# Galileo Ai
> ## Documentation Index
---
# Source: https://docs.galileo.ai/galileo/galileo-nlp-studio/galileo-product-features/3p-integrations.md
> ## Documentation Index
> Fetch the complete documentation index at: https://docs.galileo.ai/llms.txt
> Use this file to discover all available pages before exploring further.
# Third Party 3p Integrations
> Galileo has integrates seamlessly with your tools.
We have integrated with a number of Data Storage Providers, Labeling Solutions, and LLM APIs. To manage your integrations, go to *Integrations* under your *Profile Avatar Menu*.
 From your integrations page, you can turn integrations on or off.
From your integrations page, you can turn integrations on or off.
 Your credentials are stored in a safe manner. Galileo is SOC2 Compliant.
---
# Source: https://docs.galileo.ai/galileo/gen-ai-studio-products/galileo-evaluate/how-to/a-b-compare-prompts.md
> ## Documentation Index
> Fetch the complete documentation index at: https://docs.galileo.ai/llms.txt
> Use this file to discover all available pages before exploring further.
# A/B Compare Prompts
> Easily compare multiple LLM runs in a single screen for better decision making
Galileo allows you to compare multiple evaluation runs side-by-side. This lets you view how different configurations of your system (i.e. different params, prompt templates, retriever strategies, etc.) handled the same set of queries, enabling you to quickly evaluate, analyze, and annotate your experiments. Galileo allows you to do this for both single-step workflows, or multi-step / chain workflows.
**How do I get started?**
To enter the *Compare Runs* mode, select the runs you want to compare from your and click "Compare Runs" on the Action Bar.
Your credentials are stored in a safe manner. Galileo is SOC2 Compliant.
---
# Source: https://docs.galileo.ai/galileo/gen-ai-studio-products/galileo-evaluate/how-to/a-b-compare-prompts.md
> ## Documentation Index
> Fetch the complete documentation index at: https://docs.galileo.ai/llms.txt
> Use this file to discover all available pages before exploring further.
# A/B Compare Prompts
> Easily compare multiple LLM runs in a single screen for better decision making
Galileo allows you to compare multiple evaluation runs side-by-side. This lets you view how different configurations of your system (i.e. different params, prompt templates, retriever strategies, etc.) handled the same set of queries, enabling you to quickly evaluate, analyze, and annotate your experiments. Galileo allows you to do this for both single-step workflows, or multi-step / chain workflows.
**How do I get started?**
To enter the *Compare Runs* mode, select the runs you want to compare from your and click "Compare Runs" on the Action Bar.
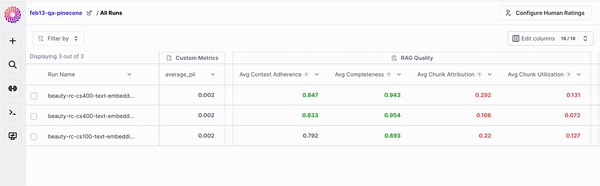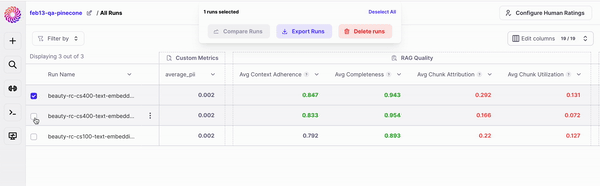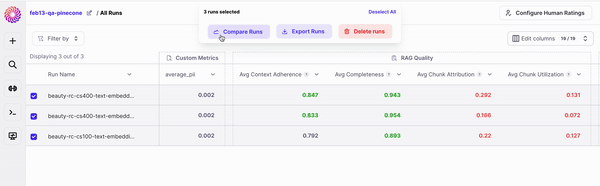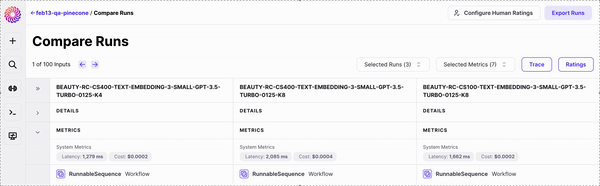 For two runs to be comparable, the same evaluation dataset must be used to create them.
Once you're in *Compare Runs* you can:
* Compare how your different configurations responded to the same input.
* Compare Metrics
* Expand to see the full Trace of the multi-step workflow and identify which steps went wrong
* Review and add Human Feedback
* Toggle back and forth between inputs on your eval set.
---
# Source: https://docs.galileo.ai/galileo/gen-ai-studio-products/galileo-observe/how-to/access-control.md
# Source: https://docs.galileo.ai/galileo/gen-ai-studio-products/galileo-evaluate/how-to/access-control.md
# Source: https://docs.galileo.ai/galileo/galileo-nlp-studio/galileo-product-features/access-control.md
> ## Documentation Index
> Fetch the complete documentation index at: https://docs.galileo.ai/llms.txt
> Use this file to discover all available pages before exploring further.
# Access Control Features | Galileo NLP Studio
> Discover Galileo NLP Studio's access control features, including user roles and group management, to securely share and manage projects within your organization.
Galileo supports fine-grained control over granting users different levels of access to the system, as well as organizing users into groups for easily sharing projects.
## System-level Roles
There are 4 roles that a user can be assigned:
**Admin** – Full access to the organization, including viewing all projects.
**Manager** – Can add and remove users.
**User** – Can create, update, share, and delete projects and resources within projects.
**Read-only** – Cannot create, update, share, or delete any projects or resources. Limited to view-only permissions.
In chart form:
| | Admin | Manager | User | Read-only |
| ------------------------------------- | ---------------------------------- | ----------------------------------------------- | ------------------------------------------ | ------------------------------------------ |
| View all projects | | | | |
| Add/delete users | | (excluding admins) | | |
| Create groups, invite users to groups | | | | |
| Create/update projects | | | | |
| Share projects | | | | |
| View projects | (all) | (only shared) | (only shared) | (only shared) |
System-level roles are chosen when users are invited to Galileo:
For two runs to be comparable, the same evaluation dataset must be used to create them.
Once you're in *Compare Runs* you can:
* Compare how your different configurations responded to the same input.
* Compare Metrics
* Expand to see the full Trace of the multi-step workflow and identify which steps went wrong
* Review and add Human Feedback
* Toggle back and forth between inputs on your eval set.
---
# Source: https://docs.galileo.ai/galileo/gen-ai-studio-products/galileo-observe/how-to/access-control.md
# Source: https://docs.galileo.ai/galileo/gen-ai-studio-products/galileo-evaluate/how-to/access-control.md
# Source: https://docs.galileo.ai/galileo/galileo-nlp-studio/galileo-product-features/access-control.md
> ## Documentation Index
> Fetch the complete documentation index at: https://docs.galileo.ai/llms.txt
> Use this file to discover all available pages before exploring further.
# Access Control Features | Galileo NLP Studio
> Discover Galileo NLP Studio's access control features, including user roles and group management, to securely share and manage projects within your organization.
Galileo supports fine-grained control over granting users different levels of access to the system, as well as organizing users into groups for easily sharing projects.
## System-level Roles
There are 4 roles that a user can be assigned:
**Admin** – Full access to the organization, including viewing all projects.
**Manager** – Can add and remove users.
**User** – Can create, update, share, and delete projects and resources within projects.
**Read-only** – Cannot create, update, share, or delete any projects or resources. Limited to view-only permissions.
In chart form:
| | Admin | Manager | User | Read-only |
| ------------------------------------- | ---------------------------------- | ----------------------------------------------- | ------------------------------------------ | ------------------------------------------ |
| View all projects | | | | |
| Add/delete users | | (excluding admins) | | |
| Create groups, invite users to groups | | | | |
| Create/update projects | | | | |
| Share projects | | | | |
| View projects | (all) | (only shared) | (only shared) | (only shared) |
System-level roles are chosen when users are invited to Galileo:
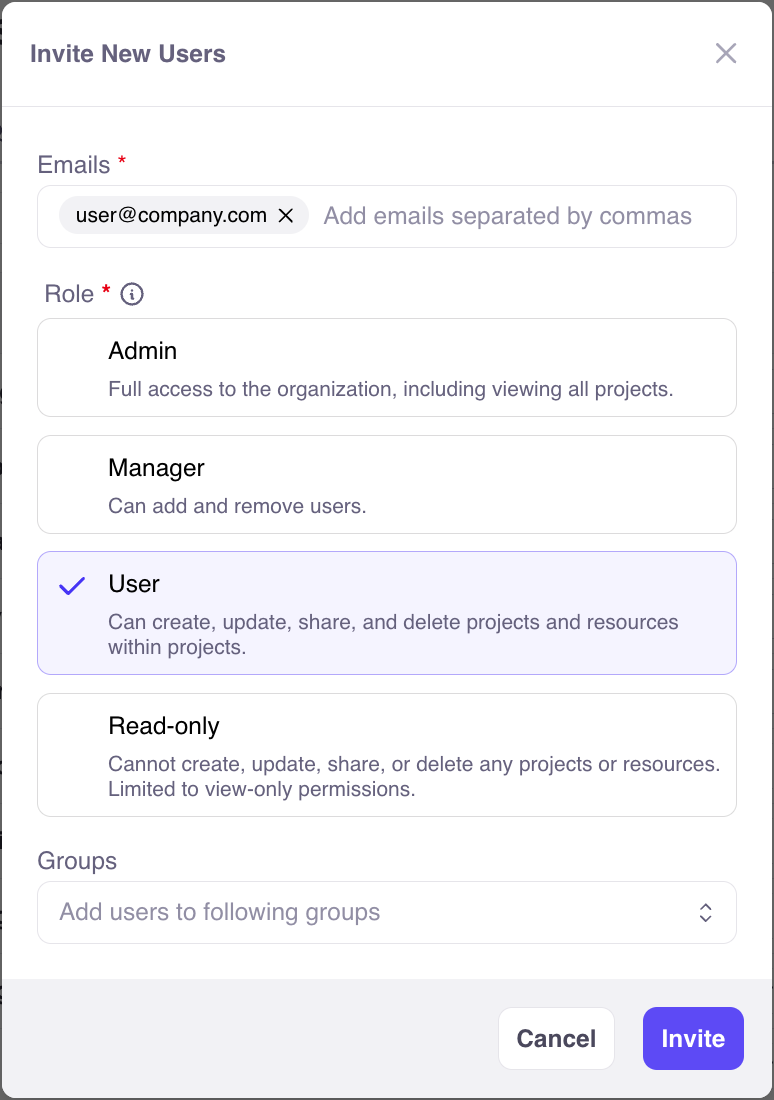 ## Groups
Users can be organized into groups to streamline sharing projects.
There are 3 types of groups:
**Public** – Group and members are visible to everyone in the organization. Anyone can join.
**Private** – Group is visible to everyone in the organization. Members are kept private. Access is granted by a group maintainer.
**Hidden** – Group and its members are hidden from non-members in the organization. Access is granted by a group maintainer.
Within a group, each member has a group role:
**Maintainer** – Can add and remove members.
**Member** – Can view other members and shared projects.
## Sharing Projects
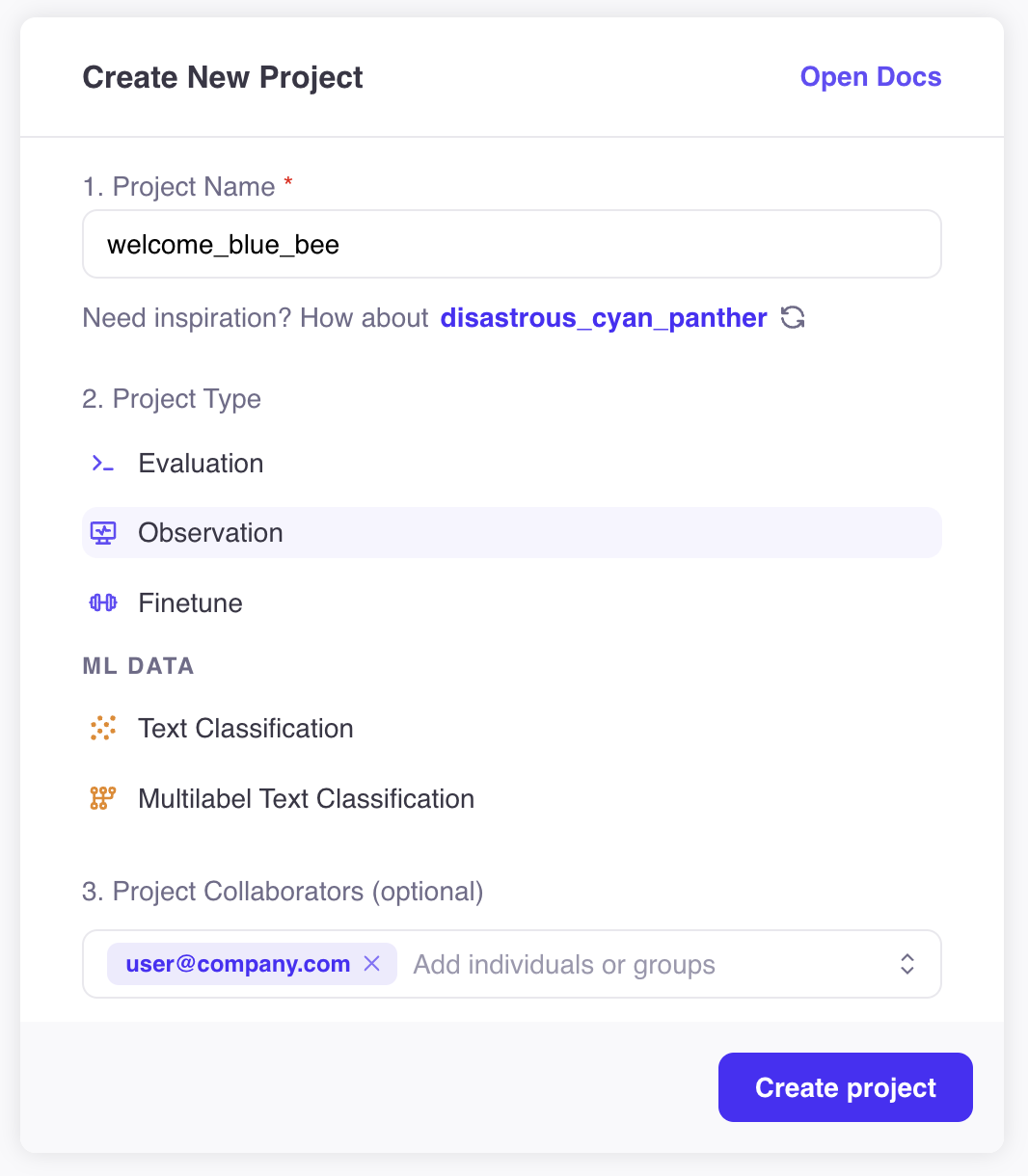
By default, only a project's creator (and managers and admins) have access to a project. Projects can be shared both with individual users and entire groups. Together, these are called *collaborators.* Collaborators can be added when you create a project:
## Groups
Users can be organized into groups to streamline sharing projects.
There are 3 types of groups:
**Public** – Group and members are visible to everyone in the organization. Anyone can join.
**Private** – Group is visible to everyone in the organization. Members are kept private. Access is granted by a group maintainer.
**Hidden** – Group and its members are hidden from non-members in the organization. Access is granted by a group maintainer.
Within a group, each member has a group role:
**Maintainer** – Can add and remove members.
**Member** – Can view other members and shared projects.
## Sharing Projects
By default, only a project's creator (and managers and admins) have access to a project. Projects can be shared both with individual users and entire groups. Together, these are called *collaborators.* Collaborators can be added when you create a project:
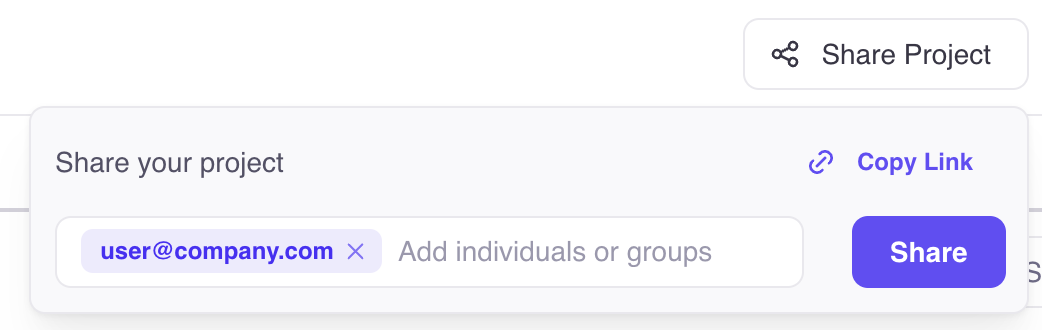
 Or anytime afterwards:
Or anytime afterwards:
 ---
# Source: https://docs.galileo.ai/galileo/gen-ai-studio-products/galileo-guardrail-metrics/action-advancement.md
> ## Documentation Index
> Fetch the complete documentation index at: https://docs.galileo.ai/llms.txt
> Use this file to discover all available pages before exploring further.
# Action Advancement
> Understand Galileo's Action Advancement Metric
***Definition:*** Determines whether the assistant successfully accomplished or advanced towards at least one user goal.
More precisely, accomplishing or advancing towards a user's goal requires the assistant to either provide a (at least partial) answer to one of the user's questions, ask for further information or clarification about a user ask, or providing confirmation that a successful action has been taken.
The answer or resolution must in addition be factually accurate, directly addressing a user's ask and align with the tool's outputs.
If the response does not have an *Action Advancement* score of 100%, then at least one judge considered that the model did not make progress on any user goal.
***Calculation:*** *Action Advancement* is computed by sending additional requests to an LLM (e.g. OpenAI's GPT4o-mini), using a carefully engineered chain-of-thought prompt that asks the model to follow the above precise definition. The metric requests multiple distinct responses to this prompt, each of which produces an explanation along with a final judgment: yes or no. The final Action Advancement score is the fraction of "yes" responses, divided by the total number of responses.
We also surface one of the generated explanations. The surfaced explanation is always chosen to align with the majority judgment among the responses.
*Note:* This metric is computed by prompting an LLM multiple times, and thus requires additional LLM calls to compute.
***Usefulness:*** This metric is most useful in Agentic Workflows, where an Agent decides the course of action to take and could select Tools. This metric helps you detect whether the right course of action was taken by the Agent, and whether it helped advance towards the user's goal.
---
# Source: https://docs.galileo.ai/galileo/gen-ai-studio-products/galileo-guardrail-metrics/action-completion.md
> ## Documentation Index
> Fetch the complete documentation index at: https://docs.galileo.ai/llms.txt
> Use this file to discover all available pages before exploring further.
# Action Completion
> Understand Galileo's Action Completion Metric
***Definition:*** Determines whether the assistant successfully accomplished all user's goals.
More precisely, accomplishing a user's goal requires the assistant to provide a complete answer in the case of a question, or providing a confirmation that a successful action has been taken in the case of a request. The answer or resolution must in addition be coherent, factually accurate, comprehensively address every aspect of the user's ask, not contradict tools outputs and summarize every relevant part returned by tools.
If the response does not have an *Action Completion* score of 100%, then at least one judge considered that the model did not accomplish every user goal.
***Calculation:*** *Action Completion* is computed by sending additional requests to an LLM (e.g. OpenAI's GPT4o), using a carefully engineered chain-of-thought prompt that asks the model to follow the above precise definition. The metric requests multiple distinct responses to this prompt, each of which produces an explanation along with a final judgment: yes or no. The final Action Completion score is the fraction of "yes" responses, divided by the total number of responses.
We also surface one of the generated explanations. The surfaced explanation is always chosen to align with the majority judgment among the responses.
*Note:* This metric is computed by prompting an LLM multiple times, and thus requires additional LLM calls to compute.
***Usefulness:*** This metric is most useful in Agentic Workflows, where an Agent decides the course of action to take and could select Tools. This metric helps you detect whether the right course of action was eventually taken by the Agent, and whether it fully accomplished all user's goals.
---
# Source: https://docs.galileo.ai/galileo/gen-ai-studio-products/galileo-protect/concepts/action.md
> ## Documentation Index
> Fetch the complete documentation index at: https://docs.galileo.ai/llms.txt
> Use this file to discover all available pages before exploring further.
# Action
> Galileo will provide a set of action types (override, passthrough), that the user can use, along with a configuration for each action type.
Actions are user-defined actions that are taken as a result of the [ruleset](/galileo/gen-ai-studio-products/galileo-protect/concepts/ruleset) being triggered.
An Action can be defined as:
```python theme={null}
gp.OverrideAction(
choices=["Sorry, I cannot answer that question."]
)
```
The action would be included in the ruleset definition as:
```py theme={null}
gp.Ruleset(
rules=[
gp.Rule(
metric=gp.RuleMetrics.pii,
operator=gp.RuleOperator.contains,
target_value="ssn"
),
gp.Rule(
metric=gp.RuleMetrics.toxicity,
operator=gp.RuleOperator.gt,
target_value=0.8
)
],
action=gp.OverrideAction(
choices=["Sorry, I cannot answer that question."]
)
)
```
---
# Source: https://docs.galileo.ai/galileo/galileo-nlp-studio/galileo-product-features/actions.md
> ## Documentation Index
> Fetch the complete documentation index at: https://docs.galileo.ai/llms.txt
> Use this file to discover all available pages before exploring further.
# Actions
> Actions help close the inspection loop and error discovery process. We support a number of actions.
---
# Source: https://docs.galileo.ai/galileo/gen-ai-studio-products/galileo-guardrail-metrics/action-advancement.md
> ## Documentation Index
> Fetch the complete documentation index at: https://docs.galileo.ai/llms.txt
> Use this file to discover all available pages before exploring further.
# Action Advancement
> Understand Galileo's Action Advancement Metric
***Definition:*** Determines whether the assistant successfully accomplished or advanced towards at least one user goal.
More precisely, accomplishing or advancing towards a user's goal requires the assistant to either provide a (at least partial) answer to one of the user's questions, ask for further information or clarification about a user ask, or providing confirmation that a successful action has been taken.
The answer or resolution must in addition be factually accurate, directly addressing a user's ask and align with the tool's outputs.
If the response does not have an *Action Advancement* score of 100%, then at least one judge considered that the model did not make progress on any user goal.
***Calculation:*** *Action Advancement* is computed by sending additional requests to an LLM (e.g. OpenAI's GPT4o-mini), using a carefully engineered chain-of-thought prompt that asks the model to follow the above precise definition. The metric requests multiple distinct responses to this prompt, each of which produces an explanation along with a final judgment: yes or no. The final Action Advancement score is the fraction of "yes" responses, divided by the total number of responses.
We also surface one of the generated explanations. The surfaced explanation is always chosen to align with the majority judgment among the responses.
*Note:* This metric is computed by prompting an LLM multiple times, and thus requires additional LLM calls to compute.
***Usefulness:*** This metric is most useful in Agentic Workflows, where an Agent decides the course of action to take and could select Tools. This metric helps you detect whether the right course of action was taken by the Agent, and whether it helped advance towards the user's goal.
---
# Source: https://docs.galileo.ai/galileo/gen-ai-studio-products/galileo-guardrail-metrics/action-completion.md
> ## Documentation Index
> Fetch the complete documentation index at: https://docs.galileo.ai/llms.txt
> Use this file to discover all available pages before exploring further.
# Action Completion
> Understand Galileo's Action Completion Metric
***Definition:*** Determines whether the assistant successfully accomplished all user's goals.
More precisely, accomplishing a user's goal requires the assistant to provide a complete answer in the case of a question, or providing a confirmation that a successful action has been taken in the case of a request. The answer or resolution must in addition be coherent, factually accurate, comprehensively address every aspect of the user's ask, not contradict tools outputs and summarize every relevant part returned by tools.
If the response does not have an *Action Completion* score of 100%, then at least one judge considered that the model did not accomplish every user goal.
***Calculation:*** *Action Completion* is computed by sending additional requests to an LLM (e.g. OpenAI's GPT4o), using a carefully engineered chain-of-thought prompt that asks the model to follow the above precise definition. The metric requests multiple distinct responses to this prompt, each of which produces an explanation along with a final judgment: yes or no. The final Action Completion score is the fraction of "yes" responses, divided by the total number of responses.
We also surface one of the generated explanations. The surfaced explanation is always chosen to align with the majority judgment among the responses.
*Note:* This metric is computed by prompting an LLM multiple times, and thus requires additional LLM calls to compute.
***Usefulness:*** This metric is most useful in Agentic Workflows, where an Agent decides the course of action to take and could select Tools. This metric helps you detect whether the right course of action was eventually taken by the Agent, and whether it fully accomplished all user's goals.
---
# Source: https://docs.galileo.ai/galileo/gen-ai-studio-products/galileo-protect/concepts/action.md
> ## Documentation Index
> Fetch the complete documentation index at: https://docs.galileo.ai/llms.txt
> Use this file to discover all available pages before exploring further.
# Action
> Galileo will provide a set of action types (override, passthrough), that the user can use, along with a configuration for each action type.
Actions are user-defined actions that are taken as a result of the [ruleset](/galileo/gen-ai-studio-products/galileo-protect/concepts/ruleset) being triggered.
An Action can be defined as:
```python theme={null}
gp.OverrideAction(
choices=["Sorry, I cannot answer that question."]
)
```
The action would be included in the ruleset definition as:
```py theme={null}
gp.Ruleset(
rules=[
gp.Rule(
metric=gp.RuleMetrics.pii,
operator=gp.RuleOperator.contains,
target_value="ssn"
),
gp.Rule(
metric=gp.RuleMetrics.toxicity,
operator=gp.RuleOperator.gt,
target_value=0.8
)
],
action=gp.OverrideAction(
choices=["Sorry, I cannot answer that question."]
)
)
```
---
# Source: https://docs.galileo.ai/galileo/galileo-nlp-studio/galileo-product-features/actions.md
> ## Documentation Index
> Fetch the complete documentation index at: https://docs.galileo.ai/llms.txt
> Use this file to discover all available pages before exploring further.
# Actions
> Actions help close the inspection loop and error discovery process. We support a number of actions.
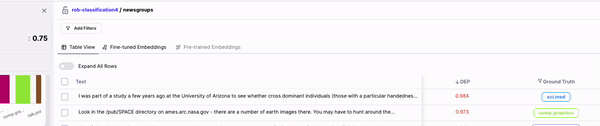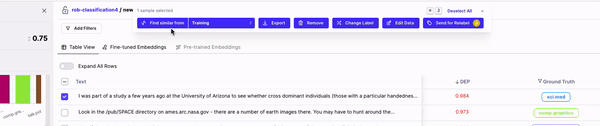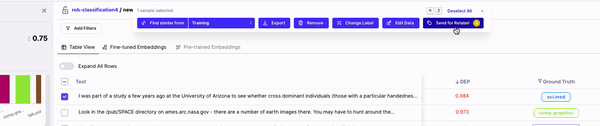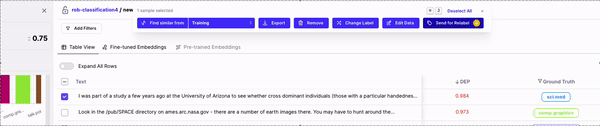 Generally these actions fall under two categories:
1. Fixing data in-tool:
* Edit Data
* Remove
* Change Label
2. Exporting Data to fix it elsewhere:
* Send to Labelers
* Export Data
### Fixing Data In-Tool
**Edit Data**
This feature is only supported for NLP tasks. Through *Edit Data* you can quickly make small changes to your text samples. For Classification tasks, you can find and replace text (indivually or in bulk). For NER tasks, you can also use *Edit Data* to shift spans, add new spans or remove spans.
**Removing Data**
Sometimes you find data samples that simply shouldn't be part of your dataset (e.g. garbage data) or simply want to remove mislabeled samples from your training dataset. "Remove data" allows you to remove these samples from your dataset. Upon selecting some samples, you'll have the option to remove them. Removed samples go to your Edits Cart, from where you can download your "fixed" dataset to train another model iteration.
**Change Label**
For Classification tasks, *Change Label* allows you to change the label of you selected samples. You can either set the label to what the model predicted or manually enter the label you'd like these samples to have.
### Exporting Data to fix it elsewhere:
At any point in the inspection process you can export any selection of data. You can download your data as a CSV, download to an S3, GCS or DeltaLake bucket, or programmatically fetch it through `dq.metrics`
Additionally, after taking actions like the ones mentioned above, your Changes will show up on the Edits Cart. From there you can export your full dataset (including or excluding changes) to train a new model run.
**Send to Labelers**
Sometimes you want your labelers to fix your data. Once you've identified a cohort of data that is mislabeled, you can use the *Send to Labelers* button and leverage our labeling integrations to send your samples to your labeling provider in one click.
---
# Source: https://docs.galileo.ai/galileo/gen-ai-studio-products/galileo-evaluate/how-to/add-tags-and-metadata-to-prompt-runs.md
> ## Documentation Index
> Fetch the complete documentation index at: https://docs.galileo.ai/llms.txt
> Use this file to discover all available pages before exploring further.
# Add Tags and Metadata to Prompt Runs
> While you are experimenting with your prompts you will probably be tuning many parameters.
Maybe you will run experiments with different models, model versions, vector stores, embedding models, etc.
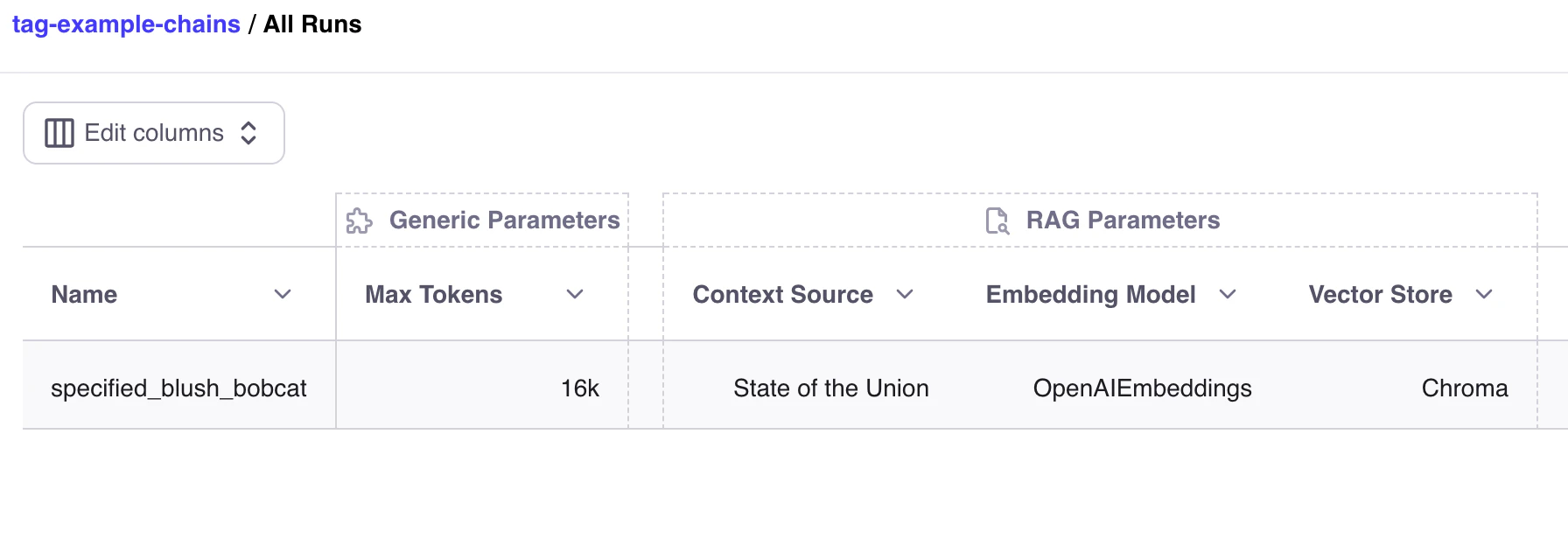
Run Tags are an easy way to log any details of your run, that you want to view later in the Galileo Evaluation UI.
## Adding tags with `promptquality`
A tag has three key components:
* key: the name of your tag i.e model name
* value: the value in your run i.e. gpt-4
* tag\_type: the type of the tag. Currently tags can be RAG or GENERIC
If we wanted to run an experiment, using gpt with a 16k token max, we could create a tag, noting that our max tokens is 16k:
```bash theme={null}
max_tokens_tag = pq.RunTag(key="Max Tokens", value="16k", tag_type=pq.TagType.GENERIC)
```
We could then add our tag to our run, however we are choosing to create a run:
### Logging Workflows
If you are using a workflow, you can add tags to your workflow by adding the tag to the [EvaluateRun](https://promptquality.docs.rungalileo.io/#promptquality.EvaluateRun) object.
```py theme={null}
evaluate_run = pq.EvaluateRun(run_name="my_run", project_name="my_project", scorers=metrics, run_tags=[max_tokens_tag])
```
### Prompt Run
We can add tags to a simple Prompt run. For info on creating Prompt runs, see [Getting Started](/galileo/gen-ai-studio-products/galileo-evaluate/quickstart)
```py theme={null}
pq.run(project_name='my_project_name',
template=template,
dataset=data,
run_tags=[max_tokens_tag]
settings=pq.Settings(model_alias='ChatGPT (16K context)',
temperature=0.8,
max_tokens=400))
```
### Prompt Sweep
We can also add tags across a Prompt sweep, with multiple templates and/or models. For info on creating Prompt sweeps, see [Prompt Sweeps](/galileo/gen-ai-studio-products/galileo-evaluate/how-to/experiment-with-multiple-prompts)
```py theme={null}
pq.run_sweep(project_name='my_project_name',
templates=templates,
dataset='my_dataset.csv',
scorers=metrics,
model_aliases=models,
run_tags=[max_tokens_tag]
execute=True)
```
### LangChain Callback
We can even add tags, through the GalileoPromptCallback, to more complex chain runs, with LangChain. For info on using Prompt with chains, see [Using Prompt with Chains or multi-step workflows](/galileo/gen-ai-studio-products/galileo-evaluate/how-to/evaluate-and-optimize-agents--chains-or-multi-step-workflows)
```py theme={null}
pq.GalileoPromptCallback(project_name='my_project_name',
scorers=[],
run_tags=[max_tokens_tag])
```
## Viewing Tags in the Galileo Evaluation UI
You can then view your tags in the Galileo Evaluation UI:
Generally these actions fall under two categories:
1. Fixing data in-tool:
* Edit Data
* Remove
* Change Label
2. Exporting Data to fix it elsewhere:
* Send to Labelers
* Export Data
### Fixing Data In-Tool
**Edit Data**
This feature is only supported for NLP tasks. Through *Edit Data* you can quickly make small changes to your text samples. For Classification tasks, you can find and replace text (indivually or in bulk). For NER tasks, you can also use *Edit Data* to shift spans, add new spans or remove spans.
**Removing Data**
Sometimes you find data samples that simply shouldn't be part of your dataset (e.g. garbage data) or simply want to remove mislabeled samples from your training dataset. "Remove data" allows you to remove these samples from your dataset. Upon selecting some samples, you'll have the option to remove them. Removed samples go to your Edits Cart, from where you can download your "fixed" dataset to train another model iteration.
**Change Label**
For Classification tasks, *Change Label* allows you to change the label of you selected samples. You can either set the label to what the model predicted or manually enter the label you'd like these samples to have.
### Exporting Data to fix it elsewhere:
At any point in the inspection process you can export any selection of data. You can download your data as a CSV, download to an S3, GCS or DeltaLake bucket, or programmatically fetch it through `dq.metrics`
Additionally, after taking actions like the ones mentioned above, your Changes will show up on the Edits Cart. From there you can export your full dataset (including or excluding changes) to train a new model run.
**Send to Labelers**
Sometimes you want your labelers to fix your data. Once you've identified a cohort of data that is mislabeled, you can use the *Send to Labelers* button and leverage our labeling integrations to send your samples to your labeling provider in one click.
---
# Source: https://docs.galileo.ai/galileo/gen-ai-studio-products/galileo-evaluate/how-to/add-tags-and-metadata-to-prompt-runs.md
> ## Documentation Index
> Fetch the complete documentation index at: https://docs.galileo.ai/llms.txt
> Use this file to discover all available pages before exploring further.
# Add Tags and Metadata to Prompt Runs
> While you are experimenting with your prompts you will probably be tuning many parameters.
Maybe you will run experiments with different models, model versions, vector stores, embedding models, etc.
Run Tags are an easy way to log any details of your run, that you want to view later in the Galileo Evaluation UI.
## Adding tags with `promptquality`
A tag has three key components:
* key: the name of your tag i.e model name
* value: the value in your run i.e. gpt-4
* tag\_type: the type of the tag. Currently tags can be RAG or GENERIC
If we wanted to run an experiment, using gpt with a 16k token max, we could create a tag, noting that our max tokens is 16k:
```bash theme={null}
max_tokens_tag = pq.RunTag(key="Max Tokens", value="16k", tag_type=pq.TagType.GENERIC)
```
We could then add our tag to our run, however we are choosing to create a run:
### Logging Workflows
If you are using a workflow, you can add tags to your workflow by adding the tag to the [EvaluateRun](https://promptquality.docs.rungalileo.io/#promptquality.EvaluateRun) object.
```py theme={null}
evaluate_run = pq.EvaluateRun(run_name="my_run", project_name="my_project", scorers=metrics, run_tags=[max_tokens_tag])
```
### Prompt Run
We can add tags to a simple Prompt run. For info on creating Prompt runs, see [Getting Started](/galileo/gen-ai-studio-products/galileo-evaluate/quickstart)
```py theme={null}
pq.run(project_name='my_project_name',
template=template,
dataset=data,
run_tags=[max_tokens_tag]
settings=pq.Settings(model_alias='ChatGPT (16K context)',
temperature=0.8,
max_tokens=400))
```
### Prompt Sweep
We can also add tags across a Prompt sweep, with multiple templates and/or models. For info on creating Prompt sweeps, see [Prompt Sweeps](/galileo/gen-ai-studio-products/galileo-evaluate/how-to/experiment-with-multiple-prompts)
```py theme={null}
pq.run_sweep(project_name='my_project_name',
templates=templates,
dataset='my_dataset.csv',
scorers=metrics,
model_aliases=models,
run_tags=[max_tokens_tag]
execute=True)
```
### LangChain Callback
We can even add tags, through the GalileoPromptCallback, to more complex chain runs, with LangChain. For info on using Prompt with chains, see [Using Prompt with Chains or multi-step workflows](/galileo/gen-ai-studio-products/galileo-evaluate/how-to/evaluate-and-optimize-agents--chains-or-multi-step-workflows)
```py theme={null}
pq.GalileoPromptCallback(project_name='my_project_name',
scorers=[],
run_tags=[max_tokens_tag])
```
## Viewing Tags in the Galileo Evaluation UI
You can then view your tags in the Galileo Evaluation UI:
 ---
# Source: https://docs.galileo.ai/galileo/gen-ai-studio-products/galileo-evaluate/integrations/llms/adding-custom-llms.md
> ## Documentation Index
> Fetch the complete documentation index at: https://docs.galileo.ai/llms.txt
> Use this file to discover all available pages before exploring further.
# Adding Custom LLM APIs / Fine Tuned LLMs
> Showcases how to use Galileo with any LLM API or custom fine-tuned LLMs, not supported out-of-the-box by Galileo.
Galileo comes pre-configured with dozens of LLM integrations across various platforms including OpenAI, Azure OpenAI, Sagemaker, and Bedrock.
However, if you're using an LLM service or custom model that Galileo doesn't have support for, you can still get all that Galileo has to offer by simply using our workflow loggers.
In this guide, we showcase how to leverage Anthropic's `claude-3-sonnet` LLM without Galileo, and then use Galileo to do deep evaluations and analysis.
First, install the required libraries. In this example - Galileo, Anthropic, and Langchain.
```py theme={null}
pip install --upgrade promptquality langchain langchain-anthropic
```
Here's a simple code snippet showing you how to query **any LLM of your choice** (in this case we're going with an Anthropic LLM) and log your results to Galileo.
```py theme={null}
import os
import promptquality as pq
from promptquality import NodeType, NodeRow
from langchain_anthropic import ChatAnthropic
from datetime import datetime
from uuid import uuid4
os.environ['GALILEO_CONSOLE_URL'] = "https://your.galileo.console.url"
os.environ["ANTHROPIC_API_KEY"] = "Your Anthropic Key"
MY_PROJECT_NAME = "my-custom-logging-project"
MY_RUN_NAME = f'custom-logging-{datetime.now().strftime("%b %d %Y %H_%M_%S")}'
config = pq.login(os.environ['GALILEO_CONSOLE_URL'])
model_name = "claude-3-sonnet-20240229"
chat_model = ChatAnthropic(model=model_name)
query = "Tell me a joke about bears!"
response = chat_model.invoke(query)
# Create the run for logging to Galileo.
evaluate_run = pq.EvaluateRun(run_name=MY_RUN_NAME, project_name=MY_PROJECT_NAME, scorers=[pq.Scorers.context_adherence_plus])
# Add the workflow to the run.
evaluate_run.add_single_step_workflow(input=query, output=response.content, model=model_name, duration_ns=2000)
# Log the run to Galileo.
evaluate_run.finish()
```
You should see a result like shown below:
```py theme={null}
👋 You have logged into 🔭 Galileo (https://your.galileo.console.url/) as galileo@rungalileo.io.
Processing complete!
Initial job complete, executing scorers asynchronously. Current status:
cost: Computing 🚧
toxicity: Computing 🚧
pii: Computing 🚧
latency: Done ✅
groundedness: Computing 🚧
🔭 View your prompt run on the Galileo console at: https://your.galileo.console.url/foo/bar/
```
---
# Source: https://docs.galileo.ai/galileo/gen-ai-studio-products/galileo-evaluate/how-to/autogen-metrics.md
> ## Documentation Index
> Fetch the complete documentation index at: https://docs.galileo.ai/llms.txt
> Use this file to discover all available pages before exploring further.
# Auto-generating an LLM-as-a-judge
> Learn how to use Galileo's Autogen feature to generate LLM-as-a-judge metrics.
Creating an LLM-as-a-judge metric is really easy with Galileo's Autogen feature. You can simply enter
a description of what you want to measure or detect, and Galileo auto-generates a metric for you.
## How it works
When you enter a description of your metric (e.g. "detect any toxic language in the inputs"), your description
is converted into a prompt and few-shot examples for your metric. This prompt and few-shot examples are used
to power an LLM-as-a-judge that uses chain-of-thought and majority voting (see [Chainpoll paper](/galileo-ai-research/chainpoll)) to calculate a metric.
You can customize the model that gets used or the number of judges used to calculate your metric.
Currently, auto-generated metrics are restricted to binary (yes/no) measurements. Multiple choice or numerical ratings are coming soon.
## How to use it
## Editing and Iterating on your auto-generated LLM-as-a-judge
You can always go back and edit your prompt or examples. Additionally, you can use [Continuous Learning via Human Feedback (CLHF)](/galileo/gen-ai-studio-products/galileo-evaluate/how-to/continuous-learning-via-human-feedback) to improve and adapt your metric.
---
# Source: https://docs.galileo.ai/galileo/galileo-nlp-studio/text-classification/automated-production-monitoring.md
> ## Documentation Index
> Fetch the complete documentation index at: https://docs.galileo.ai/llms.txt
> Use this file to discover all available pages before exploring further.
# Automated Production Monitoring
> Monitor text classification models in production with automated tools from Galileo NLP Studio to detect data drift and maintain performance.
---
# Source: https://docs.galileo.ai/galileo/gen-ai-studio-products/galileo-evaluate/integrations/llms/adding-custom-llms.md
> ## Documentation Index
> Fetch the complete documentation index at: https://docs.galileo.ai/llms.txt
> Use this file to discover all available pages before exploring further.
# Adding Custom LLM APIs / Fine Tuned LLMs
> Showcases how to use Galileo with any LLM API or custom fine-tuned LLMs, not supported out-of-the-box by Galileo.
Galileo comes pre-configured with dozens of LLM integrations across various platforms including OpenAI, Azure OpenAI, Sagemaker, and Bedrock.
However, if you're using an LLM service or custom model that Galileo doesn't have support for, you can still get all that Galileo has to offer by simply using our workflow loggers.
In this guide, we showcase how to leverage Anthropic's `claude-3-sonnet` LLM without Galileo, and then use Galileo to do deep evaluations and analysis.
First, install the required libraries. In this example - Galileo, Anthropic, and Langchain.
```py theme={null}
pip install --upgrade promptquality langchain langchain-anthropic
```
Here's a simple code snippet showing you how to query **any LLM of your choice** (in this case we're going with an Anthropic LLM) and log your results to Galileo.
```py theme={null}
import os
import promptquality as pq
from promptquality import NodeType, NodeRow
from langchain_anthropic import ChatAnthropic
from datetime import datetime
from uuid import uuid4
os.environ['GALILEO_CONSOLE_URL'] = "https://your.galileo.console.url"
os.environ["ANTHROPIC_API_KEY"] = "Your Anthropic Key"
MY_PROJECT_NAME = "my-custom-logging-project"
MY_RUN_NAME = f'custom-logging-{datetime.now().strftime("%b %d %Y %H_%M_%S")}'
config = pq.login(os.environ['GALILEO_CONSOLE_URL'])
model_name = "claude-3-sonnet-20240229"
chat_model = ChatAnthropic(model=model_name)
query = "Tell me a joke about bears!"
response = chat_model.invoke(query)
# Create the run for logging to Galileo.
evaluate_run = pq.EvaluateRun(run_name=MY_RUN_NAME, project_name=MY_PROJECT_NAME, scorers=[pq.Scorers.context_adherence_plus])
# Add the workflow to the run.
evaluate_run.add_single_step_workflow(input=query, output=response.content, model=model_name, duration_ns=2000)
# Log the run to Galileo.
evaluate_run.finish()
```
You should see a result like shown below:
```py theme={null}
👋 You have logged into 🔭 Galileo (https://your.galileo.console.url/) as galileo@rungalileo.io.
Processing complete!
Initial job complete, executing scorers asynchronously. Current status:
cost: Computing 🚧
toxicity: Computing 🚧
pii: Computing 🚧
latency: Done ✅
groundedness: Computing 🚧
🔭 View your prompt run on the Galileo console at: https://your.galileo.console.url/foo/bar/
```
---
# Source: https://docs.galileo.ai/galileo/gen-ai-studio-products/galileo-evaluate/how-to/autogen-metrics.md
> ## Documentation Index
> Fetch the complete documentation index at: https://docs.galileo.ai/llms.txt
> Use this file to discover all available pages before exploring further.
# Auto-generating an LLM-as-a-judge
> Learn how to use Galileo's Autogen feature to generate LLM-as-a-judge metrics.
Creating an LLM-as-a-judge metric is really easy with Galileo's Autogen feature. You can simply enter
a description of what you want to measure or detect, and Galileo auto-generates a metric for you.
## How it works
When you enter a description of your metric (e.g. "detect any toxic language in the inputs"), your description
is converted into a prompt and few-shot examples for your metric. This prompt and few-shot examples are used
to power an LLM-as-a-judge that uses chain-of-thought and majority voting (see [Chainpoll paper](/galileo-ai-research/chainpoll)) to calculate a metric.
You can customize the model that gets used or the number of judges used to calculate your metric.
Currently, auto-generated metrics are restricted to binary (yes/no) measurements. Multiple choice or numerical ratings are coming soon.
## How to use it
## Editing and Iterating on your auto-generated LLM-as-a-judge
You can always go back and edit your prompt or examples. Additionally, you can use [Continuous Learning via Human Feedback (CLHF)](/galileo/gen-ai-studio-products/galileo-evaluate/how-to/continuous-learning-via-human-feedback) to improve and adapt your metric.
---
# Source: https://docs.galileo.ai/galileo/galileo-nlp-studio/text-classification/automated-production-monitoring.md
> ## Documentation Index
> Fetch the complete documentation index at: https://docs.galileo.ai/llms.txt
> Use this file to discover all available pages before exploring further.
# Automated Production Monitoring
> Monitor text classification models in production with automated tools from Galileo NLP Studio to detect data drift and maintain performance.
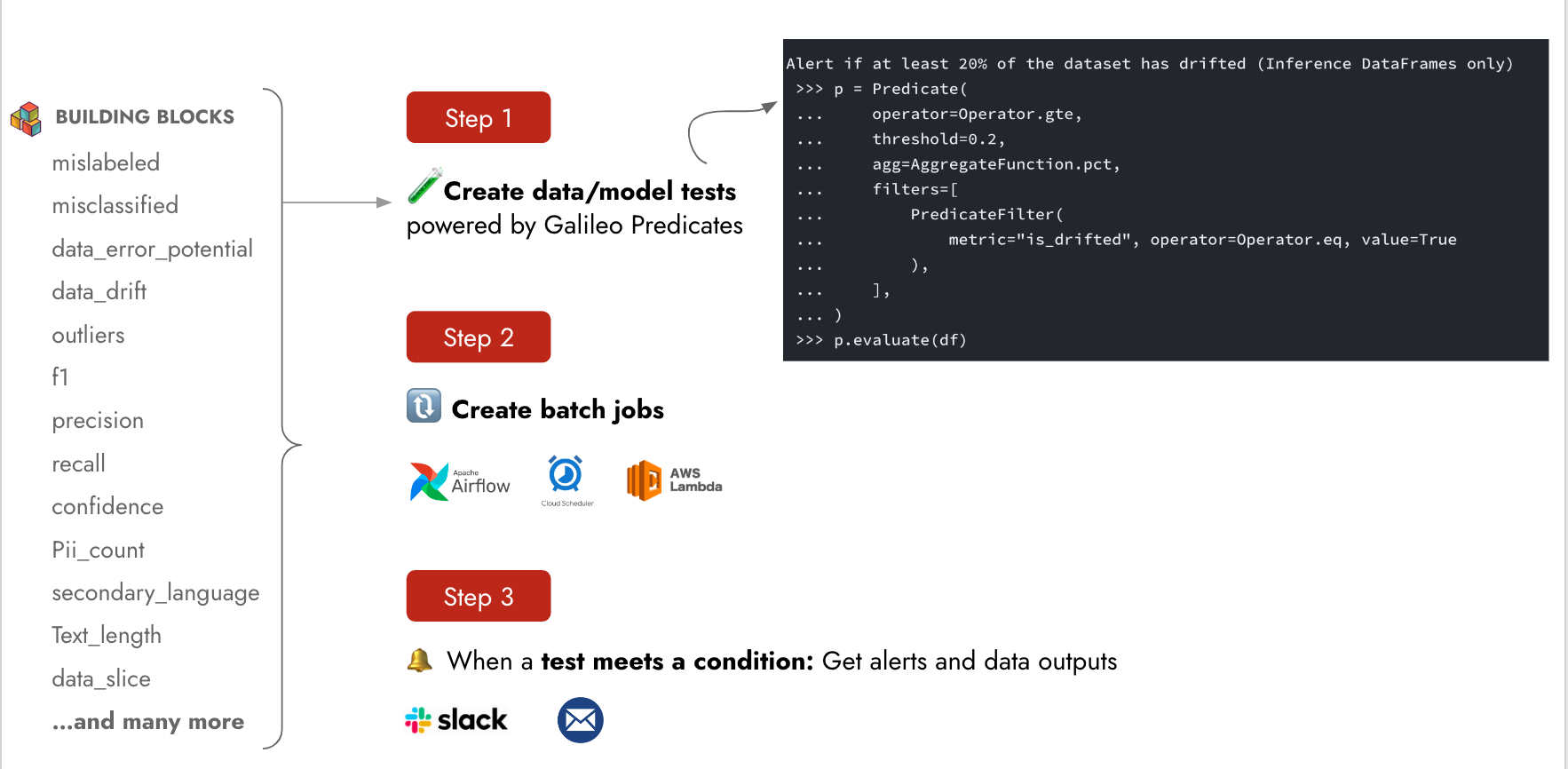 Leverage all the Galileo 'building blocks' that are logged and stored for you to create Tests using Galileo Conditions -- a class for building custom data quality checks.
Conditions are simple and flexible, allowing you to author powerful data/model tests.
## Run Report
Integrate with email or slack to automatically receive a report of Condition outcomes after a run finishes processing.
Leverage all the Galileo 'building blocks' that are logged and stored for you to create Tests using Galileo Conditions -- a class for building custom data quality checks.
Conditions are simple and flexible, allowing you to author powerful data/model tests.
## Run Report
Integrate with email or slack to automatically receive a report of Condition outcomes after a run finishes processing.
 ## Examples
```py theme={null}
Example 1: Alert if over 50% of high DEP (>=0.7) data contains PII
>>> c = Condition(
... operator=Operator.gt,
... threshold=0.5,
... agg=AggregateFunction.pct,
... filters=[
... ConditionFilter(
... metric="data_error_potential", operator=Operator.gte, value=0.7
... ),
... ConditionFilter(
... metric="galileo_pii", operator=Operator.neq, value="None"
... ),
... ],
... )
>>> dq.register_run_report(conditions=[c])
```
```py theme={null}
Example 2: Alert if at least 20% of the dataset has drifted (Inference DataFrames only)
>>> c = Condition(
... operator=Operator.gte,
... threshold=0.2,
... agg=AggregateFunction.pct,
... filters=[
... ConditionFilter(
... metric="is_drifted", operator=Operator.eq, value=True
... ),
... ],
... )
>>> dq.register_run_report(conditions=[c])
```
{" "}
[Get started](/galileo/galileo-nlp-studio/text-classification/build-your-own-conditions) building your own Reports with Galileo Conditions
---
# Source: https://docs.galileo.ai/deployments/scheduling-automatic-backups-for-your-cluster/aws-velero-account-setup-script.md
> ## Documentation Index
> Fetch the complete documentation index at: https://docs.galileo.ai/llms.txt
> Use this file to discover all available pages before exploring further.
# Aws Velero Account Setup Script
> Automate AWS Velero setup for Galileo cluster backups with this script, ensuring seamless backup scheduling and data resilience for AWS deployments.
```
#!/bin/sh -e
# Usage
# ./velero-account-setup-aws.sh
#
#
print_usage() {
echo -e "\n Usage: \n ./velero-account-setup-aws.sh \n"
}
BUCKET="${1}"
AWS_REGION="${2}"
if [ $# -ne 2 ]; then
print_usage
exit 1
fi
aws s3api create-bucket \
--bucket $BUCKET \
--region $AWS_REGION \
--create-bucket-configuration LocationConstraint=$REGION \
--no-cli-pager
aws iam create-user --user-name velero --no-cli-pager
cat > velero-policy.json < credentials-velero < ## Documentation Index
> Fetch the complete documentation index at: https://docs.galileo.ai/llms.txt
> Use this file to discover all available pages before exploring further.
# BLEU and ROUGE
> Understand BLEU & ROUGE-1 scores
***Definition:*** Metrics used heavily in sequence-to-sequence tasks measuring n-gram overlap between a generated response and a target output. Higher BLEU and ROUGE-1 scores equates to better overlap between the generated and target output.
***Calculation:*** A measure of n-gram overlap. A more lengthy explanation of BLEU provided [here](https://towardsdatascience.com/foundations-of-nlp-explained-bleu-score-and-wer-metrics-1a5ba06d812b). A more lengthy explanation of ROUGE-1 provided [here](https://www.galileo.ai/blog/rouge-ai). These metrics require a {target} column in your dataset.
***Usefulness:*** Evaluate the accuracy of model outputs in comparison to target outputs, enabling a metric to guide improvement and examination of areas where a model has trouble adhering to expected output.
*Note:* These metrics require a Ground Truth to be set. Check out [this page](/galileo/gen-ai-studio-products/galileo-evaluate/how-to/logging-and-comparing-against-your-expected-answers) to learn how to add a Ground Truth to your runs.
---
# Source: https://docs.galileo.ai/galileo/galileo-nlp-studio/text-classification/build-your-own-conditions.md
> ## Documentation Index
> Fetch the complete documentation index at: https://docs.galileo.ai/llms.txt
> Use this file to discover all available pages before exploring further.
> A class to build custom conditions for DataFrame assertions and alerting.
# null
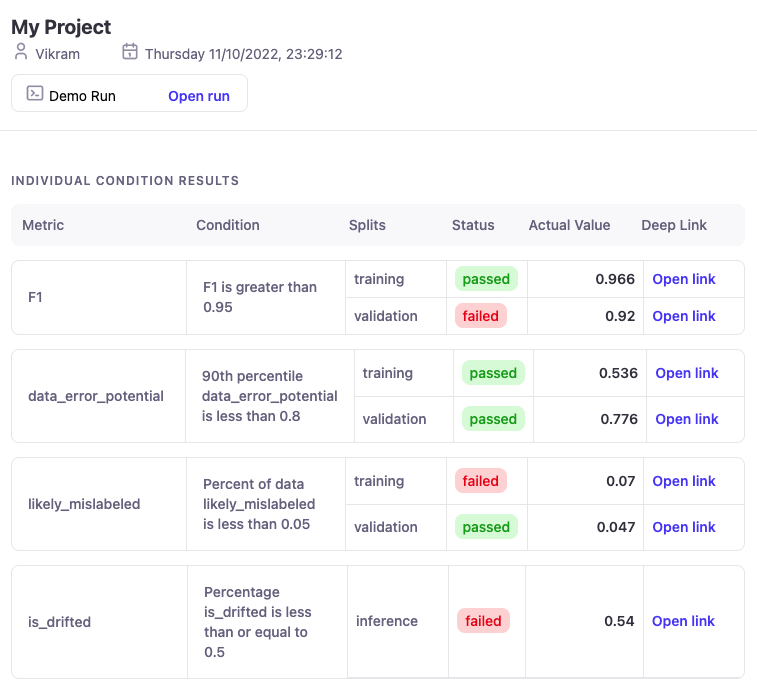
A `Condition` is a class for building custom data quality checks. Simply create a condition, and after the run is processed your conditions will be evaluated. Integrate with email or slack to have condition results alerting via a Run Report. Use Conditions to answer questions such as "Is the average confidence for my training data below 0.25" or "Has over 20% of my inference data drifted".
## What do I do with Conditions?
You can build a `Run Report` that will evaluate all conditions after a run is processed.
```py theme={null}
import dataquality as dq
dq.init("text_classification")
cond1 = dq.Condition(...)
cond2 = dq.Condition(...)
dq.register_run_report(conditions=[cond1, cond2])
# By default we email the logged in user
# Optionally pass in additional emails to receive Run Reports
dq.register_run_report(conditions=[cond1], emails=["foo@bar.com"]
```
You can also build and evaluate conditions by accessing the processed DataFrame.
```py theme={null}
from dataquality import Condition
df = dq.metrics.get_dataframe("proj_name", "run_name", "training")
cond = Condition(...)
passes, ground_truth = cond.evaluate(df)
```
## How do I build a Condition?
A `Condition` is defined as:
```py theme={null}
class Condition:
agg: AggregateFunction # An aggregate function to apply to the metric
threshold: float # Threshold value for evaluating the condition
operator: Operator # The operator to use for comparing the agg to the threshold
metric: Optional[str] = None # The DF column for evaluating the condition
filters: Optional[List[ConditionFilter]] = [] # Optional filter to apply to the DataFrame before evaluating the Condition
```
To gain an intuition for what can be accomplished, consider the following examples:
1. Is the average confidence less than 0.3?
```py theme={null}
>>> c = Condition(
... agg=AggregateFunction.avg,
... metric="confidence",
... operator=Operator.lt,
... threshold=0.3,
... )
```
2. Is the max DEP greater or equal to 0.45?
```py theme={null}
>>> c = Condition(
... agg=AggregateFunction.max,
... metric="data_error_potential",
... operator=Operator.gte,
... threshold=0.45,
... )
```
By adding filters, you can further narrow down the scope of the condition. If the aggregate function is "pct", you don't need to specify a metric, as the filters will determine the percentage of data.
3. Alert if over 80% of the dataset has confidence under 0.1
```py theme={null}
>>> c = Condition(
... operator=Operator.gt,
... threshold=0.8,
... agg=AggregateFunction.pct,
... filters=[
... ConditionFilter(
... metric="confidence", operator=Operator.lt, value=0.1
... ),
... ],
... )
```
4. Alert if at least 20% of the dataset has drifted (Inference DataFrames only)
```py theme={null}
>>> c = Condition(
... operator=Operator.gte,
... threshold=0.2,
... agg=AggregateFunction.pct,
... filters=[
... ConditionFilter(
... metric="is_drifted", operator=Operator.eq, value=True
... ),
... ],
... )
```
5. Alert 5% or more of the dataset contains PII
```py theme={null}
>>> c = Condition(
... operator=Operator.gte,
... threshold=0.05,
... agg=AggregateFunction.pct,
... filters=[
... ConditionFilter(
... metric="galileo_pii", operator=Operator.neq, value="None"
... ),
... ],
... )
```
Complex conditions can be built when the filter has a different metric than the metric used in the condition.
6. Alert if the min confidence of drifted data is less than 0.15
```py theme={null}
>>> c = Condition(
... agg=AggregateFunction.min,
... metric="confidence",
... operator=Operator.lt,
... threshold=0.15,
... filters=[
... ConditionFilter(
... metric="is_drifted", operator=Operator.eq, value=True
... )
... ],
... )
```
7. Alert if over 50% of high DEP (>=0.7) data contains PII:
```py theme={null}
>>> c = Condition(
... operator=Operator.gt,
... threshold=0.5,
... agg=AggregateFunction.pct,
... filters=[
... ConditionFilter(
... metric="data_error_potential", operator=Operator.gte, value=0.7
... ),
... ConditionFilter(
... metric="galileo_pii", operator=Operator.neq, value="None"
... ),
... ],
... )
```
You can also call conditions directly, which will assert its truth against a DataFrame.
1. Assert that average confidence less than 0.3
```py theme={null}
>>> c = Condition(
... agg=AggregateFunction.avg,
... metric="confidence",
... operator=Operator.lt,
... threshold=0.3,
... )
>>> c(df) # Will raise an AssertionError if False
```
## Aggregate Function
```
from dataquality import AggregateFunction
```
The available aggregate functions are:
```py theme={null}
class AggregateFunction(str, Enum):
avg = "avg"
min = "min"
max = "max"
sum = "sum"
pct = "pct"
```
## Operator
```py theme={null}
from dataquality import Operator
```
The available operators are:
```py theme={null}
class Operator(str, Enum):
eq = "eq"
neq = "neq"
gt = "gt"
lt = "lt"
gte = "gte"
lte = "lte"
```
## Metric & Treshold
The metric must be the name of a column in the DataFrame. Threshold is a numeric value for comparison in the Condition.
## Alerting
Alerting via email, slack in development. Please reach out to Galileo at [team@rungalileo.io](mailto:team@rungalileo.io) for more information.
```
```
```
```
---
# Source: https://docs.galileo.ai/api-reference/evaluate/cancel-jobs-for-project-run.md
> ## Documentation Index
> Fetch the complete documentation index at: https://docs.galileo.ai/llms.txt
> Use this file to discover all available pages before exploring further.
# Cancel Jobs For Project Run
> Get all jobs for a project and run.
Revoke them from Celery.
## OpenAPI
````yaml https://api.staging.galileo.ai/public/v1/openapi.json put /v1/projects/{project_id}/runs/{run_id}/cancel-jobs
openapi: 3.1.0
info:
title: FastAPI
version: 0.1.0
servers:
- url: https://api.staging.galileo.ai
description: Galileo Public APIs - staging
security: []
paths:
/v1/projects/{project_id}/runs/{run_id}/cancel-jobs:
put:
tags:
- evaluate
summary: Cancel Jobs For Project Run
description: |-
Get all jobs for a project and run.
Revoke them from Celery.
operationId: >-
cancel_jobs_for_project_run_v1_projects__project_id__runs__run_id__cancel_jobs_put
parameters:
- name: project_id
in: path
required: true
schema:
type: string
format: uuid4
title: Project Id
- name: run_id
in: path
required: true
schema:
type: string
format: uuid4
title: Run Id
responses:
'200':
description: Successful Response
content:
application/json:
schema: {}
'422':
description: Validation Error
content:
application/json:
schema:
$ref: '#/components/schemas/HTTPValidationError'
security:
- APIKeyHeader: []
- OAuth2PasswordBearer: []
- HTTPBasic: []
components:
schemas:
HTTPValidationError:
properties:
detail:
items:
$ref: '#/components/schemas/ValidationError'
type: array
title: Detail
type: object
title: HTTPValidationError
ValidationError:
properties:
loc:
items:
anyOf:
- type: string
- type: integer
type: array
title: Location
msg:
type: string
title: Message
type:
type: string
title: Error Type
type: object
required:
- loc
- msg
- type
title: ValidationError
securitySchemes:
APIKeyHeader:
type: apiKey
in: header
name: Galileo-API-Key
OAuth2PasswordBearer:
type: oauth2
flows:
password:
scopes: {}
tokenUrl: https://api.staging.galileo.ai/login
HTTPBasic:
type: http
scheme: basic
````
---
# Source: https://docs.galileo.ai/galileo-ai-research/chainpoll.md
> ## Documentation Index
> Fetch the complete documentation index at: https://docs.galileo.ai/llms.txt
> Use this file to discover all available pages before exploring further.
# Chainpoll
> ChainPoll is a powerful, flexible technique for LLM-based evaluation that is unique to Galileo. It is used to power multiple metrics across the Galileo platform.
This page provides a friendly overview of **what ChainPoll is and what makes it different**.
For a deeper, more technical look at the research behind ChainPoll, check out our paper [Chainpoll: A high efficacy method for LLM hallucination detection](https://arxiv.org/pdf/2310.18344.pdf).
## ChainPoll = Chain + Poll
ChainPoll involves two core ideas, which make up the two parts of its name:
* **Chain:** Chain-of-thought prompting
* **Poll:** Prompting an LLM multiple times
## Examples
```py theme={null}
Example 1: Alert if over 50% of high DEP (>=0.7) data contains PII
>>> c = Condition(
... operator=Operator.gt,
... threshold=0.5,
... agg=AggregateFunction.pct,
... filters=[
... ConditionFilter(
... metric="data_error_potential", operator=Operator.gte, value=0.7
... ),
... ConditionFilter(
... metric="galileo_pii", operator=Operator.neq, value="None"
... ),
... ],
... )
>>> dq.register_run_report(conditions=[c])
```
```py theme={null}
Example 2: Alert if at least 20% of the dataset has drifted (Inference DataFrames only)
>>> c = Condition(
... operator=Operator.gte,
... threshold=0.2,
... agg=AggregateFunction.pct,
... filters=[
... ConditionFilter(
... metric="is_drifted", operator=Operator.eq, value=True
... ),
... ],
... )
>>> dq.register_run_report(conditions=[c])
```
{" "}
[Get started](/galileo/galileo-nlp-studio/text-classification/build-your-own-conditions) building your own Reports with Galileo Conditions
---
# Source: https://docs.galileo.ai/deployments/scheduling-automatic-backups-for-your-cluster/aws-velero-account-setup-script.md
> ## Documentation Index
> Fetch the complete documentation index at: https://docs.galileo.ai/llms.txt
> Use this file to discover all available pages before exploring further.
# Aws Velero Account Setup Script
> Automate AWS Velero setup for Galileo cluster backups with this script, ensuring seamless backup scheduling and data resilience for AWS deployments.
```
#!/bin/sh -e
# Usage
# ./velero-account-setup-aws.sh
#
#
print_usage() {
echo -e "\n Usage: \n ./velero-account-setup-aws.sh \n"
}
BUCKET="${1}"
AWS_REGION="${2}"
if [ $# -ne 2 ]; then
print_usage
exit 1
fi
aws s3api create-bucket \
--bucket $BUCKET \
--region $AWS_REGION \
--create-bucket-configuration LocationConstraint=$REGION \
--no-cli-pager
aws iam create-user --user-name velero --no-cli-pager
cat > velero-policy.json < credentials-velero < ## Documentation Index
> Fetch the complete documentation index at: https://docs.galileo.ai/llms.txt
> Use this file to discover all available pages before exploring further.
# BLEU and ROUGE
> Understand BLEU & ROUGE-1 scores
***Definition:*** Metrics used heavily in sequence-to-sequence tasks measuring n-gram overlap between a generated response and a target output. Higher BLEU and ROUGE-1 scores equates to better overlap between the generated and target output.
***Calculation:*** A measure of n-gram overlap. A more lengthy explanation of BLEU provided [here](https://towardsdatascience.com/foundations-of-nlp-explained-bleu-score-and-wer-metrics-1a5ba06d812b). A more lengthy explanation of ROUGE-1 provided [here](https://www.galileo.ai/blog/rouge-ai). These metrics require a {target} column in your dataset.
***Usefulness:*** Evaluate the accuracy of model outputs in comparison to target outputs, enabling a metric to guide improvement and examination of areas where a model has trouble adhering to expected output.
*Note:* These metrics require a Ground Truth to be set. Check out [this page](/galileo/gen-ai-studio-products/galileo-evaluate/how-to/logging-and-comparing-against-your-expected-answers) to learn how to add a Ground Truth to your runs.
---
# Source: https://docs.galileo.ai/galileo/galileo-nlp-studio/text-classification/build-your-own-conditions.md
> ## Documentation Index
> Fetch the complete documentation index at: https://docs.galileo.ai/llms.txt
> Use this file to discover all available pages before exploring further.
> A class to build custom conditions for DataFrame assertions and alerting.
# null
A `Condition` is a class for building custom data quality checks. Simply create a condition, and after the run is processed your conditions will be evaluated. Integrate with email or slack to have condition results alerting via a Run Report. Use Conditions to answer questions such as "Is the average confidence for my training data below 0.25" or "Has over 20% of my inference data drifted".
## What do I do with Conditions?
You can build a `Run Report` that will evaluate all conditions after a run is processed.
```py theme={null}
import dataquality as dq
dq.init("text_classification")
cond1 = dq.Condition(...)
cond2 = dq.Condition(...)
dq.register_run_report(conditions=[cond1, cond2])
# By default we email the logged in user
# Optionally pass in additional emails to receive Run Reports
dq.register_run_report(conditions=[cond1], emails=["foo@bar.com"]
```
You can also build and evaluate conditions by accessing the processed DataFrame.
```py theme={null}
from dataquality import Condition
df = dq.metrics.get_dataframe("proj_name", "run_name", "training")
cond = Condition(...)
passes, ground_truth = cond.evaluate(df)
```
## How do I build a Condition?
A `Condition` is defined as:
```py theme={null}
class Condition:
agg: AggregateFunction # An aggregate function to apply to the metric
threshold: float # Threshold value for evaluating the condition
operator: Operator # The operator to use for comparing the agg to the threshold
metric: Optional[str] = None # The DF column for evaluating the condition
filters: Optional[List[ConditionFilter]] = [] # Optional filter to apply to the DataFrame before evaluating the Condition
```
To gain an intuition for what can be accomplished, consider the following examples:
1. Is the average confidence less than 0.3?
```py theme={null}
>>> c = Condition(
... agg=AggregateFunction.avg,
... metric="confidence",
... operator=Operator.lt,
... threshold=0.3,
... )
```
2. Is the max DEP greater or equal to 0.45?
```py theme={null}
>>> c = Condition(
... agg=AggregateFunction.max,
... metric="data_error_potential",
... operator=Operator.gte,
... threshold=0.45,
... )
```
By adding filters, you can further narrow down the scope of the condition. If the aggregate function is "pct", you don't need to specify a metric, as the filters will determine the percentage of data.
3. Alert if over 80% of the dataset has confidence under 0.1
```py theme={null}
>>> c = Condition(
... operator=Operator.gt,
... threshold=0.8,
... agg=AggregateFunction.pct,
... filters=[
... ConditionFilter(
... metric="confidence", operator=Operator.lt, value=0.1
... ),
... ],
... )
```
4. Alert if at least 20% of the dataset has drifted (Inference DataFrames only)
```py theme={null}
>>> c = Condition(
... operator=Operator.gte,
... threshold=0.2,
... agg=AggregateFunction.pct,
... filters=[
... ConditionFilter(
... metric="is_drifted", operator=Operator.eq, value=True
... ),
... ],
... )
```
5. Alert 5% or more of the dataset contains PII
```py theme={null}
>>> c = Condition(
... operator=Operator.gte,
... threshold=0.05,
... agg=AggregateFunction.pct,
... filters=[
... ConditionFilter(
... metric="galileo_pii", operator=Operator.neq, value="None"
... ),
... ],
... )
```
Complex conditions can be built when the filter has a different metric than the metric used in the condition.
6. Alert if the min confidence of drifted data is less than 0.15
```py theme={null}
>>> c = Condition(
... agg=AggregateFunction.min,
... metric="confidence",
... operator=Operator.lt,
... threshold=0.15,
... filters=[
... ConditionFilter(
... metric="is_drifted", operator=Operator.eq, value=True
... )
... ],
... )
```
7. Alert if over 50% of high DEP (>=0.7) data contains PII:
```py theme={null}
>>> c = Condition(
... operator=Operator.gt,
... threshold=0.5,
... agg=AggregateFunction.pct,
... filters=[
... ConditionFilter(
... metric="data_error_potential", operator=Operator.gte, value=0.7
... ),
... ConditionFilter(
... metric="galileo_pii", operator=Operator.neq, value="None"
... ),
... ],
... )
```
You can also call conditions directly, which will assert its truth against a DataFrame.
1. Assert that average confidence less than 0.3
```py theme={null}
>>> c = Condition(
... agg=AggregateFunction.avg,
... metric="confidence",
... operator=Operator.lt,
... threshold=0.3,
... )
>>> c(df) # Will raise an AssertionError if False
```
## Aggregate Function
```
from dataquality import AggregateFunction
```
The available aggregate functions are:
```py theme={null}
class AggregateFunction(str, Enum):
avg = "avg"
min = "min"
max = "max"
sum = "sum"
pct = "pct"
```
## Operator
```py theme={null}
from dataquality import Operator
```
The available operators are:
```py theme={null}
class Operator(str, Enum):
eq = "eq"
neq = "neq"
gt = "gt"
lt = "lt"
gte = "gte"
lte = "lte"
```
## Metric & Treshold
The metric must be the name of a column in the DataFrame. Threshold is a numeric value for comparison in the Condition.
## Alerting
Alerting via email, slack in development. Please reach out to Galileo at [team@rungalileo.io](mailto:team@rungalileo.io) for more information.
```
```
```
```
---
# Source: https://docs.galileo.ai/api-reference/evaluate/cancel-jobs-for-project-run.md
> ## Documentation Index
> Fetch the complete documentation index at: https://docs.galileo.ai/llms.txt
> Use this file to discover all available pages before exploring further.
# Cancel Jobs For Project Run
> Get all jobs for a project and run.
Revoke them from Celery.
## OpenAPI
````yaml https://api.staging.galileo.ai/public/v1/openapi.json put /v1/projects/{project_id}/runs/{run_id}/cancel-jobs
openapi: 3.1.0
info:
title: FastAPI
version: 0.1.0
servers:
- url: https://api.staging.galileo.ai
description: Galileo Public APIs - staging
security: []
paths:
/v1/projects/{project_id}/runs/{run_id}/cancel-jobs:
put:
tags:
- evaluate
summary: Cancel Jobs For Project Run
description: |-
Get all jobs for a project and run.
Revoke them from Celery.
operationId: >-
cancel_jobs_for_project_run_v1_projects__project_id__runs__run_id__cancel_jobs_put
parameters:
- name: project_id
in: path
required: true
schema:
type: string
format: uuid4
title: Project Id
- name: run_id
in: path
required: true
schema:
type: string
format: uuid4
title: Run Id
responses:
'200':
description: Successful Response
content:
application/json:
schema: {}
'422':
description: Validation Error
content:
application/json:
schema:
$ref: '#/components/schemas/HTTPValidationError'
security:
- APIKeyHeader: []
- OAuth2PasswordBearer: []
- HTTPBasic: []
components:
schemas:
HTTPValidationError:
properties:
detail:
items:
$ref: '#/components/schemas/ValidationError'
type: array
title: Detail
type: object
title: HTTPValidationError
ValidationError:
properties:
loc:
items:
anyOf:
- type: string
- type: integer
type: array
title: Location
msg:
type: string
title: Message
type:
type: string
title: Error Type
type: object
required:
- loc
- msg
- type
title: ValidationError
securitySchemes:
APIKeyHeader:
type: apiKey
in: header
name: Galileo-API-Key
OAuth2PasswordBearer:
type: oauth2
flows:
password:
scopes: {}
tokenUrl: https://api.staging.galileo.ai/login
HTTPBasic:
type: http
scheme: basic
````
---
# Source: https://docs.galileo.ai/galileo-ai-research/chainpoll.md
> ## Documentation Index
> Fetch the complete documentation index at: https://docs.galileo.ai/llms.txt
> Use this file to discover all available pages before exploring further.
# Chainpoll
> ChainPoll is a powerful, flexible technique for LLM-based evaluation that is unique to Galileo. It is used to power multiple metrics across the Galileo platform.
This page provides a friendly overview of **what ChainPoll is and what makes it different**.
For a deeper, more technical look at the research behind ChainPoll, check out our paper [Chainpoll: A high efficacy method for LLM hallucination detection](https://arxiv.org/pdf/2310.18344.pdf).
## ChainPoll = Chain + Poll
ChainPoll involves two core ideas, which make up the two parts of its name:
* **Chain:** Chain-of-thought prompting
* **Poll:** Prompting an LLM multiple times
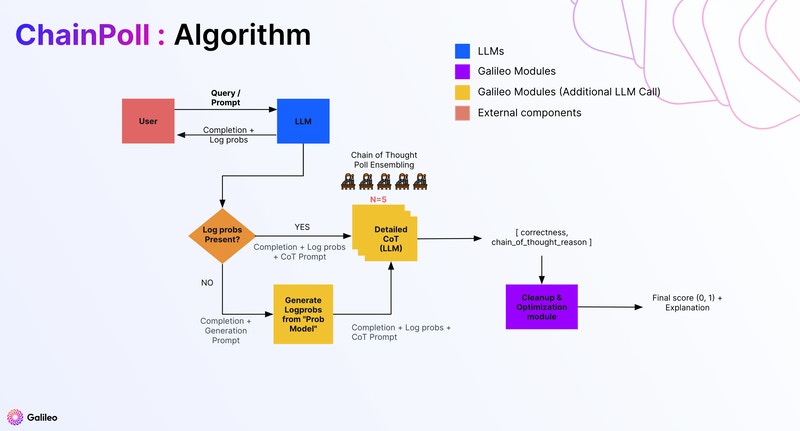 Let's cover these one by one.
### Chain
[*Chain-of-thought prompting*](https://arxiv.org/pdf/2201.11903.pdf) (CoT) is a simple but powerful way to elicit better answers from a large language model (LLM).
A chain-of-thought prompt is simply a prompt that asks the LLM to write out its step-by-step reasoning process before stating its final answer. For example:
* Prompt without CoT:
* "Roger has 5 tennis balls. He buys 2 more cans of tennis balls. Each can has 3 tennis balls. How many tennis balls does he have now?"
* Prompt with CoT:
* "Roger has 5 tennis balls. He buys 2 more cans of tennis balls. Each can has 3 tennis balls. How many tennis balls does he have now? *Think step by step, and present your reasoning before giving the answer.*"
While this might seem like a small change, it often dramatically improves the accuracy of the answer.
#### Why does CoT Work?
To better understand why CoT works, consider that the same trick *also* works for human beings!
If someone asks you a complex question, you will likely find it hard to answer *immediately,* on the spot. You'll want some time to think about it -- which could mean thinking silently, or talking through the problem out loud.
Asking an LLM for an answer *without* using CoT is like asking a human to answer a question immediately, on the spot, without pausing to think. This might work if the human has memorized the answer, or if the question is very straightforward.
For complex or difficult questions, it's useful to take some time to reflect before answers, and CoT allows the LLM to do this.
### Poll
ChainPoll extends CoT prompting by soliciting *multiple*, independently generated responses to the same prompt, and *aggregating* these responses.
Here's why this is a good idea.
As we all know, LLMs sometimes make mistakes. And these mistakes can occur randomly, rather than deterministically. If you ask an LLM the same question twice, you will often get two contradictory answers.
This is equally true of the reasoning generated by LLMs when prompted with CoT. If you ask an LLM the same question multiple times, and ask it to explain its reasoning each time, you'll often get a random mixture of valid and invalid arguments.
But here's the key observation: "*a random* *mixture of valid and invalid arguments*" is more useful than it sounds! Because:
* All *valid* arguments end up in the same place: the right answer.
* But an *invalid* argument can lead anywhere.
This turns the randomness of LLM generation into an advantage.
If we generate a diverse range of arguments, we'll get many different arguments that lead to the right answer -- because *any* valid argument leads there. We'll also get some invalid arguments, but they'll end up all over the place, not *concentrated* around any one answer. (Some of them may even produce the right answer by accident!
This idea -- generate diverse reasoning paths with CoT, and let the right answer "bubble to the top" -- is sometimes referred to as *self-consistency.*
It was introduced in [this paper](https://arxiv.org/pdf/2203.11171.pdf), as a method for solving math and logic problems with LLMs.
### From self-consistency to ChainPoll
Although ChainPoll is closely related to self-consistency, there are a few key differences. Let's break them down.
Self-consistency is a technique for picking a single *best* answer. It uses majority voting: the most common answer among the different LLM outputs is selected as the final answer of the entire procedure.
By contrast, ChainPoll works by *averaging* over the answers produced by the LLM to produce a *score*.
Most commonly, the individual answers are True-or-False, and so the average can be interpreted as the fraction of True answers among the total seto f answers.
For example, in our Context Adherence metric, we ask an LLM whether a response was consistent with a set of documents. We might get a set of responses like this:
1. A chain of thought ending in the conclusion that **Yes**, the answer was supported
2. A different chain of thought ending in the conclusion that **Yes**, the answer was supported
3. A third chain of thought ending in the conclusion that **No**, the answer was **not** supported
In this case, we would average the three answers and return a score of 0.667 (=2/3) to you.
The majority voting approach used in self-consistency would round this off to **Yes**, since that's the most common answer. But this misses some of the information present in the underlying answer.
By giving you an average, ChainPoll conveys a sense of the evaluating LLM's level of certainty. In this case, while the answer is more likely to be **Yes** than **No**, the LLM is not entirely sure, and that nuance is captured in the score.
Additionally, self-consistency has primarily been applied to "discrete reasoning" problems like math and code. While ChainPoll can be applied to such problems, we've found it also works much more broadly, for almost any kind of question that can be posed in a yes-or-no form.
## Frequently asked questions
***How does ChainPoll compare to the methods used by other LLM evaluation tools, like RAGAS and TruLens?***
We cover this in detail in the section below on **The ChainPoll advantage.**
***ChainPoll involves requesting multiple responses. Isn't that slow and expensive?***
Not as much as you might think!
We use batch requests to LLM APIs to generate ChainPoll responses, rather than generating the responses one-by-one. Because all requests in the batch have the same prompt, the API provider can process them more efficiently: the prompt only needs to be run through the LLM once, and the results can be shared across all of the sequences being generated.
This efficiency improvement often corresponds to better latency or lower cost from the perspective of the API consumer (and ultimately, you).
For instance, with the OpenAI API -- our default choice for ChainPoll -- a batch request for 3 responses from the same prompt will be billed for:
* All the *output* tokens across all 3 responses
* All the *input* tokens in the prompt, counted only once (not 3 times)
Compared to simply making 3 separate requests, this cuts down on the cost of the prompt by 2/3.
***What LLMs does Galileo use with ChainPoll? Why those?***
By default, we use OpenAI's latest version of GPT-4o-mini.
Although GPT-4o-mini can be less accurate than a more powerful LLMs such as GPT-4, it's *much* faster and cheaper. We've found that using it with ChainPoll closes a significant fraction of the accuracy gap between it and GPT-4, while still being much faster and less expensive.
That said, GPT-4 and other state-of-the-art LLMs can also benefit from ChainPoll.
***Sounds simple enough. Couldn't I just build this myself?***
Galileo continually invests in research aimed at improving the quality and efficiency of ChainPoll, as well as rigorously measuring these outcomes.
For example, in the initial research that produced ChainPoll, we found that the majority of available datasets used in earlier research on hallucination detection did not meet our standards for relevance and quality; in response, we created our own benchmark called RealHall.
By using Galileo, you automatically gain access to the fruits of these ongoing efforts, including anything we discover and implement in the future.
Additionally, Galileo ChainPoll metrics are integrated naturally with the rest of the Galileo platform. You won't have to worry about how to scale up ChainPoll requests, how to persist ChainPoll results to a database, or how to track ChainPoll metrics alongside other information you log during LLM experiments or in production.
***How do I interpret the scores?***
ChainPoll scores are averages over multiple True-or-False answers. You can interpret them as a combination of two pieces of information:
* An overall inclination toward Yes or No, and
* A level of certainty/uncertainty.
For example:
* A score of 0.667 means that the evaluating LLM said Yes 2/3 of the time, and No 1/3 of the time.
* In other words, its *overall inclination* was toward Yes, but it wasn't totally sure.
* A score of 1.0 would indicate the same overall inclination, with higher confidence.
Likewise, 0.333 is "inclined toward No, but not sure," and 0 is "inclined toward No, with higher confidence."
It's important to understand that a lower ChainPoll score doesn't *necessarily* correspond to lower quality, particularly on the level of a single example. ChainPoll scores are best used either:
* As a guide for your own explorations, pointing out things in the data for you to review, or
* As a way to compare entire runs to one other in aggregate.
## The ChainPoll advantage
ChainPoll is unique to Galileo. In this section, we'll explore how it differs from the approaches used in products like RAGAS and TruLens, and what makes ChainPoll more effective.
### ChainPoll vs. RAGAS
RAGAS offers a **Faithfulness** score, which has a similar purpose to Galileo's **Context Adherence** score.
Both of these scores evaluate whether a *response* is consistent with the information in a *context,* such as the chunks provided by a RAG retriever\*.\*
However, under the hood, the two scores work very differently.
To compute Faithfulness, RAGAS calls an LLM in two distinct steps:
1. The LLM is asked to break the *response* down into one or more granular *statements.*
1. In this step, the LLM can only see the *response*, not the *context*.
2. The LLM given the *statements* and the *context*, and is asked to judge whether or not each statement is consistent with the context.
1. In this step, the LLM can see the context, but *not* the original response. Instead, it only sees the statements that were written in step 1.
The scores for each statement (0 for inconsistent, 1 for consistent) are averaged over statements to produce a score.
This procedure can go wrong in a few different ways, none of which apply to ChainPoll.
#### Statement breakdowns can be misleading
By breaking down the response into statements and judging the statements *separately*, **RAGAS can ignore the way that different parts of the response are related.**
An LLM response is not just a disconnected list of "statements," any more than this article is. It may make a complex claim or argument that loses its structure when broken down in this way.
Consider this example, from a dataset related to Covid-19 that we use internally at Galileo.
An LLM was given a set of documents describing medical studies, and asked
```
What important risk factors to infection were found during the second case-controlled study?
```
It responded:
```
The important risk factors to infection found during the second case-controlled study were hospitalization in the preceding 90 days, residency in a nursing home, and antibiotic use.
```
As it happened, this response was *not* consistent with the documents. Although all the factors cited as risk factors were *mentioned* in the documents, they weren't actually said to be *risk factors during the second case-controlled study.*
**Galileo** **Context Adherence** caught this error, assigning the response a score of 0. Here is one of the chain-of-thought explanations it produced:
```
The response claims that the important risk factors to infection found during the second case-controlled study were hospitalization in the preceding 90 days, residency in a nursing home, and antibiotic use.
To verify this claim, we need to check the specific risk factors mentioned in the second case-controlled study document. However, the second case-controlled study document does not provide specific risk factors related to infection. It mainly focuses on data collection and limitations of the study. Therefore, the claim that hospitalization in the preceding 90 days, residency in a nursing home, and antibiotic use were important risk factors found during the study is not supported by the documents.
```
But **RAGAS Faithfulness** assigns this response a score of 1.0 (perfect).
To see what went wrong, let's review the 4 statements that RAGAS generated from the response, and its generated reasoning for why each one was consistent.
```
Statement 1/4
The second case-controlled study identified several important risk factors to infection.
Reasoning
The passage mentions that a case-control study was conducted to identify risk factors for multi-drug resistant infection in the pediatric intensive care unit (PICU).
Verdict
1 (Consistent)
---
Statement 2/4
These risk factors include hospitalization in the preceding 90 days.
Reasoning
The passage states that hospitalization in the preceding 90 days was a risk factor for infection with a resistant pathogen.
Verdict
1 (Consistent)
---
Statement 3/4
Residency in a nursing home was also found to be a significant risk factor.
Reasoning
The passage mentions that residency in a nursing home was an independent predictor of infection with a resistant pathogen.
Verdict
1 (Consistent)
---
Statement 4/4
Additionally, antibiotic use was identified as an important risk factor.
Reasoning
The passage states that antibiotic use was one of the main contents collected and analyzed in the study.
Verdict
1 (Consistent)
```
When RAGAS broke down the response into statements, it omitted key information that made the answer inconsistent.
Some of the statements are about *the second case-controlled study*, and some are about *risk factors.* Taken in isolation, each of these statements is arguably true.
But none of them captures the claim that the original LLM got wrong: that *these* *risk factors* were identified, not just in any study, but *in the second case-controlled study.*
ChainPoll allows the LLM to assess the entire input at once and come to a holistic judgment of it. By contrast, RAGAS fragments its reasoning into a sequence of disconnected steps, performed in isolation and without access to complete information.
This causes RAGAS to miss subtle or complex errors, like the one in the example above. But, given the increasing intelligence of today's LLMs, subtle and complex errors are precisely the ones you need to be worried about.
#### RAGAS does not handle refusals sensibly
Second, RAGAS Faithfulness is **unable to produce meaningful results when the LLM refuses to answer.**
In RAG, an LLM will sometimes respond with a *refusal* that claims it doesn't have enough information: an answer like "I don't know" or "Sorry, that wasn't mentioned in the context."
Like any LLM response, these are sometimes appropriate and sometimes inappropriate:
* If the requested information really *wasn't* in the retrieved context, the LLM should say so, not make something up.
* On the other hand, if the information *was* there, the LLM should not assert that it *wasn't* there.
In our tests, RAGAS Faithfulness always assigns a score of 0 to these kinds of refusal answers.
This is unhelpful: refusal answers are often *desirable* in RAG, because no retriever is perfect. If the answer isn't in your context, you don't want your LLM to make one up.
Indeed, in this case, saying "the answer wasn't in the context" is perfectly *consistent* with the context: the answer really was not there!
Yet RAGAS claims these answers are inconsistent.
Why? Because it is unable to break down a refusal answer into a collection of *statements* that look consistent with the context.
Typically, it produces no statements at all, and then returns a default score of 0. In other cases, it might produce a statement like "I don't know" and then assess this statement as "not consistent" since it doesn't make sense outside its original context as an *answer to a question.*
ChainPoll handles these cases gracefully: it assesses them like any other answer, checking whether they are consistent with the context or not. Here's an example:
The LLM response was
```
The provided context does not contain information about where the email was published. Therefore, it is not possible to determine where the email was published based on the given passages.
```
The **Galileo Context Adherence** score was 1, with an explanation of
```
The provided documents contain titles and passages that do not mention the publication details of an email. Document 1 lists an 'Email address' under the passage, but provides no information about the publication of an email. Documents 2, 3, and 4 describe the coverage of the Ebola Virus Disease outbreak and mention various countries and aspects of newspaper writings, but do not give any details about where an email was published. Hence, the context from these documents does not contain the necessary information to answer the question regarding the publication location of the email. The response from the large language model accurately reflects this lack of information.
```
#### RAGAS does not explain its answers
Although RAGAS does *generate* explanations internally (see the examples above), these are not surfaced to the user.
Moreover, as you can see above, they are briefer and less illuminating than ChainPoll explanations.
(We produced the examples above by adding callbacks to RAGAS to capture the requests it was making, and then following identifiers in the requests to link the steps together. You don't get any of that out of the box.)
### ChainPoll vs. TruLens
TruLens offers a **Groundedness** score, which targets similar needs to Galileo **Context Adherence** and RAGAS **Faithfulness:** evaluating whether a response is consistent with a context.
As we saw above with RAGAS, although these scores look similar on the surface, there are important differences in what they actually do.
TruLens **Groundedness** works as follows:
1. The response is split up into sentences.
2. An LLM is given the list of sentences, along with the context. It is asked to:
1. quote the part of the context (if any) that supports the sentence
2. rate the "information overlap" between each sentence and the context on a 0-to-10 scale.
3. The scores are mapped to a range from 0 to 1, and averaged to produce an overall score.
We've observed several failure modes of this procedure that don't apply to ChainPoll.
#### TruLens does not use chain-of-thought reasoning
Although TruEra uses the term "chain of thought" when describing what this metric does, the LLM is not actually asked to present a step-by-step *argument.*
Instead, it is merely asked to give a direct quotation from the context, then (somehow) assign a score to the "information overlap" associated with this quotation. It doesn't get any chance to "think out loud" about why any given quotation might, or might not, really constitute supporting evidence.
For example, here's what TruLens produces for the *second case-controlled study* example we reviewed above with RAGAS:
```
Statement Sentence: The important risk factors to infection found during the second case-controlled study were hospitalization in the preceding 90 days, residency in a nursing home, and antibiotic use.
Supporting Evidence: pathogen isolated in both study groups, but there was a higher prevalence of MDR pathogens in patients with risk factors compared with those without. Of all the risk factors, hospitalization in the preceding 90 days 1.90 to 12.4, P = 0.001) and residency in a nursing home were independent predictors of infection with a resistant pathogen and mortality.
Score: 8
```
The LLM quotes a passage that mentions the factors cited as risk factors in the response, without first stopping to think -- like ChainPoll does -- about whether the document actually says these are risk factors *in the second case-controlled study.*
Then, perhaps because the quoted passage is relatively long, it assigns it a score of 8/10. Yet this response is *not* consistent with the context.
#### TruLens uses an ambiguous grading system
You might have noticed another odd thing about the example just above. Even if the evidence really had been supporting evidence (which it wasn't), why "8 out of 10"? Why not 7/10, or 8/10, or 10/10?
There's no good answer to this question. TruLens does not provide the LLM with a clear grading guide, explaning exactly what makes an answer an "8/10" as opposed to a mere "7/10", and so on.
Instead, it only tells the LLM to "*Output a number between 0-10 where 0 is no information overlap and 10 is all information is overlapping.*"
If you were given this instruction, would you know how to decide when to give an 8, vs. a 7 vs. a 9? The LLM is as confused as you are.
As a result, the ratings computed inside the TruLens Groundedness score often vary whimsically, without apparent meaning. In our testing, we've observed these numbers varying widely across the 0-to-10 scale when we re-run the scorer with the same input, even when the LLM cites the same supporting quotation (or a very similar one).
At Galileo, we've observed that LLMs are often confused by numerical rating systems, and produce much more reliable and intelligible results when asked for a simple Yes-or-No answer.
This makes intuitive sense: in the absence of detailed guidelines about what each numeric score means, a 0-to-10 rating scale is *inherently* ambiguous and ill-defined.
#### Sentence breakdowns can be misleading
As we noted above when discussing RAGAS, imposing a breakdown into granular units like sentences or statements -- and then grading each unit separately -- can miss the way the units are logically connected.
Thus, TruLens can exhibit errors similar to the one we covered in the section on RAGAS when dealing with complex answers.
#### TruLens gets confused by formatting
In our testing, we noticed that TruLens Groundedness would often generate strange, malformed output that included grades for some sentences from the *context* instead of the *response.*
Here's one example. The response was
```
Bacilius subtilis can be used as an oral vaccine by expressing the COE antigen of PEDV and delivering it to the GI tract to stimulate mucosal immune responses. It can protect antigens from the harsh digestive environment and enhance immune regulation and gut health in newborn piglets. Additionally, it has adjuvant activity and can deliver heterologous antigens to the GI tract, providing additional immunity stimulation.
```
There are 3 sentences here. TruLens is supposed to assign a score to each one, together with a supporting quotation. But here is what it actually produced:
```
STATEMENT 0:
Statement Sentence: Bacillus subtilis can be used as an oral vaccine by expressing the COE antigen of PEDV and delivering it to the GI tract to stimulate mucosal immune responses.
Supporting Evidence: NOTHING FOUND
Score: 0
STATEMENT 1:
Statement Sentence: Oral administration can protect the gut and stimulate the common mucosal immune system.
Supporting Evidence: As a superior way of mucosal immunization, oral administration can protect the gut and stimulate the common mucosal immune system.
Score: 10
Statement Sentence: Oral immunization often delivers large amounts of antigens to prevent diarrheal diseases.
Supporting Evidence: Oral immunization often delivers large amounts of antigens to prevent the diarrheal diseases.
Score: 10
Statement Sentence: Bacillus subtilis is widely used as a vaccine delivery system for its unique characteristics.
Supporting Evidence: Currently, Bacillus subtilis is widely used as a vaccine delivery system for its unique characteristics.
Score: 10
Statement Sentence: Orally administered Bacillus subtilis can enhance immune regulation and gut health in pigs.
Supporting Evidence: Moreover, oral administration of B. subtilis could elicit humoral and cellular immune responses to the maintenance of gut homeostasis by dendritic cells.
Score: 5
STATEMENT 2:
Statement Sentence: Oral administration can protect the gut and stimulate the common mucosal immune system.
Supporting Evidence: As a superior way of mucosal immunization, oral administration can protect the gut and stimulate the common mucosal immune system.
Score: 10
Statement Sentence: Orally administered B. subtilis could enhance immune regulation and gut health in pigs.
Supporting Evidence: Moreover, oral administration of B. subtilis could elicit humoral and cellular immune responses to the maintenance of gut homeostasis by dendritic cells.
Score: 7
Statement Sentence: B. subtilis is widely used as a vaccine delivery system for its unique characteristics.
Supporting Evidence: Currently, Bacillus subtilis is widely used as a vaccine delivery system for its unique characteristics.
Score: 10
```
After the first statement, things go off the rails. The sentences listed under "STATEMENT 1" and "STATEMENT 2" don't appear in the response at all. And, nonsensically, the LLM has written *multiple* "Statement Sentences" under each of the "STATEMENT" headings.
In a case like this, the TruLens codebase assumes that each STATEMENT heading only has one score under it, and ends up picking the first one listed. Here, it ended up with the scores \[0, 10, 10] for the three statements. But the latter two scores are nonsense -- they're not about sentences from the response at all.
We tracked this issue down to *formatting.*
Our context included multiple paragraphs and documents, which were separated by line breaks. It turns out that TruLens' prompt format also uses line breaks to delimit sections of the prompt. Apparently the LLM became confused by which line breaks meant what.
Replacing line breaks with spaces fixed the problem in this case. But you shouldn't have to worry about this kind of thing at all. Line breaks are not an exotic edge case, after all.
The prompt formats we use for Galileo ChainPoll metrics involve a more robust delimiting strategy, including reformatting your output in some cases if needed. This prevents issues like this from arising with ChainPoll.
---
# Source: https://docs.galileo.ai/galileo/gen-ai-studio-products/galileo-evaluate/how-to/choose-your-guardrail-metrics.md
> ## Documentation Index
> Fetch the complete documentation index at: https://docs.galileo.ai/llms.txt
> Use this file to discover all available pages before exploring further.
# Choose your Guardrail Metrics
> Select and understand guardrail metrics in Galileo Evaluate to effectively assess your prompts and models, utilizing both industry-standard and proprietary metrics.
## Galileo Metrics
Galileo has built a menu of **Guardrail Metrics** for you to choose from. These metrics are tailored to your use case and are designed to help you evaluate your prompts and models.
Galileo's Guardrail Metrics are a combination of industry-standard metrics (e.g. BLEU, ROUGE-1, Perplexity) and an outcome of Galileo's in-house ML Research Team (e.g. Uncertainty, Correctness, Context Adherence).
Here's a list of the metrics supported today
### Output Quality Metrics:
* [**Uncertainty**](/galileo/gen-ai-studio-products/galileo-guardrail-metrics/uncertainty)**:** Measures the model's certainty in its generated responses. Uncertainty works at the response level as well as at the token level. It has shown a strong correlation with hallucinations or made-up facts, names, or citations.
* [**Correctness**](/galileo/gen-ai-studio-products/galileo-guardrail-metrics/correctness) - Measures whether the facts stated in the response are based on real facts. This metric requires additional LLM calls. Combined with Uncertainty, Factuality is a good way of uncovering Hallucinations.
* [**BLEU & ROUGE-1**](/galileo/gen-ai-studio-products/galileo-guardrail-metrics/bleu-and-rouge-1) - These metrics measure n-gram similarities between your Generated Responses and your Target output. These metrics are automatically computed when you add a {target} column in your dataset.
* [**Prompt Perplexity**](/galileo/gen-ai-studio-products/galileo-guardrail-metrics/prompt-perplexity) - Measure the perplexity of a prompt. Previous research has shown that as perplexity decreases, generations tend to increase in quality.
### RAG Quality Metrics:
* [**Context Adherence**](/galileo/gen-ai-studio-products/galileo-guardrail-metrics/context-adherence) - Measures whether your model's response was purely based on the context provided. This metric is intended for RAG users. We have two options for this metric: *Luna* and *Plus*.
* Context Adherence *Luna* is powered by small language models we've trained. It's free of cost.
* Context Adherence *Plus* includes an explanation or rationale for the rating. These metrics and the explanations are powered by an LLM (e.g. OpenAI GPT3.5) and thus incur additional costs. *Plus* has shown to have better performance.
* [**Completeness**](/galileo/gen-ai-studio-products/galileo-guardrail-metrics/completeness/completeness) - Measures how thoroughly your model's response covered relevant information from the context provided. This metric is intended for RAG use cases and is only available if you [log your retriever's output](/galileo/gen-ai-studio-products/galileo-evaluate/how-to/evaluate-and-optimize-rag-applications). There are two versions available:
* Completeness *Luna* is powered by small language models we've trained. It's free of cost.
* Completeness *Plus* includes an explanation or rationale for the rating. These metrics and the explanations are powered by an LLM (e.g. OpenAI GPT3.5) and thus incur additional costs. *Plus* has shown to have better performance.
* [**Chunk Attribution**](/galileo/gen-ai-studio-products/galileo-guardrail-metrics/chunk-attribution) - Measures which individual chunks retrieved in a RAG workflow influenced your model's response. This metric is intended for RAG use cases and is only available if you [log your retriever's output](/galileo/gen-ai-studio-products/galileo-evaluate/how-to/evaluate-and-optimize-rag-applications). There are two versions available:
* Chunk Attribution *Luna* is powered by small language models we've trained. It's free of cost.
* Chunk Attribution *Plus* is powered by an LLM (e.g. OpenAI GPT3.5) and thus incurs additional costs. *Plus* has shown to have better performance.
* [**Chunk Utilization**](/galileo/gen-ai-studio-products/galileo-guardrail-metrics/chunk-utilization) - For each chunk retrieved in a RAG workflow, measures the fraction of the chunk text that influenced your model's response. This metric is intended for RAG use cases and is only available if you [log your retriever's output](/galileo/gen-ai-studio-products/galileo-evaluate/how-to/evaluate-and-optimize-rag-applications). There are two versions available:
* Chunk Attribution *Luna* is powered by small language models we've trained. It's free of cost.
* Chunk Attribution *Plus* is powered by an LLM (e.g. OpenAI GPT3.5) and thus incurs additional costs. *Plus* has shown to have better performance.
* [**Context Relevance**](/galileo/gen-ai-studio-products/galileo-guardrail-metrics/context-relevance) - Measures if the context has enough information to answer the user query. This metric is intended for RAG users.
### Safety Metrics:
* [**Private Identifiable Information**](/galileo/gen-ai-studio-products/galileo-guardrail-metrics/private-identifiable-information) **-** This Guardrail Metric surfaces any instances of PII in your model's responses. We surface whether your text contains any credit card numbers, social security numbers, phone numbers, street addresses, and email addresses.
* [**Toxicity**](/galileo/gen-ai-studio-products/galileo-guardrail-metrics/toxicity) - Measures whether the model's responses contained any abusive, toxic, or foul language.
* [**Tone**](/galileo/gen-ai-studio-products/galileo-guardrail-metrics/tone) - Classifies the tone of the response into 9 different emotion categories: neutral, joy, love, fear, surprise, sadness, anger, annoyance, and confusion.
* [**Sexism**](/galileo/gen-ai-studio-products/galileo-guardrail-metrics/sexism) - Measures how 'sexist' a comment might be perceived ranging in the values of 0-1 (1 being more sexist).
* [**Prompt Injection**](https://docs.rungalileo.io/galileo/gen-ai-studio-products/galileo-guardrail-metrics/prompt-injection) - Detects and classifies various categories of prompt injection attacks.
* More coming very soon.
A more thorough description of all Guardrail Metrics can be found [here](/galileo/gen-ai-studio-products/galileo-guardrail-metrics).
When creating runs from code, you'll need to add your Guardrail Metrics as "scorers", check out "[Enabling Scorers in Run](/galileo/gen-ai-studio-products/galileo-evaluate/how-to/enabling-scorers-in-runs)" to learn how to do so.
If you want to set up your custom metrics, please see instructions [here](https://docs.rungalileo.io/galileo/galileo-gen-ai-studio/prompt-inspector/registering-and-using-custom-metrics).
---
# Source: https://docs.galileo.ai/galileo/gen-ai-studio-products/galileo-observe/how-to/choosing-your-guardrail-metrics.md
> ## Documentation Index
> Fetch the complete documentation index at: https://docs.galileo.ai/llms.txt
> Use this file to discover all available pages before exploring further.
# Choosing Your Guardrail Metrics
> Select and understand guardrail metrics in Galileo Observe to effectively evaluate your LLM applications, utilizing both industry-standard and proprietary metrics.
## How to turn metrics on or off
For metrics to be computed on your Observe project, open the `Settings & Alerts` section of your project, and turn on any metric you'd like to be calculated. Metrics are not computed retroactively, they'll only be computed on new traffic that flows through Observe.
## Galileo Metrics
Galileo has built a menu of **Guardrail Metrics** for you to choose from. These metrics are tailored to your use case and are designed to help you evaluate your LLM applications.
Galileo's Guardrail Metrics are a combination of industry-standard metrics and a product of Galileo's in-house [AI Research](/galileo-ai-research) Team (e.g. Uncertainty, Correctness, Context Adherence).
Here's a list of some of the metrics supported today:
* [**Context Adherence**](/galileo/gen-ai-studio-products/galileo-guardrail-metrics/context-adherence) - Measures whether your model's response was grounded on the context provided. This metric is intended for RAG or context-based use cases and is a good measure for hallucinations.
* [**Completeness**](/galileo/gen-ai-studio-products/galileo-guardrail-metrics/completeness) - Evaluates how comprehensively the response addresses the question using all the relevant information from the provided context. If Context Adherence is your RAG 'Precision' metric, Completeness is your RAG 'Recall'.
* [**Chunk Attribution**](/galileo/gen-ai-studio-products/galileo-guardrail-metrics/chunk-attribution) - Measures the number of chunks a model uses when generating an output. By optimizing the number of chunks a model is retrieving, teams can improve output quality and system performance and avoid the excess costs of including unused chunks in prompts to LLMs. This metric requires Galileo to [be hooked into your retriever step](/galileo/gen-ai-studio-products/galileo-observe/how-to/monitoring-your-rag-application).
* [**Chunk Utilization**](/galileo/gen-ai-studio-products/galileo-guardrail-metrics/chunk-utilization) - Measures how much of each chunk was used by a model when generating an output, and helps teams rightsize their chunk size. This metric requires Galileo to [be hooked into your retriever step](/galileo/gen-ai-studio-products/galileo-observe/how-to/monitoring-your-rag-application).
* [**Instruction Adherence**](/galileo/gen-ai-studio-products/galileo-guardrail-metrics/instruction-adherence) - Measures whether your model's response was grounded on the context provided. This metric is intended for RAG or context-based use cases and is a good measure for hallucinations.
* [**Correctness**](/galileo/gen-ai-studio-products/galileo-guardrail-metrics/correctness) - Measures whether the facts stated in the response are based on real facts. This metric requires additional LLM calls. Combined with Uncertainty, Factuality is a good way of uncovering Hallucinations.
* [**Prompt Injections**](/galileo/gen-ai-studio-products/galileo-guardrail-metrics/prompt-injection) - Identifies any adversarial attacks or prompt injections.
* [**Private Identifiable Information**](/galileo/gen-ai-studio-products/galileo-guardrail-metrics/private-identifiable-information) **-** This Guardrail Metric surfaces any instances of PII in your model's responses. We surface whether your text contains any credit card numbers, social security numbers, phone numbers, street addresses and email addresses.
* [**Toxicity**](/galileo/gen-ai-studio-products/galileo-guardrail-metrics/toxicity) - Measures whether the model's responses contained any abusive, toxic or foul language.
* [**Tone**](/galileo/gen-ai-studio-products/galileo-guardrail-metrics/tone) - Classifies the tone of the response into 9 different emotion categories: neutral, joy, love, fear, surprise, sadness, anger, annoyance, and confusion.
* [**Sexism**](/galileo/gen-ai-studio-products/galileo-guardrail-metrics/sexism) - Measures how 'sexist' a comment might be perceived ranging in the values of 0-1 (1 being more sexist).
* [**Uncertainty**](/galileo/gen-ai-studio-products/galileo-guardrail-metrics/uncertainty) - Measures the model's certainty in its generated responses. Uncertainty works at the response level as well as at the token level. It has shown a strong correlation with hallucinations or made-up facts, names, or citations.
* and more.
A more thorough description of all Guardrail Metrics can be found [here](/galileo/gen-ai-studio-products/galileo-guardrail-metrics).
## Custom Metrics
To set up custom metrics for Galileo Observe projects, please see instructions and sample code snippet [here.](https://docs.rungalileo.io/galileo/galileo-gen-ai-studio/observe-getting-started/registering-and-using-custom-metrics)
---
# Source: https://docs.galileo.ai/galileo/gen-ai-studio-products/galileo-guardrail-metrics/chunk-attribution/chunk-attribution-luna.md
> ## Documentation Index
> Fetch the complete documentation index at: https://docs.galileo.ai/llms.txt
> Use this file to discover all available pages before exploring further.
# Chunk Attribution Luna
> Understand Galileo's Chunk Attribution Luna Metric
***Definition:*** For each chunk retrieved in a RAG pipeline, Chunk Attribution measures whether or not that chunk had an effect on the model's response.
Chunk Attribution is a binary metric: each chunk is either Attributed or Not Attributed.
Chunk Attribution is closely related to Chunk Utilization: Attribution measures whether or not a chunk affected the response, and Utilization measures how much of the chunk text was involved in the effect. Only chunks that were Attributed can have Utilization scores greater than zero.
***Calculation:*** Chunk Attribution Luna is computed using a fine-tuned in-house Galileo evaluation model. The model is a transformer-based encoder that is trained to identify the relevant and utilized information in the provided a query, context, and response. The same model is used to compute Chunk Adherence, Chunk Completeness, Chunk Attribution and Utilization, and a single inference call is used to compute all the Luna metrics at once. The model is trained on carefully curated RAG datasets and optimized to closely align with the RAG Plus metrics.
For each token in the provided context, the model outputs a *utilization probability*, i.e the probability that this token affected the response. If the *utilization probability* of any token in the chunk exceeds a pre-defined threshold, that chunk is labeled as Attributed.
We recommend starting with "Luna" and seeing if this covers your needs. If you see the need for higher accuracy, you can switch over to [Chunk Attribution
Plus](/galileo/gen-ai-studio-products/galileo-guardrail-metrics/context-adherence/context-adherence-plus).
---
# Source: https://docs.galileo.ai/galileo/gen-ai-studio-products/galileo-guardrail-metrics/chunk-attribution/chunk-attribution-plus.md
> ## Documentation Index
> Fetch the complete documentation index at: https://docs.galileo.ai/llms.txt
> Use this file to discover all available pages before exploring further.
# Chunk Attribution Plus
> Understand Galileo's Chunk Attribution Plus Metric
The metric is intended for RAG workflows.
***Definition:*** For each chunk retrieved in a RAG pipeline, Chunk Attribution measures whether or not that chunk had an effect on the model's response.
Chunk Attribution is a binary metric: each chunk is either Attributed or Not Attributed.
Chunk Attribution is closely related to Chunk Utilization: Attribution measures whether or not a chunk affected the response, and Utilization measures how much of the chunk text was involved in the effect. Only chunks that were Attributed can have Utilization scores greater than zero.
***Calculation:*** Chunk Attribution is computed by sending an additional request to an OpenAI LLM, using a carefully engineered prompt that asks the model to trace information in the response back to individual chunks and sentences within those chunks.
The same prompt is used for both Chunk Attribution and Chunk Utilization, and a single LLM request is used to compute both metrics at once.
***Deep dive:*** to read more about the research behind this metric, see [RAG Quality Metrics using ChainPoll](/galileo/gen-ai-studio-products/galileo-ai-research/rag-quality-metrics-using-chainpoll).
*Note:* This metric is computed by prompting an LLM, and thus requires additional LLM calls to compute.
---
# Source: https://docs.galileo.ai/galileo/gen-ai-studio-products/galileo-guardrail-metrics/chunk-attribution.md
> ## Documentation Index
> Fetch the complete documentation index at: https://docs.galileo.ai/llms.txt
> Use this file to discover all available pages before exploring further.
# Chunk Attribution
> Understand Galileo's Chunk Attribution Metric
This metric is intended for RAG use cases and is only available if you [log your retriever's output](/galileo/gen-ai-studio-products/galileo-evaluate/how-to/evaluate-and-optimize-rag-applications).
***Definition:*** For each chunk retrieved in a RAG pipeline, Chunk Attribution measures whether or not that chunk had an effect on the model's response.
Chunk Attribution is a binary metric: each chunk is either Attributed or Not Attributed.
Chunk Attribution is closely related to Chunk Utilization: Attribution measures whether or not a chunk affected the response, and Utilization measures how much of the chunk text was involved in the effect. Only chunks that were Attributed can have Utilization scores greater than zero.
***What to do when Chunk Attribution is low?***
Chunk Attribution can help you iterate on your RAG pipeline in several different ways:
* *Tuning the number of retrieved chunks.*
* If your system is producing satisfactory responses, but many chunks are Not Attributed, then you may be able to reduce the number of chunks retrieved per example without adversely impacting response quality.
* This will improve the efficiency of the system, resulting in lower cost and latency.
* *"Debugging" anomalous model behavior in individual examples.*
* If a specific model response is unsatisfactory or unusual, and you want to understand why, Attribution can help you zero in on the chunks that affected the response.
* This lets you get to the root of the issue more quickly when inspecting individual examples.
### Luna vs Plus
We offer two ways of calculating Completeness: *Luna* and *Plus*.
[*Chunk Attribution Luna*](/galileo/gen-ai-studio-products/galileo-guardrail-metrics/context-adherence/context-adherence-luna) is computed using Galileo in-house small language models. They're free of cost. Completeness Luna is a cost-effective way to scale up you RAG evaluation workflows.
[*Chunk Attribution Plus*](/galileo/gen-ai-studio-products/galileo-guardrail-metrics/context-adherence/context-adherence-plus) is computed by sending an additional request to your LLM. It relies on OpenAI models so it incurs an additional cost. *Chunk Attribution Plus* has shown better results in internal benchmarks.
**Chunk Attribution** and **Chunk Utilization** are closely related and rely on the same models for computation. The "**chunk\_attribution\_utilization\_\{luna/plus}**" scorer will compute both.
---
# Source: https://docs.galileo.ai/galileo/gen-ai-studio-products/galileo-guardrail-metrics/chunk-relevance.md
> ## Documentation Index
> Fetch the complete documentation index at: https://docs.galileo.ai/llms.txt
> Use this file to discover all available pages before exploring further.
# Chunk Relevance
> Understand Galileo's Chunk Relevance Luna Metric
***Definition:*** For each chunk retrieved in a RAG pipeline, Chunk Relevance detects the sections of the text that contain useful information to address the query.
Chunk Relevance ranges from 0 to 1. A value of 1 means that the entire chunk is useful for answering the query, while a lower value like 0.5 means that the chunk contained some unnecessary text that is not relevant to the query.
**Explainability**
The Luna model identifies which parts of the chunks were relevant to the query. These sections can be highlighted in your retriever nodes by clicking on the icon next to the Chunk Utilization metric value in your *Retriever* nodes.
Let's cover these one by one.
### Chain
[*Chain-of-thought prompting*](https://arxiv.org/pdf/2201.11903.pdf) (CoT) is a simple but powerful way to elicit better answers from a large language model (LLM).
A chain-of-thought prompt is simply a prompt that asks the LLM to write out its step-by-step reasoning process before stating its final answer. For example:
* Prompt without CoT:
* "Roger has 5 tennis balls. He buys 2 more cans of tennis balls. Each can has 3 tennis balls. How many tennis balls does he have now?"
* Prompt with CoT:
* "Roger has 5 tennis balls. He buys 2 more cans of tennis balls. Each can has 3 tennis balls. How many tennis balls does he have now? *Think step by step, and present your reasoning before giving the answer.*"
While this might seem like a small change, it often dramatically improves the accuracy of the answer.
#### Why does CoT Work?
To better understand why CoT works, consider that the same trick *also* works for human beings!
If someone asks you a complex question, you will likely find it hard to answer *immediately,* on the spot. You'll want some time to think about it -- which could mean thinking silently, or talking through the problem out loud.
Asking an LLM for an answer *without* using CoT is like asking a human to answer a question immediately, on the spot, without pausing to think. This might work if the human has memorized the answer, or if the question is very straightforward.
For complex or difficult questions, it's useful to take some time to reflect before answers, and CoT allows the LLM to do this.
### Poll
ChainPoll extends CoT prompting by soliciting *multiple*, independently generated responses to the same prompt, and *aggregating* these responses.
Here's why this is a good idea.
As we all know, LLMs sometimes make mistakes. And these mistakes can occur randomly, rather than deterministically. If you ask an LLM the same question twice, you will often get two contradictory answers.
This is equally true of the reasoning generated by LLMs when prompted with CoT. If you ask an LLM the same question multiple times, and ask it to explain its reasoning each time, you'll often get a random mixture of valid and invalid arguments.
But here's the key observation: "*a random* *mixture of valid and invalid arguments*" is more useful than it sounds! Because:
* All *valid* arguments end up in the same place: the right answer.
* But an *invalid* argument can lead anywhere.
This turns the randomness of LLM generation into an advantage.
If we generate a diverse range of arguments, we'll get many different arguments that lead to the right answer -- because *any* valid argument leads there. We'll also get some invalid arguments, but they'll end up all over the place, not *concentrated* around any one answer. (Some of them may even produce the right answer by accident!
This idea -- generate diverse reasoning paths with CoT, and let the right answer "bubble to the top" -- is sometimes referred to as *self-consistency.*
It was introduced in [this paper](https://arxiv.org/pdf/2203.11171.pdf), as a method for solving math and logic problems with LLMs.
### From self-consistency to ChainPoll
Although ChainPoll is closely related to self-consistency, there are a few key differences. Let's break them down.
Self-consistency is a technique for picking a single *best* answer. It uses majority voting: the most common answer among the different LLM outputs is selected as the final answer of the entire procedure.
By contrast, ChainPoll works by *averaging* over the answers produced by the LLM to produce a *score*.
Most commonly, the individual answers are True-or-False, and so the average can be interpreted as the fraction of True answers among the total seto f answers.
For example, in our Context Adherence metric, we ask an LLM whether a response was consistent with a set of documents. We might get a set of responses like this:
1. A chain of thought ending in the conclusion that **Yes**, the answer was supported
2. A different chain of thought ending in the conclusion that **Yes**, the answer was supported
3. A third chain of thought ending in the conclusion that **No**, the answer was **not** supported
In this case, we would average the three answers and return a score of 0.667 (=2/3) to you.
The majority voting approach used in self-consistency would round this off to **Yes**, since that's the most common answer. But this misses some of the information present in the underlying answer.
By giving you an average, ChainPoll conveys a sense of the evaluating LLM's level of certainty. In this case, while the answer is more likely to be **Yes** than **No**, the LLM is not entirely sure, and that nuance is captured in the score.
Additionally, self-consistency has primarily been applied to "discrete reasoning" problems like math and code. While ChainPoll can be applied to such problems, we've found it also works much more broadly, for almost any kind of question that can be posed in a yes-or-no form.
## Frequently asked questions
***How does ChainPoll compare to the methods used by other LLM evaluation tools, like RAGAS and TruLens?***
We cover this in detail in the section below on **The ChainPoll advantage.**
***ChainPoll involves requesting multiple responses. Isn't that slow and expensive?***
Not as much as you might think!
We use batch requests to LLM APIs to generate ChainPoll responses, rather than generating the responses one-by-one. Because all requests in the batch have the same prompt, the API provider can process them more efficiently: the prompt only needs to be run through the LLM once, and the results can be shared across all of the sequences being generated.
This efficiency improvement often corresponds to better latency or lower cost from the perspective of the API consumer (and ultimately, you).
For instance, with the OpenAI API -- our default choice for ChainPoll -- a batch request for 3 responses from the same prompt will be billed for:
* All the *output* tokens across all 3 responses
* All the *input* tokens in the prompt, counted only once (not 3 times)
Compared to simply making 3 separate requests, this cuts down on the cost of the prompt by 2/3.
***What LLMs does Galileo use with ChainPoll? Why those?***
By default, we use OpenAI's latest version of GPT-4o-mini.
Although GPT-4o-mini can be less accurate than a more powerful LLMs such as GPT-4, it's *much* faster and cheaper. We've found that using it with ChainPoll closes a significant fraction of the accuracy gap between it and GPT-4, while still being much faster and less expensive.
That said, GPT-4 and other state-of-the-art LLMs can also benefit from ChainPoll.
***Sounds simple enough. Couldn't I just build this myself?***
Galileo continually invests in research aimed at improving the quality and efficiency of ChainPoll, as well as rigorously measuring these outcomes.
For example, in the initial research that produced ChainPoll, we found that the majority of available datasets used in earlier research on hallucination detection did not meet our standards for relevance and quality; in response, we created our own benchmark called RealHall.
By using Galileo, you automatically gain access to the fruits of these ongoing efforts, including anything we discover and implement in the future.
Additionally, Galileo ChainPoll metrics are integrated naturally with the rest of the Galileo platform. You won't have to worry about how to scale up ChainPoll requests, how to persist ChainPoll results to a database, or how to track ChainPoll metrics alongside other information you log during LLM experiments or in production.
***How do I interpret the scores?***
ChainPoll scores are averages over multiple True-or-False answers. You can interpret them as a combination of two pieces of information:
* An overall inclination toward Yes or No, and
* A level of certainty/uncertainty.
For example:
* A score of 0.667 means that the evaluating LLM said Yes 2/3 of the time, and No 1/3 of the time.
* In other words, its *overall inclination* was toward Yes, but it wasn't totally sure.
* A score of 1.0 would indicate the same overall inclination, with higher confidence.
Likewise, 0.333 is "inclined toward No, but not sure," and 0 is "inclined toward No, with higher confidence."
It's important to understand that a lower ChainPoll score doesn't *necessarily* correspond to lower quality, particularly on the level of a single example. ChainPoll scores are best used either:
* As a guide for your own explorations, pointing out things in the data for you to review, or
* As a way to compare entire runs to one other in aggregate.
## The ChainPoll advantage
ChainPoll is unique to Galileo. In this section, we'll explore how it differs from the approaches used in products like RAGAS and TruLens, and what makes ChainPoll more effective.
### ChainPoll vs. RAGAS
RAGAS offers a **Faithfulness** score, which has a similar purpose to Galileo's **Context Adherence** score.
Both of these scores evaluate whether a *response* is consistent with the information in a *context,* such as the chunks provided by a RAG retriever\*.\*
However, under the hood, the two scores work very differently.
To compute Faithfulness, RAGAS calls an LLM in two distinct steps:
1. The LLM is asked to break the *response* down into one or more granular *statements.*
1. In this step, the LLM can only see the *response*, not the *context*.
2. The LLM given the *statements* and the *context*, and is asked to judge whether or not each statement is consistent with the context.
1. In this step, the LLM can see the context, but *not* the original response. Instead, it only sees the statements that were written in step 1.
The scores for each statement (0 for inconsistent, 1 for consistent) are averaged over statements to produce a score.
This procedure can go wrong in a few different ways, none of which apply to ChainPoll.
#### Statement breakdowns can be misleading
By breaking down the response into statements and judging the statements *separately*, **RAGAS can ignore the way that different parts of the response are related.**
An LLM response is not just a disconnected list of "statements," any more than this article is. It may make a complex claim or argument that loses its structure when broken down in this way.
Consider this example, from a dataset related to Covid-19 that we use internally at Galileo.
An LLM was given a set of documents describing medical studies, and asked
```
What important risk factors to infection were found during the second case-controlled study?
```
It responded:
```
The important risk factors to infection found during the second case-controlled study were hospitalization in the preceding 90 days, residency in a nursing home, and antibiotic use.
```
As it happened, this response was *not* consistent with the documents. Although all the factors cited as risk factors were *mentioned* in the documents, they weren't actually said to be *risk factors during the second case-controlled study.*
**Galileo** **Context Adherence** caught this error, assigning the response a score of 0. Here is one of the chain-of-thought explanations it produced:
```
The response claims that the important risk factors to infection found during the second case-controlled study were hospitalization in the preceding 90 days, residency in a nursing home, and antibiotic use.
To verify this claim, we need to check the specific risk factors mentioned in the second case-controlled study document. However, the second case-controlled study document does not provide specific risk factors related to infection. It mainly focuses on data collection and limitations of the study. Therefore, the claim that hospitalization in the preceding 90 days, residency in a nursing home, and antibiotic use were important risk factors found during the study is not supported by the documents.
```
But **RAGAS Faithfulness** assigns this response a score of 1.0 (perfect).
To see what went wrong, let's review the 4 statements that RAGAS generated from the response, and its generated reasoning for why each one was consistent.
```
Statement 1/4
The second case-controlled study identified several important risk factors to infection.
Reasoning
The passage mentions that a case-control study was conducted to identify risk factors for multi-drug resistant infection in the pediatric intensive care unit (PICU).
Verdict
1 (Consistent)
---
Statement 2/4
These risk factors include hospitalization in the preceding 90 days.
Reasoning
The passage states that hospitalization in the preceding 90 days was a risk factor for infection with a resistant pathogen.
Verdict
1 (Consistent)
---
Statement 3/4
Residency in a nursing home was also found to be a significant risk factor.
Reasoning
The passage mentions that residency in a nursing home was an independent predictor of infection with a resistant pathogen.
Verdict
1 (Consistent)
---
Statement 4/4
Additionally, antibiotic use was identified as an important risk factor.
Reasoning
The passage states that antibiotic use was one of the main contents collected and analyzed in the study.
Verdict
1 (Consistent)
```
When RAGAS broke down the response into statements, it omitted key information that made the answer inconsistent.
Some of the statements are about *the second case-controlled study*, and some are about *risk factors.* Taken in isolation, each of these statements is arguably true.
But none of them captures the claim that the original LLM got wrong: that *these* *risk factors* were identified, not just in any study, but *in the second case-controlled study.*
ChainPoll allows the LLM to assess the entire input at once and come to a holistic judgment of it. By contrast, RAGAS fragments its reasoning into a sequence of disconnected steps, performed in isolation and without access to complete information.
This causes RAGAS to miss subtle or complex errors, like the one in the example above. But, given the increasing intelligence of today's LLMs, subtle and complex errors are precisely the ones you need to be worried about.
#### RAGAS does not handle refusals sensibly
Second, RAGAS Faithfulness is **unable to produce meaningful results when the LLM refuses to answer.**
In RAG, an LLM will sometimes respond with a *refusal* that claims it doesn't have enough information: an answer like "I don't know" or "Sorry, that wasn't mentioned in the context."
Like any LLM response, these are sometimes appropriate and sometimes inappropriate:
* If the requested information really *wasn't* in the retrieved context, the LLM should say so, not make something up.
* On the other hand, if the information *was* there, the LLM should not assert that it *wasn't* there.
In our tests, RAGAS Faithfulness always assigns a score of 0 to these kinds of refusal answers.
This is unhelpful: refusal answers are often *desirable* in RAG, because no retriever is perfect. If the answer isn't in your context, you don't want your LLM to make one up.
Indeed, in this case, saying "the answer wasn't in the context" is perfectly *consistent* with the context: the answer really was not there!
Yet RAGAS claims these answers are inconsistent.
Why? Because it is unable to break down a refusal answer into a collection of *statements* that look consistent with the context.
Typically, it produces no statements at all, and then returns a default score of 0. In other cases, it might produce a statement like "I don't know" and then assess this statement as "not consistent" since it doesn't make sense outside its original context as an *answer to a question.*
ChainPoll handles these cases gracefully: it assesses them like any other answer, checking whether they are consistent with the context or not. Here's an example:
The LLM response was
```
The provided context does not contain information about where the email was published. Therefore, it is not possible to determine where the email was published based on the given passages.
```
The **Galileo Context Adherence** score was 1, with an explanation of
```
The provided documents contain titles and passages that do not mention the publication details of an email. Document 1 lists an 'Email address' under the passage, but provides no information about the publication of an email. Documents 2, 3, and 4 describe the coverage of the Ebola Virus Disease outbreak and mention various countries and aspects of newspaper writings, but do not give any details about where an email was published. Hence, the context from these documents does not contain the necessary information to answer the question regarding the publication location of the email. The response from the large language model accurately reflects this lack of information.
```
#### RAGAS does not explain its answers
Although RAGAS does *generate* explanations internally (see the examples above), these are not surfaced to the user.
Moreover, as you can see above, they are briefer and less illuminating than ChainPoll explanations.
(We produced the examples above by adding callbacks to RAGAS to capture the requests it was making, and then following identifiers in the requests to link the steps together. You don't get any of that out of the box.)
### ChainPoll vs. TruLens
TruLens offers a **Groundedness** score, which targets similar needs to Galileo **Context Adherence** and RAGAS **Faithfulness:** evaluating whether a response is consistent with a context.
As we saw above with RAGAS, although these scores look similar on the surface, there are important differences in what they actually do.
TruLens **Groundedness** works as follows:
1. The response is split up into sentences.
2. An LLM is given the list of sentences, along with the context. It is asked to:
1. quote the part of the context (if any) that supports the sentence
2. rate the "information overlap" between each sentence and the context on a 0-to-10 scale.
3. The scores are mapped to a range from 0 to 1, and averaged to produce an overall score.
We've observed several failure modes of this procedure that don't apply to ChainPoll.
#### TruLens does not use chain-of-thought reasoning
Although TruEra uses the term "chain of thought" when describing what this metric does, the LLM is not actually asked to present a step-by-step *argument.*
Instead, it is merely asked to give a direct quotation from the context, then (somehow) assign a score to the "information overlap" associated with this quotation. It doesn't get any chance to "think out loud" about why any given quotation might, or might not, really constitute supporting evidence.
For example, here's what TruLens produces for the *second case-controlled study* example we reviewed above with RAGAS:
```
Statement Sentence: The important risk factors to infection found during the second case-controlled study were hospitalization in the preceding 90 days, residency in a nursing home, and antibiotic use.
Supporting Evidence: pathogen isolated in both study groups, but there was a higher prevalence of MDR pathogens in patients with risk factors compared with those without. Of all the risk factors, hospitalization in the preceding 90 days 1.90 to 12.4, P = 0.001) and residency in a nursing home were independent predictors of infection with a resistant pathogen and mortality.
Score: 8
```
The LLM quotes a passage that mentions the factors cited as risk factors in the response, without first stopping to think -- like ChainPoll does -- about whether the document actually says these are risk factors *in the second case-controlled study.*
Then, perhaps because the quoted passage is relatively long, it assigns it a score of 8/10. Yet this response is *not* consistent with the context.
#### TruLens uses an ambiguous grading system
You might have noticed another odd thing about the example just above. Even if the evidence really had been supporting evidence (which it wasn't), why "8 out of 10"? Why not 7/10, or 8/10, or 10/10?
There's no good answer to this question. TruLens does not provide the LLM with a clear grading guide, explaning exactly what makes an answer an "8/10" as opposed to a mere "7/10", and so on.
Instead, it only tells the LLM to "*Output a number between 0-10 where 0 is no information overlap and 10 is all information is overlapping.*"
If you were given this instruction, would you know how to decide when to give an 8, vs. a 7 vs. a 9? The LLM is as confused as you are.
As a result, the ratings computed inside the TruLens Groundedness score often vary whimsically, without apparent meaning. In our testing, we've observed these numbers varying widely across the 0-to-10 scale when we re-run the scorer with the same input, even when the LLM cites the same supporting quotation (or a very similar one).
At Galileo, we've observed that LLMs are often confused by numerical rating systems, and produce much more reliable and intelligible results when asked for a simple Yes-or-No answer.
This makes intuitive sense: in the absence of detailed guidelines about what each numeric score means, a 0-to-10 rating scale is *inherently* ambiguous and ill-defined.
#### Sentence breakdowns can be misleading
As we noted above when discussing RAGAS, imposing a breakdown into granular units like sentences or statements -- and then grading each unit separately -- can miss the way the units are logically connected.
Thus, TruLens can exhibit errors similar to the one we covered in the section on RAGAS when dealing with complex answers.
#### TruLens gets confused by formatting
In our testing, we noticed that TruLens Groundedness would often generate strange, malformed output that included grades for some sentences from the *context* instead of the *response.*
Here's one example. The response was
```
Bacilius subtilis can be used as an oral vaccine by expressing the COE antigen of PEDV and delivering it to the GI tract to stimulate mucosal immune responses. It can protect antigens from the harsh digestive environment and enhance immune regulation and gut health in newborn piglets. Additionally, it has adjuvant activity and can deliver heterologous antigens to the GI tract, providing additional immunity stimulation.
```
There are 3 sentences here. TruLens is supposed to assign a score to each one, together with a supporting quotation. But here is what it actually produced:
```
STATEMENT 0:
Statement Sentence: Bacillus subtilis can be used as an oral vaccine by expressing the COE antigen of PEDV and delivering it to the GI tract to stimulate mucosal immune responses.
Supporting Evidence: NOTHING FOUND
Score: 0
STATEMENT 1:
Statement Sentence: Oral administration can protect the gut and stimulate the common mucosal immune system.
Supporting Evidence: As a superior way of mucosal immunization, oral administration can protect the gut and stimulate the common mucosal immune system.
Score: 10
Statement Sentence: Oral immunization often delivers large amounts of antigens to prevent diarrheal diseases.
Supporting Evidence: Oral immunization often delivers large amounts of antigens to prevent the diarrheal diseases.
Score: 10
Statement Sentence: Bacillus subtilis is widely used as a vaccine delivery system for its unique characteristics.
Supporting Evidence: Currently, Bacillus subtilis is widely used as a vaccine delivery system for its unique characteristics.
Score: 10
Statement Sentence: Orally administered Bacillus subtilis can enhance immune regulation and gut health in pigs.
Supporting Evidence: Moreover, oral administration of B. subtilis could elicit humoral and cellular immune responses to the maintenance of gut homeostasis by dendritic cells.
Score: 5
STATEMENT 2:
Statement Sentence: Oral administration can protect the gut and stimulate the common mucosal immune system.
Supporting Evidence: As a superior way of mucosal immunization, oral administration can protect the gut and stimulate the common mucosal immune system.
Score: 10
Statement Sentence: Orally administered B. subtilis could enhance immune regulation and gut health in pigs.
Supporting Evidence: Moreover, oral administration of B. subtilis could elicit humoral and cellular immune responses to the maintenance of gut homeostasis by dendritic cells.
Score: 7
Statement Sentence: B. subtilis is widely used as a vaccine delivery system for its unique characteristics.
Supporting Evidence: Currently, Bacillus subtilis is widely used as a vaccine delivery system for its unique characteristics.
Score: 10
```
After the first statement, things go off the rails. The sentences listed under "STATEMENT 1" and "STATEMENT 2" don't appear in the response at all. And, nonsensically, the LLM has written *multiple* "Statement Sentences" under each of the "STATEMENT" headings.
In a case like this, the TruLens codebase assumes that each STATEMENT heading only has one score under it, and ends up picking the first one listed. Here, it ended up with the scores \[0, 10, 10] for the three statements. But the latter two scores are nonsense -- they're not about sentences from the response at all.
We tracked this issue down to *formatting.*
Our context included multiple paragraphs and documents, which were separated by line breaks. It turns out that TruLens' prompt format also uses line breaks to delimit sections of the prompt. Apparently the LLM became confused by which line breaks meant what.
Replacing line breaks with spaces fixed the problem in this case. But you shouldn't have to worry about this kind of thing at all. Line breaks are not an exotic edge case, after all.
The prompt formats we use for Galileo ChainPoll metrics involve a more robust delimiting strategy, including reformatting your output in some cases if needed. This prevents issues like this from arising with ChainPoll.
---
# Source: https://docs.galileo.ai/galileo/gen-ai-studio-products/galileo-evaluate/how-to/choose-your-guardrail-metrics.md
> ## Documentation Index
> Fetch the complete documentation index at: https://docs.galileo.ai/llms.txt
> Use this file to discover all available pages before exploring further.
# Choose your Guardrail Metrics
> Select and understand guardrail metrics in Galileo Evaluate to effectively assess your prompts and models, utilizing both industry-standard and proprietary metrics.
## Galileo Metrics
Galileo has built a menu of **Guardrail Metrics** for you to choose from. These metrics are tailored to your use case and are designed to help you evaluate your prompts and models.
Galileo's Guardrail Metrics are a combination of industry-standard metrics (e.g. BLEU, ROUGE-1, Perplexity) and an outcome of Galileo's in-house ML Research Team (e.g. Uncertainty, Correctness, Context Adherence).
Here's a list of the metrics supported today
### Output Quality Metrics:
* [**Uncertainty**](/galileo/gen-ai-studio-products/galileo-guardrail-metrics/uncertainty)**:** Measures the model's certainty in its generated responses. Uncertainty works at the response level as well as at the token level. It has shown a strong correlation with hallucinations or made-up facts, names, or citations.
* [**Correctness**](/galileo/gen-ai-studio-products/galileo-guardrail-metrics/correctness) - Measures whether the facts stated in the response are based on real facts. This metric requires additional LLM calls. Combined with Uncertainty, Factuality is a good way of uncovering Hallucinations.
* [**BLEU & ROUGE-1**](/galileo/gen-ai-studio-products/galileo-guardrail-metrics/bleu-and-rouge-1) - These metrics measure n-gram similarities between your Generated Responses and your Target output. These metrics are automatically computed when you add a {target} column in your dataset.
* [**Prompt Perplexity**](/galileo/gen-ai-studio-products/galileo-guardrail-metrics/prompt-perplexity) - Measure the perplexity of a prompt. Previous research has shown that as perplexity decreases, generations tend to increase in quality.
### RAG Quality Metrics:
* [**Context Adherence**](/galileo/gen-ai-studio-products/galileo-guardrail-metrics/context-adherence) - Measures whether your model's response was purely based on the context provided. This metric is intended for RAG users. We have two options for this metric: *Luna* and *Plus*.
* Context Adherence *Luna* is powered by small language models we've trained. It's free of cost.
* Context Adherence *Plus* includes an explanation or rationale for the rating. These metrics and the explanations are powered by an LLM (e.g. OpenAI GPT3.5) and thus incur additional costs. *Plus* has shown to have better performance.
* [**Completeness**](/galileo/gen-ai-studio-products/galileo-guardrail-metrics/completeness/completeness) - Measures how thoroughly your model's response covered relevant information from the context provided. This metric is intended for RAG use cases and is only available if you [log your retriever's output](/galileo/gen-ai-studio-products/galileo-evaluate/how-to/evaluate-and-optimize-rag-applications). There are two versions available:
* Completeness *Luna* is powered by small language models we've trained. It's free of cost.
* Completeness *Plus* includes an explanation or rationale for the rating. These metrics and the explanations are powered by an LLM (e.g. OpenAI GPT3.5) and thus incur additional costs. *Plus* has shown to have better performance.
* [**Chunk Attribution**](/galileo/gen-ai-studio-products/galileo-guardrail-metrics/chunk-attribution) - Measures which individual chunks retrieved in a RAG workflow influenced your model's response. This metric is intended for RAG use cases and is only available if you [log your retriever's output](/galileo/gen-ai-studio-products/galileo-evaluate/how-to/evaluate-and-optimize-rag-applications). There are two versions available:
* Chunk Attribution *Luna* is powered by small language models we've trained. It's free of cost.
* Chunk Attribution *Plus* is powered by an LLM (e.g. OpenAI GPT3.5) and thus incurs additional costs. *Plus* has shown to have better performance.
* [**Chunk Utilization**](/galileo/gen-ai-studio-products/galileo-guardrail-metrics/chunk-utilization) - For each chunk retrieved in a RAG workflow, measures the fraction of the chunk text that influenced your model's response. This metric is intended for RAG use cases and is only available if you [log your retriever's output](/galileo/gen-ai-studio-products/galileo-evaluate/how-to/evaluate-and-optimize-rag-applications). There are two versions available:
* Chunk Attribution *Luna* is powered by small language models we've trained. It's free of cost.
* Chunk Attribution *Plus* is powered by an LLM (e.g. OpenAI GPT3.5) and thus incurs additional costs. *Plus* has shown to have better performance.
* [**Context Relevance**](/galileo/gen-ai-studio-products/galileo-guardrail-metrics/context-relevance) - Measures if the context has enough information to answer the user query. This metric is intended for RAG users.
### Safety Metrics:
* [**Private Identifiable Information**](/galileo/gen-ai-studio-products/galileo-guardrail-metrics/private-identifiable-information) **-** This Guardrail Metric surfaces any instances of PII in your model's responses. We surface whether your text contains any credit card numbers, social security numbers, phone numbers, street addresses, and email addresses.
* [**Toxicity**](/galileo/gen-ai-studio-products/galileo-guardrail-metrics/toxicity) - Measures whether the model's responses contained any abusive, toxic, or foul language.
* [**Tone**](/galileo/gen-ai-studio-products/galileo-guardrail-metrics/tone) - Classifies the tone of the response into 9 different emotion categories: neutral, joy, love, fear, surprise, sadness, anger, annoyance, and confusion.
* [**Sexism**](/galileo/gen-ai-studio-products/galileo-guardrail-metrics/sexism) - Measures how 'sexist' a comment might be perceived ranging in the values of 0-1 (1 being more sexist).
* [**Prompt Injection**](https://docs.rungalileo.io/galileo/gen-ai-studio-products/galileo-guardrail-metrics/prompt-injection) - Detects and classifies various categories of prompt injection attacks.
* More coming very soon.
A more thorough description of all Guardrail Metrics can be found [here](/galileo/gen-ai-studio-products/galileo-guardrail-metrics).
When creating runs from code, you'll need to add your Guardrail Metrics as "scorers", check out "[Enabling Scorers in Run](/galileo/gen-ai-studio-products/galileo-evaluate/how-to/enabling-scorers-in-runs)" to learn how to do so.
If you want to set up your custom metrics, please see instructions [here](https://docs.rungalileo.io/galileo/galileo-gen-ai-studio/prompt-inspector/registering-and-using-custom-metrics).
---
# Source: https://docs.galileo.ai/galileo/gen-ai-studio-products/galileo-observe/how-to/choosing-your-guardrail-metrics.md
> ## Documentation Index
> Fetch the complete documentation index at: https://docs.galileo.ai/llms.txt
> Use this file to discover all available pages before exploring further.
# Choosing Your Guardrail Metrics
> Select and understand guardrail metrics in Galileo Observe to effectively evaluate your LLM applications, utilizing both industry-standard and proprietary metrics.
## How to turn metrics on or off
For metrics to be computed on your Observe project, open the `Settings & Alerts` section of your project, and turn on any metric you'd like to be calculated. Metrics are not computed retroactively, they'll only be computed on new traffic that flows through Observe.
## Galileo Metrics
Galileo has built a menu of **Guardrail Metrics** for you to choose from. These metrics are tailored to your use case and are designed to help you evaluate your LLM applications.
Galileo's Guardrail Metrics are a combination of industry-standard metrics and a product of Galileo's in-house [AI Research](/galileo-ai-research) Team (e.g. Uncertainty, Correctness, Context Adherence).
Here's a list of some of the metrics supported today:
* [**Context Adherence**](/galileo/gen-ai-studio-products/galileo-guardrail-metrics/context-adherence) - Measures whether your model's response was grounded on the context provided. This metric is intended for RAG or context-based use cases and is a good measure for hallucinations.
* [**Completeness**](/galileo/gen-ai-studio-products/galileo-guardrail-metrics/completeness) - Evaluates how comprehensively the response addresses the question using all the relevant information from the provided context. If Context Adherence is your RAG 'Precision' metric, Completeness is your RAG 'Recall'.
* [**Chunk Attribution**](/galileo/gen-ai-studio-products/galileo-guardrail-metrics/chunk-attribution) - Measures the number of chunks a model uses when generating an output. By optimizing the number of chunks a model is retrieving, teams can improve output quality and system performance and avoid the excess costs of including unused chunks in prompts to LLMs. This metric requires Galileo to [be hooked into your retriever step](/galileo/gen-ai-studio-products/galileo-observe/how-to/monitoring-your-rag-application).
* [**Chunk Utilization**](/galileo/gen-ai-studio-products/galileo-guardrail-metrics/chunk-utilization) - Measures how much of each chunk was used by a model when generating an output, and helps teams rightsize their chunk size. This metric requires Galileo to [be hooked into your retriever step](/galileo/gen-ai-studio-products/galileo-observe/how-to/monitoring-your-rag-application).
* [**Instruction Adherence**](/galileo/gen-ai-studio-products/galileo-guardrail-metrics/instruction-adherence) - Measures whether your model's response was grounded on the context provided. This metric is intended for RAG or context-based use cases and is a good measure for hallucinations.
* [**Correctness**](/galileo/gen-ai-studio-products/galileo-guardrail-metrics/correctness) - Measures whether the facts stated in the response are based on real facts. This metric requires additional LLM calls. Combined with Uncertainty, Factuality is a good way of uncovering Hallucinations.
* [**Prompt Injections**](/galileo/gen-ai-studio-products/galileo-guardrail-metrics/prompt-injection) - Identifies any adversarial attacks or prompt injections.
* [**Private Identifiable Information**](/galileo/gen-ai-studio-products/galileo-guardrail-metrics/private-identifiable-information) **-** This Guardrail Metric surfaces any instances of PII in your model's responses. We surface whether your text contains any credit card numbers, social security numbers, phone numbers, street addresses and email addresses.
* [**Toxicity**](/galileo/gen-ai-studio-products/galileo-guardrail-metrics/toxicity) - Measures whether the model's responses contained any abusive, toxic or foul language.
* [**Tone**](/galileo/gen-ai-studio-products/galileo-guardrail-metrics/tone) - Classifies the tone of the response into 9 different emotion categories: neutral, joy, love, fear, surprise, sadness, anger, annoyance, and confusion.
* [**Sexism**](/galileo/gen-ai-studio-products/galileo-guardrail-metrics/sexism) - Measures how 'sexist' a comment might be perceived ranging in the values of 0-1 (1 being more sexist).
* [**Uncertainty**](/galileo/gen-ai-studio-products/galileo-guardrail-metrics/uncertainty) - Measures the model's certainty in its generated responses. Uncertainty works at the response level as well as at the token level. It has shown a strong correlation with hallucinations or made-up facts, names, or citations.
* and more.
A more thorough description of all Guardrail Metrics can be found [here](/galileo/gen-ai-studio-products/galileo-guardrail-metrics).
## Custom Metrics
To set up custom metrics for Galileo Observe projects, please see instructions and sample code snippet [here.](https://docs.rungalileo.io/galileo/galileo-gen-ai-studio/observe-getting-started/registering-and-using-custom-metrics)
---
# Source: https://docs.galileo.ai/galileo/gen-ai-studio-products/galileo-guardrail-metrics/chunk-attribution/chunk-attribution-luna.md
> ## Documentation Index
> Fetch the complete documentation index at: https://docs.galileo.ai/llms.txt
> Use this file to discover all available pages before exploring further.
# Chunk Attribution Luna
> Understand Galileo's Chunk Attribution Luna Metric
***Definition:*** For each chunk retrieved in a RAG pipeline, Chunk Attribution measures whether or not that chunk had an effect on the model's response.
Chunk Attribution is a binary metric: each chunk is either Attributed or Not Attributed.
Chunk Attribution is closely related to Chunk Utilization: Attribution measures whether or not a chunk affected the response, and Utilization measures how much of the chunk text was involved in the effect. Only chunks that were Attributed can have Utilization scores greater than zero.
***Calculation:*** Chunk Attribution Luna is computed using a fine-tuned in-house Galileo evaluation model. The model is a transformer-based encoder that is trained to identify the relevant and utilized information in the provided a query, context, and response. The same model is used to compute Chunk Adherence, Chunk Completeness, Chunk Attribution and Utilization, and a single inference call is used to compute all the Luna metrics at once. The model is trained on carefully curated RAG datasets and optimized to closely align with the RAG Plus metrics.
For each token in the provided context, the model outputs a *utilization probability*, i.e the probability that this token affected the response. If the *utilization probability* of any token in the chunk exceeds a pre-defined threshold, that chunk is labeled as Attributed.
We recommend starting with "Luna" and seeing if this covers your needs. If you see the need for higher accuracy, you can switch over to [Chunk Attribution
Plus](/galileo/gen-ai-studio-products/galileo-guardrail-metrics/context-adherence/context-adherence-plus).
---
# Source: https://docs.galileo.ai/galileo/gen-ai-studio-products/galileo-guardrail-metrics/chunk-attribution/chunk-attribution-plus.md
> ## Documentation Index
> Fetch the complete documentation index at: https://docs.galileo.ai/llms.txt
> Use this file to discover all available pages before exploring further.
# Chunk Attribution Plus
> Understand Galileo's Chunk Attribution Plus Metric
The metric is intended for RAG workflows.
***Definition:*** For each chunk retrieved in a RAG pipeline, Chunk Attribution measures whether or not that chunk had an effect on the model's response.
Chunk Attribution is a binary metric: each chunk is either Attributed or Not Attributed.
Chunk Attribution is closely related to Chunk Utilization: Attribution measures whether or not a chunk affected the response, and Utilization measures how much of the chunk text was involved in the effect. Only chunks that were Attributed can have Utilization scores greater than zero.
***Calculation:*** Chunk Attribution is computed by sending an additional request to an OpenAI LLM, using a carefully engineered prompt that asks the model to trace information in the response back to individual chunks and sentences within those chunks.
The same prompt is used for both Chunk Attribution and Chunk Utilization, and a single LLM request is used to compute both metrics at once.
***Deep dive:*** to read more about the research behind this metric, see [RAG Quality Metrics using ChainPoll](/galileo/gen-ai-studio-products/galileo-ai-research/rag-quality-metrics-using-chainpoll).
*Note:* This metric is computed by prompting an LLM, and thus requires additional LLM calls to compute.
---
# Source: https://docs.galileo.ai/galileo/gen-ai-studio-products/galileo-guardrail-metrics/chunk-attribution.md
> ## Documentation Index
> Fetch the complete documentation index at: https://docs.galileo.ai/llms.txt
> Use this file to discover all available pages before exploring further.
# Chunk Attribution
> Understand Galileo's Chunk Attribution Metric
This metric is intended for RAG use cases and is only available if you [log your retriever's output](/galileo/gen-ai-studio-products/galileo-evaluate/how-to/evaluate-and-optimize-rag-applications).
***Definition:*** For each chunk retrieved in a RAG pipeline, Chunk Attribution measures whether or not that chunk had an effect on the model's response.
Chunk Attribution is a binary metric: each chunk is either Attributed or Not Attributed.
Chunk Attribution is closely related to Chunk Utilization: Attribution measures whether or not a chunk affected the response, and Utilization measures how much of the chunk text was involved in the effect. Only chunks that were Attributed can have Utilization scores greater than zero.
***What to do when Chunk Attribution is low?***
Chunk Attribution can help you iterate on your RAG pipeline in several different ways:
* *Tuning the number of retrieved chunks.*
* If your system is producing satisfactory responses, but many chunks are Not Attributed, then you may be able to reduce the number of chunks retrieved per example without adversely impacting response quality.
* This will improve the efficiency of the system, resulting in lower cost and latency.
* *"Debugging" anomalous model behavior in individual examples.*
* If a specific model response is unsatisfactory or unusual, and you want to understand why, Attribution can help you zero in on the chunks that affected the response.
* This lets you get to the root of the issue more quickly when inspecting individual examples.
### Luna vs Plus
We offer two ways of calculating Completeness: *Luna* and *Plus*.
[*Chunk Attribution Luna*](/galileo/gen-ai-studio-products/galileo-guardrail-metrics/context-adherence/context-adherence-luna) is computed using Galileo in-house small language models. They're free of cost. Completeness Luna is a cost-effective way to scale up you RAG evaluation workflows.
[*Chunk Attribution Plus*](/galileo/gen-ai-studio-products/galileo-guardrail-metrics/context-adherence/context-adherence-plus) is computed by sending an additional request to your LLM. It relies on OpenAI models so it incurs an additional cost. *Chunk Attribution Plus* has shown better results in internal benchmarks.
**Chunk Attribution** and **Chunk Utilization** are closely related and rely on the same models for computation. The "**chunk\_attribution\_utilization\_\{luna/plus}**" scorer will compute both.
---
# Source: https://docs.galileo.ai/galileo/gen-ai-studio-products/galileo-guardrail-metrics/chunk-relevance.md
> ## Documentation Index
> Fetch the complete documentation index at: https://docs.galileo.ai/llms.txt
> Use this file to discover all available pages before exploring further.
# Chunk Relevance
> Understand Galileo's Chunk Relevance Luna Metric
***Definition:*** For each chunk retrieved in a RAG pipeline, Chunk Relevance detects the sections of the text that contain useful information to address the query.
Chunk Relevance ranges from 0 to 1. A value of 1 means that the entire chunk is useful for answering the query, while a lower value like 0.5 means that the chunk contained some unnecessary text that is not relevant to the query.
**Explainability**
The Luna model identifies which parts of the chunks were relevant to the query. These sections can be highlighted in your retriever nodes by clicking on the icon next to the Chunk Utilization metric value in your *Retriever* nodes.
 ***Calculation:*** Chunk Relevance Luna is computed using a fine-tuned in-house Galileo evaluation model. The model is a transformer-based encoder that is trained to identify the relevant and utilized information in the provided a query, context, and response. The same model is used to compute Chunk Adherence, Chunk Completeness, Chunk Attribution, and Utilization, and a single inference call is used to compute all the Luna metrics at once. The model is trained on carefully curated RAG datasets and optimized to closely align with the RAG Plus metrics.
For each token in the provided context, the model outputs a *relevance probability*, i.e the probability that this token is useful for answering the query.
***What to do when Chunk Relevance is low?***
Low Chunk Relevance scores indicate that your chunks are probably longer than they need to be. In this case, we recommend tuning your retriever to return shorter chunks, which will improve the efficiency of the system (lower cost and latency).
---
# Source: https://docs.galileo.ai/galileo/gen-ai-studio-products/galileo-guardrail-metrics/chunk-utilization/chunk-utilization-luna.md
> ## Documentation Index
> Fetch the complete documentation index at: https://docs.galileo.ai/llms.txt
> Use this file to discover all available pages before exploring further.
# Chunk Utilization Luna
> Understand Galileo's Chunk Utilization Luna Metric
***Definition:*** For each chunk retrieved in a RAG pipeline, Chunk Utilization measures the fraction of the text in that chunk that had an impact on the model's response.
Chunk Utilization ranges from 0 to 1. A value of 1 means that the entire chunk affected the response, while a lower value like 0.5 means that the chunk contained some "extraneous" text which did not affect the response.
Chunk Utilization is closely related to Chunk Attribution: Attribution measures whether or not a chunk affected the response, and Utilization measures how much of the chunk text was involved in the effect. Only chunks that were Attributed can have Utilization scores greater than zero.
***Calculation:*** Chunk Utilization Luna is computed using a fine-tuned in-house Galileo evaluation model. The model is a transformer-based encoder that is trained to identify the relevant and utilized information in the provided a query, context, and response. The same model is used to compute Chunk Adherence, Chunk Completeness, Chunk Attribution and Utilization, and a single inference call is used to compute all the Luna metrics at once. The model is trained on carefully curated RAG datasets and optimized to closely align with the RAG Plus metrics.
For each token in the provided context, the model outputs a *utilization probability*, i.e the probability that this token affected the response. *Chunk Utilization Luna* is then computed as the fraction of tokens with high utilization probability out of all tokens in the chunk.
We recommend starting with "Luna" and seeing if this covers your needs. If you see the need for higher accuracy or would like explanations for the ratings, you can switch over to [Chunk Utilization Plus](/galileo/gen-ai-studio-products/galileo-guardrail-metrics/chunk-utilization/chunk-utilization-plus).
**Explainability**
The Luna model identifies which parts of the chunks were utilized by the model when generating its response. These sections can be highlighted in your retriever nodes by clicking on the icon next to the Chunk Utilization metric value in your *Retriever* nodes.
***Calculation:*** Chunk Relevance Luna is computed using a fine-tuned in-house Galileo evaluation model. The model is a transformer-based encoder that is trained to identify the relevant and utilized information in the provided a query, context, and response. The same model is used to compute Chunk Adherence, Chunk Completeness, Chunk Attribution, and Utilization, and a single inference call is used to compute all the Luna metrics at once. The model is trained on carefully curated RAG datasets and optimized to closely align with the RAG Plus metrics.
For each token in the provided context, the model outputs a *relevance probability*, i.e the probability that this token is useful for answering the query.
***What to do when Chunk Relevance is low?***
Low Chunk Relevance scores indicate that your chunks are probably longer than they need to be. In this case, we recommend tuning your retriever to return shorter chunks, which will improve the efficiency of the system (lower cost and latency).
---
# Source: https://docs.galileo.ai/galileo/gen-ai-studio-products/galileo-guardrail-metrics/chunk-utilization/chunk-utilization-luna.md
> ## Documentation Index
> Fetch the complete documentation index at: https://docs.galileo.ai/llms.txt
> Use this file to discover all available pages before exploring further.
# Chunk Utilization Luna
> Understand Galileo's Chunk Utilization Luna Metric
***Definition:*** For each chunk retrieved in a RAG pipeline, Chunk Utilization measures the fraction of the text in that chunk that had an impact on the model's response.
Chunk Utilization ranges from 0 to 1. A value of 1 means that the entire chunk affected the response, while a lower value like 0.5 means that the chunk contained some "extraneous" text which did not affect the response.
Chunk Utilization is closely related to Chunk Attribution: Attribution measures whether or not a chunk affected the response, and Utilization measures how much of the chunk text was involved in the effect. Only chunks that were Attributed can have Utilization scores greater than zero.
***Calculation:*** Chunk Utilization Luna is computed using a fine-tuned in-house Galileo evaluation model. The model is a transformer-based encoder that is trained to identify the relevant and utilized information in the provided a query, context, and response. The same model is used to compute Chunk Adherence, Chunk Completeness, Chunk Attribution and Utilization, and a single inference call is used to compute all the Luna metrics at once. The model is trained on carefully curated RAG datasets and optimized to closely align with the RAG Plus metrics.
For each token in the provided context, the model outputs a *utilization probability*, i.e the probability that this token affected the response. *Chunk Utilization Luna* is then computed as the fraction of tokens with high utilization probability out of all tokens in the chunk.
We recommend starting with "Luna" and seeing if this covers your needs. If you see the need for higher accuracy or would like explanations for the ratings, you can switch over to [Chunk Utilization Plus](/galileo/gen-ai-studio-products/galileo-guardrail-metrics/chunk-utilization/chunk-utilization-plus).
**Explainability**
The Luna model identifies which parts of the chunks were utilized by the model when generating its response. These sections can be highlighted in your retriever nodes by clicking on the icon next to the Chunk Utilization metric value in your *Retriever* nodes.
 ---
# Source: https://docs.galileo.ai/galileo/gen-ai-studio-products/galileo-guardrail-metrics/chunk-utilization/chunk-utilization-plus.md
> ## Documentation Index
> Fetch the complete documentation index at: https://docs.galileo.ai/llms.txt
> Use this file to discover all available pages before exploring further.
# Chunk Utilization Plus
> Leverage Chunk Utilization+ in Galileo Guardrail Metrics to optimize generative AI output segmentation and maximize model efficiency.
# Chunk Utilization Plus
Understand Galileo's Chunk Utilization Plus Metric
The metric is intended for RAG workflows.
***Definition:*** For each chunk retrieved in a RAG pipeline, Chunk Utilization measures the fraction of the text in that chunk that had an impact on the model's response.
Chunk Utilization ranges from 0 to 1. A value of 1 means that the entire chunk affected the response, while a lower value like 0.5 means that the chunk contained some "extraneous" text which did not affect the response.
Chunk Utilization is closely related to Chunk Attribution: Attribution measures whether or not a chunk affected the response, and Utilization measures how much of the chunk text was involved in the effect. Only chunks that were Attributed can have Utilization scores greater than zero.
***Calculation:*** Chunk Utilization is computed by sending an additional request to an OpenAI LLM, using a carefully engineered prompt that asks the model to trace information in the response back to individual chunks and sentences within those chunks.
The same prompt is used for both Chunk Attribution and Chunk Utilization, and a single LLM request is used to compute both metrics at once.
***Deep dive:*** to read more about the research behind this metric, see [RAG Quality Metrics using ChainPoll](/galileo/gen-ai-studio-products/galileo-ai-research/rag-quality-metrics-using-chainpoll).
*Note:* This metric is computed by prompting an LLM, and thus requires additional LLM calls to compute.
[PreviousChunk Utilization Luna](/galileo/gen-ai-studio-products/galileo-guardrail-metrics/context-adherence/context-adherence-luna)[NextUncertainty](/galileo/gen-ai-studio-products/galileo-guardrail-metrics/uncertainty)
Last updated 2 months ago
---
# Source: https://docs.galileo.ai/galileo/gen-ai-studio-products/galileo-guardrail-metrics/chunk-utilization.md
> ## Documentation Index
> Fetch the complete documentation index at: https://docs.galileo.ai/llms.txt
> Use this file to discover all available pages before exploring further.
# Chunk Utilization
> Understand Galileo's Chunk Utilization Metric
This metric is intended for RAG use cases and is only available if you [log your retriever's output](/galileo/gen-ai-studio-products/galileo-evaluate/how-to/evaluate-and-optimize-rag-applications).
***Definition:*** For each chunk retrieved in a RAG pipeline, Chunk Utilization measures the fraction of the text in that chunk that had an impact on the model's response.
Chunk Utilization ranges from 0 to 1. A value of 1 means that the entire chunk affected the response, while a lower value like 0.5 means that the chunk contained some "extraneous" text which did not affect the response.
Chunk Utilization is closely related to Chunk Attribution: Attribution measures whether or not a chunk affected the response, and Utilization measures how much of the chunk text was involved in the effect. Only chunks that were Attributed can have Utilization scores greater than zero.
***What to do when Chunk Utilization is low?***
Low Chunk Utilization scores could mean one of two things: (1) your chunks are probably longer than they need to be, or (2) the LLM generator model is failing at incorporating all the relevant information in the chunks. You can differentiate between the two scenarios by checking the [Chunk Relevance](/galileo/gen-ai-studio-products/galileo-guardrail-metrics/chunk-relevance) score. If Chunk Relevance is also low, then you are likely experiencing scenario (1). If Chunk Relevance is high, you are likely experiencing scenario (2).
In case (1), we recommend tuning your retriever to return shorter chunks, which will improve the efficiency of the system (lower cost and latency). In case (2), we recommend exploring a different LLM that may leverage the relevant information in the chunks more efficiently.
### Luna vs Plus
We offer two ways of calculating Completeness: *Luna* and *Plus*.
[*Chunk Utilization Luna*](/galileo/gen-ai-studio-products/galileo-guardrail-metrics/context-adherence/context-adherence-luna) is computed using Galileo in-house small language models. They're free of cost. Completeness Luna is a cost effective way to scale up you RAG evaluation workflows.
[*Chunk Utilization Plus*](/galileo/gen-ai-studio-products/galileo-guardrail-metrics/chunk-utilization/chunk-utilization-plus) is computed by sending an additional request to your LLM. It relies on OpenAI models so it incurs an additional cost. *Chunk Utilization Plus* has shown better results in internal benchmarks.
**Chunk Attribution** and **Chunk Utilization** are closely related and rely on the same models for computation. The "**chunk\_attribution\_utilization\_\{luna/plus}**" scorer will compute both.
---
# Source: https://docs.galileo.ai/galileo-ai-research/class-boundary-detection.md
> ## Documentation Index
> Fetch the complete documentation index at: https://docs.galileo.ai/llms.txt
> Use this file to discover all available pages before exploring further.
# Class Boundary Detection
> Detecting samples on the decision boundary
Stay tuned for future announcements.
Understanding a model's decision boundaries and the samples that exist near or on these decision boundaries is critical when evaluating a model's robustness and performance. A model with poorly defined decision boundaries is prone to making low confidence and erroneous predictions.
Galileo's **On the Boundary** feature highlights data cohorts that exist near or on these decision boundaries - i.e. data that the model struggles to discern between distinct classes. Identifying these samples reveals high ROI data that are not well distinguished by the model (i.e. confidently predicted as a certain class) and are likely to be poorly classified. Moreover, tracking these samples in production can reveal overlapping class definitions and signal a need for model and data tuning to better differentiate select classes.
Within the Galileo Console, selecting the **On the Boundary** tab filters exactly the samples existing between the model's learned definition of classes:
---
# Source: https://docs.galileo.ai/galileo/gen-ai-studio-products/galileo-guardrail-metrics/chunk-utilization/chunk-utilization-plus.md
> ## Documentation Index
> Fetch the complete documentation index at: https://docs.galileo.ai/llms.txt
> Use this file to discover all available pages before exploring further.
# Chunk Utilization Plus
> Leverage Chunk Utilization+ in Galileo Guardrail Metrics to optimize generative AI output segmentation and maximize model efficiency.
# Chunk Utilization Plus
Understand Galileo's Chunk Utilization Plus Metric
The metric is intended for RAG workflows.
***Definition:*** For each chunk retrieved in a RAG pipeline, Chunk Utilization measures the fraction of the text in that chunk that had an impact on the model's response.
Chunk Utilization ranges from 0 to 1. A value of 1 means that the entire chunk affected the response, while a lower value like 0.5 means that the chunk contained some "extraneous" text which did not affect the response.
Chunk Utilization is closely related to Chunk Attribution: Attribution measures whether or not a chunk affected the response, and Utilization measures how much of the chunk text was involved in the effect. Only chunks that were Attributed can have Utilization scores greater than zero.
***Calculation:*** Chunk Utilization is computed by sending an additional request to an OpenAI LLM, using a carefully engineered prompt that asks the model to trace information in the response back to individual chunks and sentences within those chunks.
The same prompt is used for both Chunk Attribution and Chunk Utilization, and a single LLM request is used to compute both metrics at once.
***Deep dive:*** to read more about the research behind this metric, see [RAG Quality Metrics using ChainPoll](/galileo/gen-ai-studio-products/galileo-ai-research/rag-quality-metrics-using-chainpoll).
*Note:* This metric is computed by prompting an LLM, and thus requires additional LLM calls to compute.
[PreviousChunk Utilization Luna](/galileo/gen-ai-studio-products/galileo-guardrail-metrics/context-adherence/context-adherence-luna)[NextUncertainty](/galileo/gen-ai-studio-products/galileo-guardrail-metrics/uncertainty)
Last updated 2 months ago
---
# Source: https://docs.galileo.ai/galileo/gen-ai-studio-products/galileo-guardrail-metrics/chunk-utilization.md
> ## Documentation Index
> Fetch the complete documentation index at: https://docs.galileo.ai/llms.txt
> Use this file to discover all available pages before exploring further.
# Chunk Utilization
> Understand Galileo's Chunk Utilization Metric
This metric is intended for RAG use cases and is only available if you [log your retriever's output](/galileo/gen-ai-studio-products/galileo-evaluate/how-to/evaluate-and-optimize-rag-applications).
***Definition:*** For each chunk retrieved in a RAG pipeline, Chunk Utilization measures the fraction of the text in that chunk that had an impact on the model's response.
Chunk Utilization ranges from 0 to 1. A value of 1 means that the entire chunk affected the response, while a lower value like 0.5 means that the chunk contained some "extraneous" text which did not affect the response.
Chunk Utilization is closely related to Chunk Attribution: Attribution measures whether or not a chunk affected the response, and Utilization measures how much of the chunk text was involved in the effect. Only chunks that were Attributed can have Utilization scores greater than zero.
***What to do when Chunk Utilization is low?***
Low Chunk Utilization scores could mean one of two things: (1) your chunks are probably longer than they need to be, or (2) the LLM generator model is failing at incorporating all the relevant information in the chunks. You can differentiate between the two scenarios by checking the [Chunk Relevance](/galileo/gen-ai-studio-products/galileo-guardrail-metrics/chunk-relevance) score. If Chunk Relevance is also low, then you are likely experiencing scenario (1). If Chunk Relevance is high, you are likely experiencing scenario (2).
In case (1), we recommend tuning your retriever to return shorter chunks, which will improve the efficiency of the system (lower cost and latency). In case (2), we recommend exploring a different LLM that may leverage the relevant information in the chunks more efficiently.
### Luna vs Plus
We offer two ways of calculating Completeness: *Luna* and *Plus*.
[*Chunk Utilization Luna*](/galileo/gen-ai-studio-products/galileo-guardrail-metrics/context-adherence/context-adherence-luna) is computed using Galileo in-house small language models. They're free of cost. Completeness Luna is a cost effective way to scale up you RAG evaluation workflows.
[*Chunk Utilization Plus*](/galileo/gen-ai-studio-products/galileo-guardrail-metrics/chunk-utilization/chunk-utilization-plus) is computed by sending an additional request to your LLM. It relies on OpenAI models so it incurs an additional cost. *Chunk Utilization Plus* has shown better results in internal benchmarks.
**Chunk Attribution** and **Chunk Utilization** are closely related and rely on the same models for computation. The "**chunk\_attribution\_utilization\_\{luna/plus}**" scorer will compute both.
---
# Source: https://docs.galileo.ai/galileo-ai-research/class-boundary-detection.md
> ## Documentation Index
> Fetch the complete documentation index at: https://docs.galileo.ai/llms.txt
> Use this file to discover all available pages before exploring further.
# Class Boundary Detection
> Detecting samples on the decision boundary
Stay tuned for future announcements.
Understanding a model's decision boundaries and the samples that exist near or on these decision boundaries is critical when evaluating a model's robustness and performance. A model with poorly defined decision boundaries is prone to making low confidence and erroneous predictions.
Galileo's **On the Boundary** feature highlights data cohorts that exist near or on these decision boundaries - i.e. data that the model struggles to discern between distinct classes. Identifying these samples reveals high ROI data that are not well distinguished by the model (i.e. confidently predicted as a certain class) and are likely to be poorly classified. Moreover, tracking these samples in production can reveal overlapping class definitions and signal a need for model and data tuning to better differentiate select classes.
Within the Galileo Console, selecting the **On the Boundary** tab filters exactly the samples existing between the model's learned definition of classes:

 #### On the Boundary Calculation
On the boundary samples are identified by analyzing the model's output probability distribution. Given the model's output probabilities, we analyze the model's class confusion through computing per-sample certainty ratios - a metric computed as the ratio between a model's most confident predictions. Certainty ratios provide intuitive measures of class confusion not captured by traditional methods such as confidence. Through smart thresholding, we then identify samples that are particularly confused between two or more prediction classes.
---
# Source: https://docs.galileo.ai/galileo/galileo-nlp-studio/galileo-product-features/clusters.md
> ## Documentation Index
> Fetch the complete documentation index at: https://docs.galileo.ai/llms.txt
> Use this file to discover all available pages before exploring further.
# Clustering
> To help you make sense of your data and your embeddings view, Galileo provides out-of-the-box Clustering and Explainability.
You'll find your *Clusters* on the third tab of your Insights bar, next to *Alerts* and *Metrics*.
Currently, only Text Classification tasks support clustering.
Each Cluster contains a number of samples that are semantically similar to one another (i.e. are near each other in the embedding space). We leverage our *Clustering and Custom Tokenization Algorithm* to cluster and explain the commonalities between samples in that cluster.
#### On the Boundary Calculation
On the boundary samples are identified by analyzing the model's output probability distribution. Given the model's output probabilities, we analyze the model's class confusion through computing per-sample certainty ratios - a metric computed as the ratio between a model's most confident predictions. Certainty ratios provide intuitive measures of class confusion not captured by traditional methods such as confidence. Through smart thresholding, we then identify samples that are particularly confused between two or more prediction classes.
---
# Source: https://docs.galileo.ai/galileo/galileo-nlp-studio/galileo-product-features/clusters.md
> ## Documentation Index
> Fetch the complete documentation index at: https://docs.galileo.ai/llms.txt
> Use this file to discover all available pages before exploring further.
# Clustering
> To help you make sense of your data and your embeddings view, Galileo provides out-of-the-box Clustering and Explainability.
You'll find your *Clusters* on the third tab of your Insights bar, next to *Alerts* and *Metrics*.
Currently, only Text Classification tasks support clustering.
Each Cluster contains a number of samples that are semantically similar to one another (i.e. are near each other in the embedding space). We leverage our *Clustering and Custom Tokenization Algorithm* to cluster and explain the commonalities between samples in that cluster.
 #### How to make sense of clusters?
For every cluster, the *top common words* are shown in the cluster's card. These are tokens that appear with high frequency in the clustered samples and with low frequency in samples outside of this cluster. You can use these common words to get a sense of what
Average [Data Error Potential](/galileo/gen-ai-studio-products/galileo-ai-research/galileo-data-error-potential-dep), F1, and size are also shown on the cards. You can also sort your clusters by these metrics and use them to prioritize which clusters you inspect first.
Once you've identified a cluster of interest, you can click on the cluster card to filter the dataset to samples in that cluster. You can see where it is in the embeddings view, or inspect and browse the samples in table form.
#### Advanced: Cluster Summarization
Galileo leverages GPT models to generate a topic description and summary of your clusters. This can further help you get a sense for what the samples in the cluster are about.
#### How to make sense of clusters?
For every cluster, the *top common words* are shown in the cluster's card. These are tokens that appear with high frequency in the clustered samples and with low frequency in samples outside of this cluster. You can use these common words to get a sense of what
Average [Data Error Potential](/galileo/gen-ai-studio-products/galileo-ai-research/galileo-data-error-potential-dep), F1, and size are also shown on the cards. You can also sort your clusters by these metrics and use them to prioritize which clusters you inspect first.
Once you've identified a cluster of interest, you can click on the cluster card to filter the dataset to samples in that cluster. You can see where it is in the embeddings view, or inspect and browse the samples in table form.
#### Advanced: Cluster Summarization
Galileo leverages GPT models to generate a topic description and summary of your clusters. This can further help you get a sense for what the samples in the cluster are about.
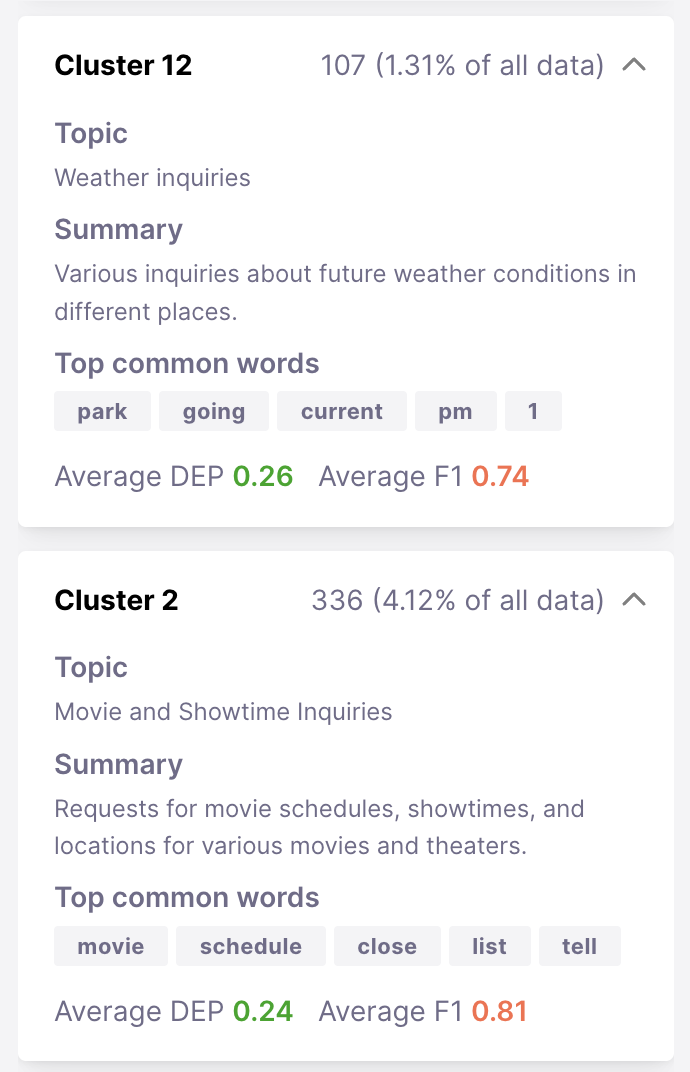 To enable this feature, hop over to your [Integrations](/galileo/how-to-and-faq/galileo-product-features/3p-integrations) page and enable your OpenAI integration. Summaries will start showing up on your future runs (i.e. they're not generated retroactively).
Note: We leverage OpenAI's APIs for this. If you enable this feature, some of your samples will be sent to OpenAI to generate the summaries
---
# Source: https://docs.galileo.ai/galileo/gen-ai-studio-products/galileo-evaluate/how-to/collaborate-with-other-personas.md
> ## Documentation Index
> Fetch the complete documentation index at: https://docs.galileo.ai/llms.txt
> Use this file to discover all available pages before exploring further.
# Collaborate with other personas
> Galileo Evaluate is geared for cross-functional collaboration. Most of the teams using Galileo consist of a mix of the following personas
To enable this feature, hop over to your [Integrations](/galileo/how-to-and-faq/galileo-product-features/3p-integrations) page and enable your OpenAI integration. Summaries will start showing up on your future runs (i.e. they're not generated retroactively).
Note: We leverage OpenAI's APIs for this. If you enable this feature, some of your samples will be sent to OpenAI to generate the summaries
---
# Source: https://docs.galileo.ai/galileo/gen-ai-studio-products/galileo-evaluate/how-to/collaborate-with-other-personas.md
> ## Documentation Index
> Fetch the complete documentation index at: https://docs.galileo.ai/llms.txt
> Use this file to discover all available pages before exploring further.
# Collaborate with other personas
> Galileo Evaluate is geared for cross-functional collaboration. Most of the teams using Galileo consist of a mix of the following personas
 * The AI Engineer: Responsible for building and productionizing an AI-powered feature or product.
* The PM or Subject Matter Expert: Often, a non-technical persona. Responsible for evaluating the quality and production-readiness of a feature or application.
* The Annotator: Often, the same as the Subject Matter Expert. Tasked with going through individual LLM requests and responses, performing qualitative evaluations and annotating the runs with findings.
To collaborate with other users, you need to [share your project](/galileo/gen-ai-studio-products/galileo-evaluate/how-to/share-a-project).
## How-to Guides for different personas
If you're an **AI Engineer,** check out the following sections:
* [Quickstart](/galileo/gen-ai-studio-products/galileo-evaluate/quickstart)
* Evaluate and Optimize [Prompts](/galileo/gen-ai-studio-products/galileo-evaluate/how-to/evaluate-and-optimize-prompts), [RAG Applications](/galileo/gen-ai-studio-products/galileo-evaluate/how-to/evaluate-and-optimize-rag-applications), [Agents or Chains](/galileo/gen-ai-studio-products/galileo-evaluate/how-to/evaluate-and-optimize-agents--chains-or-multi-step-workflows)
* [Register Custom Metrics](/galileo/gen-ai-studio-products/galileo-evaluate/how-to/register-custom-metrics)
* [Log Pre-generated Responses](/galileo/gen-ai-studio-products/galileo-evaluate/how-to/log-pre-generated-responses-in-python)
* [Prompt Management and Storage](/galileo/gen-ai-studio-products/galileo-evaluate/how-to/prompt-management-storage)
* Experiment with [Multiple Prompts](/galileo/gen-ai-studio-products/galileo-evaluate/how-to/experiment-with-multiple-prompts) or [Chain Workflows](/galileo/gen-ai-studio-products/galileo-evaluate/how-to/experiment-with-multiple-chain-workflows)
If you're a **PM or SME**, check out the following sections:
* [Choose your Guardrail Metrics](/galileo/gen-ai-studio-products/galileo-evaluate/how-to/choose-your-guardrail-metrics)
* Evaluate and Optimize [Prompts](/galileo/gen-ai-studio-products/galileo-evaluate/how-to/evaluate-and-optimize-prompts), [RAG Applications](/galileo/gen-ai-studio-products/galileo-evaluate/how-to/evaluate-and-optimize-rag-applications), [Agents or Chains](/galileo/gen-ai-studio-products/galileo-evaluate/how-to/evaluate-and-optimize-agents--chains-or-multi-step-workflows)
* [A/B Compare Prompts](/galileo/gen-ai-studio-products/galileo-evaluate/how-to/a-b-compare-prompts)
* [Evaluate with Human Feedback](/galileo/gen-ai-studio-products/galileo-evaluate/how-to/evaluate-with-human-feedback)
If you're an **Annotator**, check out:
* [Evaluate with Human Feedback](/galileo/gen-ai-studio-products/galileo-evaluate/how-to/evaluate-with-human-feedback)
---
# Source: https://docs.galileo.ai/galileo/galileo-nlp-studio/galileo-product-features/compare-across-runs.md
> ## Documentation Index
> Fetch the complete documentation index at: https://docs.galileo.ai/llms.txt
> Use this file to discover all available pages before exploring further.
# Compare Across Runs
> Track your experiments, data and models in one place
Training a model requires many runs, many iterations on the data and a lot of experiments across models and the parameters. This can quickly get messy to track.
Once you have created multiple Runs per Project within Galileo, it becomes critical to analyze and quantify progression or regression in terms of key metrics (F1, DEP, etc) for the whole dataset as well as critical subsets.
Galileo provides you with a single comparison view across all Runs within a Project or across Projects.
* The AI Engineer: Responsible for building and productionizing an AI-powered feature or product.
* The PM or Subject Matter Expert: Often, a non-technical persona. Responsible for evaluating the quality and production-readiness of a feature or application.
* The Annotator: Often, the same as the Subject Matter Expert. Tasked with going through individual LLM requests and responses, performing qualitative evaluations and annotating the runs with findings.
To collaborate with other users, you need to [share your project](/galileo/gen-ai-studio-products/galileo-evaluate/how-to/share-a-project).
## How-to Guides for different personas
If you're an **AI Engineer,** check out the following sections:
* [Quickstart](/galileo/gen-ai-studio-products/galileo-evaluate/quickstart)
* Evaluate and Optimize [Prompts](/galileo/gen-ai-studio-products/galileo-evaluate/how-to/evaluate-and-optimize-prompts), [RAG Applications](/galileo/gen-ai-studio-products/galileo-evaluate/how-to/evaluate-and-optimize-rag-applications), [Agents or Chains](/galileo/gen-ai-studio-products/galileo-evaluate/how-to/evaluate-and-optimize-agents--chains-or-multi-step-workflows)
* [Register Custom Metrics](/galileo/gen-ai-studio-products/galileo-evaluate/how-to/register-custom-metrics)
* [Log Pre-generated Responses](/galileo/gen-ai-studio-products/galileo-evaluate/how-to/log-pre-generated-responses-in-python)
* [Prompt Management and Storage](/galileo/gen-ai-studio-products/galileo-evaluate/how-to/prompt-management-storage)
* Experiment with [Multiple Prompts](/galileo/gen-ai-studio-products/galileo-evaluate/how-to/experiment-with-multiple-prompts) or [Chain Workflows](/galileo/gen-ai-studio-products/galileo-evaluate/how-to/experiment-with-multiple-chain-workflows)
If you're a **PM or SME**, check out the following sections:
* [Choose your Guardrail Metrics](/galileo/gen-ai-studio-products/galileo-evaluate/how-to/choose-your-guardrail-metrics)
* Evaluate and Optimize [Prompts](/galileo/gen-ai-studio-products/galileo-evaluate/how-to/evaluate-and-optimize-prompts), [RAG Applications](/galileo/gen-ai-studio-products/galileo-evaluate/how-to/evaluate-and-optimize-rag-applications), [Agents or Chains](/galileo/gen-ai-studio-products/galileo-evaluate/how-to/evaluate-and-optimize-agents--chains-or-multi-step-workflows)
* [A/B Compare Prompts](/galileo/gen-ai-studio-products/galileo-evaluate/how-to/a-b-compare-prompts)
* [Evaluate with Human Feedback](/galileo/gen-ai-studio-products/galileo-evaluate/how-to/evaluate-with-human-feedback)
If you're an **Annotator**, check out:
* [Evaluate with Human Feedback](/galileo/gen-ai-studio-products/galileo-evaluate/how-to/evaluate-with-human-feedback)
---
# Source: https://docs.galileo.ai/galileo/galileo-nlp-studio/galileo-product-features/compare-across-runs.md
> ## Documentation Index
> Fetch the complete documentation index at: https://docs.galileo.ai/llms.txt
> Use this file to discover all available pages before exploring further.
# Compare Across Runs
> Track your experiments, data and models in one place
Training a model requires many runs, many iterations on the data and a lot of experiments across models and the parameters. This can quickly get messy to track.
Once you have created multiple Runs per Project within Galileo, it becomes critical to analyze and quantify progression or regression in terms of key metrics (F1, DEP, etc) for the whole dataset as well as critical subsets.
Galileo provides you with a single comparison view across all Runs within a Project or across Projects.
 ---
# Source: https://docs.galileo.ai/galileo/gen-ai-studio-products/galileo-guardrail-metrics/completeness/completeness-luna.md
> ## Documentation Index
> Fetch the complete documentation index at: https://docs.galileo.ai/llms.txt
> Use this file to discover all available pages before exploring further.
# Completeness Luna
> Understand Galileo's Completeness Luna Metric
The metric is mainly intended for RAG workflows.
***Definition:*** Measures how thoroughly your model's response covered the relevant information available in the context provided.
***Calculation:*** Completeness Luna is computed using a fine-tuned in-house Galileo evaluation model. The model is a transformer-based encoder that is trained to identify the relevant and utilized information in the provided a query, context, and response. The same model is used to compute Chunk Adherence, Chunk Completeness, Chunk Attribution, and Utilization, and a single inference call is used to compute all the Luna metrics at once. The model is trained on carefully curated RAG datasets and optimized to closely align with the RAG Plus metrics.
For each token in the provided context, the model outputs a *relevance probability* and *utilization probability. Relevance probability* measures the extent to which the token is useful for answering the provided query. *Utilization probability measures the extent to which* the token affected the response.
Chunk Completeness is derived from relevance and utilization probabilities as the fraction of relevant AND utilized tokens out of all relevant tokens.
We recommend starting with "Luna" and seeing if this covers your needs. If you see the need for higher accuracy or would like explanations for the ratings, you can switch over to [Completeness
Plus](/galileo/gen-ai-studio-products/galileo-guardrail-metrics/completeness/completeness-plus).
---
# Source: https://docs.galileo.ai/galileo/gen-ai-studio-products/galileo-guardrail-metrics/completeness/completeness-plus.md
> ## Documentation Index
> Fetch the complete documentation index at: https://docs.galileo.ai/llms.txt
> Use this file to discover all available pages before exploring further.
# Completeness Plus
> Understand Galileo's Completeness Plus Metric
The metric is intended for RAG workflows.
***Definition:*** Measures how thoroughly your model's response covered the relevant information available in the context provided.
***Calculation:*** Completeness is computed by sending additional requests to an OpenAI LLM, using a carefully engineered chain-of-thought prompt that asks the model to determine what fraction of relevant information was covered in the response. The metric requests multiple distinct responses to this prompt, each of which produces an explanation along with a final numeric score between 0 and 1.
The Completeness score is an average over the individual scores.
We also surface one of the generated explanations. The surfaced explanation is chosen from the response whose *individual* score was closest to the *average* score over all the responses. For example, if we make 3 requests and receive the scores \[0.4, 0.5, 0.6], the Completeness score will be 0.5, and the explanation from the second response will be surfaced.
***Usefulness:*** To fix low *Completeness* values, we recommend adjusting the prompt to tell the model to include all the relevant information it can find in the provided context.
***Deep dive:*** to read more about the research behind this metric, see [RAG Quality Metrics using ChainPoll](/galileo/gen-ai-studio-products/galileo-ai-research/rag-quality-metrics-using-chainpoll).
*Note:* This metric is computed by prompting an LLM multiple times, and thus requires additional LLM calls to compute.
---
# Source: https://docs.galileo.ai/galileo/gen-ai-studio-products/galileo-guardrail-metrics/completeness.md
> ## Documentation Index
> Fetch the complete documentation index at: https://docs.galileo.ai/llms.txt
> Use this file to discover all available pages before exploring further.
# Completeness
> Understand Galileo's Completeness Metric
This metric is intended for RAG use cases and is only available if you [log your retriever's output](/galileo/gen-ai-studio-products/galileo-evaluate/how-to/evaluate-and-optimize-rag-applications).
***Definition:*** Measures how thoroughly your model's response covered the relevant information available in the context provided.
Completeness and Context Adherence are closely related, and designed to complement one another:
* Context Adherence answers the question, "is the model's response *consistent with* the information in the context?"
* Completeness answers the question, "is the relevant information in the context *fully reflected* in the model's response?"
In other words, if Context Adherence is "precision," then Completeness is "recall."
Consider this simple, stylized example that illustrates the distinction:
* User query: "Who was Galileo Galilei?"
* Context: "Galileo Galilei was an Italian astronomer."
* Model response: "Galileo Galilei was Italian."
This response would receive a perfect *Context Adherence* score: everything the model said is *supported* by the context.
But this is not an ideal response. The context also specified that Galileo was an astronomer, and the user probably wants to know that information as well.
Hence, this response would receive a low *Completeness* score. Tracking Completeness alongside Context Adherence allows you to detect cases like this one, where the model is "too reticent" and fails to mention relevant information.
***What to do when completeness is low?***
To fix low *Completeness* values, we recommend adjusting the prompt to tell the model to include all the relevant information it can find in the provided context.
### Luna vs Plus
We offer two ways of calculating Completeness: *Luna* and *Plus*.
[*Completeness Luna*](/galileo/gen-ai-studio-products/galileo-guardrail-metrics/completeness/completeness-luna) is computed using Galileo in-house small language models. They're free of cost, but lack 'explanations'. Completeness Luna is a cost effective way to scale up you RAG evaluation workflows.
[*Completeness Plus*](/galileo/gen-ai-studio-products/galileo-guardrail-metrics/completeness/completeness-plus) is computed using the [Chainpoll](/galileo/gen-ai-studio-products/galileo-ai-research/chainpoll) technique. It relies on OpenAI models so it incurs an additional cost. Completeness Plus has shown better results in internal benchmarks. Additionally, *Plus* offers explanations for its ratings (i.e. why a response was or was not complete).
---
# Source: https://docs.galileo.ai/galileo/gen-ai-studio-products/galileo-llm-fine-tune/console-walkthrough.md
> ## Documentation Index
> Fetch the complete documentation index at: https://docs.galileo.ai/llms.txt
> Use this file to discover all available pages before exploring further.
# Console Walkthrough
> Upon completing a run, you'll be taken to the Galileo Console.
By default, your Training split will be shown first. You can use the dropdown on the top-right to change it. The first thing you'll notice is your dataset on the right.
By default you will see on each row the Input, its Target (Expected Output), the Generated Output if available, and the [Data Error Potential (DEP)](/galileo/gen-ai-studio-products/galileo-ai-research/galileo-data-error-potential-dep) of the sample. The samples are sorted by DEP, showing the hardest samples first. Each Token in the Target also has a DEP value, which can easily be seen via highlighting.
---
# Source: https://docs.galileo.ai/galileo/gen-ai-studio-products/galileo-guardrail-metrics/completeness/completeness-luna.md
> ## Documentation Index
> Fetch the complete documentation index at: https://docs.galileo.ai/llms.txt
> Use this file to discover all available pages before exploring further.
# Completeness Luna
> Understand Galileo's Completeness Luna Metric
The metric is mainly intended for RAG workflows.
***Definition:*** Measures how thoroughly your model's response covered the relevant information available in the context provided.
***Calculation:*** Completeness Luna is computed using a fine-tuned in-house Galileo evaluation model. The model is a transformer-based encoder that is trained to identify the relevant and utilized information in the provided a query, context, and response. The same model is used to compute Chunk Adherence, Chunk Completeness, Chunk Attribution, and Utilization, and a single inference call is used to compute all the Luna metrics at once. The model is trained on carefully curated RAG datasets and optimized to closely align with the RAG Plus metrics.
For each token in the provided context, the model outputs a *relevance probability* and *utilization probability. Relevance probability* measures the extent to which the token is useful for answering the provided query. *Utilization probability measures the extent to which* the token affected the response.
Chunk Completeness is derived from relevance and utilization probabilities as the fraction of relevant AND utilized tokens out of all relevant tokens.
We recommend starting with "Luna" and seeing if this covers your needs. If you see the need for higher accuracy or would like explanations for the ratings, you can switch over to [Completeness
Plus](/galileo/gen-ai-studio-products/galileo-guardrail-metrics/completeness/completeness-plus).
---
# Source: https://docs.galileo.ai/galileo/gen-ai-studio-products/galileo-guardrail-metrics/completeness/completeness-plus.md
> ## Documentation Index
> Fetch the complete documentation index at: https://docs.galileo.ai/llms.txt
> Use this file to discover all available pages before exploring further.
# Completeness Plus
> Understand Galileo's Completeness Plus Metric
The metric is intended for RAG workflows.
***Definition:*** Measures how thoroughly your model's response covered the relevant information available in the context provided.
***Calculation:*** Completeness is computed by sending additional requests to an OpenAI LLM, using a carefully engineered chain-of-thought prompt that asks the model to determine what fraction of relevant information was covered in the response. The metric requests multiple distinct responses to this prompt, each of which produces an explanation along with a final numeric score between 0 and 1.
The Completeness score is an average over the individual scores.
We also surface one of the generated explanations. The surfaced explanation is chosen from the response whose *individual* score was closest to the *average* score over all the responses. For example, if we make 3 requests and receive the scores \[0.4, 0.5, 0.6], the Completeness score will be 0.5, and the explanation from the second response will be surfaced.
***Usefulness:*** To fix low *Completeness* values, we recommend adjusting the prompt to tell the model to include all the relevant information it can find in the provided context.
***Deep dive:*** to read more about the research behind this metric, see [RAG Quality Metrics using ChainPoll](/galileo/gen-ai-studio-products/galileo-ai-research/rag-quality-metrics-using-chainpoll).
*Note:* This metric is computed by prompting an LLM multiple times, and thus requires additional LLM calls to compute.
---
# Source: https://docs.galileo.ai/galileo/gen-ai-studio-products/galileo-guardrail-metrics/completeness.md
> ## Documentation Index
> Fetch the complete documentation index at: https://docs.galileo.ai/llms.txt
> Use this file to discover all available pages before exploring further.
# Completeness
> Understand Galileo's Completeness Metric
This metric is intended for RAG use cases and is only available if you [log your retriever's output](/galileo/gen-ai-studio-products/galileo-evaluate/how-to/evaluate-and-optimize-rag-applications).
***Definition:*** Measures how thoroughly your model's response covered the relevant information available in the context provided.
Completeness and Context Adherence are closely related, and designed to complement one another:
* Context Adherence answers the question, "is the model's response *consistent with* the information in the context?"
* Completeness answers the question, "is the relevant information in the context *fully reflected* in the model's response?"
In other words, if Context Adherence is "precision," then Completeness is "recall."
Consider this simple, stylized example that illustrates the distinction:
* User query: "Who was Galileo Galilei?"
* Context: "Galileo Galilei was an Italian astronomer."
* Model response: "Galileo Galilei was Italian."
This response would receive a perfect *Context Adherence* score: everything the model said is *supported* by the context.
But this is not an ideal response. The context also specified that Galileo was an astronomer, and the user probably wants to know that information as well.
Hence, this response would receive a low *Completeness* score. Tracking Completeness alongside Context Adherence allows you to detect cases like this one, where the model is "too reticent" and fails to mention relevant information.
***What to do when completeness is low?***
To fix low *Completeness* values, we recommend adjusting the prompt to tell the model to include all the relevant information it can find in the provided context.
### Luna vs Plus
We offer two ways of calculating Completeness: *Luna* and *Plus*.
[*Completeness Luna*](/galileo/gen-ai-studio-products/galileo-guardrail-metrics/completeness/completeness-luna) is computed using Galileo in-house small language models. They're free of cost, but lack 'explanations'. Completeness Luna is a cost effective way to scale up you RAG evaluation workflows.
[*Completeness Plus*](/galileo/gen-ai-studio-products/galileo-guardrail-metrics/completeness/completeness-plus) is computed using the [Chainpoll](/galileo/gen-ai-studio-products/galileo-ai-research/chainpoll) technique. It relies on OpenAI models so it incurs an additional cost. Completeness Plus has shown better results in internal benchmarks. Additionally, *Plus* offers explanations for its ratings (i.e. why a response was or was not complete).
---
# Source: https://docs.galileo.ai/galileo/gen-ai-studio-products/galileo-llm-fine-tune/console-walkthrough.md
> ## Documentation Index
> Fetch the complete documentation index at: https://docs.galileo.ai/llms.txt
> Use this file to discover all available pages before exploring further.
# Console Walkthrough
> Upon completing a run, you'll be taken to the Galileo Console.
By default, your Training split will be shown first. You can use the dropdown on the top-right to change it. The first thing you'll notice is your dataset on the right.
By default you will see on each row the Input, its Target (Expected Output), the Generated Output if available, and the [Data Error Potential (DEP)](/galileo/gen-ai-studio-products/galileo-ai-research/galileo-data-error-potential-dep) of the sample. The samples are sorted by DEP, showing the hardest samples first. Each Token in the Target also has a DEP value, which can easily be seen via highlighting.
 You can also view your samples in the [embeddings space](/galileo/how-to-and-faq/galileo-product-features/embeddings-view) of the model. This can help you get a semantic understanding of your dataset. Using features like *Color-By DEP,* you might discover pockets of problematic data (e.g. decision boundaries that might benefit from more samples or a cluster of garbage samples).
You can also view your samples in the [embeddings space](/galileo/how-to-and-faq/galileo-product-features/embeddings-view) of the model. This can help you get a semantic understanding of your dataset. Using features like *Color-By DEP,* you might discover pockets of problematic data (e.g. decision boundaries that might benefit from more samples or a cluster of garbage samples).
 Your left pane is called the [Insights Menu](/galileo/how-to-and-faq/galileo-product-features/insights-panel). On the top, you can see your dataset size and choose the metric you want to guide your exploration by (F1 by default). Size and metric value update as you add filters to your dataset.
Your main source of insights will be [Alerts](/galileo/how-to-and-faq/galileo-product-features/xray-insights), [Metrics](/galileo/how-to-and-faq/galileo-product-features/insights-panel), and [Clusters](/galileo/how-to-and-faq/galileo-product-features/clusters). Alerts are a distilled list of different issues we've identified in your dataset. Under *Metrics*, you'll find different charts to help you debug your data.
Clicking on an Alert will filter the dataset to the subset of data that corresponds to the Alert.
Your left pane is called the [Insights Menu](/galileo/how-to-and-faq/galileo-product-features/insights-panel). On the top, you can see your dataset size and choose the metric you want to guide your exploration by (F1 by default). Size and metric value update as you add filters to your dataset.
Your main source of insights will be [Alerts](/galileo/how-to-and-faq/galileo-product-features/xray-insights), [Metrics](/galileo/how-to-and-faq/galileo-product-features/insights-panel), and [Clusters](/galileo/how-to-and-faq/galileo-product-features/clusters). Alerts are a distilled list of different issues we've identified in your dataset. Under *Metrics*, you'll find different charts to help you debug your data.
Clicking on an Alert will filter the dataset to the subset of data that corresponds to the Alert.
 These charts are dynamic and update as you add different filters. They are also interactive - clicking on a class or group of classes will filter the dataset accordingly, allowing you to inspect and fix the samples.
These charts are dynamic and update as you add different filters. They are also interactive - clicking on a class or group of classes will filter the dataset accordingly, allowing you to inspect and fix the samples.
 The third tab is for your [Clusters](/galileo/how-to-and-faq/galileo-product-features/clusters). We automatically cluster your dataset taking into account frequent words and semantic distance. For each Cluster, we show you its average DEP score and the size of the cluster - factors you can use to determine which clusters are worth looking into.
We also show you the common words in the cluster, and, if you enable your OpenAI integration, we leverage GPT to generate summaries of your clusters (more details [here](/galileo/how-to-and-faq/galileo-product-features/clusters)).
The third tab is for your [Clusters](/galileo/how-to-and-faq/galileo-product-features/clusters). We automatically cluster your dataset taking into account frequent words and semantic distance. For each Cluster, we show you its average DEP score and the size of the cluster - factors you can use to determine which clusters are worth looking into.
We also show you the common words in the cluster, and, if you enable your OpenAI integration, we leverage GPT to generate summaries of your clusters (more details [here](/galileo/how-to-and-faq/galileo-product-features/clusters)).
 Analyzing the various Clusters side-by-side with the embeddings view is often a hepful way to discover interesting pockets of data.
Analyzing the various Clusters side-by-side with the embeddings view is often a hepful way to discover interesting pockets of data.
 ---
# Source: https://docs.galileo.ai/galileo/gen-ai-studio-products/galileo-guardrail-metrics/context-adherence/context-adherence-luna.md
> ## Documentation Index
> Fetch the complete documentation index at: https://docs.galileo.ai/llms.txt
> Use this file to discover all available pages before exploring further.
# Context Adherence Luna
> Understand Galileo's Context Adherence Luna Metric
***Definition:*** Measures whether your model's response was purely based on the context provided.
***Calculation:*** Context Adherence Luna is computed using a fine-tuned in-house Galileo evaluation model. The model is a transformer-based encoder that predicts the probability of *Context Adherence* for an input response and context. The model is trained on carefully curated RAG datasets and optimized to mimic the Context Adherence Plus metric.
The same model is used to compute Chunk Adherence, Chunk Completeness, Chunk Attribution and Utilization, and a single inference call is used to compute all the Luna metrics at once.
#### Explainability
The *Luna* model identifies which parts of the response are not adhering to the context provided. These sections can be highlighted in the response by clicking on the icon next to the *Context Adherence* metric value in *LLM* or *Chat* nodes.
---
# Source: https://docs.galileo.ai/galileo/gen-ai-studio-products/galileo-guardrail-metrics/context-adherence/context-adherence-luna.md
> ## Documentation Index
> Fetch the complete documentation index at: https://docs.galileo.ai/llms.txt
> Use this file to discover all available pages before exploring further.
# Context Adherence Luna
> Understand Galileo's Context Adherence Luna Metric
***Definition:*** Measures whether your model's response was purely based on the context provided.
***Calculation:*** Context Adherence Luna is computed using a fine-tuned in-house Galileo evaluation model. The model is a transformer-based encoder that predicts the probability of *Context Adherence* for an input response and context. The model is trained on carefully curated RAG datasets and optimized to mimic the Context Adherence Plus metric.
The same model is used to compute Chunk Adherence, Chunk Completeness, Chunk Attribution and Utilization, and a single inference call is used to compute all the Luna metrics at once.
#### Explainability
The *Luna* model identifies which parts of the response are not adhering to the context provided. These sections can be highlighted in the response by clicking on the icon next to the *Context Adherence* metric value in *LLM* or *Chat* nodes.
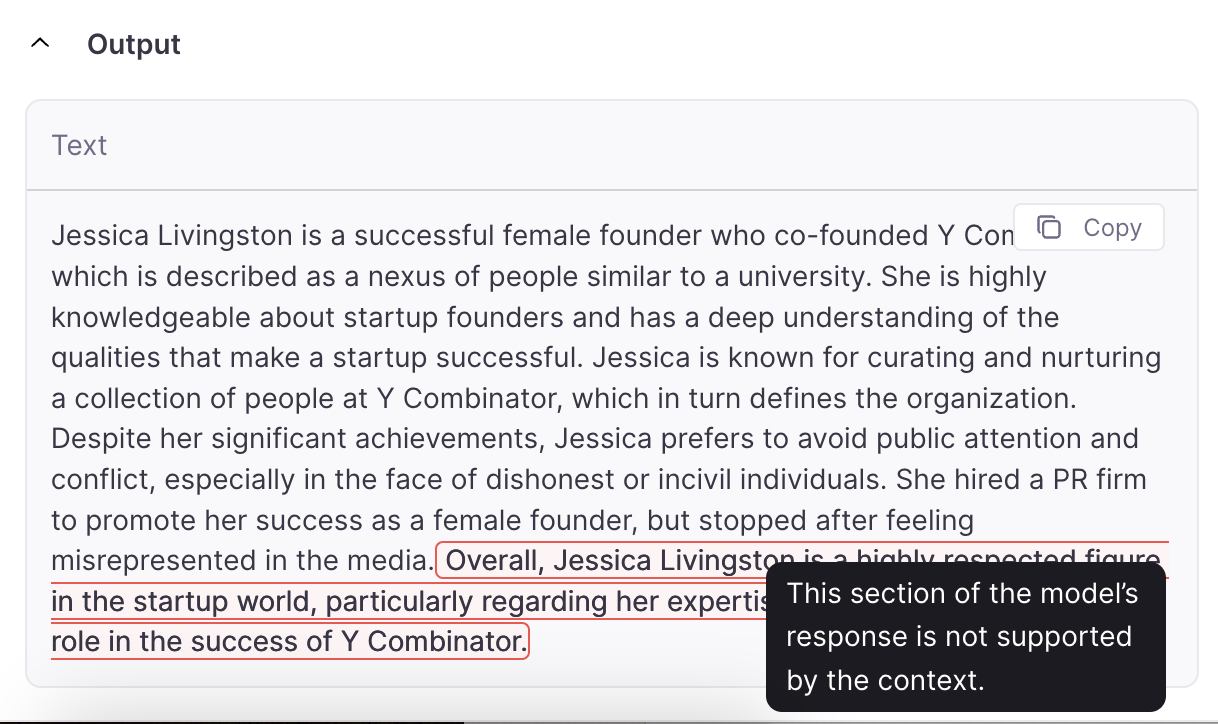 #### *What to Do When Context Adherence Is Low?*
When a response is highly adherent to the context (i.e., it has a value of 1 or close to 1), it strictly includes information from the provided context. However, when a response is not adherent (i.e., it has a value of 0 or close to 0), it likely contains facts not present in the given context.
Several factors can contribute to low context adherence:
1. **Insufficient Context**: If the source document lacks key information needed to answer the user's question, the response may be incomplete or off-topic. To address this, users should consider using various context enrichment strategies to ensure that the source documents retrieved contain the necessary information to answer the user's questions effectively.
2. **Lack of Internal Reasoning and Creativity**: While Retrieval-Augmented Generation (RAG) focuses on factual grounding, it doesn't directly enhance the internal reasoning processes of the LLM. This limitation can cause the model to struggle with logic or common-sense reasoning, potentially resulting in nonsensical outputs even if the facts are accurate.
3. **Lack of Contextual Awareness**: Although RAG provides factual grounding for the language model, it might not fully understand the nuances of the prompt or user intent. This can lead to the model incorporating irrelevant information or missing key points, thus affecting the overall quality of the response.
To improve context adherence, we recommend:
1. Ensuring your context DB has all the necessary info to answer the question
2. Adjusting the prompt to tell the model to stick to the information it's given in the context.
---
# Source: https://docs.galileo.ai/galileo/gen-ai-studio-products/galileo-guardrail-metrics/context-adherence/context-adherence-plus.md
> ## Documentation Index
> Fetch the complete documentation index at: https://docs.galileo.ai/llms.txt
> Use this file to discover all available pages before exploring further.
# Context Adherence Plus
> Understand Galileo's Context Adherence Plus Metric
***Definition:*** Measures whether your model's response was purely based on the context provided.
***Calculation:*** Context Adherence Plus is computed by sending additional requests to OpenAI's GPT3.5 (by default) and GPT4, using a carefully engineered chain-of-thought prompt that asks the model to judge whether or not the response was grounded in the context. The metric requests multiple distinct responses to this prompt, each of which produces an explanation along with a final judgment: yes or no. The *Context Adherence Plus* score is the fraction of "yes" responses, divided by the total number of responses.
We also surface one of the generated explanations. The surfaced explanation is always chosen to align with the majority judgment among the responses. In other words, if the score is greater than 0.5, the explanation will provide an argument that the response is grounded; if the score is less than 0.5, the explanation will provide an argument that it is not grounded.
#### *What to Do When Context Adherence Is Low?*
When a response is highly adherent to the context (i.e., it has a value of 1 or close to 1), it strictly includes information from the provided context. However, when a response is not adherent (i.e., it has a value of 0 or close to 0), it likely contains facts not present in the given context.
Several factors can contribute to low context adherence:
1. **Insufficient Context**: If the source document lacks key information needed to answer the user's question, the response may be incomplete or off-topic. To address this, users should consider using various context enrichment strategies to ensure that the source documents retrieved contain the necessary information to answer the user's questions effectively.
2. **Lack of Internal Reasoning and Creativity**: While Retrieval-Augmented Generation (RAG) focuses on factual grounding, it doesn't directly enhance the internal reasoning processes of the LLM. This limitation can cause the model to struggle with logic or common-sense reasoning, potentially resulting in nonsensical outputs even if the facts are accurate.
3. **Lack of Contextual Awareness**: Although RAG provides factual grounding for the language model, it might not fully understand the nuances of the prompt or user intent. This can lead to the model incorporating irrelevant information or missing key points, thus affecting the overall quality of the response.
To improve context adherence, we recommend:
1. Ensuring your context DB has all the necessary info to answer the question
2. Adjusting the prompt to tell the model to stick to the information it's given in the context.
***Deep dive:*** to read more about the research behind this metric, see [RAG Quality Metrics using ChainPoll](/galileo/gen-ai-studio-products/galileo-ai-research/rag-quality-metrics-using-chainpoll).
*Note:* This metric is computed by prompting an LLM multiple times, and thus requires additional LLM calls to compute.
---
# Source: https://docs.galileo.ai/galileo/gen-ai-studio-products/galileo-observe/faq/context-adherence-vs-instruction-adherence.md
# Source: https://docs.galileo.ai/galileo/gen-ai-studio-products/galileo-guardrail-metrics/faq/context-adherence-vs-instruction-adherence.md
# Source: https://docs.galileo.ai/galileo/gen-ai-studio-products/galileo-evaluate/faq/context-adherence-vs-instruction-adherence.md
> ## Documentation Index
> Fetch the complete documentation index at: https://docs.galileo.ai/llms.txt
> Use this file to discover all available pages before exploring further.
# Context vs. Instruction Adherence | Galileo Evaluate FAQ
> Understand the distinctions between Context Adherence and Instruction Adherence metrics in Galileo Evaluate to assess generative AI outputs accurately.
#### What are Instruction Adherence and Context Adherence
These two metrics sound similar but are built to measure different things.
* [Context Adherence](/galileo/gen-ai-studio-products/galileo-guardrail-metrics/context-adherence): Detects instances where the model stated information in its response that was not included in the provided context.
* [Instruction Adherence](/galileo/gen-ai-studio-products/galileo-guardrail-metrics/instruction-adherence): Detects instances where the model response did not follow the instructions in its prompt.
| Metric | Intention | How to Use | Further Reading |
| --------------------- | ----------------------------------------------------------- | ----------------------------------- | --------------------------------------------------------------------------------------- |
| Context Adherence | Was the information in the response grounded on the context | Low adherence means improve context | [Link](/galileo/gen-ai-studio-products/galileo-guardrail-metrics/context-adherence) |
| Instruction Adherence | Did the model follow its instructions | Low adherence means improve prompt | [Link](/galileo/gen-ai-studio-products/galileo-guardrail-metrics/instruction-adherence) |
Instruction Adherence is a [Chainpoll-powered metric](/galileo-ai-research/chainpoll). Context Adherence has two flavors: Plus (Chainpoll-powered), or Luna (powered by in-house Luna models).
#### Context Adherence
Context Adherence refers to whether the output matches the context it was provided. It is not looking
at the steps, but rather at the full context. This is more useful in RAG use-cases where you are providing
additional information to supplement the output. With this metric, correctly answering based on the provided
information will return a score closer to “1”, and output information which is not supported by the input
would return a score closer to “0”.
#### Instruction Adherence
You can use Instruction Adherence to gauge whether the instructions in your prompt, such as “you are x, first do y,
then do z” aligns with the output of that prompt. If it does, then Instruction Adherence will return that the steps
were followed correctly and a score closer to “1”. If it fails to follow instructions, Instruction Adherence will
return the reasoning and a score closer to “0”.
---
# Source: https://docs.galileo.ai/galileo/gen-ai-studio-products/galileo-guardrail-metrics/context-adherence.md
> ## Documentation Index
> Fetch the complete documentation index at: https://docs.galileo.ai/llms.txt
> Use this file to discover all available pages before exploring further.
# Context Adherence
> Understand Galileo's Context Adherence Metric
***Definition:*** *Context Adherence* is a measurement of *closed-domain* *hallucinations:* cases where your model said things that were not provided in the context.
If a response is *adherent* to the context (i.e. it has a value of 1 or close to 1), it only contains information given in the context. If a response is *not adherent* (i.e. it has a value of 0 or close to 0), it's likely to contain facts not included in the context provided to the model.
### Luna vs Plus
We offer two ways of calculating Context Adherence: *Luna* and *Plus*.
[*Context Adherence Luna*](/galileo/gen-ai-studio-products/galileo-guardrail-metrics/context-adherence/context-adherence-luna) is computed using Galileo in-house small language models (Luna). They're free of cost, but lack 'explanations'. Context Adherence Luna is a cost effective way to scale up you RAG evaluation workflows.
[*Context Adherence Plus*](/galileo/gen-ai-studio-products/galileo-guardrail-metrics/completeness/completeness-plus) is computed using the [Chainpoll](/galileo/gen-ai-studio-products/galileo-ai-research/chainpoll) technique. It relies on OpenAI models so it incurs an additional cost. Context Adherence Plus has shown better results in internal benchmarks. Additionally, *Plus* offers explanations for its ratings (i.e. why something was or was not adherent).
---
# Source: https://docs.galileo.ai/galileo/gen-ai-studio-products/galileo-evaluate/how-to/continuous-learning-via-human-feedback.md
> ## Documentation Index
> Fetch the complete documentation index at: https://docs.galileo.ai/llms.txt
> Use this file to discover all available pages before exploring further.
# Customizing your LLM-powered metrics via CLHF
> Learn how to customize your LLM-powered metrics with Continuous Learning via Human Feedback.
As you start using Galileo Preset LLM-powered metrics (e.g. Context Adherence or Instruction Adherence),
or start creating your own LLM-powered metrics via [Autogen](/galileo/gen-ai-studio-products/galileo-evaluate/how-to/autogen-metrics), you might not always agree with the results.
False positives or False Negatives in metric values are often due to domain edge cases that aren't handled
in the metric's prompt.
Galileo helps you address this problem and adapt and continuously improve metrics via Continuous Learning
via Human Feedback.
## How it works
As you identify mistakes in your metrics, you can provide 'feedback' to 'auto-improve' your metrics. Your
feedback gets translated (by LLMs) into few-shot examples that are appended to the Metric's prompt. Few-shot
examples help your LLM-as-a-judge in a few ways:
* Examples with your domain data teach it what to expect from your domain.
* Concrete examples on edge cases teach your LLM-as-a-judge how to deal with outlier scenarios.
This process has shown to increase accuracy of metrics by 20-30%.
CLHF-ed metrics are scoped to the project. I.e. you can have different teams customizing the same metric in different ways and not impact each other's projects.
### What to enter as feedback
When entering feedback, enter a critique of the explanation generated by the erroneous metric. Be as precise
as possible in your critique, outlining the exact reason behind the desired metric value.
## How to use it
See this video on how to use Continuous Learning via Human Feedback to improve your metric accuracy:
## Which metrics is this supported on?
* Context Adherence
* Instruction Adherence
* Correctness
* Any LLM-as-a-judge generated via [Galileo's Autogen](/galileo/gen-ai-studio-products/galileo-evaluate/how-to/autogen-metrics) feature
---
# Source: https://docs.galileo.ai/galileo/gen-ai-studio-products/galileo-guardrail-metrics/correctness.md
> ## Documentation Index
> Fetch the complete documentation index at: https://docs.galileo.ai/llms.txt
> Use this file to discover all available pages before exploring further.
# Correctness
> Understand Galileo's Correctness Metric
***Definition:*** Measures whether a given model response is factual or not. *Correctness (f.k.a. Factuality)* is a good way of uncovering *open-domain hallucinations:* factual errors that don't relate to any specific documents or context. A high Correctness score means the response is more likely to be accurate vs a low response indicates a high probability for hallucination.
If the response is *factual* (i.e. it has a value of 1 or close to 1), the information is believed to be correct. If a response is *not factual* (i.e. it has a value of 0 or close to 0), it's likely to contain factual errors.
***Calculation:*** *Correctness* is computed by sending an additional requests to OpenAI's GPT4-o, using a carefully engineered chain-of-thought prompt that asks the model to judge whether or not the response was factually accurate. The metric requests multiple distinct responses to this prompt, each of which produces an explanation along with a final judgment: yes or no. The Correctness score is the fraction of "yes" responses, divided by the total number of responses.
We also surface one of the generated explanations. The surfaced explanation is always chosen to align with the majority judgment among the responses. In other words, if the score is greater than 0.5, the explanation will provide an argument that the response is factual; if the score is less than 0.5, the explanation will provide an argument that it is not factual.
*Note:* This metric is computed by prompting an LLM multiple times, and thus requires additional LLM calls to compute.
***What to do when Correctness is low?***
When an response has a low Correctness score, it's likely that the response has non-factual information. We recommend:
1. Flag and examine response that are likely to be non-factual
2. Adjust the prompt to tell the model to stick to the information it's given in the context.
3. Take precaution measures to stop non-factual responses from reaching the end user.
***How to differentiate between Correctness and Context Adherence?***
Correctness measures whether a model response has factually correct information, regardless of whether that piece of information is contained in the context.
Here we are illustrating the difference between Correctness and Context Adherence using a text-to-sql example.
---
# Source: https://docs.galileo.ai/galileo/gen-ai-studio-products/galileo-evaluate/how-to/create-an-evaluation-set.md
> ## Documentation Index
> Fetch the complete documentation index at: https://docs.galileo.ai/llms.txt
> Use this file to discover all available pages before exploring further.
# Create an Evaluation Set
> Before starting your experiments, we recommend creating an evaluation set.
**Best Practices:**
1. **Representativeness:** Ensure that the evaluation set is representative of the real-world data or the population of interest. This means the data should reflect the full range of variations expected in the actual use case, including different demographics, behaviors, or other relevant characteristics.
2. **Separation from Training Data:** The evaluation set should be entirely separate from the training dataset. Using different data ensures that you are testing the application's ability to generalize to new, unseen data.
3. **Sufficient Size:** The evaluation set should be large enough to provide statistically meaningful results. The size will depend on the complexity of the application and the variability of the data. As a rule of thumb, we recommend 50-100 data points for most basic use cases. A few hundred for more mature ones.
4. **Update Regularly:** As more data becomes available, or as the real-world conditions change, update the evaluation set to continue reflecting the target environment accurately. This is especially important for models deployed in rapidly changing fields.
5. **Over-represent edge cases:** Include tough scenarios you want your application to handle well (e.g. prompt injections, abusive requests, angry users, irrelevant questions). It's important to include these to battle-test your application against outlier and abusive behavior.
Your Evaluation Set should stay constant throughout your experiments. This will allow you to make apple-to-apples comparisons for the runs on your projects.
Note: Using GPT4 or similar can be a quick and easy way to bootstrap an evaluation set. We recommend manually going over the questions and editing as well.
###
**Running Evaluations on your Eval Set**
Once you have your Eval Set, you're ready to start your first evaluation run.
* If you have not written any code yet and are looking to evaluate a model and template for your use case, check out [Creating Prompt Runs](/galileo/gen-ai-studio-products/galileo-evaluate/quickstart).
* If you have an application or prototype you'd like to evaluate, check out [Integrating Evaluate into my existing application](/galileo/gen-ai-studio-products/galileo-evaluate/quickstart/integrate-evaluate-into-my-existing-application-with-python).
---
# Source: https://docs.galileo.ai/api-reference/evaluate/create-workflows-run.md
> ## Documentation Index
> Fetch the complete documentation index at: https://docs.galileo.ai/llms.txt
> Use this file to discover all available pages before exploring further.
# Create a new Evaluate Run
> Create a new Evaluate run with workflows.
Use this endpoint to create a new Evaluate run with workflows. The request body should contain the `workflows` to be ingested and evaluated.
Additionally, specify the `project_id` or `project_name` to which the workflows should be ingested. If the project does not exist, it will be created. If the project exists, the workflows will be logged to it. If both `project_id` and `project_name` are provided, `project_id` will take precedence. The `run_name` is optional and will be auto-generated (timestamp-based) if not provided.
The body is also expected to include the configuration for the scorers to be used in the evaluation. This configuration will be used to evaluate the workflows and generate the results.
### WorkflowStep
A workflow step is the atomic unit of logging to Galileo. They represent a single execution of a workflow, such as a chain, agent, or a RAG execution. Workflows can have multiple steps, each of which can be a different type of node, such as an LLM, Retriever, or Tool.
You can log multiple workflows in a single request. Each workflow step must have the following fields:
* `type`: The type of the workflow.
* `input`: The input to the workflow.
* `output`: The output of the workflow.
## Examples
### LLM Step
```json theme={null}
{
"type": "llm",
"input": "What is the capital of France?",
"output": "Paris"
}
```
### Retriever Step
```json theme={null}
{
"type": "retriever",
"input": "What is the capital of France?",
"output": [{ "content": "Paris is the capital and largest city of France." }]
}
```
### Multi-Step
Workflow steps of type `workflow`, `agent` or `chain` can have sub-steps with children. A workflow with a retriver and an LLM step would look like this:
```json theme={null}
{
"type": "workflow",
"input": "What is the capital of France?",
"output": "Paris",
"steps": [
{
"type": "retriever",
"input": "What is the capital of France?",
"output": [{ "content": "Paris is the capital and largest city of France." }]
},
{
"type": "llm",
"input": "What is the capital of France?",
"output": "Paris"
}
]
}
```
## OpenAPI
````yaml POST /v1/evaluate/runs
openapi: 3.1.0
info:
title: FastAPI
version: 0.1.0
servers:
- url: https://api.staging.galileo.ai
description: Galileo Public APIs - staging
security: []
paths:
/v1/evaluate/runs:
post:
tags:
- evaluate
summary: Create Workflows Run
description: >-
Create a new Evaluate run with workflows.
Use this endpoint to create a new Evaluate run with workflows. The
request body should contain the `workflows` to be ingested and
evaluated.
Additionally, specify the `project_id` or `project_name` to which the
workflows should be ingested. If the project does not exist, it will be
created. If the project exists, the workflows will be logged to it. If
both `project_id` and `project_name` are provided, `project_id` will
take precedence. The `run_name` is optional and will be auto-generated
(timestamp-based) if not provided.
The body is also expected to include the configuration for the scorers
to be used in the evaluation. This configuration will be used to
evaluate the workflows and generate the results.
operationId: create_workflows_run_v1_evaluate_runs_post
requestBody:
content:
application/json:
schema:
$ref: '#/components/schemas/EvaluateRunRequest'
required: true
responses:
'200':
description: Successful Response
content:
application/json:
schema:
$ref: '#/components/schemas/EvaluateRunResponse'
'422':
description: Validation Error
content:
application/json:
schema:
$ref: '#/components/schemas/HTTPValidationError'
security:
- APIKeyHeader: []
- OAuth2PasswordBearer: []
- HTTPBasic: []
components:
schemas:
EvaluateRunRequest:
properties:
scorers:
items:
oneOf:
- $ref: '#/components/schemas/AgenticWorkflowSuccessScorer'
- $ref: '#/components/schemas/AgenticSessionSuccessScorer'
- $ref: '#/components/schemas/BleuScorer'
- $ref: '#/components/schemas/ChunkAttributionUtilizationScorer'
- $ref: '#/components/schemas/CompletenessScorer'
- $ref: '#/components/schemas/ContextAdherenceScorer'
- $ref: '#/components/schemas/ContextRelevanceScorer'
- $ref: '#/components/schemas/CorrectnessScorer'
- $ref: '#/components/schemas/GroundTruthAdherenceScorer'
- $ref: '#/components/schemas/InputPIIScorer'
- $ref: '#/components/schemas/InputSexistScorer'
- $ref: '#/components/schemas/InputToneScorer'
- $ref: '#/components/schemas/InputToxicityScorer'
- $ref: '#/components/schemas/InstructionAdherenceScorer'
- $ref: '#/components/schemas/OutputPIIScorer'
- $ref: '#/components/schemas/OutputSexistScorer'
- $ref: '#/components/schemas/OutputToneScorer'
- $ref: '#/components/schemas/OutputToxicityScorer'
- $ref: '#/components/schemas/PromptInjectionScorer'
- $ref: '#/components/schemas/PromptPerplexityScorer'
- $ref: '#/components/schemas/RougeScorer'
- $ref: '#/components/schemas/ToolErrorRateScorer'
- $ref: '#/components/schemas/ToolSelectionQualityScorer'
- $ref: '#/components/schemas/UncertaintyScorer'
discriminator:
propertyName: name
mapping:
agentic_session_success: '#/components/schemas/AgenticSessionSuccessScorer'
agentic_workflow_success: '#/components/schemas/AgenticWorkflowSuccessScorer'
bleu: '#/components/schemas/BleuScorer'
chunk_attribution_utilization: '#/components/schemas/ChunkAttributionUtilizationScorer'
completeness: '#/components/schemas/CompletenessScorer'
context_adherence: '#/components/schemas/ContextAdherenceScorer'
context_relevance: '#/components/schemas/ContextRelevanceScorer'
correctness: '#/components/schemas/CorrectnessScorer'
ground_truth_adherence: '#/components/schemas/GroundTruthAdherenceScorer'
input_pii: '#/components/schemas/InputPIIScorer'
input_sexist: '#/components/schemas/InputSexistScorer'
input_tone: '#/components/schemas/InputToneScorer'
input_toxicity: '#/components/schemas/InputToxicityScorer'
instruction_adherence: '#/components/schemas/InstructionAdherenceScorer'
output_pii: '#/components/schemas/OutputPIIScorer'
output_sexist: '#/components/schemas/OutputSexistScorer'
output_tone: '#/components/schemas/OutputToneScorer'
output_toxicity: '#/components/schemas/OutputToxicityScorer'
prompt_injection: '#/components/schemas/PromptInjectionScorer'
prompt_perplexity: '#/components/schemas/PromptPerplexityScorer'
rouge: '#/components/schemas/RougeScorer'
tool_error_rate: '#/components/schemas/ToolErrorRateScorer'
tool_selection_quality: '#/components/schemas/ToolSelectionQualityScorer'
uncertainty: '#/components/schemas/UncertaintyScorer'
type: array
title: Scorers
description: List of Galileo scorers to enable.
registered_scorers:
items:
$ref: '#/components/schemas/RegisteredScorerConfig'
type: array
title: Registered Scorers
description: List of registered scorers to enable.
generated_scorers:
items:
$ref: '#/components/schemas/GeneratedScorerConfig'
type: array
title: Generated Scorers
description: List of generated scorers to enable.
finetuned_scorers:
items:
$ref: '#/components/schemas/FinetunedScorerConfig'
type: array
title: Finetuned Scorers
description: List of finetuned scorers to enable.
workflows:
items:
oneOf:
- $ref: '#/components/schemas/WorkflowStep'
- $ref: '#/components/schemas/ChainStep'
- $ref: '#/components/schemas/LlmStep'
- $ref: '#/components/schemas/RetrieverStep'
- $ref: '#/components/schemas/ToolStep'
- $ref: '#/components/schemas/AgentStep'
discriminator:
propertyName: type
mapping:
agent: '#/components/schemas/AgentStep'
chain: '#/components/schemas/ChainStep'
llm: '#/components/schemas/LlmStep'
retriever: '#/components/schemas/RetrieverStep'
tool: '#/components/schemas/ToolStep'
workflow: '#/components/schemas/WorkflowStep'
type: array
minItems: 1
title: Workflows
description: List of workflows to include in the run.
project_id:
anyOf:
- type: string
format: uuid4
- type: 'null'
title: Project Id
description: Evaluate Project ID to which the run should be associated.
project_name:
anyOf:
- type: string
- type: 'null'
title: Project Name
description: >-
Evaluate Project name to which the run should be associated. If the
project does not exist, it will be created.
run_name:
anyOf:
- type: string
- type: 'null'
title: Run Name
description: >-
Name of the run. If no name is provided, a timestamp-based name will
be generated.
type: object
required:
- workflows
title: EvaluateRunRequest
examples:
- project_name: my-evaluate-project
run_name: my-evaluate-run
scorers:
- name: correctness
- name: output_pii
workflows:
- created_at_ns: 1769195848702731000
duration_ns: 0
input: who is a smart LLM?
metadata: {}
name: llm
output: I am!
type: llm
- project_id: 00000000-0000-0000-0000-000000000000
registered_scorers:
- name: my_registered_scorer
run_name: my-evaluate-run
workflows:
- created_at_ns: 1769195848702784500
duration_ns: 0
input: who is a smart LLM?
metadata: {}
name: llm
output: I am!
type: llm
EvaluateRunResponse:
properties:
message:
type: string
title: Message
project_id:
type: string
format: uuid4
title: Project Id
project_name:
type: string
title: Project Name
run_id:
type: string
format: uuid4
title: Run Id
run_name:
type: string
title: Run Name
workflows_count:
type: integer
title: Workflows Count
records_count:
type: integer
title: Records Count
type: object
required:
- message
- project_id
- project_name
- run_id
- run_name
- workflows_count
- records_count
title: EvaluateRunResponse
HTTPValidationError:
properties:
detail:
items:
$ref: '#/components/schemas/ValidationError'
type: array
title: Detail
type: object
title: HTTPValidationError
AgenticWorkflowSuccessScorer:
properties:
name:
type: string
const: agentic_workflow_success
title: Name
default: agentic_workflow_success
filters:
anyOf:
- items:
oneOf:
- $ref: '#/components/schemas/NodeNameFilter'
- $ref: '#/components/schemas/MetadataFilter'
discriminator:
propertyName: name
mapping:
metadata: '#/components/schemas/MetadataFilter'
node_name: '#/components/schemas/NodeNameFilter'
type: array
- type: 'null'
title: Filters
description: List of filters to apply to the scorer.
type:
type: string
enum:
- luna
- plus
title: Type
default: plus
model_name:
anyOf:
- type: string
- type: 'null'
title: Model Name
description: Alias of the model to use for the scorer.
num_judges:
anyOf:
- type: integer
maximum: 10
minimum: 1
- type: 'null'
title: Num Judges
description: Number of judges for the scorer.
type: object
title: AgenticWorkflowSuccessScorer
AgenticSessionSuccessScorer:
properties:
name:
type: string
const: agentic_session_success
title: Name
default: agentic_session_success
filters:
anyOf:
- items:
oneOf:
- $ref: '#/components/schemas/NodeNameFilter'
- $ref: '#/components/schemas/MetadataFilter'
discriminator:
propertyName: name
mapping:
metadata: '#/components/schemas/MetadataFilter'
node_name: '#/components/schemas/NodeNameFilter'
type: array
- type: 'null'
title: Filters
description: List of filters to apply to the scorer.
type:
type: string
enum:
- luna
- plus
title: Type
default: plus
model_name:
anyOf:
- type: string
- type: 'null'
title: Model Name
description: Alias of the model to use for the scorer.
num_judges:
anyOf:
- type: integer
maximum: 10
minimum: 1
- type: 'null'
title: Num Judges
description: Number of judges for the scorer.
type: object
title: AgenticSessionSuccessScorer
BleuScorer:
properties:
name:
type: string
const: bleu
title: Name
default: bleu
filters:
anyOf:
- items:
oneOf:
- $ref: '#/components/schemas/NodeNameFilter'
- $ref: '#/components/schemas/MetadataFilter'
discriminator:
propertyName: name
mapping:
metadata: '#/components/schemas/MetadataFilter'
node_name: '#/components/schemas/NodeNameFilter'
type: array
- type: 'null'
title: Filters
description: List of filters to apply to the scorer.
type: object
title: BleuScorer
ChunkAttributionUtilizationScorer:
properties:
name:
type: string
const: chunk_attribution_utilization
title: Name
default: chunk_attribution_utilization
filters:
anyOf:
- items:
oneOf:
- $ref: '#/components/schemas/NodeNameFilter'
- $ref: '#/components/schemas/MetadataFilter'
discriminator:
propertyName: name
mapping:
metadata: '#/components/schemas/MetadataFilter'
node_name: '#/components/schemas/NodeNameFilter'
type: array
- type: 'null'
title: Filters
description: List of filters to apply to the scorer.
type:
type: string
enum:
- luna
- plus
title: Type
default: luna
model_name:
anyOf:
- type: string
- type: 'null'
title: Model Name
description: Alias of the model to use for the scorer.
type: object
title: ChunkAttributionUtilizationScorer
CompletenessScorer:
properties:
name:
type: string
const: completeness
title: Name
default: completeness
filters:
anyOf:
- items:
oneOf:
- $ref: '#/components/schemas/NodeNameFilter'
- $ref: '#/components/schemas/MetadataFilter'
discriminator:
propertyName: name
mapping:
metadata: '#/components/schemas/MetadataFilter'
node_name: '#/components/schemas/NodeNameFilter'
type: array
- type: 'null'
title: Filters
description: List of filters to apply to the scorer.
type:
type: string
enum:
- luna
- plus
title: Type
default: luna
model_name:
anyOf:
- type: string
- type: 'null'
title: Model Name
description: Alias of the model to use for the scorer.
num_judges:
anyOf:
- type: integer
maximum: 10
minimum: 1
- type: 'null'
title: Num Judges
description: Number of judges for the scorer.
type: object
title: CompletenessScorer
ContextAdherenceScorer:
properties:
name:
type: string
const: context_adherence
title: Name
default: context_adherence
filters:
anyOf:
- items:
oneOf:
- $ref: '#/components/schemas/NodeNameFilter'
- $ref: '#/components/schemas/MetadataFilter'
discriminator:
propertyName: name
mapping:
metadata: '#/components/schemas/MetadataFilter'
node_name: '#/components/schemas/NodeNameFilter'
type: array
- type: 'null'
title: Filters
description: List of filters to apply to the scorer.
type:
type: string
enum:
- luna
- plus
title: Type
default: luna
model_name:
anyOf:
- type: string
- type: 'null'
title: Model Name
description: Alias of the model to use for the scorer.
num_judges:
anyOf:
- type: integer
maximum: 10
minimum: 1
- type: 'null'
title: Num Judges
description: Number of judges for the scorer.
type: object
title: ContextAdherenceScorer
ContextRelevanceScorer:
properties:
name:
type: string
const: context_relevance
title: Name
default: context_relevance
filters:
anyOf:
- items:
oneOf:
- $ref: '#/components/schemas/NodeNameFilter'
- $ref: '#/components/schemas/MetadataFilter'
discriminator:
propertyName: name
mapping:
metadata: '#/components/schemas/MetadataFilter'
node_name: '#/components/schemas/NodeNameFilter'
type: array
- type: 'null'
title: Filters
description: List of filters to apply to the scorer.
type: object
title: ContextRelevanceScorer
CorrectnessScorer:
properties:
name:
type: string
const: correctness
title: Name
default: correctness
filters:
anyOf:
- items:
oneOf:
- $ref: '#/components/schemas/NodeNameFilter'
- $ref: '#/components/schemas/MetadataFilter'
discriminator:
propertyName: name
mapping:
metadata: '#/components/schemas/MetadataFilter'
node_name: '#/components/schemas/NodeNameFilter'
type: array
- type: 'null'
title: Filters
description: List of filters to apply to the scorer.
type:
type: string
const: plus
title: Type
default: plus
model_name:
anyOf:
- type: string
- type: 'null'
title: Model Name
description: Alias of the model to use for the scorer.
num_judges:
anyOf:
- type: integer
maximum: 10
minimum: 1
- type: 'null'
title: Num Judges
description: Number of judges for the scorer.
type: object
title: CorrectnessScorer
GroundTruthAdherenceScorer:
properties:
name:
type: string
const: ground_truth_adherence
title: Name
default: ground_truth_adherence
filters:
anyOf:
- items:
oneOf:
- $ref: '#/components/schemas/NodeNameFilter'
- $ref: '#/components/schemas/MetadataFilter'
discriminator:
propertyName: name
mapping:
metadata: '#/components/schemas/MetadataFilter'
node_name: '#/components/schemas/NodeNameFilter'
type: array
- type: 'null'
title: Filters
description: List of filters to apply to the scorer.
type:
type: string
const: plus
title: Type
default: plus
model_name:
anyOf:
- type: string
- type: 'null'
title: Model Name
description: Alias of the model to use for the scorer.
num_judges:
anyOf:
- type: integer
maximum: 10
minimum: 1
- type: 'null'
title: Num Judges
description: Number of judges for the scorer.
type: object
title: GroundTruthAdherenceScorer
InputPIIScorer:
properties:
name:
type: string
const: input_pii
title: Name
default: input_pii
filters:
anyOf:
- items:
oneOf:
- $ref: '#/components/schemas/NodeNameFilter'
- $ref: '#/components/schemas/MetadataFilter'
discriminator:
propertyName: name
mapping:
metadata: '#/components/schemas/MetadataFilter'
node_name: '#/components/schemas/NodeNameFilter'
type: array
- type: 'null'
title: Filters
description: List of filters to apply to the scorer.
type: object
title: InputPIIScorer
InputSexistScorer:
properties:
name:
type: string
const: input_sexist
title: Name
default: input_sexist
filters:
anyOf:
- items:
oneOf:
- $ref: '#/components/schemas/NodeNameFilter'
- $ref: '#/components/schemas/MetadataFilter'
discriminator:
propertyName: name
mapping:
metadata: '#/components/schemas/MetadataFilter'
node_name: '#/components/schemas/NodeNameFilter'
type: array
- type: 'null'
title: Filters
description: List of filters to apply to the scorer.
type:
type: string
enum:
- luna
- plus
title: Type
default: luna
model_name:
anyOf:
- type: string
- type: 'null'
title: Model Name
description: Alias of the model to use for the scorer.
num_judges:
anyOf:
- type: integer
maximum: 10
minimum: 1
- type: 'null'
title: Num Judges
description: Number of judges for the scorer.
type: object
title: InputSexistScorer
InputToneScorer:
properties:
name:
type: string
const: input_tone
title: Name
default: input_tone
filters:
anyOf:
- items:
oneOf:
- $ref: '#/components/schemas/NodeNameFilter'
- $ref: '#/components/schemas/MetadataFilter'
discriminator:
propertyName: name
mapping:
metadata: '#/components/schemas/MetadataFilter'
node_name: '#/components/schemas/NodeNameFilter'
type: array
- type: 'null'
title: Filters
description: List of filters to apply to the scorer.
type: object
title: InputToneScorer
InputToxicityScorer:
properties:
name:
type: string
const: input_toxicity
title: Name
default: input_toxicity
filters:
anyOf:
- items:
oneOf:
- $ref: '#/components/schemas/NodeNameFilter'
- $ref: '#/components/schemas/MetadataFilter'
discriminator:
propertyName: name
mapping:
metadata: '#/components/schemas/MetadataFilter'
node_name: '#/components/schemas/NodeNameFilter'
type: array
- type: 'null'
title: Filters
description: List of filters to apply to the scorer.
type:
type: string
enum:
- luna
- plus
title: Type
default: luna
model_name:
anyOf:
- type: string
- type: 'null'
title: Model Name
description: Alias of the model to use for the scorer.
num_judges:
anyOf:
- type: integer
maximum: 10
minimum: 1
- type: 'null'
title: Num Judges
description: Number of judges for the scorer.
type: object
title: InputToxicityScorer
InstructionAdherenceScorer:
properties:
name:
type: string
const: instruction_adherence
title: Name
default: instruction_adherence
filters:
anyOf:
- items:
oneOf:
- $ref: '#/components/schemas/NodeNameFilter'
- $ref: '#/components/schemas/MetadataFilter'
discriminator:
propertyName: name
mapping:
metadata: '#/components/schemas/MetadataFilter'
node_name: '#/components/schemas/NodeNameFilter'
type: array
- type: 'null'
title: Filters
description: List of filters to apply to the scorer.
type:
type: string
const: plus
title: Type
default: plus
model_name:
anyOf:
- type: string
- type: 'null'
title: Model Name
description: Alias of the model to use for the scorer.
num_judges:
anyOf:
- type: integer
maximum: 10
minimum: 1
- type: 'null'
title: Num Judges
description: Number of judges for the scorer.
type: object
title: InstructionAdherenceScorer
OutputPIIScorer:
properties:
name:
type: string
const: output_pii
title: Name
default: output_pii
filters:
anyOf:
- items:
oneOf:
- $ref: '#/components/schemas/NodeNameFilter'
- $ref: '#/components/schemas/MetadataFilter'
discriminator:
propertyName: name
mapping:
metadata: '#/components/schemas/MetadataFilter'
node_name: '#/components/schemas/NodeNameFilter'
type: array
- type: 'null'
title: Filters
description: List of filters to apply to the scorer.
type: object
title: OutputPIIScorer
OutputSexistScorer:
properties:
name:
type: string
const: output_sexist
title: Name
default: output_sexist
filters:
anyOf:
- items:
oneOf:
- $ref: '#/components/schemas/NodeNameFilter'
- $ref: '#/components/schemas/MetadataFilter'
discriminator:
propertyName: name
mapping:
metadata: '#/components/schemas/MetadataFilter'
node_name: '#/components/schemas/NodeNameFilter'
type: array
- type: 'null'
title: Filters
description: List of filters to apply to the scorer.
type:
type: string
enum:
- luna
- plus
title: Type
default: luna
model_name:
anyOf:
- type: string
- type: 'null'
title: Model Name
description: Alias of the model to use for the scorer.
num_judges:
anyOf:
- type: integer
maximum: 10
minimum: 1
- type: 'null'
title: Num Judges
description: Number of judges for the scorer.
type: object
title: OutputSexistScorer
OutputToneScorer:
properties:
name:
type: string
const: output_tone
title: Name
default: output_tone
filters:
anyOf:
- items:
oneOf:
- $ref: '#/components/schemas/NodeNameFilter'
- $ref: '#/components/schemas/MetadataFilter'
discriminator:
propertyName: name
mapping:
metadata: '#/components/schemas/MetadataFilter'
node_name: '#/components/schemas/NodeNameFilter'
type: array
- type: 'null'
title: Filters
description: List of filters to apply to the scorer.
type: object
title: OutputToneScorer
OutputToxicityScorer:
properties:
name:
type: string
const: output_toxicity
title: Name
default: output_toxicity
filters:
anyOf:
- items:
oneOf:
- $ref: '#/components/schemas/NodeNameFilter'
- $ref: '#/components/schemas/MetadataFilter'
discriminator:
propertyName: name
mapping:
metadata: '#/components/schemas/MetadataFilter'
node_name: '#/components/schemas/NodeNameFilter'
type: array
- type: 'null'
title: Filters
description: List of filters to apply to the scorer.
type:
type: string
enum:
- luna
- plus
title: Type
default: luna
model_name:
anyOf:
- type: string
- type: 'null'
title: Model Name
description: Alias of the model to use for the scorer.
num_judges:
anyOf:
- type: integer
maximum: 10
minimum: 1
- type: 'null'
title: Num Judges
description: Number of judges for the scorer.
type: object
title: OutputToxicityScorer
PromptInjectionScorer:
properties:
name:
type: string
const: prompt_injection
title: Name
default: prompt_injection
filters:
anyOf:
- items:
oneOf:
- $ref: '#/components/schemas/NodeNameFilter'
- $ref: '#/components/schemas/MetadataFilter'
discriminator:
propertyName: name
mapping:
metadata: '#/components/schemas/MetadataFilter'
node_name: '#/components/schemas/NodeNameFilter'
type: array
- type: 'null'
title: Filters
description: List of filters to apply to the scorer.
type:
type: string
enum:
- luna
- plus
title: Type
default: luna
model_name:
anyOf:
- type: string
- type: 'null'
title: Model Name
description: Alias of the model to use for the scorer.
num_judges:
anyOf:
- type: integer
maximum: 10
minimum: 1
- type: 'null'
title: Num Judges
description: Number of judges for the scorer.
type: object
title: PromptInjectionScorer
PromptPerplexityScorer:
properties:
name:
type: string
const: prompt_perplexity
title: Name
default: prompt_perplexity
filters:
anyOf:
- items:
oneOf:
- $ref: '#/components/schemas/NodeNameFilter'
- $ref: '#/components/schemas/MetadataFilter'
discriminator:
propertyName: name
mapping:
metadata: '#/components/schemas/MetadataFilter'
node_name: '#/components/schemas/NodeNameFilter'
type: array
- type: 'null'
title: Filters
description: List of filters to apply to the scorer.
type: object
title: PromptPerplexityScorer
RougeScorer:
properties:
name:
type: string
const: rouge
title: Name
default: rouge
filters:
anyOf:
- items:
oneOf:
- $ref: '#/components/schemas/NodeNameFilter'
- $ref: '#/components/schemas/MetadataFilter'
discriminator:
propertyName: name
mapping:
metadata: '#/components/schemas/MetadataFilter'
node_name: '#/components/schemas/NodeNameFilter'
type: array
- type: 'null'
title: Filters
description: List of filters to apply to the scorer.
type: object
title: RougeScorer
ToolErrorRateScorer:
properties:
name:
type: string
const: tool_error_rate
title: Name
default: tool_error_rate
filters:
anyOf:
- items:
oneOf:
- $ref: '#/components/schemas/NodeNameFilter'
- $ref: '#/components/schemas/MetadataFilter'
discriminator:
propertyName: name
mapping:
metadata: '#/components/schemas/MetadataFilter'
node_name: '#/components/schemas/NodeNameFilter'
type: array
- type: 'null'
title: Filters
description: List of filters to apply to the scorer.
type:
type: string
enum:
- luna
- plus
title: Type
default: plus
model_name:
anyOf:
- type: string
- type: 'null'
title: Model Name
description: Alias of the model to use for the scorer.
type: object
title: ToolErrorRateScorer
ToolSelectionQualityScorer:
properties:
name:
type: string
const: tool_selection_quality
title: Name
default: tool_selection_quality
filters:
anyOf:
- items:
oneOf:
- $ref: '#/components/schemas/NodeNameFilter'
- $ref: '#/components/schemas/MetadataFilter'
discriminator:
propertyName: name
mapping:
metadata: '#/components/schemas/MetadataFilter'
node_name: '#/components/schemas/NodeNameFilter'
type: array
- type: 'null'
title: Filters
description: List of filters to apply to the scorer.
type:
type: string
enum:
- luna
- plus
title: Type
default: plus
model_name:
anyOf:
- type: string
- type: 'null'
title: Model Name
description: Alias of the model to use for the scorer.
num_judges:
anyOf:
- type: integer
maximum: 10
minimum: 1
- type: 'null'
title: Num Judges
description: Number of judges for the scorer.
type: object
title: ToolSelectionQualityScorer
UncertaintyScorer:
properties:
name:
type: string
const: uncertainty
title: Name
default: uncertainty
filters:
anyOf:
- items:
oneOf:
- $ref: '#/components/schemas/NodeNameFilter'
- $ref: '#/components/schemas/MetadataFilter'
discriminator:
propertyName: name
mapping:
metadata: '#/components/schemas/MetadataFilter'
node_name: '#/components/schemas/NodeNameFilter'
type: array
- type: 'null'
title: Filters
description: List of filters to apply to the scorer.
type: object
title: UncertaintyScorer
RegisteredScorerConfig:
properties:
name:
type: string
title: Name
description: Name of the scorer to enable.
filters:
anyOf:
- items:
oneOf:
- $ref: '#/components/schemas/NodeNameFilter'
- $ref: '#/components/schemas/MetadataFilter'
discriminator:
propertyName: name
mapping:
metadata: '#/components/schemas/MetadataFilter'
node_name: '#/components/schemas/NodeNameFilter'
type: array
- type: 'null'
title: Filters
description: List of filters to apply to the scorer.
type: object
required:
- name
title: RegisteredScorerConfig
GeneratedScorerConfig:
properties:
name:
type: string
title: Name
description: Name of the scorer to enable.
filters:
anyOf:
- items:
oneOf:
- $ref: '#/components/schemas/NodeNameFilter'
- $ref: '#/components/schemas/MetadataFilter'
discriminator:
propertyName: name
mapping:
metadata: '#/components/schemas/MetadataFilter'
node_name: '#/components/schemas/NodeNameFilter'
type: array
- type: 'null'
title: Filters
description: List of filters to apply to the scorer.
type: object
required:
- name
title: GeneratedScorerConfig
FinetunedScorerConfig:
properties:
name:
type: string
title: Name
description: Name of the scorer to enable.
filters:
anyOf:
- items:
oneOf:
- $ref: '#/components/schemas/NodeNameFilter'
- $ref: '#/components/schemas/MetadataFilter'
discriminator:
propertyName: name
mapping:
metadata: '#/components/schemas/MetadataFilter'
node_name: '#/components/schemas/NodeNameFilter'
type: array
- type: 'null'
title: Filters
description: List of filters to apply to the scorer.
type: object
required:
- name
title: FinetunedScorerConfig
WorkflowStep:
properties:
type:
type: string
const: workflow
title: Type
description: Type of the step. By default, it is set to workflow.
default: workflow
input:
anyOf:
- type: string
- $ref: '#/components/schemas/Document-Input'
- $ref: '#/components/schemas/Message'
- additionalProperties: true
type: object
- items:
type: string
type: array
- items:
$ref: '#/components/schemas/Document-Input'
type: array
- items:
$ref: '#/components/schemas/Message'
type: array
- items:
additionalProperties:
type: string
type: object
type: array
- items:
additionalProperties: true
type: object
type: array
title: Input
description: Input to the step.
redacted_input:
anyOf:
- type: string
- $ref: '#/components/schemas/Document-Input'
- $ref: '#/components/schemas/Message'
- additionalProperties: true
type: object
- items:
type: string
type: array
- items:
$ref: '#/components/schemas/Document-Input'
type: array
- items:
$ref: '#/components/schemas/Message'
type: array
- items:
additionalProperties:
type: string
type: object
type: array
- items:
additionalProperties: true
type: object
type: array
- type: 'null'
title: Redacted Input
description: >-
Redacted input of the step. This is used to redact sensitive
information.
output:
anyOf:
- type: string
- $ref: '#/components/schemas/Document-Input'
- $ref: '#/components/schemas/Message'
- additionalProperties: true
type: object
- items:
type: string
type: array
- items:
$ref: '#/components/schemas/Document-Input'
type: array
- items:
$ref: '#/components/schemas/Message'
type: array
- items:
additionalProperties:
type: string
type: object
type: array
- items:
additionalProperties: true
type: object
type: array
title: Output
description: Output of the step.
default: ''
redacted_output:
anyOf:
- type: string
- $ref: '#/components/schemas/Document-Input'
- $ref: '#/components/schemas/Message'
- additionalProperties: true
type: object
- items:
type: string
type: array
- items:
$ref: '#/components/schemas/Document-Input'
type: array
- items:
$ref: '#/components/schemas/Message'
type: array
- items:
additionalProperties:
type: string
type: object
type: array
- items:
additionalProperties: true
type: object
type: array
- type: 'null'
title: Redacted Output
description: >-
Redacted output of the step. This is used to redact sensitive
information.
name:
type: string
title: Name
description: Name of the step.
default: ''
created_at_ns:
type: integer
title: Created At Ns
description: Timestamp of the step's creation, as nanoseconds since epoch.
duration_ns:
type: integer
title: Duration Ns
description: Duration of the step in nanoseconds.
default: 0
metadata:
additionalProperties:
type: string
type: object
title: Metadata
description: Metadata associated with this step.
status_code:
anyOf:
- type: integer
- type: 'null'
title: Status Code
description: Status code of the step. Used for logging failed/errored steps.
ground_truth:
anyOf:
- type: string
- type: 'null'
title: Ground Truth
description: Ground truth expected output for the step.
steps:
items:
oneOf:
- $ref: '#/components/schemas/WorkflowStep'
- $ref: '#/components/schemas/ChainStep'
- $ref: '#/components/schemas/LlmStep'
- $ref: '#/components/schemas/RetrieverStep'
- $ref: '#/components/schemas/ToolStep'
- $ref: '#/components/schemas/AgentStep'
discriminator:
propertyName: type
mapping:
agent: '#/components/schemas/AgentStep'
chain: '#/components/schemas/ChainStep'
llm: '#/components/schemas/LlmStep'
retriever: '#/components/schemas/RetrieverStep'
tool: '#/components/schemas/ToolStep'
workflow: '#/components/schemas/WorkflowStep'
type: array
title: Steps
description: Steps in the workflow.
parent:
anyOf:
- $ref: '#/components/schemas/StepWithChildren'
- type: 'null'
description: Parent node of the current node. For internal use only.
type: object
required:
- input
title: WorkflowStep
ChainStep:
properties:
type:
type: string
const: chain
title: Type
description: Type of the step. By default, it is set to chain.
default: chain
input:
anyOf:
- type: string
- $ref: '#/components/schemas/Document-Input'
- $ref: '#/components/schemas/Message'
- additionalProperties: true
type: object
- items:
type: string
type: array
- items:
$ref: '#/components/schemas/Document-Input'
type: array
- items:
$ref: '#/components/schemas/Message'
type: array
- items:
additionalProperties:
type: string
type: object
type: array
- items:
additionalProperties: true
type: object
type: array
title: Input
description: Input to the step.
redacted_input:
anyOf:
- type: string
- $ref: '#/components/schemas/Document-Input'
- $ref: '#/components/schemas/Message'
- additionalProperties: true
type: object
- items:
type: string
type: array
- items:
$ref: '#/components/schemas/Document-Input'
type: array
- items:
$ref: '#/components/schemas/Message'
type: array
- items:
additionalProperties:
type: string
type: object
type: array
- items:
additionalProperties: true
type: object
type: array
- type: 'null'
title: Redacted Input
description: >-
Redacted input of the step. This is used to redact sensitive
information.
output:
anyOf:
- type: string
- $ref: '#/components/schemas/Document-Input'
- $ref: '#/components/schemas/Message'
- additionalProperties: true
type: object
- items:
type: string
type: array
- items:
$ref: '#/components/schemas/Document-Input'
type: array
- items:
$ref: '#/components/schemas/Message'
type: array
- items:
additionalProperties:
type: string
type: object
type: array
- items:
additionalProperties: true
type: object
type: array
title: Output
description: Output of the step.
default: ''
redacted_output:
anyOf:
- type: string
- $ref: '#/components/schemas/Document-Input'
- $ref: '#/components/schemas/Message'
- additionalProperties: true
type: object
- items:
type: string
type: array
- items:
$ref: '#/components/schemas/Document-Input'
type: array
- items:
$ref: '#/components/schemas/Message'
type: array
- items:
additionalProperties:
type: string
type: object
type: array
- items:
additionalProperties: true
type: object
type: array
- type: 'null'
title: Redacted Output
description: >-
Redacted output of the step. This is used to redact sensitive
information.
name:
type: string
title: Name
description: Name of the step.
default: ''
created_at_ns:
type: integer
title: Created At Ns
description: Timestamp of the step's creation, as nanoseconds since epoch.
duration_ns:
type: integer
title: Duration Ns
description: Duration of the step in nanoseconds.
default: 0
metadata:
additionalProperties:
type: string
type: object
title: Metadata
description: Metadata associated with this step.
status_code:
anyOf:
- type: integer
- type: 'null'
title: Status Code
description: Status code of the step. Used for logging failed/errored steps.
ground_truth:
anyOf:
- type: string
- type: 'null'
title: Ground Truth
description: Ground truth expected output for the step.
steps:
items:
oneOf:
- $ref: '#/components/schemas/WorkflowStep'
- $ref: '#/components/schemas/ChainStep'
- $ref: '#/components/schemas/LlmStep'
- $ref: '#/components/schemas/RetrieverStep'
- $ref: '#/components/schemas/ToolStep'
- $ref: '#/components/schemas/AgentStep'
discriminator:
propertyName: type
mapping:
agent: '#/components/schemas/AgentStep'
chain: '#/components/schemas/ChainStep'
llm: '#/components/schemas/LlmStep'
retriever: '#/components/schemas/RetrieverStep'
tool: '#/components/schemas/ToolStep'
workflow: '#/components/schemas/WorkflowStep'
type: array
title: Steps
description: Steps in the workflow.
parent:
anyOf:
- $ref: '#/components/schemas/StepWithChildren'
- type: 'null'
description: Parent node of the current node. For internal use only.
type: object
required:
- input
title: ChainStep
LlmStep:
properties:
type:
type: string
const: llm
title: Type
description: Type of the step. By default, it is set to llm.
default: llm
input:
anyOf:
- type: string
- additionalProperties:
type: string
type: object
- $ref: '#/components/schemas/Message'
- items:
type: string
type: array
- items:
additionalProperties:
type: string
type: object
type: array
- items:
$ref: '#/components/schemas/Message'
type: array
title: Input
description: Input to the LLM step.
redacted_input:
anyOf:
- type: string
- additionalProperties:
type: string
type: object
- $ref: '#/components/schemas/Message'
- items:
type: string
type: array
- items:
additionalProperties:
type: string
type: object
type: array
- items:
$ref: '#/components/schemas/Message'
type: array
- type: 'null'
title: Redacted Input
description: >-
Redacted input of the LLM step. This is used to redact sensitive
information.
output:
anyOf:
- type: string
- additionalProperties:
type: string
type: object
- $ref: '#/components/schemas/Message'
- items:
type: string
type: array
- items:
additionalProperties:
type: string
type: object
type: array
- items:
$ref: '#/components/schemas/Message'
type: array
title: Output
description: Output of the LLM step.
default: ''
redacted_output:
anyOf:
- type: string
- additionalProperties:
type: string
type: object
- $ref: '#/components/schemas/Message'
- items:
type: string
type: array
- items:
additionalProperties:
type: string
type: object
type: array
- items:
$ref: '#/components/schemas/Message'
type: array
- type: 'null'
title: Redacted Output
description: >-
Redacted output of the LLM step. This is used to redact sensitive
information.
name:
type: string
title: Name
description: Name of the step.
default: ''
created_at_ns:
type: integer
title: Created At Ns
description: Timestamp of the step's creation, as nanoseconds since epoch.
duration_ns:
type: integer
title: Duration Ns
description: Duration of the step in nanoseconds.
default: 0
metadata:
additionalProperties:
type: string
type: object
title: Metadata
description: Metadata associated with this step.
status_code:
anyOf:
- type: integer
- type: 'null'
title: Status Code
description: Status code of the step. Used for logging failed/errored steps.
ground_truth:
anyOf:
- type: string
- type: 'null'
title: Ground Truth
description: Ground truth expected output for the step.
tools:
anyOf:
- items:
additionalProperties: true
type: object
type: array
- type: 'null'
title: Tools
description: List of available tools passed to the LLM on invocation.
model:
anyOf:
- type: string
- type: 'null'
title: Model
description: Model used for this step.
input_tokens:
anyOf:
- type: integer
- type: 'null'
title: Input Tokens
description: Number of input tokens.
output_tokens:
anyOf:
- type: integer
- type: 'null'
title: Output Tokens
description: Number of output tokens.
total_tokens:
anyOf:
- type: integer
- type: 'null'
title: Total Tokens
description: Total number of tokens.
temperature:
anyOf:
- type: number
- type: 'null'
title: Temperature
description: Temperature used for generation.
time_to_first_token_ms:
anyOf:
- type: number
- type: 'null'
title: Time To First Token Ms
description: Time to first token in milliseconds.
type: object
required:
- input
title: LlmStep
RetrieverStep:
properties:
type:
type: string
const: retriever
title: Type
description: Type of the step. By default, it is set to retriever.
default: retriever
input:
type: string
title: Input
description: Input query to the retriever.
redacted_input:
anyOf:
- type: string
- type: 'null'
title: Redacted Input
description: >-
Redacted input of the retriever step. This is used to redact
sensitive information.
output:
items:
$ref: '#/components/schemas/Document-Input'
type: array
title: Output
description: >-
Documents retrieved from the retriever. This can be a list of
strings or `Document`s.
redacted_output:
anyOf:
- items:
$ref: '#/components/schemas/Document-Input'
type: array
- type: 'null'
title: Redacted Output
description: >-
Redacted output of the retriever step. This is used to redact
sensitive information.
name:
type: string
title: Name
description: Name of the step.
default: ''
created_at_ns:
type: integer
title: Created At Ns
description: Timestamp of the step's creation, as nanoseconds since epoch.
duration_ns:
type: integer
title: Duration Ns
description: Duration of the step in nanoseconds.
default: 0
metadata:
additionalProperties:
type: string
type: object
title: Metadata
description: Metadata associated with this step.
status_code:
anyOf:
- type: integer
- type: 'null'
title: Status Code
description: Status code of the step. Used for logging failed/errored steps.
ground_truth:
anyOf:
- type: string
- type: 'null'
title: Ground Truth
description: Ground truth expected output for the step.
type: object
required:
- input
title: RetrieverStep
ToolStep:
properties:
type:
type: string
const: tool
title: Type
description: Type of the step. By default, it is set to tool.
default: tool
input:
anyOf:
- type: string
- $ref: '#/components/schemas/Document-Input'
- $ref: '#/components/schemas/Message'
- additionalProperties: true
type: object
- items:
type: string
type: array
- items:
$ref: '#/components/schemas/Document-Input'
type: array
- items:
$ref: '#/components/schemas/Message'
type: array
- items:
additionalProperties:
type: string
type: object
type: array
- items:
additionalProperties: true
type: object
type: array
title: Input
description: Input to the step.
redacted_input:
anyOf:
- type: string
- $ref: '#/components/schemas/Document-Input'
- $ref: '#/components/schemas/Message'
- additionalProperties: true
type: object
- items:
type: string
type: array
- items:
$ref: '#/components/schemas/Document-Input'
type: array
- items:
$ref: '#/components/schemas/Message'
type: array
- items:
additionalProperties:
type: string
type: object
type: array
- items:
additionalProperties: true
type: object
type: array
- type: 'null'
title: Redacted Input
description: >-
Redacted input of the step. This is used to redact sensitive
information.
output:
anyOf:
- type: string
- $ref: '#/components/schemas/Document-Input'
- $ref: '#/components/schemas/Message'
- additionalProperties: true
type: object
- items:
type: string
type: array
- items:
$ref: '#/components/schemas/Document-Input'
type: array
- items:
$ref: '#/components/schemas/Message'
type: array
- items:
additionalProperties:
type: string
type: object
type: array
- items:
additionalProperties: true
type: object
type: array
title: Output
description: Output of the step.
default: ''
redacted_output:
anyOf:
- type: string
- $ref: '#/components/schemas/Document-Input'
- $ref: '#/components/schemas/Message'
- additionalProperties: true
type: object
- items:
type: string
type: array
- items:
$ref: '#/components/schemas/Document-Input'
type: array
- items:
$ref: '#/components/schemas/Message'
type: array
- items:
additionalProperties:
type: string
type: object
type: array
- items:
additionalProperties: true
type: object
type: array
- type: 'null'
title: Redacted Output
description: >-
Redacted output of the step. This is used to redact sensitive
information.
name:
type: string
title: Name
description: Name of the step.
default: ''
created_at_ns:
type: integer
title: Created At Ns
description: Timestamp of the step's creation, as nanoseconds since epoch.
duration_ns:
type: integer
title: Duration Ns
description: Duration of the step in nanoseconds.
default: 0
metadata:
additionalProperties:
type: string
type: object
title: Metadata
description: Metadata associated with this step.
status_code:
anyOf:
- type: integer
- type: 'null'
title: Status Code
description: Status code of the step. Used for logging failed/errored steps.
ground_truth:
anyOf:
- type: string
- type: 'null'
title: Ground Truth
description: Ground truth expected output for the step.
type: object
required:
- input
title: ToolStep
AgentStep:
properties:
type:
type: string
const: agent
title: Type
description: Type of the step. By default, it is set to agent.
default: agent
input:
anyOf:
- type: string
- $ref: '#/components/schemas/Document-Input'
- $ref: '#/components/schemas/Message'
- additionalProperties: true
type: object
- items:
type: string
type: array
- items:
$ref: '#/components/schemas/Document-Input'
type: array
- items:
$ref: '#/components/schemas/Message'
type: array
- items:
additionalProperties:
type: string
type: object
type: array
- items:
additionalProperties: true
type: object
type: array
title: Input
description: Input to the step.
redacted_input:
anyOf:
- type: string
- $ref: '#/components/schemas/Document-Input'
- $ref: '#/components/schemas/Message'
- additionalProperties: true
type: object
- items:
type: string
type: array
- items:
$ref: '#/components/schemas/Document-Input'
type: array
- items:
$ref: '#/components/schemas/Message'
type: array
- items:
additionalProperties:
type: string
type: object
type: array
- items:
additionalProperties: true
type: object
type: array
- type: 'null'
title: Redacted Input
description: >-
Redacted input of the step. This is used to redact sensitive
information.
output:
anyOf:
- type: string
- $ref: '#/components/schemas/Document-Input'
- $ref: '#/components/schemas/Message'
- additionalProperties: true
type: object
- items:
type: string
type: array
- items:
$ref: '#/components/schemas/Document-Input'
type: array
- items:
$ref: '#/components/schemas/Message'
type: array
- items:
additionalProperties:
type: string
type: object
type: array
- items:
additionalProperties: true
type: object
type: array
title: Output
description: Output of the step.
default: ''
redacted_output:
anyOf:
- type: string
- $ref: '#/components/schemas/Document-Input'
- $ref: '#/components/schemas/Message'
- additionalProperties: true
type: object
- items:
type: string
type: array
- items:
$ref: '#/components/schemas/Document-Input'
type: array
- items:
$ref: '#/components/schemas/Message'
type: array
- items:
additionalProperties:
type: string
type: object
type: array
- items:
additionalProperties: true
type: object
type: array
- type: 'null'
title: Redacted Output
description: >-
Redacted output of the step. This is used to redact sensitive
information.
name:
type: string
title: Name
description: Name of the step.
default: ''
created_at_ns:
type: integer
title: Created At Ns
description: Timestamp of the step's creation, as nanoseconds since epoch.
duration_ns:
type: integer
title: Duration Ns
description: Duration of the step in nanoseconds.
default: 0
metadata:
additionalProperties:
type: string
type: object
title: Metadata
description: Metadata associated with this step.
status_code:
anyOf:
- type: integer
- type: 'null'
title: Status Code
description: Status code of the step. Used for logging failed/errored steps.
ground_truth:
anyOf:
- type: string
- type: 'null'
title: Ground Truth
description: Ground truth expected output for the step.
steps:
items:
oneOf:
- $ref: '#/components/schemas/WorkflowStep'
- $ref: '#/components/schemas/ChainStep'
- $ref: '#/components/schemas/LlmStep'
- $ref: '#/components/schemas/RetrieverStep'
- $ref: '#/components/schemas/ToolStep'
- $ref: '#/components/schemas/AgentStep'
discriminator:
propertyName: type
mapping:
agent: '#/components/schemas/AgentStep'
chain: '#/components/schemas/ChainStep'
llm: '#/components/schemas/LlmStep'
retriever: '#/components/schemas/RetrieverStep'
tool: '#/components/schemas/ToolStep'
workflow: '#/components/schemas/WorkflowStep'
type: array
title: Steps
description: Steps in the workflow.
parent:
anyOf:
- $ref: '#/components/schemas/StepWithChildren'
- type: 'null'
description: Parent node of the current node. For internal use only.
type: object
required:
- input
title: AgentStep
ValidationError:
properties:
loc:
items:
anyOf:
- type: string
- type: integer
type: array
title: Location
msg:
type: string
title: Message
type:
type: string
title: Error Type
type: object
required:
- loc
- msg
- type
title: ValidationError
NodeNameFilter:
properties:
name:
type: string
const: node_name
title: Name
default: node_name
filter_type:
type: string
const: string
title: Filter Type
default: string
value:
type: string
title: Value
operator:
type: string
enum:
- eq
- ne
- contains
title: Operator
case_sensitive:
type: boolean
title: Case Sensitive
default: true
type: object
required:
- value
- operator
title: NodeNameFilter
description: Filters on node names in scorer jobs.
MetadataFilter:
properties:
name:
type: string
const: metadata
title: Name
default: metadata
filter_type:
type: string
const: map
title: Filter Type
default: map
operator:
type: string
enum:
- one_of
- not_in
- eq
- ne
title: Operator
key:
type: string
title: Key
value:
anyOf:
- type: string
- items:
type: string
type: array
title: Value
type: object
required:
- operator
- key
- value
title: MetadataFilter
description: Filters on metadata key-value pairs in scorer jobs.
Document-Input:
properties:
page_content:
type: string
title: Page Content
description: Content of the document.
metadata:
additionalProperties:
anyOf:
- type: boolean
- type: string
- type: integer
- type: number
type: object
title: Metadata
additionalProperties: false
type: object
required:
- page_content
title: Document
Message:
properties:
content:
type: string
title: Content
role:
anyOf:
- type: string
- $ref: '#/components/schemas/MessageRole'
title: Role
additionalProperties: true
type: object
required:
- content
- role
title: Message
StepWithChildren:
properties:
type:
$ref: '#/components/schemas/NodeType'
description: Type of the step. By default, it is set to workflow.
default: workflow
input:
anyOf:
- type: string
- $ref: '#/components/schemas/Document-Input'
- $ref: '#/components/schemas/Message'
- additionalProperties: true
type: object
- items:
type: string
type: array
- items:
$ref: '#/components/schemas/Document-Input'
type: array
- items:
$ref: '#/components/schemas/Message'
type: array
- items:
additionalProperties:
type: string
type: object
type: array
- items:
additionalProperties: true
type: object
type: array
title: Input
description: Input to the step.
redacted_input:
anyOf:
- type: string
- $ref: '#/components/schemas/Document-Input'
- $ref: '#/components/schemas/Message'
- additionalProperties: true
type: object
- items:
type: string
type: array
- items:
$ref: '#/components/schemas/Document-Input'
type: array
- items:
$ref: '#/components/schemas/Message'
type: array
- items:
additionalProperties:
type: string
type: object
type: array
- items:
additionalProperties: true
type: object
type: array
- type: 'null'
title: Redacted Input
description: >-
Redacted input of the step. This is used to redact sensitive
information.
output:
anyOf:
- type: string
- $ref: '#/components/schemas/Document-Input'
- $ref: '#/components/schemas/Message'
- additionalProperties: true
type: object
- items:
type: string
type: array
- items:
$ref: '#/components/schemas/Document-Input'
type: array
- items:
$ref: '#/components/schemas/Message'
type: array
- items:
additionalProperties:
type: string
type: object
type: array
- items:
additionalProperties: true
type: object
type: array
title: Output
description: Output of the step.
default: ''
redacted_output:
anyOf:
- type: string
- $ref: '#/components/schemas/Document-Input'
- $ref: '#/components/schemas/Message'
- additionalProperties: true
type: object
- items:
type: string
type: array
- items:
$ref: '#/components/schemas/Document-Input'
type: array
- items:
$ref: '#/components/schemas/Message'
type: array
- items:
additionalProperties:
type: string
type: object
type: array
- items:
additionalProperties: true
type: object
type: array
- type: 'null'
title: Redacted Output
description: >-
Redacted output of the step. This is used to redact sensitive
information.
name:
type: string
title: Name
description: Name of the step.
default: ''
created_at_ns:
type: integer
title: Created At Ns
description: Timestamp of the step's creation, as nanoseconds since epoch.
duration_ns:
type: integer
title: Duration Ns
description: Duration of the step in nanoseconds.
default: 0
metadata:
additionalProperties:
type: string
type: object
title: Metadata
description: Metadata associated with this step.
status_code:
anyOf:
- type: integer
- type: 'null'
title: Status Code
description: Status code of the step. Used for logging failed/errored steps.
ground_truth:
anyOf:
- type: string
- type: 'null'
title: Ground Truth
description: Ground truth expected output for the step.
steps:
items:
oneOf:
- $ref: '#/components/schemas/WorkflowStep'
- $ref: '#/components/schemas/ChainStep'
- $ref: '#/components/schemas/LlmStep'
- $ref: '#/components/schemas/RetrieverStep'
- $ref: '#/components/schemas/ToolStep'
- $ref: '#/components/schemas/AgentStep'
discriminator:
propertyName: type
mapping:
agent: '#/components/schemas/AgentStep'
chain: '#/components/schemas/ChainStep'
llm: '#/components/schemas/LlmStep'
retriever: '#/components/schemas/RetrieverStep'
tool: '#/components/schemas/ToolStep'
workflow: '#/components/schemas/WorkflowStep'
type: array
title: Steps
description: Steps in the workflow.
parent:
anyOf:
- $ref: '#/components/schemas/StepWithChildren'
- type: 'null'
description: Parent node of the current node. For internal use only.
type: object
required:
- input
title: StepWithChildren
MessageRole:
type: string
enum:
- agent
- assistant
- function
- system
- tool
- user
title: MessageRole
NodeType:
type: string
enum:
- chain
- chat
- llm
- retriever
- tool
- agent
- workflow
- trace
- session
title: NodeType
securitySchemes:
APIKeyHeader:
type: apiKey
in: header
name: Galileo-API-Key
OAuth2PasswordBearer:
type: oauth2
flows:
password:
scopes: {}
tokenUrl: https://api.staging.galileo.ai/login
HTTPBasic:
type: http
scheme: basic
````
---
# Source: https://docs.galileo.ai/galileo/gen-ai-studio-products/galileo-protect/how-to/creating-and-using-stages.md
> ## Documentation Index
> Fetch the complete documentation index at: https://docs.galileo.ai/llms.txt
> Use this file to discover all available pages before exploring further.
# Creating And Using Stages
> Learn to create and manage stages in Galileo Protect, enabling structured AI monitoring and progressive error resolution throughout the deployment lifecycle.
[Stages](/galileo/gen-ai-studio-products/galileo-protect/concepts/stage) can be managed centrally (i.e. registered once and updated dynamically) or locally within the application. Stages consist of [Rulesets](/galileo/gen-ai-studio-products/galileo-protect/concepts/ruleset) that are applied during one invocation. A stage can be composed of multiple rulesets, each executed independently and defined as a prioritized list (i.e. order matters). The [Action](/galileo/gen-ai-studio-products/galileo-protect/concepts/action) for the ruleset with the highest priority is chosen for composing the response.
We recommend defining a stage on your user queries and one on your application's output.
All stages must have names and belong to a project. The project ID is required to create a stage. The stage ID is returned when the stage is created and is required to invoke the stage. Optionally, you can provide a description of the stage.
Check out [Concepts > Stages](/galileo/gen-ai-studio-products/galileo-protect/concepts/stage) for the difference between a Central and a Local stage, and when to use each.
## Creating a Stage
To create a stage, you can use the following code snippet:
```py theme={null}
import galileo_protect as gp
gp.create_stage(name="my first stage", project_id="", description="This is my first stage", type="local") # type can be "central" or "local", default is "local"
```
If you're using central stages, we recommend including the ruleset definitions during stage creation. This way, you can manage the rulesets centrally and update them without changing the invocation code.
```py theme={null}
import galileo_protect as gp
gp.create_stage(name="my first stage", project_id="", description="This is my first stage", type="central", prioritized_rulesets=[
{
"rules": [
{
"metric": "pii",
"operator": "contains",
"target_value": "ssn",
},
],
"action": {
"type": "OVERRIDE",
"choices": [
"Personal Identifiable Information detected in the model output. Sorry, I cannot answer that question."
],
},
},
])
```
If you're using local stages, you can define the rulesets within the `gp.invoke()` function during the invocation instead of the `create_stage` operation.
## Defining and Using Actions
Actions define the operation to perform when a ruleset is triggered when using Galileo Protect. These can be:
1. [Override Action](https://protect.docs.rungalileo.io/?h=status#galileo_protect.OverrideAction): The override action allows configuring various choices from which one is chosen at random when all the rulesets for the stage are triggered.
2. [Passthrough Action](https://protect.docs.rungalileo.io/?h=status#galileo_protect.PassthroughAction): The pass-through action does a simple pass-through of the text. This is the default action in case no other action is defined and used when no rulesets are triggered.
## Subscribing to Events for Actions
Actions include configuration for subscriptions which can be set to event destinations (like webhooks) to HTTP POST requests notifications are sent when the ruleset is triggered. Subscriptions can be configured in actions of any type as:
```py theme={null}
"action": {
"type": "OVERRIDE",
"choices": [
"Personal Identifiable Information detected in the model output. Sorry, I cannot answer that question."
],
"subscriptions": [{"url": ""}],
}
```
By default, notifications are sent to the subscription when they are triggered, but notifications can be sent based on any of the execution statuses. In the below example, notifications will be sent to the specified webhook if there's an error or the ruleset is not triggered.
```py theme={null}
"action": {
"type": "OVERRIDE",
"choices": [
"Personal Identifiable Information detected in the model output. Sorry, I cannot answer that question."
],
"subscriptions": [{"statuses": ["error", "not_triggered"], "url": ""}],
}
```
The subscribers are sent HTTP POST requests with a payload that matches the [response from the Protect invocation](https://protect.docs.rungalileo.io/#galileo_protect.Response) and is of schema:
```py theme={null}
{
"text": "string",
"trace_metadata": {
"id": "string",
"received_at": 0,
"response_at": 0,
"execution_time": -1
},
"status": "string"
}
```
---
# Source: https://docs.galileo.ai/galileo/gen-ai-studio-products/galileo-evaluate/integrations/custom-chain.md
> ## Documentation Index
> Fetch the complete documentation index at: https://docs.galileo.ai/llms.txt
> Use this file to discover all available pages before exploring further.
# Logging Workflows
> No matter how you're orchestrating your workflows, we have an interface to help you upload them to Galileo.
To log your runs with Galileo, you'd start with the same typical flow of logging into Galileo:
```py theme={null}
import promptquality as pq
pq.login()
```
Next you can construct your [EvaluateRun](https://promptquality.docs.rungalileo.io/#promptquality.EvaluateRun) object:
```py theme={null}
from promptquality import EvaluateRun
metrics = [pq.Scorers.context_adherence_plus, pq.Scorers.prompt_injection]
evaluate_run = EvaluateRun(run_name="my_run", project_name="my_project", scorers=metrics)
```
Then you can generate your workflows.
A workflow starts with a user input, could contain multiple AI / tool / retriever nodes, and usually ends with an LLM node summarizing the entire turn to the user.
Datasets should also be constructed in such a way that a sample represents the entry to one workflow (i.e., one user input).
An evaluate run typically consists of multiple workflows, or multiple AI turns.
Here's an example of how you can log your workflows using your llm app:
```py theme={null}
def my_llm_app(input, evaluate_run):
context = " ... [text explaining hallucinations] ... "
template = "Given the following context answer the question. \n Context: {context} \n Question: {question}"
wf = evaluate_run.add_workflow(input=input)
# Get response from your llm.
prompt = template.format(context=context, question=input)
llm_response = llm.call(prompt) # Pseudo-code, replace with your LLM call.
# Log llm step to Galileo
wf.add_llm(input=prompt, output=llm_response, model=)
# Conclude the workflow and add the final output.
wf.conclude(output=llm_response)
return llm_response
# Your evaluation dataset.
eval_set = [
"What are hallucinations?",
"What are intrinsic hallucinations?",
"What are extrinsic hallucinations?"
]
for input in eval_set:
my_llm_app(input, evaluate_run)
```
Finally, log your Evaluate run to Galileo:
```py theme={null}
evaluate_run.finish()
```
## Logging RAG Workflows
If you're looking to log RAG workflows it's easy to add a retriever step. Here's an example with RAG:
```py theme={null}
def my_llm_app(input, evaluate_run):
template = "Given the following context answer the question. \n Context: {context} \n Question: {question}"
wf = evaluate_run.add_workflow(input=input)
# Fetch documents from your retriever
documents = retriever.retrieve(input) # Pseudo-code, replace with your real retriever.
# Log retriever step to Galileo
wf.add_retriever(input=input, documents=documents)
# Get response from your llm.
prompt = template.format(context="\n".join(documents), question=input)
llm_response = llm.call(prompt) # Pseudo-code, replace with your LLM call.
# Log llm step to Galileo
wf.add_llm(input=prompt, output=llm_response, model=)
# Conclude the workflow and add the final output.
wf.conclude(output=llm_response)
return llm_response
# Your evaluation dataset.
eval_set = [
"What are hallucinations?",
"What are intrinsic hallucinations?",
"What are extrinsic hallucinations?"
]
context = "You're an AI assistant helping a user with hallucinations."
for input in eval_set:
my_llm_app(input, evaluate_run)
```
## Logging Agent Workflows
We also support logging Agent workflows. As above, a workflow starts with a user message, contains various steps taken by the system and ends with a response to the user. \
When logging entire sessions, such as multi-turn conversations between a user and an agent, the session should be split into a sequence of Workflows, delimited by the user's messages.
Below is an example on how to log an agentic workflow (say in the middle of a multi-turn conversation) made of the following steps:
* the user query
* an LLM call with tools, and the LLM decides to call tools
* a tool execution
* an LLM call without tools, where the LLM responds back to the user.
```py theme={null}
# Initiate the agentic workflow with the last user message as input
last_user_message = chat_history[-1].content
agent_wf = evaluate_run.add_agent_workflow(input=last_user_message)
# Call the LLM (which select tools)
# input = LLM input = chat history until now
# output = LLM output = LLM call to tools
llm_response = llm_call(chat_history, tools=tools)
agent_wf.add_llm(
input=chat_history,
output=llm_response.tool_call,
tools=tools_dict
)
llm_message = llm_response_to_llm_message(llm_response)
chat_history.append(llm_message)
# Execute the tool call
# input = Tool input = arguments
# output = Tool output = function's return value
tool_response = execute_tool(llm_response.tool_call)
agent_wf.add_tool(
input=llm_response.tool_call.arguments,
output=tool_response,
name=llm_response.tool_call.name
)
tool_message = tool_response_to_tool_message(tool_response)
chat_history.append(tool_message)
# Call the LLM to respond to the user
# input = LLM input = chat history until now
# output = LLM output = LLM response to the user
llm_response = llm_call(chat_history)
agent_wf.add_llm(
input=chat_history,
output=llm_response.content,
)
chat_history.append(llm_response)
# Conclude the agentic workflow with the last response
agent_wf.conclude(output=llm_response.content)
```
## Logging Retriever and LLM Metadata
If you want to log more complex inputs and outputs to your nodes, we provide support for that as well.
For retriever outputs we support the [Document](https://promptquality.docs.rungalileo.io/#promptquality.Document) object.
```py theme={null}
wf = evaluate_run.add_workflow(input="Who's a good bot?", output="I am!", duration_ns=2000)
wf.add_retriever(
input="Who's a good bot?",
documents=[pq.Document(content="Research shows that I am a good bot.", metadata={"length": 35})],
duration_ns=1000
)
```
For LLM inputs and outputs we support the [Message](https://promptquality.docs.rungalileo.io/#promptquality.Message) object.
```py theme={null}
wf = evaluate_run.add_workflow(input="Who's a good bot?", output="I am!", duration_ns=2000)
wf.add_llm(
input=pq.Message(content="Given this context: Research shows that I am a good bot. answer this: Who's a good bot?"),
output=pq.Message(content="I am!", role=pq.MessageRole.assistant),
model=pq.Models.chat_gpt,
input_tokens=25,
output_tokens=3,
total_tokens=28,
duration_ns=1000
)
```
Often times an llm interaction consists of multiple messages. You can log these as well.
```py theme={null}
wf = evaluate_run.add_workflow(input="Who's a good bot?", output="I am!", duration_ns=2000)
wf.add_llm(
input=[
pq.Message(content="You're a good bot that answers questions.", role=pq.MessageRole.system),
pq.Message(content="Given this context: Research shows that I am a good bot. answer this: Who's a good bot?"),
],
output=pq.Message(content="I am!", role=pq.MessageRole.assistant),
model=pq.Models.chat_gpt,
)
```
## Logging Nested Workflows
If you have more complex workflows that involve nesting workflows within workflows, we support that too.
Here's an example of how you can log nested workflow using conclude to step out of the nested workflow, back into the base workflow:
```py theme={null}
wf = evaluate_run.add_workflow("input", "output", duration_ns=100)
# Add a workflow inside the base workflow.
nested_wf = wf.add_sub_workflow(input="inner input")
# Add an LLM step inside the nested workflow.
nested_wf.add_llm(input="prompt", output="response", model=pq.Models.chat_gpt, duration_ns=60)
# Conclude the nested workflow and step back into the base workflow.
nested_wf.conclude(output="inner output", duration_ns=60)
# Add another LLM step in the base workflow.
wf.add_llm("outer prompt", "outer response", "chatgpt", duration_ns=40)
```
---
# Source: https://docs.galileo.ai/galileo/gen-ai-studio-products/galileo-evaluate/how-to/customize-chainpoll-powered-metrics.md
> ## Documentation Index
> Fetch the complete documentation index at: https://docs.galileo.ai/llms.txt
> Use this file to discover all available pages before exploring further.
# Customize Chainpoll-powered Metrics
> Improve metric accuracy by customizing your Chainpoll-powered metrics
[**ChainPoll**](/galileo/gen-ai-studio-products/galileo-ai-research/chainpoll) is a powerful, flexible technique for LLM-based evaluation built by Galileo's Research team. It is used to power multiple Guardrail Metrics across the Galileo platform:
* Context Adherence Plus
* Chunk Attribution & Utilization
* Completeness Plus
* Correctness
Chainpoll leverages a chain-of-thought prompting technique and prompting an LLM multiple times to calculate metric values. There are two levers one can customize for a Chainpoll metric:
* The model that gets queried
* The number of times we prompt that model
Generally, better models will provide more accurate metric values, and a higher number of judges will increase the accuracy and stability of metric values. We've configured our Chainpoll-powered metrics to balance the trade-off of Cost and Accuracy.
## Changing the model or number of judges of a Chainpoll metric
We allow customizing execution parameters for the [AI-powered metrics](/galileo/gen-ai-studio-products/galileo-guardrail-metrics) from our Guardrail Store. By default, these metrics use gpt-4o-mini for the model and 3 judges (except for chunk attribution & utilization, which uses 1 judge and for which the number of judges cannot be customized). To customize this, when creating your run you can customize these metrics as:
```python theme={null}
pq.EvaluateRun(..., scorers=[
pq.CustomizedChainPollScorer(
scorer_name=pq.CustomizedScorerName.context_adherence_plus,
model_alias=pq.Models.gpt_4o,
num_judges=7)
])
```
#### Customizable Metrics
The metrics that can be customized are:
1. Chunk Attribution & Chunk Utilization: `pq.CustomizedScorerName.chunk_attribution_utilization_plus`
2. Completeness: `pq.CustomizedScorerName.completeness_plus`
3. Context Adherence: `pq.CustomizedScorerName.context_adherence_plus`
4. Correctness: `pq.CustomizedScorerName.correctness`
#### Models supported
* OpenAI or Azure models that use the Chat Completions API
* Gemini 1.5 Flash and Pro through VertexAI
When entering the model name, use a model alias from [this list](https://promptquality.docs.rungalileo.io/#promptquality.Models).
#### Number of Judges supported
Judges can be set to integers between `0` and `10`.
Note: Chunk Attribution and Chunk Utilization don't benefit from increasing the number of judges.
---
# Source: https://docs.galileo.ai/galileo-ai-research/data-drift-detection.md
> ## Documentation Index
> Fetch the complete documentation index at: https://docs.galileo.ai/llms.txt
> Use this file to discover all available pages before exploring further.
# Data Drift Detection
> Discover Galileo's data drift detection methods to monitor AI model performance, identify data changes, and maintain model reliability in production.
When developing and deploying models, a key concern is data coverage and freshness. As the real world data distribution continually evolves, it is increasingly important to monitor how data shifts affect a model's ability to produce trustworthy predictions. At the heart of this concern is the model's training data: does the data used to train our model properly capture the current state of the world - *or more importantly* is our model making or expected to make predictions over new types of data not seen during training?
To address these questions, we look to the problem of **data drift detection.**
## What is Data Drift?
In machine learning we generally view data drift as data - e.g. production data - differing from the data used to train a model - i.e. coming from a different underlying distribution. There are many factors that can lead to dataset drift and several ways that drift can manifest. Broadly there are two main categories of data drift: 1) virtual drift (covariate shift) and 2) concept drift.
### Virtual Drift
Virtual data drift refers to a change in the type of data seen (the feature space) without a change in the relationship between a given data sample and the label it is assigned - i.e. a change in the underlying data distribution P(x) without a change in P(y|x). Virtual drift can manifest in many different forms, such as changing syntactic structure and style (e.g. new ways of asking a particular question to a QA system) or the appearance of novel words, phrases, and / or concepts (e.g. Covid).
Virtual drift generally manifests when there is insufficient training data coverage and / or new concepts appear in the real world. Virtual data drift can reveal incorrectly learned decision boundaries, increasing the potential for incorrect, non-trustworthy predictions (especially in the case of an overfit model).
### Concept shift
In contrast to virtual drift, concept drift refers to a change in the way that labels are assigned for a given data sample - i.e. a change in P(Y|X) without a change to P(X). This typically manifests as the label for a given data sample changing over time. For example, concept drift occurs if there is a change in the labeling criteria / guidelines - certain samples previously labeled *Class A* should now be labeled *Class B*.
## Data Drift in Galileo
Without access to ground truth labels or the underlying labeling criteria, surfacing *concept drift* is intractable. Therefore, Galileo focuses on detecting **virtual data drift**. Specifically, we aim to detect data samples that are sufficiently different from the data used during training.
> **Data Drift in Galileo**: Detecting data samples that would appear to come from a different distribution than the training data distribution
### Data Drift Across Data Split
Data drift as a measure of shifted data distributions is *not* limited to changes within production data. The characteristics of data drift - an evolving / shifting feature space - can occur for any non-training data split. Therefore, Galileo surfaces data drift errors not only for inference data splits, but also for validation and test splits. We refer to them separately as **Drifted** vs. **Out of Coverage** data.
**Drifted Data:** Drifted *production data* within an *inference run.* These samples represent the classical paradigm of data drift capturing changes within the real world data distribution. Tracking production data drift is essential for understanding potential changes to model performance in production, the appearance of important new concepts, and indications of a stale training dataset. As production models react to an evolving world, these samples highlight high value samples to be monitored and added to future model re-training datasets.
**Out of Coverage Data:** Drifted *validation* or *test* data. These samples capture two primary data gaps:
1. Data samples that our model *fails* to properly generalize on - for example due to overfitting or under-representation within the training dataset (generalization drift). These data samples represent concepts that are represented in the training data but show generalization gaps.
2. Data concepts that are *not represented* within the training data and thus the model may struggle to effectively generalize over.
### Viewing Drifted Samples
In the Galileo Console, you can view drifted samples either through the *Out of Coverage or* *Drifted* data tabs. Since drift compares data distribution, drift is always computed and shown with respect to a reference data distribution - the training dataset.
In the embeddings view, we overlay the current split and reference training data embeddings to provide a visual representation of alignment and data gaps (i.e. drifted data) within the embedding space.
Viewing Drifted Samples within an Inference Run
**Note:** that the 2-dimensional embeddings view is limited in its ability to capture high dimensional embeddings interactions and represents an approximate overlapping of data distributions - i.e. drifted / not drifted data may not always look "drifted" in the embeddings view.
## Galileo's Drift Detection Algorithm
We implement an embedding based, non-parametric nearest neighbor algorithm for detecting out of distribution (OOD) data - i.e. drifted and out of coverage samples. Differentiating algorithm characteristics include:
* **Embedding Based**: Leverage hierarchical, semantic structure encoded in neural network embeddings - particularly realized through working with (large) pre-trained models, e.g. large language models (LLMs)
* **Non-parametric**: does not impose any distributional assumptions on the underlying embedding space, providing *simplicity*, *flexibility*, and *generality*
* **Interpretability**: the general simplicity of nearest neighbor based algorithms provides easy interpretability
### Transforming the Embedding Space - Core Distance
The foundation of nearest neighbor algorithms is a representation of the embedding space through local neighborhood information - defining a neighborhood statistic. Although different methods exist for computing a neighborhood statistic, we utilize a simple and inexpensive estimate of local neighborhood density: *K Core-Distance*. Used in algorithms such as *HDBSCAN* \[1] \_\_ and \_LOF\_ \[2]\_, K C\_ore-Distance is computed as the cosine-distance to a samples kth nearest neighbor within the neural network embedding space.
> K Core-Distance(x) = cosine distance to x's kth nearest neighbor
#### *What to Do When Context Adherence Is Low?*
When a response is highly adherent to the context (i.e., it has a value of 1 or close to 1), it strictly includes information from the provided context. However, when a response is not adherent (i.e., it has a value of 0 or close to 0), it likely contains facts not present in the given context.
Several factors can contribute to low context adherence:
1. **Insufficient Context**: If the source document lacks key information needed to answer the user's question, the response may be incomplete or off-topic. To address this, users should consider using various context enrichment strategies to ensure that the source documents retrieved contain the necessary information to answer the user's questions effectively.
2. **Lack of Internal Reasoning and Creativity**: While Retrieval-Augmented Generation (RAG) focuses on factual grounding, it doesn't directly enhance the internal reasoning processes of the LLM. This limitation can cause the model to struggle with logic or common-sense reasoning, potentially resulting in nonsensical outputs even if the facts are accurate.
3. **Lack of Contextual Awareness**: Although RAG provides factual grounding for the language model, it might not fully understand the nuances of the prompt or user intent. This can lead to the model incorporating irrelevant information or missing key points, thus affecting the overall quality of the response.
To improve context adherence, we recommend:
1. Ensuring your context DB has all the necessary info to answer the question
2. Adjusting the prompt to tell the model to stick to the information it's given in the context.
---
# Source: https://docs.galileo.ai/galileo/gen-ai-studio-products/galileo-guardrail-metrics/context-adherence/context-adherence-plus.md
> ## Documentation Index
> Fetch the complete documentation index at: https://docs.galileo.ai/llms.txt
> Use this file to discover all available pages before exploring further.
# Context Adherence Plus
> Understand Galileo's Context Adherence Plus Metric
***Definition:*** Measures whether your model's response was purely based on the context provided.
***Calculation:*** Context Adherence Plus is computed by sending additional requests to OpenAI's GPT3.5 (by default) and GPT4, using a carefully engineered chain-of-thought prompt that asks the model to judge whether or not the response was grounded in the context. The metric requests multiple distinct responses to this prompt, each of which produces an explanation along with a final judgment: yes or no. The *Context Adherence Plus* score is the fraction of "yes" responses, divided by the total number of responses.
We also surface one of the generated explanations. The surfaced explanation is always chosen to align with the majority judgment among the responses. In other words, if the score is greater than 0.5, the explanation will provide an argument that the response is grounded; if the score is less than 0.5, the explanation will provide an argument that it is not grounded.
#### *What to Do When Context Adherence Is Low?*
When a response is highly adherent to the context (i.e., it has a value of 1 or close to 1), it strictly includes information from the provided context. However, when a response is not adherent (i.e., it has a value of 0 or close to 0), it likely contains facts not present in the given context.
Several factors can contribute to low context adherence:
1. **Insufficient Context**: If the source document lacks key information needed to answer the user's question, the response may be incomplete or off-topic. To address this, users should consider using various context enrichment strategies to ensure that the source documents retrieved contain the necessary information to answer the user's questions effectively.
2. **Lack of Internal Reasoning and Creativity**: While Retrieval-Augmented Generation (RAG) focuses on factual grounding, it doesn't directly enhance the internal reasoning processes of the LLM. This limitation can cause the model to struggle with logic or common-sense reasoning, potentially resulting in nonsensical outputs even if the facts are accurate.
3. **Lack of Contextual Awareness**: Although RAG provides factual grounding for the language model, it might not fully understand the nuances of the prompt or user intent. This can lead to the model incorporating irrelevant information or missing key points, thus affecting the overall quality of the response.
To improve context adherence, we recommend:
1. Ensuring your context DB has all the necessary info to answer the question
2. Adjusting the prompt to tell the model to stick to the information it's given in the context.
***Deep dive:*** to read more about the research behind this metric, see [RAG Quality Metrics using ChainPoll](/galileo/gen-ai-studio-products/galileo-ai-research/rag-quality-metrics-using-chainpoll).
*Note:* This metric is computed by prompting an LLM multiple times, and thus requires additional LLM calls to compute.
---
# Source: https://docs.galileo.ai/galileo/gen-ai-studio-products/galileo-observe/faq/context-adherence-vs-instruction-adherence.md
# Source: https://docs.galileo.ai/galileo/gen-ai-studio-products/galileo-guardrail-metrics/faq/context-adherence-vs-instruction-adherence.md
# Source: https://docs.galileo.ai/galileo/gen-ai-studio-products/galileo-evaluate/faq/context-adherence-vs-instruction-adherence.md
> ## Documentation Index
> Fetch the complete documentation index at: https://docs.galileo.ai/llms.txt
> Use this file to discover all available pages before exploring further.
# Context vs. Instruction Adherence | Galileo Evaluate FAQ
> Understand the distinctions between Context Adherence and Instruction Adherence metrics in Galileo Evaluate to assess generative AI outputs accurately.
#### What are Instruction Adherence and Context Adherence
These two metrics sound similar but are built to measure different things.
* [Context Adherence](/galileo/gen-ai-studio-products/galileo-guardrail-metrics/context-adherence): Detects instances where the model stated information in its response that was not included in the provided context.
* [Instruction Adherence](/galileo/gen-ai-studio-products/galileo-guardrail-metrics/instruction-adherence): Detects instances where the model response did not follow the instructions in its prompt.
| Metric | Intention | How to Use | Further Reading |
| --------------------- | ----------------------------------------------------------- | ----------------------------------- | --------------------------------------------------------------------------------------- |
| Context Adherence | Was the information in the response grounded on the context | Low adherence means improve context | [Link](/galileo/gen-ai-studio-products/galileo-guardrail-metrics/context-adherence) |
| Instruction Adherence | Did the model follow its instructions | Low adherence means improve prompt | [Link](/galileo/gen-ai-studio-products/galileo-guardrail-metrics/instruction-adherence) |
Instruction Adherence is a [Chainpoll-powered metric](/galileo-ai-research/chainpoll). Context Adherence has two flavors: Plus (Chainpoll-powered), or Luna (powered by in-house Luna models).
#### Context Adherence
Context Adherence refers to whether the output matches the context it was provided. It is not looking
at the steps, but rather at the full context. This is more useful in RAG use-cases where you are providing
additional information to supplement the output. With this metric, correctly answering based on the provided
information will return a score closer to “1”, and output information which is not supported by the input
would return a score closer to “0”.
#### Instruction Adherence
You can use Instruction Adherence to gauge whether the instructions in your prompt, such as “you are x, first do y,
then do z” aligns with the output of that prompt. If it does, then Instruction Adherence will return that the steps
were followed correctly and a score closer to “1”. If it fails to follow instructions, Instruction Adherence will
return the reasoning and a score closer to “0”.
---
# Source: https://docs.galileo.ai/galileo/gen-ai-studio-products/galileo-guardrail-metrics/context-adherence.md
> ## Documentation Index
> Fetch the complete documentation index at: https://docs.galileo.ai/llms.txt
> Use this file to discover all available pages before exploring further.
# Context Adherence
> Understand Galileo's Context Adherence Metric
***Definition:*** *Context Adherence* is a measurement of *closed-domain* *hallucinations:* cases where your model said things that were not provided in the context.
If a response is *adherent* to the context (i.e. it has a value of 1 or close to 1), it only contains information given in the context. If a response is *not adherent* (i.e. it has a value of 0 or close to 0), it's likely to contain facts not included in the context provided to the model.
### Luna vs Plus
We offer two ways of calculating Context Adherence: *Luna* and *Plus*.
[*Context Adherence Luna*](/galileo/gen-ai-studio-products/galileo-guardrail-metrics/context-adherence/context-adherence-luna) is computed using Galileo in-house small language models (Luna). They're free of cost, but lack 'explanations'. Context Adherence Luna is a cost effective way to scale up you RAG evaluation workflows.
[*Context Adherence Plus*](/galileo/gen-ai-studio-products/galileo-guardrail-metrics/completeness/completeness-plus) is computed using the [Chainpoll](/galileo/gen-ai-studio-products/galileo-ai-research/chainpoll) technique. It relies on OpenAI models so it incurs an additional cost. Context Adherence Plus has shown better results in internal benchmarks. Additionally, *Plus* offers explanations for its ratings (i.e. why something was or was not adherent).
---
# Source: https://docs.galileo.ai/galileo/gen-ai-studio-products/galileo-evaluate/how-to/continuous-learning-via-human-feedback.md
> ## Documentation Index
> Fetch the complete documentation index at: https://docs.galileo.ai/llms.txt
> Use this file to discover all available pages before exploring further.
# Customizing your LLM-powered metrics via CLHF
> Learn how to customize your LLM-powered metrics with Continuous Learning via Human Feedback.
As you start using Galileo Preset LLM-powered metrics (e.g. Context Adherence or Instruction Adherence),
or start creating your own LLM-powered metrics via [Autogen](/galileo/gen-ai-studio-products/galileo-evaluate/how-to/autogen-metrics), you might not always agree with the results.
False positives or False Negatives in metric values are often due to domain edge cases that aren't handled
in the metric's prompt.
Galileo helps you address this problem and adapt and continuously improve metrics via Continuous Learning
via Human Feedback.
## How it works
As you identify mistakes in your metrics, you can provide 'feedback' to 'auto-improve' your metrics. Your
feedback gets translated (by LLMs) into few-shot examples that are appended to the Metric's prompt. Few-shot
examples help your LLM-as-a-judge in a few ways:
* Examples with your domain data teach it what to expect from your domain.
* Concrete examples on edge cases teach your LLM-as-a-judge how to deal with outlier scenarios.
This process has shown to increase accuracy of metrics by 20-30%.
CLHF-ed metrics are scoped to the project. I.e. you can have different teams customizing the same metric in different ways and not impact each other's projects.
### What to enter as feedback
When entering feedback, enter a critique of the explanation generated by the erroneous metric. Be as precise
as possible in your critique, outlining the exact reason behind the desired metric value.
## How to use it
See this video on how to use Continuous Learning via Human Feedback to improve your metric accuracy:
## Which metrics is this supported on?
* Context Adherence
* Instruction Adherence
* Correctness
* Any LLM-as-a-judge generated via [Galileo's Autogen](/galileo/gen-ai-studio-products/galileo-evaluate/how-to/autogen-metrics) feature
---
# Source: https://docs.galileo.ai/galileo/gen-ai-studio-products/galileo-guardrail-metrics/correctness.md
> ## Documentation Index
> Fetch the complete documentation index at: https://docs.galileo.ai/llms.txt
> Use this file to discover all available pages before exploring further.
# Correctness
> Understand Galileo's Correctness Metric
***Definition:*** Measures whether a given model response is factual or not. *Correctness (f.k.a. Factuality)* is a good way of uncovering *open-domain hallucinations:* factual errors that don't relate to any specific documents or context. A high Correctness score means the response is more likely to be accurate vs a low response indicates a high probability for hallucination.
If the response is *factual* (i.e. it has a value of 1 or close to 1), the information is believed to be correct. If a response is *not factual* (i.e. it has a value of 0 or close to 0), it's likely to contain factual errors.
***Calculation:*** *Correctness* is computed by sending an additional requests to OpenAI's GPT4-o, using a carefully engineered chain-of-thought prompt that asks the model to judge whether or not the response was factually accurate. The metric requests multiple distinct responses to this prompt, each of which produces an explanation along with a final judgment: yes or no. The Correctness score is the fraction of "yes" responses, divided by the total number of responses.
We also surface one of the generated explanations. The surfaced explanation is always chosen to align with the majority judgment among the responses. In other words, if the score is greater than 0.5, the explanation will provide an argument that the response is factual; if the score is less than 0.5, the explanation will provide an argument that it is not factual.
*Note:* This metric is computed by prompting an LLM multiple times, and thus requires additional LLM calls to compute.
***What to do when Correctness is low?***
When an response has a low Correctness score, it's likely that the response has non-factual information. We recommend:
1. Flag and examine response that are likely to be non-factual
2. Adjust the prompt to tell the model to stick to the information it's given in the context.
3. Take precaution measures to stop non-factual responses from reaching the end user.
***How to differentiate between Correctness and Context Adherence?***
Correctness measures whether a model response has factually correct information, regardless of whether that piece of information is contained in the context.
Here we are illustrating the difference between Correctness and Context Adherence using a text-to-sql example.
---
# Source: https://docs.galileo.ai/galileo/gen-ai-studio-products/galileo-evaluate/how-to/create-an-evaluation-set.md
> ## Documentation Index
> Fetch the complete documentation index at: https://docs.galileo.ai/llms.txt
> Use this file to discover all available pages before exploring further.
# Create an Evaluation Set
> Before starting your experiments, we recommend creating an evaluation set.
**Best Practices:**
1. **Representativeness:** Ensure that the evaluation set is representative of the real-world data or the population of interest. This means the data should reflect the full range of variations expected in the actual use case, including different demographics, behaviors, or other relevant characteristics.
2. **Separation from Training Data:** The evaluation set should be entirely separate from the training dataset. Using different data ensures that you are testing the application's ability to generalize to new, unseen data.
3. **Sufficient Size:** The evaluation set should be large enough to provide statistically meaningful results. The size will depend on the complexity of the application and the variability of the data. As a rule of thumb, we recommend 50-100 data points for most basic use cases. A few hundred for more mature ones.
4. **Update Regularly:** As more data becomes available, or as the real-world conditions change, update the evaluation set to continue reflecting the target environment accurately. This is especially important for models deployed in rapidly changing fields.
5. **Over-represent edge cases:** Include tough scenarios you want your application to handle well (e.g. prompt injections, abusive requests, angry users, irrelevant questions). It's important to include these to battle-test your application against outlier and abusive behavior.
Your Evaluation Set should stay constant throughout your experiments. This will allow you to make apple-to-apples comparisons for the runs on your projects.
Note: Using GPT4 or similar can be a quick and easy way to bootstrap an evaluation set. We recommend manually going over the questions and editing as well.
###
**Running Evaluations on your Eval Set**
Once you have your Eval Set, you're ready to start your first evaluation run.
* If you have not written any code yet and are looking to evaluate a model and template for your use case, check out [Creating Prompt Runs](/galileo/gen-ai-studio-products/galileo-evaluate/quickstart).
* If you have an application or prototype you'd like to evaluate, check out [Integrating Evaluate into my existing application](/galileo/gen-ai-studio-products/galileo-evaluate/quickstart/integrate-evaluate-into-my-existing-application-with-python).
---
# Source: https://docs.galileo.ai/api-reference/evaluate/create-workflows-run.md
> ## Documentation Index
> Fetch the complete documentation index at: https://docs.galileo.ai/llms.txt
> Use this file to discover all available pages before exploring further.
# Create a new Evaluate Run
> Create a new Evaluate run with workflows.
Use this endpoint to create a new Evaluate run with workflows. The request body should contain the `workflows` to be ingested and evaluated.
Additionally, specify the `project_id` or `project_name` to which the workflows should be ingested. If the project does not exist, it will be created. If the project exists, the workflows will be logged to it. If both `project_id` and `project_name` are provided, `project_id` will take precedence. The `run_name` is optional and will be auto-generated (timestamp-based) if not provided.
The body is also expected to include the configuration for the scorers to be used in the evaluation. This configuration will be used to evaluate the workflows and generate the results.
### WorkflowStep
A workflow step is the atomic unit of logging to Galileo. They represent a single execution of a workflow, such as a chain, agent, or a RAG execution. Workflows can have multiple steps, each of which can be a different type of node, such as an LLM, Retriever, or Tool.
You can log multiple workflows in a single request. Each workflow step must have the following fields:
* `type`: The type of the workflow.
* `input`: The input to the workflow.
* `output`: The output of the workflow.
## Examples
### LLM Step
```json theme={null}
{
"type": "llm",
"input": "What is the capital of France?",
"output": "Paris"
}
```
### Retriever Step
```json theme={null}
{
"type": "retriever",
"input": "What is the capital of France?",
"output": [{ "content": "Paris is the capital and largest city of France." }]
}
```
### Multi-Step
Workflow steps of type `workflow`, `agent` or `chain` can have sub-steps with children. A workflow with a retriver and an LLM step would look like this:
```json theme={null}
{
"type": "workflow",
"input": "What is the capital of France?",
"output": "Paris",
"steps": [
{
"type": "retriever",
"input": "What is the capital of France?",
"output": [{ "content": "Paris is the capital and largest city of France." }]
},
{
"type": "llm",
"input": "What is the capital of France?",
"output": "Paris"
}
]
}
```
## OpenAPI
````yaml POST /v1/evaluate/runs
openapi: 3.1.0
info:
title: FastAPI
version: 0.1.0
servers:
- url: https://api.staging.galileo.ai
description: Galileo Public APIs - staging
security: []
paths:
/v1/evaluate/runs:
post:
tags:
- evaluate
summary: Create Workflows Run
description: >-
Create a new Evaluate run with workflows.
Use this endpoint to create a new Evaluate run with workflows. The
request body should contain the `workflows` to be ingested and
evaluated.
Additionally, specify the `project_id` or `project_name` to which the
workflows should be ingested. If the project does not exist, it will be
created. If the project exists, the workflows will be logged to it. If
both `project_id` and `project_name` are provided, `project_id` will
take precedence. The `run_name` is optional and will be auto-generated
(timestamp-based) if not provided.
The body is also expected to include the configuration for the scorers
to be used in the evaluation. This configuration will be used to
evaluate the workflows and generate the results.
operationId: create_workflows_run_v1_evaluate_runs_post
requestBody:
content:
application/json:
schema:
$ref: '#/components/schemas/EvaluateRunRequest'
required: true
responses:
'200':
description: Successful Response
content:
application/json:
schema:
$ref: '#/components/schemas/EvaluateRunResponse'
'422':
description: Validation Error
content:
application/json:
schema:
$ref: '#/components/schemas/HTTPValidationError'
security:
- APIKeyHeader: []
- OAuth2PasswordBearer: []
- HTTPBasic: []
components:
schemas:
EvaluateRunRequest:
properties:
scorers:
items:
oneOf:
- $ref: '#/components/schemas/AgenticWorkflowSuccessScorer'
- $ref: '#/components/schemas/AgenticSessionSuccessScorer'
- $ref: '#/components/schemas/BleuScorer'
- $ref: '#/components/schemas/ChunkAttributionUtilizationScorer'
- $ref: '#/components/schemas/CompletenessScorer'
- $ref: '#/components/schemas/ContextAdherenceScorer'
- $ref: '#/components/schemas/ContextRelevanceScorer'
- $ref: '#/components/schemas/CorrectnessScorer'
- $ref: '#/components/schemas/GroundTruthAdherenceScorer'
- $ref: '#/components/schemas/InputPIIScorer'
- $ref: '#/components/schemas/InputSexistScorer'
- $ref: '#/components/schemas/InputToneScorer'
- $ref: '#/components/schemas/InputToxicityScorer'
- $ref: '#/components/schemas/InstructionAdherenceScorer'
- $ref: '#/components/schemas/OutputPIIScorer'
- $ref: '#/components/schemas/OutputSexistScorer'
- $ref: '#/components/schemas/OutputToneScorer'
- $ref: '#/components/schemas/OutputToxicityScorer'
- $ref: '#/components/schemas/PromptInjectionScorer'
- $ref: '#/components/schemas/PromptPerplexityScorer'
- $ref: '#/components/schemas/RougeScorer'
- $ref: '#/components/schemas/ToolErrorRateScorer'
- $ref: '#/components/schemas/ToolSelectionQualityScorer'
- $ref: '#/components/schemas/UncertaintyScorer'
discriminator:
propertyName: name
mapping:
agentic_session_success: '#/components/schemas/AgenticSessionSuccessScorer'
agentic_workflow_success: '#/components/schemas/AgenticWorkflowSuccessScorer'
bleu: '#/components/schemas/BleuScorer'
chunk_attribution_utilization: '#/components/schemas/ChunkAttributionUtilizationScorer'
completeness: '#/components/schemas/CompletenessScorer'
context_adherence: '#/components/schemas/ContextAdherenceScorer'
context_relevance: '#/components/schemas/ContextRelevanceScorer'
correctness: '#/components/schemas/CorrectnessScorer'
ground_truth_adherence: '#/components/schemas/GroundTruthAdherenceScorer'
input_pii: '#/components/schemas/InputPIIScorer'
input_sexist: '#/components/schemas/InputSexistScorer'
input_tone: '#/components/schemas/InputToneScorer'
input_toxicity: '#/components/schemas/InputToxicityScorer'
instruction_adherence: '#/components/schemas/InstructionAdherenceScorer'
output_pii: '#/components/schemas/OutputPIIScorer'
output_sexist: '#/components/schemas/OutputSexistScorer'
output_tone: '#/components/schemas/OutputToneScorer'
output_toxicity: '#/components/schemas/OutputToxicityScorer'
prompt_injection: '#/components/schemas/PromptInjectionScorer'
prompt_perplexity: '#/components/schemas/PromptPerplexityScorer'
rouge: '#/components/schemas/RougeScorer'
tool_error_rate: '#/components/schemas/ToolErrorRateScorer'
tool_selection_quality: '#/components/schemas/ToolSelectionQualityScorer'
uncertainty: '#/components/schemas/UncertaintyScorer'
type: array
title: Scorers
description: List of Galileo scorers to enable.
registered_scorers:
items:
$ref: '#/components/schemas/RegisteredScorerConfig'
type: array
title: Registered Scorers
description: List of registered scorers to enable.
generated_scorers:
items:
$ref: '#/components/schemas/GeneratedScorerConfig'
type: array
title: Generated Scorers
description: List of generated scorers to enable.
finetuned_scorers:
items:
$ref: '#/components/schemas/FinetunedScorerConfig'
type: array
title: Finetuned Scorers
description: List of finetuned scorers to enable.
workflows:
items:
oneOf:
- $ref: '#/components/schemas/WorkflowStep'
- $ref: '#/components/schemas/ChainStep'
- $ref: '#/components/schemas/LlmStep'
- $ref: '#/components/schemas/RetrieverStep'
- $ref: '#/components/schemas/ToolStep'
- $ref: '#/components/schemas/AgentStep'
discriminator:
propertyName: type
mapping:
agent: '#/components/schemas/AgentStep'
chain: '#/components/schemas/ChainStep'
llm: '#/components/schemas/LlmStep'
retriever: '#/components/schemas/RetrieverStep'
tool: '#/components/schemas/ToolStep'
workflow: '#/components/schemas/WorkflowStep'
type: array
minItems: 1
title: Workflows
description: List of workflows to include in the run.
project_id:
anyOf:
- type: string
format: uuid4
- type: 'null'
title: Project Id
description: Evaluate Project ID to which the run should be associated.
project_name:
anyOf:
- type: string
- type: 'null'
title: Project Name
description: >-
Evaluate Project name to which the run should be associated. If the
project does not exist, it will be created.
run_name:
anyOf:
- type: string
- type: 'null'
title: Run Name
description: >-
Name of the run. If no name is provided, a timestamp-based name will
be generated.
type: object
required:
- workflows
title: EvaluateRunRequest
examples:
- project_name: my-evaluate-project
run_name: my-evaluate-run
scorers:
- name: correctness
- name: output_pii
workflows:
- created_at_ns: 1769195848702731000
duration_ns: 0
input: who is a smart LLM?
metadata: {}
name: llm
output: I am!
type: llm
- project_id: 00000000-0000-0000-0000-000000000000
registered_scorers:
- name: my_registered_scorer
run_name: my-evaluate-run
workflows:
- created_at_ns: 1769195848702784500
duration_ns: 0
input: who is a smart LLM?
metadata: {}
name: llm
output: I am!
type: llm
EvaluateRunResponse:
properties:
message:
type: string
title: Message
project_id:
type: string
format: uuid4
title: Project Id
project_name:
type: string
title: Project Name
run_id:
type: string
format: uuid4
title: Run Id
run_name:
type: string
title: Run Name
workflows_count:
type: integer
title: Workflows Count
records_count:
type: integer
title: Records Count
type: object
required:
- message
- project_id
- project_name
- run_id
- run_name
- workflows_count
- records_count
title: EvaluateRunResponse
HTTPValidationError:
properties:
detail:
items:
$ref: '#/components/schemas/ValidationError'
type: array
title: Detail
type: object
title: HTTPValidationError
AgenticWorkflowSuccessScorer:
properties:
name:
type: string
const: agentic_workflow_success
title: Name
default: agentic_workflow_success
filters:
anyOf:
- items:
oneOf:
- $ref: '#/components/schemas/NodeNameFilter'
- $ref: '#/components/schemas/MetadataFilter'
discriminator:
propertyName: name
mapping:
metadata: '#/components/schemas/MetadataFilter'
node_name: '#/components/schemas/NodeNameFilter'
type: array
- type: 'null'
title: Filters
description: List of filters to apply to the scorer.
type:
type: string
enum:
- luna
- plus
title: Type
default: plus
model_name:
anyOf:
- type: string
- type: 'null'
title: Model Name
description: Alias of the model to use for the scorer.
num_judges:
anyOf:
- type: integer
maximum: 10
minimum: 1
- type: 'null'
title: Num Judges
description: Number of judges for the scorer.
type: object
title: AgenticWorkflowSuccessScorer
AgenticSessionSuccessScorer:
properties:
name:
type: string
const: agentic_session_success
title: Name
default: agentic_session_success
filters:
anyOf:
- items:
oneOf:
- $ref: '#/components/schemas/NodeNameFilter'
- $ref: '#/components/schemas/MetadataFilter'
discriminator:
propertyName: name
mapping:
metadata: '#/components/schemas/MetadataFilter'
node_name: '#/components/schemas/NodeNameFilter'
type: array
- type: 'null'
title: Filters
description: List of filters to apply to the scorer.
type:
type: string
enum:
- luna
- plus
title: Type
default: plus
model_name:
anyOf:
- type: string
- type: 'null'
title: Model Name
description: Alias of the model to use for the scorer.
num_judges:
anyOf:
- type: integer
maximum: 10
minimum: 1
- type: 'null'
title: Num Judges
description: Number of judges for the scorer.
type: object
title: AgenticSessionSuccessScorer
BleuScorer:
properties:
name:
type: string
const: bleu
title: Name
default: bleu
filters:
anyOf:
- items:
oneOf:
- $ref: '#/components/schemas/NodeNameFilter'
- $ref: '#/components/schemas/MetadataFilter'
discriminator:
propertyName: name
mapping:
metadata: '#/components/schemas/MetadataFilter'
node_name: '#/components/schemas/NodeNameFilter'
type: array
- type: 'null'
title: Filters
description: List of filters to apply to the scorer.
type: object
title: BleuScorer
ChunkAttributionUtilizationScorer:
properties:
name:
type: string
const: chunk_attribution_utilization
title: Name
default: chunk_attribution_utilization
filters:
anyOf:
- items:
oneOf:
- $ref: '#/components/schemas/NodeNameFilter'
- $ref: '#/components/schemas/MetadataFilter'
discriminator:
propertyName: name
mapping:
metadata: '#/components/schemas/MetadataFilter'
node_name: '#/components/schemas/NodeNameFilter'
type: array
- type: 'null'
title: Filters
description: List of filters to apply to the scorer.
type:
type: string
enum:
- luna
- plus
title: Type
default: luna
model_name:
anyOf:
- type: string
- type: 'null'
title: Model Name
description: Alias of the model to use for the scorer.
type: object
title: ChunkAttributionUtilizationScorer
CompletenessScorer:
properties:
name:
type: string
const: completeness
title: Name
default: completeness
filters:
anyOf:
- items:
oneOf:
- $ref: '#/components/schemas/NodeNameFilter'
- $ref: '#/components/schemas/MetadataFilter'
discriminator:
propertyName: name
mapping:
metadata: '#/components/schemas/MetadataFilter'
node_name: '#/components/schemas/NodeNameFilter'
type: array
- type: 'null'
title: Filters
description: List of filters to apply to the scorer.
type:
type: string
enum:
- luna
- plus
title: Type
default: luna
model_name:
anyOf:
- type: string
- type: 'null'
title: Model Name
description: Alias of the model to use for the scorer.
num_judges:
anyOf:
- type: integer
maximum: 10
minimum: 1
- type: 'null'
title: Num Judges
description: Number of judges for the scorer.
type: object
title: CompletenessScorer
ContextAdherenceScorer:
properties:
name:
type: string
const: context_adherence
title: Name
default: context_adherence
filters:
anyOf:
- items:
oneOf:
- $ref: '#/components/schemas/NodeNameFilter'
- $ref: '#/components/schemas/MetadataFilter'
discriminator:
propertyName: name
mapping:
metadata: '#/components/schemas/MetadataFilter'
node_name: '#/components/schemas/NodeNameFilter'
type: array
- type: 'null'
title: Filters
description: List of filters to apply to the scorer.
type:
type: string
enum:
- luna
- plus
title: Type
default: luna
model_name:
anyOf:
- type: string
- type: 'null'
title: Model Name
description: Alias of the model to use for the scorer.
num_judges:
anyOf:
- type: integer
maximum: 10
minimum: 1
- type: 'null'
title: Num Judges
description: Number of judges for the scorer.
type: object
title: ContextAdherenceScorer
ContextRelevanceScorer:
properties:
name:
type: string
const: context_relevance
title: Name
default: context_relevance
filters:
anyOf:
- items:
oneOf:
- $ref: '#/components/schemas/NodeNameFilter'
- $ref: '#/components/schemas/MetadataFilter'
discriminator:
propertyName: name
mapping:
metadata: '#/components/schemas/MetadataFilter'
node_name: '#/components/schemas/NodeNameFilter'
type: array
- type: 'null'
title: Filters
description: List of filters to apply to the scorer.
type: object
title: ContextRelevanceScorer
CorrectnessScorer:
properties:
name:
type: string
const: correctness
title: Name
default: correctness
filters:
anyOf:
- items:
oneOf:
- $ref: '#/components/schemas/NodeNameFilter'
- $ref: '#/components/schemas/MetadataFilter'
discriminator:
propertyName: name
mapping:
metadata: '#/components/schemas/MetadataFilter'
node_name: '#/components/schemas/NodeNameFilter'
type: array
- type: 'null'
title: Filters
description: List of filters to apply to the scorer.
type:
type: string
const: plus
title: Type
default: plus
model_name:
anyOf:
- type: string
- type: 'null'
title: Model Name
description: Alias of the model to use for the scorer.
num_judges:
anyOf:
- type: integer
maximum: 10
minimum: 1
- type: 'null'
title: Num Judges
description: Number of judges for the scorer.
type: object
title: CorrectnessScorer
GroundTruthAdherenceScorer:
properties:
name:
type: string
const: ground_truth_adherence
title: Name
default: ground_truth_adherence
filters:
anyOf:
- items:
oneOf:
- $ref: '#/components/schemas/NodeNameFilter'
- $ref: '#/components/schemas/MetadataFilter'
discriminator:
propertyName: name
mapping:
metadata: '#/components/schemas/MetadataFilter'
node_name: '#/components/schemas/NodeNameFilter'
type: array
- type: 'null'
title: Filters
description: List of filters to apply to the scorer.
type:
type: string
const: plus
title: Type
default: plus
model_name:
anyOf:
- type: string
- type: 'null'
title: Model Name
description: Alias of the model to use for the scorer.
num_judges:
anyOf:
- type: integer
maximum: 10
minimum: 1
- type: 'null'
title: Num Judges
description: Number of judges for the scorer.
type: object
title: GroundTruthAdherenceScorer
InputPIIScorer:
properties:
name:
type: string
const: input_pii
title: Name
default: input_pii
filters:
anyOf:
- items:
oneOf:
- $ref: '#/components/schemas/NodeNameFilter'
- $ref: '#/components/schemas/MetadataFilter'
discriminator:
propertyName: name
mapping:
metadata: '#/components/schemas/MetadataFilter'
node_name: '#/components/schemas/NodeNameFilter'
type: array
- type: 'null'
title: Filters
description: List of filters to apply to the scorer.
type: object
title: InputPIIScorer
InputSexistScorer:
properties:
name:
type: string
const: input_sexist
title: Name
default: input_sexist
filters:
anyOf:
- items:
oneOf:
- $ref: '#/components/schemas/NodeNameFilter'
- $ref: '#/components/schemas/MetadataFilter'
discriminator:
propertyName: name
mapping:
metadata: '#/components/schemas/MetadataFilter'
node_name: '#/components/schemas/NodeNameFilter'
type: array
- type: 'null'
title: Filters
description: List of filters to apply to the scorer.
type:
type: string
enum:
- luna
- plus
title: Type
default: luna
model_name:
anyOf:
- type: string
- type: 'null'
title: Model Name
description: Alias of the model to use for the scorer.
num_judges:
anyOf:
- type: integer
maximum: 10
minimum: 1
- type: 'null'
title: Num Judges
description: Number of judges for the scorer.
type: object
title: InputSexistScorer
InputToneScorer:
properties:
name:
type: string
const: input_tone
title: Name
default: input_tone
filters:
anyOf:
- items:
oneOf:
- $ref: '#/components/schemas/NodeNameFilter'
- $ref: '#/components/schemas/MetadataFilter'
discriminator:
propertyName: name
mapping:
metadata: '#/components/schemas/MetadataFilter'
node_name: '#/components/schemas/NodeNameFilter'
type: array
- type: 'null'
title: Filters
description: List of filters to apply to the scorer.
type: object
title: InputToneScorer
InputToxicityScorer:
properties:
name:
type: string
const: input_toxicity
title: Name
default: input_toxicity
filters:
anyOf:
- items:
oneOf:
- $ref: '#/components/schemas/NodeNameFilter'
- $ref: '#/components/schemas/MetadataFilter'
discriminator:
propertyName: name
mapping:
metadata: '#/components/schemas/MetadataFilter'
node_name: '#/components/schemas/NodeNameFilter'
type: array
- type: 'null'
title: Filters
description: List of filters to apply to the scorer.
type:
type: string
enum:
- luna
- plus
title: Type
default: luna
model_name:
anyOf:
- type: string
- type: 'null'
title: Model Name
description: Alias of the model to use for the scorer.
num_judges:
anyOf:
- type: integer
maximum: 10
minimum: 1
- type: 'null'
title: Num Judges
description: Number of judges for the scorer.
type: object
title: InputToxicityScorer
InstructionAdherenceScorer:
properties:
name:
type: string
const: instruction_adherence
title: Name
default: instruction_adherence
filters:
anyOf:
- items:
oneOf:
- $ref: '#/components/schemas/NodeNameFilter'
- $ref: '#/components/schemas/MetadataFilter'
discriminator:
propertyName: name
mapping:
metadata: '#/components/schemas/MetadataFilter'
node_name: '#/components/schemas/NodeNameFilter'
type: array
- type: 'null'
title: Filters
description: List of filters to apply to the scorer.
type:
type: string
const: plus
title: Type
default: plus
model_name:
anyOf:
- type: string
- type: 'null'
title: Model Name
description: Alias of the model to use for the scorer.
num_judges:
anyOf:
- type: integer
maximum: 10
minimum: 1
- type: 'null'
title: Num Judges
description: Number of judges for the scorer.
type: object
title: InstructionAdherenceScorer
OutputPIIScorer:
properties:
name:
type: string
const: output_pii
title: Name
default: output_pii
filters:
anyOf:
- items:
oneOf:
- $ref: '#/components/schemas/NodeNameFilter'
- $ref: '#/components/schemas/MetadataFilter'
discriminator:
propertyName: name
mapping:
metadata: '#/components/schemas/MetadataFilter'
node_name: '#/components/schemas/NodeNameFilter'
type: array
- type: 'null'
title: Filters
description: List of filters to apply to the scorer.
type: object
title: OutputPIIScorer
OutputSexistScorer:
properties:
name:
type: string
const: output_sexist
title: Name
default: output_sexist
filters:
anyOf:
- items:
oneOf:
- $ref: '#/components/schemas/NodeNameFilter'
- $ref: '#/components/schemas/MetadataFilter'
discriminator:
propertyName: name
mapping:
metadata: '#/components/schemas/MetadataFilter'
node_name: '#/components/schemas/NodeNameFilter'
type: array
- type: 'null'
title: Filters
description: List of filters to apply to the scorer.
type:
type: string
enum:
- luna
- plus
title: Type
default: luna
model_name:
anyOf:
- type: string
- type: 'null'
title: Model Name
description: Alias of the model to use for the scorer.
num_judges:
anyOf:
- type: integer
maximum: 10
minimum: 1
- type: 'null'
title: Num Judges
description: Number of judges for the scorer.
type: object
title: OutputSexistScorer
OutputToneScorer:
properties:
name:
type: string
const: output_tone
title: Name
default: output_tone
filters:
anyOf:
- items:
oneOf:
- $ref: '#/components/schemas/NodeNameFilter'
- $ref: '#/components/schemas/MetadataFilter'
discriminator:
propertyName: name
mapping:
metadata: '#/components/schemas/MetadataFilter'
node_name: '#/components/schemas/NodeNameFilter'
type: array
- type: 'null'
title: Filters
description: List of filters to apply to the scorer.
type: object
title: OutputToneScorer
OutputToxicityScorer:
properties:
name:
type: string
const: output_toxicity
title: Name
default: output_toxicity
filters:
anyOf:
- items:
oneOf:
- $ref: '#/components/schemas/NodeNameFilter'
- $ref: '#/components/schemas/MetadataFilter'
discriminator:
propertyName: name
mapping:
metadata: '#/components/schemas/MetadataFilter'
node_name: '#/components/schemas/NodeNameFilter'
type: array
- type: 'null'
title: Filters
description: List of filters to apply to the scorer.
type:
type: string
enum:
- luna
- plus
title: Type
default: luna
model_name:
anyOf:
- type: string
- type: 'null'
title: Model Name
description: Alias of the model to use for the scorer.
num_judges:
anyOf:
- type: integer
maximum: 10
minimum: 1
- type: 'null'
title: Num Judges
description: Number of judges for the scorer.
type: object
title: OutputToxicityScorer
PromptInjectionScorer:
properties:
name:
type: string
const: prompt_injection
title: Name
default: prompt_injection
filters:
anyOf:
- items:
oneOf:
- $ref: '#/components/schemas/NodeNameFilter'
- $ref: '#/components/schemas/MetadataFilter'
discriminator:
propertyName: name
mapping:
metadata: '#/components/schemas/MetadataFilter'
node_name: '#/components/schemas/NodeNameFilter'
type: array
- type: 'null'
title: Filters
description: List of filters to apply to the scorer.
type:
type: string
enum:
- luna
- plus
title: Type
default: luna
model_name:
anyOf:
- type: string
- type: 'null'
title: Model Name
description: Alias of the model to use for the scorer.
num_judges:
anyOf:
- type: integer
maximum: 10
minimum: 1
- type: 'null'
title: Num Judges
description: Number of judges for the scorer.
type: object
title: PromptInjectionScorer
PromptPerplexityScorer:
properties:
name:
type: string
const: prompt_perplexity
title: Name
default: prompt_perplexity
filters:
anyOf:
- items:
oneOf:
- $ref: '#/components/schemas/NodeNameFilter'
- $ref: '#/components/schemas/MetadataFilter'
discriminator:
propertyName: name
mapping:
metadata: '#/components/schemas/MetadataFilter'
node_name: '#/components/schemas/NodeNameFilter'
type: array
- type: 'null'
title: Filters
description: List of filters to apply to the scorer.
type: object
title: PromptPerplexityScorer
RougeScorer:
properties:
name:
type: string
const: rouge
title: Name
default: rouge
filters:
anyOf:
- items:
oneOf:
- $ref: '#/components/schemas/NodeNameFilter'
- $ref: '#/components/schemas/MetadataFilter'
discriminator:
propertyName: name
mapping:
metadata: '#/components/schemas/MetadataFilter'
node_name: '#/components/schemas/NodeNameFilter'
type: array
- type: 'null'
title: Filters
description: List of filters to apply to the scorer.
type: object
title: RougeScorer
ToolErrorRateScorer:
properties:
name:
type: string
const: tool_error_rate
title: Name
default: tool_error_rate
filters:
anyOf:
- items:
oneOf:
- $ref: '#/components/schemas/NodeNameFilter'
- $ref: '#/components/schemas/MetadataFilter'
discriminator:
propertyName: name
mapping:
metadata: '#/components/schemas/MetadataFilter'
node_name: '#/components/schemas/NodeNameFilter'
type: array
- type: 'null'
title: Filters
description: List of filters to apply to the scorer.
type:
type: string
enum:
- luna
- plus
title: Type
default: plus
model_name:
anyOf:
- type: string
- type: 'null'
title: Model Name
description: Alias of the model to use for the scorer.
type: object
title: ToolErrorRateScorer
ToolSelectionQualityScorer:
properties:
name:
type: string
const: tool_selection_quality
title: Name
default: tool_selection_quality
filters:
anyOf:
- items:
oneOf:
- $ref: '#/components/schemas/NodeNameFilter'
- $ref: '#/components/schemas/MetadataFilter'
discriminator:
propertyName: name
mapping:
metadata: '#/components/schemas/MetadataFilter'
node_name: '#/components/schemas/NodeNameFilter'
type: array
- type: 'null'
title: Filters
description: List of filters to apply to the scorer.
type:
type: string
enum:
- luna
- plus
title: Type
default: plus
model_name:
anyOf:
- type: string
- type: 'null'
title: Model Name
description: Alias of the model to use for the scorer.
num_judges:
anyOf:
- type: integer
maximum: 10
minimum: 1
- type: 'null'
title: Num Judges
description: Number of judges for the scorer.
type: object
title: ToolSelectionQualityScorer
UncertaintyScorer:
properties:
name:
type: string
const: uncertainty
title: Name
default: uncertainty
filters:
anyOf:
- items:
oneOf:
- $ref: '#/components/schemas/NodeNameFilter'
- $ref: '#/components/schemas/MetadataFilter'
discriminator:
propertyName: name
mapping:
metadata: '#/components/schemas/MetadataFilter'
node_name: '#/components/schemas/NodeNameFilter'
type: array
- type: 'null'
title: Filters
description: List of filters to apply to the scorer.
type: object
title: UncertaintyScorer
RegisteredScorerConfig:
properties:
name:
type: string
title: Name
description: Name of the scorer to enable.
filters:
anyOf:
- items:
oneOf:
- $ref: '#/components/schemas/NodeNameFilter'
- $ref: '#/components/schemas/MetadataFilter'
discriminator:
propertyName: name
mapping:
metadata: '#/components/schemas/MetadataFilter'
node_name: '#/components/schemas/NodeNameFilter'
type: array
- type: 'null'
title: Filters
description: List of filters to apply to the scorer.
type: object
required:
- name
title: RegisteredScorerConfig
GeneratedScorerConfig:
properties:
name:
type: string
title: Name
description: Name of the scorer to enable.
filters:
anyOf:
- items:
oneOf:
- $ref: '#/components/schemas/NodeNameFilter'
- $ref: '#/components/schemas/MetadataFilter'
discriminator:
propertyName: name
mapping:
metadata: '#/components/schemas/MetadataFilter'
node_name: '#/components/schemas/NodeNameFilter'
type: array
- type: 'null'
title: Filters
description: List of filters to apply to the scorer.
type: object
required:
- name
title: GeneratedScorerConfig
FinetunedScorerConfig:
properties:
name:
type: string
title: Name
description: Name of the scorer to enable.
filters:
anyOf:
- items:
oneOf:
- $ref: '#/components/schemas/NodeNameFilter'
- $ref: '#/components/schemas/MetadataFilter'
discriminator:
propertyName: name
mapping:
metadata: '#/components/schemas/MetadataFilter'
node_name: '#/components/schemas/NodeNameFilter'
type: array
- type: 'null'
title: Filters
description: List of filters to apply to the scorer.
type: object
required:
- name
title: FinetunedScorerConfig
WorkflowStep:
properties:
type:
type: string
const: workflow
title: Type
description: Type of the step. By default, it is set to workflow.
default: workflow
input:
anyOf:
- type: string
- $ref: '#/components/schemas/Document-Input'
- $ref: '#/components/schemas/Message'
- additionalProperties: true
type: object
- items:
type: string
type: array
- items:
$ref: '#/components/schemas/Document-Input'
type: array
- items:
$ref: '#/components/schemas/Message'
type: array
- items:
additionalProperties:
type: string
type: object
type: array
- items:
additionalProperties: true
type: object
type: array
title: Input
description: Input to the step.
redacted_input:
anyOf:
- type: string
- $ref: '#/components/schemas/Document-Input'
- $ref: '#/components/schemas/Message'
- additionalProperties: true
type: object
- items:
type: string
type: array
- items:
$ref: '#/components/schemas/Document-Input'
type: array
- items:
$ref: '#/components/schemas/Message'
type: array
- items:
additionalProperties:
type: string
type: object
type: array
- items:
additionalProperties: true
type: object
type: array
- type: 'null'
title: Redacted Input
description: >-
Redacted input of the step. This is used to redact sensitive
information.
output:
anyOf:
- type: string
- $ref: '#/components/schemas/Document-Input'
- $ref: '#/components/schemas/Message'
- additionalProperties: true
type: object
- items:
type: string
type: array
- items:
$ref: '#/components/schemas/Document-Input'
type: array
- items:
$ref: '#/components/schemas/Message'
type: array
- items:
additionalProperties:
type: string
type: object
type: array
- items:
additionalProperties: true
type: object
type: array
title: Output
description: Output of the step.
default: ''
redacted_output:
anyOf:
- type: string
- $ref: '#/components/schemas/Document-Input'
- $ref: '#/components/schemas/Message'
- additionalProperties: true
type: object
- items:
type: string
type: array
- items:
$ref: '#/components/schemas/Document-Input'
type: array
- items:
$ref: '#/components/schemas/Message'
type: array
- items:
additionalProperties:
type: string
type: object
type: array
- items:
additionalProperties: true
type: object
type: array
- type: 'null'
title: Redacted Output
description: >-
Redacted output of the step. This is used to redact sensitive
information.
name:
type: string
title: Name
description: Name of the step.
default: ''
created_at_ns:
type: integer
title: Created At Ns
description: Timestamp of the step's creation, as nanoseconds since epoch.
duration_ns:
type: integer
title: Duration Ns
description: Duration of the step in nanoseconds.
default: 0
metadata:
additionalProperties:
type: string
type: object
title: Metadata
description: Metadata associated with this step.
status_code:
anyOf:
- type: integer
- type: 'null'
title: Status Code
description: Status code of the step. Used for logging failed/errored steps.
ground_truth:
anyOf:
- type: string
- type: 'null'
title: Ground Truth
description: Ground truth expected output for the step.
steps:
items:
oneOf:
- $ref: '#/components/schemas/WorkflowStep'
- $ref: '#/components/schemas/ChainStep'
- $ref: '#/components/schemas/LlmStep'
- $ref: '#/components/schemas/RetrieverStep'
- $ref: '#/components/schemas/ToolStep'
- $ref: '#/components/schemas/AgentStep'
discriminator:
propertyName: type
mapping:
agent: '#/components/schemas/AgentStep'
chain: '#/components/schemas/ChainStep'
llm: '#/components/schemas/LlmStep'
retriever: '#/components/schemas/RetrieverStep'
tool: '#/components/schemas/ToolStep'
workflow: '#/components/schemas/WorkflowStep'
type: array
title: Steps
description: Steps in the workflow.
parent:
anyOf:
- $ref: '#/components/schemas/StepWithChildren'
- type: 'null'
description: Parent node of the current node. For internal use only.
type: object
required:
- input
title: WorkflowStep
ChainStep:
properties:
type:
type: string
const: chain
title: Type
description: Type of the step. By default, it is set to chain.
default: chain
input:
anyOf:
- type: string
- $ref: '#/components/schemas/Document-Input'
- $ref: '#/components/schemas/Message'
- additionalProperties: true
type: object
- items:
type: string
type: array
- items:
$ref: '#/components/schemas/Document-Input'
type: array
- items:
$ref: '#/components/schemas/Message'
type: array
- items:
additionalProperties:
type: string
type: object
type: array
- items:
additionalProperties: true
type: object
type: array
title: Input
description: Input to the step.
redacted_input:
anyOf:
- type: string
- $ref: '#/components/schemas/Document-Input'
- $ref: '#/components/schemas/Message'
- additionalProperties: true
type: object
- items:
type: string
type: array
- items:
$ref: '#/components/schemas/Document-Input'
type: array
- items:
$ref: '#/components/schemas/Message'
type: array
- items:
additionalProperties:
type: string
type: object
type: array
- items:
additionalProperties: true
type: object
type: array
- type: 'null'
title: Redacted Input
description: >-
Redacted input of the step. This is used to redact sensitive
information.
output:
anyOf:
- type: string
- $ref: '#/components/schemas/Document-Input'
- $ref: '#/components/schemas/Message'
- additionalProperties: true
type: object
- items:
type: string
type: array
- items:
$ref: '#/components/schemas/Document-Input'
type: array
- items:
$ref: '#/components/schemas/Message'
type: array
- items:
additionalProperties:
type: string
type: object
type: array
- items:
additionalProperties: true
type: object
type: array
title: Output
description: Output of the step.
default: ''
redacted_output:
anyOf:
- type: string
- $ref: '#/components/schemas/Document-Input'
- $ref: '#/components/schemas/Message'
- additionalProperties: true
type: object
- items:
type: string
type: array
- items:
$ref: '#/components/schemas/Document-Input'
type: array
- items:
$ref: '#/components/schemas/Message'
type: array
- items:
additionalProperties:
type: string
type: object
type: array
- items:
additionalProperties: true
type: object
type: array
- type: 'null'
title: Redacted Output
description: >-
Redacted output of the step. This is used to redact sensitive
information.
name:
type: string
title: Name
description: Name of the step.
default: ''
created_at_ns:
type: integer
title: Created At Ns
description: Timestamp of the step's creation, as nanoseconds since epoch.
duration_ns:
type: integer
title: Duration Ns
description: Duration of the step in nanoseconds.
default: 0
metadata:
additionalProperties:
type: string
type: object
title: Metadata
description: Metadata associated with this step.
status_code:
anyOf:
- type: integer
- type: 'null'
title: Status Code
description: Status code of the step. Used for logging failed/errored steps.
ground_truth:
anyOf:
- type: string
- type: 'null'
title: Ground Truth
description: Ground truth expected output for the step.
steps:
items:
oneOf:
- $ref: '#/components/schemas/WorkflowStep'
- $ref: '#/components/schemas/ChainStep'
- $ref: '#/components/schemas/LlmStep'
- $ref: '#/components/schemas/RetrieverStep'
- $ref: '#/components/schemas/ToolStep'
- $ref: '#/components/schemas/AgentStep'
discriminator:
propertyName: type
mapping:
agent: '#/components/schemas/AgentStep'
chain: '#/components/schemas/ChainStep'
llm: '#/components/schemas/LlmStep'
retriever: '#/components/schemas/RetrieverStep'
tool: '#/components/schemas/ToolStep'
workflow: '#/components/schemas/WorkflowStep'
type: array
title: Steps
description: Steps in the workflow.
parent:
anyOf:
- $ref: '#/components/schemas/StepWithChildren'
- type: 'null'
description: Parent node of the current node. For internal use only.
type: object
required:
- input
title: ChainStep
LlmStep:
properties:
type:
type: string
const: llm
title: Type
description: Type of the step. By default, it is set to llm.
default: llm
input:
anyOf:
- type: string
- additionalProperties:
type: string
type: object
- $ref: '#/components/schemas/Message'
- items:
type: string
type: array
- items:
additionalProperties:
type: string
type: object
type: array
- items:
$ref: '#/components/schemas/Message'
type: array
title: Input
description: Input to the LLM step.
redacted_input:
anyOf:
- type: string
- additionalProperties:
type: string
type: object
- $ref: '#/components/schemas/Message'
- items:
type: string
type: array
- items:
additionalProperties:
type: string
type: object
type: array
- items:
$ref: '#/components/schemas/Message'
type: array
- type: 'null'
title: Redacted Input
description: >-
Redacted input of the LLM step. This is used to redact sensitive
information.
output:
anyOf:
- type: string
- additionalProperties:
type: string
type: object
- $ref: '#/components/schemas/Message'
- items:
type: string
type: array
- items:
additionalProperties:
type: string
type: object
type: array
- items:
$ref: '#/components/schemas/Message'
type: array
title: Output
description: Output of the LLM step.
default: ''
redacted_output:
anyOf:
- type: string
- additionalProperties:
type: string
type: object
- $ref: '#/components/schemas/Message'
- items:
type: string
type: array
- items:
additionalProperties:
type: string
type: object
type: array
- items:
$ref: '#/components/schemas/Message'
type: array
- type: 'null'
title: Redacted Output
description: >-
Redacted output of the LLM step. This is used to redact sensitive
information.
name:
type: string
title: Name
description: Name of the step.
default: ''
created_at_ns:
type: integer
title: Created At Ns
description: Timestamp of the step's creation, as nanoseconds since epoch.
duration_ns:
type: integer
title: Duration Ns
description: Duration of the step in nanoseconds.
default: 0
metadata:
additionalProperties:
type: string
type: object
title: Metadata
description: Metadata associated with this step.
status_code:
anyOf:
- type: integer
- type: 'null'
title: Status Code
description: Status code of the step. Used for logging failed/errored steps.
ground_truth:
anyOf:
- type: string
- type: 'null'
title: Ground Truth
description: Ground truth expected output for the step.
tools:
anyOf:
- items:
additionalProperties: true
type: object
type: array
- type: 'null'
title: Tools
description: List of available tools passed to the LLM on invocation.
model:
anyOf:
- type: string
- type: 'null'
title: Model
description: Model used for this step.
input_tokens:
anyOf:
- type: integer
- type: 'null'
title: Input Tokens
description: Number of input tokens.
output_tokens:
anyOf:
- type: integer
- type: 'null'
title: Output Tokens
description: Number of output tokens.
total_tokens:
anyOf:
- type: integer
- type: 'null'
title: Total Tokens
description: Total number of tokens.
temperature:
anyOf:
- type: number
- type: 'null'
title: Temperature
description: Temperature used for generation.
time_to_first_token_ms:
anyOf:
- type: number
- type: 'null'
title: Time To First Token Ms
description: Time to first token in milliseconds.
type: object
required:
- input
title: LlmStep
RetrieverStep:
properties:
type:
type: string
const: retriever
title: Type
description: Type of the step. By default, it is set to retriever.
default: retriever
input:
type: string
title: Input
description: Input query to the retriever.
redacted_input:
anyOf:
- type: string
- type: 'null'
title: Redacted Input
description: >-
Redacted input of the retriever step. This is used to redact
sensitive information.
output:
items:
$ref: '#/components/schemas/Document-Input'
type: array
title: Output
description: >-
Documents retrieved from the retriever. This can be a list of
strings or `Document`s.
redacted_output:
anyOf:
- items:
$ref: '#/components/schemas/Document-Input'
type: array
- type: 'null'
title: Redacted Output
description: >-
Redacted output of the retriever step. This is used to redact
sensitive information.
name:
type: string
title: Name
description: Name of the step.
default: ''
created_at_ns:
type: integer
title: Created At Ns
description: Timestamp of the step's creation, as nanoseconds since epoch.
duration_ns:
type: integer
title: Duration Ns
description: Duration of the step in nanoseconds.
default: 0
metadata:
additionalProperties:
type: string
type: object
title: Metadata
description: Metadata associated with this step.
status_code:
anyOf:
- type: integer
- type: 'null'
title: Status Code
description: Status code of the step. Used for logging failed/errored steps.
ground_truth:
anyOf:
- type: string
- type: 'null'
title: Ground Truth
description: Ground truth expected output for the step.
type: object
required:
- input
title: RetrieverStep
ToolStep:
properties:
type:
type: string
const: tool
title: Type
description: Type of the step. By default, it is set to tool.
default: tool
input:
anyOf:
- type: string
- $ref: '#/components/schemas/Document-Input'
- $ref: '#/components/schemas/Message'
- additionalProperties: true
type: object
- items:
type: string
type: array
- items:
$ref: '#/components/schemas/Document-Input'
type: array
- items:
$ref: '#/components/schemas/Message'
type: array
- items:
additionalProperties:
type: string
type: object
type: array
- items:
additionalProperties: true
type: object
type: array
title: Input
description: Input to the step.
redacted_input:
anyOf:
- type: string
- $ref: '#/components/schemas/Document-Input'
- $ref: '#/components/schemas/Message'
- additionalProperties: true
type: object
- items:
type: string
type: array
- items:
$ref: '#/components/schemas/Document-Input'
type: array
- items:
$ref: '#/components/schemas/Message'
type: array
- items:
additionalProperties:
type: string
type: object
type: array
- items:
additionalProperties: true
type: object
type: array
- type: 'null'
title: Redacted Input
description: >-
Redacted input of the step. This is used to redact sensitive
information.
output:
anyOf:
- type: string
- $ref: '#/components/schemas/Document-Input'
- $ref: '#/components/schemas/Message'
- additionalProperties: true
type: object
- items:
type: string
type: array
- items:
$ref: '#/components/schemas/Document-Input'
type: array
- items:
$ref: '#/components/schemas/Message'
type: array
- items:
additionalProperties:
type: string
type: object
type: array
- items:
additionalProperties: true
type: object
type: array
title: Output
description: Output of the step.
default: ''
redacted_output:
anyOf:
- type: string
- $ref: '#/components/schemas/Document-Input'
- $ref: '#/components/schemas/Message'
- additionalProperties: true
type: object
- items:
type: string
type: array
- items:
$ref: '#/components/schemas/Document-Input'
type: array
- items:
$ref: '#/components/schemas/Message'
type: array
- items:
additionalProperties:
type: string
type: object
type: array
- items:
additionalProperties: true
type: object
type: array
- type: 'null'
title: Redacted Output
description: >-
Redacted output of the step. This is used to redact sensitive
information.
name:
type: string
title: Name
description: Name of the step.
default: ''
created_at_ns:
type: integer
title: Created At Ns
description: Timestamp of the step's creation, as nanoseconds since epoch.
duration_ns:
type: integer
title: Duration Ns
description: Duration of the step in nanoseconds.
default: 0
metadata:
additionalProperties:
type: string
type: object
title: Metadata
description: Metadata associated with this step.
status_code:
anyOf:
- type: integer
- type: 'null'
title: Status Code
description: Status code of the step. Used for logging failed/errored steps.
ground_truth:
anyOf:
- type: string
- type: 'null'
title: Ground Truth
description: Ground truth expected output for the step.
type: object
required:
- input
title: ToolStep
AgentStep:
properties:
type:
type: string
const: agent
title: Type
description: Type of the step. By default, it is set to agent.
default: agent
input:
anyOf:
- type: string
- $ref: '#/components/schemas/Document-Input'
- $ref: '#/components/schemas/Message'
- additionalProperties: true
type: object
- items:
type: string
type: array
- items:
$ref: '#/components/schemas/Document-Input'
type: array
- items:
$ref: '#/components/schemas/Message'
type: array
- items:
additionalProperties:
type: string
type: object
type: array
- items:
additionalProperties: true
type: object
type: array
title: Input
description: Input to the step.
redacted_input:
anyOf:
- type: string
- $ref: '#/components/schemas/Document-Input'
- $ref: '#/components/schemas/Message'
- additionalProperties: true
type: object
- items:
type: string
type: array
- items:
$ref: '#/components/schemas/Document-Input'
type: array
- items:
$ref: '#/components/schemas/Message'
type: array
- items:
additionalProperties:
type: string
type: object
type: array
- items:
additionalProperties: true
type: object
type: array
- type: 'null'
title: Redacted Input
description: >-
Redacted input of the step. This is used to redact sensitive
information.
output:
anyOf:
- type: string
- $ref: '#/components/schemas/Document-Input'
- $ref: '#/components/schemas/Message'
- additionalProperties: true
type: object
- items:
type: string
type: array
- items:
$ref: '#/components/schemas/Document-Input'
type: array
- items:
$ref: '#/components/schemas/Message'
type: array
- items:
additionalProperties:
type: string
type: object
type: array
- items:
additionalProperties: true
type: object
type: array
title: Output
description: Output of the step.
default: ''
redacted_output:
anyOf:
- type: string
- $ref: '#/components/schemas/Document-Input'
- $ref: '#/components/schemas/Message'
- additionalProperties: true
type: object
- items:
type: string
type: array
- items:
$ref: '#/components/schemas/Document-Input'
type: array
- items:
$ref: '#/components/schemas/Message'
type: array
- items:
additionalProperties:
type: string
type: object
type: array
- items:
additionalProperties: true
type: object
type: array
- type: 'null'
title: Redacted Output
description: >-
Redacted output of the step. This is used to redact sensitive
information.
name:
type: string
title: Name
description: Name of the step.
default: ''
created_at_ns:
type: integer
title: Created At Ns
description: Timestamp of the step's creation, as nanoseconds since epoch.
duration_ns:
type: integer
title: Duration Ns
description: Duration of the step in nanoseconds.
default: 0
metadata:
additionalProperties:
type: string
type: object
title: Metadata
description: Metadata associated with this step.
status_code:
anyOf:
- type: integer
- type: 'null'
title: Status Code
description: Status code of the step. Used for logging failed/errored steps.
ground_truth:
anyOf:
- type: string
- type: 'null'
title: Ground Truth
description: Ground truth expected output for the step.
steps:
items:
oneOf:
- $ref: '#/components/schemas/WorkflowStep'
- $ref: '#/components/schemas/ChainStep'
- $ref: '#/components/schemas/LlmStep'
- $ref: '#/components/schemas/RetrieverStep'
- $ref: '#/components/schemas/ToolStep'
- $ref: '#/components/schemas/AgentStep'
discriminator:
propertyName: type
mapping:
agent: '#/components/schemas/AgentStep'
chain: '#/components/schemas/ChainStep'
llm: '#/components/schemas/LlmStep'
retriever: '#/components/schemas/RetrieverStep'
tool: '#/components/schemas/ToolStep'
workflow: '#/components/schemas/WorkflowStep'
type: array
title: Steps
description: Steps in the workflow.
parent:
anyOf:
- $ref: '#/components/schemas/StepWithChildren'
- type: 'null'
description: Parent node of the current node. For internal use only.
type: object
required:
- input
title: AgentStep
ValidationError:
properties:
loc:
items:
anyOf:
- type: string
- type: integer
type: array
title: Location
msg:
type: string
title: Message
type:
type: string
title: Error Type
type: object
required:
- loc
- msg
- type
title: ValidationError
NodeNameFilter:
properties:
name:
type: string
const: node_name
title: Name
default: node_name
filter_type:
type: string
const: string
title: Filter Type
default: string
value:
type: string
title: Value
operator:
type: string
enum:
- eq
- ne
- contains
title: Operator
case_sensitive:
type: boolean
title: Case Sensitive
default: true
type: object
required:
- value
- operator
title: NodeNameFilter
description: Filters on node names in scorer jobs.
MetadataFilter:
properties:
name:
type: string
const: metadata
title: Name
default: metadata
filter_type:
type: string
const: map
title: Filter Type
default: map
operator:
type: string
enum:
- one_of
- not_in
- eq
- ne
title: Operator
key:
type: string
title: Key
value:
anyOf:
- type: string
- items:
type: string
type: array
title: Value
type: object
required:
- operator
- key
- value
title: MetadataFilter
description: Filters on metadata key-value pairs in scorer jobs.
Document-Input:
properties:
page_content:
type: string
title: Page Content
description: Content of the document.
metadata:
additionalProperties:
anyOf:
- type: boolean
- type: string
- type: integer
- type: number
type: object
title: Metadata
additionalProperties: false
type: object
required:
- page_content
title: Document
Message:
properties:
content:
type: string
title: Content
role:
anyOf:
- type: string
- $ref: '#/components/schemas/MessageRole'
title: Role
additionalProperties: true
type: object
required:
- content
- role
title: Message
StepWithChildren:
properties:
type:
$ref: '#/components/schemas/NodeType'
description: Type of the step. By default, it is set to workflow.
default: workflow
input:
anyOf:
- type: string
- $ref: '#/components/schemas/Document-Input'
- $ref: '#/components/schemas/Message'
- additionalProperties: true
type: object
- items:
type: string
type: array
- items:
$ref: '#/components/schemas/Document-Input'
type: array
- items:
$ref: '#/components/schemas/Message'
type: array
- items:
additionalProperties:
type: string
type: object
type: array
- items:
additionalProperties: true
type: object
type: array
title: Input
description: Input to the step.
redacted_input:
anyOf:
- type: string
- $ref: '#/components/schemas/Document-Input'
- $ref: '#/components/schemas/Message'
- additionalProperties: true
type: object
- items:
type: string
type: array
- items:
$ref: '#/components/schemas/Document-Input'
type: array
- items:
$ref: '#/components/schemas/Message'
type: array
- items:
additionalProperties:
type: string
type: object
type: array
- items:
additionalProperties: true
type: object
type: array
- type: 'null'
title: Redacted Input
description: >-
Redacted input of the step. This is used to redact sensitive
information.
output:
anyOf:
- type: string
- $ref: '#/components/schemas/Document-Input'
- $ref: '#/components/schemas/Message'
- additionalProperties: true
type: object
- items:
type: string
type: array
- items:
$ref: '#/components/schemas/Document-Input'
type: array
- items:
$ref: '#/components/schemas/Message'
type: array
- items:
additionalProperties:
type: string
type: object
type: array
- items:
additionalProperties: true
type: object
type: array
title: Output
description: Output of the step.
default: ''
redacted_output:
anyOf:
- type: string
- $ref: '#/components/schemas/Document-Input'
- $ref: '#/components/schemas/Message'
- additionalProperties: true
type: object
- items:
type: string
type: array
- items:
$ref: '#/components/schemas/Document-Input'
type: array
- items:
$ref: '#/components/schemas/Message'
type: array
- items:
additionalProperties:
type: string
type: object
type: array
- items:
additionalProperties: true
type: object
type: array
- type: 'null'
title: Redacted Output
description: >-
Redacted output of the step. This is used to redact sensitive
information.
name:
type: string
title: Name
description: Name of the step.
default: ''
created_at_ns:
type: integer
title: Created At Ns
description: Timestamp of the step's creation, as nanoseconds since epoch.
duration_ns:
type: integer
title: Duration Ns
description: Duration of the step in nanoseconds.
default: 0
metadata:
additionalProperties:
type: string
type: object
title: Metadata
description: Metadata associated with this step.
status_code:
anyOf:
- type: integer
- type: 'null'
title: Status Code
description: Status code of the step. Used for logging failed/errored steps.
ground_truth:
anyOf:
- type: string
- type: 'null'
title: Ground Truth
description: Ground truth expected output for the step.
steps:
items:
oneOf:
- $ref: '#/components/schemas/WorkflowStep'
- $ref: '#/components/schemas/ChainStep'
- $ref: '#/components/schemas/LlmStep'
- $ref: '#/components/schemas/RetrieverStep'
- $ref: '#/components/schemas/ToolStep'
- $ref: '#/components/schemas/AgentStep'
discriminator:
propertyName: type
mapping:
agent: '#/components/schemas/AgentStep'
chain: '#/components/schemas/ChainStep'
llm: '#/components/schemas/LlmStep'
retriever: '#/components/schemas/RetrieverStep'
tool: '#/components/schemas/ToolStep'
workflow: '#/components/schemas/WorkflowStep'
type: array
title: Steps
description: Steps in the workflow.
parent:
anyOf:
- $ref: '#/components/schemas/StepWithChildren'
- type: 'null'
description: Parent node of the current node. For internal use only.
type: object
required:
- input
title: StepWithChildren
MessageRole:
type: string
enum:
- agent
- assistant
- function
- system
- tool
- user
title: MessageRole
NodeType:
type: string
enum:
- chain
- chat
- llm
- retriever
- tool
- agent
- workflow
- trace
- session
title: NodeType
securitySchemes:
APIKeyHeader:
type: apiKey
in: header
name: Galileo-API-Key
OAuth2PasswordBearer:
type: oauth2
flows:
password:
scopes: {}
tokenUrl: https://api.staging.galileo.ai/login
HTTPBasic:
type: http
scheme: basic
````
---
# Source: https://docs.galileo.ai/galileo/gen-ai-studio-products/galileo-protect/how-to/creating-and-using-stages.md
> ## Documentation Index
> Fetch the complete documentation index at: https://docs.galileo.ai/llms.txt
> Use this file to discover all available pages before exploring further.
# Creating And Using Stages
> Learn to create and manage stages in Galileo Protect, enabling structured AI monitoring and progressive error resolution throughout the deployment lifecycle.
[Stages](/galileo/gen-ai-studio-products/galileo-protect/concepts/stage) can be managed centrally (i.e. registered once and updated dynamically) or locally within the application. Stages consist of [Rulesets](/galileo/gen-ai-studio-products/galileo-protect/concepts/ruleset) that are applied during one invocation. A stage can be composed of multiple rulesets, each executed independently and defined as a prioritized list (i.e. order matters). The [Action](/galileo/gen-ai-studio-products/galileo-protect/concepts/action) for the ruleset with the highest priority is chosen for composing the response.
We recommend defining a stage on your user queries and one on your application's output.
All stages must have names and belong to a project. The project ID is required to create a stage. The stage ID is returned when the stage is created and is required to invoke the stage. Optionally, you can provide a description of the stage.
Check out [Concepts > Stages](/galileo/gen-ai-studio-products/galileo-protect/concepts/stage) for the difference between a Central and a Local stage, and when to use each.
## Creating a Stage
To create a stage, you can use the following code snippet:
```py theme={null}
import galileo_protect as gp
gp.create_stage(name="my first stage", project_id="", description="This is my first stage", type="local") # type can be "central" or "local", default is "local"
```
If you're using central stages, we recommend including the ruleset definitions during stage creation. This way, you can manage the rulesets centrally and update them without changing the invocation code.
```py theme={null}
import galileo_protect as gp
gp.create_stage(name="my first stage", project_id="", description="This is my first stage", type="central", prioritized_rulesets=[
{
"rules": [
{
"metric": "pii",
"operator": "contains",
"target_value": "ssn",
},
],
"action": {
"type": "OVERRIDE",
"choices": [
"Personal Identifiable Information detected in the model output. Sorry, I cannot answer that question."
],
},
},
])
```
If you're using local stages, you can define the rulesets within the `gp.invoke()` function during the invocation instead of the `create_stage` operation.
## Defining and Using Actions
Actions define the operation to perform when a ruleset is triggered when using Galileo Protect. These can be:
1. [Override Action](https://protect.docs.rungalileo.io/?h=status#galileo_protect.OverrideAction): The override action allows configuring various choices from which one is chosen at random when all the rulesets for the stage are triggered.
2. [Passthrough Action](https://protect.docs.rungalileo.io/?h=status#galileo_protect.PassthroughAction): The pass-through action does a simple pass-through of the text. This is the default action in case no other action is defined and used when no rulesets are triggered.
## Subscribing to Events for Actions
Actions include configuration for subscriptions which can be set to event destinations (like webhooks) to HTTP POST requests notifications are sent when the ruleset is triggered. Subscriptions can be configured in actions of any type as:
```py theme={null}
"action": {
"type": "OVERRIDE",
"choices": [
"Personal Identifiable Information detected in the model output. Sorry, I cannot answer that question."
],
"subscriptions": [{"url": ""}],
}
```
By default, notifications are sent to the subscription when they are triggered, but notifications can be sent based on any of the execution statuses. In the below example, notifications will be sent to the specified webhook if there's an error or the ruleset is not triggered.
```py theme={null}
"action": {
"type": "OVERRIDE",
"choices": [
"Personal Identifiable Information detected in the model output. Sorry, I cannot answer that question."
],
"subscriptions": [{"statuses": ["error", "not_triggered"], "url": ""}],
}
```
The subscribers are sent HTTP POST requests with a payload that matches the [response from the Protect invocation](https://protect.docs.rungalileo.io/#galileo_protect.Response) and is of schema:
```py theme={null}
{
"text": "string",
"trace_metadata": {
"id": "string",
"received_at": 0,
"response_at": 0,
"execution_time": -1
},
"status": "string"
}
```
---
# Source: https://docs.galileo.ai/galileo/gen-ai-studio-products/galileo-evaluate/integrations/custom-chain.md
> ## Documentation Index
> Fetch the complete documentation index at: https://docs.galileo.ai/llms.txt
> Use this file to discover all available pages before exploring further.
# Logging Workflows
> No matter how you're orchestrating your workflows, we have an interface to help you upload them to Galileo.
To log your runs with Galileo, you'd start with the same typical flow of logging into Galileo:
```py theme={null}
import promptquality as pq
pq.login()
```
Next you can construct your [EvaluateRun](https://promptquality.docs.rungalileo.io/#promptquality.EvaluateRun) object:
```py theme={null}
from promptquality import EvaluateRun
metrics = [pq.Scorers.context_adherence_plus, pq.Scorers.prompt_injection]
evaluate_run = EvaluateRun(run_name="my_run", project_name="my_project", scorers=metrics)
```
Then you can generate your workflows.
A workflow starts with a user input, could contain multiple AI / tool / retriever nodes, and usually ends with an LLM node summarizing the entire turn to the user.
Datasets should also be constructed in such a way that a sample represents the entry to one workflow (i.e., one user input).
An evaluate run typically consists of multiple workflows, or multiple AI turns.
Here's an example of how you can log your workflows using your llm app:
```py theme={null}
def my_llm_app(input, evaluate_run):
context = " ... [text explaining hallucinations] ... "
template = "Given the following context answer the question. \n Context: {context} \n Question: {question}"
wf = evaluate_run.add_workflow(input=input)
# Get response from your llm.
prompt = template.format(context=context, question=input)
llm_response = llm.call(prompt) # Pseudo-code, replace with your LLM call.
# Log llm step to Galileo
wf.add_llm(input=prompt, output=llm_response, model=)
# Conclude the workflow and add the final output.
wf.conclude(output=llm_response)
return llm_response
# Your evaluation dataset.
eval_set = [
"What are hallucinations?",
"What are intrinsic hallucinations?",
"What are extrinsic hallucinations?"
]
for input in eval_set:
my_llm_app(input, evaluate_run)
```
Finally, log your Evaluate run to Galileo:
```py theme={null}
evaluate_run.finish()
```
## Logging RAG Workflows
If you're looking to log RAG workflows it's easy to add a retriever step. Here's an example with RAG:
```py theme={null}
def my_llm_app(input, evaluate_run):
template = "Given the following context answer the question. \n Context: {context} \n Question: {question}"
wf = evaluate_run.add_workflow(input=input)
# Fetch documents from your retriever
documents = retriever.retrieve(input) # Pseudo-code, replace with your real retriever.
# Log retriever step to Galileo
wf.add_retriever(input=input, documents=documents)
# Get response from your llm.
prompt = template.format(context="\n".join(documents), question=input)
llm_response = llm.call(prompt) # Pseudo-code, replace with your LLM call.
# Log llm step to Galileo
wf.add_llm(input=prompt, output=llm_response, model=)
# Conclude the workflow and add the final output.
wf.conclude(output=llm_response)
return llm_response
# Your evaluation dataset.
eval_set = [
"What are hallucinations?",
"What are intrinsic hallucinations?",
"What are extrinsic hallucinations?"
]
context = "You're an AI assistant helping a user with hallucinations."
for input in eval_set:
my_llm_app(input, evaluate_run)
```
## Logging Agent Workflows
We also support logging Agent workflows. As above, a workflow starts with a user message, contains various steps taken by the system and ends with a response to the user. \
When logging entire sessions, such as multi-turn conversations between a user and an agent, the session should be split into a sequence of Workflows, delimited by the user's messages.
Below is an example on how to log an agentic workflow (say in the middle of a multi-turn conversation) made of the following steps:
* the user query
* an LLM call with tools, and the LLM decides to call tools
* a tool execution
* an LLM call without tools, where the LLM responds back to the user.
```py theme={null}
# Initiate the agentic workflow with the last user message as input
last_user_message = chat_history[-1].content
agent_wf = evaluate_run.add_agent_workflow(input=last_user_message)
# Call the LLM (which select tools)
# input = LLM input = chat history until now
# output = LLM output = LLM call to tools
llm_response = llm_call(chat_history, tools=tools)
agent_wf.add_llm(
input=chat_history,
output=llm_response.tool_call,
tools=tools_dict
)
llm_message = llm_response_to_llm_message(llm_response)
chat_history.append(llm_message)
# Execute the tool call
# input = Tool input = arguments
# output = Tool output = function's return value
tool_response = execute_tool(llm_response.tool_call)
agent_wf.add_tool(
input=llm_response.tool_call.arguments,
output=tool_response,
name=llm_response.tool_call.name
)
tool_message = tool_response_to_tool_message(tool_response)
chat_history.append(tool_message)
# Call the LLM to respond to the user
# input = LLM input = chat history until now
# output = LLM output = LLM response to the user
llm_response = llm_call(chat_history)
agent_wf.add_llm(
input=chat_history,
output=llm_response.content,
)
chat_history.append(llm_response)
# Conclude the agentic workflow with the last response
agent_wf.conclude(output=llm_response.content)
```
## Logging Retriever and LLM Metadata
If you want to log more complex inputs and outputs to your nodes, we provide support for that as well.
For retriever outputs we support the [Document](https://promptquality.docs.rungalileo.io/#promptquality.Document) object.
```py theme={null}
wf = evaluate_run.add_workflow(input="Who's a good bot?", output="I am!", duration_ns=2000)
wf.add_retriever(
input="Who's a good bot?",
documents=[pq.Document(content="Research shows that I am a good bot.", metadata={"length": 35})],
duration_ns=1000
)
```
For LLM inputs and outputs we support the [Message](https://promptquality.docs.rungalileo.io/#promptquality.Message) object.
```py theme={null}
wf = evaluate_run.add_workflow(input="Who's a good bot?", output="I am!", duration_ns=2000)
wf.add_llm(
input=pq.Message(content="Given this context: Research shows that I am a good bot. answer this: Who's a good bot?"),
output=pq.Message(content="I am!", role=pq.MessageRole.assistant),
model=pq.Models.chat_gpt,
input_tokens=25,
output_tokens=3,
total_tokens=28,
duration_ns=1000
)
```
Often times an llm interaction consists of multiple messages. You can log these as well.
```py theme={null}
wf = evaluate_run.add_workflow(input="Who's a good bot?", output="I am!", duration_ns=2000)
wf.add_llm(
input=[
pq.Message(content="You're a good bot that answers questions.", role=pq.MessageRole.system),
pq.Message(content="Given this context: Research shows that I am a good bot. answer this: Who's a good bot?"),
],
output=pq.Message(content="I am!", role=pq.MessageRole.assistant),
model=pq.Models.chat_gpt,
)
```
## Logging Nested Workflows
If you have more complex workflows that involve nesting workflows within workflows, we support that too.
Here's an example of how you can log nested workflow using conclude to step out of the nested workflow, back into the base workflow:
```py theme={null}
wf = evaluate_run.add_workflow("input", "output", duration_ns=100)
# Add a workflow inside the base workflow.
nested_wf = wf.add_sub_workflow(input="inner input")
# Add an LLM step inside the nested workflow.
nested_wf.add_llm(input="prompt", output="response", model=pq.Models.chat_gpt, duration_ns=60)
# Conclude the nested workflow and step back into the base workflow.
nested_wf.conclude(output="inner output", duration_ns=60)
# Add another LLM step in the base workflow.
wf.add_llm("outer prompt", "outer response", "chatgpt", duration_ns=40)
```
---
# Source: https://docs.galileo.ai/galileo/gen-ai-studio-products/galileo-evaluate/how-to/customize-chainpoll-powered-metrics.md
> ## Documentation Index
> Fetch the complete documentation index at: https://docs.galileo.ai/llms.txt
> Use this file to discover all available pages before exploring further.
# Customize Chainpoll-powered Metrics
> Improve metric accuracy by customizing your Chainpoll-powered metrics
[**ChainPoll**](/galileo/gen-ai-studio-products/galileo-ai-research/chainpoll) is a powerful, flexible technique for LLM-based evaluation built by Galileo's Research team. It is used to power multiple Guardrail Metrics across the Galileo platform:
* Context Adherence Plus
* Chunk Attribution & Utilization
* Completeness Plus
* Correctness
Chainpoll leverages a chain-of-thought prompting technique and prompting an LLM multiple times to calculate metric values. There are two levers one can customize for a Chainpoll metric:
* The model that gets queried
* The number of times we prompt that model
Generally, better models will provide more accurate metric values, and a higher number of judges will increase the accuracy and stability of metric values. We've configured our Chainpoll-powered metrics to balance the trade-off of Cost and Accuracy.
## Changing the model or number of judges of a Chainpoll metric
We allow customizing execution parameters for the [AI-powered metrics](/galileo/gen-ai-studio-products/galileo-guardrail-metrics) from our Guardrail Store. By default, these metrics use gpt-4o-mini for the model and 3 judges (except for chunk attribution & utilization, which uses 1 judge and for which the number of judges cannot be customized). To customize this, when creating your run you can customize these metrics as:
```python theme={null}
pq.EvaluateRun(..., scorers=[
pq.CustomizedChainPollScorer(
scorer_name=pq.CustomizedScorerName.context_adherence_plus,
model_alias=pq.Models.gpt_4o,
num_judges=7)
])
```
#### Customizable Metrics
The metrics that can be customized are:
1. Chunk Attribution & Chunk Utilization: `pq.CustomizedScorerName.chunk_attribution_utilization_plus`
2. Completeness: `pq.CustomizedScorerName.completeness_plus`
3. Context Adherence: `pq.CustomizedScorerName.context_adherence_plus`
4. Correctness: `pq.CustomizedScorerName.correctness`
#### Models supported
* OpenAI or Azure models that use the Chat Completions API
* Gemini 1.5 Flash and Pro through VertexAI
When entering the model name, use a model alias from [this list](https://promptquality.docs.rungalileo.io/#promptquality.Models).
#### Number of Judges supported
Judges can be set to integers between `0` and `10`.
Note: Chunk Attribution and Chunk Utilization don't benefit from increasing the number of judges.
---
# Source: https://docs.galileo.ai/galileo-ai-research/data-drift-detection.md
> ## Documentation Index
> Fetch the complete documentation index at: https://docs.galileo.ai/llms.txt
> Use this file to discover all available pages before exploring further.
# Data Drift Detection
> Discover Galileo's data drift detection methods to monitor AI model performance, identify data changes, and maintain model reliability in production.
When developing and deploying models, a key concern is data coverage and freshness. As the real world data distribution continually evolves, it is increasingly important to monitor how data shifts affect a model's ability to produce trustworthy predictions. At the heart of this concern is the model's training data: does the data used to train our model properly capture the current state of the world - *or more importantly* is our model making or expected to make predictions over new types of data not seen during training?
To address these questions, we look to the problem of **data drift detection.**
## What is Data Drift?
In machine learning we generally view data drift as data - e.g. production data - differing from the data used to train a model - i.e. coming from a different underlying distribution. There are many factors that can lead to dataset drift and several ways that drift can manifest. Broadly there are two main categories of data drift: 1) virtual drift (covariate shift) and 2) concept drift.
### Virtual Drift
Virtual data drift refers to a change in the type of data seen (the feature space) without a change in the relationship between a given data sample and the label it is assigned - i.e. a change in the underlying data distribution P(x) without a change in P(y|x). Virtual drift can manifest in many different forms, such as changing syntactic structure and style (e.g. new ways of asking a particular question to a QA system) or the appearance of novel words, phrases, and / or concepts (e.g. Covid).
Virtual drift generally manifests when there is insufficient training data coverage and / or new concepts appear in the real world. Virtual data drift can reveal incorrectly learned decision boundaries, increasing the potential for incorrect, non-trustworthy predictions (especially in the case of an overfit model).
### Concept shift
In contrast to virtual drift, concept drift refers to a change in the way that labels are assigned for a given data sample - i.e. a change in P(Y|X) without a change to P(X). This typically manifests as the label for a given data sample changing over time. For example, concept drift occurs if there is a change in the labeling criteria / guidelines - certain samples previously labeled *Class A* should now be labeled *Class B*.
## Data Drift in Galileo
Without access to ground truth labels or the underlying labeling criteria, surfacing *concept drift* is intractable. Therefore, Galileo focuses on detecting **virtual data drift**. Specifically, we aim to detect data samples that are sufficiently different from the data used during training.
> **Data Drift in Galileo**: Detecting data samples that would appear to come from a different distribution than the training data distribution
### Data Drift Across Data Split
Data drift as a measure of shifted data distributions is *not* limited to changes within production data. The characteristics of data drift - an evolving / shifting feature space - can occur for any non-training data split. Therefore, Galileo surfaces data drift errors not only for inference data splits, but also for validation and test splits. We refer to them separately as **Drifted** vs. **Out of Coverage** data.
**Drifted Data:** Drifted *production data* within an *inference run.* These samples represent the classical paradigm of data drift capturing changes within the real world data distribution. Tracking production data drift is essential for understanding potential changes to model performance in production, the appearance of important new concepts, and indications of a stale training dataset. As production models react to an evolving world, these samples highlight high value samples to be monitored and added to future model re-training datasets.
**Out of Coverage Data:** Drifted *validation* or *test* data. These samples capture two primary data gaps:
1. Data samples that our model *fails* to properly generalize on - for example due to overfitting or under-representation within the training dataset (generalization drift). These data samples represent concepts that are represented in the training data but show generalization gaps.
2. Data concepts that are *not represented* within the training data and thus the model may struggle to effectively generalize over.
### Viewing Drifted Samples
In the Galileo Console, you can view drifted samples either through the *Out of Coverage or* *Drifted* data tabs. Since drift compares data distribution, drift is always computed and shown with respect to a reference data distribution - the training dataset.
In the embeddings view, we overlay the current split and reference training data embeddings to provide a visual representation of alignment and data gaps (i.e. drifted data) within the embedding space.
Viewing Drifted Samples within an Inference Run
**Note:** that the 2-dimensional embeddings view is limited in its ability to capture high dimensional embeddings interactions and represents an approximate overlapping of data distributions - i.e. drifted / not drifted data may not always look "drifted" in the embeddings view.
## Galileo's Drift Detection Algorithm
We implement an embedding based, non-parametric nearest neighbor algorithm for detecting out of distribution (OOD) data - i.e. drifted and out of coverage samples. Differentiating algorithm characteristics include:
* **Embedding Based**: Leverage hierarchical, semantic structure encoded in neural network embeddings - particularly realized through working with (large) pre-trained models, e.g. large language models (LLMs)
* **Non-parametric**: does not impose any distributional assumptions on the underlying embedding space, providing *simplicity*, *flexibility*, and *generality*
* **Interpretability**: the general simplicity of nearest neighbor based algorithms provides easy interpretability
### Transforming the Embedding Space - Core Distance
The foundation of nearest neighbor algorithms is a representation of the embedding space through local neighborhood information - defining a neighborhood statistic. Although different methods exist for computing a neighborhood statistic, we utilize a simple and inexpensive estimate of local neighborhood density: *K Core-Distance*. Used in algorithms such as *HDBSCAN* \[1] \_\_ and \_LOF\_ \[2]\_, K C\_ore-Distance is computed as the cosine-distance to a samples kth nearest neighbor within the neural network embedding space.
> K Core-Distance(x) = cosine distance to x's kth nearest neighbor
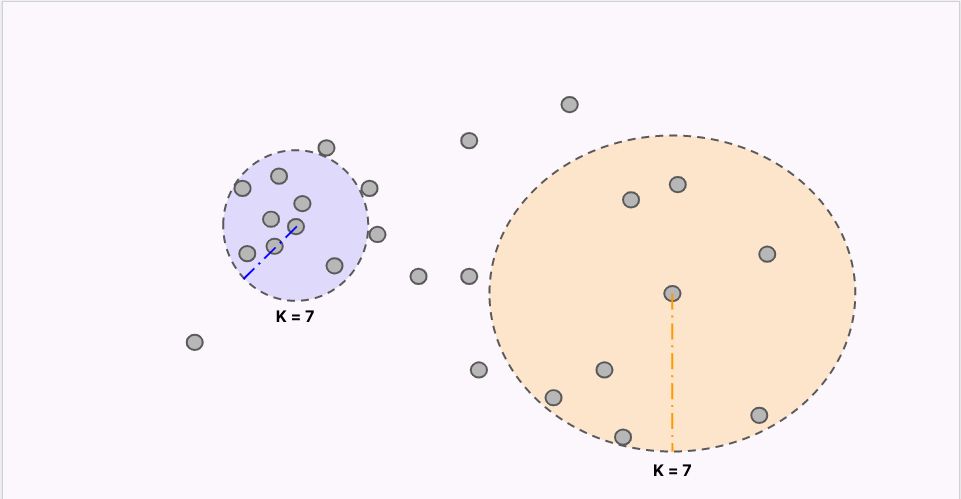 ### The Drift Detection Algorithm
#### 1. Mapping the Embedding Space
OOD data are computed with respect to a reference distribution - in our case, the model's *training data distribution*. Therefore, the first step of the algorithm is mapping the structure of the training embedding data distribution by computing the K Core-Distance for each data sample.
> Map the training embedding distribution --> K Core-Distance distribution
#### 2. Selecting a Threshold for Data Drift
After mapping the reference distribution, we must decide a threshold above which new data should be considered OOD. Selecting a threshold based on the K Core-Distance directly is not generalizable for 2 primary reasons: 1) \*\*\*\* Each dataset has a unique and different K Core-Distance distribution, which in tern influences reason 2) cosine distance is not easily interpretable without context - i.e. a cosine distance of 0.6 has different meanings given two different datasets.
For these reasons, we determine a threshold as a *threshold at x% precision*.
> e.g. Threshold at 95% precision - The K Core-Distance representing the 95th percentile of the reference distribution
### The Drift Detection Algorithm
#### 1. Mapping the Embedding Space
OOD data are computed with respect to a reference distribution - in our case, the model's *training data distribution*. Therefore, the first step of the algorithm is mapping the structure of the training embedding data distribution by computing the K Core-Distance for each data sample.
> Map the training embedding distribution --> K Core-Distance distribution
#### 2. Selecting a Threshold for Data Drift
After mapping the reference distribution, we must decide a threshold above which new data should be considered OOD. Selecting a threshold based on the K Core-Distance directly is not generalizable for 2 primary reasons: 1) \*\*\*\* Each dataset has a unique and different K Core-Distance distribution, which in tern influences reason 2) cosine distance is not easily interpretable without context - i.e. a cosine distance of 0.6 has different meanings given two different datasets.
For these reasons, we determine a threshold as a *threshold at x% precision*.
> e.g. Threshold at 95% precision - The K Core-Distance representing the 95th percentile of the reference distribution
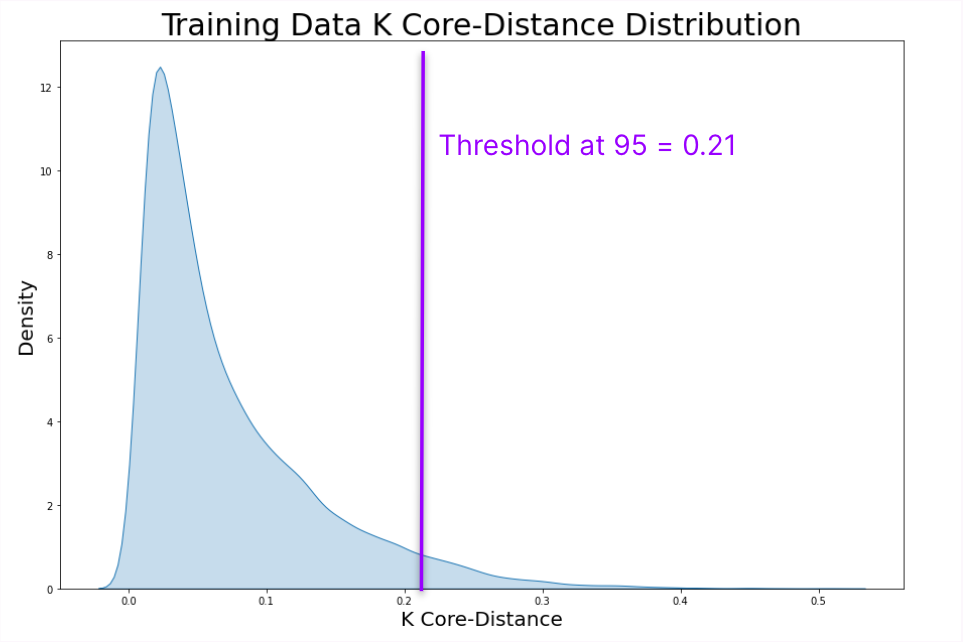 #### 3. Determining that a Sample is Drifted / Out of Coverage
Given a query data sample *q*, we can quickly determine whether *q* should be considered OOD.
1. Embed *q* within the reference (training) embedding space
2. Compute the K Core-Distance of *q* in the training embedding space.
3. Compare *q's* K Core-Distance to the threshold determined for the reference distribution.
#### 3. Determining that a Sample is Drifted / Out of Coverage
Given a query data sample *q*, we can quickly determine whether *q* should be considered OOD.
1. Embed *q* within the reference (training) embedding space
2. Compute the K Core-Distance of *q* in the training embedding space.
3. Compare *q's* K Core-Distance to the threshold determined for the reference distribution.
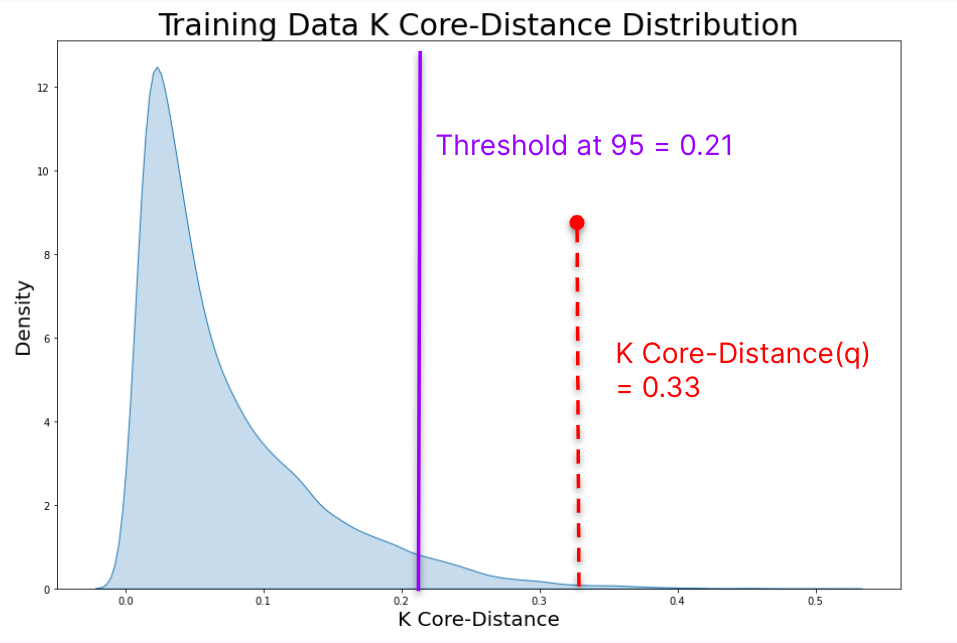 ### Interpretability
A major benefits of this algorithm is that it provides interpretability and flexibility. By mapping the reference embedding space to a K Core-Distance distribution, we frame OOD detection as a distribution comparison problem.
> Given a query sample, how does it compare to the reference distribution?
Moreover, by picking a threshold based on a distribution percentile, we remove any dependance on the range of K Core-Distances for a given dataset - i.e. a dataset agnostic mechanism.
**Drift / Out of Coverage Scores**: Building on this distributional perspective, we can compute a per-sample score indicating how out of distribution a data sample is.
> Drift / Out of Coverage Score - The *percentile* a sample falls in with respect to the reference K Core-Distance distribution.
Unlike analyzing K Core-Distances directly, our *drift / out of coverage score* is fully dataset agnostic. For example, consider the example from above.
With a K Core-Distance of 0.33 and a threshold of 0.21, we considered the *q* as drifted. However, in general 0.33 has very little meaning without the context. In comparison, a *drift\_score of 0.99* captures the necessary distributional context - indicating that *q* falls within the 99th percentile of the reference distribution and is very likely to be out of distribution.
### Interpretability
A major benefits of this algorithm is that it provides interpretability and flexibility. By mapping the reference embedding space to a K Core-Distance distribution, we frame OOD detection as a distribution comparison problem.
> Given a query sample, how does it compare to the reference distribution?
Moreover, by picking a threshold based on a distribution percentile, we remove any dependance on the range of K Core-Distances for a given dataset - i.e. a dataset agnostic mechanism.
**Drift / Out of Coverage Scores**: Building on this distributional perspective, we can compute a per-sample score indicating how out of distribution a data sample is.
> Drift / Out of Coverage Score - The *percentile* a sample falls in with respect to the reference K Core-Distance distribution.
Unlike analyzing K Core-Distances directly, our *drift / out of coverage score* is fully dataset agnostic. For example, consider the example from above.
With a K Core-Distance of 0.33 and a threshold of 0.21, we considered the *q* as drifted. However, in general 0.33 has very little meaning without the context. In comparison, a *drift\_score of 0.99* captures the necessary distributional context - indicating that *q* falls within the 99th percentile of the reference distribution and is very likely to be out of distribution.
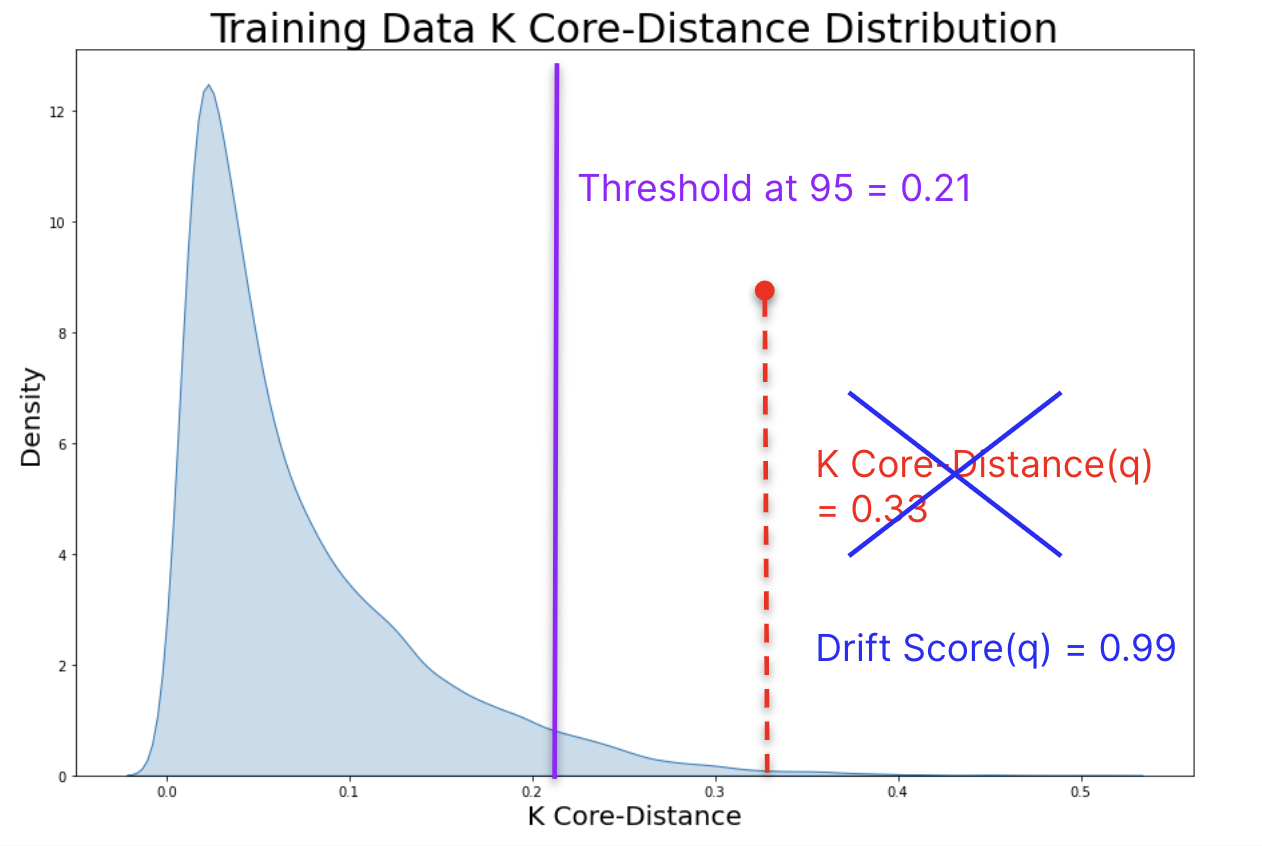 ### References + Additional Resources
\[1] McInnes, Leland, John Healy, and Steve Astels. "hdbscan: Hierarchical density based clustering." *J. Open Source Softw.* 2.11 (2017): 205.
\[2] Breunig, Markus M., et al. "LOF: identifying density-based local outliers." *Proceedings of the 2000 ACM SIGMOD international conference on Management of data*. 2000.
\[3] Sun, Yiyou, et al. "Out-of-distribution Detection with Deep Nearest Neighbors." *arXiv preprint arXiv:2204.06507* (2022).
---
# Source: https://docs.galileo.ai/deployments/data-privacy-and-compliance.md
> ## Documentation Index
> Fetch the complete documentation index at: https://docs.galileo.ai/llms.txt
> Use this file to discover all available pages before exploring further.
# Data Privacy And Compliance
> This page covers concerns regarding residency of data and compliances provided by Galileo.
## Security Standards
Clusters hosted by Galileo are hosted in Amazon Web Services, ensuring the highest degree of physical security and environmental control. All intermediate environments which transfer or store data are reviewed to meet rigid security standards.
## Incident Response, Disaster Recovery & Business Continuity
Galileo has a well-defined incident response and disaster recovery policy. In the unlikely event of an incident, Galileo will:
* Assemble response team members, including two assigned on-call engineers available at all times of day
* Immediately revoke relevant access or passwords
* Notify Galileo's Engineering and Customer Success Teams
* Notify customers impacted of the intrusion and if/how their data was compromised
* Provide a resolution timeline
* Conduct an audit of systems to ascertain the source of the breach
* Refine existing practices to prevent future impact and harden systems
* Communicate the improvement plan to customers impacted
## Compliance
Galileo provides on-going training for employees for all information security practices and policies, and maintains measures to address violations of procedures. As part of onboarding and off-boarding team members, access controls are managed to ensure those in role are only given access to what the role requires.
Galileo is SOC 2 Type 1 and Type 2 compliant, and therefore we adhere to the requirements of this compliance throughout the year. These include independent audit.
---
# Source: https://docs.galileo.ai/client-reference/finetune-nlp-studio/data-quality.md
> ## Documentation Index
> Fetch the complete documentation index at: https://docs.galileo.ai/llms.txt
> Use this file to discover all available pages before exploring further.
# Data Quality | Fine-Tune NLP Studio Client Reference
> Enhance your data quality in Galileo's NLP and CV Studio using the 'dataquality' Python package; find installation and usage details here.
For a full reference check out: [https://dataquality.docs.rungalileo.io/](https://dataquality.docs.rungalileo.io/)
Installation:
`pip install dataquality`
---
# Source: https://docs.galileo.ai/galileo/gen-ai-studio-products/galileo-evaluate/integrations/data-storage/databricks.md
> ## Documentation Index
> Fetch the complete documentation index at: https://docs.galileo.ai/llms.txt
> Use this file to discover all available pages before exploring further.
# Databricks
> Integrating into Databricks to seamlessly export your data to Delta Lake
Galileo supports integrating into *Databricks Unity Catalog*. This allows you to directly export data your Evaluate or Observe data to Databricks.
Before starting, make sure you've created a Databricks Unity [Catalog](https://docs.databricks.com/en/catalogs/create-catalog.html) and have a [Compute Instance](https://docs.databricks.com/en/compute/configure.html)
To set up your Databricks integration, go to 'Settings & Permissions', followed by 'Integrations'. Open "Databricks" from the Data Storage section.
You'll be prompted for:
* Hostname
* Path
* Catalog names
* API Token
You can get these under the 'Connection Details' of your 'SQL Warehouses'
### References + Additional Resources
\[1] McInnes, Leland, John Healy, and Steve Astels. "hdbscan: Hierarchical density based clustering." *J. Open Source Softw.* 2.11 (2017): 205.
\[2] Breunig, Markus M., et al. "LOF: identifying density-based local outliers." *Proceedings of the 2000 ACM SIGMOD international conference on Management of data*. 2000.
\[3] Sun, Yiyou, et al. "Out-of-distribution Detection with Deep Nearest Neighbors." *arXiv preprint arXiv:2204.06507* (2022).
---
# Source: https://docs.galileo.ai/deployments/data-privacy-and-compliance.md
> ## Documentation Index
> Fetch the complete documentation index at: https://docs.galileo.ai/llms.txt
> Use this file to discover all available pages before exploring further.
# Data Privacy And Compliance
> This page covers concerns regarding residency of data and compliances provided by Galileo.
## Security Standards
Clusters hosted by Galileo are hosted in Amazon Web Services, ensuring the highest degree of physical security and environmental control. All intermediate environments which transfer or store data are reviewed to meet rigid security standards.
## Incident Response, Disaster Recovery & Business Continuity
Galileo has a well-defined incident response and disaster recovery policy. In the unlikely event of an incident, Galileo will:
* Assemble response team members, including two assigned on-call engineers available at all times of day
* Immediately revoke relevant access or passwords
* Notify Galileo's Engineering and Customer Success Teams
* Notify customers impacted of the intrusion and if/how their data was compromised
* Provide a resolution timeline
* Conduct an audit of systems to ascertain the source of the breach
* Refine existing practices to prevent future impact and harden systems
* Communicate the improvement plan to customers impacted
## Compliance
Galileo provides on-going training for employees for all information security practices and policies, and maintains measures to address violations of procedures. As part of onboarding and off-boarding team members, access controls are managed to ensure those in role are only given access to what the role requires.
Galileo is SOC 2 Type 1 and Type 2 compliant, and therefore we adhere to the requirements of this compliance throughout the year. These include independent audit.
---
# Source: https://docs.galileo.ai/client-reference/finetune-nlp-studio/data-quality.md
> ## Documentation Index
> Fetch the complete documentation index at: https://docs.galileo.ai/llms.txt
> Use this file to discover all available pages before exploring further.
# Data Quality | Fine-Tune NLP Studio Client Reference
> Enhance your data quality in Galileo's NLP and CV Studio using the 'dataquality' Python package; find installation and usage details here.
For a full reference check out: [https://dataquality.docs.rungalileo.io/](https://dataquality.docs.rungalileo.io/)
Installation:
`pip install dataquality`
---
# Source: https://docs.galileo.ai/galileo/gen-ai-studio-products/galileo-evaluate/integrations/data-storage/databricks.md
> ## Documentation Index
> Fetch the complete documentation index at: https://docs.galileo.ai/llms.txt
> Use this file to discover all available pages before exploring further.
# Databricks
> Integrating into Databricks to seamlessly export your data to Delta Lake
Galileo supports integrating into *Databricks Unity Catalog*. This allows you to directly export data your Evaluate or Observe data to Databricks.
Before starting, make sure you've created a Databricks Unity [Catalog](https://docs.databricks.com/en/catalogs/create-catalog.html) and have a [Compute Instance](https://docs.databricks.com/en/compute/configure.html)
To set up your Databricks integration, go to 'Settings & Permissions', followed by 'Integrations'. Open "Databricks" from the Data Storage section.
You'll be prompted for:
* Hostname
* Path
* Catalog names
* API Token
You can get these under the 'Connection Details' of your 'SQL Warehouses'
 Once your integration is set up, you should be able to export data to your Databricks Delta Lake. Enter a name for the cluster and table, and Galileo will export your data straight into your Databricks Unity Catalog.
Once your integration is set up, you should be able to export data to your Databricks Delta Lake. Enter a name for the cluster and table, and Galileo will export your data straight into your Databricks Unity Catalog.
 ---
# Source: https://docs.galileo.ai/galileo/galileo-nlp-studio/galileo-product-features/dataset-slices.md
> ## Documentation Index
> Fetch the complete documentation index at: https://docs.galileo.ai/llms.txt
> Use this file to discover all available pages before exploring further.
# Dataset Slices
> Slices is a powerful Galileo feature that allows you to monitor, across training runs, a sub-population of the dataset based on metadata filters.
### Creating Your First Simple Slice
Imagine you want to monitor model performance on samples containing the keyword "star wars." To do so, you can simply type "star wars" into the search panel and save the resulting data as a new custom **Slice** (see Figure below).
---
# Source: https://docs.galileo.ai/galileo/galileo-nlp-studio/galileo-product-features/dataset-slices.md
> ## Documentation Index
> Fetch the complete documentation index at: https://docs.galileo.ai/llms.txt
> Use this file to discover all available pages before exploring further.
# Dataset Slices
> Slices is a powerful Galileo feature that allows you to monitor, across training runs, a sub-population of the dataset based on metadata filters.
### Creating Your First Simple Slice
Imagine you want to monitor model performance on samples containing the keyword "star wars." To do so, you can simply type "star wars" into the search panel and save the resulting data as a new custom **Slice** (see Figure below).
 When creating a new slice you are presented a pop up that allows you to give a **custom name** to your slice and displays slice level details: 1) Slice project scope, 2) Slice Recipe (filter rules to create the slice). Your newly created slice will be available across all training runs within the selected project.
When creating a new slice you are presented a pop up that allows you to give a **custom name** to your slice and displays slice level details: 1) Slice project scope, 2) Slice Recipe (filter rules to create the slice). Your newly created slice will be available across all training runs within the selected project.
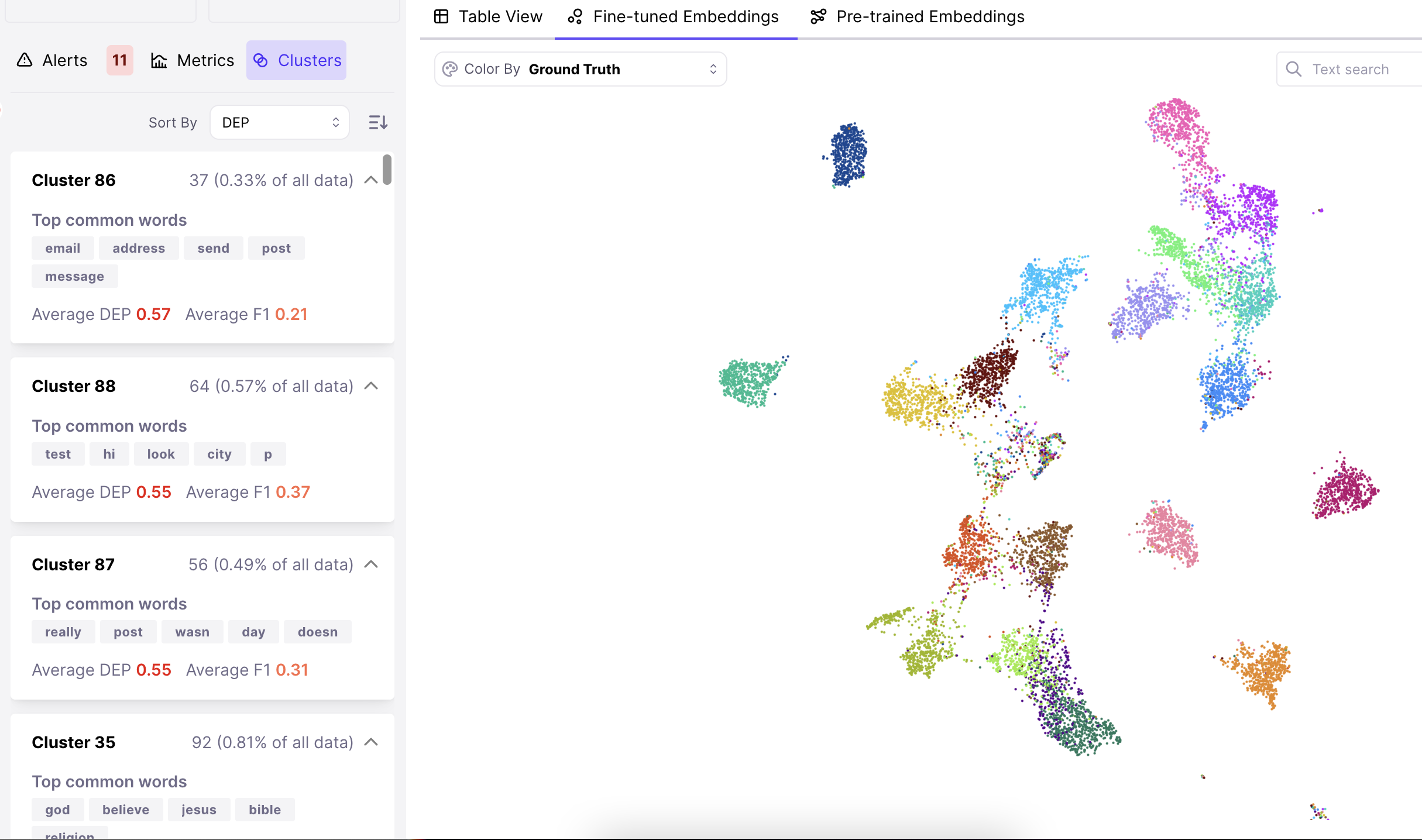 ### Complex Slices
You can create a custom slice in many different ways e.g. using [similarity search](/galileo/how-to-and-faq/galileo-product-features/similarity-search), using subsets etc. Moreover, you can create complex slices based on multiple filtering criteria. For example, the figure below walks through creating a slice by first using similarity search and then filtering for samples that contain the keyword "worst."
### Complex Slices
You can create a custom slice in many different ways e.g. using [similarity search](/galileo/how-to-and-faq/galileo-product-features/similarity-search), using subsets etc. Moreover, you can create complex slices based on multiple filtering criteria. For example, the figure below walks through creating a slice by first using similarity search and then filtering for samples that contain the keyword "worst."
 The final "Slice Recipe" is as follows:
The final "Slice Recipe" is as follows:
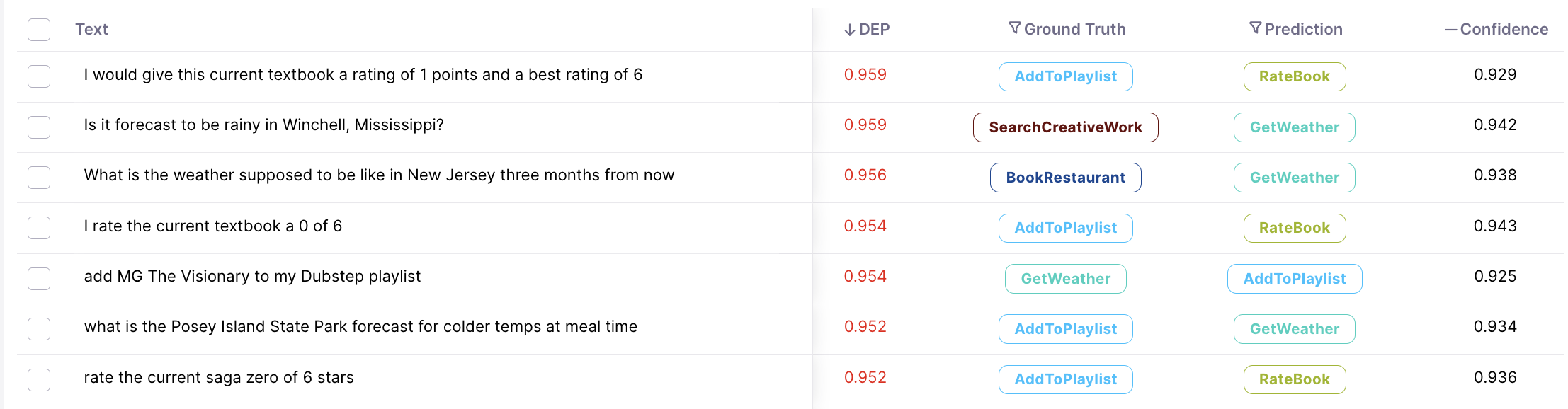 ---
# Source: https://docs.galileo.ai/galileo/galileo-nlp-studio/galileo-product-features/dataset-view.md
> ## Documentation Index
> Fetch the complete documentation index at: https://docs.galileo.ai/llms.txt
> Use this file to discover all available pages before exploring further.
# Dataset View
> The Dataset View provides an interactive data table for inspecting your datasets.
Individual data samples from your dataset or selected data subset are shown, where each sample is a row in the table. In addition to the text, a sample's associated gold label, predicted label, and DEP score are included as data attribute columns. By default, the samples are sorted by decreasing DEP score.
---
# Source: https://docs.galileo.ai/galileo/galileo-nlp-studio/galileo-product-features/dataset-view.md
> ## Documentation Index
> Fetch the complete documentation index at: https://docs.galileo.ai/llms.txt
> Use this file to discover all available pages before exploring further.
# Dataset View
> The Dataset View provides an interactive data table for inspecting your datasets.
Individual data samples from your dataset or selected data subset are shown, where each sample is a row in the table. In addition to the text, a sample's associated gold label, predicted label, and DEP score are included as data attribute columns. By default, the samples are sorted by decreasing DEP score.
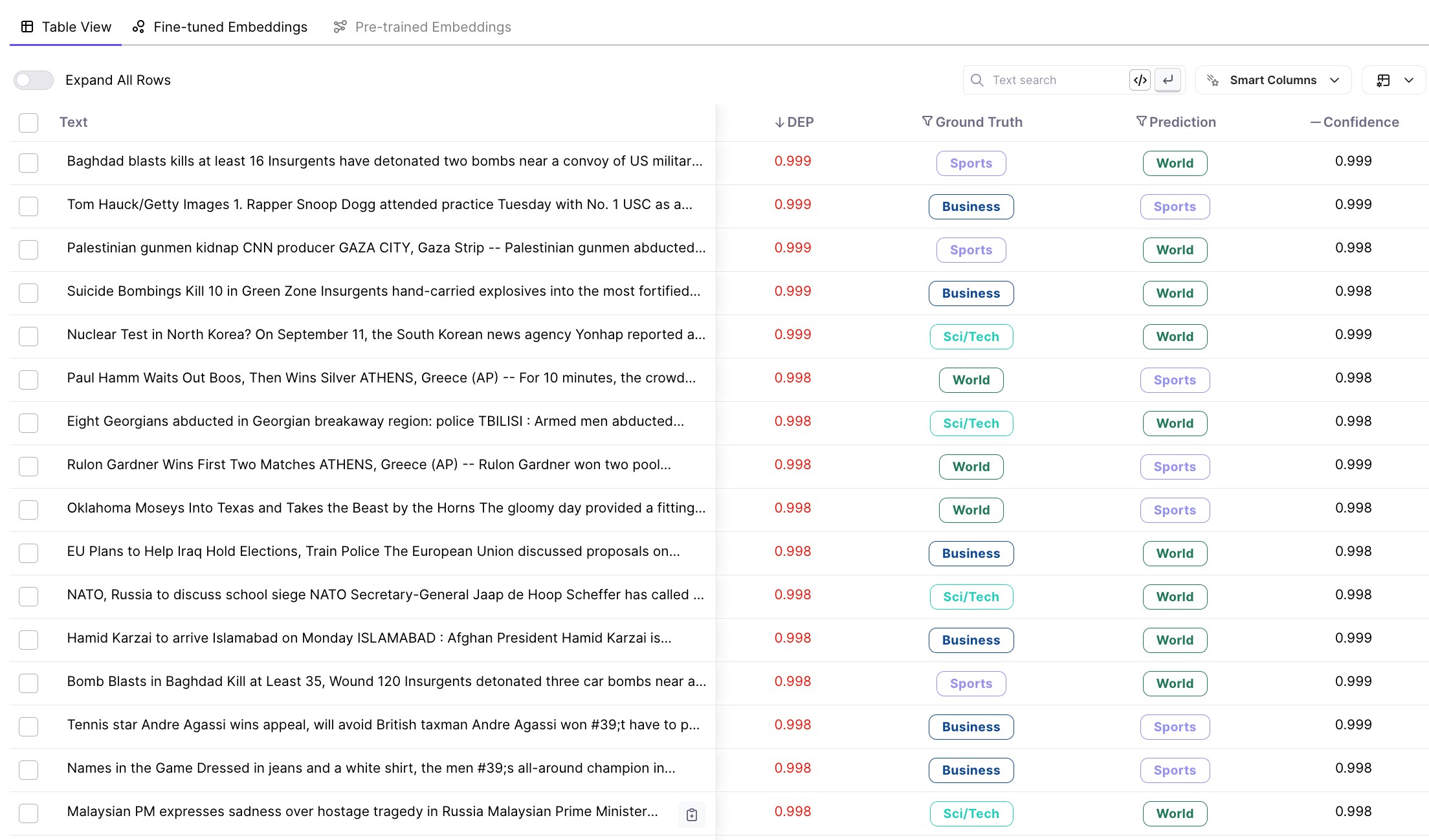 ### Customization
As shown below, the Dataset View can be customized in the following ways:
* Sorting by DEP, Confidence or Metadata Columns
* Filtering to a specific class, DEP range, error type or metadata values
* Selecting and de-selecting dataset columns
### Customization
As shown below, the Dataset View can be customized in the following ways:
* Sorting by DEP, Confidence or Metadata Columns
* Filtering to a specific class, DEP range, error type or metadata values
* Selecting and de-selecting dataset columns
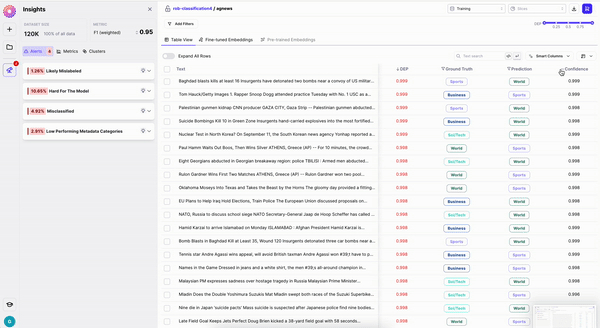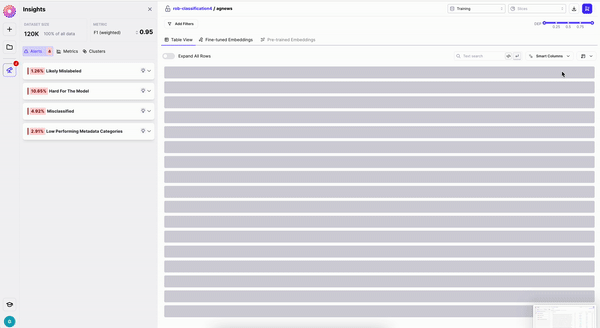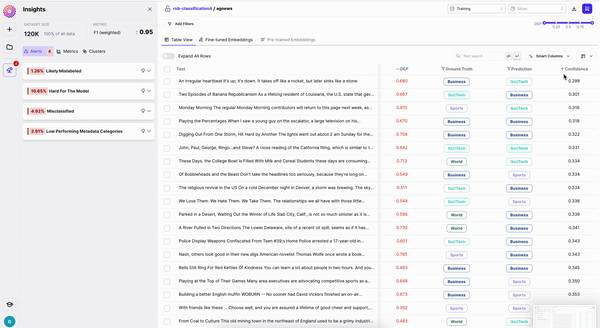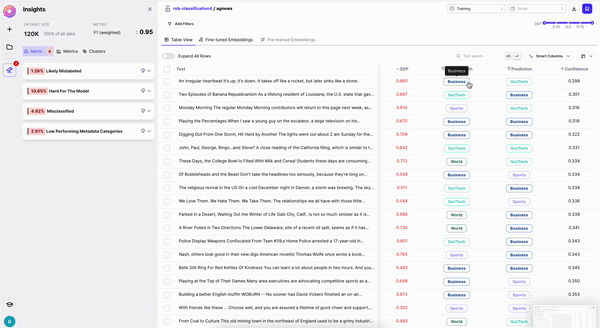 ### Data Selection
Each row or data sample can be selected to perform an action. As demonstrated in Test Drive Galileo - Movie Reviews, we can easily identify and export data samples with annotation errors for relabeling and/or further inspection. See [Actions](/galileo/how-to-and-faq/galileo-product-features/actions) for more details.
### Data Selection
Each row or data sample can be selected to perform an action. As demonstrated in Test Drive Galileo - Movie Reviews, we can easily identify and export data samples with annotation errors for relabeling and/or further inspection. See [Actions](/galileo/how-to-and-faq/galileo-product-features/actions) for more details.
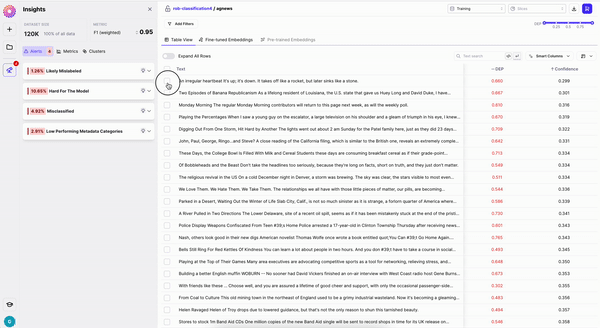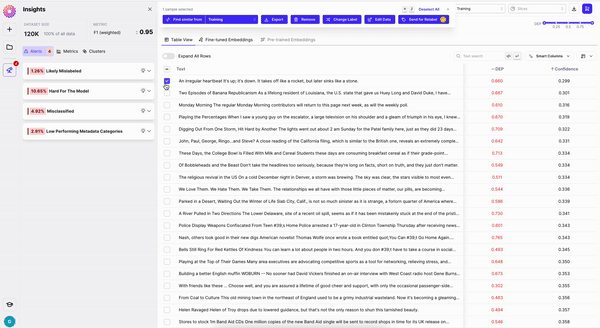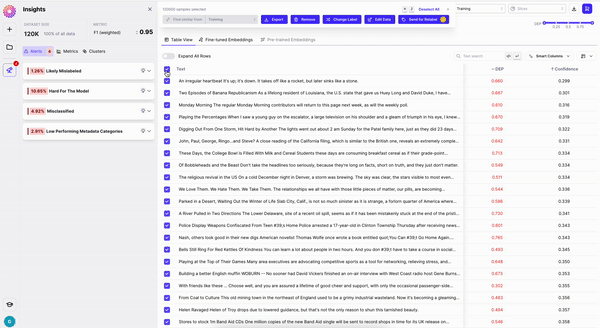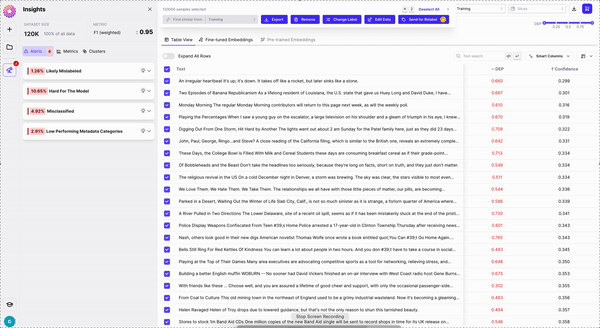 ---
# Source: https://docs.galileo.ai/deployments/dependencies.md
> ## Documentation Index
> Fetch the complete documentation index at: https://docs.galileo.ai/llms.txt
> Use this file to discover all available pages before exploring further.
# Dependencies
> Understand Galileo deployment prerequisites and dependencies to ensure a smooth installation and integration across supported platforms.
### Core Dependencies
* Kubernetes Cluster: Galileo is deployed within a Kubernetes environment, leveraging various Kubernetes resources.
### Data Stores
* PostgreSQL: Used for persistent data storage (if not using AWS RDS or GCP CloudSQL).
* ClickHouse: A columnar database used for storing and querying large volumes of data efficiently. It supports analytics and real-time reporting.
* MinIO: Serves as the object storage solution (if not using AWS S3 or GCP Cloud Storage).
### Messaging
* RabbitMQ: Acts as the message broker for asynchronous communication.
### Monitoring and Logging
* Prometheus: For metrics collection and monitoring. This will also send metrics to Galileo's centralized Grafana server for observability.
* Prometheus Adapter: This component is crucial for enabling Kubernetes Horizontal Pod Autoscaler (HPA) to use Prometheus metrics for scaling applications. It must be activated through the `.Values.prometheus_adapter.enabled` Helm configuration. Care should be taken to avoid conflicts with existing services, such as the metrics-server, potentially requiring resource renaming for seamless integration.
* Grafana: For visualizing metrics. Optional, as users might not require metric visualization.
* Fluentd: For logging and forwarding to AWS CloudWatch. Optional, depending on the logging and log forwarding requirements.
* Alertmanager: Manages alerts for the monitoring system. Optional, if no alerting is needed or a different alerting mechanism is in place.
Ensure that the corresponding Helm values (`prometheus_adapter.enabled`, `fluentd.enabled`, `alertmanager.enabled`) are configured according to your deployment needs.
### Networking
* Ingress NGINX: Manages external access to the services.
* Calico: Provides network policies.
* Cert-Manager: Handles certificate management.
### Configuration and Management
* Helm: Galileo leverages Helm for package management and deployment. Ensure Helm is configured correctly to deploy the charts listed above.
### Miscellaneous
* Cluster Autoscaler: Automatically adjusts the size of the Kubernetes cluster.
* Kube-State-Metrics: Generates metrics about the state of Kubernetes objects.
* Metrics Server: Aggregates resource usage data.
* Node Exporter: Collects metrics from the nodes.
* ClickHouse Keeper: Acts as the service for managing ClickHouse replicas and coordinating distributed tasks, similar to Zookeeper. Essential for ClickHouse high availability and consistency.
---
# Source: https://docs.galileo.ai/deployments/deploying-galileo-aks.md
> ## Documentation Index
> Fetch the complete documentation index at: https://docs.galileo.ai/llms.txt
> Use this file to discover all available pages before exploring further.
# Azure AKS
> This page details the steps to deploy a Galileo Kubernetes cluster in Microsoft Azure's AKS service environment.
\*\*
Total time for deployment:\*\* 30-45 minutes
## Recommended Cluster Configuration
| Configuration | Recommended Value |
| ------------------------------------------------------ | --------------------------- |
| **Nodes in the cluster’s core nodegroup** | 4 (min) 5 (max) 4 (desired) |
| **CPU per core node** | 4 CPU |
| **RAM per core node** | 16 GiB RAM |
| **Number of nodes in the cluster’s runners nodegroup** | 1 (min) 5 (max) 1 (desired) |
| **CPU per runner node** | 8 CPU |
| **RAM per runner node** | 32 GiB RAM |
| **Minimum volume size per node** | 200 GiB |
| **Required Kubernetes API version** | 1.21 |
| **Storage class** | standard |
## Step 1: \[Optional] Create a dedicated resource group for Galileo cluster
```sh theme={null}
az group create --name galileo --location eastus
```
## Step 2: Provision an AKS cluster
```sh theme={null}
az aks create -g galileo -n galileo --enable-managed-identity --node-count 4 --max-count 7 --min-count 4 -s Standard_D4_v4 --nodepool-name gcore --nodepool-labels "galileo-node-type=galileo-core" --enable-cluster-autoscaler
```
## Step 3: Add Galileo Runner nodepool
```sh theme={null}
Az aks nodepool add -g galileo -n grunner --cluster-name galileo --node-count 1 --max-count 5 --min-count 1 --node-count 1 -s Standard_D8_v4 --labels "galileo-node-type=galileo-runner" --enable-cluster-autoscaler
```
## Step 4: Get cluster credentials
```sh theme={null}
az aks get-credentials --resource-group galileo --name galileo
```
## Step 5: Apply Galileo manifest
```sh theme={null}
kubectl apply -f galileo.yaml
```
## Step 6: Customer DNS Configuration
Galileo has 4 main URLs (shown below). In order to make the URLs accessible across the company, you have to set the following DNS addresses in your DNS provider after the platform is deployed.
| Service | URL |
| ------- | ------------------------------------------- |
| API | **api.galileo**.company.\[com\|ai\|io…] |
| Data | **data.galileo**.company.\[com\|ai\|io…] |
| UI | **console.galileo**.company.\[com\|ai\|io…] |
| Grafana | **grafana.galileo**.company.\[com\|ai\|io…] |
## Creating a GPU-enabled Node Group
For specialized tasks that require GPU processing, such as machine learning workloads, Galileo supports the configuration of GPU-enabled node pools.
The supported GPUs are H100, A100, L40S, L4 (shorter context window), A10 (shorter context window). And the corresponding node types are Standard\_NC40ads\_H100\_v5, Standard\_NC24ads\_A100\_v4, Standard\_NV12ads\_A10\_v5.
1. **Node Group Creation**: Create a node group with name `galileo-ml`, and label `galileo-node-type=galileo-ml`
2. Reach out to Galileo to get exact number of GPUs needed for your load. But feel free to set min=1, max=5 by default.
---
# Source: https://docs.galileo.ai/deployments/deploying-galileo-eks-zero-access.md
> ## Documentation Index
> Fetch the complete documentation index at: https://docs.galileo.ai/llms.txt
> Use this file to discover all available pages before exploring further.
# Zero Access Deployment | Galileo on EKS
> Create a private Kubernetes Cluster with EKS in your AWS Account, upload containers to your container registry, and deploy Galileo.
\*\*
Total time for deployment:\*\* 45-60 minutes
**This deployment requires the use of AWS CLI commands. If you only have cloud console access, follow the optional instructions below to get** [**eksctl**](https://eksctl.io/introduction/#installation) **working with AWS CloudShell.**
### Step 0: (Optional) Deploying via AWS CloudShell
To use [`eksctl`](https://eksctl.io/introduction/#installation) via CloudShell in the AWS console, open a CloudShell session and do the following:
```sh theme={null}
# Create directory
mkdir -p $HOME/.local/bin
cd $HOME/.local/bin
# eksctl
curl --silent --location "https://github.com/weaveworks/eksctl/releases/latest/download/eksctl_$(uname -s)_amd64.tar.gz" | tar xz -C /tmp
sudo mv /tmp/eksctl $HOME/.local/bin
```
The rest of the installation deployment can now be run from the CloudShell session. You can use `vim` to create/edit the required yaml and json files within the shell session.
### Recommended Cluster Configuration
Galileo recommends the following Kubernetes deployment configuration:
| Configuration | Recommended Value |
| ------------------------------------------------------ | --------------------------- |
| **Nodes in the cluster’s core nodegroup** | 4 (min) 5 (max) 4 (desired) |
| **CPU per core node** | 4 CPU |
| **RAM per core node** | 16 GiB RAM |
| **Number of nodes in the cluster’s runners nodegroup** | 1 (min) 5 (max) 1 (desired) |
| **CPU per runner node** | 8 CPU |
| **RAM per runner node** | 32 GiB RAM |
| **Minimum volume size per node** | 200 GiB |
| **Required Kubernetes API version** | 1.21 |
| **Storage class** | gp2 |
Here's an [example EKS cluster configuration](/galileo/how-to-and-faq/enterprise-only/deploying-galileo-eks-zero-access/eks-cluster-config-example-zero-access).
### Step 1: Deploying the EKS Cluster
The cluster itself can be deployed in a single command using [eksctl](https://eksctl.io/introduction/#installation). Using the cluster template [here](/galileo/how-to-and-faq/enterprise-only/deploying-galileo-eks-zero-access/eks-cluster-config-example-zero-access), create a `galileo-cluster.yaml` file and edit the contents to replace CLUSTER`_NAME` with a name for your cluster like `galileo`. Also check and update all `availabilityZones` as appropriate.
With the yaml file saved, run the following command to deploy the cluster:
```sh theme={null}
eksctl create cluster -f galileo-cluster.yaml
```
### **Step 2: Required Configuration Values**
Customer specific cluster values (e.g. domain name, slack channel for notifications etc) will be placed in a base64 encoded string, stored as a secret in GitHub that Galileo’s deployment automation will read in and use when templating a cluster’s resource files.\\
**Mandatory fields the Galileo team requires:**
| Mandatory Field | Description |
| ---------------------------- | ----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- |
| **Domain Name** | The customer wishes to deploy the cluster under e.g. google.com |
| **Root subdomain** | e.g. "**galileo**" as in **galileo**.google.com |
| **Trusted SSL Certificates** | These certificate should support the provided domain name. You should submit 2 base64 encoded strings;
---
# Source: https://docs.galileo.ai/deployments/dependencies.md
> ## Documentation Index
> Fetch the complete documentation index at: https://docs.galileo.ai/llms.txt
> Use this file to discover all available pages before exploring further.
# Dependencies
> Understand Galileo deployment prerequisites and dependencies to ensure a smooth installation and integration across supported platforms.
### Core Dependencies
* Kubernetes Cluster: Galileo is deployed within a Kubernetes environment, leveraging various Kubernetes resources.
### Data Stores
* PostgreSQL: Used for persistent data storage (if not using AWS RDS or GCP CloudSQL).
* ClickHouse: A columnar database used for storing and querying large volumes of data efficiently. It supports analytics and real-time reporting.
* MinIO: Serves as the object storage solution (if not using AWS S3 or GCP Cloud Storage).
### Messaging
* RabbitMQ: Acts as the message broker for asynchronous communication.
### Monitoring and Logging
* Prometheus: For metrics collection and monitoring. This will also send metrics to Galileo's centralized Grafana server for observability.
* Prometheus Adapter: This component is crucial for enabling Kubernetes Horizontal Pod Autoscaler (HPA) to use Prometheus metrics for scaling applications. It must be activated through the `.Values.prometheus_adapter.enabled` Helm configuration. Care should be taken to avoid conflicts with existing services, such as the metrics-server, potentially requiring resource renaming for seamless integration.
* Grafana: For visualizing metrics. Optional, as users might not require metric visualization.
* Fluentd: For logging and forwarding to AWS CloudWatch. Optional, depending on the logging and log forwarding requirements.
* Alertmanager: Manages alerts for the monitoring system. Optional, if no alerting is needed or a different alerting mechanism is in place.
Ensure that the corresponding Helm values (`prometheus_adapter.enabled`, `fluentd.enabled`, `alertmanager.enabled`) are configured according to your deployment needs.
### Networking
* Ingress NGINX: Manages external access to the services.
* Calico: Provides network policies.
* Cert-Manager: Handles certificate management.
### Configuration and Management
* Helm: Galileo leverages Helm for package management and deployment. Ensure Helm is configured correctly to deploy the charts listed above.
### Miscellaneous
* Cluster Autoscaler: Automatically adjusts the size of the Kubernetes cluster.
* Kube-State-Metrics: Generates metrics about the state of Kubernetes objects.
* Metrics Server: Aggregates resource usage data.
* Node Exporter: Collects metrics from the nodes.
* ClickHouse Keeper: Acts as the service for managing ClickHouse replicas and coordinating distributed tasks, similar to Zookeeper. Essential for ClickHouse high availability and consistency.
---
# Source: https://docs.galileo.ai/deployments/deploying-galileo-aks.md
> ## Documentation Index
> Fetch the complete documentation index at: https://docs.galileo.ai/llms.txt
> Use this file to discover all available pages before exploring further.
# Azure AKS
> This page details the steps to deploy a Galileo Kubernetes cluster in Microsoft Azure's AKS service environment.
\*\*
Total time for deployment:\*\* 30-45 minutes
## Recommended Cluster Configuration
| Configuration | Recommended Value |
| ------------------------------------------------------ | --------------------------- |
| **Nodes in the cluster’s core nodegroup** | 4 (min) 5 (max) 4 (desired) |
| **CPU per core node** | 4 CPU |
| **RAM per core node** | 16 GiB RAM |
| **Number of nodes in the cluster’s runners nodegroup** | 1 (min) 5 (max) 1 (desired) |
| **CPU per runner node** | 8 CPU |
| **RAM per runner node** | 32 GiB RAM |
| **Minimum volume size per node** | 200 GiB |
| **Required Kubernetes API version** | 1.21 |
| **Storage class** | standard |
## Step 1: \[Optional] Create a dedicated resource group for Galileo cluster
```sh theme={null}
az group create --name galileo --location eastus
```
## Step 2: Provision an AKS cluster
```sh theme={null}
az aks create -g galileo -n galileo --enable-managed-identity --node-count 4 --max-count 7 --min-count 4 -s Standard_D4_v4 --nodepool-name gcore --nodepool-labels "galileo-node-type=galileo-core" --enable-cluster-autoscaler
```
## Step 3: Add Galileo Runner nodepool
```sh theme={null}
Az aks nodepool add -g galileo -n grunner --cluster-name galileo --node-count 1 --max-count 5 --min-count 1 --node-count 1 -s Standard_D8_v4 --labels "galileo-node-type=galileo-runner" --enable-cluster-autoscaler
```
## Step 4: Get cluster credentials
```sh theme={null}
az aks get-credentials --resource-group galileo --name galileo
```
## Step 5: Apply Galileo manifest
```sh theme={null}
kubectl apply -f galileo.yaml
```
## Step 6: Customer DNS Configuration
Galileo has 4 main URLs (shown below). In order to make the URLs accessible across the company, you have to set the following DNS addresses in your DNS provider after the platform is deployed.
| Service | URL |
| ------- | ------------------------------------------- |
| API | **api.galileo**.company.\[com\|ai\|io…] |
| Data | **data.galileo**.company.\[com\|ai\|io…] |
| UI | **console.galileo**.company.\[com\|ai\|io…] |
| Grafana | **grafana.galileo**.company.\[com\|ai\|io…] |
## Creating a GPU-enabled Node Group
For specialized tasks that require GPU processing, such as machine learning workloads, Galileo supports the configuration of GPU-enabled node pools.
The supported GPUs are H100, A100, L40S, L4 (shorter context window), A10 (shorter context window). And the corresponding node types are Standard\_NC40ads\_H100\_v5, Standard\_NC24ads\_A100\_v4, Standard\_NV12ads\_A10\_v5.
1. **Node Group Creation**: Create a node group with name `galileo-ml`, and label `galileo-node-type=galileo-ml`
2. Reach out to Galileo to get exact number of GPUs needed for your load. But feel free to set min=1, max=5 by default.
---
# Source: https://docs.galileo.ai/deployments/deploying-galileo-eks-zero-access.md
> ## Documentation Index
> Fetch the complete documentation index at: https://docs.galileo.ai/llms.txt
> Use this file to discover all available pages before exploring further.
# Zero Access Deployment | Galileo on EKS
> Create a private Kubernetes Cluster with EKS in your AWS Account, upload containers to your container registry, and deploy Galileo.
\*\*
Total time for deployment:\*\* 45-60 minutes
**This deployment requires the use of AWS CLI commands. If you only have cloud console access, follow the optional instructions below to get** [**eksctl**](https://eksctl.io/introduction/#installation) **working with AWS CloudShell.**
### Step 0: (Optional) Deploying via AWS CloudShell
To use [`eksctl`](https://eksctl.io/introduction/#installation) via CloudShell in the AWS console, open a CloudShell session and do the following:
```sh theme={null}
# Create directory
mkdir -p $HOME/.local/bin
cd $HOME/.local/bin
# eksctl
curl --silent --location "https://github.com/weaveworks/eksctl/releases/latest/download/eksctl_$(uname -s)_amd64.tar.gz" | tar xz -C /tmp
sudo mv /tmp/eksctl $HOME/.local/bin
```
The rest of the installation deployment can now be run from the CloudShell session. You can use `vim` to create/edit the required yaml and json files within the shell session.
### Recommended Cluster Configuration
Galileo recommends the following Kubernetes deployment configuration:
| Configuration | Recommended Value |
| ------------------------------------------------------ | --------------------------- |
| **Nodes in the cluster’s core nodegroup** | 4 (min) 5 (max) 4 (desired) |
| **CPU per core node** | 4 CPU |
| **RAM per core node** | 16 GiB RAM |
| **Number of nodes in the cluster’s runners nodegroup** | 1 (min) 5 (max) 1 (desired) |
| **CPU per runner node** | 8 CPU |
| **RAM per runner node** | 32 GiB RAM |
| **Minimum volume size per node** | 200 GiB |
| **Required Kubernetes API version** | 1.21 |
| **Storage class** | gp2 |
Here's an [example EKS cluster configuration](/galileo/how-to-and-faq/enterprise-only/deploying-galileo-eks-zero-access/eks-cluster-config-example-zero-access).
### Step 1: Deploying the EKS Cluster
The cluster itself can be deployed in a single command using [eksctl](https://eksctl.io/introduction/#installation). Using the cluster template [here](/galileo/how-to-and-faq/enterprise-only/deploying-galileo-eks-zero-access/eks-cluster-config-example-zero-access), create a `galileo-cluster.yaml` file and edit the contents to replace CLUSTER`_NAME` with a name for your cluster like `galileo`. Also check and update all `availabilityZones` as appropriate.
With the yaml file saved, run the following command to deploy the cluster:
```sh theme={null}
eksctl create cluster -f galileo-cluster.yaml
```
### **Step 2: Required Configuration Values**
Customer specific cluster values (e.g. domain name, slack channel for notifications etc) will be placed in a base64 encoded string, stored as a secret in GitHub that Galileo’s deployment automation will read in and use when templating a cluster’s resource files.\\
**Mandatory fields the Galileo team requires:**
| Mandatory Field | Description |
| ---------------------------- | ----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- |
| **Domain Name** | The customer wishes to deploy the cluster under e.g. google.com |
| **Root subdomain** | e.g. "**galileo**" as in **galileo**.google.com |
| **Trusted SSL Certificates** | These certificate should support the provided domain name. You should submit 2 base64 encoded strings;
1. one for the full certificate chain
2. one for the signing key. |
### Step 3: Deploy the Galileo Applications
VPN access is required to connect to the Kubernetes API when interacting with a private cluster. If you do not have appropriate VPN access with private DNS resolution, you can use a bastion machine with public ssh access as a bridge to the private cluster. The bastion will only act as a simple shell environment, so a machine type of `t3.micro` or equivalent will suffice.
Except where specifically noted, these steps are to be performed on a machine with internet access
1. Download version 1.23 of `kubectl` as explained [here](https://docs.aws.amazon.com/eks/latest/userguide/install-kubectl.html), and `scp` that file to the working directory of the bastion.
2. Generate the cluster config file by running `aws eks update-kubeconfig --name $CLUSTER_NAME --region $REGION`
3. If using a bastion machine, prepare the required environment with the following:
1. Either `scp` or copy and paste the contents of `~/.kube/config` from your local machine to the same directory on the bastion
2. `scp` the provided `deployment-manifest.yaml` file to the working directory of the bastion
4. With your VPN connected, or if using a bastion, ssh'ing into the bastion's shell:
1. Run `kubectl cluster-info` to verify your cluster config is set appropriately. If the cluster information is returned, you can proceed with the deployment.
2. Run `kubectl apply -f deployment-manifest.yaml` to deploy the Galileo applications. Re-run this command if there are errors related to custom resources not being defined as there are sometimes race conditions when applying large templates.
### **Step 4: Customer DNS Configuration**
Galileo has 4 main URLs (shown below). In order to make the URLs accessible across the company, you have to set the following DNS addresses in your DNS provider after the platform is deployed.
\*\*
Time taken :\*\* 5-10 minutes (post the ingress endpoint / load balancer provisioning)
| Service | URL |
| ------- | ------------------------------------------- |
| API | **api.galileo**.company.\[com\|ai\|io…] |
| Data | **data.galileo**.company.\[com\|ai\|io…] |
| UI | **console.galileo**.company.\[com\|ai\|io…] |
| Grafana | **grafana.galileo**.company.\[com\|ai\|io…] |
Each URL must be entered as a CNAME record into your DNS management system as the ELB address. You can find this address by running `kubectl -n galileo get svc/ingress-nginx-controller` and looking at the value for `EXTERNAL-IP`.
---
# Source: https://docs.galileo.ai/deployments/deploying-galileo-eks.md
> ## Documentation Index
> Fetch the complete documentation index at: https://docs.galileo.ai/llms.txt
> Use this file to discover all available pages before exploring further.
# Deploying Galileo on Amazon EKS
> Deploy Galileo on Amazon EKS with a step-by-step guide for configuring, managing, and scaling Galileo's infrastructure using Kubernetes clusters.
## Setting Up Your Kubernetes Cluster with EKS, IAM, and Trust Policies for Galileo Applications
This guide provides a comprehensive walkthrough for configuring and deploying an EKS (Elastic Kubernetes Service) environment to support Galileo applications. Galileo applications are designed to operate efficiently on managed Kubernetes services like EKS (Amazon Elastic Kubernetes Service) and GKE (Google Kubernetes Engine). This document, however, will specifically address the setup process within an EKS environment, including the integration of IAM (Identity and Access Management) roles and Trust Policies, alongside configuring the necessary Galileo DNS endpoints.
### Prerequisites
Before you begin, ensure you have the following:
* An AWS account with administrative access
* `kubectl` installed on your local machine
* `aws-cli` version 2 installed and configured
* Basic knowledge of Kubernetes, AWS EKS, and IAM policies
Below lists the 4 steps to set deploy Galileo onto a an EKS environment.
### Setting Up the EKS Cluster
1. **Create an EKS Cluster**: Use the AWS Management Console or AWS CLI to create an EKS cluster in your preferred region. For CLI, use the command `aws eks create-cluster` with the necessary parameters.
2. **Configure kubectl**: Once your cluster is active, configure `kubectl` to communicate with your EKS cluster by running `aws eks update-kubeconfig --region --name `.
### Configuring IAM Roles and Trust Policies
1. **Create IAM Roles for EKS**: Navigate to the IAM console and create a new role. Select "EKS" as the trusted entity and attach policies that grant required permissions for managing the cluster.
2. **Set Up Trust Policies**: Edit the trust relationship of the IAM roles to allow the EKS service to assume these roles on behalf of your Kubernetes pods.
### Integrating Galileo DNS Endpoints
1. **Determine Galileo DNS Endpoints**: Identify the four DNS endpoints required by Galileo applications to function correctly. These typically include endpoints for database connections, API gateways, telemetry services, and external integrations.
2. **Configure DNS in Kubernetes**: Utilize ConfigMaps or external-dns controllers in Kubernetes to route your applications to the identified Galileo DNS endpoints effectively.
### Deploying Galileo Applications
1. **Prepare Application Manifests**: Ensure your Galileo application Kubernetes manifests are correctly set up with the necessary configurations, including environment variables pointing to the Galileo DNS endpoints.
2. **Deploy Applications**: Use `kubectl apply` to deploy your Galileo applications onto the EKS cluster. Monitor the deployment status to ensure they are running as expected.
**Total time for deployment:** 30-45 minutes
**This deployment requires the use of AWS CLI commands. If you only have cloud console access, follow the optional instructions below to get** [**eksctl**](https://eksctl.io/introduction/#installation) **working with AWS CloudShell.**
### Step 0: (Optional) Deploying via AWS CloudShell
To use [`eksctl`](https://eksctl.io/introduction/#installation) via CloudShell in the AWS console, open a CloudShell session and do the following:
```
# Create directory
mkdir -p $HOME/.local/bin
cd $HOME/.local/bin
# eksctl
curl --silent --location "https://github.com/weaveworks/eksctl/releases/latest/download/eksctl_$(uname -s)_amd64.tar.gz" | tar xz -C /tmp
sudo mv /tmp/eksctl $HOME/.local/bin
```
The rest of the installation deployment can now be run from the CloudShell session. You can use `vim` to create/edit the required yaml and json files within the shell session.
### Recommended Cluster Configuration
Galileo recommends the following Kubernetes deployment configuration:
| Configuration | Recommended Value |
| ------------------------------------------------------ | --------------------------- |
| **Nodes in the cluster’s core nodegroup** | 4 (min) 5 (max) 4 (desired) |
| **CPU per core node** | 4 CPU |
| **RAM per core node** | 16 GiB RAM |
| **Number of nodes in the cluster’s runners nodegroup** | 1 (min) 5 (max) 1 (desired) |
| **CPU per runner node** | 8 CPU |
| **RAM per runner node** | 32 GiB RAM |
| **Minimum volume size per node** | 200 GiB |
| **Required Kubernetes API version** | 1.21 |
| **Storage class** | gp2 |
Here's an [example EKS cluster configuration](/galileo/how-to-and-faq/enterprise-only/deploying-galileo-eks/eks-cluster-config-example).
### Step 1: Creating Roles and Policies for the Cluster
* **Galileo IAM Policy:** This policy is attached to the Galileo IAM Role. Add the following to a file called `galileo-policy.json`
```
{
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Action": [
"eks:AccessKubernetesApi",
"eks:DescribeCluster"
],
"Resource": "arn:aws:eks:CLUSTER_REGION:ACCOUNT_ID:cluster/CLUSTER_NAME"
}
]
}
```
* **Galileo IAM Trust Policy:** This trust policy enables an external Galileo user to assume your Galileo IAM Role to deploy changes to your cluster securely. Add the following to a file called `galileo-trust-policy.json`
```json theme={null}
{
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Principal": {
"AWS": ["arn:aws:iam::273352303610:role/GalileoConnect"],
"Service": "ec2.amazonaws.com"
},
"Action": "sts:AssumeRole"
}
]
}
```
* **Galileo IAM Role with Policy:** Role should only include the Galileo IAM Policy mentioned in this table. Create a file called `create-galileo-role-and-policies.sh`, make it executable with `chmod +x create-galileo-role-and-policies.sh` and run it. Make sure to run in the same directory as the json files created in the above steps.
```bash theme={null}
#!/bin/sh -ex
aws iam create-policy --policy-name Galileo --policy-document file://galileo-policy.json
aws iam create-role --role-name Galileo --assume-role-policy-document file://galileo-trust-policy.json
aws iam attach-role-policy --role-name Galileo --policy-arn $(aws iam list-policies | jq -r '.Policies[] | select (.PolicyName == "Galileo") | .Arn')
```
### Step 2: Deploying the EKS Cluster
With the role and policies created, the cluster itself can be deployed in a single command using [eksctl](https://eksctl.io/introduction/#installation). Using the cluster template [here](/galileo/how-to-and-faq/enterprise-only/deploying-galileo-eks/eks-cluster-config-example), create a `galileo-cluster.yaml` file and edit the contents to replace `CUSTOMER_NAME` with your company name like `galileo`. Also check and update all `availabilityZones` as appropriate.
With the yaml file saved, run the following command to deploy the cluster:
```
eksctl create cluster -f galileo-cluster.yaml
```
### Step 3: EKS IAM Identity Mapping
This ensures that only users who have access to this role can deploy changes to the cluster. Account owners can also make changes. This is easy to do with [eksctl](https://eksctl.io/usage/iam-identity-mappings/) with the following command:
```sh theme={null}
eksctl create iamidentitymapping
--cluster customer-cluster
--region your-region-id
--arn "arn:aws:iam::CUSTOMER-ACCOUNT-ID:role/Galileo"
--username galileo
--group system:masters
```
**NOTE for the user:** For connected clusters, Galileo will apply changes from github actions. So github.com should be allow-listed for your cluster’s ingress rules if you have any specific network requirements.
### **Step 4: Required Configuration Values**
Customer specific cluster values (e.g. domain name, slack channel for notifications etc) will be placed in a base64 encoded string, stored as a secret in GitHub that Galileo’s deployment automation will read in and use when templating a cluster’s resource files.\\
| Mandatory Field | Description |
| ------------------------------------------------------------------------------ | ------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------ |
| **AWS Account ID** | The Customer's AWS Account ID that the customer will use for provisioning Galileo |
| **Galileo IAM Role Name** | The AWS IAM Role name the customer has created for the galileo deployment account to assume. |
| **EKS Cluster Name** | The EKS cluster name that Galileo will deploy the platform to. |
| **Domain Name** | The customer wishes to deploy the cluster under e.g. google.com |
| **Root subdomain** | e.g. "galileo" as in galileo.google.com |
| **Trusted SSL Certificates (Optional)** | By default, Galileo provisions Let’s Encrypt certificates. But if you wish to use your own trusted SSL certificates, you should submit a base64 encoded string of
1. the full certificate chain, and
2. another, separate base64 encoded string of the signing key. |
| **AWS Access Key ID and Secret Access Key for Internal S3 Uploads (Optional)** | If you would like to export data into an s3 bucket of your choice. Please let us know the access key and secret key of the account that can make those upload calls. |
**NOTE for the user:** Let Galileo know if you’d like to use LetsEncrypt or your own certificate before deployment.
### Step 5: Access to Deployment Logs
As a customer, you have full access to the deployment logs in Google Cloud Storage. You (customer) are able to view all configuration there. A customer email address must be provided to have access to this log.
### **Step 6: Customer DNS Configuration**
Galileo has 4 main URLs (shown below). In order to make the URLs accessible across the company, you have to set the following DNS addresses in your DNS provider after the platform is deployed.
\*\*
Time taken :\*\* 5-10 minutes (post the ingress endpoint / load balancer provisioning)
\| Service | URL | | --- | --- | | API | **api.galileo**.company.\[com|ai|io…] | | UI | **console.galileo**.company.\[com|ai|io…] | | Grafana | **grafana.galileo**.company.\[com|ai|io…] |
Each URL must be entered as a CNAME record into your DNS management system as the ELB address. You can find this address by listing the kubernetes ingresses that the platform has provisioned.
## Creating a GPU-enabled Node Pool
For specialized tasks that require GPU processing, such as machine learning workloads, Galileo supports the configuration of GPU-enabled node pools. Here's how you can set up and manage a node pool with GPU-enabled nodes using `eksctl`, a command line tool for creating and managing Kubernetes clusters on Amazon EKS.
The supported GPUs are H100, A100, L40S, L4 (shorter context window), A10 (shorter context window). And the corresponding node types are p5.4xlarge, g6e.2xlarge, g6.2xlarge.
1. **Node Pool Creation**: Use `eksctl` to create a node pool with an Amazon Machine Image (AMI) that supports GPUs.
```
eksctl create nodegroup --cluster your-cluster-name --name galileo-ml --node-type {NODE_TYPE} --nodes-min 1 --nodes-max 5 --node-ami {AMI_WITH_GPU_DRIVER} --node-labels "galileo-node-type=galileo-ml" --region your-region-id
```
In this command, replace `your-cluster-name` and `your-region-id` with your specific details. The `--node-ami` option is used to specify the exact AMI that supports CUDA and GPU workloads.
2. Reach out to Galileo to get exact number of GPUs needed for your load. But feel free to set min=1, max=5 by default.
## Using Managed RDS Postgres DB server
To use Managed RDS Postgres DB Server. You should create RDS Aurora directly in AWS console and Create K8s Secret and config map in kubernetes so that Galileo app can use it to connect to the DB server
### Creating RDS Aurora cluster
1. Go to AWS Console --> RDS Service and create a RDS Subnet group.
* Select the VPC in which EKS cluster is running.
* Select AZs A and B and the respective private subnets
1. Next Create a RDS aurora Postgres Cluster. Config for the cluster are listed below. General fields like cluster name, username, password etc can we enter as per cloud best practice.
| Field | Recommended Value |
| --------------------- | ------------------------------------- |
| **Engine Version** | 16.x |
| **DB Instance class** | db.t3.medium |
| **VPC** | EKS cluster VPC ID |
| **DB Subnet Group** | Select subnet group created in step 1 |
| **Security Group ID** | Select Primary EKS cluster SG |
| **Enable Encryption** | true |
1. Create K8s Secret
* **Kubernetes resources:** Add the following to a file called `galileo-rds-details.yaml`. Update all marker \${xxx} text with appropriate values. Then run `kubectl apply -f galileo-rds-details.yaml`
```yaml theme={null}
---
apiVersion: v1
kind: Namespace
metadata:
name: galileo
---
apiVersion: v1
kind: Secret
metadata:
name: postgres
namespace: galileo
type: Opaque
data:
GALILEO_POSTGRES_USER: "${db_username}"
GALILEO_POSTGRES_PASSWORD: "${db_username}"
GALILEO_POSTGRES_REPLICA_PASSWORD: "${db_master_password}"
GALILEO_DATABASE_URL_WRITE: "postgresql+psycopg2://${db_username}:${db_master_password}@${db_endpoint}/${database_name}"
GALILEO_DATABASE_URL_READ: "postgresql+psycopg2://${db_username}:${db_master_password}@${db_endpoint}/${database_name}"
---
apiVersion: v1
kind: ConfigMap
metadata:
name: grafana-datasources
namespace: galileo
labels:
app: grafana
data:
datasources.yaml: |
apiVersion: 1
datasources:
- access: proxy
isDefault: true
name: prometheus
type: prometheus
url: "http://prometheus.galileo.svc.cluster.local:9090"
version: 1
- name: postgres
type: postgres
url: "${db_endpoint}"
database: ${database_name}
user: ${db_username}
secureJsonData:
password: ${db_master_password}
jsonData:
sslmode: "disable"
---
```
---
# Source: https://docs.galileo.ai/deployments/deploying-galileo-exoscale.md
> ## Documentation Index
> Fetch the complete documentation index at: https://docs.galileo.ai/llms.txt
> Use this file to discover all available pages before exploring further.
# Exoscale
> The Galileo applications run on managed Kubernetes-like environments, but this document will specifically cover the configuration and deployment of an Exoscale Cloud SKS environment.
\*\*
Total time for deployment:\*\* 30-45 minutes
**This deployment requires the use of** [**Exoscale CLI commands**](https://community.exoscale.com/documentation/tools/exoscale-command-line-interface/)**. Before you start install the Exo CLI following the official documentation.**
##
[](#recommended-cluster-configuration)
Recommended Cluster Configuration
| Configuration | Recommended Value |
| -------------------------------------------------- | ----------------- |
| Nodes in the cluster’s core nodegroup | 5 |
| CPU per core node | 4 CPU |
| RAM per core node | 16 GiB RAM |
| Minimum volume size per node | 400 GiB |
| Number of nodes in the cluster’s runners nodegroup | 2 |
| CPU per runner node | 8 CPU |
| RAM per runner node | 32 GiB RAM |
| Minimum volume size per node | 200 GiB |
| Required Kubernetes API version | 1.24 |
## Deploying the SKS Cluster
1. **Create security groups**
```sh theme={null}
exo compute security-group create sks-security-group
exo compute security-group rule add sks-security-group \
--description "NodePort services" \
--protocol tcp \
--network 0.0.0.0/0 \
--port 30000-32767
exo compute security-group rule add sks-security-group \
--description "SKS kubelet" \
--protocol tcp \
--port 10250 \
--security-group sks-security-group
exo compute security-group rule add sks-security-group \
--description "Calico traffic" \
--protocol udp \
--port 4789 \
--security-group sks-security-group
```
1. **Create SKS cluster**
```sh theme={null}
exo compute sks create galileo \
--kubernetes-version "1.24"
--zone ch-gva-2 \
--nodepool-name galileo-core \
--nodepool-size 6 \
--nodepool-disk-size 400 \
--nodepool-instance-prefix "galileo-core" \
--nodepool-instance-type "extra-large" \
--nodepool-label "galileo-node-type=galileo-core" \
--nodepool-security-group sks-security-group
exo compute sks nodepool add galileo galileo-runner \
--zone ch-gva-2 \
--size 2 \
--size 400 \
--instance-prefix "galileo-runner" \
--instance-type "extra-large" \
--label "galileo-node-type=galileo-runner" \
--security-group sks-security-group
```
## Deploy distributed block storage
Longhorn is Open-Source Software that you can install inside your SKS cluster. Installation of Longhorn takes a few minutes, you need a SKS Cluster and access to this cluster via kubectl.
```sh theme={null}
kubectl apply -f https://raw.githubusercontent.com/longhorn/longhorn/1.3.1/deploy/longhorn.yaml
```
## Required Configuration Values
Customer specific cluster values (e.g. domain name, slack channel for notifications etc) will be placed in a base64 encoded string, stored as a secret in GitHub that Galileo’s deployment automation will read in and use when templating a cluster's resource files.
| Mandatory Field | Description |
| --------------------------------------- | ------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------ |
| **SKS Cluster Name** | The SKS cluster name |
| **Galileo runner instance pool ID** | SKS galileo-runner instance pool ID |
| **Exoscale API keys** | Exoscale EXOSCALE\_API\_KEY and EXOSCALE\_API\_SECRET with Object Storage Buckets permissions: - create - get - list |
| **Exoscale storage host** | e.g sos-ch-gva-2.exo.io |
| **Domain Name** | The customer wishes to deploy the cluster under e.g. google.com |
| **Root subdomain** | e.g. "galileo" as in galileo.google.com |
| **Trusted SSL Certificates (Optional)** | By default, Galileo provisions Let’s Encrypt certificates. But if you wish to use your own trusted SSL certificates, you should submit a base64 encoded string of
1. the full certificate chain, and
2. another, separate base64 encoded string of the signing key. |
## Access to Deployment Logs
As a customer, you have full access to the deployment logs in Google Cloud Storage. You (customer) are able to view all configurations there. A customer email address must be provided to have access to this log.
## Customer DNS Configuration
Galileo has 4 main URLs (shown below). In order to make the URLs accessible across the company, you have to set the following DNS addresses in your DNS provider after the platform is deployed.
| Service | URL |
| ------- | ----------------------------------------------- |
| API | \*\*api.galileo.\*\*company.\[com\|ai\|io…] |
| Data | \*\*data.galileo.\*\*company.\[com\|ai\|io…] |
| UI | \*\*console.galileo.\*\*company.\[com\|ai\|io…] |
| Grafana | **grafana.galileo**.company.\[com\|ai\|io…] |
---
# Source: https://docs.galileo.ai/deployments/deploying-galileo-gke.md
> ## Documentation Index
> Fetch the complete documentation index at: https://docs.galileo.ai/llms.txt
> Use this file to discover all available pages before exploring further.
# Deploying Galileo on Google GKE
> Deploy Galileo on Google Kubernetes Engine (GKE) with this guide, covering configuration steps, cluster setup, and infrastructure scaling strategies.
## Setting Up Your Kubernetes Cluster for Galileo Applications on Google Kubernetes Engine (GKE)
Welcome to your guide on configuring and deploying a Google Kubernetes Engine (GKE) environment optimized for Galileo applications. Galileo, tailored for dynamic and scalable deployments, requires a robust and adaptable infrastructure—qualities inherent to Kubernetes. This guide will navigate you through the preparatory steps involving Identity and Access Management (IAM) and the DNS setup crucial for integrating Galileo's services.
### Prerequisites
Before diving into the setup, ensure you have the following:
* A Google Cloud account.
* The Google Cloud SDK installed and initialized.
* Kubernetes command-line tool (`kubectl`) installed.
* Basic familiarity with GKE, IAM roles, and Kubernetes concepts.
### Setting Up IAM
Identity and Access Management (IAM) plays a critical role in securing and granting the appropriate permissions for your Kubernetes cluster. Here's how to configure IAM for your GKE environment:
1. **Create a Project**: Sign in to your Google Cloud Console and create a new project for your Galileo application if you haven't done so already.
2. **Set Up IAM Roles**: Navigate to the IAM & Admin section in the Google Cloud Console. Here, assign the necessary roles to your Google Cloud account, ensuring you have rights for GKE administration. Essential roles include `roles/container.admin` (for managing clusters), `roles/iam.serviceAccountUser` (to use service accounts with your clusters), and any other roles specific to your operational needs.
3. **Configure Service Accounts**: Create a service account dedicated to your GKE cluster to segregate duties and enhance security. Assign the service account the minimal roles necessary to operate your Galileo applications efficiently.
### Configuring DNS for Galileo
Your Galileo application requires four DNS endpoints for optimal functionality. These endpoints handle different aspects of the application's operations and need to be properly set up:
1. **Acquire a Domain**: If not already owned, purchase a domain name that will serve as the base URL for Galileo.
2. **Set Up DNS Records**: Utilize your domain registrar's DNS management tools to create four DNS A records pointing to the Galileo application's operational endpoints. These records will route traffic correctly within your GKE environment.
More details in the [Step 3: Customer DNS Configuration](/galileo/how-to-and-faq/enterprise-only/deploying-galileo-gke#step-3-customer-dns-configuration) section.
### Deploying Your Cluster on GKE
With IAM configured and DNS set up, you’re now ready to deploy your Kubernetes cluster on GKE.
1. **Create the Cluster**: Use the `gcloud` command-line tool to create your cluster. Ensure that it is configured with the correct machine type, node count, and other specifications suitable for your Galileo application needs.
2. **Deploy Galileo**: With your cluster running, deploy your Galileo application. Employ `kubectl` to manage resources and deploy services necessary for your application.
3. **Verify Deployment**: After deployment, verify that your Galileo application is running smoothly by checking the service status and ensuring that external endpoints are reachable.
\*\*
Total time for deployment:\*\* 30-45 minutes
**This deployment requires the use of Google Cloud's CLI,** `**gcloud**`**. Please follow** [**these instructions**](https://cloud.google.com/sdk/docs/install) **to install and set up gcloud for your GCP account.**
###
Recommended Cluster Configuration
Galileo recommends the following Kubernetes deployment configuration. These details are captured in the bootstrap script Galileo provides.
| Configuration | Recommended Value |
| ------------------------------------------------------ | --------------------------- |
| **Nodes in the cluster’s core nodegroup** | 4 (min) 5 (max) 4 (desired) |
| **CPU per core node** | 4 CPU |
| **RAM per core node** | 16 GiB RAM |
| **Number of nodes in the cluster’s runners nodegroup** | 1 (min) 5 (max) 1 (desired) |
| **CPU per runner node** | 8 CPU |
| **RAM per runner node** | 32 GiB RAM |
| **Minimum volume size per node** | 200 GiB |
| **Required Kubernetes API version** | 1.21 |
| **Storage class** | standard |
### Step 0: Deploying the GKE Cluster
Run [this script](https://docs.rungalileo.io/galileo/how-to-and-faq/enterprise-only/deploying-galileo-gke/galileo-gcp-setup-script) as instructed. If you have specialized tasks that require GPU processing make sure CREATE\_ML\_NODE\_POOL=true is set before running the script. If you have any questions, please reach out to a Galilean in the slack channel Galileo shares with you and your team.
### **Step 1: Required Configuration Values**
Customer specific cluster values (e.g. domain name, slack channel for notifications etc) will be placed in a base64 encoded string, stored as a secret in GitHub that Galileo’s deployment automation will read in and use when templating a cluster’s resource files.\\
**Mandatory fields the Galileo team requires:**
| Mandatory Field | Description |
| ------------------------------------------------ | ------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------ |
| **GCP Account ID** | The Customer's GCP Account ID that the customer will use for provisioning Galileo |
| **Customer GCP Project Name** | The Name of the GCP project the customer is using to provision Galileo. |
| **Customer Service Account Address for Galileo** | The Service account address the customer has created for the galileo deployment account to assume. |
| **GKE Cluster Name** | The GKE cluster name that Galileo will deploy the platform to. |
| **Domain Name** | The customer wishes to deploy the cluster under e.g. google.com |
| **GKE Cluster Region** | The region of the cluster. |
| **Root subdomain** | e.g. "galileo" as in galileo.google.com |
| **Trusted SSL Certificates (Optional)** | By default, Galileo provisions Let’s Encrypt certificates. But if you wish to use your own trusted SSL certificates, you should submit a base64 encoded string of
1. the full certificate chain, and
2. another, separate base64 encoded string of the signing key. |
### Step 2: Access to Deployment Logs
As a customer, you have full access to the deployment logs in Google Cloud Storage. You (customer) are able to view all configuration there. A customer email address must be provided to have access to this log.
### **Step 3: Customer DNS Configuration**
Galileo has 4 main URLs (shown below). In order to make the URLs accessible across the company, you have to set the following DNS addresses in your DNS provider after the platform is deployed.
\*\*
Time taken :\*\* 5-10 minutes (post the ingress endpoint / load balancer provisioning)
| Service | URL |
| ------- | ------------------------------------------- |
| API | **api.galileo**.company.\[com\|ai\|io…] |
| Data | **data.galileo**.company.\[com\|ai\|io…] |
| UI | **console.galileo**.company.\[com\|ai\|io…] |
| Grafana | **grafana.galileo**.company.\[com\|ai\|io…] |
### Step 4: Post-deployment health-checks
#### Set up Firewall Rule for Horizontal Pod Autoscaler
On GKE, only a few ports allow inbound traffic by default. Unfortunately, this breaks our HPA setup. You can run `kubectl -n galileo get hpa` and check `unknown` values to confirm this. In order to fix this, please follow the steps below:
1. Go to `Firewall policies` page on GCP console, and click `CREATE FIREWALL RULE`
2. Set `Target tags` to the [network tags of the GCE VMs](https://cloud.google.com/kubernetes-engine/docs/how-to/private-clusters#gke_private_clusters_10-). You can find the tags like this on the GCE instance detail page.
3. Set `source IPv4 ranges` to the range that includes the cluster internal endpoint, which can be found on cluster basics (([link](https://cloud.google.com/kubernetes-engine/docs/how-to/private-clusters#step_1_view_control_planes_cidr_block))).
4. Allow TCP port 6443.
5. After creating the firewall rule, wait for a few minutes, and rerun `kubectl -n galileo get hpa` to confirm `unknown` is gone.
## Creating a GPU-enabled Node Group
For specialized tasks that require GPU processing, such as machine learning workloads, Galileo supports the configuration of GPU-enabled node pools.
The supported GPUs are H100, A100, L40S, L4 (shorter context window), A10 (shorter context window). And the corresponding node types are a3-highgpu-1g, a2-highgpu-1g, g2-standard-8.
1. **Node Group Creation**: Create a node group with name `galileo-ml` , and label `galileo-node-type=galileo-ml`
2. Reach out to Galileo to get exact number of GPUs needed for your load. But feel free to set min=1, max=5 by default.
---
# Source: https://docs.galileo.ai/galileo/gen-ai-studio-products/galileo-llm-fine-tune/quickstart/dq.auto.md
> ## Documentation Index
> Fetch the complete documentation index at: https://docs.galileo.ai/llms.txt
> Use this file to discover all available pages before exploring further.
# Configuring Dq Auto
> Automatic Data Insights on your Seq2Seq dataset
### auto
While using auto with default settings is as simple as running `dq.auto()`, you can also set granular control over dataset settings, training parameters, and generation configuration. The `auto` function takes in optional parameters for `dataset_config`, `training_config`, and `generation_config`. If a configuration parameter is omitted, default values from below will be used.
#### Example
```py theme={null}
from dataquality.integrations.seq2seq.auto import auto
from dataquality.integrations.seq2seq.schema import (
Seq2SeqDatasetConfig,
Seq2SeqGenerationConfig,
Seq2SeqTrainingConfig
)
# Config parameters can be found below
dataset_config = Seq2SeqDatasetConfig(...)
training_config = Seq2SeqTrainingConfig(...)
generation_config = Seq2SeqGenerationConfig(...)
auto(
project_name="s2s_auto",
run_name="my_run",
dataset_config=dataset_config,
training_config=training_config
generation_config=generation_config
)
```
## Parameters
* **Parameters**
* **project\_name** (`Union`\[`str`, `None`]) -- Optional project name. If not set, a default name will be used. Default "s2s\_auto"
* **run\_name** (`Union`\[`str`, `None`]) -- Optional run name. If not set, a random name will be generated
* **train\_path** (`Union`\[`str`, `None`]) -- Optional training data to use. Must be a path to a local file of type `.csv`, `.json`, or `.jsonl`.
* **dataset\_config** (`Union`\[`Seq2SeqDatasetConfig`, `None`]) -- Optional config for loading the dataset. See `Seq2SeqDatasetConfig` for more details
* **training\_config** (`Union`\[`Seq2SeqTrainingConfig`, `None`]) -- Optional config for training the model. See `Seq2SeqTrainingConfig` for more details
* **generation\_config** (`Union`\[`Seq2SeqGenerationConfig`, `None`]) -- Optional config for post training model generation. See `Seq2SeqGenerationConfig` for more details
* **wait** (`bool`) -- Whether to wait for Galileo to complete processing your run. Default True
### Dataset Config
Use the `Seq2SeqGenerationConfig()` class to set the dataset for auto training.
Given either a pandas dataframe, local file path, or huggingface dataset path, this function will load the data, train a huggingface transformer model, and provide Galileo insights via a link to the Galileo Console.
One of `hf_data`, `train_path`, or `train_data` should be provided.
```py theme={null}
from dataquality.integrations.seq2seq.schema import Seq2SeqDatasetConfig
dataset_config = Seq2SeqDatasetConfig(
train_path="/Home/Datasets/train.csv",
val_path="/Home/Datasets/val.csv",
test_path="/Home/Datasets/test.csv",
input_col="text",
target_col="label",
)
```
### Parameters
* **Parameters**
* **hf\_data** (`Union`\[`DatasetDict`, `str`, `None`]) -- Use this param if you have huggingface data in the hub or in memory. Otherwise see train\_path or train\_data, val\_path or val\_data, and test\_path or test\_data. If provided, other dataset parameters are ignored.
* **train\_path** (`Union`\[`str`, `None`]) -- Optional training data to use. Must be a path to a local file of type `.csv`, `.json`, or `.jsonl`.
* **val\_path** (`Union`\[`str`, `None`]) -- Optional validation data to use. Must be a path to a local file of type `.csv`, `.json`, or `.jsonl`. If not provided, but test\_path is, that will be used as the evaluation set. If neither val nor test are available, the train data will be randomly split 80/20 for use as evaluation data.
* **test\_path** (`Union`\[`str`, `None`]) -- Optional test data to use. Must be a path to a local file of type `.csv`, `.json`, or `.jsonl`. The test data, if provided with val, will be used after training is complete, as the hold-out set. If no validation data is provided, this will instead be used as the evaluation set.
* **train\_data** (`Union`\[`DataFrame`, `Dataset`, `None`]) -- Optional training data to use. Can be one of \* Pandas dataframe \* Huggingface dataset \* Huggingface dataset hub path
* **val\_data** (`Union`\[`DataFrame`, `Dataset`, `None`]) -- Optional validation data to use. The validation data is what is used for the evaluation dataset in huggingface, and what is used for early stopping. If not provided, but test\_data is, that will be used as the evaluation set. If neither val nor test are available, the train data will be randomly split 80/20 for use as evaluation data. Can be one of \* Pandas dataframe \* Huggingface dataset \* Huggingface dataset hub path
* **test\_data** (`Union`\[`DataFrame`, `Dataset`, `None`]) -- Optional test data to use. The test data, if provided with val, will be used after training is complete, as the hold-out set. If no validation data is provided, this will instead be used as the evaluation set. Can be one of \* Pandas dataframe \* Huggingface dataset \* Huggingface dataset hub path
* **input\_col** (`str`) -- Column name of the model input in the provided dataset. Default `text`
* **target\_col** (`str`) -- Column name of the model target output in the provided dataset. Default `label`
## Training Config
Use the `Seq2SeqTrainingConfig()` class to set the training parameters for auto training.
```
from dataquality.integrations.seq2seq.schema import Seq2SeqTrainingConfig
training_config = Seq2SeqTrainingConfig(
epochs=3
learning_rate=3e-4,
batch_size=4,
)
```
### Parameters
* **Parameters**
* **model** (`int`) -- The pretrained AutoModel from huggingface that will be used to tokenize and train on the provided data. Default `google/flan-t5-base`
* **epochs** (`int`) -- The number of epochs to train. Defaults to 3. If set to 0, training/fine-tuning will be skipped and auto will only do a forward pass with the data to gather all the necessary info to display it in the console.
* **learning\_rate** (`float`) -- Optional learning rate. Defaults to 3e-4
* **batch\_size** (`int`) -- Optional batch size. Default 4
* **accumulation\_steps** (`int`) -- Optional accumulation steps. Default 4
* **max\_input\_tokens** (`int`) -- Optional the maximum length in number of tokens for the inputs to the transformer model. If not set, will use tokenizer default or default 512 if tokenizer has no default
* **max\_target\_tokens** (`int`) -- Optional the maximum length in number of tokens for the target outputs to the transformer model. If not set, will use tokenizer default or default 128 if tokenizer has no default
* **create\_data\_embs** (`Optional`\[`bool`]) -- Whether to create data embeddings for this run. If True, Sentence-Transformers will be used to generate data embeddings for this dataset and uploaded with this run. You can access these embeddings via dq.metrics.get\_data\_embeddings in the emb column or dq.metrics.get\_dataframe(..., include\_data\_embs=True) in the data\_emb col. Default True if a GPU is available, else default False.
### Generation Config
Use the `Seq2SeqGenerationConfig()` class to set the training parameters for auto training.
```
from dataquality.integrations.seq2seq.schema import Seq2SeqGenerationConfig
generation_config = Seq2SeqGenerationConfig(
max_new_tokens=16,
temperature=0.2,
)
```
### Parameters
* **Parameters**
* **max\_new\_tokens** (`int`) -- The maximum numbers of tokens to generate, ignoring the number of tokens in the prompt. Default 16
* **temperature** (`float`) -- The value used to modulate the next token probabilities. Default 0.2
* **do\_sample** (`float`) -- Whether or not to use sampling ; use greedy decoding otherwise. Default False
* **top\_p** (`float`) -- If set to float \< 1, only the smallest set of most probable tokens with probabilities that add up to `top_p` or higher are kept for generation. Default 1.0
* **top\_k** (`int`) -- The number of highest probability vocabulary tokens to keep for top-k-filtering. Default 50
* **generation\_splits** (`Union[List[str], None]`) -- Optional list of splits to perform generation on after training the model. These generated outputs will show up in the console for specified splits. Default \["test"]
### Examples
An example using `auto` with a hosted huggingface summarization dataset
```
import dataquality.integrations.seq2seq.auto as auto
dq.auto(hf_data="tatsu-lab/alpaca")
```
An example of using `auto` with a local jsonl file
```
import dataquality.integrations.seq2seq.auto as auto
from dataquality.integrations.seq2seq.schema import Seq2SeqDatasetConfig
dataset_config = Seq2SeqDatasetConfig(
train_path="./train.jsonl",
val_path="./val.jsonl",
test_path="./test.jsonl",
input_col="text",
target_col="label",
)
dq.auto(
project_name="data_from_local",
run_name="run_1_raw_data",
dataset_config=dataset_config,
)
```
Where `train.jsonl` might be a file with `prompt` and `completion` columns that looks like:
```
{"prompt": "Write a short story about a curious cat.", "completion": "Once upon a time, in a small town, there lived a curious cat named Whiskers. Whiskers was known for exploring every nook and cranny, always on the lookout for adventure."}
{"prompt": "Describe your favorite vacation destination.", "completion": "My favorite vacation destination is a remote tropical island. The crystal-clear waters, white sandy beaches, and lush green forests make it a paradise on Earth."}
{"prompt": "List your top 5 favorite books.", "completion": "1. 'To Kill a Mockingbird' by Harper Lee\n2. 'The Great Gatsby' by F. Scott Fitzgerald\n3. 'Harry Potter and the Sorcerer's Stone' by J.K. Rowling\n4. 'Pride and Prejudice' by Jane Austen\n5. 'The Catcher in the Rye' by J.D. Salinger"}
{"prompt": "Explain the concept of time travel.", "completion": "Time travel is a theoretical concept that involves moving between different points in time. While it remains a popular subject in science fiction, it has not been achieved in reality."}
{"prompt": "Share your favorite recipe.", "completion": "One of my favorite recipes is for homemade lasagna. It's a comforting dish made with layers of pasta, ricotta cheese, marinara sauce, ground beef, and melted mozzarella. It's a family favorite!"}
```
### Get started with a notebook
* [Auto Notebook](https://colab.research.google.com/github/rungalileo/examples/blob/main/examples/sequence_to_sequence/LLM_Fine_Tuning_chat_data_with_DQ_auto_using_%F0%9F%94%AD_Galileo.ipynb)
* [Auto Notebook for Chat Data](https://colab.research.google.com/github/rungalileo/examples/blob/main/examples/sequence_to_sequence/LLM_Fine_Tuning_chat_data_with_DQ_auto_using_%F0%9F%94%AD_Galileo.ipynb)
---
# Source: https://docs.galileo.ai/galileo/gen-ai-studio-products/galileo-protect/how-to/editing-centralized-stages.md
> ## Documentation Index
> Fetch the complete documentation index at: https://docs.galileo.ai/llms.txt
> Use this file to discover all available pages before exploring further.
# Editing Centralized Stages
> Edit centralized stages in Galileo Protect with this guide, ensuring accurate ruleset updates and maintaining effective AI monitoring across applications.
The following only applies to [centralized stages](/galileo/gen-ai-studio-products/galileo-protect/concepts/stage).
Once you've created and registered a [centralized stage](/galileo/gen-ai-studio-products/galileo-protect/concepts/stage#different-types-of-stages) you can continue updating your stage configuration. Your changes will immediately be reflected in any further invocations.
To update a stage, you can call `gp.update_stage()`:
```py theme={null}
import galileo_protect as gp
gp.update_stage(project_id="", # Alternatively, use project_name
stage_id="", # Alternatively, use stage_name
prioritized_rulesets=[
{
"rules": [
{
"metric": "pii",
"operator": "contains",
"target_value": "ssn",
},
],
"action": {
"type": "OVERRIDE",
"choices": [
"Personal Identifiable Information detected in the model output. Sorry, I cannot answer that question."
],
},
},
])
```
Your changes will immediately be reflected. Any subsequent calls to `gp.invoke()` will use the updated `prioritized_rulesets.`
---
# Source: https://docs.galileo.ai/deployments/deploying-galileo-eks-zero-access/eks-cluster-config-example-zero-access.md
> ## Documentation Index
> Fetch the complete documentation index at: https://docs.galileo.ai/llms.txt
> Use this file to discover all available pages before exploring further.
# EKS Cluster Config Example | Zero Access Deployment
> Access a zero-access EKS cluster configuration example for secure Galileo deployments on Amazon EKS, following best practices for Kubernetes security.
```Bash theme={null}
---
apiVersion: eksctl.io/v1alpha5
kind: ClusterConfig
metadata:
name: CLUSTER_NAME
region: us-east-2
version: "1.23"
tags:
env: CLUSTER_NAME
vpc:
id: VPC_ID
subnets:
private:
us-east-2a:
id: SUBNET_1_ID
us-east-2b:
id: SUBNET_2_ID
cloudWatch:
clusterLogging:
enableTypes: ["*"]
privateCluster:
enabled: true
addons:
- name: vpc-cni
version: 1.11.0
- name: aws-ebs-csi-driver
version: 1.11.4
managedNodeGroups:
- name: galileo-core
privateNetworking: true
availabilityZones: ["us-east-2a", "us-east-2b"]
labels: { galileo-node-type: galileo-core }
tags:
{
"k8s.io/cluster-autoscaler/CLUSTER_NAME": "owned",
"k8s.io/cluster-autoscaler/enabled": "true",
}
amiFamily: AmazonLinux2
instanceType: m5a.xlarge
minSize: 4
maxSize: 5
desiredCapacity: 4
volumeSize: 200 # GiB
volumeType: gp2
iam:
attachPolicyARNs:
- arn:aws:iam::aws:policy/AmazonEKSWorkerNodePolicy
- arn:aws:iam::aws:policy/AmazonEKS_CNI_Policy
- arn:aws:iam::aws:policy/AmazonEC2ContainerRegistryReadOnly
- arn:aws:iam::aws:policy/AmazonS3FullAccess
- arn:aws:iam::aws:policy/AmazonSSMManagedInstanceCore
withAddonPolicies:
autoScaler: true
cloudWatch: true
ebs: true
updateConfig:
maxUnavailable: 2
- name: galileo-runner
privateNetworking: true
availabilityZones: ["us-east-2a", "us-east-2b"]
labels: { galileo-node-type: galileo-runner }
tags:
{
"k8s.io/cluster-autoscaler/CLUSTER_NAME": "owned",
"k8s.io/cluster-autoscaler/enabled": "true",
}
amiFamily: AmazonLinux2
instanceType: m5a.2xlarge
minSize: 1
maxSize: 5
desiredCapacity: 1
volumeSize: 200 # GiB
volumeType: gp2
iam:
attachPolicyARNs:
- arn:aws:iam::aws:policy/AmazonEKSWorkerNodePolicy
- arn:aws:iam::aws:policy/AmazonEKS_CNI_Policy
- arn:aws:iam::aws:policy/AmazonEC2ContainerRegistryReadOnly
- arn:aws:iam::aws:policy/AmazonS3FullAccess
- arn:aws:iam::aws:policy/AmazonSSMManagedInstanceCore
withAddonPolicies:
autoScaler: true
cloudWatch: true
ebs: true
updateConfig:
maxUnavailable: 2
```
---
# Source: https://docs.galileo.ai/deployments/deploying-galileo-eks/eks-cluster-config-example.md
> ## Documentation Index
> Fetch the complete documentation index at: https://docs.galileo.ai/llms.txt
> Use this file to discover all available pages before exploring further.
# EKS Cluster Config Example | Galileo Deployment
> Review a detailed EKS cluster configuration example for deploying Galileo on Amazon EKS, ensuring efficient Kubernetes setup and management.
```Bash theme={null}
---
apiVersion: eksctl.io/v1alpha5
kind: ClusterConfig
metadata:
name: CLUSTER_NAME
region: us-east-2
version: "1.28"
tags:
env: CLUSTER_NAME
availabilityZones: ["us-east-2a", "us-east-2b"]
cloudWatch:
clusterLogging:
enableTypes: ["*"]
addons:
- name: vpc-cni
version: 1.13.4
- name: aws-ebs-csi-driver
version: 1.29.1
managedNodeGroups:
- name: galileo-core
privateNetworking: true
availabilityZones: ["us-east-2a", "us-east-2b"]
labels: { galileo-node-type: galileo-core }
tags:
{
"k8s.io/cluster-autoscaler/CLUSTER_NAME": "owned",
"k8s.io/cluster-autoscaler/enabled": "true",
}
amiFamily: AmazonLinux2
instanceType: m5a.xlarge
minSize: 2
maxSize: 5
desiredCapacity: 2
volumeSize: 200
volumeType: gp3
volumeEncrypted: true
disableIMDSv1: false
iam:
attachPolicyARNs:
- arn:aws:iam::aws:policy/AmazonEKSWorkerNodePolicy
- arn:aws:iam::aws:policy/AmazonEKS_CNI_Policy
- arn:aws:iam::aws:policy/AmazonEC2ContainerRegistryReadOnly
- arn:aws:iam::aws:policy/AmazonS3FullAccess
- arn:aws:iam::aws:policy/AmazonSSMManagedInstanceCore
withAddonPolicies:
autoScaler: true
cloudWatch: true
ebs: true
updateConfig:
maxUnavailable: 2
- name: galileo-runner
privateNetworking: true
availabilityZones: ["us-east-2a", "us-east-2b"]
labels: { galileo-node-type: galileo-runner }
tags:
{
"k8s.io/cluster-autoscaler/CLUSTER_NAME": "owned",
"k8s.io/cluster-autoscaler/enabled": "true",
}
amiFamily: AmazonLinux2
instanceType: m5a.2xlarge
minSize: 1
maxSize: 5
desiredCapacity: 1
volumeSize: 200 # GiB
volumeType: gp3
volumeEncrypted: true
disableIMDSv1: false
iam:
attachPolicyARNs:
- arn:aws:iam::aws:policy/AmazonEKSWorkerNodePolicy
- arn:aws:iam::aws:policy/AmazonEKS_CNI_Policy
- arn:aws:iam::aws:policy/AmazonEC2ContainerRegistryReadOnly
- arn:aws:iam::aws:policy/AmazonS3FullAccess
- arn:aws:iam::aws:policy/AmazonSSMManagedInstanceCore
withAddonPolicies:
autoScaler: true
cloudWatch: true
ebs: true
updateConfig:
maxUnavailable: 1
```
---
# Source: https://docs.galileo.ai/galileo/galileo-nlp-studio/galileo-product-features/embeddings-view.md
> ## Documentation Index
> Fetch the complete documentation index at: https://docs.galileo.ai/llms.txt
> Use this file to discover all available pages before exploring further.
# Embeddings View
> The Embeddings View provides a visual playground for you to interact with your datasets.
To visualize your datasets, we leverage your model's embeddings logged during training, validation, testing or inference. Given these embeddings, we plot the data points on the 2D plane using the techniques explained below.
## Scalable Visualization
After experimenting with a host of different dimensionality reduction techniques, we have adopted the principles of UMAP \[[1](https://arxiv.org/abs/1802.03426)]. Given a high dimensional dataset, UMAP seeks to preserve the positional information of each data sample while projecting the data into a lower dimensional space (the 2D plane in our case). We additionally use a parameterized version of UMAP along with custom compression techniques to efficiently scale our data visualization to O(million) samples.
## Embedding View Interaction
The Embedding View allows you to visually detect patterns in the data, interactively select dataset sub populations for further exploration, and visualize different dataset features and insights to identify model decision boundaries and better gauge overall model performance. Visualizing data embeddings provides a key component in going beyond traditional dataset level metrics for analyzing model performance and understanding data quality.
### General Navigation
Navigating the embedding view is made easy with interactive plotting. While exploring your dataset you can easily adjust and drag the embedding plane with the P*an* tool, zoom in and out on specific data regions with S*croll to Zoom,* and reset the visualization with the *Reset Axes* tool\*.\* To interact with individual data samples, simply hover the cursor over a data sample of interest to display information and insights.
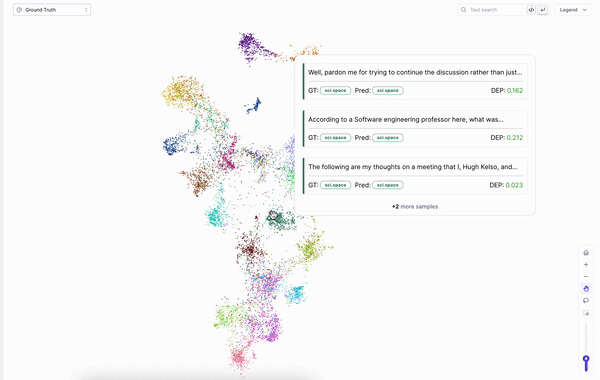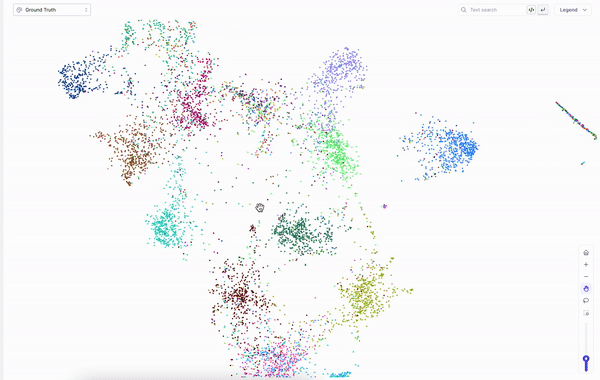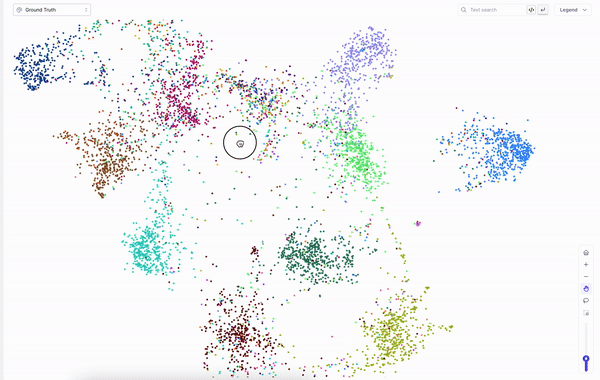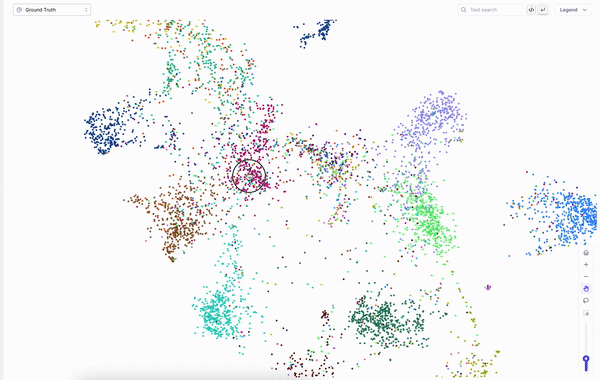 ### Color By
One powerful feature is the ability to color data points by different data fields e.g. `ground truth labels`, `data error potential (DEP)`, etc. Different data coloring schemes reveal different dataset insights (i.e. using color by `predicted labels` reveals the model's perceived decision boundaries) and altogether provide a more holistic view of the data.
### Color By
One powerful feature is the ability to color data points by different data fields e.g. `ground truth labels`, `data error potential (DEP)`, etc. Different data coloring schemes reveal different dataset insights (i.e. using color by `predicted labels` reveals the model's perceived decision boundaries) and altogether provide a more holistic view of the data.
 ### Subset Selection
Once you have identified a data subset of interest, you can explicitly select this subset to further analyze and view insights on. We offer two different selection tools: *lasso selection* and *box* *select*.
After selecting a data subset, the embeddings view, insights charts, and the general data table are all updated to reflect *just* the selected data. As shown below, given a cluster of miss-classified data points, you can make a lasso selection to easily inspect subset specific insights. For example, you can view model performance on the selected sub population, as well as develop insights into which classes are most significantly underperforming.
### Subset Selection
Once you have identified a data subset of interest, you can explicitly select this subset to further analyze and view insights on. We offer two different selection tools: *lasso selection* and *box* *select*.
After selecting a data subset, the embeddings view, insights charts, and the general data table are all updated to reflect *just* the selected data. As shown below, given a cluster of miss-classified data points, you can make a lasso selection to easily inspect subset specific insights. For example, you can view model performance on the selected sub population, as well as develop insights into which classes are most significantly underperforming.
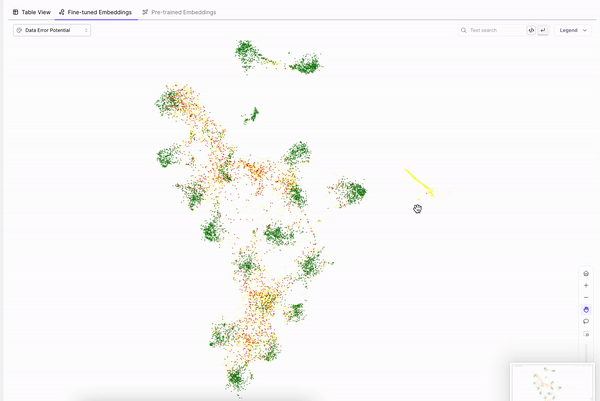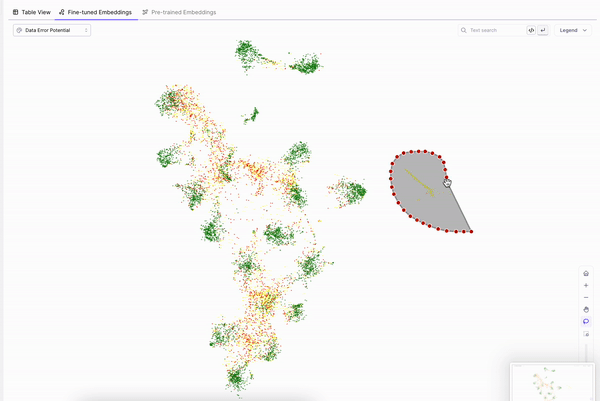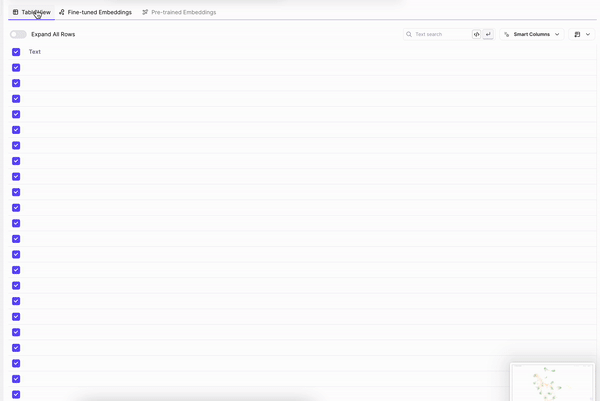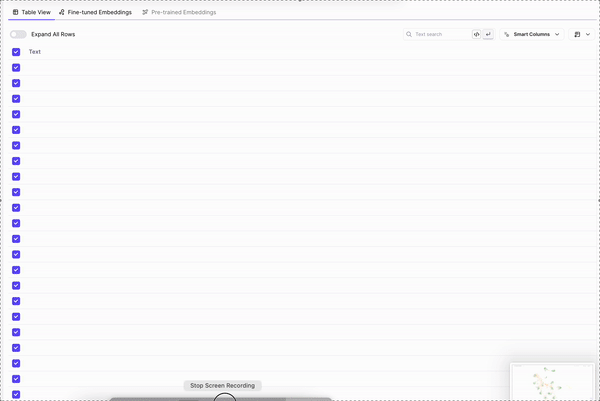 ### Similarity Search
In the Embeddings View, you can easily interact with Galileo's *similarity search* feature. Hovering over a data point reveals the "Show similar" button. When selected, your inspection dataset is restricted to the data samples with most similar embeddings to the selected data sample, allowing you to quickly inspect model performance over a highly focused data sub-population. See the [*similarity search*](/galileo/how-to-and-faq/galileo-product-features/similarity-search) \_\_ documentation for more details.
### Similarity Search
In the Embeddings View, you can easily interact with Galileo's *similarity search* feature. Hovering over a data point reveals the "Show similar" button. When selected, your inspection dataset is restricted to the data samples with most similar embeddings to the selected data sample, allowing you to quickly inspect model performance over a highly focused data sub-population. See the [*similarity search*](/galileo/how-to-and-faq/galileo-product-features/similarity-search) \_\_ documentation for more details.
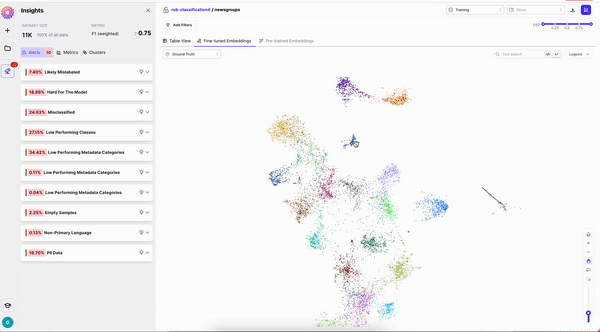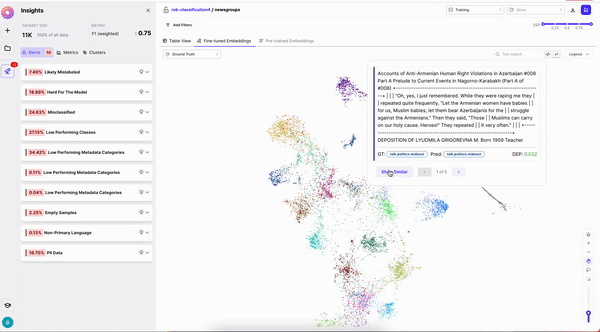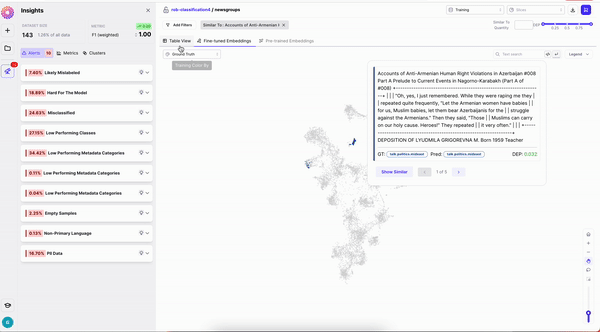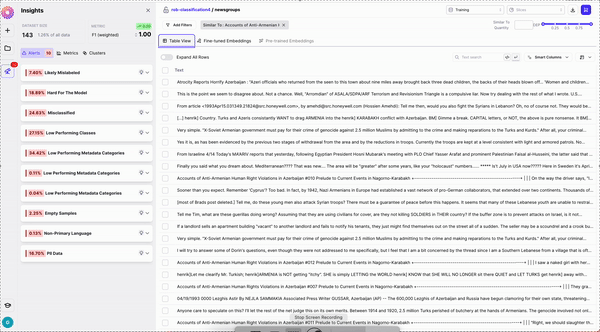 ---
# Source: https://docs.galileo.ai/galileo/gen-ai-studio-products/galileo-evaluate/how-to/enabling-scorers-in-runs.md
> ## Documentation Index
> Fetch the complete documentation index at: https://docs.galileo.ai/llms.txt
> Use this file to discover all available pages before exploring further.
# Enabling Scorers in Runs
> Learn how to turn on metrics when creating runs in your Python environment.
Galileo provides users the ability to tune which metrics to use for their evaluation.
Check out [Choose your Guardrail Metrics](/galileo/gen-ai-studio-products/galileo-evaluate/how-to/choose-your-guardrail-metrics) to understand which metrics or scorers apply to your use case.
## Using scorers
To use scorers during a prompt run, sweep, or even a more complex workflow, simply pass them in through the scorers argument:
```py theme={null}
import promptquality as pq
pq.run(..., scorers=[pq.Scorers.correctness, pq.Scorers.context_adherence])
```
## Disabling default scorers
By default, we turn on a few scorers for you (PII, Toxicity, BLEU, ROUGE). If you want to disable a default scorer you can pass in a ScorersConfiguration object.
```py theme={null}
pq.run(...,
scorers=[pq.Scorers.correctness,pq.Scorers.context_adherence],
scorers_config=pq.ScorersConfiguration(latency=False)
)
```
You can even use the ScorersConfiguration to turn on other scorers, rather than using the scorers argument.
```py theme={null}
pq.run(..., scorers_config=pq.ScorersConfiguration(latency=False, groundedness=True))
```
## Logging Workflows
If you're logging workflows using [EvaluateRun](https://promptquality.docs.rungalileo.io/#promptquality.EvaluateRun), you can add your scorers similarly:
```py theme={null}
evaluate_run = pq.EvaluateRun(run_name="my_run", project_name="my_project", scorers=[pq.Scorers.correctness, pq.Scorers.context_adherence])
```
## Customizing Plus Scorers
We allow customizing execution parameters for the [Chainpoll](/galileo/gen-ai-studio-products/galileo-ai-research/chainpoll)-powered metrics from our Guardrail Store. Check out [Customizing Chainpoll-powered Metrics](/galileo/gen-ai-studio-products/galileo-evaluate/how-to/customize-chainpoll-powered-metrics).
---
# Source: https://docs.galileo.ai/galileo/galileo-nlp-studio/galileo-product-features/error-types-breakdown.md
> ## Documentation Index
> Fetch the complete documentation index at: https://docs.galileo.ai/llms.txt
> Use this file to discover all available pages before exploring further.
# Error Types Breakdown
> For use cases with complex data and error types (e.g. Named Entity Recognition, Object Detection or Semantic Segmentation), the **Error Types Chart** gives you an insight into exactly how the Ground Truth differed from your model's predictions
It allows you to get a sense of what types of mistakes your model is making, with what frequency and, in the case of Object Detection, what impact these errors had on your overall performance metric.
---
# Source: https://docs.galileo.ai/galileo/gen-ai-studio-products/galileo-evaluate/how-to/enabling-scorers-in-runs.md
> ## Documentation Index
> Fetch the complete documentation index at: https://docs.galileo.ai/llms.txt
> Use this file to discover all available pages before exploring further.
# Enabling Scorers in Runs
> Learn how to turn on metrics when creating runs in your Python environment.
Galileo provides users the ability to tune which metrics to use for their evaluation.
Check out [Choose your Guardrail Metrics](/galileo/gen-ai-studio-products/galileo-evaluate/how-to/choose-your-guardrail-metrics) to understand which metrics or scorers apply to your use case.
## Using scorers
To use scorers during a prompt run, sweep, or even a more complex workflow, simply pass them in through the scorers argument:
```py theme={null}
import promptquality as pq
pq.run(..., scorers=[pq.Scorers.correctness, pq.Scorers.context_adherence])
```
## Disabling default scorers
By default, we turn on a few scorers for you (PII, Toxicity, BLEU, ROUGE). If you want to disable a default scorer you can pass in a ScorersConfiguration object.
```py theme={null}
pq.run(...,
scorers=[pq.Scorers.correctness,pq.Scorers.context_adherence],
scorers_config=pq.ScorersConfiguration(latency=False)
)
```
You can even use the ScorersConfiguration to turn on other scorers, rather than using the scorers argument.
```py theme={null}
pq.run(..., scorers_config=pq.ScorersConfiguration(latency=False, groundedness=True))
```
## Logging Workflows
If you're logging workflows using [EvaluateRun](https://promptquality.docs.rungalileo.io/#promptquality.EvaluateRun), you can add your scorers similarly:
```py theme={null}
evaluate_run = pq.EvaluateRun(run_name="my_run", project_name="my_project", scorers=[pq.Scorers.correctness, pq.Scorers.context_adherence])
```
## Customizing Plus Scorers
We allow customizing execution parameters for the [Chainpoll](/galileo/gen-ai-studio-products/galileo-ai-research/chainpoll)-powered metrics from our Guardrail Store. Check out [Customizing Chainpoll-powered Metrics](/galileo/gen-ai-studio-products/galileo-evaluate/how-to/customize-chainpoll-powered-metrics).
---
# Source: https://docs.galileo.ai/galileo/galileo-nlp-studio/galileo-product-features/error-types-breakdown.md
> ## Documentation Index
> Fetch the complete documentation index at: https://docs.galileo.ai/llms.txt
> Use this file to discover all available pages before exploring further.
# Error Types Breakdown
> For use cases with complex data and error types (e.g. Named Entity Recognition, Object Detection or Semantic Segmentation), the **Error Types Chart** gives you an insight into exactly how the Ground Truth differed from your model's predictions
It allows you to get a sense of what types of mistakes your model is making, with what frequency and, in the case of Object Detection, what impact these errors had on your overall performance metric.
 Error Types for a Object Detection model
**How does this work?**
For Named Entity Recognition, Galileo surfaces *Ghost Spans, Span Shifts, Missed Spans* or *Wrong Tag Errors*.
For Object Detection, Galileo leverages the [TIDE](https://arxiv.org/abs/2008.08115) framework to find associations between Ground Truth and Predicted objects and break differences between the two into one of: *Localization*, *Classification*, *Background*, *Missed*, *Duplicates* or *Localization and Classification* mistakes. See a thorough write-up of how that's done and the definition of each error type [here](/galileo/gen-ai-studio-products/galileo-ai-research/errors-in-object-detection).
**How should I leverage this chart?**
Click on an error type to filter the dataset to samples with that error type. From there, you can inspect your erroneous samples and fix them.
One common flow we see is selecting *Ghost Spans (NER)* or *Background Confusion Errors* (Obj. Detection) combined with a high DEP filter can be used to surface Missed Annotations from your labelers. You can send these samples to your labeling tool or fix them with the Galileo console.
---
# Source: https://docs.galileo.ai/galileo/gen-ai-studio-products/galileo-observe/faq/errors-computing-metrics.md
# Source: https://docs.galileo.ai/galileo/gen-ai-studio-products/galileo-guardrail-metrics/faq/errors-computing-metrics.md
# Source: https://docs.galileo.ai/galileo/gen-ai-studio-products/galileo-evaluate/faq/errors-computing-metrics.md
> ## Documentation Index
> Fetch the complete documentation index at: https://docs.galileo.ai/llms.txt
> Use this file to discover all available pages before exploring further.
# Error Computing Metrics | Galileo Evaluate FAQ
> Find solutions to common errors in computing metrics within Galileo Evaluate, including missing integrations and rate limit issues, to streamline your AI evaluations.
Hovering over the "Error" or "Failure" pill will open a tooltip explaining what's gone wrong.
#### Missing Integration Errors
Uncertainty, Perplexity, Context Adherence *Plus*, Completeness *Plus*, Attribution *Plus*, and Chunk Utilization *Plus* metrics rely on integrations with OpenAI models (through OpenAI or Azure). If you see this error, you need to [set up your OpenAI or Azure Integration](/galileo/gen-ai-studio-products/galileo-evaluate/integrations/llms) with valid credentials.
If you're using Azure, you must ensure you have access to the right model(s) for the metrics you want to calculate. See the requirements under [Galileo Guardrail Store](/galileo/gen-ai-studio-products/galileo-guardrail-metrics).
For Observe, the credentials of the *project creator* will be used for metric computation. Ask them to add the integration on their account.
**No Access To The Required Models**
Similar to the error above, this likely means that your Integration does not have access to the required models. Check out the model requirements for your metrics under [Galileo Guardrail Store](/galileo/gen-ai-studio-products/galileo-guardrail-metrics) and ask your Azure/OpenAI admin to add the necessary models before retrying again.
**Rate-limits**
Galileo does not enforce any rate limits. However, some of our metrics rely on OpenAI models and thus are limited to their rate limits. If you see this occurring often, you might want to try and increase the rate limits on your organization in OpenAI. Alternatively, we recommend using different keys or organizations for different projects, or for your production and pre-production traffic.
#### Unable to parse JSON response
Context Adherence *Plus*, Completeness *Plus*, Attribution Plus, and Chunk Utilization *Plus* use [Chainpoll](https://arxiv.org/abs/2310.18344) to calculate metric values. Chainpoll metrics call on OpenAI for a part of their calculation and require OpenAI responses to be in a valid JSON format. When you see this message, it means that the response that OpenAI sent back was not in valid JSON. Retrying might solve this problem.
#### Context Length exceeded
This error will happen if your prompt (or prompt + response for some metrics) exceeds the supported context window of the underlying models. Reach out to Galileo if you run into this error, and we can work with you to build ways around it.
#### Error executing your custom metric
If you're seeing this, it means your custom or registered metric did not execute correctly. The stack trace is shown to help you debug what went wrong.
---
# Source: https://docs.galileo.ai/galileo-ai-research/errors-in-object-detection.md
> ## Documentation Index
> Fetch the complete documentation index at: https://docs.galileo.ai/llms.txt
> Use this file to discover all available pages before exploring further.
# Errors In Object Detection
> This page describes the rich error types offered by Galileo for Object Detection
An Object Detection (OD) model receives an image as input and outputs a list of rectangular boxes representing objects within the image. Each box is associated with a label/class and can be positioned anywhere on the image. Unlike other tasks with limited output spaces (such as single labels in classification or labels and spans in NER), OD entails a significantly larger number of possible outputs due to two factors:
1. The model can generate a substantial quantity of boxes (several thousand for YOLO before NMS).
2. Each box can be positioned at any location on the image, as long as it has integer coordinates.
This level of freedom necessitates the use of complex algorithms to establish diverse pairings between predictions and annotations, which in turn gives very rich error types. In this article we will explain what these error types are and how to use Galileo to focus on any of them and fix your data.
For a high-level introduction to error types and Galileo see [here](/galileo/how-to-and-faq/galileo-product-features/error-types-breakdown).
## The 6 Error Types
The initial stage in assigning error types to flawed boxes involves identifying the boxes that are not deemed correct. We will refer to inaccurate predictions as False Positives (FP) and erroneous annotations as False Negatives (FN). There are many ways in which a predicted box can turn into a FP, so we will classify them further in more granular buckets:
* **Duplicate Error:** the predicted box highly overlaps with an annotation that is already used
* **Classification Error:** the predicted box highly overlaps with an annotation of different label
* **Localization Error:** the predicted box slightly overlaps with an annotation of same label
* **Classification and Localization Error:** the predicted box slightly overlaps with an annotation of different label
* **Background Error:** the predicted box does not even slightly overlap with an annotation.
Similarly, some FN annotations will be assigned the following error type:
* **Missed Error:** the annotation was not used by any prediction (either used to declare a prediction a TP or used to bin a prediction in any of the above errors).
The following illustration summarizes the above discussion:
Error Types for a Object Detection model
**How does this work?**
For Named Entity Recognition, Galileo surfaces *Ghost Spans, Span Shifts, Missed Spans* or *Wrong Tag Errors*.
For Object Detection, Galileo leverages the [TIDE](https://arxiv.org/abs/2008.08115) framework to find associations between Ground Truth and Predicted objects and break differences between the two into one of: *Localization*, *Classification*, *Background*, *Missed*, *Duplicates* or *Localization and Classification* mistakes. See a thorough write-up of how that's done and the definition of each error type [here](/galileo/gen-ai-studio-products/galileo-ai-research/errors-in-object-detection).
**How should I leverage this chart?**
Click on an error type to filter the dataset to samples with that error type. From there, you can inspect your erroneous samples and fix them.
One common flow we see is selecting *Ghost Spans (NER)* or *Background Confusion Errors* (Obj. Detection) combined with a high DEP filter can be used to surface Missed Annotations from your labelers. You can send these samples to your labeling tool or fix them with the Galileo console.
---
# Source: https://docs.galileo.ai/galileo/gen-ai-studio-products/galileo-observe/faq/errors-computing-metrics.md
# Source: https://docs.galileo.ai/galileo/gen-ai-studio-products/galileo-guardrail-metrics/faq/errors-computing-metrics.md
# Source: https://docs.galileo.ai/galileo/gen-ai-studio-products/galileo-evaluate/faq/errors-computing-metrics.md
> ## Documentation Index
> Fetch the complete documentation index at: https://docs.galileo.ai/llms.txt
> Use this file to discover all available pages before exploring further.
# Error Computing Metrics | Galileo Evaluate FAQ
> Find solutions to common errors in computing metrics within Galileo Evaluate, including missing integrations and rate limit issues, to streamline your AI evaluations.
Hovering over the "Error" or "Failure" pill will open a tooltip explaining what's gone wrong.
#### Missing Integration Errors
Uncertainty, Perplexity, Context Adherence *Plus*, Completeness *Plus*, Attribution *Plus*, and Chunk Utilization *Plus* metrics rely on integrations with OpenAI models (through OpenAI or Azure). If you see this error, you need to [set up your OpenAI or Azure Integration](/galileo/gen-ai-studio-products/galileo-evaluate/integrations/llms) with valid credentials.
If you're using Azure, you must ensure you have access to the right model(s) for the metrics you want to calculate. See the requirements under [Galileo Guardrail Store](/galileo/gen-ai-studio-products/galileo-guardrail-metrics).
For Observe, the credentials of the *project creator* will be used for metric computation. Ask them to add the integration on their account.
**No Access To The Required Models**
Similar to the error above, this likely means that your Integration does not have access to the required models. Check out the model requirements for your metrics under [Galileo Guardrail Store](/galileo/gen-ai-studio-products/galileo-guardrail-metrics) and ask your Azure/OpenAI admin to add the necessary models before retrying again.
**Rate-limits**
Galileo does not enforce any rate limits. However, some of our metrics rely on OpenAI models and thus are limited to their rate limits. If you see this occurring often, you might want to try and increase the rate limits on your organization in OpenAI. Alternatively, we recommend using different keys or organizations for different projects, or for your production and pre-production traffic.
#### Unable to parse JSON response
Context Adherence *Plus*, Completeness *Plus*, Attribution Plus, and Chunk Utilization *Plus* use [Chainpoll](https://arxiv.org/abs/2310.18344) to calculate metric values. Chainpoll metrics call on OpenAI for a part of their calculation and require OpenAI responses to be in a valid JSON format. When you see this message, it means that the response that OpenAI sent back was not in valid JSON. Retrying might solve this problem.
#### Context Length exceeded
This error will happen if your prompt (or prompt + response for some metrics) exceeds the supported context window of the underlying models. Reach out to Galileo if you run into this error, and we can work with you to build ways around it.
#### Error executing your custom metric
If you're seeing this, it means your custom or registered metric did not execute correctly. The stack trace is shown to help you debug what went wrong.
---
# Source: https://docs.galileo.ai/galileo-ai-research/errors-in-object-detection.md
> ## Documentation Index
> Fetch the complete documentation index at: https://docs.galileo.ai/llms.txt
> Use this file to discover all available pages before exploring further.
# Errors In Object Detection
> This page describes the rich error types offered by Galileo for Object Detection
An Object Detection (OD) model receives an image as input and outputs a list of rectangular boxes representing objects within the image. Each box is associated with a label/class and can be positioned anywhere on the image. Unlike other tasks with limited output spaces (such as single labels in classification or labels and spans in NER), OD entails a significantly larger number of possible outputs due to two factors:
1. The model can generate a substantial quantity of boxes (several thousand for YOLO before NMS).
2. Each box can be positioned at any location on the image, as long as it has integer coordinates.
This level of freedom necessitates the use of complex algorithms to establish diverse pairings between predictions and annotations, which in turn gives very rich error types. In this article we will explain what these error types are and how to use Galileo to focus on any of them and fix your data.
For a high-level introduction to error types and Galileo see [here](/galileo/how-to-and-faq/galileo-product-features/error-types-breakdown).
## The 6 Error Types
The initial stage in assigning error types to flawed boxes involves identifying the boxes that are not deemed correct. We will refer to inaccurate predictions as False Positives (FP) and erroneous annotations as False Negatives (FN). There are many ways in which a predicted box can turn into a FP, so we will classify them further in more granular buckets:
* **Duplicate Error:** the predicted box highly overlaps with an annotation that is already used
* **Classification Error:** the predicted box highly overlaps with an annotation of different label
* **Localization Error:** the predicted box slightly overlaps with an annotation of same label
* **Classification and Localization Error:** the predicted box slightly overlaps with an annotation of different label
* **Background Error:** the predicted box does not even slightly overlap with an annotation.
Similarly, some FN annotations will be assigned the following error type:
* **Missed Error:** the annotation was not used by any prediction (either used to declare a prediction a TP or used to bin a prediction in any of the above errors).
The following illustration summarizes the above discussion:
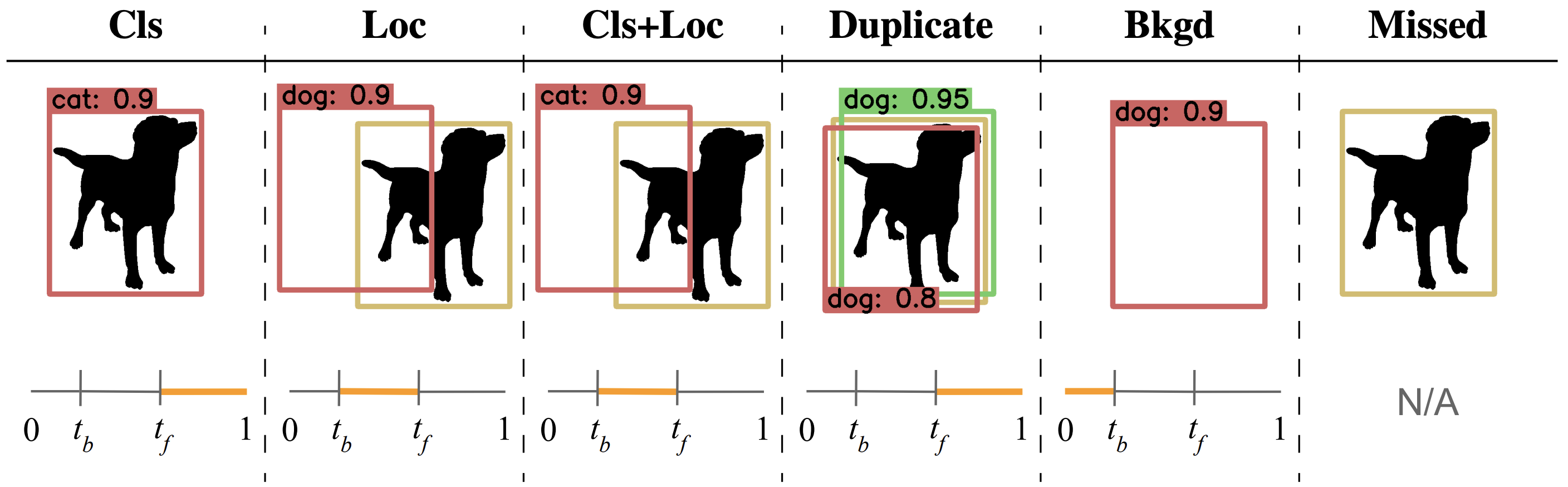 Note that the above error types were introduced in the [TIDE toolbox](https://dbolya.github.io/tide/) paper. We refer to their paper and to the Technical deep dive below for more details.
## The 6 error types and Galileo
### Count and Impact on mAP
In the Galileo Console, we surface two metrics for each of the 6 error types: their count and their impact on mAP. The count is simply the number of boxes tagged with that error type, and the impact on mAP is the amount by which mAP would increase if we were to fix all errors of that type.
Note that the above error types were introduced in the [TIDE toolbox](https://dbolya.github.io/tide/) paper. We refer to their paper and to the Technical deep dive below for more details.
## The 6 error types and Galileo
### Count and Impact on mAP
In the Galileo Console, we surface two metrics for each of the 6 error types: their count and their impact on mAP. The count is simply the number of boxes tagged with that error type, and the impact on mAP is the amount by which mAP would increase if we were to fix all errors of that type.
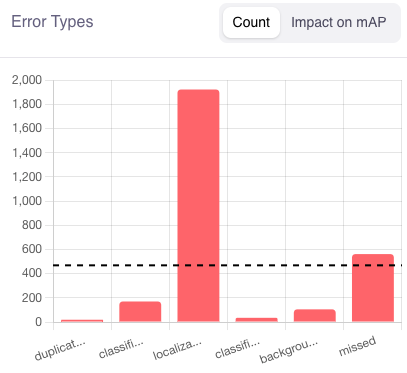 We suggest starting analyzing the error with highest impact on mAP and trying to understand why the model and annotations disagree.
### Focus on a single Error Type to gain insight
Galileo allows you to focus on any of the error types in order to dig and understand in each case whether the data quality is poor or the model is not well trained. For this you can either click on an error type in the above bar chart, or simply add the error type filter by clicking on Add Filters.
Once a single error type is selected, Galileo will only display the boxes with that error type together with any other box that is necessary context in order to explain that error type.
For example, a prediction is tagged as a classification error because it significantly overlaps with an annotation of different label. In this case, we will show this annotation and its label.
We refer to the Technical deep dive below for more details on associated boxes.
### Improve your data quality
Galileo offers the possibility to fix your annotations in a few clicks from the console. After adding a filter by error type, select the images with miss-annotated boxes either one-by-one, or by selecting them all and, if any, unselecting the images with correct annotations.
We suggest starting analyzing the error with highest impact on mAP and trying to understand why the model and annotations disagree.
### Focus on a single Error Type to gain insight
Galileo allows you to focus on any of the error types in order to dig and understand in each case whether the data quality is poor or the model is not well trained. For this you can either click on an error type in the above bar chart, or simply add the error type filter by clicking on Add Filters.
Once a single error type is selected, Galileo will only display the boxes with that error type together with any other box that is necessary context in order to explain that error type.
For example, a prediction is tagged as a classification error because it significantly overlaps with an annotation of different label. In this case, we will show this annotation and its label.
We refer to the Technical deep dive below for more details on associated boxes.
### Improve your data quality
Galileo offers the possibility to fix your annotations in a few clicks from the console. After adding a filter by error type, select the images with miss-annotated boxes either one-by-one, or by selecting them all and, if any, unselecting the images with correct annotations.
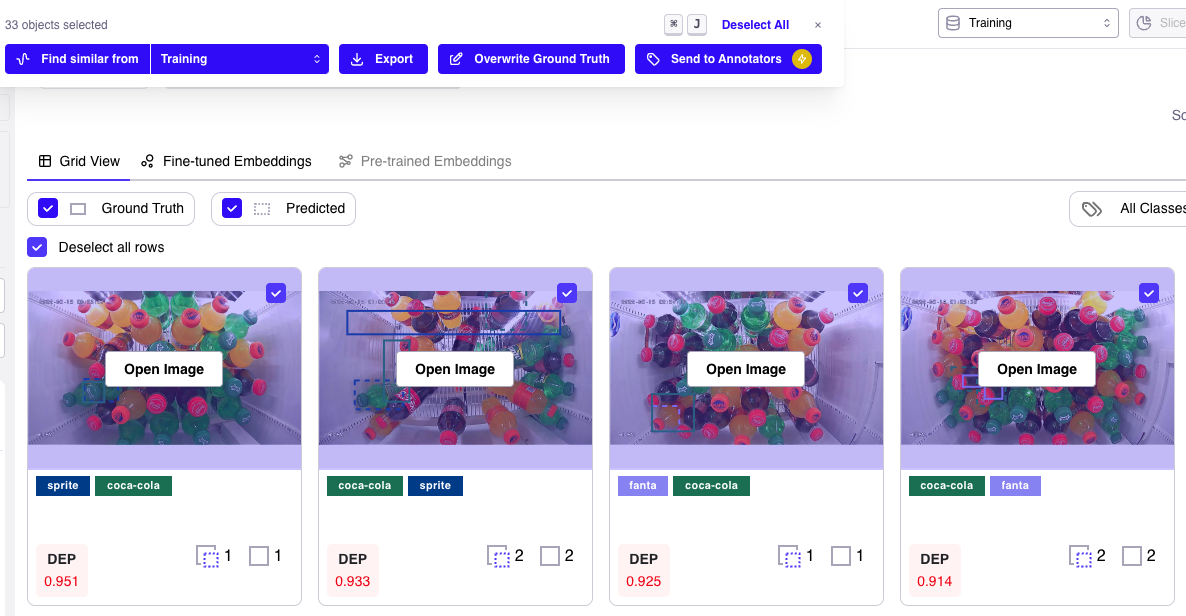 Clicking on Overwrite Ground Truth will overwrite the annotation with the prediction that links to that annotation. More concretely, we explain below the typical scenario for every error type.
* **Duplicate error:** this is often a model error, and duplicates can be reduced by decreasing the IoU threshold in the NMS step. However, sometimes a duplicate box will have more accurate localization that both the TP prediction and the annotation, in which case we would overwrite the annotation with the duplicate box.
Clicking on Overwrite Ground Truth will overwrite the annotation with the prediction that links to that annotation. More concretely, we explain below the typical scenario for every error type.
* **Duplicate error:** this is often a model error, and duplicates can be reduced by decreasing the IoU threshold in the NMS step. However, sometimes a duplicate box will have more accurate localization that both the TP prediction and the annotation, in which case we would overwrite the annotation with the duplicate box.
 * **Classification error:** more often than not, classification errors in OD represent mislabeled annotation. Correcting this error would simply relabel the annotation with the predicted one. Note that these errors have overlap with the Likely Mislabeled feature.
* **Classification error:** more often than not, classification errors in OD represent mislabeled annotation. Correcting this error would simply relabel the annotation with the predicted one. Note that these errors have overlap with the Likely Mislabeled feature.
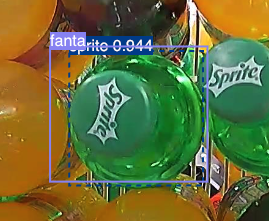 * **Localization error:** localization errors surface inaccuracies in the annotations localization. Correcting this error would overwrite the annotation's coordinates with the predicted ones. Note that this error is very sensitive to the IoU threshold chosen (the mAP threshold).
* **Localization error:** localization errors surface inaccuracies in the annotations localization. Correcting this error would overwrite the annotation's coordinates with the predicted ones. Note that this error is very sensitive to the IoU threshold chosen (the mAP threshold).
 * **Classification and Localization error:** these errors are less predictable and can be due to various phenomena. We suggest going through these images one-by-one and taking action accordingly.
* **Background error:** more often than not a background error is due to a missed annotation. In this setting, the Overwrite Ground Truth button adds the missing annotation.
* **Missed error:** these errors are sometimes due to the model not predicting the appropriate box, and sometimes due to poor annotations. Some common scenarios include:
* poor/gibberish annotations that do not represent an object or do not represent an object that we want to predict
* **Classification and Localization error:** these errors are less predictable and can be due to various phenomena. We suggest going through these images one-by-one and taking action accordingly.
* **Background error:** more often than not a background error is due to a missed annotation. In this setting, the Overwrite Ground Truth button adds the missing annotation.
* **Missed error:** these errors are sometimes due to the model not predicting the appropriate box, and sometimes due to poor annotations. Some common scenarios include:
* poor/gibberish annotations that do not represent an object or do not represent an object that we want to predict
 * multiple annotations for the same object
* multiple annotations for the same object
 In this case, overwriting the ground truth means removing the bad annotation.
## The 6 error types: Technical deep dive
In this section, we will elaborate on our methodology for determining the suitable error type associated with a box that fails to meet the criteria for correctness.
### Coarse Errors: FPs and FNs
The first step consists of a coarser association is determining all wrong predictions (False Positives, FP), and all wrong annotations (False Negatives, FN). This algorithm is also used for calculating the main metric in Object Detection: the mean Average Precision (mAP). We summarize the steps necessary for finding our error types, and refer to a [modern definition](https://jonathan-hui.medium.com/map-mean-average-precision-for-object-detection-45c121a31173) for more details:
1. Pick a global IoU threshold. This is used to decide when two boxes overlap enough to be paired together.
2. Loop over labels. For every label, only consider the predictions and annotations of that label.
3. Sort all predictions descending by their score and go through them one by one. At the beginning all annotation are unused.
4. If a prediction overlaps enough with an unused annotation: call that prediction at True Positive (TP) and declare that annotation as used.
5. If it doesn't, call that prediction a FP.
6. When all predictions are exhausted, call all unused annotations become FNs.
The Galileo console offers three IoU thresholds: 0.5, 0.7 and 0.9. Note that the higher the threshold, the harder it is for a prediction to be a TP as it has to considerably overlap with a detection. Moreover, this is even harder for smaller objects, where moving a box by a few pixels dramatically decreases the IoU.
In this case, overwriting the ground truth means removing the bad annotation.
## The 6 error types: Technical deep dive
In this section, we will elaborate on our methodology for determining the suitable error type associated with a box that fails to meet the criteria for correctness.
### Coarse Errors: FPs and FNs
The first step consists of a coarser association is determining all wrong predictions (False Positives, FP), and all wrong annotations (False Negatives, FN). This algorithm is also used for calculating the main metric in Object Detection: the mean Average Precision (mAP). We summarize the steps necessary for finding our error types, and refer to a [modern definition](https://jonathan-hui.medium.com/map-mean-average-precision-for-object-detection-45c121a31173) for more details:
1. Pick a global IoU threshold. This is used to decide when two boxes overlap enough to be paired together.
2. Loop over labels. For every label, only consider the predictions and annotations of that label.
3. Sort all predictions descending by their score and go through them one by one. At the beginning all annotation are unused.
4. If a prediction overlaps enough with an unused annotation: call that prediction at True Positive (TP) and declare that annotation as used.
5. If it doesn't, call that prediction a FP.
6. When all predictions are exhausted, call all unused annotations become FNs.
The Galileo console offers three IoU thresholds: 0.5, 0.7 and 0.9. Note that the higher the threshold, the harder it is for a prediction to be a TP as it has to considerably overlap with a detection. Moreover, this is even harder for smaller objects, where moving a box by a few pixels dramatically decreases the IoU.
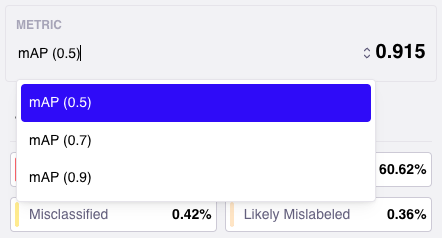 ### Finer Errors: The 6 Error Types of TIDE
The 6 error types cited above were introduced in the [TIDE toolbox](https://dbolya.github.io/tide/) paper, to which we refer for more details. For a concise definition, we will re-use the illustration posted above.
### Finer Errors: The 6 Error Types of TIDE
The 6 error types cited above were introduced in the [TIDE toolbox](https://dbolya.github.io/tide/) paper, to which we refer for more details. For a concise definition, we will re-use the illustration posted above.
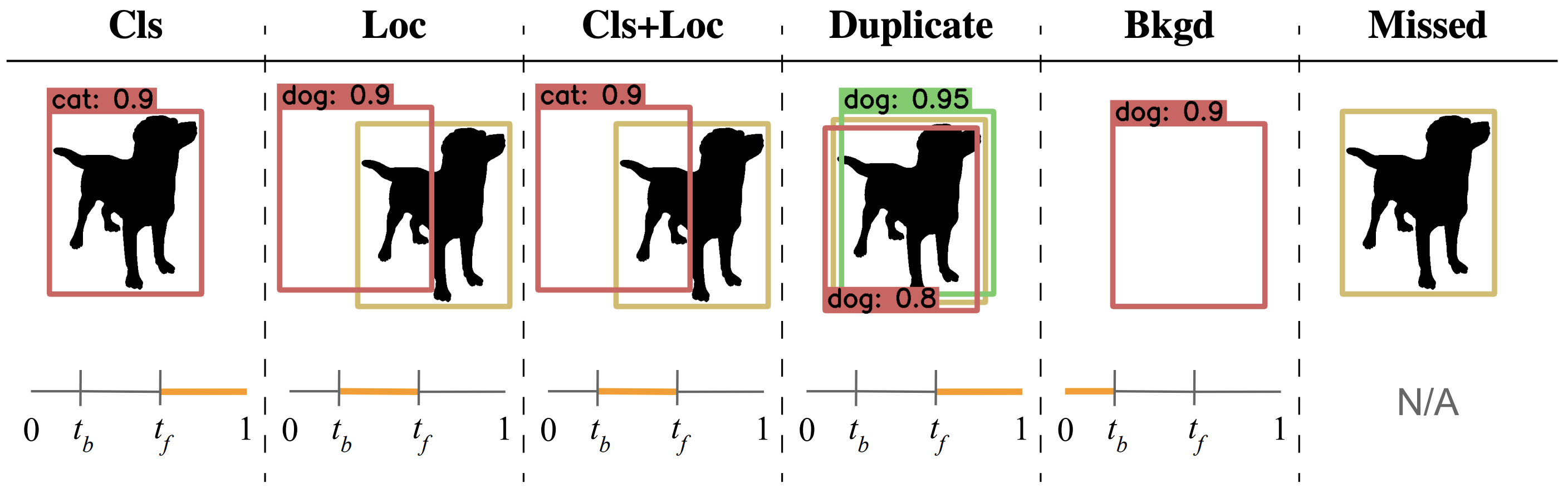 The `[0,1]` interval appearing below the image indicates the range (in orange) for the IoU between the predicted box (in red) and an annotated box (in yellow). Note that it contains two thresholds: the background threshold `t_b` and the foreground threshold `t_f`. Galileo sets the background threshold `t_b` at `0.1` and the foreground threshold `t_f` at the `mAP threshold` used to compute the mAP score. As an example, a predicted box overlapping with an annotation with `IoU >= t_f` will be given the classification error type if the class of the annotation doesn't match that of the prediction.
With the above ambiguous definition, there are cases where a predicted box could be part of multiple error types. To avoid ambiguity, Galileo classifies the errors in the following order:
1. **Localization**
2. **Classification**
3. **Duplicate**
4. **Background**
5. **Classification and Localization.**
That is, we check in order, if the predicted box
1. has IoU with an annotation with same label in the range `[t_b, t_f]`
2. has IoU with an annotation with different label in the range `[t_f, 1]`
3. has IoU with an annotation already used, with same label in the range `[t_f, 1]`
4. has IoU `< t_b` with all annotations.
If none of these occur, then the box is a classification and localization error (it is easy to see that this implies that the prediction has IoU in the range `[t_b, t_f]` with a box of different label).
Finally, the **Missed** error type is given to any annotation that is already considered a FN, and that was not used in the above definition by either a Classification Error or a Localization Error. Note that Missed annotations can overlap with predictions, for example, they can overlap `< t_b` with a classification and localization error.
### Associated boxes
The above definitions beg for better terminology. We will say that an annotation is associated with a prediction, or that a prediction links to an annotation in any of the following cases
* the prediction is a TP corresponding to the annotation
* the prediction is an FP (except background error), and the annotation is the one involved in the IoU deciding so.
For example, if a predicted box is tagged as a classification error, it will link to the annotations with which it overlaps and has a different label. In particular, this associated annotation explains the error type of the predicted box and provides the necessary context to understand the error.
The `[0,1]` interval appearing below the image indicates the range (in orange) for the IoU between the predicted box (in red) and an annotated box (in yellow). Note that it contains two thresholds: the background threshold `t_b` and the foreground threshold `t_f`. Galileo sets the background threshold `t_b` at `0.1` and the foreground threshold `t_f` at the `mAP threshold` used to compute the mAP score. As an example, a predicted box overlapping with an annotation with `IoU >= t_f` will be given the classification error type if the class of the annotation doesn't match that of the prediction.
With the above ambiguous definition, there are cases where a predicted box could be part of multiple error types. To avoid ambiguity, Galileo classifies the errors in the following order:
1. **Localization**
2. **Classification**
3. **Duplicate**
4. **Background**
5. **Classification and Localization.**
That is, we check in order, if the predicted box
1. has IoU with an annotation with same label in the range `[t_b, t_f]`
2. has IoU with an annotation with different label in the range `[t_f, 1]`
3. has IoU with an annotation already used, with same label in the range `[t_f, 1]`
4. has IoU `< t_b` with all annotations.
If none of these occur, then the box is a classification and localization error (it is easy to see that this implies that the prediction has IoU in the range `[t_b, t_f]` with a box of different label).
Finally, the **Missed** error type is given to any annotation that is already considered a FN, and that was not used in the above definition by either a Classification Error or a Localization Error. Note that Missed annotations can overlap with predictions, for example, they can overlap `< t_b` with a classification and localization error.
### Associated boxes
The above definitions beg for better terminology. We will say that an annotation is associated with a prediction, or that a prediction links to an annotation in any of the following cases
* the prediction is a TP corresponding to the annotation
* the prediction is an FP (except background error), and the annotation is the one involved in the IoU deciding so.
For example, if a predicted box is tagged as a classification error, it will link to the annotations with which it overlaps and has a different label. In particular, this associated annotation explains the error type of the predicted box and provides the necessary context to understand the error.
 The Galileo Console will always show the context in order to explain all error types. This explains why predicted boxes will be visible when filtering and only showing Missed errors, or why annotations will be visible when filtering for, say, Classification errors.
Note that an annotation can be associated with multiple predictions (the simplest case to see is for a TP and a duplicate, but there are countless other possibilities). With this definition, one can notice that a Missed error is an annotation that is either associated with no box or only a classification and localization error (or multiple, but this is rare).
---
# Source: https://docs.galileo.ai/galileo/gen-ai-studio-products/galileo-evaluate/how-to/evaluate-and-optimize-agents--chains-or-multi-step-workflows.md
> ## Documentation Index
> Fetch the complete documentation index at: https://docs.galileo.ai/llms.txt
> Use this file to discover all available pages before exploring further.
# Evaluate and Optimize Agents
> How to use Galileo Evaluate with Agents
Galileo Evaluate helps you evaluate and optimize Agents with out-of-the-box Tracing and Analytics. Galileo allows you to run and log experiments, trace all the steps taken by your Agent, and use [Galileo Preset](/galileo/gen-ai-studio-products/galileo-guardrail-metrics) or [Custom Metrics](/galileo/gen-ai-studio-products/galileo-evaluate/how-to/choose-your-guardrail-metrics) to evaluate and debug your end-to-end system .
## Getting Started
The first step in evaluating your application is creating an evaluation run. To do this, run your evaluation set (e.g. a set of inputs that mimic the inputs you expect to get from users) through your Agent create a run.
Follow our instructions on how to [Integrate Evaluate into your existing application](/galileo/gen-ai-studio-products/galileo-evaluate/integrations).
## Tracing and Visualizing your Agent
Once you log your evaluation runs, you can go to the Galileo Console to analyze your Agent executions. For each execution, you'll be able to see what the input into the workflow was and what the final response was, as well as any steps of decisions taken to get to the final result.
The Galileo Console will always show the context in order to explain all error types. This explains why predicted boxes will be visible when filtering and only showing Missed errors, or why annotations will be visible when filtering for, say, Classification errors.
Note that an annotation can be associated with multiple predictions (the simplest case to see is for a TP and a duplicate, but there are countless other possibilities). With this definition, one can notice that a Missed error is an annotation that is either associated with no box or only a classification and localization error (or multiple, but this is rare).
---
# Source: https://docs.galileo.ai/galileo/gen-ai-studio-products/galileo-evaluate/how-to/evaluate-and-optimize-agents--chains-or-multi-step-workflows.md
> ## Documentation Index
> Fetch the complete documentation index at: https://docs.galileo.ai/llms.txt
> Use this file to discover all available pages before exploring further.
# Evaluate and Optimize Agents
> How to use Galileo Evaluate with Agents
Galileo Evaluate helps you evaluate and optimize Agents with out-of-the-box Tracing and Analytics. Galileo allows you to run and log experiments, trace all the steps taken by your Agent, and use [Galileo Preset](/galileo/gen-ai-studio-products/galileo-guardrail-metrics) or [Custom Metrics](/galileo/gen-ai-studio-products/galileo-evaluate/how-to/choose-your-guardrail-metrics) to evaluate and debug your end-to-end system .
## Getting Started
The first step in evaluating your application is creating an evaluation run. To do this, run your evaluation set (e.g. a set of inputs that mimic the inputs you expect to get from users) through your Agent create a run.
Follow our instructions on how to [Integrate Evaluate into your existing application](/galileo/gen-ai-studio-products/galileo-evaluate/integrations).
## Tracing and Visualizing your Agent
Once you log your evaluation runs, you can go to the Galileo Console to analyze your Agent executions. For each execution, you'll be able to see what the input into the workflow was and what the final response was, as well as any steps of decisions taken to get to the final result.
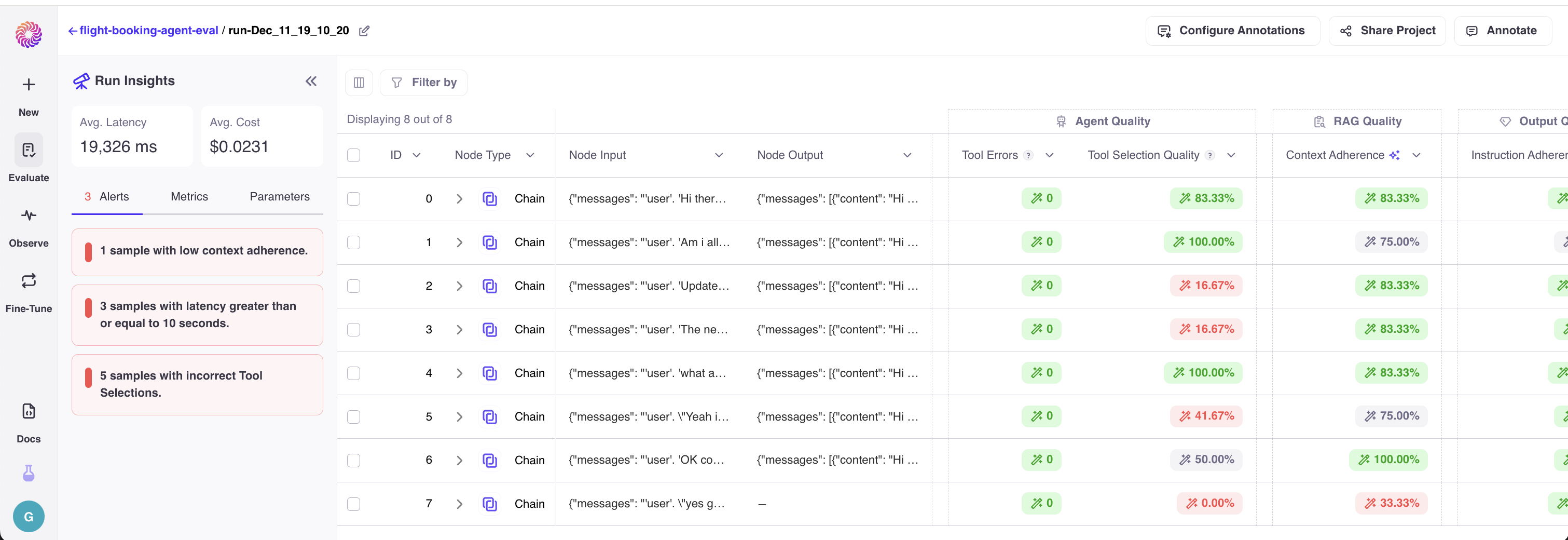 Clicking on any row on the table will open the Expanded View for that workflow or step. You can dig through the steps that your Agent took to understand how it got to the final response, and trace any mistakes back to an incorrect step.
Clicking on any row on the table will open the Expanded View for that workflow or step. You can dig through the steps that your Agent took to understand how it got to the final response, and trace any mistakes back to an incorrect step.
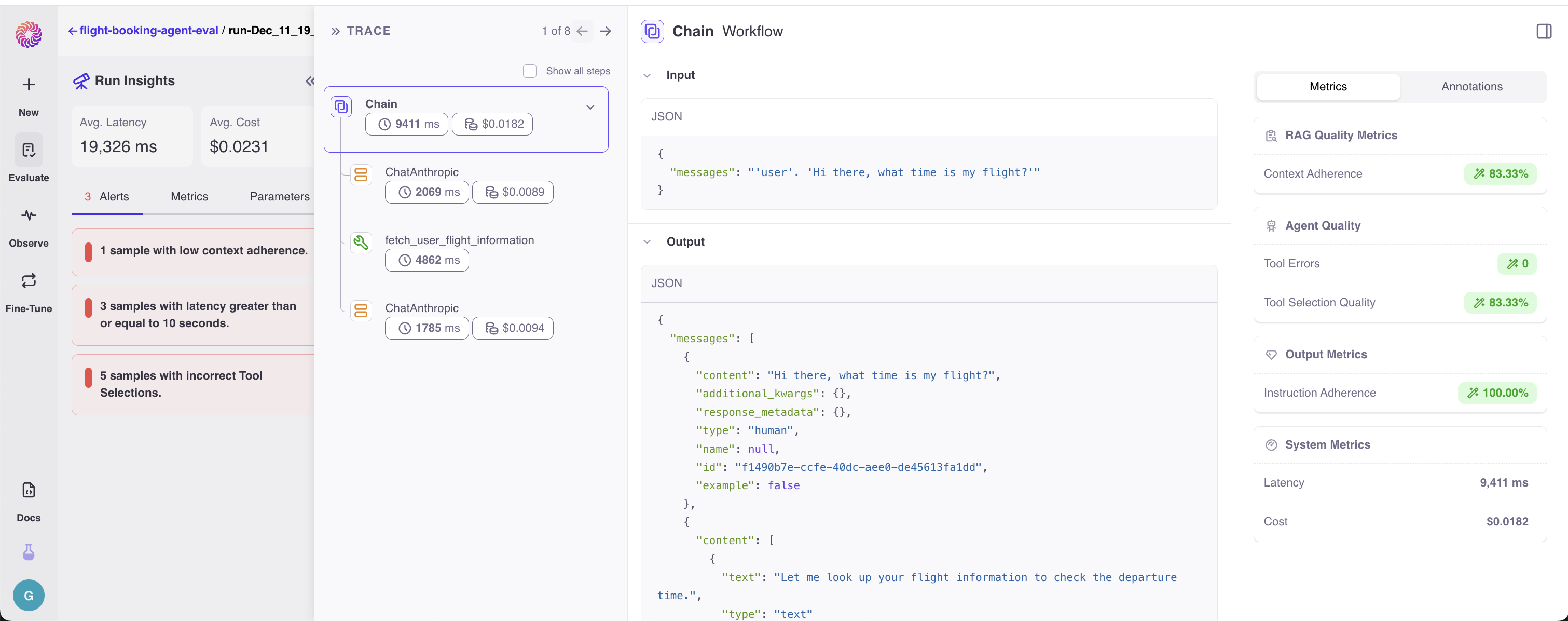 ## Metrics
Galileo has [Galileo Preset Metrics](/galileo/gen-ai-studio-products/galileo-guardrail-metrics) to help you evaluate and debug application. In addition, Galileo supports user-defined [custom metrics](/galileo/gen-ai-studio-products/galileo-evaluate/how-to/choose-your-guardrail-metrics). When logging your evaluation run, make sure to include the metrics you want computed for your run.
More information on how to [evaluate and debug them on the console](/galileo/gen-ai-studio-products/galileo-observe/how-to/identifying-and-debugging-issues).
For Agents, the metrics we recommend to use are:
* [Action Completion](/galileo/gen-ai-studio-products/galileo-guardrail-metrics/action-completion): A metric at the session level detecting whether the agent successfully accomplished all user's goals. This metric will show use-cases where the Agent is not able to fully help the user in all of its tasks.
* [Action Advancement](/galileo/gen-ai-studio-products/galileo-guardrail-metrics/action-advancement): A metric at the workflow level detecting whether the agent successfully accomplished or advanced towards at least one user goal. This metric will show use-cases where the Agent is not able to help the user in any of its tasks.
* [Tool Selection Quality](/galileo/gen-ai-studio-products/galileo-guardrail-metrics/tool-selection-quality): A metric on your LLM steps that detects whether the correct Tool and Parameters were chosen by the LLM. When you use LLMs to determine the sequence of steps that happen in your Agent, this metric will help you find 'planning' errors in your Agent.
* [Tool Errors](/galileo/gen-ai-studio-products/galileo-guardrail-metrics/tool-error): A metric on your Tool steps that detects whether they executed correctly. Tools are a common building block for Agents. Detecting errors and patterns in those errors is an important step in your debugging journey.
* [Instruction Adherence](/galileo/gen-ai-studio-products/galileo-guardrail-metrics/instruction-adherence): A metric on your LLM steps that measures whether the LLM followed its instructions.
* [Context Adherence](/galileo/gen-ai-studio-products/galileo-guardrail-metrics/context-adherence): If your Agent uses a Retriever or has summarization steps, this metric can help detect hallucinations or ungrounded facts in the response.
You can always create or generate your own Metric for your use case, or tailor any of these metrics via Continuous Learning via Human Feedback (CLHF).
## Iterative Experimentation
Now that you've identified something wrong with your Chain or Agent, try to change your chain or agent configuration, prompt template, or model settings and re-run your evaluation under the same project. Your project view will allow you to quickly compare evaluation runs and see which [configuration](/galileo/gen-ai-studio-products/galileo-evaluate/how-to/evaluate-and-optimize-agents--chains-or-multi-step-workflows#keeping-track-of-what-changed-in-your-experiment) of your system worked best.
#### Keeping track of what changed in your experiment
As you start experimenting, you're going to want to keep track of what you're attempting with each experiment. To do so, use Prompt Tags. Prompt Tags are tags you can add to the run (e.g. "agent\_architecture" = "voyage-2", "agent\_architecture" = "reflexion").
Prompt Tags will help you remember what you tried with each experiment. Read more about [how to add Prompt Tags here](/galileo/gen-ai-studio-products/galileo-evaluate/how-to/add-tags-and-metadata-to-prompt-runs).
---
# Source: https://docs.galileo.ai/galileo/gen-ai-studio-products/galileo-evaluate/how-to/evaluate-and-optimize-prompts.md
> ## Documentation Index
> Fetch the complete documentation index at: https://docs.galileo.ai/llms.txt
> Use this file to discover all available pages before exploring further.
# Evaluate and Optimize Prompts
> How to use Galileo Evaluate for prompt engineering
Galileo Evaluate enables you to evaluate and optimize your prompts with out-of-the-box Guardrail metrics.
1. **Pip Install** `promptquality` and create runs in your Python notebook.
2. Next, you execute **promptquality.run()** like shown below.
```Bash theme={null}
import promptquality as pq
pq.login({YOUR_GALILEO_URL})
template = "Explain {{topic}} to me like I'm a 5 year old"
data = {"topic": ["Quantum Physics", "Politics", "Large Language Models"]}
pq.run(project_name='my_first_project',
template=template,
dataset=data,
settings=pq.Settings(model_alias='ChatGPT (16K context)',
temperature=0.8,
max_tokens=400))
```
The code snippet above uses ChatGPT API endpoint from OpenAI. Want to use other models (Azure OpenAI, Cohere, Anthropic, Mistral, etc)? Check out the integration page
[here](/galileo/gen-ai-studio-products/galileo-evaluate/integrations/llms).
---
# Source: https://docs.galileo.ai/galileo/gen-ai-studio-products/galileo-evaluate/how-to/evaluate-and-optimize-rag-applications.md
> ## Documentation Index
> Fetch the complete documentation index at: https://docs.galileo.ai/llms.txt
> Use this file to discover all available pages before exploring further.
# Evaluate and Optimize RAG Applications
> How to use Galileo Evaluate with RAG applications
Galileo Evaluate enables you to evaluate and optimize your Retrieval-Augmented Generation (RAG) application with out-of-the-box Tracing and Analytics.
## Getting Started
The first step in evaluating your application is creating an evaluation run. To do this, run your evaluation set (e.g. a set of inputs that mimic the inputs you expect to get from users) through your RAG system and create a prompt run.
Follow [these instructions](/galileo/gen-ai-studio-products/galileo-evaluate/integrations/custom-chain#logging-rag-workflows) to integrate `promptquality` into your RAG workflows and create Evaluation Runs on Galileo.
If you're using LangChain, we recommend you use the Galileo Langchain callback instead. See [these instructions](/galileo/gen-ai-studio-products/galileo-evaluate/integrations/langchain) for more details.
#### Keeping track of what changed in your experiment
As you start experimenting, you're going to want to keep track of what you're attempting with each experiment. To do so, use Prompt Tags. Prompt Tags are tags you can add to the run (e.g. "embedding\_model" = "voyage-2", "embedding\_model" = "text-embedding-ada-002").
Prompt Tags will help you remember what you tried with each experiment. Read more about [how to add Prompt Tags here](/galileo/gen-ai-studio-products/galileo-evaluate/how-to/add-tags-and-metadata-to-prompt-runs).
## Tracing your Retrieval System
Once you log your evaluation runs, you can go to the Galileo Console to analyze your workflow executions. For each execution, you'll be able to see what the input into the workflow was and what the final response was, as well as any intermediate results.
## Metrics
Galileo has [Galileo Preset Metrics](/galileo/gen-ai-studio-products/galileo-guardrail-metrics) to help you evaluate and debug application. In addition, Galileo supports user-defined [custom metrics](/galileo/gen-ai-studio-products/galileo-evaluate/how-to/choose-your-guardrail-metrics). When logging your evaluation run, make sure to include the metrics you want computed for your run.
More information on how to [evaluate and debug them on the console](/galileo/gen-ai-studio-products/galileo-observe/how-to/identifying-and-debugging-issues).
For Agents, the metrics we recommend to use are:
* [Action Completion](/galileo/gen-ai-studio-products/galileo-guardrail-metrics/action-completion): A metric at the session level detecting whether the agent successfully accomplished all user's goals. This metric will show use-cases where the Agent is not able to fully help the user in all of its tasks.
* [Action Advancement](/galileo/gen-ai-studio-products/galileo-guardrail-metrics/action-advancement): A metric at the workflow level detecting whether the agent successfully accomplished or advanced towards at least one user goal. This metric will show use-cases where the Agent is not able to help the user in any of its tasks.
* [Tool Selection Quality](/galileo/gen-ai-studio-products/galileo-guardrail-metrics/tool-selection-quality): A metric on your LLM steps that detects whether the correct Tool and Parameters were chosen by the LLM. When you use LLMs to determine the sequence of steps that happen in your Agent, this metric will help you find 'planning' errors in your Agent.
* [Tool Errors](/galileo/gen-ai-studio-products/galileo-guardrail-metrics/tool-error): A metric on your Tool steps that detects whether they executed correctly. Tools are a common building block for Agents. Detecting errors and patterns in those errors is an important step in your debugging journey.
* [Instruction Adherence](/galileo/gen-ai-studio-products/galileo-guardrail-metrics/instruction-adherence): A metric on your LLM steps that measures whether the LLM followed its instructions.
* [Context Adherence](/galileo/gen-ai-studio-products/galileo-guardrail-metrics/context-adherence): If your Agent uses a Retriever or has summarization steps, this metric can help detect hallucinations or ungrounded facts in the response.
You can always create or generate your own Metric for your use case, or tailor any of these metrics via Continuous Learning via Human Feedback (CLHF).
## Iterative Experimentation
Now that you've identified something wrong with your Chain or Agent, try to change your chain or agent configuration, prompt template, or model settings and re-run your evaluation under the same project. Your project view will allow you to quickly compare evaluation runs and see which [configuration](/galileo/gen-ai-studio-products/galileo-evaluate/how-to/evaluate-and-optimize-agents--chains-or-multi-step-workflows#keeping-track-of-what-changed-in-your-experiment) of your system worked best.
#### Keeping track of what changed in your experiment
As you start experimenting, you're going to want to keep track of what you're attempting with each experiment. To do so, use Prompt Tags. Prompt Tags are tags you can add to the run (e.g. "agent\_architecture" = "voyage-2", "agent\_architecture" = "reflexion").
Prompt Tags will help you remember what you tried with each experiment. Read more about [how to add Prompt Tags here](/galileo/gen-ai-studio-products/galileo-evaluate/how-to/add-tags-and-metadata-to-prompt-runs).
---
# Source: https://docs.galileo.ai/galileo/gen-ai-studio-products/galileo-evaluate/how-to/evaluate-and-optimize-prompts.md
> ## Documentation Index
> Fetch the complete documentation index at: https://docs.galileo.ai/llms.txt
> Use this file to discover all available pages before exploring further.
# Evaluate and Optimize Prompts
> How to use Galileo Evaluate for prompt engineering
Galileo Evaluate enables you to evaluate and optimize your prompts with out-of-the-box Guardrail metrics.
1. **Pip Install** `promptquality` and create runs in your Python notebook.
2. Next, you execute **promptquality.run()** like shown below.
```Bash theme={null}
import promptquality as pq
pq.login({YOUR_GALILEO_URL})
template = "Explain {{topic}} to me like I'm a 5 year old"
data = {"topic": ["Quantum Physics", "Politics", "Large Language Models"]}
pq.run(project_name='my_first_project',
template=template,
dataset=data,
settings=pq.Settings(model_alias='ChatGPT (16K context)',
temperature=0.8,
max_tokens=400))
```
The code snippet above uses ChatGPT API endpoint from OpenAI. Want to use other models (Azure OpenAI, Cohere, Anthropic, Mistral, etc)? Check out the integration page
[here](/galileo/gen-ai-studio-products/galileo-evaluate/integrations/llms).
---
# Source: https://docs.galileo.ai/galileo/gen-ai-studio-products/galileo-evaluate/how-to/evaluate-and-optimize-rag-applications.md
> ## Documentation Index
> Fetch the complete documentation index at: https://docs.galileo.ai/llms.txt
> Use this file to discover all available pages before exploring further.
# Evaluate and Optimize RAG Applications
> How to use Galileo Evaluate with RAG applications
Galileo Evaluate enables you to evaluate and optimize your Retrieval-Augmented Generation (RAG) application with out-of-the-box Tracing and Analytics.
## Getting Started
The first step in evaluating your application is creating an evaluation run. To do this, run your evaluation set (e.g. a set of inputs that mimic the inputs you expect to get from users) through your RAG system and create a prompt run.
Follow [these instructions](/galileo/gen-ai-studio-products/galileo-evaluate/integrations/custom-chain#logging-rag-workflows) to integrate `promptquality` into your RAG workflows and create Evaluation Runs on Galileo.
If you're using LangChain, we recommend you use the Galileo Langchain callback instead. See [these instructions](/galileo/gen-ai-studio-products/galileo-evaluate/integrations/langchain) for more details.
#### Keeping track of what changed in your experiment
As you start experimenting, you're going to want to keep track of what you're attempting with each experiment. To do so, use Prompt Tags. Prompt Tags are tags you can add to the run (e.g. "embedding\_model" = "voyage-2", "embedding\_model" = "text-embedding-ada-002").
Prompt Tags will help you remember what you tried with each experiment. Read more about [how to add Prompt Tags here](/galileo/gen-ai-studio-products/galileo-evaluate/how-to/add-tags-and-metadata-to-prompt-runs).
## Tracing your Retrieval System
Once you log your evaluation runs, you can go to the Galileo Console to analyze your workflow executions. For each execution, you'll be able to see what the input into the workflow was and what the final response was, as well as any intermediate results.
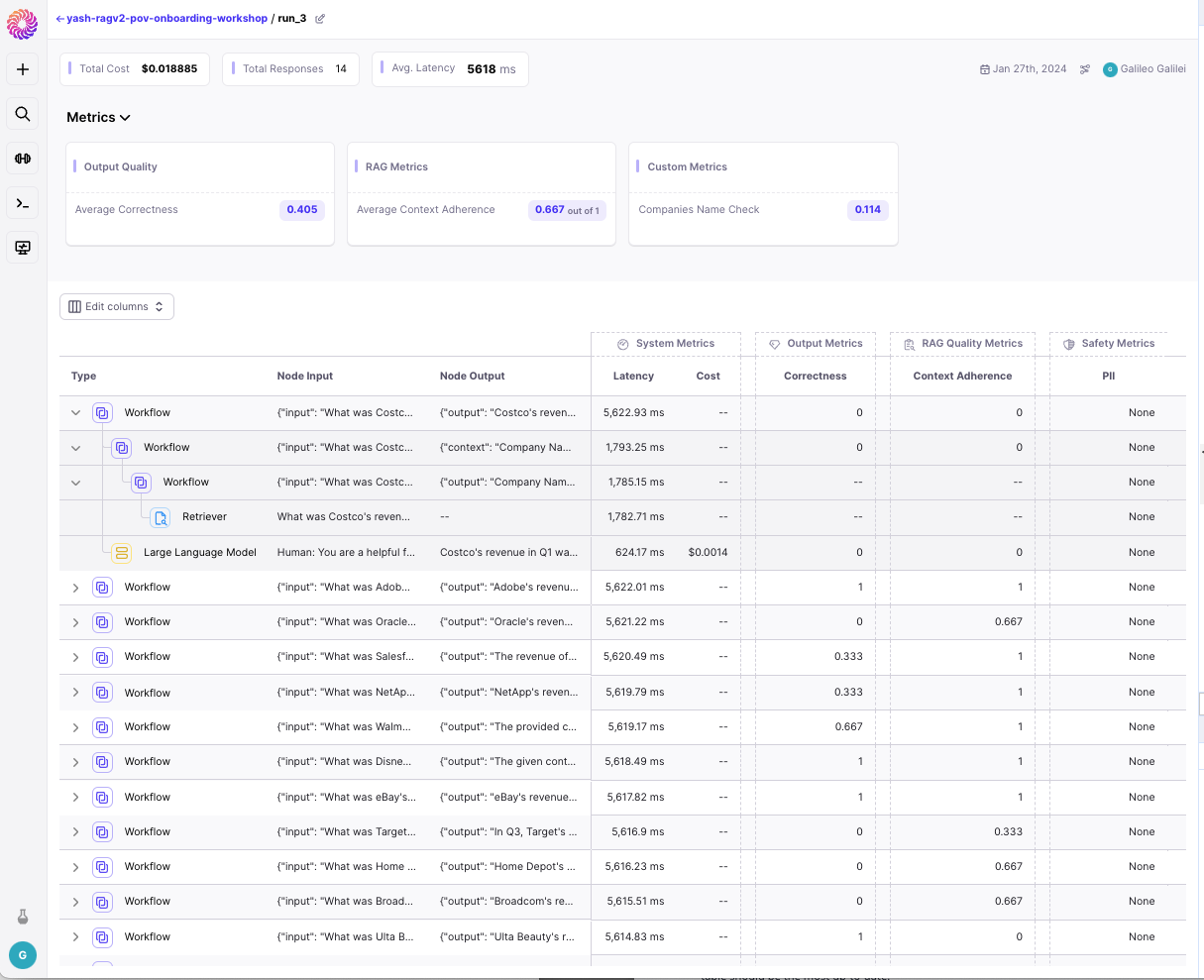 Clicking on any row will open the Expanded View for that node. The Retriever Node will show you all the chunks that your retriever returned. Once you start debugging your executions, this will allow you to trace poor-quality responses back to the step that went wrong.
## Evaluating and Optimizing the performance of your RAG application
Galileo has out-of-the-box [Guardrail Metrics](/galileo/gen-ai-studio-products/galileo-guardrail-metrics) to help you assess and evaluate the quality of your application. In addition, Galileo supports user-defined [custom metrics](/galileo/gen-ai-studio-products/galileo-evaluate/how-to/choose-your-guardrail-metrics). When logging your evaluation run, make sure to include the metrics you want computed for your run.
For RAG applications, we recommend using the following:
#### Context Adherence
*Context Adherence* (fka Groundedness) measures whether your model's response was purely based on the context provided, i.e. the response didn't state any facts not contained in the context provided. For RAG users, *Context Adherence* is a measurement of hallucinations.
If a response is *grounded* in the context (i.e. it has a value of 1 or close to 1), it only contains information given in the context. If a response is *not grounded* (i.e. it has a value of 0 or close to 0), it's likely to contain facts not included in the context provided to the model.
To fix low *Context Adherence* values, we recommend (1) ensuring your context DB has all the necessary info to answer the question, and (2) adjusting the prompt to tell the model to stick to the information it's given in the context.
*Note:* This metric has two options: [Context Adherence Basic](/galileo/gen-ai-studio-products/galileo-guardrail-metrics/context-adherence/context-adherence-luna) and [Context Adherence Plus](/galileo/gen-ai-studio-products/galileo-guardrail-metrics/completeness/completeness-plus).
#### Context Relevance
*Context Relevance* measures if the context has enough information to answer the user query.
High Context Relevance values indicate strong confidence that there is enough context to answer the question. Low Context Relevance values are a sign that you need to increase your Top K, modify your retrieval strategy, or use better embeddings.
#### Completeness
If *Context Adherence* is your precision metric for RAG, *Completeness* is your recall. In other words, it tries to answer the question: "Out of all the information in the context that's pertinent to the question, how much was covered in the answer?"
Low Completeness values indicate there's relevant information to the question included in your context that was not included in the model's response.
*Note:* This metric has two options: [Completeness Basic](/galileo/gen-ai-studio-products/galileo-guardrail-metrics/completeness/completeness-luna) and [Completeness Plus](/galileo/gen-ai-studio-products/galileo-guardrail-metrics/completeness/completeness-plus).
#### Chunk Attribution
Chunk Attribution is a chunk-level metric that denotes whether a chunk was or wasn't used by the model in generating the response. Attribution helps you more quickly identify why the model said what it did, without needing to read over the whole context.
Additionally, Attribution helps you optimize your retrieval strategy.
*Note:* This metric has two options: [Chunk Attribution Basic](/galileo/gen-ai-studio-products/galileo-guardrail-metrics/context-adherence/context-adherence-luna) and [Chunk Attribution Plus](/galileo/gen-ai-studio-products/galileo-guardrail-metrics/context-adherence/context-adherence-plus).
#### Chunk Utilization
Chunk Utilization measures how much of the text included in your chunk was used by the model to generate a response. Chunk Utilization helps you optimize your chunking strategy.
*Note:* This metric has two options: [Chunk Utilization Basic](/galileo/gen-ai-studio-products/galileo-guardrail-metrics/context-adherence/context-adherence-luna) and [Chunk Utilization Plus](/galileo/gen-ai-studio-products/galileo-guardrail-metrics/chunk-utilization/chunk-utilization-plus).
#### Non-RAG specific Metrics
Other metrics such as [*Uncertainty*](/galileo/gen-ai-studio-products/galileo-guardrail-metrics/uncertainty) and [*Correctness*](/galileo/gen-ai-studio-products/galileo-guardrail-metrics/correctness) might be useful as well. If these don't cover all your needs, you can always write custom metrics.
## Iterative Experimentation
Now that you've identified something wrong with your RAG application, try to change your retriever logic, prompt template, or model settings and re-run your evaluation under the same project. Your project view will allow you to quickly compare evaluation runs and see which [configuration](/galileo/gen-ai-studio-products/galileo-evaluate/how-to/evaluate-and-optimize-rag-applications#keeping-track-of-what-changed-in-your-experiment) of your system worked best.
---
# Source: https://docs.galileo.ai/galileo/gen-ai-studio-products/galileo-evaluate/how-to/evaluate-with-human-feedback.md
> ## Documentation Index
> Fetch the complete documentation index at: https://docs.galileo.ai/llms.txt
> Use this file to discover all available pages before exploring further.
# Evaluate with Human Feedback
> Galileo allows you to do qualitative human evaluations of your prompts and responses.
#### Configure your Human Ratings settings
You can configure your Human Ratings settings by clicking on "Configure Human Ratings" from your Project or Run view. Your configuration is applied to all runs in the Project, to allow you to compare all runs on the same rating dimensions.
You can configure multiple dimensions or "Rating Types" to rate your run on. Each Rating Type will be used to rate your responses on a different dimension (e.g. quality, conciseness, hallucination potential, etc).
Types are Name and have a Format. We support 5 formats:
* /
* 1 - 5 s
* Numerical ratings
* Categorical ratings (self-defined categories)
* Free-form text
Along with each rating, you can also allow raters to provide a rationale.
To align everyone on the Rating Criteria or rubric, you can define it as part of your Human Ratings configuration.
Clicking on any row will open the Expanded View for that node. The Retriever Node will show you all the chunks that your retriever returned. Once you start debugging your executions, this will allow you to trace poor-quality responses back to the step that went wrong.
## Evaluating and Optimizing the performance of your RAG application
Galileo has out-of-the-box [Guardrail Metrics](/galileo/gen-ai-studio-products/galileo-guardrail-metrics) to help you assess and evaluate the quality of your application. In addition, Galileo supports user-defined [custom metrics](/galileo/gen-ai-studio-products/galileo-evaluate/how-to/choose-your-guardrail-metrics). When logging your evaluation run, make sure to include the metrics you want computed for your run.
For RAG applications, we recommend using the following:
#### Context Adherence
*Context Adherence* (fka Groundedness) measures whether your model's response was purely based on the context provided, i.e. the response didn't state any facts not contained in the context provided. For RAG users, *Context Adherence* is a measurement of hallucinations.
If a response is *grounded* in the context (i.e. it has a value of 1 or close to 1), it only contains information given in the context. If a response is *not grounded* (i.e. it has a value of 0 or close to 0), it's likely to contain facts not included in the context provided to the model.
To fix low *Context Adherence* values, we recommend (1) ensuring your context DB has all the necessary info to answer the question, and (2) adjusting the prompt to tell the model to stick to the information it's given in the context.
*Note:* This metric has two options: [Context Adherence Basic](/galileo/gen-ai-studio-products/galileo-guardrail-metrics/context-adherence/context-adherence-luna) and [Context Adherence Plus](/galileo/gen-ai-studio-products/galileo-guardrail-metrics/completeness/completeness-plus).
#### Context Relevance
*Context Relevance* measures if the context has enough information to answer the user query.
High Context Relevance values indicate strong confidence that there is enough context to answer the question. Low Context Relevance values are a sign that you need to increase your Top K, modify your retrieval strategy, or use better embeddings.
#### Completeness
If *Context Adherence* is your precision metric for RAG, *Completeness* is your recall. In other words, it tries to answer the question: "Out of all the information in the context that's pertinent to the question, how much was covered in the answer?"
Low Completeness values indicate there's relevant information to the question included in your context that was not included in the model's response.
*Note:* This metric has two options: [Completeness Basic](/galileo/gen-ai-studio-products/galileo-guardrail-metrics/completeness/completeness-luna) and [Completeness Plus](/galileo/gen-ai-studio-products/galileo-guardrail-metrics/completeness/completeness-plus).
#### Chunk Attribution
Chunk Attribution is a chunk-level metric that denotes whether a chunk was or wasn't used by the model in generating the response. Attribution helps you more quickly identify why the model said what it did, without needing to read over the whole context.
Additionally, Attribution helps you optimize your retrieval strategy.
*Note:* This metric has two options: [Chunk Attribution Basic](/galileo/gen-ai-studio-products/galileo-guardrail-metrics/context-adherence/context-adherence-luna) and [Chunk Attribution Plus](/galileo/gen-ai-studio-products/galileo-guardrail-metrics/context-adherence/context-adherence-plus).
#### Chunk Utilization
Chunk Utilization measures how much of the text included in your chunk was used by the model to generate a response. Chunk Utilization helps you optimize your chunking strategy.
*Note:* This metric has two options: [Chunk Utilization Basic](/galileo/gen-ai-studio-products/galileo-guardrail-metrics/context-adherence/context-adherence-luna) and [Chunk Utilization Plus](/galileo/gen-ai-studio-products/galileo-guardrail-metrics/chunk-utilization/chunk-utilization-plus).
#### Non-RAG specific Metrics
Other metrics such as [*Uncertainty*](/galileo/gen-ai-studio-products/galileo-guardrail-metrics/uncertainty) and [*Correctness*](/galileo/gen-ai-studio-products/galileo-guardrail-metrics/correctness) might be useful as well. If these don't cover all your needs, you can always write custom metrics.
## Iterative Experimentation
Now that you've identified something wrong with your RAG application, try to change your retriever logic, prompt template, or model settings and re-run your evaluation under the same project. Your project view will allow you to quickly compare evaluation runs and see which [configuration](/galileo/gen-ai-studio-products/galileo-evaluate/how-to/evaluate-and-optimize-rag-applications#keeping-track-of-what-changed-in-your-experiment) of your system worked best.
---
# Source: https://docs.galileo.ai/galileo/gen-ai-studio-products/galileo-evaluate/how-to/evaluate-with-human-feedback.md
> ## Documentation Index
> Fetch the complete documentation index at: https://docs.galileo.ai/llms.txt
> Use this file to discover all available pages before exploring further.
# Evaluate with Human Feedback
> Galileo allows you to do qualitative human evaluations of your prompts and responses.
#### Configure your Human Ratings settings
You can configure your Human Ratings settings by clicking on "Configure Human Ratings" from your Project or Run view. Your configuration is applied to all runs in the Project, to allow you to compare all runs on the same rating dimensions.
You can configure multiple dimensions or "Rating Types" to rate your run on. Each Rating Type will be used to rate your responses on a different dimension (e.g. quality, conciseness, hallucination potential, etc).
Types are Name and have a Format. We support 5 formats:
* /
* 1 - 5 s
* Numerical ratings
* Categorical ratings (self-defined categories)
* Free-form text
Along with each rating, you can also allow raters to provide a rationale.
To align everyone on the Rating Criteria or rubric, you can define it as part of your Human Ratings configuration.
 #### Adding Ratings
Add your Ratings from the *Feedback* tab of your Trace or Expanded View.
Note: Ratings on Chains or Workflows apply to the entire chain (not just the Node in view).
#### Adding Ratings
Add your Ratings from the *Feedback* tab of your Trace or Expanded View.
Note: Ratings on Chains or Workflows apply to the entire chain (not just the Node in view).
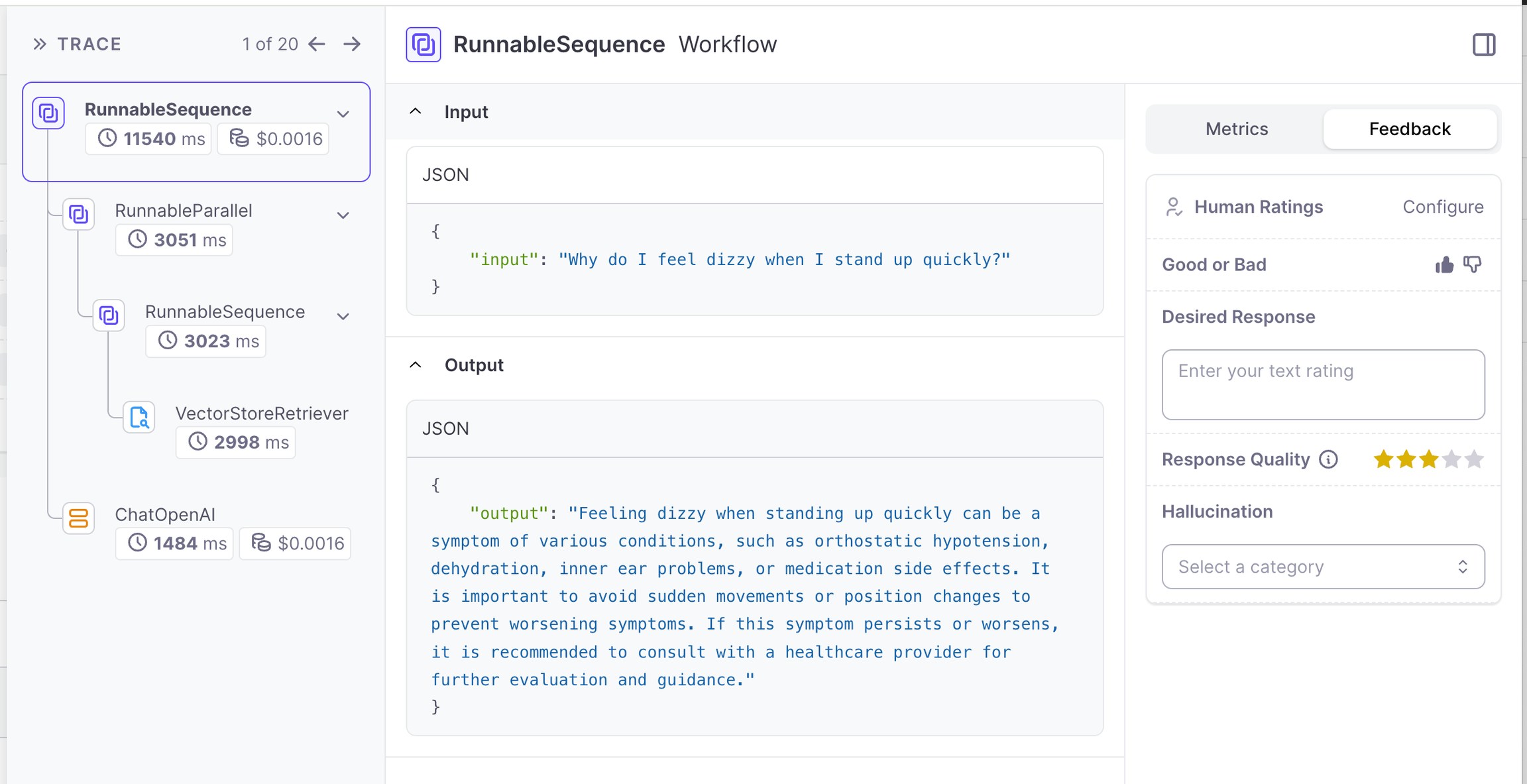 ---
# Source: https://docs.galileo.ai/galileo/gen-ai-studio-products/galileo-evaluate/how-to/experiment-with-multiple-chain-workflows.md
> ## Documentation Index
> Fetch the complete documentation index at: https://docs.galileo.ai/llms.txt
> Use this file to discover all available pages before exploring further.
# Experiment with Multiple Workflows
> If you're building a multi-step workflow or chain (e.g. a RAG system, an Agent, or a chain) and want to experiment with multiple combinations of parameters or your versions at once, Chain Sweeps are your friend.
A Chain Sweep allows you to execute, in bulk, multiple chains or workflows iterating over different versions or parameters of your system.
First, you'll need to wrap your workflow or chain in a function. This function should take anything you want to experiment with as an argument (e.g. chunk size, embedding model, top\_k).
Here we create a function `rag_chain_executor` utilizing our workflow logging integration.
```py theme={null}
import promptquality as pq
from promptquality import EvaluateRun
# Login to Galileo.
pq.login(console_url=os.environ["GALILEO_CONSOLE_URL"])
def rag_chain_executor(chunk_size: int, chunk_overlap: int, model_name: str) -> None:
# Formulate your input data.
questions = [...] # Pseudo-code, replace with your evaluation set.
# Create an evaluate run.
evaluate_run = EvaluateRun(
scorers=[Scorers.sexist, Scorers.pii, Scorers.toxicity],
project_name="",
)
# Log a workflow for each question in your evaluation set.
for question in questions:
template = "Given the following context answer the question. \n Context: {context} \n Question: {question}"
wf = evaluate_run.add_workflow(input=question)
# Fetch documents from your retriever
documents = retriever.retrieve(question, chunk_size, chunk_overlap) # Pseudo-code, replace with your evaluation set.
# Log retriever step to Galileo
wf.add_retriever(input=question, documents=documents)
# Get response from your llm.
prompt = template.format(context="\n".join(documents), question=question)
llm_response = llm(model_name).call(prompt) # Pseudo-code, replace with your evaluation set.
# Log llm step to Galileo
wf.add_llm(input=prompt, output=llm_response, model=model_name)
# Conclude the workflow and add the final output.
wf.conclude(output=llm_response)
evaluate_run.finish()
return llm_response
```
Alertnatively we can create the function `rag_chain_executor` utilizing a LangChain integration.
```py theme={null}
import promptquality as pq
# Login to Galileo.
pq.login(console_url=os.environ["GALILEO_CONSOLE_URL"])
from langchain.docstore.document import Document
from langchain.text_splitter import CharacterTextSplitter
from langchain_community.vectorstores import FAISS
from langchain_openai import OpenAIEmbeddings
documents = [Document(page_content=doc) for doc in source_documents]
questions = [...]
def rag_chain_executor(chunk_size: int, chunk_overlap: int, model_name: str) -> None:
# Example of a RAG chain that uses the params in the function signature
text_splitter = CharacterTextSplitter(
chunk_size=chunk_size, chunk_overlap=chunk_overlap
)
texts = text_splitter.split_documents(documents)
embeddings = OpenAIEmbeddings(openai_api_key="")
db = FAISS.from_documents(texts, embeddings)
retriever = db.as_retriever()
model = ChatOpenAI(openai_api_key="", model_name=model_name)
qa = ConversationalRetrievalChain.from_llm(model, retriever=retriever)
# Before running your chain, add the Galileo Prompt Callback on the invoke/run/batch step
prompt_handler = pq.GalileoPromptCallback(
scorers=[Scorers.sexist, Scorers.pii, Scorers.toxicity],
project_name="",
)
for question in questions:
result = qa.invoke(
{"question": question, "chat_history": []},
config=dict(callbacks=[prompt_handler]),
)
# Call .finish() on your callback to upload your results to Galileo
prompt_handler.finish()
```
Finally, call pq.sweep() with your chain's wrapper function and a dict containing all the different params you'd like to run your chain over:
```py theme={null}
pq.sweep(
rag_chain_executor,
{
"chunk_size": [50, 100, 200],
"chunk_overlap": [0, 25, 50],
"model_name": ["gpt-3.5-turbo", "gpt-3.5-turbo-instruct", "gpt-4-0125-preview"],
},
)
```
See the [PromptQuality Python Library Docs](https://promptquality.docs.rungalileo.io/#promptquality.sweep) for the function docstrings.
---
# Source: https://docs.galileo.ai/galileo/gen-ai-studio-products/galileo-evaluate/how-to/experiment-with-multiple-prompts.md
> ## Documentation Index
> Fetch the complete documentation index at: https://docs.galileo.ai/llms.txt
> Use this file to discover all available pages before exploring further.
# Experiment with Multiple Prompts
> Experiment with multiple prompts in Galileo Evaluate to optimize generative AI performance using iterative testing and comprehensive analysis tools.
In Galileo, you can execute multiple prompt runs using what we call "Prompt Sweeps".
A sweep allows you to execute, in bulk, multiple LLM runs with different combinations of - prompt templates, models, data, and hyperparameters such as temperature. Prompt Sweeps allows you to battle test an LLM completion step in your workflow.
Looking to run "sweeps" on more complex systems, such as Chains, RAG, or Agents? Check out [Chain Sweeps](/galileo/gen-ai-studio-products/galileo-evaluate/how-to/experiment-with-multiple-chain-workflows).
```Python theme={null}
import promptquality as pq
from promptquality import Scorers
from promptquality import SupportedModels
models = [
SupportedModels.text_davinci_3,
SupportedModels.chat_gpt_16k,
SupportedModels.gpt_4
]
templates = [
""" Given the following context, please answer the question.
Context: {context}
Question: {question}
Your answer: """,
""" You are a helpful assistant. Given the following context,
please answer the question.
----
Context: {context}
----
Question: {question}
----
Your answer:
""",
""" You are a helpful assistant. Given the following context,
please answer the question. Provide an accurate and factual answer.
----
Context: {context}
----
Question: {question}
----
Your answer: """,
""" You are a helpful assistant. Given the following context,
please answer the question. Provide an accurate and factual answer.
If the question is about science, religion or politics, say "I don't
have enough information to answer that question based on the given context."
----
Context: {context}
----
Question: {question}
----
Your answer: """]
from promptquality import Scorers
from promptquality import SupportedModels
metrics = [
Scorers.context_adherence_plus,
Scorers.context_relevance,
Scorers.correctness,
Scorers.latency,
Scorers.sexist,
Scorers.pii
# Uncertainty, BLEU and ROUGE are automatically included
]
pq.run_sweep(project_name='my_project_name',
templates=templates,
dataset='my_dataset.csv',
scorers=metrics,
model_aliases=models,
execute=True)
```
See the [PromptQuality Python Library Docs](https://promptquality.docs.rungalileo.io/) for more information.
---
# Source: https://docs.galileo.ai/galileo/gen-ai-studio-products/galileo-evaluate/how-to/export-your-evaluation-runs.md
> ## Documentation Index
> Fetch the complete documentation index at: https://docs.galileo.ai/llms.txt
> Use this file to discover all available pages before exploring further.
# Export your Evaluation Runs
> To download the results of your evaluation you can use the Export function. To export your runs, simply click on _Export Prompt Data._
---
# Source: https://docs.galileo.ai/galileo/gen-ai-studio-products/galileo-evaluate/how-to/experiment-with-multiple-chain-workflows.md
> ## Documentation Index
> Fetch the complete documentation index at: https://docs.galileo.ai/llms.txt
> Use this file to discover all available pages before exploring further.
# Experiment with Multiple Workflows
> If you're building a multi-step workflow or chain (e.g. a RAG system, an Agent, or a chain) and want to experiment with multiple combinations of parameters or your versions at once, Chain Sweeps are your friend.
A Chain Sweep allows you to execute, in bulk, multiple chains or workflows iterating over different versions or parameters of your system.
First, you'll need to wrap your workflow or chain in a function. This function should take anything you want to experiment with as an argument (e.g. chunk size, embedding model, top\_k).
Here we create a function `rag_chain_executor` utilizing our workflow logging integration.
```py theme={null}
import promptquality as pq
from promptquality import EvaluateRun
# Login to Galileo.
pq.login(console_url=os.environ["GALILEO_CONSOLE_URL"])
def rag_chain_executor(chunk_size: int, chunk_overlap: int, model_name: str) -> None:
# Formulate your input data.
questions = [...] # Pseudo-code, replace with your evaluation set.
# Create an evaluate run.
evaluate_run = EvaluateRun(
scorers=[Scorers.sexist, Scorers.pii, Scorers.toxicity],
project_name="",
)
# Log a workflow for each question in your evaluation set.
for question in questions:
template = "Given the following context answer the question. \n Context: {context} \n Question: {question}"
wf = evaluate_run.add_workflow(input=question)
# Fetch documents from your retriever
documents = retriever.retrieve(question, chunk_size, chunk_overlap) # Pseudo-code, replace with your evaluation set.
# Log retriever step to Galileo
wf.add_retriever(input=question, documents=documents)
# Get response from your llm.
prompt = template.format(context="\n".join(documents), question=question)
llm_response = llm(model_name).call(prompt) # Pseudo-code, replace with your evaluation set.
# Log llm step to Galileo
wf.add_llm(input=prompt, output=llm_response, model=model_name)
# Conclude the workflow and add the final output.
wf.conclude(output=llm_response)
evaluate_run.finish()
return llm_response
```
Alertnatively we can create the function `rag_chain_executor` utilizing a LangChain integration.
```py theme={null}
import promptquality as pq
# Login to Galileo.
pq.login(console_url=os.environ["GALILEO_CONSOLE_URL"])
from langchain.docstore.document import Document
from langchain.text_splitter import CharacterTextSplitter
from langchain_community.vectorstores import FAISS
from langchain_openai import OpenAIEmbeddings
documents = [Document(page_content=doc) for doc in source_documents]
questions = [...]
def rag_chain_executor(chunk_size: int, chunk_overlap: int, model_name: str) -> None:
# Example of a RAG chain that uses the params in the function signature
text_splitter = CharacterTextSplitter(
chunk_size=chunk_size, chunk_overlap=chunk_overlap
)
texts = text_splitter.split_documents(documents)
embeddings = OpenAIEmbeddings(openai_api_key="")
db = FAISS.from_documents(texts, embeddings)
retriever = db.as_retriever()
model = ChatOpenAI(openai_api_key="", model_name=model_name)
qa = ConversationalRetrievalChain.from_llm(model, retriever=retriever)
# Before running your chain, add the Galileo Prompt Callback on the invoke/run/batch step
prompt_handler = pq.GalileoPromptCallback(
scorers=[Scorers.sexist, Scorers.pii, Scorers.toxicity],
project_name="",
)
for question in questions:
result = qa.invoke(
{"question": question, "chat_history": []},
config=dict(callbacks=[prompt_handler]),
)
# Call .finish() on your callback to upload your results to Galileo
prompt_handler.finish()
```
Finally, call pq.sweep() with your chain's wrapper function and a dict containing all the different params you'd like to run your chain over:
```py theme={null}
pq.sweep(
rag_chain_executor,
{
"chunk_size": [50, 100, 200],
"chunk_overlap": [0, 25, 50],
"model_name": ["gpt-3.5-turbo", "gpt-3.5-turbo-instruct", "gpt-4-0125-preview"],
},
)
```
See the [PromptQuality Python Library Docs](https://promptquality.docs.rungalileo.io/#promptquality.sweep) for the function docstrings.
---
# Source: https://docs.galileo.ai/galileo/gen-ai-studio-products/galileo-evaluate/how-to/experiment-with-multiple-prompts.md
> ## Documentation Index
> Fetch the complete documentation index at: https://docs.galileo.ai/llms.txt
> Use this file to discover all available pages before exploring further.
# Experiment with Multiple Prompts
> Experiment with multiple prompts in Galileo Evaluate to optimize generative AI performance using iterative testing and comprehensive analysis tools.
In Galileo, you can execute multiple prompt runs using what we call "Prompt Sweeps".
A sweep allows you to execute, in bulk, multiple LLM runs with different combinations of - prompt templates, models, data, and hyperparameters such as temperature. Prompt Sweeps allows you to battle test an LLM completion step in your workflow.
Looking to run "sweeps" on more complex systems, such as Chains, RAG, or Agents? Check out [Chain Sweeps](/galileo/gen-ai-studio-products/galileo-evaluate/how-to/experiment-with-multiple-chain-workflows).
```Python theme={null}
import promptquality as pq
from promptquality import Scorers
from promptquality import SupportedModels
models = [
SupportedModels.text_davinci_3,
SupportedModels.chat_gpt_16k,
SupportedModels.gpt_4
]
templates = [
""" Given the following context, please answer the question.
Context: {context}
Question: {question}
Your answer: """,
""" You are a helpful assistant. Given the following context,
please answer the question.
----
Context: {context}
----
Question: {question}
----
Your answer:
""",
""" You are a helpful assistant. Given the following context,
please answer the question. Provide an accurate and factual answer.
----
Context: {context}
----
Question: {question}
----
Your answer: """,
""" You are a helpful assistant. Given the following context,
please answer the question. Provide an accurate and factual answer.
If the question is about science, religion or politics, say "I don't
have enough information to answer that question based on the given context."
----
Context: {context}
----
Question: {question}
----
Your answer: """]
from promptquality import Scorers
from promptquality import SupportedModels
metrics = [
Scorers.context_adherence_plus,
Scorers.context_relevance,
Scorers.correctness,
Scorers.latency,
Scorers.sexist,
Scorers.pii
# Uncertainty, BLEU and ROUGE are automatically included
]
pq.run_sweep(project_name='my_project_name',
templates=templates,
dataset='my_dataset.csv',
scorers=metrics,
model_aliases=models,
execute=True)
```
See the [PromptQuality Python Library Docs](https://promptquality.docs.rungalileo.io/) for more information.
---
# Source: https://docs.galileo.ai/galileo/gen-ai-studio-products/galileo-evaluate/how-to/export-your-evaluation-runs.md
> ## Documentation Index
> Fetch the complete documentation index at: https://docs.galileo.ai/llms.txt
> Use this file to discover all available pages before exploring further.
# Export your Evaluation Runs
> To download the results of your evaluation you can use the Export function. To export your runs, simply click on _Export Prompt Data._
 Your exported file will contain all Inputs, Outputs, Metrics, Annotations and Metadata for your Evaluation Run.
**Supported file types:**
* CSV
* JSONL
\*\* Exporting to your Cloud Data Storage platforms \*\*
You can also export directly into your Databricks Delta Lake. Check out our [instructions](/galileo/gen-ai-studio-products/galileo-evaluate/integrations/data-storage/databricks) on how to set up your Databricks integration.
---
# Source: https://docs.galileo.ai/galileo/gen-ai-studio-products/galileo-observe/how-to/exporting-your-data.md
> ## Documentation Index
> Fetch the complete documentation index at: https://docs.galileo.ai/llms.txt
> Use this file to discover all available pages before exploring further.
# Exporting Your Data
> To download your Observe Data you can use the Export function.
To export your data, you can go to the *Data* tab in your Observe Project, select the rows you'd like to export (or leave unselected for all) and click *Export.*
Your exported file will contain all Inputs, Outputs, Metrics, Annotations and Metadata for your Evaluation Run.
**Supported file types:**
* CSV
* JSONL
\*\* Exporting to your Cloud Data Storage platforms \*\*
You can also export directly into your Databricks Delta Lake. Check out our [instructions](/galileo/gen-ai-studio-products/galileo-evaluate/integrations/data-storage/databricks) on how to set up your Databricks integration.
---
# Source: https://docs.galileo.ai/galileo/gen-ai-studio-products/galileo-observe/how-to/exporting-your-data.md
> ## Documentation Index
> Fetch the complete documentation index at: https://docs.galileo.ai/llms.txt
> Use this file to discover all available pages before exploring further.
# Exporting Your Data
> To download your Observe Data you can use the Export function.
To export your data, you can go to the *Data* tab in your Observe Project, select the rows you'd like to export (or leave unselected for all) and click *Export.*
 Your exported file will contain all Inputs, Outputs, Metrics, and Metadata for all the rows in the filtered time range in view.
**Supported file types:**
* CSV
* JSONL
\*\* Exporting to your Cloud Data Storage platforms \*\*
You can also export directly into your Databricks Delta Lake. Check out our [instructions](/galileo/gen-ai-studio-products/galileo-evaluate/integrations/data-storage/databricks) on how to set up your Databricks integration.
---
# Source: https://docs.galileo.ai/galileo/galileo-nlp-studio/faqs.md
> ## Documentation Index
> Fetch the complete documentation index at: https://docs.galileo.ai/llms.txt
> Use this file to discover all available pages before exploring further.
# FAQs
> You have questions, we have (some) answers!
### Text Classification
1. [How to find mislabeled samples?](https://www.loom.com/share/19b5eb751b7c4d1598fafdbc552a4a82)
2. [How to analyze misclassified samples?](https://www.loom.com/share/8fbcf48384964bdb9aa60d21310a3a6f)
3. [What is DEP and how to use it?](https://www.loom.com/share/a49dfbd68a624bcfaff5601bf3c6b449)
4. [How to inspect my model's embeddings?](https://www.loom.com/share/f5e0e38d265b4a818b89892dd8ee5600)
5. [How to best leverage Similarity Search?](https://www.loom.com/share/f9dae455fcfa4442b738f2ccbb3b155f)
### Named Entity Recognition
1. [NER: What's new?](https://www.loom.com/share/eebad1acedac49a3851216bbf509f83b)
2. [How to identify spans that were hard to train on?](https://www.loom.com/share/4843dd3c79124b2c80c399915ba5c68e)
1. *Most Frequent High DEP words*
2. *Span-level Embeddings*
3. What do the different Error Types mean?
1. [Ghost Span Errors](https://www.loom.com/share/96f941703a424f4993cf38105ee262e3)
2. [Missed Span Errors](https://www.loom.com/share/a70cf72e9bb9445496ed5b186a76a710)
3. [Span Shift Errors](https://www.loom.com/share/92e4cd59389e4c31bedcde852c912d0a)
4. [Wrong Tag Errors](https://www.loom.com/share/1e945e1245344452ac5b745ea6139d18)
### Questions
* [**How do I install the Galileo Python client?**](/galileo/how-to-and-faq/faqs#q-how-do-i-install-the-galileo-python-client)
* [**I'm seeing errors importing dataquality in jupyter/google colab**](/galileo/how-to-and-faq/faqs#q-im-seeing-errors-importing-dataquality-in-jupyter-google-colab)
* [**My run finished, but there's no data in the console! What went wrong?**](/galileo/how-to-and-faq/faqs#q-my-run-finished-but-theres-no-data-in-the-console-what-went-wrong)
* [**Can I Log custom metadata to my dataset?**](/galileo/how-to-and-faq/faqs#q-can-i-log-custom-metadata-to-my-dataset)
* [**How do I disable Galileo logging during model training?**](/galileo/how-to-and-faq/faqs#q-how-do-i-disable-galileo-logging-during-model-training)
* [**How do I load a Galileo exported file for re-training?**](/galileo/how-to-and-faq/faqs#q-how-do-i-load-a-galileo-exported-file-for-re-training)
* [**How do I get my NER data into huggingface format?**](/galileo/how-to-and-faq/faqs#q-how-do-i-get-my-ner-data-into-huggingface-format)
* [**My spans JSON column for my NER data can't be loaded with json.loads**](/galileo/how-to-and-faq/faqs#q-my-spansjson-column-for-my-ner-data-cant-be-loaded-with-json.loads)
* [**Galileo marked an incorrect span as a span shift error, but it looks like a wront tag error. What's going on?**](/galileo/how-to-and-faq/faqs#q-galileo-marked-an-incorrect-span-as-a-span-shift-error-but-it-looks-like-a-wrong-tag-error.-whats)
* [**What do you mean when you say the deployment logs are written to Google Cloud?**](/galileo/how-to-and-faq/faqs#q-what-do-you-mean-when-you-say-the-deployment-logs-are-written-to-google-cloud)
* [**Does Galileo store data in the cloud?**](/galileo/how-to-and-faq/faqs#q-does-galileo-store-data-in-the-cloud)
* [**Where are the client logs stored?**](/galileo/how-to-and-faq/faqs#q-where-are-the-client-logs-stored)
* [**Do you offer air-gapped deployments?**](/galileo/how-to-and-faq/faqs#q-do-you-offer-air-gapped-deployments)
* [**How do I contact Galileo?**](/galileo/how-to-and-faq/faqs#q-how-do-i-contact-galileo)
* [**How do I convert my vaex dataframe to pandas when using dq.metrics.get\_dataframe?**](/galileo/how-to-and-faq/faqs#q-how-do-i-convert-my-vaex-dataframe-to-a-pandas-dataframe-when-using-the-dq.metrics.get_dataframe)
* [**Importing dataquality throws a permissions error \`PermissionError\`**](/galileo/how-to-and-faq/faqs#q-importing-dataquality-throws-a-permissions-error-permissionerror)
* [**vaex-core fails to build with Python 3.10 on MacOs Monterey**](/galileo/how-to-and-faq/faqs#q-vaex-core-fails-to-build-with-python-3.10-on-macos-monterey)
* [**Training a model is really slow. Can I make it go faster?**](/galileo/how-to-and-faq/faqs#q-training-a-model-is-really-slow.-can-i-make-it-go-faster)
### Q: How do I install the Galileo Python client?
```
pip install dataquality
```
### Q: I'm seeing errors importing dataquality in Jupyter / Google Colab
Make sure you running at least `dataquality >= 0.8.6` The first thing to try in this case it to **restart your kernel**. Dataquality uses certain python packages that require your kernel to be restarted after installation. In Jupyter you can click "Kernel -> Restart"
Your exported file will contain all Inputs, Outputs, Metrics, and Metadata for all the rows in the filtered time range in view.
**Supported file types:**
* CSV
* JSONL
\*\* Exporting to your Cloud Data Storage platforms \*\*
You can also export directly into your Databricks Delta Lake. Check out our [instructions](/galileo/gen-ai-studio-products/galileo-evaluate/integrations/data-storage/databricks) on how to set up your Databricks integration.
---
# Source: https://docs.galileo.ai/galileo/galileo-nlp-studio/faqs.md
> ## Documentation Index
> Fetch the complete documentation index at: https://docs.galileo.ai/llms.txt
> Use this file to discover all available pages before exploring further.
# FAQs
> You have questions, we have (some) answers!
### Text Classification
1. [How to find mislabeled samples?](https://www.loom.com/share/19b5eb751b7c4d1598fafdbc552a4a82)
2. [How to analyze misclassified samples?](https://www.loom.com/share/8fbcf48384964bdb9aa60d21310a3a6f)
3. [What is DEP and how to use it?](https://www.loom.com/share/a49dfbd68a624bcfaff5601bf3c6b449)
4. [How to inspect my model's embeddings?](https://www.loom.com/share/f5e0e38d265b4a818b89892dd8ee5600)
5. [How to best leverage Similarity Search?](https://www.loom.com/share/f9dae455fcfa4442b738f2ccbb3b155f)
### Named Entity Recognition
1. [NER: What's new?](https://www.loom.com/share/eebad1acedac49a3851216bbf509f83b)
2. [How to identify spans that were hard to train on?](https://www.loom.com/share/4843dd3c79124b2c80c399915ba5c68e)
1. *Most Frequent High DEP words*
2. *Span-level Embeddings*
3. What do the different Error Types mean?
1. [Ghost Span Errors](https://www.loom.com/share/96f941703a424f4993cf38105ee262e3)
2. [Missed Span Errors](https://www.loom.com/share/a70cf72e9bb9445496ed5b186a76a710)
3. [Span Shift Errors](https://www.loom.com/share/92e4cd59389e4c31bedcde852c912d0a)
4. [Wrong Tag Errors](https://www.loom.com/share/1e945e1245344452ac5b745ea6139d18)
### Questions
* [**How do I install the Galileo Python client?**](/galileo/how-to-and-faq/faqs#q-how-do-i-install-the-galileo-python-client)
* [**I'm seeing errors importing dataquality in jupyter/google colab**](/galileo/how-to-and-faq/faqs#q-im-seeing-errors-importing-dataquality-in-jupyter-google-colab)
* [**My run finished, but there's no data in the console! What went wrong?**](/galileo/how-to-and-faq/faqs#q-my-run-finished-but-theres-no-data-in-the-console-what-went-wrong)
* [**Can I Log custom metadata to my dataset?**](/galileo/how-to-and-faq/faqs#q-can-i-log-custom-metadata-to-my-dataset)
* [**How do I disable Galileo logging during model training?**](/galileo/how-to-and-faq/faqs#q-how-do-i-disable-galileo-logging-during-model-training)
* [**How do I load a Galileo exported file for re-training?**](/galileo/how-to-and-faq/faqs#q-how-do-i-load-a-galileo-exported-file-for-re-training)
* [**How do I get my NER data into huggingface format?**](/galileo/how-to-and-faq/faqs#q-how-do-i-get-my-ner-data-into-huggingface-format)
* [**My spans JSON column for my NER data can't be loaded with json.loads**](/galileo/how-to-and-faq/faqs#q-my-spansjson-column-for-my-ner-data-cant-be-loaded-with-json.loads)
* [**Galileo marked an incorrect span as a span shift error, but it looks like a wront tag error. What's going on?**](/galileo/how-to-and-faq/faqs#q-galileo-marked-an-incorrect-span-as-a-span-shift-error-but-it-looks-like-a-wrong-tag-error.-whats)
* [**What do you mean when you say the deployment logs are written to Google Cloud?**](/galileo/how-to-and-faq/faqs#q-what-do-you-mean-when-you-say-the-deployment-logs-are-written-to-google-cloud)
* [**Does Galileo store data in the cloud?**](/galileo/how-to-and-faq/faqs#q-does-galileo-store-data-in-the-cloud)
* [**Where are the client logs stored?**](/galileo/how-to-and-faq/faqs#q-where-are-the-client-logs-stored)
* [**Do you offer air-gapped deployments?**](/galileo/how-to-and-faq/faqs#q-do-you-offer-air-gapped-deployments)
* [**How do I contact Galileo?**](/galileo/how-to-and-faq/faqs#q-how-do-i-contact-galileo)
* [**How do I convert my vaex dataframe to pandas when using dq.metrics.get\_dataframe?**](/galileo/how-to-and-faq/faqs#q-how-do-i-convert-my-vaex-dataframe-to-a-pandas-dataframe-when-using-the-dq.metrics.get_dataframe)
* [**Importing dataquality throws a permissions error \`PermissionError\`**](/galileo/how-to-and-faq/faqs#q-importing-dataquality-throws-a-permissions-error-permissionerror)
* [**vaex-core fails to build with Python 3.10 on MacOs Monterey**](/galileo/how-to-and-faq/faqs#q-vaex-core-fails-to-build-with-python-3.10-on-macos-monterey)
* [**Training a model is really slow. Can I make it go faster?**](/galileo/how-to-and-faq/faqs#q-training-a-model-is-really-slow.-can-i-make-it-go-faster)
### Q: How do I install the Galileo Python client?
```
pip install dataquality
```
### Q: I'm seeing errors importing dataquality in Jupyter / Google Colab
Make sure you running at least `dataquality >= 0.8.6` The first thing to try in this case it to **restart your kernel**. Dataquality uses certain python packages that require your kernel to be restarted after installation. In Jupyter you can click "Kernel -> Restart"
 In Colab you can click "Runtime -> Disconnect and delete runtime"
In Colab you can click "Runtime -> Disconnect and delete runtime"
 If you already had [vaex](https://github.com/vaexio) installed on your machine prior to installing `dataquality,` there is a known bug when upgrading. **Solution:** `pip uninstall -y vaex-core vaex-hdf5 && pip install --upgrade --force-reinstall dataquality` \`\`**And then restart your jupyter/colab kernel**
### Q: My run finished, but there's no data in the console! What went wrong?
Make sure you ran `dq.finish()` after the run.
t's possible that:
* your run hasn't finished processing
* you've logged some data incorrectly
* you may have found a bug (congrats!
First, to see what happened to your data, you can run `dq.wait_for_run()` (you can optionally pass in the project and run name, or the most recent will be used)
This function will wait for your run to finish processing. If it's completed, check the console again by refreshing.
If that shows an exception, your run failed to be processed. You can see the logs from your model training by running `dq.get_dq_log_file()` which will download and return the path to your logfile. That may indicate the issue. Feel free to reach out to us for more help!
### Q: Can I log custom metadata to my dataset?
Yes (glad you asked)! You can attach any metadata fields you'd like to your original dataset, as long as they are primitive datatypes (numbers and strings).
In all available logging functions for input data, you can attach custom metadata:
```py theme={null}
df = pd.DataFrame(
{
"id": [0,1,2,3],
"text": ["sen 1","sen 2","sen 3","sen 4"],
"label": [0, 1, 1, 0],
"customer_score": [0.66, 0.98, 0.12, 0.05],
"sentiment": ["happy", "sad", "happy", "angry"]
}
)
dq.log_dataset(df, meta=["customer_score", "sentiment"])
```
```py theme={null}
texts = [
"Text sample 1",
"Text sample 2",
"Text sample 3",
"Text sample 4"
]
labels = ["B", "C", "A", "A"]
meta = {
"sample_importance": ["high", "low", "low", "medium"]
"quality_ranking": [9.7, 2.4, 5.5, 1.2]
}
ids = [0, 1, 2, 3]
split = "training"
dq.log_data_samples(texts=texts, labels=labels, ids=ids, meta=meta split=split)
```
This data will show up in the console under the column dropdown
If you already had [vaex](https://github.com/vaexio) installed on your machine prior to installing `dataquality,` there is a known bug when upgrading. **Solution:** `pip uninstall -y vaex-core vaex-hdf5 && pip install --upgrade --force-reinstall dataquality` \`\`**And then restart your jupyter/colab kernel**
### Q: My run finished, but there's no data in the console! What went wrong?
Make sure you ran `dq.finish()` after the run.
t's possible that:
* your run hasn't finished processing
* you've logged some data incorrectly
* you may have found a bug (congrats!
First, to see what happened to your data, you can run `dq.wait_for_run()` (you can optionally pass in the project and run name, or the most recent will be used)
This function will wait for your run to finish processing. If it's completed, check the console again by refreshing.
If that shows an exception, your run failed to be processed. You can see the logs from your model training by running `dq.get_dq_log_file()` which will download and return the path to your logfile. That may indicate the issue. Feel free to reach out to us for more help!
### Q: Can I log custom metadata to my dataset?
Yes (glad you asked)! You can attach any metadata fields you'd like to your original dataset, as long as they are primitive datatypes (numbers and strings).
In all available logging functions for input data, you can attach custom metadata:
```py theme={null}
df = pd.DataFrame(
{
"id": [0,1,2,3],
"text": ["sen 1","sen 2","sen 3","sen 4"],
"label": [0, 1, 1, 0],
"customer_score": [0.66, 0.98, 0.12, 0.05],
"sentiment": ["happy", "sad", "happy", "angry"]
}
)
dq.log_dataset(df, meta=["customer_score", "sentiment"])
```
```py theme={null}
texts = [
"Text sample 1",
"Text sample 2",
"Text sample 3",
"Text sample 4"
]
labels = ["B", "C", "A", "A"]
meta = {
"sample_importance": ["high", "low", "low", "medium"]
"quality_ranking": [9.7, 2.4, 5.5, 1.2]
}
ids = [0, 1, 2, 3]
split = "training"
dq.log_data_samples(texts=texts, labels=labels, ids=ids, meta=meta split=split)
```
This data will show up in the console under the column dropdown
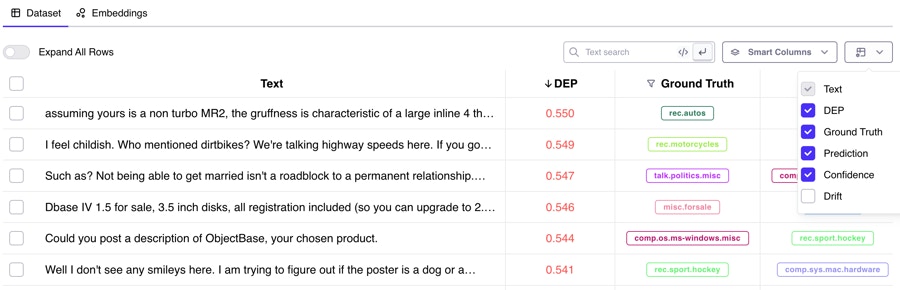 And you can see any performance metric grouped by your categorical metadata
And you can see any performance metric grouped by your categorical metadata
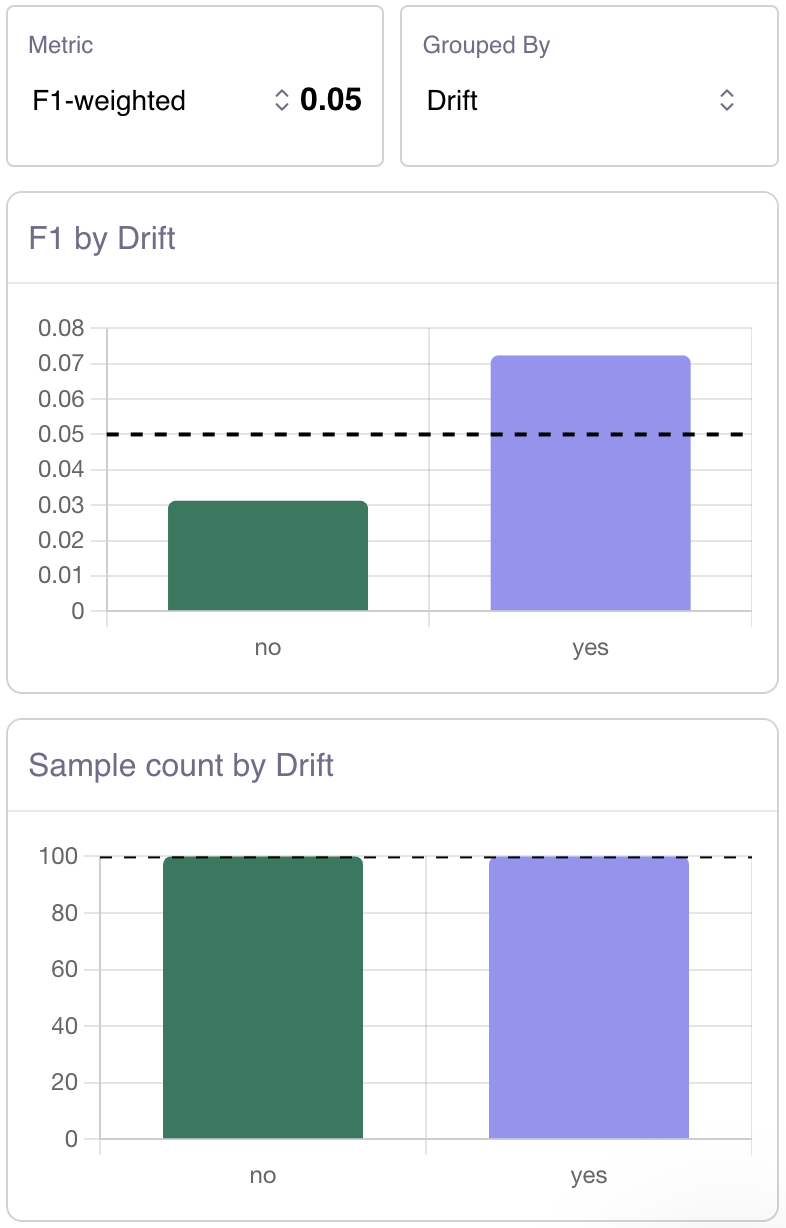 Lastly, once active, you can further filter your data by your metadata fields, helping find high-value cohorts
Lastly, once active, you can further filter your data by your metadata fields, helping find high-value cohorts
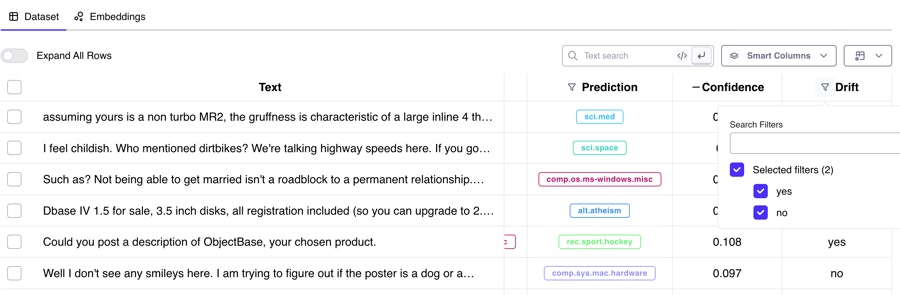 \*\*\*\*
### Q: How do I disable Galileo logging during model training?
***
See Disabling Galileo
### Q: How do I load a Galileo exported file for re-training?
***
```py theme={null}
from datasets import Dataset, dataset_dict
file_name_train = "exported_galileo_sample_file_train.parquet"
file_name_val = "exported_galileo_sample_file_val.parquet"
file_name_test = "exported_galileo_sample_file_test.parquet"
ds_train = Dataset.from_parquet(file_name_train)
ds_val = Dataset.from_parquet(file_name_val)
ds_test = Dataset.from_parquet(file_name_test)
ds_exported = dataset_dict.DatasetDict({"train": ds_train, "validation": ds_val, "test": ds_test})
labels = ds_new["train"]["ner_labels"][0]
tokenized_datasets = hf.tokenize_and_log_dataset(ds_exported, tokenizer, labels)
train_dataloader = hf.get_dataloader(tokenized_datasets["train"], collate_fn=data_collator, batch_size=MINIBATCH_SIZE, shuffle=True)
val_dataloader = hf.get_dataloader(tokenized_datasets["validation"], collate_fn=data_collator, batch_size=MINIBATCH_SIZE, shuffle=False)
test_dataloader = hf.get_dataloader(tokenized_datasets["test"], collate_fn=data_collator, batch_size=MINIBATCH_SIZE, shuffle=False)
```
### Q: How do I get my NER data into huggingface format?
***
```py theme={null}
import dataquality as dq
from datasets import Dataset
dq.login()
# A vaex dataframe
df = dq.metrics.get_dataframe(
project_name, run_name, split, hf_format=True, tagging_schema="BIO"
)
df.export("data.parquet")
ds = Dataset.from_parquet("data.parquet")
```
### Q: My `spans` JSON column for my NER data can't be loaded with `json.loads`
If you're seeing an error similar to: `JSONDecodeError: Expecting ',' delimiter: line 1 column 84 (char 83)` It's likely the case that you have some data in your `text` field that is not valid json (extra quotes `"` or `'`). Unfortunately, we cannot modify the content of your span text, but we can strip out the `text` field with some regex. Given a pandas dataframe `df` with column `spans` (from a Galileo export) you can replace `df["spans"] = df.apply(json.loads)` with (make sure to `import re`) `df["spans"] = df.apply(lambda row: json.loads(re.sub(r","text".}", "}", row)))`
### Q: Galileo marked an incorrect span as a span shift error, but it looks like a wrong tag error. What's going on?
Great observation! Let's take a real example below, from the WikiNER IT dataset. As you can see, the `Anemone apennina` clearly looks like a wrong tag error (correct span boundaries, incorrect class prediction), but is marked as a span shift.
\*\*\*\*
### Q: How do I disable Galileo logging during model training?
***
See Disabling Galileo
### Q: How do I load a Galileo exported file for re-training?
***
```py theme={null}
from datasets import Dataset, dataset_dict
file_name_train = "exported_galileo_sample_file_train.parquet"
file_name_val = "exported_galileo_sample_file_val.parquet"
file_name_test = "exported_galileo_sample_file_test.parquet"
ds_train = Dataset.from_parquet(file_name_train)
ds_val = Dataset.from_parquet(file_name_val)
ds_test = Dataset.from_parquet(file_name_test)
ds_exported = dataset_dict.DatasetDict({"train": ds_train, "validation": ds_val, "test": ds_test})
labels = ds_new["train"]["ner_labels"][0]
tokenized_datasets = hf.tokenize_and_log_dataset(ds_exported, tokenizer, labels)
train_dataloader = hf.get_dataloader(tokenized_datasets["train"], collate_fn=data_collator, batch_size=MINIBATCH_SIZE, shuffle=True)
val_dataloader = hf.get_dataloader(tokenized_datasets["validation"], collate_fn=data_collator, batch_size=MINIBATCH_SIZE, shuffle=False)
test_dataloader = hf.get_dataloader(tokenized_datasets["test"], collate_fn=data_collator, batch_size=MINIBATCH_SIZE, shuffle=False)
```
### Q: How do I get my NER data into huggingface format?
***
```py theme={null}
import dataquality as dq
from datasets import Dataset
dq.login()
# A vaex dataframe
df = dq.metrics.get_dataframe(
project_name, run_name, split, hf_format=True, tagging_schema="BIO"
)
df.export("data.parquet")
ds = Dataset.from_parquet("data.parquet")
```
### Q: My `spans` JSON column for my NER data can't be loaded with `json.loads`
If you're seeing an error similar to: `JSONDecodeError: Expecting ',' delimiter: line 1 column 84 (char 83)` It's likely the case that you have some data in your `text` field that is not valid json (extra quotes `"` or `'`). Unfortunately, we cannot modify the content of your span text, but we can strip out the `text` field with some regex. Given a pandas dataframe `df` with column `spans` (from a Galileo export) you can replace `df["spans"] = df.apply(json.loads)` with (make sure to `import re`) `df["spans"] = df.apply(lambda row: json.loads(re.sub(r","text".}", "}", row)))`
### Q: Galileo marked an incorrect span as a span shift error, but it looks like a wrong tag error. What's going on?
Great observation! Let's take a real example below, from the WikiNER IT dataset. As you can see, the `Anemone apennina` clearly looks like a wrong tag error (correct span boundaries, incorrect class prediction), but is marked as a span shift.
 We can further validate this with `dq.metrics.get_dataframe`. We can see that there are 2 spans with identical character boundaries, one with a label and one without (which is the prediction span).
We can further validate this with `dq.metrics.get_dataframe`. We can see that there are 2 spans with identical character boundaries, one with a label and one without (which is the prediction span).
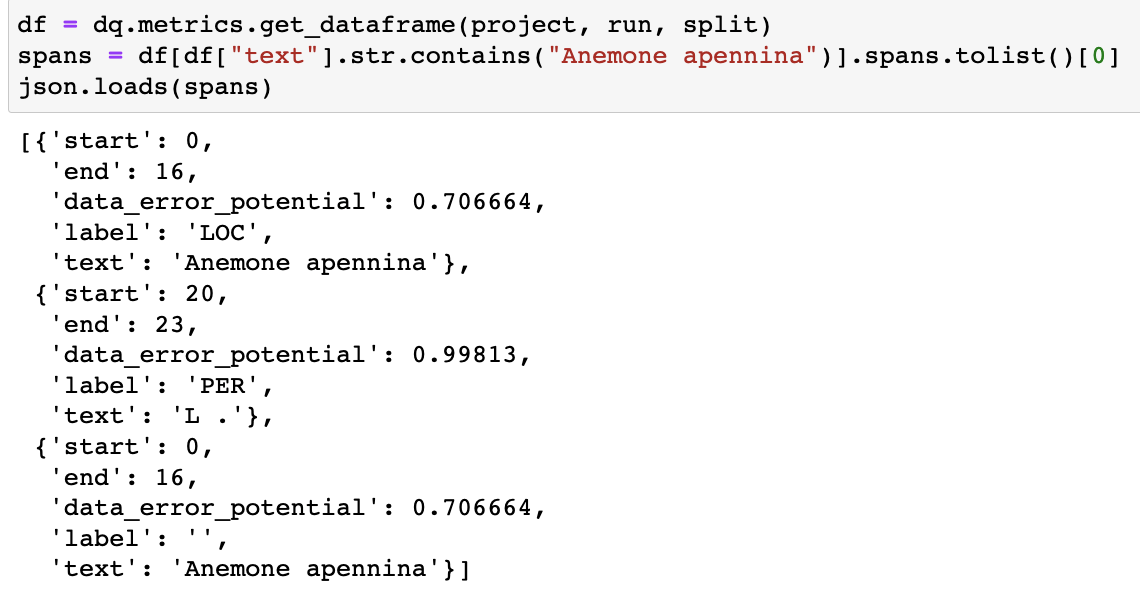 So what is going on here? When Galileo computes error types for each span, they are computed at the *byte-pair (BPE)* level using the span **token** indices, not \*\*\*\* the **character** indices. When looking at the console, however, you are seeing the **character** level indices, because that's much more intuitive view of your data. That conversion from **token** (fine-grained) to \*\*character\*\* (coarse-grained) level indices can cause index differences to overlap as a result of less-granular information.
We can again validate this with `dq.metrics` by looking at the raw data logged to Galileo. As we can see, at the **token** level, the span start and end indices do not align, and in fact overlap (ids 21948 and 21950), which is the reason for the span\_shift error
So what is going on here? When Galileo computes error types for each span, they are computed at the *byte-pair (BPE)* level using the span **token** indices, not \*\*\*\* the **character** indices. When looking at the console, however, you are seeing the **character** level indices, because that's much more intuitive view of your data. That conversion from **token** (fine-grained) to \*\*character\*\* (coarse-grained) level indices can cause index differences to overlap as a result of less-granular information.
We can again validate this with `dq.metrics` by looking at the raw data logged to Galileo. As we can see, at the **token** level, the span start and end indices do not align, and in fact overlap (ids 21948 and 21950), which is the reason for the span\_shift error
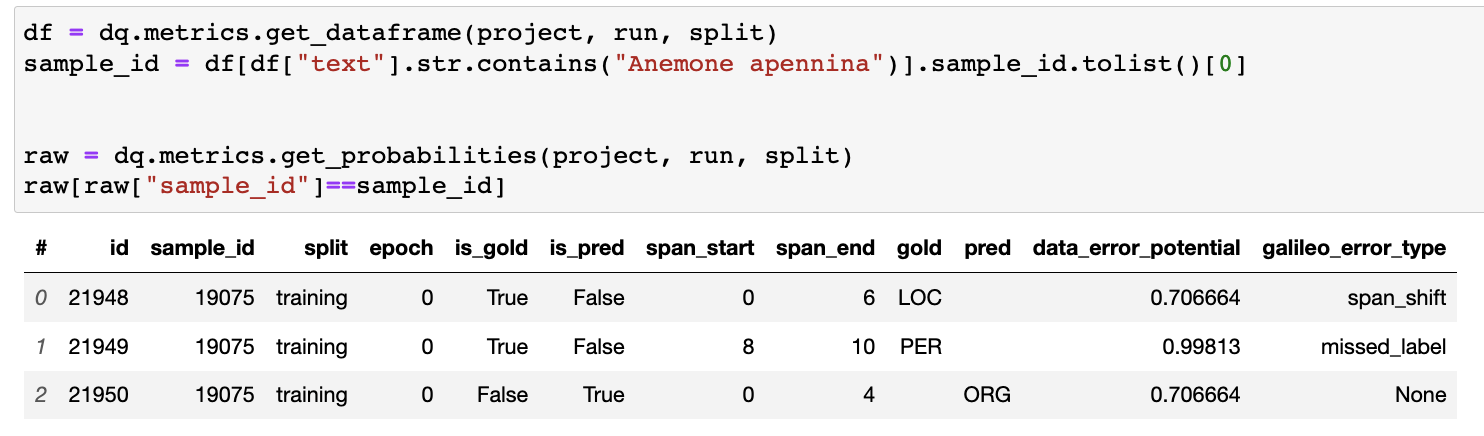 ### Q: What do you mean when you say the deployment logs are written to Google Cloud?
We manage deployments and updates to the versions of services running in your cluster via Github Actions. Each deployment/update produces logs that go into a bucket on Galileo's cloud (GCP). During our private deployment process \*\*\*\* (for Enterprise users), we allow customers to provide us with their emails, so they can have access to these deployment logs.
### Q: Where are the client logs stored?
The client logs are stored in the home (\~) folder of the machine where the training occurs.
### Q: Does Galileo store data in the cloud?
For Enterprise Users, data does not leave the customer VPC/Data Center. For users of the Free version of our product, we store data and model outputs in secured servers in the cloud. We pride ourselves in taking data security very seriously.
### Q: Do you offer air-gapped deployments?
Yes, we do! Contact us to learn more.
### Q: How do I contact Galileo?
You can write us at team\[at]rungalileo.io
### Q: How do I convert my vaex dataframe to a pandas DataFrame when using the `dq.metrics.get_dataframe`
Simply add `dq.metrics.get_dataframe(...).to_pandas_df()`
### **Importing dataquality throws a permissions error** `**PermissionError**`
Galileo creates a folder in your system's `HOME` directory. If you are seeing a `PermissionsError` it means that your system does not have access to your current `HOME` directory. This may happen in an automated CI system like AWS Glue. To overcome this, simply change your `HOME` python Environment Variable to somewhere accessible. For example, the current directory you are in
```py theme={null}
import os
# Set the HOME directory to the current working directory
os.environ["HOME"] = os.getcwd()
import dataquality as dq
```
This will only affect the current python runtime, it will not change your system's `HOME` directory. Because of that, if you run a new python script in this environment again, you will need to set the `HOME` variable in each new runtime.
### Q: vaex-core fails to build with Python 3.10 on MacOs Monterey
When installing dataquality with python 3.10 on MacOS Monterey you might encounter an issue when building vaex-core binaries. To fix any issues that come up, please follow the instructions in the failure output which may include running `xcodebuild -runFirstLaunch` and also allowing for any clang permission requests that pop up.
### Q: Training a model is really slow. Can I make it go faster?
For larger datasets you can speed up model training by running CUDA.
**Note: You** ***must*** **be running CUDA 11.X for this functionality to work.**
Cuda's CUML libraries require CUDA 11.X to work properly. You can check your CUDA version by running `nvcc -V`. **Do not run nvidia-smi**, that does not give you the true CUDA version. To learn more about this installation or to do it manually, see the [installation guide](https://docs.rapids.ai/install).
If you are training on datasets in the millions, and noticing that the Galileo processing is slowing down at the "Dimensionality Reduction" stage, you can optionally run those steps on the GPU/TPU that you are training your model with.
In order to leverage this feature, simply install `dataquality` with the `[cuda]` extra.
```
pip install 'dataquality[cuda]' --extra-index-url=https://pypi.nvidia.com/
```
We pass in the `extra-index-url` to the install, because the extra required packages are hosted by Nvidia, and exist on Nvidia's personal pypi repository, not the standard pypi repository.
After running that installation, dataquality will automatically pick up on the available libraries, and leverage your GPU/TPU to apply the dimensionality reduction.
**Please validate that the installation ran correctly by running** `import cuml` **in your environment.** This must complete successfully.
To manually install these packages (at your own risk), you can run
```
pip install cuml-cu11 ucx-py-cu11 rmm-cu11 raft-dask-cu11 pylibraft-cu11 dask-cudf-cu11 cudf-cu11 --extra-index-url=https://pypi.nvidia.com/
```
---
# Source: https://docs.galileo.ai/galileo/gen-ai-studio-products/galileo-llm-fine-tune/finding-similar-samples.md
> ## Documentation Index
> Fetch the complete documentation index at: https://docs.galileo.ai/llms.txt
> Use this file to discover all available pages before exploring further.
# Finding Similar Samples
> Similarity search allows you to discover **similar samples** within your datasets
. Given a data sample, similarity search leverages the power of embeddings and similarity search clustering algorithms to surface the most contextually similar samples.
The similarity search feature can be accessed through the "Find Similar From" action button in both the **Table View** and the **Embeddings View.** You can change the split name to choose which split (training, validation, test or inference) you want to find similar samples in.
### Q: What do you mean when you say the deployment logs are written to Google Cloud?
We manage deployments and updates to the versions of services running in your cluster via Github Actions. Each deployment/update produces logs that go into a bucket on Galileo's cloud (GCP). During our private deployment process \*\*\*\* (for Enterprise users), we allow customers to provide us with their emails, so they can have access to these deployment logs.
### Q: Where are the client logs stored?
The client logs are stored in the home (\~) folder of the machine where the training occurs.
### Q: Does Galileo store data in the cloud?
For Enterprise Users, data does not leave the customer VPC/Data Center. For users of the Free version of our product, we store data and model outputs in secured servers in the cloud. We pride ourselves in taking data security very seriously.
### Q: Do you offer air-gapped deployments?
Yes, we do! Contact us to learn more.
### Q: How do I contact Galileo?
You can write us at team\[at]rungalileo.io
### Q: How do I convert my vaex dataframe to a pandas DataFrame when using the `dq.metrics.get_dataframe`
Simply add `dq.metrics.get_dataframe(...).to_pandas_df()`
### **Importing dataquality throws a permissions error** `**PermissionError**`
Galileo creates a folder in your system's `HOME` directory. If you are seeing a `PermissionsError` it means that your system does not have access to your current `HOME` directory. This may happen in an automated CI system like AWS Glue. To overcome this, simply change your `HOME` python Environment Variable to somewhere accessible. For example, the current directory you are in
```py theme={null}
import os
# Set the HOME directory to the current working directory
os.environ["HOME"] = os.getcwd()
import dataquality as dq
```
This will only affect the current python runtime, it will not change your system's `HOME` directory. Because of that, if you run a new python script in this environment again, you will need to set the `HOME` variable in each new runtime.
### Q: vaex-core fails to build with Python 3.10 on MacOs Monterey
When installing dataquality with python 3.10 on MacOS Monterey you might encounter an issue when building vaex-core binaries. To fix any issues that come up, please follow the instructions in the failure output which may include running `xcodebuild -runFirstLaunch` and also allowing for any clang permission requests that pop up.
### Q: Training a model is really slow. Can I make it go faster?
For larger datasets you can speed up model training by running CUDA.
**Note: You** ***must*** **be running CUDA 11.X for this functionality to work.**
Cuda's CUML libraries require CUDA 11.X to work properly. You can check your CUDA version by running `nvcc -V`. **Do not run nvidia-smi**, that does not give you the true CUDA version. To learn more about this installation or to do it manually, see the [installation guide](https://docs.rapids.ai/install).
If you are training on datasets in the millions, and noticing that the Galileo processing is slowing down at the "Dimensionality Reduction" stage, you can optionally run those steps on the GPU/TPU that you are training your model with.
In order to leverage this feature, simply install `dataquality` with the `[cuda]` extra.
```
pip install 'dataquality[cuda]' --extra-index-url=https://pypi.nvidia.com/
```
We pass in the `extra-index-url` to the install, because the extra required packages are hosted by Nvidia, and exist on Nvidia's personal pypi repository, not the standard pypi repository.
After running that installation, dataquality will automatically pick up on the available libraries, and leverage your GPU/TPU to apply the dimensionality reduction.
**Please validate that the installation ran correctly by running** `import cuml` **in your environment.** This must complete successfully.
To manually install these packages (at your own risk), you can run
```
pip install cuml-cu11 ucx-py-cu11 rmm-cu11 raft-dask-cu11 pylibraft-cu11 dask-cudf-cu11 cudf-cu11 --extra-index-url=https://pypi.nvidia.com/
```
---
# Source: https://docs.galileo.ai/galileo/gen-ai-studio-products/galileo-llm-fine-tune/finding-similar-samples.md
> ## Documentation Index
> Fetch the complete documentation index at: https://docs.galileo.ai/llms.txt
> Use this file to discover all available pages before exploring further.
# Finding Similar Samples
> Similarity search allows you to discover **similar samples** within your datasets
. Given a data sample, similarity search leverages the power of embeddings and similarity search clustering algorithms to surface the most contextually similar samples.
The similarity search feature can be accessed through the "Find Similar From" action button in both the **Table View** and the **Embeddings View.** You can change the split name to choose which split (training, validation, test or inference) you want to find similar samples in.
 This is useful when you find low-quality data (mislabeled, garbage, empty, etc) and you want to find other samples similar to it so that you can take bulk action (e.g. remove, etc). Galileo automatically assigns a smart threshold to give you the most similar data samples.
---
# Source: https://docs.galileo.ai/galileo/galileo-nlp-studio/galileo-product-features/galileo-+-delta-lake-databricks.md
> ## Documentation Index
> Fetch the complete documentation index at: https://docs.galileo.ai/llms.txt
> Use this file to discover all available pages before exploring further.
# Galileo + Delta Lake Databricks
> Integrate Galileo with Delta Lake on Databricks to manage large-scale data, ensuring seamless collaboration and enhanced NLP workflows.
# Galileo + Delta Lake (Databricks)
This page shows how to export data directly into Delta Lake from the Galileo UI and then reading the same data using Galileo's Python SDK and executing a Galileo Run.
### Setting Up a Databricks Connection
First, go to the Integrations Page and set up your Databricks connection.
Setting up Databricks connection in Galileo
This is useful when you find low-quality data (mislabeled, garbage, empty, etc) and you want to find other samples similar to it so that you can take bulk action (e.g. remove, etc). Galileo automatically assigns a smart threshold to give you the most similar data samples.
---
# Source: https://docs.galileo.ai/galileo/galileo-nlp-studio/galileo-product-features/galileo-+-delta-lake-databricks.md
> ## Documentation Index
> Fetch the complete documentation index at: https://docs.galileo.ai/llms.txt
> Use this file to discover all available pages before exploring further.
# Galileo + Delta Lake Databricks
> Integrate Galileo with Delta Lake on Databricks to manage large-scale data, ensuring seamless collaboration and enhanced NLP workflows.
# Galileo + Delta Lake (Databricks)
This page shows how to export data directly into Delta Lake from the Galileo UI and then reading the same data using Galileo's Python SDK and executing a Galileo Run.
### Setting Up a Databricks Connection
First, go to the Integrations Page and set up your Databricks connection.
Setting up Databricks connection in Galileo
 ### Using Galileo to Read from Delta Lake and Execute a Run
The following code snippet shows how to read labeled data from Delta Lake and execute a Galileo training run.
```py theme={null}
import os
import pandas as pd
from deltalake import DeltaTable, write_deltalake
# Dataframe with 2 columns: text and label
df_train = pd.DataFrame({"text": newsgroups_train.data, "label": newsgroups_train.target})
df_test = pd.DataFrame({"text": newsgroups_test.data, "label": newsgroups_test.target})
write_deltalake("tmp/delta_lake_path", df_train)
write_deltalake("tmp/delta_lake_path", df_test)
df_train_from_deltalake = DeltaTable("tmp/delta_lake_path").to_pandas()
df_test_from_deltalake = DeltaTable("tmp/delta_lake_path").to_pandas()
dq.auto(
train_data=df_test_from_deltalake,
test_data=df_test_from_deltalake,
labels=newsgroups_train.target_names,
project_name="my_newsgroups_project",
run_name="run_1"
)
```
### Exporting Data from Galileo UI into Delta Lake
### Using Galileo to Read from Delta Lake and Execute a Run
The following code snippet shows how to read labeled data from Delta Lake and execute a Galileo training run.
```py theme={null}
import os
import pandas as pd
from deltalake import DeltaTable, write_deltalake
# Dataframe with 2 columns: text and label
df_train = pd.DataFrame({"text": newsgroups_train.data, "label": newsgroups_train.target})
df_test = pd.DataFrame({"text": newsgroups_test.data, "label": newsgroups_test.target})
write_deltalake("tmp/delta_lake_path", df_train)
write_deltalake("tmp/delta_lake_path", df_test)
df_train_from_deltalake = DeltaTable("tmp/delta_lake_path").to_pandas()
df_test_from_deltalake = DeltaTable("tmp/delta_lake_path").to_pandas()
dq.auto(
train_data=df_test_from_deltalake,
test_data=df_test_from_deltalake,
labels=newsgroups_train.target_names,
project_name="my_newsgroups_project",
run_name="run_1"
)
```
### Exporting Data from Galileo UI into Delta Lake
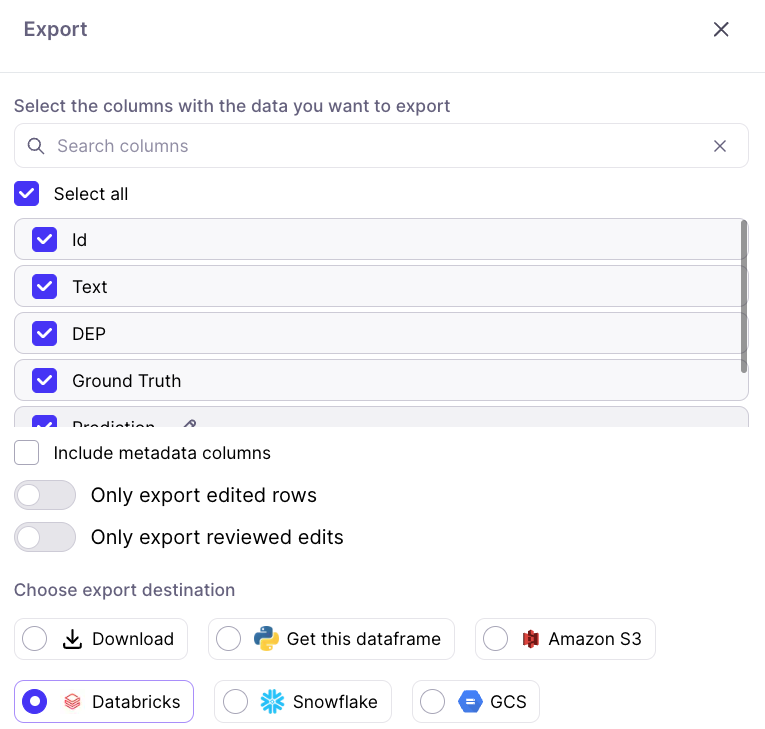 ---
# Source: https://docs.galileo.ai/galileo-ai-research/galileo-data-error-potential-dep.md
> ## Documentation Index
> Fetch the complete documentation index at: https://docs.galileo.ai/llms.txt
> Use this file to discover all available pages before exploring further.
# Galileo Data Error Potential (Dep)
> Learn about Galileo's Data Error Potential (DEP) score, a metric to identify and categorize machine learning data errors, enhancing data quality and model performance.
Today teams typically leverage model confidence scores to separate well trained from poorly trained data. This has two major problems:
* **Confidence scores** are highly model centric. There is high bias towards training performance and very little use of inherent data quality to segregate the good data from the bad (results below)
* Even with powerful pre-trained models, confidence scores are unable to capture nuanced sub-categories of data errors (details below)
The **Galileo Data Error Potential (DEP)** score has been built to provide a per sample holistic data quality score to identify samples in the dataset contributing to low or high model performance i.e. ‘pulling’ the model up or down respectively. In other words, the DEP score measures the potential for "misfit" of an observation to the given model.
Categorization of "misfit" data samples includes:
* Mislabelled samples (annotation mistakes)
* Boundary samples or overlapping classes
* Outlier samples or Anomalies
* Noisy Input
* Misclassified samples
* Other errors
This sub-categorization is crucial as different dataset actions are required for each category of errors. For example, one can augment the dataset with samples similar to boundary samples to improve classification.
As shown in below, we assign a DEP score to every sample in the data. The *Data Error Potential (DEP) Slider* can be used to filter samples based on DEP score, allowing you to filter for samples with DEP greater than x, less than y, or within a specific range \[x, y].
---
# Source: https://docs.galileo.ai/galileo-ai-research/galileo-data-error-potential-dep.md
> ## Documentation Index
> Fetch the complete documentation index at: https://docs.galileo.ai/llms.txt
> Use this file to discover all available pages before exploring further.
# Galileo Data Error Potential (Dep)
> Learn about Galileo's Data Error Potential (DEP) score, a metric to identify and categorize machine learning data errors, enhancing data quality and model performance.
Today teams typically leverage model confidence scores to separate well trained from poorly trained data. This has two major problems:
* **Confidence scores** are highly model centric. There is high bias towards training performance and very little use of inherent data quality to segregate the good data from the bad (results below)
* Even with powerful pre-trained models, confidence scores are unable to capture nuanced sub-categories of data errors (details below)
The **Galileo Data Error Potential (DEP)** score has been built to provide a per sample holistic data quality score to identify samples in the dataset contributing to low or high model performance i.e. ‘pulling’ the model up or down respectively. In other words, the DEP score measures the potential for "misfit" of an observation to the given model.
Categorization of "misfit" data samples includes:
* Mislabelled samples (annotation mistakes)
* Boundary samples or overlapping classes
* Outlier samples or Anomalies
* Noisy Input
* Misclassified samples
* Other errors
This sub-categorization is crucial as different dataset actions are required for each category of errors. For example, one can augment the dataset with samples similar to boundary samples to improve classification.
As shown in below, we assign a DEP score to every sample in the data. The *Data Error Potential (DEP) Slider* can be used to filter samples based on DEP score, allowing you to filter for samples with DEP greater than x, less than y, or within a specific range \[x, y].
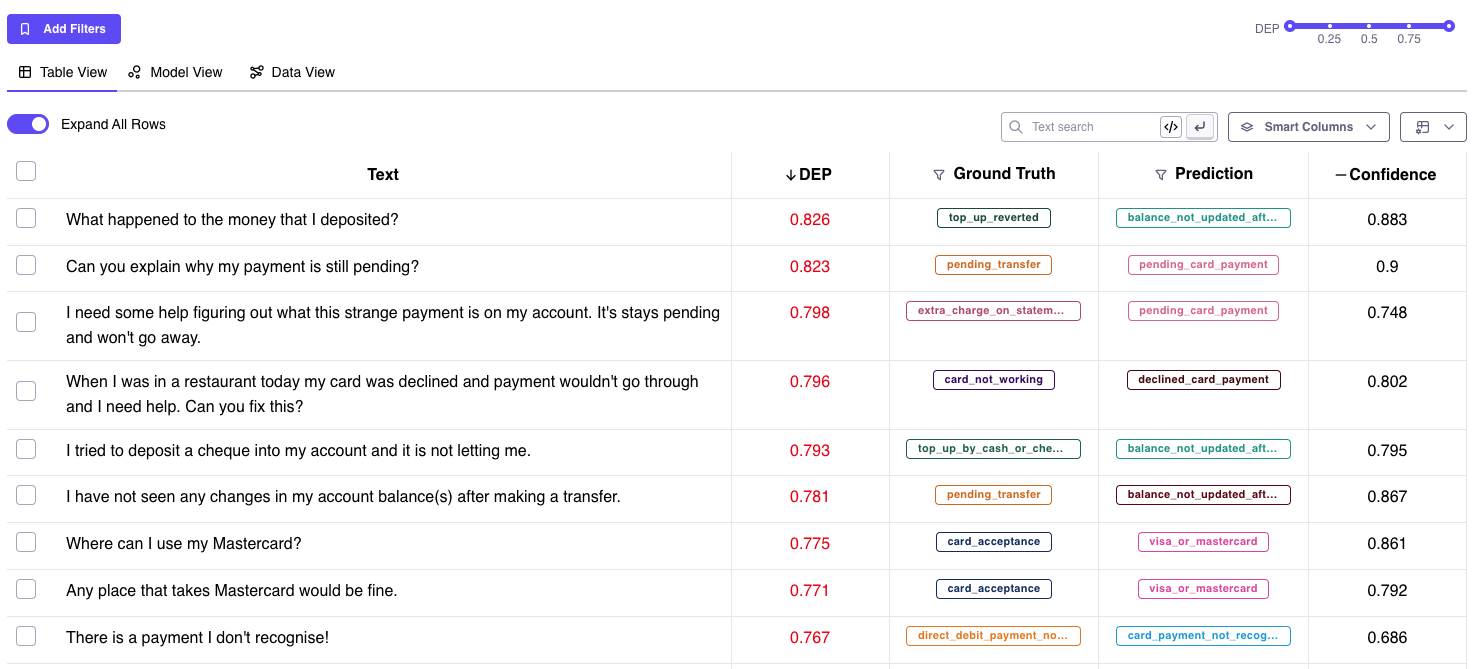 #### DEP score calculation
The base calculation behind the DEP score is a hybrid ‘**Area Under Margin’ (AUM)** mechanism. AUM is the cross-epoch average of the model uncertainty for each data sample (calculated as the difference between the ground truth confidence and the maximum confidence on a non ground truth label).
**AUM = p(y\*) - p(ymax)y^max!=y\***
We then dynamically leverage K-Distinct Neighbors, IH Metrics (multiple weak learners) and Energy Functions on Logits, to clearly separate out annotator mistakes from samples that are confusing to the model or are outliers and noise. The 'dynamic' element comes from the fact that DEP takes into account the level of class imbalance, variability etc to cater to the nuances of each dataset.
#### DEP score efficacy
To measure the efficacy of the DEP score, we performed experiments on a public dataset and induced varying degrees of noise. We observed that unlike Confidence scores, the DEP score was successfully able to separate bad data (red) from the good (green). This demonstrates true data-centricity (model independence) of Galileo’s DEP score. Below are results from experiments on the public Banking Intent dataset. The dotted lines indicate a dynamic thresholding value (adapting to each dataset) that segments noisy (red) and clean (green) samples of the dataset.
| Galileo DEP score | Model confidence score |
| ------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------ | ------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------ |
|
#### DEP score calculation
The base calculation behind the DEP score is a hybrid ‘**Area Under Margin’ (AUM)** mechanism. AUM is the cross-epoch average of the model uncertainty for each data sample (calculated as the difference between the ground truth confidence and the maximum confidence on a non ground truth label).
**AUM = p(y\*) - p(ymax)y^max!=y\***
We then dynamically leverage K-Distinct Neighbors, IH Metrics (multiple weak learners) and Energy Functions on Logits, to clearly separate out annotator mistakes from samples that are confusing to the model or are outliers and noise. The 'dynamic' element comes from the fact that DEP takes into account the level of class imbalance, variability etc to cater to the nuances of each dataset.
#### DEP score efficacy
To measure the efficacy of the DEP score, we performed experiments on a public dataset and induced varying degrees of noise. We observed that unlike Confidence scores, the DEP score was successfully able to separate bad data (red) from the good (green). This demonstrates true data-centricity (model independence) of Galileo’s DEP score. Below are results from experiments on the public Banking Intent dataset. The dotted lines indicate a dynamic thresholding value (adapting to each dataset) that segments noisy (red) and clean (green) samples of the dataset.
| Galileo DEP score | Model confidence score |
| ------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------ | ------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------ |
|  |
|  |
|
|
| 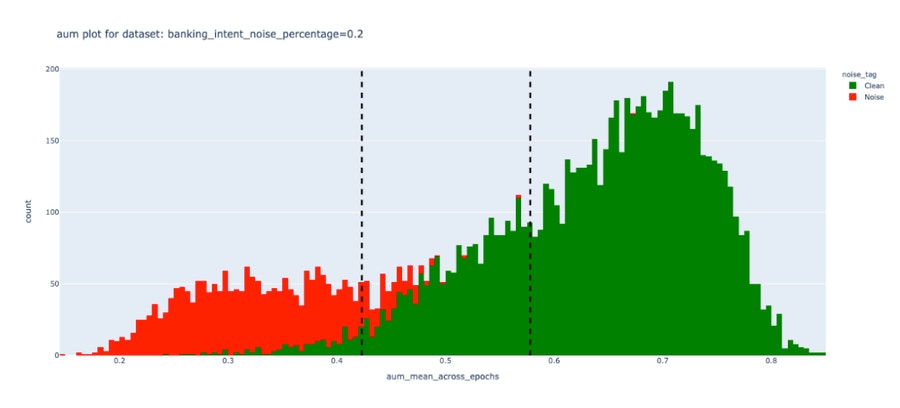 |
| 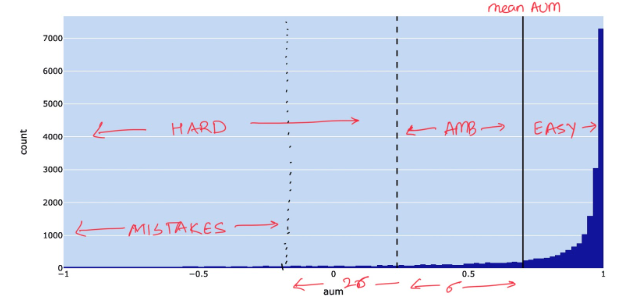 |
### DEP Thresholding
The goal is to plot AUM scores and highlight the mean AUM and mean F1 of the dataset. Two different thresholds, t\_easy and t\_hard, are marked as follows:
* t\_easy = mean AUM, so all samples above the mean AUM are considered easy.
* t\_hard = \[t\_mean - t\_std, -1], so samples in this range are considered hard or ambiguous.
The samples between t\_mean and t\_mean - t\_std are considered ambiguous.
|
### DEP Thresholding
The goal is to plot AUM scores and highlight the mean AUM and mean F1 of the dataset. Two different thresholds, t\_easy and t\_hard, are marked as follows:
* t\_easy = mean AUM, so all samples above the mean AUM are considered easy.
* t\_hard = \[t\_mean - t\_std, -1], so samples in this range are considered hard or ambiguous.
The samples between t\_mean and t\_mean - t\_std are considered ambiguous.
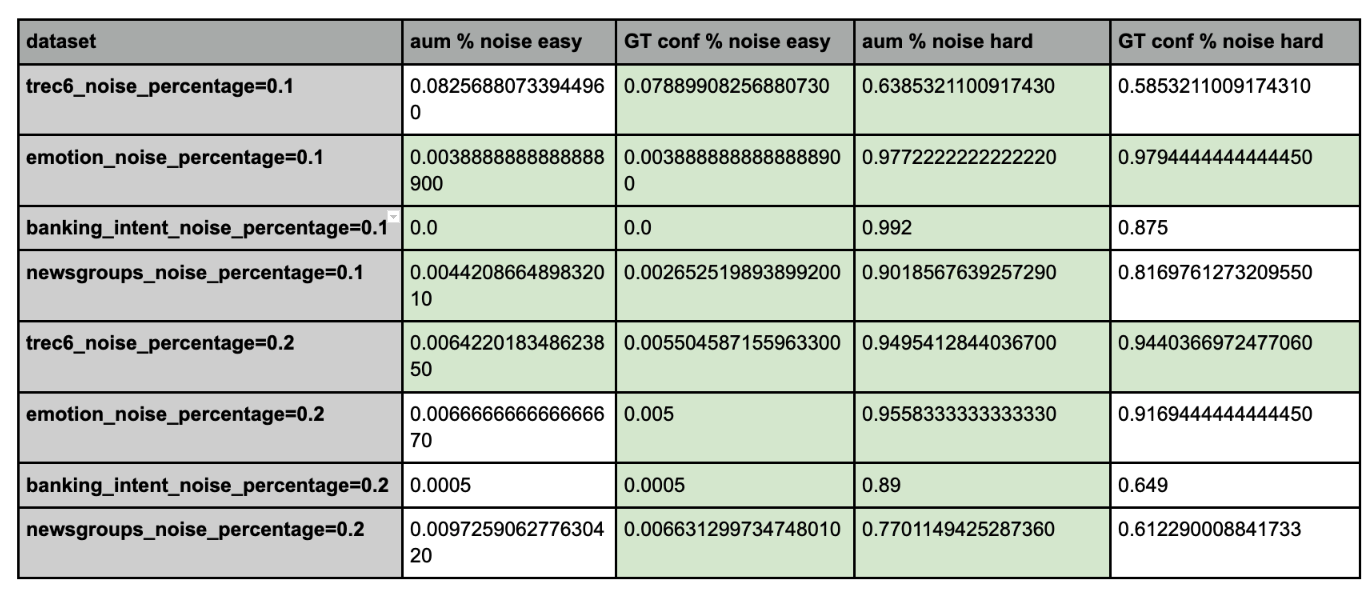 ### DEP Benchmarks
To ensure DEP calibrations follow the fundamentals of a good ML metric, it should have more noisy samples in hard section and correspondingly less noisy data in easy region. AUM outperforms prediction confidence as well as similar metrics such as **Ground Truth confidence** as well as **Model uncertainty**, in being able to surface more noisy samples in the hard category.
Below are some benchmarks we calibrated on various well-known and peer reviewed datasets.
![]()
{" "}
### DEP Benchmarks
To ensure DEP calibrations follow the fundamentals of a good ML metric, it should have more noisy samples in hard section and correspondingly less noisy data in easy region. AUM outperforms prediction confidence as well as similar metrics such as **Ground Truth confidence** as well as **Model uncertainty**, in being able to surface more noisy samples in the hard category.
Below are some benchmarks we calibrated on various well-known and peer reviewed datasets.
![]()
{" "}
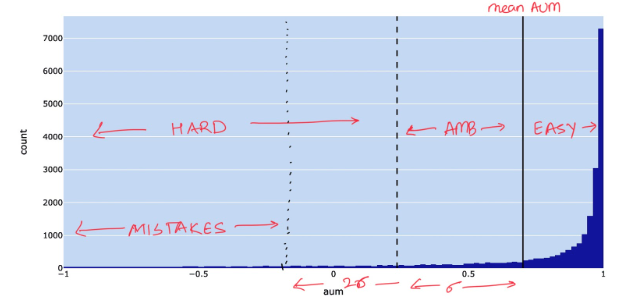 {" "}
{" "}
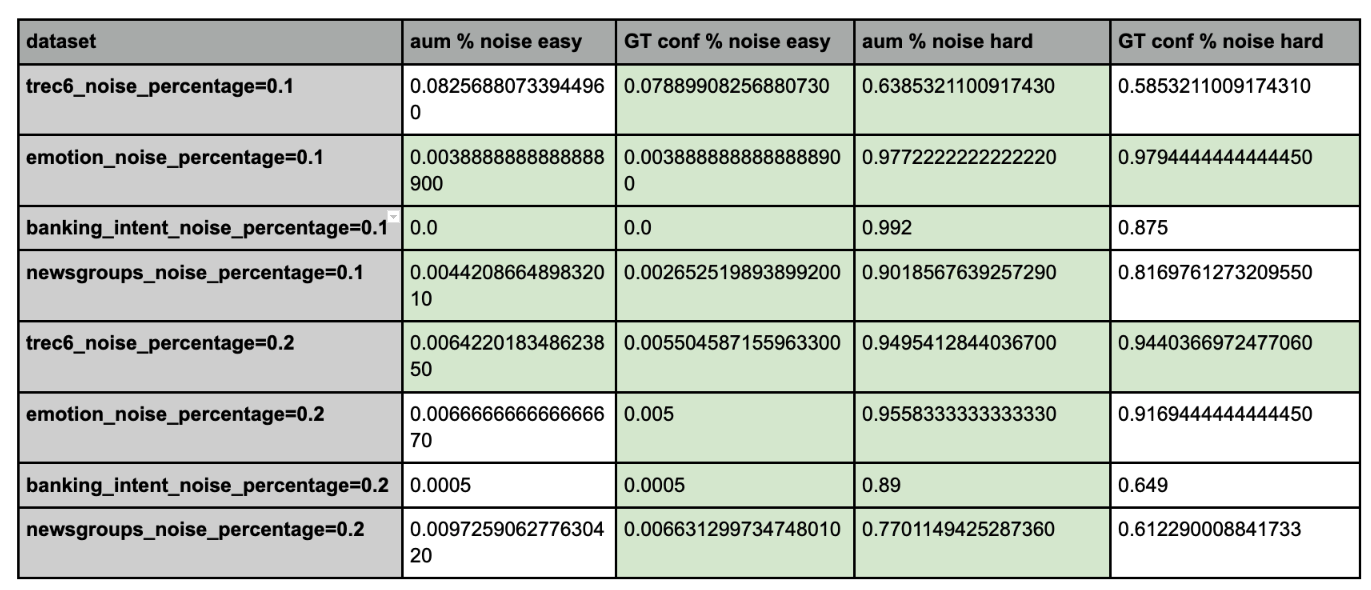 {" "}
{" "}
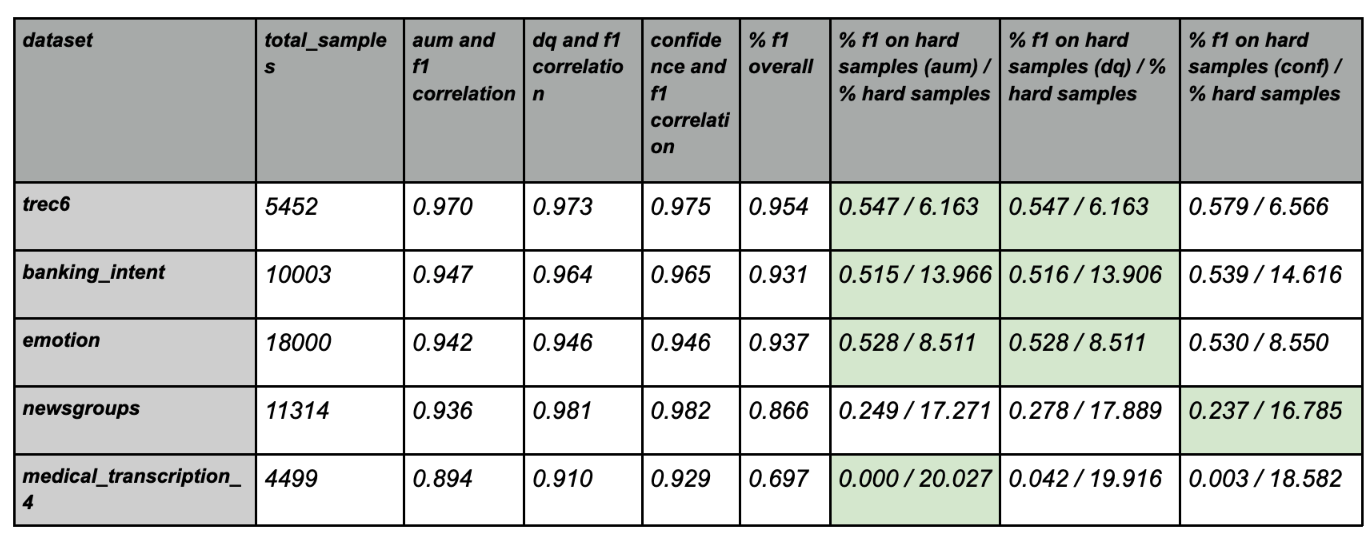 {" "}
{" "}
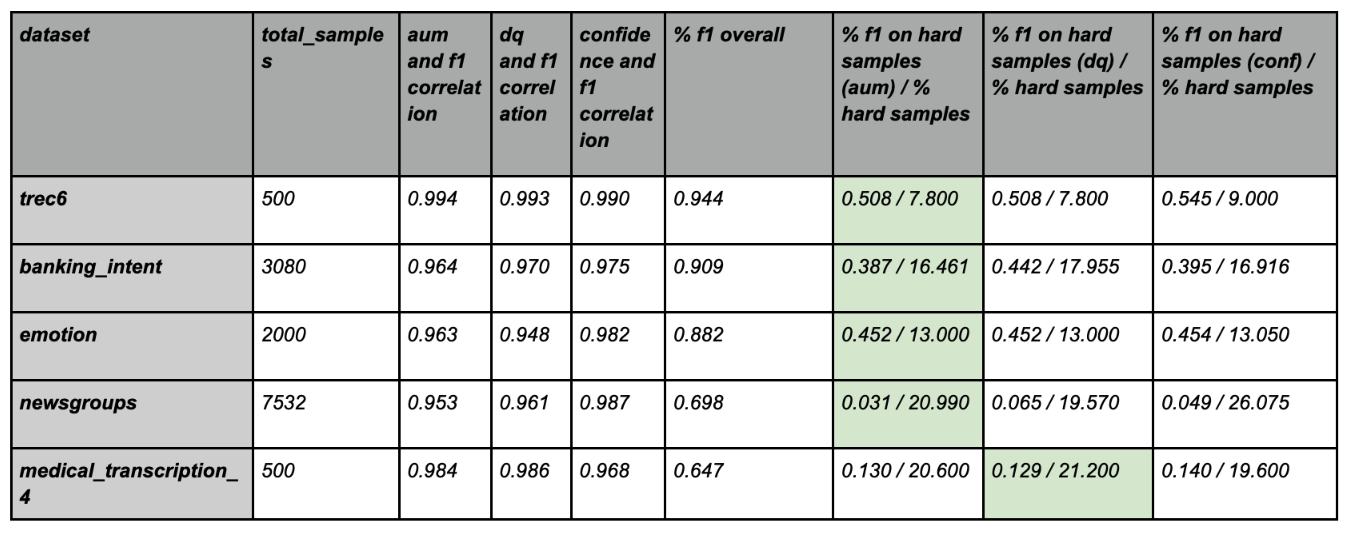 [PreviousRAG Quality Metrics using ChainPoll](/galileo/gen-ai-studio-products/galileo-ai-research/rag-quality-metrics-using-chainpoll)
[NextData Drift Detection](/galileo/gen-ai-studio-products/galileo-ai-research/data-drift-detection)
---
# Source: https://docs.galileo.ai/galileo/gen-ai-studio-products/galileo-evaluate.md
> ## Documentation Index
> Fetch the complete documentation index at: https://docs.galileo.ai/llms.txt
> Use this file to discover all available pages before exploring further.
# Overview of Galileo Evaluate
> Stop experimenting in spreadsheets and notebooks. Use Evaluate’s powerful insights to build GenAI systems that just work.
[PreviousRAG Quality Metrics using ChainPoll](/galileo/gen-ai-studio-products/galileo-ai-research/rag-quality-metrics-using-chainpoll)
[NextData Drift Detection](/galileo/gen-ai-studio-products/galileo-ai-research/data-drift-detection)
---
# Source: https://docs.galileo.ai/galileo/gen-ai-studio-products/galileo-evaluate.md
> ## Documentation Index
> Fetch the complete documentation index at: https://docs.galileo.ai/llms.txt
> Use this file to discover all available pages before exploring further.
# Overview of Galileo Evaluate
> Stop experimenting in spreadsheets and notebooks. Use Evaluate’s powerful insights to build GenAI systems that just work.
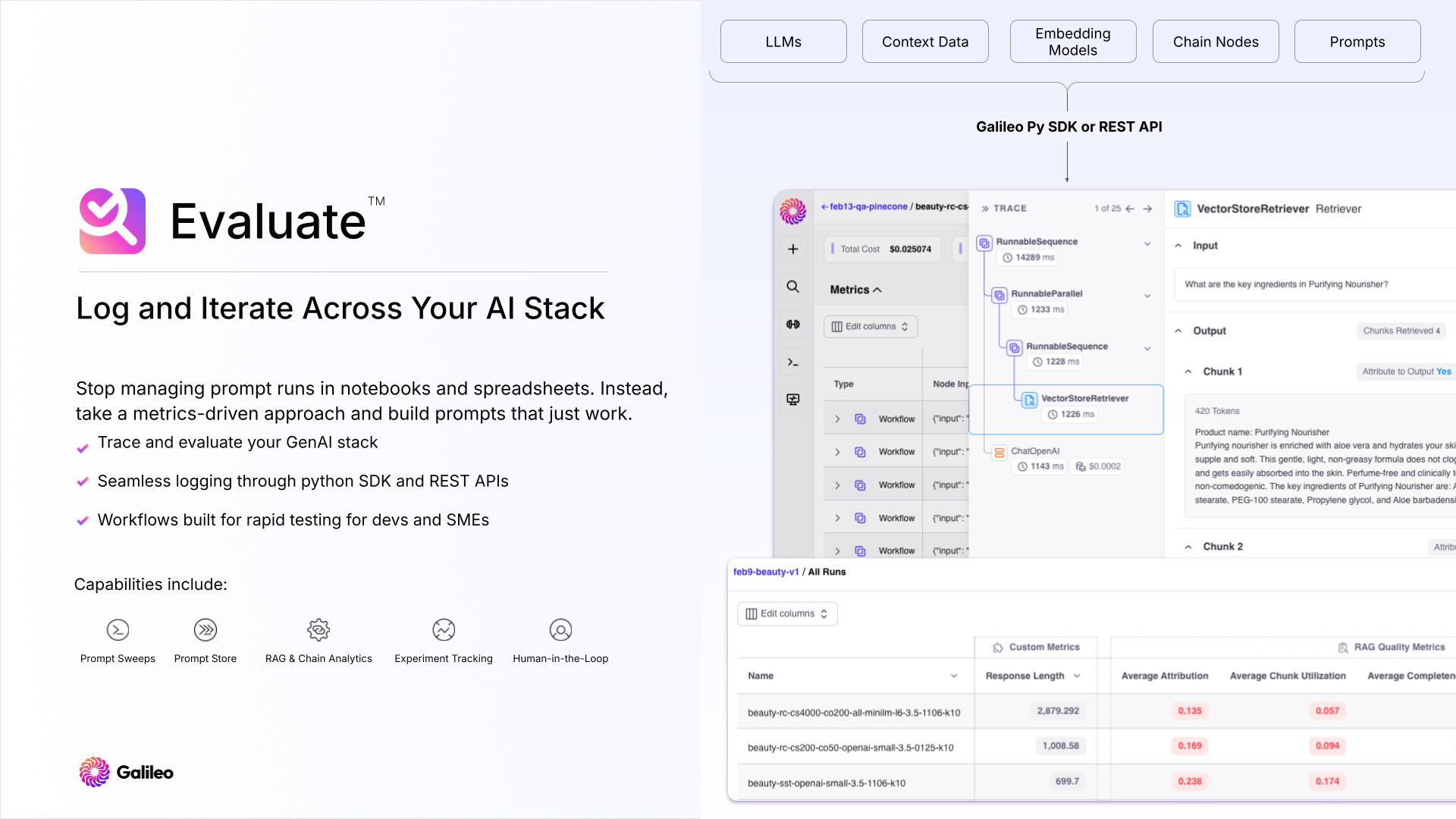 *Galileo Evaluate* is a powerful bench for rapid, collaborative experimentation and evaluation of your LLM applications.
## Core features
* **Tracing and Visualizations** - Track the end-to-end execution of your queries. See what happened along the way and where things went wrong.
* **State-of-the-art Metrics -** Combine our research-backed Guardrail Metrics with your own Custom Metrics to evaluate your system.
* **Experiment Management** - Track all your experiments in one place. Find the best configuration for your system.
*Galileo Evaluate* is a powerful bench for rapid, collaborative experimentation and evaluation of your LLM applications.
## Core features
* **Tracing and Visualizations** - Track the end-to-end execution of your queries. See what happened along the way and where things went wrong.
* **State-of-the-art Metrics -** Combine our research-backed Guardrail Metrics with your own Custom Metrics to evaluate your system.
* **Experiment Management** - Track all your experiments in one place. Find the best configuration for your system.
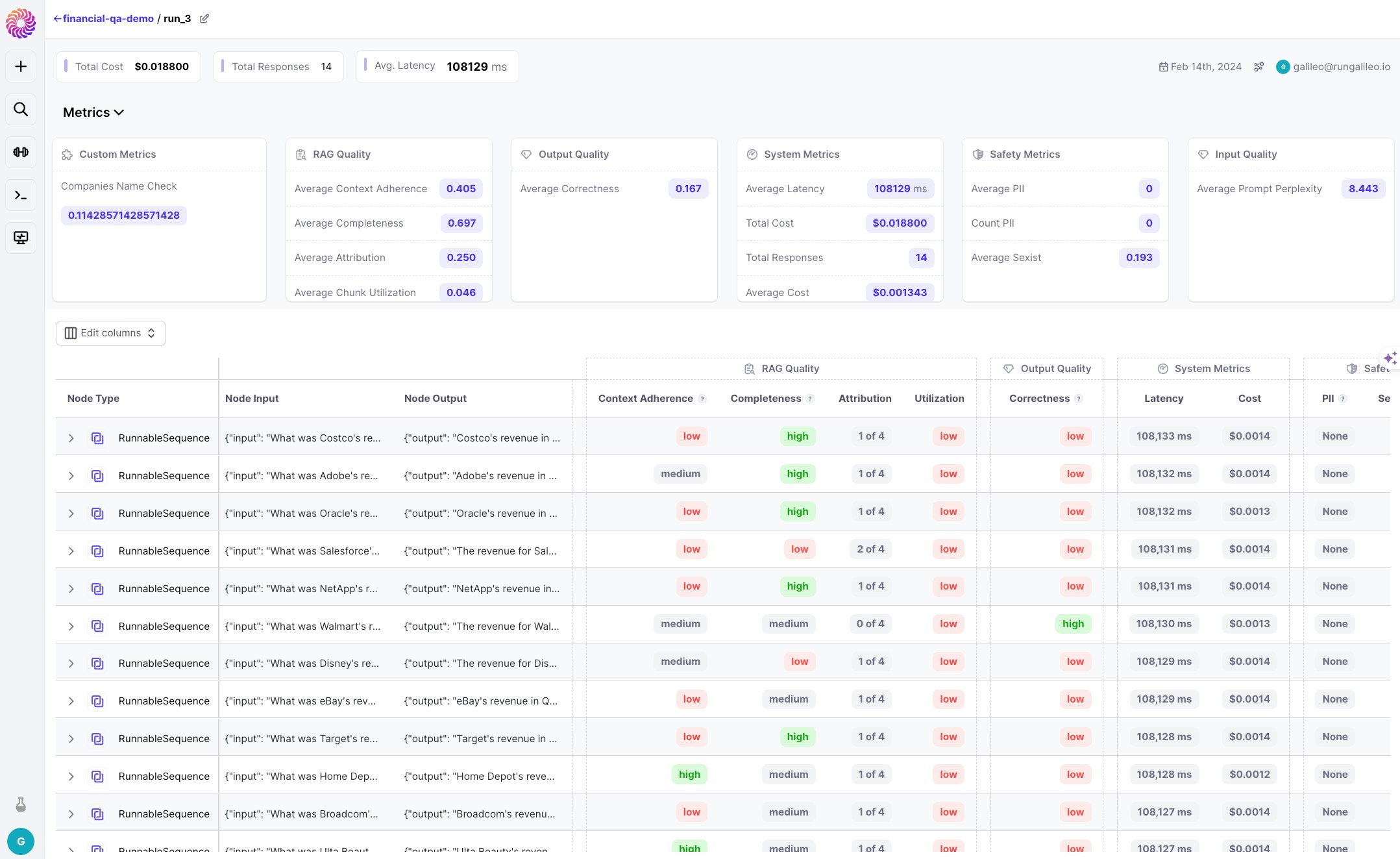 ### The Workflow
Integrate promptquality into your system or test a template model combination through the Playground. Choose and register your metrics to define what success means for your use case.
Identify poor perfomance, trace it to the broken step, form hypothesis on what could be behind it.
Tweak your system and try again until your quality bar is met.
### Getting Started
---
# Source: https://docs.galileo.ai/deployments/deploying-galileo-gke/galileo-gcp-setup-script.md
> ## Documentation Index
> Fetch the complete documentation index at: https://docs.galileo.ai/llms.txt
> Use this file to discover all available pages before exploring further.
# Cluster Setup Script
> Utilize the Galileo GCP setup script for automating Google Cloud Platform (GCP) configuration to deploy Galileo seamlessly on GKE clusters.
```Bash theme={null}
#!/bin/sh -e
#
# Usage
# CUSTOMER_NAME=customer-name REGION=us-central1 ZONE_ID=a CREATE_ML_NODE_POOL=false ./bootstrap.sh
if [ -z "$CUSTOMER_NAME" ]; then
echo "Error: CUSTOMER_NAME is not set"
exit 0
fi
PROJECT="$CUSTOMER_NAME-galileo"
REGION=${REGION:="us-central1"}
ZONE_ID=${ZONE_ID:="c"}
ZONE="$REGION-$ZONE_ID"
CLUSTER_NAME="galileo"
echo "Bootstrapping cluster with the following parameters:"
echo "PROJECT: ${PROJECT}"
echo "REGION: ${REGION}"
echo "ZONE: ${ZONE}"
echo "CLUSTER_NAME: ${CLUSTER_NAME}"
#
# Create a project for Galileo.
#
echo "Create a project for Galileo."
gcloud projects create $PROJECT || true
#
# Enabling services as referenced here https://cloud.google.com/migrate/containers/docs/config-dev-env#enabling_required_services
#
echo "Enabling services as referenced here https://cloud.google.com/migrate/containers/docs/config-dev-env#enabling_required_services"
gcloud services enable --project=$PROJECT servicemanagement.googleapis.com servicecontrol.googleapis.com cloudresourcemanager.googleapis.com compute.googleapis.com container.googleapis.com containerregistry.googleapis.com cloudbuild.googleapis.com
#
# Grab the project number.
#
echo "Grab the project number."
PROJECT_NUMBER=$(gcloud projects describe $PROJECT --format json | jq -r -c .projectNumber)
#
# Create service accounts and policy bindings.
#
echo "Create service accounts and policy bindings."
gcloud iam service-accounts create galileoconnect \
--project "$PROJECT"
gcloud iam service-accounts add-iam-policy-binding galileoconnect@$PROJECT.iam.gserviceaccount.com \
--project "$PROJECT" \
--member "group:devs@rungalileo.io" \
--role "roles/iam.serviceAccountUser"
gcloud iam service-accounts add-iam-policy-binding galileoconnect@$PROJECT.iam.gserviceaccount.com \
--project "$PROJECT" \
--member "group:devs@rungalileo.io" \
--role "roles/iam.serviceAccountTokenCreator"
gcloud projects add-iam-policy-binding $PROJECT --member="serviceAccount:galileoconnect@$PROJECT.iam.gserviceaccount.com" --role="roles/container.admin"
gcloud projects add-iam-policy-binding $PROJECT --member="serviceAccount:galileoconnect@$PROJECT.iam.gserviceaccount.com" --role="roles/container.clusterViewer"
#
# Waiting before provisioning workload identity.
#
echo "Waiting before provisioning workload identity..."
sleep 5
#
# Create a workload identity pool.
#
echo "Create a workload identity pool."
gcloud iam workload-identity-pools create galileoconnectpool \
--project "$PROJECT" \
--location "global" \
--description "Workload ID Pool for Galileo via GitHub Actions" \
--display-name "GalileoConnectPool"
#
# Create a workload identity provider .
#
echo "Create a workload identity provider ."
gcloud iam workload-identity-pools providers create-oidc galileoconnectprovider \
--project "$PROJECT" \
--location "global" \
--workload-identity-pool "galileoconnectpool" \
--display-name "GalileoConnectProvider" \
--attribute-mapping="google.subject=assertion.sub,attribute.actor=assertion.actor,attribute.aud=assertion.aud,attribute.repository_owner=assertion.repository_owner,attribute.repository=assertion.repository" \
--issuer-uri="https://token.actions.githubusercontent.com"
#
# Bind the service account to the workload identity provider.
#
echo "Bind the service account to the workload identity provider."
gcloud iam service-accounts add-iam-policy-binding "galileoconnect@${PROJECT}.iam.gserviceaccount.com" \
--project "$PROJECT" \
--role="roles/iam.workloadIdentityUser" \
--member="principalSet://iam.googleapis.com/projects/${PROJECT_NUMBER}/locations/global/workloadIdentityPools/galileoconnectpool/attribute.repository/rungalileo/deploy"
#
# Create the cluster (with one node pool) and the runners node pool.
# The network config below assumes you have a default VPC in your account.
# If you want to use a different VPC, please update the option values for
# `--network` and `--subnetwork` below.
#
echo "Create the cluster (with one node pool) and the runners node pool."
gcloud beta container \
--project $PROJECT clusters create $CLUSTER_NAME \
--zone $ZONE \
--no-enable-basic-auth \
--cluster-version "1.27" \
--release-channel "regular" \
--machine-type "e2-standard-4" \
--image-type "cos_containerd" \
--disk-type "pd-standard" \
--disk-size "300" \
--node-labels galileo-node-type=galileo-core \
--metadata disable-legacy-endpoints=true \
--scopes "https://www.googleapis.com/auth/devstorage.read_write","https://www.googleapis.com/auth/logging.write","https://www.googleapis.com/auth/monitoring","https://www.googleapis.com/auth/servicecontrol","https://www.googleapis.com/auth/service.management.readonly","https://www.googleapis.com/auth/trace.append" \
--max-pods-per-node "110" \
--num-nodes "4" \
--logging=SYSTEM,WORKLOAD \
--monitoring=SYSTEM \
--enable-ip-alias \
--network "projects/$PROJECT/global/networks/default" \
--subnetwork "projects/$PROJECT/regions/$REGION/subnetworks/default" \
--no-enable-intra-node-visibility \
--default-max-pods-per-node "110" \
--enable-autoscaling \
--min-nodes "4" \
--max-nodes "5" \
--no-enable-master-authorized-networks \
--addons HorizontalPodAutoscaling,HttpLoadBalancing,GcePersistentDiskCsiDriver \
--enable-autoupgrade \
--enable-autorepair \
--max-surge-upgrade 1 \
--max-unavailable-upgrade 0 \
--enable-autoprovisioning \
--min-cpu 0 \
--max-cpu 50 \
--min-memory 0 \
--max-memory 200 \
--autoprovisioning-scopes=https://www.googleapis.com/auth/logging.write,https://www.googleapis.com/auth/monitoring \
--enable-autoprovisioning-autorepair \
--enable-autoprovisioning-autoupgrade \
--autoprovisioning-max-surge-upgrade 1 \
--autoprovisioning-max-unavailable-upgrade 0 \
--enable-shielded-nodes \
--node-locations $ZONE \
--enable-network-policy
gcloud beta container \
--project $PROJECT node-pools create "galileo-runners" \
--cluster $CLUSTER_NAME \
--zone $ZONE \
--machine-type "e2-standard-8" \
--image-type "cos_containerd" \
--disk-type "pd-standard" \
--disk-size "100" \
--node-labels galileo-node-type=galileo-runner \
--metadata disable-legacy-endpoints=true \
--scopes "https://www.googleapis.com/auth/devstorage.read_write","https://www.googleapis.com/auth/logging.write","https://www.googleapis.com/auth/monitoring","https://www.googleapis.com/auth/servicecontrol","https://www.googleapis.com/auth/service.management.readonly","https://www.googleapis.com/auth/trace.append" \
--num-nodes "1" \
--enable-autoscaling \
--min-nodes "1" \
--max-nodes "5" \
--enable-autoupgrade \
--enable-autorepair \
--max-surge-upgrade 1 \
--max-unavailable-upgrade 0 \
--max-pods-per-node "110" \
--node-locations $ZONE
if [[ -n "$CREATE_ML_NODE_POOL" && "$CREATE_ML_NODE_POOL" == "true" ]]; then
gcloud beta container \
--project $PROJECT node-pools create "galileo-ml" \
--cluster $CLUSTER_NAME \
--zone $ZONE \
--machine-type "g2-standard-8" \
--image-type "cos_containerd" \
--disk-type "pd-standard" \
--disk-size "100" \
--node-labels galileo-node-type=galileo-ml \
--metadata disable-legacy-endpoints=true \
--scopes "https://www.googleapis.com/auth/devstorage.read_write","https://www.googleapis.com/auth/logging.write","https://www.googleapis.com/auth/monitoring","https://www.googleapis.com/auth/servicecontrol","https://www.googleapis.com/auth/service.management.readonly","https://www.googleapis.com/auth/trace.append" \
--num-nodes "1" \
--accelerator type=nvidia-l4,count=1,gpu-driver-version=latest \
--node-locations $ZONE \
--enable-autoscaling \
--enable-autoupgrade \
--enable-autorepair \
--max-surge-upgrade 1 \
--max-unavailable-upgrade 0 \
--max-pods-per-node "110" \
--min-nodes 1 \
--max-nodes 5
fi
```
---
# Source: https://docs.galileo.ai/galileo/gen-ai-studio-products/galileo-guardrail-metrics.md
> ## Documentation Index
> Fetch the complete documentation index at: https://docs.galileo.ai/llms.txt
> Use this file to discover all available pages before exploring further.
# Overview of Galileo Guardrail Metrics
> Utilize Galileo's Guardrail Metrics to monitor generative AI models, ensuring adherence to quality, correctness, and alignment with project goals.
Understand Galileo's Guardrail Metrics in LLM Studio
Galileo has built a menu of **Guardrail Metrics** to help you evaluate, observe and protect your generative AI applications. These metrics are tailored to your use case and are designed to help you ensure your application quality and behavior. The `Scorer` definition for each metric is listed immediately below.
### The Workflow
Integrate promptquality into your system or test a template model combination through the Playground. Choose and register your metrics to define what success means for your use case.
Identify poor perfomance, trace it to the broken step, form hypothesis on what could be behind it.
Tweak your system and try again until your quality bar is met.
### Getting Started
---
# Source: https://docs.galileo.ai/deployments/deploying-galileo-gke/galileo-gcp-setup-script.md
> ## Documentation Index
> Fetch the complete documentation index at: https://docs.galileo.ai/llms.txt
> Use this file to discover all available pages before exploring further.
# Cluster Setup Script
> Utilize the Galileo GCP setup script for automating Google Cloud Platform (GCP) configuration to deploy Galileo seamlessly on GKE clusters.
```Bash theme={null}
#!/bin/sh -e
#
# Usage
# CUSTOMER_NAME=customer-name REGION=us-central1 ZONE_ID=a CREATE_ML_NODE_POOL=false ./bootstrap.sh
if [ -z "$CUSTOMER_NAME" ]; then
echo "Error: CUSTOMER_NAME is not set"
exit 0
fi
PROJECT="$CUSTOMER_NAME-galileo"
REGION=${REGION:="us-central1"}
ZONE_ID=${ZONE_ID:="c"}
ZONE="$REGION-$ZONE_ID"
CLUSTER_NAME="galileo"
echo "Bootstrapping cluster with the following parameters:"
echo "PROJECT: ${PROJECT}"
echo "REGION: ${REGION}"
echo "ZONE: ${ZONE}"
echo "CLUSTER_NAME: ${CLUSTER_NAME}"
#
# Create a project for Galileo.
#
echo "Create a project for Galileo."
gcloud projects create $PROJECT || true
#
# Enabling services as referenced here https://cloud.google.com/migrate/containers/docs/config-dev-env#enabling_required_services
#
echo "Enabling services as referenced here https://cloud.google.com/migrate/containers/docs/config-dev-env#enabling_required_services"
gcloud services enable --project=$PROJECT servicemanagement.googleapis.com servicecontrol.googleapis.com cloudresourcemanager.googleapis.com compute.googleapis.com container.googleapis.com containerregistry.googleapis.com cloudbuild.googleapis.com
#
# Grab the project number.
#
echo "Grab the project number."
PROJECT_NUMBER=$(gcloud projects describe $PROJECT --format json | jq -r -c .projectNumber)
#
# Create service accounts and policy bindings.
#
echo "Create service accounts and policy bindings."
gcloud iam service-accounts create galileoconnect \
--project "$PROJECT"
gcloud iam service-accounts add-iam-policy-binding galileoconnect@$PROJECT.iam.gserviceaccount.com \
--project "$PROJECT" \
--member "group:devs@rungalileo.io" \
--role "roles/iam.serviceAccountUser"
gcloud iam service-accounts add-iam-policy-binding galileoconnect@$PROJECT.iam.gserviceaccount.com \
--project "$PROJECT" \
--member "group:devs@rungalileo.io" \
--role "roles/iam.serviceAccountTokenCreator"
gcloud projects add-iam-policy-binding $PROJECT --member="serviceAccount:galileoconnect@$PROJECT.iam.gserviceaccount.com" --role="roles/container.admin"
gcloud projects add-iam-policy-binding $PROJECT --member="serviceAccount:galileoconnect@$PROJECT.iam.gserviceaccount.com" --role="roles/container.clusterViewer"
#
# Waiting before provisioning workload identity.
#
echo "Waiting before provisioning workload identity..."
sleep 5
#
# Create a workload identity pool.
#
echo "Create a workload identity pool."
gcloud iam workload-identity-pools create galileoconnectpool \
--project "$PROJECT" \
--location "global" \
--description "Workload ID Pool for Galileo via GitHub Actions" \
--display-name "GalileoConnectPool"
#
# Create a workload identity provider .
#
echo "Create a workload identity provider ."
gcloud iam workload-identity-pools providers create-oidc galileoconnectprovider \
--project "$PROJECT" \
--location "global" \
--workload-identity-pool "galileoconnectpool" \
--display-name "GalileoConnectProvider" \
--attribute-mapping="google.subject=assertion.sub,attribute.actor=assertion.actor,attribute.aud=assertion.aud,attribute.repository_owner=assertion.repository_owner,attribute.repository=assertion.repository" \
--issuer-uri="https://token.actions.githubusercontent.com"
#
# Bind the service account to the workload identity provider.
#
echo "Bind the service account to the workload identity provider."
gcloud iam service-accounts add-iam-policy-binding "galileoconnect@${PROJECT}.iam.gserviceaccount.com" \
--project "$PROJECT" \
--role="roles/iam.workloadIdentityUser" \
--member="principalSet://iam.googleapis.com/projects/${PROJECT_NUMBER}/locations/global/workloadIdentityPools/galileoconnectpool/attribute.repository/rungalileo/deploy"
#
# Create the cluster (with one node pool) and the runners node pool.
# The network config below assumes you have a default VPC in your account.
# If you want to use a different VPC, please update the option values for
# `--network` and `--subnetwork` below.
#
echo "Create the cluster (with one node pool) and the runners node pool."
gcloud beta container \
--project $PROJECT clusters create $CLUSTER_NAME \
--zone $ZONE \
--no-enable-basic-auth \
--cluster-version "1.27" \
--release-channel "regular" \
--machine-type "e2-standard-4" \
--image-type "cos_containerd" \
--disk-type "pd-standard" \
--disk-size "300" \
--node-labels galileo-node-type=galileo-core \
--metadata disable-legacy-endpoints=true \
--scopes "https://www.googleapis.com/auth/devstorage.read_write","https://www.googleapis.com/auth/logging.write","https://www.googleapis.com/auth/monitoring","https://www.googleapis.com/auth/servicecontrol","https://www.googleapis.com/auth/service.management.readonly","https://www.googleapis.com/auth/trace.append" \
--max-pods-per-node "110" \
--num-nodes "4" \
--logging=SYSTEM,WORKLOAD \
--monitoring=SYSTEM \
--enable-ip-alias \
--network "projects/$PROJECT/global/networks/default" \
--subnetwork "projects/$PROJECT/regions/$REGION/subnetworks/default" \
--no-enable-intra-node-visibility \
--default-max-pods-per-node "110" \
--enable-autoscaling \
--min-nodes "4" \
--max-nodes "5" \
--no-enable-master-authorized-networks \
--addons HorizontalPodAutoscaling,HttpLoadBalancing,GcePersistentDiskCsiDriver \
--enable-autoupgrade \
--enable-autorepair \
--max-surge-upgrade 1 \
--max-unavailable-upgrade 0 \
--enable-autoprovisioning \
--min-cpu 0 \
--max-cpu 50 \
--min-memory 0 \
--max-memory 200 \
--autoprovisioning-scopes=https://www.googleapis.com/auth/logging.write,https://www.googleapis.com/auth/monitoring \
--enable-autoprovisioning-autorepair \
--enable-autoprovisioning-autoupgrade \
--autoprovisioning-max-surge-upgrade 1 \
--autoprovisioning-max-unavailable-upgrade 0 \
--enable-shielded-nodes \
--node-locations $ZONE \
--enable-network-policy
gcloud beta container \
--project $PROJECT node-pools create "galileo-runners" \
--cluster $CLUSTER_NAME \
--zone $ZONE \
--machine-type "e2-standard-8" \
--image-type "cos_containerd" \
--disk-type "pd-standard" \
--disk-size "100" \
--node-labels galileo-node-type=galileo-runner \
--metadata disable-legacy-endpoints=true \
--scopes "https://www.googleapis.com/auth/devstorage.read_write","https://www.googleapis.com/auth/logging.write","https://www.googleapis.com/auth/monitoring","https://www.googleapis.com/auth/servicecontrol","https://www.googleapis.com/auth/service.management.readonly","https://www.googleapis.com/auth/trace.append" \
--num-nodes "1" \
--enable-autoscaling \
--min-nodes "1" \
--max-nodes "5" \
--enable-autoupgrade \
--enable-autorepair \
--max-surge-upgrade 1 \
--max-unavailable-upgrade 0 \
--max-pods-per-node "110" \
--node-locations $ZONE
if [[ -n "$CREATE_ML_NODE_POOL" && "$CREATE_ML_NODE_POOL" == "true" ]]; then
gcloud beta container \
--project $PROJECT node-pools create "galileo-ml" \
--cluster $CLUSTER_NAME \
--zone $ZONE \
--machine-type "g2-standard-8" \
--image-type "cos_containerd" \
--disk-type "pd-standard" \
--disk-size "100" \
--node-labels galileo-node-type=galileo-ml \
--metadata disable-legacy-endpoints=true \
--scopes "https://www.googleapis.com/auth/devstorage.read_write","https://www.googleapis.com/auth/logging.write","https://www.googleapis.com/auth/monitoring","https://www.googleapis.com/auth/servicecontrol","https://www.googleapis.com/auth/service.management.readonly","https://www.googleapis.com/auth/trace.append" \
--num-nodes "1" \
--accelerator type=nvidia-l4,count=1,gpu-driver-version=latest \
--node-locations $ZONE \
--enable-autoscaling \
--enable-autoupgrade \
--enable-autorepair \
--max-surge-upgrade 1 \
--max-unavailable-upgrade 0 \
--max-pods-per-node "110" \
--min-nodes 1 \
--max-nodes 5
fi
```
---
# Source: https://docs.galileo.ai/galileo/gen-ai-studio-products/galileo-guardrail-metrics.md
> ## Documentation Index
> Fetch the complete documentation index at: https://docs.galileo.ai/llms.txt
> Use this file to discover all available pages before exploring further.
# Overview of Galileo Guardrail Metrics
> Utilize Galileo's Guardrail Metrics to monitor generative AI models, ensuring adherence to quality, correctness, and alignment with project goals.
Understand Galileo's Guardrail Metrics in LLM Studio
Galileo has built a menu of **Guardrail Metrics** to help you evaluate, observe and protect your generative AI applications. These metrics are tailored to your use case and are designed to help you ensure your application quality and behavior. The `Scorer` definition for each metric is listed immediately below.
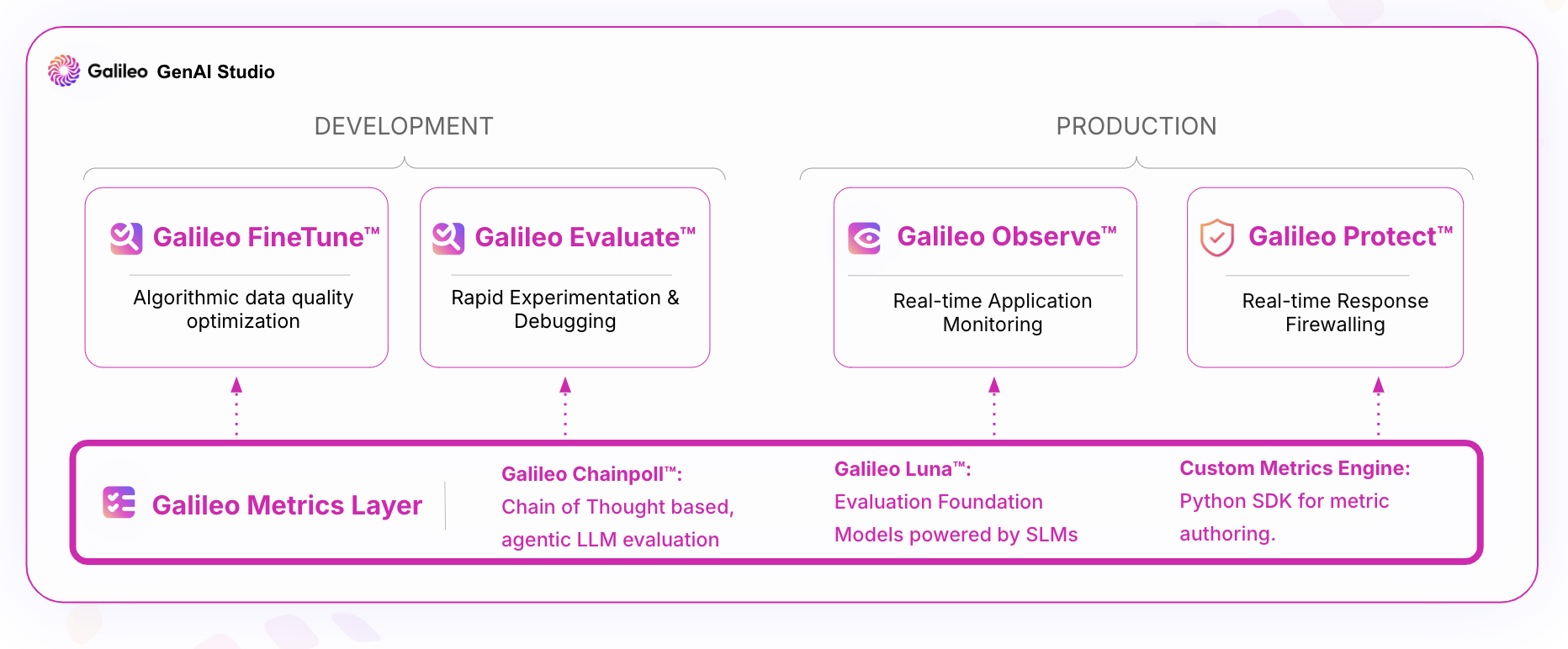 Galileo's Guardrail Metrics are a combination of industry-standard metrics and an outcome of Galileo's in-house ML Research Team.
#### Output Quality Metrics
* [Correctness](/galileo/gen-ai-studio-products/galileo-guardrail-metrics/correctness) (Open Domain Hallucinations)
* [Instruction Adherence:](/galileo/gen-ai-studio-products/galileo-guardrail-metrics/instruction-adherence) `Scorers.instruction_adherence_plus`
* [Uncertainty](/galileo/gen-ai-studio-products/galileo-guardrail-metrics/uncertainty)
* [Ground Truth Adherence:](/galileo/gen-ai-studio-products/galileo-guardrail-metrics/ground-truth-adherence) `Scorers.ground_truth_adherence_plus`
* [Completeness](/galileo/gen-ai-studio-products/galileo-guardrail-metrics/completeness/completeness-plus)
* [Completeness Luna](/galileo/gen-ai-studio-products/galileo-guardrail-metrics/completeness/completeness-luna): `Scorers.completeness_luna`
* [Completeness Plus](/galileo/gen-ai-studio-products/galileo-guardrail-metrics/completeness/completeness-plus): `Scorers.completeness_plus`
* [BLEU and ROUGE](/galileo/gen-ai-studio-products/galileo-guardrail-metrics/bleu-and-rouge-1)
#### Agent Quality Metrics
* [Action Completion:](/galileo/gen-ai-studio-products/galileo-guardrail-metrics/action-completion) `Scorers.action_completion_plus`
* [Action Advancement:](/galileo/gen-ai-studio-products/galileo-guardrail-metrics/action-advancement) `Scorers.action_advancement_plus`
* [Tool Selection Quality:](/galileo/gen-ai-studio-products/galileo-guardrail-metrics/tool-selection-quality) `Scorers.tool_selection_quality_plus`
* [Tool Error:](/galileo/gen-ai-studio-products/galileo-guardrail-metrics/tool-error) `Scorers.tool_errors_plus`
#### RAG Quality Metrics
* [Context Adherence](/galileo/gen-ai-studio-products/galileo-guardrail-metrics/context-adherence) (Closed Domain Hallucinations)
* [Context Adherence Luna](/galileo/gen-ai-studio-products/galileo-guardrail-metrics/context-adherence/context-adherence-luna): `Scorers.context_adherence_luna`
* [Context Adherence Plus](/galileo/gen-ai-studio-products/galileo-guardrail-metrics/context-adherence/context-adherence-plus): `Scorers.context_adherence_plus`
* [Chunk Attribution](/galileo/gen-ai-studio-products/galileo-guardrail-metrics/chunk-attribution)
* [Chunk Attribution Luna](/galileo/gen-ai-studio-products/galileo-guardrail-metrics/chunk-attribution/chunk-attribution-luna): `Scorers.chunk_attribution_utilization_luna`
* [Chunk Attribution Plus](/galileo/gen-ai-studio-products/galileo-guardrail-metrics/chunk-attribution/chunk-attribution-plus): `Scorers.chunk_attribution_utilization_plus`
* [Chunk Utilization](/galileo/gen-ai-studio-products/galileo-guardrail-metrics/chunk-utilization)
* [Chunk Utilization Luna](/galileo/gen-ai-studio-products/galileo-guardrail-metrics/chunk-utilization/chunk-utilization-luna): `Scorers.chunk_attribution_utilization_luna`
* [Chunk Utilization Plus](/galileo/gen-ai-studio-products/galileo-guardrail-metrics/chunk-utilization/chunk-utilization-plus): `Scorers.chunk_attribution_utilization_plus`
#### Input Quality Metrics
* [Prompt Perplexity](/galileo/gen-ai-studio-products/galileo-guardrail-metrics/prompt-perplexity)
#### Safety Metrics
* [Input & Output PII](/galileo/gen-ai-studio-products/galileo-guardrail-metrics/private-identifiable-information)
* [Input & Output Tone](/galileo/gen-ai-studio-products/galileo-guardrail-metrics/tone)
* [Input & Output Toxicity](/galileo/gen-ai-studio-products/galileo-guardrail-metrics/toxicity)
* [Input & Output Sexism](/galileo/gen-ai-studio-products/galileo-guardrail-metrics/sexism)
* [Prompt Injection](/galileo/gen-ai-studio-products/galileo-guardrail-metrics/prompt-injection)
Looking for something more specific? You can always add your own [custom metric](/galileo/gen-ai-studio-products/galileo-observe/how-to/registering-and-using-custom-metrics).
---
# Source: https://docs.galileo.ai/galileo/gen-ai-studio-products/galileo-llm-fine-tune.md
> ## Documentation Index
> Fetch the complete documentation index at: https://docs.galileo.ai/llms.txt
> Use this file to discover all available pages before exploring further.
# Overview of Galileo LLM Fine-Tune
> Fine-tune large language models with Galileo's LLM Fine-Tune tools, enabling precise adjustments for optimized AI performance and output quality.
Galileo Fine-Tune is in beta. If you're interested in trying out this module, reach out to join our Early Access Program.
Fine Tuning an LLM with the famous Alpaca Dataset and using Galileo to find errors
Using Galileo Fine-Tune you can improve the quality of your fine-tuned LLMs by improving the quality of your training data. Research has shown that small high-quality datasets can lead to powerful LLMs. Galileo Fine-Tune helps you achieve that.
Galileo integrates into your training workflow through its `dataquality` Python library. During Training, Galileo sees your samples and your model's output to find errors in your data. Galileo uses **Guardrail Metrics** as well as its **Data Error Potential** score to help you find your most problematic samples.
The **Galileo Data Error Potential (DEP)** score has been built to provide a per-sample holistic data quality score to identify samples in the dataset contributing to low or high model performance i.e. ‘pulling’ the model up or down respectively. In other words, the DEP score measures the potential for "misfit" of an observation to the given model.
Galileo surfaces token-level DEP scores to understand which parts of your Target Output or Ground Truth your model is struggling with.
**Getting Started**
See the [Quickstart](/galileo/gen-ai-studio-products/galileo-llm-fine-tune/quickstart) section to get started.
There are a few ways to get started using Galileo Finetune. You can choose between hooking into your model training, or uploading your data via Galileo Auto.
---
# Source: https://docs.galileo.ai/galileo/gen-ai-studio-products/galileo-observe.md
> ## Documentation Index
> Fetch the complete documentation index at: https://docs.galileo.ai/llms.txt
> Use this file to discover all available pages before exploring further.
# Overview of Galileo Observe
> Monitor and analyze generative AI models with Galileo Observe, using real-time data insights to maintain performance and ensure quality outputs.
LLMs and LLM applications can have unpredictable behaviors. Mission-critical generative AI applications in production
require meticulous observability to ensure performance, security and positive user experience.
Galileo Observe helps you monitor your generative AI applications in production. With Observe you will understand how
your users are using your application and identify where things are going wrong. Keep tabs on your production system,
instantly receive alerts when bad things happen, and perform deep root cause analysis though the Observe dashboard.
Galileo's Guardrail Metrics are a combination of industry-standard metrics and an outcome of Galileo's in-house ML Research Team.
#### Output Quality Metrics
* [Correctness](/galileo/gen-ai-studio-products/galileo-guardrail-metrics/correctness) (Open Domain Hallucinations)
* [Instruction Adherence:](/galileo/gen-ai-studio-products/galileo-guardrail-metrics/instruction-adherence) `Scorers.instruction_adherence_plus`
* [Uncertainty](/galileo/gen-ai-studio-products/galileo-guardrail-metrics/uncertainty)
* [Ground Truth Adherence:](/galileo/gen-ai-studio-products/galileo-guardrail-metrics/ground-truth-adherence) `Scorers.ground_truth_adherence_plus`
* [Completeness](/galileo/gen-ai-studio-products/galileo-guardrail-metrics/completeness/completeness-plus)
* [Completeness Luna](/galileo/gen-ai-studio-products/galileo-guardrail-metrics/completeness/completeness-luna): `Scorers.completeness_luna`
* [Completeness Plus](/galileo/gen-ai-studio-products/galileo-guardrail-metrics/completeness/completeness-plus): `Scorers.completeness_plus`
* [BLEU and ROUGE](/galileo/gen-ai-studio-products/galileo-guardrail-metrics/bleu-and-rouge-1)
#### Agent Quality Metrics
* [Action Completion:](/galileo/gen-ai-studio-products/galileo-guardrail-metrics/action-completion) `Scorers.action_completion_plus`
* [Action Advancement:](/galileo/gen-ai-studio-products/galileo-guardrail-metrics/action-advancement) `Scorers.action_advancement_plus`
* [Tool Selection Quality:](/galileo/gen-ai-studio-products/galileo-guardrail-metrics/tool-selection-quality) `Scorers.tool_selection_quality_plus`
* [Tool Error:](/galileo/gen-ai-studio-products/galileo-guardrail-metrics/tool-error) `Scorers.tool_errors_plus`
#### RAG Quality Metrics
* [Context Adherence](/galileo/gen-ai-studio-products/galileo-guardrail-metrics/context-adherence) (Closed Domain Hallucinations)
* [Context Adherence Luna](/galileo/gen-ai-studio-products/galileo-guardrail-metrics/context-adherence/context-adherence-luna): `Scorers.context_adherence_luna`
* [Context Adherence Plus](/galileo/gen-ai-studio-products/galileo-guardrail-metrics/context-adherence/context-adherence-plus): `Scorers.context_adherence_plus`
* [Chunk Attribution](/galileo/gen-ai-studio-products/galileo-guardrail-metrics/chunk-attribution)
* [Chunk Attribution Luna](/galileo/gen-ai-studio-products/galileo-guardrail-metrics/chunk-attribution/chunk-attribution-luna): `Scorers.chunk_attribution_utilization_luna`
* [Chunk Attribution Plus](/galileo/gen-ai-studio-products/galileo-guardrail-metrics/chunk-attribution/chunk-attribution-plus): `Scorers.chunk_attribution_utilization_plus`
* [Chunk Utilization](/galileo/gen-ai-studio-products/galileo-guardrail-metrics/chunk-utilization)
* [Chunk Utilization Luna](/galileo/gen-ai-studio-products/galileo-guardrail-metrics/chunk-utilization/chunk-utilization-luna): `Scorers.chunk_attribution_utilization_luna`
* [Chunk Utilization Plus](/galileo/gen-ai-studio-products/galileo-guardrail-metrics/chunk-utilization/chunk-utilization-plus): `Scorers.chunk_attribution_utilization_plus`
#### Input Quality Metrics
* [Prompt Perplexity](/galileo/gen-ai-studio-products/galileo-guardrail-metrics/prompt-perplexity)
#### Safety Metrics
* [Input & Output PII](/galileo/gen-ai-studio-products/galileo-guardrail-metrics/private-identifiable-information)
* [Input & Output Tone](/galileo/gen-ai-studio-products/galileo-guardrail-metrics/tone)
* [Input & Output Toxicity](/galileo/gen-ai-studio-products/galileo-guardrail-metrics/toxicity)
* [Input & Output Sexism](/galileo/gen-ai-studio-products/galileo-guardrail-metrics/sexism)
* [Prompt Injection](/galileo/gen-ai-studio-products/galileo-guardrail-metrics/prompt-injection)
Looking for something more specific? You can always add your own [custom metric](/galileo/gen-ai-studio-products/galileo-observe/how-to/registering-and-using-custom-metrics).
---
# Source: https://docs.galileo.ai/galileo/gen-ai-studio-products/galileo-llm-fine-tune.md
> ## Documentation Index
> Fetch the complete documentation index at: https://docs.galileo.ai/llms.txt
> Use this file to discover all available pages before exploring further.
# Overview of Galileo LLM Fine-Tune
> Fine-tune large language models with Galileo's LLM Fine-Tune tools, enabling precise adjustments for optimized AI performance and output quality.
Galileo Fine-Tune is in beta. If you're interested in trying out this module, reach out to join our Early Access Program.
Fine Tuning an LLM with the famous Alpaca Dataset and using Galileo to find errors
Using Galileo Fine-Tune you can improve the quality of your fine-tuned LLMs by improving the quality of your training data. Research has shown that small high-quality datasets can lead to powerful LLMs. Galileo Fine-Tune helps you achieve that.
Galileo integrates into your training workflow through its `dataquality` Python library. During Training, Galileo sees your samples and your model's output to find errors in your data. Galileo uses **Guardrail Metrics** as well as its **Data Error Potential** score to help you find your most problematic samples.
The **Galileo Data Error Potential (DEP)** score has been built to provide a per-sample holistic data quality score to identify samples in the dataset contributing to low or high model performance i.e. ‘pulling’ the model up or down respectively. In other words, the DEP score measures the potential for "misfit" of an observation to the given model.
Galileo surfaces token-level DEP scores to understand which parts of your Target Output or Ground Truth your model is struggling with.
**Getting Started**
See the [Quickstart](/galileo/gen-ai-studio-products/galileo-llm-fine-tune/quickstart) section to get started.
There are a few ways to get started using Galileo Finetune. You can choose between hooking into your model training, or uploading your data via Galileo Auto.
---
# Source: https://docs.galileo.ai/galileo/gen-ai-studio-products/galileo-observe.md
> ## Documentation Index
> Fetch the complete documentation index at: https://docs.galileo.ai/llms.txt
> Use this file to discover all available pages before exploring further.
# Overview of Galileo Observe
> Monitor and analyze generative AI models with Galileo Observe, using real-time data insights to maintain performance and ensure quality outputs.
LLMs and LLM applications can have unpredictable behaviors. Mission-critical generative AI applications in production
require meticulous observability to ensure performance, security and positive user experience.
Galileo Observe helps you monitor your generative AI applications in production. With Observe you will understand how
your users are using your application and identify where things are going wrong. Keep tabs on your production system,
instantly receive alerts when bad things happen, and perform deep root cause analysis though the Observe dashboard.
 ## Core features
#### Real-time Monitoring
Keep a close watch on your Large Language Model (LLM) applications in production. Monitor the performance, behavior,
and health of your applications in real-time.
#### Guardrail Metrics
Galileo has built a number of [Guardrail Metrics](/galileo/gen-ai-studio-products/galileo-guardrail-metrics) to monitor
the quality and safety of your LLM applications in production. The same set of metrics you used during Evaluation and
Experimentation in pre-production can be used to keep tabs on your productionized system:
* Context Adherence
* Completeness
* Correctness
* Instruction Adherence
* Prompt Injections
* PII
* And more.
#### Custom Metrics
Every use case is different. And out-of-the-box metrics won't cover all your needs. Galileo allows you to customize our Guardrail Metrics
or to register your own.
#### Insights and Alerts
Always on, Galileo Observe sends you an alert when things go south. Trace errors down to the LLM call, Agent plan or
Vector Store lookup.
Stay informed about potential issues, anomalies, or improvements that require your attention.
### The Workflow
Integrate Observe into your production system
Define what you want to measure and set your expectations. Get alerted when anything goes wrong.
Debug and perform root cause analysis. Form hypothesis and test them using Evaluate, or use Protect to block these scenarios from occurring again.
### Getting Started
---
# Source: https://docs.galileo.ai/galileo/gen-ai-studio-products/galileo-protect.md
> ## Documentation Index
> Fetch the complete documentation index at: https://docs.galileo.ai/llms.txt
> Use this file to discover all available pages before exploring further.
# Overview of Galileo Protect
> Explore Galileo Protect to safeguard AI applications with customizable rulesets, error detection, and robust metrics for enhanced AI governance.
**Proactive GenAI security is here** -- Protect intercepts prompts and outputs to prevent unwanted behaviors and safeguard your brand and your end-users.
With Protect you can protect your system and your users from:
* Harmful requests and security threats (e.g. Prompt Injections, toxic language)
* Data Privacy protection (e.g. PII leakage)
* Hallucinations
Protect leverages [Galileo's Guardrail Metrics](/galileo/gen-ai-studio-products/galileo-guardrail-metrics) to power its safeguards.
## Core features
#### Real-time Monitoring
Keep a close watch on your Large Language Model (LLM) applications in production. Monitor the performance, behavior,
and health of your applications in real-time.
#### Guardrail Metrics
Galileo has built a number of [Guardrail Metrics](/galileo/gen-ai-studio-products/galileo-guardrail-metrics) to monitor
the quality and safety of your LLM applications in production. The same set of metrics you used during Evaluation and
Experimentation in pre-production can be used to keep tabs on your productionized system:
* Context Adherence
* Completeness
* Correctness
* Instruction Adherence
* Prompt Injections
* PII
* And more.
#### Custom Metrics
Every use case is different. And out-of-the-box metrics won't cover all your needs. Galileo allows you to customize our Guardrail Metrics
or to register your own.
#### Insights and Alerts
Always on, Galileo Observe sends you an alert when things go south. Trace errors down to the LLM call, Agent plan or
Vector Store lookup.
Stay informed about potential issues, anomalies, or improvements that require your attention.
### The Workflow
Integrate Observe into your production system
Define what you want to measure and set your expectations. Get alerted when anything goes wrong.
Debug and perform root cause analysis. Form hypothesis and test them using Evaluate, or use Protect to block these scenarios from occurring again.
### Getting Started
---
# Source: https://docs.galileo.ai/galileo/gen-ai-studio-products/galileo-protect.md
> ## Documentation Index
> Fetch the complete documentation index at: https://docs.galileo.ai/llms.txt
> Use this file to discover all available pages before exploring further.
# Overview of Galileo Protect
> Explore Galileo Protect to safeguard AI applications with customizable rulesets, error detection, and robust metrics for enhanced AI governance.
**Proactive GenAI security is here** -- Protect intercepts prompts and outputs to prevent unwanted behaviors and safeguard your brand and your end-users.
With Protect you can protect your system and your users from:
* Harmful requests and security threats (e.g. Prompt Injections, toxic language)
* Data Privacy protection (e.g. PII leakage)
* Hallucinations
Protect leverages [Galileo's Guardrail Metrics](/galileo/gen-ai-studio-products/galileo-guardrail-metrics) to power its safeguards.
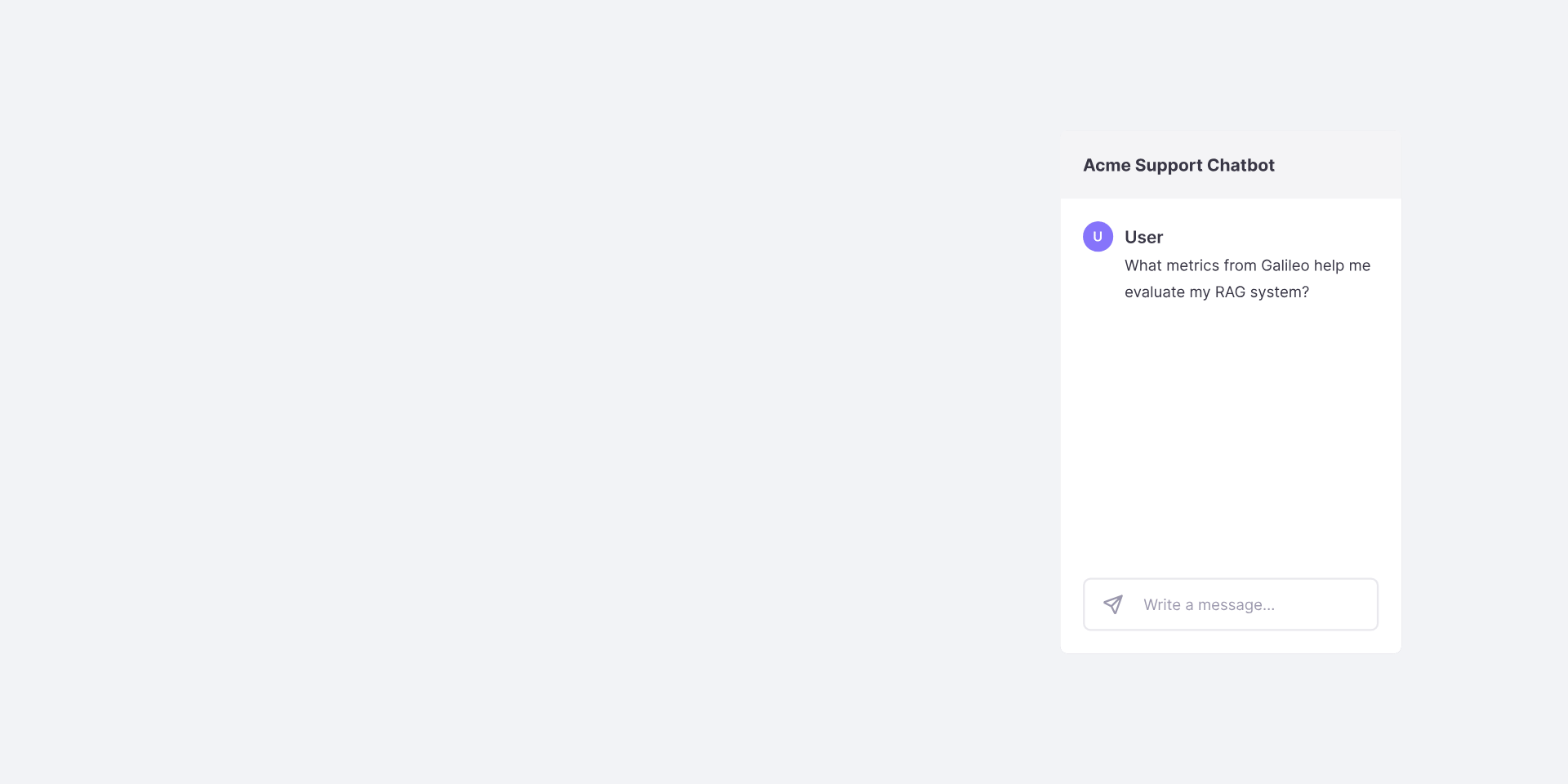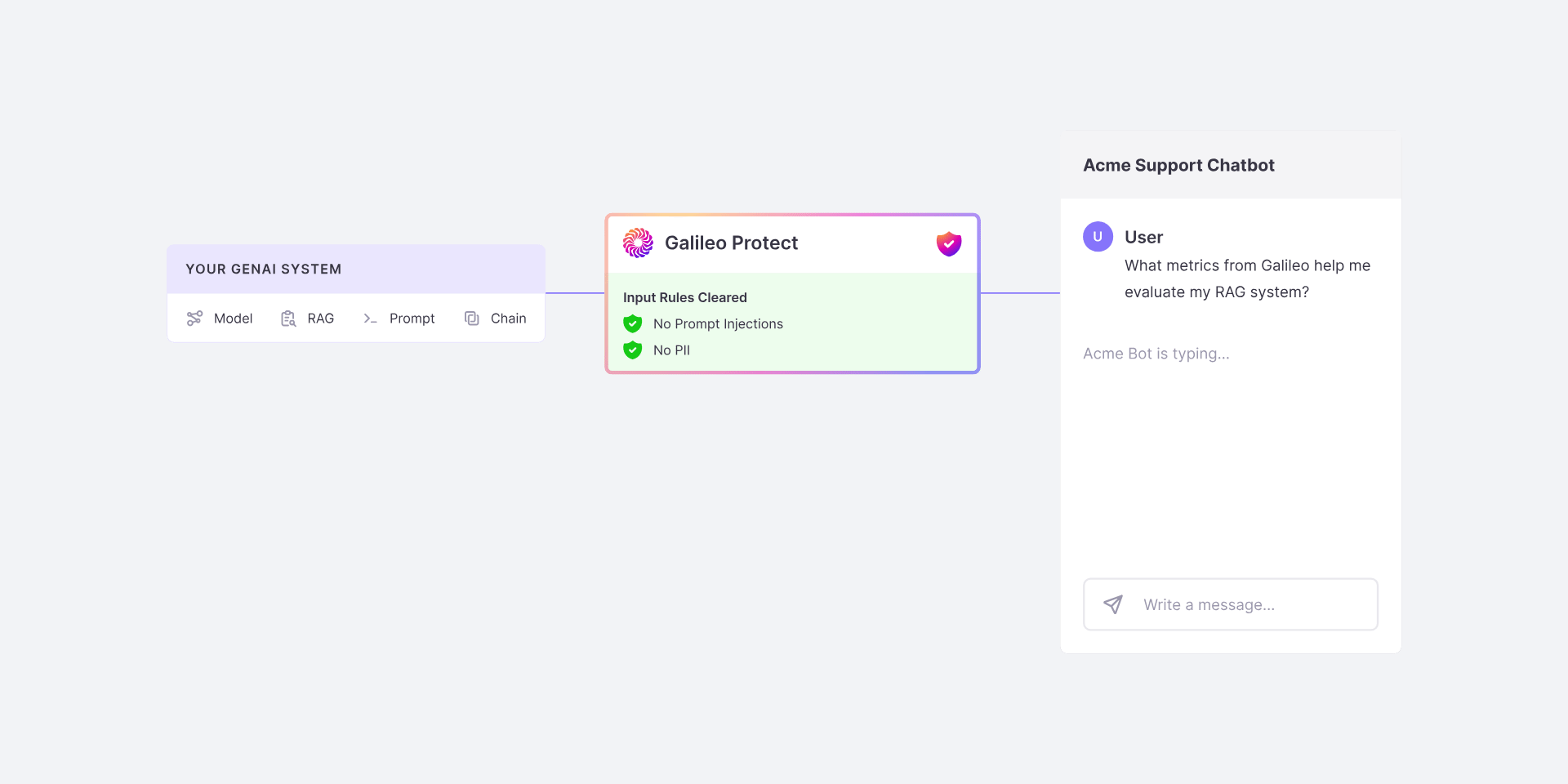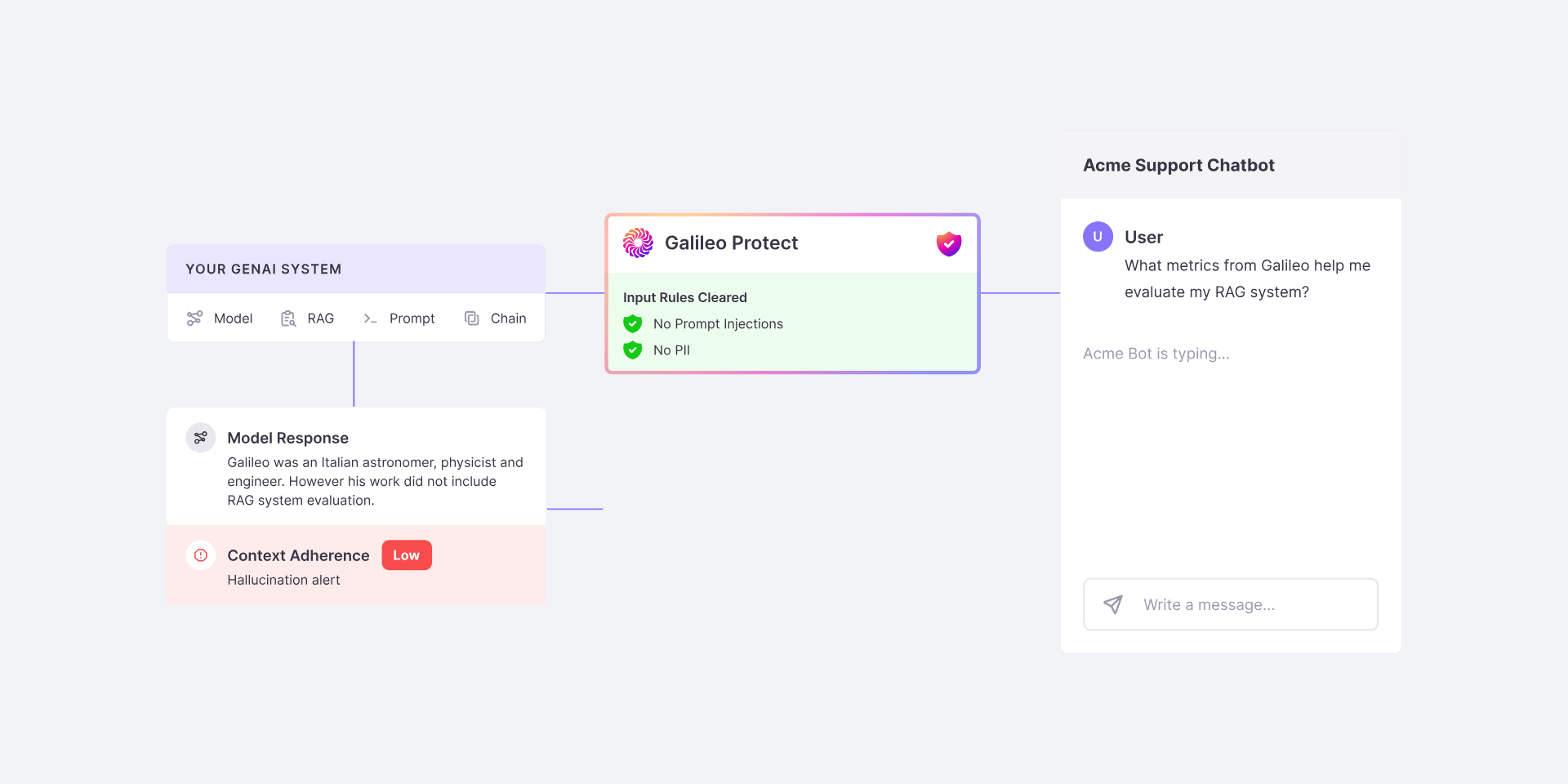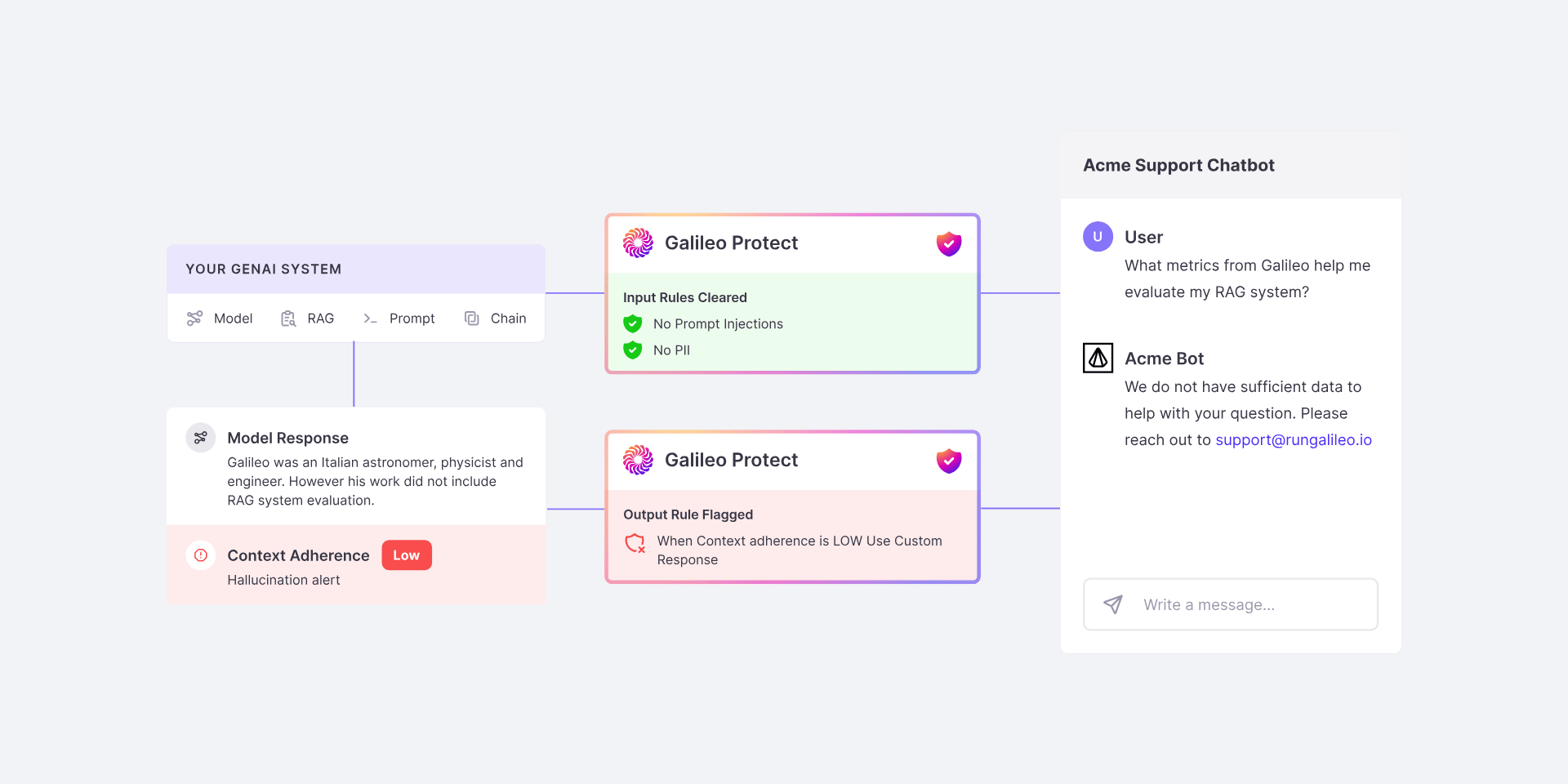 ### The Workflow
Define you need protection from. Choose a set of metrics and conditions to
help you achieve that. Determine what your system should do when those rules are broken.
Run your Protect rules through a comprehensive evaluation to ensure Protect
is working for you. Run your evaluation set and check for any over- or
under-triggering. Iterate on your conditions until you're satisfied.
Deploy your Protect checks to production. (Optional) Register your stages so
they can be updated on the fly.
Use Observe to monitor your system in production.
### Getting Started
---
# Source: https://docs.galileo.ai/galileo.md
> ## Documentation Index
> Fetch the complete documentation index at: https://docs.galileo.ai/llms.txt
> Use this file to discover all available pages before exploring further.
# What is Galileo?
> Evaluate, Observe, and Protect your GenAI applications
Galileo is the leading Generative AI Evaluation & Observability Stack for the Enterprise.
Large Language Models are unlocking unprecedented possibilities. But going from a flashy demo to a production-ready app isn’t easy. You need to:
* Rapidly iterate across complex prompts, numerous models, context data, embedding model params, vector stores, chunking strategies, chain nodes and more -- getting to the **right** configuration of your 'GenAI System' **for your use case** needs experimentation and thorough evaluation.
* Carefully keep harmful responses away from your users, while keeping harmful users from attacking your GenAI systems.
* Monitor live traffic to your GenAI application, identify vulnerabilities, debug and re-launch.
Galileo GenAI Studio is the all-in-one evaluation and observability stack that provides all of the above.
### Metrics
Most significantly -- you cannot evaluate what you cannot measure -- Galileo Research has constantly pushed the envelope with our **proprietary research backed Guardrail Metrics** for best in class:
* Hallucination detection (see our published [Hallucination Index](https://www.rungalileo.io/hallucinationindex?utm%5Fsource=LinkedIn\&utm%5Fmedium=Post\&utm%5Fcampaign=HallucinationIndex)) ,
* Security threat vector identification,
* Data privacy protection,
* and much more...
***
### Modules
The GenAI Studio is composed of 3 modules. Each module is powered by the centralized Galileo Guardrail Store.
### The Workflow
Define you need protection from. Choose a set of metrics and conditions to
help you achieve that. Determine what your system should do when those rules are broken.
Run your Protect rules through a comprehensive evaluation to ensure Protect
is working for you. Run your evaluation set and check for any over- or
under-triggering. Iterate on your conditions until you're satisfied.
Deploy your Protect checks to production. (Optional) Register your stages so
they can be updated on the fly.
Use Observe to monitor your system in production.
### Getting Started
---
# Source: https://docs.galileo.ai/galileo.md
> ## Documentation Index
> Fetch the complete documentation index at: https://docs.galileo.ai/llms.txt
> Use this file to discover all available pages before exploring further.
# What is Galileo?
> Evaluate, Observe, and Protect your GenAI applications
Galileo is the leading Generative AI Evaluation & Observability Stack for the Enterprise.
Large Language Models are unlocking unprecedented possibilities. But going from a flashy demo to a production-ready app isn’t easy. You need to:
* Rapidly iterate across complex prompts, numerous models, context data, embedding model params, vector stores, chunking strategies, chain nodes and more -- getting to the **right** configuration of your 'GenAI System' **for your use case** needs experimentation and thorough evaluation.
* Carefully keep harmful responses away from your users, while keeping harmful users from attacking your GenAI systems.
* Monitor live traffic to your GenAI application, identify vulnerabilities, debug and re-launch.
Galileo GenAI Studio is the all-in-one evaluation and observability stack that provides all of the above.
### Metrics
Most significantly -- you cannot evaluate what you cannot measure -- Galileo Research has constantly pushed the envelope with our **proprietary research backed Guardrail Metrics** for best in class:
* Hallucination detection (see our published [Hallucination Index](https://www.rungalileo.io/hallucinationindex?utm%5Fsource=LinkedIn\&utm%5Fmedium=Post\&utm%5Fcampaign=HallucinationIndex)) ,
* Security threat vector identification,
* Data privacy protection,
* and much more...
***
### Modules
The GenAI Studio is composed of 3 modules. Each module is powered by the centralized Galileo Guardrail Store.
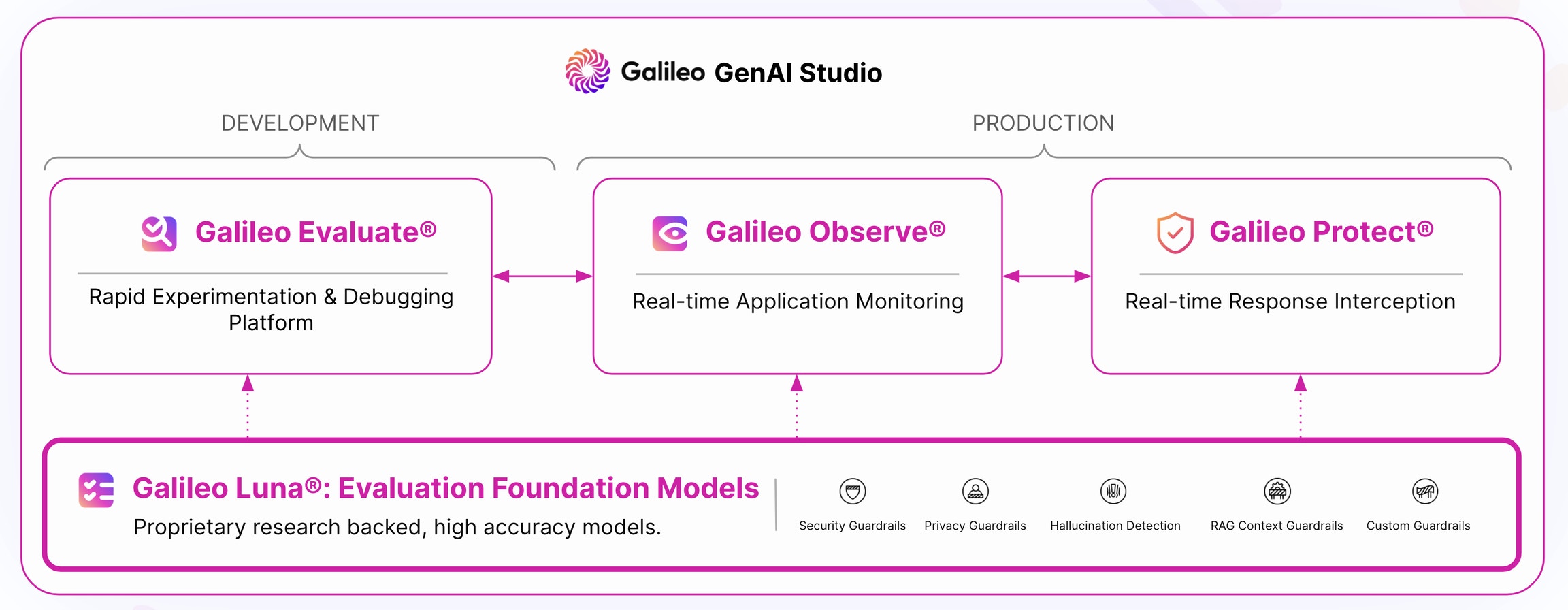 Get started with:
Rapid Evaluation of Prompts, Chains and RAG systems
Real-time Observability for GenAI Apps and Models
Real-time Request and Response Interception
### Want to try Galileo? Get in touch with us [here](https://www.rungalileo.io/get-started)!
---
# Source: https://docs.galileo.ai/deployments/scheduling-automatic-backups-for-your-cluster/gcp-velero-account-setup-script.md
> ## Documentation Index
> Fetch the complete documentation index at: https://docs.galileo.ai/llms.txt
> Use this file to discover all available pages before exploring further.
# Gcp Velero Account Setup Script
> Set up Velero for Google Cloud backups with this GCP account script, enabling automated backup scheduling and robust data protection for Galileo clusters.
```
#!/bin/sh -e
# Usage
# ./velero-account-setup-gcp.sh
#
#
GSA_NAME=velero
ROLE_PERMISSIONS=(
compute.disks.get
compute.disks.create
compute.disks.createSnapshot
compute.snapshots.get
compute.snapshots.create
compute.snapshots.useReadOnly
compute.snapshots.delete
compute.zones.get
storage.objects.create
storage.objects.delete
storage.objects.get
storage.objects.list
)
print_usage() {
echo -e "\n Usage: \n ./velero-account-setup-gcp.sh \n"
}
BUCKET="${1}"
if [ -z "$BUCKET" ]; then
print_usage
exit 1
fi
gsutil mb gs://$BUCKET
PROJECT_ID=$(gcloud config get-value project)
gcloud iam service-accounts create $GSA_NAME \
--display-name "Velero service account"
SERVICE_ACCOUNT_EMAIL=$(gcloud iam service-accounts list \
--filter="displayName:Velero service account" \
--format 'value(email)')
gcloud iam roles create velero.server \
--project $PROJECT_ID \
--title "Velero Server" \
--permissions "$(IFS=","; echo "${ROLE_PERMISSIONS[*]}")"
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member serviceAccount:$SERVICE_ACCOUNT_EMAIL \
--role projects/$PROJECT_ID/roles/velero.server
gsutil iam ch serviceAccount:$SERVICE_ACCOUNT_EMAIL:objectAdmin gs://${BUCKET}
gcloud iam service-accounts keys create credentials-velero \
--iam-account $SERVICE_ACCOUNT_EMAIL
```
---
# Source: https://docs.galileo.ai/api-reference/evaluate/get-evaluate-run-results.md
> ## Documentation Index
> Fetch the complete documentation index at: https://docs.galileo.ai/llms.txt
> Use this file to discover all available pages before exploring further.
# Get Evaluate Run Results
> Fetch evaluation results for a specific run including rows and aggregate information.
## OpenAPI
````yaml https://api.staging.galileo.ai/public/v1/openapi.json post /v1/evaluate/run-workflows
openapi: 3.1.0
info:
title: FastAPI
version: 0.1.0
servers:
- url: https://api.staging.galileo.ai
description: Galileo Public APIs - staging
security: []
paths:
/v1/evaluate/run-workflows:
post:
tags:
- evaluate
summary: Get Evaluate Run Results
description: >-
Fetch evaluation results for a specific run including rows and aggregate
information.
operationId: get_evaluate_run_results_v1_evaluate_run_workflows_post
requestBody:
content:
application/json:
schema:
$ref: '#/components/schemas/EvaluateRunResultsRequest'
required: true
responses:
'200':
description: Successful Response
content:
application/json:
schema:
$ref: '#/components/schemas/WorkflowsReadResponse'
'422':
description: Validation Error
content:
application/json:
schema:
$ref: '#/components/schemas/HTTPValidationError'
security:
- APIKeyHeader: []
- OAuth2PasswordBearer: []
- HTTPBasic: []
components:
schemas:
EvaluateRunResultsRequest:
properties:
starting_token:
type: integer
title: Starting Token
default: 0
limit:
type: integer
title: Limit
default: 100
project_id:
anyOf:
- type: string
format: uuid4
- type: 'null'
title: Project Id
project_name:
anyOf:
- type: string
- type: 'null'
title: Project Name
run_id:
anyOf:
- type: string
format: uuid4
- type: 'null'
title: Run Id
run_name:
anyOf:
- type: string
- type: 'null'
title: Run Name
type: object
title: EvaluateRunResultsRequest
WorkflowsReadResponse:
properties:
starting_token:
type: integer
title: Starting Token
default: 0
limit:
type: integer
title: Limit
default: 100
paginated:
type: boolean
title: Paginated
default: false
next_starting_token:
anyOf:
- type: integer
- type: 'null'
title: Next Starting Token
workflows:
items:
$ref: '#/components/schemas/BaseGalileoStep'
type: array
title: Workflows
type: object
required:
- workflows
title: WorkflowsReadResponse
description: Response model for workflow evaluation results
HTTPValidationError:
properties:
detail:
items:
$ref: '#/components/schemas/ValidationError'
type: array
title: Detail
type: object
title: HTTPValidationError
BaseGalileoStep:
properties:
type:
$ref: '#/components/schemas/NodeType'
description: Type of the step. By default, it is set to workflow.
default: workflow
input:
type: string
title: Input
description: Input to the step.
redacted_input:
type: string
title: Redacted Input
description: >-
Redacted input of the step. This is used to redact sensitive
information.
output:
type: string
title: Output
description: Output of the step.
redacted_output:
type: string
title: Redacted Output
description: >-
Redacted output of the step. This is used to redact sensitive
information.
name:
type: string
title: Name
description: Name of the step.
default: ''
created_at_ns:
type: integer
title: Created At Ns
description: Timestamp of the step's creation, as nanoseconds since epoch.
duration_ns:
type: integer
title: Duration Ns
description: Duration of the step in nanoseconds.
default: 0
metadata:
additionalProperties:
type: string
type: object
title: Metadata
description: Metadata associated with this step.
status_code:
anyOf:
- type: integer
- type: 'null'
title: Status Code
description: Status code of the step. Used for logging failed/errored steps.
ground_truth:
anyOf:
- type: string
- type: 'null'
title: Ground Truth
description: Ground truth expected output for the step.
root_workflow_id:
anyOf:
- type: string
format: uuid4
- type: 'null'
title: Root Workflow Id
workflow_id:
anyOf:
- type: string
format: uuid4
- type: 'null'
title: Workflow Id
step_id:
anyOf:
- type: string
format: uuid4
- type: 'null'
title: Step Id
steps:
anyOf:
- items:
$ref: '#/components/schemas/BaseGalileoStep'
type: array
- type: 'null'
title: Steps
metrics:
items:
$ref: '#/components/schemas/StepMetric'
type: array
title: Metrics
additionalProperties: true
type: object
required:
- input
title: BaseGalileoStep
ValidationError:
properties:
loc:
items:
anyOf:
- type: string
- type: integer
type: array
title: Location
msg:
type: string
title: Message
type:
type: string
title: Error Type
type: object
required:
- loc
- msg
- type
title: ValidationError
NodeType:
type: string
enum:
- chain
- chat
- llm
- retriever
- tool
- agent
- workflow
- trace
- session
title: NodeType
StepMetric:
properties:
name:
type: string
title: Name
value:
title: Value
status:
anyOf:
- type: string
- type: 'null'
title: Status
explanation:
anyOf:
- type: string
- type: 'null'
title: Explanation
rationale:
anyOf:
- type: string
- type: 'null'
title: Rationale
cost:
anyOf:
- type: number
- type: 'null'
title: Cost
model_alias:
anyOf:
- type: string
- type: 'null'
title: Model Alias
num_judges:
anyOf:
- type: integer
- type: 'null'
title: Num Judges
display_value:
anyOf:
- {}
- type: 'null'
title: Display Value
data_type:
$ref: '#/components/schemas/DataTypeOptions'
default: unknown
type: object
required:
- name
- value
title: StepMetric
DataTypeOptions:
type: string
enum:
- unknown
- text
- label
- floating_point
- integer
- timestamp
- milli_seconds
- boolean
- uuid
- percentage
- dollars
- array
- template_label
- thumb_rating_percentage
- user_id
- text_offsets
- segments
- hallucination_segments
- thumb_rating
- score_rating
- star_rating
- tags_rating
- thumb_rating_aggregate
- score_rating_aggregate
- star_rating_aggregate
- tags_rating_aggregate
title: DataTypeOptions
securitySchemes:
APIKeyHeader:
type: apiKey
in: header
name: Galileo-API-Key
OAuth2PasswordBearer:
type: oauth2
flows:
password:
scopes: {}
tokenUrl: https://api.staging.galileo.ai/login
HTTPBasic:
type: http
scheme: basic
````
---
# Source: https://docs.galileo.ai/api-reference/auth/get-token.md
> ## Documentation Index
> Fetch the complete documentation index at: https://docs.galileo.ai/llms.txt
> Use this file to discover all available pages before exploring further.
# Get Token
## OpenAPI
````yaml https://api.staging.galileo.ai/public/v1/openapi.json get /v1/token
openapi: 3.1.0
info:
title: FastAPI
version: 0.1.0
servers:
- url: https://api.staging.galileo.ai
description: Galileo Public APIs - staging
security: []
paths:
/v1/token:
get:
tags:
- auth
summary: Get Token
operationId: get_token_v1_token_get
parameters:
- name: organization_id
in: query
required: false
schema:
anyOf:
- type: string
format: uuid4
- type: 'null'
title: Organization Id
- name: organization_slug
in: query
required: false
schema:
anyOf:
- type: string
- type: 'null'
title: Organization Slug
responses:
'200':
description: Successful Response
content:
application/json:
schema:
$ref: '#/components/schemas/GetTokenResponse'
'422':
description: Validation Error
content:
application/json:
schema:
$ref: '#/components/schemas/HTTPValidationError'
security:
- APIKeyHeader: []
- OAuth2PasswordBearer: []
- HTTPBasic: []
components:
schemas:
GetTokenResponse:
properties:
access_token:
type: string
title: Access Token
token_type:
type: string
title: Token Type
default: bearer
expires_at:
type: string
format: date-time
title: Expires At
type: object
required:
- access_token
- expires_at
title: GetTokenResponse
HTTPValidationError:
properties:
detail:
items:
$ref: '#/components/schemas/ValidationError'
type: array
title: Detail
type: object
title: HTTPValidationError
ValidationError:
properties:
loc:
items:
anyOf:
- type: string
- type: integer
type: array
title: Location
msg:
type: string
title: Message
type:
type: string
title: Error Type
type: object
required:
- loc
- msg
- type
title: ValidationError
securitySchemes:
APIKeyHeader:
type: apiKey
in: header
name: Galileo-API-Key
OAuth2PasswordBearer:
type: oauth2
flows:
password:
scopes: {}
tokenUrl: https://api.staging.galileo.ai/login
HTTPBasic:
type: http
scheme: basic
````
---
# Source: https://docs.galileo.ai/api-reference/observe/get-workflows.md
> ## Documentation Index
> Fetch the complete documentation index at: https://docs.galileo.ai/llms.txt
> Use this file to discover all available pages before exploring further.
# Get Workflows
> Get workflows for a specific run in an Observe project.
## OpenAPI
````yaml https://api.staging.galileo.ai/public/v1/openapi.json post /v1/observe/projects/{project_id}/workflows
openapi: 3.1.0
info:
title: FastAPI
version: 0.1.0
servers:
- url: https://api.staging.galileo.ai
description: Galileo Public APIs - staging
security: []
paths:
/v1/observe/projects/{project_id}/workflows:
post:
tags:
- observe
summary: Get Workflows
description: Get workflows for a specific run in an Observe project.
operationId: get_workflows_v1_observe_projects__project_id__workflows_post
parameters:
- name: project_id
in: path
required: true
schema:
type: string
format: uuid4
title: Project Id
- name: start_time
in: query
required: false
schema:
anyOf:
- type: string
format: date-time
- type: 'null'
title: Start Time
- name: end_time
in: query
required: false
schema:
anyOf:
- type: string
format: date-time
- type: 'null'
title: End Time
requestBody:
content:
application/json:
schema:
$ref: '#/components/schemas/GetObserveWorkflowsRequest'
responses:
'200':
description: Successful Response
content:
application/json:
schema:
$ref: '#/components/schemas/WorkflowsReadResponse'
'422':
description: Validation Error
content:
application/json:
schema:
$ref: '#/components/schemas/HTTPValidationError'
security:
- APIKeyHeader: []
- OAuth2PasswordBearer: []
- HTTPBasic: []
components:
schemas:
GetObserveWorkflowsRequest:
properties:
starting_token:
type: integer
title: Starting Token
default: 0
limit:
type: integer
title: Limit
default: 100
filters:
items:
oneOf:
- $ref: '#/components/schemas/UserMetadataFilter'
discriminator:
propertyName: name
mapping:
user_metadata: '#/components/schemas/UserMetadataFilter'
type: array
title: Filters
type: object
title: GetObserveWorkflowsRequest
WorkflowsReadResponse:
properties:
starting_token:
type: integer
title: Starting Token
default: 0
limit:
type: integer
title: Limit
default: 100
paginated:
type: boolean
title: Paginated
default: false
next_starting_token:
anyOf:
- type: integer
- type: 'null'
title: Next Starting Token
workflows:
items:
$ref: '#/components/schemas/BaseGalileoStep'
type: array
title: Workflows
type: object
required:
- workflows
title: WorkflowsReadResponse
description: Response model for workflow evaluation results
HTTPValidationError:
properties:
detail:
items:
$ref: '#/components/schemas/ValidationError'
type: array
title: Detail
type: object
title: HTTPValidationError
UserMetadataFilter:
properties:
name:
type: string
const: user_metadata
title: Name
default: user_metadata
operator:
type: string
enum:
- one_of
- not_in
- eq
- ne
title: Operator
key:
type: string
title: Key
value:
anyOf:
- type: string
- items:
type: string
type: array
title: Value
type: object
required:
- operator
- key
- value
title: UserMetadataFilter
BaseGalileoStep:
properties:
type:
$ref: '#/components/schemas/NodeType'
description: Type of the step. By default, it is set to workflow.
default: workflow
input:
type: string
title: Input
description: Input to the step.
redacted_input:
type: string
title: Redacted Input
description: >-
Redacted input of the step. This is used to redact sensitive
information.
output:
type: string
title: Output
description: Output of the step.
redacted_output:
type: string
title: Redacted Output
description: >-
Redacted output of the step. This is used to redact sensitive
information.
name:
type: string
title: Name
description: Name of the step.
default: ''
created_at_ns:
type: integer
title: Created At Ns
description: Timestamp of the step's creation, as nanoseconds since epoch.
duration_ns:
type: integer
title: Duration Ns
description: Duration of the step in nanoseconds.
default: 0
metadata:
additionalProperties:
type: string
type: object
title: Metadata
description: Metadata associated with this step.
status_code:
anyOf:
- type: integer
- type: 'null'
title: Status Code
description: Status code of the step. Used for logging failed/errored steps.
ground_truth:
anyOf:
- type: string
- type: 'null'
title: Ground Truth
description: Ground truth expected output for the step.
root_workflow_id:
anyOf:
- type: string
format: uuid4
- type: 'null'
title: Root Workflow Id
workflow_id:
anyOf:
- type: string
format: uuid4
- type: 'null'
title: Workflow Id
step_id:
anyOf:
- type: string
format: uuid4
- type: 'null'
title: Step Id
steps:
anyOf:
- items:
$ref: '#/components/schemas/BaseGalileoStep'
type: array
- type: 'null'
title: Steps
metrics:
items:
$ref: '#/components/schemas/StepMetric'
type: array
title: Metrics
additionalProperties: true
type: object
required:
- input
title: BaseGalileoStep
ValidationError:
properties:
loc:
items:
anyOf:
- type: string
- type: integer
type: array
title: Location
msg:
type: string
title: Message
type:
type: string
title: Error Type
type: object
required:
- loc
- msg
- type
title: ValidationError
NodeType:
type: string
enum:
- chain
- chat
- llm
- retriever
- tool
- agent
- workflow
- trace
- session
title: NodeType
StepMetric:
properties:
name:
type: string
title: Name
value:
title: Value
status:
anyOf:
- type: string
- type: 'null'
title: Status
explanation:
anyOf:
- type: string
- type: 'null'
title: Explanation
rationale:
anyOf:
- type: string
- type: 'null'
title: Rationale
cost:
anyOf:
- type: number
- type: 'null'
title: Cost
model_alias:
anyOf:
- type: string
- type: 'null'
title: Model Alias
num_judges:
anyOf:
- type: integer
- type: 'null'
title: Num Judges
display_value:
anyOf:
- {}
- type: 'null'
title: Display Value
data_type:
$ref: '#/components/schemas/DataTypeOptions'
default: unknown
type: object
required:
- name
- value
title: StepMetric
DataTypeOptions:
type: string
enum:
- unknown
- text
- label
- floating_point
- integer
- timestamp
- milli_seconds
- boolean
- uuid
- percentage
- dollars
- array
- template_label
- thumb_rating_percentage
- user_id
- text_offsets
- segments
- hallucination_segments
- thumb_rating
- score_rating
- star_rating
- tags_rating
- thumb_rating_aggregate
- score_rating_aggregate
- star_rating_aggregate
- tags_rating_aggregate
title: DataTypeOptions
securitySchemes:
APIKeyHeader:
type: apiKey
in: header
name: Galileo-API-Key
OAuth2PasswordBearer:
type: oauth2
flows:
password:
scopes: {}
tokenUrl: https://api.staging.galileo.ai/login
HTTPBasic:
type: http
scheme: basic
````
---
# Source: https://docs.galileo.ai/galileo/gen-ai-studio-products/galileo-observe/getting-started.md
# Source: https://docs.galileo.ai/galileo/galileo-nlp-studio/text-classification/getting-started.md
# Source: https://docs.galileo.ai/galileo/galileo-nlp-studio/natural-language-inference/getting-started.md
# Source: https://docs.galileo.ai/galileo/galileo-nlp-studio/named-entity-recognition/getting-started.md
# Source: https://docs.galileo.ai/galileo/galileo-nlp-studio/multi-label-text-classification/getting-started.md
# Source: https://docs.galileo.ai/api-reference/getting-started.md
> ## Documentation Index
> Fetch the complete documentation index at: https://docs.galileo.ai/llms.txt
> Use this file to discover all available pages before exploring further.
# API Reference | Getting Started with Galileo
> Get started with Galileo's REST API: learn about base URLs, authentication methods, and how to verify your API setup for seamless integration.
Galileo provides a public REST API that you can use to interact with the Galileo platform. This API allows you to perform various operations across Evaluate, Observe and Protect. This guide will help you get started with the Galileo REST API.
## Base API URL
The first thing you need to talk to the Galileo API is the base URL of your Galileo API instance.
If you know the URL that you use to access the Galileo console, you can replace `console` in it with `api`. For example, if your Galileo console URL is `https://console.galileo.myenterprise.com`, then your base URL for the API is `https://api.galileo.myenterprise.com`.
### Verify the Base URL
To verify the base URL of your Galileo API instance, you can send a `GET` request to the [`healthcheck` endpoint](/api-reference/health/healthcheck).
```bash theme={null}
curl -X GET https://api.galileo.myenterprise.com/v1/healthcheck
```
## Authentication
For interacting with our public endpoints, you can use any of the following methods to authenticate your requests:
### API Key
To use your [API key](/galileo/gen-ai-studio-products/galileo-evaluate/quickstart#getting-an-api-key) to authenticate your requests, include the key in the HTTP headers for your requests.
```json theme={null}
{ "Galileo-API-Key": "" }
```
### HTTP Basic Auth
To use HTTP Basic Auth to authenticate your requests, include your username and password in the HTTP headers for your requests.
```json theme={null}
{ "Authorization": "Basic :)>" }
```
### JWT Token
To use a JWT token to authenticate your requests, include the token in the HTTP headers for your requests.
```json theme={null}
{ "Authorization": "Bearer " }
```
We recommend using this method for high-volume requests because it is more secure (expires after 24 hours) and scalable than using an API key.
To generate a JWT token, send a `GET` request to the [`get-token` endpoint](/api-reference/auth/get-token) using the API Key or HTTP Basic auth.
---
# Source: https://docs.galileo.ai/galileo/gen-ai-studio-products/galileo-guardrail-metrics/ground-truth-adherence.md
> ## Documentation Index
> Fetch the complete documentation index at: https://docs.galileo.ai/llms.txt
> Use this file to discover all available pages before exploring further.
# Ground Truth Adherence
> Measure ground truth adherence in generative AI models with Galileo's Guardrail Metrics, ensuring accurate and aligned outputs with dataset benchmarks.
***Definition:*** Measures whether the model's response is semantically equivalent to your Ground Truth.
If the response has a *High Ground Truth Adherence* (i.e. it has a value of 1 or close to 1), the model's response was semantically equivalent to the Groud Truth. If a response has a *Low Ground Truth Adherence* (i.e. it has a value of 0 or close to 0), the model's response is likely semantically different from the Ground Truth.
*Note:* This metric requires a Ground Truth to be set. Check out [this page](/galileo/gen-ai-studio-products/galileo-evaluate/how-to/logging-and-comparing-against-your-expected-answers) to learn how to add a Ground Truth to your runs.
***Calculation:*** *Ground Truth Adherence* is computed by sending additional requests to OpenAI's GPT4o, using a carefully engineered chain-of-thought prompt that asks the model to judge whether or not the Ground Truth and Response are equivalent. The metric requests multiple distinct responses to this prompt, each of which produces an explanation along with a final judgment: yes or no. The Ground Truth Adherence score is the fraction of "yes" responses, divided by the total number of responses.
We also surface one of the generated explanations. The surfaced explanation is always chosen to align with the majority judgment among the responses.
*Note:* This metric is computed by prompting an LLM multiple times, and thus requires additional LLM calls to compute.
---
# Source: https://docs.galileo.ai/api-reference/health/healthcheck.md
> ## Documentation Index
> Fetch the complete documentation index at: https://docs.galileo.ai/llms.txt
> Use this file to discover all available pages before exploring further.
# Healthcheck
## OpenAPI
````yaml https://api.staging.galileo.ai/public/v1/openapi.json get /v1/healthcheck
openapi: 3.1.0
info:
title: FastAPI
version: 0.1.0
servers:
- url: https://api.staging.galileo.ai
description: Galileo Public APIs - staging
security: []
paths:
/v1/healthcheck:
get:
tags:
- health
summary: Healthcheck
operationId: healthcheck_v1_healthcheck_get
responses:
'200':
description: Successful Response
content:
application/json:
schema:
$ref: '#/components/schemas/HealthcheckResponse'
components:
schemas:
HealthcheckResponse:
properties:
api_version:
type: string
title: Api Version
message:
type: string
title: Message
version:
type: string
title: Version
type: object
required:
- api_version
- message
- version
title: HealthcheckResponse
````
---
# Source: https://docs.galileo.ai/galileo/gen-ai-studio-products/galileo-protect/how-to.md
# Source: https://docs.galileo.ai/galileo/gen-ai-studio-products/galileo-observe/how-to.md
# Source: https://docs.galileo.ai/galileo/gen-ai-studio-products/galileo-evaluate/how-to.md
> ## Documentation Index
> Fetch the complete documentation index at: https://docs.galileo.ai/llms.txt
> Use this file to discover all available pages before exploring further.
# How-To Guide | Galileo Evaluate
> Follow step-by-step instructions in Galileo Evaluate to assess generative AI models, configure metrics, and analyze performance effectively.
### Logging Runs
### Use Cases
### Prompt Engineering
### Metrics
### Getting Insights
### Collaboration
### Advanced Features
### Best Practices
{" "}
---
# Source: https://docs.galileo.ai/galileo/gen-ai-studio-products/galileo-evaluate/concepts/human-ratings.md
> ## Documentation Index
> Fetch the complete documentation index at: https://docs.galileo.ai/llms.txt
> Use this file to discover all available pages before exploring further.
# Human Ratings
> Learn how human ratings in Galileo Evaluate enable accurate model evaluations and improve performance through qualitative feedback.
What are Galileo human ratings?
Galileo allows users to create or rate [runs](/galileo/gen-ai-studio-products/galileo-evaluate/concepts/run) based on human ratings offering inside of [Galileo Evaluate](/galileo/gen-ai-studio-products/galileo-evaluate). Human ratings show in the Feedback section inside of Galileo Evaluate to offer the capability to see these ratings side-by-side with the runs and customize them based on the goals of the human rating. They allow users to add their own rating to a given run. The human rating types offered include:
* /
* 1 - 5
* Numerical ratings
* Categorical ratings (self-defined categories)
* Free-form text
Along with each rating, you can also allow users to provide a rationale. These ratings are aggregated against all of the runs in a [project](/galileo/gen-ai-studio-products/galileo-evaluate/concepts/project) or run.
Get started with:
Rapid Evaluation of Prompts, Chains and RAG systems
Real-time Observability for GenAI Apps and Models
Real-time Request and Response Interception
### Want to try Galileo? Get in touch with us [here](https://www.rungalileo.io/get-started)!
---
# Source: https://docs.galileo.ai/deployments/scheduling-automatic-backups-for-your-cluster/gcp-velero-account-setup-script.md
> ## Documentation Index
> Fetch the complete documentation index at: https://docs.galileo.ai/llms.txt
> Use this file to discover all available pages before exploring further.
# Gcp Velero Account Setup Script
> Set up Velero for Google Cloud backups with this GCP account script, enabling automated backup scheduling and robust data protection for Galileo clusters.
```
#!/bin/sh -e
# Usage
# ./velero-account-setup-gcp.sh
#
#
GSA_NAME=velero
ROLE_PERMISSIONS=(
compute.disks.get
compute.disks.create
compute.disks.createSnapshot
compute.snapshots.get
compute.snapshots.create
compute.snapshots.useReadOnly
compute.snapshots.delete
compute.zones.get
storage.objects.create
storage.objects.delete
storage.objects.get
storage.objects.list
)
print_usage() {
echo -e "\n Usage: \n ./velero-account-setup-gcp.sh \n"
}
BUCKET="${1}"
if [ -z "$BUCKET" ]; then
print_usage
exit 1
fi
gsutil mb gs://$BUCKET
PROJECT_ID=$(gcloud config get-value project)
gcloud iam service-accounts create $GSA_NAME \
--display-name "Velero service account"
SERVICE_ACCOUNT_EMAIL=$(gcloud iam service-accounts list \
--filter="displayName:Velero service account" \
--format 'value(email)')
gcloud iam roles create velero.server \
--project $PROJECT_ID \
--title "Velero Server" \
--permissions "$(IFS=","; echo "${ROLE_PERMISSIONS[*]}")"
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member serviceAccount:$SERVICE_ACCOUNT_EMAIL \
--role projects/$PROJECT_ID/roles/velero.server
gsutil iam ch serviceAccount:$SERVICE_ACCOUNT_EMAIL:objectAdmin gs://${BUCKET}
gcloud iam service-accounts keys create credentials-velero \
--iam-account $SERVICE_ACCOUNT_EMAIL
```
---
# Source: https://docs.galileo.ai/api-reference/evaluate/get-evaluate-run-results.md
> ## Documentation Index
> Fetch the complete documentation index at: https://docs.galileo.ai/llms.txt
> Use this file to discover all available pages before exploring further.
# Get Evaluate Run Results
> Fetch evaluation results for a specific run including rows and aggregate information.
## OpenAPI
````yaml https://api.staging.galileo.ai/public/v1/openapi.json post /v1/evaluate/run-workflows
openapi: 3.1.0
info:
title: FastAPI
version: 0.1.0
servers:
- url: https://api.staging.galileo.ai
description: Galileo Public APIs - staging
security: []
paths:
/v1/evaluate/run-workflows:
post:
tags:
- evaluate
summary: Get Evaluate Run Results
description: >-
Fetch evaluation results for a specific run including rows and aggregate
information.
operationId: get_evaluate_run_results_v1_evaluate_run_workflows_post
requestBody:
content:
application/json:
schema:
$ref: '#/components/schemas/EvaluateRunResultsRequest'
required: true
responses:
'200':
description: Successful Response
content:
application/json:
schema:
$ref: '#/components/schemas/WorkflowsReadResponse'
'422':
description: Validation Error
content:
application/json:
schema:
$ref: '#/components/schemas/HTTPValidationError'
security:
- APIKeyHeader: []
- OAuth2PasswordBearer: []
- HTTPBasic: []
components:
schemas:
EvaluateRunResultsRequest:
properties:
starting_token:
type: integer
title: Starting Token
default: 0
limit:
type: integer
title: Limit
default: 100
project_id:
anyOf:
- type: string
format: uuid4
- type: 'null'
title: Project Id
project_name:
anyOf:
- type: string
- type: 'null'
title: Project Name
run_id:
anyOf:
- type: string
format: uuid4
- type: 'null'
title: Run Id
run_name:
anyOf:
- type: string
- type: 'null'
title: Run Name
type: object
title: EvaluateRunResultsRequest
WorkflowsReadResponse:
properties:
starting_token:
type: integer
title: Starting Token
default: 0
limit:
type: integer
title: Limit
default: 100
paginated:
type: boolean
title: Paginated
default: false
next_starting_token:
anyOf:
- type: integer
- type: 'null'
title: Next Starting Token
workflows:
items:
$ref: '#/components/schemas/BaseGalileoStep'
type: array
title: Workflows
type: object
required:
- workflows
title: WorkflowsReadResponse
description: Response model for workflow evaluation results
HTTPValidationError:
properties:
detail:
items:
$ref: '#/components/schemas/ValidationError'
type: array
title: Detail
type: object
title: HTTPValidationError
BaseGalileoStep:
properties:
type:
$ref: '#/components/schemas/NodeType'
description: Type of the step. By default, it is set to workflow.
default: workflow
input:
type: string
title: Input
description: Input to the step.
redacted_input:
type: string
title: Redacted Input
description: >-
Redacted input of the step. This is used to redact sensitive
information.
output:
type: string
title: Output
description: Output of the step.
redacted_output:
type: string
title: Redacted Output
description: >-
Redacted output of the step. This is used to redact sensitive
information.
name:
type: string
title: Name
description: Name of the step.
default: ''
created_at_ns:
type: integer
title: Created At Ns
description: Timestamp of the step's creation, as nanoseconds since epoch.
duration_ns:
type: integer
title: Duration Ns
description: Duration of the step in nanoseconds.
default: 0
metadata:
additionalProperties:
type: string
type: object
title: Metadata
description: Metadata associated with this step.
status_code:
anyOf:
- type: integer
- type: 'null'
title: Status Code
description: Status code of the step. Used for logging failed/errored steps.
ground_truth:
anyOf:
- type: string
- type: 'null'
title: Ground Truth
description: Ground truth expected output for the step.
root_workflow_id:
anyOf:
- type: string
format: uuid4
- type: 'null'
title: Root Workflow Id
workflow_id:
anyOf:
- type: string
format: uuid4
- type: 'null'
title: Workflow Id
step_id:
anyOf:
- type: string
format: uuid4
- type: 'null'
title: Step Id
steps:
anyOf:
- items:
$ref: '#/components/schemas/BaseGalileoStep'
type: array
- type: 'null'
title: Steps
metrics:
items:
$ref: '#/components/schemas/StepMetric'
type: array
title: Metrics
additionalProperties: true
type: object
required:
- input
title: BaseGalileoStep
ValidationError:
properties:
loc:
items:
anyOf:
- type: string
- type: integer
type: array
title: Location
msg:
type: string
title: Message
type:
type: string
title: Error Type
type: object
required:
- loc
- msg
- type
title: ValidationError
NodeType:
type: string
enum:
- chain
- chat
- llm
- retriever
- tool
- agent
- workflow
- trace
- session
title: NodeType
StepMetric:
properties:
name:
type: string
title: Name
value:
title: Value
status:
anyOf:
- type: string
- type: 'null'
title: Status
explanation:
anyOf:
- type: string
- type: 'null'
title: Explanation
rationale:
anyOf:
- type: string
- type: 'null'
title: Rationale
cost:
anyOf:
- type: number
- type: 'null'
title: Cost
model_alias:
anyOf:
- type: string
- type: 'null'
title: Model Alias
num_judges:
anyOf:
- type: integer
- type: 'null'
title: Num Judges
display_value:
anyOf:
- {}
- type: 'null'
title: Display Value
data_type:
$ref: '#/components/schemas/DataTypeOptions'
default: unknown
type: object
required:
- name
- value
title: StepMetric
DataTypeOptions:
type: string
enum:
- unknown
- text
- label
- floating_point
- integer
- timestamp
- milli_seconds
- boolean
- uuid
- percentage
- dollars
- array
- template_label
- thumb_rating_percentage
- user_id
- text_offsets
- segments
- hallucination_segments
- thumb_rating
- score_rating
- star_rating
- tags_rating
- thumb_rating_aggregate
- score_rating_aggregate
- star_rating_aggregate
- tags_rating_aggregate
title: DataTypeOptions
securitySchemes:
APIKeyHeader:
type: apiKey
in: header
name: Galileo-API-Key
OAuth2PasswordBearer:
type: oauth2
flows:
password:
scopes: {}
tokenUrl: https://api.staging.galileo.ai/login
HTTPBasic:
type: http
scheme: basic
````
---
# Source: https://docs.galileo.ai/api-reference/auth/get-token.md
> ## Documentation Index
> Fetch the complete documentation index at: https://docs.galileo.ai/llms.txt
> Use this file to discover all available pages before exploring further.
# Get Token
## OpenAPI
````yaml https://api.staging.galileo.ai/public/v1/openapi.json get /v1/token
openapi: 3.1.0
info:
title: FastAPI
version: 0.1.0
servers:
- url: https://api.staging.galileo.ai
description: Galileo Public APIs - staging
security: []
paths:
/v1/token:
get:
tags:
- auth
summary: Get Token
operationId: get_token_v1_token_get
parameters:
- name: organization_id
in: query
required: false
schema:
anyOf:
- type: string
format: uuid4
- type: 'null'
title: Organization Id
- name: organization_slug
in: query
required: false
schema:
anyOf:
- type: string
- type: 'null'
title: Organization Slug
responses:
'200':
description: Successful Response
content:
application/json:
schema:
$ref: '#/components/schemas/GetTokenResponse'
'422':
description: Validation Error
content:
application/json:
schema:
$ref: '#/components/schemas/HTTPValidationError'
security:
- APIKeyHeader: []
- OAuth2PasswordBearer: []
- HTTPBasic: []
components:
schemas:
GetTokenResponse:
properties:
access_token:
type: string
title: Access Token
token_type:
type: string
title: Token Type
default: bearer
expires_at:
type: string
format: date-time
title: Expires At
type: object
required:
- access_token
- expires_at
title: GetTokenResponse
HTTPValidationError:
properties:
detail:
items:
$ref: '#/components/schemas/ValidationError'
type: array
title: Detail
type: object
title: HTTPValidationError
ValidationError:
properties:
loc:
items:
anyOf:
- type: string
- type: integer
type: array
title: Location
msg:
type: string
title: Message
type:
type: string
title: Error Type
type: object
required:
- loc
- msg
- type
title: ValidationError
securitySchemes:
APIKeyHeader:
type: apiKey
in: header
name: Galileo-API-Key
OAuth2PasswordBearer:
type: oauth2
flows:
password:
scopes: {}
tokenUrl: https://api.staging.galileo.ai/login
HTTPBasic:
type: http
scheme: basic
````
---
# Source: https://docs.galileo.ai/api-reference/observe/get-workflows.md
> ## Documentation Index
> Fetch the complete documentation index at: https://docs.galileo.ai/llms.txt
> Use this file to discover all available pages before exploring further.
# Get Workflows
> Get workflows for a specific run in an Observe project.
## OpenAPI
````yaml https://api.staging.galileo.ai/public/v1/openapi.json post /v1/observe/projects/{project_id}/workflows
openapi: 3.1.0
info:
title: FastAPI
version: 0.1.0
servers:
- url: https://api.staging.galileo.ai
description: Galileo Public APIs - staging
security: []
paths:
/v1/observe/projects/{project_id}/workflows:
post:
tags:
- observe
summary: Get Workflows
description: Get workflows for a specific run in an Observe project.
operationId: get_workflows_v1_observe_projects__project_id__workflows_post
parameters:
- name: project_id
in: path
required: true
schema:
type: string
format: uuid4
title: Project Id
- name: start_time
in: query
required: false
schema:
anyOf:
- type: string
format: date-time
- type: 'null'
title: Start Time
- name: end_time
in: query
required: false
schema:
anyOf:
- type: string
format: date-time
- type: 'null'
title: End Time
requestBody:
content:
application/json:
schema:
$ref: '#/components/schemas/GetObserveWorkflowsRequest'
responses:
'200':
description: Successful Response
content:
application/json:
schema:
$ref: '#/components/schemas/WorkflowsReadResponse'
'422':
description: Validation Error
content:
application/json:
schema:
$ref: '#/components/schemas/HTTPValidationError'
security:
- APIKeyHeader: []
- OAuth2PasswordBearer: []
- HTTPBasic: []
components:
schemas:
GetObserveWorkflowsRequest:
properties:
starting_token:
type: integer
title: Starting Token
default: 0
limit:
type: integer
title: Limit
default: 100
filters:
items:
oneOf:
- $ref: '#/components/schemas/UserMetadataFilter'
discriminator:
propertyName: name
mapping:
user_metadata: '#/components/schemas/UserMetadataFilter'
type: array
title: Filters
type: object
title: GetObserveWorkflowsRequest
WorkflowsReadResponse:
properties:
starting_token:
type: integer
title: Starting Token
default: 0
limit:
type: integer
title: Limit
default: 100
paginated:
type: boolean
title: Paginated
default: false
next_starting_token:
anyOf:
- type: integer
- type: 'null'
title: Next Starting Token
workflows:
items:
$ref: '#/components/schemas/BaseGalileoStep'
type: array
title: Workflows
type: object
required:
- workflows
title: WorkflowsReadResponse
description: Response model for workflow evaluation results
HTTPValidationError:
properties:
detail:
items:
$ref: '#/components/schemas/ValidationError'
type: array
title: Detail
type: object
title: HTTPValidationError
UserMetadataFilter:
properties:
name:
type: string
const: user_metadata
title: Name
default: user_metadata
operator:
type: string
enum:
- one_of
- not_in
- eq
- ne
title: Operator
key:
type: string
title: Key
value:
anyOf:
- type: string
- items:
type: string
type: array
title: Value
type: object
required:
- operator
- key
- value
title: UserMetadataFilter
BaseGalileoStep:
properties:
type:
$ref: '#/components/schemas/NodeType'
description: Type of the step. By default, it is set to workflow.
default: workflow
input:
type: string
title: Input
description: Input to the step.
redacted_input:
type: string
title: Redacted Input
description: >-
Redacted input of the step. This is used to redact sensitive
information.
output:
type: string
title: Output
description: Output of the step.
redacted_output:
type: string
title: Redacted Output
description: >-
Redacted output of the step. This is used to redact sensitive
information.
name:
type: string
title: Name
description: Name of the step.
default: ''
created_at_ns:
type: integer
title: Created At Ns
description: Timestamp of the step's creation, as nanoseconds since epoch.
duration_ns:
type: integer
title: Duration Ns
description: Duration of the step in nanoseconds.
default: 0
metadata:
additionalProperties:
type: string
type: object
title: Metadata
description: Metadata associated with this step.
status_code:
anyOf:
- type: integer
- type: 'null'
title: Status Code
description: Status code of the step. Used for logging failed/errored steps.
ground_truth:
anyOf:
- type: string
- type: 'null'
title: Ground Truth
description: Ground truth expected output for the step.
root_workflow_id:
anyOf:
- type: string
format: uuid4
- type: 'null'
title: Root Workflow Id
workflow_id:
anyOf:
- type: string
format: uuid4
- type: 'null'
title: Workflow Id
step_id:
anyOf:
- type: string
format: uuid4
- type: 'null'
title: Step Id
steps:
anyOf:
- items:
$ref: '#/components/schemas/BaseGalileoStep'
type: array
- type: 'null'
title: Steps
metrics:
items:
$ref: '#/components/schemas/StepMetric'
type: array
title: Metrics
additionalProperties: true
type: object
required:
- input
title: BaseGalileoStep
ValidationError:
properties:
loc:
items:
anyOf:
- type: string
- type: integer
type: array
title: Location
msg:
type: string
title: Message
type:
type: string
title: Error Type
type: object
required:
- loc
- msg
- type
title: ValidationError
NodeType:
type: string
enum:
- chain
- chat
- llm
- retriever
- tool
- agent
- workflow
- trace
- session
title: NodeType
StepMetric:
properties:
name:
type: string
title: Name
value:
title: Value
status:
anyOf:
- type: string
- type: 'null'
title: Status
explanation:
anyOf:
- type: string
- type: 'null'
title: Explanation
rationale:
anyOf:
- type: string
- type: 'null'
title: Rationale
cost:
anyOf:
- type: number
- type: 'null'
title: Cost
model_alias:
anyOf:
- type: string
- type: 'null'
title: Model Alias
num_judges:
anyOf:
- type: integer
- type: 'null'
title: Num Judges
display_value:
anyOf:
- {}
- type: 'null'
title: Display Value
data_type:
$ref: '#/components/schemas/DataTypeOptions'
default: unknown
type: object
required:
- name
- value
title: StepMetric
DataTypeOptions:
type: string
enum:
- unknown
- text
- label
- floating_point
- integer
- timestamp
- milli_seconds
- boolean
- uuid
- percentage
- dollars
- array
- template_label
- thumb_rating_percentage
- user_id
- text_offsets
- segments
- hallucination_segments
- thumb_rating
- score_rating
- star_rating
- tags_rating
- thumb_rating_aggregate
- score_rating_aggregate
- star_rating_aggregate
- tags_rating_aggregate
title: DataTypeOptions
securitySchemes:
APIKeyHeader:
type: apiKey
in: header
name: Galileo-API-Key
OAuth2PasswordBearer:
type: oauth2
flows:
password:
scopes: {}
tokenUrl: https://api.staging.galileo.ai/login
HTTPBasic:
type: http
scheme: basic
````
---
# Source: https://docs.galileo.ai/galileo/gen-ai-studio-products/galileo-observe/getting-started.md
# Source: https://docs.galileo.ai/galileo/galileo-nlp-studio/text-classification/getting-started.md
# Source: https://docs.galileo.ai/galileo/galileo-nlp-studio/natural-language-inference/getting-started.md
# Source: https://docs.galileo.ai/galileo/galileo-nlp-studio/named-entity-recognition/getting-started.md
# Source: https://docs.galileo.ai/galileo/galileo-nlp-studio/multi-label-text-classification/getting-started.md
# Source: https://docs.galileo.ai/api-reference/getting-started.md
> ## Documentation Index
> Fetch the complete documentation index at: https://docs.galileo.ai/llms.txt
> Use this file to discover all available pages before exploring further.
# API Reference | Getting Started with Galileo
> Get started with Galileo's REST API: learn about base URLs, authentication methods, and how to verify your API setup for seamless integration.
Galileo provides a public REST API that you can use to interact with the Galileo platform. This API allows you to perform various operations across Evaluate, Observe and Protect. This guide will help you get started with the Galileo REST API.
## Base API URL
The first thing you need to talk to the Galileo API is the base URL of your Galileo API instance.
If you know the URL that you use to access the Galileo console, you can replace `console` in it with `api`. For example, if your Galileo console URL is `https://console.galileo.myenterprise.com`, then your base URL for the API is `https://api.galileo.myenterprise.com`.
### Verify the Base URL
To verify the base URL of your Galileo API instance, you can send a `GET` request to the [`healthcheck` endpoint](/api-reference/health/healthcheck).
```bash theme={null}
curl -X GET https://api.galileo.myenterprise.com/v1/healthcheck
```
## Authentication
For interacting with our public endpoints, you can use any of the following methods to authenticate your requests:
### API Key
To use your [API key](/galileo/gen-ai-studio-products/galileo-evaluate/quickstart#getting-an-api-key) to authenticate your requests, include the key in the HTTP headers for your requests.
```json theme={null}
{ "Galileo-API-Key": "" }
```
### HTTP Basic Auth
To use HTTP Basic Auth to authenticate your requests, include your username and password in the HTTP headers for your requests.
```json theme={null}
{ "Authorization": "Basic :)>" }
```
### JWT Token
To use a JWT token to authenticate your requests, include the token in the HTTP headers for your requests.
```json theme={null}
{ "Authorization": "Bearer " }
```
We recommend using this method for high-volume requests because it is more secure (expires after 24 hours) and scalable than using an API key.
To generate a JWT token, send a `GET` request to the [`get-token` endpoint](/api-reference/auth/get-token) using the API Key or HTTP Basic auth.
---
# Source: https://docs.galileo.ai/galileo/gen-ai-studio-products/galileo-guardrail-metrics/ground-truth-adherence.md
> ## Documentation Index
> Fetch the complete documentation index at: https://docs.galileo.ai/llms.txt
> Use this file to discover all available pages before exploring further.
# Ground Truth Adherence
> Measure ground truth adherence in generative AI models with Galileo's Guardrail Metrics, ensuring accurate and aligned outputs with dataset benchmarks.
***Definition:*** Measures whether the model's response is semantically equivalent to your Ground Truth.
If the response has a *High Ground Truth Adherence* (i.e. it has a value of 1 or close to 1), the model's response was semantically equivalent to the Groud Truth. If a response has a *Low Ground Truth Adherence* (i.e. it has a value of 0 or close to 0), the model's response is likely semantically different from the Ground Truth.
*Note:* This metric requires a Ground Truth to be set. Check out [this page](/galileo/gen-ai-studio-products/galileo-evaluate/how-to/logging-and-comparing-against-your-expected-answers) to learn how to add a Ground Truth to your runs.
***Calculation:*** *Ground Truth Adherence* is computed by sending additional requests to OpenAI's GPT4o, using a carefully engineered chain-of-thought prompt that asks the model to judge whether or not the Ground Truth and Response are equivalent. The metric requests multiple distinct responses to this prompt, each of which produces an explanation along with a final judgment: yes or no. The Ground Truth Adherence score is the fraction of "yes" responses, divided by the total number of responses.
We also surface one of the generated explanations. The surfaced explanation is always chosen to align with the majority judgment among the responses.
*Note:* This metric is computed by prompting an LLM multiple times, and thus requires additional LLM calls to compute.
---
# Source: https://docs.galileo.ai/api-reference/health/healthcheck.md
> ## Documentation Index
> Fetch the complete documentation index at: https://docs.galileo.ai/llms.txt
> Use this file to discover all available pages before exploring further.
# Healthcheck
## OpenAPI
````yaml https://api.staging.galileo.ai/public/v1/openapi.json get /v1/healthcheck
openapi: 3.1.0
info:
title: FastAPI
version: 0.1.0
servers:
- url: https://api.staging.galileo.ai
description: Galileo Public APIs - staging
security: []
paths:
/v1/healthcheck:
get:
tags:
- health
summary: Healthcheck
operationId: healthcheck_v1_healthcheck_get
responses:
'200':
description: Successful Response
content:
application/json:
schema:
$ref: '#/components/schemas/HealthcheckResponse'
components:
schemas:
HealthcheckResponse:
properties:
api_version:
type: string
title: Api Version
message:
type: string
title: Message
version:
type: string
title: Version
type: object
required:
- api_version
- message
- version
title: HealthcheckResponse
````
---
# Source: https://docs.galileo.ai/galileo/gen-ai-studio-products/galileo-protect/how-to.md
# Source: https://docs.galileo.ai/galileo/gen-ai-studio-products/galileo-observe/how-to.md
# Source: https://docs.galileo.ai/galileo/gen-ai-studio-products/galileo-evaluate/how-to.md
> ## Documentation Index
> Fetch the complete documentation index at: https://docs.galileo.ai/llms.txt
> Use this file to discover all available pages before exploring further.
# How-To Guide | Galileo Evaluate
> Follow step-by-step instructions in Galileo Evaluate to assess generative AI models, configure metrics, and analyze performance effectively.
### Logging Runs
### Use Cases
### Prompt Engineering
### Metrics
### Getting Insights
### Collaboration
### Advanced Features
### Best Practices
{" "}
---
# Source: https://docs.galileo.ai/galileo/gen-ai-studio-products/galileo-evaluate/concepts/human-ratings.md
> ## Documentation Index
> Fetch the complete documentation index at: https://docs.galileo.ai/llms.txt
> Use this file to discover all available pages before exploring further.
# Human Ratings
> Learn how human ratings in Galileo Evaluate enable accurate model evaluations and improve performance through qualitative feedback.
What are Galileo human ratings?
Galileo allows users to create or rate [runs](/galileo/gen-ai-studio-products/galileo-evaluate/concepts/run) based on human ratings offering inside of [Galileo Evaluate](/galileo/gen-ai-studio-products/galileo-evaluate). Human ratings show in the Feedback section inside of Galileo Evaluate to offer the capability to see these ratings side-by-side with the runs and customize them based on the goals of the human rating. They allow users to add their own rating to a given run. The human rating types offered include:
* /
* 1 - 5
* Numerical ratings
* Categorical ratings (self-defined categories)
* Free-form text
Along with each rating, you can also allow users to provide a rationale. These ratings are aggregated against all of the runs in a [project](/galileo/gen-ai-studio-products/galileo-evaluate/concepts/project) or run.
 Human ratings are a great way to extend Galileo's generative AI evaluation platform to meet the needs of human evaluators, reviewers, business users, subject matter experts, data scientists, or developers. Because they are entirely customizable (through the Configure button) they can enable users to add their own feedback to a run. This is helpful in cases where [metrics](/galileo/gen-ai-studio-products/galileo-evaluate/concepts/metrics) don't capture everything being evaluated, review of metrics is being done, or additional information is gathered during evaluation. For more information, visit the [Evaluate with Human Feedback](/galileo/gen-ai-studio-products/galileo-evaluate/how-to/evaluate-with-human-feedback) page.
---
# Source: https://docs.galileo.ai/galileo/gen-ai-studio-products/galileo-evaluate/how-to/identify-hallucinations.md
> ## Documentation Index
> Fetch the complete documentation index at: https://docs.galileo.ai/llms.txt
> Use this file to discover all available pages before exploring further.
# Identify Hallucinations
> How to use Galileo Evaluate to find Hallucinations
*Hallucination* can have many definitions. In the realm of closed-book question answering, hallucinations may pertain to *Correctness* (i.e. is my output factually consistent). In open-book scenarios, hallucinations might be linked to the grounding of information or *Adherence* (i.e., whether the facts presented in my response "**adhere to**" or "**are grounded in**" the documents I supplied). Hallucinations happen when models produce responses outside of the context being forced upon the model via the prompt.Galileo aims to help you identify and solve these hallucinations.
## Guardrail Metrics
Galileo's Guardrail Metrics are built to help you shed light on where and why the model produces an undesirable output.
### Uncertainty
Uncertainty measures the model's certainty in its generated tokens. Because uncertainty works at the token level, it can be a great way of identifying *where* in the response the model started hallucinating.
When prompted for citations of papers on the phenomenon of "Human & AI collaboration", OpenAI's ChatGPT responds with this:
Human ratings are a great way to extend Galileo's generative AI evaluation platform to meet the needs of human evaluators, reviewers, business users, subject matter experts, data scientists, or developers. Because they are entirely customizable (through the Configure button) they can enable users to add their own feedback to a run. This is helpful in cases where [metrics](/galileo/gen-ai-studio-products/galileo-evaluate/concepts/metrics) don't capture everything being evaluated, review of metrics is being done, or additional information is gathered during evaluation. For more information, visit the [Evaluate with Human Feedback](/galileo/gen-ai-studio-products/galileo-evaluate/how-to/evaluate-with-human-feedback) page.
---
# Source: https://docs.galileo.ai/galileo/gen-ai-studio-products/galileo-evaluate/how-to/identify-hallucinations.md
> ## Documentation Index
> Fetch the complete documentation index at: https://docs.galileo.ai/llms.txt
> Use this file to discover all available pages before exploring further.
# Identify Hallucinations
> How to use Galileo Evaluate to find Hallucinations
*Hallucination* can have many definitions. In the realm of closed-book question answering, hallucinations may pertain to *Correctness* (i.e. is my output factually consistent). In open-book scenarios, hallucinations might be linked to the grounding of information or *Adherence* (i.e., whether the facts presented in my response "**adhere to**" or "**are grounded in**" the documents I supplied). Hallucinations happen when models produce responses outside of the context being forced upon the model via the prompt.Galileo aims to help you identify and solve these hallucinations.
## Guardrail Metrics
Galileo's Guardrail Metrics are built to help you shed light on where and why the model produces an undesirable output.
### Uncertainty
Uncertainty measures the model's certainty in its generated tokens. Because uncertainty works at the token level, it can be a great way of identifying *where* in the response the model started hallucinating.
When prompted for citations of papers on the phenomenon of "Human & AI collaboration", OpenAI's ChatGPT responds with this:
 A quick Google Search reveals that the cited paper doesn't exist. The arxiv link takes us to a completely [unrelated paper](https://arxiv.org/abs/1903.03097).
While not every 'high uncertainty' token (shown in red) will contain hallucinations, and not every hallucination will contain high uncertainty tokens, we've seen a strong correlation between the two. Looking for *Uncertainty* is usually a good first step in identifying hallucinations.
*Note:* Uncertainty requires log probabilities and only works for certain models for now.
### Context Adherence
Context Adherence measures whether your model's response was purely based on the context provided, i.e. the response didn't state any facts not contained in the context provided. For RAG users, *Context Adherence* is a measurement of hallucinations.
If a response is *grounded* in the context (i.e. it has a value of 1 or close to 1), it only contains information given in the context. If a response is *not grounded* (i.e. it has a value of 0 or close to 0), it's likely to contain facts not included in the context provided to the model.
A quick Google Search reveals that the cited paper doesn't exist. The arxiv link takes us to a completely [unrelated paper](https://arxiv.org/abs/1903.03097).
While not every 'high uncertainty' token (shown in red) will contain hallucinations, and not every hallucination will contain high uncertainty tokens, we've seen a strong correlation between the two. Looking for *Uncertainty* is usually a good first step in identifying hallucinations.
*Note:* Uncertainty requires log probabilities and only works for certain models for now.
### Context Adherence
Context Adherence measures whether your model's response was purely based on the context provided, i.e. the response didn't state any facts not contained in the context provided. For RAG users, *Context Adherence* is a measurement of hallucinations.
If a response is *grounded* in the context (i.e. it has a value of 1 or close to 1), it only contains information given in the context. If a response is *not grounded* (i.e. it has a value of 0 or close to 0), it's likely to contain facts not included in the context provided to the model.
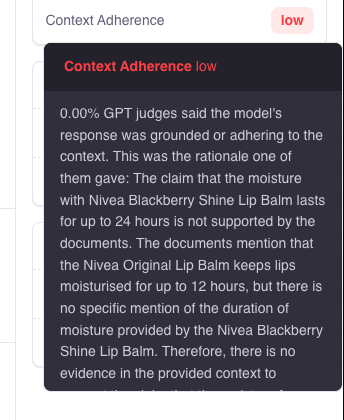 ### Correctness
*Correctness* measures whether the facts stated in the response are based on real facts. This metric requires additional LLM calls.
If the response is *factually consistent* (value close to 1), the information is likely be correct. We use our proprietary **ChainPoll Technique** ([Research Paper Link](https://arxiv.org/abs/2310.18344)) using a combination of Chain-of-Thought prompting and Ensembling techniques to provide the user with a 0-1 score and an explanation to the Hallucination. The explanation why something was deemed incorrect or not can be seen upon hovering over the metric value.
Note
Because **correctness** relies on external Large Language Models and their knowledge base, its results are only as good as those models' knowledge base.
### Correctness
*Correctness* measures whether the facts stated in the response are based on real facts. This metric requires additional LLM calls.
If the response is *factually consistent* (value close to 1), the information is likely be correct. We use our proprietary **ChainPoll Technique** ([Research Paper Link](https://arxiv.org/abs/2310.18344)) using a combination of Chain-of-Thought prompting and Ensembling techniques to provide the user with a 0-1 score and an explanation to the Hallucination. The explanation why something was deemed incorrect or not can be seen upon hovering over the metric value.
Note
Because **correctness** relies on external Large Language Models and their knowledge base, its results are only as good as those models' knowledge base.
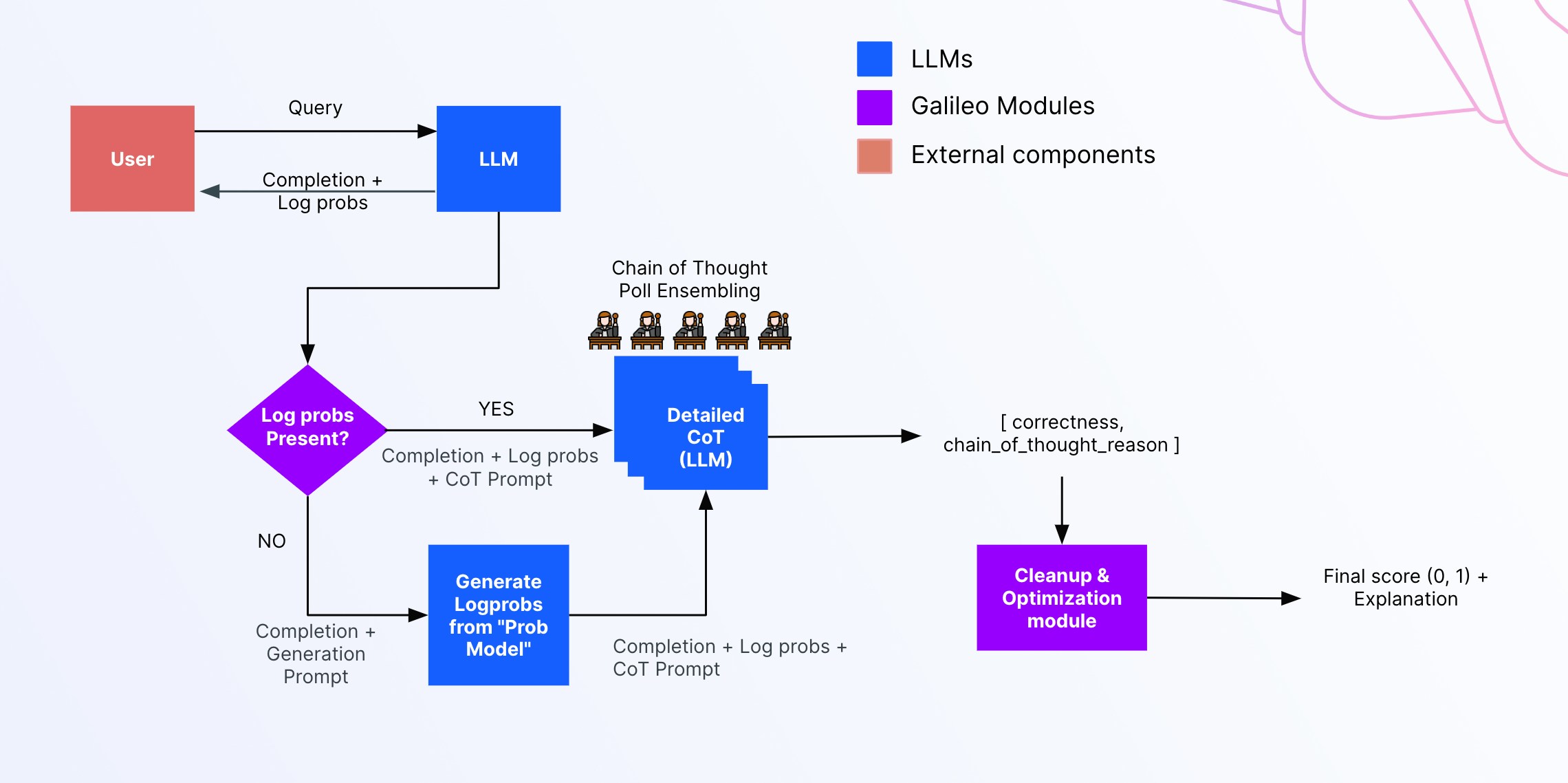 ## What if I have my own definition of Hallucination?
Enterprise users often have their own unique interpretations of what constitutes hallucinations. Galileo supports [*Custom Metrics*](/galileo/gen-ai-studio-products/galileo-evaluate/how-to/choose-your-guardrail-metrics#custom-metrics) and incorporates [*Human Feedback and Ratings*](/galileo/gen-ai-studio-products/galileo-evaluate/how-to/evaluate-with-human-feedback), empowering you to tailor Galileo Prompt to align with your specific needs and the particular definition of hallucinations relevant to your use case.
With Galileo's Experimentation and Evaluation features, you can systematically iterate on your prompts and models, ensuring a rigorous and scientific approach to improving the quality of responses and addressing hallucination-related challenges.
---
# Source: https://docs.galileo.ai/galileo/gen-ai-studio-products/galileo-observe/how-to/identifying-and-debugging-issues.md
> ## Documentation Index
> Fetch the complete documentation index at: https://docs.galileo.ai/llms.txt
> Use this file to discover all available pages before exploring further.
# Identifying And Debugging Issues
> Once your monitored LLM app is up and running and you've selected your Guardrail Metrics, you can start monitoring your LLM app using Galileo.
Charts for Cost, Latency, Usage, API failures, Input/Output Tokens and any of your chosen Guardrail Metrics will appear on the *Metrics* tab.
## What if I have my own definition of Hallucination?
Enterprise users often have their own unique interpretations of what constitutes hallucinations. Galileo supports [*Custom Metrics*](/galileo/gen-ai-studio-products/galileo-evaluate/how-to/choose-your-guardrail-metrics#custom-metrics) and incorporates [*Human Feedback and Ratings*](/galileo/gen-ai-studio-products/galileo-evaluate/how-to/evaluate-with-human-feedback), empowering you to tailor Galileo Prompt to align with your specific needs and the particular definition of hallucinations relevant to your use case.
With Galileo's Experimentation and Evaluation features, you can systematically iterate on your prompts and models, ensuring a rigorous and scientific approach to improving the quality of responses and addressing hallucination-related challenges.
---
# Source: https://docs.galileo.ai/galileo/gen-ai-studio-products/galileo-observe/how-to/identifying-and-debugging-issues.md
> ## Documentation Index
> Fetch the complete documentation index at: https://docs.galileo.ai/llms.txt
> Use this file to discover all available pages before exploring further.
# Identifying And Debugging Issues
> Once your monitored LLM app is up and running and you've selected your Guardrail Metrics, you can start monitoring your LLM app using Galileo.
Charts for Cost, Latency, Usage, API failures, Input/Output Tokens and any of your chosen Guardrail Metrics will appear on the *Metrics* tab.
 You can use the *Time Range* and *Bucket Interval* controls at the top of the screen to control what's being displayed on your screen.
Upon identifying a spike in a particular metric (e.g. a drastic dip in *Groundedness*), click and drag over the spike to filter the requests to that particular window. Then go to the *Data* tab, to see the requests in question that caused the issue.
You can use the *Time Range* and *Bucket Interval* controls at the top of the screen to control what's being displayed on your screen.
Upon identifying a spike in a particular metric (e.g. a drastic dip in *Groundedness*), click and drag over the spike to filter the requests to that particular window. Then go to the *Data* tab, to see the requests in question that caused the issue.
 ---
# Source: https://docs.galileo.ai/galileo/galileo-nlp-studio/galileo-product-features/insights-panel.md
> ## Documentation Index
> Fetch the complete documentation index at: https://docs.galileo.ai/llms.txt
> Use this file to discover all available pages before exploring further.
# Insights Panel
> Utilize Galileo's Insights Panel to analyze data trends, detect issues, and gain actionable insights for improving NLP model performance.
Galileo provides a dynamic *Insights Panel* that provides a bird's eye view of your model's performance on the data currently in scope. Specifically, the Insights Panel contains three sections:
* [Alerts](/galileo/how-to-and-faq/galileo-product-features/xray-insights)
* Metrics (see below)
* [Clusters](/galileo/how-to-and-faq/galileo-product-features/clusters)
**Metrics**
Under the "Metrics" tab you can find a number of charts and insights that update dynamically. Through these charts you can get greater insights into the subset of data you're currently looking at. These content of these charts differ depending on the task type. Generally, they include
* Overall model and dataset metrics
* Class level model performance
* Class level DEP scores
* Class distributions
* Top most misclassified pairs
* Error distributions
* Class Overlap
The Insights Panel allows you to keep a constant check on model performance as you continue the inspection process (through the [Dataset View](/galileo/how-to-and-faq/galileo-product-features/dataset-view) and [Embeddings View](/galileo/how-to-and-faq/galileo-product-features/embeddings-view)).
---
# Source: https://docs.galileo.ai/galileo/galileo-nlp-studio/galileo-product-features/insights-panel.md
> ## Documentation Index
> Fetch the complete documentation index at: https://docs.galileo.ai/llms.txt
> Use this file to discover all available pages before exploring further.
# Insights Panel
> Utilize Galileo's Insights Panel to analyze data trends, detect issues, and gain actionable insights for improving NLP model performance.
Galileo provides a dynamic *Insights Panel* that provides a bird's eye view of your model's performance on the data currently in scope. Specifically, the Insights Panel contains three sections:
* [Alerts](/galileo/how-to-and-faq/galileo-product-features/xray-insights)
* Metrics (see below)
* [Clusters](/galileo/how-to-and-faq/galileo-product-features/clusters)
**Metrics**
Under the "Metrics" tab you can find a number of charts and insights that update dynamically. Through these charts you can get greater insights into the subset of data you're currently looking at. These content of these charts differ depending on the task type. Generally, they include
* Overall model and dataset metrics
* Class level model performance
* Class level DEP scores
* Class distributions
* Top most misclassified pairs
* Error distributions
* Class Overlap
The Insights Panel allows you to keep a constant check on model performance as you continue the inspection process (through the [Dataset View](/galileo/how-to-and-faq/galileo-product-features/dataset-view) and [Embeddings View](/galileo/how-to-and-faq/galileo-product-features/embeddings-view)).
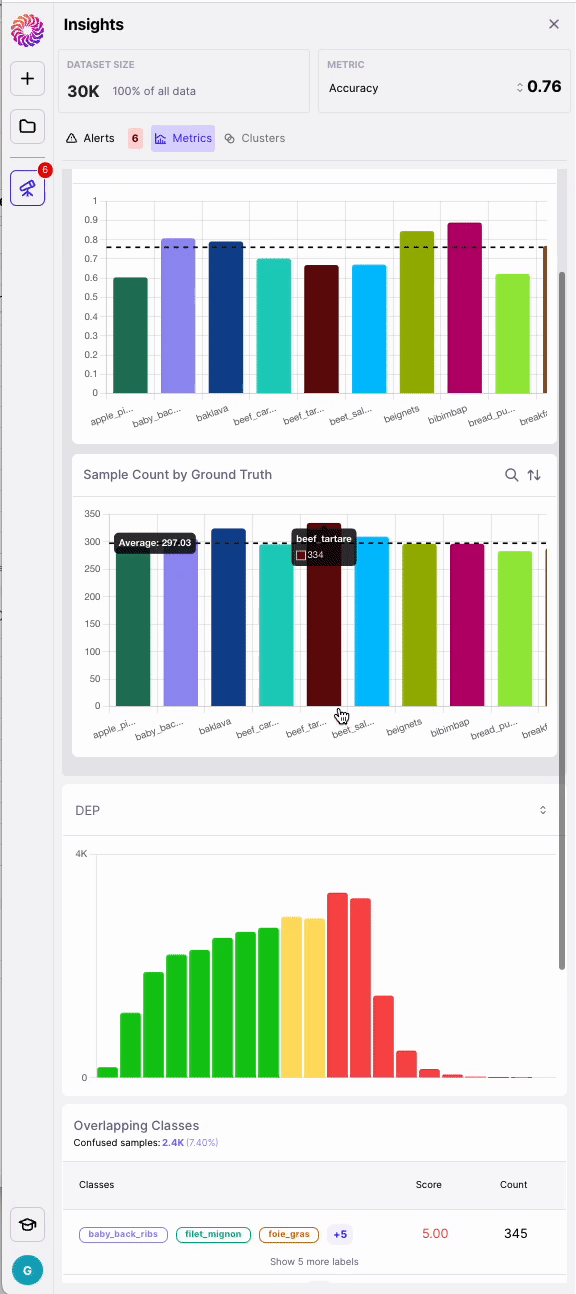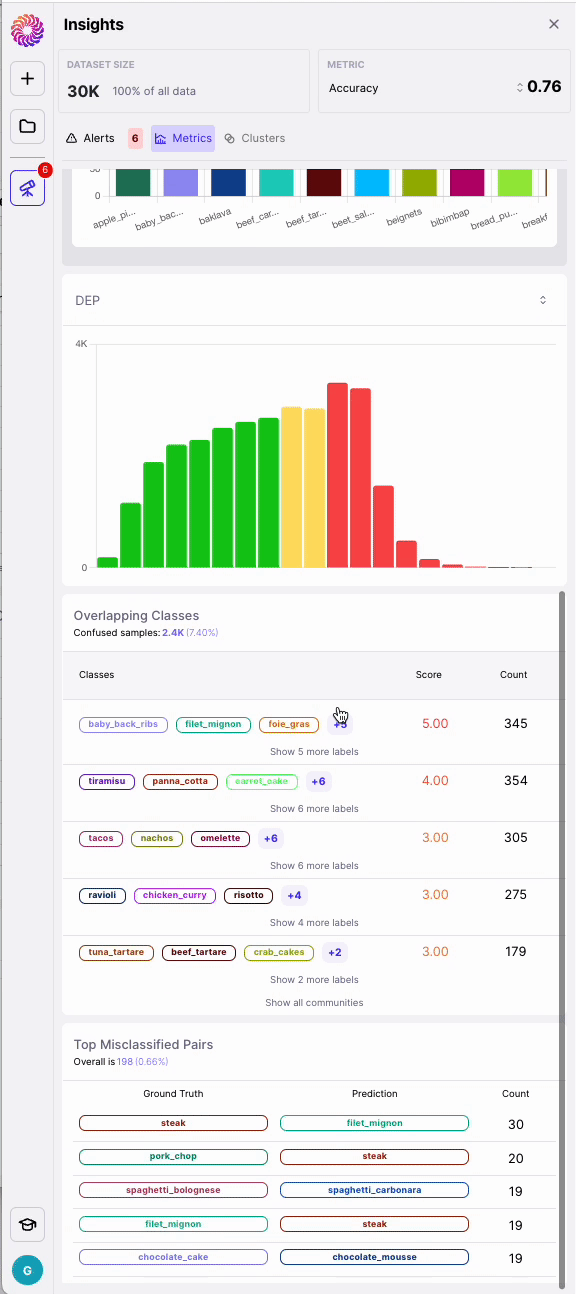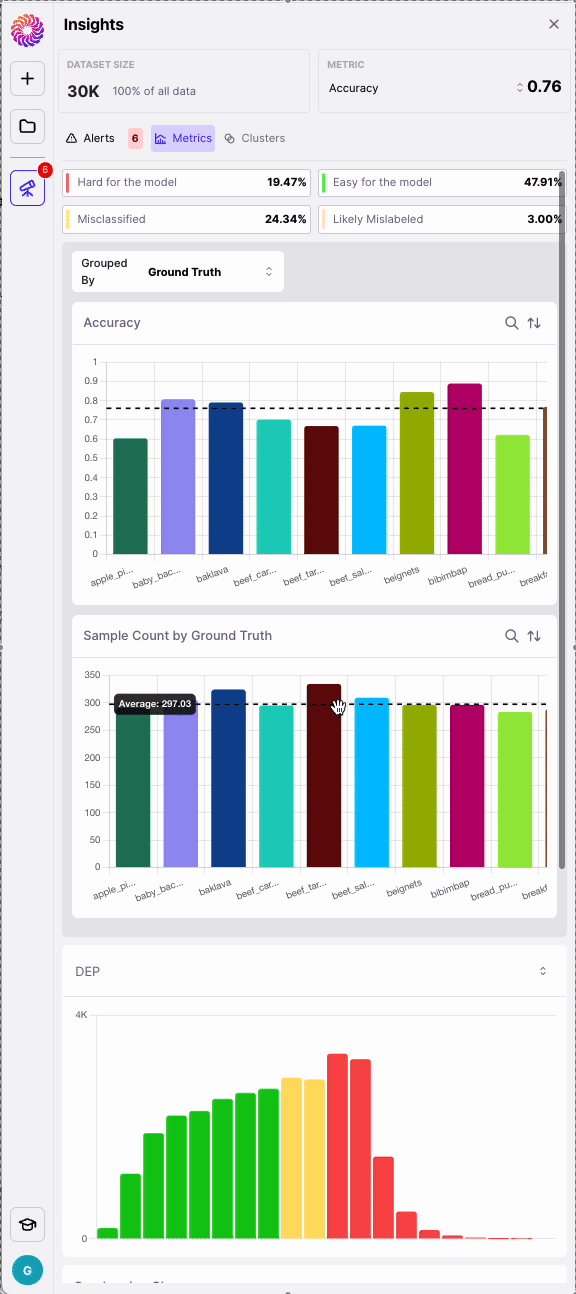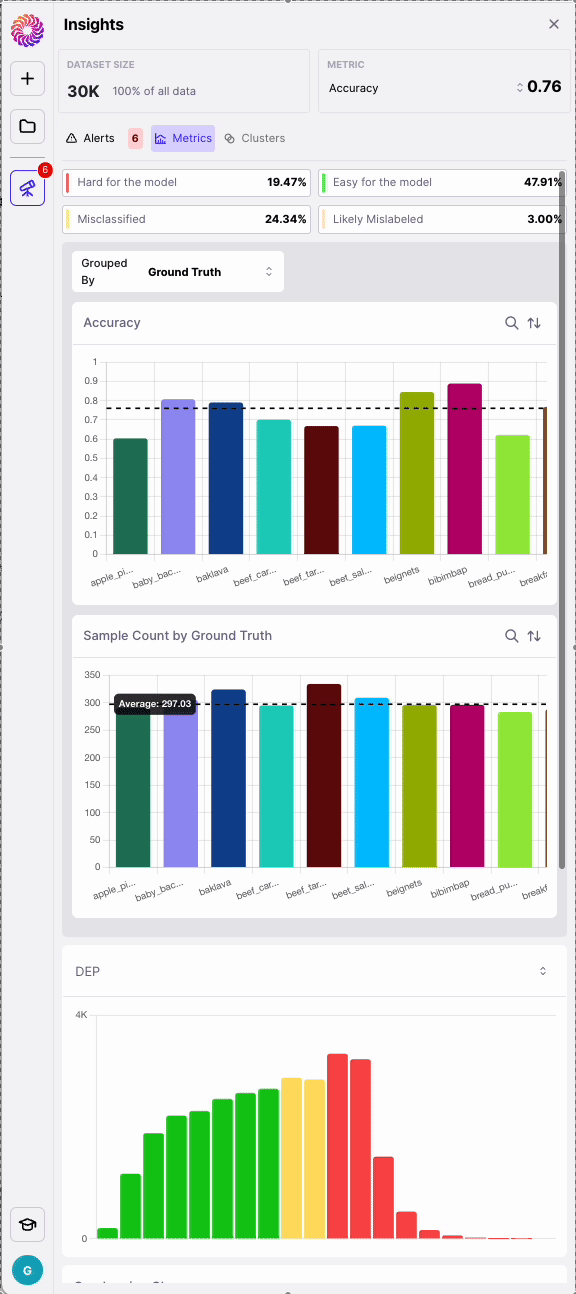 ### Model and Dataset Metrics
The top of the Insights Panel displays aggregate model performance (default to F1 for NLP, Accuracy, mAP and IOU for Image Classification, Object Detection or Semantic Segmentation) and allow you to select between Precision, Recall, and F1. Additionally, the Insights Panel shows the number of current data samples in scope along with what % of the total data is represented.
### Model and Dataset Metrics
The top of the Insights Panel displays aggregate model performance (default to F1 for NLP, Accuracy, mAP and IOU for Image Classification, Object Detection or Semantic Segmentation) and allow you to select between Precision, Recall, and F1. Additionally, the Insights Panel shows the number of current data samples in scope along with what % of the total data is represented.
 ### Class Level Model Performance
Based on the model metric selected (F1, Precision, Recall), the "Model performance" bar chart displays class level model performance.
### Class Level Model Performance
Based on the model metric selected (F1, Precision, Recall), the "Model performance" bar chart displays class level model performance.
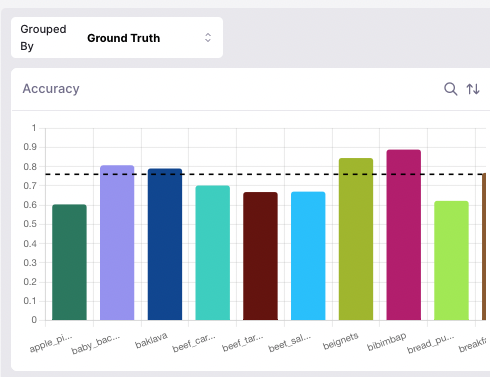 ### Class Distribution
The Class Distribution chart shows the breakdown of samples within each class. This insights chart is critical for quickly drawing insights about the class makeup of the data in scope and for detecting issues with class imbalance.
### Class Distribution
The Class Distribution chart shows the breakdown of samples within each class. This insights chart is critical for quickly drawing insights about the class makeup of the data in scope and for detecting issues with class imbalance.
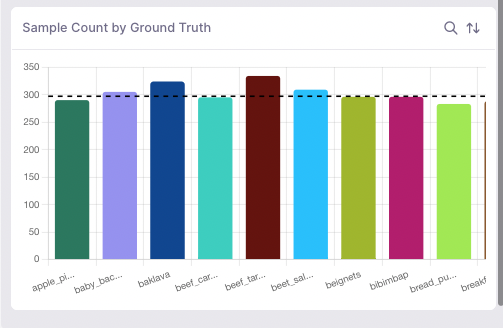 ### Top most misclassified pairs
At the bottom of the Insights Panel we show the "Top five 5 most misclassified data label pairs", where each pair shows a gold label, the incorrect prediction label, and the number of samples falling into this misclassified pairing. This insights chart provides a snapshot into the most common mistakes made by the model (i.e. mistaking ground truth label X for prediction label Y).
### Top most misclassified pairs
At the bottom of the Insights Panel we show the "Top five 5 most misclassified data label pairs", where each pair shows a gold label, the incorrect prediction label, and the number of samples falling into this misclassified pairing. This insights chart provides a snapshot into the most common mistakes made by the model (i.e. mistaking ground truth label X for prediction label Y).
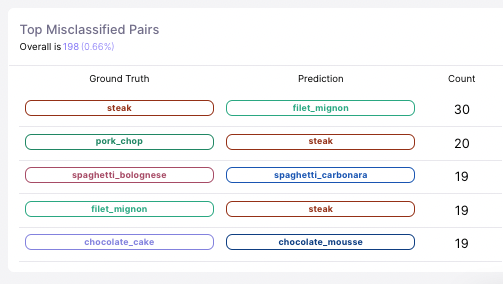 ### Interacting with Insights Charts
In addition to providing visual insights, each insights chart can also be interacted with. Within the "Model performance", "Data Error Potential (DEP)", and "Class distribution" charts selecting one of the bars restricts the data in scope to data with `Gold Label` equal to the selected `bar label`.
An even more powerful interaction exists in the "Top 5 most misclassified label pairs" panel. Clicking on a row within this insights chart filters for *misclassified data* matching the `gold label` and `prediction label` of the misclassified label pair.
### Interacting with Insights Charts
In addition to providing visual insights, each insights chart can also be interacted with. Within the "Model performance", "Data Error Potential (DEP)", and "Class distribution" charts selecting one of the bars restricts the data in scope to data with `Gold Label` equal to the selected `bar label`.
An even more powerful interaction exists in the "Top 5 most misclassified label pairs" panel. Clicking on a row within this insights chart filters for *misclassified data* matching the `gold label` and `prediction label` of the misclassified label pair.
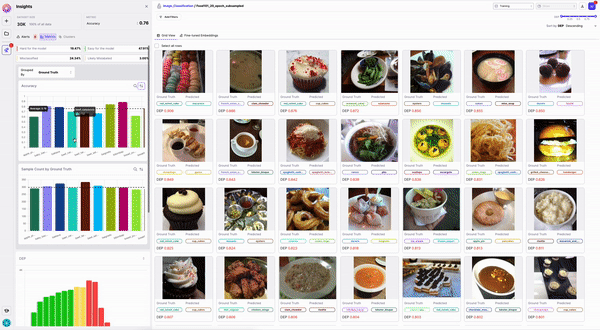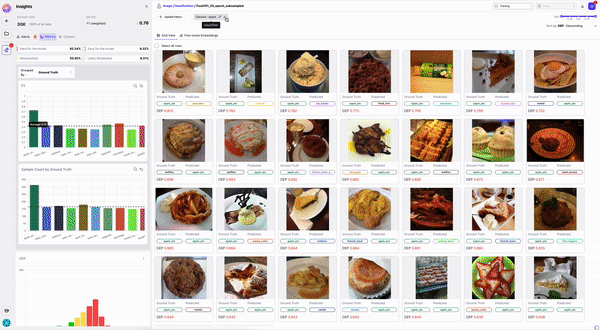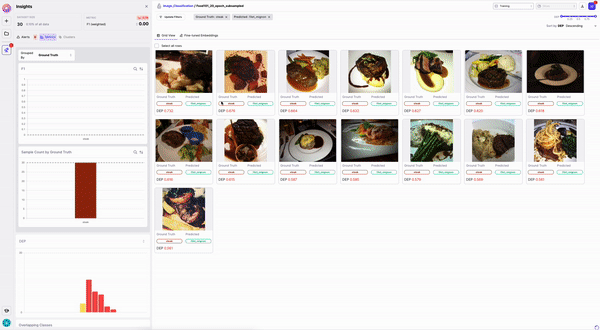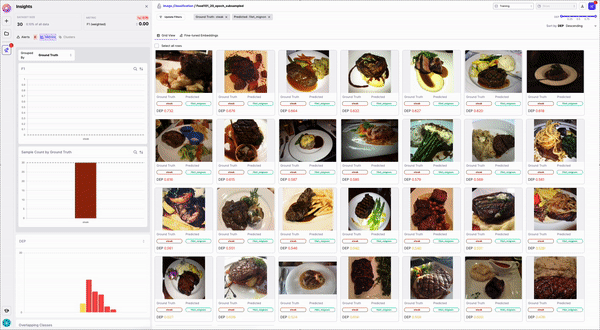 ---
# Source: https://docs.galileo.ai/galileo/gen-ai-studio-products/galileo-guardrail-metrics/instruction-adherence.md
> ## Documentation Index
> Fetch the complete documentation index at: https://docs.galileo.ai/llms.txt
> Use this file to discover all available pages before exploring further.
# Instruction Adherence
> Assess instruction adherence in AI outputs using Galileo Guardrail Metrics to ensure prompt-driven models generate precise and actionable results.
***Definition:*** Measures whether a model followed or adhered to the system or prompt instructions when generating a response. *Instruction Adherence* is a good way to uncover hallucinations where the model is ignoring instructions.
If the response has a *High Instruction Adherence* (i.e. it has a value of 1 or close to 1), the model likely followed its instructions when generating its response. If a response has a *Low Instruction Adherence* (i.e. it has a value of 0 or close to 0), the model likely went off-script and ignored parts of its instructions when generating a response.
***Calculation:*** *Instruction Adherence* is computed by sending additional requests to OpenAI's GPT4o, using a carefully engineered chain-of-thought prompt that asks the model to judge whether or not the response was generated in adherence to the instructions. The metric requests multiple distinct responses to this prompt, each of which produces an explanation along with a final judgment: yes or no. The Instruction Adherence score is the fraction of "yes" responses, divided by the total number of responses.
We also surface one of the generated explanations. The surfaced explanation is always chosen to align with the majority judgment among the responses.
*Note:* This metric is computed by prompting an LLM multiple times, and thus requires additional LLM calls to compute.
***What to do when Instruction Adherence is low?***
When a response has a low Instruction Adherence score, the model likely ignored its instructions when generating the response. We recommend:
1. Flag and examine response that did not follow instructions
2. Experiment with different prompts to see which version the model is more likely to adhere to
3. Take precaution measures to stop non-factual responses from reaching the end user.
***How to differentiate between Instruction Adherence and Context Adherence?***
Context Adherence measures whether the response is adhering to the *Context* provided (e.g. your retrieved documents), whereas Instruction Adherence measures whether the response is adhering to the instructions in your prompt template.
---
# Source: https://docs.galileo.ai/galileo/gen-ai-studio-products/galileo-evaluate/quickstart/integrate-evaluate-into-my-existing-application-with-python.md
> ## Documentation Index
> Fetch the complete documentation index at: https://docs.galileo.ai/llms.txt
> Use this file to discover all available pages before exploring further.
# Integrate Evaluate Into My Existing Application With Python
> Learn how to integrate Galileo Evaluate into your Python applications, featuring step-by-step guidance and code samples for streamlined integration.
If you already have a prototype or an application you're looking to run experiments and evaluations over, Galileo Evaluate allows you to hook into it and log the inputs, outputs, and any intermediate steps to Galileo for further analysis.
In this QuickStart, we'll show you how to:
* Integrate with your workflows
* Integrate with your Langchain apps
Let's dive in!
### Logging Workflows
If you're looking to log your workflows, we provide an interface for uploading your executions.
```py theme={null}
import promptquality as pq
pq.login()
```
```py theme={null}
from promptquality import EvaluateRun
metrics = [pq.Scorers.context_adherence_plus, pq.Scorers.prompt_injection]
evaluate_run = EvaluateRun(run_name="my_run", project_name="my_project", scorers=metrics)
```
```py theme={null}
# Define your inputs.
eval_set = [
"What are hallucinations?",
"What are intrinsic hallucinations?",
"What are extrinsic hallucinations?"
]
# Define your run.
evaluate_run = EvaluateRun(run_name="my_run", project_name="my_project", scorers=metrics)
# Run the evaluation set on your app and log the results.
for input in eval_set:
output = llm.call(input) # Pseudo-code, replace with your LLM call.
evaluate_run.add_single_step_workflow(input=input, output=output, model=)
```
Finally, log your Evaluate run to Galileo:
```py theme={null}
evaluate_run.finish()
```
Please check out this page [here](/galileo/gen-ai-studio-products/galileo-evaluate/integrations/custom-chain) for more information on logging experiments with our Python logger.
1. Initialize client and create or select your project
```TypeScript theme={null}
import { GalileoEvaluateWorkflow } from "@rungalileo/galileo";
// Initialize and create project
const evaluateWorkflow = new GalileoEvaluateWorkflow("Evaluate Project"); // Project Name
await evaluateWorkflow.init();
```
2. Log your workflows
```TypeScript theme={null}
// Evaluate dataset
const evaluateSet = [
"What are hallucinations?",
"What are intrinsic hallucinations?",
"What are extrinsic hallucinations?"
]
// Add workflows
const myLlmApp = (input) => {
const template = "Given the following context answer the question. \n Context: {context} \n Question: {question}"
// Add workflow
evaluateWorkflow.addWorkflow({ input });
// Get context from Retriever
// Pseudo-code, replace with your Retriever call
const retrieverCall = () => 'You're an AI assistant helping a user with hallucinations.';
const context = retrieverCall()
// Log Retriever Step
evaluateWorkflow.addRetrieverStep({
input: template,
output: context
})
// Get response from your LLM
// Pseudo-code, replace with your LLM call
const prompt = template.replace('{context}', context).replace('{question}', input)
const llmCall = (_prompt) => 'An LLM response…';
const llmResponse = llmCall(prompt);
// Log LLM step
evaluateWorkflow.addLlmStep({
durationNs: parseInt((Math.random() * 3) * 1000000000),
input: prompt,
output: llmResponse,
})
// Conclude workflow
evaluateWorkflow.concludeWorkflow(llmResponse);
}
evaluateSet.forEach((input) => myLlmApp(input));
```
3. Log your Evaluate run to Galileo
```TypeScript theme={null}
// Configure run and upload workflows to Galileo
// Optional: Set run name, tags, registered scorers, and customized scorers
// Note: If no run name is provided a timestamp will be used
await evaluateWorkflow.uploadWorkflows(
{
adherence_nli: true,
chunk_attribution_utilization_nli: true,
completeness_nli: true,
context_relevance: true,
factuality: true,
instruction_adherence: true,
ground_truth_adherence: true,
pii: true,
prompt_injection: true,
prompt_perplexity: true,
sexist: true,
tone: true,
toxicity: true,
}
);
```
### Langchain
Galileo supports the logging of chains from `langchain`. To log these chains, we require using the callback from our Python client [`promptquality`](https://docs.rungalileo.io/galileo/python-clients/index).
Before creating a run, you'll want to make sure you have an evaluation set (a set of questions / sample inputs you want to run through your prototype for evaluation). Your evaluation set should be consistent across runs.
First, we are going to construct a simple RAG chain with Galileo's documentations stored in a vectorDB using Langchain:
```py theme={null}
from langchain.embeddings import OpenAIEmbeddings
from langchain.vectorstores import Chroma
from langchain.chat_models import ChatOpenAI
from langchain.document_loaders import WebBaseLoader
from langchain.text_splitter import RecursiveCharacterTextSplitter
from typing import List
from langchain.prompts import ChatPromptTemplate
from langchain.schema import StrOutputParser
from langchain.schema.runnable import RunnablePassthrough
from langchain.schema.document import Document
# Load text from webpage
loader = WebBaseLoader("https://www.rungalileo.io/blog/deep-dive-into-llm-hallucinations-across-generative-tasks")
data = loader.load()
# Split text into documents
text_splitter = RecursiveCharacterTextSplitter(chunk_size=500, chunk_overlap=0)
splits = text_splitter.split_documents(data)
# Add text to vector db
embedding = OpenAIEmbeddings()
vectordb = Chroma.from_documents(documents=splits, embedding=embedding)
# Create a retriever
retriever = vectordb.as_retriever()
def format_docs(docs: List[Document]) -> str:
return "\n\n".join([d.page_content for d in docs])
template = """Answer the question based only on the following context:
{context}
Question: {question}
"""
prompt = ChatPromptTemplate.from_template(template)
model = ChatOpenAI()
chain = {"context": retriever | format_docs, "question": RunnablePassthrough()} | prompt | model | StrOutputParser()
```
Next, you can log in with Galileo:
```py theme={null}
import promptquality as pq
pq.login({YOUR_GALILEO_URL})
```
After that, you can set up the `GalileoPromptCallback`:
```py theme={null}
from promptquality import Scorers
scorers = [Scorers.context_adherence_basic,
Scorers.completeness_basic,
Scorers.pii,
...]
#This is the list of metrics you want to evaluate your run over.
galileo_handler = pq.GalileoPromptCallback(
project_name="quickstart_project", scorers=scorers,
)
#Each "run" will appear under this project. Choose a name that'll help you identify what you're evaluating
```
Finally, you can run the chain experiments across multiple intputs with Galileo Callback:
```py theme={null}
inputs = [
"What are hallucinations?",
"What are intrinsic hallucinations?",
"What are extrinsic hallucinations?"
]
chain.batch(inputs, config=dict(callbacks=[galileo_handler]))
# publish the results of your run
galileo_handler.finish()
```
For more detailed information on Galileo's Langchain integration, check out instructions [here](/galileo/gen-ai-studio-products/galileo-evaluate/integrations/langchain).
---
# Source: https://docs.galileo.ai/galileo/gen-ai-studio-products/galileo-evaluate/integrations.md
> ## Documentation Index
> Fetch the complete documentation index at: https://docs.galileo.ai/llms.txt
> Use this file to discover all available pages before exploring further.
# Integrations | Galileo Evaluate
> Discover Galileo Evaluate's integrations with AI tools and platforms, enabling seamless connectivity and enhanced generative AI evaluation workflows.
---
# Source: https://docs.galileo.ai/api-reference/protect/invoke.md
> ## Documentation Index
> Fetch the complete documentation index at: https://docs.galileo.ai/llms.txt
> Use this file to discover all available pages before exploring further.
# Invoke Protect
> Learn how to use the 'Invoke Protect' API endpoint in Galileo's Protect module to process payloads with specified rulesets effectively.
## OpenAPI
````yaml POST /v1/protect/invoke
openapi: 3.1.0
info:
title: FastAPI
version: 0.1.0
servers:
- url: https://api.staging.galileo.ai
description: Galileo Public APIs - staging
security: []
paths:
/v1/protect/invoke:
post:
tags:
- protect
summary: Invoke
operationId: invoke_v1_protect_invoke_post
requestBody:
content:
application/json:
schema:
$ref: '#/components/schemas/ProtectRequest'
required: true
responses:
'200':
description: Successful Response
content:
application/json:
schema:
anyOf:
- $ref: '#/components/schemas/ProtectResponse'
- $ref: '#/components/schemas/InvokeResponse'
title: Response Invoke V1 Protect Invoke Post
'422':
description: Validation Error
content:
application/json:
schema:
$ref: '#/components/schemas/HTTPValidationError'
security:
- APIKeyHeader: []
- OAuth2PasswordBearer: []
- HTTPBasic: []
components:
schemas:
ProtectRequest:
properties:
prioritized_rulesets:
items:
$ref: '#/components/schemas/Ruleset'
type: array
title: Prioritized Rulesets
description: Rulesets to be applied to the payload.
payload:
$ref: '#/components/schemas/Payload'
description: Payload to be processed.
project_name:
anyOf:
- type: string
- type: 'null'
title: Project Name
description: Project name.
project_id:
anyOf:
- type: string
format: uuid4
- type: 'null'
title: Project Id
description: Project ID.
stage_name:
anyOf:
- type: string
- type: 'null'
title: Stage Name
description: Stage name.
stage_id:
anyOf:
- type: string
format: uuid4
- type: 'null'
title: Stage Id
description: Stage ID.
stage_version:
anyOf:
- type: integer
- type: 'null'
title: Stage Version
description: >-
Stage version to use for the request, if it's a central stage with a
previously registered version.
timeout:
type: number
title: Timeout
description: >-
Optional timeout for the guardrail execution in seconds. This is not
the timeout for the request. If not set, a default timeout of 5
minutes will be used.
default: 300
metadata:
anyOf:
- additionalProperties:
type: string
type: object
- type: 'null'
title: Metadata
description: >-
Optional additional metadata. This will be echoed back in the
response.
headers:
anyOf:
- additionalProperties:
type: string
type: object
- type: 'null'
title: Headers
description: >-
Optional additional HTTP headers that should be included in the
response.
type: object
required:
- payload
title: ProtectRequest
description: Protect request schema with custom OpenAPI title.
ProtectResponse:
properties:
status:
type: string
description: Status of the request after processing the rules.
text:
type: string
title: Text
description: Text from the request after processing the rules.
trace_metadata:
$ref: '#/components/schemas/TraceMetadata'
additionalProperties: true
type: object
required:
- text
- trace_metadata
title: ProtectResponse
description: Protect response schema with custom OpenAPI title.
InvokeResponse:
properties:
status:
type: string
description: Status of the execution.
api_version:
type: string
title: Api Version
default: 1.0.0
text:
type: string
title: Text
description: Text from the request after processing the rules.
trace_metadata:
$ref: '#/components/schemas/TraceMetadata'
stage_metadata:
$ref: '#/components/schemas/StageMetadata'
ruleset_results:
items:
$ref: '#/components/schemas/RulesetResult'
type: array
title: Ruleset Results
description: Results of the rule execution.
metric_results:
additionalProperties:
$ref: '#/components/schemas/MetricComputation'
type: object
title: Metric Results
description: Results of the metric computation.
action_result:
$ref: '#/components/schemas/ActionResult'
metadata:
anyOf:
- additionalProperties:
type: string
type: object
- type: 'null'
title: Metadata
description: >-
Optional additional metadata. This being echoed back from the
request.
headers:
anyOf:
- additionalProperties:
type: string
type: object
- type: 'null'
title: Headers
description: >-
Optional additional HTTP headers that should be included in the
response.
type: object
required:
- text
- trace_metadata
- stage_metadata
- action_result
title: InvokeResponse
HTTPValidationError:
properties:
detail:
items:
$ref: '#/components/schemas/ValidationError'
type: array
title: Detail
type: object
title: HTTPValidationError
Ruleset:
properties:
rules:
items:
$ref: '#/components/schemas/Rule'
type: array
minItems: 1
title: Rules
description: List of rules to evaluate. Atleast 1 rule is required.
action:
oneOf:
- $ref: '#/components/schemas/OverrideAction-Input'
- $ref: '#/components/schemas/PassthroughAction-Input'
title: Action
description: Action to take if all the rules are met.
discriminator:
propertyName: type
mapping:
OVERRIDE: '#/components/schemas/OverrideAction-Input'
PASSTHROUGH: '#/components/schemas/PassthroughAction-Input'
description:
anyOf:
- type: string
- type: 'null'
title: Description
description: Description of the ruleset.
type: object
title: Ruleset
Payload:
properties:
input:
anyOf:
- type: string
- type: 'null'
title: Input
description: Input text to be processed.
output:
anyOf:
- type: string
- type: 'null'
title: Output
description: Output text to be processed.
type: object
title: Payload
TraceMetadata:
properties:
id:
type: string
format: uuid4
title: Id
description: Unique identifier for the request.
received_at:
type: integer
title: Received At
description: Time the request was received by the server in nanoseconds.
response_at:
type: integer
title: Response At
description: Time the response was sent by the server in nanoseconds.
execution_time:
type: number
title: Execution Time
description: Execution time for the request (in seconds).
default: -1
type: object
title: TraceMetadata
StageMetadata:
properties:
project_id:
type: string
format: uuid4
title: Project Id
stage_id:
type: string
format: uuid4
title: Stage Id
stage_name:
type: string
title: Stage Name
stage_version:
type: integer
title: Stage Version
stage_type:
$ref: '#/components/schemas/StageType'
type: object
required:
- project_id
- stage_id
- stage_name
- stage_version
- stage_type
title: StageMetadata
RulesetResult:
properties:
status:
type: string
description: Status of the execution.
rules:
items:
$ref: '#/components/schemas/Rule'
type: array
minItems: 1
title: Rules
description: List of rules to evaluate. Atleast 1 rule is required.
action:
oneOf:
- $ref: '#/components/schemas/OverrideAction-Output'
- $ref: '#/components/schemas/PassthroughAction-Output'
title: Action
description: Action to take if all the rules are met.
discriminator:
propertyName: type
mapping:
OVERRIDE: '#/components/schemas/OverrideAction-Output'
PASSTHROUGH: '#/components/schemas/PassthroughAction-Output'
description:
anyOf:
- type: string
- type: 'null'
title: Description
description: Description of the ruleset.
rule_results:
items:
$ref: '#/components/schemas/RuleResult'
type: array
title: Rule Results
description: Results of the rule execution.
type: object
title: RulesetResult
MetricComputation:
properties:
value:
anyOf:
- type: number
- type: integer
- type: string
- items:
anyOf:
- type: number
- type: integer
- type: string
- type: 'null'
type: array
- additionalProperties:
anyOf:
- type: number
- type: integer
- type: string
- type: 'null'
type: object
- type: 'null'
title: Value
execution_time:
anyOf:
- type: number
- type: 'null'
title: Execution Time
status:
type: string
error_message:
anyOf:
- type: string
- type: 'null'
title: Error Message
type: object
title: MetricComputation
ActionResult:
properties:
type:
$ref: '#/components/schemas/ActionType'
description: Type of action that was taken.
value:
type: string
title: Value
description: Value of the action that was taken.
type: object
required:
- type
- value
title: ActionResult
ValidationError:
properties:
loc:
items:
anyOf:
- type: string
- type: integer
type: array
title: Location
msg:
type: string
title: Message
type:
type: string
title: Error Type
type: object
required:
- loc
- msg
- type
title: ValidationError
Rule:
properties:
metric:
type: string
title: Metric
description: Name of the metric.
operator:
$ref: '#/components/schemas/RuleOperator'
description: Operator to use for comparison.
target_value:
anyOf:
- type: string
- type: number
- type: integer
- items: {}
type: array
- type: 'null'
title: Target Value
description: Value to compare with for this metric (right hand side).
type: object
required:
- metric
- operator
- target_value
title: Rule
OverrideAction-Input:
properties:
type:
type: string
const: OVERRIDE
title: Type
default: OVERRIDE
subscriptions:
items:
$ref: '#/components/schemas/SubscriptionConfig'
type: array
title: Subscriptions
description: >-
List of subscriptions to send a notification to when this action is
applied and the ruleset status matches any of the configured
statuses.
choices:
items:
type: string
type: array
minItems: 1
title: Choices
description: >-
List of choices to override the response with. If there are multiple
choices, one will be chosen at random when applying this action.
type: object
required:
- choices
title: OverrideAction
PassthroughAction-Input:
properties:
type:
type: string
const: PASSTHROUGH
title: Type
default: PASSTHROUGH
subscriptions:
items:
$ref: '#/components/schemas/SubscriptionConfig'
type: array
title: Subscriptions
description: >-
List of subscriptions to send a notification to when this action is
applied and the ruleset status matches any of the configured
statuses.
type: object
title: PassthroughAction
StageType:
type: string
enum:
- local
- central
title: StageType
OverrideAction-Output:
properties:
type:
type: string
const: OVERRIDE
title: Type
default: OVERRIDE
subscriptions:
items:
$ref: '#/components/schemas/SubscriptionConfig'
type: array
title: Subscriptions
description: >-
List of subscriptions to send a notification to when this action is
applied and the ruleset status matches any of the configured
statuses.
choices:
items:
type: string
type: array
minItems: 1
title: Choices
description: >-
List of choices to override the response with. If there are multiple
choices, one will be chosen at random when applying this action.
type: object
required:
- choices
title: OverrideAction
PassthroughAction-Output:
properties:
type:
type: string
const: PASSTHROUGH
title: Type
default: PASSTHROUGH
subscriptions:
items:
$ref: '#/components/schemas/SubscriptionConfig'
type: array
title: Subscriptions
description: >-
List of subscriptions to send a notification to when this action is
applied and the ruleset status matches any of the configured
statuses.
type: object
title: PassthroughAction
RuleResult:
properties:
status:
type: string
description: Status of the execution.
metric:
type: string
title: Metric
description: Name of the metric.
operator:
$ref: '#/components/schemas/RuleOperator'
description: Operator to use for comparison.
target_value:
anyOf:
- type: string
- type: number
- type: integer
- items: {}
type: array
- type: 'null'
title: Target Value
description: Value to compare with for this metric (right hand side).
value:
anyOf:
- {}
- type: 'null'
title: Value
description: Result of the metric computation.
execution_time:
anyOf:
- type: number
- type: 'null'
title: Execution Time
description: Execution time for the rule in seconds.
type: object
required:
- metric
- operator
- target_value
title: RuleResult
ActionType:
type: string
enum:
- OVERRIDE
- PASSTHROUGH
title: ActionType
RuleOperator:
type: string
enum:
- gt
- lt
- gte
- lte
- eq
- neq
- contains
- all
- any
- empty
- not_empty
title: RuleOperator
SubscriptionConfig:
properties:
statuses:
items:
$ref: '#/components/schemas/ExecutionStatus'
type: array
title: Statuses
description: >-
List of statuses that will cause a notification to be sent to the
configured URL.
default:
- triggered
url:
type: string
minLength: 1
format: uri
title: Url
description: >-
URL to send the event to. This can be a webhook URL, a message queue
URL, an event bus or a custom endpoint that can receive an HTTP POST
request.
type: object
required:
- url
title: SubscriptionConfig
ExecutionStatus:
type: string
enum:
- triggered
- failed
- error
- timeout
- paused
- not_triggered
- skipped
title: ExecutionStatus
description: Status of the execution.
securitySchemes:
APIKeyHeader:
type: apiKey
in: header
name: Galileo-API-Key
OAuth2PasswordBearer:
type: oauth2
flows:
password:
scopes: {}
tokenUrl: https://api.staging.galileo.ai/login
HTTPBasic:
type: http
scheme: basic
````
---
# Source: https://docs.galileo.ai/galileo/gen-ai-studio-products/galileo-protect/how-to/invoking-rulesets.md
> ## Documentation Index
> Fetch the complete documentation index at: https://docs.galileo.ai/llms.txt
> Use this file to discover all available pages before exploring further.
# Invoking Rulesets
> Invoke rulesets in Galileo Protect to apply AI safeguards effectively, with comprehensive guidance on ruleset usage, configuration, and execution.
You'll need to *invoke* Protect whenever there's an input or output you want to validate.
You might choose to run multiple validations on different *stages* of your workflow (e.g. once when you get the query from your user, another time once the model has generated a response for the given task).
## Projects and Stages
Before invoking Protect, you need to create a project and a stage. This will be used to associate your invocations and organize them.
To create a new project:
```py theme={null}
import galileo_protect as gp
gp.create_project("")
```
And to create a new stage thereafter:
```py theme={null}
stage = gp.create_stage(name="")
stage_id = stage.id
```
If you want to add a stage to a pre-existing project, please also specify the project ID alongwith your stage creation request:
```py theme={null}
stage = gp.create_stage(name="", project_id="")
stage_id = stage.id
```
## Invocations
At invocation time, you can either pass the project ID and stage name or the stage ID directly. These can be set as environment variables or passed directly to the `invoke` method as below.
```py theme={null}
response = gp.invoke(
payload=gp.Payload(output="here is my SSN 123-45-6789"),
prioritized_rulesets=[
gp.Ruleset(
rules=[
gp.Rule(
metric=gp.RuleMetrics.pii,
operator=gp.RuleOperator.contains,
target_value="ssn",
)
],
action=gp.OverrideAction(
choices=["Sorry, I cannot answer that question."]
),
)
],
stage_id=stage_id,
)
response.text
```
To invoke Protect using the REST API, simply make a `POST` request to the `/v1/protect/invoke` endpoint with your [Rules](/galileo/gen-ai-studio-products/galileo-protect/concepts/rule) and [Actions](/galileo/gen-ai-studio-products/galileo-protect/concepts/action).
If the project or stage name don't exist, a project + stage will be created for you for convenience.
```javascript theme={null}
const body = {
prioritized_rulesets: [
{
rules: [
{
metric: "pii",
operator: "contains",
target_value: "ssn",
},
],
action: {
type: "OVERRIDE",
choices: ["Sorry, I cannot answer that question."],
},
},
],
payload: {
output: "here is my SSN 123-45-6789",
},
project_name: "",
stage_name: "",
};
const options = {
method: "POST",
headers: {
"Galileo-API-Key": "",
"Content-Type": "application/json",
},
body: JSON.stringify(body),
};
fetch("https://api.your.galileo.cluster.com/v1/protect/invoke", options)
.then((response) => response.json())
.then((response) => console.log(response))
.catch((err) => console.error(err));
```
For more information on how to define Rules and Actions, see [Rules](/galileo/gen-ai-studio-products/galileo-protect/concepts/rule) and [Actions](/galileo/gen-ai-studio-products/galileo-protect/concepts/action).
---
# Source: https://docs.galileo.ai/galileo/gen-ai-studio-products/galileo-protect/integrations/langchain.md
# Source: https://docs.galileo.ai/galileo/gen-ai-studio-products/galileo-observe/integrations/langchain.md
# Source: https://docs.galileo.ai/galileo/gen-ai-studio-products/galileo-evaluate/integrations/langchain.md
> ## Documentation Index
> Fetch the complete documentation index at: https://docs.galileo.ai/llms.txt
> Use this file to discover all available pages before exploring further.
# LangChain Integration | Galileo Evaluate
> Galileo allows you to integrate with your Langchain application natively through callbacks
Galileo supports the logging of chains from `langchain`. To log these chains, we require using the callback from our Python client [`promptquality`](https://docs.rungalileo.io/galileo/python-clients/index).
For logging your data, first login:
```py theme={null}
import promptquality as pq
pq.login()
```
After that, you can set up the `GalileoPromptCallback`:
```py theme={null}
from promptquality import Scorers
scorers = [Scorers.context_adherence_luna,
Scorers.completeness_luna,
Scorers.pii,
...]
galileo_handler = pq.GalileoPromptCallback(
project_name=, scorers=scorers,
)
```
* project\_name: each "run" will appear under this project. Choose a name that'll help you identify what you're evaluating
* scorers: This is the list of metrics you want to evaluate your run over. Check out [Galileo Guardrail Metrics](/galileo/gen-ai-studio-products/galileo-guardrail-metrics) and [Custom Metrics](/galileo/gen-ai-studio-products/galileo-evaluate/how-to/register-custom-metrics) for more information.
### Executing and Logging
Next, run your chain over your Evaluation set and log the results to Galileo.
When you execute your chain (with `run`, `invoke` or `batch`), just include the callback instance created earlier in the callbacks as:
If using `.run()`:
```py theme={null}
chain.run(, callbacks=[galileo_handler])
```
If using `.invoke()`:
```py theme={null}
chain.invoke(inputs, config=dict(callbacks=[galileo_handler]))
```
If using `.batch()`:
```py theme={null}
.batch(..., config=dict(callbacks=[galileo_handler]))
```
**Important**: Once you complete executing for your dataset, tell Galileo the run is complete by:
```py theme={null}
galileo_handler.finish()
```
The `finish` step uploads the run to Galileo and starts the execution of the scorers server-side. This step will also display the link you can use to interact with the run on the Galileo console.
A full example can be found [here](/galileo/gen-ai-studio-products/galileo-evaluate/how-to/evaluate-and-optimize-agents-chains-or-multi-step-workflows/examples-with-langchain).
***Note 1:*** Please make sure to set the callback at *execution* time, not at definition time so that the callback is invoked for all nodes of the chain.
***Note 2:*** We recommend using `.invoke` instead of `.batch` because `langchain` reports latencies for the *entire* batch instead of each individual chain execution.
---
# Source: https://docs.galileo.ai/galileo-ai-research/likely-mislabeled.md
> ## Documentation Index
> Fetch the complete documentation index at: https://docs.galileo.ai/llms.txt
> Use this file to discover all available pages before exploring further.
# Likely Mislabeled
> Garbage in, Garbage out
Training ML models with noisy, mislabeled data can dramatically affect model performance. Dataset errors easily permeate the training process, leading to issues in convergence, inaccurate decision boundaries, and poor model generalization.
On the evaluation side, mislabeled data in a test set will also hurt the ML model's performance, often resulting in lower benchmark scores. Since this is one the biggest factor in deciding whether a model is ready to deploy, we cannot overstate the importance of also having clean test sets.
Therefore, identifying and fixing labeling errors is extremely crucial for both training effective and reliable ML models, and evaluating them accordingly. However, accurately identifying labeling errors is challenging and deploying ineffective algorithms can lead to large, manual efforts with little realized return on investment.
Galileo's mislabel detection algorithm addresses these challenges by employing state of the art statistical methods for identifying data that are highly likely to be *mislabeled*. In the Galileo Console, these samples can be accessed through the *Likely Mislabeled* data tab.
In addition, we surface a tunable parameter which allows the user to fine-tune the method for their use case. The slider balances between precision (minimize number of mistakes) and recall (maximize number of mislabeled samples detected). Hovering over the slider will display a short description, while hovering over the thumb button displays the number of likely mislabeled samples to expect in that position.
For illustration, we highlight a few data samples from the [**Conversational Intent**](https://www.kaggle.com/datasets/joydeb28/nlp-benchmarking-data-for-intent-and-entity) dataset that are correctly identified as mislabeled.
---
# Source: https://docs.galileo.ai/galileo/gen-ai-studio-products/galileo-guardrail-metrics/instruction-adherence.md
> ## Documentation Index
> Fetch the complete documentation index at: https://docs.galileo.ai/llms.txt
> Use this file to discover all available pages before exploring further.
# Instruction Adherence
> Assess instruction adherence in AI outputs using Galileo Guardrail Metrics to ensure prompt-driven models generate precise and actionable results.
***Definition:*** Measures whether a model followed or adhered to the system or prompt instructions when generating a response. *Instruction Adherence* is a good way to uncover hallucinations where the model is ignoring instructions.
If the response has a *High Instruction Adherence* (i.e. it has a value of 1 or close to 1), the model likely followed its instructions when generating its response. If a response has a *Low Instruction Adherence* (i.e. it has a value of 0 or close to 0), the model likely went off-script and ignored parts of its instructions when generating a response.
***Calculation:*** *Instruction Adherence* is computed by sending additional requests to OpenAI's GPT4o, using a carefully engineered chain-of-thought prompt that asks the model to judge whether or not the response was generated in adherence to the instructions. The metric requests multiple distinct responses to this prompt, each of which produces an explanation along with a final judgment: yes or no. The Instruction Adherence score is the fraction of "yes" responses, divided by the total number of responses.
We also surface one of the generated explanations. The surfaced explanation is always chosen to align with the majority judgment among the responses.
*Note:* This metric is computed by prompting an LLM multiple times, and thus requires additional LLM calls to compute.
***What to do when Instruction Adherence is low?***
When a response has a low Instruction Adherence score, the model likely ignored its instructions when generating the response. We recommend:
1. Flag and examine response that did not follow instructions
2. Experiment with different prompts to see which version the model is more likely to adhere to
3. Take precaution measures to stop non-factual responses from reaching the end user.
***How to differentiate between Instruction Adherence and Context Adherence?***
Context Adherence measures whether the response is adhering to the *Context* provided (e.g. your retrieved documents), whereas Instruction Adherence measures whether the response is adhering to the instructions in your prompt template.
---
# Source: https://docs.galileo.ai/galileo/gen-ai-studio-products/galileo-evaluate/quickstart/integrate-evaluate-into-my-existing-application-with-python.md
> ## Documentation Index
> Fetch the complete documentation index at: https://docs.galileo.ai/llms.txt
> Use this file to discover all available pages before exploring further.
# Integrate Evaluate Into My Existing Application With Python
> Learn how to integrate Galileo Evaluate into your Python applications, featuring step-by-step guidance and code samples for streamlined integration.
If you already have a prototype or an application you're looking to run experiments and evaluations over, Galileo Evaluate allows you to hook into it and log the inputs, outputs, and any intermediate steps to Galileo for further analysis.
In this QuickStart, we'll show you how to:
* Integrate with your workflows
* Integrate with your Langchain apps
Let's dive in!
### Logging Workflows
If you're looking to log your workflows, we provide an interface for uploading your executions.
```py theme={null}
import promptquality as pq
pq.login()
```
```py theme={null}
from promptquality import EvaluateRun
metrics = [pq.Scorers.context_adherence_plus, pq.Scorers.prompt_injection]
evaluate_run = EvaluateRun(run_name="my_run", project_name="my_project", scorers=metrics)
```
```py theme={null}
# Define your inputs.
eval_set = [
"What are hallucinations?",
"What are intrinsic hallucinations?",
"What are extrinsic hallucinations?"
]
# Define your run.
evaluate_run = EvaluateRun(run_name="my_run", project_name="my_project", scorers=metrics)
# Run the evaluation set on your app and log the results.
for input in eval_set:
output = llm.call(input) # Pseudo-code, replace with your LLM call.
evaluate_run.add_single_step_workflow(input=input, output=output, model=)
```
Finally, log your Evaluate run to Galileo:
```py theme={null}
evaluate_run.finish()
```
Please check out this page [here](/galileo/gen-ai-studio-products/galileo-evaluate/integrations/custom-chain) for more information on logging experiments with our Python logger.
1. Initialize client and create or select your project
```TypeScript theme={null}
import { GalileoEvaluateWorkflow } from "@rungalileo/galileo";
// Initialize and create project
const evaluateWorkflow = new GalileoEvaluateWorkflow("Evaluate Project"); // Project Name
await evaluateWorkflow.init();
```
2. Log your workflows
```TypeScript theme={null}
// Evaluate dataset
const evaluateSet = [
"What are hallucinations?",
"What are intrinsic hallucinations?",
"What are extrinsic hallucinations?"
]
// Add workflows
const myLlmApp = (input) => {
const template = "Given the following context answer the question. \n Context: {context} \n Question: {question}"
// Add workflow
evaluateWorkflow.addWorkflow({ input });
// Get context from Retriever
// Pseudo-code, replace with your Retriever call
const retrieverCall = () => 'You're an AI assistant helping a user with hallucinations.';
const context = retrieverCall()
// Log Retriever Step
evaluateWorkflow.addRetrieverStep({
input: template,
output: context
})
// Get response from your LLM
// Pseudo-code, replace with your LLM call
const prompt = template.replace('{context}', context).replace('{question}', input)
const llmCall = (_prompt) => 'An LLM response…';
const llmResponse = llmCall(prompt);
// Log LLM step
evaluateWorkflow.addLlmStep({
durationNs: parseInt((Math.random() * 3) * 1000000000),
input: prompt,
output: llmResponse,
})
// Conclude workflow
evaluateWorkflow.concludeWorkflow(llmResponse);
}
evaluateSet.forEach((input) => myLlmApp(input));
```
3. Log your Evaluate run to Galileo
```TypeScript theme={null}
// Configure run and upload workflows to Galileo
// Optional: Set run name, tags, registered scorers, and customized scorers
// Note: If no run name is provided a timestamp will be used
await evaluateWorkflow.uploadWorkflows(
{
adherence_nli: true,
chunk_attribution_utilization_nli: true,
completeness_nli: true,
context_relevance: true,
factuality: true,
instruction_adherence: true,
ground_truth_adherence: true,
pii: true,
prompt_injection: true,
prompt_perplexity: true,
sexist: true,
tone: true,
toxicity: true,
}
);
```
### Langchain
Galileo supports the logging of chains from `langchain`. To log these chains, we require using the callback from our Python client [`promptquality`](https://docs.rungalileo.io/galileo/python-clients/index).
Before creating a run, you'll want to make sure you have an evaluation set (a set of questions / sample inputs you want to run through your prototype for evaluation). Your evaluation set should be consistent across runs.
First, we are going to construct a simple RAG chain with Galileo's documentations stored in a vectorDB using Langchain:
```py theme={null}
from langchain.embeddings import OpenAIEmbeddings
from langchain.vectorstores import Chroma
from langchain.chat_models import ChatOpenAI
from langchain.document_loaders import WebBaseLoader
from langchain.text_splitter import RecursiveCharacterTextSplitter
from typing import List
from langchain.prompts import ChatPromptTemplate
from langchain.schema import StrOutputParser
from langchain.schema.runnable import RunnablePassthrough
from langchain.schema.document import Document
# Load text from webpage
loader = WebBaseLoader("https://www.rungalileo.io/blog/deep-dive-into-llm-hallucinations-across-generative-tasks")
data = loader.load()
# Split text into documents
text_splitter = RecursiveCharacterTextSplitter(chunk_size=500, chunk_overlap=0)
splits = text_splitter.split_documents(data)
# Add text to vector db
embedding = OpenAIEmbeddings()
vectordb = Chroma.from_documents(documents=splits, embedding=embedding)
# Create a retriever
retriever = vectordb.as_retriever()
def format_docs(docs: List[Document]) -> str:
return "\n\n".join([d.page_content for d in docs])
template = """Answer the question based only on the following context:
{context}
Question: {question}
"""
prompt = ChatPromptTemplate.from_template(template)
model = ChatOpenAI()
chain = {"context": retriever | format_docs, "question": RunnablePassthrough()} | prompt | model | StrOutputParser()
```
Next, you can log in with Galileo:
```py theme={null}
import promptquality as pq
pq.login({YOUR_GALILEO_URL})
```
After that, you can set up the `GalileoPromptCallback`:
```py theme={null}
from promptquality import Scorers
scorers = [Scorers.context_adherence_basic,
Scorers.completeness_basic,
Scorers.pii,
...]
#This is the list of metrics you want to evaluate your run over.
galileo_handler = pq.GalileoPromptCallback(
project_name="quickstart_project", scorers=scorers,
)
#Each "run" will appear under this project. Choose a name that'll help you identify what you're evaluating
```
Finally, you can run the chain experiments across multiple intputs with Galileo Callback:
```py theme={null}
inputs = [
"What are hallucinations?",
"What are intrinsic hallucinations?",
"What are extrinsic hallucinations?"
]
chain.batch(inputs, config=dict(callbacks=[galileo_handler]))
# publish the results of your run
galileo_handler.finish()
```
For more detailed information on Galileo's Langchain integration, check out instructions [here](/galileo/gen-ai-studio-products/galileo-evaluate/integrations/langchain).
---
# Source: https://docs.galileo.ai/galileo/gen-ai-studio-products/galileo-evaluate/integrations.md
> ## Documentation Index
> Fetch the complete documentation index at: https://docs.galileo.ai/llms.txt
> Use this file to discover all available pages before exploring further.
# Integrations | Galileo Evaluate
> Discover Galileo Evaluate's integrations with AI tools and platforms, enabling seamless connectivity and enhanced generative AI evaluation workflows.
---
# Source: https://docs.galileo.ai/api-reference/protect/invoke.md
> ## Documentation Index
> Fetch the complete documentation index at: https://docs.galileo.ai/llms.txt
> Use this file to discover all available pages before exploring further.
# Invoke Protect
> Learn how to use the 'Invoke Protect' API endpoint in Galileo's Protect module to process payloads with specified rulesets effectively.
## OpenAPI
````yaml POST /v1/protect/invoke
openapi: 3.1.0
info:
title: FastAPI
version: 0.1.0
servers:
- url: https://api.staging.galileo.ai
description: Galileo Public APIs - staging
security: []
paths:
/v1/protect/invoke:
post:
tags:
- protect
summary: Invoke
operationId: invoke_v1_protect_invoke_post
requestBody:
content:
application/json:
schema:
$ref: '#/components/schemas/ProtectRequest'
required: true
responses:
'200':
description: Successful Response
content:
application/json:
schema:
anyOf:
- $ref: '#/components/schemas/ProtectResponse'
- $ref: '#/components/schemas/InvokeResponse'
title: Response Invoke V1 Protect Invoke Post
'422':
description: Validation Error
content:
application/json:
schema:
$ref: '#/components/schemas/HTTPValidationError'
security:
- APIKeyHeader: []
- OAuth2PasswordBearer: []
- HTTPBasic: []
components:
schemas:
ProtectRequest:
properties:
prioritized_rulesets:
items:
$ref: '#/components/schemas/Ruleset'
type: array
title: Prioritized Rulesets
description: Rulesets to be applied to the payload.
payload:
$ref: '#/components/schemas/Payload'
description: Payload to be processed.
project_name:
anyOf:
- type: string
- type: 'null'
title: Project Name
description: Project name.
project_id:
anyOf:
- type: string
format: uuid4
- type: 'null'
title: Project Id
description: Project ID.
stage_name:
anyOf:
- type: string
- type: 'null'
title: Stage Name
description: Stage name.
stage_id:
anyOf:
- type: string
format: uuid4
- type: 'null'
title: Stage Id
description: Stage ID.
stage_version:
anyOf:
- type: integer
- type: 'null'
title: Stage Version
description: >-
Stage version to use for the request, if it's a central stage with a
previously registered version.
timeout:
type: number
title: Timeout
description: >-
Optional timeout for the guardrail execution in seconds. This is not
the timeout for the request. If not set, a default timeout of 5
minutes will be used.
default: 300
metadata:
anyOf:
- additionalProperties:
type: string
type: object
- type: 'null'
title: Metadata
description: >-
Optional additional metadata. This will be echoed back in the
response.
headers:
anyOf:
- additionalProperties:
type: string
type: object
- type: 'null'
title: Headers
description: >-
Optional additional HTTP headers that should be included in the
response.
type: object
required:
- payload
title: ProtectRequest
description: Protect request schema with custom OpenAPI title.
ProtectResponse:
properties:
status:
type: string
description: Status of the request after processing the rules.
text:
type: string
title: Text
description: Text from the request after processing the rules.
trace_metadata:
$ref: '#/components/schemas/TraceMetadata'
additionalProperties: true
type: object
required:
- text
- trace_metadata
title: ProtectResponse
description: Protect response schema with custom OpenAPI title.
InvokeResponse:
properties:
status:
type: string
description: Status of the execution.
api_version:
type: string
title: Api Version
default: 1.0.0
text:
type: string
title: Text
description: Text from the request after processing the rules.
trace_metadata:
$ref: '#/components/schemas/TraceMetadata'
stage_metadata:
$ref: '#/components/schemas/StageMetadata'
ruleset_results:
items:
$ref: '#/components/schemas/RulesetResult'
type: array
title: Ruleset Results
description: Results of the rule execution.
metric_results:
additionalProperties:
$ref: '#/components/schemas/MetricComputation'
type: object
title: Metric Results
description: Results of the metric computation.
action_result:
$ref: '#/components/schemas/ActionResult'
metadata:
anyOf:
- additionalProperties:
type: string
type: object
- type: 'null'
title: Metadata
description: >-
Optional additional metadata. This being echoed back from the
request.
headers:
anyOf:
- additionalProperties:
type: string
type: object
- type: 'null'
title: Headers
description: >-
Optional additional HTTP headers that should be included in the
response.
type: object
required:
- text
- trace_metadata
- stage_metadata
- action_result
title: InvokeResponse
HTTPValidationError:
properties:
detail:
items:
$ref: '#/components/schemas/ValidationError'
type: array
title: Detail
type: object
title: HTTPValidationError
Ruleset:
properties:
rules:
items:
$ref: '#/components/schemas/Rule'
type: array
minItems: 1
title: Rules
description: List of rules to evaluate. Atleast 1 rule is required.
action:
oneOf:
- $ref: '#/components/schemas/OverrideAction-Input'
- $ref: '#/components/schemas/PassthroughAction-Input'
title: Action
description: Action to take if all the rules are met.
discriminator:
propertyName: type
mapping:
OVERRIDE: '#/components/schemas/OverrideAction-Input'
PASSTHROUGH: '#/components/schemas/PassthroughAction-Input'
description:
anyOf:
- type: string
- type: 'null'
title: Description
description: Description of the ruleset.
type: object
title: Ruleset
Payload:
properties:
input:
anyOf:
- type: string
- type: 'null'
title: Input
description: Input text to be processed.
output:
anyOf:
- type: string
- type: 'null'
title: Output
description: Output text to be processed.
type: object
title: Payload
TraceMetadata:
properties:
id:
type: string
format: uuid4
title: Id
description: Unique identifier for the request.
received_at:
type: integer
title: Received At
description: Time the request was received by the server in nanoseconds.
response_at:
type: integer
title: Response At
description: Time the response was sent by the server in nanoseconds.
execution_time:
type: number
title: Execution Time
description: Execution time for the request (in seconds).
default: -1
type: object
title: TraceMetadata
StageMetadata:
properties:
project_id:
type: string
format: uuid4
title: Project Id
stage_id:
type: string
format: uuid4
title: Stage Id
stage_name:
type: string
title: Stage Name
stage_version:
type: integer
title: Stage Version
stage_type:
$ref: '#/components/schemas/StageType'
type: object
required:
- project_id
- stage_id
- stage_name
- stage_version
- stage_type
title: StageMetadata
RulesetResult:
properties:
status:
type: string
description: Status of the execution.
rules:
items:
$ref: '#/components/schemas/Rule'
type: array
minItems: 1
title: Rules
description: List of rules to evaluate. Atleast 1 rule is required.
action:
oneOf:
- $ref: '#/components/schemas/OverrideAction-Output'
- $ref: '#/components/schemas/PassthroughAction-Output'
title: Action
description: Action to take if all the rules are met.
discriminator:
propertyName: type
mapping:
OVERRIDE: '#/components/schemas/OverrideAction-Output'
PASSTHROUGH: '#/components/schemas/PassthroughAction-Output'
description:
anyOf:
- type: string
- type: 'null'
title: Description
description: Description of the ruleset.
rule_results:
items:
$ref: '#/components/schemas/RuleResult'
type: array
title: Rule Results
description: Results of the rule execution.
type: object
title: RulesetResult
MetricComputation:
properties:
value:
anyOf:
- type: number
- type: integer
- type: string
- items:
anyOf:
- type: number
- type: integer
- type: string
- type: 'null'
type: array
- additionalProperties:
anyOf:
- type: number
- type: integer
- type: string
- type: 'null'
type: object
- type: 'null'
title: Value
execution_time:
anyOf:
- type: number
- type: 'null'
title: Execution Time
status:
type: string
error_message:
anyOf:
- type: string
- type: 'null'
title: Error Message
type: object
title: MetricComputation
ActionResult:
properties:
type:
$ref: '#/components/schemas/ActionType'
description: Type of action that was taken.
value:
type: string
title: Value
description: Value of the action that was taken.
type: object
required:
- type
- value
title: ActionResult
ValidationError:
properties:
loc:
items:
anyOf:
- type: string
- type: integer
type: array
title: Location
msg:
type: string
title: Message
type:
type: string
title: Error Type
type: object
required:
- loc
- msg
- type
title: ValidationError
Rule:
properties:
metric:
type: string
title: Metric
description: Name of the metric.
operator:
$ref: '#/components/schemas/RuleOperator'
description: Operator to use for comparison.
target_value:
anyOf:
- type: string
- type: number
- type: integer
- items: {}
type: array
- type: 'null'
title: Target Value
description: Value to compare with for this metric (right hand side).
type: object
required:
- metric
- operator
- target_value
title: Rule
OverrideAction-Input:
properties:
type:
type: string
const: OVERRIDE
title: Type
default: OVERRIDE
subscriptions:
items:
$ref: '#/components/schemas/SubscriptionConfig'
type: array
title: Subscriptions
description: >-
List of subscriptions to send a notification to when this action is
applied and the ruleset status matches any of the configured
statuses.
choices:
items:
type: string
type: array
minItems: 1
title: Choices
description: >-
List of choices to override the response with. If there are multiple
choices, one will be chosen at random when applying this action.
type: object
required:
- choices
title: OverrideAction
PassthroughAction-Input:
properties:
type:
type: string
const: PASSTHROUGH
title: Type
default: PASSTHROUGH
subscriptions:
items:
$ref: '#/components/schemas/SubscriptionConfig'
type: array
title: Subscriptions
description: >-
List of subscriptions to send a notification to when this action is
applied and the ruleset status matches any of the configured
statuses.
type: object
title: PassthroughAction
StageType:
type: string
enum:
- local
- central
title: StageType
OverrideAction-Output:
properties:
type:
type: string
const: OVERRIDE
title: Type
default: OVERRIDE
subscriptions:
items:
$ref: '#/components/schemas/SubscriptionConfig'
type: array
title: Subscriptions
description: >-
List of subscriptions to send a notification to when this action is
applied and the ruleset status matches any of the configured
statuses.
choices:
items:
type: string
type: array
minItems: 1
title: Choices
description: >-
List of choices to override the response with. If there are multiple
choices, one will be chosen at random when applying this action.
type: object
required:
- choices
title: OverrideAction
PassthroughAction-Output:
properties:
type:
type: string
const: PASSTHROUGH
title: Type
default: PASSTHROUGH
subscriptions:
items:
$ref: '#/components/schemas/SubscriptionConfig'
type: array
title: Subscriptions
description: >-
List of subscriptions to send a notification to when this action is
applied and the ruleset status matches any of the configured
statuses.
type: object
title: PassthroughAction
RuleResult:
properties:
status:
type: string
description: Status of the execution.
metric:
type: string
title: Metric
description: Name of the metric.
operator:
$ref: '#/components/schemas/RuleOperator'
description: Operator to use for comparison.
target_value:
anyOf:
- type: string
- type: number
- type: integer
- items: {}
type: array
- type: 'null'
title: Target Value
description: Value to compare with for this metric (right hand side).
value:
anyOf:
- {}
- type: 'null'
title: Value
description: Result of the metric computation.
execution_time:
anyOf:
- type: number
- type: 'null'
title: Execution Time
description: Execution time for the rule in seconds.
type: object
required:
- metric
- operator
- target_value
title: RuleResult
ActionType:
type: string
enum:
- OVERRIDE
- PASSTHROUGH
title: ActionType
RuleOperator:
type: string
enum:
- gt
- lt
- gte
- lte
- eq
- neq
- contains
- all
- any
- empty
- not_empty
title: RuleOperator
SubscriptionConfig:
properties:
statuses:
items:
$ref: '#/components/schemas/ExecutionStatus'
type: array
title: Statuses
description: >-
List of statuses that will cause a notification to be sent to the
configured URL.
default:
- triggered
url:
type: string
minLength: 1
format: uri
title: Url
description: >-
URL to send the event to. This can be a webhook URL, a message queue
URL, an event bus or a custom endpoint that can receive an HTTP POST
request.
type: object
required:
- url
title: SubscriptionConfig
ExecutionStatus:
type: string
enum:
- triggered
- failed
- error
- timeout
- paused
- not_triggered
- skipped
title: ExecutionStatus
description: Status of the execution.
securitySchemes:
APIKeyHeader:
type: apiKey
in: header
name: Galileo-API-Key
OAuth2PasswordBearer:
type: oauth2
flows:
password:
scopes: {}
tokenUrl: https://api.staging.galileo.ai/login
HTTPBasic:
type: http
scheme: basic
````
---
# Source: https://docs.galileo.ai/galileo/gen-ai-studio-products/galileo-protect/how-to/invoking-rulesets.md
> ## Documentation Index
> Fetch the complete documentation index at: https://docs.galileo.ai/llms.txt
> Use this file to discover all available pages before exploring further.
# Invoking Rulesets
> Invoke rulesets in Galileo Protect to apply AI safeguards effectively, with comprehensive guidance on ruleset usage, configuration, and execution.
You'll need to *invoke* Protect whenever there's an input or output you want to validate.
You might choose to run multiple validations on different *stages* of your workflow (e.g. once when you get the query from your user, another time once the model has generated a response for the given task).
## Projects and Stages
Before invoking Protect, you need to create a project and a stage. This will be used to associate your invocations and organize them.
To create a new project:
```py theme={null}
import galileo_protect as gp
gp.create_project("")
```
And to create a new stage thereafter:
```py theme={null}
stage = gp.create_stage(name="")
stage_id = stage.id
```
If you want to add a stage to a pre-existing project, please also specify the project ID alongwith your stage creation request:
```py theme={null}
stage = gp.create_stage(name="", project_id="")
stage_id = stage.id
```
## Invocations
At invocation time, you can either pass the project ID and stage name or the stage ID directly. These can be set as environment variables or passed directly to the `invoke` method as below.
```py theme={null}
response = gp.invoke(
payload=gp.Payload(output="here is my SSN 123-45-6789"),
prioritized_rulesets=[
gp.Ruleset(
rules=[
gp.Rule(
metric=gp.RuleMetrics.pii,
operator=gp.RuleOperator.contains,
target_value="ssn",
)
],
action=gp.OverrideAction(
choices=["Sorry, I cannot answer that question."]
),
)
],
stage_id=stage_id,
)
response.text
```
To invoke Protect using the REST API, simply make a `POST` request to the `/v1/protect/invoke` endpoint with your [Rules](/galileo/gen-ai-studio-products/galileo-protect/concepts/rule) and [Actions](/galileo/gen-ai-studio-products/galileo-protect/concepts/action).
If the project or stage name don't exist, a project + stage will be created for you for convenience.
```javascript theme={null}
const body = {
prioritized_rulesets: [
{
rules: [
{
metric: "pii",
operator: "contains",
target_value: "ssn",
},
],
action: {
type: "OVERRIDE",
choices: ["Sorry, I cannot answer that question."],
},
},
],
payload: {
output: "here is my SSN 123-45-6789",
},
project_name: "",
stage_name: "",
};
const options = {
method: "POST",
headers: {
"Galileo-API-Key": "",
"Content-Type": "application/json",
},
body: JSON.stringify(body),
};
fetch("https://api.your.galileo.cluster.com/v1/protect/invoke", options)
.then((response) => response.json())
.then((response) => console.log(response))
.catch((err) => console.error(err));
```
For more information on how to define Rules and Actions, see [Rules](/galileo/gen-ai-studio-products/galileo-protect/concepts/rule) and [Actions](/galileo/gen-ai-studio-products/galileo-protect/concepts/action).
---
# Source: https://docs.galileo.ai/galileo/gen-ai-studio-products/galileo-protect/integrations/langchain.md
# Source: https://docs.galileo.ai/galileo/gen-ai-studio-products/galileo-observe/integrations/langchain.md
# Source: https://docs.galileo.ai/galileo/gen-ai-studio-products/galileo-evaluate/integrations/langchain.md
> ## Documentation Index
> Fetch the complete documentation index at: https://docs.galileo.ai/llms.txt
> Use this file to discover all available pages before exploring further.
# LangChain Integration | Galileo Evaluate
> Galileo allows you to integrate with your Langchain application natively through callbacks
Galileo supports the logging of chains from `langchain`. To log these chains, we require using the callback from our Python client [`promptquality`](https://docs.rungalileo.io/galileo/python-clients/index).
For logging your data, first login:
```py theme={null}
import promptquality as pq
pq.login()
```
After that, you can set up the `GalileoPromptCallback`:
```py theme={null}
from promptquality import Scorers
scorers = [Scorers.context_adherence_luna,
Scorers.completeness_luna,
Scorers.pii,
...]
galileo_handler = pq.GalileoPromptCallback(
project_name=, scorers=scorers,
)
```
* project\_name: each "run" will appear under this project. Choose a name that'll help you identify what you're evaluating
* scorers: This is the list of metrics you want to evaluate your run over. Check out [Galileo Guardrail Metrics](/galileo/gen-ai-studio-products/galileo-guardrail-metrics) and [Custom Metrics](/galileo/gen-ai-studio-products/galileo-evaluate/how-to/register-custom-metrics) for more information.
### Executing and Logging
Next, run your chain over your Evaluation set and log the results to Galileo.
When you execute your chain (with `run`, `invoke` or `batch`), just include the callback instance created earlier in the callbacks as:
If using `.run()`:
```py theme={null}
chain.run(, callbacks=[galileo_handler])
```
If using `.invoke()`:
```py theme={null}
chain.invoke(inputs, config=dict(callbacks=[galileo_handler]))
```
If using `.batch()`:
```py theme={null}
.batch(..., config=dict(callbacks=[galileo_handler]))
```
**Important**: Once you complete executing for your dataset, tell Galileo the run is complete by:
```py theme={null}
galileo_handler.finish()
```
The `finish` step uploads the run to Galileo and starts the execution of the scorers server-side. This step will also display the link you can use to interact with the run on the Galileo console.
A full example can be found [here](/galileo/gen-ai-studio-products/galileo-evaluate/how-to/evaluate-and-optimize-agents-chains-or-multi-step-workflows/examples-with-langchain).
***Note 1:*** Please make sure to set the callback at *execution* time, not at definition time so that the callback is invoked for all nodes of the chain.
***Note 2:*** We recommend using `.invoke` instead of `.batch` because `langchain` reports latencies for the *entire* batch instead of each individual chain execution.
---
# Source: https://docs.galileo.ai/galileo-ai-research/likely-mislabeled.md
> ## Documentation Index
> Fetch the complete documentation index at: https://docs.galileo.ai/llms.txt
> Use this file to discover all available pages before exploring further.
# Likely Mislabeled
> Garbage in, Garbage out
Training ML models with noisy, mislabeled data can dramatically affect model performance. Dataset errors easily permeate the training process, leading to issues in convergence, inaccurate decision boundaries, and poor model generalization.
On the evaluation side, mislabeled data in a test set will also hurt the ML model's performance, often resulting in lower benchmark scores. Since this is one the biggest factor in deciding whether a model is ready to deploy, we cannot overstate the importance of also having clean test sets.
Therefore, identifying and fixing labeling errors is extremely crucial for both training effective and reliable ML models, and evaluating them accordingly. However, accurately identifying labeling errors is challenging and deploying ineffective algorithms can lead to large, manual efforts with little realized return on investment.
Galileo's mislabel detection algorithm addresses these challenges by employing state of the art statistical methods for identifying data that are highly likely to be *mislabeled*. In the Galileo Console, these samples can be accessed through the *Likely Mislabeled* data tab.
In addition, we surface a tunable parameter which allows the user to fine-tune the method for their use case. The slider balances between precision (minimize number of mistakes) and recall (maximize number of mislabeled samples detected). Hovering over the slider will display a short description, while hovering over the thumb button displays the number of likely mislabeled samples to expect in that position.
For illustration, we highlight a few data samples from the [**Conversational Intent**](https://www.kaggle.com/datasets/joydeb28/nlp-benchmarking-data-for-intent-and-entity) dataset that are correctly identified as mislabeled.
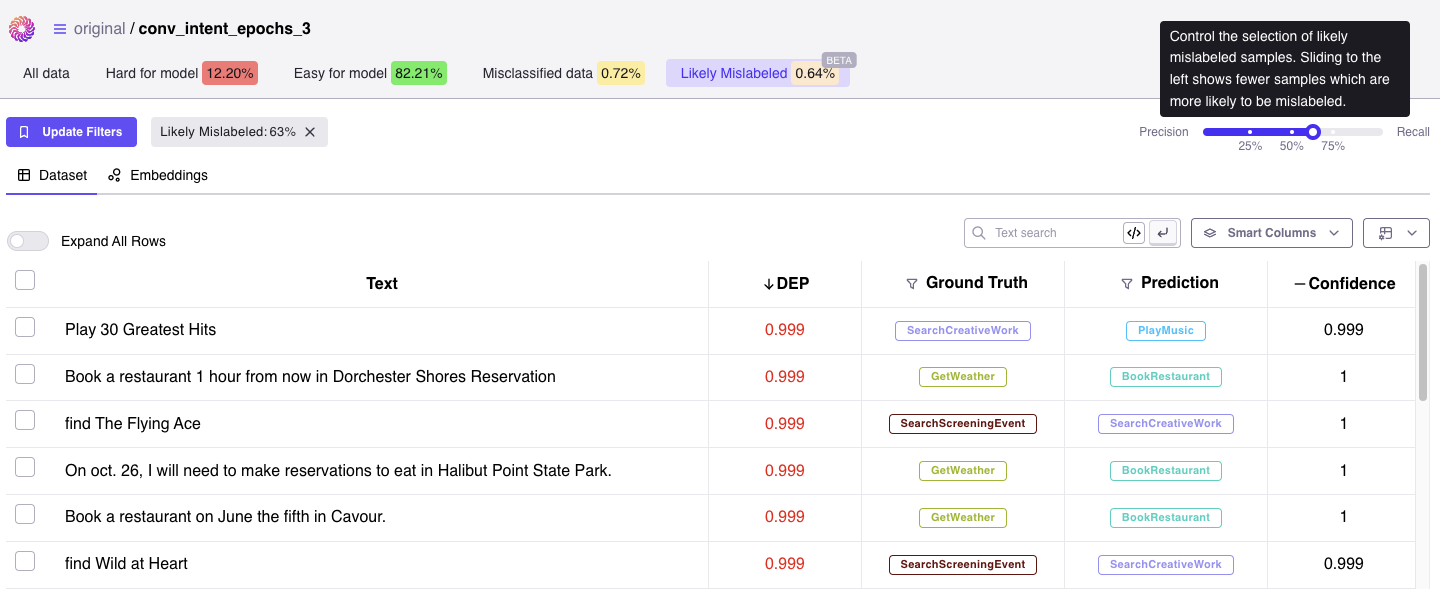 ### Adjusting the slider for your use-case
The *Likely Mislabeled* slider allows the user to fine-tune both the qualitative and quantitive output of the algorithm, depending on your use-case.
### Adjusting the slider for your use-case
The *Likely Mislabeled* slider allows the user to fine-tune both the qualitative and quantitive output of the algorithm, depending on your use-case.
 On one extreme it will optimize for maximum Recall: this maximizes the number of mislabeled samples caught by the algorithm and in most cases ensures 90% of mislabeled points caught (see results below).
On the other extreme it will optimize for maximum Precision: this minimizes the number of errors made by the algorithm, i.e., it minimizes the number of datapoints which are not mislabeled but are marked as likely mislabeled.
#### Setting the threshold for a common use-case: fixed re-labelling budget
Suppose that we have a relabelling budget of only 200 samples. Start with the slider on the Recall side where the algorithm returns all the samples that are likely to be mislabeled. As you move the thumb of the slider towards the Precision side, a hovering box will appear and you should notice the number of samples decreasing, allowing you to fine-tune the algorithm for returning the 200 samples that are most likely to be mislabeled.
### Likely Mislabeled Computation
Galileo's *Likely Mislabeled* *Algorithm* is adapted from the well known '**Confident Learning**' algorithm. The working hypothesis of confident learning is that counting and comparing a model's "confident" predictions to the ground truth can reveal class pairs that are most likely to have class confusion. We then leverage and combine this global information with per-sample level scores, such as [DEP](/galileo/gen-ai-studio-products/galileo-ai-research/galileo-data-error-potential-dep) (which summarizes individual data sample training dynamics), to identify samples most likely to be mislabeled.
This technique particularly shines in multi-class settings with potentially overlapping class definitions, where labelers are more likely to confuse specific scenarios.
### DEP vs. Likely Mislabeled
Although related, [Galileo's DEP score](/galileo/gen-ai-studio-products/galileo-ai-research/galileo-data-error-potential-dep) is distinctly different from the *Likely Mislabeled* algorithm: samples with a higher DEP score are not necessarily more likely to be mislabeled (even though the opposite is true). While *Likely Mislabeled* focuses solely on the potential for being mislabeled, DEP more generally measures the potential for "misfit" of an observation to the given model. As described in our documentation, the categorization of "misfit" data samples includes:
* *Mislabeled* *samples* (annotation mistakes)
* Boundary samples or overlapping classes
* Outlier samples or Anomalies
* Noisy Input
* Misclassified samples
* Other errors
Through summarizing per-sample training dynamics, DEP captures and categorizes *many* different sample level errors without specifically differentiating / pinpointing a specific one.
### Likely Mislabeled evaluation
To measure the effectiveness of the *Likely Mislabeled* algorithm, we performed experiments on 10+ datasets covering various scenarios such as binary/multi-class text classification, balanced/unbalanced distribution of classes, etc. We then added various degrees of noise to these datasets and trained different models on them. Finally, we evaluated the algorithm on how well it is able to identify the noise manually added.
Below are plots indicating the Precision and Recall of the algorithm.
On one extreme it will optimize for maximum Recall: this maximizes the number of mislabeled samples caught by the algorithm and in most cases ensures 90% of mislabeled points caught (see results below).
On the other extreme it will optimize for maximum Precision: this minimizes the number of errors made by the algorithm, i.e., it minimizes the number of datapoints which are not mislabeled but are marked as likely mislabeled.
#### Setting the threshold for a common use-case: fixed re-labelling budget
Suppose that we have a relabelling budget of only 200 samples. Start with the slider on the Recall side where the algorithm returns all the samples that are likely to be mislabeled. As you move the thumb of the slider towards the Precision side, a hovering box will appear and you should notice the number of samples decreasing, allowing you to fine-tune the algorithm for returning the 200 samples that are most likely to be mislabeled.
### Likely Mislabeled Computation
Galileo's *Likely Mislabeled* *Algorithm* is adapted from the well known '**Confident Learning**' algorithm. The working hypothesis of confident learning is that counting and comparing a model's "confident" predictions to the ground truth can reveal class pairs that are most likely to have class confusion. We then leverage and combine this global information with per-sample level scores, such as [DEP](/galileo/gen-ai-studio-products/galileo-ai-research/galileo-data-error-potential-dep) (which summarizes individual data sample training dynamics), to identify samples most likely to be mislabeled.
This technique particularly shines in multi-class settings with potentially overlapping class definitions, where labelers are more likely to confuse specific scenarios.
### DEP vs. Likely Mislabeled
Although related, [Galileo's DEP score](/galileo/gen-ai-studio-products/galileo-ai-research/galileo-data-error-potential-dep) is distinctly different from the *Likely Mislabeled* algorithm: samples with a higher DEP score are not necessarily more likely to be mislabeled (even though the opposite is true). While *Likely Mislabeled* focuses solely on the potential for being mislabeled, DEP more generally measures the potential for "misfit" of an observation to the given model. As described in our documentation, the categorization of "misfit" data samples includes:
* *Mislabeled* *samples* (annotation mistakes)
* Boundary samples or overlapping classes
* Outlier samples or Anomalies
* Noisy Input
* Misclassified samples
* Other errors
Through summarizing per-sample training dynamics, DEP captures and categorizes *many* different sample level errors without specifically differentiating / pinpointing a specific one.
### Likely Mislabeled evaluation
To measure the effectiveness of the *Likely Mislabeled* algorithm, we performed experiments on 10+ datasets covering various scenarios such as binary/multi-class text classification, balanced/unbalanced distribution of classes, etc. We then added various degrees of noise to these datasets and trained different models on them. Finally, we evaluated the algorithm on how well it is able to identify the noise manually added.
Below are plots indicating the Precision and Recall of the algorithm.
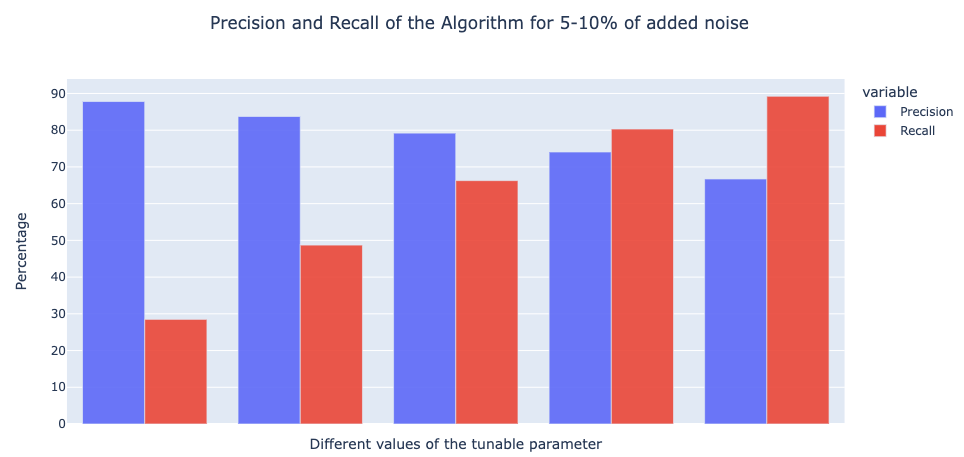
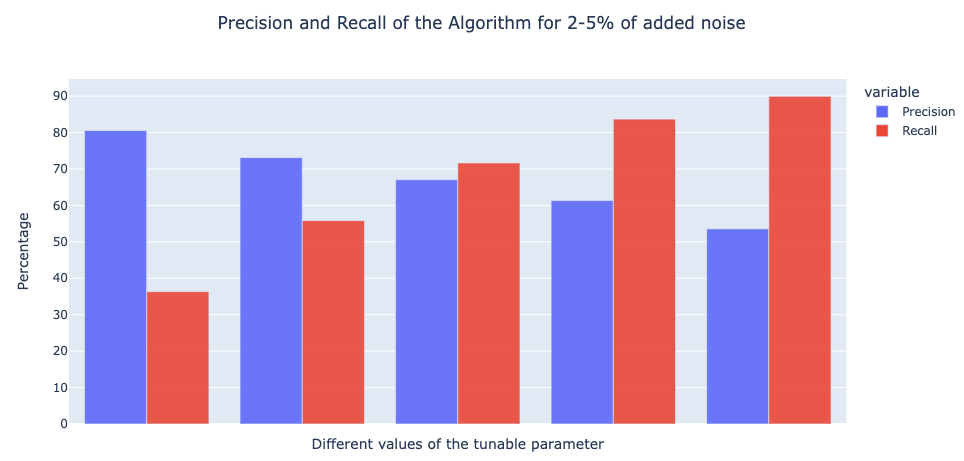
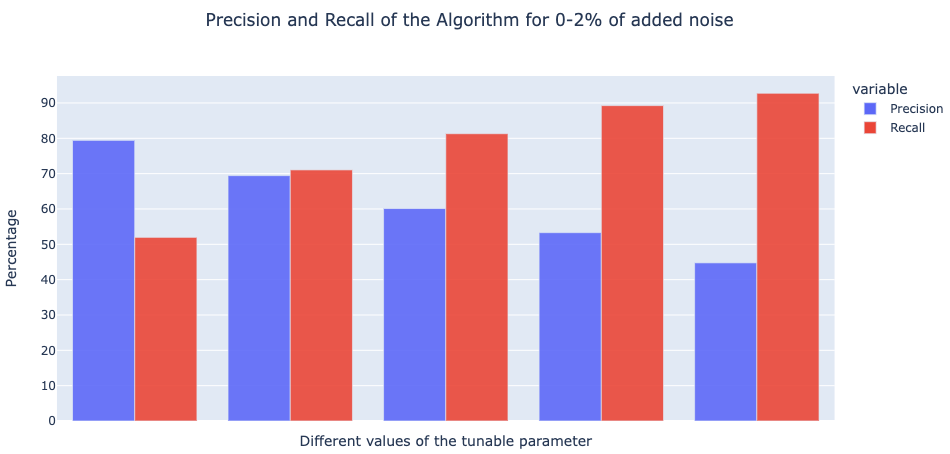 ---
# Source: https://docs.galileo.ai/api-reference/evaluate-alerts/list-evaluate-alerts.md
> ## Documentation Index
> Fetch the complete documentation index at: https://docs.galileo.ai/llms.txt
> Use this file to discover all available pages before exploring further.
# List Evaluate Alerts
## OpenAPI
````yaml https://api.staging.galileo.ai/public/v1/openapi.json get /v1/projects/{project_id}/runs/{run_id}/prompts/alerts
openapi: 3.1.0
info:
title: FastAPI
version: 0.1.0
servers:
- url: https://api.staging.galileo.ai
description: Galileo Public APIs - staging
security: []
paths:
/v1/projects/{project_id}/runs/{run_id}/prompts/alerts:
get:
tags:
- evaluate-alerts
summary: List Evaluate Alerts
operationId: >-
list_evaluate_alerts_v1_projects__project_id__runs__run_id__prompts_alerts_get
parameters:
- name: run_id
in: path
required: true
schema:
type: string
format: uuid4
title: Run Id
- name: project_id
in: path
required: true
schema:
type: string
format: uuid4
title: Project Id
responses:
'200':
description: Successful Response
content:
application/json:
schema:
type: array
items:
$ref: '#/components/schemas/EvaluateAlertDB'
title: >-
Response List Evaluate Alerts V1 Projects Project Id Runs
Run Id Prompts Alerts Get
'422':
description: Validation Error
content:
application/json:
schema:
$ref: '#/components/schemas/HTTPValidationError'
security:
- APIKeyHeader: []
- OAuth2PasswordBearer: []
- HTTPBasic: []
components:
schemas:
EvaluateAlertDB:
properties:
project_id:
type: string
format: uuid4
title: Project Id
run_id:
type: string
format: uuid4
title: Run Id
alert_name:
type: string
title: Alert Name
filter:
oneOf:
- $ref: '#/components/schemas/RangePromptFilterParam'
- $ref: '#/components/schemas/ValuePromptFilterParam'
- $ref: '#/components/schemas/CategoricalPromptFilterParam'
title: Filter
discriminator:
propertyName: filter_type
mapping:
category: '#/components/schemas/CategoricalPromptFilterParam'
range: '#/components/schemas/RangePromptFilterParam'
value: '#/components/schemas/ValuePromptFilterParam'
field_name:
type: string
title: Field Name
description:
type: string
title: Description
extra:
anyOf:
- additionalProperties: true
type: object
- type: 'null'
title: Extra
id:
type: string
format: uuid4
title: Id
created_at:
type: string
format: date-time
title: Created At
updated_at:
type: string
format: date-time
title: Updated At
type: object
required:
- project_id
- run_id
- alert_name
- filter
- field_name
- description
- id
- created_at
- updated_at
title: EvaluateAlertDB
HTTPValidationError:
properties:
detail:
items:
$ref: '#/components/schemas/ValidationError'
type: array
title: Detail
type: object
title: HTTPValidationError
RangePromptFilterParam:
properties:
column:
type: string
title: Column
filter_type:
type: string
const: range
title: Filter Type
low:
type: number
title: Low
high:
type: number
title: High
type: object
required:
- column
- filter_type
- low
- high
title: RangePromptFilterParam
ValuePromptFilterParam:
properties:
column:
type: string
title: Column
filter_type:
type: string
const: value
title: Filter Type
value:
anyOf:
- type: integer
- type: number
- type: boolean
- type: string
title: Value
relation:
$ref: '#/components/schemas/Operator'
type: object
required:
- column
- filter_type
- value
- relation
title: ValuePromptFilterParam
CategoricalPromptFilterParam:
properties:
column:
type: string
title: Column
filter_type:
type: string
const: category
title: Filter Type
categories:
items:
type: string
type: array
title: Categories
operator:
$ref: '#/components/schemas/CategoryFilterOperator'
description: >-
Operator to use when checking if the value is in the categories. If
None, we default to 'or'.
default: any
type: object
required:
- column
- filter_type
- categories
title: CategoricalPromptFilterParam
ValidationError:
properties:
loc:
items:
anyOf:
- type: string
- type: integer
type: array
title: Location
msg:
type: string
title: Message
type:
type: string
title: Error Type
type: object
required:
- loc
- msg
- type
title: ValidationError
Operator:
type: string
enum:
- eq
- ne
- gt
- gte
- lt
- lte
- in
- not_in
- contains
- has_all
- between
- like
title: Operator
CategoryFilterOperator:
type: string
enum:
- any
- all
- exact
- none
title: CategoryFilterOperator
securitySchemes:
APIKeyHeader:
type: apiKey
in: header
name: Galileo-API-Key
OAuth2PasswordBearer:
type: oauth2
flows:
password:
scopes: {}
tokenUrl: https://api.staging.galileo.ai/login
HTTPBasic:
type: http
scheme: basic
````
---
# Source: https://docs.galileo.ai/galileo/gen-ai-studio-products/galileo-evaluate/integrations/llms.md
> ## Documentation Index
> Fetch the complete documentation index at: https://docs.galileo.ai/llms.txt
> Use this file to discover all available pages before exploring further.
# LLMs
> Integrate large language models (LLMs) into Galileo Evaluate to assess performance, refine outputs, and enhance generative AI model capabilities.
This section only applies if you want to:
* Query your LLMs via the Galileo Playground or via promptquality.runs()
* Or leverage any of our the metrics that are powered by OpenAI / Azure models. If you have an application or prototype where you're querying a model in code you can integrate Galileo into your code. Jump to [Evaluating and Optimizing Agents, Chains, or multi-stage workflows](/galileo/gen-ai-studio-products/galileo-evaluate/how-to/evaluate-and-optimize-agents--chains-or-multi-step-workflows) to learn more.
Galileo integrates with publicly accessible LLM APIs as well as Open Source LLMs (privately hosted). Before you start using **Evaluate** on your own LLMs, you need to set up your models on the system.
* Go to the 'Galileo Home Page'.
* Click on your 'Profile' (bottom left).
* Client on 'Settings & Permissions'.
* Click on 'Integrations'.
You can set up and manage all your LLM API and Custom Model integrations from the 'Integrations' page.
*Note:* These integrations are user-specific to ensure that different users in an organization can use their own API keys when interacting with the LLMs.
## Public APIs supported
### OpenAI
We support both the [Chat](https://platform.openai.com/docs/api-reference/chat) and [Completions](https://platform.openai.com/docs/api-reference/completions) APIs from OpenAI, with all of the active models. This can be set up from the Galileo console or from the [Python client](https://promptquality.docs.rungalileo.io/#promptquality.add_openai_integration).
*Note:* OpenAI Models power a few of Galileo's Guardrail Metrics (e.g. Correctness, Context Adherence, Chunk Attribution, Chunk Utilization, Completeness). To improve your evaluation experience, we recommend setting up this integration
even if the model you're prompting or testing is a different one.
### Azure OpenAI
If you use OpenAI models through Azure, you can set up your Azure integration. This can be set up from the Galileo console or from the [Python client](https://promptquality.docs.rungalileo.io/#promptquality.add_azure_integration).
### Google Vertex AI
For integrating with models served by Google via Vertex AI (like PaLM 2 and Gemini), we recommend setting up a Service Account within your Google Cloud project that has [Vertex AI enabled](/galileo/gen-ai-studio-products/galileo-evaluate/integrations/llms). This service account requires at minimum [the 'Vertex AI User (roles/aiplatform.user)' role's policies](https://cloud.google.com/vertex-ai/docs/generative-ai/access-control) to be attached.
Once the role is created, create a new key for this service account. The contents of the JSON file provided are what you'll copy over into the Integrations page for Galileo.
by Google Vertex AI. Galileo's ChainPoll metrics **are** available, but perplexity and uncertainty scores are not available for model predictions from Google Vertex AI.
### AWS Bedrock
Add your AWS Bedrock integration in the Galileo Integrations page. You should see a green light indicating a successful integration. Now, you should see new **Bedrock models** show up in the Prompt Playground.
Uncertainty and Galileo ChainPoll metrics cannot be generated using models served by AWS Bedrock.
### AWS Sagemaker
If you're hosting models on AWS Sagemaker, you can query them via Galileo. Set up your AWS Sagemaker integration via the Integrations page.
You'll need to enter your authentication credentials (as an access key \<> secret pair or an AWS role that can be assumed) alongwith the AWS region in which your endpoints are hosted. For each endpoint, you can configure the name of the endpoint and an alias alongwith the schema mapping in [`dpath notation`](https://pypi.org/project/dpath/).
Required parameters for each endpoint are:
* Prompt: To pass the prompt to the payload.
* Response: To parse the response from the response.
Optional parameters, which are included in the payload if set, are:
* Temperature
* Max tokens
* Top K
* Top P
* Frequency penalty
* Presence penalty
Check out [this video](https://www.loom.com/share/27a11ceb14b94c84a6248c67515edee8) for step-by-step instructions.
Uncertainty and Galileo ChainPoll metrics cannot be generated using models served by AWS Sagemaker.
### Other Custom Models
If you are prompting via [Langchain](https://python.langchain.com/docs/get_started/introduction), Galileo can use custom models through Langchain the same way you might use OpenAI in Langchain. Check out '[Using Prompt with Chains or multi-step workflows](/galileo/gen-ai-studio-products/galileo-evaluate/how-to/evaluate-and-optimize-agents--chains-or-multi-step-workflows)' for more details on how to integrate Galileo into your Langchain application.
To prompt your custom models through the Galileo UI, they need to be hosted on AWS Sagemaker ([see above](/galileo/gen-ai-studio-products/galileo-evaluate/integrations/llms#aws-sagemaker)).
---
# Source: https://docs.galileo.ai/galileo/gen-ai-studio-products/galileo-evaluate/how-to/log-pre-generated-responses-in-python.md
> ## Documentation Index
> Fetch the complete documentation index at: https://docs.galileo.ai/llms.txt
> Use this file to discover all available pages before exploring further.
# Log Pre-generated Responses in Python
> If you already have a dataset of requests and application responses, and you want to log and evaluate these on Galileo without re-generating the responses, you can do so via our worflows.
First, log in to Galileo:
```py theme={null}
import promptquality as pq
pq.login()
```
Now you can take your previously generated data and log it to Galileo.
```py theme={null}
from promptquality import EvaluateRun
metrics = [pq.Scorers.context_adherence_plus, pq.Scorers.prompt_injection]
evaluate_run = EvaluateRun(run_name="my_run", project_name="my_project", scorers=metrics)
```
```py theme={null}
# Your previously generated requests & responses
data = [
{
'request': 'What\'s the capital of United States?',
'response': 'Washington D.C.',
'context': 'Washington D.C. is the capital of United States'
},
{
'request': 'What\'s the capital of France?',
'response': 'Paris',
'context': 'Paris is the capital of France'
}
]
metrics = [pq.Scorers.context_adherence_plus, pq.Scorers.prompt_injection]
evaluate_run = EvaluateRun(run_name="my_run", project_name="my_project", scorers=metrics)
for row in data:
template = "Given the following context answer the question. \n Context: {context} \n Question: {question}"
wf = evaluate_run.add_workflow(input=row["request"], output=row["response"])
wf.add_llm(
input=template.format(context=row['context'], question=row["request"]),
output=row["response"],
model=pq.Models.chat_gpt,
)
```
Finally, log your Evaluate run to Galileo:
```py theme={null}
evaluate_run.finish()
```
Once complete, this step will display the link to access the run from your Galileo Console.
## Logging as a RAG workflow
To log the above dataset as a RAG workflow, you can modify the code snippet as follows:
```py theme={null}
for row in data:
template = "Given the following context answer the question. \n Context: {context} \n Question: {question}"
wf = evaluate_run.add_workflow(input=row["request"], output=row["response"])
# Add the retriever step with the context retrieved.
wf.add_retriever(
input=row["request"],
documents=[row['context']],
)
wf.add_llm(
input=template.format(context=row['context'], question=row["request"]),
output=row["response"],
model=pq.Models.chat_gpt,
)
```
---
# Source: https://docs.galileo.ai/api-reference/observe/log-workflows.md
> ## Documentation Index
> Fetch the complete documentation index at: https://docs.galileo.ai/llms.txt
> Use this file to discover all available pages before exploring further.
# Log Workflows to an Observe Project
> Log workflows to an Observe project.
Use this endpoint to log workflows to an Observe project. The request body should contain the
`workflows` to be ingested.
Additionally, specify the `project_id` or `project_name` to which the workflows should be ingested.
If the project does not exist, it will be created. If the project exists, the workflows will be logged to it.
If both `project_id` and `project_name` are provided, `project_id` will take precedence.
### WorkflowStep
A workflow step is the atomic unit of logging to Galileo. They represent a single execution of a workflow, such as a chain, agent, or a RAG execution. Workflows can have multiple steps, each of which can be a different type of node, such as an LLM, Retriever, or Tool.
You can log multiple workflows in a single request. Each workflow step must have the following fields:
* `type`: The type of the workflow.
* `input`: The input to the workflow.
* `output`: The output of the workflow.
## Examples
### LLM Step
```json theme={null}
{
"type": "llm",
"input": "What is the capital of France?",
"output": "Paris"
}
```
### Retriever Step
```json theme={null}
{
"type": "retriever",
"input": "What is the capital of France?",
"output": [{ "content": "Paris is the capital and largest city of France." }]
}
```
### Multi-Step
Workflow steps of type `workflow`, `agent` or `chain` can have sub-steps with children. A workflow with a retriver and an LLM step would look like this:
```json theme={null}
{
"type": "workflow",
"input": "What is the capital of France?",
"output": "Paris",
"steps": [
{
"type": "retriever",
"input": "What is the capital of France?",
"output": [{ "content": "Paris is the capital and largest city of France." }]
},
{
"type": "llm",
"input": "What is the capital of France?",
"output": "Paris"
}
]
}
```
## OpenAPI
````yaml POST /v1/observe/workflows
openapi: 3.1.0
info:
title: FastAPI
version: 0.1.0
servers:
- url: https://api.staging.galileo.ai
description: Galileo Public APIs - staging
security: []
paths:
/v1/observe/workflows:
post:
tags:
- observe
summary: Log Workflows
description: >-
Log workflows to an Observe project.
Use this endpoint to log workflows to an Observe project. The request
body should contain the
`workflows` to be ingested.
Additionally, specify the `project_id` or `project_name` to which the
workflows should be ingested.
If the project does not exist, it will be created. If the project
exists, the workflows will be logged to it.
If both `project_id` and `project_name` are provided, `project_id` will
take precedence.
operationId: log_workflows_v1_observe_workflows_post
requestBody:
content:
application/json:
schema:
$ref: '#/components/schemas/WorkflowsIngestRequest'
required: true
responses:
'200':
description: Successful Response
content:
application/json:
schema:
$ref: '#/components/schemas/WorkflowsIngestResponse'
'422':
description: Validation Error
content:
application/json:
schema:
$ref: '#/components/schemas/HTTPValidationError'
security:
- APIKeyHeader: []
- OAuth2PasswordBearer: []
- HTTPBasic: []
components:
schemas:
WorkflowsIngestRequest:
properties:
workflows:
items:
oneOf:
- $ref: '#/components/schemas/WorkflowStep'
- $ref: '#/components/schemas/ChainStep'
- $ref: '#/components/schemas/LlmStep'
- $ref: '#/components/schemas/RetrieverStep'
- $ref: '#/components/schemas/ToolStep'
- $ref: '#/components/schemas/AgentStep'
discriminator:
propertyName: type
mapping:
agent: '#/components/schemas/AgentStep'
chain: '#/components/schemas/ChainStep'
llm: '#/components/schemas/LlmStep'
retriever: '#/components/schemas/RetrieverStep'
tool: '#/components/schemas/ToolStep'
workflow: '#/components/schemas/WorkflowStep'
type: array
minItems: 1
title: Workflows
description: List of workflows to log.
project_id:
anyOf:
- type: string
format: uuid4
- type: 'null'
title: Project Id
description: Project ID for the Observe project.
project_name:
anyOf:
- type: string
- type: 'null'
title: Project Name
description: Project name for the Observe project.
type: object
required:
- workflows
title: WorkflowsIngestRequest
examples:
- project_name: my-observe-project
workflows:
- created_at_ns: 1769195837805226000
duration_ns: 0
input: who is a smart LLM?
metadata: {}
name: llm
output: I am!
type: llm
- project_id: 00000000-0000-0000-0000-000000000000
workflows:
- created_at_ns: 1769195837805279700
duration_ns: 0
input: who is a smart LLM?
metadata: {}
name: llm
output: I am!
type: llm
WorkflowsIngestResponse:
properties:
message:
type: string
title: Message
project_id:
type: string
format: uuid4
title: Project Id
project_name:
type: string
title: Project Name
workflows_count:
type: integer
title: Workflows Count
records_count:
type: integer
title: Records Count
type: object
required:
- message
- project_id
- project_name
- workflows_count
- records_count
title: WorkflowsIngestResponse
HTTPValidationError:
properties:
detail:
items:
$ref: '#/components/schemas/ValidationError'
type: array
title: Detail
type: object
title: HTTPValidationError
WorkflowStep:
properties:
type:
type: string
const: workflow
title: Type
description: Type of the step. By default, it is set to workflow.
default: workflow
input:
anyOf:
- type: string
- $ref: '#/components/schemas/Document-Input'
- $ref: '#/components/schemas/Message'
- additionalProperties: true
type: object
- items:
type: string
type: array
- items:
$ref: '#/components/schemas/Document-Input'
type: array
- items:
$ref: '#/components/schemas/Message'
type: array
- items:
additionalProperties:
type: string
type: object
type: array
- items:
additionalProperties: true
type: object
type: array
title: Input
description: Input to the step.
redacted_input:
anyOf:
- type: string
- $ref: '#/components/schemas/Document-Input'
- $ref: '#/components/schemas/Message'
- additionalProperties: true
type: object
- items:
type: string
type: array
- items:
$ref: '#/components/schemas/Document-Input'
type: array
- items:
$ref: '#/components/schemas/Message'
type: array
- items:
additionalProperties:
type: string
type: object
type: array
- items:
additionalProperties: true
type: object
type: array
- type: 'null'
title: Redacted Input
description: >-
Redacted input of the step. This is used to redact sensitive
information.
output:
anyOf:
- type: string
- $ref: '#/components/schemas/Document-Input'
- $ref: '#/components/schemas/Message'
- additionalProperties: true
type: object
- items:
type: string
type: array
- items:
$ref: '#/components/schemas/Document-Input'
type: array
- items:
$ref: '#/components/schemas/Message'
type: array
- items:
additionalProperties:
type: string
type: object
type: array
- items:
additionalProperties: true
type: object
type: array
title: Output
description: Output of the step.
default: ''
redacted_output:
anyOf:
- type: string
- $ref: '#/components/schemas/Document-Input'
- $ref: '#/components/schemas/Message'
- additionalProperties: true
type: object
- items:
type: string
type: array
- items:
$ref: '#/components/schemas/Document-Input'
type: array
- items:
$ref: '#/components/schemas/Message'
type: array
- items:
additionalProperties:
type: string
type: object
type: array
- items:
additionalProperties: true
type: object
type: array
- type: 'null'
title: Redacted Output
description: >-
Redacted output of the step. This is used to redact sensitive
information.
name:
type: string
title: Name
description: Name of the step.
default: ''
created_at_ns:
type: integer
title: Created At Ns
description: Timestamp of the step's creation, as nanoseconds since epoch.
duration_ns:
type: integer
title: Duration Ns
description: Duration of the step in nanoseconds.
default: 0
metadata:
additionalProperties:
type: string
type: object
title: Metadata
description: Metadata associated with this step.
status_code:
anyOf:
- type: integer
- type: 'null'
title: Status Code
description: Status code of the step. Used for logging failed/errored steps.
ground_truth:
anyOf:
- type: string
- type: 'null'
title: Ground Truth
description: Ground truth expected output for the step.
steps:
items:
oneOf:
- $ref: '#/components/schemas/WorkflowStep'
- $ref: '#/components/schemas/ChainStep'
- $ref: '#/components/schemas/LlmStep'
- $ref: '#/components/schemas/RetrieverStep'
- $ref: '#/components/schemas/ToolStep'
- $ref: '#/components/schemas/AgentStep'
discriminator:
propertyName: type
mapping:
agent: '#/components/schemas/AgentStep'
chain: '#/components/schemas/ChainStep'
llm: '#/components/schemas/LlmStep'
retriever: '#/components/schemas/RetrieverStep'
tool: '#/components/schemas/ToolStep'
workflow: '#/components/schemas/WorkflowStep'
type: array
title: Steps
description: Steps in the workflow.
parent:
anyOf:
- $ref: '#/components/schemas/StepWithChildren'
- type: 'null'
description: Parent node of the current node. For internal use only.
type: object
required:
- input
title: WorkflowStep
ChainStep:
properties:
type:
type: string
const: chain
title: Type
description: Type of the step. By default, it is set to chain.
default: chain
input:
anyOf:
- type: string
- $ref: '#/components/schemas/Document-Input'
- $ref: '#/components/schemas/Message'
- additionalProperties: true
type: object
- items:
type: string
type: array
- items:
$ref: '#/components/schemas/Document-Input'
type: array
- items:
$ref: '#/components/schemas/Message'
type: array
- items:
additionalProperties:
type: string
type: object
type: array
- items:
additionalProperties: true
type: object
type: array
title: Input
description: Input to the step.
redacted_input:
anyOf:
- type: string
- $ref: '#/components/schemas/Document-Input'
- $ref: '#/components/schemas/Message'
- additionalProperties: true
type: object
- items:
type: string
type: array
- items:
$ref: '#/components/schemas/Document-Input'
type: array
- items:
$ref: '#/components/schemas/Message'
type: array
- items:
additionalProperties:
type: string
type: object
type: array
- items:
additionalProperties: true
type: object
type: array
- type: 'null'
title: Redacted Input
description: >-
Redacted input of the step. This is used to redact sensitive
information.
output:
anyOf:
- type: string
- $ref: '#/components/schemas/Document-Input'
- $ref: '#/components/schemas/Message'
- additionalProperties: true
type: object
- items:
type: string
type: array
- items:
$ref: '#/components/schemas/Document-Input'
type: array
- items:
$ref: '#/components/schemas/Message'
type: array
- items:
additionalProperties:
type: string
type: object
type: array
- items:
additionalProperties: true
type: object
type: array
title: Output
description: Output of the step.
default: ''
redacted_output:
anyOf:
- type: string
- $ref: '#/components/schemas/Document-Input'
- $ref: '#/components/schemas/Message'
- additionalProperties: true
type: object
- items:
type: string
type: array
- items:
$ref: '#/components/schemas/Document-Input'
type: array
- items:
$ref: '#/components/schemas/Message'
type: array
- items:
additionalProperties:
type: string
type: object
type: array
- items:
additionalProperties: true
type: object
type: array
- type: 'null'
title: Redacted Output
description: >-
Redacted output of the step. This is used to redact sensitive
information.
name:
type: string
title: Name
description: Name of the step.
default: ''
created_at_ns:
type: integer
title: Created At Ns
description: Timestamp of the step's creation, as nanoseconds since epoch.
duration_ns:
type: integer
title: Duration Ns
description: Duration of the step in nanoseconds.
default: 0
metadata:
additionalProperties:
type: string
type: object
title: Metadata
description: Metadata associated with this step.
status_code:
anyOf:
- type: integer
- type: 'null'
title: Status Code
description: Status code of the step. Used for logging failed/errored steps.
ground_truth:
anyOf:
- type: string
- type: 'null'
title: Ground Truth
description: Ground truth expected output for the step.
steps:
items:
oneOf:
- $ref: '#/components/schemas/WorkflowStep'
- $ref: '#/components/schemas/ChainStep'
- $ref: '#/components/schemas/LlmStep'
- $ref: '#/components/schemas/RetrieverStep'
- $ref: '#/components/schemas/ToolStep'
- $ref: '#/components/schemas/AgentStep'
discriminator:
propertyName: type
mapping:
agent: '#/components/schemas/AgentStep'
chain: '#/components/schemas/ChainStep'
llm: '#/components/schemas/LlmStep'
retriever: '#/components/schemas/RetrieverStep'
tool: '#/components/schemas/ToolStep'
workflow: '#/components/schemas/WorkflowStep'
type: array
title: Steps
description: Steps in the workflow.
parent:
anyOf:
- $ref: '#/components/schemas/StepWithChildren'
- type: 'null'
description: Parent node of the current node. For internal use only.
type: object
required:
- input
title: ChainStep
LlmStep:
properties:
type:
type: string
const: llm
title: Type
description: Type of the step. By default, it is set to llm.
default: llm
input:
anyOf:
- type: string
- additionalProperties:
type: string
type: object
- $ref: '#/components/schemas/Message'
- items:
type: string
type: array
- items:
additionalProperties:
type: string
type: object
type: array
- items:
$ref: '#/components/schemas/Message'
type: array
title: Input
description: Input to the LLM step.
redacted_input:
anyOf:
- type: string
- additionalProperties:
type: string
type: object
- $ref: '#/components/schemas/Message'
- items:
type: string
type: array
- items:
additionalProperties:
type: string
type: object
type: array
- items:
$ref: '#/components/schemas/Message'
type: array
- type: 'null'
title: Redacted Input
description: >-
Redacted input of the LLM step. This is used to redact sensitive
information.
output:
anyOf:
- type: string
- additionalProperties:
type: string
type: object
- $ref: '#/components/schemas/Message'
- items:
type: string
type: array
- items:
additionalProperties:
type: string
type: object
type: array
- items:
$ref: '#/components/schemas/Message'
type: array
title: Output
description: Output of the LLM step.
default: ''
redacted_output:
anyOf:
- type: string
- additionalProperties:
type: string
type: object
- $ref: '#/components/schemas/Message'
- items:
type: string
type: array
- items:
additionalProperties:
type: string
type: object
type: array
- items:
$ref: '#/components/schemas/Message'
type: array
- type: 'null'
title: Redacted Output
description: >-
Redacted output of the LLM step. This is used to redact sensitive
information.
name:
type: string
title: Name
description: Name of the step.
default: ''
created_at_ns:
type: integer
title: Created At Ns
description: Timestamp of the step's creation, as nanoseconds since epoch.
duration_ns:
type: integer
title: Duration Ns
description: Duration of the step in nanoseconds.
default: 0
metadata:
additionalProperties:
type: string
type: object
title: Metadata
description: Metadata associated with this step.
status_code:
anyOf:
- type: integer
- type: 'null'
title: Status Code
description: Status code of the step. Used for logging failed/errored steps.
ground_truth:
anyOf:
- type: string
- type: 'null'
title: Ground Truth
description: Ground truth expected output for the step.
tools:
anyOf:
- items:
additionalProperties: true
type: object
type: array
- type: 'null'
title: Tools
description: List of available tools passed to the LLM on invocation.
model:
anyOf:
- type: string
- type: 'null'
title: Model
description: Model used for this step.
input_tokens:
anyOf:
- type: integer
- type: 'null'
title: Input Tokens
description: Number of input tokens.
output_tokens:
anyOf:
- type: integer
- type: 'null'
title: Output Tokens
description: Number of output tokens.
total_tokens:
anyOf:
- type: integer
- type: 'null'
title: Total Tokens
description: Total number of tokens.
temperature:
anyOf:
- type: number
- type: 'null'
title: Temperature
description: Temperature used for generation.
time_to_first_token_ms:
anyOf:
- type: number
- type: 'null'
title: Time To First Token Ms
description: Time to first token in milliseconds.
type: object
required:
- input
title: LlmStep
RetrieverStep:
properties:
type:
type: string
const: retriever
title: Type
description: Type of the step. By default, it is set to retriever.
default: retriever
input:
type: string
title: Input
description: Input query to the retriever.
redacted_input:
anyOf:
- type: string
- type: 'null'
title: Redacted Input
description: >-
Redacted input of the retriever step. This is used to redact
sensitive information.
output:
items:
$ref: '#/components/schemas/Document-Input'
type: array
title: Output
description: >-
Documents retrieved from the retriever. This can be a list of
strings or `Document`s.
redacted_output:
anyOf:
- items:
$ref: '#/components/schemas/Document-Input'
type: array
- type: 'null'
title: Redacted Output
description: >-
Redacted output of the retriever step. This is used to redact
sensitive information.
name:
type: string
title: Name
description: Name of the step.
default: ''
created_at_ns:
type: integer
title: Created At Ns
description: Timestamp of the step's creation, as nanoseconds since epoch.
duration_ns:
type: integer
title: Duration Ns
description: Duration of the step in nanoseconds.
default: 0
metadata:
additionalProperties:
type: string
type: object
title: Metadata
description: Metadata associated with this step.
status_code:
anyOf:
- type: integer
- type: 'null'
title: Status Code
description: Status code of the step. Used for logging failed/errored steps.
ground_truth:
anyOf:
- type: string
- type: 'null'
title: Ground Truth
description: Ground truth expected output for the step.
type: object
required:
- input
title: RetrieverStep
ToolStep:
properties:
type:
type: string
const: tool
title: Type
description: Type of the step. By default, it is set to tool.
default: tool
input:
anyOf:
- type: string
- $ref: '#/components/schemas/Document-Input'
- $ref: '#/components/schemas/Message'
- additionalProperties: true
type: object
- items:
type: string
type: array
- items:
$ref: '#/components/schemas/Document-Input'
type: array
- items:
$ref: '#/components/schemas/Message'
type: array
- items:
additionalProperties:
type: string
type: object
type: array
- items:
additionalProperties: true
type: object
type: array
title: Input
description: Input to the step.
redacted_input:
anyOf:
- type: string
- $ref: '#/components/schemas/Document-Input'
- $ref: '#/components/schemas/Message'
- additionalProperties: true
type: object
- items:
type: string
type: array
- items:
$ref: '#/components/schemas/Document-Input'
type: array
- items:
$ref: '#/components/schemas/Message'
type: array
- items:
additionalProperties:
type: string
type: object
type: array
- items:
additionalProperties: true
type: object
type: array
- type: 'null'
title: Redacted Input
description: >-
Redacted input of the step. This is used to redact sensitive
information.
output:
anyOf:
- type: string
- $ref: '#/components/schemas/Document-Input'
- $ref: '#/components/schemas/Message'
- additionalProperties: true
type: object
- items:
type: string
type: array
- items:
$ref: '#/components/schemas/Document-Input'
type: array
- items:
$ref: '#/components/schemas/Message'
type: array
- items:
additionalProperties:
type: string
type: object
type: array
- items:
additionalProperties: true
type: object
type: array
title: Output
description: Output of the step.
default: ''
redacted_output:
anyOf:
- type: string
- $ref: '#/components/schemas/Document-Input'
- $ref: '#/components/schemas/Message'
- additionalProperties: true
type: object
- items:
type: string
type: array
- items:
$ref: '#/components/schemas/Document-Input'
type: array
- items:
$ref: '#/components/schemas/Message'
type: array
- items:
additionalProperties:
type: string
type: object
type: array
- items:
additionalProperties: true
type: object
type: array
- type: 'null'
title: Redacted Output
description: >-
Redacted output of the step. This is used to redact sensitive
information.
name:
type: string
title: Name
description: Name of the step.
default: ''
created_at_ns:
type: integer
title: Created At Ns
description: Timestamp of the step's creation, as nanoseconds since epoch.
duration_ns:
type: integer
title: Duration Ns
description: Duration of the step in nanoseconds.
default: 0
metadata:
additionalProperties:
type: string
type: object
title: Metadata
description: Metadata associated with this step.
status_code:
anyOf:
- type: integer
- type: 'null'
title: Status Code
description: Status code of the step. Used for logging failed/errored steps.
ground_truth:
anyOf:
- type: string
- type: 'null'
title: Ground Truth
description: Ground truth expected output for the step.
type: object
required:
- input
title: ToolStep
AgentStep:
properties:
type:
type: string
const: agent
title: Type
description: Type of the step. By default, it is set to agent.
default: agent
input:
anyOf:
- type: string
- $ref: '#/components/schemas/Document-Input'
- $ref: '#/components/schemas/Message'
- additionalProperties: true
type: object
- items:
type: string
type: array
- items:
$ref: '#/components/schemas/Document-Input'
type: array
- items:
$ref: '#/components/schemas/Message'
type: array
- items:
additionalProperties:
type: string
type: object
type: array
- items:
additionalProperties: true
type: object
type: array
title: Input
description: Input to the step.
redacted_input:
anyOf:
- type: string
- $ref: '#/components/schemas/Document-Input'
- $ref: '#/components/schemas/Message'
- additionalProperties: true
type: object
- items:
type: string
type: array
- items:
$ref: '#/components/schemas/Document-Input'
type: array
- items:
$ref: '#/components/schemas/Message'
type: array
- items:
additionalProperties:
type: string
type: object
type: array
- items:
additionalProperties: true
type: object
type: array
- type: 'null'
title: Redacted Input
description: >-
Redacted input of the step. This is used to redact sensitive
information.
output:
anyOf:
- type: string
- $ref: '#/components/schemas/Document-Input'
- $ref: '#/components/schemas/Message'
- additionalProperties: true
type: object
- items:
type: string
type: array
- items:
$ref: '#/components/schemas/Document-Input'
type: array
- items:
$ref: '#/components/schemas/Message'
type: array
- items:
additionalProperties:
type: string
type: object
type: array
- items:
additionalProperties: true
type: object
type: array
title: Output
description: Output of the step.
default: ''
redacted_output:
anyOf:
- type: string
- $ref: '#/components/schemas/Document-Input'
- $ref: '#/components/schemas/Message'
- additionalProperties: true
type: object
- items:
type: string
type: array
- items:
$ref: '#/components/schemas/Document-Input'
type: array
- items:
$ref: '#/components/schemas/Message'
type: array
- items:
additionalProperties:
type: string
type: object
type: array
- items:
additionalProperties: true
type: object
type: array
- type: 'null'
title: Redacted Output
description: >-
Redacted output of the step. This is used to redact sensitive
information.
name:
type: string
title: Name
description: Name of the step.
default: ''
created_at_ns:
type: integer
title: Created At Ns
description: Timestamp of the step's creation, as nanoseconds since epoch.
duration_ns:
type: integer
title: Duration Ns
description: Duration of the step in nanoseconds.
default: 0
metadata:
additionalProperties:
type: string
type: object
title: Metadata
description: Metadata associated with this step.
status_code:
anyOf:
- type: integer
- type: 'null'
title: Status Code
description: Status code of the step. Used for logging failed/errored steps.
ground_truth:
anyOf:
- type: string
- type: 'null'
title: Ground Truth
description: Ground truth expected output for the step.
steps:
items:
oneOf:
- $ref: '#/components/schemas/WorkflowStep'
- $ref: '#/components/schemas/ChainStep'
- $ref: '#/components/schemas/LlmStep'
- $ref: '#/components/schemas/RetrieverStep'
- $ref: '#/components/schemas/ToolStep'
- $ref: '#/components/schemas/AgentStep'
discriminator:
propertyName: type
mapping:
agent: '#/components/schemas/AgentStep'
chain: '#/components/schemas/ChainStep'
llm: '#/components/schemas/LlmStep'
retriever: '#/components/schemas/RetrieverStep'
tool: '#/components/schemas/ToolStep'
workflow: '#/components/schemas/WorkflowStep'
type: array
title: Steps
description: Steps in the workflow.
parent:
anyOf:
- $ref: '#/components/schemas/StepWithChildren'
- type: 'null'
description: Parent node of the current node. For internal use only.
type: object
required:
- input
title: AgentStep
ValidationError:
properties:
loc:
items:
anyOf:
- type: string
- type: integer
type: array
title: Location
msg:
type: string
title: Message
type:
type: string
title: Error Type
type: object
required:
- loc
- msg
- type
title: ValidationError
Document-Input:
properties:
page_content:
type: string
title: Page Content
description: Content of the document.
metadata:
additionalProperties:
anyOf:
- type: boolean
- type: string
- type: integer
- type: number
type: object
title: Metadata
additionalProperties: false
type: object
required:
- page_content
title: Document
Message:
properties:
content:
type: string
title: Content
role:
anyOf:
- type: string
- $ref: '#/components/schemas/MessageRole'
title: Role
additionalProperties: true
type: object
required:
- content
- role
title: Message
StepWithChildren:
properties:
type:
$ref: '#/components/schemas/NodeType'
description: Type of the step. By default, it is set to workflow.
default: workflow
input:
anyOf:
- type: string
- $ref: '#/components/schemas/Document-Input'
- $ref: '#/components/schemas/Message'
- additionalProperties: true
type: object
- items:
type: string
type: array
- items:
$ref: '#/components/schemas/Document-Input'
type: array
- items:
$ref: '#/components/schemas/Message'
type: array
- items:
additionalProperties:
type: string
type: object
type: array
- items:
additionalProperties: true
type: object
type: array
title: Input
description: Input to the step.
redacted_input:
anyOf:
- type: string
- $ref: '#/components/schemas/Document-Input'
- $ref: '#/components/schemas/Message'
- additionalProperties: true
type: object
- items:
type: string
type: array
- items:
$ref: '#/components/schemas/Document-Input'
type: array
- items:
$ref: '#/components/schemas/Message'
type: array
- items:
additionalProperties:
type: string
type: object
type: array
- items:
additionalProperties: true
type: object
type: array
- type: 'null'
title: Redacted Input
description: >-
Redacted input of the step. This is used to redact sensitive
information.
output:
anyOf:
- type: string
- $ref: '#/components/schemas/Document-Input'
- $ref: '#/components/schemas/Message'
- additionalProperties: true
type: object
- items:
type: string
type: array
- items:
$ref: '#/components/schemas/Document-Input'
type: array
- items:
$ref: '#/components/schemas/Message'
type: array
- items:
additionalProperties:
type: string
type: object
type: array
- items:
additionalProperties: true
type: object
type: array
title: Output
description: Output of the step.
default: ''
redacted_output:
anyOf:
- type: string
- $ref: '#/components/schemas/Document-Input'
- $ref: '#/components/schemas/Message'
- additionalProperties: true
type: object
- items:
type: string
type: array
- items:
$ref: '#/components/schemas/Document-Input'
type: array
- items:
$ref: '#/components/schemas/Message'
type: array
- items:
additionalProperties:
type: string
type: object
type: array
- items:
additionalProperties: true
type: object
type: array
- type: 'null'
title: Redacted Output
description: >-
Redacted output of the step. This is used to redact sensitive
information.
name:
type: string
title: Name
description: Name of the step.
default: ''
created_at_ns:
type: integer
title: Created At Ns
description: Timestamp of the step's creation, as nanoseconds since epoch.
duration_ns:
type: integer
title: Duration Ns
description: Duration of the step in nanoseconds.
default: 0
metadata:
additionalProperties:
type: string
type: object
title: Metadata
description: Metadata associated with this step.
status_code:
anyOf:
- type: integer
- type: 'null'
title: Status Code
description: Status code of the step. Used for logging failed/errored steps.
ground_truth:
anyOf:
- type: string
- type: 'null'
title: Ground Truth
description: Ground truth expected output for the step.
steps:
items:
oneOf:
- $ref: '#/components/schemas/WorkflowStep'
- $ref: '#/components/schemas/ChainStep'
- $ref: '#/components/schemas/LlmStep'
- $ref: '#/components/schemas/RetrieverStep'
- $ref: '#/components/schemas/ToolStep'
- $ref: '#/components/schemas/AgentStep'
discriminator:
propertyName: type
mapping:
agent: '#/components/schemas/AgentStep'
chain: '#/components/schemas/ChainStep'
llm: '#/components/schemas/LlmStep'
retriever: '#/components/schemas/RetrieverStep'
tool: '#/components/schemas/ToolStep'
workflow: '#/components/schemas/WorkflowStep'
type: array
title: Steps
description: Steps in the workflow.
parent:
anyOf:
- $ref: '#/components/schemas/StepWithChildren'
- type: 'null'
description: Parent node of the current node. For internal use only.
type: object
required:
- input
title: StepWithChildren
MessageRole:
type: string
enum:
- agent
- assistant
- function
- system
- tool
- user
title: MessageRole
NodeType:
type: string
enum:
- chain
- chat
- llm
- retriever
- tool
- agent
- workflow
- trace
- session
title: NodeType
securitySchemes:
APIKeyHeader:
type: apiKey
in: header
name: Galileo-API-Key
OAuth2PasswordBearer:
type: oauth2
flows:
password:
scopes: {}
tokenUrl: https://api.staging.galileo.ai/login
HTTPBasic:
type: http
scheme: basic
````
---
# Source: https://docs.galileo.ai/galileo/gen-ai-studio-products/galileo-evaluate/how-to/logging-and-comparing-against-your-expected-answers.md
> ## Documentation Index
> Fetch the complete documentation index at: https://docs.galileo.ai/llms.txt
> Use this file to discover all available pages before exploring further.
# Logging and Comparing against your Expected Answers
> Expected outputs are a key element for evaluating LLM applications. They provide benchmarks to measure model accuracy, identify errors, and ensure consistent assessments.
By comparing model responses to these predefined targets, you can pinpoint areas of improvement and track performance changes over time.
Including expected outputs in your evaluation process also aids in benchmarking your application, ensuring fair and replicable evaluations.
## Logging Expected Output
There are a few ways to create runs, and each way has a slightly different way of logging your Expected Output:
### PQ.run() or Playground UI
If you're using `pq.run()` or creating runs through the [Playground UI](/galileo/gen-ai-studio-products/galileo-evaluate/quickstart), simply include your expected answers in a column called `output` in your evaluation set.
### Python Logger
If you're logging your runs via [EvaluateRun](https://promptquality.docs.rungalileo.io/#promptquality.EvaluateRun),
you can set the expected output using the `ground_truth` parameter in the workflow creation methods.
To log your runs with Galileo, you'd start with the same typical flow of logging into Galileo:
```py theme={null}
import promptquality as pq
pq.login()
```
Next you can construct your [EvaluateRun](https://promptquality.docs.rungalileo.io/#promptquality.EvaluateRun) object:
```py theme={null}
from promptquality import EvaluateRun
metrics = [pq.Scorers.context_adherence_plus, pq.Scorers.prompt_injection]
evaluate_run = EvaluateRun(run_name="my_run", project_name="my_project", scorers=metrics)
```
Now you can integrate this logging into your existing application and include the expected output in your evaluation set.
```py theme={null}
def my_llm_app(input, ground_truth, evaluate_run):
context = "You're a helpful AI assistant."
template = "Given the following context answer the question. \n Context: {context} \n Question: {question}"
# Add groundtruth to your workflow.
wf = evaluate_run.add_workflow(input=input, ground_truth=ground_truth)
# Get response from your llm.
prompt = template.format(context=context, question=input)
llm_response = llm.call(prompt) # Pseudo-code, replace with your LLM call.
# Log llm step to Galileo
wf.add_llm(input=prompt, output=llm_response, model=)
# Conclude the workflow and add the final output.
wf.conclude(output=llm_response)
return llm_response
# Your evaluation dataset.
eval_set = [
{
"input": "What are plants?",
"ground_truth": "Plants are living organisms that typically grow in soil and have roots, stems, and leaves."
},
{
"input": "What is the capital of France?",
"ground_truth": "Paris"
}
]
for row in eval_set:
my_llm_app(row["input"], row["ground_truth"], evaluate_run)
```
### Langchain Callback
If you're using a Langchain Callback, add your expected output by calling `add_expected_outputs` on your callback handler.
```py theme={null}
my_chain = ... # your langchain chain
galileo_handler = pq.GalileoPromptCallback(
project_name="my_project", scorers=scorers,
)
inputs = ['What is 2+2?', 'Which city is the Golden Gate Bridge in?']
expected_outputs = ['4', 'San Francisco']
my_chain.batch(inputs, config=dict(callbacks=[galileo_handler]))
# Sets the expected output from each of the inputs.
galileo_handler.add_expected_outputs(expected_outputs)
galileo_handler.finish()
```
### REST Endpoint
If you're logging Evaluation runs via the [REST endpoint](/galileo/clients/log-evaluate-runs-via-rest-apis), set the *target* field in the root node of each workflow.
```py theme={null}
...
{
node_id: "A_UNIQUE_ID",
node_type: "chain",
node_name: "Chain",
node_input: "What is 2+2?",
node_output: "3",
chain_root_id: "A_UNIQUE_ID",
step: 0,
has_children: true,
creation_timestamp: 0,
expected_output: "4"
},
...
```
Important note: Set the *expected\_output* on the root node of your workflow. Typically this will be the sole LLM node in your workflow or a "chain" node with other children nodes.
## Comparing Output and Expected Output
When Expected Output gets logged, it'll appear next to your Output wherever your output is shown.
---
# Source: https://docs.galileo.ai/api-reference/evaluate-alerts/list-evaluate-alerts.md
> ## Documentation Index
> Fetch the complete documentation index at: https://docs.galileo.ai/llms.txt
> Use this file to discover all available pages before exploring further.
# List Evaluate Alerts
## OpenAPI
````yaml https://api.staging.galileo.ai/public/v1/openapi.json get /v1/projects/{project_id}/runs/{run_id}/prompts/alerts
openapi: 3.1.0
info:
title: FastAPI
version: 0.1.0
servers:
- url: https://api.staging.galileo.ai
description: Galileo Public APIs - staging
security: []
paths:
/v1/projects/{project_id}/runs/{run_id}/prompts/alerts:
get:
tags:
- evaluate-alerts
summary: List Evaluate Alerts
operationId: >-
list_evaluate_alerts_v1_projects__project_id__runs__run_id__prompts_alerts_get
parameters:
- name: run_id
in: path
required: true
schema:
type: string
format: uuid4
title: Run Id
- name: project_id
in: path
required: true
schema:
type: string
format: uuid4
title: Project Id
responses:
'200':
description: Successful Response
content:
application/json:
schema:
type: array
items:
$ref: '#/components/schemas/EvaluateAlertDB'
title: >-
Response List Evaluate Alerts V1 Projects Project Id Runs
Run Id Prompts Alerts Get
'422':
description: Validation Error
content:
application/json:
schema:
$ref: '#/components/schemas/HTTPValidationError'
security:
- APIKeyHeader: []
- OAuth2PasswordBearer: []
- HTTPBasic: []
components:
schemas:
EvaluateAlertDB:
properties:
project_id:
type: string
format: uuid4
title: Project Id
run_id:
type: string
format: uuid4
title: Run Id
alert_name:
type: string
title: Alert Name
filter:
oneOf:
- $ref: '#/components/schemas/RangePromptFilterParam'
- $ref: '#/components/schemas/ValuePromptFilterParam'
- $ref: '#/components/schemas/CategoricalPromptFilterParam'
title: Filter
discriminator:
propertyName: filter_type
mapping:
category: '#/components/schemas/CategoricalPromptFilterParam'
range: '#/components/schemas/RangePromptFilterParam'
value: '#/components/schemas/ValuePromptFilterParam'
field_name:
type: string
title: Field Name
description:
type: string
title: Description
extra:
anyOf:
- additionalProperties: true
type: object
- type: 'null'
title: Extra
id:
type: string
format: uuid4
title: Id
created_at:
type: string
format: date-time
title: Created At
updated_at:
type: string
format: date-time
title: Updated At
type: object
required:
- project_id
- run_id
- alert_name
- filter
- field_name
- description
- id
- created_at
- updated_at
title: EvaluateAlertDB
HTTPValidationError:
properties:
detail:
items:
$ref: '#/components/schemas/ValidationError'
type: array
title: Detail
type: object
title: HTTPValidationError
RangePromptFilterParam:
properties:
column:
type: string
title: Column
filter_type:
type: string
const: range
title: Filter Type
low:
type: number
title: Low
high:
type: number
title: High
type: object
required:
- column
- filter_type
- low
- high
title: RangePromptFilterParam
ValuePromptFilterParam:
properties:
column:
type: string
title: Column
filter_type:
type: string
const: value
title: Filter Type
value:
anyOf:
- type: integer
- type: number
- type: boolean
- type: string
title: Value
relation:
$ref: '#/components/schemas/Operator'
type: object
required:
- column
- filter_type
- value
- relation
title: ValuePromptFilterParam
CategoricalPromptFilterParam:
properties:
column:
type: string
title: Column
filter_type:
type: string
const: category
title: Filter Type
categories:
items:
type: string
type: array
title: Categories
operator:
$ref: '#/components/schemas/CategoryFilterOperator'
description: >-
Operator to use when checking if the value is in the categories. If
None, we default to 'or'.
default: any
type: object
required:
- column
- filter_type
- categories
title: CategoricalPromptFilterParam
ValidationError:
properties:
loc:
items:
anyOf:
- type: string
- type: integer
type: array
title: Location
msg:
type: string
title: Message
type:
type: string
title: Error Type
type: object
required:
- loc
- msg
- type
title: ValidationError
Operator:
type: string
enum:
- eq
- ne
- gt
- gte
- lt
- lte
- in
- not_in
- contains
- has_all
- between
- like
title: Operator
CategoryFilterOperator:
type: string
enum:
- any
- all
- exact
- none
title: CategoryFilterOperator
securitySchemes:
APIKeyHeader:
type: apiKey
in: header
name: Galileo-API-Key
OAuth2PasswordBearer:
type: oauth2
flows:
password:
scopes: {}
tokenUrl: https://api.staging.galileo.ai/login
HTTPBasic:
type: http
scheme: basic
````
---
# Source: https://docs.galileo.ai/galileo/gen-ai-studio-products/galileo-evaluate/integrations/llms.md
> ## Documentation Index
> Fetch the complete documentation index at: https://docs.galileo.ai/llms.txt
> Use this file to discover all available pages before exploring further.
# LLMs
> Integrate large language models (LLMs) into Galileo Evaluate to assess performance, refine outputs, and enhance generative AI model capabilities.
This section only applies if you want to:
* Query your LLMs via the Galileo Playground or via promptquality.runs()
* Or leverage any of our the metrics that are powered by OpenAI / Azure models. If you have an application or prototype where you're querying a model in code you can integrate Galileo into your code. Jump to [Evaluating and Optimizing Agents, Chains, or multi-stage workflows](/galileo/gen-ai-studio-products/galileo-evaluate/how-to/evaluate-and-optimize-agents--chains-or-multi-step-workflows) to learn more.
Galileo integrates with publicly accessible LLM APIs as well as Open Source LLMs (privately hosted). Before you start using **Evaluate** on your own LLMs, you need to set up your models on the system.
* Go to the 'Galileo Home Page'.
* Click on your 'Profile' (bottom left).
* Client on 'Settings & Permissions'.
* Click on 'Integrations'.
You can set up and manage all your LLM API and Custom Model integrations from the 'Integrations' page.
*Note:* These integrations are user-specific to ensure that different users in an organization can use their own API keys when interacting with the LLMs.
## Public APIs supported
### OpenAI
We support both the [Chat](https://platform.openai.com/docs/api-reference/chat) and [Completions](https://platform.openai.com/docs/api-reference/completions) APIs from OpenAI, with all of the active models. This can be set up from the Galileo console or from the [Python client](https://promptquality.docs.rungalileo.io/#promptquality.add_openai_integration).
*Note:* OpenAI Models power a few of Galileo's Guardrail Metrics (e.g. Correctness, Context Adherence, Chunk Attribution, Chunk Utilization, Completeness). To improve your evaluation experience, we recommend setting up this integration
even if the model you're prompting or testing is a different one.
### Azure OpenAI
If you use OpenAI models through Azure, you can set up your Azure integration. This can be set up from the Galileo console or from the [Python client](https://promptquality.docs.rungalileo.io/#promptquality.add_azure_integration).
### Google Vertex AI
For integrating with models served by Google via Vertex AI (like PaLM 2 and Gemini), we recommend setting up a Service Account within your Google Cloud project that has [Vertex AI enabled](/galileo/gen-ai-studio-products/galileo-evaluate/integrations/llms). This service account requires at minimum [the 'Vertex AI User (roles/aiplatform.user)' role's policies](https://cloud.google.com/vertex-ai/docs/generative-ai/access-control) to be attached.
Once the role is created, create a new key for this service account. The contents of the JSON file provided are what you'll copy over into the Integrations page for Galileo.
by Google Vertex AI. Galileo's ChainPoll metrics **are** available, but perplexity and uncertainty scores are not available for model predictions from Google Vertex AI.
### AWS Bedrock
Add your AWS Bedrock integration in the Galileo Integrations page. You should see a green light indicating a successful integration. Now, you should see new **Bedrock models** show up in the Prompt Playground.
Uncertainty and Galileo ChainPoll metrics cannot be generated using models served by AWS Bedrock.
### AWS Sagemaker
If you're hosting models on AWS Sagemaker, you can query them via Galileo. Set up your AWS Sagemaker integration via the Integrations page.
You'll need to enter your authentication credentials (as an access key \<> secret pair or an AWS role that can be assumed) alongwith the AWS region in which your endpoints are hosted. For each endpoint, you can configure the name of the endpoint and an alias alongwith the schema mapping in [`dpath notation`](https://pypi.org/project/dpath/).
Required parameters for each endpoint are:
* Prompt: To pass the prompt to the payload.
* Response: To parse the response from the response.
Optional parameters, which are included in the payload if set, are:
* Temperature
* Max tokens
* Top K
* Top P
* Frequency penalty
* Presence penalty
Check out [this video](https://www.loom.com/share/27a11ceb14b94c84a6248c67515edee8) for step-by-step instructions.
Uncertainty and Galileo ChainPoll metrics cannot be generated using models served by AWS Sagemaker.
### Other Custom Models
If you are prompting via [Langchain](https://python.langchain.com/docs/get_started/introduction), Galileo can use custom models through Langchain the same way you might use OpenAI in Langchain. Check out '[Using Prompt with Chains or multi-step workflows](/galileo/gen-ai-studio-products/galileo-evaluate/how-to/evaluate-and-optimize-agents--chains-or-multi-step-workflows)' for more details on how to integrate Galileo into your Langchain application.
To prompt your custom models through the Galileo UI, they need to be hosted on AWS Sagemaker ([see above](/galileo/gen-ai-studio-products/galileo-evaluate/integrations/llms#aws-sagemaker)).
---
# Source: https://docs.galileo.ai/galileo/gen-ai-studio-products/galileo-evaluate/how-to/log-pre-generated-responses-in-python.md
> ## Documentation Index
> Fetch the complete documentation index at: https://docs.galileo.ai/llms.txt
> Use this file to discover all available pages before exploring further.
# Log Pre-generated Responses in Python
> If you already have a dataset of requests and application responses, and you want to log and evaluate these on Galileo without re-generating the responses, you can do so via our worflows.
First, log in to Galileo:
```py theme={null}
import promptquality as pq
pq.login()
```
Now you can take your previously generated data and log it to Galileo.
```py theme={null}
from promptquality import EvaluateRun
metrics = [pq.Scorers.context_adherence_plus, pq.Scorers.prompt_injection]
evaluate_run = EvaluateRun(run_name="my_run", project_name="my_project", scorers=metrics)
```
```py theme={null}
# Your previously generated requests & responses
data = [
{
'request': 'What\'s the capital of United States?',
'response': 'Washington D.C.',
'context': 'Washington D.C. is the capital of United States'
},
{
'request': 'What\'s the capital of France?',
'response': 'Paris',
'context': 'Paris is the capital of France'
}
]
metrics = [pq.Scorers.context_adherence_plus, pq.Scorers.prompt_injection]
evaluate_run = EvaluateRun(run_name="my_run", project_name="my_project", scorers=metrics)
for row in data:
template = "Given the following context answer the question. \n Context: {context} \n Question: {question}"
wf = evaluate_run.add_workflow(input=row["request"], output=row["response"])
wf.add_llm(
input=template.format(context=row['context'], question=row["request"]),
output=row["response"],
model=pq.Models.chat_gpt,
)
```
Finally, log your Evaluate run to Galileo:
```py theme={null}
evaluate_run.finish()
```
Once complete, this step will display the link to access the run from your Galileo Console.
## Logging as a RAG workflow
To log the above dataset as a RAG workflow, you can modify the code snippet as follows:
```py theme={null}
for row in data:
template = "Given the following context answer the question. \n Context: {context} \n Question: {question}"
wf = evaluate_run.add_workflow(input=row["request"], output=row["response"])
# Add the retriever step with the context retrieved.
wf.add_retriever(
input=row["request"],
documents=[row['context']],
)
wf.add_llm(
input=template.format(context=row['context'], question=row["request"]),
output=row["response"],
model=pq.Models.chat_gpt,
)
```
---
# Source: https://docs.galileo.ai/api-reference/observe/log-workflows.md
> ## Documentation Index
> Fetch the complete documentation index at: https://docs.galileo.ai/llms.txt
> Use this file to discover all available pages before exploring further.
# Log Workflows to an Observe Project
> Log workflows to an Observe project.
Use this endpoint to log workflows to an Observe project. The request body should contain the
`workflows` to be ingested.
Additionally, specify the `project_id` or `project_name` to which the workflows should be ingested.
If the project does not exist, it will be created. If the project exists, the workflows will be logged to it.
If both `project_id` and `project_name` are provided, `project_id` will take precedence.
### WorkflowStep
A workflow step is the atomic unit of logging to Galileo. They represent a single execution of a workflow, such as a chain, agent, or a RAG execution. Workflows can have multiple steps, each of which can be a different type of node, such as an LLM, Retriever, or Tool.
You can log multiple workflows in a single request. Each workflow step must have the following fields:
* `type`: The type of the workflow.
* `input`: The input to the workflow.
* `output`: The output of the workflow.
## Examples
### LLM Step
```json theme={null}
{
"type": "llm",
"input": "What is the capital of France?",
"output": "Paris"
}
```
### Retriever Step
```json theme={null}
{
"type": "retriever",
"input": "What is the capital of France?",
"output": [{ "content": "Paris is the capital and largest city of France." }]
}
```
### Multi-Step
Workflow steps of type `workflow`, `agent` or `chain` can have sub-steps with children. A workflow with a retriver and an LLM step would look like this:
```json theme={null}
{
"type": "workflow",
"input": "What is the capital of France?",
"output": "Paris",
"steps": [
{
"type": "retriever",
"input": "What is the capital of France?",
"output": [{ "content": "Paris is the capital and largest city of France." }]
},
{
"type": "llm",
"input": "What is the capital of France?",
"output": "Paris"
}
]
}
```
## OpenAPI
````yaml POST /v1/observe/workflows
openapi: 3.1.0
info:
title: FastAPI
version: 0.1.0
servers:
- url: https://api.staging.galileo.ai
description: Galileo Public APIs - staging
security: []
paths:
/v1/observe/workflows:
post:
tags:
- observe
summary: Log Workflows
description: >-
Log workflows to an Observe project.
Use this endpoint to log workflows to an Observe project. The request
body should contain the
`workflows` to be ingested.
Additionally, specify the `project_id` or `project_name` to which the
workflows should be ingested.
If the project does not exist, it will be created. If the project
exists, the workflows will be logged to it.
If both `project_id` and `project_name` are provided, `project_id` will
take precedence.
operationId: log_workflows_v1_observe_workflows_post
requestBody:
content:
application/json:
schema:
$ref: '#/components/schemas/WorkflowsIngestRequest'
required: true
responses:
'200':
description: Successful Response
content:
application/json:
schema:
$ref: '#/components/schemas/WorkflowsIngestResponse'
'422':
description: Validation Error
content:
application/json:
schema:
$ref: '#/components/schemas/HTTPValidationError'
security:
- APIKeyHeader: []
- OAuth2PasswordBearer: []
- HTTPBasic: []
components:
schemas:
WorkflowsIngestRequest:
properties:
workflows:
items:
oneOf:
- $ref: '#/components/schemas/WorkflowStep'
- $ref: '#/components/schemas/ChainStep'
- $ref: '#/components/schemas/LlmStep'
- $ref: '#/components/schemas/RetrieverStep'
- $ref: '#/components/schemas/ToolStep'
- $ref: '#/components/schemas/AgentStep'
discriminator:
propertyName: type
mapping:
agent: '#/components/schemas/AgentStep'
chain: '#/components/schemas/ChainStep'
llm: '#/components/schemas/LlmStep'
retriever: '#/components/schemas/RetrieverStep'
tool: '#/components/schemas/ToolStep'
workflow: '#/components/schemas/WorkflowStep'
type: array
minItems: 1
title: Workflows
description: List of workflows to log.
project_id:
anyOf:
- type: string
format: uuid4
- type: 'null'
title: Project Id
description: Project ID for the Observe project.
project_name:
anyOf:
- type: string
- type: 'null'
title: Project Name
description: Project name for the Observe project.
type: object
required:
- workflows
title: WorkflowsIngestRequest
examples:
- project_name: my-observe-project
workflows:
- created_at_ns: 1769195837805226000
duration_ns: 0
input: who is a smart LLM?
metadata: {}
name: llm
output: I am!
type: llm
- project_id: 00000000-0000-0000-0000-000000000000
workflows:
- created_at_ns: 1769195837805279700
duration_ns: 0
input: who is a smart LLM?
metadata: {}
name: llm
output: I am!
type: llm
WorkflowsIngestResponse:
properties:
message:
type: string
title: Message
project_id:
type: string
format: uuid4
title: Project Id
project_name:
type: string
title: Project Name
workflows_count:
type: integer
title: Workflows Count
records_count:
type: integer
title: Records Count
type: object
required:
- message
- project_id
- project_name
- workflows_count
- records_count
title: WorkflowsIngestResponse
HTTPValidationError:
properties:
detail:
items:
$ref: '#/components/schemas/ValidationError'
type: array
title: Detail
type: object
title: HTTPValidationError
WorkflowStep:
properties:
type:
type: string
const: workflow
title: Type
description: Type of the step. By default, it is set to workflow.
default: workflow
input:
anyOf:
- type: string
- $ref: '#/components/schemas/Document-Input'
- $ref: '#/components/schemas/Message'
- additionalProperties: true
type: object
- items:
type: string
type: array
- items:
$ref: '#/components/schemas/Document-Input'
type: array
- items:
$ref: '#/components/schemas/Message'
type: array
- items:
additionalProperties:
type: string
type: object
type: array
- items:
additionalProperties: true
type: object
type: array
title: Input
description: Input to the step.
redacted_input:
anyOf:
- type: string
- $ref: '#/components/schemas/Document-Input'
- $ref: '#/components/schemas/Message'
- additionalProperties: true
type: object
- items:
type: string
type: array
- items:
$ref: '#/components/schemas/Document-Input'
type: array
- items:
$ref: '#/components/schemas/Message'
type: array
- items:
additionalProperties:
type: string
type: object
type: array
- items:
additionalProperties: true
type: object
type: array
- type: 'null'
title: Redacted Input
description: >-
Redacted input of the step. This is used to redact sensitive
information.
output:
anyOf:
- type: string
- $ref: '#/components/schemas/Document-Input'
- $ref: '#/components/schemas/Message'
- additionalProperties: true
type: object
- items:
type: string
type: array
- items:
$ref: '#/components/schemas/Document-Input'
type: array
- items:
$ref: '#/components/schemas/Message'
type: array
- items:
additionalProperties:
type: string
type: object
type: array
- items:
additionalProperties: true
type: object
type: array
title: Output
description: Output of the step.
default: ''
redacted_output:
anyOf:
- type: string
- $ref: '#/components/schemas/Document-Input'
- $ref: '#/components/schemas/Message'
- additionalProperties: true
type: object
- items:
type: string
type: array
- items:
$ref: '#/components/schemas/Document-Input'
type: array
- items:
$ref: '#/components/schemas/Message'
type: array
- items:
additionalProperties:
type: string
type: object
type: array
- items:
additionalProperties: true
type: object
type: array
- type: 'null'
title: Redacted Output
description: >-
Redacted output of the step. This is used to redact sensitive
information.
name:
type: string
title: Name
description: Name of the step.
default: ''
created_at_ns:
type: integer
title: Created At Ns
description: Timestamp of the step's creation, as nanoseconds since epoch.
duration_ns:
type: integer
title: Duration Ns
description: Duration of the step in nanoseconds.
default: 0
metadata:
additionalProperties:
type: string
type: object
title: Metadata
description: Metadata associated with this step.
status_code:
anyOf:
- type: integer
- type: 'null'
title: Status Code
description: Status code of the step. Used for logging failed/errored steps.
ground_truth:
anyOf:
- type: string
- type: 'null'
title: Ground Truth
description: Ground truth expected output for the step.
steps:
items:
oneOf:
- $ref: '#/components/schemas/WorkflowStep'
- $ref: '#/components/schemas/ChainStep'
- $ref: '#/components/schemas/LlmStep'
- $ref: '#/components/schemas/RetrieverStep'
- $ref: '#/components/schemas/ToolStep'
- $ref: '#/components/schemas/AgentStep'
discriminator:
propertyName: type
mapping:
agent: '#/components/schemas/AgentStep'
chain: '#/components/schemas/ChainStep'
llm: '#/components/schemas/LlmStep'
retriever: '#/components/schemas/RetrieverStep'
tool: '#/components/schemas/ToolStep'
workflow: '#/components/schemas/WorkflowStep'
type: array
title: Steps
description: Steps in the workflow.
parent:
anyOf:
- $ref: '#/components/schemas/StepWithChildren'
- type: 'null'
description: Parent node of the current node. For internal use only.
type: object
required:
- input
title: WorkflowStep
ChainStep:
properties:
type:
type: string
const: chain
title: Type
description: Type of the step. By default, it is set to chain.
default: chain
input:
anyOf:
- type: string
- $ref: '#/components/schemas/Document-Input'
- $ref: '#/components/schemas/Message'
- additionalProperties: true
type: object
- items:
type: string
type: array
- items:
$ref: '#/components/schemas/Document-Input'
type: array
- items:
$ref: '#/components/schemas/Message'
type: array
- items:
additionalProperties:
type: string
type: object
type: array
- items:
additionalProperties: true
type: object
type: array
title: Input
description: Input to the step.
redacted_input:
anyOf:
- type: string
- $ref: '#/components/schemas/Document-Input'
- $ref: '#/components/schemas/Message'
- additionalProperties: true
type: object
- items:
type: string
type: array
- items:
$ref: '#/components/schemas/Document-Input'
type: array
- items:
$ref: '#/components/schemas/Message'
type: array
- items:
additionalProperties:
type: string
type: object
type: array
- items:
additionalProperties: true
type: object
type: array
- type: 'null'
title: Redacted Input
description: >-
Redacted input of the step. This is used to redact sensitive
information.
output:
anyOf:
- type: string
- $ref: '#/components/schemas/Document-Input'
- $ref: '#/components/schemas/Message'
- additionalProperties: true
type: object
- items:
type: string
type: array
- items:
$ref: '#/components/schemas/Document-Input'
type: array
- items:
$ref: '#/components/schemas/Message'
type: array
- items:
additionalProperties:
type: string
type: object
type: array
- items:
additionalProperties: true
type: object
type: array
title: Output
description: Output of the step.
default: ''
redacted_output:
anyOf:
- type: string
- $ref: '#/components/schemas/Document-Input'
- $ref: '#/components/schemas/Message'
- additionalProperties: true
type: object
- items:
type: string
type: array
- items:
$ref: '#/components/schemas/Document-Input'
type: array
- items:
$ref: '#/components/schemas/Message'
type: array
- items:
additionalProperties:
type: string
type: object
type: array
- items:
additionalProperties: true
type: object
type: array
- type: 'null'
title: Redacted Output
description: >-
Redacted output of the step. This is used to redact sensitive
information.
name:
type: string
title: Name
description: Name of the step.
default: ''
created_at_ns:
type: integer
title: Created At Ns
description: Timestamp of the step's creation, as nanoseconds since epoch.
duration_ns:
type: integer
title: Duration Ns
description: Duration of the step in nanoseconds.
default: 0
metadata:
additionalProperties:
type: string
type: object
title: Metadata
description: Metadata associated with this step.
status_code:
anyOf:
- type: integer
- type: 'null'
title: Status Code
description: Status code of the step. Used for logging failed/errored steps.
ground_truth:
anyOf:
- type: string
- type: 'null'
title: Ground Truth
description: Ground truth expected output for the step.
steps:
items:
oneOf:
- $ref: '#/components/schemas/WorkflowStep'
- $ref: '#/components/schemas/ChainStep'
- $ref: '#/components/schemas/LlmStep'
- $ref: '#/components/schemas/RetrieverStep'
- $ref: '#/components/schemas/ToolStep'
- $ref: '#/components/schemas/AgentStep'
discriminator:
propertyName: type
mapping:
agent: '#/components/schemas/AgentStep'
chain: '#/components/schemas/ChainStep'
llm: '#/components/schemas/LlmStep'
retriever: '#/components/schemas/RetrieverStep'
tool: '#/components/schemas/ToolStep'
workflow: '#/components/schemas/WorkflowStep'
type: array
title: Steps
description: Steps in the workflow.
parent:
anyOf:
- $ref: '#/components/schemas/StepWithChildren'
- type: 'null'
description: Parent node of the current node. For internal use only.
type: object
required:
- input
title: ChainStep
LlmStep:
properties:
type:
type: string
const: llm
title: Type
description: Type of the step. By default, it is set to llm.
default: llm
input:
anyOf:
- type: string
- additionalProperties:
type: string
type: object
- $ref: '#/components/schemas/Message'
- items:
type: string
type: array
- items:
additionalProperties:
type: string
type: object
type: array
- items:
$ref: '#/components/schemas/Message'
type: array
title: Input
description: Input to the LLM step.
redacted_input:
anyOf:
- type: string
- additionalProperties:
type: string
type: object
- $ref: '#/components/schemas/Message'
- items:
type: string
type: array
- items:
additionalProperties:
type: string
type: object
type: array
- items:
$ref: '#/components/schemas/Message'
type: array
- type: 'null'
title: Redacted Input
description: >-
Redacted input of the LLM step. This is used to redact sensitive
information.
output:
anyOf:
- type: string
- additionalProperties:
type: string
type: object
- $ref: '#/components/schemas/Message'
- items:
type: string
type: array
- items:
additionalProperties:
type: string
type: object
type: array
- items:
$ref: '#/components/schemas/Message'
type: array
title: Output
description: Output of the LLM step.
default: ''
redacted_output:
anyOf:
- type: string
- additionalProperties:
type: string
type: object
- $ref: '#/components/schemas/Message'
- items:
type: string
type: array
- items:
additionalProperties:
type: string
type: object
type: array
- items:
$ref: '#/components/schemas/Message'
type: array
- type: 'null'
title: Redacted Output
description: >-
Redacted output of the LLM step. This is used to redact sensitive
information.
name:
type: string
title: Name
description: Name of the step.
default: ''
created_at_ns:
type: integer
title: Created At Ns
description: Timestamp of the step's creation, as nanoseconds since epoch.
duration_ns:
type: integer
title: Duration Ns
description: Duration of the step in nanoseconds.
default: 0
metadata:
additionalProperties:
type: string
type: object
title: Metadata
description: Metadata associated with this step.
status_code:
anyOf:
- type: integer
- type: 'null'
title: Status Code
description: Status code of the step. Used for logging failed/errored steps.
ground_truth:
anyOf:
- type: string
- type: 'null'
title: Ground Truth
description: Ground truth expected output for the step.
tools:
anyOf:
- items:
additionalProperties: true
type: object
type: array
- type: 'null'
title: Tools
description: List of available tools passed to the LLM on invocation.
model:
anyOf:
- type: string
- type: 'null'
title: Model
description: Model used for this step.
input_tokens:
anyOf:
- type: integer
- type: 'null'
title: Input Tokens
description: Number of input tokens.
output_tokens:
anyOf:
- type: integer
- type: 'null'
title: Output Tokens
description: Number of output tokens.
total_tokens:
anyOf:
- type: integer
- type: 'null'
title: Total Tokens
description: Total number of tokens.
temperature:
anyOf:
- type: number
- type: 'null'
title: Temperature
description: Temperature used for generation.
time_to_first_token_ms:
anyOf:
- type: number
- type: 'null'
title: Time To First Token Ms
description: Time to first token in milliseconds.
type: object
required:
- input
title: LlmStep
RetrieverStep:
properties:
type:
type: string
const: retriever
title: Type
description: Type of the step. By default, it is set to retriever.
default: retriever
input:
type: string
title: Input
description: Input query to the retriever.
redacted_input:
anyOf:
- type: string
- type: 'null'
title: Redacted Input
description: >-
Redacted input of the retriever step. This is used to redact
sensitive information.
output:
items:
$ref: '#/components/schemas/Document-Input'
type: array
title: Output
description: >-
Documents retrieved from the retriever. This can be a list of
strings or `Document`s.
redacted_output:
anyOf:
- items:
$ref: '#/components/schemas/Document-Input'
type: array
- type: 'null'
title: Redacted Output
description: >-
Redacted output of the retriever step. This is used to redact
sensitive information.
name:
type: string
title: Name
description: Name of the step.
default: ''
created_at_ns:
type: integer
title: Created At Ns
description: Timestamp of the step's creation, as nanoseconds since epoch.
duration_ns:
type: integer
title: Duration Ns
description: Duration of the step in nanoseconds.
default: 0
metadata:
additionalProperties:
type: string
type: object
title: Metadata
description: Metadata associated with this step.
status_code:
anyOf:
- type: integer
- type: 'null'
title: Status Code
description: Status code of the step. Used for logging failed/errored steps.
ground_truth:
anyOf:
- type: string
- type: 'null'
title: Ground Truth
description: Ground truth expected output for the step.
type: object
required:
- input
title: RetrieverStep
ToolStep:
properties:
type:
type: string
const: tool
title: Type
description: Type of the step. By default, it is set to tool.
default: tool
input:
anyOf:
- type: string
- $ref: '#/components/schemas/Document-Input'
- $ref: '#/components/schemas/Message'
- additionalProperties: true
type: object
- items:
type: string
type: array
- items:
$ref: '#/components/schemas/Document-Input'
type: array
- items:
$ref: '#/components/schemas/Message'
type: array
- items:
additionalProperties:
type: string
type: object
type: array
- items:
additionalProperties: true
type: object
type: array
title: Input
description: Input to the step.
redacted_input:
anyOf:
- type: string
- $ref: '#/components/schemas/Document-Input'
- $ref: '#/components/schemas/Message'
- additionalProperties: true
type: object
- items:
type: string
type: array
- items:
$ref: '#/components/schemas/Document-Input'
type: array
- items:
$ref: '#/components/schemas/Message'
type: array
- items:
additionalProperties:
type: string
type: object
type: array
- items:
additionalProperties: true
type: object
type: array
- type: 'null'
title: Redacted Input
description: >-
Redacted input of the step. This is used to redact sensitive
information.
output:
anyOf:
- type: string
- $ref: '#/components/schemas/Document-Input'
- $ref: '#/components/schemas/Message'
- additionalProperties: true
type: object
- items:
type: string
type: array
- items:
$ref: '#/components/schemas/Document-Input'
type: array
- items:
$ref: '#/components/schemas/Message'
type: array
- items:
additionalProperties:
type: string
type: object
type: array
- items:
additionalProperties: true
type: object
type: array
title: Output
description: Output of the step.
default: ''
redacted_output:
anyOf:
- type: string
- $ref: '#/components/schemas/Document-Input'
- $ref: '#/components/schemas/Message'
- additionalProperties: true
type: object
- items:
type: string
type: array
- items:
$ref: '#/components/schemas/Document-Input'
type: array
- items:
$ref: '#/components/schemas/Message'
type: array
- items:
additionalProperties:
type: string
type: object
type: array
- items:
additionalProperties: true
type: object
type: array
- type: 'null'
title: Redacted Output
description: >-
Redacted output of the step. This is used to redact sensitive
information.
name:
type: string
title: Name
description: Name of the step.
default: ''
created_at_ns:
type: integer
title: Created At Ns
description: Timestamp of the step's creation, as nanoseconds since epoch.
duration_ns:
type: integer
title: Duration Ns
description: Duration of the step in nanoseconds.
default: 0
metadata:
additionalProperties:
type: string
type: object
title: Metadata
description: Metadata associated with this step.
status_code:
anyOf:
- type: integer
- type: 'null'
title: Status Code
description: Status code of the step. Used for logging failed/errored steps.
ground_truth:
anyOf:
- type: string
- type: 'null'
title: Ground Truth
description: Ground truth expected output for the step.
type: object
required:
- input
title: ToolStep
AgentStep:
properties:
type:
type: string
const: agent
title: Type
description: Type of the step. By default, it is set to agent.
default: agent
input:
anyOf:
- type: string
- $ref: '#/components/schemas/Document-Input'
- $ref: '#/components/schemas/Message'
- additionalProperties: true
type: object
- items:
type: string
type: array
- items:
$ref: '#/components/schemas/Document-Input'
type: array
- items:
$ref: '#/components/schemas/Message'
type: array
- items:
additionalProperties:
type: string
type: object
type: array
- items:
additionalProperties: true
type: object
type: array
title: Input
description: Input to the step.
redacted_input:
anyOf:
- type: string
- $ref: '#/components/schemas/Document-Input'
- $ref: '#/components/schemas/Message'
- additionalProperties: true
type: object
- items:
type: string
type: array
- items:
$ref: '#/components/schemas/Document-Input'
type: array
- items:
$ref: '#/components/schemas/Message'
type: array
- items:
additionalProperties:
type: string
type: object
type: array
- items:
additionalProperties: true
type: object
type: array
- type: 'null'
title: Redacted Input
description: >-
Redacted input of the step. This is used to redact sensitive
information.
output:
anyOf:
- type: string
- $ref: '#/components/schemas/Document-Input'
- $ref: '#/components/schemas/Message'
- additionalProperties: true
type: object
- items:
type: string
type: array
- items:
$ref: '#/components/schemas/Document-Input'
type: array
- items:
$ref: '#/components/schemas/Message'
type: array
- items:
additionalProperties:
type: string
type: object
type: array
- items:
additionalProperties: true
type: object
type: array
title: Output
description: Output of the step.
default: ''
redacted_output:
anyOf:
- type: string
- $ref: '#/components/schemas/Document-Input'
- $ref: '#/components/schemas/Message'
- additionalProperties: true
type: object
- items:
type: string
type: array
- items:
$ref: '#/components/schemas/Document-Input'
type: array
- items:
$ref: '#/components/schemas/Message'
type: array
- items:
additionalProperties:
type: string
type: object
type: array
- items:
additionalProperties: true
type: object
type: array
- type: 'null'
title: Redacted Output
description: >-
Redacted output of the step. This is used to redact sensitive
information.
name:
type: string
title: Name
description: Name of the step.
default: ''
created_at_ns:
type: integer
title: Created At Ns
description: Timestamp of the step's creation, as nanoseconds since epoch.
duration_ns:
type: integer
title: Duration Ns
description: Duration of the step in nanoseconds.
default: 0
metadata:
additionalProperties:
type: string
type: object
title: Metadata
description: Metadata associated with this step.
status_code:
anyOf:
- type: integer
- type: 'null'
title: Status Code
description: Status code of the step. Used for logging failed/errored steps.
ground_truth:
anyOf:
- type: string
- type: 'null'
title: Ground Truth
description: Ground truth expected output for the step.
steps:
items:
oneOf:
- $ref: '#/components/schemas/WorkflowStep'
- $ref: '#/components/schemas/ChainStep'
- $ref: '#/components/schemas/LlmStep'
- $ref: '#/components/schemas/RetrieverStep'
- $ref: '#/components/schemas/ToolStep'
- $ref: '#/components/schemas/AgentStep'
discriminator:
propertyName: type
mapping:
agent: '#/components/schemas/AgentStep'
chain: '#/components/schemas/ChainStep'
llm: '#/components/schemas/LlmStep'
retriever: '#/components/schemas/RetrieverStep'
tool: '#/components/schemas/ToolStep'
workflow: '#/components/schemas/WorkflowStep'
type: array
title: Steps
description: Steps in the workflow.
parent:
anyOf:
- $ref: '#/components/schemas/StepWithChildren'
- type: 'null'
description: Parent node of the current node. For internal use only.
type: object
required:
- input
title: AgentStep
ValidationError:
properties:
loc:
items:
anyOf:
- type: string
- type: integer
type: array
title: Location
msg:
type: string
title: Message
type:
type: string
title: Error Type
type: object
required:
- loc
- msg
- type
title: ValidationError
Document-Input:
properties:
page_content:
type: string
title: Page Content
description: Content of the document.
metadata:
additionalProperties:
anyOf:
- type: boolean
- type: string
- type: integer
- type: number
type: object
title: Metadata
additionalProperties: false
type: object
required:
- page_content
title: Document
Message:
properties:
content:
type: string
title: Content
role:
anyOf:
- type: string
- $ref: '#/components/schemas/MessageRole'
title: Role
additionalProperties: true
type: object
required:
- content
- role
title: Message
StepWithChildren:
properties:
type:
$ref: '#/components/schemas/NodeType'
description: Type of the step. By default, it is set to workflow.
default: workflow
input:
anyOf:
- type: string
- $ref: '#/components/schemas/Document-Input'
- $ref: '#/components/schemas/Message'
- additionalProperties: true
type: object
- items:
type: string
type: array
- items:
$ref: '#/components/schemas/Document-Input'
type: array
- items:
$ref: '#/components/schemas/Message'
type: array
- items:
additionalProperties:
type: string
type: object
type: array
- items:
additionalProperties: true
type: object
type: array
title: Input
description: Input to the step.
redacted_input:
anyOf:
- type: string
- $ref: '#/components/schemas/Document-Input'
- $ref: '#/components/schemas/Message'
- additionalProperties: true
type: object
- items:
type: string
type: array
- items:
$ref: '#/components/schemas/Document-Input'
type: array
- items:
$ref: '#/components/schemas/Message'
type: array
- items:
additionalProperties:
type: string
type: object
type: array
- items:
additionalProperties: true
type: object
type: array
- type: 'null'
title: Redacted Input
description: >-
Redacted input of the step. This is used to redact sensitive
information.
output:
anyOf:
- type: string
- $ref: '#/components/schemas/Document-Input'
- $ref: '#/components/schemas/Message'
- additionalProperties: true
type: object
- items:
type: string
type: array
- items:
$ref: '#/components/schemas/Document-Input'
type: array
- items:
$ref: '#/components/schemas/Message'
type: array
- items:
additionalProperties:
type: string
type: object
type: array
- items:
additionalProperties: true
type: object
type: array
title: Output
description: Output of the step.
default: ''
redacted_output:
anyOf:
- type: string
- $ref: '#/components/schemas/Document-Input'
- $ref: '#/components/schemas/Message'
- additionalProperties: true
type: object
- items:
type: string
type: array
- items:
$ref: '#/components/schemas/Document-Input'
type: array
- items:
$ref: '#/components/schemas/Message'
type: array
- items:
additionalProperties:
type: string
type: object
type: array
- items:
additionalProperties: true
type: object
type: array
- type: 'null'
title: Redacted Output
description: >-
Redacted output of the step. This is used to redact sensitive
information.
name:
type: string
title: Name
description: Name of the step.
default: ''
created_at_ns:
type: integer
title: Created At Ns
description: Timestamp of the step's creation, as nanoseconds since epoch.
duration_ns:
type: integer
title: Duration Ns
description: Duration of the step in nanoseconds.
default: 0
metadata:
additionalProperties:
type: string
type: object
title: Metadata
description: Metadata associated with this step.
status_code:
anyOf:
- type: integer
- type: 'null'
title: Status Code
description: Status code of the step. Used for logging failed/errored steps.
ground_truth:
anyOf:
- type: string
- type: 'null'
title: Ground Truth
description: Ground truth expected output for the step.
steps:
items:
oneOf:
- $ref: '#/components/schemas/WorkflowStep'
- $ref: '#/components/schemas/ChainStep'
- $ref: '#/components/schemas/LlmStep'
- $ref: '#/components/schemas/RetrieverStep'
- $ref: '#/components/schemas/ToolStep'
- $ref: '#/components/schemas/AgentStep'
discriminator:
propertyName: type
mapping:
agent: '#/components/schemas/AgentStep'
chain: '#/components/schemas/ChainStep'
llm: '#/components/schemas/LlmStep'
retriever: '#/components/schemas/RetrieverStep'
tool: '#/components/schemas/ToolStep'
workflow: '#/components/schemas/WorkflowStep'
type: array
title: Steps
description: Steps in the workflow.
parent:
anyOf:
- $ref: '#/components/schemas/StepWithChildren'
- type: 'null'
description: Parent node of the current node. For internal use only.
type: object
required:
- input
title: StepWithChildren
MessageRole:
type: string
enum:
- agent
- assistant
- function
- system
- tool
- user
title: MessageRole
NodeType:
type: string
enum:
- chain
- chat
- llm
- retriever
- tool
- agent
- workflow
- trace
- session
title: NodeType
securitySchemes:
APIKeyHeader:
type: apiKey
in: header
name: Galileo-API-Key
OAuth2PasswordBearer:
type: oauth2
flows:
password:
scopes: {}
tokenUrl: https://api.staging.galileo.ai/login
HTTPBasic:
type: http
scheme: basic
````
---
# Source: https://docs.galileo.ai/galileo/gen-ai-studio-products/galileo-evaluate/how-to/logging-and-comparing-against-your-expected-answers.md
> ## Documentation Index
> Fetch the complete documentation index at: https://docs.galileo.ai/llms.txt
> Use this file to discover all available pages before exploring further.
# Logging and Comparing against your Expected Answers
> Expected outputs are a key element for evaluating LLM applications. They provide benchmarks to measure model accuracy, identify errors, and ensure consistent assessments.
By comparing model responses to these predefined targets, you can pinpoint areas of improvement and track performance changes over time.
Including expected outputs in your evaluation process also aids in benchmarking your application, ensuring fair and replicable evaluations.
## Logging Expected Output
There are a few ways to create runs, and each way has a slightly different way of logging your Expected Output:
### PQ.run() or Playground UI
If you're using `pq.run()` or creating runs through the [Playground UI](/galileo/gen-ai-studio-products/galileo-evaluate/quickstart), simply include your expected answers in a column called `output` in your evaluation set.
### Python Logger
If you're logging your runs via [EvaluateRun](https://promptquality.docs.rungalileo.io/#promptquality.EvaluateRun),
you can set the expected output using the `ground_truth` parameter in the workflow creation methods.
To log your runs with Galileo, you'd start with the same typical flow of logging into Galileo:
```py theme={null}
import promptquality as pq
pq.login()
```
Next you can construct your [EvaluateRun](https://promptquality.docs.rungalileo.io/#promptquality.EvaluateRun) object:
```py theme={null}
from promptquality import EvaluateRun
metrics = [pq.Scorers.context_adherence_plus, pq.Scorers.prompt_injection]
evaluate_run = EvaluateRun(run_name="my_run", project_name="my_project", scorers=metrics)
```
Now you can integrate this logging into your existing application and include the expected output in your evaluation set.
```py theme={null}
def my_llm_app(input, ground_truth, evaluate_run):
context = "You're a helpful AI assistant."
template = "Given the following context answer the question. \n Context: {context} \n Question: {question}"
# Add groundtruth to your workflow.
wf = evaluate_run.add_workflow(input=input, ground_truth=ground_truth)
# Get response from your llm.
prompt = template.format(context=context, question=input)
llm_response = llm.call(prompt) # Pseudo-code, replace with your LLM call.
# Log llm step to Galileo
wf.add_llm(input=prompt, output=llm_response, model=)
# Conclude the workflow and add the final output.
wf.conclude(output=llm_response)
return llm_response
# Your evaluation dataset.
eval_set = [
{
"input": "What are plants?",
"ground_truth": "Plants are living organisms that typically grow in soil and have roots, stems, and leaves."
},
{
"input": "What is the capital of France?",
"ground_truth": "Paris"
}
]
for row in eval_set:
my_llm_app(row["input"], row["ground_truth"], evaluate_run)
```
### Langchain Callback
If you're using a Langchain Callback, add your expected output by calling `add_expected_outputs` on your callback handler.
```py theme={null}
my_chain = ... # your langchain chain
galileo_handler = pq.GalileoPromptCallback(
project_name="my_project", scorers=scorers,
)
inputs = ['What is 2+2?', 'Which city is the Golden Gate Bridge in?']
expected_outputs = ['4', 'San Francisco']
my_chain.batch(inputs, config=dict(callbacks=[galileo_handler]))
# Sets the expected output from each of the inputs.
galileo_handler.add_expected_outputs(expected_outputs)
galileo_handler.finish()
```
### REST Endpoint
If you're logging Evaluation runs via the [REST endpoint](/galileo/clients/log-evaluate-runs-via-rest-apis), set the *target* field in the root node of each workflow.
```py theme={null}
...
{
node_id: "A_UNIQUE_ID",
node_type: "chain",
node_name: "Chain",
node_input: "What is 2+2?",
node_output: "3",
chain_root_id: "A_UNIQUE_ID",
step: 0,
has_children: true,
creation_timestamp: 0,
expected_output: "4"
},
...
```
Important note: Set the *expected\_output* on the root node of your workflow. Typically this will be the sole LLM node in your workflow or a "chain" node with other children nodes.
## Comparing Output and Expected Output
When Expected Output gets logged, it'll appear next to your Output wherever your output is shown.
 ## Metrics
When you add a ground truth, [BLEU and ROUGE-1](/galileo/gen-ai-studio-products/galileo-guardrail-metrics/bleu-and-rouge-1) will automatically be computed and appear on the UI.
BLEU and ROUGE measure syntactical equivalence (i.e. word-by-word similarity) between your Ground Truth and actual responses.
Additionally, [Ground Truth Adherence](/galileo/gen-ai-studio-products/galileo-guardrail-metrics/ground-truth-adherence) can be added as a metric to measure the semantic equivalence
between your Ground Truth and actual responses.
---
# Source: https://docs.galileo.ai/galileo/galileo-nlp-studio/text-classification/logging-data-to-galileo.md
# Source: https://docs.galileo.ai/galileo/galileo-nlp-studio/natural-language-inference/logging-data-to-galileo.md
> ## Documentation Index
> Fetch the complete documentation index at: https://docs.galileo.ai/llms.txt
> Use this file to discover all available pages before exploring further.
# Logging Data | Natural Language Inference in Galileo
> The fastest way to find data errors in Galileo.
When focusing on data-centric techniques for modeling, we believe it is important to focus on the data while keeping the model static. To enable this rapid workflow, we suggest you use the `dq.auto` workflow:
After installing dataquality: `pip install dataquality`
You simply add your data and wait for the model to train under the hood, and for Galileo to process the data. This processing can take between 5-15 minutes, depending on how much data you have.
`auto` will wait until Galileo is completely done processing your data. At that point, you can go to the Galileo Console and begin inspecting.
```
import dataquality as dq
dq.auto(train_data=train_df, val_data=val_df, test_data=test_df)
```
There are 3 general ways to use `auto`
* Pass dataframes to `train_data`, `val_data` and `test_data` (pandas or huggingface)
* Pass paths to local files to `train_data`, `val_data` and `test_data`
* Pass a path to a huggingface Dataset to the `hf_data` parameter
`dq.auto` supports both Text Classification and Named Entity Recognition tasks, with Multi-Label support coming soon. `dq.auto` automatically determines the task type based off of the provided data schema.
To see the other available parameters as well as more usage examples, see `help(dq.auto)`
To learn more about how `dq.auto` works, and why we suggest this paradigm, see DQ Auto
#### Looking to inspect your own model?
Use `auto` if:
* You are looking to apply the most data-centric techniques to improve your data
* You don’t yet have a model to train
* You want to agnostically understand and fix your available training data
If you have a well-trained model and want to understand its performance on your data, or you are looking to deploy an existing model and monitor it with Galileo, please use our custom framework integrations.
## Galileo Auto
Welcome to `auto`, your newest superpower in the world of Machine Learning!
We know now that **more** data isn’t the answer, **better** data is. But how do you find that data? We already know the answer to that: Galileo
But how do you get started now, and iterate quickly with ***data-centric*** techniques?
Enter: `dq.auto` the secret sauce to instant data insights. We handle the training, you focus on the data.
### What is DQ auto?
`dq.auto` is a helper function to train the most cutting-edge transformer (or any of your choosing from HuggingFace) on your dataset so it can be processed by Galileo. You provide the data, let Galileo train the model, and you’re off to the races.
The goal of this tool, and Galileo at large, is to build a data-centric view of machine learning. Keep your model static and iterate on the dataset until it’s well-formed and well-representative of your problem space. This is the path to robust and stable ML models.
### What DQ auto *isn't?*
`auto` is ***not*** an AutoML tool. It will not perform hyperparameter tuning, and will not search through a gallery of models to optimize every percentage of f1.
In fact, `auto` is quite the opposite. It intentionally keeps the model static, forcing you to understand and fix your data to improve performance.
### Why?
It turns out that in many (most) cases, **you don’t need to train your own model to find data insights**. In fact, you often don’t need to build your own custom model at all! [HuggingFace](https://huggingface.co/), and in particular [transformers](https://huggingface.co/docs/transformers/index), has brought the most cutting-edge deep learning algorithms straight to your fingertips, allowing you to leverage the best research has to offer in 1 line of code.
Transformer models have consistently outperformed their predecessors, and HuggingFace is constantly updating their fleet of *free* models for anyone to download.
So if you don’t *need* to build a custom model anymore, why not let Galileo do it for you?
### Get Started
Simply install: `pip install --upgrade dataquality`
and use!
```py theme={null}
import dataquality as dq
# Get insights on the official 'emotion' dataset
dq.auto(hf_data="emotion")
```
You can also provide data as files or pandas dataframes
```py theme={null}
import pandas as pd
from sklearn.datasets import fetch_20newsgroups
import dataquality as dq
# Load the newsgroups dataset from sklearn
newsgroups_train = fetch_20newsgroups(subset='train')
newsgroups_test = fetch_20newsgroups(subset='test')
# Convert to pandas dataframes
df_train = pd.DataFrame({"text": newsgroups_train.data, "label": newsgroups_train.target})
df_test = pd.DataFrame({"text": newsgroups_test.data, "label": newsgroups_test.target})
dq.auto(
train_data=df_train,
test_data=df_test,
labels=newsgroups_train.target_names,
project_name="newsgroups_work",
run_name="run_1_raw_data"
)
```
`dq.auto` works for:
* Text Classification datasets (given columns `text` and `label`). [Trec6 Example.](https://huggingface.co/datasets/rungalileo/trec6)
* NER datasets (give columns `tokens` and `tags` or `ner_tags`). [MIT\_movies Example.](https://huggingface.co/datasets/rungalileo/mit_movies)
`auto` will automatically figure out your task and start the process for you.
For more docs and examples, see `help(dq.auto)` in your notebook! Happy data fixing
---
# Source: https://docs.galileo.ai/galileo/gen-ai-studio-products/galileo-observe/how-to/logging-data-via-python.md
> ## Documentation Index
> Fetch the complete documentation index at: https://docs.galileo.ai/llms.txt
> Use this file to discover all available pages before exploring further.
# Logging Data Via Python
> Learn how to manually log your data via our Python Logger
If you use Langchain in your production app, we recommend integrating via our [Langchain callback](/galileo/gen-ai-studio-products/galileo-observe/getting-started#integrating-with-langchain).
You can use our Python Logger to log your data to Galileo with the [ObserveWorkflows](https://observe.docs.rungalileo.io/#galileo_observe.ObserveWorkflows) module.
Here's an example of how to integrate the logger into your llm app:
First you can create your ObserveWorkflows object with your existing project.
```py theme={null}
from galileo_observe import ObserveWorkflows
observe_logger = ObserveWorkflows(project_name="my_first_project")
```
Then you can use the workflows object to log your workflows.
```py theme={null}
def my_llm_app(input, observe_logger):
template = "You're a helpful AI assistant, answer the following question. Question: {question}"
wf = observe_logger.add_workflow(input=input)
# Get response from your llm.
prompt = template.format(question=input)
llm_response = llm.call(prompt) # Pseudo-code, replace with your LLM call.
# Log llm step to Galileo
wf.add_llm(input=prompt, output=llm_response, model=)
# Conclude the worfklow by adding the final output.
wf.conclude(output=llm_response)
# log the workflow to Galileo.
observe_logger.upload_workflows()
return llm_response
```
You can also do this with your RAG workflows:
```py theme={null}
def my_llm_app(input, observe_logger):
template = "Given the following context answer the question. \n Context: {context} \n Question: {question}"
wf = observe_logger.add_workflow(input=input)
# Fetch documents from your retriever
documents = retriever.retrieve(input) # Pseudo-code, replace with your retriever call.
# Log retriever step to Galileo
wf.add_retriever(input=input, documents=documents)
# Get response from your llm.
prompt = template.format(context="\n".join(documents), question=input)
llm_response = llm.call(prompt) # Pseudo-code, replace with your LLM call.
# Log llm step to Galileo
wf.add_llm(input=prompt, output=llm_response, model=)
# Conclude the worfklow by adding the final output.
wf.conclude(output=llm_response)
# log the workflow to Galileo.
observe_logger.upload_workflows()
return llm_response
```
## Logging Agent Workflows
We also support logging Agent workflows. Here's an example of how you can log an Agent workflow:
```py theme={null}
agent_wf = evaluate_run.add_agent_workflow(input=)
# Log a Tool-Calling LLM step
agent_wf.add_llm(input=, output=
## Metrics
When you add a ground truth, [BLEU and ROUGE-1](/galileo/gen-ai-studio-products/galileo-guardrail-metrics/bleu-and-rouge-1) will automatically be computed and appear on the UI.
BLEU and ROUGE measure syntactical equivalence (i.e. word-by-word similarity) between your Ground Truth and actual responses.
Additionally, [Ground Truth Adherence](/galileo/gen-ai-studio-products/galileo-guardrail-metrics/ground-truth-adherence) can be added as a metric to measure the semantic equivalence
between your Ground Truth and actual responses.
---
# Source: https://docs.galileo.ai/galileo/galileo-nlp-studio/text-classification/logging-data-to-galileo.md
# Source: https://docs.galileo.ai/galileo/galileo-nlp-studio/natural-language-inference/logging-data-to-galileo.md
> ## Documentation Index
> Fetch the complete documentation index at: https://docs.galileo.ai/llms.txt
> Use this file to discover all available pages before exploring further.
# Logging Data | Natural Language Inference in Galileo
> The fastest way to find data errors in Galileo.
When focusing on data-centric techniques for modeling, we believe it is important to focus on the data while keeping the model static. To enable this rapid workflow, we suggest you use the `dq.auto` workflow:
After installing dataquality: `pip install dataquality`
You simply add your data and wait for the model to train under the hood, and for Galileo to process the data. This processing can take between 5-15 minutes, depending on how much data you have.
`auto` will wait until Galileo is completely done processing your data. At that point, you can go to the Galileo Console and begin inspecting.
```
import dataquality as dq
dq.auto(train_data=train_df, val_data=val_df, test_data=test_df)
```
There are 3 general ways to use `auto`
* Pass dataframes to `train_data`, `val_data` and `test_data` (pandas or huggingface)
* Pass paths to local files to `train_data`, `val_data` and `test_data`
* Pass a path to a huggingface Dataset to the `hf_data` parameter
`dq.auto` supports both Text Classification and Named Entity Recognition tasks, with Multi-Label support coming soon. `dq.auto` automatically determines the task type based off of the provided data schema.
To see the other available parameters as well as more usage examples, see `help(dq.auto)`
To learn more about how `dq.auto` works, and why we suggest this paradigm, see DQ Auto
#### Looking to inspect your own model?
Use `auto` if:
* You are looking to apply the most data-centric techniques to improve your data
* You don’t yet have a model to train
* You want to agnostically understand and fix your available training data
If you have a well-trained model and want to understand its performance on your data, or you are looking to deploy an existing model and monitor it with Galileo, please use our custom framework integrations.
## Galileo Auto
Welcome to `auto`, your newest superpower in the world of Machine Learning!
We know now that **more** data isn’t the answer, **better** data is. But how do you find that data? We already know the answer to that: Galileo
But how do you get started now, and iterate quickly with ***data-centric*** techniques?
Enter: `dq.auto` the secret sauce to instant data insights. We handle the training, you focus on the data.
### What is DQ auto?
`dq.auto` is a helper function to train the most cutting-edge transformer (or any of your choosing from HuggingFace) on your dataset so it can be processed by Galileo. You provide the data, let Galileo train the model, and you’re off to the races.
The goal of this tool, and Galileo at large, is to build a data-centric view of machine learning. Keep your model static and iterate on the dataset until it’s well-formed and well-representative of your problem space. This is the path to robust and stable ML models.
### What DQ auto *isn't?*
`auto` is ***not*** an AutoML tool. It will not perform hyperparameter tuning, and will not search through a gallery of models to optimize every percentage of f1.
In fact, `auto` is quite the opposite. It intentionally keeps the model static, forcing you to understand and fix your data to improve performance.
### Why?
It turns out that in many (most) cases, **you don’t need to train your own model to find data insights**. In fact, you often don’t need to build your own custom model at all! [HuggingFace](https://huggingface.co/), and in particular [transformers](https://huggingface.co/docs/transformers/index), has brought the most cutting-edge deep learning algorithms straight to your fingertips, allowing you to leverage the best research has to offer in 1 line of code.
Transformer models have consistently outperformed their predecessors, and HuggingFace is constantly updating their fleet of *free* models for anyone to download.
So if you don’t *need* to build a custom model anymore, why not let Galileo do it for you?
### Get Started
Simply install: `pip install --upgrade dataquality`
and use!
```py theme={null}
import dataquality as dq
# Get insights on the official 'emotion' dataset
dq.auto(hf_data="emotion")
```
You can also provide data as files or pandas dataframes
```py theme={null}
import pandas as pd
from sklearn.datasets import fetch_20newsgroups
import dataquality as dq
# Load the newsgroups dataset from sklearn
newsgroups_train = fetch_20newsgroups(subset='train')
newsgroups_test = fetch_20newsgroups(subset='test')
# Convert to pandas dataframes
df_train = pd.DataFrame({"text": newsgroups_train.data, "label": newsgroups_train.target})
df_test = pd.DataFrame({"text": newsgroups_test.data, "label": newsgroups_test.target})
dq.auto(
train_data=df_train,
test_data=df_test,
labels=newsgroups_train.target_names,
project_name="newsgroups_work",
run_name="run_1_raw_data"
)
```
`dq.auto` works for:
* Text Classification datasets (given columns `text` and `label`). [Trec6 Example.](https://huggingface.co/datasets/rungalileo/trec6)
* NER datasets (give columns `tokens` and `tags` or `ner_tags`). [MIT\_movies Example.](https://huggingface.co/datasets/rungalileo/mit_movies)
`auto` will automatically figure out your task and start the process for you.
For more docs and examples, see `help(dq.auto)` in your notebook! Happy data fixing
---
# Source: https://docs.galileo.ai/galileo/gen-ai-studio-products/galileo-observe/how-to/logging-data-via-python.md
> ## Documentation Index
> Fetch the complete documentation index at: https://docs.galileo.ai/llms.txt
> Use this file to discover all available pages before exploring further.
# Logging Data Via Python
> Learn how to manually log your data via our Python Logger
If you use Langchain in your production app, we recommend integrating via our [Langchain callback](/galileo/gen-ai-studio-products/galileo-observe/getting-started#integrating-with-langchain).
You can use our Python Logger to log your data to Galileo with the [ObserveWorkflows](https://observe.docs.rungalileo.io/#galileo_observe.ObserveWorkflows) module.
Here's an example of how to integrate the logger into your llm app:
First you can create your ObserveWorkflows object with your existing project.
```py theme={null}
from galileo_observe import ObserveWorkflows
observe_logger = ObserveWorkflows(project_name="my_first_project")
```
Then you can use the workflows object to log your workflows.
```py theme={null}
def my_llm_app(input, observe_logger):
template = "You're a helpful AI assistant, answer the following question. Question: {question}"
wf = observe_logger.add_workflow(input=input)
# Get response from your llm.
prompt = template.format(question=input)
llm_response = llm.call(prompt) # Pseudo-code, replace with your LLM call.
# Log llm step to Galileo
wf.add_llm(input=prompt, output=llm_response, model=)
# Conclude the worfklow by adding the final output.
wf.conclude(output=llm_response)
# log the workflow to Galileo.
observe_logger.upload_workflows()
return llm_response
```
You can also do this with your RAG workflows:
```py theme={null}
def my_llm_app(input, observe_logger):
template = "Given the following context answer the question. \n Context: {context} \n Question: {question}"
wf = observe_logger.add_workflow(input=input)
# Fetch documents from your retriever
documents = retriever.retrieve(input) # Pseudo-code, replace with your retriever call.
# Log retriever step to Galileo
wf.add_retriever(input=input, documents=documents)
# Get response from your llm.
prompt = template.format(context="\n".join(documents), question=input)
llm_response = llm.call(prompt) # Pseudo-code, replace with your LLM call.
# Log llm step to Galileo
wf.add_llm(input=prompt, output=llm_response, model=)
# Conclude the worfklow by adding the final output.
wf.conclude(output=llm_response)
# log the workflow to Galileo.
observe_logger.upload_workflows()
return llm_response
```
## Logging Agent Workflows
We also support logging Agent workflows. Here's an example of how you can log an Agent workflow:
```py theme={null}
agent_wf = evaluate_run.add_agent_workflow(input=)
# Log a Tool-Calling LLM step
agent_wf.add_llm(input=, output=