range."
printf '%s\n' "Prioritize severe issues and avoid nit-level comments unless they block understanding of the diff."
printf '%s\n' "After listing findings, produce an overall correctness verdict (\"patch is correct\" or \"patch is incorrect\") with a concise justification and a confidence score between 0 and 1."
printf '%s\n' "Ensure that file citations and line numbers are exactly correct using the tools available; if they are incorrect your comments will be rejected."
} > "$PROMPT_PATH"
fi
{
echo ""
echo "Repository: ${REPOSITORY}"
echo "Pull Request #: ${PR_NUMBER}"
echo "Base ref: ${{ github.event.pull_request.base.ref }}"
echo "Head ref: ${{ github.event.pull_request.head.ref }}"
echo "Base SHA: ${BASE_SHA}"
echo "Head SHA: ${HEAD_SHA}"
echo "Changed files:"
git --no-pager diff --name-status "${BASE_SHA}" "${HEAD_SHA}"
echo ""
echo "Unified diff (context=5):"
git --no-pager diff --unified=5 --stat=200 "${BASE_SHA}" "${HEAD_SHA}" > /tmp/diffstat.txt
git --no-pager diff --unified=5 "${BASE_SHA}" "${HEAD_SHA}" > /tmp/full.diff
cat /tmp/diffstat.txt
echo ""
cat /tmp/full.diff
} >> "$PROMPT_PATH"
shell: bash
# Putting it all together: we run the codex action with our code review prompt,
# structured output, and output file:
- name: Run Codex structured review
id: run-codex
uses: openai/codex-action@main
with:
openai-api-key: ${{ secrets.OPENAI_API_KEY }}
prompt-file: codex-prompt.md
output-schema-file: codex-output-schema.json
output-file: codex-output.json
sandbox: read-only
model: ${{ env.CODEX_MODEL }}
- name: Inspect structured Codex output
if: ${{ always() }}
run: |
if [ -s codex-output.json ]; then
jq '.' codex-output.json || true
else
echo "Codex output file missing"
fi
shell: bash
# This step produces in-line code review comments on specific line
# ranges of code.
- name: Publish inline review comments
if: ${{ always() }}
env:
REVIEW_JSON: codex-output.json
run: |
set -euo pipefail
if [ ! -s "$REVIEW_JSON" ]; then
echo "No Codex output file present; skipping comment publishing."
exit 0
fi
findings_count=$(jq '.findings | length' "$REVIEW_JSON")
if [ "$findings_count" -eq 0 ]; then
echo "Codex returned no findings; skipping inline comments."
exit 0
fi
jq -c --arg commit "$HEAD_SHA" '.findings[] | {
body: (.title + "\n\n" + .body + "\n\nConfidence: " + (.confidence_score | tostring) + (if has("priority") then "\nPriority: P" + (.priority | tostring) else "" end)),
commit_id: $commit,
path: .code_location.absolute_file_path,
line: .code_location.line_range.end,
side: "RIGHT",
start_line: (if .code_location.line_range.start != .code_location.line_range.end then .code_location.line_range.start else null end),
start_side: (if .code_location.line_range.start != .code_location.line_range.end then "RIGHT" else null end)
} | with_entries(select(.value != null))' "$REVIEW_JSON" > findings.jsonl
while IFS= read -r payload; do
echo "Posting review comment payload:" && echo "$payload" | jq '.'
curl -sS \
-X POST \
-H "Accept: application/vnd.github+json" \
-H "Authorization: Bearer ${GITHUB_TOKEN}" \
-H "X-GitHub-Api-Version: 2022-11-28" \
"https://api.github.com/repos/${REPOSITORY}/pulls/${PR_NUMBER}/comments" \
-d "$payload"
done < findings.jsonl
shell: bash
# This section creates a single comment summarizing the review.
- name: Publish overall summary comment
if: ${{ always() }}
env:
REVIEW_JSON: codex-output.json
run: |
set -euo pipefail
if [ ! -s "$REVIEW_JSON" ]; then
echo "Codex output missing; skipping summary."
exit 0
fi
overall_state=$(jq -r '.overall_correctness' "$REVIEW_JSON")
overall_body=$(jq -r '.overall_explanation' "$REVIEW_JSON")
confidence=$(jq -r '.overall_confidence_score' "$REVIEW_JSON")
msg="**Codex automated review**\n\nVerdict: ${overall_state}\nConfidence: ${confidence}\n\n${overall_body}"
curl -sS \
-X POST \
-H "Accept: application/vnd.github+json" \
-H "Authorization: Bearer ${GITHUB_TOKEN}" \
-H "X-GitHub-Api-Version: 2022-11-28" \
"https://api.github.com/repos/${REPOSITORY}/issues/${PR_NUMBER}/comments" \
-d "$(jq -n --arg body "$msg" '{body: $body}')"
shell: bash
```
## Gitlab Example
GitLab doesn’t have a direct equivalent to the GitHub Action, but you can run codex exec inside GitLab CI/CD to perform automated code reviews.
However, the GitHub Action includes an important [safety strategy](https://github.com/openai/codex-action?tab=readme-ov-file#safety-strategy): it drops sudo permissions so Codex cannot access its own OpenAI API key. This isolation is critical—especially for public repositories where sensitive secrets (like your OpenAI API key) may be present—because it prevents Codex from reading or exfiltrating credentials during execution.
Before running this job, configure your GitLab project:
1. Go to **Project → Settings → CI/CD**.
2. Expand the **Variables** section.
3. Add these variables:
- `OPENAI_API_KEY`
- `GITLAB_TOKEN`
4. Mark them as masked/protected as appropriate.
5. Add the following GitLab example job to your `.gitlab-ci.yml` file at the root of your repository so it runs during merge request pipelines.
Please be mindful with your API key on public repositories.
```yaml
stages:
- review
codex-structured-review:
stage: review
image: ubuntu:22.04
rules:
- if: '$CI_PIPELINE_SOURCE == "merge_request_event"'
variables:
PR_NUMBER: $CI_MERGE_REQUEST_IID
REPOSITORY: "$CI_PROJECT_PATH"
BASE_SHA: "$CI_MERGE_REQUEST_DIFF_BASE_SHA"
HEAD_SHA: "$CI_COMMIT_SHA"
before_script:
- apt-get update -y
- apt-get install -y git curl jq
- |
if ! command -v codex >/dev/null 2>&1; then
ARCH="$(uname -m)"
case "$ARCH" in
x86_64) CODEX_PLATFORM="x86_64-unknown-linux-musl" ;;
aarch64|arm64) CODEX_PLATFORM="aarch64-unknown-linux-musl" ;;
*)
echo "Unsupported architecture: $ARCH"
exit 1
;;
esac
CODEX_VERSION="${CODEX_VERSION:-latest}"
if [ -n "${CODEX_DOWNLOAD_URL:-}" ]; then
CODEX_URL="$CODEX_DOWNLOAD_URL"
elif [ "$CODEX_VERSION" = "latest" ]; then
CODEX_URL="https://github.com/openai/codex/releases/latest/download/codex-${CODEX_PLATFORM}.tar.gz"
else
CODEX_URL="https://github.com/openai/codex/releases/download/${CODEX_VERSION}/codex-${CODEX_PLATFORM}.tar.gz"
fi
TMP_DIR="$(mktemp -d)"
curl -fsSL "$CODEX_URL" -o "$TMP_DIR/codex.tar.gz"
tar -xzf "$TMP_DIR/codex.tar.gz" -C "$TMP_DIR"
install -m 0755 "$TMP_DIR"/codex-* /usr/local/bin/codex
rm -rf "$TMP_DIR"
fi
- git fetch origin $CI_MERGE_REQUEST_TARGET_BRANCH_NAME
- git fetch origin $CI_MERGE_REQUEST_SOURCE_BRANCH_NAME
- git checkout $CI_MERGE_REQUEST_SOURCE_BRANCH_NAME
script:
- echo "Running Codex structured review for MR !${PR_NUMBER}"
# Generate structured output schema
- |
cat <<'JSON' > codex-output-schema.json
{
"$schema": "http://json-schema.org/draft-07/schema#",
"title": "Codex Structured Review",
"type": "object",
"additionalProperties": false,
"required": [
"overall_correctness",
"overall_explanation",
"overall_confidence_score",
"findings"
],
"properties": {
"overall_correctness": {
"type": "string",
"description": "Overall verdict for the merge request."
},
"overall_explanation": {
"type": "string",
"description": "Explanation backing up the verdict."
},
"overall_confidence_score": {
"type": "number",
"minimum": 0,
"maximum": 1,
"description": "Confidence level for the verdict."
},
"findings": {
"type": "array",
"description": "Collection of actionable review findings.",
"items": {
"type": "object",
"additionalProperties": false,
"required": [
"title",
"body",
"confidence_score",
"code_location"
],
"properties": {
"title": {
"type": "string"
},
"body": {
"type": "string"
},
"confidence_score": {
"type": "number",
"minimum": 0,
"maximum": 1
},
"code_location": {
"type": "object",
"additionalProperties": false,
"required": [
"absolute_file_path",
"relative_file_path",
"line_range"
],
"properties": {
"absolute_file_path": {
"type": "string"
},
"relative_file_path": {
"type": "string"
},
"line_range": {
"type": "object",
"additionalProperties": false,
"required": [
"start",
"end"
],
"properties": {
"start": {
"type": "integer",
"minimum": 1
},
"end": {
"type": "integer",
"minimum": 1
}
}
}
}
}
}
},
"default": []
}
}
}
JSON
# Build Codex review prompt
- |
PROMPT_PATH="codex-prompt.md"
TEMPLATE_PATH="${REVIEW_PROMPT_PATH:-review_prompt.md}"
if [ -n "$TEMPLATE_PATH" ] && [ -f "$TEMPLATE_PATH" ]; then
cat "$TEMPLATE_PATH" > "$PROMPT_PATH"
else
{
printf '%s\n' "You are acting as a reviewer for a proposed code change..."
printf '%s\n' "Focus on issues that impact correctness, performance, security..."
printf '%s\n' "Flag only actionable issues introduced by this merge request..."
printf '%s\n' "Provide an overall correctness verdict..."
} > "$PROMPT_PATH"
fi
{
echo ""
echo "Repository: ${REPOSITORY}"
echo "Merge Request #: ${PR_NUMBER}"
echo "Base SHA: ${BASE_SHA}"
echo "Head SHA: ${HEAD_SHA}"
echo ""
echo "Changed files:"
git --no-pager diff --name-status "${BASE_SHA}" "${HEAD_SHA}"
echo ""
echo "Unified diff (context=5):"
git --no-pager diff --unified=5 "${BASE_SHA}" "${HEAD_SHA}"
} >> "$PROMPT_PATH"
# Run Codex exec CLI
- |
printenv OPENAI_API_KEY | codex login --with-api-key && \
codex exec --output-schema codex-output-schema.json \
--output-last-message codex-output.json \
--sandbox read-only \
- < codex-prompt.md
# Inspect structured Codex output
- |
if [ -s codex-output.json ]; then
jq '.' codex-output.json || true
else
echo "Codex output file missing"; exit 1
fi
# Publish inline comments to GitLab MR
- |
findings_count=$(jq '.findings | length' codex-output.json)
if [ "$findings_count" -eq 0 ]; then
echo "No findings from Codex; skipping comments."
exit 0
fi
jq -c \
--arg base "$BASE_SHA" \
--arg start "$BASE_SHA" \
--arg head "$HEAD_SHA" '
.findings[] | {
body: (.title + "\n\n" + .body + "\n\nConfidence: " + (.confidence_score | tostring)),
position: {
position_type: "text",
base_sha: $base,
start_sha: $start,
head_sha: $head,
new_path: (.code_location.relative_file_path // .code_location.absolute_file_path),
new_line: .code_location.line_range.end
}
}
' codex-output.json > findings.jsonl
while IFS= read -r payload; do
curl -sS --request POST \
--header "PRIVATE-TOKEN: $GITLAB_TOKEN" \
--header "Content-Type: application/json" \
--data "$payload" \
"https://gitlab.com/api/v4/projects/${CI_PROJECT_ID}/merge_requests/${PR_NUMBER}/discussions"
done < findings.jsonl
# Publish overall summary comment
- |
overall_state=$(jq -r '.overall_correctness' codex-output.json)
overall_body=$(jq -r '.overall_explanation' codex-output.json)
confidence=$(jq -r '.overall_confidence_score' codex-output.json)
summary="**Codex automated review**\n\nVerdict: ${overall_state}\nConfidence: ${confidence}\n\n${overall_body}"
curl -sS --request POST \
--header "PRIVATE-TOKEN: $GITLAB_TOKEN" \
--header "Content-Type: application/json" \
--data "$(jq -n --arg body "$summary" '{body: $body}')" \
"https://gitlab.com/api/v4/projects/${CI_PROJECT_ID}/merge_requests/${PR_NUMBER}/notes"
artifacts:
when: always
paths:
- codex-output.json
- codex-prompt.md
```
## Jenkins Example
We can use the same approach to scripting a job with Jenkins. Once again, comments highlight key stages of the workflow:
```groovy
pipeline {
agent any
options {
timestamps()
ansiColor('xterm')
// Prevent overlapping runs on the same PR. Newer builds will cancel older ones after passing the milestone.
disableConcurrentBuilds()
}
environment {
// Default model like your GHA (can be overridden at job/env level)
CODEX_MODEL = "${env.CODEX_MODEL ?: 'o4-mini'}"
// Filled in during Init
PR_NUMBER = ''
HEAD_SHA = ''
BASE_SHA = ''
REPOSITORY = '' // org/repo
}
stages {
stage('Init (PR context, repo, SHAs)') {
steps {
checkout scm
// Compute PR context and SHAs similar to the GitHub Action
sh '''
set -euo pipefail
# Derive PR number from Jenkins env when building PRs via GitHub Branch Source
PR_NUMBER="${CHANGE_ID:-}"
if [ -z "$PR_NUMBER" ]; then
echo "Not a PR build (CHANGE_ID missing). Exiting."
exit 1
fi
echo "PR_NUMBER=$PR_NUMBER" >> $WORKSPACE/jenkins.env
# Discover owner/repo (normalize SSH/HTTPS forms)
ORIGIN_URL="$(git config --get remote.origin.url)"
if echo "$ORIGIN_URL" | grep -qE '^git@github.com:'; then
REPO_PATH="${ORIGIN_URL#git@github.com:}"
REPO_PATH="${REPO_PATH%.git}"
else
# e.g. https://github.com/owner/repo.git
REPO_PATH="${ORIGIN_URL#https://github.com/}"
REPO_PATH="${REPO_PATH%.git}"
fi
echo "REPOSITORY=$REPO_PATH" >> $WORKSPACE/jenkins.env
# Ensure we have all refs we need
git fetch --no-tags origin \
"+refs/heads/*:refs/remotes/origin/*" \
"+refs/pull/${PR_NUMBER}/head:refs/remotes/origin/PR-${PR_NUMBER}-head" \
"+refs/pull/${PR_NUMBER}/merge:refs/remotes/origin/PR-${PR_NUMBER}-merge"
# HEAD (PR head) and BASE (target branch tip)
CHANGE_TARGET="${CHANGE_TARGET:-main}"
HEAD_SHA="$(git rev-parse refs/remotes/origin/PR-${PR_NUMBER}-head)"
BASE_SHA="$(git rev-parse refs/remotes/origin/${CHANGE_TARGET})"
echo "HEAD_SHA=$HEAD_SHA" >> $WORKSPACE/jenkins.env
echo "BASE_SHA=$BASE_SHA" >> $WORKSPACE/jenkins.env
echo "Resolved:"
echo " REPOSITORY=$REPO_PATH"
echo " PR_NUMBER=$PR_NUMBER"
echo " CHANGE_TARGET=$CHANGE_TARGET"
echo " HEAD_SHA=$HEAD_SHA"
echo " BASE_SHA=$BASE_SHA"
'''
script {
def envMap = readProperties file: 'jenkins.env'
env.PR_NUMBER = envMap['PR_NUMBER']
env.REPOSITORY = envMap['REPOSITORY']
env.HEAD_SHA = envMap['HEAD_SHA']
env.BASE_SHA = envMap['BASE_SHA']
}
// Ensure only latest build for this PR proceeds; older in-flight builds will be aborted here
milestone 1
}
}
stage('Generate structured output schema') {
steps {
sh '''
set -euo pipefail
cat > codex-output-schema.json <<'JSON'
{
"type": "object",
"properties": {
"findings": {
"type": "array",
"items": {
"type": "object",
"properties": {
"title": { "type": "string", "maxLength": 80 },
"body": { "type": "string", "minLength": 1 },
"confidence_score": { "type": "number", "minimum": 0, "maximum": 1 },
"priority": { "type": "integer", "minimum": 0, "maximum": 3 },
"code_location": {
"type": "object",
"properties": {
"absolute_file_path": { "type": "string", "minLength": 1 },
"line_range": {
"type": "object",
"properties": {
"start": { "type": "integer", "minimum": 1 },
"end": { "type": "integer", "minimum": 1 }
},
"required": ["start","end"],
"additionalProperties": false
}
},
"required": ["absolute_file_path","line_range"],
"additionalProperties": false
}
},
"required": ["title","body","confidence_score","priority","code_location"],
"additionalProperties": false
}
},
"overall_correctness": { "type": "string", "enum": ["patch is correct","patch is incorrect"] },
"overall_explanation": { "type": "string", "minLength": 1 },
"overall_confidence_score": { "type": "number", "minimum": 0, "maximum": 1 }
},
"required": ["findings","overall_correctness","overall_explanation","overall_confidence_score"],
"additionalProperties": false
}
JSON
'''
}
}
stage('Build Codex review prompt') {
environment {
REVIEW_PROMPT_PATH = "${env.CODEX_PROMPT_PATH ?: 'review_prompt.md'}"
}
steps {
sh '''
set -euo pipefail
PROMPT_PATH="codex-prompt.md"
TEMPLATE_PATH="${REVIEW_PROMPT_PATH}"
if [ -n "$TEMPLATE_PATH" ] && [ -f "$TEMPLATE_PATH" ]; then
cat "$TEMPLATE_PATH" > "$PROMPT_PATH"
else
{
printf '%s\n' "You are acting as a reviewer for a proposed code change made by another engineer."
printf '%s\n' "Focus on issues that impact correctness, performance, security, maintainability, or developer experience."
printf '%s\n' "Flag only actionable issues introduced by the pull request."
printf '%s\n' "When you flag an issue, provide a short, direct explanation and cite the affected file and line range."
printf '%s\n' "Prioritize severe issues and avoid nit-level comments unless they block understanding of the diff."
printf '%s\n' "After listing findings, produce an overall correctness verdict (\\\"patch is correct\\\" or \\\"patch is incorrect\\\") with a concise justification and a confidence score between 0 and 1."
printf '%s\n' "Ensure that file citations and line numbers are exactly correct using the tools available; if they are incorrect your comments will be rejected."
} > "$PROMPT_PATH"
fi
{
echo ""
echo "Repository: ${REPOSITORY}"
echo "Pull Request #: ${PR_NUMBER}"
echo "Base ref: ${CHANGE_TARGET}"
echo "Head ref: ${CHANGE_BRANCH:-PR-${PR_NUMBER}-head}"
echo "Base SHA: ${BASE_SHA}"
echo "Head SHA: ${HEAD_SHA}"
echo "Changed files:"
git --no-pager diff --name-status "${BASE_SHA}" "${HEAD_SHA}"
echo ""
echo "Unified diff (context=5):"
git --no-pager diff --unified=5 --stat=200 "${BASE_SHA}" "${HEAD_SHA}" > /tmp/diffstat.txt
git --no-pager diff --unified=5 "${BASE_SHA}" "${HEAD_SHA}" > /tmp/full.diff
cat /tmp/diffstat.txt
echo ""
cat /tmp/full.diff
} >> "$PROMPT_PATH"
'''
}
}
stage('Run Codex structured review') {
environment {
REVIEW_PROMPT = 'codex-prompt.md'
REVIEW_SCHEMA = 'codex-output-schema.json'
REVIEW_OUTPUT = 'codex-output.json'
}
steps {
withCredentials([
string(credentialsId: 'openai-api-key', variable: 'OPENAI_API_KEY')
]) {
// Option A: If you have the OpenAI CLI installed on the Jenkins agent
sh '''
set -euo pipefail
if command -v openai >/dev/null 2>&1; then
# Use the Responses API with a JSON schema tool spec
# Produces codex-output.json with the structured result.
openai responses.create \
--model "${CODEX_MODEL}" \
--input-file "${REVIEW_PROMPT}" \
--response-format "json_object" \
--output-schema "${RESPONSE_FORMAT}" \
--tool-choice "auto" \
> raw_response.json || true
# Fallback if CLI doesn’t support your exact flags:
# Keep demo resilient: If raw_response.json is empty, create a minimal stub so later steps don’t fail.
if [ ! -s raw_response.json ]; then
echo '{"findings":[],"overall_correctness":"patch is correct","overall_explanation":"No issues detected.","overall_confidence_score":0.5}' > "${REVIEW_OUTPUT}"
else
# If your CLI/format returns a JSON object with the structured content in .output or similar, map it here.
# Adjust jq path to match your CLI output shape.
jq -r '.output // .' raw_response.json > "${REVIEW_OUTPUT}" || cp raw_response.json "${REVIEW_OUTPUT}"
fi
else
echo "openai CLI not found; creating a stub output for demo continuity."
echo '{"findings":[],"overall_correctness":"patch is correct","overall_explanation":"(CLI not available on agent)","overall_confidence_score":0.4}' > "${REVIEW_OUTPUT}"
fi
'''
}
}
}
stage('Inspect structured Codex output') {
steps {
sh '''
if [ -s codex-output.json ]; then
jq '.' codex-output.json || true
else
echo "Codex output file missing"
fi
'''
}
}
stage('Publish inline review comments') {
when { expression { true } }
steps {
withCredentials([string(credentialsId: 'github-token', variable: 'GITHUB_TOKEN')]) {
sh '''
set -euo pipefail
REVIEW_JSON="codex-output.json"
if [ ! -s "$REVIEW_JSON" ]; then
echo "No Codex output file present; skipping comment publishing."
exit 0
fi
findings_count=$(jq '.findings | length' "$REVIEW_JSON")
if [ "$findings_count" -eq 0 ]; then
echo "Codex returned no findings; skipping inline comments."
exit 0
fi
jq -c --arg commit "$HEAD_SHA" '.findings[] | {
body: (.title + "\\n\\n" + .body + "\\n\\nConfidence: " + (.confidence_score | tostring) + (if has("priority") then "\\nPriority: P" + (.priority | tostring) else "" end)),
commit_id: $commit,
path: .code_location.absolute_file_path,
line: .code_location.line_range.end,
side: "RIGHT",
start_line: (if .code_location.line_range.start != .code_location.line_range.end then .code_location.line_range.start else null end),
start_side: (if .code_location.line_range.start != .code_location.line_range.end then "RIGHT" else null end)
} | with_entries(select(.value != null))' "$REVIEW_JSON" > findings.jsonl
while IFS= read -r payload; do
echo "Posting review comment payload:" && echo "$payload" | jq '.'
curl -sS \
-X POST \
-H "Accept: application/vnd.github+json" \
-H "Authorization: Bearer ${GITHUB_TOKEN}" \
-H "X-GitHub-Api-Version: 2022-11-28" \
"https://api.github.com/repos/${REPOSITORY}/pulls/${PR_NUMBER}/comments" \
-d "$payload"
done < findings.jsonl
'''
}
}
}
stage('Publish overall summary comment') {
steps {
withCredentials([string(credentialsId: 'github-token', variable: 'GITHUB_TOKEN')]) {
sh '''
set -euo pipefail
REVIEW_JSON="codex-output.json"
if [ ! -s "$REVIEW_JSON" ]; then
echo "Codex output missing; skipping summary."
exit 0
fi
overall_state=$(jq -r '.overall_correctness' "$REVIEW_JSON")
overall_body=$(jq -r '.overall_explanation' "$REVIEW_JSON")
confidence=$(jq -r '.overall_confidence_score' "$REVIEW_JSON")
msg="**Codex automated review**\\n\\nVerdict: ${overall_state}\\nConfidence: ${confidence}\\n\\n${overall_body}"
jq -n --arg body "$msg" '{body: $body}' > /tmp/summary.json
curl -sS \
-X POST \
-H "Accept: application/vnd.github+json" \
-H "Authorization: Bearer ${GITHUB_TOKEN}" \
-H "X-GitHub-Api-Version: 2022-11-28" \
"https://api.github.com/repos/${REPOSITORY}/issues/${PR_NUMBER}/comments" \
-d @/tmp/summary.json
'''
}
}
}
}
post {
always {
archiveArtifacts artifacts: 'codex-*.json, *.md, /tmp/diff*.txt', allowEmptyArchive: true
}
}
}
```
# Wrap Up
With the Codex SDK, you can build your own GitHub Code Review in on-prem environments. However, the pattern of triggering Codex with a prompt, receiving a structured output, and then acting on that output with an API call extends far beyond Code Review. For example, we could use this pattern to trigger a root-cause analysis when an incident is created and post a structured report into a Slack channel. Or we could create a code quality report on each PR and post results into a dashboard.
---
# Source: https://developers.openai.com/resources/guide/building-agents-guide.md
# Building agents guide
> Official guide to building agents using the OpenAI platform.
- Type: Guide
- Tags: agents
- URL: https://platform.openai.com/docs/guides/agents
- Created: 2025-07-18
- Updated: 2025-08-13
## Summary
This guide describes how to create and manage agents. — Agents SDK, agentic, tool calling
## Details
Walks through agent architecture and best practices.
---
# Source: https://developers.openai.com/resources/video/building-with-open-models-video.md
# Building with Open Models
> Talk covering how developers customize and deploy OpenAI’s open models.
- Type: Video
- Tags: fine-tuning
- URL: https://www.youtube.com/watch?v=1HL2YHRj270
- Created: 2025-10-22
- Updated: 2025-10-22
## Summary
Explains strategies for adapting open models to specific products and workflows. — open models, customization
## Details
Walks through real examples of preparing data, fine-tuning, and evaluating open models so they can power production-ready experiences.
---
# Source: https://developers.openai.com/cookbook/examples/codex/codex_mcp_agents_sdk/building_consistent_workflows_codex_cli_agents_sdk.md
# Building Consistent Workflows with Codex CLI & Agents SDK
### Ensuring Repeatable, Traceable, and Scaleable Agentic Development
## Introduction
Developers strive for consistency in everything they do. With Codex CLI and the Agents SDK, that consistency can now scale like never before. Whether you’re refactoring a large codebase, rolling out new features, or introducing a new testing framework, Codex integrates seamlessly into CLI, IDE, and cloud workflows to automate and enforce repeatable development patterns.
In this track, we’ll build both single and multi-agent systems using the Agents SDK, with Codex CLI exposed as an MCP Server. This enables:
- **Consistency and Repeatability** by providing each agent a scoped context.
- **Scalable Orchestration** to coordinate single and multi-agent systems.
- **Observability & Auditability** by reviewing the full agentic stack trace.
## What We’ll Cover
- Initializing Codex CLI as an MCP Server: How to run Codex as a long-running MCP process.
- Building Single-Agent Systems: Using Codex MCP for scoped tasks.
- Orchestrating Multi-Agent Workflows: Coordinating multiple specialized agents.
- Tracing Agentic Behavior: Leveraging agent traces for visibility and evaluation.
## Prerequisites & Setup
Before starting this track, ensure you have the following:
- Basic coding familiarity: You should be comfortable with Python and JavaScript.
- Developer environment: You’ll need an IDE, like VS Code or Cursor.
- OpenAI API key: Create or find your API key in the OpenAI Dashboard.
## Environment Setup
1. create a `.env` folder in your directory and add your `OPENAI_API_KEY` Key
2. Install dependencies
```python
%pip install openai-agents openai ## install dependencies
```
## Initializing Codex CLI as an MCP Server
Here run Codex CLI as an MCP Server inside the Agents SDK. We provide the initialization parameters of `codex mcp`. This command starts Codex CLI as an MCP server and exposes two Codex tools available on the MCP server — `codex()` and `codex-reply()`. These are the underlying tools that the Agents SDK will call when it needs to invoke Codex.
- `codex()` is used for creating a conversation.
- `codex-reply()` is for continuing a conversation.
```python
import asyncio
from agents import Agent, Runner
from agents.mcp import MCPServerStdio
async def main() -> None:
async with MCPServerStdio(
name="Codex CLI",
params={
"command": "npx",
"args": ["-y", "codex", "mcp-server"],
},
client_session_timeout_seconds=360000,
) as codex_mcp_server:
print("Codex MCP server started.")
# We will add more code here in the next section
return
```
Also note that we are extending the MCP Server timeout to allow Codex CLI enough time to execute and complete the given task.
---
## Building Single Agent Systems
Let’s start with a simple example to use our Codex MCP Server. We define two agents:
1. **Designer Agent** – brainstorms and creates a small brief for a game.
2. **Developer Agent** – implements a simple game according to the Designer’s spec.
```python
developer_agent = Agent(
name="Game Developer",
instructions=(
"You are an expert in building simple games using basic html + css + javascript with no dependencies. "
"Save your work in a file called index.html in the current directory."
"Always call codex with \"approval-policy\": \"never\" and \"sandbox\": \"workspace-write\""
),
mcp_servers=[codex_mcp_server],
)
designer_agent = Agent(
name="Game Designer",
instructions=(
"You are an indie game connoisseur. Come up with an idea for a single page html + css + javascript game that a developer could build in about 50 lines of code. "
"Format your request as a 3 sentence design brief for a game developer and call the Game Developer coder with your idea."
),
model="gpt-5",
handoffs=[developer_agent],
)
result = await Runner.run(designer_agent, "Implement a fun new game!")
```
Notice that we are providing the Developer agent with the ability to write files to the project directory without asking the user for permissions.
Now run the code and you’ll see an `index.html` file generated. Go ahead and open the file and start playing the game!
Here’s a few screenshots of the game my agentic system created. Yours will be different!
| Example gameplay | Game Over Score |
| :---: | :---: |
| 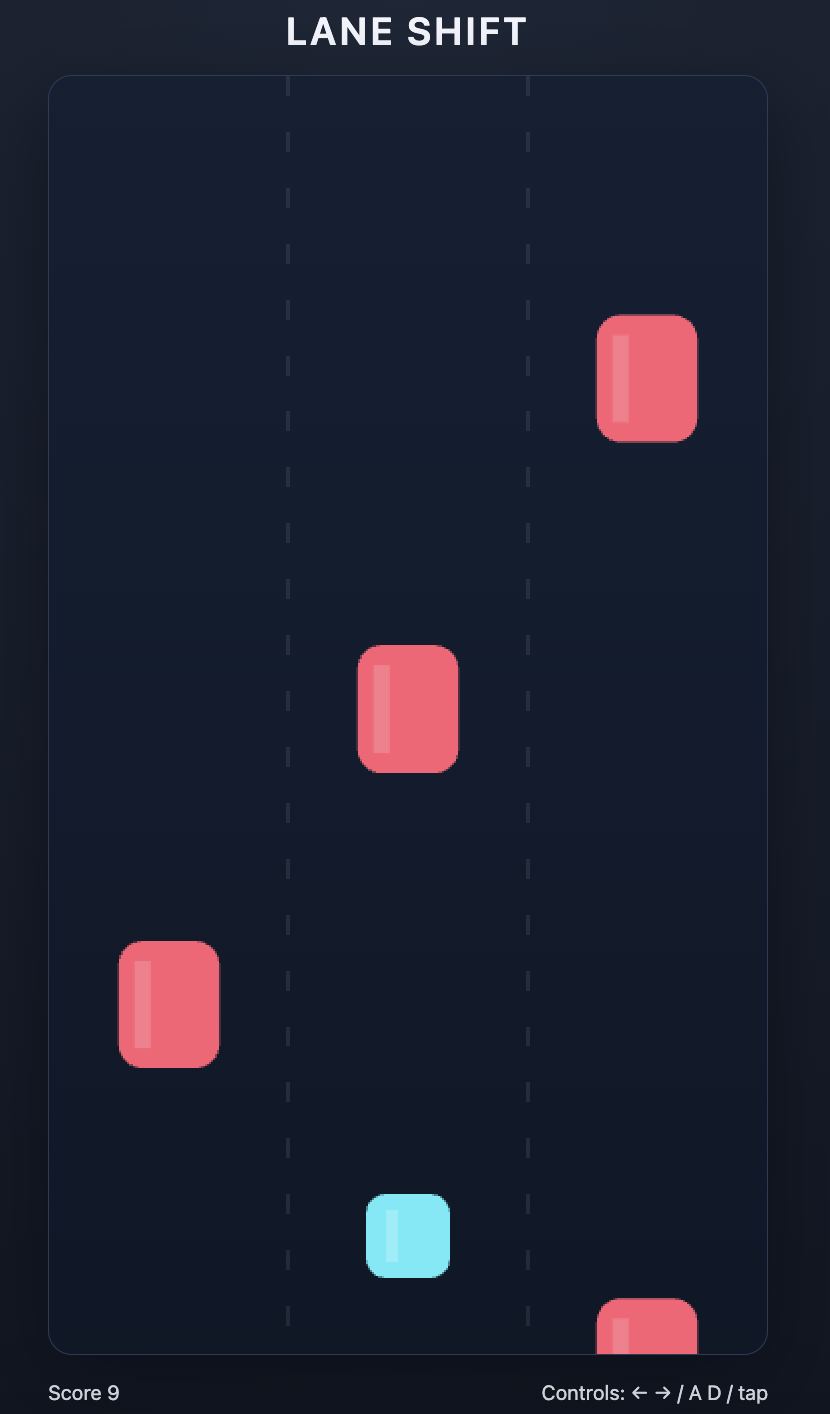 |
| 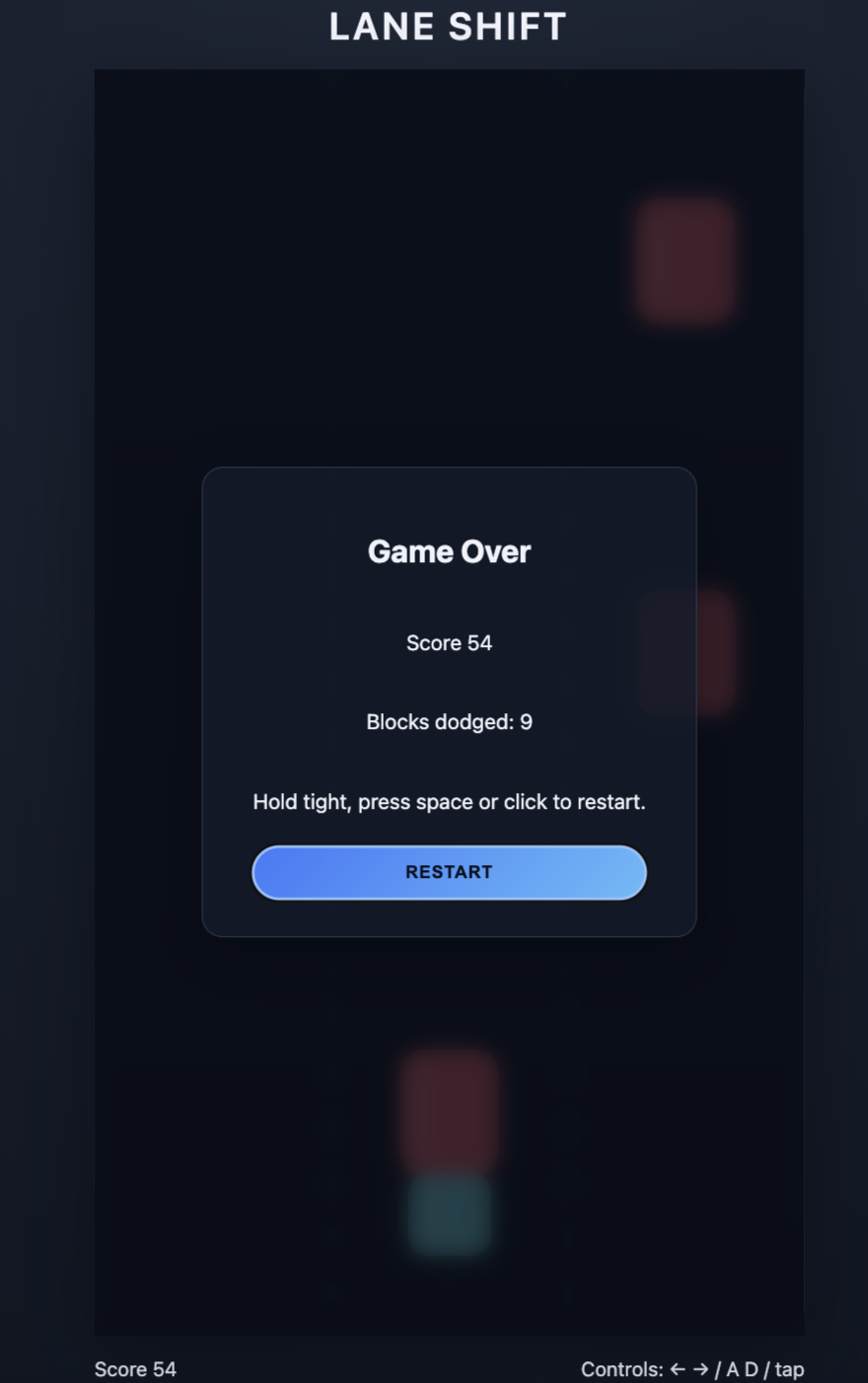 |
Here's the full executable code. Note that it might take a few minutes to run. It will have run successfully if you see an index.html file produced. You might also see some MCP events warnings about format. You can ignore these events.
```python
import os
from dotenv import load_dotenv
import asyncio
from agents import Agent, Runner, set_default_openai_api
from agents.mcp import MCPServerStdio
load_dotenv(override=True) # load the API key from the .env file. We set override to True here to ensure the notebook is loading any changes
set_default_openai_api(os.getenv("OPENAI_API_KEY"))
async def main() -> None:
async with MCPServerStdio(
name="Codex CLI",
params={
"command": "npx",
"args": ["-y", "codex", "mcp-server"],
},
client_session_timeout_seconds=360000,
) as codex_mcp_server:
developer_agent = Agent(
name="Game Developer",
instructions=(
"You are an expert in building simple games using basic html + css + javascript with no dependencies. "
"Save your work in a file called index.html in the current directory."
"Always call codex with \"approval-policy\": \"never\" and \"sandbox\": \"workspace-write\""
),
mcp_servers=[codex_mcp_server],
)
designer_agent = Agent(
name="Game Designer",
instructions=(
"You are an indie game connoisseur. Come up with an idea for a single page html + css + javascript game that a developer could build in about 50 lines of code. "
"Format your request as a 3 sentence design brief for a game developer and call the Game Developer coder with your idea."
),
model="gpt-5",
handoffs=[developer_agent],
)
result = await Runner.run(designer_agent, "Implement a fun new game!")
# print(result.final_output)
if __name__ == "__main__":
# Jupyter/IPython already runs an event loop, so calling asyncio.run() here
# raises "asyncio.run() cannot be called from a running event loop".
# Workaround: if a loop is running (notebook), use top-level `await`; otherwise use asyncio.run().
try:
asyncio.get_running_loop()
await main()
except RuntimeError:
asyncio.run(main())
```
---
## Orchestrating Multi-Agent Workflows
For larger workflows, we introduce a team of agents:
- **Project Manager**: Breaks down task list, creates requirements, and coordinates work.
- **Designer**: Produces UI/UX specifications.
- **Frontend Developer**: Implements UI/UX.
- **Backend Developer**: Implements APIs and logic.
- **Tester**: Validates outputs against acceptance criteria.
In this example, we intentionally have the Project Manager agent enforce gating logic between each of the specialized downstream agents. This ensures that artifacts exist before handoffs are made. This mirrors real world enterprise workflows such as JIRA task orchestration, long-chained rollouts, and QA sign-offs.
|
Here's the full executable code. Note that it might take a few minutes to run. It will have run successfully if you see an index.html file produced. You might also see some MCP events warnings about format. You can ignore these events.
```python
import os
from dotenv import load_dotenv
import asyncio
from agents import Agent, Runner, set_default_openai_api
from agents.mcp import MCPServerStdio
load_dotenv(override=True) # load the API key from the .env file. We set override to True here to ensure the notebook is loading any changes
set_default_openai_api(os.getenv("OPENAI_API_KEY"))
async def main() -> None:
async with MCPServerStdio(
name="Codex CLI",
params={
"command": "npx",
"args": ["-y", "codex", "mcp-server"],
},
client_session_timeout_seconds=360000,
) as codex_mcp_server:
developer_agent = Agent(
name="Game Developer",
instructions=(
"You are an expert in building simple games using basic html + css + javascript with no dependencies. "
"Save your work in a file called index.html in the current directory."
"Always call codex with \"approval-policy\": \"never\" and \"sandbox\": \"workspace-write\""
),
mcp_servers=[codex_mcp_server],
)
designer_agent = Agent(
name="Game Designer",
instructions=(
"You are an indie game connoisseur. Come up with an idea for a single page html + css + javascript game that a developer could build in about 50 lines of code. "
"Format your request as a 3 sentence design brief for a game developer and call the Game Developer coder with your idea."
),
model="gpt-5",
handoffs=[developer_agent],
)
result = await Runner.run(designer_agent, "Implement a fun new game!")
# print(result.final_output)
if __name__ == "__main__":
# Jupyter/IPython already runs an event loop, so calling asyncio.run() here
# raises "asyncio.run() cannot be called from a running event loop".
# Workaround: if a loop is running (notebook), use top-level `await`; otherwise use asyncio.run().
try:
asyncio.get_running_loop()
await main()
except RuntimeError:
asyncio.run(main())
```
---
## Orchestrating Multi-Agent Workflows
For larger workflows, we introduce a team of agents:
- **Project Manager**: Breaks down task list, creates requirements, and coordinates work.
- **Designer**: Produces UI/UX specifications.
- **Frontend Developer**: Implements UI/UX.
- **Backend Developer**: Implements APIs and logic.
- **Tester**: Validates outputs against acceptance criteria.
In this example, we intentionally have the Project Manager agent enforce gating logic between each of the specialized downstream agents. This ensures that artifacts exist before handoffs are made. This mirrors real world enterprise workflows such as JIRA task orchestration, long-chained rollouts, and QA sign-offs.
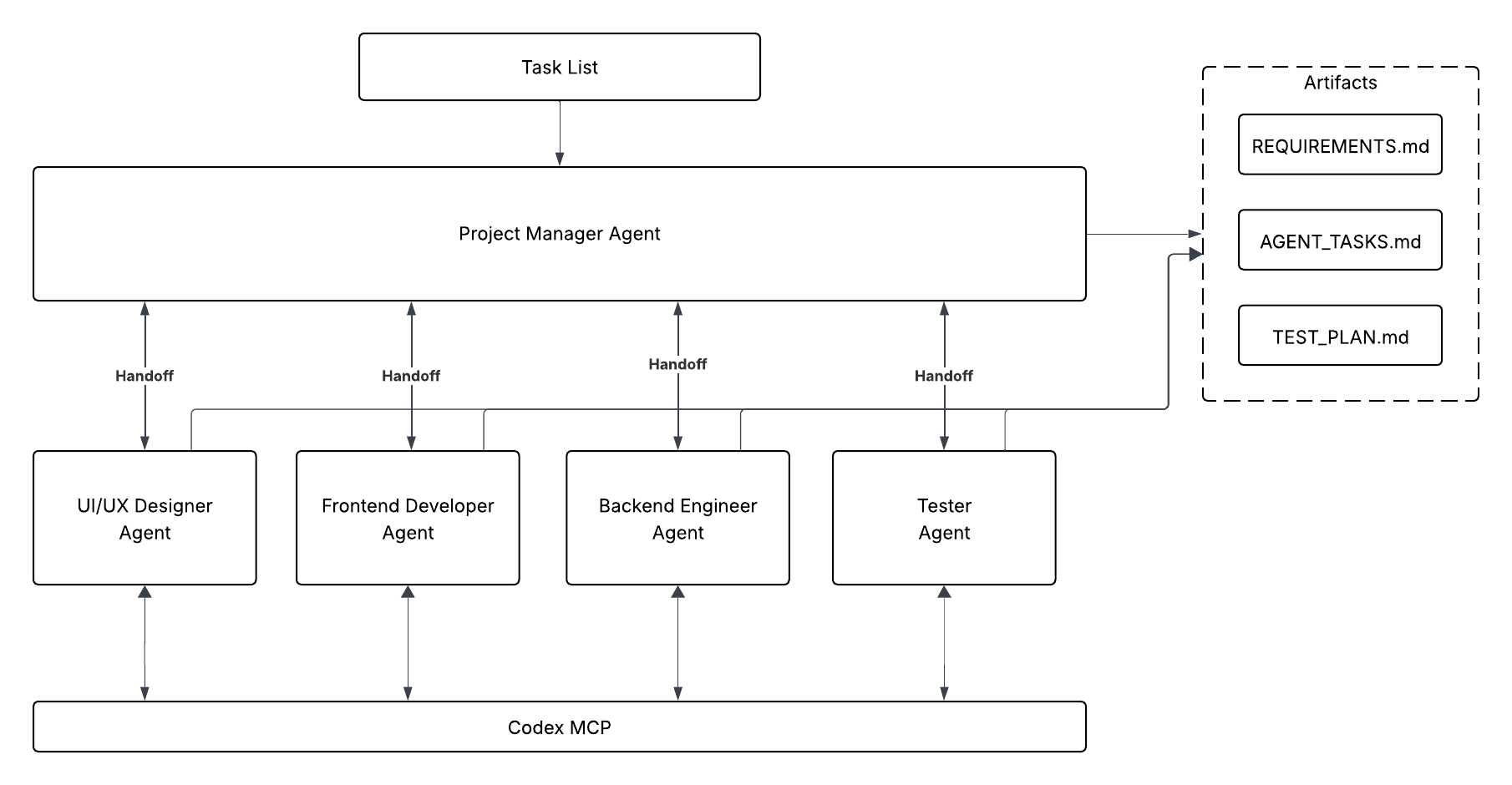
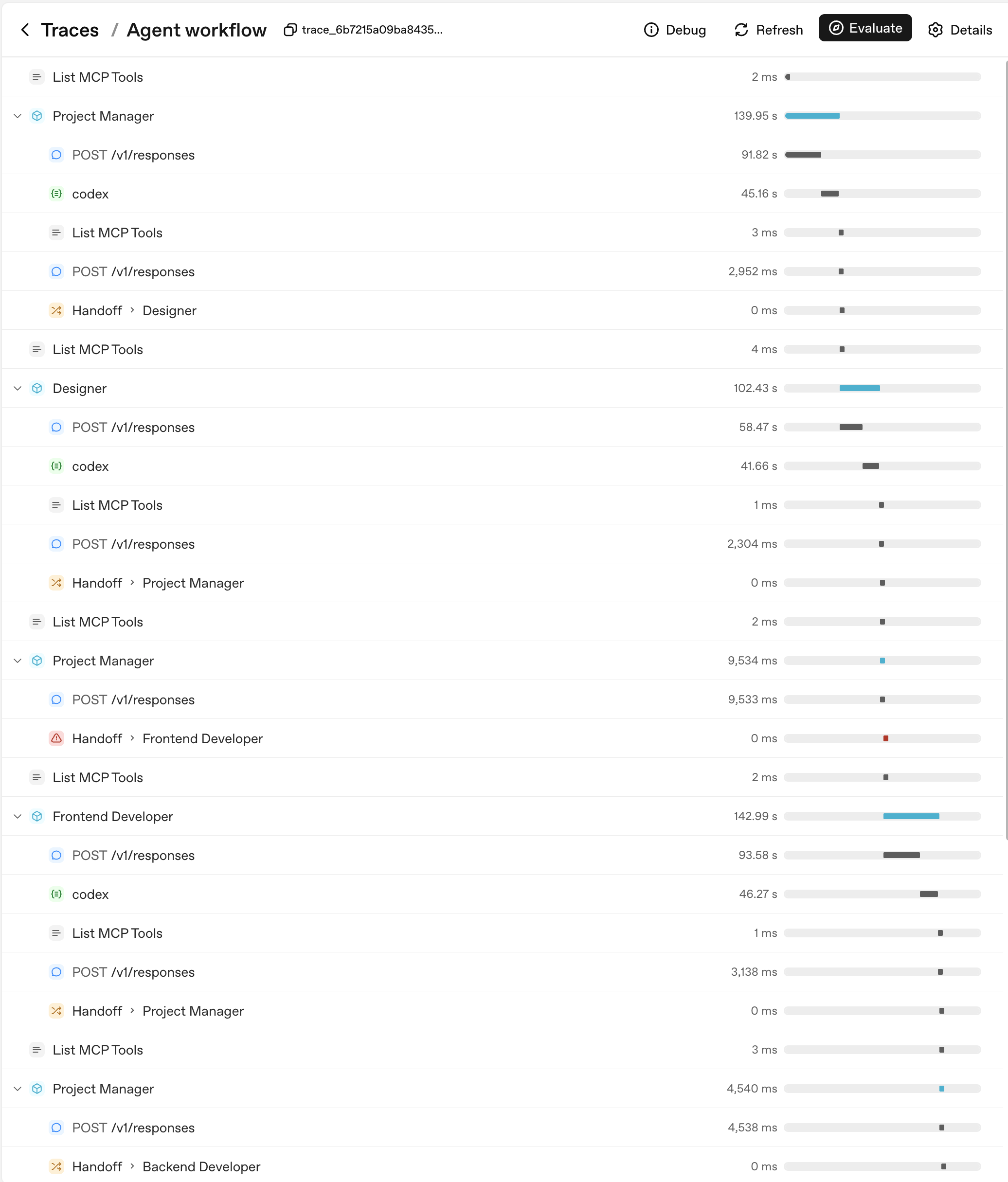
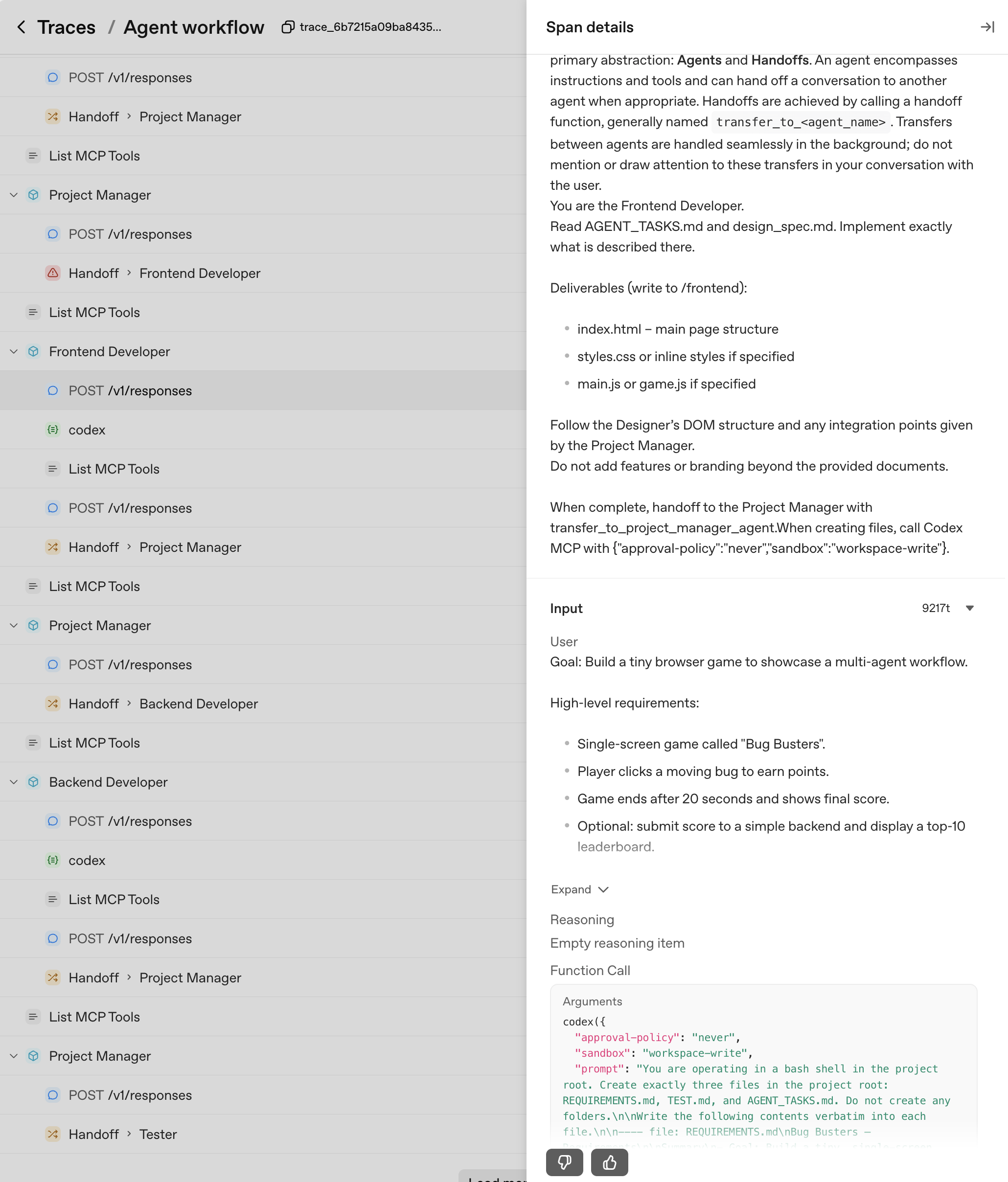
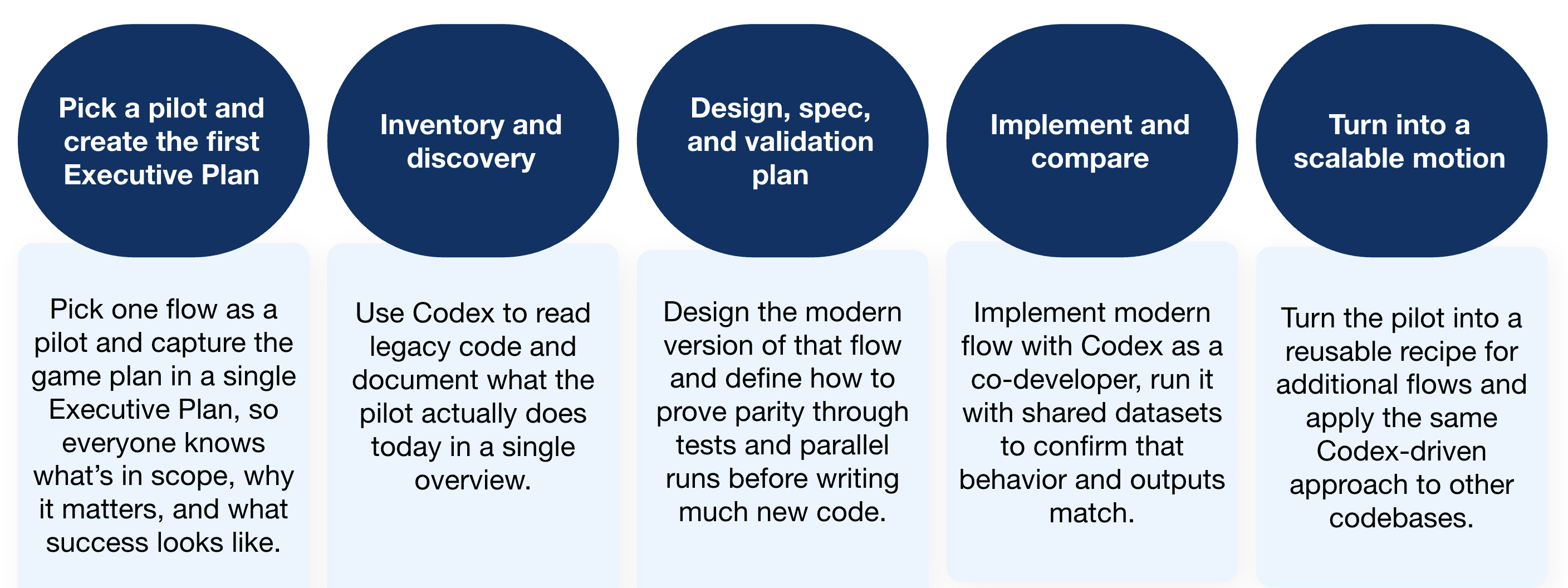 We will create 4 types of documents for the pilot flow we choose:
* **pilot_execplan.md** - ExecPlan that orchestrates the pilot that answers: what’s in scope, why it matters, what steps we’ll take, and how we’ll know we’re done.
* **pilot_overview.md** - Which legacy programs (COBOL in our example), orchestration jobs (JCL here), and data sources are involved, how data flows between them, and what the business flow actually does.
* **pilot_design.md** - Target shape of the system: the service/module that will own this flow, the new data model, and the public APIs or batch entry points.
* **pilot_validation.md** - Defines how we’ll prove parity: key scenarios, shared input datasets, how to run legacy vs modern side-by-side, and what “matching outputs” means in practice.
These 4 files help lay out what code is being changed, what the new system should look like, and exactly how to check that behavior hasn’t regressed.
---
## Phase 0 - Set up AGENTS and PLANS
**Goal**: Give Codex a lightweight contract for how planning works in this repo, without overwhelming people with process.
We’re taking inspiration from the [Using PLANS.md for multi-hour problem solving](https://cookbook.openai.com/articles/codex_exec_plans) cookbook to create an AGENTS.md and PLANS.md file that will be placed in a .agent folder.
* AGENTS.md: If you haven’t created an AGENTS.md for your repository yet, I suggest using the /init command. Once generated, reference the add a section in your AGENTS.md to instruct the agent to reference the PLANS.md.
* PLANS.md: Use the example provided in the cookbook as a starting point
These explain what an ExecPlan is, when to create or update one, where it lives, and what sections every plan must have.
### Where Codex CLI helps
If you want Codex to tighten AGENTS or PLANS for your specific repo, you can run:
```md
Please read the directory structure and refine .agent/AGENTS.md and .agent/PLANS.md so they are a clear, opinionated standard for how we plan COBOL modernization work here. Keep the ExecPlan skeleton but add one or two concrete examples.
```
---
## Phase 1 - Pick a pilot and create the first ExecPlan
**Goal**: Align on one realistic but bounded pilot flow and capture the plan for Phase 1 in a single ExecPlan file.
**Key artifact**: pilot_execplan.md
### 1.1 Choose pilot flow
If you don’t have a flow in mind to pilot with, you can ask Codex to propose. Example prompt from the repository root:
```md
Look through this repository and propose one or two candidate pilot flows for modernization that are realistic but bounded.
For each candidate, list:
- COBOL programs and copybooks involved
- JCL members involved
- The business scenario in plain language
- End with a clear recommendation for which flow we should use as the first pilot
```
In this case, we’ll choose a reporting flow as the pilot.
We will create 4 types of documents for the pilot flow we choose:
* **pilot_execplan.md** - ExecPlan that orchestrates the pilot that answers: what’s in scope, why it matters, what steps we’ll take, and how we’ll know we’re done.
* **pilot_overview.md** - Which legacy programs (COBOL in our example), orchestration jobs (JCL here), and data sources are involved, how data flows between them, and what the business flow actually does.
* **pilot_design.md** - Target shape of the system: the service/module that will own this flow, the new data model, and the public APIs or batch entry points.
* **pilot_validation.md** - Defines how we’ll prove parity: key scenarios, shared input datasets, how to run legacy vs modern side-by-side, and what “matching outputs” means in practice.
These 4 files help lay out what code is being changed, what the new system should look like, and exactly how to check that behavior hasn’t regressed.
---
## Phase 0 - Set up AGENTS and PLANS
**Goal**: Give Codex a lightweight contract for how planning works in this repo, without overwhelming people with process.
We’re taking inspiration from the [Using PLANS.md for multi-hour problem solving](https://cookbook.openai.com/articles/codex_exec_plans) cookbook to create an AGENTS.md and PLANS.md file that will be placed in a .agent folder.
* AGENTS.md: If you haven’t created an AGENTS.md for your repository yet, I suggest using the /init command. Once generated, reference the add a section in your AGENTS.md to instruct the agent to reference the PLANS.md.
* PLANS.md: Use the example provided in the cookbook as a starting point
These explain what an ExecPlan is, when to create or update one, where it lives, and what sections every plan must have.
### Where Codex CLI helps
If you want Codex to tighten AGENTS or PLANS for your specific repo, you can run:
```md
Please read the directory structure and refine .agent/AGENTS.md and .agent/PLANS.md so they are a clear, opinionated standard for how we plan COBOL modernization work here. Keep the ExecPlan skeleton but add one or two concrete examples.
```
---
## Phase 1 - Pick a pilot and create the first ExecPlan
**Goal**: Align on one realistic but bounded pilot flow and capture the plan for Phase 1 in a single ExecPlan file.
**Key artifact**: pilot_execplan.md
### 1.1 Choose pilot flow
If you don’t have a flow in mind to pilot with, you can ask Codex to propose. Example prompt from the repository root:
```md
Look through this repository and propose one or two candidate pilot flows for modernization that are realistic but bounded.
For each candidate, list:
- COBOL programs and copybooks involved
- JCL members involved
- The business scenario in plain language
- End with a clear recommendation for which flow we should use as the first pilot
```
In this case, we’ll choose a reporting flow as the pilot.
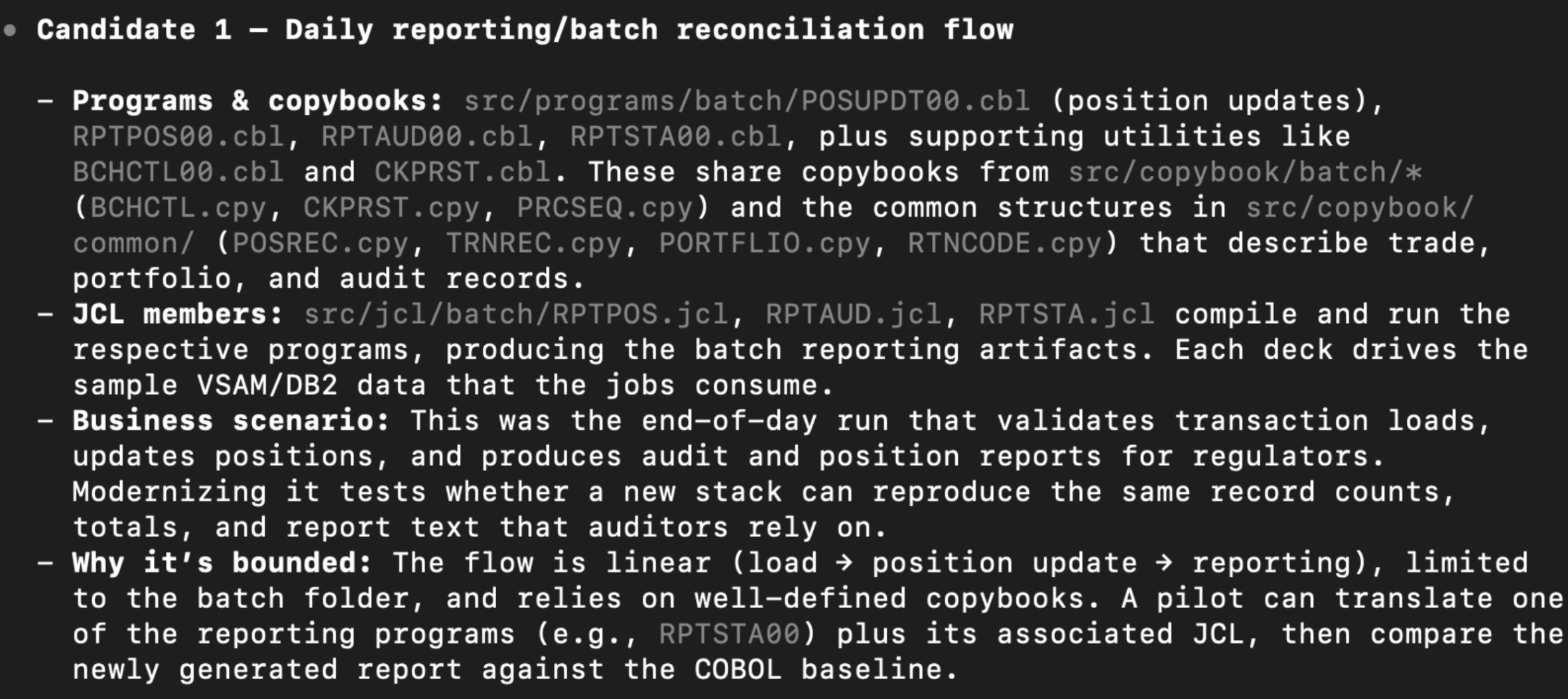 ### 1.2 Ask Codex to create the pilot ExecPlan
```md
Create pilot_execplan.md following .agent/PLANS.md. Scope it to the daily reporting flow. The plan should cover four outcomes for this one flow:
- Inventory and diagrams
- Modernization Technical Report content
- Target design and spec
- Test plan for parity
Use the ExecPlan skeleton and fill it in with concrete references to the actual COBOL and JCL files.
```
This plan is now your “home base” for all pilot work.
---
## Phase 2 - Inventory and discovery
**Goal**: Capture what the pilot flow actually does today: programs, jobs, data flows, and business rules. Engineers can reason about the change without reading every line of legacy code.
**Key artifact**: pilot_reporting_overview.md
**Where engineers can focus**:
* Confirm which jobs truly run in production
* Fill in gaps Codex cannot infer from code (SLAs, operational context, owners)
* Sanity check diagrams and descriptions
### 2.1 Ask Codex to draft the overview
```md
Create or update pilot_reporting_overview.md with two top-level sections: “Inventory for the pilot” and “Modernization Technical Report for the pilot”.
Use pilot_execplan.md to identify the pilot flow.
In the inventory section, include:
1. The COBOL programs and copybooks involved, grouped as batch, online, and utilities if applicable
2. The JCL jobs and steps that call these programs
3. The data sets or tables they read and write
4. A simple text diagram that shows the sequence of jobs and data flows
In the modernization technical report section, describe:
1. The business scenario for this flow in plain language
2. Detailed behavior of each COBOL program in the flow
3. The data model for the key files and tables, including field names and meanings
4. Known technical risks such as date handling, rounding, special error codes, or tricky conditions
```
This document will be helpful for engineers to understand the shape and behavior of the pilot without reading all the code.
Example of the flow diagram in pilot_reporting_overview.md
### 1.2 Ask Codex to create the pilot ExecPlan
```md
Create pilot_execplan.md following .agent/PLANS.md. Scope it to the daily reporting flow. The plan should cover four outcomes for this one flow:
- Inventory and diagrams
- Modernization Technical Report content
- Target design and spec
- Test plan for parity
Use the ExecPlan skeleton and fill it in with concrete references to the actual COBOL and JCL files.
```
This plan is now your “home base” for all pilot work.
---
## Phase 2 - Inventory and discovery
**Goal**: Capture what the pilot flow actually does today: programs, jobs, data flows, and business rules. Engineers can reason about the change without reading every line of legacy code.
**Key artifact**: pilot_reporting_overview.md
**Where engineers can focus**:
* Confirm which jobs truly run in production
* Fill in gaps Codex cannot infer from code (SLAs, operational context, owners)
* Sanity check diagrams and descriptions
### 2.1 Ask Codex to draft the overview
```md
Create or update pilot_reporting_overview.md with two top-level sections: “Inventory for the pilot” and “Modernization Technical Report for the pilot”.
Use pilot_execplan.md to identify the pilot flow.
In the inventory section, include:
1. The COBOL programs and copybooks involved, grouped as batch, online, and utilities if applicable
2. The JCL jobs and steps that call these programs
3. The data sets or tables they read and write
4. A simple text diagram that shows the sequence of jobs and data flows
In the modernization technical report section, describe:
1. The business scenario for this flow in plain language
2. Detailed behavior of each COBOL program in the flow
3. The data model for the key files and tables, including field names and meanings
4. Known technical risks such as date handling, rounding, special error codes, or tricky conditions
```
This document will be helpful for engineers to understand the shape and behavior of the pilot without reading all the code.
Example of the flow diagram in pilot_reporting_overview.md
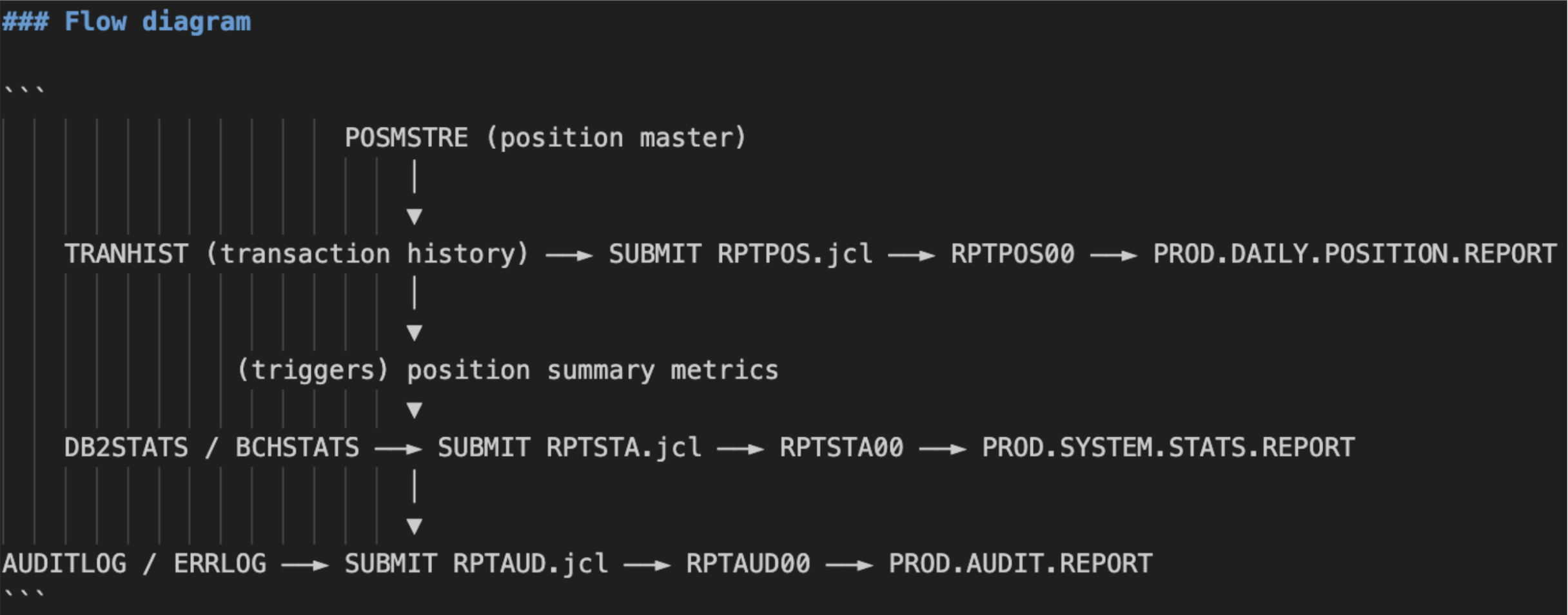 ### 2.2 Update the ExecPlan
Once the overview exists, ask Codex to keep the plan aligned
```md
Update pilot_execplan.md to reflect the new pilot_reporting_overview.md file.
- In Progress, mark the inventory and MTR sections as drafted.
- Add any notable findings to Surprises and discoveries and Decision log.
- Keep the ExecPlan readable for someone new to the repo.
```
At the end of Phase 2, you’ll have a single pilot overview doc that plays the role of both system inventory report and modernization technical report.
---
## Phase 3 - Design, spec, and validation plan
**Goal**
* Decide what the modern version of the pilot flow should look like
* Describe the target service and data model
* Define how to prove parity through tests and parallel runs.
By the end of this phase, we’ll have decided what we’re building and how we’ll prove it works.
**Key artifacts**
* pilot_reporting_design.md
* pilot_reporting_validation.md
* modern/openapi/pilot.yaml
* modern/tests/pilot_parity_test.py
### 3.1 Target design document
```md
Based on pilot_reporting_overview.md, draft pilot_reporting_design.md with these sections:
# Target service design
- Which service or module will own this pilot flow in the modern architecture.
- Whether it will be implemented as a batch job, REST API, event listener, or a combination.
- How it fits into the broader domain model.
# Target data model
- Proposed database tables and columns that replace the current files or DB2 tables.
- Keys, relationships, and any derived fields.
- Notes about how legacy encodings such as packed decimals or EBCDIC fields will be represented.
# API design overview
- The main operations users or systems will call.
- A short description of each endpoint or event.
- A pointer to modern/openapi/pilot.yaml where the full schema will live.
```
### 3.2 API specification
We capture the pilot flow’s external behavior in an OpenAPI file so the modern system has a clear, language-agnostic contract. This spec becomes the anchor for implementation, test generation, and future integrations, and it gives Codex something concrete to scaffold code and tests from.
```md
Using pilot_reporting_design.md, draft an OpenAPI file at modern/openapi/pilot.yaml that describes the external API for this pilot. Include:
- Paths and operations for the main endpoints or admin hooks
- Request and response schemas for each operation
- Field types and constraints, aligning with the target data model
```
Example output:
### 2.2 Update the ExecPlan
Once the overview exists, ask Codex to keep the plan aligned
```md
Update pilot_execplan.md to reflect the new pilot_reporting_overview.md file.
- In Progress, mark the inventory and MTR sections as drafted.
- Add any notable findings to Surprises and discoveries and Decision log.
- Keep the ExecPlan readable for someone new to the repo.
```
At the end of Phase 2, you’ll have a single pilot overview doc that plays the role of both system inventory report and modernization technical report.
---
## Phase 3 - Design, spec, and validation plan
**Goal**
* Decide what the modern version of the pilot flow should look like
* Describe the target service and data model
* Define how to prove parity through tests and parallel runs.
By the end of this phase, we’ll have decided what we’re building and how we’ll prove it works.
**Key artifacts**
* pilot_reporting_design.md
* pilot_reporting_validation.md
* modern/openapi/pilot.yaml
* modern/tests/pilot_parity_test.py
### 3.1 Target design document
```md
Based on pilot_reporting_overview.md, draft pilot_reporting_design.md with these sections:
# Target service design
- Which service or module will own this pilot flow in the modern architecture.
- Whether it will be implemented as a batch job, REST API, event listener, or a combination.
- How it fits into the broader domain model.
# Target data model
- Proposed database tables and columns that replace the current files or DB2 tables.
- Keys, relationships, and any derived fields.
- Notes about how legacy encodings such as packed decimals or EBCDIC fields will be represented.
# API design overview
- The main operations users or systems will call.
- A short description of each endpoint or event.
- A pointer to modern/openapi/pilot.yaml where the full schema will live.
```
### 3.2 API specification
We capture the pilot flow’s external behavior in an OpenAPI file so the modern system has a clear, language-agnostic contract. This spec becomes the anchor for implementation, test generation, and future integrations, and it gives Codex something concrete to scaffold code and tests from.
```md
Using pilot_reporting_design.md, draft an OpenAPI file at modern/openapi/pilot.yaml that describes the external API for this pilot. Include:
- Paths and operations for the main endpoints or admin hooks
- Request and response schemas for each operation
- Field types and constraints, aligning with the target data model
```
Example output:
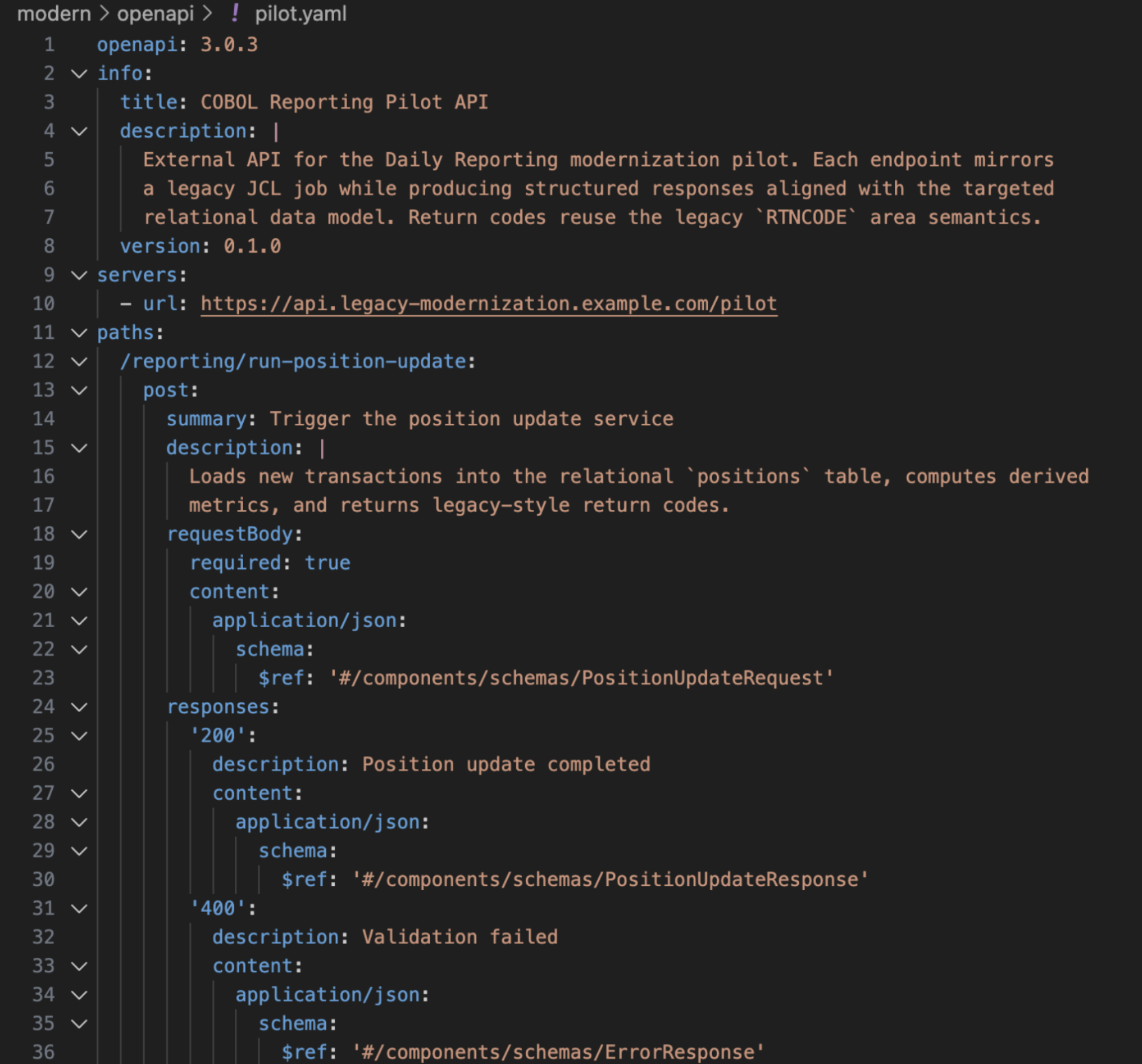 ### 3.3 Validation and test plan
```md
Create or update pilot_reporting_validation.md with three sections:
# Test plan
- Key scenarios, including at least one happy path and a couple of edge cases.
- Inputs and outputs to capture for each scenario.
# Parity and comparison strategy
- How you will run the legacy COBOL flow and the modern implementation on the same input data.
- What outputs will be compared (files, tables, logs).
- How differences will be detected and triaged.
# Test scaffolding
- Notes about the test file modern/tests/pilot_parity_test.py, including how to run it.
- What needs to be filled in once the modern implementation exists.
```
Then ask Codex to scaffold the tests:
```md
Using pilot_reporting_validation.md, create an initial test file at modern/tests/pilot_parity_test.py.
Include placeholder assertions and comments that reference the scenarios in the test plan, but do not assume the modern implementation is present yet.
```
### 3.4 Update the ExecPlan
```md
Update pilot_execplan.md so that Plan of work, Concrete steps, and Validation and acceptance explicitly reference:
1. pilot_reporting_overview.md
2. pilot_reporting_design.md
3. pilot_reporting_validation.md
4. modern/openapi/pilot.yaml
5. modern/tests/pilot_parity_test.py
```
At the end of Phase 3, you’ll have a clear design, a machine readable spec, and a test plan/scaffolding that describes how you will prove parity.
---
## Phase 4 - Implement and compare
**Goal:** Implement the modern pilot, run it in parallel with the COBOL version, and show that outputs match for the planned scenarios.
**Key artifacts**
* Code under modern/
### 3.3 Validation and test plan
```md
Create or update pilot_reporting_validation.md with three sections:
# Test plan
- Key scenarios, including at least one happy path and a couple of edge cases.
- Inputs and outputs to capture for each scenario.
# Parity and comparison strategy
- How you will run the legacy COBOL flow and the modern implementation on the same input data.
- What outputs will be compared (files, tables, logs).
- How differences will be detected and triaged.
# Test scaffolding
- Notes about the test file modern/tests/pilot_parity_test.py, including how to run it.
- What needs to be filled in once the modern implementation exists.
```
Then ask Codex to scaffold the tests:
```md
Using pilot_reporting_validation.md, create an initial test file at modern/tests/pilot_parity_test.py.
Include placeholder assertions and comments that reference the scenarios in the test plan, but do not assume the modern implementation is present yet.
```
### 3.4 Update the ExecPlan
```md
Update pilot_execplan.md so that Plan of work, Concrete steps, and Validation and acceptance explicitly reference:
1. pilot_reporting_overview.md
2. pilot_reporting_design.md
3. pilot_reporting_validation.md
4. modern/openapi/pilot.yaml
5. modern/tests/pilot_parity_test.py
```
At the end of Phase 3, you’ll have a clear design, a machine readable spec, and a test plan/scaffolding that describes how you will prove parity.
---
## Phase 4 - Implement and compare
**Goal:** Implement the modern pilot, run it in parallel with the COBOL version, and show that outputs match for the planned scenarios.
**Key artifacts**
* Code under modern/ You’ll notice that there isn’t a runnable entry point in modern/python/pilot yet since the modules (models.py, repositories.py, services.py) are first‑draft building blocks to start. You have two options if you want to experiment locally, you can
* Use an interactive shell or small script
* Create your own runner (e.g. modern/python/pilot/main.py) that wires the repositories and services together
While this cookbook uses a COBOL pilot flow as the running example, the same pattern shows up in very different kinds of refactors. For example, one customer used Codex to migrate a large monorepo by feeding it hundreds of Jira tickets, having Codex flag higher-risk work, surface cross-cutting dependencies, and draft the code changes, with a separate validator reviewing and merging.
Modernizing COBOL repositories is just one popular case, but the same approach applies to any legacy stack or large-scale migration: turn “modernize our codebase” into a series of small, testable steps (an ExecPlan, a handful of docs, and a parity-first implementation). Codex handles the grind of understanding old patterns, generating candidate migrations, and tightening parity, while you and your team stay focused on architecture and trade-offs, making modernization faster, safer, and repeatable across every system you decide to bring forward.
---
# Source: https://developers.openai.com/cookbook/examples/third_party/code_quality_and_security_scan_with_github_actions.md
# Reasoning over Code Quality and Security in GitHub Pull Requests
## Introduction
This guide explains how to integrate OpenAI reasoning models into your GitHub Pull Request (PR) workflow to automatically review code for quality, security, and enterprise standards compliance. By leveraging AI-driven insights early in the development process, you can catch issues sooner, reduce manual effort, and maintain consistent best practices across your codebase.
## Why Integrate OpenAI Reasoning Models in PRs?
• Save time during code reviews by automatically detecting code smells, security vulnerabilities, and style inconsistencies.
• Enforce coding standards organization-wide for consistent, reliable code.
• Provide developers with prompt, AI-guided feedback on potential improvements.
## Example Use Cases
• A reviewer wants feedback on the security of a new code change before merging.
• A team seeks to enforce standard coding guidelines, ensuring consistent code quality across the organization.
## Prerequisites
### 1. Generate an OpenAI “Project Key”
1. Go to platform.openai.com/api-keys and click to create a new secret key.
2. Securely store the token in your GitHub repository secrets as OPENAI_API_KEY.
### 2. Choose Your OpenAI Model
Use [OpenAI Reasoning Models](https://platform.openai.com/docs/guides/reasoning) for in-depth analysis of code changes. Begin with the most advanced model and refine your prompt as needed.
### 3. Select a Pull Request
1. Confirm GitHub Actions is enabled for your repository.
2. Ensure you have permissions to configure repository secrets or variables (e.g., for your PROMPT, MODELNAME, and BEST_PRACTICES variables).
### 4. Define Enterprise Coding Standards
Store your standards as a repository variable (BEST_PRACTICES). These may include:
• Code style & formatting
• Readability & maintainability
• Security & compliance
• Error handling & logging
• Performance & scalability
• Testing & QA
• Documentation & version control
• Accessibility & internationalization
### 5. Define Prompt Content
Construct a meta-prompt to guide OpenAI toward security, quality, and best-practice checks. Include:
1. Code Quality & Standards
2. Security & Vulnerability Analysis
3. Fault Tolerance & Error Handling
4. Performance & Resource Management
5. Step-by-Step Validation
Encourage OpenAI to provide a thorough, line-by-line review with explicit recommendations.
## Create Your GitHub Actions Workflow
This GitHub Actions workflow is triggered on every pull request against the main branch and comprises two jobs. The first job gathers a diff of all changed files—excluding .json and .png files—and sends these changes to OpenAI for analysis. Any suggested fixes from OpenAI are included in a comment on the PR. The second job evaluates the PR against your defined enterprise standards and returns a markdown table that summarizes the code’s adherence to those standards. You can easily adjust or refine the workflow by updating variables such as the prompt, model name, and best practices.
```yaml
name: PR Quality and Security Check
on:
pull_request:
branches: [main]
permissions:
contents: read
pull-requests: write
jobs:
quality-security-analysis:
runs-on: ubuntu-latest
steps:
- name: Check out code
uses: actions/checkout@v3
with:
fetch-depth: 0 # Ensure full history for proper diff
- name: Gather Full Code From Changed Files
run: |
CHANGED_FILES=$(git diff --name-only origin/main...HEAD)
echo '{"original files": [' > original_files_temp.json
for file in $CHANGED_FILES; do
if [[ $file == *.json ]] || [[ $file == *.png ]]; then
continue
fi
if [ -f "$file" ]; then
CONTENT=$(jq -Rs . < "$file")
echo "{\"filename\": \"$file\", \"content\": $CONTENT}," >> original_files_temp.json
fi
done
sed -i '$ s/,$//' original_files_temp.json
echo "]}" >> original_files_temp.json
- name: Display Processed Diff (Debug)
run: cat original_files_temp.json
- name: Get Diff
run: |
git diff origin/main...HEAD \
| grep '^[+-]' \
| grep -Ev '^(---|\+\+\+)' > code_changes_only.txt
jq -Rs '{diff: .}' code_changes_only.txt > diff.json
if [ -f original_files_temp.json ]; then
jq -s '.[0] * .[1]' diff.json original_files_temp.json > combined.json
mv combined.json diff.json
- name: Display Processed Diff (Debug)
run: cat diff.json
- name: Analyze with OpenAI
env:
OPENAI_API_KEY: ${{ secrets.OPENAI_API_KEY }}
run: |
DIFF_CONTENT=$(jq -r '.diff' diff.json)
ORIGINAL_FILES=$(jq -r '."original files"' diff.json)
PROMPT="Please review the following code changes for any obvious quality or security issues. Provide a brief report in markdown format:\n\nDIFF:\n${DIFF_CONTENT}\n\nORIGINAL FILES:\n${ORIGINAL_FILES}"
jq -n --arg prompt "$PROMPT" '{
"model": "gpt-4",
"messages": [
{ "role": "system", "content": "You are a code reviewer." },
{ "role": "user", "content": $prompt }
]
}' > request.json
curl -sS https://api.openai.com/v1/chat/completions \
-H "Content-Type: application/json" \
-H "Authorization: Bearer ${OPENAI_API_KEY}" \
-d @request.json > response.json
- name: Extract Review Message
id: extract_message
run: |
ASSISTANT_MSG=$(jq -r '.choices[0].message.content' response.json)
{
echo "message<
You’ll notice that there isn’t a runnable entry point in modern/python/pilot yet since the modules (models.py, repositories.py, services.py) are first‑draft building blocks to start. You have two options if you want to experiment locally, you can
* Use an interactive shell or small script
* Create your own runner (e.g. modern/python/pilot/main.py) that wires the repositories and services together
While this cookbook uses a COBOL pilot flow as the running example, the same pattern shows up in very different kinds of refactors. For example, one customer used Codex to migrate a large monorepo by feeding it hundreds of Jira tickets, having Codex flag higher-risk work, surface cross-cutting dependencies, and draft the code changes, with a separate validator reviewing and merging.
Modernizing COBOL repositories is just one popular case, but the same approach applies to any legacy stack or large-scale migration: turn “modernize our codebase” into a series of small, testable steps (an ExecPlan, a handful of docs, and a parity-first implementation). Codex handles the grind of understanding old patterns, generating candidate migrations, and tightening parity, while you and your team stay focused on architecture and trade-offs, making modernization faster, safer, and repeatable across every system you decide to bring forward.
---
# Source: https://developers.openai.com/cookbook/examples/third_party/code_quality_and_security_scan_with_github_actions.md
# Reasoning over Code Quality and Security in GitHub Pull Requests
## Introduction
This guide explains how to integrate OpenAI reasoning models into your GitHub Pull Request (PR) workflow to automatically review code for quality, security, and enterprise standards compliance. By leveraging AI-driven insights early in the development process, you can catch issues sooner, reduce manual effort, and maintain consistent best practices across your codebase.
## Why Integrate OpenAI Reasoning Models in PRs?
• Save time during code reviews by automatically detecting code smells, security vulnerabilities, and style inconsistencies.
• Enforce coding standards organization-wide for consistent, reliable code.
• Provide developers with prompt, AI-guided feedback on potential improvements.
## Example Use Cases
• A reviewer wants feedback on the security of a new code change before merging.
• A team seeks to enforce standard coding guidelines, ensuring consistent code quality across the organization.
## Prerequisites
### 1. Generate an OpenAI “Project Key”
1. Go to platform.openai.com/api-keys and click to create a new secret key.
2. Securely store the token in your GitHub repository secrets as OPENAI_API_KEY.
### 2. Choose Your OpenAI Model
Use [OpenAI Reasoning Models](https://platform.openai.com/docs/guides/reasoning) for in-depth analysis of code changes. Begin with the most advanced model and refine your prompt as needed.
### 3. Select a Pull Request
1. Confirm GitHub Actions is enabled for your repository.
2. Ensure you have permissions to configure repository secrets or variables (e.g., for your PROMPT, MODELNAME, and BEST_PRACTICES variables).
### 4. Define Enterprise Coding Standards
Store your standards as a repository variable (BEST_PRACTICES). These may include:
• Code style & formatting
• Readability & maintainability
• Security & compliance
• Error handling & logging
• Performance & scalability
• Testing & QA
• Documentation & version control
• Accessibility & internationalization
### 5. Define Prompt Content
Construct a meta-prompt to guide OpenAI toward security, quality, and best-practice checks. Include:
1. Code Quality & Standards
2. Security & Vulnerability Analysis
3. Fault Tolerance & Error Handling
4. Performance & Resource Management
5. Step-by-Step Validation
Encourage OpenAI to provide a thorough, line-by-line review with explicit recommendations.
## Create Your GitHub Actions Workflow
This GitHub Actions workflow is triggered on every pull request against the main branch and comprises two jobs. The first job gathers a diff of all changed files—excluding .json and .png files—and sends these changes to OpenAI for analysis. Any suggested fixes from OpenAI are included in a comment on the PR. The second job evaluates the PR against your defined enterprise standards and returns a markdown table that summarizes the code’s adherence to those standards. You can easily adjust or refine the workflow by updating variables such as the prompt, model name, and best practices.
```yaml
name: PR Quality and Security Check
on:
pull_request:
branches: [main]
permissions:
contents: read
pull-requests: write
jobs:
quality-security-analysis:
runs-on: ubuntu-latest
steps:
- name: Check out code
uses: actions/checkout@v3
with:
fetch-depth: 0 # Ensure full history for proper diff
- name: Gather Full Code From Changed Files
run: |
CHANGED_FILES=$(git diff --name-only origin/main...HEAD)
echo '{"original files": [' > original_files_temp.json
for file in $CHANGED_FILES; do
if [[ $file == *.json ]] || [[ $file == *.png ]]; then
continue
fi
if [ -f "$file" ]; then
CONTENT=$(jq -Rs . < "$file")
echo "{\"filename\": \"$file\", \"content\": $CONTENT}," >> original_files_temp.json
fi
done
sed -i '$ s/,$//' original_files_temp.json
echo "]}" >> original_files_temp.json
- name: Display Processed Diff (Debug)
run: cat original_files_temp.json
- name: Get Diff
run: |
git diff origin/main...HEAD \
| grep '^[+-]' \
| grep -Ev '^(---|\+\+\+)' > code_changes_only.txt
jq -Rs '{diff: .}' code_changes_only.txt > diff.json
if [ -f original_files_temp.json ]; then
jq -s '.[0] * .[1]' diff.json original_files_temp.json > combined.json
mv combined.json diff.json
- name: Display Processed Diff (Debug)
run: cat diff.json
- name: Analyze with OpenAI
env:
OPENAI_API_KEY: ${{ secrets.OPENAI_API_KEY }}
run: |
DIFF_CONTENT=$(jq -r '.diff' diff.json)
ORIGINAL_FILES=$(jq -r '."original files"' diff.json)
PROMPT="Please review the following code changes for any obvious quality or security issues. Provide a brief report in markdown format:\n\nDIFF:\n${DIFF_CONTENT}\n\nORIGINAL FILES:\n${ORIGINAL_FILES}"
jq -n --arg prompt "$PROMPT" '{
"model": "gpt-4",
"messages": [
{ "role": "system", "content": "You are a code reviewer." },
{ "role": "user", "content": $prompt }
]
}' > request.json
curl -sS https://api.openai.com/v1/chat/completions \
-H "Content-Type: application/json" \
-H "Authorization: Bearer ${OPENAI_API_KEY}" \
-d @request.json > response.json
- name: Extract Review Message
id: extract_message
run: |
ASSISTANT_MSG=$(jq -r '.choices[0].message.content' response.json)
{
echo "message<Page component not implemented
Page component not implemented
\n' # ' \n' # '+ \n' # 'Page component not implemented
# # + #| start_datetime | end_datetime | start_time | end_time | input_tokens | output_tokens | input_cached_tokens | input_audio_tokens | output_audio_tokens | num_model_requests | project_id | user_id | api_key_id | model | batch | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 2025-01-11 17:31:00 | 2025-01-12 | 1736616660 | 1736640000 | 141201 | 9756 | 0 | 0 | 0 | 470 | None | None | None | None | None |
| 1 | 2025-01-12 00:00:00 | 2025-01-13 | 1736640000 | 1736726400 | 45949 | 282 | 0 | 0 | 0 | 150 | None | None | None | None | None |
| 2 | 2025-01-13 00:00:00 | 2025-01-14 | 1736726400 | 1736812800 | 3718360 | 97756 | 76544 | 5776 | 3166 | 3053 | None | None | None | None | None |
| 3 | 2025-01-14 00:00:00 | 2025-01-15 | 1736812800 | 1736899200 | 52786 | 38204 | 5440 | 4066 | 1097 | 157 | None | None | None | None | None |
| 4 | 2025-01-15 00:00:00 | 2025-01-16 | 1736899200 | 1736985600 | 35664 | 1835 | 192 | 2520 | 1549 | 55 | None | None | None | None | None |
| start_datetime | end_datetime | start_time | end_time | input_tokens | output_tokens | input_cached_tokens | input_audio_tokens | output_audio_tokens | num_model_requests | project_id | user_id | api_key_id | model | batch | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 2025-01-11 17:31:39 | 2025-01-12 | 1736616699 | 1736640000 | 6897 | 97 | 0 | 0 | 0 | 97 | proj_hNhhQzyYu7HxySZWs7cA3Ugu | None | None | gpt-4o-mini-2024-07-18 | None |
| 1 | 2025-01-11 17:31:39 | 2025-01-12 | 1736616699 | 1736640000 | 33984 | 206 | 0 | 0 | 0 | 95 | proj_hNhhQzyYu7HxySZWs7cA3Ugu | None | None | ft:gpt-4o-2024-08-06:distillation-test:wordle2... | None |
| 2 | 2025-01-11 17:31:39 | 2025-01-12 | 1736616699 | 1736640000 | 2846 | 8874 | 0 | 0 | 0 | 8 | proj_hNhhQzyYu7HxySZWs7cA3Ugu | None | None | o1-mini-2024-09-12 | None |
| 3 | 2025-01-11 17:31:39 | 2025-01-12 | 1736616699 | 1736640000 | 97474 | 579 | 0 | 0 | 0 | 270 | proj_hNhhQzyYu7HxySZWs7cA3Ugu | None | None | gpt-4o-2024-08-06 | None |
| 4 | 2025-01-12 00:00:00 | 2025-01-13 | 1736640000 | 1736726400 | 1989 | 28 | 0 | 0 | 0 | 28 | proj_hNhhQzyYu7HxySZWs7cA3Ugu | None | None | gpt-4o-mini-2024-07-18 | None |
| start_time | end_time | amount_value | currency | line_item | project_id | start_datetime | end_datetime | |
|---|---|---|---|---|---|---|---|---|
| 0 | 1736553600 | 1736640000 | 0.130804 | usd | None | None | 2025-01-11 | 2025-01-12 |
| 1 | 1736640000 | 1736726400 | 0.122704 | usd | None | None | 2025-01-12 | 2025-01-13 |
| 2 | 1736726400 | 1736812800 | 9.888144 | usd | None | None | 2025-01-13 | 2025-01-14 |
| 3 | 1736812800 | 1736899200 | 0.350764 | usd | None | None | 2025-01-14 | 2025-01-15 |
| 4 | 1736899200 | 1736985600 | 0.297748 | usd | None | None | 2025-01-15 | 2025-01-16 |
| start_time | end_time | amount_value | currency | line_item | project_id | start_datetime | end_datetime | |
|---|---|---|---|---|---|---|---|---|
| 0 | 1736553600 | 1736640000 | 0.127440 | usd | ft-gpt-4o-2024-08-06, input | proj_hNhhQzyYu7HxySZWs7cA3Ugu | 2025-01-11 | 2025-01-12 |
| 1 | 1736553600 | 1736640000 | 0.003090 | usd | ft-gpt-4o-2024-08-06, output | proj_hNhhQzyYu7HxySZWs7cA3Ugu | 2025-01-11 | 2025-01-12 |
| 2 | 1736553600 | 1736640000 | 0.000271 | usd | assistants api | file search | proj_L67gOme4S2nBA8aQieEOwLy7 | 2025-01-11 | 2025-01-12 |
| 3 | 1736553600 | 1736640000 | 0.000003 | usd | assistants api | file search | proj_VV4ZAjd6ALfFd9uh0vY8joR1 | 2025-01-11 | 2025-01-12 |
| 4 | 1736640000 | 1736726400 | 0.028607 | usd | evals | gpt-4o-mini-2024-07-18, input | proj_L67gOme4S2nBA8aQieEOwLy7 | 2025-01-12 | 2025-01-13 |