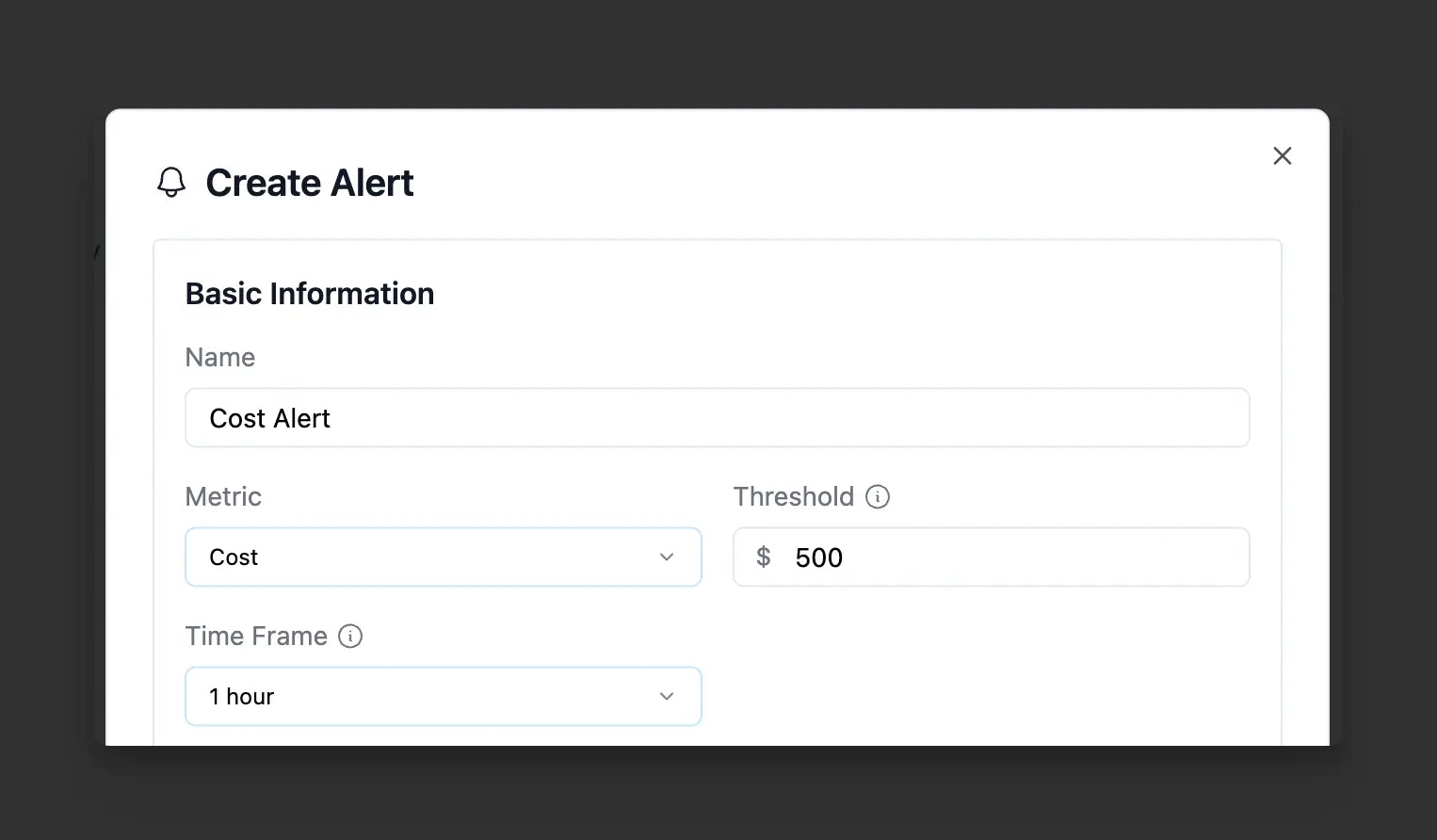
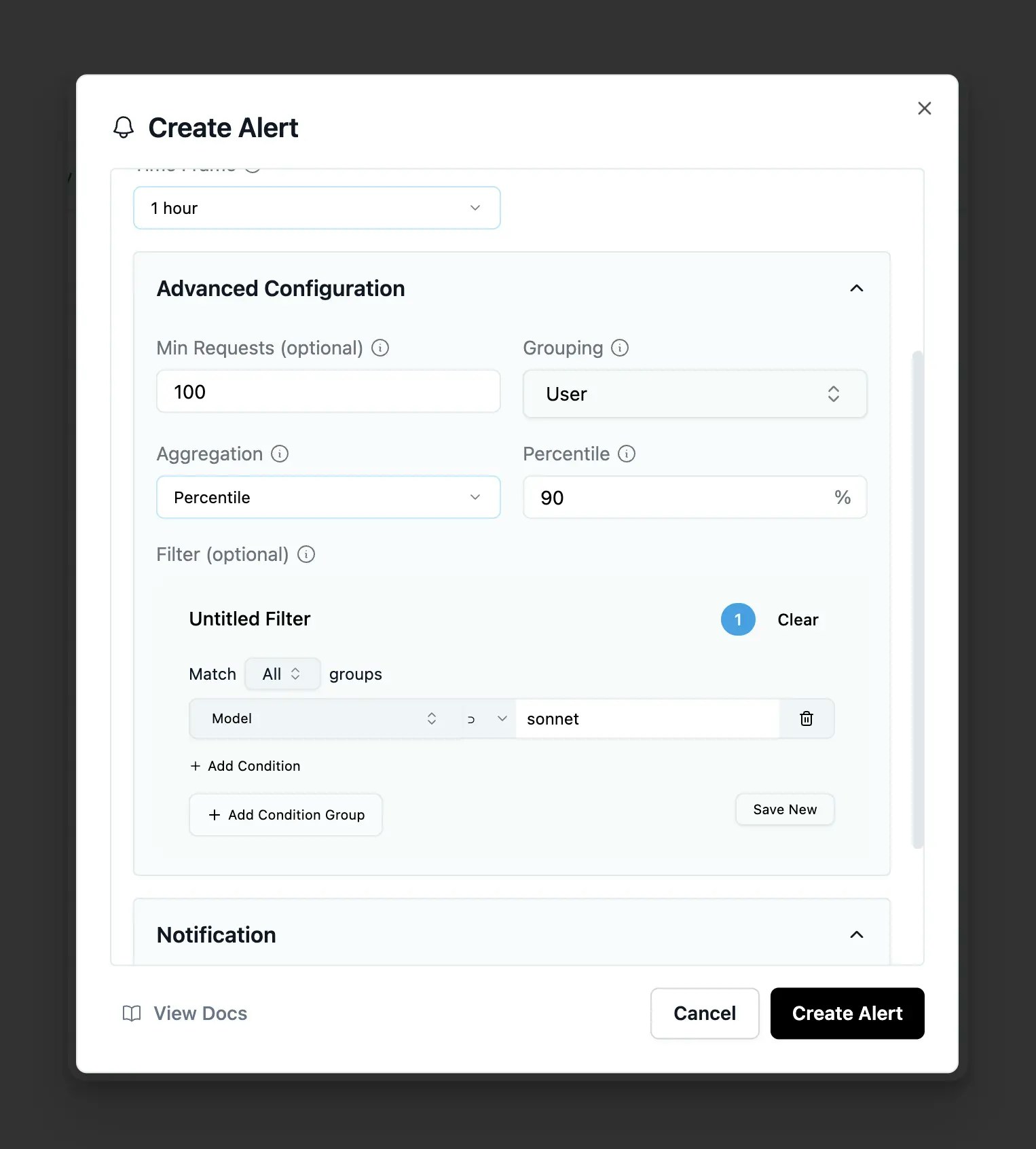
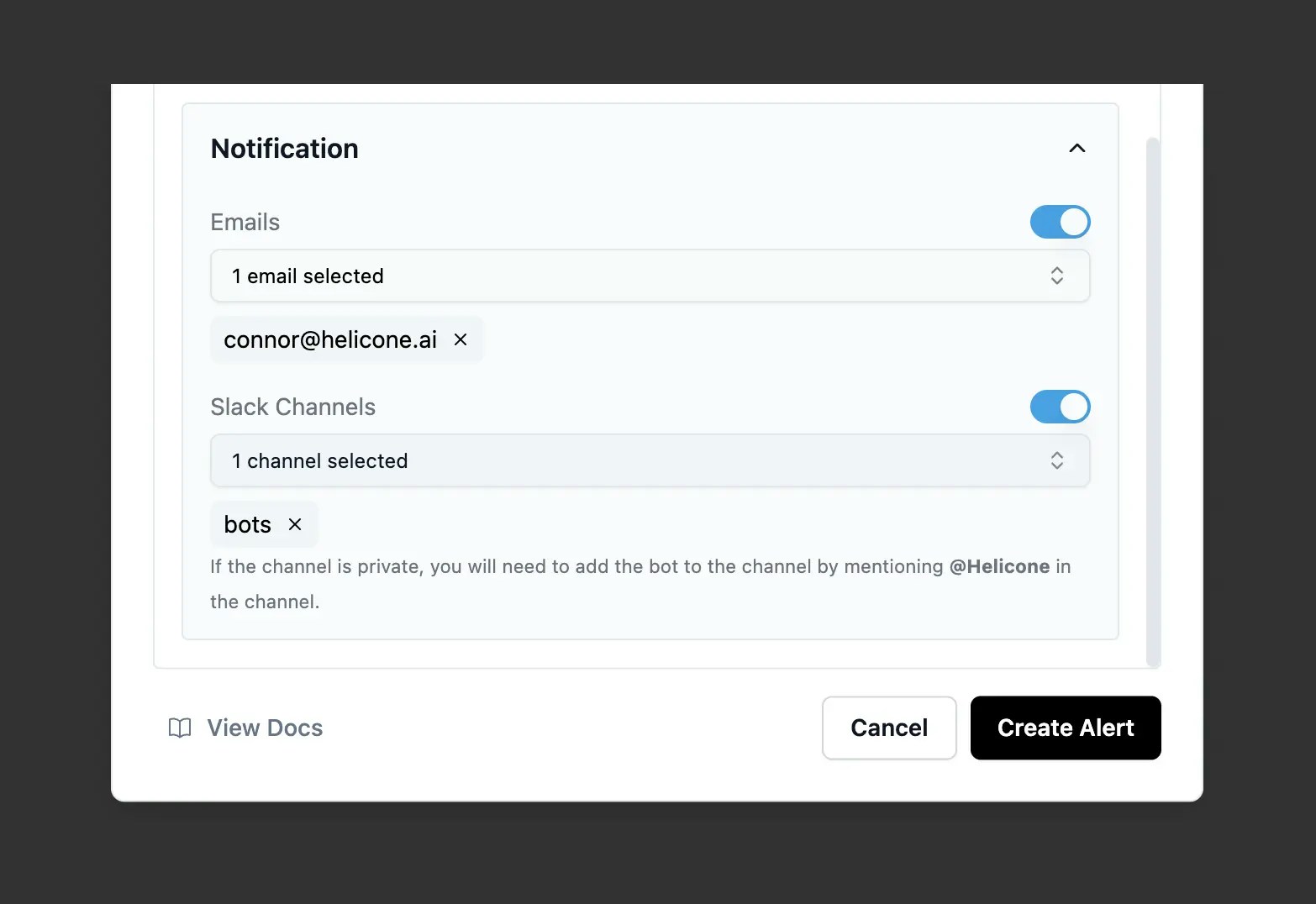
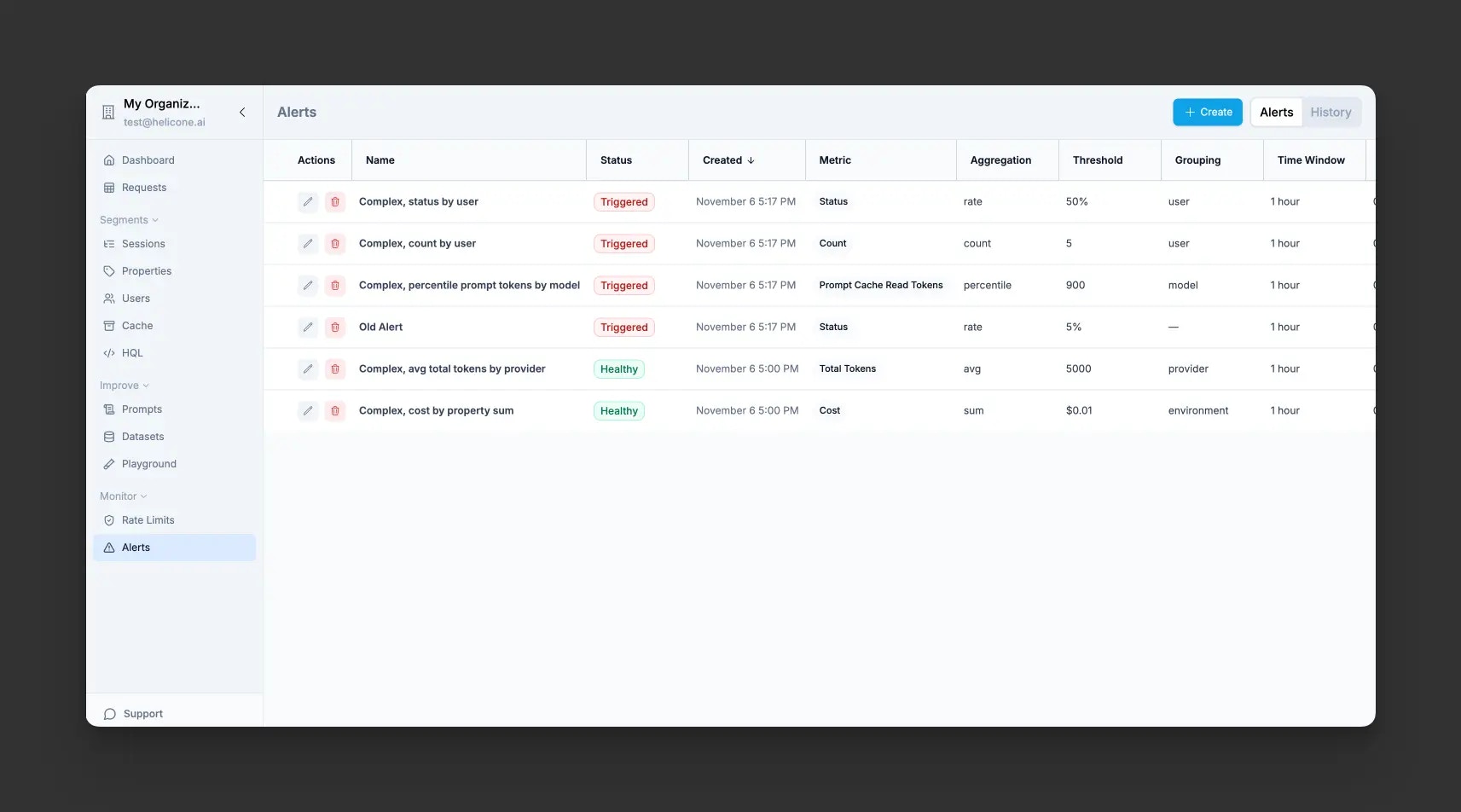
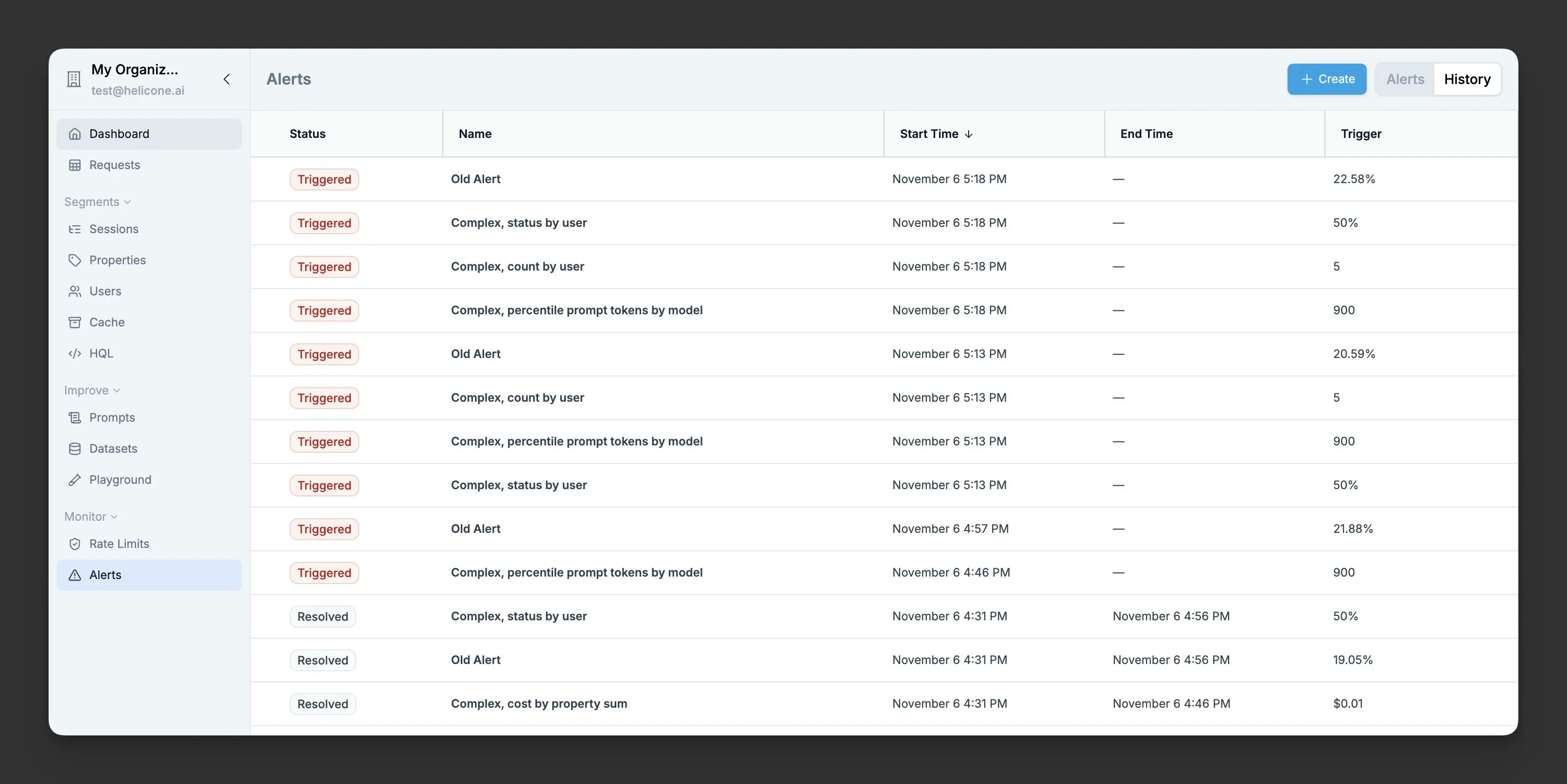
 View all configured alerts, their current status, and recent trigger history in the dashboard. When an alert triggers, you can immediately see affected requests and investigate the issue.
View all configured alerts, their current status, and recent trigger history in the dashboard. When an alert triggers, you can immediately see affected requests and investigate the issue.
 The session view shows:
* **Timeline visualization** of agent operations flowing from reasoning to tool execution
* **Hierarchical session paths** showing the flow from `/stock-chat` to specific operations like `/price/tsla`
* **Individual request details** with status, timing, and model information
* **Complete conversation context** across multiple tool calls
Each operation is logged with rich metadata:
* **Tool executions** show success/failure status and detailed results
* **LLM reasoning calls** include full conversation context
* **Session paths** create a logical hierarchy of operations
* **Timing information** helps identify performance bottlenecks
## Debugging Complex Agent Interactions
Using Helicone Sessions provides several debugging advantages:
### Separate Tool Tracking
Each tool execution is logged individually, making it easy to identify which tools fail or succeed.
### Rich Metadata
Tool calls include detailed input/output information and error states for comprehensive debugging.
### Session Flow Visualization
See exactly how your agent chains tools together and where decision points occur.
### Performance Monitoring
Track timing for both LLM reasoning and tool execution to optimize agent performance.
## Complete Implementation
View all configured alerts, their current status, and recent trigger history in the dashboard. When an alert triggers, you can immediately see affected requests and investigate the issue.
The session view shows:
* **Timeline visualization** of agent operations flowing from reasoning to tool execution
* **Hierarchical session paths** showing the flow from `/stock-chat` to specific operations like `/price/tsla`
* **Individual request details** with status, timing, and model information
* **Complete conversation context** across multiple tool calls
Each operation is logged with rich metadata:
* **Tool executions** show success/failure status and detailed results
* **LLM reasoning calls** include full conversation context
* **Session paths** create a logical hierarchy of operations
* **Timing information** helps identify performance bottlenecks
## Debugging Complex Agent Interactions
Using Helicone Sessions provides several debugging advantages:
### Separate Tool Tracking
Each tool execution is logged individually, making it easy to identify which tools fail or succeed.
### Rich Metadata
Tool calls include detailed input/output information and error states for comprehensive debugging.
### Session Flow Visualization
See exactly how your agent chains tools together and where decision points occur.
### Performance Monitoring
Track timing for both LLM reasoning and tool execution to optimize agent performance.
## Complete Implementation
View all configured alerts, their current status, and recent trigger history in the dashboard. When an alert triggers, you can immediately see affected requests and investigate the issue.
 ## Related Features
## Related Features
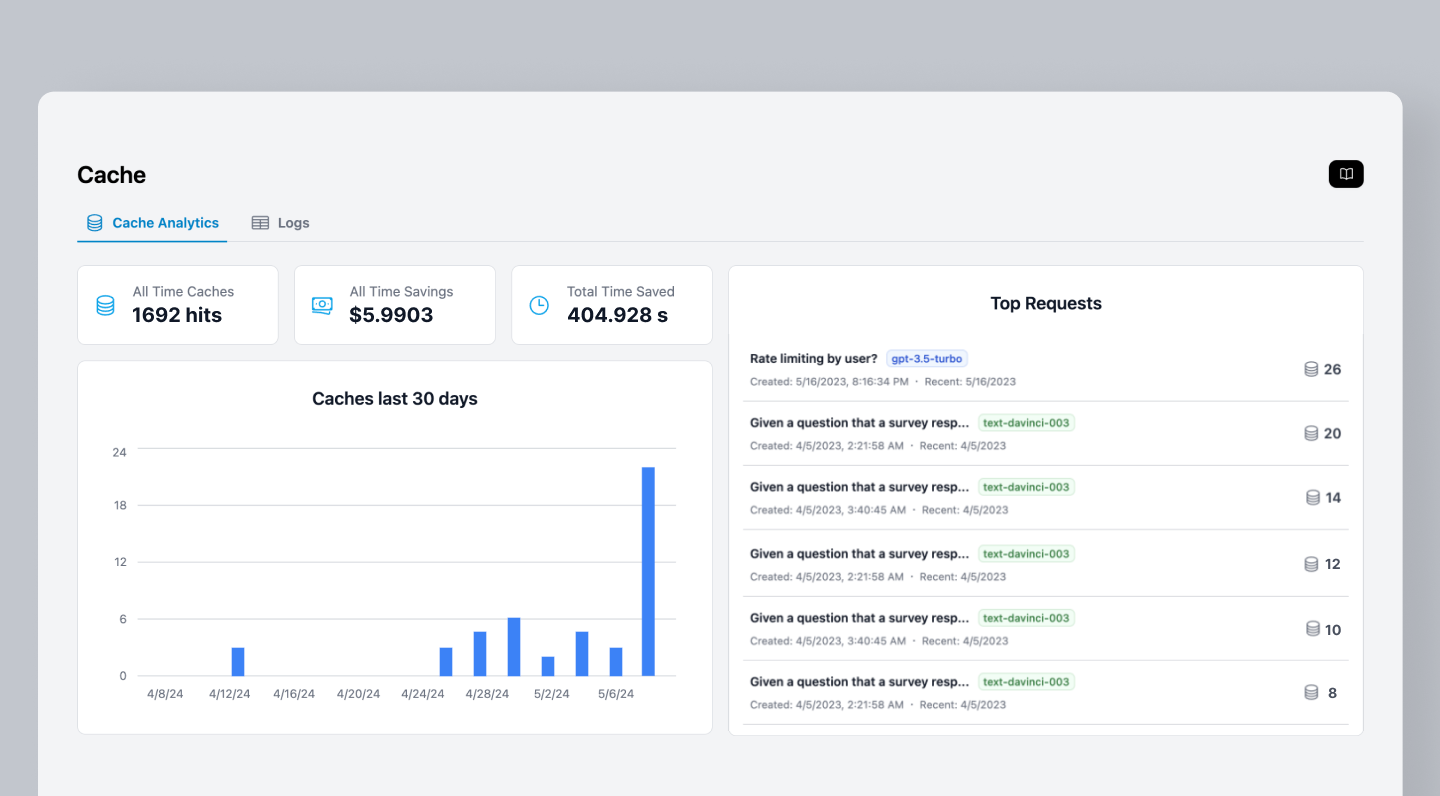 ## Understanding Caching
### Cache Response Headers
Check cache status by examining response headers:
```typescript theme={null}
const response = await client.chat.completions.create(
{ /* your request */ },
{
headers: { "Helicone-Cache-Enabled": "true" }
}
);
// Access raw response to check headers
const chatCompletion = await client.chat.completions.with_raw_response.create(
{ /* your request */ },
{
headers: { "Helicone-Cache-Enabled": "true" }
}
);
const cacheStatus = chatCompletion.http_response.headers.get('Helicone-Cache');
console.log(cacheStatus); // "HIT" or "MISS"
const bucketIndex = chatCompletion.http_response.headers.get('Helicone-Cache-Bucket-Idx');
console.log(bucketIndex); // Index of cached response used
```
### Cache Duration
Set how long responses stay cached using the `Cache-Control` header:
```typescript theme={null}
{
"Cache-Control": "max-age=3600" // 1 hour
}
```
**Common durations:**
* 1 hour: `max-age=3600`
* 1 day: `max-age=86400`
* 7 days: `max-age=604800` (default)
* 30 days: `max-age=2592000`
## Understanding Caching
### Cache Response Headers
Check cache status by examining response headers:
```typescript theme={null}
const response = await client.chat.completions.create(
{ /* your request */ },
{
headers: { "Helicone-Cache-Enabled": "true" }
}
);
// Access raw response to check headers
const chatCompletion = await client.chat.completions.with_raw_response.create(
{ /* your request */ },
{
headers: { "Helicone-Cache-Enabled": "true" }
}
);
const cacheStatus = chatCompletion.http_response.headers.get('Helicone-Cache');
console.log(cacheStatus); // "HIT" or "MISS"
const bucketIndex = chatCompletion.http_response.headers.get('Helicone-Cache-Bucket-Idx');
console.log(bucketIndex); // Index of cached response used
```
### Cache Duration
Set how long responses stay cached using the `Cache-Control` header:
```typescript theme={null}
{
"Cache-Control": "max-age=3600" // 1 hour
}
```
**Common durations:**
* 1 hour: `max-age=3600`
* 1 day: `max-age=86400`
* 7 days: `max-age=604800` (default)
* 30 days: `max-age=2592000`
HeliconeManualLogger API, see the API Reference here.`,
howToIntegrate: "How to Integrate",
howToPromptThinkingModelsCookbookDescription: "Best practices to to effectively prompt thinking models like Deepseek and OpenAI o1-o3 for optimal results.",
howToUseSessions: "To group related API calls and analyze them collectively, you can use Helicone's session tracking features. This is useful for grouping all interactions within a single conversation or user session.",
includeHeadersInRequests: "Include headers in your requests",
includeSessionHeaders: "Include the session headers when you make API requests. This way, the session information is attached to each request, allowing Helicone to group and analyze them together.",
installRequiredDependencies: "Install required dependencies",
installSDK: tool => `Install ${tool}`,
logYourRequest: "Log your request",
modelRegistryDescription: "You can find all 100+ supported models at helicone.ai/models.",
modifyBasePath: "Modify the base URL path",
optional: "Optional",
relatedGuides: "Related Guides",
replayLlmSessionsCookbookDescription: "Learn how to replay and modify LLM sessions using Helicone to optimize your AI agents and improve their performance.",
sessionManagement: "Session Management",
setApiKey: "Set up your Helicone API key in your .env file",
setUpToolBaseUrl: tool => `Set up your ${tool} base URL`,
setUpToolApiKey: tool => `Set up your ${tool} API key as an environment variable`,
startUsing: tool => `Start using ${tool} with Helicone`,
useTheSDK: tool => `Use the ${tool} SDK`,
verifyInHelicone: "Verify your requests in Helicone",
verifyInHeliconeDesciption: tool => `With the above setup, any calls to ${tool} will automatically be logged and monitored by Helicone. Review them in your Helicone dashboard.`,
viewRequestsInDashboard: "View requests in the Helicone dashboard",
viewRequestsInDashboardDescription: product => `All your ${product} requests are now visible in your Helicone dashboard.`,
whyUseSessions: "By including the session headers in each request, you have more granular control over session tracking. This approach is especially useful if you want to handle sessions dynamically or manage multiple sessions concurrently."
};
## Introduction
The [Claude Agent SDK](https://platform.claude.com/docs/en/agent-sdk/typescript) allows you to build powerful AI agents that can use tools and make decisions autonomously.
HeliconeManualLogger API, see the API Reference here.`,
howToIntegrate: "How to Integrate",
howToPromptThinkingModelsCookbookDescription: "Best practices to to effectively prompt thinking models like Deepseek and OpenAI o1-o3 for optimal results.",
howToUseSessions: "To group related API calls and analyze them collectively, you can use Helicone's session tracking features. This is useful for grouping all interactions within a single conversation or user session.",
includeHeadersInRequests: "Include headers in your requests",
includeSessionHeaders: "Include the session headers when you make API requests. This way, the session information is attached to each request, allowing Helicone to group and analyze them together.",
installRequiredDependencies: "Install required dependencies",
installSDK: tool => `Install ${tool}`,
logYourRequest: "Log your request",
modelRegistryDescription: "You can find all 100+ supported models at helicone.ai/models.",
modifyBasePath: "Modify the base URL path",
optional: "Optional",
relatedGuides: "Related Guides",
replayLlmSessionsCookbookDescription: "Learn how to replay and modify LLM sessions using Helicone to optimize your AI agents and improve their performance.",
sessionManagement: "Session Management",
setApiKey: "Set up your Helicone API key in your .env file",
setUpToolBaseUrl: tool => `Set up your ${tool} base URL`,
setUpToolApiKey: tool => `Set up your ${tool} API key as an environment variable`,
startUsing: tool => `Start using ${tool} with Helicone`,
useTheSDK: tool => `Use the ${tool} SDK`,
verifyInHelicone: "Verify your requests in Helicone",
verifyInHeliconeDesciption: tool => `With the above setup, any calls to ${tool} will automatically be logged and monitored by Helicone. Review them in your Helicone dashboard.`,
viewRequestsInDashboard: "View requests in the Helicone dashboard",
viewRequestsInDashboardDescription: product => `All your ${product} requests are now visible in your Helicone dashboard.`,
whyUseSessions: "By including the session headers in each request, you have more granular control over session tracking. This approach is especially useful if you want to handle sessions dynamically or manage multiple sessions concurrently."
};
HeliconeManualLogger API, see the API Reference here.`,
howToIntegrate: "How to Integrate",
howToPromptThinkingModelsCookbookDescription: "Best practices to to effectively prompt thinking models like Deepseek and OpenAI o1-o3 for optimal results.",
howToUseSessions: "To group related API calls and analyze them collectively, you can use Helicone's session tracking features. This is useful for grouping all interactions within a single conversation or user session.",
includeHeadersInRequests: "Include headers in your requests",
includeSessionHeaders: "Include the session headers when you make API requests. This way, the session information is attached to each request, allowing Helicone to group and analyze them together.",
installRequiredDependencies: "Install required dependencies",
installSDK: tool => `Install ${tool}`,
logYourRequest: "Log your request",
modelRegistryDescription: "You can find all 100+ supported models at helicone.ai/models.",
modifyBasePath: "Modify the base URL path",
optional: "Optional",
relatedGuides: "Related Guides",
replayLlmSessionsCookbookDescription: "Learn how to replay and modify LLM sessions using Helicone to optimize your AI agents and improve their performance.",
sessionManagement: "Session Management",
setApiKey: "Set up your Helicone API key in your .env file",
setUpToolBaseUrl: tool => `Set up your ${tool} base URL`,
setUpToolApiKey: tool => `Set up your ${tool} API key as an environment variable`,
startUsing: tool => `Start using ${tool} with Helicone`,
useTheSDK: tool => `Use the ${tool} SDK`,
verifyInHelicone: "Verify your requests in Helicone",
verifyInHeliconeDesciption: tool => `With the above setup, any calls to ${tool} will automatically be logged and monitored by Helicone. Review them in your Helicone dashboard.`,
viewRequestsInDashboard: "View requests in the Helicone dashboard",
viewRequestsInDashboardDescription: product => `All your ${product} requests are now visible in your Helicone dashboard.`,
whyUseSessions: "By including the session headers in each request, you have more granular control over session tracking. This approach is especially useful if you want to handle sessions dynamically or manage multiple sessions concurrently."
};
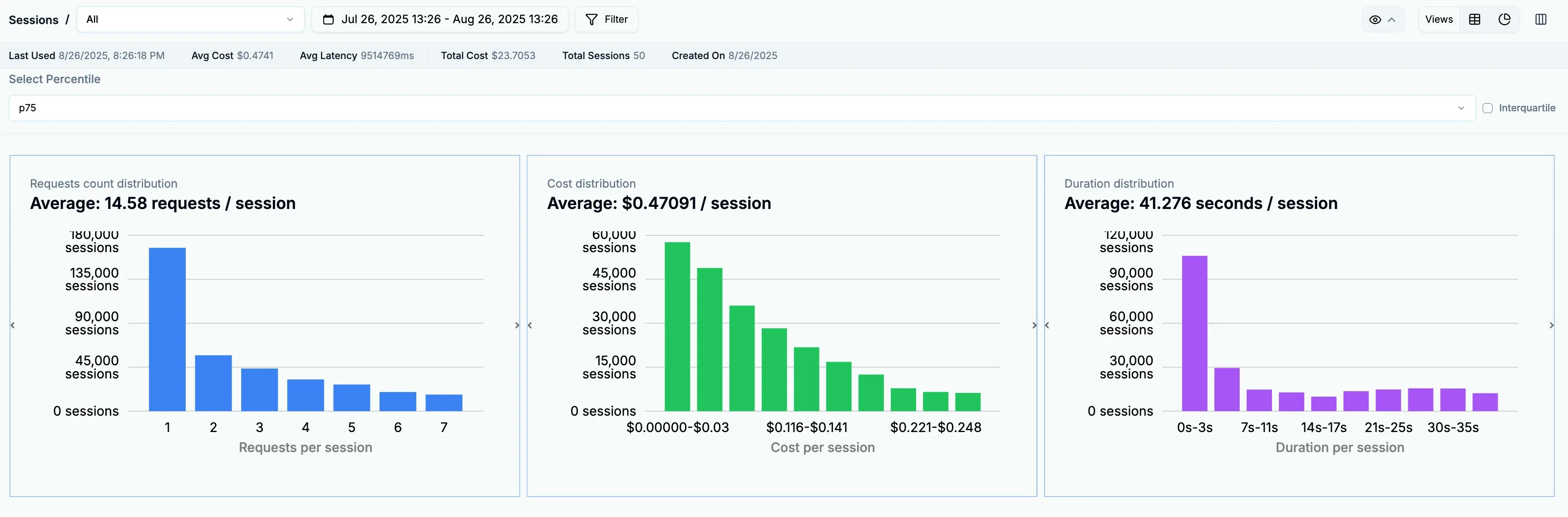 ### Sessions: Your Cost Foundation
[Sessions](/features/sessions) group related requests to show the true cost of user interactions. Instead of seeing individual API calls, you see complete workflows:
```typescript theme={null}
// Track a complete customer support interaction
const response = await client.chat.completions.create(
{
model: "gpt-4o",
messages: [...]
},
{
headers: {
"Helicone-Session-Id": "support-ticket-123",
"Helicone-Session-Name": "Customer Support"
}
}
);
```
This reveals insights like:
* A support chat costs \$0.12 on average with 5 API calls
* Document analysis workflows cost \$0.45 with 12 API calls
* Quick queries cost \$0.02 with a single call
### Segmentation That Matters
Use [custom properties](/features/advanced-usage/custom-properties) to slice costs by the dimensions that matter to your business:
### Sessions: Your Cost Foundation
[Sessions](/features/sessions) group related requests to show the true cost of user interactions. Instead of seeing individual API calls, you see complete workflows:
```typescript theme={null}
// Track a complete customer support interaction
const response = await client.chat.completions.create(
{
model: "gpt-4o",
messages: [...]
},
{
headers: {
"Helicone-Session-Id": "support-ticket-123",
"Helicone-Session-Name": "Customer Support"
}
}
);
```
This reveals insights like:
* A support chat costs \$0.12 on average with 5 API calls
* Document analysis workflows cost \$0.45 with 12 API calls
* Quick queries cost \$0.02 with a single call
### Segmentation That Matters
Use [custom properties](/features/advanced-usage/custom-properties) to slice costs by the dimensions that matter to your business:
 ```typescript theme={null}
headers: {
"Helicone-Property-UserTier": "premium",
"Helicone-Property-Feature": "document-analysis",
"Helicone-Property-Environment": "production"
}
```
Now you can answer questions like:
* Do premium users justify their higher usage costs?
* Which features are cost-efficient vs. cost-intensive?
* How much are we spending on development vs. production?
## AI Gateway Cost Optimization
The [AI Gateway](/gateway/overview) doesn't just track costs - it actively optimizes them through intelligent routing.
### Automatic Model Selection
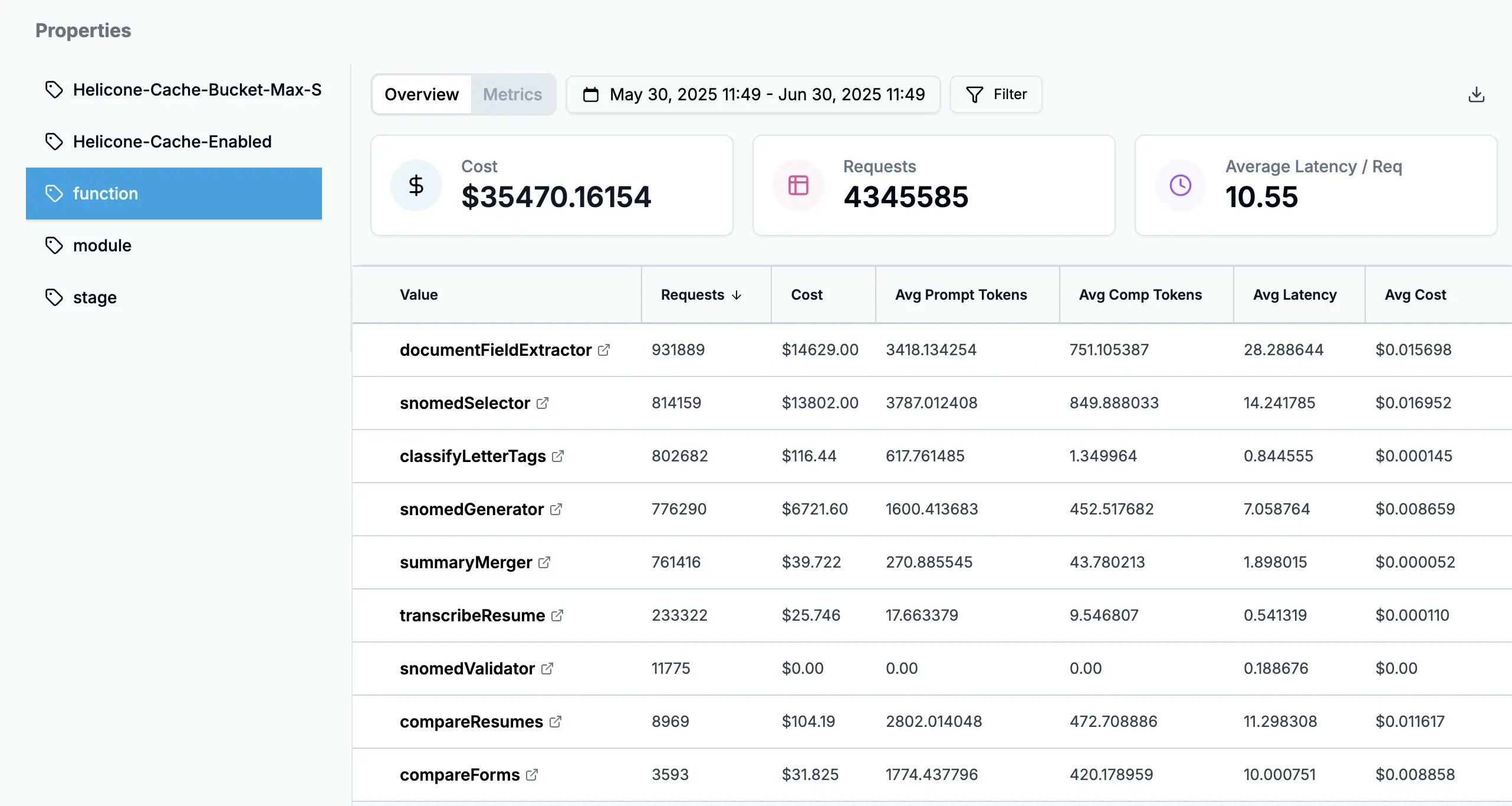
The [Model Registry](https://helicone.ai/models) shows all supported models with real-time pricing across providers. The AI Gateway automatically sorts by cost to find the cheapest option:
```typescript theme={null}
headers: {
"Helicone-Property-UserTier": "premium",
"Helicone-Property-Feature": "document-analysis",
"Helicone-Property-Environment": "production"
}
```
Now you can answer questions like:
* Do premium users justify their higher usage costs?
* Which features are cost-efficient vs. cost-intensive?
* How much are we spending on development vs. production?
## AI Gateway Cost Optimization
The [AI Gateway](/gateway/overview) doesn't just track costs - it actively optimizes them through intelligent routing.
### Automatic Model Selection
The [Model Registry](https://helicone.ai/models) shows all supported models with real-time pricing across providers. The AI Gateway automatically sorts by cost to find the cheapest option:
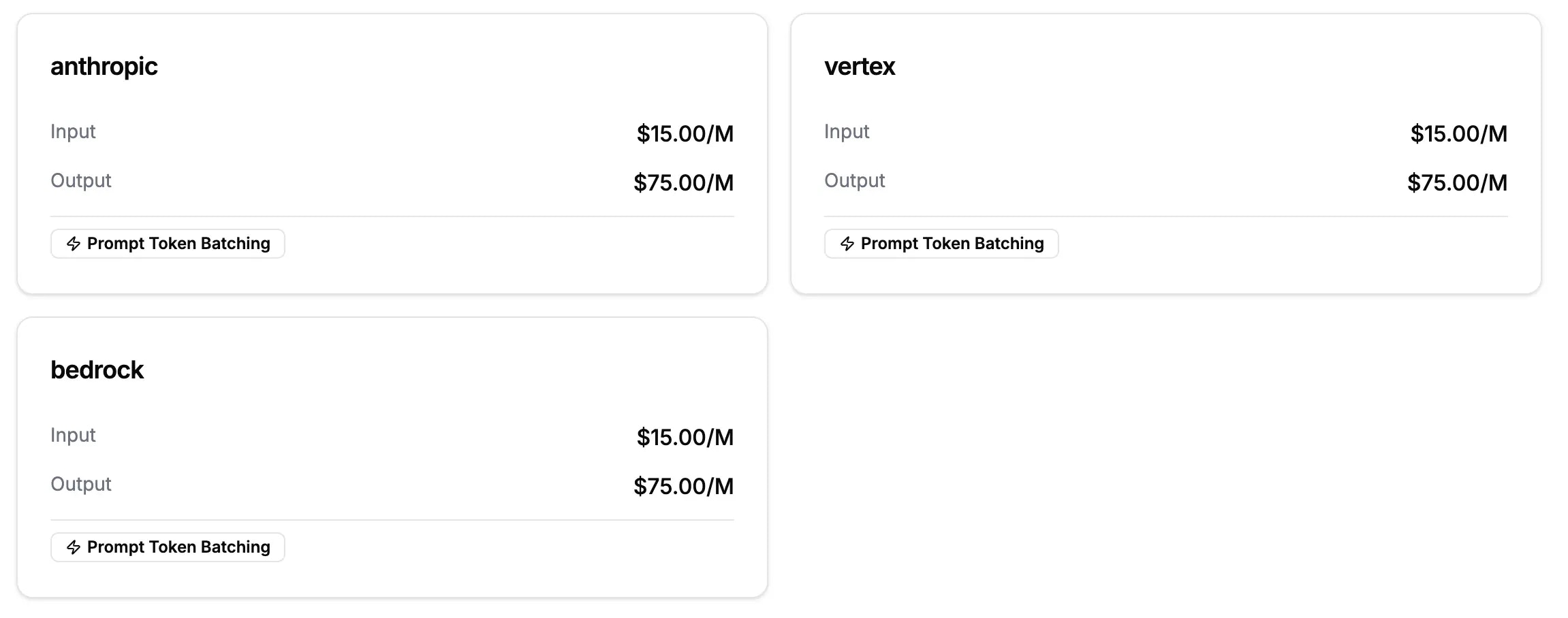 ### How Automatic Optimization Works
1. **[BYOK Priority](/gateway/provider-routing#option-2-your-own-keys-byok)** - Uses your existing credits first (AWS, Azure, etc.)
2. **[Cost-Based Routing](/gateway/provider-routing#smart-routing-algorithm)** - Automatically selects the cheapest available provider
3. **[Smart Fallbacks](/gateway/provider-routing#failover-triggers)** - If one provider fails, routes to the next cheapest option
```typescript theme={null}
// One request, multiple potential providers
await gateway.chat.completions.create({
model: "claude-3.5-sonnet",
messages: [...]
});
// Gateway automatically routes to cheapest available:
// 1. Your AWS Bedrock key ($3/1M tokens)
// 2. Your Anthropic key ($3/1M tokens)
// 3. Next cheapest provider...
```
## Cost Prevention & Alerts
### How Automatic Optimization Works
1. **[BYOK Priority](/gateway/provider-routing#option-2-your-own-keys-byok)** - Uses your existing credits first (AWS, Azure, etc.)
2. **[Cost-Based Routing](/gateway/provider-routing#smart-routing-algorithm)** - Automatically selects the cheapest available provider
3. **[Smart Fallbacks](/gateway/provider-routing#failover-triggers)** - If one provider fails, routes to the next cheapest option
```typescript theme={null}
// One request, multiple potential providers
await gateway.chat.completions.create({
model: "claude-3.5-sonnet",
messages: [...]
});
// Gateway automatically routes to cheapest available:
// 1. Your AWS Bedrock key ($3/1M tokens)
// 2. Your Anthropic key ($3/1M tokens)
// 3. Next cheapest provider...
```
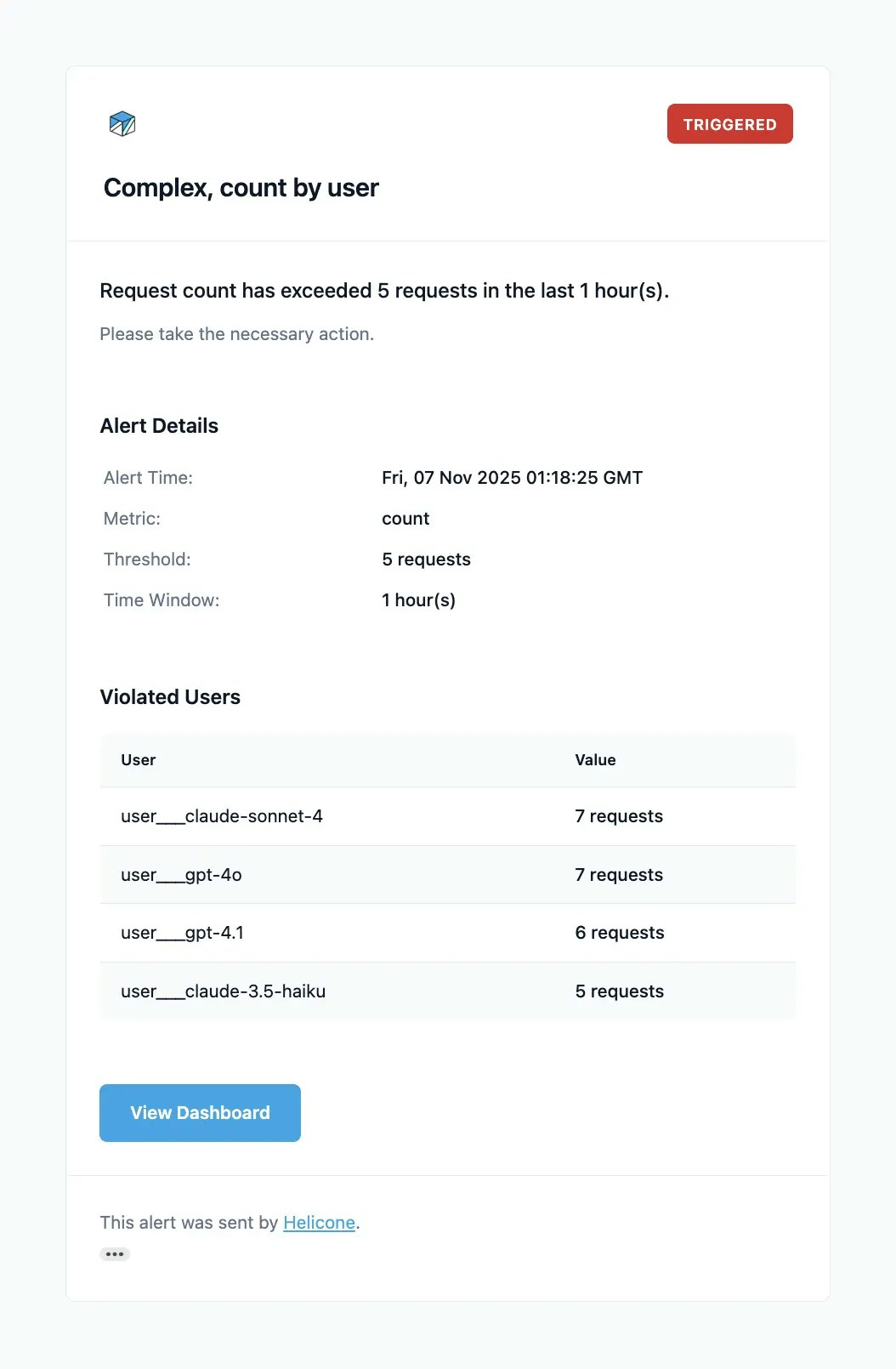
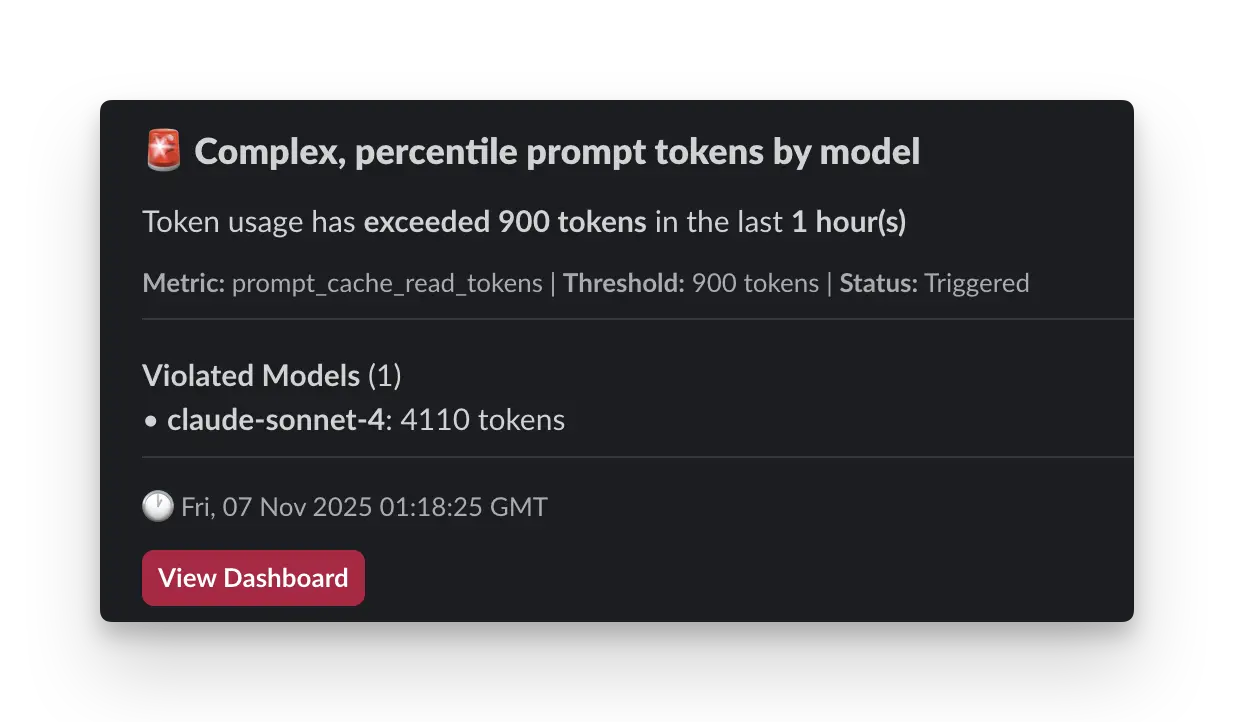
## Cost Prevention & Alerts
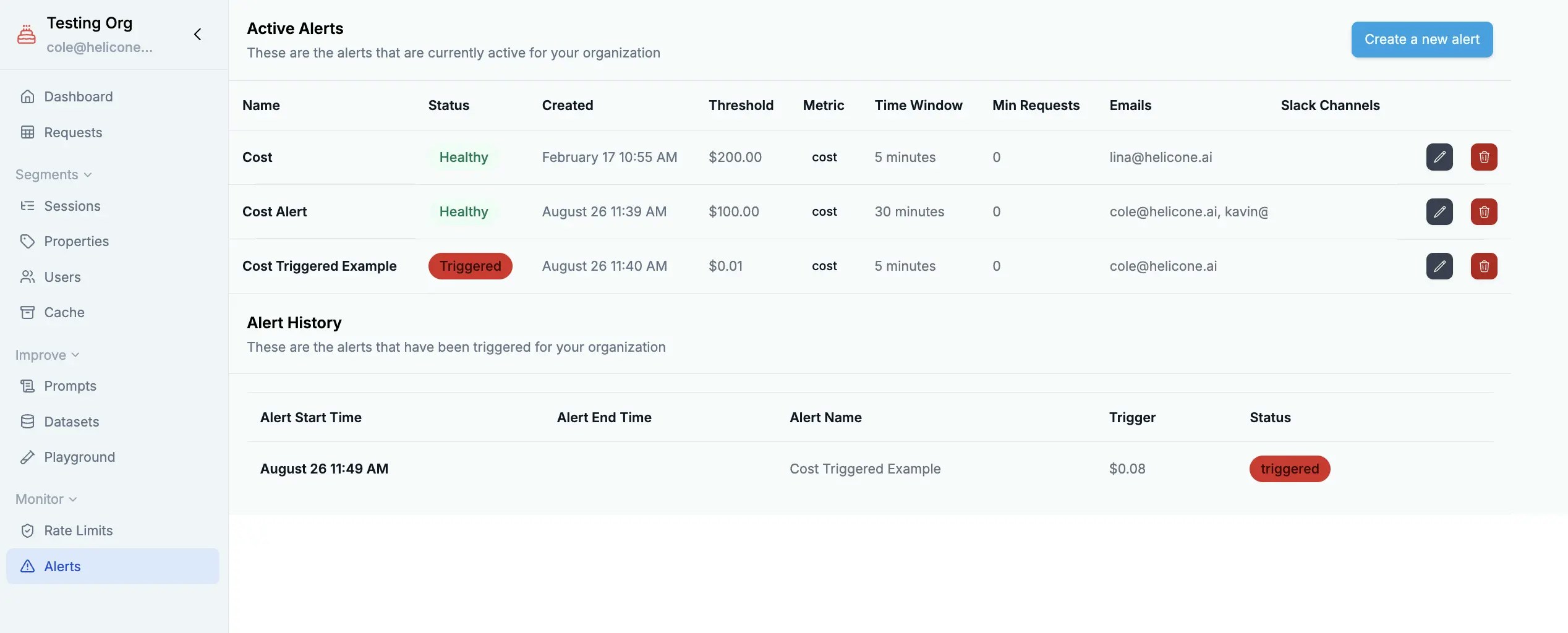 ### Setting Smart Alerts
Configure [cost alerts](/features/alerts) to catch spending issues before they become problems. Set graduated thresholds (50%, 80%, 95% of budget) and use different limits for development vs. production environments.
The key is understanding your baseline spending patterns and setting alerts that give you time to react without causing alert fatigue.
### Setting Smart Alerts
Configure [cost alerts](/features/alerts) to catch spending issues before they become problems. Set graduated thresholds (50%, 80%, 95% of budget) and use different limits for development vs. production environments.
The key is understanding your baseline spending patterns and setting alerts that give you time to react without causing alert fatigue.
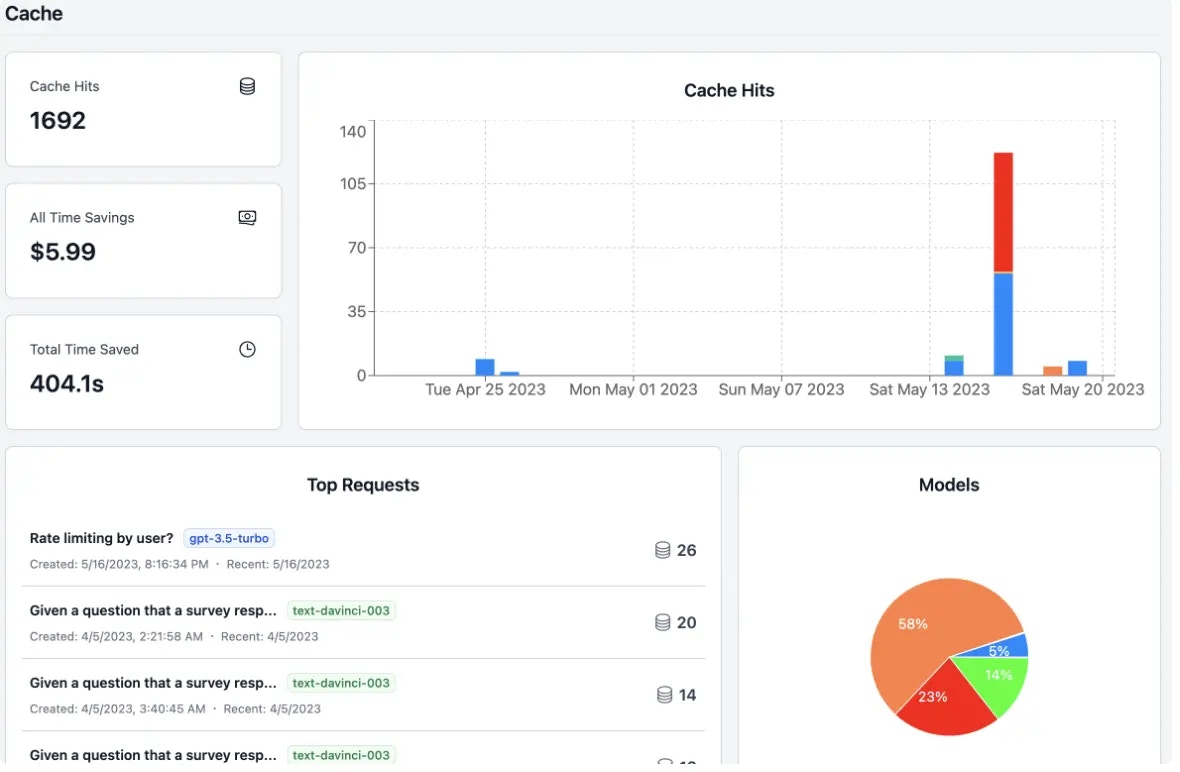 ```typescript theme={null}
headers: {
"Helicone-Cache-Enabled": "true",
"Cache-Control": "max-age=3600" // 1 hour cache
}
```
Best caching opportunities:
* FAQ responses in support bots
* Static content generation
* Development and testing environments
## Automated Reports
Get regular cost summaries delivered to your inbox or Slack channels. Reports provide insights into spending trends, model usage, and optimization opportunities.
### What Reports Include
* Weekly spending summaries and trends
* Model usage breakdown by cost
* Top cost drivers and expensive requests
* Week-over-week comparisons
* Optimization recommendations
### Setting Up Reports
Configure automated reports in **Settings → Reports** to receive them via:
* **Email** - Weekly digests to any email address
* **Slack** - Post to your team channels
```typescript theme={null}
headers: {
"Helicone-Cache-Enabled": "true",
"Cache-Control": "max-age=3600" // 1 hour cache
}
```
Best caching opportunities:
* FAQ responses in support bots
* Static content generation
* Development and testing environments
## Automated Reports
Get regular cost summaries delivered to your inbox or Slack channels. Reports provide insights into spending trends, model usage, and optimization opportunities.
### What Reports Include
* Weekly spending summaries and trends
* Model usage breakdown by cost
* Top cost drivers and expensive requests
* Week-over-week comparisons
* Optimization recommendations
### Setting Up Reports
Configure automated reports in **Settings → Reports** to receive them via:
* **Email** - Weekly digests to any email address
* **Slack** - Post to your team channels
HeliconeManualLogger API, see the API Reference here.`,
howToIntegrate: "How to Integrate",
howToPromptThinkingModelsCookbookDescription: "Best practices to to effectively prompt thinking models like Deepseek and OpenAI o1-o3 for optimal results.",
howToUseSessions: "To group related API calls and analyze them collectively, you can use Helicone's session tracking features. This is useful for grouping all interactions within a single conversation or user session.",
includeHeadersInRequests: "Include headers in your requests",
includeSessionHeaders: "Include the session headers when you make API requests. This way, the session information is attached to each request, allowing Helicone to group and analyze them together.",
installRequiredDependencies: "Install required dependencies",
installSDK: tool => `Install ${tool}`,
logYourRequest: "Log your request",
modelRegistryDescription: "You can find all 100+ supported models at helicone.ai/models.",
modifyBasePath: "Modify the base URL path",
optional: "Optional",
relatedGuides: "Related Guides",
replayLlmSessionsCookbookDescription: "Learn how to replay and modify LLM sessions using Helicone to optimize your AI agents and improve their performance.",
sessionManagement: "Session Management",
setApiKey: "Set up your Helicone API key in your .env file",
setUpToolBaseUrl: tool => `Set up your ${tool} base URL`,
setUpToolApiKey: tool => `Set up your ${tool} API key as an environment variable`,
startUsing: tool => `Start using ${tool} with Helicone`,
useTheSDK: tool => `Use the ${tool} SDK`,
verifyInHelicone: "Verify your requests in Helicone",
verifyInHeliconeDesciption: tool => `With the above setup, any calls to ${tool} will automatically be logged and monitored by Helicone. Review them in your Helicone dashboard.`,
viewRequestsInDashboard: "View requests in the Helicone dashboard",
viewRequestsInDashboardDescription: product => `All your ${product} requests are now visible in your Helicone dashboard.`,
whyUseSessions: "By including the session headers in each request, you have more granular control over session tracking. This approach is especially useful if you want to handle sessions dynamically or manage multiple sessions concurrently."
};
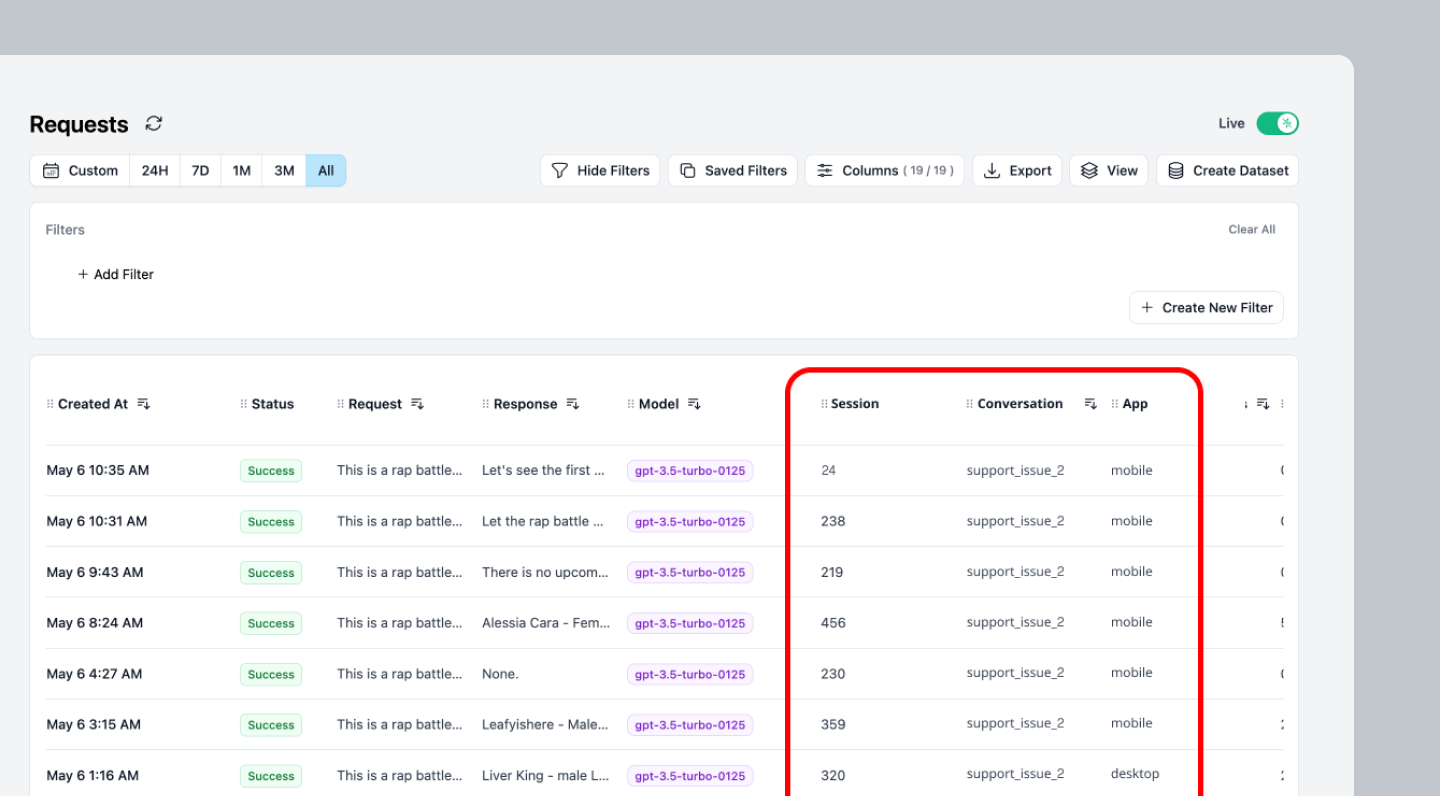 ## Why use Custom Properties
* **Track unit economics**: Calculate cost per user, conversation, or feature to understand your application's profitability
* **Debug complex workflows**: Group related requests in multi-step AI processes for easier troubleshooting
* **Analyze performance by segment**: Compare latency and costs across different user types, features, or environments
## Quick Start
Use headers to add Custom Properties to your LLM requests.
## Why use Custom Properties
* **Track unit economics**: Calculate cost per user, conversation, or feature to understand your application's profitability
* **Debug complex workflows**: Group related requests in multi-step AI processes for easier troubleshooting
* **Analyze performance by segment**: Compare latency and costs across different user types, features, or environments
## Quick Start
Use headers to add Custom Properties to your LLM requests.
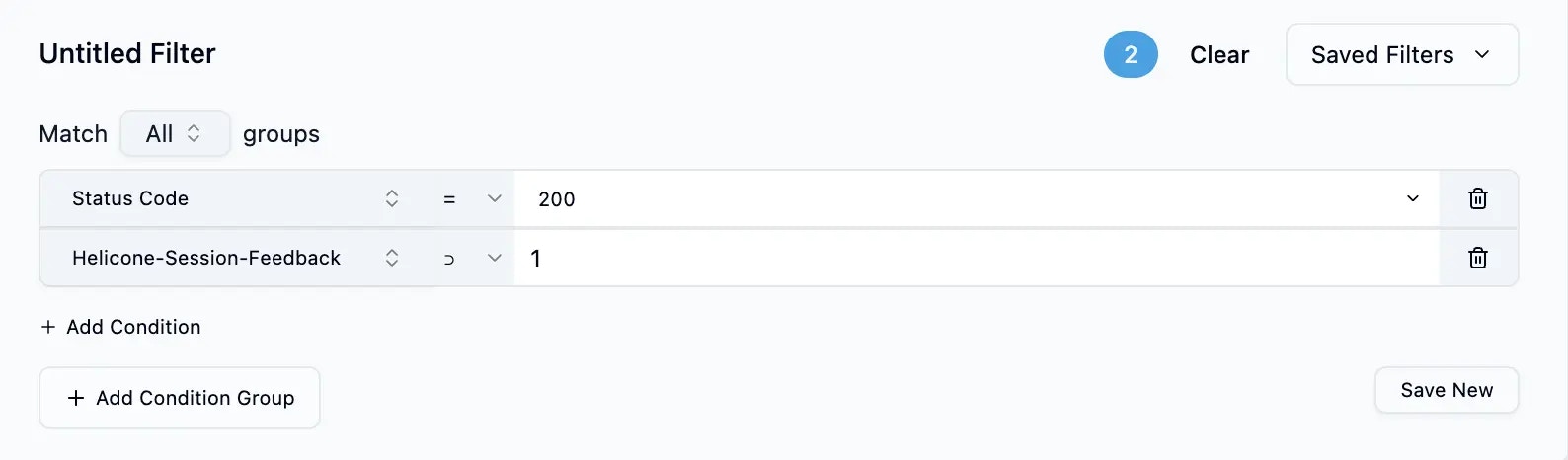
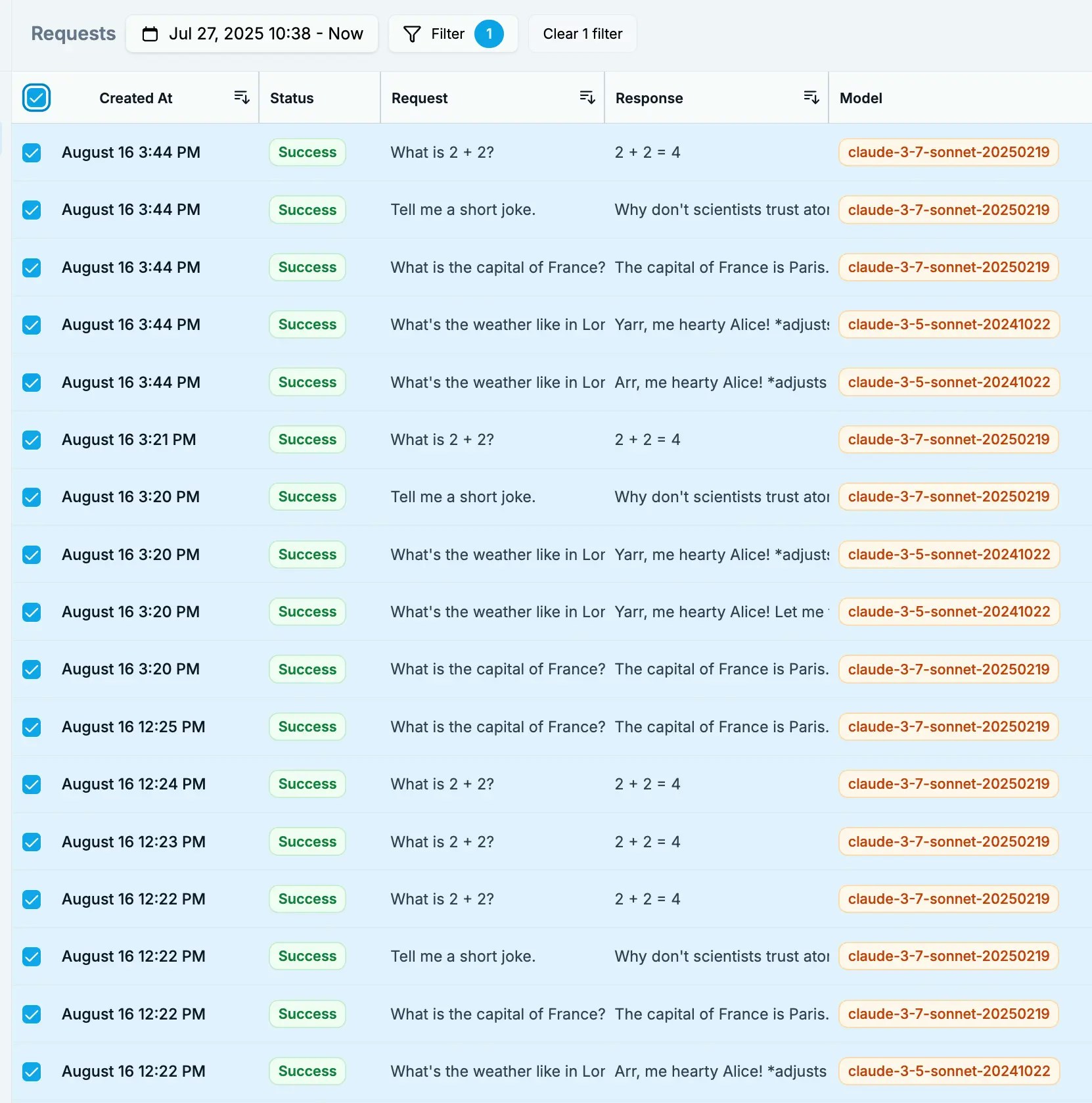
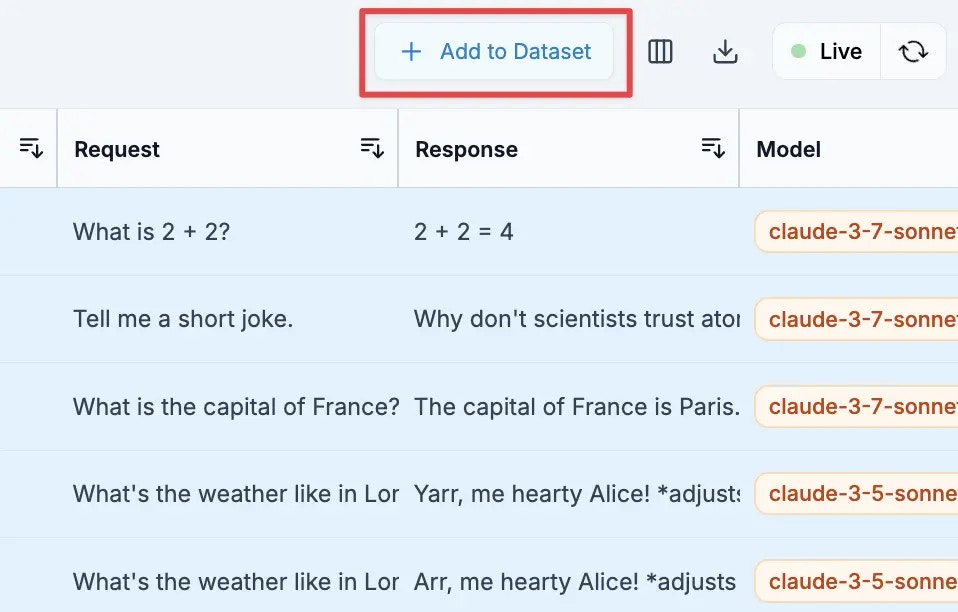
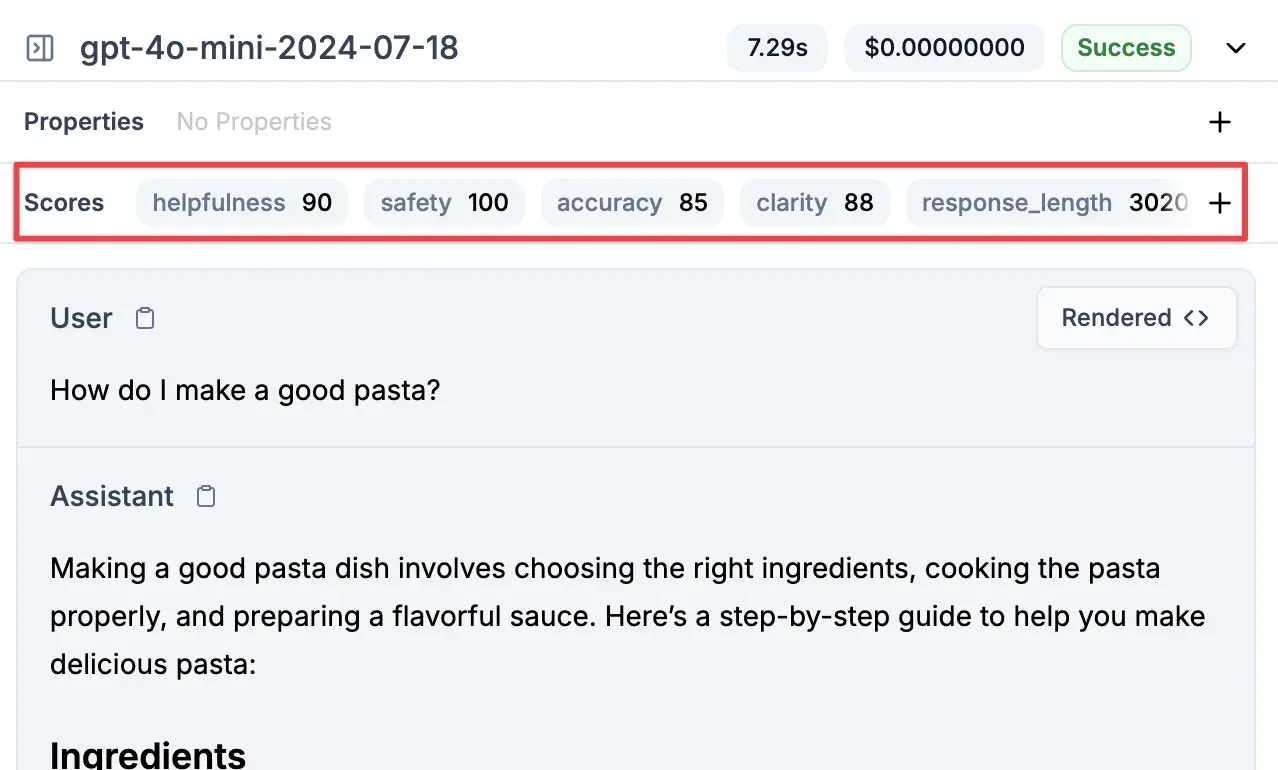
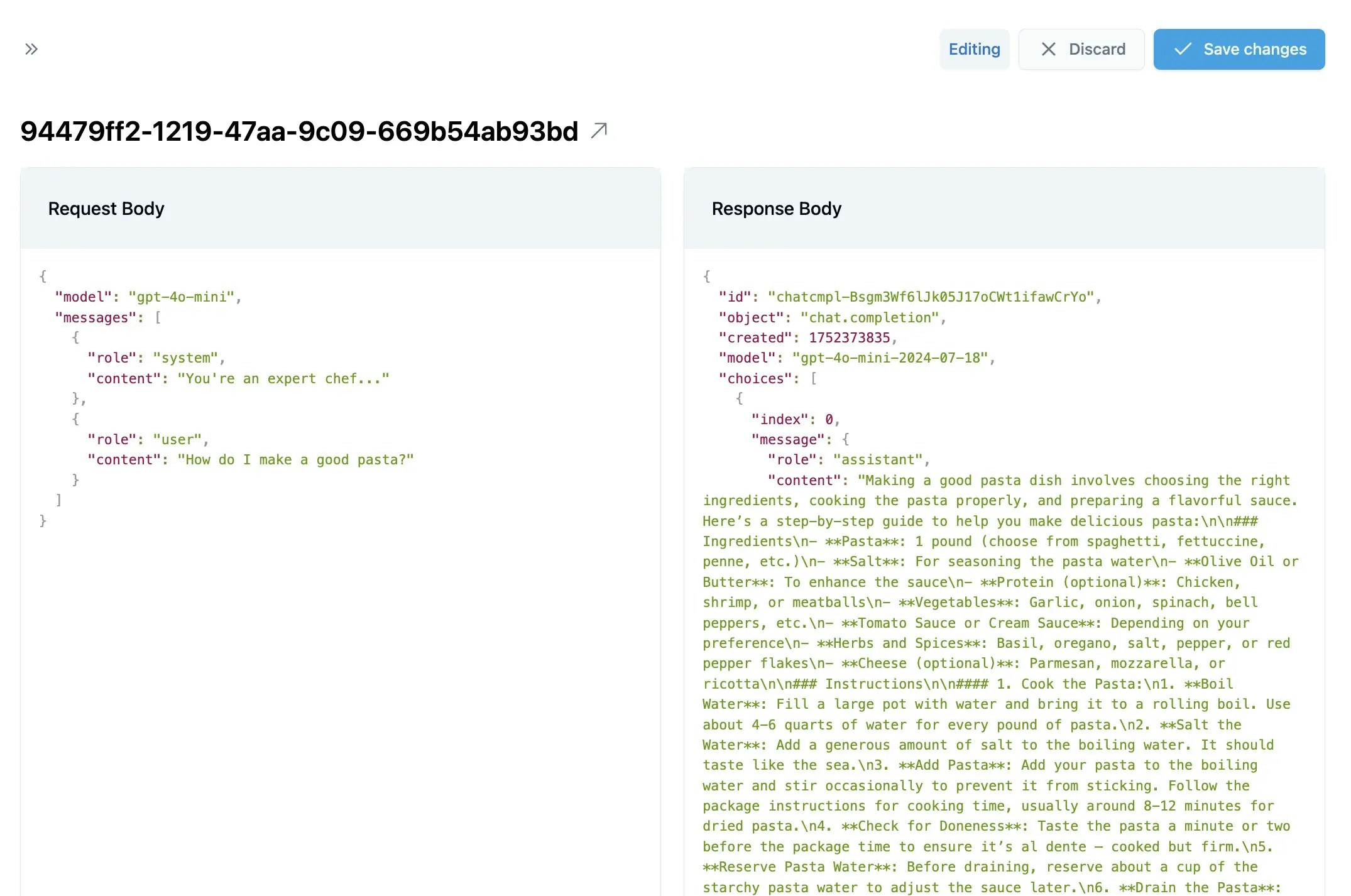 Examine each request/response pair for:
* **Accuracy** - Is the response correct and helpful?
* **Consistency** - Does it match the style and format you want?
* **Completeness** - Does it fully address the user's request?
Examine each request/response pair for:
* **Accuracy** - Is the response correct and helpful?
* **Consistency** - Does it match the style and format you want?
* **Completeness** - Does it fully address the user's request?
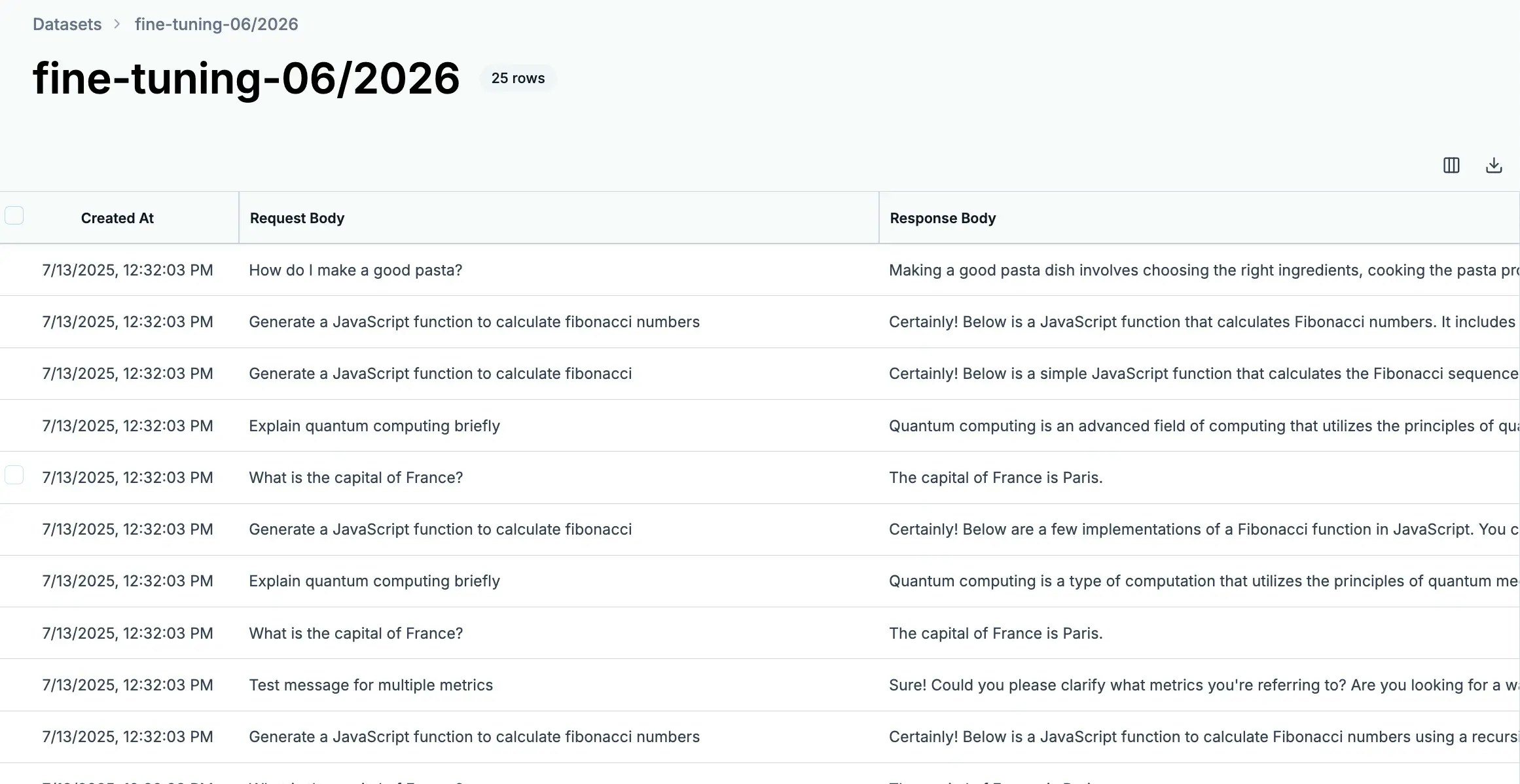 From the dashboard you can:
* **Track progress** - Monitor dataset size and last updated time
* **Access datasets** - Click to view and curate contents
* **Export data** - Download datasets when ready for fine-tuning
* **Maintain quality** - Regularly review and improve your collections
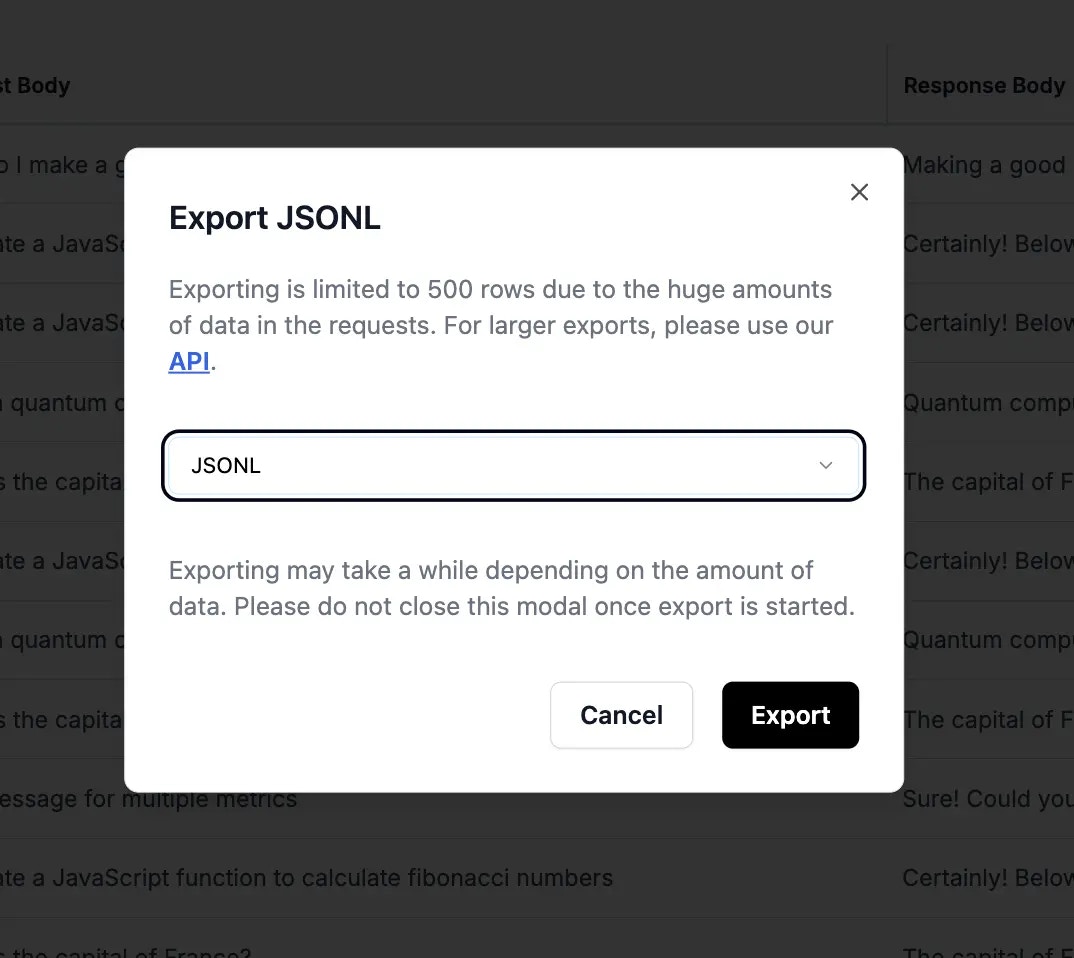
## Exporting Data
### Export Formats
Download your datasets in various formats:
From the dashboard you can:
* **Track progress** - Monitor dataset size and last updated time
* **Access datasets** - Click to view and curate contents
* **Export data** - Download datasets when ready for fine-tuning
* **Maintain quality** - Regularly review and improve your collections
## Exporting Data
### Export Formats
Download your datasets in various formats:
 Build a data flywheel for model improvement:
1. **Tag requests** with custom properties for easy filtering
2. **Score outputs** based on user feedback or automated metrics
3. **Auto-collect winners** into datasets when they meet quality thresholds
4. **Regular retraining** with newly curated examples
5. **A/B test** new models against production traffic
Build a data flywheel for model improvement:
1. **Tag requests** with custom properties for easy filtering
2. **Score outputs** based on user feedback or automated metrics
3. **Auto-collect winners** into datasets when they meet quality thresholds
4. **Regular retraining** with newly curated examples
5. **A/B test** new models against production traffic
 We are currently developing dedicated error filters to further enhance your debugging experience. If you are interested in this feature, please support us by upvoting the feature request [here](https://www.helicone.ai/roadmap).
# Debugging Prompts with Playground
We are currently developing dedicated error filters to further enhance your debugging experience. If you are interested in this feature, please support us by upvoting the feature request [here](https://www.helicone.ai/roadmap).
# Debugging Prompts with Playground
 2. Click on the 'Playground' button.
2. Click on the 'Playground' button.
 3. Input and execute your prompt to view the results.
3. Input and execute your prompt to view the results.
 Please note, the Playground tool is a sandbox environment, so feel free to experiment with different prompts and settings to optimize results for your project.
---
# Source: https://docs.helicone.ai/getting-started/integration-method/deepinfra.md
> ## Documentation Index
> Fetch the complete documentation index at: https://docs.helicone.ai/llms.txt
> Use this file to discover all available pages before exploring further.
# Deepinfra Integration
> Connect Helicone with OpenAI-compatible models on Deepinfra. Simple setup process using a custom base_url for seamless integration with your Deepinfra-based AI applications.
Please note, the Playground tool is a sandbox environment, so feel free to experiment with different prompts and settings to optimize results for your project.
---
# Source: https://docs.helicone.ai/getting-started/integration-method/deepinfra.md
> ## Documentation Index
> Fetch the complete documentation index at: https://docs.helicone.ai/llms.txt
> Use this file to discover all available pages before exploring further.
# Deepinfra Integration
> Connect Helicone with OpenAI-compatible models on Deepinfra. Simple setup process using a custom base_url for seamless integration with your Deepinfra-based AI applications.
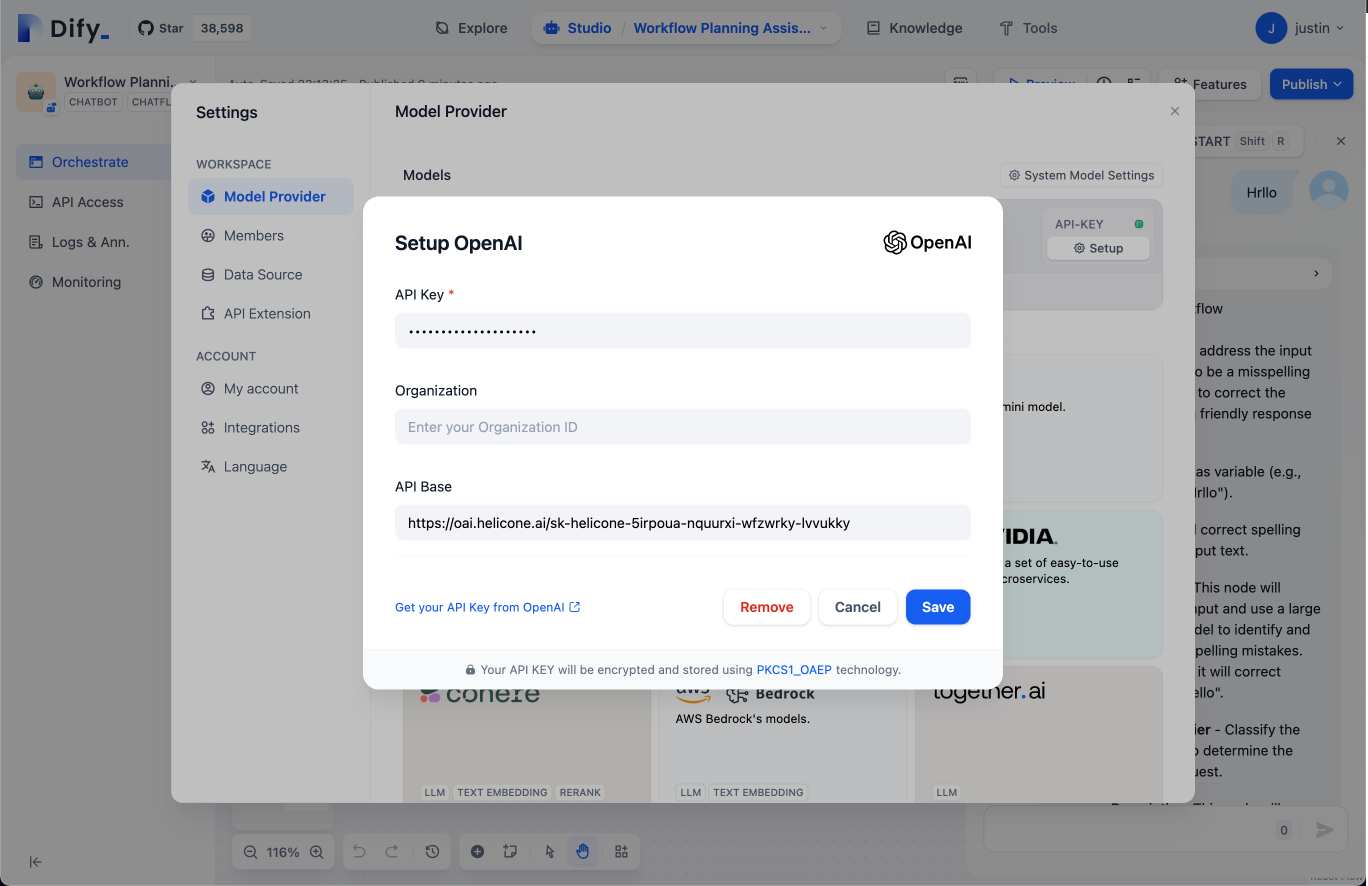 It's that simple!
It's that simple!
HeliconeManualLogger API, see the API Reference here.`,
howToIntegrate: "How to Integrate",
howToPromptThinkingModelsCookbookDescription: "Best practices to to effectively prompt thinking models like Deepseek and OpenAI o1-o3 for optimal results.",
howToUseSessions: "To group related API calls and analyze them collectively, you can use Helicone's session tracking features. This is useful for grouping all interactions within a single conversation or user session.",
includeHeadersInRequests: "Include headers in your requests",
includeSessionHeaders: "Include the session headers when you make API requests. This way, the session information is attached to each request, allowing Helicone to group and analyze them together.",
installRequiredDependencies: "Install required dependencies",
installSDK: tool => `Install ${tool}`,
logYourRequest: "Log your request",
modelRegistryDescription: "You can find all 100+ supported models at helicone.ai/models.",
modifyBasePath: "Modify the base URL path",
optional: "Optional",
relatedGuides: "Related Guides",
replayLlmSessionsCookbookDescription: "Learn how to replay and modify LLM sessions using Helicone to optimize your AI agents and improve their performance.",
sessionManagement: "Session Management",
setApiKey: "Set up your Helicone API key in your .env file",
setUpToolBaseUrl: tool => `Set up your ${tool} base URL`,
setUpToolApiKey: tool => `Set up your ${tool} API key as an environment variable`,
startUsing: tool => `Start using ${tool} with Helicone`,
useTheSDK: tool => `Use the ${tool} SDK`,
verifyInHelicone: "Verify your requests in Helicone",
verifyInHeliconeDesciption: tool => `With the above setup, any calls to ${tool} will automatically be logged and monitored by Helicone. Review them in your Helicone dashboard.`,
viewRequestsInDashboard: "View requests in the Helicone dashboard",
viewRequestsInDashboardDescription: product => `All your ${product} requests are now visible in your Helicone dashboard.`,
whyUseSessions: "By including the session headers in each request, you have more granular control over session tracking. This approach is especially useful if you want to handle sessions dynamically or manage multiple sessions concurrently."
};
## Introduction
[DSPy](https://dspy.ai) is a declarative framework for building modular AI software with structured code instead of brittle prompts, offering algorithms that compile AI programs into effective prompts and weights for language models across classifiers, RAG pipelines, and agent loops.
## Integration Steps
{strings.installRequiredDependencies}
```bash Python theme={null} pip install dspy ```{strings.viewRequestsInDashboard}
```python Python theme={null} import dspy import os from dotenv import load_dotenv load_dotenv() # Configure DSPy to use Helicone AI Gateway lm = dspy.LM( 'gpt-4o-mini', # or any other model from the Helicone model registry api_key=os.getenv('HELICONE_API_KEY'), api_base='https://ai-gateway.helicone.ai/' ) dspy.configure(lm=lm) print(lm("Hello, world!")) ```HeliconeManualLogger API, see the API Reference here.`,
howToIntegrate: "How to Integrate",
howToPromptThinkingModelsCookbookDescription: "Best practices to to effectively prompt thinking models like Deepseek and OpenAI o1-o3 for optimal results.",
howToUseSessions: "To group related API calls and analyze them collectively, you can use Helicone's session tracking features. This is useful for grouping all interactions within a single conversation or user session.",
includeHeadersInRequests: "Include headers in your requests",
includeSessionHeaders: "Include the session headers when you make API requests. This way, the session information is attached to each request, allowing Helicone to group and analyze them together.",
installRequiredDependencies: "Install required dependencies",
installSDK: tool => `Install ${tool}`,
logYourRequest: "Log your request",
modelRegistryDescription: "You can find all 100+ supported models at helicone.ai/models.",
modifyBasePath: "Modify the base URL path",
optional: "Optional",
relatedGuides: "Related Guides",
replayLlmSessionsCookbookDescription: "Learn how to replay and modify LLM sessions using Helicone to optimize your AI agents and improve their performance.",
sessionManagement: "Session Management",
setApiKey: "Set up your Helicone API key in your .env file",
setUpToolBaseUrl: tool => `Set up your ${tool} base URL`,
setUpToolApiKey: tool => `Set up your ${tool} API key as an environment variable`,
startUsing: tool => `Start using ${tool} with Helicone`,
useTheSDK: tool => `Use the ${tool} SDK`,
verifyInHelicone: "Verify your requests in Helicone",
verifyInHeliconeDesciption: tool => `With the above setup, any calls to ${tool} will automatically be logged and monitored by Helicone. Review them in your Helicone dashboard.`,
viewRequestsInDashboard: "View requests in the Helicone dashboard",
viewRequestsInDashboardDescription: product => `All your ${product} requests are now visible in your Helicone dashboard.`,
whyUseSessions: "By including the session headers in each request, you have more granular control over session tracking. This approach is especially useful if you want to handle sessions dynamically or manage multiple sessions concurrently."
};
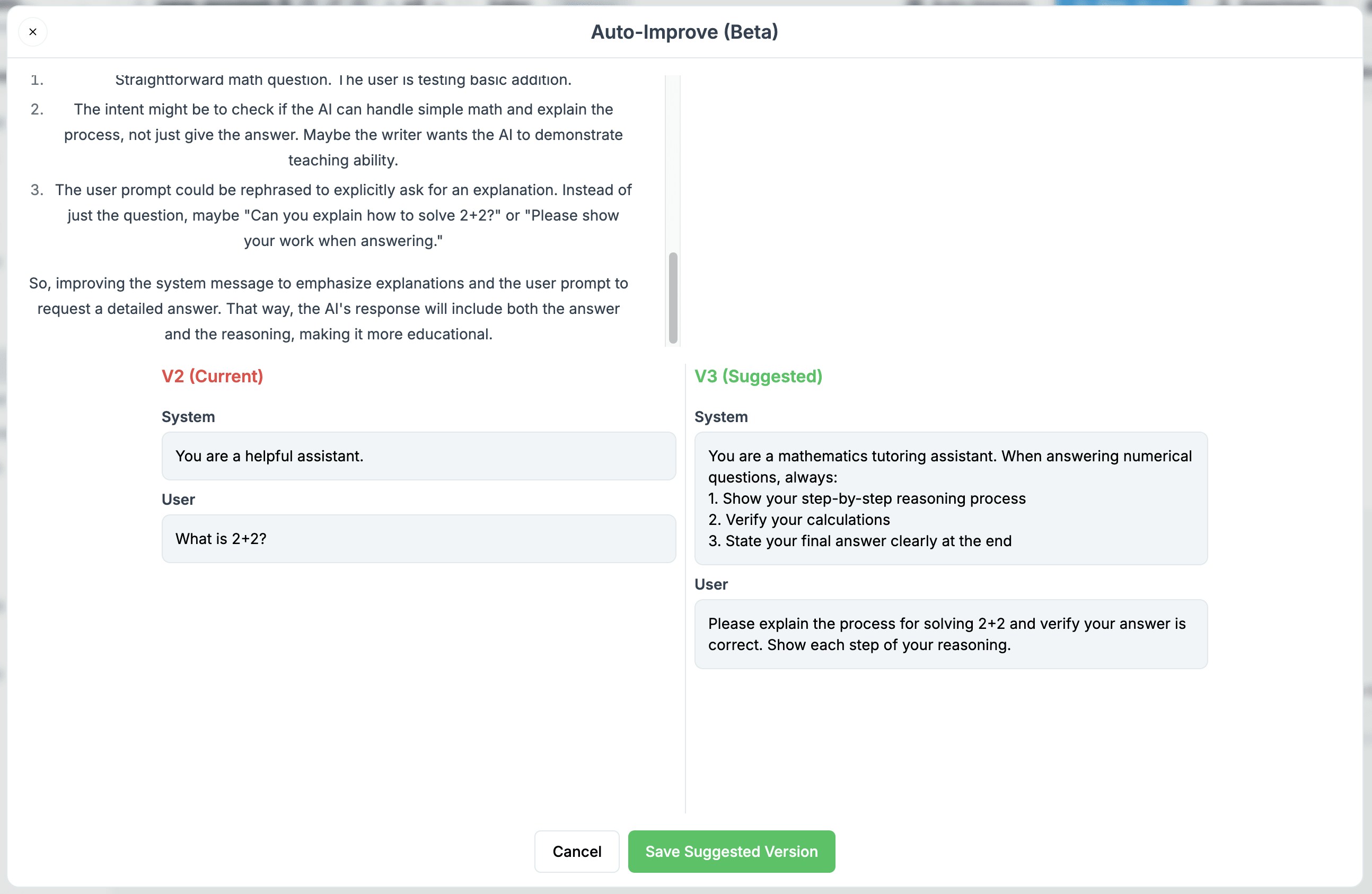 ### Key Benefits
* **Semantic Analysis**: Goes beyond simple text improvements by understanding the purpose behind each instruction
* **Maintains Intent**: Preserves your original goals while enhancing how they're communicated
* **Time Saving**: Skip hours of prompt iteration and testing
* **Learning Tool**: Understand what makes an effective prompt by comparing your original with the improved version
## Using Prompts in Your Code
### Key Benefits
* **Semantic Analysis**: Goes beyond simple text improvements by understanding the purpose behind each instruction
* **Maintains Intent**: Preserves your original goals while enhancing how they're communicated
* **Time Saving**: Skip hours of prompt iteration and testing
* **Learning Tool**: Understand what makes an effective prompt by comparing your original with the improved version
## Using Prompts in Your Code
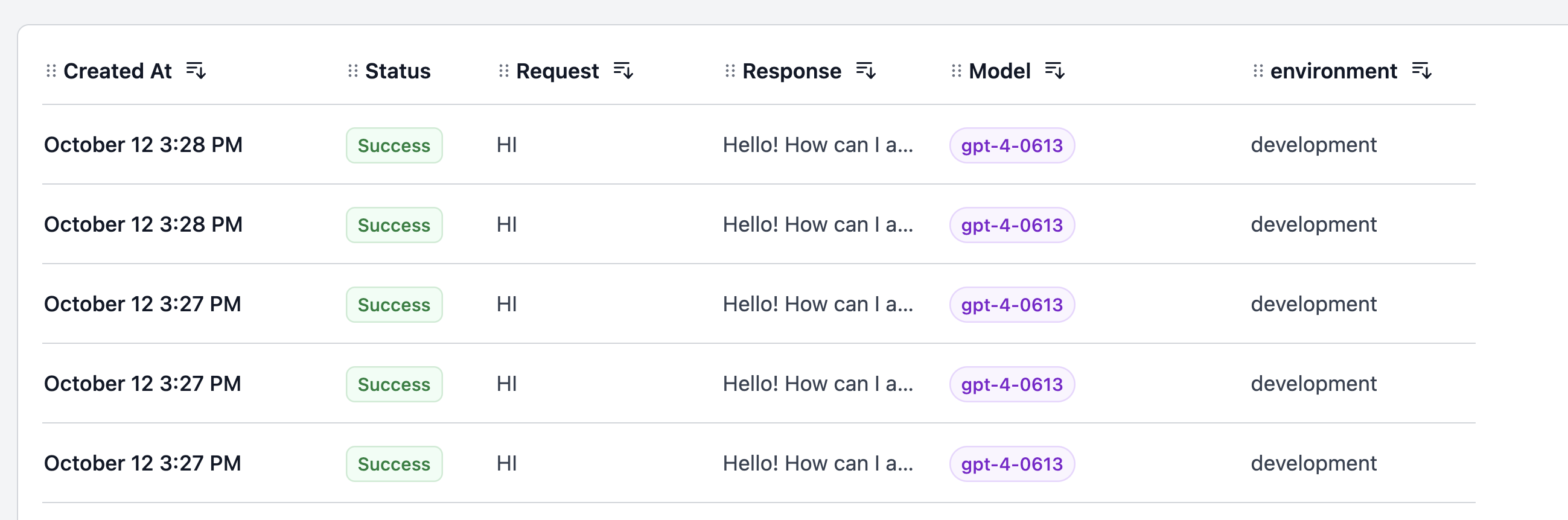
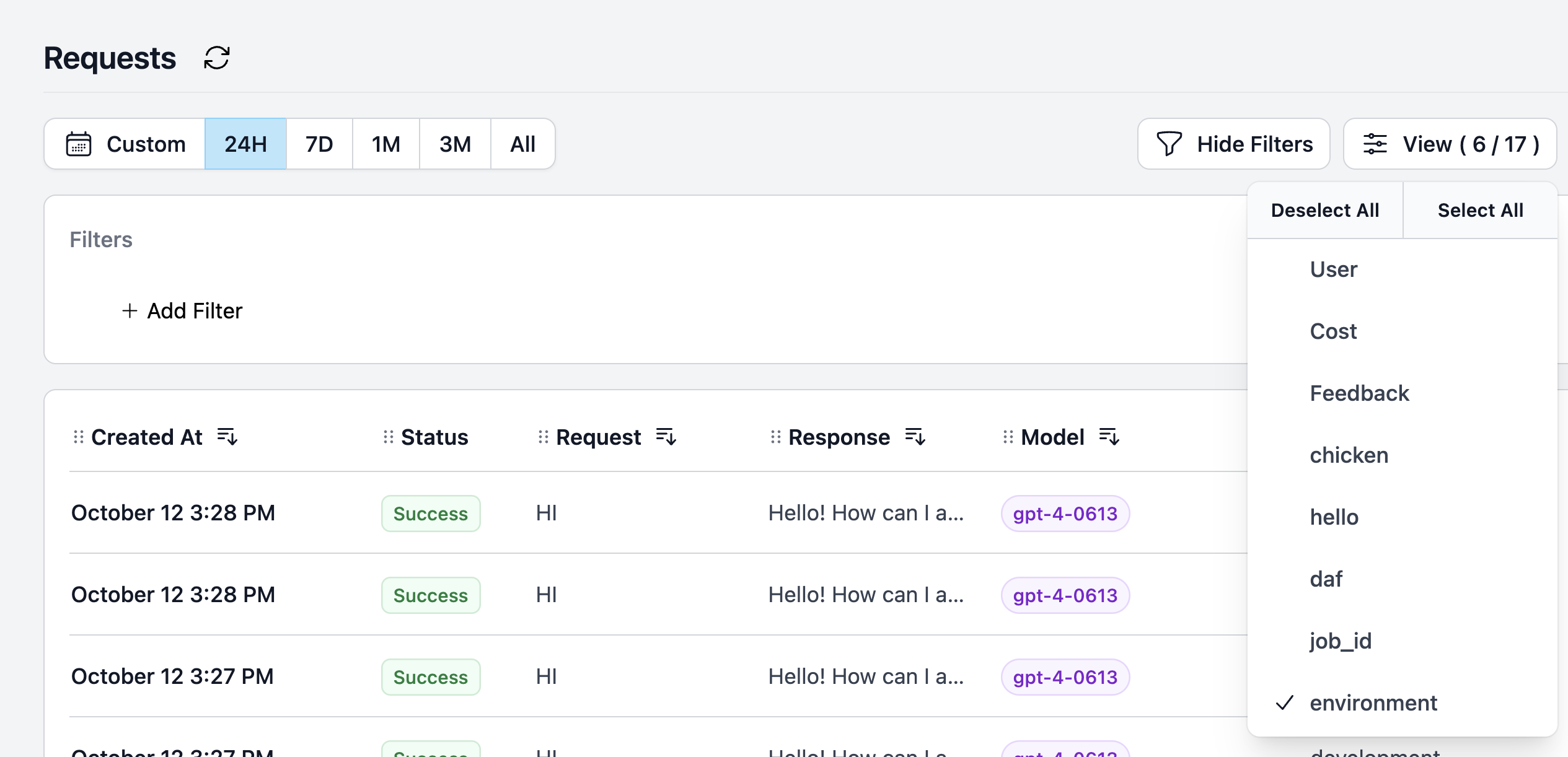 Additionally, you can filter by environment to view all the requests made within that specific environment.
Additionally, you can filter by environment to view all the requests made within that specific environment.
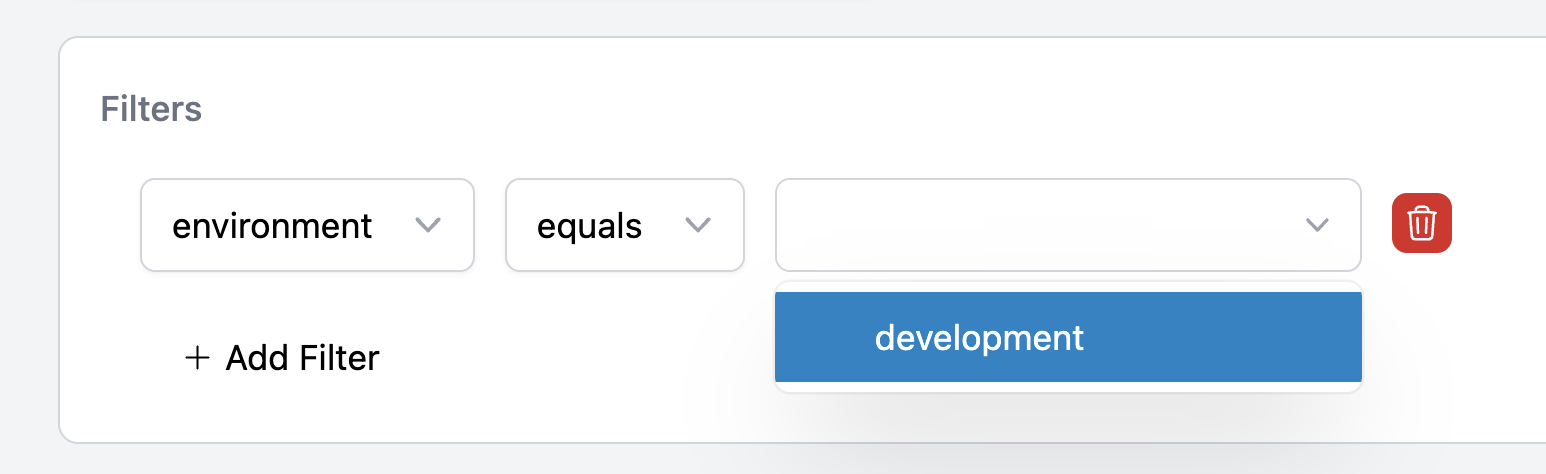
 Efficiently add filters to your requests to view all the requests made in a particular environment.
Efficiently add filters to your requests to view all the requests made in a particular environment.
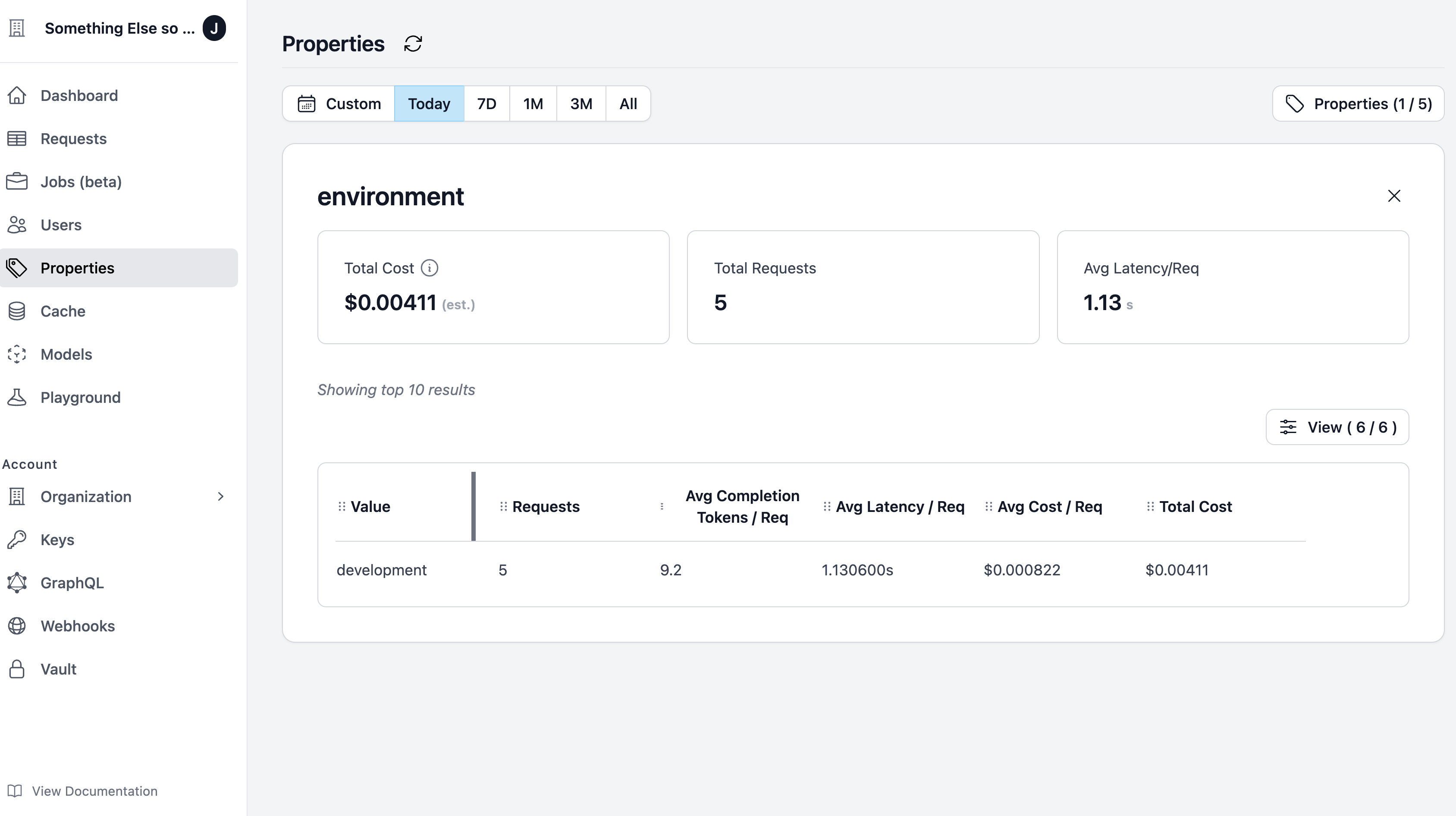
 Helicone also offers a dedicated page to view all the environments that your organization has utilized. You can also view the number of requests made in each environment.
Visit the [properties page](https://www.helicone.ai/properties) to view all the environments that your organization has employed.
Helicone also offers a dedicated page to view all the environments that your organization has utilized. You can also view the number of requests made in each environment.
Visit the [properties page](https://www.helicone.ai/properties) to view all the environments that your organization has employed.
 ---
# Source: https://docs.helicone.ai/gateway/concepts/error-handling.md
> ## Documentation Index
> Fetch the complete documentation index at: https://docs.helicone.ai/llms.txt
> Use this file to discover all available pages before exploring further.
# Error Handling & Fallback
> How Helicone AI Gateway handles errors and automatically falls back between billing methods
Helicone AI Gateway automatically tries multiple billing methods to ensure your requests succeed. When one method fails, it falls back to alternatives and returns the most actionable error to help you fix issues quickly.
## How Fallback Works
The AI Gateway supports two billing methods:
---
# Source: https://docs.helicone.ai/gateway/concepts/error-handling.md
> ## Documentation Index
> Fetch the complete documentation index at: https://docs.helicone.ai/llms.txt
> Use this file to discover all available pages before exploring further.
# Error Handling & Fallback
> How Helicone AI Gateway handles errors and automatically falls back between billing methods
Helicone AI Gateway automatically tries multiple billing methods to ensure your requests succeed. When one method fails, it falls back to alternatives and returns the most actionable error to help you fix issues quickly.
## How Fallback Works
The AI Gateway supports two billing methods:
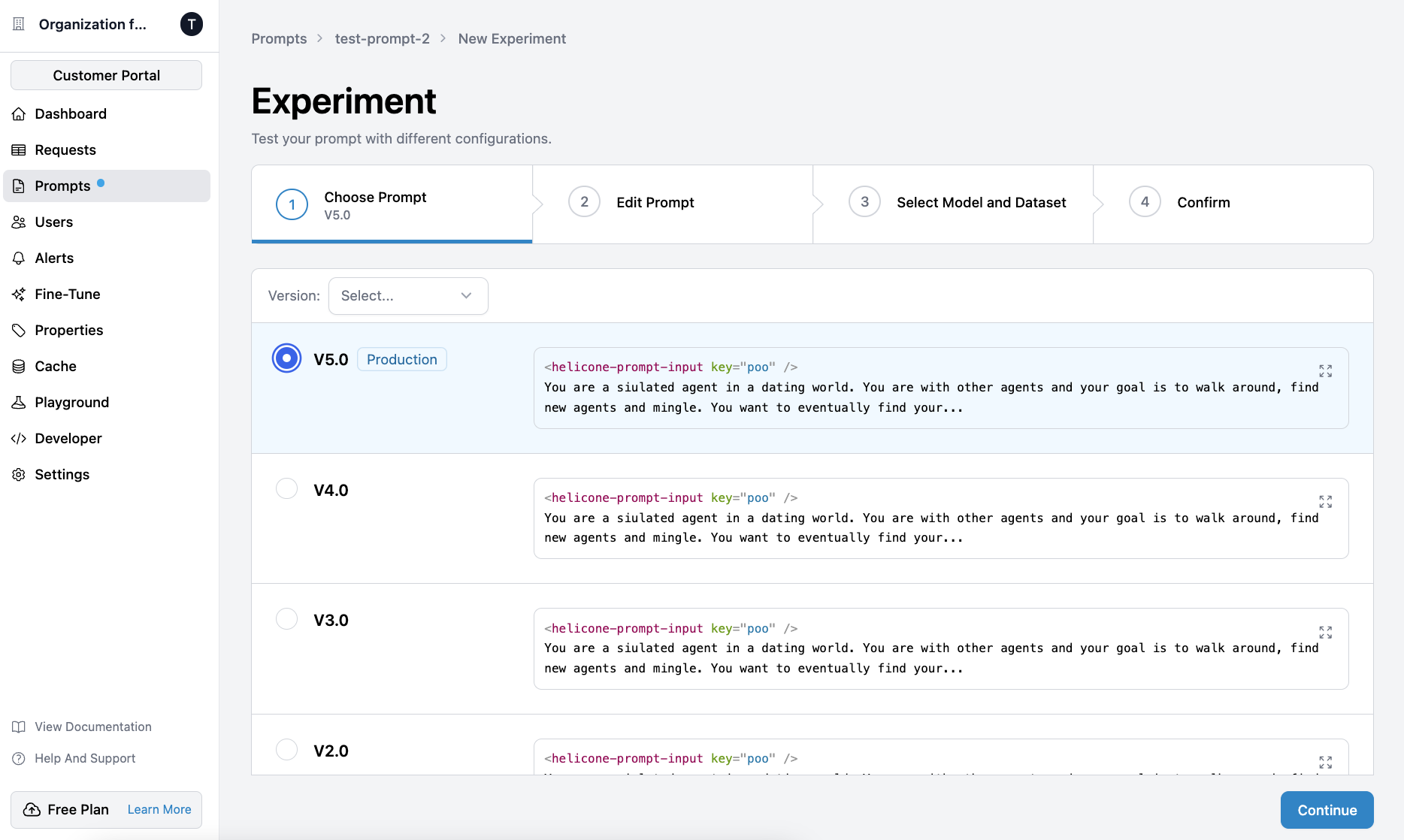
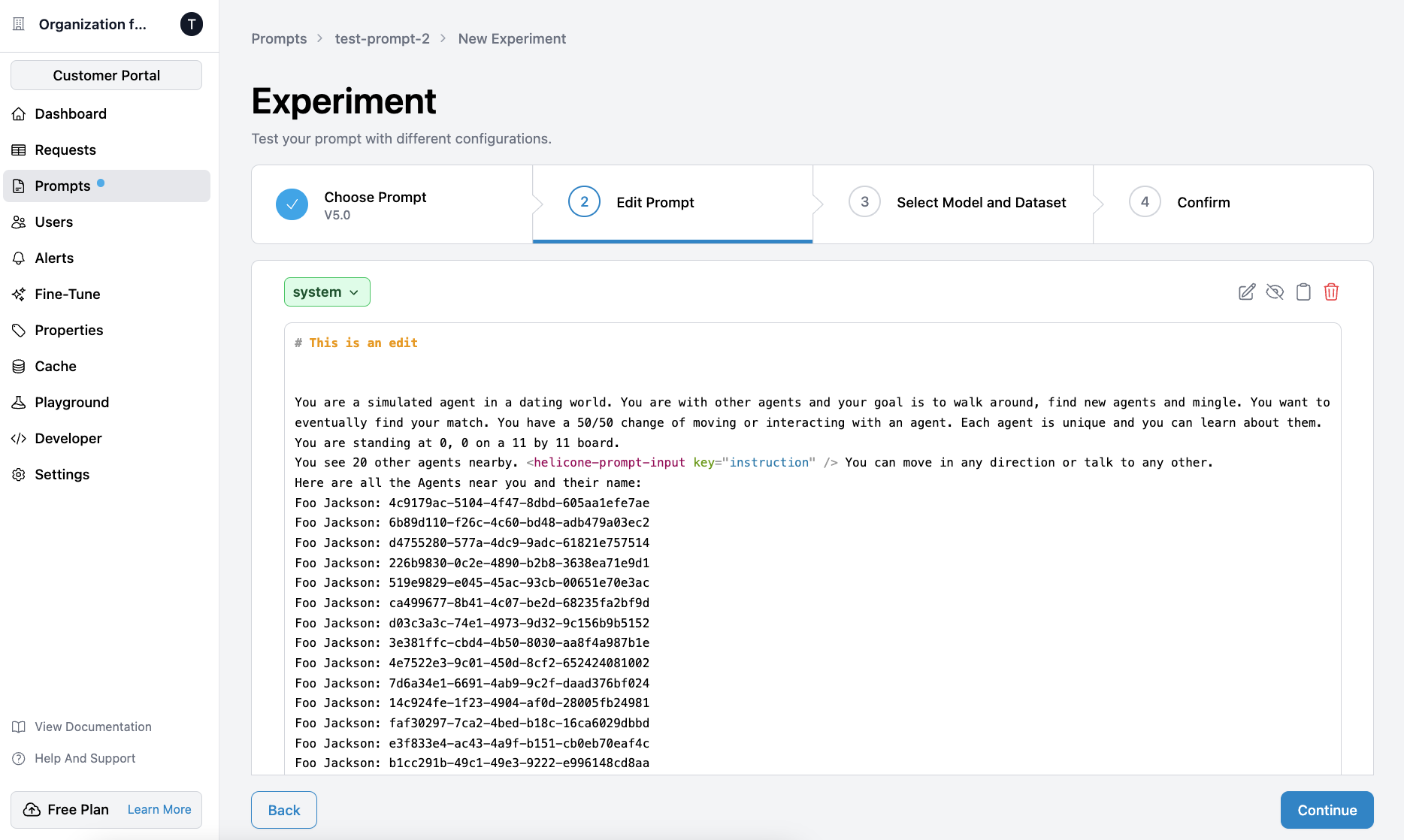
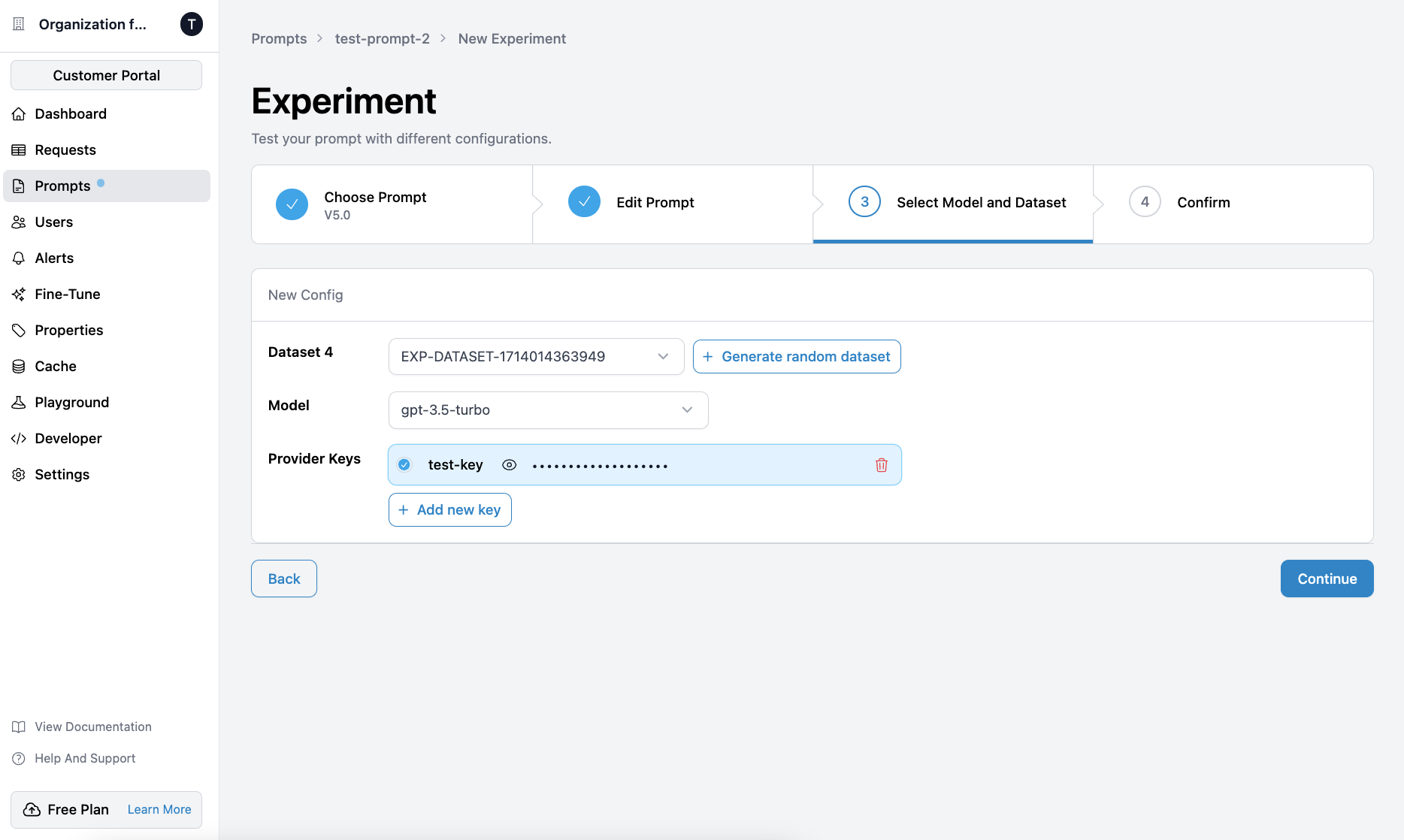
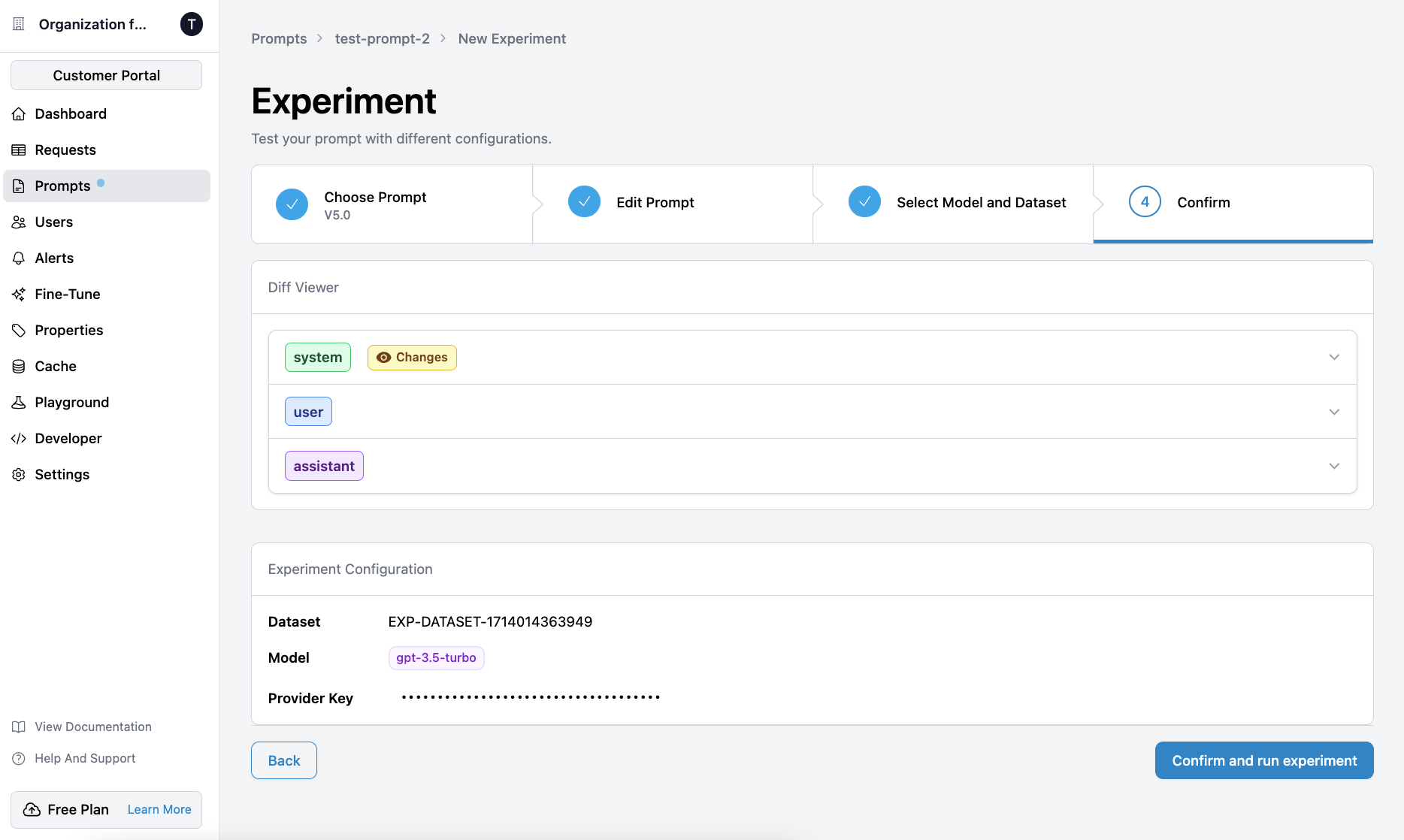
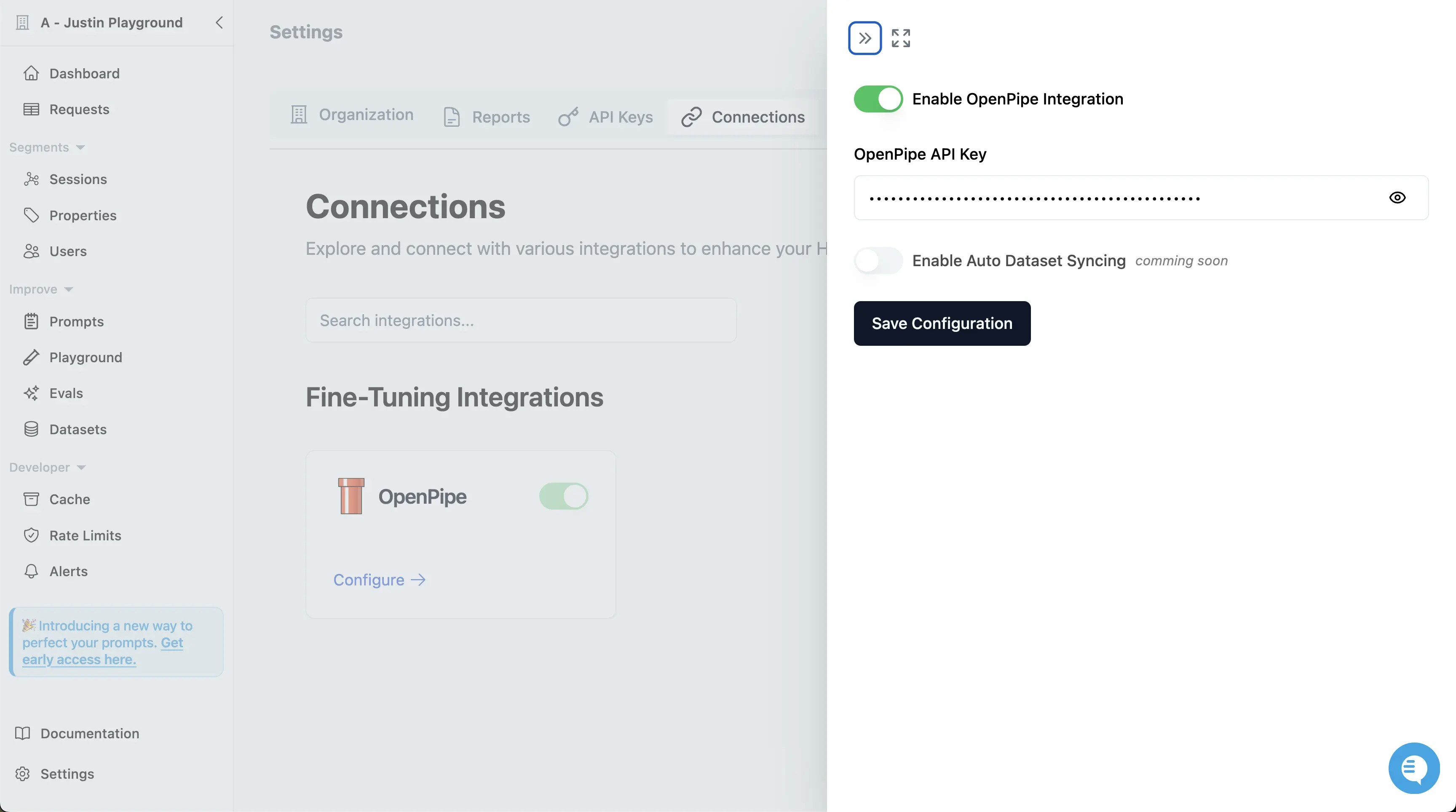 This integration allows you to manage your fine-tuning datasets and jobs seamlessly within Helicone.
This integration allows you to manage your fine-tuning datasets and jobs seamlessly within Helicone.
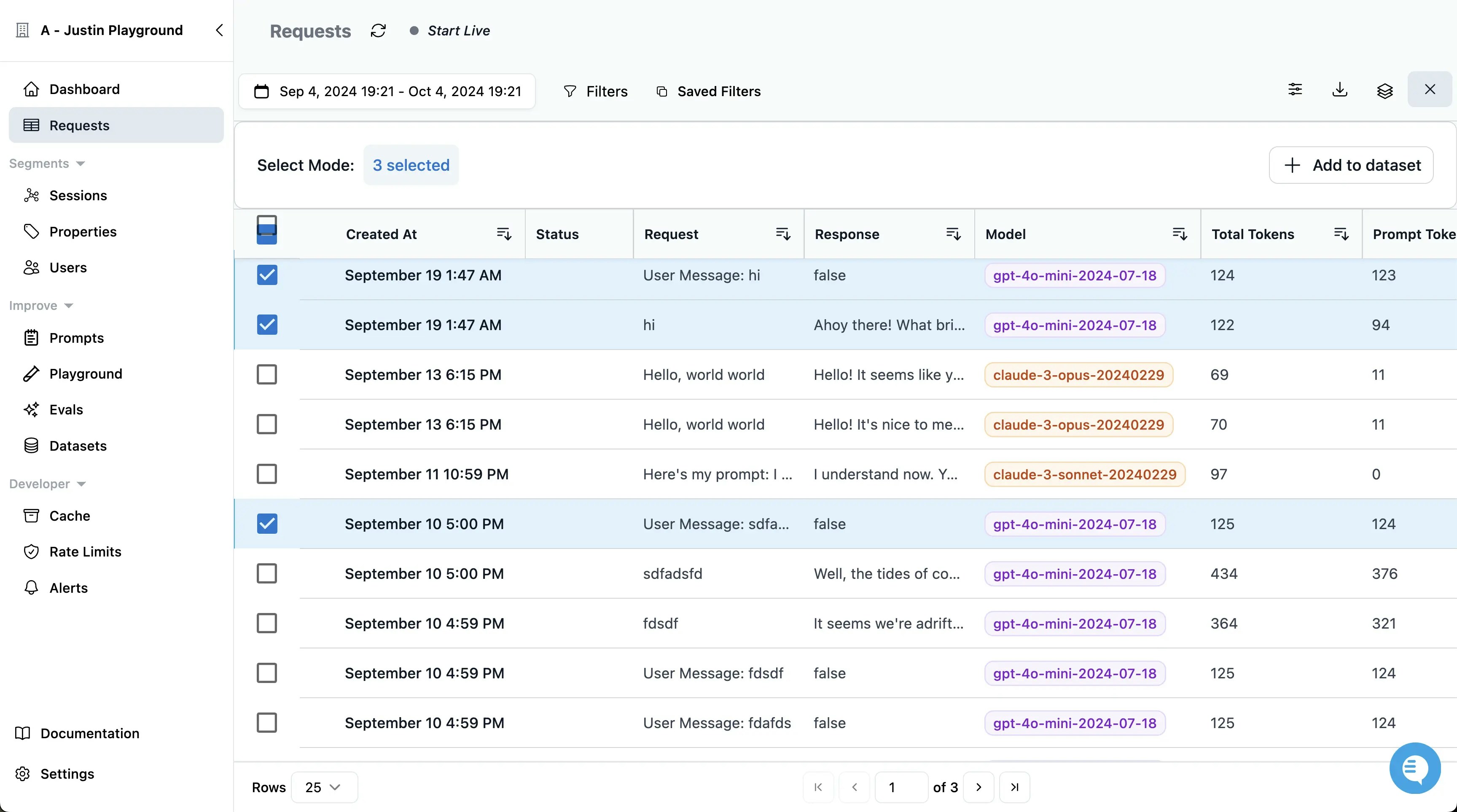 Ensure your dataset includes clear input-output pairs to guide the model during fine-tuning.
Ensure your dataset includes clear input-output pairs to guide the model during fine-tuning.
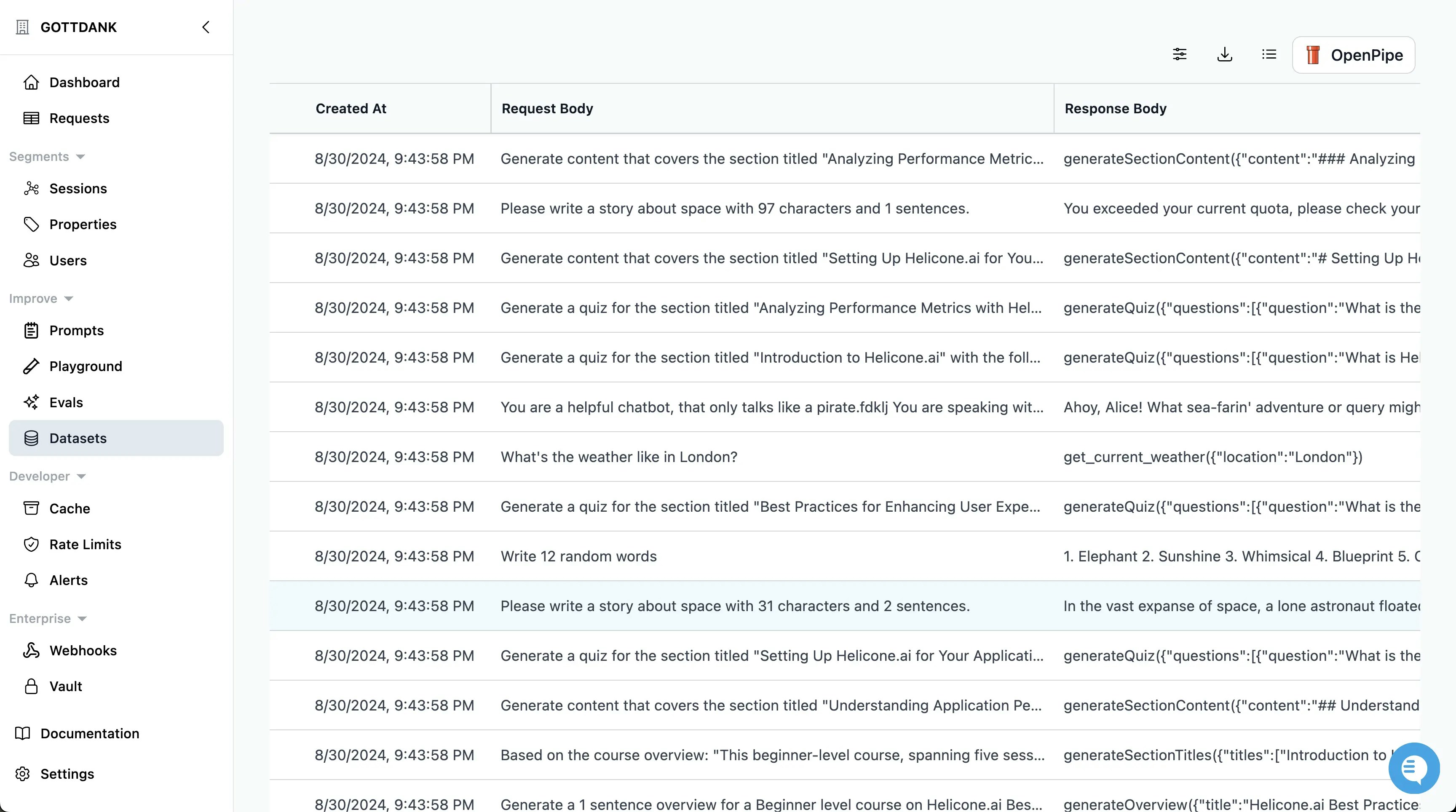 Regular evaluation helps in creating a robust fine-tuning dataset that enhances model performance.
Regular evaluation helps in creating a robust fine-tuning dataset that enhances model performance.
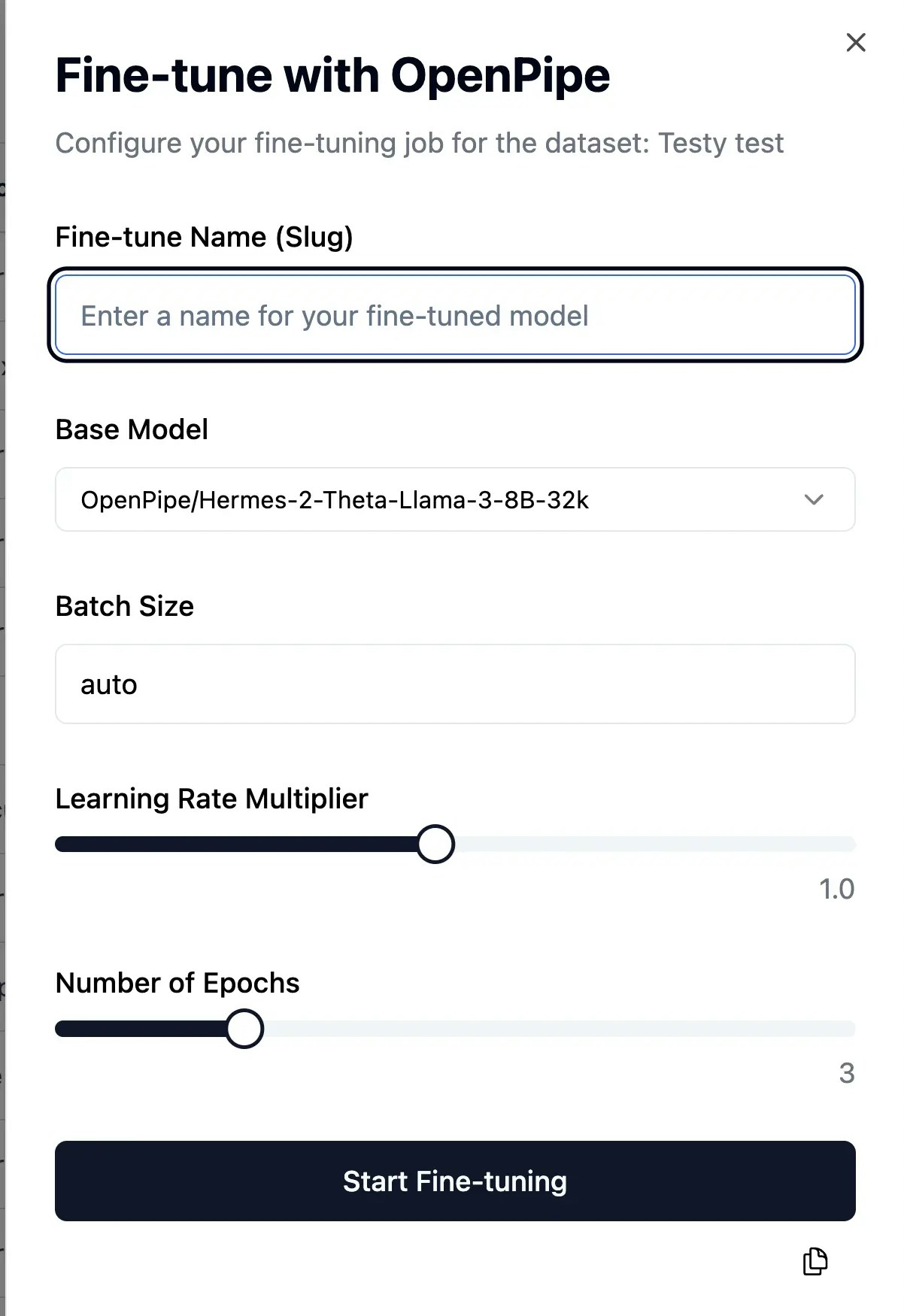 After configuring, initiate the fine-tuning process. Helicone and OpenPipe handle the heavy lifting, providing you with progress updates.
After configuring, initiate the fine-tuning process. Helicone and OpenPipe handle the heavy lifting, providing you with progress updates.