# Fireworks Ai
> Build production-ready AI agents with Fireworks and leading open-source frameworks
---
# Source: https://docs.fireworks.ai/ecosystem/integrations/agent-frameworks.md
# Agent Frameworks
> Build production-ready AI agents with Fireworks and leading open-source frameworks
Fireworks AI seamlessly integrates with the best open-source agent frameworks, enabling you to build magical, production-ready applications powered by state-of-the-art language models.
## Supported Frameworks
Build LLM applications with powerful orchestration and tool integration
Efficient data retrieval and document indexing for LLM-based agents
Orchestrate collaborative multi-agent systems for complex tasks
Type-safe AI agent development with Pydantic validation
Modern agent orchestration with seamless OpenAI-compatible integration
## Need Help?
For assistance with agent framework integrations, [contact our team](https://fireworks.ai/contact) or join our [Discord community](https://discord.gg/fireworks-ai).
---
# Source: https://docs.fireworks.ai/tools-sdks/firectl/commands/alias-evaluator-revision.md
# firectl alias evaluator-revision
> Alias an evaluator revision
```
firectl alias evaluator-revision [flags]
```
### Examples
```
firectl alias evaluator-revision accounts/my-account/evaluators/my-evaluator/versions/abc123 --alias-id current
```
### Flags
```
--alias-id string Alias ID to assign (e.g. current)
-h, --help help for evaluator-revision
```
### Global flags
```
-a, --account-id string The Fireworks account ID. If not specified, reads account_id from ~/.fireworks/auth.ini.
--api-key string An API key used to authenticate with Fireworks.
-p, --profile string fireworks auth and settings profile to use.
```
---
> To find navigation and other pages in this documentation, fetch the llms.txt file at: https://docs.fireworks.ai/llms.txt
---
# Source: https://docs.fireworks.ai/faq-new/deployment-infrastructure/are-there-any-quotas-for-serverless.md
# Are there any quotas for serverless?
Yes, serverless deployments have rate limits and quotas.
For detailed information about serverless quotas, rate limits, and daily token limits, see our [Rate Limits & Quotas guide](/guides/quotas_usage/rate-limits#rate-limits-on-serverless).
---
# Source: https://docs.fireworks.ai/faq-new/billing-pricing/are-there-discounts-for-bulk-usage.md
# Are there discounts for bulk usage?
We offer discounts for bulk or pre-paid purchases. Contact [inquiries@fireworks.ai](mailto:inquiries@fireworks.ai) to discuss volume pricing.
---
# Source: https://docs.fireworks.ai/faq-new/billing-pricing/are-there-extra-fees-for-serving-fine-tuned-models.md
# Are there extra fees for serving fine-tuned models?
No, deploying fine-tuned models to serverless infrastructure is free. Here's what you need to know:
**What's free**:
* Deploying fine-tuned models to serverless infrastructure
* Hosting the models on serverless infrastructure
* Deploying up to 100 fine-tuned models
**What you pay for**:
* **Usage costs** on a per-token basis when the model is actually used
* The **fine-tuning process** itself, if applicable
Only a limited set of models are supported for serverless hosting of fine-tuned models. Checkout the [Fireworks Model Library](https://app.fireworks.ai/models?filter=LLM\&serverlessWithLoRA=true) to see models with serverless support for fine-tuning.
*Note*: This differs from on-demand deployments, which include hourly hosting costs.
---
# Source: https://docs.fireworks.ai/api-reference/audio-streaming-transcriptions.md
# Streaming Transcription
Streaming transcription is performed over a WebSocket. Provide the transcription parameters and establish a WebSocket connection to the endpoint.
Stream short audio chunks (50-400ms) in binary frames of PCM 16-bit little-endian at 16kHz sample rate and single channel (mono). In parallel, receive transcription from the WebSocket.
Stream audio to get transcription continuously in real-time.
Stream audio to get transcription continuously in real-time.
Stream audio to get transcription continuously in real-time.
### URLs
Fireworks provides serverless, real-time ASR via WebSocket endpoints. Please select the appropriate version:
#### Streaming ASR v1 (default)
Production-ready and generally recommended for all use cases.
```
wss://audio-streaming.api.fireworks.ai/v1/audio/transcriptions/streaming
```
#### Streaming ASR v2 (preview)
An early-access version of our next-generation streaming transcription service. V2 is good for use cases that require lower latency and higher accuracy in noisy situations.
```
wss://audio-streaming-v2.api.fireworks.ai/v1/audio/transcriptions/streaming
```
### Headers
Your Fireworks API key, e.g. `Authorization=API_KEY`. Alternatively, can be provided as a query param.
### Query Parameters
Your Fireworks API key. Required when headers cannot be set (e.g., browser WebSocket connections). Can alternatively be provided via the Authorization header.
The format in which to return the response. Currently only `verbose_json` is recommended for streaming.
The target language for transcription. See the [Supported Languages](#supported-languages) section below for a complete list of available languages.
The input prompt that the model will use when generating the transcription. Can be used to specify custom words or specify the style of the transcription. E.g. `Um, here's, uh, what was recorded.` will make the model to include the filler words into the transcription.
Sampling temperature to use when decoding text tokens during transcription.
The timestamp granularities to populate for this streaming transcription. Defaults to null. Set to `word,segment` to enable timestamp granularities. Use a list for timestamp\_granularities in all client libraries. A comma-separated string like `word,segment` only works when manually included in the URL (e.g. in curl).
### Client messages
This field is for client to send audio chunks over to server. Stream short audio chunks (50-400ms) in binary frames of PCM 16-bit little-endian at 16kHz sample rate and single channel (mono).
This field is for client event initiating the context clean up.
A unique identifier for the event.
A constant string that identifies the type of event as "stt.state.clear".
The ID of the context or session to be cleared.
This field is for client event initiating tracing.
A unique identifier for the event.
A constant string indicating the event type is "stt.input.trace".
The ID used to correlate this trace event across systems.
### Server messages
The task that was performed — either `transcribe` or `translate`.
The language of the transcribed/translated text.
The transcribed/translated text.
Extracted words and their corresponding timestamps.
The text content of the word.
The language of the word.
The probability of the word.
The hallucination score of the word.
Start time of the word in seconds. Appears only when timestamp\_granularities is set to `word,segment`.
End time of the word in seconds. Appears only when timestamp\_granularities is set to `word,segment`.
Indicates whether this word has been finalized.
Segments of the transcribed/translated text and their corresponding details.
The ID of the segment.
The text content of the segment.
Extracted words in the segment.
Start time of the segment in seconds. Appears only when timestamp\_granularities is set to `word,segment`.
End time of the segment in seconds. Appears only when timestamp\_granularities is set to `word,segment`.
This field is for server to communicate it successfully cleared the context.
A unique identifier for the event.
A constant string indicating the event type is "stt.state.cleared"
The ID of the context or session that has been successfully cleared.
This field is for server to complete tracing.
A unique identifier for the event.
A constant string indicating the event type is "stt.output.trace".
The ID used to correlate this output trace with the corresponding input trace.
### Streaming Audio
Stream short audio chunks (50-400ms) in binary frames of PCM 16-bit little-endian at 16kHz sample rate and single channel (mono). Typically, you will:
1. Resample your audio to 16 kHz if it is not already.
2. Convert it to mono.
3. Send 50ms chunks (16,000 Hz \* 0.05s = 800 samples) of audio in 16-bit PCM (signed, little-endian) format.
### Handling Responses
The client maintains a state dictionary, starting with an empty dictionary `{}`. When the server sends the first transcription message, it contains a list of segments. Each segment has an `id` and `text`:
```python theme={null}
# Server initial message:
{
"segments": [
{"id": "0", "text": "This is the first sentence"},
{"id": "1", "text": "This is the second sentence"}
]
}
# Client initial state:
{
"0": "This is the first sentence",
"1": "This is the second sentence",
}
```
When the server sends the next updates to the transcription, the client updates the state dictionary based on the segment `id`:
```python theme={null}
# Server continuous message:
{
"segments": [
{"id": "1", "text": "This is the second sentence modified"},
{"id": "2", "text": "This is the third sentence"}
]
}
# Client updated state:
{
"0": "This is the first sentence",
"1": "This is the second sentence modified", # overwritten
"2": "This is the third sentence", # new
}
```
### Handling Connection Interruptions & Timeouts
Real-time streaming transcription over WebSockets can run for a long time. The longer a WebSocket session runs, the more likely it is to experience interruptions from network glitches to service hiccups.
It is important to be aware of this and build your client to recover gracefully so the stream keeps going without user impact.
In the following section, we’ll outline recommended practices for handling connection interruptions and timeouts effectively.
#### When a connection drops
Although Fireworks is designed to keep streams running smoothly, occasional interruptions can still occur. If the WebSocket is disrupted (e.g., bandwidth limitation or network failures),
your application must initialize a new WebSocket connection, start a fresh streaming session and begin sending audio as soon as the server confirms the connection is open.
#### Avoid losing audio during reconnects
While you’re reconnecting, audio could be still being produced and you could lose that audio segment if it is not transferred to our API during this period.
To minimize the risk of dropping audio during a reconnect, one effective approach is to store the audio data in a buffer until it can re-establish the connection to our API and then sends the data for transcription.
### Keep timestamps continuous across sessions
When timestamps are enabled, the result will include the start and end time of the segment in seconds. And each new WebSocket session will reset the timestamps to start from 00:00:00.
To keep a continuous timeline, we recommend to maintain a running “stream start offset” in your app and add that offset to timestamps from each new session so they align with the overall audio timeline.
### Example Usage
Check out a brief Python example below or example sources:
* [Python notebook](https://colab.research.google.com/github/fw-ai/cookbook/blob/main/learn/audio/audio_streaming_speech_to_text/audio_streaming_speech_to_text.ipynb)
* [Python sources](https://github.com/fw-ai/cookbook/tree/main/learn/audio/audio_streaming_speech_to_text/python)
* [Node.js sources](https://github.com/fw-ai/cookbook/tree/main/learn/audio/audio_streaming_speech_to_text/nodejs)
```python theme={null}
!pip3 install requests torch torchaudio websocket-client
import io
import time
import json
import torch
import requests
import torchaudio
import threading
import websocket
import urllib.parse
lock = threading.Lock()
state = {}
def on_open(ws):
def send_audio_chunks():
for chunk in audio_chunk_bytes:
ws.send(chunk, opcode=websocket.ABNF.OPCODE_BINARY)
time.sleep(chunk_size_ms / 1000)
final_checkpoint = json.dumps({"checkpoint_id": "final"})
ws.send(final_checkpoint, opcode=websocket.ABNF.OPCODE_TEXT)
threading.Thread(target=send_audio_chunks).start()
def on_message(ws, message):
message = json.loads(message)
if message.get("checkpoint_id") == "final":
ws.close()
return
update = {s["id"]: s["text"] for s in message["segments"]}
with lock:
state.update(update)
print("\n".join(f" - {k}: {v}" for k, v in state.items()))
def on_error(ws, error):
print(f"WebSocket error: {error}")
# Open a connection URL with query params
url = "wss://audio-streaming.api.fireworks.ai/v1/audio/transcriptions/streaming"
params = urllib.parse.urlencode({
"language": "en",
})
ws = websocket.WebSocketApp(
f"{url}?{params}",
header={"Authorization": ""},
on_open=on_open,
on_message=on_message,
on_error=on_error,
)
ws.run_forever()
```
### Dedicated endpoint
For fixed throughput and predictable SLAs, you may request a dedicated endpoint for streaming transcription at [inquiries@fireworks.ai](mailto:inquiries@fireworks.ai) or [discord](https://www.google.com/url?q=https%3A%2F%2Fdiscord.gg%2Ffireworks-ai).
### Supported Languages
The following languages are supported for transcription:
| Language Code | Language Name |
| ------------- | ------------------- |
| en | English |
| zh | Chinese |
| de | German |
| es | Spanish |
| ru | Russian |
| ko | Korean |
| fr | French |
| ja | Japanese |
| pt | Portuguese |
| tr | Turkish |
| pl | Polish |
| ca | Catalan |
| nl | Dutch |
| ar | Arabic |
| sv | Swedish |
| it | Italian |
| id | Indonesian |
| hi | Hindi |
| fi | Finnish |
| vi | Vietnamese |
| he | Hebrew |
| uk | Ukrainian |
| el | Greek |
| ms | Malay |
| cs | Czech |
| ro | Romanian |
| da | Danish |
| hu | Hungarian |
| ta | Tamil |
| no | Norwegian |
| th | Thai |
| ur | Urdu |
| hr | Croatian |
| bg | Bulgarian |
| lt | Lithuanian |
| la | Latin |
| mi | Maori |
| ml | Malayalam |
| cy | Welsh |
| sk | Slovak |
| te | Telugu |
| fa | Persian |
| lv | Latvian |
| bn | Bengali |
| sr | Serbian |
| az | Azerbaijani |
| sl | Slovenian |
| kn | Kannada |
| et | Estonian |
| mk | Macedonian |
| br | Breton |
| eu | Basque |
| is | Icelandic |
| hy | Armenian |
| ne | Nepali |
| mn | Mongolian |
| bs | Bosnian |
| kk | Kazakh |
| sq | Albanian |
| sw | Swahili |
| gl | Galician |
| mr | Marathi |
| pa | Punjabi |
| si | Sinhala |
| km | Khmer |
| sn | Shona |
| yo | Yoruba |
| so | Somali |
| af | Afrikaans |
| oc | Occitan |
| ka | Georgian |
| be | Belarusian |
| tg | Tajik |
| sd | Sindhi |
| gu | Gujarati |
| am | Amharic |
| yi | Yiddish |
| lo | Lao |
| uz | Uzbek |
| fo | Faroese |
| ht | Haitian Creole |
| ps | Pashto |
| tk | Turkmen |
| nn | Nynorsk |
| mt | Maltese |
| sa | Sanskrit |
| lb | Luxembourgish |
| my | Myanmar |
| bo | Tibetan |
| tl | Tagalog |
| mg | Malagasy |
| as | Assamese |
| tt | Tatar |
| haw | Hawaiian |
| ln | Lingala |
| ha | Hausa |
| ba | Bashkir |
| jw | Javanese |
| su | Sundanese |
| yue | Cantonese |
| zh-hant | Traditional Chinese |
| zh-hans | Simplified Chinese |
---
# Source: https://docs.fireworks.ai/api-reference/audio-transcriptions.md
# Transcribe audio
Send a sample audio to get a transcription.
### Headers
Your Fireworks API key, e.g. `Authorization=API_KEY`.
### Request
##### (multi-part form)
The input audio file to transcribe or an URL to the public audio file.
Max audio file size is 1 GB, there is no limit for audio duration. Common file formats such as mp3, flac, and wav are supported. Note that the audio will be resampled to 16kHz, downmixed to mono, and reformatted to 16-bit signed little-endian format before transcription. Pre-converting the file before sending it to the API can improve runtime performance.
String name of the ASR model to use. Can be one of `whisper-v3` or `whisper-v3-turbo`. Please use the following serverless endpoints:
* [https://audio-prod.api.fireworks.ai](https://audio-prod.api.fireworks.ai) (for `whisper-v3`);
* [https://audio-turbo.api.fireworks.ai](https://audio-turbo.api.fireworks.ai) (for `whisper-v3-turbo`);
String name of the voice activity detection (VAD) model to use. Can be one of `silero`, or `whisperx-pyannet`.
String name of the alignment model to use. Currently supported:
* `mms_fa` optimal accuracy for multilingual speech.
* `tdnn_ffn` optimal accuracy for English-only speech.
* `gentle` best accuracy for English-only speech (requires a dedicated endpoint, contact us at [inquiries@fireworks.ai](mailto:inquiries@fireworks.ai)).
The target language for transcription. See the [Supported Languages](#supported-languages) section below for a complete list of available languages.
The input prompt that the model will use when generating the transcription. Can be used to specify custom words or specify the style of the transcription. E.g. `Um, here's, uh, what was recorded.` will make the model to include the filler words into the transcription.
Sampling temperature to use when decoding text tokens during transcription. Alternatively, fallback decoding can be enabled by passing a list of temperatures like `0.0,0.2,0.4,0.6,0.8,1.0`. This can help to improve performance.
The format in which to return the response. Can be one of `json`, `text`, `srt`, `verbose_json`, or `vtt`.
The timestamp granularities to populate for this transcription. `response_format` must be set `verbose_json` to use timestamp granularities. Either or both of these options are supported. Can be one of `word`, `segment`, or `word,segment`. If not present, defaults to `segment`.
Whether to get speaker diarization for the transcription. Can be one of `true`, or `false`. If not present, defaults to `false`.
Enabling diarization also requires other fields to hold specific values:
1. `response_format` must be set `verbose_json`.
2. `timestamp_granularities` must include `word` to use diarization.
The minimum number of speakers to detect for diarization. `diarize` must be set `true` to use `min_speakers`. If not present, defaults to `1`.
The maximum number of speakers to detect for diarization. `diarize` must be set `true` to use `max_speakers`. If not present, defaults to `inf`.
Audio preprocessing mode. Currently supported:
* `none` to skip audio preprocessing.
* `dynamic` for arbitrary audio content with variable loudness.
* `soft_dynamic` for speech intense recording such as podcasts and voice-overs.
* `bass_dynamic` for boosting lower frequencies;
### Response
The task which was performed. Either `transcribe` or `translate`.
The language of the transcribed/translated text.
The duration of the transcribed/translated audio, in seconds.
The transcribed/translated text.
Extracted words and their corresponding timestamps.
The text content of the word.
The language of the word.
The probability of the word.
The hallucination score of the word.
Start time of the word in seconds.
End time of the word in seconds.
Speaker label for the word.
Segments of the transcribed/translated text and their corresponding details.
The id of the segment.
The text content of the segment.
Start time of the segment in seconds.
End time of the segment in seconds.
Speaker label for the segment.
Extracted words in the segment.
```curl curl theme={null}
# Download audio file
curl -L -o "audio.flac" "https://tinyurl.com/4997djsh"
# Make request
curl -X POST "https://audio-prod.api.fireworks.ai/v1/audio/transcriptions" \
-H "Authorization: " \
-F "file=@audio.flac"
```
```python fireworks sdk theme={null}
!pip install fireworks-ai requests python-dotenv
from fireworks.client.audio import AudioInference
import requests
import os
from dotenv import load_dotenv
import time
# Create a .env file with your API key
load_dotenv()
# Download audio sample
audio = requests.get("https://tinyurl.com/4cb74vas").content
# Prepare client
client = AudioInference(
model="whisper-v3",
base_url="https://audio-prod.api.fireworks.ai",
# Or for the turbo version
# model="whisper-v3-turbo",
# base_url="https://audio-turbo.api.fireworks.ai",
api_key=os.getenv("FIREWORKS_API_KEY"),
)
# Make request
start = time.time()
r = await client.transcribe_async(audio=audio)
print(f"Took: {(time.time() - start):.3f}s. Text: '{r.text}'")
```
```python Python (openai sdk) theme={null}
!pip install openai requests python-dotenv
from openai import OpenAI
import os
import requests
from dotenv import load_dotenv
load_dotenv()
client = OpenAI(
base_url="https://audio-prod.api.fireworks.ai/v1",
api_key=os.getenv("FIREWORKS_API_KEY")
)
audio_file= requests.get("https://tinyurl.com/4cb74vas").content
transcription = client.audio.transcriptions.create(
model="whisper-v3",
file=audio_file
)
print(transcription.text)
```
### Supported Languages
The following languages are supported for transcription:
| Language Code | Language Name |
| ------------- | ------------------- |
| en | English |
| zh | Chinese |
| de | German |
| es | Spanish |
| ru | Russian |
| ko | Korean |
| fr | French |
| ja | Japanese |
| pt | Portuguese |
| tr | Turkish |
| pl | Polish |
| ca | Catalan |
| nl | Dutch |
| ar | Arabic |
| sv | Swedish |
| it | Italian |
| id | Indonesian |
| hi | Hindi |
| fi | Finnish |
| vi | Vietnamese |
| he | Hebrew |
| uk | Ukrainian |
| el | Greek |
| ms | Malay |
| cs | Czech |
| ro | Romanian |
| da | Danish |
| hu | Hungarian |
| ta | Tamil |
| no | Norwegian |
| th | Thai |
| ur | Urdu |
| hr | Croatian |
| bg | Bulgarian |
| lt | Lithuanian |
| la | Latin |
| mi | Maori |
| ml | Malayalam |
| cy | Welsh |
| sk | Slovak |
| te | Telugu |
| fa | Persian |
| lv | Latvian |
| bn | Bengali |
| sr | Serbian |
| az | Azerbaijani |
| sl | Slovenian |
| kn | Kannada |
| et | Estonian |
| mk | Macedonian |
| br | Breton |
| eu | Basque |
| is | Icelandic |
| hy | Armenian |
| ne | Nepali |
| mn | Mongolian |
| bs | Bosnian |
| kk | Kazakh |
| sq | Albanian |
| sw | Swahili |
| gl | Galician |
| mr | Marathi |
| pa | Punjabi |
| si | Sinhala |
| km | Khmer |
| sn | Shona |
| yo | Yoruba |
| so | Somali |
| af | Afrikaans |
| oc | Occitan |
| ka | Georgian |
| be | Belarusian |
| tg | Tajik |
| sd | Sindhi |
| gu | Gujarati |
| am | Amharic |
| yi | Yiddish |
| lo | Lao |
| uz | Uzbek |
| fo | Faroese |
| ht | Haitian Creole |
| ps | Pashto |
| tk | Turkmen |
| nn | Nynorsk |
| mt | Maltese |
| sa | Sanskrit |
| lb | Luxembourgish |
| my | Myanmar |
| bo | Tibetan |
| tl | Tagalog |
| mg | Malagasy |
| as | Assamese |
| tt | Tatar |
| haw | Hawaiian |
| ln | Lingala |
| ha | Hausa |
| ba | Bashkir |
| jw | Javanese |
| su | Sundanese |
| yue | Cantonese |
| zh-hant | Traditional Chinese |
| zh-hans | Simplified Chinese |
---
# Source: https://docs.fireworks.ai/api-reference/audio-translations.md
# Translate audio
### Headers
Your Fireworks API key, e.g. `Authorization=API_KEY`.
### Request
##### (multi-part form)
The input audio file to translate or an URL to the public audio file.
Max audio file size is 1 GB, there is no limit for audio duration. Common file formats such as mp3, flac, and wav are supported. Note that the audio will be resampled to 16kHz, downmixed to mono, and reformatted to 16-bit signed little-endian format before transcription. Pre-converting the file before sending it to the API can improve runtime performance.
String name of the ASR model to use. Can be one of `whisper-v3` or `whisper-v3-turbo`. Please use the following serverless endpoints:
* [https://audio-prod.api.fireworks.ai](https://audio-prod.api.fireworks.ai) (for `whisper-v3`);
* [https://audio-turbo.api.fireworks.ai](https://audio-turbo.api.fireworks.ai) (for `whisper-v3-turbo`);
String name of the voice activity detection (VAD) model to use. Can be one of `silero`, or `whisperx-pyannet`.
String name of the alignment model to use. Currently supported:
* `mms_fa` optimal accuracy for multilingual speech.
* `tdnn_ffn` optimal accuracy for English-only speech.
* `gentle` best accuracy for English-only speech (requires a dedicated endpoint, contact us at [inquiries@fireworks.ai](mailto:inquiries@fireworks.ai)).
The source language for transcription. See the [Supported Languages](#supported-languages) section below for a complete list of available languages.
The input prompt that the model will use when generating the transcription. Can be used to specify custom words or specify the style of the transcription. E.g. `Um, here's, uh, what was recorded.` will make the model to include the filler words into the transcription.
Sampling temperature to use when decoding text tokens during transcription. Alternatively, fallback decoding can be enabled by passing a list of temperatures like `0.0,0.2,0.4,0.6,0.8,1.0`. This can help to improve performance.
The format in which to return the response. Can be one of `json`, `text`, `srt`, `verbose_json`, or `vtt`.
The timestamp granularities to populate for this transcription. response\_format must be set `verbose_json` to use timestamp granularities. Either or both of these options are supported. Can be one of `word`, `segment`, or `word,segment`. If not present, defaults to `segment`.
Audio preprocessing mode. Currently supported:
* `none` to skip audio preprocessing.
* `dynamic` for arbitrary audio content with variable loudness.
* `soft_dynamic` for speech intense recording such as podcasts and voice-overs.
* `bass_dynamic` for boosting lower frequencies;
### Response
The task which was performed. Either `transcribe` or `translate`.
The language of the transcribed/translated text.
The duration of the transcribed/translated audio, in seconds.
The transcribed/translated text.
Extracted words and their corresponding timestamps.
The text content of the word.
Start time of the word in seconds.
End time of the word in seconds.
Segments of the transcribed/translated text and their corresponding details.
```curl curl theme={null}
# Download audio file
curl -L -o "audio.flac" "https://tinyurl.com/4997djsh"
# Make request
curl -X POST "https://audio-prod.api.fireworks.ai/v1/audio/translations" \
-H "Authorization: " \
-F "file=@audio.flac"
```
```python Python (fireworks sdk) theme={null}
!pip install fireworks-ai requests
from fireworks.client.audio import AudioInference
import requests
import time
from dotenv import load_dotenv
import os
load_dotenv()
# Prepare client
audio = requests.get("https://tinyurl.com/3cy7x44v").content
client = AudioInference(
model="whisper-v3",
base_url="https://audio-prod.api.fireworks.ai",
#
# Or for the turbo version
# model="whisper-v3-turbo",
# base_url="https://audio-turbo.api.fireworks.ai",
api_key=os.getenv("FIREWORKS_API_KEY")
)
# Make request
start = time.time()
r = await client.translate_async(audio=audio)
print(f"Took: {(time.time() - start):.3f}s. Text: '{r.text}'")
```
```python Python (openai sdk) theme={null}
!pip install openai requests
from openai import OpenAI
import requests
from dotenv import load_dotenv
import os
load_dotenv()
client = OpenAI(
base_url="https://audio-prod.api.fireworks.ai/v1",
api_key=os.getenv("FIREWORKS_API_KEY"),
)
audio_file= requests.get("https://tinyurl.com/3cy7x44v").content
translation = client.audio.translations.create(
model="whisper-v3",
file=audio_file,
)
print(translation.text)
```
### Supported Languages
Translation is from one of the supported languages to English, the following languages are supported for translation:
| Language Code | Language Name |
| ------------- | -------------- |
| en | English |
| zh | Chinese |
| de | German |
| es | Spanish |
| ru | Russian |
| ko | Korean |
| fr | French |
| ja | Japanese |
| pt | Portuguese |
| tr | Turkish |
| pl | Polish |
| ca | Catalan |
| nl | Dutch |
| ar | Arabic |
| sv | Swedish |
| it | Italian |
| id | Indonesian |
| hi | Hindi |
| fi | Finnish |
| vi | Vietnamese |
| he | Hebrew |
| uk | Ukrainian |
| el | Greek |
| ms | Malay |
| cs | Czech |
| ro | Romanian |
| da | Danish |
| hu | Hungarian |
| ta | Tamil |
| no | Norwegian |
| th | Thai |
| ur | Urdu |
| hr | Croatian |
| bg | Bulgarian |
| lt | Lithuanian |
| la | Latin |
| mi | Maori |
| ml | Malayalam |
| cy | Welsh |
| sk | Slovak |
| te | Telugu |
| fa | Persian |
| lv | Latvian |
| bn | Bengali |
| sr | Serbian |
| az | Azerbaijani |
| sl | Slovenian |
| kn | Kannada |
| et | Estonian |
| mk | Macedonian |
| br | Breton |
| eu | Basque |
| is | Icelandic |
| hy | Armenian |
| ne | Nepali |
| mn | Mongolian |
| bs | Bosnian |
| kk | Kazakh |
| sq | Albanian |
| sw | Swahili |
| gl | Galician |
| mr | Marathi |
| pa | Punjabi |
| si | Sinhala |
| km | Khmer |
| sn | Shona |
| yo | Yoruba |
| so | Somali |
| af | Afrikaans |
| oc | Occitan |
| ka | Georgian |
| be | Belarusian |
| tg | Tajik |
| sd | Sindhi |
| gu | Gujarati |
| am | Amharic |
| yi | Yiddish |
| lo | Lao |
| uz | Uzbek |
| fo | Faroese |
| ht | Haitian Creole |
| ps | Pashto |
| tk | Turkmen |
| nn | Nynorsk |
| mt | Maltese |
| sa | Sanskrit |
| lb | Luxembourgish |
| my | Myanmar |
| bo | Tibetan |
| tl | Tagalog |
| mg | Malagasy |
| as | Assamese |
| tt | Tatar |
| haw | Hawaiian |
| ln | Lingala |
| ha | Hausa |
| ba | Bashkir |
| jw | Javanese |
| su | Sundanese |
| yue | Cantonese |
---
# Source: https://docs.fireworks.ai/guides/security_compliance/audit_logs.md
# Audit & Access Logs
> Monitor and track account activities with audit logging for Enterprise accounts
Audit logs are available for Enterprise accounts. This feature enhances security visibility, incident investigation, and compliance reporting.
Audit logs include data access logs. All read, write, and delete operations on storage are logged, normalized, and enriched with account context for complete visibility.
## View audit logs
You can view audit logs, including data access logs, using the Fireworks CLI:
```bash theme={null}
firectl ls audit-logs
```
 ---
# Source: https://docs.fireworks.ai/tools-sdks/firectl/commands/authentication.md
# Authentication
> Authentication for access to your account
### Signing in
Users using Google SSO can run:
```
firectl signin
```
If you are using [custom SSO](/accounts/sso), also specify the account ID:
```
firectl signin my-enterprise-account
```
### Authenticate with API Key
To authenticate with an API key, append `--api-key` to any firectl command.
```
firectl --api-key API_KEY
```
To persist the API key for all subsequent commands, run:
```
firectl set-api-key API_KEY
```
---
# Source: https://docs.fireworks.ai/deployments/autoscaling.md
# Autoscaling
> Configure how your deployment scales based on traffic
Control how your deployment scales based on traffic and load.
## Configuration options
| Flag | Type | Default | Description |
| ------------------------ | --------- | ------------- | ------------------------------------------------------ |
| `--min-replica-count` | Integer | 0 | Minimum number of replicas. Set to 0 for scale-to-zero |
| `--max-replica-count` | Integer | 1 | Maximum number of replicas |
| `--scale-up-window` | Duration | 30s | Wait time before scaling up |
| `--scale-down-window` | Duration | 10m | Wait time before scaling down |
| `--scale-to-zero-window` | Duration | 1h | Idle time before scaling to zero (min: 5m) |
| `--load-targets` | Key-value | `default=0.8` | Scaling thresholds. See options below |
**Load target options** (use as `--load-targets =[,=...]`):
* `default=` - General load target from 0 to 1
* `tokens_generated_per_second=` - Desired tokens per second per replica
* `requests_per_second=` - Desired requests per second per replica
* `concurrent_requests=` - Desired concurrent requests per replica
When multiple targets are specified, the maximum replica count across all is used.
## Common patterns
Scale to zero when idle to minimize costs:
```bash theme={null}
firectl create deployment \
--min-replica-count 0 \
--max-replica-count 3 \
--scale-to-zero-window 1h
```
Best for: Development, testing, or intermittent production workloads.
Keep replicas running for instant response:
```bash theme={null}
firectl create deployment \
--min-replica-count 2 \
--max-replica-count 10 \
--scale-up-window 15s \
--load-targets concurrent_requests=5
```
Best for: Low-latency requirements, avoiding cold starts, high-traffic applications.
Match known traffic patterns:
```bash theme={null}
firectl create deployment \
--min-replica-count 3 \
--max-replica-count 5 \
--scale-down-window 30m \
--load-targets tokens_generated_per_second=150
```
Best for: Steady workloads where you know typical load ranges.
Cold starts take up to a few minutes when scaling from 0→1. Deployments with min replicas = 0 are auto-deleted after 7 days of no traffic. [Reserved capacity](/deployments/reservations) guarantees availability during scale-up.
---
# Source: https://docs.fireworks.ai/api-reference-dlde/batch-delete-batch-jobs.md
# Batch Delete Batch Jobs
## OpenAPI
````yaml post /v1/accounts/{account_id}/batchJobs:batchDelete
paths:
path: /v1/accounts/{account_id}/batchJobs:batchDelete
method: post
servers:
- url: https://api.fireworks.ai
request:
security:
- title: BearerAuth
parameters:
query: {}
header:
Authorization:
type: http
scheme: bearer
description: >-
Bearer authentication using your Fireworks API key. Format:
Bearer
cookie: {}
parameters:
path:
account_id:
schema:
- type: string
required: true
description: The Account Id
query: {}
header: {}
cookie: {}
body:
application/json:
schemaArray:
- type: object
properties:
names:
allOf:
- type: array
items:
type: string
description: The resource names of the batch jobs to delete.
required: true
refIdentifier: '#/components/schemas/GatewayBatchDeleteBatchJobsBody'
requiredProperties:
- names
examples:
example:
value:
names:
-
response:
'200':
application/json:
schemaArray:
- type: object
properties: {}
examples:
example:
value: {}
description: A successful response.
deprecated: false
type: path
components:
schemas: {}
````
---
# Source: https://docs.fireworks.ai/api-reference-dlde/batch-delete-environments.md
# Batch Delete Environments
## OpenAPI
````yaml post /v1/accounts/{account_id}/environments:batchDelete
paths:
path: /v1/accounts/{account_id}/environments:batchDelete
method: post
servers:
- url: https://api.fireworks.ai
request:
security:
- title: BearerAuth
parameters:
query: {}
header:
Authorization:
type: http
scheme: bearer
description: >-
Bearer authentication using your Fireworks API key. Format:
Bearer
cookie: {}
parameters:
path:
account_id:
schema:
- type: string
required: true
description: The Account Id
query: {}
header: {}
cookie: {}
body:
application/json:
schemaArray:
- type: object
properties:
names:
allOf:
- type: array
items:
type: string
description: The resource names of the environments to delete.
required: true
refIdentifier: '#/components/schemas/GatewayBatchDeleteEnvironmentsBody'
requiredProperties:
- names
examples:
example:
value:
names:
-
response:
'200':
application/json:
schemaArray:
- type: object
properties: {}
examples:
example:
value: {}
description: A successful response.
deprecated: false
type: path
components:
schemas: {}
````
---
# Source: https://docs.fireworks.ai/api-reference-dlde/batch-delete-node-pools.md
# Batch Delete Node Pools
## OpenAPI
````yaml post /v1/accounts/{account_id}/nodePools:batchDelete
paths:
path: /v1/accounts/{account_id}/nodePools:batchDelete
method: post
servers:
- url: https://api.fireworks.ai
request:
security:
- title: BearerAuth
parameters:
query: {}
header:
Authorization:
type: http
scheme: bearer
description: >-
Bearer authentication using your Fireworks API key. Format:
Bearer
cookie: {}
parameters:
path:
account_id:
schema:
- type: string
required: true
description: The Account Id
query: {}
header: {}
cookie: {}
body:
application/json:
schemaArray:
- type: object
properties:
names:
allOf:
- type: array
items:
type: string
description: The resource names of the node pools to delete.
required: true
refIdentifier: '#/components/schemas/GatewayBatchDeleteNodePoolsBody'
requiredProperties:
- names
examples:
example:
value:
names:
-
response:
'200':
application/json:
schemaArray:
- type: object
properties: {}
examples:
example:
value: {}
description: A successful response.
deprecated: false
type: path
components:
schemas: {}
````
---
# Source: https://docs.fireworks.ai/guides/batch-inference.md
# Batch API
> Process large-scale async workloads
Process large volumes of requests asynchronously at 50% lower cost. Batch API is ideal for:
* Production-scale inference workloads
* Large-scale testing and benchmarking
* Training smaller models with larger ones ([distillation guide](https://fireworks.ai/blog/deepseek-r1-distillation-reasoning))
Batch jobs automatically use [prompt caching](/guides/prompt-caching) for additional 50% cost savings on cached tokens. Maximize cache hits by placing static content first in your prompts.
## Getting Started
Datasets must be in JSONL format (one JSON object per line):
**Requirements:**
* **File format:** JSONL (each line is a valid JSON object)
* **Size limit:** Under 500MB
* **Required fields:** `custom_id` (unique) and `body` (request parameters)
**Example dataset:**
```json theme={null}
{"custom_id": "request-1", "body": {"messages": [{"role": "system", "content": "You are a helpful assistant."}, {"role": "user", "content": "What is the capital of France?"}], "max_tokens": 100}}
{"custom_id": "request-2", "body": {"messages": [{"role": "user", "content": "Explain quantum computing"}], "temperature": 0.7}}
{"custom_id": "request-3", "body": {"messages": [{"role": "user", "content": "Tell me a joke"}]}}
```
Save as `batch_input_data.jsonl` locally.
You can simply navigate to the dataset tab, click `Create Dataset` and follow the wizard.
---
# Source: https://docs.fireworks.ai/tools-sdks/firectl/commands/authentication.md
# Authentication
> Authentication for access to your account
### Signing in
Users using Google SSO can run:
```
firectl signin
```
If you are using [custom SSO](/accounts/sso), also specify the account ID:
```
firectl signin my-enterprise-account
```
### Authenticate with API Key
To authenticate with an API key, append `--api-key` to any firectl command.
```
firectl --api-key API_KEY
```
To persist the API key for all subsequent commands, run:
```
firectl set-api-key API_KEY
```
---
# Source: https://docs.fireworks.ai/deployments/autoscaling.md
# Autoscaling
> Configure how your deployment scales based on traffic
Control how your deployment scales based on traffic and load.
## Configuration options
| Flag | Type | Default | Description |
| ------------------------ | --------- | ------------- | ------------------------------------------------------ |
| `--min-replica-count` | Integer | 0 | Minimum number of replicas. Set to 0 for scale-to-zero |
| `--max-replica-count` | Integer | 1 | Maximum number of replicas |
| `--scale-up-window` | Duration | 30s | Wait time before scaling up |
| `--scale-down-window` | Duration | 10m | Wait time before scaling down |
| `--scale-to-zero-window` | Duration | 1h | Idle time before scaling to zero (min: 5m) |
| `--load-targets` | Key-value | `default=0.8` | Scaling thresholds. See options below |
**Load target options** (use as `--load-targets =[,=...]`):
* `default=` - General load target from 0 to 1
* `tokens_generated_per_second=` - Desired tokens per second per replica
* `requests_per_second=` - Desired requests per second per replica
* `concurrent_requests=` - Desired concurrent requests per replica
When multiple targets are specified, the maximum replica count across all is used.
## Common patterns
Scale to zero when idle to minimize costs:
```bash theme={null}
firectl create deployment \
--min-replica-count 0 \
--max-replica-count 3 \
--scale-to-zero-window 1h
```
Best for: Development, testing, or intermittent production workloads.
Keep replicas running for instant response:
```bash theme={null}
firectl create deployment \
--min-replica-count 2 \
--max-replica-count 10 \
--scale-up-window 15s \
--load-targets concurrent_requests=5
```
Best for: Low-latency requirements, avoiding cold starts, high-traffic applications.
Match known traffic patterns:
```bash theme={null}
firectl create deployment \
--min-replica-count 3 \
--max-replica-count 5 \
--scale-down-window 30m \
--load-targets tokens_generated_per_second=150
```
Best for: Steady workloads where you know typical load ranges.
Cold starts take up to a few minutes when scaling from 0→1. Deployments with min replicas = 0 are auto-deleted after 7 days of no traffic. [Reserved capacity](/deployments/reservations) guarantees availability during scale-up.
---
# Source: https://docs.fireworks.ai/api-reference-dlde/batch-delete-batch-jobs.md
# Batch Delete Batch Jobs
## OpenAPI
````yaml post /v1/accounts/{account_id}/batchJobs:batchDelete
paths:
path: /v1/accounts/{account_id}/batchJobs:batchDelete
method: post
servers:
- url: https://api.fireworks.ai
request:
security:
- title: BearerAuth
parameters:
query: {}
header:
Authorization:
type: http
scheme: bearer
description: >-
Bearer authentication using your Fireworks API key. Format:
Bearer
cookie: {}
parameters:
path:
account_id:
schema:
- type: string
required: true
description: The Account Id
query: {}
header: {}
cookie: {}
body:
application/json:
schemaArray:
- type: object
properties:
names:
allOf:
- type: array
items:
type: string
description: The resource names of the batch jobs to delete.
required: true
refIdentifier: '#/components/schemas/GatewayBatchDeleteBatchJobsBody'
requiredProperties:
- names
examples:
example:
value:
names:
-
response:
'200':
application/json:
schemaArray:
- type: object
properties: {}
examples:
example:
value: {}
description: A successful response.
deprecated: false
type: path
components:
schemas: {}
````
---
# Source: https://docs.fireworks.ai/api-reference-dlde/batch-delete-environments.md
# Batch Delete Environments
## OpenAPI
````yaml post /v1/accounts/{account_id}/environments:batchDelete
paths:
path: /v1/accounts/{account_id}/environments:batchDelete
method: post
servers:
- url: https://api.fireworks.ai
request:
security:
- title: BearerAuth
parameters:
query: {}
header:
Authorization:
type: http
scheme: bearer
description: >-
Bearer authentication using your Fireworks API key. Format:
Bearer
cookie: {}
parameters:
path:
account_id:
schema:
- type: string
required: true
description: The Account Id
query: {}
header: {}
cookie: {}
body:
application/json:
schemaArray:
- type: object
properties:
names:
allOf:
- type: array
items:
type: string
description: The resource names of the environments to delete.
required: true
refIdentifier: '#/components/schemas/GatewayBatchDeleteEnvironmentsBody'
requiredProperties:
- names
examples:
example:
value:
names:
-
response:
'200':
application/json:
schemaArray:
- type: object
properties: {}
examples:
example:
value: {}
description: A successful response.
deprecated: false
type: path
components:
schemas: {}
````
---
# Source: https://docs.fireworks.ai/api-reference-dlde/batch-delete-node-pools.md
# Batch Delete Node Pools
## OpenAPI
````yaml post /v1/accounts/{account_id}/nodePools:batchDelete
paths:
path: /v1/accounts/{account_id}/nodePools:batchDelete
method: post
servers:
- url: https://api.fireworks.ai
request:
security:
- title: BearerAuth
parameters:
query: {}
header:
Authorization:
type: http
scheme: bearer
description: >-
Bearer authentication using your Fireworks API key. Format:
Bearer
cookie: {}
parameters:
path:
account_id:
schema:
- type: string
required: true
description: The Account Id
query: {}
header: {}
cookie: {}
body:
application/json:
schemaArray:
- type: object
properties:
names:
allOf:
- type: array
items:
type: string
description: The resource names of the node pools to delete.
required: true
refIdentifier: '#/components/schemas/GatewayBatchDeleteNodePoolsBody'
requiredProperties:
- names
examples:
example:
value:
names:
-
response:
'200':
application/json:
schemaArray:
- type: object
properties: {}
examples:
example:
value: {}
description: A successful response.
deprecated: false
type: path
components:
schemas: {}
````
---
# Source: https://docs.fireworks.ai/guides/batch-inference.md
# Batch API
> Process large-scale async workloads
Process large volumes of requests asynchronously at 50% lower cost. Batch API is ideal for:
* Production-scale inference workloads
* Large-scale testing and benchmarking
* Training smaller models with larger ones ([distillation guide](https://fireworks.ai/blog/deepseek-r1-distillation-reasoning))
Batch jobs automatically use [prompt caching](/guides/prompt-caching) for additional 50% cost savings on cached tokens. Maximize cache hits by placing static content first in your prompts.
## Getting Started
Datasets must be in JSONL format (one JSON object per line):
**Requirements:**
* **File format:** JSONL (each line is a valid JSON object)
* **Size limit:** Under 500MB
* **Required fields:** `custom_id` (unique) and `body` (request parameters)
**Example dataset:**
```json theme={null}
{"custom_id": "request-1", "body": {"messages": [{"role": "system", "content": "You are a helpful assistant."}, {"role": "user", "content": "What is the capital of France?"}], "max_tokens": 100}}
{"custom_id": "request-2", "body": {"messages": [{"role": "user", "content": "Explain quantum computing"}], "temperature": 0.7}}
{"custom_id": "request-3", "body": {"messages": [{"role": "user", "content": "Tell me a joke"}]}}
```
Save as `batch_input_data.jsonl` locally.
You can simply navigate to the dataset tab, click `Create Dataset` and follow the wizard.
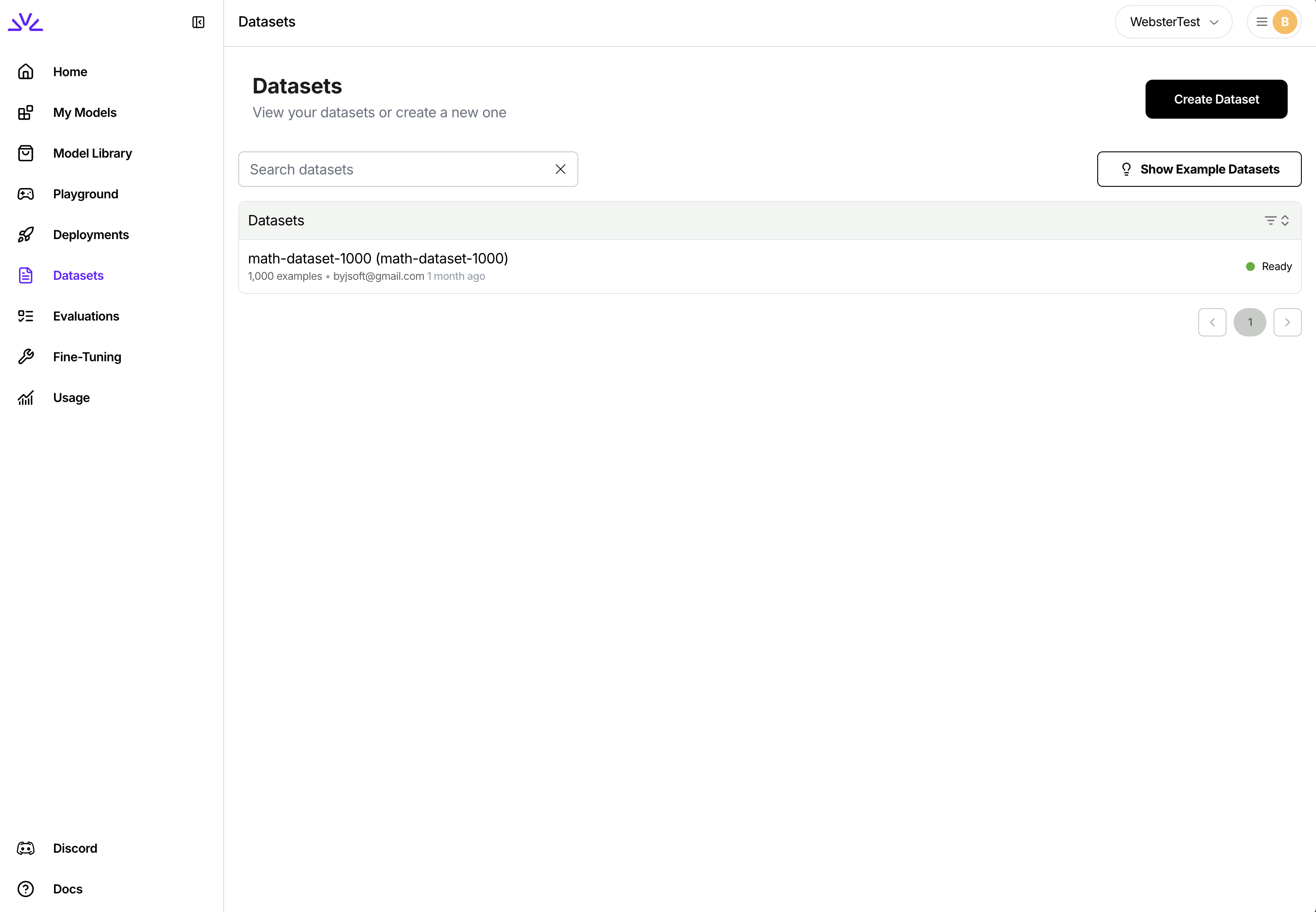 ```bash theme={null}
firectl create dataset batch-input-dataset ./batch_input_data.jsonl
```
You need to make two separate HTTP requests. One for creating the dataset entry and one for uploading the dataset. Full reference here: [Create dataset](/api-reference/create-dataset).
```bash theme={null}
# Create Dataset Entry
curl -X POST "https://api.fireworks.ai/v1/accounts/${ACCOUNT_ID}/datasets" \
-H "Authorization: Bearer ${API_KEY}" \
-H "Content-Type: application/json" \
-d '{
"datasetId": "batch-input-dataset",
"dataset": { "userUploaded": {} }
}'
# Upload JSONL file
curl -X POST "https://api.fireworks.ai/v1/accounts/${ACCOUNT_ID}/datasets/batch-input-dataset:upload" \
-H "Authorization: Bearer ${API_KEY}" \
-F "file=@./batch_input_data.jsonl"
```
Navigate to the Batch Inference tab and click "Create Batch Inference Job". Select your input dataset:
```bash theme={null}
firectl create dataset batch-input-dataset ./batch_input_data.jsonl
```
You need to make two separate HTTP requests. One for creating the dataset entry and one for uploading the dataset. Full reference here: [Create dataset](/api-reference/create-dataset).
```bash theme={null}
# Create Dataset Entry
curl -X POST "https://api.fireworks.ai/v1/accounts/${ACCOUNT_ID}/datasets" \
-H "Authorization: Bearer ${API_KEY}" \
-H "Content-Type: application/json" \
-d '{
"datasetId": "batch-input-dataset",
"dataset": { "userUploaded": {} }
}'
# Upload JSONL file
curl -X POST "https://api.fireworks.ai/v1/accounts/${ACCOUNT_ID}/datasets/batch-input-dataset:upload" \
-H "Authorization: Bearer ${API_KEY}" \
-F "file=@./batch_input_data.jsonl"
```
Navigate to the Batch Inference tab and click "Create Batch Inference Job". Select your input dataset:
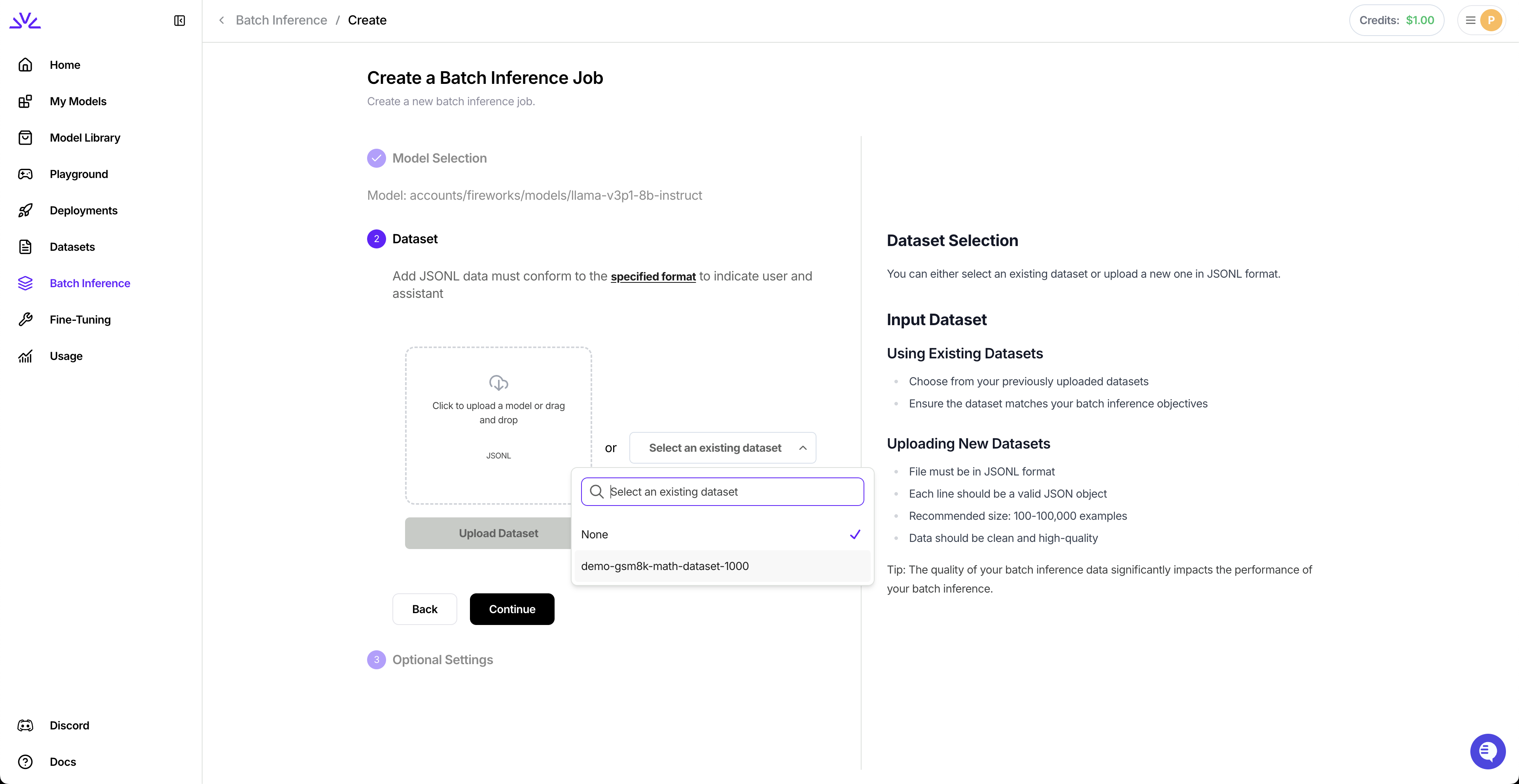 Choose your model:
Choose your model:
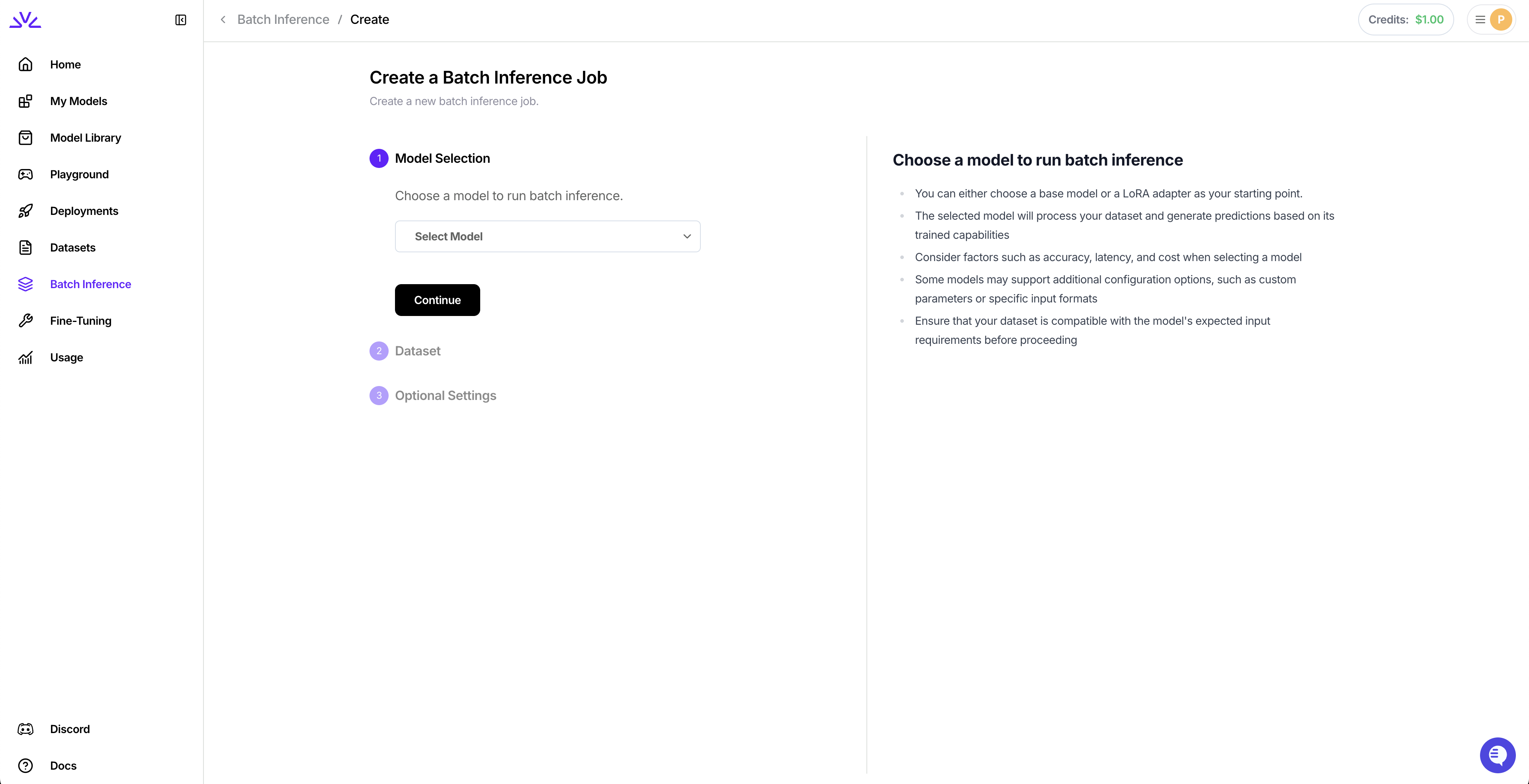 Configure optional settings:
Configure optional settings:
 ```bash theme={null}
firectl create batch-inference-job \
--model accounts/fireworks/models/llama-v3p1-8b-instruct \
--input-dataset-id batch-input-dataset
```
With additional parameters:
```bash theme={null}
firectl create batch-inference-job \
--job-id my-batch-job \
--model accounts/fireworks/models/llama-v3p1-8b-instruct \
--input-dataset-id batch-input-dataset \
--output-dataset-id batch-output-dataset \
--max-tokens 1024 \
--temperature 0.7 \
--top-p 0.9
```
```bash theme={null}
curl -X POST "https://api.fireworks.ai/v1/accounts/${ACCOUNT_ID}/batchInferenceJobs?batchInferenceJobId=my-batch-job" \
-H "Authorization: Bearer ${API_KEY}" \
-H "Content-Type: application/json" \
-d '{
"model": "accounts/fireworks/models/llama-v3p1-8b-instruct",
"inputDatasetId": "accounts/'${ACCOUNT_ID}'/datasets/batch-input-dataset",
"outputDatasetId": "accounts/'${ACCOUNT_ID}'/datasets/batch-output-dataset",
"inferenceParameters": {
"maxTokens": 1024,
"temperature": 0.7,
"topP": 0.9
}
}'
```
View all your batch inference jobs in the dashboard:
```bash theme={null}
firectl create batch-inference-job \
--model accounts/fireworks/models/llama-v3p1-8b-instruct \
--input-dataset-id batch-input-dataset
```
With additional parameters:
```bash theme={null}
firectl create batch-inference-job \
--job-id my-batch-job \
--model accounts/fireworks/models/llama-v3p1-8b-instruct \
--input-dataset-id batch-input-dataset \
--output-dataset-id batch-output-dataset \
--max-tokens 1024 \
--temperature 0.7 \
--top-p 0.9
```
```bash theme={null}
curl -X POST "https://api.fireworks.ai/v1/accounts/${ACCOUNT_ID}/batchInferenceJobs?batchInferenceJobId=my-batch-job" \
-H "Authorization: Bearer ${API_KEY}" \
-H "Content-Type: application/json" \
-d '{
"model": "accounts/fireworks/models/llama-v3p1-8b-instruct",
"inputDatasetId": "accounts/'${ACCOUNT_ID}'/datasets/batch-input-dataset",
"outputDatasetId": "accounts/'${ACCOUNT_ID}'/datasets/batch-output-dataset",
"inferenceParameters": {
"maxTokens": 1024,
"temperature": 0.7,
"topP": 0.9
}
}'
```
View all your batch inference jobs in the dashboard:
 ```bash theme={null}
# Get job status
firectl get batch-inference-job my-batch-job
# List all batch jobs
firectl list batch-inference-jobs
```
```bash theme={null}
# Get specific job
curl -X GET "https://api.fireworks.ai/v1/accounts/${ACCOUNT_ID}/batchInferenceJobs/my-batch-job" \
-H "Authorization: Bearer ${API_KEY}"
# List all jobs
curl -X GET "https://api.fireworks.ai/v1/accounts/${ACCOUNT_ID}/batchInferenceJobs" \
-H "Authorization: Bearer ${API_KEY}"
```
Navigate to the output dataset and download the results:
```bash theme={null}
# Get job status
firectl get batch-inference-job my-batch-job
# List all batch jobs
firectl list batch-inference-jobs
```
```bash theme={null}
# Get specific job
curl -X GET "https://api.fireworks.ai/v1/accounts/${ACCOUNT_ID}/batchInferenceJobs/my-batch-job" \
-H "Authorization: Bearer ${API_KEY}"
# List all jobs
curl -X GET "https://api.fireworks.ai/v1/accounts/${ACCOUNT_ID}/batchInferenceJobs" \
-H "Authorization: Bearer ${API_KEY}"
```
Navigate to the output dataset and download the results:
 ```bash theme={null}
firectl download dataset batch-output-dataset
```
```bash theme={null}
# Get download endpoint and save response
curl -s -X GET "https://api.fireworks.ai/v1/accounts/${ACCOUNT_ID}/datasets/batch-output-dataset:getDownloadEndpoint" \
-H "Authorization: Bearer ${API_KEY}" \
-d '{}' > download.json
# Extract and download all files
jq -r '.filenameToSignedUrls | to_entries[] | "\(.key) \(.value)"' download.json | \
while read -r object_path signed_url; do
fname=$(basename "$object_path")
echo "Downloading → $fname"
curl -L -o "$fname" "$signed_url"
done
```
The output dataset contains two files: a **results file** (successful responses in JSONL format) and an **error file** (failed requests with debugging info).
## Reference
Batch jobs progress through several states:
| State | Description |
| -------------- | ----------------------------------------------------- |
| **VALIDATING** | Dataset is being validated for format requirements |
| **PENDING** | Job is queued and waiting for resources |
| **RUNNING** | Actively processing requests |
| **COMPLETED** | All requests successfully processed |
| **FAILED** | Unrecoverable error occurred (check status message) |
| **EXPIRED** | Exceeded 24-hour limit (completed requests are saved) |
* **Base Models** – Any model in the [Model Library](https://fireworks.ai/models)
* **Custom Models** – Your uploaded or fine-tuned models
*Note: Newly added models may have a delay before being supported. See [Quantization](/models/quantization) for precision info.*
* **Per-request limits:** Same as [Chat Completion API limits](/api-reference/post-chatcompletions)
* **Input dataset:** Max 500MB
* **Output dataset:** Max 8GB (job may expire early if reached)
* **Job timeout:** 24 hours maximum
Jobs expire after 24 hours. Completed rows are billed and saved to the output dataset.
**Resume processing:**
```bash theme={null}
firectl create batch-inference-job \
--continue-from original-job-id \
--model accounts/fireworks/models/llama-v3p1-8b-instruct \
--output-dataset-id new-output-dataset
```
This processes only unfinished/failed requests from the original job.
**Download complete lineage:**
```bash theme={null}
firectl download dataset output-dataset-id --download-lineage
```
Downloads all datasets in the continuation chain.
* **Validate thoroughly:** Check dataset format before uploading
* **Descriptive IDs:** Use meaningful `custom_id` values for tracking
* **Optimize tokens:** Set reasonable `max_tokens` limits
* **Monitor progress:** Track long-running jobs regularly
* **Cache optimization:** Place static content first in prompts
## Next Steps
Maximize cost savings with automatic prompt caching
Create custom models for your batch workloads
Full API documentation for Batch API
---
# Source: https://docs.fireworks.ai/deployments/benchmarking.md
# Performance benchmarking
> Measure and optimize your deployment's performance with load testing
Understanding your deployment's performance under various load conditions is essential for production readiness. Fireworks provides tools and best practices for benchmarking throughput, latency, and identifying bottlenecks.
## Fireworks Benchmark Tool
Use our open-source benchmarking tool to measure and optimize your deployment's performance:
**[Fireworks Benchmark Tool](https://github.com/fw-ai/benchmark)**
This tool allows you to:
* Test throughput and latency under various load conditions
* Simulate production traffic patterns
* Identify performance bottlenecks
* Compare different deployment configurations
### Installation
```bash theme={null}
git clone https://github.com/fw-ai/benchmark.git
cd benchmark
pip install -r requirements.txt
```
### Basic usage
Run a basic benchmark test:
```bash theme={null}
python benchmark.py \
--model "accounts/fireworks/models/llama-v3p1-8b-instruct" \
--deployment "your-deployment-id" \
--num-requests 1000 \
--concurrency 10
```
### Key metrics to monitor
When benchmarking your deployment, focus on these key metrics:
* **Throughput**: Requests per second (RPS) your deployment can handle
* **Latency**: Time to first token (TTFT) and end-to-end response time
* **Token generation rate**: Tokens per second during generation
* **Error rate**: Failed requests under load
## Custom benchmarking
You can also develop custom performance testing scripts or integrate with monitoring tools to track metrics over time. Consider:
* Using production-like request patterns and payloads
* Testing with various concurrency levels
* Monitoring resource utilization (GPU, memory, network)
* Testing autoscaling behavior under load
## Best practices
1. **Warm up your deployment**: Run a few requests before benchmarking to ensure models are loaded
2. **Test realistic scenarios**: Use request patterns and payloads similar to your production workload
3. **Gradually increase load**: Start with low concurrency and gradually increase to find your deployment's limits
4. **Monitor for errors**: Track error rates and response codes to identify issues under load
5. **Compare configurations**: Test different deployment shapes, quantization levels, and hardware to optimize cost and performance
## Next steps
Configure autoscaling to handle variable load
Optimize your client code for maximum throughput
---
# Source: https://docs.fireworks.ai/api-reference-dlde/cancel-batch-job.md
# Cancel Batch Job
> Cancels an existing batch job if it is queued, pending, or running.
## OpenAPI
````yaml post /v1/accounts/{account_id}/batchJobs/{batch_job_id}:cancel
paths:
path: /v1/accounts/{account_id}/batchJobs/{batch_job_id}:cancel
method: post
servers:
- url: https://api.fireworks.ai
request:
security:
- title: BearerAuth
parameters:
query: {}
header:
Authorization:
type: http
scheme: bearer
description: >-
Bearer authentication using your Fireworks API key. Format:
Bearer
cookie: {}
parameters:
path:
account_id:
schema:
- type: string
required: true
description: The Account Id
batch_job_id:
schema:
- type: string
required: true
description: The Batch Job Id
query: {}
header: {}
cookie: {}
body:
application/json:
schemaArray:
- type: object
properties: {}
required: true
refIdentifier: '#/components/schemas/GatewayCancelBatchJobBody'
examples:
example:
value: {}
response:
'200':
application/json:
schemaArray:
- type: object
properties: {}
examples:
example:
value: {}
description: A successful response.
deprecated: false
type: path
components:
schemas: {}
````
---
# Source: https://docs.fireworks.ai/tools-sdks/firectl/commands/cancel-dpo-job.md
# firectl cancel dpo-job
> Cancels a running dpo job.
```
firectl cancel dpo-job [flags]
```
### Examples
```
firectl cancel dpo-job my-dpo-job
firectl cancel dpo-job accounts/my-account/dpo-jobs/my-dpo-job
```
### Flags
```
-h, --help help for dpo-job
--wait Wait until the dpo job is cancelled.
--wait-timeout duration Maximum time to wait when using --wait flag. (default 10m0s)
```
### Global flags
```
-a, --account-id string The Fireworks account ID. If not specified, reads account_id from ~/.fireworks/auth.ini.
--api-key string An API key used to authenticate with Fireworks.
-p, --profile string fireworks auth and settings profile to use.
```
---
> To find navigation and other pages in this documentation, fetch the llms.txt file at: https://docs.fireworks.ai/llms.txt
---
# Source: https://docs.fireworks.ai/tools-sdks/firectl/commands/cancel-reinforcement-fine-tuning-job.md
# Source: https://docs.fireworks.ai/api-reference/cancel-reinforcement-fine-tuning-job.md
# Source: https://docs.fireworks.ai/tools-sdks/firectl/commands/cancel-reinforcement-fine-tuning-job.md
# Source: https://docs.fireworks.ai/api-reference/cancel-reinforcement-fine-tuning-job.md
# Source: https://docs.fireworks.ai/tools-sdks/firectl/commands/cancel-reinforcement-fine-tuning-job.md
# Source: https://docs.fireworks.ai/api-reference/cancel-reinforcement-fine-tuning-job.md
# Cancel Reinforcement Fine-tuning Job
## OpenAPI
````yaml post /v1/accounts/{account_id}/reinforcementFineTuningJobs/{reinforcement_fine_tuning_job_id}:cancel
paths:
path: >-
/v1/accounts/{account_id}/reinforcementFineTuningJobs/{reinforcement_fine_tuning_job_id}:cancel
method: post
servers:
- url: https://api.fireworks.ai
request:
security:
- title: BearerAuth
parameters:
query: {}
header:
Authorization:
type: http
scheme: bearer
description: >-
Bearer authentication using your Fireworks API key. Format:
Bearer
cookie: {}
parameters:
path:
account_id:
schema:
- type: string
required: true
description: The Account Id
reinforcement_fine_tuning_job_id:
schema:
- type: string
required: true
description: The Reinforcement Fine-tuning Job Id
query: {}
header: {}
cookie: {}
body:
application/json:
schemaArray:
- type: object
properties: {}
required: true
refIdentifier: '#/components/schemas/GatewayCancelReinforcementFineTuningJobBody'
examples:
example:
value: {}
response:
'200':
application/json:
schemaArray:
- type: object
properties: {}
examples:
example:
value: {}
description: A successful response.
deprecated: false
type: path
components:
schemas: {}
````
---
# Source: https://docs.fireworks.ai/tools-sdks/firectl/commands/cancel-supervised-fine-tuning-job.md
# firectl cancel supervised-fine-tuning-job
> Cancels a running supervised fine-tuning job.
```
firectl cancel supervised-fine-tuning-job [flags]
```
### Examples
```
firectl cancel supervised-fine-tuning-job my-sft-job
firectl cancel supervised-fine-tuning-job accounts/my-account/supervisedFineTuningJobs/my-sft-job
```
### Flags
```
-h, --help help for supervised-fine-tuning-job
```
### Global flags
```
-a, --account-id string The Fireworks account ID. If not specified, reads account_id from ~/.fireworks/auth.ini.
--api-key string An API key used to authenticate with Fireworks.
-p, --profile string fireworks auth and settings profile to use.
```
---
> To find navigation and other pages in this documentation, fetch the llms.txt file at: https://docs.fireworks.ai/llms.txt
---
# Source: https://docs.fireworks.ai/updates/changelog.md
# Changelog
# Evaluator Improvements, Kimi K2 Thinking on Serverless, and New API Endpoints
## **Improved Evaluator Creation Experience**
The evaluator creation workflow has been significantly enhanced with GitHub template integration. You can now:
* Fork evaluator templates directly from GitHub repositories
* Browse and preview templates before using them
* Create evaluators with a streamlined save dialog
* View evaluators in a new sortable and paginated table
## **MLOps & Observability Integrations**
New documentation for integrating Fireworks with MLOps and observability tools:
* [Weights & Biases (W\&B)](/ecosystem/integrations/wandb) integration for experiment tracking during fine-tuning
* MLflow integration for model management and experiment logging
## ✨ New Models
* **[Kimi K2 Thinking](https://app.fireworks.ai/models/fireworks/kimi-k2-thinking)** is now available in the Model Library
* **[KAT Dev 32B](https://app.fireworks.ai/models/fireworks/kat-dev-32b)** is now available in the Model Library
* **[KAT Dev 72B Exp](https://app.fireworks.ai/models/fireworks/kat-dev-72b-exp)** is now available in the Model Library
## ☁️ Serverless
* **[Kimi K2 Thinking](https://app.fireworks.ai/models/fireworks/kimi-k2-thinking)** is now available on serverless
## 📚 New REST API Endpoints
New REST API endpoints are now available for managing Reinforcement Fine-Tuning Steps and deployments:
* [Create Reinforcement Fine-Tuning Step](/api-reference/create-reinforcement-fine-tuning-step)
* [List Reinforcement Fine-Tuning Steps](/api-reference/list-reinforcement-fine-tuning-steps)
* [Get Reinforcement Fine-Tuning Step](/api-reference/get-reinforcement-fine-tuning-step)
* [Delete Reinforcement Fine-Tuning Step](/api-reference/delete-reinforcement-fine-tuning-step)
* [Scale Deployment](/api-reference/scale-deployment)
* [List Deployment Shape Versions](/api-reference/list-deployment-shape-versions)
* [Get Deployment Shape Version](/api-reference/get-deployment-shape-version)
* [Get Dataset Download Endpoint](/api-reference/get-dataset-download-endpoint)
- **Deployment Region Selector:** Added GPU accelerator hints to the region selector, with Global set as default for optimal availability (Web App)
- **Preference Fine-Tuning (DPO):** Added to the Fine-Tuning page for training models with human preference data (Web App)
- **Redeem Credits:** Credit code redemption is now available to all users from the Billing page (Web App)
- **Model Library Search:** Improved fuzzy search with hybrid matching for better model discovery (Web App)
- **Cogito Models:** Added Cogito namespace to the Model Library for easier discovery (Web App)
- **Custom Model Editing:** You can now edit display name and description inline on custom model detail pages (Web App)
- **Loss Curve Charts:** Fixed an issue where loss curves were not updating in real-time during fine-tuning jobs (Web App)
- **Deployment Shapes:** Fixed deployment shape selection for fine-tuned models (PEFT and live-merge) (Web App)
- **Usage Charts:** Fixed replica calculation in multi-series usage charts (Web App)
- **Session Management:** Removed auto-logout on inactivity for improved user experience (Web App)
- **Onboarding:** Updated onboarding survey with improved profile and questionnaire flow (Web App)
- **Fine-Tuning Form:** Max context length now defaults to and is capped by the selected base model's context length (Web App)
- **Secrets for Evaluators:** Added documentation for using secrets in evaluators to securely call external services (Docs)
- **Region Selection:** Deprecated regions are now filtered from deployment options (Web App)
- **Playground:** Embedding and reranker models are now filtered from playground model selection (Web App)
- **LoRA Rank:** Updated valid LoRA rank range to 4-32 in documentation (Docs)
- **SFT Documentation:** Added documentation for batch size, learning rate warmup, and gradient accumulation settings (Docs)
- **Direct Routing:** Added OpenAI SDK code examples for direct routing (Docs)
- **Recommended Models:** Updated model recommendations with migration guidance from Claude, GPT, and Gemini (Docs)
## ☀️ Sunsetting Build SDK
The Build SDK is being deprecated in favor of a new Python SDK generated
directly from our REST API. The new SDK is more up-to-date, flexible, and
continuously synchronized with our REST API. Please note that the last version
of the Build SDK will be `0.19.20`, and the new SDK will start at `1.0.0`.
Python package managers will not automatically update to the new SDK, so you
will need to manually update your dependencies and refactor your code.
Existing codebases using the Build SDK will continue to function as before and
will not be affected unless you choose to upgrade to the new SDK version.
The new SDK replaces the Build SDK's `LLM` and `Dataset` classes with REST
API-aligned methods. If you upgrade to version `1.0.0` or later, you will need
to migrate your code.
## 🚀 Improved RFT Experience
We've drastically improved the RFT experience with better reliability,
developer-friendly SDK for hooking up your existing agents, support for
multi-turn training, better observability in our Web App, and better overall
developer experience.
See [Reinforcement Fine-Tuning](/fine-tuning/reinforcement-fine-tuning-models) for more details.
## Supervised Fine-Tuning
We now support supervised fine tuning with separate thinking traces for reasoning models (e.g. DeepSeek R1, GPT OSS, Qwen3 Thinking etc) that ensures training-inference consistency. An example including thinking traces would look like:
```json theme={null}
{
"messages": [
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": "What is the capital of France?"},
{"role": "assistant", "content": "Paris.", "reasoning_content": "The user is asking about the capital city of France, it should be Paris."}
]
}
{
"messages": [
{"role": "user", "content": "What is 1+1?"},
{"role": "assistant", "content": "2", "weight": 0, "reasoning_content": "The user is asking about the result of 1+1, the answer is 2."},
{"role": "user", "content": "Now what is 2+2?"},
{"role": "assistant", "content": "4", "reasoning_content": "The user is asking about the result of 2+2, the answer should be 4."}
]
}
```
We are also properly supporting multi-turn fine tuning (with or without thinking traces) for GPT OSS model family that ensures training-inference consistency.
## Supervised Fine-Tuning
We now support Qwen3 MoE model (Qwen3 dense models are already supported) and GPT OSS models for supervised fine-tuning. GPT OSS model fine tunning support is single-turn without thinking traces at the moment.
## 🎨 Vision-Language Model Fine-Tuning
You can now fine-tune Vision-Language Models (VLMs) on Fireworks AI using the Qwen 2.5 VL model family.
This extends our Supervised Fine-tuning V2 platform to support multimodal training with both images and text data.
**Supported models:**
* Qwen 2.5 VL 3B Instruct
* Qwen 2.5 VL 7B Instruct
* Qwen 2.5 VL 32B Instruct
* Qwen 2.5 VL 72B Instruct
**Features:**
* Fine-tune on datasets containing both images and text in JSONL format with base64-encoded images
* Support for up to 64K context length during training
* Built on the same Supervised Fine-tuning V2 infrastructure as text models
See the [VLM fine-tuning documentation](/fine-tuning/fine-tuning-vlm) for setup instructions and dataset formatting requirements.
## 🔧 Build SDK: Deployment Configuration Application Requirement
The Build SDK now requires you to call `.apply()` to apply any deployment configurations to Fireworks when using `deployment_type="on-demand"` or `deployment_type="on-demand-lora"`. This change ensures explicit control over when deployments are created and helps prevent accidental deployment creation.
**Key changes:**
* `.apply()` is now required for on-demand and on-demand-lora deployments
* Serverless deployments do not require `.apply()` calls
* If you do not call `.apply()`, you are expected to set up the deployment through the deployment page at [https://app.fireworks.ai/dashboard/deployments](https://app.fireworks.ai/dashboard/deployments)
**Migration guide:**
* Add `llm.apply()` after creating LLM instances with `deployment_type="on-demand"` or `deployment_type="on-demand-lora"`
* No changes needed for serverless deployments
* See updated documentation for examples and best practices
This change improves deployment management and provides better control over resource creation.
This applies to Python SDK version `>=0.19.14`.
## 🚀 Bring Your Own Rollout and Reward Development for Reinforcement Learning
You can now develop your own custom rollout and reward functionality while using
Fireworks to manage the training and deployment of your models. This gives you
full control over your reinforcement learning workflows while leveraging
Fireworks' infrastructure for model training and deployment.
See the new [LLM.reinforcement\_step()](/tools-sdks/python-client/sdk-reference#reinforcement-step) method and [ReinforcementStep](/tools-sdks/python-client/sdk-reference#reinforcementstep) class for usage examples and details.
## Supervised Fine-Tuning V2
We now support Llama 4 MoE model supervised fine-tuning (Llama 4 Scout, Llama 4 Maverick, Text only).
## 🏗️ Build SDK `LLM` Deployment Logic Refactor
Based on early feedback from users and internal testing, we've refactored the
`LLM` class deployment logic in the Build SDK to make it easier to understand.
**Key changes:**
* The `id` parameter is now required when `deployment_type` is `"on-demand"`
* The `base_id` parameter is now required when `deployment_type` is `"on-demand-lora"`
* The `deployment_display_name` parameter is now optional and defaults to the filename where the LLM was instantiated
A new deployment will be created if a deployment with the same `id` does not
exist. Otherwise, the existing deployment will be reused.
## 🚀 Support for Responses API in Python SDK
You can now use the Responses API in the Python SDK. This is useful if you want to use the Responses API in your own applications.
See the [Responses API guide](/guides/response-api) for usage examples and details.
## Support for LinkedIn authentication
You can now log in to Fireworks using your LinkedIn account. This is useful if
you already have a LinkedIn account and want to use it to log in to Fireworks.
To log in with LinkedIn, go to the [Fireworks login
page](https://fireworks.ai/login) and click the "Continue with LinkedIn"
button.
You can also log in with LinkedIn from the CLI using the `firectl login`
command.
**How it works:**
* Fireworks uses your LinkedIn primary email address for account identification
* You can switch between different Fireworks accounts by changing your LinkedIn primary email
* See our [LinkedIn authentication FAQ](/faq-new/account-access/what-email-does-linkedin-authentication-use) for detailed instructions on managing email addresses
## Support for GitHub authentication
You can now log in to Fireworks using your GitHub account. This is useful if
you already have a GitHub account and want to use it to log in to Fireworks.
To log in with GitHub, go to the [Fireworks login
page](https://fireworks.ai/login) and click the "Continue with GitHub"
button.
You can also log in with GitHub from the CLI using the `firectl login`
command.
## 🚨 Document Inlining Deprecation
Document Inlining has been deprecated and is no longer available on the Fireworks platform. This feature allowed LLMs to process images and PDFs through the chat completions API by appending `#transform=inline` to document URLs.
**Migration recommendations:**
* For image processing: Use Vision Language Models (VLMs) like [Qwen2.5-VL 32B Instruct](https://app.fireworks.ai/models/fireworks/qwen2p5-vl-32b-instruct)
* For PDF processing: Use dedicated PDF processing libraries combined with text-based LLMs
* For structured extraction: Leverage our [structured responses](/structured-responses/structured-response-formatting) capabilities
For assistance with migration, please contact our support team or visit our [Discord community](https://discord.gg/fireworks-ai).
## 🎯 Build SDK: Reward-kit integration for evaluator development
The Build SDK now natively integrates with [reward-kit](https://github.com/fw-ai-external/reward-kit) to simplify evaluator development for [Reinforcement Fine-Tuning (RFT)](/fine-tuning/reinforcement-fine-tuning-models). You can now create custom evaluators in Python with automatic dependency management and seamless deployment to Fireworks infrastructure.
**Key features:**
* Native reward-kit integration for evaluator development
* Automatic packaging of dependencies from `pyproject.toml` or `requirements.txt`
* Local testing capabilities before deployment
* Direct integration with Fireworks datasets and evaluation jobs
* Support for third-party libraries and complex evaluation logic
See our [Developing Evaluators](/tools-sdks/python-client/developing-evaluators) guide to get started with your first evaluator in minutes.
## Added new Responses API for advanced conversational workflows and integrations
* Continue conversations across multiple turns using the `previous_response_id` parameter to maintain context without resending full history
* Stream responses in real time as they are generated for responsive applications
* Control response storage with the `store` parameter—choose whether responses are retrievable by ID or ephemeral
See the [Response API guide](/guides/response-api) for usage examples and details.
## Supervised Fine-Tuning V2
Supervised Fine-Tuning V2 released.
**Key features:**
* Supports Qwen 2/2.5/3 series, Phi 4, Gemma 3, the Llama 3 family, Deepseek V2, V3, R1
* Longer context window up to full context length of the supported models
* Multi-turn function calling fine-tuning
* Quantization aware training
More details in the [blogpost](https://fireworks.ai/blog/supervised-finetuning-v2).
## Reinforcement Fine-Tuning (RFT)
Reinforcement Fine-Tuning released. Train expert models to surpass closed source frontier models through verifiable reward. More details in [blospost](https://fireworks.ai/blog/reinforcement-fine-tuning-models).
## Diarization and batch processing support added to audio inference
See our [blog post](https://fireworks.ai/blog/audio-summer-updates-and-new-features) for details.
## 🚀 Easier & faster LoRA fine-tune deployments on Fireworks
You can now deploy a LoRA fine-tune with a single command and get speeds that approximately match the base model:
```bash theme={null}
firectl create deployment "accounts/fireworks/models/"
```
Previously, this involved two distinct steps, and the resulting deployment was slower than the base model:
1. Create a deployment using `firectl create deployment "accounts/fireworks/models/" --enable-addons`
2. Then deploy the addon to the deployment: `firectl load-lora --deployment `
For more information, see our [deployment documentation](https://docs.fireworks.ai/models/deploying#deploying-to-on-demand).
This change is for dedicated deployments with a single LoRA. You can still deploy multiple LoRAs on a deployment or deploy LoRA(s) on some Serverless models as described in the documentation.
---
# Source: https://docs.fireworks.ai/fine-tuning/cli-reference.md
# Training Guide: CLI
> Launch RFT jobs using the eval-protocol CLI
The Eval Protocol CLI provides the fastest, most reproducible way to launch RFT jobs. This page covers everything you need to know about using `eval-protocol create rft`.
Before launching, review [Training Prerequisites & Validation](/fine-tuning/training-prerequisites) for requirements, validation checks, and common errors.
Already familiar with [firectl](/fine-tuning/cli-reference#using-firectl-cli-alternative)? Use it as an alternative to eval-protocol.
## Installation and setup
The following guide will help you:
* Upload your evaluator to Fireworks. If you don't have one yet, see [Concepts > Evaluators](/fine-tuning/evaluators)
* Upload your dataset to Fireworks
* Create and launch the RFT job
```bash theme={null}
pip install eval-protocol
```
Verify installation:
```bash theme={null}
eval-protocol --version
```
Configure your Fireworks API key:
```bash theme={null}
export FIREWORKS_API_KEY="fw_your_api_key_here"
```
Or create a `.env` file:
```bash theme={null}
FIREWORKS_API_KEY=fw_your_api_key_here
```
Before training, verify your evaluator works. This command discovers and runs your `@evaluation_test` with pytest. If a Dockerfile is present, it builds an image and runs the test in Docker; otherwise it runs on your host.
```bash theme={null}
cd evaluator_directory
ep local-test
```
From the directory where your evaluator and dataset (dataset.jsonl) are located,
```bash theme={null}
eval-protocol create rft \
--base-model accounts/fireworks/models/llama-v3p1-8b-instruct \
--output-model my-model-name
```
The CLI will:
* Upload evaluator code (if changed)
* Upload dataset (if changed)
* Create the RFT job
* Display dashboard links for monitoring
Expected output:
```
Created Reinforcement Fine-tuning Job
name: accounts/your-account/reinforcementFineTuningJobs/abc123
Dashboard Links:
Evaluator: https://app.fireworks.ai/dashboard/evaluators/your-evaluator
Dataset: https://app.fireworks.ai/dashboard/datasets/your-dataset
RFT Job: https://app.fireworks.ai/dashboard/fine-tuning/reinforcement/abc123
```
Click the RFT Job link to watch training progress in real-time. See [Monitor Training](/fine-tuning/monitor-training) for details.
## Common CLI options
Customize your RFT job with these flags:
**Model and output**:
```bash theme={null}
--base-model accounts/fireworks/models/llama-v3p1-8b-instruct # Base model to fine-tune
--output-model my-custom-name # Name for fine-tuned model
```
**Training parameters**:
```bash theme={null}
--epochs 2 # Number of training epochs (default: 1)
--learning-rate 5e-5 # Learning rate (default: 1e-4)
--lora-rank 16 # LoRA rank (default: 8)
--batch-size 65536 # Batch size in tokens (default: 32768)
```
**Rollout (sampling) parameters**:
```bash theme={null}
--inference-temperature 0.8 # Sampling temperature (default: 0.7)
--inference-n 8 # Number of rollouts per prompt (default: 4)
--inference-max-tokens 4096 # Max tokens per response (default: 2048)
--inference-top-p 0.95 # Top-p sampling (default: 1.0)
--inference-top-k 50 # Top-k sampling (default: 40)
```
**Remote environments**:
```bash theme={null}
--remote-server-url https://your-evaluator.example.com # For remote rollout processing
```
**Force re-upload**:
```bash theme={null}
--force # Re-upload evaluator even if unchanged
```
See all options:
```bash theme={null}
eval-protocol create rft --help
```
## Advanced options
Track training metrics in W\&B for deeper analysis:
```bash theme={null}
eval-protocol create rft \
--base-model accounts/fireworks/models/llama-v3p1-8b-instruct \
--wandb-project my-rft-experiments \
--wandb-entity my-org
```
Set `WANDB_API_KEY` in your environment first.
Save intermediate checkpoints during training:
```bash theme={null}
firectl create rftj \
--base-model accounts/fireworks/models/llama-v3p1-8b-instruct \
--checkpoint-frequency 500 # Save every 500 steps
...
```
Available in `firectl` only.
Speed up training with multiple GPUs:
```bash theme={null}
firectl create rftj \
--base-model accounts/fireworks/models/llama-v3p1-70b-instruct \
--accelerator-count 4 # Use 4 GPUs
...
```
Recommended for large models (70B+).
For evaluators that need more time:
```bash theme={null}
firectl create rftj \
--rollout-timeout 300 # 5 minutes per rollout
...
```
Default is 60 seconds. Increase for complex evaluations.
## Examples
**Fast experimentation** (small model, 1 epoch):
```bash theme={null}
eval-protocol create rft \
--base-model accounts/fireworks/models/qwen3-0p6b \
--output-model quick-test
```
**High-quality training** (more rollouts, higher temperature):
```bash theme={null}
eval-protocol create rft \
--base-model accounts/fireworks/models/llama-v3p1-8b-instruct \
--output-model high-quality-model \
--inference-n 8 \
--inference-temperature 1.0
```
**Remote environment** (for multi-turn agents):
```bash theme={null}
eval-protocol create rft \
--base-model accounts/fireworks/models/llama-v3p1-8b-instruct \
--remote-server-url https://your-agent.example.com \
--output-model remote-agent
```
**Multiple epochs with custom learning rate**:
```bash theme={null}
eval-protocol create rft \
--base-model accounts/fireworks/models/llama-v3p1-8b-instruct \
--epochs 3 \
--learning-rate 5e-5 \
--output-model multi-epoch-model
```
## Using `firectl` CLI (Alternative)
For users already familiar with Fireworks `firectl`, you can create RFT jobs directly:
```bash theme={null}
firectl create rftj \
--base-model accounts/fireworks/models/llama-v3p1-8b-instruct \
--dataset accounts/your-account/datasets/my-dataset \
--evaluator accounts/your-account/evaluators/my-evaluator \
--output-model my-finetuned-model
```
**Differences from `eval-protocol`**:
* Requires fully qualified resource names (accounts/...)
* Must manually upload evaluators and datasets first
* More verbose but offers finer control
* Same underlying API as `eval-protocol`
See [firectl documentation](/tools-sdks/firectl/commands/create-reinforcement-fine-tuning-job) for all options.
## Next steps
Review requirements, validation, and common errors
Track job progress, inspect rollouts, and debug issues
Learn how to adjust parameters for better results
---
# Source: https://docs.fireworks.ai/deployments/client-side-performance-optimization.md
# Client-side performance optimization
> Optimize your client code for maximum performance with dedicated deployments
When using a dedicated deployment, it is important to optimize the client-side
HTTP connection pooling for maximum performance. We recommend using our [Python
SDK](/tools-sdks/python-client/sdk-introduction) as it has good defaults for
connection pooling and utilizes
[aiohttp](https://docs.aiohttp.org/en/stable/index.html) for optimal performance
with Python's `asyncio` library. It also includes retry logic for handling `429`
errors that Fireworks returns when the server is overloaded. We have run
benchmarks that demonstrate the performance benefits.
## General optimization recommendations
Based on our benchmarks, we recommend the following:
1. Use a client library optimized for high concurrency, such as
[aiohttp](https://docs.aiohttp.org/en/stable/index.html) in Python or
[http.Agent](https://nodejs.org/api/http.html#class-httpagent) in Node.js.
2. Keep the [`connection pool size`](https://docs.aiohttp.org/en/stable/client_advanced.html#limiting-connection-pool-size) high (1000+).
3. Increase concurrency until performance stops improving or you observe too many `429` errors.
4. Use [direct routing](/deployments/direct-routing) to avoid the global API load balancer and route requests directly to your deployment.
## Code example: Optimal concurrent requests (Python)
Here's how to implement optimal concurrent requests using `asyncio` and the `LLM` class:
```python main.py theme={null}
import asyncio
from fireworks import LLM
async def make_concurrent_requests(
messages: list[str],
max_workers: int = 1000,
max_connections: int = 1000, # this is the default value in the SDK
):
"""Make concurrent requests with optimized connection pooling"""
llm = LLM(
model="your-model-name",
deployment_type="on-demand",
id="your-deployment-id",
max_connections=max_connections
)
# Apply deployment configuration to Fireworks
llm.apply()
# Semaphore to limit concurrent requests
semaphore = asyncio.Semaphore(max_workers)
async def single_request(message: str):
"""Make a single request with semaphore control"""
async with semaphore:
response = await llm.chat.completions.acreate(
messages=[{"role": "user", "content": message}],
max_tokens=100
)
return response.choices[0].message.content
# Create all request tasks
tasks = [
single_request(message)
for message in messages
]
# Execute all requests concurrently
results = await asyncio.gather(*tasks)
return results
# Usage example
async def main():
messages = ["Hello!"] * 1000 # 1000 requests
results = await make_concurrent_requests(
messages=messages,
)
print(f"Completed {len(results)} requests")
if __name__ == "__main__":
asyncio.run(main())
```
This implementation:
* Uses `asyncio.Semaphore` to control concurrency to avoid overwhelming the server
* Allows configuration of the maximum number of concurrent connections to the Fireworks API
---
# Source: https://docs.fireworks.ai/guides/completions-api.md
# Completions API
> Use the completions API for raw text generation with custom prompt templates
The completions API provides raw text generation without automatic message formatting. Use this when you need full control over prompt formatting or when working with base models.
## When to use completions
**Use the completions API for:**
* Custom prompt templates with specific formatting requirements
* Base models (non-instruct/non-chat variants)
* Fine-grained control over token-level formatting
* Legacy applications that depend on raw completion format
**For most use cases, use [chat completions](/guides/querying-text-models) instead.** Chat completions handles message formatting automatically and works better with instruct-tuned models.
## Basic usage
```python theme={null}
import os
from openai import OpenAI
client = OpenAI(
api_key=os.environ.get("FIREWORKS_API_KEY"),
base_url="https://api.fireworks.ai/inference/v1"
)
response = client.completions.create(
model="accounts/fireworks/models/deepseek-v3p1",
prompt="Once upon a time"
)
print(response.choices[0].text)
```
```javascript theme={null}
import OpenAI from "openai";
const client = new OpenAI({
apiKey: process.env.FIREWORKS_API_KEY,
baseURL: "https://api.fireworks.ai/inference/v1",
});
const response = await client.completions.create({
model: "accounts/fireworks/models/deepseek-v3p1",
prompt: "Once upon a time",
});
console.log(response.choices[0].text);
```
```bash theme={null}
curl https://api.fireworks.ai/inference/v1/completions \
-H "Content-Type: application/json" \
-H "Authorization: Bearer $FIREWORKS_API_KEY" \
-d '{
"model": "accounts/fireworks/models/deepseek-v3p1",
"prompt": "Once upon a time"
}'
```
Most models automatically prepend the beginning-of-sequence (BOS) token (e.g., `
```bash theme={null}
firectl download dataset batch-output-dataset
```
```bash theme={null}
# Get download endpoint and save response
curl -s -X GET "https://api.fireworks.ai/v1/accounts/${ACCOUNT_ID}/datasets/batch-output-dataset:getDownloadEndpoint" \
-H "Authorization: Bearer ${API_KEY}" \
-d '{}' > download.json
# Extract and download all files
jq -r '.filenameToSignedUrls | to_entries[] | "\(.key) \(.value)"' download.json | \
while read -r object_path signed_url; do
fname=$(basename "$object_path")
echo "Downloading → $fname"
curl -L -o "$fname" "$signed_url"
done
```
The output dataset contains two files: a **results file** (successful responses in JSONL format) and an **error file** (failed requests with debugging info).
## Reference
Batch jobs progress through several states:
| State | Description |
| -------------- | ----------------------------------------------------- |
| **VALIDATING** | Dataset is being validated for format requirements |
| **PENDING** | Job is queued and waiting for resources |
| **RUNNING** | Actively processing requests |
| **COMPLETED** | All requests successfully processed |
| **FAILED** | Unrecoverable error occurred (check status message) |
| **EXPIRED** | Exceeded 24-hour limit (completed requests are saved) |
* **Base Models** – Any model in the [Model Library](https://fireworks.ai/models)
* **Custom Models** – Your uploaded or fine-tuned models
*Note: Newly added models may have a delay before being supported. See [Quantization](/models/quantization) for precision info.*
* **Per-request limits:** Same as [Chat Completion API limits](/api-reference/post-chatcompletions)
* **Input dataset:** Max 500MB
* **Output dataset:** Max 8GB (job may expire early if reached)
* **Job timeout:** 24 hours maximum
Jobs expire after 24 hours. Completed rows are billed and saved to the output dataset.
**Resume processing:**
```bash theme={null}
firectl create batch-inference-job \
--continue-from original-job-id \
--model accounts/fireworks/models/llama-v3p1-8b-instruct \
--output-dataset-id new-output-dataset
```
This processes only unfinished/failed requests from the original job.
**Download complete lineage:**
```bash theme={null}
firectl download dataset output-dataset-id --download-lineage
```
Downloads all datasets in the continuation chain.
* **Validate thoroughly:** Check dataset format before uploading
* **Descriptive IDs:** Use meaningful `custom_id` values for tracking
* **Optimize tokens:** Set reasonable `max_tokens` limits
* **Monitor progress:** Track long-running jobs regularly
* **Cache optimization:** Place static content first in prompts
## Next Steps
Maximize cost savings with automatic prompt caching
Create custom models for your batch workloads
Full API documentation for Batch API
---
# Source: https://docs.fireworks.ai/deployments/benchmarking.md
# Performance benchmarking
> Measure and optimize your deployment's performance with load testing
Understanding your deployment's performance under various load conditions is essential for production readiness. Fireworks provides tools and best practices for benchmarking throughput, latency, and identifying bottlenecks.
## Fireworks Benchmark Tool
Use our open-source benchmarking tool to measure and optimize your deployment's performance:
**[Fireworks Benchmark Tool](https://github.com/fw-ai/benchmark)**
This tool allows you to:
* Test throughput and latency under various load conditions
* Simulate production traffic patterns
* Identify performance bottlenecks
* Compare different deployment configurations
### Installation
```bash theme={null}
git clone https://github.com/fw-ai/benchmark.git
cd benchmark
pip install -r requirements.txt
```
### Basic usage
Run a basic benchmark test:
```bash theme={null}
python benchmark.py \
--model "accounts/fireworks/models/llama-v3p1-8b-instruct" \
--deployment "your-deployment-id" \
--num-requests 1000 \
--concurrency 10
```
### Key metrics to monitor
When benchmarking your deployment, focus on these key metrics:
* **Throughput**: Requests per second (RPS) your deployment can handle
* **Latency**: Time to first token (TTFT) and end-to-end response time
* **Token generation rate**: Tokens per second during generation
* **Error rate**: Failed requests under load
## Custom benchmarking
You can also develop custom performance testing scripts or integrate with monitoring tools to track metrics over time. Consider:
* Using production-like request patterns and payloads
* Testing with various concurrency levels
* Monitoring resource utilization (GPU, memory, network)
* Testing autoscaling behavior under load
## Best practices
1. **Warm up your deployment**: Run a few requests before benchmarking to ensure models are loaded
2. **Test realistic scenarios**: Use request patterns and payloads similar to your production workload
3. **Gradually increase load**: Start with low concurrency and gradually increase to find your deployment's limits
4. **Monitor for errors**: Track error rates and response codes to identify issues under load
5. **Compare configurations**: Test different deployment shapes, quantization levels, and hardware to optimize cost and performance
## Next steps
Configure autoscaling to handle variable load
Optimize your client code for maximum throughput
---
# Source: https://docs.fireworks.ai/api-reference-dlde/cancel-batch-job.md
# Cancel Batch Job
> Cancels an existing batch job if it is queued, pending, or running.
## OpenAPI
````yaml post /v1/accounts/{account_id}/batchJobs/{batch_job_id}:cancel
paths:
path: /v1/accounts/{account_id}/batchJobs/{batch_job_id}:cancel
method: post
servers:
- url: https://api.fireworks.ai
request:
security:
- title: BearerAuth
parameters:
query: {}
header:
Authorization:
type: http
scheme: bearer
description: >-
Bearer authentication using your Fireworks API key. Format:
Bearer
cookie: {}
parameters:
path:
account_id:
schema:
- type: string
required: true
description: The Account Id
batch_job_id:
schema:
- type: string
required: true
description: The Batch Job Id
query: {}
header: {}
cookie: {}
body:
application/json:
schemaArray:
- type: object
properties: {}
required: true
refIdentifier: '#/components/schemas/GatewayCancelBatchJobBody'
examples:
example:
value: {}
response:
'200':
application/json:
schemaArray:
- type: object
properties: {}
examples:
example:
value: {}
description: A successful response.
deprecated: false
type: path
components:
schemas: {}
````
---
# Source: https://docs.fireworks.ai/tools-sdks/firectl/commands/cancel-dpo-job.md
# firectl cancel dpo-job
> Cancels a running dpo job.
```
firectl cancel dpo-job [flags]
```
### Examples
```
firectl cancel dpo-job my-dpo-job
firectl cancel dpo-job accounts/my-account/dpo-jobs/my-dpo-job
```
### Flags
```
-h, --help help for dpo-job
--wait Wait until the dpo job is cancelled.
--wait-timeout duration Maximum time to wait when using --wait flag. (default 10m0s)
```
### Global flags
```
-a, --account-id string The Fireworks account ID. If not specified, reads account_id from ~/.fireworks/auth.ini.
--api-key string An API key used to authenticate with Fireworks.
-p, --profile string fireworks auth and settings profile to use.
```
---
> To find navigation and other pages in this documentation, fetch the llms.txt file at: https://docs.fireworks.ai/llms.txt
---
# Source: https://docs.fireworks.ai/tools-sdks/firectl/commands/cancel-reinforcement-fine-tuning-job.md
# Source: https://docs.fireworks.ai/api-reference/cancel-reinforcement-fine-tuning-job.md
# Source: https://docs.fireworks.ai/tools-sdks/firectl/commands/cancel-reinforcement-fine-tuning-job.md
# Source: https://docs.fireworks.ai/api-reference/cancel-reinforcement-fine-tuning-job.md
# Source: https://docs.fireworks.ai/tools-sdks/firectl/commands/cancel-reinforcement-fine-tuning-job.md
# Source: https://docs.fireworks.ai/api-reference/cancel-reinforcement-fine-tuning-job.md
# Cancel Reinforcement Fine-tuning Job
## OpenAPI
````yaml post /v1/accounts/{account_id}/reinforcementFineTuningJobs/{reinforcement_fine_tuning_job_id}:cancel
paths:
path: >-
/v1/accounts/{account_id}/reinforcementFineTuningJobs/{reinforcement_fine_tuning_job_id}:cancel
method: post
servers:
- url: https://api.fireworks.ai
request:
security:
- title: BearerAuth
parameters:
query: {}
header:
Authorization:
type: http
scheme: bearer
description: >-
Bearer authentication using your Fireworks API key. Format:
Bearer
cookie: {}
parameters:
path:
account_id:
schema:
- type: string
required: true
description: The Account Id
reinforcement_fine_tuning_job_id:
schema:
- type: string
required: true
description: The Reinforcement Fine-tuning Job Id
query: {}
header: {}
cookie: {}
body:
application/json:
schemaArray:
- type: object
properties: {}
required: true
refIdentifier: '#/components/schemas/GatewayCancelReinforcementFineTuningJobBody'
examples:
example:
value: {}
response:
'200':
application/json:
schemaArray:
- type: object
properties: {}
examples:
example:
value: {}
description: A successful response.
deprecated: false
type: path
components:
schemas: {}
````
---
# Source: https://docs.fireworks.ai/tools-sdks/firectl/commands/cancel-supervised-fine-tuning-job.md
# firectl cancel supervised-fine-tuning-job
> Cancels a running supervised fine-tuning job.
```
firectl cancel supervised-fine-tuning-job [flags]
```
### Examples
```
firectl cancel supervised-fine-tuning-job my-sft-job
firectl cancel supervised-fine-tuning-job accounts/my-account/supervisedFineTuningJobs/my-sft-job
```
### Flags
```
-h, --help help for supervised-fine-tuning-job
```
### Global flags
```
-a, --account-id string The Fireworks account ID. If not specified, reads account_id from ~/.fireworks/auth.ini.
--api-key string An API key used to authenticate with Fireworks.
-p, --profile string fireworks auth and settings profile to use.
```
---
> To find navigation and other pages in this documentation, fetch the llms.txt file at: https://docs.fireworks.ai/llms.txt
---
# Source: https://docs.fireworks.ai/updates/changelog.md
# Changelog
# Evaluator Improvements, Kimi K2 Thinking on Serverless, and New API Endpoints
## **Improved Evaluator Creation Experience**
The evaluator creation workflow has been significantly enhanced with GitHub template integration. You can now:
* Fork evaluator templates directly from GitHub repositories
* Browse and preview templates before using them
* Create evaluators with a streamlined save dialog
* View evaluators in a new sortable and paginated table
## **MLOps & Observability Integrations**
New documentation for integrating Fireworks with MLOps and observability tools:
* [Weights & Biases (W\&B)](/ecosystem/integrations/wandb) integration for experiment tracking during fine-tuning
* MLflow integration for model management and experiment logging
## ✨ New Models
* **[Kimi K2 Thinking](https://app.fireworks.ai/models/fireworks/kimi-k2-thinking)** is now available in the Model Library
* **[KAT Dev 32B](https://app.fireworks.ai/models/fireworks/kat-dev-32b)** is now available in the Model Library
* **[KAT Dev 72B Exp](https://app.fireworks.ai/models/fireworks/kat-dev-72b-exp)** is now available in the Model Library
## ☁️ Serverless
* **[Kimi K2 Thinking](https://app.fireworks.ai/models/fireworks/kimi-k2-thinking)** is now available on serverless
## 📚 New REST API Endpoints
New REST API endpoints are now available for managing Reinforcement Fine-Tuning Steps and deployments:
* [Create Reinforcement Fine-Tuning Step](/api-reference/create-reinforcement-fine-tuning-step)
* [List Reinforcement Fine-Tuning Steps](/api-reference/list-reinforcement-fine-tuning-steps)
* [Get Reinforcement Fine-Tuning Step](/api-reference/get-reinforcement-fine-tuning-step)
* [Delete Reinforcement Fine-Tuning Step](/api-reference/delete-reinforcement-fine-tuning-step)
* [Scale Deployment](/api-reference/scale-deployment)
* [List Deployment Shape Versions](/api-reference/list-deployment-shape-versions)
* [Get Deployment Shape Version](/api-reference/get-deployment-shape-version)
* [Get Dataset Download Endpoint](/api-reference/get-dataset-download-endpoint)
- **Deployment Region Selector:** Added GPU accelerator hints to the region selector, with Global set as default for optimal availability (Web App)
- **Preference Fine-Tuning (DPO):** Added to the Fine-Tuning page for training models with human preference data (Web App)
- **Redeem Credits:** Credit code redemption is now available to all users from the Billing page (Web App)
- **Model Library Search:** Improved fuzzy search with hybrid matching for better model discovery (Web App)
- **Cogito Models:** Added Cogito namespace to the Model Library for easier discovery (Web App)
- **Custom Model Editing:** You can now edit display name and description inline on custom model detail pages (Web App)
- **Loss Curve Charts:** Fixed an issue where loss curves were not updating in real-time during fine-tuning jobs (Web App)
- **Deployment Shapes:** Fixed deployment shape selection for fine-tuned models (PEFT and live-merge) (Web App)
- **Usage Charts:** Fixed replica calculation in multi-series usage charts (Web App)
- **Session Management:** Removed auto-logout on inactivity for improved user experience (Web App)
- **Onboarding:** Updated onboarding survey with improved profile and questionnaire flow (Web App)
- **Fine-Tuning Form:** Max context length now defaults to and is capped by the selected base model's context length (Web App)
- **Secrets for Evaluators:** Added documentation for using secrets in evaluators to securely call external services (Docs)
- **Region Selection:** Deprecated regions are now filtered from deployment options (Web App)
- **Playground:** Embedding and reranker models are now filtered from playground model selection (Web App)
- **LoRA Rank:** Updated valid LoRA rank range to 4-32 in documentation (Docs)
- **SFT Documentation:** Added documentation for batch size, learning rate warmup, and gradient accumulation settings (Docs)
- **Direct Routing:** Added OpenAI SDK code examples for direct routing (Docs)
- **Recommended Models:** Updated model recommendations with migration guidance from Claude, GPT, and Gemini (Docs)
## ☀️ Sunsetting Build SDK
The Build SDK is being deprecated in favor of a new Python SDK generated
directly from our REST API. The new SDK is more up-to-date, flexible, and
continuously synchronized with our REST API. Please note that the last version
of the Build SDK will be `0.19.20`, and the new SDK will start at `1.0.0`.
Python package managers will not automatically update to the new SDK, so you
will need to manually update your dependencies and refactor your code.
Existing codebases using the Build SDK will continue to function as before and
will not be affected unless you choose to upgrade to the new SDK version.
The new SDK replaces the Build SDK's `LLM` and `Dataset` classes with REST
API-aligned methods. If you upgrade to version `1.0.0` or later, you will need
to migrate your code.
## 🚀 Improved RFT Experience
We've drastically improved the RFT experience with better reliability,
developer-friendly SDK for hooking up your existing agents, support for
multi-turn training, better observability in our Web App, and better overall
developer experience.
See [Reinforcement Fine-Tuning](/fine-tuning/reinforcement-fine-tuning-models) for more details.
## Supervised Fine-Tuning
We now support supervised fine tuning with separate thinking traces for reasoning models (e.g. DeepSeek R1, GPT OSS, Qwen3 Thinking etc) that ensures training-inference consistency. An example including thinking traces would look like:
```json theme={null}
{
"messages": [
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": "What is the capital of France?"},
{"role": "assistant", "content": "Paris.", "reasoning_content": "The user is asking about the capital city of France, it should be Paris."}
]
}
{
"messages": [
{"role": "user", "content": "What is 1+1?"},
{"role": "assistant", "content": "2", "weight": 0, "reasoning_content": "The user is asking about the result of 1+1, the answer is 2."},
{"role": "user", "content": "Now what is 2+2?"},
{"role": "assistant", "content": "4", "reasoning_content": "The user is asking about the result of 2+2, the answer should be 4."}
]
}
```
We are also properly supporting multi-turn fine tuning (with or without thinking traces) for GPT OSS model family that ensures training-inference consistency.
## Supervised Fine-Tuning
We now support Qwen3 MoE model (Qwen3 dense models are already supported) and GPT OSS models for supervised fine-tuning. GPT OSS model fine tunning support is single-turn without thinking traces at the moment.
## 🎨 Vision-Language Model Fine-Tuning
You can now fine-tune Vision-Language Models (VLMs) on Fireworks AI using the Qwen 2.5 VL model family.
This extends our Supervised Fine-tuning V2 platform to support multimodal training with both images and text data.
**Supported models:**
* Qwen 2.5 VL 3B Instruct
* Qwen 2.5 VL 7B Instruct
* Qwen 2.5 VL 32B Instruct
* Qwen 2.5 VL 72B Instruct
**Features:**
* Fine-tune on datasets containing both images and text in JSONL format with base64-encoded images
* Support for up to 64K context length during training
* Built on the same Supervised Fine-tuning V2 infrastructure as text models
See the [VLM fine-tuning documentation](/fine-tuning/fine-tuning-vlm) for setup instructions and dataset formatting requirements.
## 🔧 Build SDK: Deployment Configuration Application Requirement
The Build SDK now requires you to call `.apply()` to apply any deployment configurations to Fireworks when using `deployment_type="on-demand"` or `deployment_type="on-demand-lora"`. This change ensures explicit control over when deployments are created and helps prevent accidental deployment creation.
**Key changes:**
* `.apply()` is now required for on-demand and on-demand-lora deployments
* Serverless deployments do not require `.apply()` calls
* If you do not call `.apply()`, you are expected to set up the deployment through the deployment page at [https://app.fireworks.ai/dashboard/deployments](https://app.fireworks.ai/dashboard/deployments)
**Migration guide:**
* Add `llm.apply()` after creating LLM instances with `deployment_type="on-demand"` or `deployment_type="on-demand-lora"`
* No changes needed for serverless deployments
* See updated documentation for examples and best practices
This change improves deployment management and provides better control over resource creation.
This applies to Python SDK version `>=0.19.14`.
## 🚀 Bring Your Own Rollout and Reward Development for Reinforcement Learning
You can now develop your own custom rollout and reward functionality while using
Fireworks to manage the training and deployment of your models. This gives you
full control over your reinforcement learning workflows while leveraging
Fireworks' infrastructure for model training and deployment.
See the new [LLM.reinforcement\_step()](/tools-sdks/python-client/sdk-reference#reinforcement-step) method and [ReinforcementStep](/tools-sdks/python-client/sdk-reference#reinforcementstep) class for usage examples and details.
## Supervised Fine-Tuning V2
We now support Llama 4 MoE model supervised fine-tuning (Llama 4 Scout, Llama 4 Maverick, Text only).
## 🏗️ Build SDK `LLM` Deployment Logic Refactor
Based on early feedback from users and internal testing, we've refactored the
`LLM` class deployment logic in the Build SDK to make it easier to understand.
**Key changes:**
* The `id` parameter is now required when `deployment_type` is `"on-demand"`
* The `base_id` parameter is now required when `deployment_type` is `"on-demand-lora"`
* The `deployment_display_name` parameter is now optional and defaults to the filename where the LLM was instantiated
A new deployment will be created if a deployment with the same `id` does not
exist. Otherwise, the existing deployment will be reused.
## 🚀 Support for Responses API in Python SDK
You can now use the Responses API in the Python SDK. This is useful if you want to use the Responses API in your own applications.
See the [Responses API guide](/guides/response-api) for usage examples and details.
## Support for LinkedIn authentication
You can now log in to Fireworks using your LinkedIn account. This is useful if
you already have a LinkedIn account and want to use it to log in to Fireworks.
To log in with LinkedIn, go to the [Fireworks login
page](https://fireworks.ai/login) and click the "Continue with LinkedIn"
button.
You can also log in with LinkedIn from the CLI using the `firectl login`
command.
**How it works:**
* Fireworks uses your LinkedIn primary email address for account identification
* You can switch between different Fireworks accounts by changing your LinkedIn primary email
* See our [LinkedIn authentication FAQ](/faq-new/account-access/what-email-does-linkedin-authentication-use) for detailed instructions on managing email addresses
## Support for GitHub authentication
You can now log in to Fireworks using your GitHub account. This is useful if
you already have a GitHub account and want to use it to log in to Fireworks.
To log in with GitHub, go to the [Fireworks login
page](https://fireworks.ai/login) and click the "Continue with GitHub"
button.
You can also log in with GitHub from the CLI using the `firectl login`
command.
## 🚨 Document Inlining Deprecation
Document Inlining has been deprecated and is no longer available on the Fireworks platform. This feature allowed LLMs to process images and PDFs through the chat completions API by appending `#transform=inline` to document URLs.
**Migration recommendations:**
* For image processing: Use Vision Language Models (VLMs) like [Qwen2.5-VL 32B Instruct](https://app.fireworks.ai/models/fireworks/qwen2p5-vl-32b-instruct)
* For PDF processing: Use dedicated PDF processing libraries combined with text-based LLMs
* For structured extraction: Leverage our [structured responses](/structured-responses/structured-response-formatting) capabilities
For assistance with migration, please contact our support team or visit our [Discord community](https://discord.gg/fireworks-ai).
## 🎯 Build SDK: Reward-kit integration for evaluator development
The Build SDK now natively integrates with [reward-kit](https://github.com/fw-ai-external/reward-kit) to simplify evaluator development for [Reinforcement Fine-Tuning (RFT)](/fine-tuning/reinforcement-fine-tuning-models). You can now create custom evaluators in Python with automatic dependency management and seamless deployment to Fireworks infrastructure.
**Key features:**
* Native reward-kit integration for evaluator development
* Automatic packaging of dependencies from `pyproject.toml` or `requirements.txt`
* Local testing capabilities before deployment
* Direct integration with Fireworks datasets and evaluation jobs
* Support for third-party libraries and complex evaluation logic
See our [Developing Evaluators](/tools-sdks/python-client/developing-evaluators) guide to get started with your first evaluator in minutes.
## Added new Responses API for advanced conversational workflows and integrations
* Continue conversations across multiple turns using the `previous_response_id` parameter to maintain context without resending full history
* Stream responses in real time as they are generated for responsive applications
* Control response storage with the `store` parameter—choose whether responses are retrievable by ID or ephemeral
See the [Response API guide](/guides/response-api) for usage examples and details.
## Supervised Fine-Tuning V2
Supervised Fine-Tuning V2 released.
**Key features:**
* Supports Qwen 2/2.5/3 series, Phi 4, Gemma 3, the Llama 3 family, Deepseek V2, V3, R1
* Longer context window up to full context length of the supported models
* Multi-turn function calling fine-tuning
* Quantization aware training
More details in the [blogpost](https://fireworks.ai/blog/supervised-finetuning-v2).
## Reinforcement Fine-Tuning (RFT)
Reinforcement Fine-Tuning released. Train expert models to surpass closed source frontier models through verifiable reward. More details in [blospost](https://fireworks.ai/blog/reinforcement-fine-tuning-models).
## Diarization and batch processing support added to audio inference
See our [blog post](https://fireworks.ai/blog/audio-summer-updates-and-new-features) for details.
## 🚀 Easier & faster LoRA fine-tune deployments on Fireworks
You can now deploy a LoRA fine-tune with a single command and get speeds that approximately match the base model:
```bash theme={null}
firectl create deployment "accounts/fireworks/models/"
```
Previously, this involved two distinct steps, and the resulting deployment was slower than the base model:
1. Create a deployment using `firectl create deployment "accounts/fireworks/models/" --enable-addons`
2. Then deploy the addon to the deployment: `firectl load-lora --deployment `
For more information, see our [deployment documentation](https://docs.fireworks.ai/models/deploying#deploying-to-on-demand).
This change is for dedicated deployments with a single LoRA. You can still deploy multiple LoRAs on a deployment or deploy LoRA(s) on some Serverless models as described in the documentation.
---
# Source: https://docs.fireworks.ai/fine-tuning/cli-reference.md
# Training Guide: CLI
> Launch RFT jobs using the eval-protocol CLI
The Eval Protocol CLI provides the fastest, most reproducible way to launch RFT jobs. This page covers everything you need to know about using `eval-protocol create rft`.
Before launching, review [Training Prerequisites & Validation](/fine-tuning/training-prerequisites) for requirements, validation checks, and common errors.
Already familiar with [firectl](/fine-tuning/cli-reference#using-firectl-cli-alternative)? Use it as an alternative to eval-protocol.
## Installation and setup
The following guide will help you:
* Upload your evaluator to Fireworks. If you don't have one yet, see [Concepts > Evaluators](/fine-tuning/evaluators)
* Upload your dataset to Fireworks
* Create and launch the RFT job
```bash theme={null}
pip install eval-protocol
```
Verify installation:
```bash theme={null}
eval-protocol --version
```
Configure your Fireworks API key:
```bash theme={null}
export FIREWORKS_API_KEY="fw_your_api_key_here"
```
Or create a `.env` file:
```bash theme={null}
FIREWORKS_API_KEY=fw_your_api_key_here
```
Before training, verify your evaluator works. This command discovers and runs your `@evaluation_test` with pytest. If a Dockerfile is present, it builds an image and runs the test in Docker; otherwise it runs on your host.
```bash theme={null}
cd evaluator_directory
ep local-test
```
From the directory where your evaluator and dataset (dataset.jsonl) are located,
```bash theme={null}
eval-protocol create rft \
--base-model accounts/fireworks/models/llama-v3p1-8b-instruct \
--output-model my-model-name
```
The CLI will:
* Upload evaluator code (if changed)
* Upload dataset (if changed)
* Create the RFT job
* Display dashboard links for monitoring
Expected output:
```
Created Reinforcement Fine-tuning Job
name: accounts/your-account/reinforcementFineTuningJobs/abc123
Dashboard Links:
Evaluator: https://app.fireworks.ai/dashboard/evaluators/your-evaluator
Dataset: https://app.fireworks.ai/dashboard/datasets/your-dataset
RFT Job: https://app.fireworks.ai/dashboard/fine-tuning/reinforcement/abc123
```
Click the RFT Job link to watch training progress in real-time. See [Monitor Training](/fine-tuning/monitor-training) for details.
## Common CLI options
Customize your RFT job with these flags:
**Model and output**:
```bash theme={null}
--base-model accounts/fireworks/models/llama-v3p1-8b-instruct # Base model to fine-tune
--output-model my-custom-name # Name for fine-tuned model
```
**Training parameters**:
```bash theme={null}
--epochs 2 # Number of training epochs (default: 1)
--learning-rate 5e-5 # Learning rate (default: 1e-4)
--lora-rank 16 # LoRA rank (default: 8)
--batch-size 65536 # Batch size in tokens (default: 32768)
```
**Rollout (sampling) parameters**:
```bash theme={null}
--inference-temperature 0.8 # Sampling temperature (default: 0.7)
--inference-n 8 # Number of rollouts per prompt (default: 4)
--inference-max-tokens 4096 # Max tokens per response (default: 2048)
--inference-top-p 0.95 # Top-p sampling (default: 1.0)
--inference-top-k 50 # Top-k sampling (default: 40)
```
**Remote environments**:
```bash theme={null}
--remote-server-url https://your-evaluator.example.com # For remote rollout processing
```
**Force re-upload**:
```bash theme={null}
--force # Re-upload evaluator even if unchanged
```
See all options:
```bash theme={null}
eval-protocol create rft --help
```
## Advanced options
Track training metrics in W\&B for deeper analysis:
```bash theme={null}
eval-protocol create rft \
--base-model accounts/fireworks/models/llama-v3p1-8b-instruct \
--wandb-project my-rft-experiments \
--wandb-entity my-org
```
Set `WANDB_API_KEY` in your environment first.
Save intermediate checkpoints during training:
```bash theme={null}
firectl create rftj \
--base-model accounts/fireworks/models/llama-v3p1-8b-instruct \
--checkpoint-frequency 500 # Save every 500 steps
...
```
Available in `firectl` only.
Speed up training with multiple GPUs:
```bash theme={null}
firectl create rftj \
--base-model accounts/fireworks/models/llama-v3p1-70b-instruct \
--accelerator-count 4 # Use 4 GPUs
...
```
Recommended for large models (70B+).
For evaluators that need more time:
```bash theme={null}
firectl create rftj \
--rollout-timeout 300 # 5 minutes per rollout
...
```
Default is 60 seconds. Increase for complex evaluations.
## Examples
**Fast experimentation** (small model, 1 epoch):
```bash theme={null}
eval-protocol create rft \
--base-model accounts/fireworks/models/qwen3-0p6b \
--output-model quick-test
```
**High-quality training** (more rollouts, higher temperature):
```bash theme={null}
eval-protocol create rft \
--base-model accounts/fireworks/models/llama-v3p1-8b-instruct \
--output-model high-quality-model \
--inference-n 8 \
--inference-temperature 1.0
```
**Remote environment** (for multi-turn agents):
```bash theme={null}
eval-protocol create rft \
--base-model accounts/fireworks/models/llama-v3p1-8b-instruct \
--remote-server-url https://your-agent.example.com \
--output-model remote-agent
```
**Multiple epochs with custom learning rate**:
```bash theme={null}
eval-protocol create rft \
--base-model accounts/fireworks/models/llama-v3p1-8b-instruct \
--epochs 3 \
--learning-rate 5e-5 \
--output-model multi-epoch-model
```
## Using `firectl` CLI (Alternative)
For users already familiar with Fireworks `firectl`, you can create RFT jobs directly:
```bash theme={null}
firectl create rftj \
--base-model accounts/fireworks/models/llama-v3p1-8b-instruct \
--dataset accounts/your-account/datasets/my-dataset \
--evaluator accounts/your-account/evaluators/my-evaluator \
--output-model my-finetuned-model
```
**Differences from `eval-protocol`**:
* Requires fully qualified resource names (accounts/...)
* Must manually upload evaluators and datasets first
* More verbose but offers finer control
* Same underlying API as `eval-protocol`
See [firectl documentation](/tools-sdks/firectl/commands/create-reinforcement-fine-tuning-job) for all options.
## Next steps
Review requirements, validation, and common errors
Track job progress, inspect rollouts, and debug issues
Learn how to adjust parameters for better results
---
# Source: https://docs.fireworks.ai/deployments/client-side-performance-optimization.md
# Client-side performance optimization
> Optimize your client code for maximum performance with dedicated deployments
When using a dedicated deployment, it is important to optimize the client-side
HTTP connection pooling for maximum performance. We recommend using our [Python
SDK](/tools-sdks/python-client/sdk-introduction) as it has good defaults for
connection pooling and utilizes
[aiohttp](https://docs.aiohttp.org/en/stable/index.html) for optimal performance
with Python's `asyncio` library. It also includes retry logic for handling `429`
errors that Fireworks returns when the server is overloaded. We have run
benchmarks that demonstrate the performance benefits.
## General optimization recommendations
Based on our benchmarks, we recommend the following:
1. Use a client library optimized for high concurrency, such as
[aiohttp](https://docs.aiohttp.org/en/stable/index.html) in Python or
[http.Agent](https://nodejs.org/api/http.html#class-httpagent) in Node.js.
2. Keep the [`connection pool size`](https://docs.aiohttp.org/en/stable/client_advanced.html#limiting-connection-pool-size) high (1000+).
3. Increase concurrency until performance stops improving or you observe too many `429` errors.
4. Use [direct routing](/deployments/direct-routing) to avoid the global API load balancer and route requests directly to your deployment.
## Code example: Optimal concurrent requests (Python)
Here's how to implement optimal concurrent requests using `asyncio` and the `LLM` class:
```python main.py theme={null}
import asyncio
from fireworks import LLM
async def make_concurrent_requests(
messages: list[str],
max_workers: int = 1000,
max_connections: int = 1000, # this is the default value in the SDK
):
"""Make concurrent requests with optimized connection pooling"""
llm = LLM(
model="your-model-name",
deployment_type="on-demand",
id="your-deployment-id",
max_connections=max_connections
)
# Apply deployment configuration to Fireworks
llm.apply()
# Semaphore to limit concurrent requests
semaphore = asyncio.Semaphore(max_workers)
async def single_request(message: str):
"""Make a single request with semaphore control"""
async with semaphore:
response = await llm.chat.completions.acreate(
messages=[{"role": "user", "content": message}],
max_tokens=100
)
return response.choices[0].message.content
# Create all request tasks
tasks = [
single_request(message)
for message in messages
]
# Execute all requests concurrently
results = await asyncio.gather(*tasks)
return results
# Usage example
async def main():
messages = ["Hello!"] * 1000 # 1000 requests
results = await make_concurrent_requests(
messages=messages,
)
print(f"Completed {len(results)} requests")
if __name__ == "__main__":
asyncio.run(main())
```
This implementation:
* Uses `asyncio.Semaphore` to control concurrency to avoid overwhelming the server
* Allows configuration of the maximum number of concurrent connections to the Fireworks API
---
# Source: https://docs.fireworks.ai/guides/completions-api.md
# Completions API
> Use the completions API for raw text generation with custom prompt templates
The completions API provides raw text generation without automatic message formatting. Use this when you need full control over prompt formatting or when working with base models.
## When to use completions
**Use the completions API for:**
* Custom prompt templates with specific formatting requirements
* Base models (non-instruct/non-chat variants)
* Fine-grained control over token-level formatting
* Legacy applications that depend on raw completion format
**For most use cases, use [chat completions](/guides/querying-text-models) instead.** Chat completions handles message formatting automatically and works better with instruct-tuned models.
## Basic usage
```python theme={null}
import os
from openai import OpenAI
client = OpenAI(
api_key=os.environ.get("FIREWORKS_API_KEY"),
base_url="https://api.fireworks.ai/inference/v1"
)
response = client.completions.create(
model="accounts/fireworks/models/deepseek-v3p1",
prompt="Once upon a time"
)
print(response.choices[0].text)
```
```javascript theme={null}
import OpenAI from "openai";
const client = new OpenAI({
apiKey: process.env.FIREWORKS_API_KEY,
baseURL: "https://api.fireworks.ai/inference/v1",
});
const response = await client.completions.create({
model: "accounts/fireworks/models/deepseek-v3p1",
prompt: "Once upon a time",
});
console.log(response.choices[0].text);
```
```bash theme={null}
curl https://api.fireworks.ai/inference/v1/completions \
-H "Content-Type: application/json" \
-H "Authorization: Bearer $FIREWORKS_API_KEY" \
-d '{
"model": "accounts/fireworks/models/deepseek-v3p1",
"prompt": "Once upon a time"
}'
```
Most models automatically prepend the beginning-of-sequence (BOS) token (e.g., ``) to your prompt. Verify this with the `raw_output` parameter if needed.
## Custom prompt templates
The completions API is useful when you need to implement custom prompt formats:
```python theme={null}
# Custom few-shot prompt template
prompt = """Task: Classify the sentiment of the following text.
Text: I love this product!
Sentiment: Positive
Text: This is terrible.
Sentiment: Negative
Text: The weather is nice today.
Sentiment:"""
response = client.completions.create(
model="accounts/fireworks/models/deepseek-v3p1",
prompt=prompt,
max_tokens=10,
temperature=0
)
print(response.choices[0].text) # Output: " Positive"
```
## Common parameters
All [chat completions parameters](/guides/querying-text-models#configuration--debugging) work with completions:
* `temperature` - Control randomness (0-2)
* `max_tokens` - Limit output length
* `top_p`, `top_k`, `min_p` - Sampling parameters
* `stream` - Stream responses token-by-token
* `frequency_penalty`, `presence_penalty` - Reduce repetition
See the [API reference](/api-reference/post-completions) for complete parameter documentation.
## Querying deployments
Use completions with [on-demand deployments](/guides/ondemand-deployments) by specifying the deployment identifier:
```python theme={null}
response = client.completions.create(
model="accounts/fireworks/models/deepseek-v3p1#accounts//deployments/",
prompt="Your prompt here"
)
```
## Next steps
Use chat completions for most use cases
Stream responses for real-time UX
Complete API documentation
---
# Source: https://docs.fireworks.ai/getting-started/concepts.md
# Concepts
> This document outlines basic Fireworks AI concepts.
## Resources
### Account
Your account is the top-level resource under which other resources are located. Quotas and billing are enforced at the account level, so usage for all users in an account contribute to the same quotas and bill.
* For developer accounts, the account ID is auto-generated from the email address used to sign up.
* Enterprise accounts can optionally choose a custom, unique account ID.
### User
A user is an email address associated with an account. Users added to an account have full access to delete, edit, and create resources within the account, such as deployments and models.
### Models and model types
A model is a set of model weights and metadata associated with the model. Each model has a [**globally unique name**](/getting-started/concepts#resource-names-and-ids) of the form `accounts//models/`. There are two types of models:
**Base models:** A base model consists of the full set of model weights, including models pre-trained from scratch and full fine-tunes.
* Fireworks has a library of common base models that can be used for [**serverless inference**](/models/overview#serverless-inference) as well as [**dedicated deployments**](/models/overview#dedicated-deployments). Model IDs for these models are pre-populated. For example, `llama-v3p1-70b-instruct` is the model ID for the Llama 3.1 70B model that Fireworks provides. The ID for each model can be found on its page ([**example**](https://app.fireworks.ai/models/fireworks/qwen3-coder-480b-a35b-instruct))
* Users can also [upload their own](/models/uploading-custom-models) custom base models and specify model IDs.
**LoRA (low-rank adaptation) addons:** A LoRA addon is a small, fine-tuned model that significantly reduces the amount of memory required to deploy compared to a fully fine-tuned model. Fireworks supports [**training**](/fine-tuning/finetuning-intro), [**uploading**](/models/uploading-custom-models#importing-fine-tuned-models), and [**serving**](/fine-tuning/fine-tuning-models#deploying-a-fine-tuned-model) LoRA addons. LoRA addons must be deployed on a serverless or dedicated deployment for its corresponding base model. Model IDs for LoRAs can be either auto-generated or user-specified.
### Deployments and deployment types
A model must be deployed before it can be used for inference. A deployment is a collection (one or more) model servers that host one base model and optionally one or more LoRA addons.
Fireworks supports two types of deployments:
* **Serverless deployments:** Fireworks hosts popular base models on shared "serverless" deployments. Users pay-per-token to query these models and do not need to configure GPUs. The most popular serverless deployments also support serverless LoRA addons. See our [Quickstart - Serverless](/getting-started/quickstart) guide to get started.
* **Dedicated deployments:** Dedicated deployments enable users to configure private deployments with a wide array of hardware (see [on-demand deployments guide](/guides/ondemand-deployments)). Dedicated deployments give users performance guarantees and the most flexibility and control over what models can be deployed. Both LoRA addons and base models can be deployed to dedicated deployments. Dedicated deployments are billed by a GPU-second basis (see [**pricing**](https://fireworks.ai/pricing#ondemand) page).
See the [**Querying text models guide**](/guides/querying-text-models) for a comprehensive overview of making LLM inference.
### Deployed model
Users can specify a model to query for inference using the model name and deployment name. Alternatively, users can refer to a "deployed model" name that refers to a unique instance of a base model or LoRA addon that is loaded into a deployment. See [On-demand deployments](/guides/ondemand-deployments) guide for more.
### Dataset
A dataset is an immutable set of training examples that can be used to fine-tune a model.
### Fine-tuning job
A fine-tuning job is an offline training job that uses a dataset to train a LoRA addon model.
## Resource names and IDs
A resource name is a globally unique identifier of a resource. The format of a name also identifies the type and hierarchy of the resource, for example:
Resource IDs must satisfy the following constraints:
* Between 1 and 63 characters (inclusive)
* Consists of a-z, 0-9, and hyphen (-)
* Does not begin or end with a hyphen (-)
* Does not begin with a digit
## Control plane and data plane
The Fireworks API can be split into a control plane and a data plane.
* The **control plane** consists of APIs used for managing the lifecycle of resources. This
includes your account, models, and deployments.
* The **data plane** consists of the APIs used for inference and the backend services that power
them.
## Interfaces
Users can interact with Fireworks through one of many interfaces:
* The **web app** at [https://app.fireworks.ai](https://app.fireworks.ai)
* The [`firectl`](/tools-sdks/firectl/firectl) CLI
* [OpenAI compatible API](/tools-sdks/openai-compatibility)
* [Python SDK](/tools-sdks/python-client/sdk-introduction)
---
# Source: https://docs.fireworks.ai/api-reference-dlde/connect-environment.md
# Connect Environment
> Connects the environment to a node pool.
Returns an error if there is an existing pending connection.
## OpenAPI
````yaml post /v1/accounts/{account_id}/environments/{environment_id}:connect
paths:
path: /v1/accounts/{account_id}/environments/{environment_id}:connect
method: post
servers:
- url: https://api.fireworks.ai
request:
security:
- title: BearerAuth
parameters:
query: {}
header:
Authorization:
type: http
scheme: bearer
description: >-
Bearer authentication using your Fireworks API key. Format:
Bearer
cookie: {}
parameters:
path:
account_id:
schema:
- type: string
required: true
description: The Account Id
environment_id:
schema:
- type: string
required: true
description: The Environment Id
query: {}
header: {}
cookie: {}
body:
application/json:
schemaArray:
- type: object
properties:
connection:
allOf:
- $ref: '#/components/schemas/gatewayEnvironmentConnection'
vscodeVersion:
allOf:
- type: string
title: >-
VSCode version on the client side that initiated the
connect request
required: true
refIdentifier: '#/components/schemas/GatewayConnectEnvironmentBody'
requiredProperties:
- connection
examples:
example:
value:
connection:
nodePoolId:
numRanks: 123
role:
useLocalStorage: true
vscodeVersion:
response:
'200':
application/json:
schemaArray:
- type: object
properties: {}
examples:
example:
value: {}
description: A successful response.
deprecated: false
type: path
components:
schemas:
gatewayEnvironmentConnection:
type: object
properties:
nodePoolId:
type: string
description: The resource id of the node pool the environment is connected to.
numRanks:
type: integer
format: int32
description: |-
For GPU node pools: one GPU per rank w/ host packing,
for CPU node pools: one host per rank.
If not specified, the default is 1.
role:
type: string
description: |-
The ARN of the AWS IAM role that the connection should assume.
If not specified, the connection will fall back to the node
pool's node_role.
zone:
type: string
description: >-
Current for the last zone that this environment is connected to. We
want to warn the users about cross zone migration latency when they
are
connecting to node pool in a different zone as their persistent
volume.
readOnly: true
useLocalStorage:
type: boolean
description: >-
If true, the node's local storage will be mounted on /tmp. This flag
has
no effect if the node does not have local storage.
title: 'Next ID: 8'
required:
- nodePoolId
````
---
# Source: https://docs.fireworks.ai/fine-tuning/connect-environments.md
# Remote Environment Setup
> Implement the /init endpoint to run evaluations in your infrastructure
If you already have an agent running in your product, or need to run rollouts on your own infrastructure, you can integrate it with RFT using the `RemoteRolloutProcessor`. This delegates rollout execution to an HTTP service you control.
Remote agent are ideal for:
* Multi-turn agentic workflows with tool use
* Access to private databases, APIs, or internal services
* Integration with existing agent codebases
* Complex simulations that require your infrastructure
New to RFT? Start with [local agent](/fine-tuning/quickstart-math) instead. They're simpler and cover most use cases. Only use remote agent environments when you need access to private infrastructure or have an existing agent to integrate.
## How remote rollouts work
 During training, Fireworks calls your service's `POST /init` endpoint with the dataset row and correlation metadata.
Your agent executes the task (e.g., multi-turn conversation, tool calls, simulation steps), logging progress via Fireworks tracing.
Your service sends structured logs tagged with rollout metadata to Fireworks so the system can track completion.
Once Fireworks detects completion, it pulls the full trace and evaluates it using your scoring logic.
Everything except implementing your remote server is handled automatically by Eval Protocol. You only need to implement the `/init` endpoint and add Fireworks tracing.
## Implementing the /init endpoint
Your remote service must implement a single `/init` endpoint that accepts rollout requests.
### Request schema
Model configuration including model name and inference parameters like temperature, max\_tokens, etc.
Array of conversation messages to send to the model
Array of available tools for the model (for function calling)
Base URL for making LLM calls through Fireworks tracing (includes correlation metadata)
Rollout execution metadata for correlation (rollout\_id, run\_id, row\_id, etc.)
Fireworks API key to use for model calls
### Example request
```json theme={null}
{
"completion_params": {
"model": "accounts/fireworks/models/llama-v3p1-8b-instruct",
"temperature": 0.7,
"max_tokens": 2048
},
"messages": [
{ "role": "user", "content": "What is the weather in San Francisco?" }
],
"tools": [
{
"type": "function",
"function": {
"name": "get_weather",
"description": "Get the weather for a city",
"parameters": {
"type": "object",
"properties": {
"city": { "type": "string" }
}
}
}
}
],
"model_base_url": "https://tracing.fireworks.ai/rollout_id/brave-night-42/invocation_id/wise-ocean-15/experiment_id/calm-forest-28/run_id/quick-river-07/row_id/bright-star-91",
"metadata": {
"invocation_id": "wise-ocean-15",
"experiment_id": "calm-forest-28",
"rollout_id": "brave-night-42",
"run_id": "quick-river-07",
"row_id": "bright-star-91"
},
"api_key": "fw_your_api_key"
}
```
## Metadata correlation
The `metadata` object contains correlation IDs that you must include when logging to Fireworks tracing. This allows Eval Protocol to match logs and traces back to specific evaluation rows.
Required metadata fields:
* `invocation_id` - Identifies the evaluation invocation
* `experiment_id` - Groups related experiments
* `rollout_id` - Unique ID for this specific rollout (most important)
* `run_id` - Identifies the evaluation run
* `row_id` - Links to the dataset row
`RemoteRolloutProcessor` automatically generates these IDs and sends them to your server. You don't need to create them yourself—just pass them through to your logging.
## Fireworks tracing integration
Your remote server must use Fireworks tracing to report rollout status. Eval Protocol polls these logs to detect when rollouts complete.
### Basic setup
```python theme={null}
import logging
from eval_protocol import Status, InitRequest, FireworksTracingHttpHandler, RolloutIdFilter
# Configure Fireworks tracing handler globally
fireworks_handler = FireworksTracingHttpHandler()
logging.getLogger().addHandler(fireworks_handler)
@app.post("/init")
def init(request: InitRequest):
# Create rollout-specific logger with filter
rollout_logger = logging.getLogger(f"eval_server.{request.metadata.rollout_id}")
rollout_logger.addFilter(RolloutIdFilter(request.metadata.rollout_id))
try:
# Execute your agent logic here
result = execute_agent(request)
# Log successful completion with structured status
rollout_logger.info(
f"Rollout {request.metadata.rollout_id} completed",
extra={"status": Status.rollout_finished()}
)
return {"status": "success"}
except Exception as e:
# Log errors with structured status
rollout_logger.error(
f"Rollout {request.metadata.rollout_id} failed: {e}",
extra={"status": Status.rollout_error(str(e))}
)
raise
```
### Key components
1. **FireworksTracingHttpHandler**: Sends logs to Fireworks tracing service
2. **RolloutIdFilter**: Tags logs with the rollout ID for correlation
3. **Status objects**: Structured status reporting that Eval Protocol can parse
* `Status.rollout_finished()` - Signals successful completion
* `Status.rollout_error(message)` - Signals failure with error details
### Alternative: Environment variable approach
For simpler setups, you can use the `EP_ROLLOUT_ID` environment variable instead of manual filters.
If your server processes one rollout at a time (e.g., serverless functions, container per request):
```python theme={null}
import os
import logging
from eval_protocol import Status, InitRequest, FireworksTracingHttpHandler
# Set rollout ID in environment
os.environ["EP_ROLLOUT_ID"] = request.metadata.rollout_id
# Configure handler (automatically picks up EP_ROLLOUT_ID)
fireworks_handler = FireworksTracingHttpHandler()
logging.getLogger().addHandler(fireworks_handler)
logger = logging.getLogger(__name__)
@app.post("/init")
def init(request: InitRequest):
# Logs are automatically tagged with rollout_id
logger.info("Processing rollout...")
# ... execute agent logic ...
```
If your `/init` handler spawns separate Python processes for each rollout:
```python theme={null}
import os
import logging
import multiprocessing
from eval_protocol import FireworksTracingHttpHandler, InitRequest
def execute_rollout_step_sync(request):
# Set EP_ROLLOUT_ID in the child process
os.environ["EP_ROLLOUT_ID"] = request.metadata.rollout_id
logging.getLogger().addHandler(FireworksTracingHttpHandler())
# Execute your rollout logic here
# Logs are automatically tagged
@app.post("/init")
async def init(request: InitRequest):
# Do NOT set EP_ROLLOUT_ID in parent process
p = multiprocessing.Process(
target=execute_rollout_step_sync,
args=(request,)
)
p.start()
return {"status": "started"}
```
### How Eval Protocol uses tracing
1. **Your server logs completion**: Uses `Status.rollout_finished()` or `Status.rollout_error()`
2. **Eval Protocol polls**: Searches Fireworks logs by `rollout_id` tag until completion signal found
3. **Status extraction**: Reads structured status fields (`code`, `message`, `details`) to determine outcome
4. **Trace retrieval**: Fetches full trace of model calls and tool use for evaluation
## Complete example
Here's a minimal but complete remote server implementation:
```python theme={null}
from fastapi import FastAPI
from fastapi.responses import JSONResponse
from eval_protocol import InitRequest, FireworksTracingHttpHandler, RolloutIdFilter, Status
import logging
app = FastAPI()
# Setup Fireworks tracing
fireworks_handler = FireworksTracingHttpHandler()
logging.getLogger().addHandler(fireworks_handler)
@app.post("/init")
async def init(request: InitRequest):
# Create rollout-specific logger
rollout_logger = logging.getLogger(f"eval_server.{request.metadata.rollout_id}")
rollout_logger.addFilter(RolloutIdFilter(request.metadata.rollout_id))
rollout_logger.info(f"Starting rollout {request.metadata.rollout_id}")
try:
# Your agent logic here
# 1. Make model calls using request.model_base_url
# 2. Call tools, interact with environment
# 3. Collect results
result = run_your_agent(
messages=request.messages,
tools=request.tools,
model_config=request.completion_params,
api_key=request.api_key
)
# Signal completion
rollout_logger.info(
f"Rollout {request.metadata.rollout_id} completed successfully",
extra={"status": Status.rollout_finished()}
)
return {"status": "success", "result": result}
except Exception as e:
# Signal error
rollout_logger.error(
f"Rollout {request.metadata.rollout_id} failed: {str(e)}",
extra={"status": Status.rollout_error(str(e))}
)
return JSONResponse(
status_code=500,
content={"status": "error", "message": str(e)}
)
def run_your_agent(messages, tools, model_config, api_key):
# Implement your agent logic here
# Make model calls, use tools, etc.
pass
```
## Testing locally
Before deploying, test your remote server locally:
```bash theme={null}
uvicorn main:app --reload --port 8080
```
In your evaluator test, point to your local server:
```python theme={null}
from eval_protocol.pytest import RemoteRolloutProcessor
rollout_processor = RemoteRolloutProcessor(
remote_base_url="http://localhost:8080"
)
```
```bash theme={null}
pytest my-evaluator-name.py -vs
```
This sends test rollouts to your local server and verifies the integration works.
## Deploying your service
Once tested locally, deploy to production:
* ✅ Service is publicly accessible (or accessible via VPN/private network)
* ✅ HTTPS endpoint with valid SSL certificate (recommended)
* ✅ Authentication/authorization configured
* ✅ Monitoring and logging set up
* ✅ Auto-scaling configured for concurrent rollouts
* ✅ Error handling and retry logic implemented
* ✅ Service availability SLA meets training requirements
**Vercel/Serverless**:
* One rollout per function invocation
* Use environment variable approach
* Configure timeout for long-running evaluations
**AWS ECS/Kubernetes**:
* Handle concurrent requests with proper worker configuration
* Use RolloutIdFilter approach
* Set up load balancing
**On-premise**:
* Ensure network connectivity from Fireworks
* Configure firewall rules
* Set up VPN if needed for security
## Connecting to RFT
Once your remote server is deployed, create an RFT job that uses it:
```bash theme={null}
eval-protocol create rft \
--base-model accounts/fireworks/models/llama-v3p1-8b-instruct \
--remote-server-url https://your-evaluator.example.com \
--dataset my-dataset
```
The RFT job will send all rollouts to your remote server for evaluation during training.
## Troubleshooting
**Symptoms**: Rollouts show as timed out or never complete
**Solutions**:
* Check that your service is logging `Status.rollout_finished()` correctly
* Verify Fireworks tracing handler is configured
* Ensure rollout\_id is included in log tags
* Check for exceptions being swallowed without logging
**Symptoms**: Eval Protocol can't match logs to rollouts
**Solutions**:
* Verify you're using the exact `rollout_id` from request metadata
* Check that RolloutIdFilter or EP\_ROLLOUT\_ID is set correctly
* Ensure logs are being sent to Fireworks (check tracing dashboard)
**Symptoms**: Training is slow, high rollout latency
**Solutions**:
* Scale your service to handle concurrent requests
* Optimize your agent logic (caching, async operations)
* Add more workers or instances
* Profile your code to find bottlenecks
**Symptoms**: Model calls fail, API errors
**Solutions**:
* Verify API key is passed correctly from request
* Check that your service has network access to Fireworks
* Ensure model\_base\_url is used for traced calls
## Example implementations
Learn by example:
Complete walkthrough using a Vercel TypeScript server for SVG generation
Minimal Python implementation showing the basics
## Next steps
Launch your RFT job using the CLI
Track rollout progress and debug issues
Full Remote Rollout Processor tutorial
Design effective reward functions
---
# Source: https://docs.fireworks.ai/examples/cookbooks.md
# Cookbooks
> Interactive Jupyter notebooks demonstrating advanced use cases and best practices with Fireworks AI
Explore our collection of notebooks that showcase real-world applications, best practices, and advanced techniques for building with Fireworks AI.
## Fine-Tuning & Training
Transfer large model capabilities to efficient models using a two-stage SFT + RFT approach.
**Techniques:** Supervised Fine-Tuning (SFT) + Reinforcement Fine-Tuning (RFT)
**Results:** 52% → 70% accuracy on GSM8K mathematical reasoning
Beat frontier closed-source models for product catalog cleansing with vision-language model fine-tuning.
**Techniques:** Supervised Fine-Tuning (SFT)
**Results:** 48% increase in quality from base model
## Multimodal AI
Extract structured data from invoices, forms, and financial documents using state-of-the-art OCR and document understanding.
**Use Cases:** Forms, invoices, financial documents, product catalogs
**Results:** 90.8% accuracy on invoice extraction (100% on invoice numbers and dates)
Real-time audio transcription with streaming support and low latency.
**Features:** Streaming support, low-latency transcription, production-ready
## API Features
Leverage Model Context Protocol (MCP) for GitHub repository analysis, code search, and documentation Q\&A.
**Features:** Repository analysis, code search, documentation Q\&A, GitMCP integration
**Models:** Qwen 3 235B with external tool support
---
# Source: https://docs.fireworks.ai/tools-sdks/firectl/commands/create-api-key.md
# Source: https://docs.fireworks.ai/api-reference/create-api-key.md
# Source: https://docs.fireworks.ai/tools-sdks/firectl/commands/create-api-key.md
# Source: https://docs.fireworks.ai/api-reference/create-api-key.md
# Source: https://docs.fireworks.ai/tools-sdks/firectl/commands/create-api-key.md
# Source: https://docs.fireworks.ai/api-reference/create-api-key.md
# Create API Key
## OpenAPI
````yaml post /v1/accounts/{account_id}/users/{user_id}/apiKeys
paths:
path: /v1/accounts/{account_id}/users/{user_id}/apiKeys
method: post
servers:
- url: https://api.fireworks.ai
request:
security:
- title: BearerAuth
parameters:
query: {}
header:
Authorization:
type: http
scheme: bearer
description: >-
Bearer authentication using your Fireworks API key. Format:
Bearer
cookie: {}
parameters:
path:
account_id:
schema:
- type: string
required: true
description: The Account Id
user_id:
schema:
- type: string
required: true
description: The User Id
query: {}
header: {}
cookie: {}
body:
application/json:
schemaArray:
- type: object
properties:
apiKey:
allOf:
- $ref: '#/components/schemas/gatewayApiKey'
description: The API key to be created.
required: true
refIdentifier: '#/components/schemas/GatewayCreateApiKeyBody'
requiredProperties:
- apiKey
examples:
example:
value:
apiKey:
displayName:
expireTime: '2023-11-07T05:31:56Z'
response:
'200':
application/json:
schemaArray:
- type: object
properties:
keyId:
allOf:
- &ref_0
type: string
description: >-
Unique identifier (Key ID) for the API key, used primarily
for deletion.
readOnly: true
displayName:
allOf:
- &ref_1
type: string
description: >-
Display name for the API key, defaults to "default" if not
specified.
key:
allOf:
- &ref_2
type: string
description: >-
The actual API key value, only available upon creation and
not stored thereafter.
readOnly: true
createTime:
allOf:
- &ref_3
type: string
format: date-time
description: Timestamp indicating when the API key was created.
readOnly: true
secure:
allOf:
- &ref_4
type: boolean
description: >-
Indicates whether the plaintext value of the API key is
unknown to Fireworks.
If true, Fireworks does not know this API key's plaintext
value. If false, Fireworks does
know the plaintext value.
readOnly: true
email:
allOf:
- &ref_5
type: string
description: Email of the user who owns this API key.
readOnly: true
prefix:
allOf:
- &ref_6
type: string
title: >-
The first few characters of the API key to visually
identify it
readOnly: true
expireTime:
allOf:
- &ref_7
type: string
format: date-time
description: >-
Timestamp indicating when the API key will expire. If not
set, the key never expires.
refIdentifier: '#/components/schemas/gatewayApiKey'
examples:
example:
value:
keyId:
displayName:
key:
createTime: '2023-11-07T05:31:56Z'
secure: true
email:
prefix:
expireTime: '2023-11-07T05:31:56Z'
description: A successful response.
deprecated: false
type: path
components:
schemas:
gatewayApiKey:
type: object
properties:
keyId: *ref_0
displayName: *ref_1
key: *ref_2
createTime: *ref_3
secure: *ref_4
email: *ref_5
prefix: *ref_6
expireTime: *ref_7
````
---
# Source: https://docs.fireworks.ai/api-reference-dlde/create-aws-iam-role-binding.md
# Create Aws Iam Role Binding
## OpenAPI
````yaml post /v1/accounts/{account_id}/awsIamRoleBindings
paths:
path: /v1/accounts/{account_id}/awsIamRoleBindings
method: post
servers:
- url: https://api.fireworks.ai
request:
security:
- title: BearerAuth
parameters:
query: {}
header:
Authorization:
type: http
scheme: bearer
description: >-
Bearer authentication using your Fireworks API key. Format:
Bearer
cookie: {}
parameters:
path:
account_id:
schema:
- type: string
required: true
description: The Account Id
query: {}
header: {}
cookie: {}
body:
application/json:
schemaArray:
- type: object
properties:
principal:
allOf:
- &ref_0
type: string
description: >-
The principal that is allowed to assume the AWS IAM role.
This must be
the email address of the user.
role:
allOf:
- &ref_1
type: string
description: >-
The AWS IAM role ARN that is allowed to be assumed by the
principal.
required: true
refIdentifier: '#/components/schemas/gatewayAwsIamRoleBinding'
requiredProperties: &ref_2
- principal
- role
examples:
example:
value:
principal:
role:
description: The properties of the AWS IAM role binding being created.
response:
'200':
application/json:
schemaArray:
- type: object
properties:
accountId:
allOf:
- type: string
description: The account ID that this binding is associated with.
readOnly: true
createTime:
allOf:
- type: string
format: date-time
description: The creation time of the AWS IAM role binding.
readOnly: true
principal:
allOf:
- *ref_0
role:
allOf:
- *ref_1
refIdentifier: '#/components/schemas/gatewayAwsIamRoleBinding'
requiredProperties: *ref_2
examples:
example:
value:
accountId:
createTime: '2023-11-07T05:31:56Z'
principal:
role:
description: A successful response.
deprecated: false
type: path
components:
schemas: {}
````
---
# Source: https://docs.fireworks.ai/tools-sdks/firectl/commands/create-batch-inference-job.md
# Source: https://docs.fireworks.ai/api-reference/create-batch-inference-job.md
# Source: https://docs.fireworks.ai/tools-sdks/firectl/commands/create-batch-inference-job.md
# Source: https://docs.fireworks.ai/api-reference/create-batch-inference-job.md
# Source: https://docs.fireworks.ai/tools-sdks/firectl/commands/create-batch-inference-job.md
# Source: https://docs.fireworks.ai/api-reference/create-batch-inference-job.md
# Create Batch Inference Job
## OpenAPI
````yaml post /v1/accounts/{account_id}/batchInferenceJobs
paths:
path: /v1/accounts/{account_id}/batchInferenceJobs
method: post
servers:
- url: https://api.fireworks.ai
request:
security:
- title: BearerAuth
parameters:
query: {}
header:
Authorization:
type: http
scheme: bearer
description: >-
Bearer authentication using your Fireworks API key. Format:
Bearer
cookie: {}
parameters:
path:
account_id:
schema:
- type: string
required: true
description: The Account Id
query:
batchInferenceJobId:
schema:
- type: string
required: false
description: ID of the batch inference job.
header: {}
cookie: {}
body:
application/json:
schemaArray:
- type: object
properties:
displayName:
allOf:
- &ref_0
type: string
title: >-
Human-readable display name of the batch inference job.
e.g. "My Batch Inference Job"
state:
allOf:
- &ref_1
$ref: '#/components/schemas/gatewayJobState'
description: >-
JobState represents the state an asynchronous job can be
in.
readOnly: true
status:
allOf:
- &ref_2
$ref: '#/components/schemas/gatewayStatus'
readOnly: true
model:
allOf:
- &ref_3
type: string
description: >-
The name of the model to use for inference. This is
required, except when continued_from_job_name is
specified.
inputDatasetId:
allOf:
- &ref_4
type: string
description: >-
The name of the dataset used for inference. This is
required, except when continued_from_job_name is
specified.
outputDatasetId:
allOf:
- &ref_5
type: string
description: >-
The name of the dataset used for storing the results. This
will also contain the error file.
inferenceParameters:
allOf:
- &ref_6
$ref: '#/components/schemas/gatewayInferenceParameters'
description: Parameters controlling the inference process.
precision:
allOf:
- &ref_7
$ref: '#/components/schemas/DeploymentPrecision'
description: >-
The precision with which the model should be served.
If PRECISION_UNSPECIFIED, a default will be chosen based
on the model.
jobProgress:
allOf:
- &ref_8
$ref: '#/components/schemas/gatewayJobProgress'
description: Job progress.
readOnly: true
continuedFromJobName:
allOf:
- &ref_9
type: string
description: >-
The resource name of the batch inference job that this job
continues from.
Used for lineage tracking to understand job continuation
chains.
required: true
title: 'Next ID: 31'
refIdentifier: '#/components/schemas/gatewayBatchInferenceJob'
examples:
example:
value:
displayName:
model:
inputDatasetId:
outputDatasetId:
inferenceParameters:
maxTokens: 123
temperature: 123
topP: 123
'n': 123
extraBody:
topK: 123
precision: PRECISION_UNSPECIFIED
continuedFromJobName:
response:
'200':
application/json:
schemaArray:
- type: object
properties:
name:
allOf:
- type: string
title: >-
The resource name of the batch inference job. e.g.
accounts/my-account/batchInferenceJobs/my-batch-inference-job
readOnly: true
displayName:
allOf:
- *ref_0
createTime:
allOf:
- type: string
format: date-time
description: The creation time of the batch inference job.
readOnly: true
createdBy:
allOf:
- type: string
description: >-
The email address of the user who initiated this batch
inference job.
readOnly: true
state:
allOf:
- *ref_1
status:
allOf:
- *ref_2
model:
allOf:
- *ref_3
inputDatasetId:
allOf:
- *ref_4
outputDatasetId:
allOf:
- *ref_5
inferenceParameters:
allOf:
- *ref_6
updateTime:
allOf:
- type: string
format: date-time
description: The update time for the batch inference job.
readOnly: true
precision:
allOf:
- *ref_7
jobProgress:
allOf:
- *ref_8
continuedFromJobName:
allOf:
- *ref_9
title: 'Next ID: 31'
refIdentifier: '#/components/schemas/gatewayBatchInferenceJob'
examples:
example:
value:
name:
displayName:
createTime: '2023-11-07T05:31:56Z'
createdBy:
state: JOB_STATE_UNSPECIFIED
status:
code: OK
message:
model:
inputDatasetId:
outputDatasetId:
inferenceParameters:
maxTokens: 123
temperature: 123
topP: 123
'n': 123
extraBody:
topK: 123
updateTime: '2023-11-07T05:31:56Z'
precision: PRECISION_UNSPECIFIED
jobProgress:
percent: 123
epoch: 123
totalInputRequests: 123
totalProcessedRequests: 123
successfullyProcessedRequests: 123
failedRequests: 123
outputRows: 123
inputTokens: 123
outputTokens: 123
cachedInputTokenCount: 123
continuedFromJobName:
description: A successful response.
deprecated: false
type: path
components:
schemas:
DeploymentPrecision:
type: string
enum:
- PRECISION_UNSPECIFIED
- FP16
- FP8
- FP8_MM
- FP8_AR
- FP8_MM_KV_ATTN
- FP8_KV
- FP8_MM_V2
- FP8_V2
- FP8_MM_KV_ATTN_V2
- NF4
- FP4
- BF16
- FP4_BLOCKSCALED_MM
- FP4_MX_MOE
default: PRECISION_UNSPECIFIED
title: >-
- PRECISION_UNSPECIFIED: if left unspecified we will treat this as a
legacy model created before
self serve
gatewayCode:
type: string
enum:
- OK
- CANCELLED
- UNKNOWN
- INVALID_ARGUMENT
- DEADLINE_EXCEEDED
- NOT_FOUND
- ALREADY_EXISTS
- PERMISSION_DENIED
- UNAUTHENTICATED
- RESOURCE_EXHAUSTED
- FAILED_PRECONDITION
- ABORTED
- OUT_OF_RANGE
- UNIMPLEMENTED
- INTERNAL
- UNAVAILABLE
- DATA_LOSS
default: OK
description: |-
- OK: Not an error; returned on success.
HTTP Mapping: 200 OK
- CANCELLED: The operation was cancelled, typically by the caller.
HTTP Mapping: 499 Client Closed Request
- UNKNOWN: Unknown error. For example, this error may be returned when
a `Status` value received from another address space belongs to
an error space that is not known in this address space. Also
errors raised by APIs that do not return enough error information
may be converted to this error.
HTTP Mapping: 500 Internal Server Error
- INVALID_ARGUMENT: The client specified an invalid argument. Note that this differs
from `FAILED_PRECONDITION`. `INVALID_ARGUMENT` indicates arguments
that are problematic regardless of the state of the system
(e.g., a malformed file name).
HTTP Mapping: 400 Bad Request
- DEADLINE_EXCEEDED: The deadline expired before the operation could complete. For operations
that change the state of the system, this error may be returned
even if the operation has completed successfully. For example, a
successful response from a server could have been delayed long
enough for the deadline to expire.
HTTP Mapping: 504 Gateway Timeout
- NOT_FOUND: Some requested entity (e.g., file or directory) was not found.
Note to server developers: if a request is denied for an entire class
of users, such as gradual feature rollout or undocumented allowlist,
`NOT_FOUND` may be used. If a request is denied for some users within
a class of users, such as user-based access control, `PERMISSION_DENIED`
must be used.
HTTP Mapping: 404 Not Found
- ALREADY_EXISTS: The entity that a client attempted to create (e.g., file or directory)
already exists.
HTTP Mapping: 409 Conflict
- PERMISSION_DENIED: The caller does not have permission to execute the specified
operation. `PERMISSION_DENIED` must not be used for rejections
caused by exhausting some resource (use `RESOURCE_EXHAUSTED`
instead for those errors). `PERMISSION_DENIED` must not be
used if the caller can not be identified (use `UNAUTHENTICATED`
instead for those errors). This error code does not imply the
request is valid or the requested entity exists or satisfies
other pre-conditions.
HTTP Mapping: 403 Forbidden
- UNAUTHENTICATED: The request does not have valid authentication credentials for the
operation.
HTTP Mapping: 401 Unauthorized
- RESOURCE_EXHAUSTED: Some resource has been exhausted, perhaps a per-user quota, or
perhaps the entire file system is out of space.
HTTP Mapping: 429 Too Many Requests
- FAILED_PRECONDITION: The operation was rejected because the system is not in a state
required for the operation's execution. For example, the directory
to be deleted is non-empty, an rmdir operation is applied to
a non-directory, etc.
Service implementors can use the following guidelines to decide
between `FAILED_PRECONDITION`, `ABORTED`, and `UNAVAILABLE`:
(a) Use `UNAVAILABLE` if the client can retry just the failing call.
(b) Use `ABORTED` if the client should retry at a higher level. For
example, when a client-specified test-and-set fails, indicating the
client should restart a read-modify-write sequence.
(c) Use `FAILED_PRECONDITION` if the client should not retry until
the system state has been explicitly fixed. For example, if an "rmdir"
fails because the directory is non-empty, `FAILED_PRECONDITION`
should be returned since the client should not retry unless
the files are deleted from the directory.
HTTP Mapping: 400 Bad Request
- ABORTED: The operation was aborted, typically due to a concurrency issue such as
a sequencer check failure or transaction abort.
See the guidelines above for deciding between `FAILED_PRECONDITION`,
`ABORTED`, and `UNAVAILABLE`.
HTTP Mapping: 409 Conflict
- OUT_OF_RANGE: The operation was attempted past the valid range. E.g., seeking or
reading past end-of-file.
Unlike `INVALID_ARGUMENT`, this error indicates a problem that may
be fixed if the system state changes. For example, a 32-bit file
system will generate `INVALID_ARGUMENT` if asked to read at an
offset that is not in the range [0,2^32-1], but it will generate
`OUT_OF_RANGE` if asked to read from an offset past the current
file size.
There is a fair bit of overlap between `FAILED_PRECONDITION` and
`OUT_OF_RANGE`. We recommend using `OUT_OF_RANGE` (the more specific
error) when it applies so that callers who are iterating through
a space can easily look for an `OUT_OF_RANGE` error to detect when
they are done.
HTTP Mapping: 400 Bad Request
- UNIMPLEMENTED: The operation is not implemented or is not supported/enabled in this
service.
HTTP Mapping: 501 Not Implemented
- INTERNAL: Internal errors. This means that some invariants expected by the
underlying system have been broken. This error code is reserved
for serious errors.
HTTP Mapping: 500 Internal Server Error
- UNAVAILABLE: The service is currently unavailable. This is most likely a
transient condition, which can be corrected by retrying with
a backoff. Note that it is not always safe to retry
non-idempotent operations.
See the guidelines above for deciding between `FAILED_PRECONDITION`,
`ABORTED`, and `UNAVAILABLE`.
HTTP Mapping: 503 Service Unavailable
- DATA_LOSS: Unrecoverable data loss or corruption.
HTTP Mapping: 500 Internal Server Error
title: >-
Mimics
[https://github.com/googleapis/googleapis/blob/master/google/rpc/code.proto]
gatewayInferenceParameters:
type: object
properties:
maxTokens:
type: integer
format: int32
description: Maximum number of tokens to generate per response.
temperature:
type: number
format: float
description: Sampling temperature, typically between 0 and 2.
topP:
type: number
format: float
description: Top-p sampling parameter, typically between 0 and 1.
'n':
type: integer
format: int32
description: Number of response candidates to generate per input.
extraBody:
type: string
description: |-
Additional parameters for the inference request as a JSON string.
For example: "{\"stop\": [\"\\n\"]}".
topK:
type: integer
format: int32
description: >-
Top-k sampling parameter, limits the token selection to the top k
tokens.
description: Parameters for the inference requests.
gatewayJobProgress:
type: object
properties:
percent:
type: integer
format: int32
description: Progress percent, within the range from 0 to 100.
epoch:
type: integer
format: int32
description: >-
The epoch for which the progress percent is reported, usually
starting from 0.
This is optional for jobs that don't run in an epoch fasion, e.g.
BIJ, EVJ.
totalInputRequests:
type: integer
format: int32
description: Total number of input requests/rows in the job.
totalProcessedRequests:
type: integer
format: int32
description: >-
Total number of requests that have been processed (successfully or
failed).
successfullyProcessedRequests:
type: integer
format: int32
description: Number of requests that were processed successfully.
failedRequests:
type: integer
format: int32
description: Number of requests that failed to process.
outputRows:
type: integer
format: int32
description: Number of output rows generated.
inputTokens:
type: integer
format: int32
description: Total number of input tokens processed.
outputTokens:
type: integer
format: int32
description: Total number of output tokens generated.
cachedInputTokenCount:
type: integer
format: int32
description: The number of input tokens that hit the prompt cache.
description: Progress of a job, e.g. RLOR, EVJ, BIJ etc.
gatewayJobState:
type: string
enum:
- JOB_STATE_UNSPECIFIED
- JOB_STATE_CREATING
- JOB_STATE_RUNNING
- JOB_STATE_COMPLETED
- JOB_STATE_FAILED
- JOB_STATE_CANCELLED
- JOB_STATE_DELETING
- JOB_STATE_WRITING_RESULTS
- JOB_STATE_VALIDATING
- JOB_STATE_DELETING_CLEANING_UP
- JOB_STATE_PENDING
- JOB_STATE_EXPIRED
- JOB_STATE_RE_QUEUEING
- JOB_STATE_CREATING_INPUT_DATASET
- JOB_STATE_IDLE
- JOB_STATE_CANCELLING
- JOB_STATE_EARLY_STOPPED
default: JOB_STATE_UNSPECIFIED
description: JobState represents the state an asynchronous job can be in.
gatewayStatus:
type: object
properties:
code:
$ref: '#/components/schemas/gatewayCode'
description: The status code.
message:
type: string
description: A developer-facing error message in English.
title: >-
Mimics
[https://github.com/googleapis/googleapis/blob/master/google/rpc/status.proto]
````
---
# Source: https://docs.fireworks.ai/api-reference-dlde/create-batch-job.md
# Create Batch Job
## OpenAPI
````yaml post /v1/accounts/{account_id}/batchJobs
paths:
path: /v1/accounts/{account_id}/batchJobs
method: post
servers:
- url: https://api.fireworks.ai
request:
security:
- title: BearerAuth
parameters:
query: {}
header:
Authorization:
type: http
scheme: bearer
description: >-
Bearer authentication using your Fireworks API key. Format:
Bearer
cookie: {}
parameters:
path:
account_id:
schema:
- type: string
required: true
description: The Account Id
query: {}
header: {}
cookie: {}
body:
application/json:
schemaArray:
- type: object
properties:
displayName:
allOf:
- &ref_0
type: string
description: >-
Human-readable display name of the batch job. e.g. "My
Batch Job"
Must be fewer than 64 characters long.
nodePoolId:
allOf:
- &ref_1
type: string
title: >-
The ID of the node pool that this batch job should use.
e.g. my-node-pool
environmentId:
allOf:
- &ref_2
type: string
description: >-
The ID of the environment that this batch job should use.
e.g. my-env
If specified, image_ref must not be specified.
snapshotId:
allOf:
- &ref_3
type: string
description: >-
The ID of the snapshot used by this batch job.
If specified, environment_id must be specified and
image_ref must not be
specified.
numRanks:
allOf:
- &ref_4
type: integer
format: int32
description: |-
For GPU node pools: one GPU per rank w/ host packing,
for CPU node pools: one host per rank.
envVars:
allOf:
- &ref_5
type: object
additionalProperties:
type: string
description: >-
Environment variables to be passed during this job's
execution.
role:
allOf:
- &ref_6
type: string
description: >-
The ARN of the AWS IAM role that the batch job should
assume.
If not specified, the connection will fall back to the
node
pool's node_role.
pythonExecutor:
allOf:
- &ref_7
$ref: '#/components/schemas/gatewayPythonExecutor'
notebookExecutor:
allOf:
- &ref_8
$ref: '#/components/schemas/gatewayNotebookExecutor'
shellExecutor:
allOf:
- &ref_9
$ref: '#/components/schemas/gatewayShellExecutor'
imageRef:
allOf:
- &ref_10
type: string
description: >-
The container image used by this job. If specified,
environment_id and
snapshot_id must not be specified.
annotations:
allOf:
- &ref_11
type: object
additionalProperties:
type: string
description: >-
Arbitrary, user-specified metadata.
Keys and values must adhere to Kubernetes constraints:
https://kubernetes.io/docs/concepts/overview/working-with-objects/annotations/#syntax-and-character-set
Additionally, the "fireworks.ai/" prefix is reserved.
state:
allOf:
- &ref_12
$ref: '#/components/schemas/gatewayBatchJobState'
description: The current state of the batch job.
readOnly: true
shared:
allOf:
- &ref_13
type: boolean
description: >-
Whether the batch job is shared with all users in the
account.
This allows all users to update, delete, clone, and create
environments
using the batch job.
required: true
title: 'Next ID: 22'
refIdentifier: '#/components/schemas/gatewayBatchJob'
requiredProperties: &ref_14
- nodePoolId
examples:
example:
value:
displayName:
nodePoolId:
environmentId:
snapshotId:
numRanks: 123
envVars: {}
role:
pythonExecutor:
targetType: TARGET_TYPE_UNSPECIFIED
target:
args:
-
notebookExecutor:
notebookFilename:
shellExecutor:
command:
imageRef:
annotations: {}
shared: true
description: The properties of the batch job being created.
response:
'200':
application/json:
schemaArray:
- type: object
properties:
name:
allOf:
- type: string
title: >-
The resource name of the batch job.
e.g.
accounts/my-account/clusters/my-cluster/batchJobs/123456789
readOnly: true
displayName:
allOf:
- *ref_0
createTime:
allOf:
- type: string
format: date-time
description: The creation time of the batch job.
readOnly: true
startTime:
allOf:
- type: string
format: date-time
description: The time when the batch job started running.
readOnly: true
endTime:
allOf:
- type: string
format: date-time
description: >-
The time when the batch job completed, failed, or was
cancelled.
readOnly: true
createdBy:
allOf:
- type: string
description: The email address of the user who created this batch job.
readOnly: true
nodePoolId:
allOf:
- *ref_1
environmentId:
allOf:
- *ref_2
snapshotId:
allOf:
- *ref_3
numRanks:
allOf:
- *ref_4
envVars:
allOf:
- *ref_5
role:
allOf:
- *ref_6
pythonExecutor:
allOf:
- *ref_7
notebookExecutor:
allOf:
- *ref_8
shellExecutor:
allOf:
- *ref_9
imageRef:
allOf:
- *ref_10
annotations:
allOf:
- *ref_11
state:
allOf:
- *ref_12
status:
allOf:
- type: string
description: >-
Detailed information about the current status of the batch
job.
readOnly: true
shared:
allOf:
- *ref_13
updateTime:
allOf:
- type: string
format: date-time
description: The update time for the batch job.
readOnly: true
title: 'Next ID: 22'
refIdentifier: '#/components/schemas/gatewayBatchJob'
requiredProperties: *ref_14
examples:
example:
value:
name:
displayName:
createTime: '2023-11-07T05:31:56Z'
startTime: '2023-11-07T05:31:56Z'
endTime: '2023-11-07T05:31:56Z'
createdBy:
nodePoolId:
environmentId:
snapshotId:
numRanks: 123
envVars: {}
role:
pythonExecutor:
targetType: TARGET_TYPE_UNSPECIFIED
target:
args:
-
notebookExecutor:
notebookFilename:
shellExecutor:
command:
imageRef:
annotations: {}
state: STATE_UNSPECIFIED
status:
shared: true
updateTime: '2023-11-07T05:31:56Z'
description: A successful response.
deprecated: false
type: path
components:
schemas:
PythonExecutorTargetType:
type: string
enum:
- TARGET_TYPE_UNSPECIFIED
- MODULE
- FILENAME
default: TARGET_TYPE_UNSPECIFIED
description: |2-
- MODULE: Runs a python module, i.e. passed as -m argument.
- FILENAME: Runs a python file.
gatewayBatchJobState:
type: string
enum:
- STATE_UNSPECIFIED
- CREATING
- QUEUED
- PENDING
- RUNNING
- COMPLETED
- FAILED
- CANCELLING
- CANCELLED
- DELETING
default: STATE_UNSPECIFIED
description: |-
- CREATING: The batch job is being created.
- QUEUED: The batch job is in the queue and waiting to be scheduled.
Currently unused.
- PENDING: The batch job scheduled and is waiting for resource allocation.
- RUNNING: The batch job is running.
- COMPLETED: The batch job has finished successfully.
- FAILED: The batch job has failed.
- CANCELLING: The batch job is being cancelled.
- CANCELLED: The batch job was cancelled.
- DELETING: The batch job is being deleted.
title: 'Next ID: 10'
gatewayNotebookExecutor:
type: object
properties:
notebookFilename:
type: string
description: Path to a notebook file to be executed.
description: Execute a notebook file.
required:
- notebookFilename
gatewayPythonExecutor:
type: object
properties:
targetType:
$ref: '#/components/schemas/PythonExecutorTargetType'
description: The type of Python target to run.
target:
type: string
description: A Python module or filename depending on TargetType.
args:
type: array
items:
type: string
description: Command line arguments to pass to the Python process.
description: Execute a Python process.
required:
- targetType
- target
gatewayShellExecutor:
type: object
properties:
command:
type: string
title: Command we want to run for the shell script
description: Execute a shell script.
required:
- command
````
---
# Source: https://docs.fireworks.ai/api-reference/create-batch-request.md
# Create Batch Request
Create a batch request for our audio transcription service
### Headers
Your Fireworks API key, e.g. `Authorization=FIREWORKS_API_KEY`. Alternatively, can be provided as a query param.
### Path Parameters
The relative route of the target API operation (e.g. `"v1/audio/transcriptions"`, `"v1/audio/translations"`). This should correspond to a valid route supported by the backend service.
### Query Parameters
Identifies the target backend service or model to handle the request. Currently supported:
* `audio-prod`: [https://audio-prod.api.fireworks.ai](https://audio-prod.api.fireworks.ai)
* `audio-turbo`: [https://audio-turbo.api.fireworks.ai](https://audio-turbo.api.fireworks.ai)
### Body
Request body fields vary depending on the selected `endpoint_id` and `path`.
The request body must conform to the schema defined by the corresponding synchronous API.\
For example, transcription requests typically accept fields such as `model`, `diarize`, and `response_format`.\
Refer to the relevant synchronous API for required fields:
* [Transcribe audio](https://docs.fireworks.ai/api-reference/audio-transcriptions)
* [Translate audio](https://docs.fireworks.ai/api-reference/audio-translations)
### Response
The status of the batch request submission.\
A value of `"submitted"` indicates the batch request was accepted and queued for processing.
A unique identifier assigned to the batch job.
This ID can be used to check job status or retrieve results later.
The unique identifier of the account associated with the batch job.
The backend service selected to process the request.\
This typically matches the `endpoint_id` used during submission.
A human-readable message describing the result of the submission.\
Typically `"Request submitted successfully"` if accepted.
```curl curl theme={null}
# Download audio file
curl -L -o "audio.flac" "https://tinyurl.com/4997djsh"
# Make request
curl -X POST "https://audio-batch.api.fireworks.ai/v1/audio/transcriptions?endpoint_id=audio-prod" \
-H "Authorization: " \
-F "file=@audio.flac"
```
```python python theme={null}
!pip install requests
import os
import requests
# input API key and download audio
api_key = ""
audio = requests.get("https://tinyurl.com/4cb74vas").content
# Prepare request data
url = "https://audio-batch.api.fireworks.ai/v1/audio/transcriptions?endpoint_id=audio-prod"
headers = {"Authorization": api_key}
payload = {
"model": "whisper-v3",
"response_format": "json"
}
files = {"file": ("audio.flac", audio, "audio/flac")}
# Send request
response = requests.post(url, headers=headers, data=payload, files=files)
print(response.text)
```
To check the status of your batch request, use the [Check Batch Status](https://docs.fireworks.ai/api-reference/get-batch-status) endpoint with the returned `batch_id`.
---
# Source: https://docs.fireworks.ai/api-reference-dlde/create-cluster.md
# Create Cluster
## OpenAPI
````yaml post /v1/accounts/{account_id}/clusters
paths:
path: /v1/accounts/{account_id}/clusters
method: post
servers:
- url: https://api.fireworks.ai
request:
security:
- title: BearerAuth
parameters:
query: {}
header:
Authorization:
type: http
scheme: bearer
description: >-
Bearer authentication using your Fireworks API key. Format:
Bearer
cookie: {}
parameters:
path:
account_id:
schema:
- type: string
required: true
description: The Account Id
query: {}
header: {}
cookie: {}
body:
application/json:
schemaArray:
- type: object
properties:
cluster:
allOf:
- $ref: '#/components/schemas/gatewayCluster'
description: The properties of the cluster being created.
clusterId:
allOf:
- type: string
title: The cluster ID to use in the cluster name. e.g. my-cluster
required: true
refIdentifier: '#/components/schemas/GatewayCreateClusterBody'
requiredProperties:
- cluster
- clusterId
examples:
example:
value:
cluster:
displayName:
eksCluster:
awsAccountId:
fireworksManagerRole:
region:
clusterName:
storageBucketName:
metricWriterRole:
loadBalancerControllerRole:
workloadIdentityPoolProviderId:
inferenceRole:
fakeCluster:
projectId:
location:
clusterName:
clusterId:
response:
'200':
application/json:
schemaArray:
- type: object
properties:
name:
allOf:
- &ref_0
type: string
title: >-
The resource name of the cluster. e.g.
accounts/my-account/clusters/my-cluster
readOnly: true
displayName:
allOf:
- &ref_1
type: string
description: >-
Human-readable display name of the cluster. e.g. "My
Cluster"
Must be fewer than 64 characters long.
createTime:
allOf:
- &ref_2
type: string
format: date-time
description: The creation time of the cluster.
readOnly: true
eksCluster:
allOf:
- &ref_3
$ref: '#/components/schemas/gatewayEksCluster'
fakeCluster:
allOf:
- &ref_4
$ref: '#/components/schemas/gatewayFakeCluster'
state:
allOf:
- &ref_5
$ref: '#/components/schemas/gatewayClusterState'
description: The current state of the cluster.
readOnly: true
status:
allOf:
- &ref_6
$ref: '#/components/schemas/gatewayStatus'
description: >-
Detailed information about the current status of the
cluster.
readOnly: true
updateTime:
allOf:
- &ref_7
type: string
format: date-time
description: The update time for the cluster.
readOnly: true
title: 'Next ID: 15'
refIdentifier: '#/components/schemas/gatewayCluster'
examples:
example:
value:
name:
displayName:
createTime: '2023-11-07T05:31:56Z'
eksCluster:
awsAccountId:
fireworksManagerRole:
region:
clusterName:
storageBucketName:
metricWriterRole:
loadBalancerControllerRole:
workloadIdentityPoolProviderId:
inferenceRole:
fakeCluster:
projectId:
location:
clusterName:
state: STATE_UNSPECIFIED
status:
code: OK
message:
updateTime: '2023-11-07T05:31:56Z'
description: A successful response.
deprecated: false
type: path
components:
schemas:
gatewayCluster:
type: object
properties:
name: *ref_0
displayName: *ref_1
createTime: *ref_2
eksCluster: *ref_3
fakeCluster: *ref_4
state: *ref_5
status: *ref_6
updateTime: *ref_7
title: 'Next ID: 15'
gatewayClusterState:
type: string
enum:
- STATE_UNSPECIFIED
- CREATING
- READY
- DELETING
- FAILED
default: STATE_UNSPECIFIED
description: |2-
- CREATING: The cluster is still being created.
- READY: The cluster is ready to be used.
- DELETING: The cluster is being deleted.
- FAILED: Cluster is not operational.
Consult 'status' for detailed messaging.
Cluster needs to be deleted and re-created.
gatewayCode:
type: string
enum:
- OK
- CANCELLED
- UNKNOWN
- INVALID_ARGUMENT
- DEADLINE_EXCEEDED
- NOT_FOUND
- ALREADY_EXISTS
- PERMISSION_DENIED
- UNAUTHENTICATED
- RESOURCE_EXHAUSTED
- FAILED_PRECONDITION
- ABORTED
- OUT_OF_RANGE
- UNIMPLEMENTED
- INTERNAL
- UNAVAILABLE
- DATA_LOSS
default: OK
description: |-
- OK: Not an error; returned on success.
HTTP Mapping: 200 OK
- CANCELLED: The operation was cancelled, typically by the caller.
HTTP Mapping: 499 Client Closed Request
- UNKNOWN: Unknown error. For example, this error may be returned when
a `Status` value received from another address space belongs to
an error space that is not known in this address space. Also
errors raised by APIs that do not return enough error information
may be converted to this error.
HTTP Mapping: 500 Internal Server Error
- INVALID_ARGUMENT: The client specified an invalid argument. Note that this differs
from `FAILED_PRECONDITION`. `INVALID_ARGUMENT` indicates arguments
that are problematic regardless of the state of the system
(e.g., a malformed file name).
HTTP Mapping: 400 Bad Request
- DEADLINE_EXCEEDED: The deadline expired before the operation could complete. For operations
that change the state of the system, this error may be returned
even if the operation has completed successfully. For example, a
successful response from a server could have been delayed long
enough for the deadline to expire.
HTTP Mapping: 504 Gateway Timeout
- NOT_FOUND: Some requested entity (e.g., file or directory) was not found.
Note to server developers: if a request is denied for an entire class
of users, such as gradual feature rollout or undocumented allowlist,
`NOT_FOUND` may be used. If a request is denied for some users within
a class of users, such as user-based access control, `PERMISSION_DENIED`
must be used.
HTTP Mapping: 404 Not Found
- ALREADY_EXISTS: The entity that a client attempted to create (e.g., file or directory)
already exists.
HTTP Mapping: 409 Conflict
- PERMISSION_DENIED: The caller does not have permission to execute the specified
operation. `PERMISSION_DENIED` must not be used for rejections
caused by exhausting some resource (use `RESOURCE_EXHAUSTED`
instead for those errors). `PERMISSION_DENIED` must not be
used if the caller can not be identified (use `UNAUTHENTICATED`
instead for those errors). This error code does not imply the
request is valid or the requested entity exists or satisfies
other pre-conditions.
HTTP Mapping: 403 Forbidden
- UNAUTHENTICATED: The request does not have valid authentication credentials for the
operation.
HTTP Mapping: 401 Unauthorized
- RESOURCE_EXHAUSTED: Some resource has been exhausted, perhaps a per-user quota, or
perhaps the entire file system is out of space.
HTTP Mapping: 429 Too Many Requests
- FAILED_PRECONDITION: The operation was rejected because the system is not in a state
required for the operation's execution. For example, the directory
to be deleted is non-empty, an rmdir operation is applied to
a non-directory, etc.
Service implementors can use the following guidelines to decide
between `FAILED_PRECONDITION`, `ABORTED`, and `UNAVAILABLE`:
(a) Use `UNAVAILABLE` if the client can retry just the failing call.
(b) Use `ABORTED` if the client should retry at a higher level. For
example, when a client-specified test-and-set fails, indicating the
client should restart a read-modify-write sequence.
(c) Use `FAILED_PRECONDITION` if the client should not retry until
the system state has been explicitly fixed. For example, if an "rmdir"
fails because the directory is non-empty, `FAILED_PRECONDITION`
should be returned since the client should not retry unless
the files are deleted from the directory.
HTTP Mapping: 400 Bad Request
- ABORTED: The operation was aborted, typically due to a concurrency issue such as
a sequencer check failure or transaction abort.
See the guidelines above for deciding between `FAILED_PRECONDITION`,
`ABORTED`, and `UNAVAILABLE`.
HTTP Mapping: 409 Conflict
- OUT_OF_RANGE: The operation was attempted past the valid range. E.g., seeking or
reading past end-of-file.
Unlike `INVALID_ARGUMENT`, this error indicates a problem that may
be fixed if the system state changes. For example, a 32-bit file
system will generate `INVALID_ARGUMENT` if asked to read at an
offset that is not in the range [0,2^32-1], but it will generate
`OUT_OF_RANGE` if asked to read from an offset past the current
file size.
There is a fair bit of overlap between `FAILED_PRECONDITION` and
`OUT_OF_RANGE`. We recommend using `OUT_OF_RANGE` (the more specific
error) when it applies so that callers who are iterating through
a space can easily look for an `OUT_OF_RANGE` error to detect when
they are done.
HTTP Mapping: 400 Bad Request
- UNIMPLEMENTED: The operation is not implemented or is not supported/enabled in this
service.
HTTP Mapping: 501 Not Implemented
- INTERNAL: Internal errors. This means that some invariants expected by the
underlying system have been broken. This error code is reserved
for serious errors.
HTTP Mapping: 500 Internal Server Error
- UNAVAILABLE: The service is currently unavailable. This is most likely a
transient condition, which can be corrected by retrying with
a backoff. Note that it is not always safe to retry
non-idempotent operations.
See the guidelines above for deciding between `FAILED_PRECONDITION`,
`ABORTED`, and `UNAVAILABLE`.
HTTP Mapping: 503 Service Unavailable
- DATA_LOSS: Unrecoverable data loss or corruption.
HTTP Mapping: 500 Internal Server Error
title: >-
Mimics
[https://github.com/googleapis/googleapis/blob/master/google/rpc/code.proto]
gatewayEksCluster:
type: object
properties:
awsAccountId:
type: string
description: The 12-digit AWS account ID where this cluster lives.
fireworksManagerRole:
type: string
title: >-
The IAM role ARN used to manage Fireworks resources on AWS.
If not specified, the default is
arn:aws:iam:::role/FireworksManagerRole
region:
type: string
description: >-
The AWS region where this cluster lives. See
https://docs.aws.amazon.com/AmazonRDS/latest/UserGuide/Concepts.RegionsAndAvailabilityZones.html
for a list of available regions.
clusterName:
type: string
description: The EKS cluster name.
storageBucketName:
type: string
description: The S3 bucket name.
metricWriterRole:
type: string
description: >-
The IAM role ARN used by Google Managed Prometheus role that will
write metrics
to Fireworks managed Prometheus. The role must be assumable by the
`system:serviceaccount:gmp-system:collector` service account on the
EKS cluster.
If not specified, no metrics will be written to GCP.
loadBalancerControllerRole:
type: string
description: >-
The IAM role ARN used by the EKS load balancer controller (i.e. the
load balancer
automatically created for the k8s gateway resource). If not
specified, no gateway
will be created.
workloadIdentityPoolProviderId:
type: string
title: |-
The ID of the GCP workload identity pool provider in the Fireworks
project for this cluster. The pool ID is assumed to be "byoc-pool"
inferenceRole:
type: string
description: The IAM role ARN used by the inference pods on the cluster.
title: |-
An Amazon Elastic Kubernetes Service cluster.
Next ID: 16
required:
- awsAccountId
- region
gatewayFakeCluster:
type: object
properties:
projectId:
type: string
location:
type: string
clusterName:
type: string
title: A fake cluster using https://pkg.go.dev/k8s.io/client-go/kubernetes/fake
gatewayStatus:
type: object
properties:
code:
$ref: '#/components/schemas/gatewayCode'
description: The status code.
message:
type: string
description: A developer-facing error message in English.
title: >-
Mimics
[https://github.com/googleapis/googleapis/blob/master/google/rpc/status.proto]
````
---
# Source: https://docs.fireworks.ai/tools-sdks/firectl/commands/create-dataset.md
# Source: https://docs.fireworks.ai/api-reference/create-dataset.md
# Source: https://docs.fireworks.ai/tools-sdks/firectl/commands/create-dataset.md
# Source: https://docs.fireworks.ai/api-reference/create-dataset.md
# Source: https://docs.fireworks.ai/tools-sdks/firectl/commands/create-dataset.md
# Source: https://docs.fireworks.ai/api-reference/create-dataset.md
# Create Dataset
## OpenAPI
````yaml post /v1/accounts/{account_id}/datasets
paths:
path: /v1/accounts/{account_id}/datasets
method: post
servers:
- url: https://api.fireworks.ai
request:
security:
- title: BearerAuth
parameters:
query: {}
header:
Authorization:
type: http
scheme: bearer
description: >-
Bearer authentication using your Fireworks API key. Format:
Bearer
cookie: {}
parameters:
path:
account_id:
schema:
- type: string
required: true
description: The Account Id
query: {}
header: {}
cookie: {}
body:
application/json:
schemaArray:
- type: object
properties:
dataset:
allOf:
- $ref: '#/components/schemas/gatewayDataset'
datasetId:
allOf:
- type: string
sourceDatasetId:
allOf:
- type: string
title: >-
If set, indicates we are creating a new dataset by
filtering this existing dataset ID
filter:
allOf:
- type: string
title: >-
Filter condition (SQL-like WHERE clause) to apply to the
source dataset
required: true
refIdentifier: '#/components/schemas/GatewayCreateDatasetBody'
requiredProperties:
- dataset
- datasetId
examples:
example:
value:
dataset:
displayName:
exampleCount:
userUploaded: {}
evaluationResult:
evaluationJobId:
transformed:
sourceDatasetId:
filter:
originalFormat: FORMAT_UNSPECIFIED
splitted:
sourceDatasetId:
evalProtocol: {}
externalUrl:
format: FORMAT_UNSPECIFIED
sourceJobName:
datasetId:
sourceDatasetId:
filter:
response:
'200':
application/json:
schemaArray:
- type: object
properties:
name:
allOf:
- &ref_0
type: string
readOnly: true
displayName:
allOf:
- &ref_1
type: string
createTime:
allOf:
- &ref_2
type: string
format: date-time
readOnly: true
state:
allOf:
- &ref_3
$ref: '#/components/schemas/gatewayDatasetState'
readOnly: true
status:
allOf:
- &ref_4
$ref: '#/components/schemas/gatewayStatus'
readOnly: true
exampleCount:
allOf:
- &ref_5
type: string
format: int64
userUploaded:
allOf:
- &ref_6
$ref: '#/components/schemas/gatewayUserUploaded'
evaluationResult:
allOf:
- &ref_7
$ref: '#/components/schemas/gatewayEvaluationResult'
transformed:
allOf:
- &ref_8
$ref: '#/components/schemas/gatewayTransformed'
splitted:
allOf:
- &ref_9
$ref: '#/components/schemas/gatewaySplitted'
evalProtocol:
allOf:
- &ref_10
$ref: '#/components/schemas/gatewayEvalProtocol'
externalUrl:
allOf:
- &ref_11
type: string
title: >-
The external URI of the dataset. e.g.
gs://foo/bar/baz.jsonl
format:
allOf:
- &ref_12
$ref: '#/components/schemas/DatasetFormat'
createdBy:
allOf:
- &ref_13
type: string
description: >-
The email address of the user who initiated this
fine-tuning job.
readOnly: true
updateTime:
allOf:
- &ref_14
type: string
format: date-time
description: The update time for the dataset.
readOnly: true
sourceJobName:
allOf:
- &ref_15
type: string
description: >-
The resource name of the job that created this dataset
(e.g., batch inference job).
Used for lineage tracking to understand dataset
provenance.
estimatedTokenCount:
allOf:
- &ref_16
type: string
format: int64
description: The estimated number of tokens in the dataset.
readOnly: true
title: 'Next ID: 23'
refIdentifier: '#/components/schemas/gatewayDataset'
examples:
example:
value:
name:
displayName:
createTime: '2023-11-07T05:31:56Z'
state: STATE_UNSPECIFIED
status:
code: OK
message:
exampleCount:
userUploaded: {}
evaluationResult:
evaluationJobId:
transformed:
sourceDatasetId:
filter:
originalFormat: FORMAT_UNSPECIFIED
splitted:
sourceDatasetId:
evalProtocol: {}
externalUrl:
format: FORMAT_UNSPECIFIED
createdBy:
updateTime: '2023-11-07T05:31:56Z'
sourceJobName:
estimatedTokenCount:
description: A successful response.
deprecated: false
type: path
components:
schemas:
DatasetFormat:
type: string
enum:
- FORMAT_UNSPECIFIED
- CHAT
- COMPLETION
- RL
default: FORMAT_UNSPECIFIED
gatewayCode:
type: string
enum:
- OK
- CANCELLED
- UNKNOWN
- INVALID_ARGUMENT
- DEADLINE_EXCEEDED
- NOT_FOUND
- ALREADY_EXISTS
- PERMISSION_DENIED
- UNAUTHENTICATED
- RESOURCE_EXHAUSTED
- FAILED_PRECONDITION
- ABORTED
- OUT_OF_RANGE
- UNIMPLEMENTED
- INTERNAL
- UNAVAILABLE
- DATA_LOSS
default: OK
description: |-
- OK: Not an error; returned on success.
HTTP Mapping: 200 OK
- CANCELLED: The operation was cancelled, typically by the caller.
HTTP Mapping: 499 Client Closed Request
- UNKNOWN: Unknown error. For example, this error may be returned when
a `Status` value received from another address space belongs to
an error space that is not known in this address space. Also
errors raised by APIs that do not return enough error information
may be converted to this error.
HTTP Mapping: 500 Internal Server Error
- INVALID_ARGUMENT: The client specified an invalid argument. Note that this differs
from `FAILED_PRECONDITION`. `INVALID_ARGUMENT` indicates arguments
that are problematic regardless of the state of the system
(e.g., a malformed file name).
HTTP Mapping: 400 Bad Request
- DEADLINE_EXCEEDED: The deadline expired before the operation could complete. For operations
that change the state of the system, this error may be returned
even if the operation has completed successfully. For example, a
successful response from a server could have been delayed long
enough for the deadline to expire.
HTTP Mapping: 504 Gateway Timeout
- NOT_FOUND: Some requested entity (e.g., file or directory) was not found.
Note to server developers: if a request is denied for an entire class
of users, such as gradual feature rollout or undocumented allowlist,
`NOT_FOUND` may be used. If a request is denied for some users within
a class of users, such as user-based access control, `PERMISSION_DENIED`
must be used.
HTTP Mapping: 404 Not Found
- ALREADY_EXISTS: The entity that a client attempted to create (e.g., file or directory)
already exists.
HTTP Mapping: 409 Conflict
- PERMISSION_DENIED: The caller does not have permission to execute the specified
operation. `PERMISSION_DENIED` must not be used for rejections
caused by exhausting some resource (use `RESOURCE_EXHAUSTED`
instead for those errors). `PERMISSION_DENIED` must not be
used if the caller can not be identified (use `UNAUTHENTICATED`
instead for those errors). This error code does not imply the
request is valid or the requested entity exists or satisfies
other pre-conditions.
HTTP Mapping: 403 Forbidden
- UNAUTHENTICATED: The request does not have valid authentication credentials for the
operation.
HTTP Mapping: 401 Unauthorized
- RESOURCE_EXHAUSTED: Some resource has been exhausted, perhaps a per-user quota, or
perhaps the entire file system is out of space.
HTTP Mapping: 429 Too Many Requests
- FAILED_PRECONDITION: The operation was rejected because the system is not in a state
required for the operation's execution. For example, the directory
to be deleted is non-empty, an rmdir operation is applied to
a non-directory, etc.
Service implementors can use the following guidelines to decide
between `FAILED_PRECONDITION`, `ABORTED`, and `UNAVAILABLE`:
(a) Use `UNAVAILABLE` if the client can retry just the failing call.
(b) Use `ABORTED` if the client should retry at a higher level. For
example, when a client-specified test-and-set fails, indicating the
client should restart a read-modify-write sequence.
(c) Use `FAILED_PRECONDITION` if the client should not retry until
the system state has been explicitly fixed. For example, if an "rmdir"
fails because the directory is non-empty, `FAILED_PRECONDITION`
should be returned since the client should not retry unless
the files are deleted from the directory.
HTTP Mapping: 400 Bad Request
- ABORTED: The operation was aborted, typically due to a concurrency issue such as
a sequencer check failure or transaction abort.
See the guidelines above for deciding between `FAILED_PRECONDITION`,
`ABORTED`, and `UNAVAILABLE`.
HTTP Mapping: 409 Conflict
- OUT_OF_RANGE: The operation was attempted past the valid range. E.g., seeking or
reading past end-of-file.
Unlike `INVALID_ARGUMENT`, this error indicates a problem that may
be fixed if the system state changes. For example, a 32-bit file
system will generate `INVALID_ARGUMENT` if asked to read at an
offset that is not in the range [0,2^32-1], but it will generate
`OUT_OF_RANGE` if asked to read from an offset past the current
file size.
There is a fair bit of overlap between `FAILED_PRECONDITION` and
`OUT_OF_RANGE`. We recommend using `OUT_OF_RANGE` (the more specific
error) when it applies so that callers who are iterating through
a space can easily look for an `OUT_OF_RANGE` error to detect when
they are done.
HTTP Mapping: 400 Bad Request
- UNIMPLEMENTED: The operation is not implemented or is not supported/enabled in this
service.
HTTP Mapping: 501 Not Implemented
- INTERNAL: Internal errors. This means that some invariants expected by the
underlying system have been broken. This error code is reserved
for serious errors.
HTTP Mapping: 500 Internal Server Error
- UNAVAILABLE: The service is currently unavailable. This is most likely a
transient condition, which can be corrected by retrying with
a backoff. Note that it is not always safe to retry
non-idempotent operations.
See the guidelines above for deciding between `FAILED_PRECONDITION`,
`ABORTED`, and `UNAVAILABLE`.
HTTP Mapping: 503 Service Unavailable
- DATA_LOSS: Unrecoverable data loss or corruption.
HTTP Mapping: 500 Internal Server Error
title: >-
Mimics
[https://github.com/googleapis/googleapis/blob/master/google/rpc/code.proto]
gatewayDataset:
type: object
properties:
name: *ref_0
displayName: *ref_1
createTime: *ref_2
state: *ref_3
status: *ref_4
exampleCount: *ref_5
userUploaded: *ref_6
evaluationResult: *ref_7
transformed: *ref_8
splitted: *ref_9
evalProtocol: *ref_10
externalUrl: *ref_11
format: *ref_12
createdBy: *ref_13
updateTime: *ref_14
sourceJobName: *ref_15
estimatedTokenCount: *ref_16
title: 'Next ID: 23'
gatewayDatasetState:
type: string
enum:
- STATE_UNSPECIFIED
- UPLOADING
- READY
default: STATE_UNSPECIFIED
gatewayEvalProtocol:
type: object
gatewayEvaluationResult:
type: object
properties:
evaluationJobId:
type: string
required:
- evaluationJobId
gatewaySplitted:
type: object
properties:
sourceDatasetId:
type: string
required:
- sourceDatasetId
gatewayStatus:
type: object
properties:
code:
$ref: '#/components/schemas/gatewayCode'
description: The status code.
message:
type: string
description: A developer-facing error message in English.
title: >-
Mimics
[https://github.com/googleapis/googleapis/blob/master/google/rpc/status.proto]
gatewayTransformed:
type: object
properties:
sourceDatasetId:
type: string
filter:
type: string
originalFormat:
$ref: '#/components/schemas/DatasetFormat'
required:
- sourceDatasetId
gatewayUserUploaded:
type: object
````
---
# Source: https://docs.fireworks.ai/api-reference/create-deployed-model.md
# Load LoRA
## OpenAPI
````yaml post /v1/accounts/{account_id}/deployedModels
paths:
path: /v1/accounts/{account_id}/deployedModels
method: post
servers:
- url: https://api.fireworks.ai
request:
security:
- title: BearerAuth
parameters:
query: {}
header:
Authorization:
type: http
scheme: bearer
description: >-
Bearer authentication using your Fireworks API key. Format:
Bearer
cookie: {}
parameters:
path:
account_id:
schema:
- type: string
required: true
description: The Account Id
query:
replaceMergedAddon:
schema:
- type: boolean
required: false
description: >-
Merges new addon to the base model, while unmerging/deleting any
existing addon in the deployment. Must be specified for hot
reload deployments
header: {}
cookie: {}
body:
application/json:
schemaArray:
- type: object
properties:
displayName:
allOf:
- &ref_0
type: string
description:
allOf:
- &ref_1
type: string
description: Description of the resource.
model:
allOf:
- &ref_2
type: string
title: |-
The resource name of the model to be deployed.
e.g. accounts/my-account/models/my-model
deployment:
allOf:
- &ref_3
type: string
description: >-
The resource name of the base deployment the model is
deployed to.
default:
allOf:
- &ref_4
type: boolean
description: >-
If true, this is the default target when querying this
model without
the `#` suffix.
The first deployment a model is deployed to will have this
field set to true.
state:
allOf:
- &ref_5
$ref: '#/components/schemas/gatewayDeployedModelState'
description: The state of the deployed model.
readOnly: true
serverless:
allOf:
- &ref_6
type: boolean
title: True if the underlying deployment is managed by Fireworks
status:
allOf:
- &ref_7
$ref: '#/components/schemas/gatewayStatus'
description: Contains model deploy/undeploy details.
readOnly: true
public:
allOf:
- &ref_8
type: boolean
description: If true, the deployed model will be publicly reachable.
required: true
title: 'Next ID: 20'
refIdentifier: '#/components/schemas/gatewayDeployedModel'
examples:
example:
value:
displayName:
description:
model:
deployment:
default: true
serverless: true
public: true
response:
'200':
application/json:
schemaArray:
- type: object
properties:
name:
allOf:
- type: string
title: >-
The resource name. e.g.
accounts/my-account/deployedModels/my-deployed-model
readOnly: true
displayName:
allOf:
- *ref_0
description:
allOf:
- *ref_1
createTime:
allOf:
- type: string
format: date-time
description: The creation time of the resource.
readOnly: true
model:
allOf:
- *ref_2
deployment:
allOf:
- *ref_3
default:
allOf:
- *ref_4
state:
allOf:
- *ref_5
serverless:
allOf:
- *ref_6
status:
allOf:
- *ref_7
public:
allOf:
- *ref_8
updateTime:
allOf:
- type: string
format: date-time
description: The update time for the deployed model.
readOnly: true
title: 'Next ID: 20'
refIdentifier: '#/components/schemas/gatewayDeployedModel'
examples:
example:
value:
name:
displayName:
description:
createTime: '2023-11-07T05:31:56Z'
model:
deployment:
default: true
state: STATE_UNSPECIFIED
serverless: true
status:
code: OK
message:
public: true
updateTime: '2023-11-07T05:31:56Z'
description: A successful response.
deprecated: false
type: path
components:
schemas:
gatewayCode:
type: string
enum:
- OK
- CANCELLED
- UNKNOWN
- INVALID_ARGUMENT
- DEADLINE_EXCEEDED
- NOT_FOUND
- ALREADY_EXISTS
- PERMISSION_DENIED
- UNAUTHENTICATED
- RESOURCE_EXHAUSTED
- FAILED_PRECONDITION
- ABORTED
- OUT_OF_RANGE
- UNIMPLEMENTED
- INTERNAL
- UNAVAILABLE
- DATA_LOSS
default: OK
description: |-
- OK: Not an error; returned on success.
HTTP Mapping: 200 OK
- CANCELLED: The operation was cancelled, typically by the caller.
HTTP Mapping: 499 Client Closed Request
- UNKNOWN: Unknown error. For example, this error may be returned when
a `Status` value received from another address space belongs to
an error space that is not known in this address space. Also
errors raised by APIs that do not return enough error information
may be converted to this error.
HTTP Mapping: 500 Internal Server Error
- INVALID_ARGUMENT: The client specified an invalid argument. Note that this differs
from `FAILED_PRECONDITION`. `INVALID_ARGUMENT` indicates arguments
that are problematic regardless of the state of the system
(e.g., a malformed file name).
HTTP Mapping: 400 Bad Request
- DEADLINE_EXCEEDED: The deadline expired before the operation could complete. For operations
that change the state of the system, this error may be returned
even if the operation has completed successfully. For example, a
successful response from a server could have been delayed long
enough for the deadline to expire.
HTTP Mapping: 504 Gateway Timeout
- NOT_FOUND: Some requested entity (e.g., file or directory) was not found.
Note to server developers: if a request is denied for an entire class
of users, such as gradual feature rollout or undocumented allowlist,
`NOT_FOUND` may be used. If a request is denied for some users within
a class of users, such as user-based access control, `PERMISSION_DENIED`
must be used.
HTTP Mapping: 404 Not Found
- ALREADY_EXISTS: The entity that a client attempted to create (e.g., file or directory)
already exists.
HTTP Mapping: 409 Conflict
- PERMISSION_DENIED: The caller does not have permission to execute the specified
operation. `PERMISSION_DENIED` must not be used for rejections
caused by exhausting some resource (use `RESOURCE_EXHAUSTED`
instead for those errors). `PERMISSION_DENIED` must not be
used if the caller can not be identified (use `UNAUTHENTICATED`
instead for those errors). This error code does not imply the
request is valid or the requested entity exists or satisfies
other pre-conditions.
HTTP Mapping: 403 Forbidden
- UNAUTHENTICATED: The request does not have valid authentication credentials for the
operation.
HTTP Mapping: 401 Unauthorized
- RESOURCE_EXHAUSTED: Some resource has been exhausted, perhaps a per-user quota, or
perhaps the entire file system is out of space.
HTTP Mapping: 429 Too Many Requests
- FAILED_PRECONDITION: The operation was rejected because the system is not in a state
required for the operation's execution. For example, the directory
to be deleted is non-empty, an rmdir operation is applied to
a non-directory, etc.
Service implementors can use the following guidelines to decide
between `FAILED_PRECONDITION`, `ABORTED`, and `UNAVAILABLE`:
(a) Use `UNAVAILABLE` if the client can retry just the failing call.
(b) Use `ABORTED` if the client should retry at a higher level. For
example, when a client-specified test-and-set fails, indicating the
client should restart a read-modify-write sequence.
(c) Use `FAILED_PRECONDITION` if the client should not retry until
the system state has been explicitly fixed. For example, if an "rmdir"
fails because the directory is non-empty, `FAILED_PRECONDITION`
should be returned since the client should not retry unless
the files are deleted from the directory.
HTTP Mapping: 400 Bad Request
- ABORTED: The operation was aborted, typically due to a concurrency issue such as
a sequencer check failure or transaction abort.
See the guidelines above for deciding between `FAILED_PRECONDITION`,
`ABORTED`, and `UNAVAILABLE`.
HTTP Mapping: 409 Conflict
- OUT_OF_RANGE: The operation was attempted past the valid range. E.g., seeking or
reading past end-of-file.
Unlike `INVALID_ARGUMENT`, this error indicates a problem that may
be fixed if the system state changes. For example, a 32-bit file
system will generate `INVALID_ARGUMENT` if asked to read at an
offset that is not in the range [0,2^32-1], but it will generate
`OUT_OF_RANGE` if asked to read from an offset past the current
file size.
There is a fair bit of overlap between `FAILED_PRECONDITION` and
`OUT_OF_RANGE`. We recommend using `OUT_OF_RANGE` (the more specific
error) when it applies so that callers who are iterating through
a space can easily look for an `OUT_OF_RANGE` error to detect when
they are done.
HTTP Mapping: 400 Bad Request
- UNIMPLEMENTED: The operation is not implemented or is not supported/enabled in this
service.
HTTP Mapping: 501 Not Implemented
- INTERNAL: Internal errors. This means that some invariants expected by the
underlying system have been broken. This error code is reserved
for serious errors.
HTTP Mapping: 500 Internal Server Error
- UNAVAILABLE: The service is currently unavailable. This is most likely a
transient condition, which can be corrected by retrying with
a backoff. Note that it is not always safe to retry
non-idempotent operations.
See the guidelines above for deciding between `FAILED_PRECONDITION`,
`ABORTED`, and `UNAVAILABLE`.
HTTP Mapping: 503 Service Unavailable
- DATA_LOSS: Unrecoverable data loss or corruption.
HTTP Mapping: 500 Internal Server Error
title: >-
Mimics
[https://github.com/googleapis/googleapis/blob/master/google/rpc/code.proto]
gatewayDeployedModelState:
type: string
enum:
- STATE_UNSPECIFIED
- UNDEPLOYING
- DEPLOYING
- DEPLOYED
- UPDATING
default: STATE_UNSPECIFIED
description: |-
- UNDEPLOYING: The model is being undeployed.
- DEPLOYING: The model is being deployed.
- DEPLOYED: The model is deployed and ready for inference.
- UPDATING: there are updates happening with the deployed model
title: 'Next ID: 6'
gatewayStatus:
type: object
properties:
code:
$ref: '#/components/schemas/gatewayCode'
description: The status code.
message:
type: string
description: A developer-facing error message in English.
title: >-
Mimics
[https://github.com/googleapis/googleapis/blob/master/google/rpc/status.proto]
````
---
# Source: https://docs.fireworks.ai/tools-sdks/firectl/commands/create-deployment.md
# Source: https://docs.fireworks.ai/api-reference/create-deployment.md
# Source: https://docs.fireworks.ai/tools-sdks/firectl/commands/create-deployment.md
# Source: https://docs.fireworks.ai/api-reference/create-deployment.md
# Source: https://docs.fireworks.ai/tools-sdks/firectl/commands/create-deployment.md
# Source: https://docs.fireworks.ai/api-reference/create-deployment.md
# Create Deployment
## OpenAPI
````yaml post /v1/accounts/{account_id}/deployments
paths:
path: /v1/accounts/{account_id}/deployments
method: post
servers:
- url: https://api.fireworks.ai
request:
security:
- title: BearerAuth
parameters:
query: {}
header:
Authorization:
type: http
scheme: bearer
description: >-
Bearer authentication using your Fireworks API key. Format:
Bearer
cookie: {}
parameters:
path:
account_id:
schema:
- type: string
required: true
description: The Account Id
query:
disableAutoDeploy:
schema:
- type: boolean
required: false
description: >-
By default, a deployment created with a currently undeployed
base model
will be deployed to this deployment. If true, this auto-deploy
function
is disabled.
disableSpeculativeDecoding:
schema:
- type: boolean
required: false
description: >-
By default, a deployment will use the speculative decoding
settings from
the base model. If true, this will disable speculative decoding.
deploymentId:
schema:
- type: string
required: false
description: >-
The ID of the deployment. If not specified, a random ID will be
generated.
validateOnly:
schema:
- type: boolean
required: false
description: >-
If true, this will not create the deployment, but will return
the deployment
that would be created.
skipShapeValidation:
schema:
- type: boolean
required: false
description: >-
By default, a deployment will ensure the deployment shape
provided is validated.
If true, we will not require the deployment shape to be
validated.
header: {}
cookie: {}
body:
application/json:
schemaArray:
- type: object
properties:
displayName:
allOf:
- &ref_0
type: string
description: >-
Human-readable display name of the deployment. e.g. "My
Deployment"
Must be fewer than 64 characters long.
description:
allOf:
- &ref_1
type: string
description: Description of the deployment.
expireTime:
allOf:
- &ref_2
type: string
format: date-time
description: >-
The time at which this deployment will automatically be
deleted.
state:
allOf:
- &ref_3
$ref: '#/components/schemas/gatewayDeploymentState'
description: The state of the deployment.
readOnly: true
status:
allOf:
- &ref_4
$ref: '#/components/schemas/gatewayStatus'
description: >-
Detailed status information regarding the most recent
operation.
readOnly: true
minReplicaCount:
allOf:
- &ref_5
type: integer
format: int32
description: |-
The minimum number of replicas.
If not specified, the default is 0.
maxReplicaCount:
allOf:
- &ref_6
type: integer
format: int32
description: >-
The maximum number of replicas.
If not specified, the default is max(min_replica_count,
1).
May be set to 0 to downscale the deployment to 0.
autoscalingPolicy:
allOf:
- &ref_7
$ref: '#/components/schemas/gatewayAutoscalingPolicy'
baseModel:
allOf:
- &ref_8
type: string
title: >-
The base model name. e.g.
accounts/fireworks/models/falcon-7b
acceleratorCount:
allOf:
- &ref_9
type: integer
format: int32
description: >-
The number of accelerators used per replica.
If not specified, the default is the estimated minimum
required by the
base model.
acceleratorType:
allOf:
- &ref_10
$ref: '#/components/schemas/gatewayAcceleratorType'
description: |-
The type of accelerator to use.
If not specified, the default is NVIDIA_A100_80GB.
precision:
allOf:
- &ref_11
$ref: '#/components/schemas/DeploymentPrecision'
description: The precision with which the model should be served.
enableAddons:
allOf:
- &ref_12
type: boolean
description: If true, PEFT addons are enabled for this deployment.
draftTokenCount:
allOf:
- &ref_13
type: integer
format: int32
description: >-
The number of candidate tokens to generate per step for
speculative
decoding.
Default is the base model's draft_token_count. Set
CreateDeploymentRequest.disable_speculative_decoding to
false to disable
this behavior.
draftModel:
allOf:
- &ref_14
type: string
description: >-
The draft model name for speculative decoding. e.g.
accounts/fireworks/models/my-draft-model
If empty, speculative decoding using a draft model is
disabled.
Default is the base model's default_draft_model. Set
CreateDeploymentRequest.disable_speculative_decoding to
false to disable
this behavior.
ngramSpeculationLength:
allOf:
- &ref_15
type: integer
format: int32
description: >-
The length of previous input sequence to be considered for
N-gram speculation.
enableSessionAffinity:
allOf:
- &ref_16
type: boolean
description: Whether to apply sticky routing based on `user` field.
directRouteApiKeys:
allOf:
- &ref_17
type: array
items:
type: string
description: >-
The set of API keys used to access the direct route
deployment. If direct routing is not enabled, this field
is unused.
directRouteType:
allOf:
- &ref_18
$ref: '#/components/schemas/gatewayDirectRouteType'
description: >-
If set, this deployment will expose an endpoint that
bypasses the Fireworks API gateway.
deploymentTemplate:
allOf:
- &ref_19
type: string
description: >-
The name of the deployment template to use for this
deployment. Only
available to enterprise accounts.
autoTune:
allOf:
- &ref_20
$ref: '#/components/schemas/gatewayAutoTune'
description: The performance profile to use for this deployment.
placement:
allOf:
- &ref_21
$ref: '#/components/schemas/gatewayPlacement'
description: >-
The desired geographic region where the deployment must be
placed.
If unspecified, the default is the GLOBAL multi-region.
region:
allOf:
- &ref_22
$ref: '#/components/schemas/gatewayRegion'
description: >-
The geographic region where the deployment is presently
located. This region may change
over time, but within the `placement` constraint.
readOnly: true
disableDeploymentSizeValidation:
allOf:
- &ref_23
type: boolean
description: Whether the deployment size validation is disabled.
enableMtp:
allOf:
- &ref_24
type: boolean
description: If true, MTP is enabled for this deployment.
enableHotReloadLatestAddon:
allOf:
- &ref_25
type: boolean
description: >-
Allows up to 1 addon at a time to be loaded, and will
merge it into the base model.
deploymentShape:
allOf:
- &ref_26
type: string
description: >-
The name of the deployment shape that this deployment is
using.
On the server side, this will be replaced with the
deployment shape version name.
activeModelVersion:
allOf:
- &ref_27
type: string
description: >-
The model version that is currently active and applied to
running replicas of a deployment.
targetModelVersion:
allOf:
- &ref_28
type: string
description: >-
The target model version that is being rolled out to the
deployment.
In a ready steady state, the target model version is the
same as the active model version.
required: true
title: 'Next ID: 82'
refIdentifier: '#/components/schemas/gatewayDeployment'
requiredProperties: &ref_29
- baseModel
examples:
example:
value:
displayName:
description:
expireTime: '2023-11-07T05:31:56Z'
minReplicaCount: 123
maxReplicaCount: 123
autoscalingPolicy:
scaleUpWindow:
scaleDownWindow:
scaleToZeroWindow:
loadTargets: {}
baseModel:
acceleratorCount: 123
acceleratorType: ACCELERATOR_TYPE_UNSPECIFIED
precision: PRECISION_UNSPECIFIED
enableAddons: true
draftTokenCount: 123
draftModel:
ngramSpeculationLength: 123
enableSessionAffinity: true
directRouteApiKeys:
-
directRouteType: DIRECT_ROUTE_TYPE_UNSPECIFIED
deploymentTemplate:
autoTune:
longPrompt: true
placement:
region: REGION_UNSPECIFIED
multiRegion: MULTI_REGION_UNSPECIFIED
regions:
- REGION_UNSPECIFIED
disableDeploymentSizeValidation: true
enableMtp: true
enableHotReloadLatestAddon: true
deploymentShape:
activeModelVersion:
targetModelVersion:
description: The properties of the deployment being created.
response:
'200':
application/json:
schemaArray:
- type: object
properties:
name:
allOf:
- type: string
title: >-
The resource name of the deployment. e.g.
accounts/my-account/deployments/my-deployment
readOnly: true
displayName:
allOf:
- *ref_0
description:
allOf:
- *ref_1
createTime:
allOf:
- type: string
format: date-time
description: The creation time of the deployment.
readOnly: true
expireTime:
allOf:
- *ref_2
purgeTime:
allOf:
- type: string
format: date-time
description: The time at which the resource will be hard deleted.
readOnly: true
deleteTime:
allOf:
- type: string
format: date-time
description: The time at which the resource will be soft deleted.
readOnly: true
state:
allOf:
- *ref_3
status:
allOf:
- *ref_4
minReplicaCount:
allOf:
- *ref_5
maxReplicaCount:
allOf:
- *ref_6
desiredReplicaCount:
allOf:
- type: integer
format: int32
description: >-
The desired number of replicas for this deployment. This
represents the target
replica count that the system is trying to achieve.
readOnly: true
replicaCount:
allOf:
- type: integer
format: int32
readOnly: true
autoscalingPolicy:
allOf:
- *ref_7
baseModel:
allOf:
- *ref_8
acceleratorCount:
allOf:
- *ref_9
acceleratorType:
allOf:
- *ref_10
precision:
allOf:
- *ref_11
cluster:
allOf:
- type: string
description: >-
If set, this deployment is deployed to a cloud-premise
cluster.
readOnly: true
enableAddons:
allOf:
- *ref_12
draftTokenCount:
allOf:
- *ref_13
draftModel:
allOf:
- *ref_14
ngramSpeculationLength:
allOf:
- *ref_15
enableSessionAffinity:
allOf:
- *ref_16
directRouteApiKeys:
allOf:
- *ref_17
numPeftDeviceCached:
allOf:
- type: integer
format: int32
title: How many peft adapters to keep on gpu side for caching
readOnly: true
directRouteType:
allOf:
- *ref_18
directRouteHandle:
allOf:
- type: string
description: >-
The handle for calling a direct route. The meaning of the
handle depends on the
direct route type of the deployment:
INTERNET -> The host name for accessing the deployment
GCP_PRIVATE_SERVICE_CONNECT -> The service attachment name used to create the PSC endpoint.
AWS_PRIVATELINK -> The service name used to create the VPC endpoint.
readOnly: true
deploymentTemplate:
allOf:
- *ref_19
autoTune:
allOf:
- *ref_20
placement:
allOf:
- *ref_21
region:
allOf:
- *ref_22
updateTime:
allOf:
- type: string
format: date-time
description: The update time for the deployment.
readOnly: true
disableDeploymentSizeValidation:
allOf:
- *ref_23
enableMtp:
allOf:
- *ref_24
enableHotReloadLatestAddon:
allOf:
- *ref_25
deploymentShape:
allOf:
- *ref_26
activeModelVersion:
allOf:
- *ref_27
targetModelVersion:
allOf:
- *ref_28
title: 'Next ID: 82'
refIdentifier: '#/components/schemas/gatewayDeployment'
requiredProperties: *ref_29
examples:
example:
value:
name:
displayName:
description:
createTime: '2023-11-07T05:31:56Z'
expireTime: '2023-11-07T05:31:56Z'
purgeTime: '2023-11-07T05:31:56Z'
deleteTime: '2023-11-07T05:31:56Z'
state: STATE_UNSPECIFIED
status:
code: OK
message:
minReplicaCount: 123
maxReplicaCount: 123
desiredReplicaCount: 123
replicaCount: 123
autoscalingPolicy:
scaleUpWindow:
scaleDownWindow:
scaleToZeroWindow:
loadTargets: {}
baseModel:
acceleratorCount: 123
acceleratorType: ACCELERATOR_TYPE_UNSPECIFIED
precision: PRECISION_UNSPECIFIED
cluster:
enableAddons: true
draftTokenCount: 123
draftModel:
ngramSpeculationLength: 123
enableSessionAffinity: true
directRouteApiKeys:
-
numPeftDeviceCached: 123
directRouteType: DIRECT_ROUTE_TYPE_UNSPECIFIED
directRouteHandle:
deploymentTemplate:
autoTune:
longPrompt: true
placement:
region: REGION_UNSPECIFIED
multiRegion: MULTI_REGION_UNSPECIFIED
regions:
- REGION_UNSPECIFIED
region: REGION_UNSPECIFIED
updateTime: '2023-11-07T05:31:56Z'
disableDeploymentSizeValidation: true
enableMtp: true
enableHotReloadLatestAddon: true
deploymentShape:
activeModelVersion:
targetModelVersion:
description: A successful response.
deprecated: false
type: path
components:
schemas:
DeploymentPrecision:
type: string
enum:
- PRECISION_UNSPECIFIED
- FP16
- FP8
- FP8_MM
- FP8_AR
- FP8_MM_KV_ATTN
- FP8_KV
- FP8_MM_V2
- FP8_V2
- FP8_MM_KV_ATTN_V2
- NF4
- FP4
- BF16
- FP4_BLOCKSCALED_MM
- FP4_MX_MOE
default: PRECISION_UNSPECIFIED
title: >-
- PRECISION_UNSPECIFIED: if left unspecified we will treat this as a
legacy model created before
self serve
gatewayAcceleratorType:
type: string
enum:
- ACCELERATOR_TYPE_UNSPECIFIED
- NVIDIA_A100_80GB
- NVIDIA_H100_80GB
- AMD_MI300X_192GB
- NVIDIA_A10G_24GB
- NVIDIA_A100_40GB
- NVIDIA_L4_24GB
- NVIDIA_H200_141GB
- NVIDIA_B200_180GB
- AMD_MI325X_256GB
default: ACCELERATOR_TYPE_UNSPECIFIED
gatewayAutoTune:
type: object
properties:
longPrompt:
type: boolean
description: If true, this deployment is optimized for long prompt lengths.
gatewayAutoscalingPolicy:
type: object
properties:
scaleUpWindow:
type: string
description: >-
The duration the autoscaler will wait before scaling up a deployment
after observing
increased load. Default is 30s.
scaleDownWindow:
type: string
description: >-
The duration the autoscaler will wait before scaling down a
deployment after observing
decreased load. Default is 10m.
scaleToZeroWindow:
type: string
description: >-
The duration after which there are no requests that the deployment
will be scaled down
to zero replicas, if min_replica_count==0. Default is 1h.
This must be at least 5 minutes.
loadTargets:
type: object
additionalProperties:
type: number
format: float
title: >-
Map of load metric names to their target utilization factors.
Currently only the "default" key is supported, which specifies the
default target for all metrics.
If not specified, the default target is 0.8
gatewayCode:
type: string
enum:
- OK
- CANCELLED
- UNKNOWN
- INVALID_ARGUMENT
- DEADLINE_EXCEEDED
- NOT_FOUND
- ALREADY_EXISTS
- PERMISSION_DENIED
- UNAUTHENTICATED
- RESOURCE_EXHAUSTED
- FAILED_PRECONDITION
- ABORTED
- OUT_OF_RANGE
- UNIMPLEMENTED
- INTERNAL
- UNAVAILABLE
- DATA_LOSS
default: OK
description: |-
- OK: Not an error; returned on success.
HTTP Mapping: 200 OK
- CANCELLED: The operation was cancelled, typically by the caller.
HTTP Mapping: 499 Client Closed Request
- UNKNOWN: Unknown error. For example, this error may be returned when
a `Status` value received from another address space belongs to
an error space that is not known in this address space. Also
errors raised by APIs that do not return enough error information
may be converted to this error.
HTTP Mapping: 500 Internal Server Error
- INVALID_ARGUMENT: The client specified an invalid argument. Note that this differs
from `FAILED_PRECONDITION`. `INVALID_ARGUMENT` indicates arguments
that are problematic regardless of the state of the system
(e.g., a malformed file name).
HTTP Mapping: 400 Bad Request
- DEADLINE_EXCEEDED: The deadline expired before the operation could complete. For operations
that change the state of the system, this error may be returned
even if the operation has completed successfully. For example, a
successful response from a server could have been delayed long
enough for the deadline to expire.
HTTP Mapping: 504 Gateway Timeout
- NOT_FOUND: Some requested entity (e.g., file or directory) was not found.
Note to server developers: if a request is denied for an entire class
of users, such as gradual feature rollout or undocumented allowlist,
`NOT_FOUND` may be used. If a request is denied for some users within
a class of users, such as user-based access control, `PERMISSION_DENIED`
must be used.
HTTP Mapping: 404 Not Found
- ALREADY_EXISTS: The entity that a client attempted to create (e.g., file or directory)
already exists.
HTTP Mapping: 409 Conflict
- PERMISSION_DENIED: The caller does not have permission to execute the specified
operation. `PERMISSION_DENIED` must not be used for rejections
caused by exhausting some resource (use `RESOURCE_EXHAUSTED`
instead for those errors). `PERMISSION_DENIED` must not be
used if the caller can not be identified (use `UNAUTHENTICATED`
instead for those errors). This error code does not imply the
request is valid or the requested entity exists or satisfies
other pre-conditions.
HTTP Mapping: 403 Forbidden
- UNAUTHENTICATED: The request does not have valid authentication credentials for the
operation.
HTTP Mapping: 401 Unauthorized
- RESOURCE_EXHAUSTED: Some resource has been exhausted, perhaps a per-user quota, or
perhaps the entire file system is out of space.
HTTP Mapping: 429 Too Many Requests
- FAILED_PRECONDITION: The operation was rejected because the system is not in a state
required for the operation's execution. For example, the directory
to be deleted is non-empty, an rmdir operation is applied to
a non-directory, etc.
Service implementors can use the following guidelines to decide
between `FAILED_PRECONDITION`, `ABORTED`, and `UNAVAILABLE`:
(a) Use `UNAVAILABLE` if the client can retry just the failing call.
(b) Use `ABORTED` if the client should retry at a higher level. For
example, when a client-specified test-and-set fails, indicating the
client should restart a read-modify-write sequence.
(c) Use `FAILED_PRECONDITION` if the client should not retry until
the system state has been explicitly fixed. For example, if an "rmdir"
fails because the directory is non-empty, `FAILED_PRECONDITION`
should be returned since the client should not retry unless
the files are deleted from the directory.
HTTP Mapping: 400 Bad Request
- ABORTED: The operation was aborted, typically due to a concurrency issue such as
a sequencer check failure or transaction abort.
See the guidelines above for deciding between `FAILED_PRECONDITION`,
`ABORTED`, and `UNAVAILABLE`.
HTTP Mapping: 409 Conflict
- OUT_OF_RANGE: The operation was attempted past the valid range. E.g., seeking or
reading past end-of-file.
Unlike `INVALID_ARGUMENT`, this error indicates a problem that may
be fixed if the system state changes. For example, a 32-bit file
system will generate `INVALID_ARGUMENT` if asked to read at an
offset that is not in the range [0,2^32-1], but it will generate
`OUT_OF_RANGE` if asked to read from an offset past the current
file size.
There is a fair bit of overlap between `FAILED_PRECONDITION` and
`OUT_OF_RANGE`. We recommend using `OUT_OF_RANGE` (the more specific
error) when it applies so that callers who are iterating through
a space can easily look for an `OUT_OF_RANGE` error to detect when
they are done.
HTTP Mapping: 400 Bad Request
- UNIMPLEMENTED: The operation is not implemented or is not supported/enabled in this
service.
HTTP Mapping: 501 Not Implemented
- INTERNAL: Internal errors. This means that some invariants expected by the
underlying system have been broken. This error code is reserved
for serious errors.
HTTP Mapping: 500 Internal Server Error
- UNAVAILABLE: The service is currently unavailable. This is most likely a
transient condition, which can be corrected by retrying with
a backoff. Note that it is not always safe to retry
non-idempotent operations.
See the guidelines above for deciding between `FAILED_PRECONDITION`,
`ABORTED`, and `UNAVAILABLE`.
HTTP Mapping: 503 Service Unavailable
- DATA_LOSS: Unrecoverable data loss or corruption.
HTTP Mapping: 500 Internal Server Error
title: >-
Mimics
[https://github.com/googleapis/googleapis/blob/master/google/rpc/code.proto]
gatewayDeploymentState:
type: string
enum:
- STATE_UNSPECIFIED
- CREATING
- READY
- DELETING
- FAILED
- UPDATING
- DELETED
default: STATE_UNSPECIFIED
description: |2-
- CREATING: The deployment is still being created.
- READY: The deployment is ready to be used.
- DELETING: The deployment is being deleted.
- FAILED: The deployment failed to be created. See the `status` field for
additional details on why it failed.
- UPDATING: There are in-progress updates happening with the deployment.
- DELETED: The deployment is soft-deleted.
gatewayDirectRouteType:
type: string
enum:
- DIRECT_ROUTE_TYPE_UNSPECIFIED
- INTERNET
- GCP_PRIVATE_SERVICE_CONNECT
- AWS_PRIVATELINK
default: DIRECT_ROUTE_TYPE_UNSPECIFIED
title: |-
- DIRECT_ROUTE_TYPE_UNSPECIFIED: No direct routing
- INTERNET: The direct route is exposed via the public internet
- GCP_PRIVATE_SERVICE_CONNECT: The direct route is exposed via GCP Private Service Connect
- AWS_PRIVATELINK: The direct route is exposed via AWS PrivateLink
gatewayMultiRegion:
type: string
enum:
- MULTI_REGION_UNSPECIFIED
- GLOBAL
- US
default: MULTI_REGION_UNSPECIFIED
gatewayPlacement:
type: object
properties:
region:
$ref: '#/components/schemas/gatewayRegion'
description: The region where the deployment must be placed.
multiRegion:
$ref: '#/components/schemas/gatewayMultiRegion'
description: The multi-region where the deployment must be placed.
regions:
type: array
items:
$ref: '#/components/schemas/gatewayRegion'
title: The list of regions where the deployment must be placed
description: >-
The desired geographic region where the deployment must be placed.
Exactly one field will be
specified.
gatewayRegion:
type: string
enum:
- REGION_UNSPECIFIED
- US_IOWA_1
- US_VIRGINIA_1
- US_ILLINOIS_1
- AP_TOKYO_1
- US_ARIZONA_1
- US_TEXAS_1
- US_ILLINOIS_2
- EU_FRANKFURT_1
- US_TEXAS_2
- EU_ICELAND_1
- EU_ICELAND_2
- US_WASHINGTON_1
- US_WASHINGTON_2
- US_WASHINGTON_3
- AP_TOKYO_2
- US_CALIFORNIA_1
- US_UTAH_1
- US_TEXAS_3
- US_GEORGIA_1
- US_GEORGIA_2
- US_WASHINGTON_4
- US_GEORGIA_3
default: REGION_UNSPECIFIED
title: |-
- US_IOWA_1: GCP us-central1 (Iowa)
- US_VIRGINIA_1: AWS us-east-1 (N. Virginia)
- US_ILLINOIS_1: OCI us-chicago-1
- AP_TOKYO_1: OCI ap-tokyo-1
- US_ARIZONA_1: OCI us-phoenix-1
- US_TEXAS_1: Lambda us-south-3 (C. Texas)
- US_ILLINOIS_2: Lambda us-midwest-1 (Illinois)
- EU_FRANKFURT_1: OCI eu-frankfurt-1
- US_TEXAS_2: Lambda us-south-2 (N. Texas)
- EU_ICELAND_1: Crusoe eu-iceland1
- EU_ICELAND_2: Crusoe eu-iceland1 (network1)
- US_WASHINGTON_1: Voltage Park us-pyl-1 (Detach audio cluster from control_plane)
- US_WASHINGTON_2: Voltage Park us-seattle-2
- US_WASHINGTON_3: Vultr Seattle 1
- AP_TOKYO_2: AWS ap-northeast-1
- US_CALIFORNIA_1: AWS us-west-1 (N. California)
- US_UTAH_1: GCP us-west3 (Utah)
- US_TEXAS_3: Crusoe us-southcentral1
- US_GEORGIA_1: DigitalOcean us-atl1
- US_GEORGIA_2: Vultr Atlanta 1
- US_WASHINGTON_4: Coreweave us-west-09b-1
- US_GEORGIA_3: Alicloud us-southeast-1
gatewayStatus:
type: object
properties:
code:
$ref: '#/components/schemas/gatewayCode'
description: The status code.
message:
type: string
description: A developer-facing error message in English.
title: >-
Mimics
[https://github.com/googleapis/googleapis/blob/master/google/rpc/status.proto]
````
---
# Source: https://docs.fireworks.ai/tools-sdks/firectl/commands/create-dpo-job.md
# Source: https://docs.fireworks.ai/api-reference/create-dpo-job.md
# Source: https://docs.fireworks.ai/tools-sdks/firectl/commands/create-dpo-job.md
# Source: https://docs.fireworks.ai/api-reference/create-dpo-job.md
# Source: https://docs.fireworks.ai/tools-sdks/firectl/commands/create-dpo-job.md
# Source: https://docs.fireworks.ai/api-reference/create-dpo-job.md
# null
## OpenAPI
````yaml post /v1/accounts/{account_id}/dpoJobs
paths:
path: /v1/accounts/{account_id}/dpoJobs
method: post
servers:
- url: https://api.fireworks.ai
request:
security:
- title: BearerAuth
parameters:
query: {}
header:
Authorization:
type: http
scheme: bearer
description: >-
Bearer authentication using your Fireworks API key. Format:
Bearer
cookie: {}
parameters:
path:
account_id:
schema:
- type: string
required: true
description: The Account Id
query:
dpoJobId:
schema:
- type: string
required: false
description: >-
ID of the DPO job, a random ID will be generated if not
specified.
header: {}
cookie: {}
body:
application/json:
schemaArray:
- type: object
properties:
displayName:
allOf:
- &ref_0
type: string
dataset:
allOf:
- &ref_1
type: string
description: The name of the dataset used for training.
state:
allOf:
- &ref_2
$ref: '#/components/schemas/gatewayJobState'
readOnly: true
status:
allOf:
- &ref_3
$ref: '#/components/schemas/gatewayStatus'
readOnly: true
trainingConfig:
allOf:
- &ref_4
$ref: '#/components/schemas/gatewayBaseTrainingConfig'
description: Common training configurations.
wandbConfig:
allOf:
- &ref_5
$ref: '#/components/schemas/gatewayWandbConfig'
description: >-
The Weights & Biases team/user account for logging job
progress.
required: true
title: 'Next ID: 13'
refIdentifier: '#/components/schemas/gatewayDpoJob'
requiredProperties: &ref_6
- dataset
examples:
example:
value:
displayName:
dataset:
trainingConfig:
outputModel:
baseModel:
warmStartFrom:
jinjaTemplate:
learningRate: 123
maxContextLength: 123
loraRank: 123
region: REGION_UNSPECIFIED
epochs: 123
batchSize: 123
gradientAccumulationSteps: 123
learningRateWarmupSteps: 123
wandbConfig:
enabled: true
apiKey:
project:
entity:
runId:
response:
'200':
application/json:
schemaArray:
- type: object
properties:
name:
allOf:
- type: string
readOnly: true
displayName:
allOf:
- *ref_0
createTime:
allOf:
- type: string
format: date-time
readOnly: true
completedTime:
allOf:
- type: string
format: date-time
readOnly: true
dataset:
allOf:
- *ref_1
state:
allOf:
- *ref_2
status:
allOf:
- *ref_3
createdBy:
allOf:
- type: string
description: The email address of the user who initiated this dpo job.
readOnly: true
trainingConfig:
allOf:
- *ref_4
wandbConfig:
allOf:
- *ref_5
title: 'Next ID: 13'
refIdentifier: '#/components/schemas/gatewayDpoJob'
requiredProperties: *ref_6
examples:
example:
value:
name:
displayName:
createTime: '2023-11-07T05:31:56Z'
completedTime: '2023-11-07T05:31:56Z'
dataset:
state: JOB_STATE_UNSPECIFIED
status:
code: OK
message:
createdBy:
trainingConfig:
outputModel:
baseModel:
warmStartFrom:
jinjaTemplate:
learningRate: 123
maxContextLength: 123
loraRank: 123
region: REGION_UNSPECIFIED
epochs: 123
batchSize: 123
gradientAccumulationSteps: 123
learningRateWarmupSteps: 123
wandbConfig:
enabled: true
apiKey:
project:
entity:
runId:
url:
description: A successful response.
deprecated: false
type: path
components:
schemas:
gatewayBaseTrainingConfig:
type: object
properties:
outputModel:
type: string
description: >-
The model ID to be assigned to the resulting fine-tuned model. If
not specified, the job ID will be used.
baseModel:
type: string
description: |-
The name of the base model to be fine-tuned
Only one of 'base_model' or 'warm_start_from' should be specified.
warmStartFrom:
type: string
description: |-
The PEFT addon model in Fireworks format to be fine-tuned from
Only one of 'base_model' or 'warm_start_from' should be specified.
jinjaTemplate:
type: string
title: >-
The Jinja template for conversation formatting. If not specified,
defaults to the base model's conversation template configuration
learningRate:
type: number
format: float
description: The learning rate used for training.
maxContextLength:
type: integer
format: int32
description: The maximum context length to use with the model.
loraRank:
type: integer
format: int32
description: The rank of the LoRA layers.
region:
$ref: '#/components/schemas/gatewayRegion'
description: The region where the fine-tuning job is located.
epochs:
type: integer
format: int32
description: The number of epochs to train for.
batchSize:
type: integer
format: int32
description: >-
The maximum packed number of tokens per batch for training in
sequence packing.
gradientAccumulationSteps:
type: integer
format: int32
title: Number of gradient accumulation steps
learningRateWarmupSteps:
type: integer
format: int32
title: Number of steps for learning rate warm up
title: |-
BaseTrainingConfig contains common configuration fields shared across
different training job types.
Next ID: 19
gatewayCode:
type: string
enum:
- OK
- CANCELLED
- UNKNOWN
- INVALID_ARGUMENT
- DEADLINE_EXCEEDED
- NOT_FOUND
- ALREADY_EXISTS
- PERMISSION_DENIED
- UNAUTHENTICATED
- RESOURCE_EXHAUSTED
- FAILED_PRECONDITION
- ABORTED
- OUT_OF_RANGE
- UNIMPLEMENTED
- INTERNAL
- UNAVAILABLE
- DATA_LOSS
default: OK
description: |-
- OK: Not an error; returned on success.
HTTP Mapping: 200 OK
- CANCELLED: The operation was cancelled, typically by the caller.
HTTP Mapping: 499 Client Closed Request
- UNKNOWN: Unknown error. For example, this error may be returned when
a `Status` value received from another address space belongs to
an error space that is not known in this address space. Also
errors raised by APIs that do not return enough error information
may be converted to this error.
HTTP Mapping: 500 Internal Server Error
- INVALID_ARGUMENT: The client specified an invalid argument. Note that this differs
from `FAILED_PRECONDITION`. `INVALID_ARGUMENT` indicates arguments
that are problematic regardless of the state of the system
(e.g., a malformed file name).
HTTP Mapping: 400 Bad Request
- DEADLINE_EXCEEDED: The deadline expired before the operation could complete. For operations
that change the state of the system, this error may be returned
even if the operation has completed successfully. For example, a
successful response from a server could have been delayed long
enough for the deadline to expire.
HTTP Mapping: 504 Gateway Timeout
- NOT_FOUND: Some requested entity (e.g., file or directory) was not found.
Note to server developers: if a request is denied for an entire class
of users, such as gradual feature rollout or undocumented allowlist,
`NOT_FOUND` may be used. If a request is denied for some users within
a class of users, such as user-based access control, `PERMISSION_DENIED`
must be used.
HTTP Mapping: 404 Not Found
- ALREADY_EXISTS: The entity that a client attempted to create (e.g., file or directory)
already exists.
HTTP Mapping: 409 Conflict
- PERMISSION_DENIED: The caller does not have permission to execute the specified
operation. `PERMISSION_DENIED` must not be used for rejections
caused by exhausting some resource (use `RESOURCE_EXHAUSTED`
instead for those errors). `PERMISSION_DENIED` must not be
used if the caller can not be identified (use `UNAUTHENTICATED`
instead for those errors). This error code does not imply the
request is valid or the requested entity exists or satisfies
other pre-conditions.
HTTP Mapping: 403 Forbidden
- UNAUTHENTICATED: The request does not have valid authentication credentials for the
operation.
HTTP Mapping: 401 Unauthorized
- RESOURCE_EXHAUSTED: Some resource has been exhausted, perhaps a per-user quota, or
perhaps the entire file system is out of space.
HTTP Mapping: 429 Too Many Requests
- FAILED_PRECONDITION: The operation was rejected because the system is not in a state
required for the operation's execution. For example, the directory
to be deleted is non-empty, an rmdir operation is applied to
a non-directory, etc.
Service implementors can use the following guidelines to decide
between `FAILED_PRECONDITION`, `ABORTED`, and `UNAVAILABLE`:
(a) Use `UNAVAILABLE` if the client can retry just the failing call.
(b) Use `ABORTED` if the client should retry at a higher level. For
example, when a client-specified test-and-set fails, indicating the
client should restart a read-modify-write sequence.
(c) Use `FAILED_PRECONDITION` if the client should not retry until
the system state has been explicitly fixed. For example, if an "rmdir"
fails because the directory is non-empty, `FAILED_PRECONDITION`
should be returned since the client should not retry unless
the files are deleted from the directory.
HTTP Mapping: 400 Bad Request
- ABORTED: The operation was aborted, typically due to a concurrency issue such as
a sequencer check failure or transaction abort.
See the guidelines above for deciding between `FAILED_PRECONDITION`,
`ABORTED`, and `UNAVAILABLE`.
HTTP Mapping: 409 Conflict
- OUT_OF_RANGE: The operation was attempted past the valid range. E.g., seeking or
reading past end-of-file.
Unlike `INVALID_ARGUMENT`, this error indicates a problem that may
be fixed if the system state changes. For example, a 32-bit file
system will generate `INVALID_ARGUMENT` if asked to read at an
offset that is not in the range [0,2^32-1], but it will generate
`OUT_OF_RANGE` if asked to read from an offset past the current
file size.
There is a fair bit of overlap between `FAILED_PRECONDITION` and
`OUT_OF_RANGE`. We recommend using `OUT_OF_RANGE` (the more specific
error) when it applies so that callers who are iterating through
a space can easily look for an `OUT_OF_RANGE` error to detect when
they are done.
HTTP Mapping: 400 Bad Request
- UNIMPLEMENTED: The operation is not implemented or is not supported/enabled in this
service.
HTTP Mapping: 501 Not Implemented
- INTERNAL: Internal errors. This means that some invariants expected by the
underlying system have been broken. This error code is reserved
for serious errors.
HTTP Mapping: 500 Internal Server Error
- UNAVAILABLE: The service is currently unavailable. This is most likely a
transient condition, which can be corrected by retrying with
a backoff. Note that it is not always safe to retry
non-idempotent operations.
See the guidelines above for deciding between `FAILED_PRECONDITION`,
`ABORTED`, and `UNAVAILABLE`.
HTTP Mapping: 503 Service Unavailable
- DATA_LOSS: Unrecoverable data loss or corruption.
HTTP Mapping: 500 Internal Server Error
title: >-
Mimics
[https://github.com/googleapis/googleapis/blob/master/google/rpc/code.proto]
gatewayJobState:
type: string
enum:
- JOB_STATE_UNSPECIFIED
- JOB_STATE_CREATING
- JOB_STATE_RUNNING
- JOB_STATE_COMPLETED
- JOB_STATE_FAILED
- JOB_STATE_CANCELLED
- JOB_STATE_DELETING
- JOB_STATE_WRITING_RESULTS
- JOB_STATE_VALIDATING
- JOB_STATE_DELETING_CLEANING_UP
- JOB_STATE_PENDING
- JOB_STATE_EXPIRED
- JOB_STATE_RE_QUEUEING
- JOB_STATE_CREATING_INPUT_DATASET
- JOB_STATE_IDLE
- JOB_STATE_CANCELLING
- JOB_STATE_EARLY_STOPPED
default: JOB_STATE_UNSPECIFIED
description: JobState represents the state an asynchronous job can be in.
gatewayRegion:
type: string
enum:
- REGION_UNSPECIFIED
- US_IOWA_1
- US_VIRGINIA_1
- US_ILLINOIS_1
- AP_TOKYO_1
- US_ARIZONA_1
- US_TEXAS_1
- US_ILLINOIS_2
- EU_FRANKFURT_1
- US_TEXAS_2
- EU_ICELAND_1
- EU_ICELAND_2
- US_WASHINGTON_1
- US_WASHINGTON_2
- US_WASHINGTON_3
- AP_TOKYO_2
- US_CALIFORNIA_1
- US_UTAH_1
- US_TEXAS_3
- US_GEORGIA_1
- US_GEORGIA_2
- US_WASHINGTON_4
- US_GEORGIA_3
default: REGION_UNSPECIFIED
title: |-
- US_IOWA_1: GCP us-central1 (Iowa)
- US_VIRGINIA_1: AWS us-east-1 (N. Virginia)
- US_ILLINOIS_1: OCI us-chicago-1
- AP_TOKYO_1: OCI ap-tokyo-1
- US_ARIZONA_1: OCI us-phoenix-1
- US_TEXAS_1: Lambda us-south-3 (C. Texas)
- US_ILLINOIS_2: Lambda us-midwest-1 (Illinois)
- EU_FRANKFURT_1: OCI eu-frankfurt-1
- US_TEXAS_2: Lambda us-south-2 (N. Texas)
- EU_ICELAND_1: Crusoe eu-iceland1
- EU_ICELAND_2: Crusoe eu-iceland1 (network1)
- US_WASHINGTON_1: Voltage Park us-pyl-1 (Detach audio cluster from control_plane)
- US_WASHINGTON_2: Voltage Park us-seattle-2
- US_WASHINGTON_3: Vultr Seattle 1
- AP_TOKYO_2: AWS ap-northeast-1
- US_CALIFORNIA_1: AWS us-west-1 (N. California)
- US_UTAH_1: GCP us-west3 (Utah)
- US_TEXAS_3: Crusoe us-southcentral1
- US_GEORGIA_1: DigitalOcean us-atl1
- US_GEORGIA_2: Vultr Atlanta 1
- US_WASHINGTON_4: Coreweave us-west-09b-1
- US_GEORGIA_3: Alicloud us-southeast-1
gatewayStatus:
type: object
properties:
code:
$ref: '#/components/schemas/gatewayCode'
description: The status code.
message:
type: string
description: A developer-facing error message in English.
title: >-
Mimics
[https://github.com/googleapis/googleapis/blob/master/google/rpc/status.proto]
gatewayWandbConfig:
type: object
properties:
enabled:
type: boolean
description: Whether to enable wandb logging.
apiKey:
type: string
description: The API key for the wandb service.
project:
type: string
description: The project name for the wandb service.
entity:
type: string
description: The entity name for the wandb service.
runId:
type: string
description: The run ID for the wandb service.
url:
type: string
description: The URL for the wandb service.
readOnly: true
description: >-
WandbConfig is the configuration for the Weights & Biases (wandb)
logging which
will be used by a training job.
````
---
# Source: https://docs.fireworks.ai/api-reference-dlde/create-environment.md
# Create Environment
## OpenAPI
````yaml post /v1/accounts/{account_id}/environments
paths:
path: /v1/accounts/{account_id}/environments
method: post
servers:
- url: https://api.fireworks.ai
request:
security:
- title: BearerAuth
parameters:
query: {}
header:
Authorization:
type: http
scheme: bearer
description: >-
Bearer authentication using your Fireworks API key. Format:
Bearer
cookie: {}
parameters:
path:
account_id:
schema:
- type: string
required: true
description: The Account Id
query: {}
header: {}
cookie: {}
body:
application/json:
schemaArray:
- type: object
properties:
environment:
allOf:
- $ref: '#/components/schemas/gatewayEnvironment'
description: The properties of the Environment being created.
environmentId:
allOf:
- type: string
title: >-
The environment ID to use in the environment name. e.g.
my-env
required: true
refIdentifier: '#/components/schemas/GatewayCreateEnvironmentBody'
requiredProperties:
- environment
- environmentId
examples:
example:
value:
environment:
displayName:
baseImageRef:
shared: true
annotations: {}
environmentId:
response:
'200':
application/json:
schemaArray:
- type: object
properties:
name:
allOf:
- &ref_0
type: string
title: >-
The resource name of the environment. e.g.
accounts/my-account/clusters/my-cluster/environments/my-env
readOnly: true
displayName:
allOf:
- &ref_1
type: string
title: >-
Human-readable display name of the environment. e.g. "My
Environment"
createTime:
allOf:
- &ref_2
type: string
format: date-time
description: The creation time of the environment.
readOnly: true
createdBy:
allOf:
- &ref_3
type: string
description: >-
The email address of the user who created this
environment.
readOnly: true
state:
allOf:
- &ref_4
$ref: '#/components/schemas/gatewayEnvironmentState'
description: The current state of the environment.
readOnly: true
status:
allOf:
- &ref_5
$ref: '#/components/schemas/gatewayStatus'
description: The current error status of the environment.
readOnly: true
connection:
allOf:
- &ref_6
$ref: '#/components/schemas/gatewayEnvironmentConnection'
description: Information about the current environment connection.
readOnly: true
baseImageRef:
allOf:
- &ref_7
type: string
description: >-
The URI of the base container image used for this
environment.
imageRef:
allOf:
- &ref_8
type: string
description: >-
The URI of the container image used for this environment.
This is a
image is an immutable snapshot of the base_image_ref when
the environment
was created.
readOnly: true
snapshotImageRef:
allOf:
- &ref_9
type: string
description: >-
The URI of the latest container image snapshot for this
environment.
readOnly: true
shared:
allOf:
- &ref_10
type: boolean
description: >-
Whether the environment is shared with all users in the
account.
This allows all users to connect, disconnect, update,
delete, clone, and
create batch jobs using the environment.
annotations:
allOf:
- &ref_11
type: object
additionalProperties:
type: string
description: >-
Arbitrary, user-specified metadata.
Keys and values must adhere to Kubernetes constraints:
https://kubernetes.io/docs/concepts/overview/working-with-objects/annotations/#syntax-and-character-set
Additionally, the "fireworks.ai/" prefix is reserved.
updateTime:
allOf:
- &ref_12
type: string
format: date-time
description: The update time for the environment.
readOnly: true
title: 'Next ID: 14'
refIdentifier: '#/components/schemas/gatewayEnvironment'
examples:
example:
value:
name:
displayName:
createTime: '2023-11-07T05:31:56Z'
createdBy:
state: STATE_UNSPECIFIED
status:
code: OK
message:
connection:
nodePoolId:
numRanks: 123
role:
zone:
useLocalStorage: true
baseImageRef:
imageRef:
snapshotImageRef:
shared: true
annotations: {}
updateTime: '2023-11-07T05:31:56Z'
description: A successful response.
deprecated: false
type: path
components:
schemas:
gatewayCode:
type: string
enum:
- OK
- CANCELLED
- UNKNOWN
- INVALID_ARGUMENT
- DEADLINE_EXCEEDED
- NOT_FOUND
- ALREADY_EXISTS
- PERMISSION_DENIED
- UNAUTHENTICATED
- RESOURCE_EXHAUSTED
- FAILED_PRECONDITION
- ABORTED
- OUT_OF_RANGE
- UNIMPLEMENTED
- INTERNAL
- UNAVAILABLE
- DATA_LOSS
default: OK
description: |-
- OK: Not an error; returned on success.
HTTP Mapping: 200 OK
- CANCELLED: The operation was cancelled, typically by the caller.
HTTP Mapping: 499 Client Closed Request
- UNKNOWN: Unknown error. For example, this error may be returned when
a `Status` value received from another address space belongs to
an error space that is not known in this address space. Also
errors raised by APIs that do not return enough error information
may be converted to this error.
HTTP Mapping: 500 Internal Server Error
- INVALID_ARGUMENT: The client specified an invalid argument. Note that this differs
from `FAILED_PRECONDITION`. `INVALID_ARGUMENT` indicates arguments
that are problematic regardless of the state of the system
(e.g., a malformed file name).
HTTP Mapping: 400 Bad Request
- DEADLINE_EXCEEDED: The deadline expired before the operation could complete. For operations
that change the state of the system, this error may be returned
even if the operation has completed successfully. For example, a
successful response from a server could have been delayed long
enough for the deadline to expire.
HTTP Mapping: 504 Gateway Timeout
- NOT_FOUND: Some requested entity (e.g., file or directory) was not found.
Note to server developers: if a request is denied for an entire class
of users, such as gradual feature rollout or undocumented allowlist,
`NOT_FOUND` may be used. If a request is denied for some users within
a class of users, such as user-based access control, `PERMISSION_DENIED`
must be used.
HTTP Mapping: 404 Not Found
- ALREADY_EXISTS: The entity that a client attempted to create (e.g., file or directory)
already exists.
HTTP Mapping: 409 Conflict
- PERMISSION_DENIED: The caller does not have permission to execute the specified
operation. `PERMISSION_DENIED` must not be used for rejections
caused by exhausting some resource (use `RESOURCE_EXHAUSTED`
instead for those errors). `PERMISSION_DENIED` must not be
used if the caller can not be identified (use `UNAUTHENTICATED`
instead for those errors). This error code does not imply the
request is valid or the requested entity exists or satisfies
other pre-conditions.
HTTP Mapping: 403 Forbidden
- UNAUTHENTICATED: The request does not have valid authentication credentials for the
operation.
HTTP Mapping: 401 Unauthorized
- RESOURCE_EXHAUSTED: Some resource has been exhausted, perhaps a per-user quota, or
perhaps the entire file system is out of space.
HTTP Mapping: 429 Too Many Requests
- FAILED_PRECONDITION: The operation was rejected because the system is not in a state
required for the operation's execution. For example, the directory
to be deleted is non-empty, an rmdir operation is applied to
a non-directory, etc.
Service implementors can use the following guidelines to decide
between `FAILED_PRECONDITION`, `ABORTED`, and `UNAVAILABLE`:
(a) Use `UNAVAILABLE` if the client can retry just the failing call.
(b) Use `ABORTED` if the client should retry at a higher level. For
example, when a client-specified test-and-set fails, indicating the
client should restart a read-modify-write sequence.
(c) Use `FAILED_PRECONDITION` if the client should not retry until
the system state has been explicitly fixed. For example, if an "rmdir"
fails because the directory is non-empty, `FAILED_PRECONDITION`
should be returned since the client should not retry unless
the files are deleted from the directory.
HTTP Mapping: 400 Bad Request
- ABORTED: The operation was aborted, typically due to a concurrency issue such as
a sequencer check failure or transaction abort.
See the guidelines above for deciding between `FAILED_PRECONDITION`,
`ABORTED`, and `UNAVAILABLE`.
HTTP Mapping: 409 Conflict
- OUT_OF_RANGE: The operation was attempted past the valid range. E.g., seeking or
reading past end-of-file.
Unlike `INVALID_ARGUMENT`, this error indicates a problem that may
be fixed if the system state changes. For example, a 32-bit file
system will generate `INVALID_ARGUMENT` if asked to read at an
offset that is not in the range [0,2^32-1], but it will generate
`OUT_OF_RANGE` if asked to read from an offset past the current
file size.
There is a fair bit of overlap between `FAILED_PRECONDITION` and
`OUT_OF_RANGE`. We recommend using `OUT_OF_RANGE` (the more specific
error) when it applies so that callers who are iterating through
a space can easily look for an `OUT_OF_RANGE` error to detect when
they are done.
HTTP Mapping: 400 Bad Request
- UNIMPLEMENTED: The operation is not implemented or is not supported/enabled in this
service.
HTTP Mapping: 501 Not Implemented
- INTERNAL: Internal errors. This means that some invariants expected by the
underlying system have been broken. This error code is reserved
for serious errors.
HTTP Mapping: 500 Internal Server Error
- UNAVAILABLE: The service is currently unavailable. This is most likely a
transient condition, which can be corrected by retrying with
a backoff. Note that it is not always safe to retry
non-idempotent operations.
See the guidelines above for deciding between `FAILED_PRECONDITION`,
`ABORTED`, and `UNAVAILABLE`.
HTTP Mapping: 503 Service Unavailable
- DATA_LOSS: Unrecoverable data loss or corruption.
HTTP Mapping: 500 Internal Server Error
title: >-
Mimics
[https://github.com/googleapis/googleapis/blob/master/google/rpc/code.proto]
gatewayEnvironment:
type: object
properties:
name: *ref_0
displayName: *ref_1
createTime: *ref_2
createdBy: *ref_3
state: *ref_4
status: *ref_5
connection: *ref_6
baseImageRef: *ref_7
imageRef: *ref_8
snapshotImageRef: *ref_9
shared: *ref_10
annotations: *ref_11
updateTime: *ref_12
title: 'Next ID: 14'
gatewayEnvironmentConnection:
type: object
properties:
nodePoolId:
type: string
description: The resource id of the node pool the environment is connected to.
numRanks:
type: integer
format: int32
description: |-
For GPU node pools: one GPU per rank w/ host packing,
for CPU node pools: one host per rank.
If not specified, the default is 1.
role:
type: string
description: |-
The ARN of the AWS IAM role that the connection should assume.
If not specified, the connection will fall back to the node
pool's node_role.
zone:
type: string
description: >-
Current for the last zone that this environment is connected to. We
want to warn the users about cross zone migration latency when they
are
connecting to node pool in a different zone as their persistent
volume.
readOnly: true
useLocalStorage:
type: boolean
description: >-
If true, the node's local storage will be mounted on /tmp. This flag
has
no effect if the node does not have local storage.
title: 'Next ID: 8'
required:
- nodePoolId
gatewayEnvironmentState:
type: string
enum:
- STATE_UNSPECIFIED
- CREATING
- DISCONNECTED
- CONNECTING
- CONNECTED
- DISCONNECTING
- RECONNECTING
- DELETING
default: STATE_UNSPECIFIED
description: |-
- CREATING: The environment is being created.
- DISCONNECTED: The environment is not connected.
- CONNECTING: The environment is being connected to a node.
- CONNECTED: The environment is connected to a node.
- DISCONNECTING: The environment is being disconnected from a node.
- RECONNECTING: The environment is reconnecting with new connection parameters.
- DELETING: The environment is being deleted.
title: 'Next ID: 8'
gatewayStatus:
type: object
properties:
code:
$ref: '#/components/schemas/gatewayCode'
description: The status code.
message:
type: string
description: A developer-facing error message in English.
title: >-
Mimics
[https://github.com/googleapis/googleapis/blob/master/google/rpc/status.proto]
````
---
# Source: https://docs.fireworks.ai/api-reference/create-evaluation-job.md
# Create Evaluation Job
## OpenAPI
````yaml post /v1/accounts/{account_id}/evaluationJobs
openapi: 3.1.0
info:
title: Gateway REST API
version: 4.15.25
servers:
- url: https://api.fireworks.ai
security:
- BearerAuth: []
tags:
- name: Gateway
paths:
/v1/accounts/{account_id}/evaluationJobs:
post:
tags:
- Gateway
summary: Create Evaluation Job
operationId: Gateway_CreateEvaluationJob
parameters:
- name: account_id
in: path
required: true
description: The Account Id
schema:
type: string
requestBody:
content:
application/json:
schema:
$ref: '#/components/schemas/GatewayCreateEvaluationJobBody'
required: true
responses:
'200':
description: A successful response.
content:
application/json:
schema:
$ref: '#/components/schemas/gatewayEvaluationJob'
components:
schemas:
GatewayCreateEvaluationJobBody:
type: object
properties:
evaluationJob:
$ref: '#/components/schemas/gatewayEvaluationJob'
evaluationJobId:
type: string
leaderboardIds:
type: array
items:
type: string
description: Optional leaderboards to attach this job to upon creation.
required:
- evaluationJob
gatewayEvaluationJob:
type: object
properties:
name:
type: string
readOnly: true
displayName:
type: string
createTime:
type: string
format: date-time
readOnly: true
createdBy:
type: string
readOnly: true
state:
$ref: '#/components/schemas/gatewayJobState'
readOnly: true
status:
$ref: '#/components/schemas/gatewayStatus'
readOnly: true
evaluator:
type: string
description: >-
The fully-qualified resource name of the Evaluation used by this
job.
Format: accounts/{account_id}/evaluators/{evaluator_id}
inputDataset:
type: string
description: >-
The fully-qualified resource name of the input Dataset used by this
job.
Format: accounts/{account_id}/datasets/{dataset_id}
outputDataset:
type: string
description: >-
The fully-qualified resource name of the output Dataset created by
this job.
Format: accounts/{account_id}/datasets/{output_dataset_id}
metrics:
type: object
additionalProperties:
type: number
format: double
readOnly: true
outputStats:
type: string
description: The output dataset's aggregated stats for the evaluation job.
updateTime:
type: string
format: date-time
description: The update time for the evaluation job.
readOnly: true
title: 'Next ID: 18'
required:
- evaluator
- inputDataset
- outputDataset
gatewayJobState:
type: string
enum:
- JOB_STATE_UNSPECIFIED
- JOB_STATE_CREATING
- JOB_STATE_RUNNING
- JOB_STATE_COMPLETED
- JOB_STATE_FAILED
- JOB_STATE_CANCELLED
- JOB_STATE_DELETING
- JOB_STATE_WRITING_RESULTS
- JOB_STATE_VALIDATING
- JOB_STATE_DELETING_CLEANING_UP
- JOB_STATE_PENDING
- JOB_STATE_EXPIRED
- JOB_STATE_RE_QUEUEING
- JOB_STATE_CREATING_INPUT_DATASET
- JOB_STATE_IDLE
- JOB_STATE_CANCELLING
- JOB_STATE_EARLY_STOPPED
- JOB_STATE_PAUSED
default: JOB_STATE_UNSPECIFIED
description: |-
JobState represents the state an asynchronous job can be in.
- JOB_STATE_PAUSED: Job is paused, typically due to account suspension or manual intervention.
gatewayStatus:
type: object
properties:
code:
$ref: '#/components/schemas/gatewayCode'
description: The status code.
message:
type: string
description: A developer-facing error message in English.
title: >-
Mimics
[https://github.com/googleapis/googleapis/blob/master/google/rpc/status.proto]
gatewayCode:
type: string
enum:
- OK
- CANCELLED
- UNKNOWN
- INVALID_ARGUMENT
- DEADLINE_EXCEEDED
- NOT_FOUND
- ALREADY_EXISTS
- PERMISSION_DENIED
- UNAUTHENTICATED
- RESOURCE_EXHAUSTED
- FAILED_PRECONDITION
- ABORTED
- OUT_OF_RANGE
- UNIMPLEMENTED
- INTERNAL
- UNAVAILABLE
- DATA_LOSS
default: OK
description: |-
- OK: Not an error; returned on success.
HTTP Mapping: 200 OK
- CANCELLED: The operation was cancelled, typically by the caller.
HTTP Mapping: 499 Client Closed Request
- UNKNOWN: Unknown error. For example, this error may be returned when
a `Status` value received from another address space belongs to
an error space that is not known in this address space. Also
errors raised by APIs that do not return enough error information
may be converted to this error.
HTTP Mapping: 500 Internal Server Error
- INVALID_ARGUMENT: The client specified an invalid argument. Note that this differs
from `FAILED_PRECONDITION`. `INVALID_ARGUMENT` indicates arguments
that are problematic regardless of the state of the system
(e.g., a malformed file name).
HTTP Mapping: 400 Bad Request
- DEADLINE_EXCEEDED: The deadline expired before the operation could complete. For operations
that change the state of the system, this error may be returned
even if the operation has completed successfully. For example, a
successful response from a server could have been delayed long
enough for the deadline to expire.
HTTP Mapping: 504 Gateway Timeout
- NOT_FOUND: Some requested entity (e.g., file or directory) was not found.
Note to server developers: if a request is denied for an entire class
of users, such as gradual feature rollout or undocumented allowlist,
`NOT_FOUND` may be used. If a request is denied for some users within
a class of users, such as user-based access control, `PERMISSION_DENIED`
must be used.
HTTP Mapping: 404 Not Found
- ALREADY_EXISTS: The entity that a client attempted to create (e.g., file or directory)
already exists.
HTTP Mapping: 409 Conflict
- PERMISSION_DENIED: The caller does not have permission to execute the specified
operation. `PERMISSION_DENIED` must not be used for rejections
caused by exhausting some resource (use `RESOURCE_EXHAUSTED`
instead for those errors). `PERMISSION_DENIED` must not be
used if the caller can not be identified (use `UNAUTHENTICATED`
instead for those errors). This error code does not imply the
request is valid or the requested entity exists or satisfies
other pre-conditions.
HTTP Mapping: 403 Forbidden
- UNAUTHENTICATED: The request does not have valid authentication credentials for the
operation.
HTTP Mapping: 401 Unauthorized
- RESOURCE_EXHAUSTED: Some resource has been exhausted, perhaps a per-user quota, or
perhaps the entire file system is out of space.
HTTP Mapping: 429 Too Many Requests
- FAILED_PRECONDITION: The operation was rejected because the system is not in a state
required for the operation's execution. For example, the directory
to be deleted is non-empty, an rmdir operation is applied to
a non-directory, etc.
Service implementors can use the following guidelines to decide
between `FAILED_PRECONDITION`, `ABORTED`, and `UNAVAILABLE`:
(a) Use `UNAVAILABLE` if the client can retry just the failing call.
(b) Use `ABORTED` if the client should retry at a higher level. For
example, when a client-specified test-and-set fails, indicating the
client should restart a read-modify-write sequence.
(c) Use `FAILED_PRECONDITION` if the client should not retry until
the system state has been explicitly fixed. For example, if an "rmdir"
fails because the directory is non-empty, `FAILED_PRECONDITION`
should be returned since the client should not retry unless
the files are deleted from the directory.
HTTP Mapping: 400 Bad Request
- ABORTED: The operation was aborted, typically due to a concurrency issue such as
a sequencer check failure or transaction abort.
See the guidelines above for deciding between `FAILED_PRECONDITION`,
`ABORTED`, and `UNAVAILABLE`.
HTTP Mapping: 409 Conflict
- OUT_OF_RANGE: The operation was attempted past the valid range. E.g., seeking or
reading past end-of-file.
Unlike `INVALID_ARGUMENT`, this error indicates a problem that may
be fixed if the system state changes. For example, a 32-bit file
system will generate `INVALID_ARGUMENT` if asked to read at an
offset that is not in the range [0,2^32-1], but it will generate
`OUT_OF_RANGE` if asked to read from an offset past the current
file size.
There is a fair bit of overlap between `FAILED_PRECONDITION` and
`OUT_OF_RANGE`. We recommend using `OUT_OF_RANGE` (the more specific
error) when it applies so that callers who are iterating through
a space can easily look for an `OUT_OF_RANGE` error to detect when
they are done.
HTTP Mapping: 400 Bad Request
- UNIMPLEMENTED: The operation is not implemented or is not supported/enabled in this
service.
HTTP Mapping: 501 Not Implemented
- INTERNAL: Internal errors. This means that some invariants expected by the
underlying system have been broken. This error code is reserved
for serious errors.
HTTP Mapping: 500 Internal Server Error
- UNAVAILABLE: The service is currently unavailable. This is most likely a
transient condition, which can be corrected by retrying with
a backoff. Note that it is not always safe to retry
non-idempotent operations.
See the guidelines above for deciding between `FAILED_PRECONDITION`,
`ABORTED`, and `UNAVAILABLE`.
HTTP Mapping: 503 Service Unavailable
- DATA_LOSS: Unrecoverable data loss or corruption.
HTTP Mapping: 500 Internal Server Error
title: >-
Mimics
[https://github.com/googleapis/googleapis/blob/master/google/rpc/code.proto]
securitySchemes:
BearerAuth:
type: http
scheme: bearer
description: >-
Bearer authentication using your Fireworks API key. Format: Bearer
bearerFormat: API_KEY
````
---
> To find navigation and other pages in this documentation, fetch the llms.txt file at: https://docs.fireworks.ai/llms.txt
---
# Source: https://docs.fireworks.ai/api-reference/create-evaluator.md
# Create Evaluator
> Creates a custom evaluator for scoring model outputs. Evaluators use the
[Eval Protocol](https://evalprotocol.io) to define test cases, run model
inference, and score responses. They are used with evaluation jobs and
Reinforcement Fine-Tuning (RFT).
## Source Code Requirements
Your project should contain:
- `requirements.txt` - Python dependencies for your evaluator
- `test_*.py` - Pytest test file(s) with
[`@evaluation_test`](https://evalprotocol.io/reference/evaluation-test)
decorated functions
- Any additional code/modules your evaluator needs
## Workflow
**Recommended:** Use the [`ep upload`](https://evalprotocol.io/reference/cli#ep-upload)
CLI command to handle all these steps automatically.
If using the API directly:
1. Call this endpoint to create the evaluator resource
2. Package your source directory as a `.tar.gz` (respecting `.gitignore`)
3. Call [Get Evaluator Upload Endpoint](/api-reference/get-evaluator-upload-endpoint) to get a signed upload URL
4. `PUT` the tar.gz file to the signed URL
5. Call [Validate Evaluator Upload](/api-reference/validate-evaluator-upload) to trigger server-side validation
6. Poll [Get Evaluator](/api-reference/get-evaluator) until ready
Once active, reference the evaluator in [Create Evaluation Job](/api-reference/create-evaluation-job) or [Create Reinforcement Fine-tuning Job](/api-reference/create-reinforcement-fine-tuning-job).
## OpenAPI
````yaml post /v1/accounts/{account_id}/evaluatorsV2
openapi: 3.1.0
info:
title: Gateway REST API
version: 4.15.25
servers:
- url: https://api.fireworks.ai
security:
- BearerAuth: []
tags:
- name: Gateway
paths:
/v1/accounts/{account_id}/evaluatorsV2:
post:
tags:
- Gateway
summary: Create Evaluator
description: >-
Creates a custom evaluator for scoring model outputs. Evaluators use the
[Eval Protocol](https://evalprotocol.io) to define test cases, run model
inference, and score responses. They are used with evaluation jobs and
Reinforcement Fine-Tuning (RFT).
## Source Code Requirements
Your project should contain:
- `requirements.txt` - Python dependencies for your evaluator
- `test_*.py` - Pytest test file(s) with
[`@evaluation_test`](https://evalprotocol.io/reference/evaluation-test)
decorated functions
- Any additional code/modules your evaluator needs
## Workflow
**Recommended:** Use the [`ep
upload`](https://evalprotocol.io/reference/cli#ep-upload)
CLI command to handle all these steps automatically.
If using the API directly:
1. Call this endpoint to create the evaluator resource
2. Package your source directory as a `.tar.gz` (respecting
`.gitignore`)
3. Call [Get Evaluator Upload
Endpoint](/api-reference/get-evaluator-upload-endpoint) to get a signed
upload URL
4. `PUT` the tar.gz file to the signed URL
5. Call [Validate Evaluator
Upload](/api-reference/validate-evaluator-upload) to trigger server-side
validation
6. Poll [Get Evaluator](/api-reference/get-evaluator) until ready
Once active, reference the evaluator in [Create Evaluation
Job](/api-reference/create-evaluation-job) or [Create Reinforcement
Fine-tuning Job](/api-reference/create-reinforcement-fine-tuning-job).
operationId: Gateway_CreateEvaluatorV2
parameters:
- name: account_id
in: path
required: true
description: The Account Id
schema:
type: string
requestBody:
content:
application/json:
schema:
$ref: '#/components/schemas/GatewayCreateEvaluatorV2Body'
required: true
responses:
'200':
description: A successful response.
content:
application/json:
schema:
$ref: '#/components/schemas/gatewayEvaluator'
components:
schemas:
GatewayCreateEvaluatorV2Body:
type: object
properties:
evaluator:
$ref: '#/components/schemas/gatewayEvaluator'
evaluatorId:
type: string
required:
- evaluator
gatewayEvaluator:
type: object
properties:
name:
type: string
readOnly: true
displayName:
type: string
description:
type: string
createTime:
type: string
format: date-time
readOnly: true
createdBy:
type: string
readOnly: true
updateTime:
type: string
format: date-time
readOnly: true
state:
$ref: '#/components/schemas/gatewayEvaluatorState'
readOnly: true
requirements:
type: string
title: Content for the requirements.txt for package installation
entryPoint:
type: string
title: >-
entry point of the evaluator inside the codebase. In
module::function or path::function format
status:
$ref: '#/components/schemas/gatewayStatus'
title: Status of the evaluator, used to expose build status to the user
readOnly: true
commitHash:
type: string
title: Commit hash of this evaluator from the user's original codebase
source:
$ref: '#/components/schemas/gatewayEvaluatorSource'
description: Source information for the evaluator codebase.
defaultDataset:
type: string
title: Default dataset that is associated with the evaluator
title: 'Next ID: 17'
gatewayEvaluatorState:
type: string
enum:
- STATE_UNSPECIFIED
- ACTIVE
- BUILDING
- BUILD_FAILED
default: STATE_UNSPECIFIED
title: |-
- ACTIVE: The evaluator is ready to use for evaluation
- BUILDING: The evaluator is being built, i.e. building the e2b template
- BUILD_FAILED: The evaluator build failed, and it cannot be used for evaluation
gatewayStatus:
type: object
properties:
code:
$ref: '#/components/schemas/gatewayCode'
description: The status code.
message:
type: string
description: A developer-facing error message in English.
title: >-
Mimics
[https://github.com/googleapis/googleapis/blob/master/google/rpc/status.proto]
gatewayEvaluatorSource:
type: object
properties:
type:
$ref: '#/components/schemas/EvaluatorSourceType'
description: Identifies how the evaluator source code is provided.
githubRepositoryName:
type: string
description: >-
Normalized GitHub repository name (e.g. owner/repository) when the
source is GitHub.
gatewayCode:
type: string
enum:
- OK
- CANCELLED
- UNKNOWN
- INVALID_ARGUMENT
- DEADLINE_EXCEEDED
- NOT_FOUND
- ALREADY_EXISTS
- PERMISSION_DENIED
- UNAUTHENTICATED
- RESOURCE_EXHAUSTED
- FAILED_PRECONDITION
- ABORTED
- OUT_OF_RANGE
- UNIMPLEMENTED
- INTERNAL
- UNAVAILABLE
- DATA_LOSS
default: OK
description: |-
- OK: Not an error; returned on success.
HTTP Mapping: 200 OK
- CANCELLED: The operation was cancelled, typically by the caller.
HTTP Mapping: 499 Client Closed Request
- UNKNOWN: Unknown error. For example, this error may be returned when
a `Status` value received from another address space belongs to
an error space that is not known in this address space. Also
errors raised by APIs that do not return enough error information
may be converted to this error.
HTTP Mapping: 500 Internal Server Error
- INVALID_ARGUMENT: The client specified an invalid argument. Note that this differs
from `FAILED_PRECONDITION`. `INVALID_ARGUMENT` indicates arguments
that are problematic regardless of the state of the system
(e.g., a malformed file name).
HTTP Mapping: 400 Bad Request
- DEADLINE_EXCEEDED: The deadline expired before the operation could complete. For operations
that change the state of the system, this error may be returned
even if the operation has completed successfully. For example, a
successful response from a server could have been delayed long
enough for the deadline to expire.
HTTP Mapping: 504 Gateway Timeout
- NOT_FOUND: Some requested entity (e.g., file or directory) was not found.
Note to server developers: if a request is denied for an entire class
of users, such as gradual feature rollout or undocumented allowlist,
`NOT_FOUND` may be used. If a request is denied for some users within
a class of users, such as user-based access control, `PERMISSION_DENIED`
must be used.
HTTP Mapping: 404 Not Found
- ALREADY_EXISTS: The entity that a client attempted to create (e.g., file or directory)
already exists.
HTTP Mapping: 409 Conflict
- PERMISSION_DENIED: The caller does not have permission to execute the specified
operation. `PERMISSION_DENIED` must not be used for rejections
caused by exhausting some resource (use `RESOURCE_EXHAUSTED`
instead for those errors). `PERMISSION_DENIED` must not be
used if the caller can not be identified (use `UNAUTHENTICATED`
instead for those errors). This error code does not imply the
request is valid or the requested entity exists or satisfies
other pre-conditions.
HTTP Mapping: 403 Forbidden
- UNAUTHENTICATED: The request does not have valid authentication credentials for the
operation.
HTTP Mapping: 401 Unauthorized
- RESOURCE_EXHAUSTED: Some resource has been exhausted, perhaps a per-user quota, or
perhaps the entire file system is out of space.
HTTP Mapping: 429 Too Many Requests
- FAILED_PRECONDITION: The operation was rejected because the system is not in a state
required for the operation's execution. For example, the directory
to be deleted is non-empty, an rmdir operation is applied to
a non-directory, etc.
Service implementors can use the following guidelines to decide
between `FAILED_PRECONDITION`, `ABORTED`, and `UNAVAILABLE`:
(a) Use `UNAVAILABLE` if the client can retry just the failing call.
(b) Use `ABORTED` if the client should retry at a higher level. For
example, when a client-specified test-and-set fails, indicating the
client should restart a read-modify-write sequence.
(c) Use `FAILED_PRECONDITION` if the client should not retry until
the system state has been explicitly fixed. For example, if an "rmdir"
fails because the directory is non-empty, `FAILED_PRECONDITION`
should be returned since the client should not retry unless
the files are deleted from the directory.
HTTP Mapping: 400 Bad Request
- ABORTED: The operation was aborted, typically due to a concurrency issue such as
a sequencer check failure or transaction abort.
See the guidelines above for deciding between `FAILED_PRECONDITION`,
`ABORTED`, and `UNAVAILABLE`.
HTTP Mapping: 409 Conflict
- OUT_OF_RANGE: The operation was attempted past the valid range. E.g., seeking or
reading past end-of-file.
Unlike `INVALID_ARGUMENT`, this error indicates a problem that may
be fixed if the system state changes. For example, a 32-bit file
system will generate `INVALID_ARGUMENT` if asked to read at an
offset that is not in the range [0,2^32-1], but it will generate
`OUT_OF_RANGE` if asked to read from an offset past the current
file size.
There is a fair bit of overlap between `FAILED_PRECONDITION` and
`OUT_OF_RANGE`. We recommend using `OUT_OF_RANGE` (the more specific
error) when it applies so that callers who are iterating through
a space can easily look for an `OUT_OF_RANGE` error to detect when
they are done.
HTTP Mapping: 400 Bad Request
- UNIMPLEMENTED: The operation is not implemented or is not supported/enabled in this
service.
HTTP Mapping: 501 Not Implemented
- INTERNAL: Internal errors. This means that some invariants expected by the
underlying system have been broken. This error code is reserved
for serious errors.
HTTP Mapping: 500 Internal Server Error
- UNAVAILABLE: The service is currently unavailable. This is most likely a
transient condition, which can be corrected by retrying with
a backoff. Note that it is not always safe to retry
non-idempotent operations.
See the guidelines above for deciding between `FAILED_PRECONDITION`,
`ABORTED`, and `UNAVAILABLE`.
HTTP Mapping: 503 Service Unavailable
- DATA_LOSS: Unrecoverable data loss or corruption.
HTTP Mapping: 500 Internal Server Error
title: >-
Mimics
[https://github.com/googleapis/googleapis/blob/master/google/rpc/code.proto]
EvaluatorSourceType:
type: string
enum:
- TYPE_UNSPECIFIED
- TYPE_UPLOAD
- TYPE_GITHUB
- TYPE_TEMPORARY
default: TYPE_UNSPECIFIED
title: |-
- TYPE_UPLOAD: Source code is uploaded by the user
- TYPE_GITHUB: Source code is from a GitHub repository
- TYPE_TEMPORARY: Source code is a temporary UI uploaded code
securitySchemes:
BearerAuth:
type: http
scheme: bearer
description: >-
Bearer authentication using your Fireworks API key. Format: Bearer
bearerFormat: API_KEY
````
---
> To find navigation and other pages in this documentation, fetch the llms.txt file at: https://docs.fireworks.ai/llms.txt
---
# Source: https://docs.fireworks.ai/tools-sdks/firectl/commands/create-identity-provider.md
# firectl create identity-provider
> Creates a new identity provider.
```
firectl create identity-provider [flags]
```
### Examples
```
# Create SAML identity provider
firectl create identity-provider --display-name="Company SAML" \
--saml-metadata-url="https://company.okta.com/app/xyz/sso/saml/metadata"
# Create OIDC identity provider
firectl create identity-provider --display-name="Company OIDC" \
--oidc-issuer="https://auth.company.com" \
--oidc-client-id="abc123" \
--oidc-client-secret="secret456"
# Create OIDC identity provider with multiple domains
firectl create identity-provider --display-name="Example OIDC" \
--oidc-issuer="https://accounts.google.com" \
--oidc-client-id="client123" \
--oidc-client-secret="secret456" \
--tenant-domains="example.com,example.co.uk"
```
### Flags
```
--display-name string The display name of the identity provider (required)
-h, --help help for identity-provider
--oidc-client-id string The OIDC client ID for OIDC providers
--oidc-client-secret string The OIDC client secret for OIDC providers
--oidc-issuer string The OIDC issuer URL for OIDC providers
--saml-metadata-url string The SAML metadata URL for SAML providers
--tenant-domains string Comma-separated list of allowed domains for the organization (e.g., 'example.com,example.co.uk'). If not provided, domain will be derived from account email.
```
### Global flags
```
-a, --account-id string The Fireworks account ID. If not specified, reads account_id from ~/.fireworks/auth.ini.
--api-key string An API key used to authenticate with Fireworks.
--dry-run Print the request proto without running it.
-o, --output Output Set the output format to "text", "json", or "flag". (default text)
-p, --profile string fireworks auth and settings profile to use.
```
---
# Source: https://docs.fireworks.ai/tools-sdks/firectl/commands/create-model.md
# Source: https://docs.fireworks.ai/api-reference/create-model.md
# Source: https://docs.fireworks.ai/tools-sdks/firectl/commands/create-model.md
# Source: https://docs.fireworks.ai/api-reference/create-model.md
# Source: https://docs.fireworks.ai/tools-sdks/firectl/commands/create-model.md
# Source: https://docs.fireworks.ai/api-reference/create-model.md
# Create Model
## OpenAPI
````yaml post /v1/accounts/{account_id}/models
paths:
path: /v1/accounts/{account_id}/models
method: post
servers:
- url: https://api.fireworks.ai
request:
security:
- title: BearerAuth
parameters:
query: {}
header:
Authorization:
type: http
scheme: bearer
description: >-
Bearer authentication using your Fireworks API key. Format:
Bearer
cookie: {}
parameters:
path:
account_id:
schema:
- type: string
required: true
description: The Account Id
query: {}
header: {}
cookie: {}
body:
application/json:
schemaArray:
- type: object
properties:
model:
allOf:
- $ref: '#/components/schemas/gatewayModel'
description: The properties of the Model being created.
modelId:
allOf:
- type: string
description: ID of the model.
cluster:
allOf:
- type: string
description: >-
The resource name of the BYOC cluster to which this model
belongs.
e.g. accounts/my-account/clusters/my-cluster. Empty if it
belongs to
a Fireworks cluster.
required: true
refIdentifier: '#/components/schemas/GatewayCreateModelBody'
requiredProperties:
- modelId
examples:
example:
value:
model:
displayName:
description:
kind: KIND_UNSPECIFIED
githubUrl:
huggingFaceUrl:
baseModelDetails:
worldSize: 123
checkpointFormat: CHECKPOINT_FORMAT_UNSPECIFIED
parameterCount:
moe: true
tunable: true
modelType:
supportsFireattention: true
supportsMtp: true
peftDetails:
baseModel:
r: 123
targetModules:
-
mergeAddonModelName:
teftDetails: {}
public: true
conversationConfig:
style:
system:
template:
contextLength: 123
supportsImageInput: true
supportsTools: true
defaultDraftModel:
defaultDraftTokenCount: 123
deprecationDate:
year: 123
month: 123
day: 123
supportsLora: true
useHfApplyChatTemplate: true
trainingContextLength: 123
snapshotType: FULL_SNAPSHOT
modelId:
cluster:
response:
'200':
application/json:
schemaArray:
- type: object
properties:
name:
allOf:
- &ref_0
type: string
title: >-
The resource name of the model. e.g.
accounts/my-account/models/my-model
readOnly: true
displayName:
allOf:
- &ref_1
type: string
description: |-
Human-readable display name of the model. e.g. "My Model"
Must be fewer than 64 characters long.
description:
allOf:
- &ref_2
type: string
description: >-
The description of the model. Must be fewer than 1000
characters long.
createTime:
allOf:
- &ref_3
type: string
format: date-time
description: The creation time of the model.
readOnly: true
state:
allOf:
- &ref_4
$ref: '#/components/schemas/gatewayModelState'
description: The state of the model.
readOnly: true
status:
allOf:
- &ref_5
$ref: '#/components/schemas/gatewayStatus'
description: >-
Contains detailed message when the last model operation
fails.
readOnly: true
kind:
allOf:
- &ref_6
$ref: '#/components/schemas/gatewayModelKind'
description: |-
The kind of model.
If not specified, the default is HF_PEFT_ADDON.
githubUrl:
allOf:
- &ref_7
type: string
description: The URL to GitHub repository of the model.
huggingFaceUrl:
allOf:
- &ref_8
type: string
description: The URL to the Hugging Face model.
baseModelDetails:
allOf:
- &ref_9
$ref: '#/components/schemas/gatewayBaseModelDetails'
description: >-
Base model details.
Required if kind is HF_BASE_MODEL. Must not be set
otherwise.
peftDetails:
allOf:
- &ref_10
$ref: '#/components/schemas/gatewayPEFTDetails'
description: |-
PEFT addon details.
Required if kind is HF_PEFT_ADDON or HF_TEFT_ADDON.
teftDetails:
allOf:
- &ref_11
$ref: '#/components/schemas/gatewayTEFTDetails'
description: >-
TEFT addon details.
Required if kind is HF_TEFT_ADDON. Must not be set
otherwise.
public:
allOf:
- &ref_12
type: boolean
description: If true, the model will be publicly readable.
conversationConfig:
allOf:
- &ref_13
$ref: '#/components/schemas/gatewayConversationConfig'
description: >-
If set, the Chat Completions API will be enabled for this
model.
contextLength:
allOf:
- &ref_14
type: integer
format: int32
description: The maximum context length supported by the model.
supportsImageInput:
allOf:
- &ref_15
type: boolean
description: If set, images can be provided as input to the model.
supportsTools:
allOf:
- &ref_16
type: boolean
description: >-
If set, tools (i.e. functions) can be provided as input to
the model,
and the model may respond with one or more tool calls.
importedFrom:
allOf:
- &ref_17
type: string
description: >-
The name of the the model from which this was imported.
This field is empty
if the model was not imported.
readOnly: true
fineTuningJob:
allOf:
- &ref_18
type: string
description: >-
If the model was created from a fine-tuning job, this is
the fine-tuning
job name.
readOnly: true
defaultDraftModel:
allOf:
- &ref_19
type: string
description: >-
The default draft model to use when creating a deployment.
If empty,
speculative decoding is disabled by default.
defaultDraftTokenCount:
allOf:
- &ref_20
type: integer
format: int32
description: >-
The default draft token count to use when creating a
deployment.
Must be specified if default_draft_model is specified.
deployedModelRefs:
allOf:
- &ref_21
type: array
items:
type: object
$ref: '#/components/schemas/gatewayDeployedModelRef'
description: Populated from GetModel API call only.
readOnly: true
cluster:
allOf:
- &ref_22
type: string
description: >-
The resource name of the BYOC cluster to which this model
belongs.
e.g. accounts/my-account/clusters/my-cluster. Empty if it
belongs to
a Fireworks cluster.
readOnly: true
deprecationDate:
allOf:
- &ref_23
$ref: '#/components/schemas/typeDate'
description: >-
If specified, this is the date when the serverless
deployment of the model will be taken down.
calibrated:
allOf:
- &ref_24
type: boolean
description: >-
If true, the model is calibrated and can be deployed to
non-FP16 precisions.
readOnly: true
tunable:
allOf:
- &ref_25
type: boolean
description: >-
If true, the model can be fine-tuned. The value will be
true if the tunable field is true, and
the model is validated against the model_type field.
readOnly: true
supportsLora:
allOf:
- &ref_26
type: boolean
description: Whether this model supports LoRA.
useHfApplyChatTemplate:
allOf:
- &ref_27
type: boolean
description: >-
If true, the model will use the Hugging Face
apply_chat_template API to apply the chat template.
updateTime:
allOf:
- &ref_28
type: string
format: date-time
description: The update time for the model.
readOnly: true
defaultSamplingParams:
allOf:
- &ref_29
type: object
additionalProperties:
type: number
format: float
description: >-
A json object that contains the default sampling
parameters for the model.
readOnly: true
rlTunable:
allOf:
- &ref_30
type: boolean
description: If true, the model is RL tunable.
readOnly: true
supportedPrecisions:
allOf:
- &ref_31
type: array
items:
$ref: '#/components/schemas/DeploymentPrecision'
title: Supported precisions
readOnly: true
supportedPrecisionsWithCalibration:
allOf:
- &ref_32
type: array
items:
$ref: '#/components/schemas/DeploymentPrecision'
title: Supported precisions if calibrated
readOnly: true
trainingContextLength:
allOf:
- &ref_33
type: integer
format: int32
description: The maximum context length supported by the model.
snapshotType:
allOf:
- &ref_34
$ref: '#/components/schemas/ModelSnapshotType'
title: 'Next ID: 56'
refIdentifier: '#/components/schemas/gatewayModel'
examples:
example:
value:
name:
displayName:
description:
createTime: '2023-11-07T05:31:56Z'
state: STATE_UNSPECIFIED
status:
code: OK
message:
kind: KIND_UNSPECIFIED
githubUrl:
huggingFaceUrl:
baseModelDetails:
worldSize: 123
checkpointFormat: CHECKPOINT_FORMAT_UNSPECIFIED
parameterCount:
moe: true
tunable: true
modelType:
supportsFireattention: true
defaultPrecision: PRECISION_UNSPECIFIED
supportsMtp: true
peftDetails:
baseModel:
r: 123
targetModules:
-
baseModelType:
mergeAddonModelName:
teftDetails: {}
public: true
conversationConfig:
style:
system:
template:
contextLength: 123
supportsImageInput: true
supportsTools: true
importedFrom:
fineTuningJob:
defaultDraftModel:
defaultDraftTokenCount: 123
deployedModelRefs:
- name:
deployment:
state: STATE_UNSPECIFIED
default: true
public: true
cluster:
deprecationDate:
year: 123
month: 123
day: 123
calibrated: true
tunable: true
supportsLora: true
useHfApplyChatTemplate: true
updateTime: '2023-11-07T05:31:56Z'
defaultSamplingParams: {}
rlTunable: true
supportedPrecisions:
- PRECISION_UNSPECIFIED
supportedPrecisionsWithCalibration:
- PRECISION_UNSPECIFIED
trainingContextLength: 123
snapshotType: FULL_SNAPSHOT
description: A successful response.
deprecated: false
type: path
components:
schemas:
BaseModelDetailsCheckpointFormat:
type: string
enum:
- CHECKPOINT_FORMAT_UNSPECIFIED
- NATIVE
- HUGGINGFACE
default: CHECKPOINT_FORMAT_UNSPECIFIED
DeploymentPrecision:
type: string
enum:
- PRECISION_UNSPECIFIED
- FP16
- FP8
- FP8_MM
- FP8_AR
- FP8_MM_KV_ATTN
- FP8_KV
- FP8_MM_V2
- FP8_V2
- FP8_MM_KV_ATTN_V2
- NF4
- FP4
- BF16
- FP4_BLOCKSCALED_MM
- FP4_MX_MOE
default: PRECISION_UNSPECIFIED
title: >-
- PRECISION_UNSPECIFIED: if left unspecified we will treat this as a
legacy model created before
self serve
ModelSnapshotType:
type: string
enum:
- FULL_SNAPSHOT
- INCREMENTAL_SNAPSHOT
default: FULL_SNAPSHOT
gatewayBaseModelDetails:
type: object
properties:
worldSize:
type: integer
format: int32
description: |-
The default number of GPUs the model is served with.
If not specified, the default is 1.
checkpointFormat:
$ref: '#/components/schemas/BaseModelDetailsCheckpointFormat'
parameterCount:
type: string
format: int64
description: >-
The number of model parameters. For serverless models, this
determines the
price per token.
moe:
type: boolean
description: >-
If true, this is a Mixture of Experts (MoE) model. For serverless
models,
this affects the price per token.
tunable:
type: boolean
description: If true, this model is available for fine-tuning.
modelType:
type: string
description: The type of the model.
supportsFireattention:
type: boolean
description: Whether this model supports fireattention.
defaultPrecision:
$ref: '#/components/schemas/DeploymentPrecision'
description: Default precision of the model.
readOnly: true
supportsMtp:
type: boolean
description: If true, this model supports MTP.
title: 'Next ID: 11'
gatewayCode:
type: string
enum:
- OK
- CANCELLED
- UNKNOWN
- INVALID_ARGUMENT
- DEADLINE_EXCEEDED
- NOT_FOUND
- ALREADY_EXISTS
- PERMISSION_DENIED
- UNAUTHENTICATED
- RESOURCE_EXHAUSTED
- FAILED_PRECONDITION
- ABORTED
- OUT_OF_RANGE
- UNIMPLEMENTED
- INTERNAL
- UNAVAILABLE
- DATA_LOSS
default: OK
description: |-
- OK: Not an error; returned on success.
HTTP Mapping: 200 OK
- CANCELLED: The operation was cancelled, typically by the caller.
HTTP Mapping: 499 Client Closed Request
- UNKNOWN: Unknown error. For example, this error may be returned when
a `Status` value received from another address space belongs to
an error space that is not known in this address space. Also
errors raised by APIs that do not return enough error information
may be converted to this error.
HTTP Mapping: 500 Internal Server Error
- INVALID_ARGUMENT: The client specified an invalid argument. Note that this differs
from `FAILED_PRECONDITION`. `INVALID_ARGUMENT` indicates arguments
that are problematic regardless of the state of the system
(e.g., a malformed file name).
HTTP Mapping: 400 Bad Request
- DEADLINE_EXCEEDED: The deadline expired before the operation could complete. For operations
that change the state of the system, this error may be returned
even if the operation has completed successfully. For example, a
successful response from a server could have been delayed long
enough for the deadline to expire.
HTTP Mapping: 504 Gateway Timeout
- NOT_FOUND: Some requested entity (e.g., file or directory) was not found.
Note to server developers: if a request is denied for an entire class
of users, such as gradual feature rollout or undocumented allowlist,
`NOT_FOUND` may be used. If a request is denied for some users within
a class of users, such as user-based access control, `PERMISSION_DENIED`
must be used.
HTTP Mapping: 404 Not Found
- ALREADY_EXISTS: The entity that a client attempted to create (e.g., file or directory)
already exists.
HTTP Mapping: 409 Conflict
- PERMISSION_DENIED: The caller does not have permission to execute the specified
operation. `PERMISSION_DENIED` must not be used for rejections
caused by exhausting some resource (use `RESOURCE_EXHAUSTED`
instead for those errors). `PERMISSION_DENIED` must not be
used if the caller can not be identified (use `UNAUTHENTICATED`
instead for those errors). This error code does not imply the
request is valid or the requested entity exists or satisfies
other pre-conditions.
HTTP Mapping: 403 Forbidden
- UNAUTHENTICATED: The request does not have valid authentication credentials for the
operation.
HTTP Mapping: 401 Unauthorized
- RESOURCE_EXHAUSTED: Some resource has been exhausted, perhaps a per-user quota, or
perhaps the entire file system is out of space.
HTTP Mapping: 429 Too Many Requests
- FAILED_PRECONDITION: The operation was rejected because the system is not in a state
required for the operation's execution. For example, the directory
to be deleted is non-empty, an rmdir operation is applied to
a non-directory, etc.
Service implementors can use the following guidelines to decide
between `FAILED_PRECONDITION`, `ABORTED`, and `UNAVAILABLE`:
(a) Use `UNAVAILABLE` if the client can retry just the failing call.
(b) Use `ABORTED` if the client should retry at a higher level. For
example, when a client-specified test-and-set fails, indicating the
client should restart a read-modify-write sequence.
(c) Use `FAILED_PRECONDITION` if the client should not retry until
the system state has been explicitly fixed. For example, if an "rmdir"
fails because the directory is non-empty, `FAILED_PRECONDITION`
should be returned since the client should not retry unless
the files are deleted from the directory.
HTTP Mapping: 400 Bad Request
- ABORTED: The operation was aborted, typically due to a concurrency issue such as
a sequencer check failure or transaction abort.
See the guidelines above for deciding between `FAILED_PRECONDITION`,
`ABORTED`, and `UNAVAILABLE`.
HTTP Mapping: 409 Conflict
- OUT_OF_RANGE: The operation was attempted past the valid range. E.g., seeking or
reading past end-of-file.
Unlike `INVALID_ARGUMENT`, this error indicates a problem that may
be fixed if the system state changes. For example, a 32-bit file
system will generate `INVALID_ARGUMENT` if asked to read at an
offset that is not in the range [0,2^32-1], but it will generate
`OUT_OF_RANGE` if asked to read from an offset past the current
file size.
There is a fair bit of overlap between `FAILED_PRECONDITION` and
`OUT_OF_RANGE`. We recommend using `OUT_OF_RANGE` (the more specific
error) when it applies so that callers who are iterating through
a space can easily look for an `OUT_OF_RANGE` error to detect when
they are done.
HTTP Mapping: 400 Bad Request
- UNIMPLEMENTED: The operation is not implemented or is not supported/enabled in this
service.
HTTP Mapping: 501 Not Implemented
- INTERNAL: Internal errors. This means that some invariants expected by the
underlying system have been broken. This error code is reserved
for serious errors.
HTTP Mapping: 500 Internal Server Error
- UNAVAILABLE: The service is currently unavailable. This is most likely a
transient condition, which can be corrected by retrying with
a backoff. Note that it is not always safe to retry
non-idempotent operations.
See the guidelines above for deciding between `FAILED_PRECONDITION`,
`ABORTED`, and `UNAVAILABLE`.
HTTP Mapping: 503 Service Unavailable
- DATA_LOSS: Unrecoverable data loss or corruption.
HTTP Mapping: 500 Internal Server Error
title: >-
Mimics
[https://github.com/googleapis/googleapis/blob/master/google/rpc/code.proto]
gatewayConversationConfig:
type: object
properties:
style:
type: string
description: The chat template to use.
system:
type: string
description: The system prompt (if the chat style supports it).
template:
type: string
description: The Jinja template (if style is "jinja").
required:
- style
gatewayDeployedModelRef:
type: object
properties:
name:
type: string
title: >-
The resource name. e.g.
accounts/my-account/deployedModels/my-deployed-model
readOnly: true
deployment:
type: string
description: The resource name of the base deployment the model is deployed to.
readOnly: true
state:
$ref: '#/components/schemas/gatewayDeployedModelState'
description: The state of the deployed model.
readOnly: true
default:
type: boolean
description: >-
If true, this is the default target when querying this model without
the `#` suffix.
The first deployment a model is deployed to will have this field set
to
true automatically.
readOnly: true
public:
type: boolean
description: If true, the deployed model will be publicly reachable.
readOnly: true
title: 'Next ID: 6'
gatewayDeployedModelState:
type: string
enum:
- STATE_UNSPECIFIED
- UNDEPLOYING
- DEPLOYING
- DEPLOYED
- UPDATING
default: STATE_UNSPECIFIED
description: |-
- UNDEPLOYING: The model is being undeployed.
- DEPLOYING: The model is being deployed.
- DEPLOYED: The model is deployed and ready for inference.
- UPDATING: there are updates happening with the deployed model
title: 'Next ID: 6'
gatewayModel:
type: object
properties:
name: *ref_0
displayName: *ref_1
description: *ref_2
createTime: *ref_3
state: *ref_4
status: *ref_5
kind: *ref_6
githubUrl: *ref_7
huggingFaceUrl: *ref_8
baseModelDetails: *ref_9
peftDetails: *ref_10
teftDetails: *ref_11
public: *ref_12
conversationConfig: *ref_13
contextLength: *ref_14
supportsImageInput: *ref_15
supportsTools: *ref_16
importedFrom: *ref_17
fineTuningJob: *ref_18
defaultDraftModel: *ref_19
defaultDraftTokenCount: *ref_20
deployedModelRefs: *ref_21
cluster: *ref_22
deprecationDate: *ref_23
calibrated: *ref_24
tunable: *ref_25
supportsLora: *ref_26
useHfApplyChatTemplate: *ref_27
updateTime: *ref_28
defaultSamplingParams: *ref_29
rlTunable: *ref_30
supportedPrecisions: *ref_31
supportedPrecisionsWithCalibration: *ref_32
trainingContextLength: *ref_33
snapshotType: *ref_34
title: 'Next ID: 56'
gatewayModelKind:
type: string
enum:
- KIND_UNSPECIFIED
- HF_BASE_MODEL
- HF_PEFT_ADDON
- HF_TEFT_ADDON
- FLUMINA_BASE_MODEL
- FLUMINA_ADDON
- DRAFT_ADDON
- FIRE_AGENT
- LIVE_MERGE
- CUSTOM_MODEL
- EMBEDDING_MODEL
- SNAPSHOT_MODEL
default: KIND_UNSPECIFIED
description: |2-
- HF_BASE_MODEL: An LLM base model.
- HF_PEFT_ADDON: A parameter-efficent fine-tuned addon.
- HF_TEFT_ADDON: A token-eficient fine-tuned addon.
- FLUMINA_BASE_MODEL: A Flumina base model.
- FLUMINA_ADDON: A Flumina addon.
- DRAFT_ADDON: A draft model used for speculative decoding in a deployment.
- FIRE_AGENT: A FireAgent model.
- LIVE_MERGE: A live-merge model.
- CUSTOM_MODEL: A customized model
- EMBEDDING_MODEL: An Embedding model.
- SNAPSHOT_MODEL: A snapshot model.
gatewayModelState:
type: string
enum:
- STATE_UNSPECIFIED
- UPLOADING
- READY
default: STATE_UNSPECIFIED
description: |-
- UPLOADING: The model is still being uploaded (upload is asynchronous).
- READY: The model is ready to be used.
title: 'Next ID: 7'
gatewayPEFTDetails:
type: object
properties:
baseModel:
type: string
title: The base model name. e.g. accounts/fireworks/models/falcon-7b
r:
type: integer
format: int32
description: |-
The rank of the update matrices.
Must be between 4 and 64, inclusive.
targetModules:
type: array
items:
type: string
title: >-
This is the target modules for an adapter that we extract from
for more information what target module means, check out
https://huggingface.co/docs/peft/conceptual_guides/lora#common-lora-parameters-in-peft
baseModelType:
type: string
description: The type of the model.
readOnly: true
mergeAddonModelName:
type: string
title: >-
The resource name of the model to merge with base model, e.g
accounts/fireworks/models/falcon-7b-lora
title: |-
PEFT addon details.
Next ID: 6
required:
- baseModel
- r
- targetModules
gatewayStatus:
type: object
properties:
code:
$ref: '#/components/schemas/gatewayCode'
description: The status code.
message:
type: string
description: A developer-facing error message in English.
title: >-
Mimics
[https://github.com/googleapis/googleapis/blob/master/google/rpc/status.proto]
gatewayTEFTDetails:
type: object
typeDate:
type: object
properties:
year:
type: integer
format: int32
description: >-
Year of the date. Must be from 1 to 9999, or 0 to specify a date
without
a year.
month:
type: integer
format: int32
description: >-
Month of a year. Must be from 1 to 12, or 0 to specify a year
without a
month and day.
day:
type: integer
format: int32
description: >-
Day of a month. Must be from 1 to 31 and valid for the year and
month, or 0
to specify a year by itself or a year and month where the day isn't
significant.
description: >-
* A full date, with non-zero year, month, and day values
* A month and day value, with a zero year, such as an anniversary
* A year on its own, with zero month and day values
* A year and month value, with a zero day, such as a credit card
expiration
date
Related types are [google.type.TimeOfDay][google.type.TimeOfDay] and
`google.protobuf.Timestamp`.
title: >-
Represents a whole or partial calendar date, such as a birthday. The
time of
day and time zone are either specified elsewhere or are insignificant.
The
date is relative to the Gregorian Calendar. This can represent one of
the
following:
````
---
# Source: https://docs.fireworks.ai/api-reference-dlde/create-node-pool-binding.md
# Create Node Pool Binding
## OpenAPI
````yaml post /v1/accounts/{account_id}/nodePoolBindings
paths:
path: /v1/accounts/{account_id}/nodePoolBindings
method: post
servers:
- url: https://api.fireworks.ai
request:
security:
- title: BearerAuth
parameters:
query: {}
header:
Authorization:
type: http
scheme: bearer
description: >-
Bearer authentication using your Fireworks API key. Format:
Bearer
During training, Fireworks calls your service's `POST /init` endpoint with the dataset row and correlation metadata.
Your agent executes the task (e.g., multi-turn conversation, tool calls, simulation steps), logging progress via Fireworks tracing.
Your service sends structured logs tagged with rollout metadata to Fireworks so the system can track completion.
Once Fireworks detects completion, it pulls the full trace and evaluates it using your scoring logic.
Everything except implementing your remote server is handled automatically by Eval Protocol. You only need to implement the `/init` endpoint and add Fireworks tracing.
## Implementing the /init endpoint
Your remote service must implement a single `/init` endpoint that accepts rollout requests.
### Request schema
Model configuration including model name and inference parameters like temperature, max\_tokens, etc.
Array of conversation messages to send to the model
Array of available tools for the model (for function calling)
Base URL for making LLM calls through Fireworks tracing (includes correlation metadata)
Rollout execution metadata for correlation (rollout\_id, run\_id, row\_id, etc.)
Fireworks API key to use for model calls
### Example request
```json theme={null}
{
"completion_params": {
"model": "accounts/fireworks/models/llama-v3p1-8b-instruct",
"temperature": 0.7,
"max_tokens": 2048
},
"messages": [
{ "role": "user", "content": "What is the weather in San Francisco?" }
],
"tools": [
{
"type": "function",
"function": {
"name": "get_weather",
"description": "Get the weather for a city",
"parameters": {
"type": "object",
"properties": {
"city": { "type": "string" }
}
}
}
}
],
"model_base_url": "https://tracing.fireworks.ai/rollout_id/brave-night-42/invocation_id/wise-ocean-15/experiment_id/calm-forest-28/run_id/quick-river-07/row_id/bright-star-91",
"metadata": {
"invocation_id": "wise-ocean-15",
"experiment_id": "calm-forest-28",
"rollout_id": "brave-night-42",
"run_id": "quick-river-07",
"row_id": "bright-star-91"
},
"api_key": "fw_your_api_key"
}
```
## Metadata correlation
The `metadata` object contains correlation IDs that you must include when logging to Fireworks tracing. This allows Eval Protocol to match logs and traces back to specific evaluation rows.
Required metadata fields:
* `invocation_id` - Identifies the evaluation invocation
* `experiment_id` - Groups related experiments
* `rollout_id` - Unique ID for this specific rollout (most important)
* `run_id` - Identifies the evaluation run
* `row_id` - Links to the dataset row
`RemoteRolloutProcessor` automatically generates these IDs and sends them to your server. You don't need to create them yourself—just pass them through to your logging.
## Fireworks tracing integration
Your remote server must use Fireworks tracing to report rollout status. Eval Protocol polls these logs to detect when rollouts complete.
### Basic setup
```python theme={null}
import logging
from eval_protocol import Status, InitRequest, FireworksTracingHttpHandler, RolloutIdFilter
# Configure Fireworks tracing handler globally
fireworks_handler = FireworksTracingHttpHandler()
logging.getLogger().addHandler(fireworks_handler)
@app.post("/init")
def init(request: InitRequest):
# Create rollout-specific logger with filter
rollout_logger = logging.getLogger(f"eval_server.{request.metadata.rollout_id}")
rollout_logger.addFilter(RolloutIdFilter(request.metadata.rollout_id))
try:
# Execute your agent logic here
result = execute_agent(request)
# Log successful completion with structured status
rollout_logger.info(
f"Rollout {request.metadata.rollout_id} completed",
extra={"status": Status.rollout_finished()}
)
return {"status": "success"}
except Exception as e:
# Log errors with structured status
rollout_logger.error(
f"Rollout {request.metadata.rollout_id} failed: {e}",
extra={"status": Status.rollout_error(str(e))}
)
raise
```
### Key components
1. **FireworksTracingHttpHandler**: Sends logs to Fireworks tracing service
2. **RolloutIdFilter**: Tags logs with the rollout ID for correlation
3. **Status objects**: Structured status reporting that Eval Protocol can parse
* `Status.rollout_finished()` - Signals successful completion
* `Status.rollout_error(message)` - Signals failure with error details
### Alternative: Environment variable approach
For simpler setups, you can use the `EP_ROLLOUT_ID` environment variable instead of manual filters.
If your server processes one rollout at a time (e.g., serverless functions, container per request):
```python theme={null}
import os
import logging
from eval_protocol import Status, InitRequest, FireworksTracingHttpHandler
# Set rollout ID in environment
os.environ["EP_ROLLOUT_ID"] = request.metadata.rollout_id
# Configure handler (automatically picks up EP_ROLLOUT_ID)
fireworks_handler = FireworksTracingHttpHandler()
logging.getLogger().addHandler(fireworks_handler)
logger = logging.getLogger(__name__)
@app.post("/init")
def init(request: InitRequest):
# Logs are automatically tagged with rollout_id
logger.info("Processing rollout...")
# ... execute agent logic ...
```
If your `/init` handler spawns separate Python processes for each rollout:
```python theme={null}
import os
import logging
import multiprocessing
from eval_protocol import FireworksTracingHttpHandler, InitRequest
def execute_rollout_step_sync(request):
# Set EP_ROLLOUT_ID in the child process
os.environ["EP_ROLLOUT_ID"] = request.metadata.rollout_id
logging.getLogger().addHandler(FireworksTracingHttpHandler())
# Execute your rollout logic here
# Logs are automatically tagged
@app.post("/init")
async def init(request: InitRequest):
# Do NOT set EP_ROLLOUT_ID in parent process
p = multiprocessing.Process(
target=execute_rollout_step_sync,
args=(request,)
)
p.start()
return {"status": "started"}
```
### How Eval Protocol uses tracing
1. **Your server logs completion**: Uses `Status.rollout_finished()` or `Status.rollout_error()`
2. **Eval Protocol polls**: Searches Fireworks logs by `rollout_id` tag until completion signal found
3. **Status extraction**: Reads structured status fields (`code`, `message`, `details`) to determine outcome
4. **Trace retrieval**: Fetches full trace of model calls and tool use for evaluation
## Complete example
Here's a minimal but complete remote server implementation:
```python theme={null}
from fastapi import FastAPI
from fastapi.responses import JSONResponse
from eval_protocol import InitRequest, FireworksTracingHttpHandler, RolloutIdFilter, Status
import logging
app = FastAPI()
# Setup Fireworks tracing
fireworks_handler = FireworksTracingHttpHandler()
logging.getLogger().addHandler(fireworks_handler)
@app.post("/init")
async def init(request: InitRequest):
# Create rollout-specific logger
rollout_logger = logging.getLogger(f"eval_server.{request.metadata.rollout_id}")
rollout_logger.addFilter(RolloutIdFilter(request.metadata.rollout_id))
rollout_logger.info(f"Starting rollout {request.metadata.rollout_id}")
try:
# Your agent logic here
# 1. Make model calls using request.model_base_url
# 2. Call tools, interact with environment
# 3. Collect results
result = run_your_agent(
messages=request.messages,
tools=request.tools,
model_config=request.completion_params,
api_key=request.api_key
)
# Signal completion
rollout_logger.info(
f"Rollout {request.metadata.rollout_id} completed successfully",
extra={"status": Status.rollout_finished()}
)
return {"status": "success", "result": result}
except Exception as e:
# Signal error
rollout_logger.error(
f"Rollout {request.metadata.rollout_id} failed: {str(e)}",
extra={"status": Status.rollout_error(str(e))}
)
return JSONResponse(
status_code=500,
content={"status": "error", "message": str(e)}
)
def run_your_agent(messages, tools, model_config, api_key):
# Implement your agent logic here
# Make model calls, use tools, etc.
pass
```
## Testing locally
Before deploying, test your remote server locally:
```bash theme={null}
uvicorn main:app --reload --port 8080
```
In your evaluator test, point to your local server:
```python theme={null}
from eval_protocol.pytest import RemoteRolloutProcessor
rollout_processor = RemoteRolloutProcessor(
remote_base_url="http://localhost:8080"
)
```
```bash theme={null}
pytest my-evaluator-name.py -vs
```
This sends test rollouts to your local server and verifies the integration works.
## Deploying your service
Once tested locally, deploy to production:
* ✅ Service is publicly accessible (or accessible via VPN/private network)
* ✅ HTTPS endpoint with valid SSL certificate (recommended)
* ✅ Authentication/authorization configured
* ✅ Monitoring and logging set up
* ✅ Auto-scaling configured for concurrent rollouts
* ✅ Error handling and retry logic implemented
* ✅ Service availability SLA meets training requirements
**Vercel/Serverless**:
* One rollout per function invocation
* Use environment variable approach
* Configure timeout for long-running evaluations
**AWS ECS/Kubernetes**:
* Handle concurrent requests with proper worker configuration
* Use RolloutIdFilter approach
* Set up load balancing
**On-premise**:
* Ensure network connectivity from Fireworks
* Configure firewall rules
* Set up VPN if needed for security
## Connecting to RFT
Once your remote server is deployed, create an RFT job that uses it:
```bash theme={null}
eval-protocol create rft \
--base-model accounts/fireworks/models/llama-v3p1-8b-instruct \
--remote-server-url https://your-evaluator.example.com \
--dataset my-dataset
```
The RFT job will send all rollouts to your remote server for evaluation during training.
## Troubleshooting
**Symptoms**: Rollouts show as timed out or never complete
**Solutions**:
* Check that your service is logging `Status.rollout_finished()` correctly
* Verify Fireworks tracing handler is configured
* Ensure rollout\_id is included in log tags
* Check for exceptions being swallowed without logging
**Symptoms**: Eval Protocol can't match logs to rollouts
**Solutions**:
* Verify you're using the exact `rollout_id` from request metadata
* Check that RolloutIdFilter or EP\_ROLLOUT\_ID is set correctly
* Ensure logs are being sent to Fireworks (check tracing dashboard)
**Symptoms**: Training is slow, high rollout latency
**Solutions**:
* Scale your service to handle concurrent requests
* Optimize your agent logic (caching, async operations)
* Add more workers or instances
* Profile your code to find bottlenecks
**Symptoms**: Model calls fail, API errors
**Solutions**:
* Verify API key is passed correctly from request
* Check that your service has network access to Fireworks
* Ensure model\_base\_url is used for traced calls
## Example implementations
Learn by example:
Complete walkthrough using a Vercel TypeScript server for SVG generation
Minimal Python implementation showing the basics
## Next steps
Launch your RFT job using the CLI
Track rollout progress and debug issues
Full Remote Rollout Processor tutorial
Design effective reward functions
---
# Source: https://docs.fireworks.ai/examples/cookbooks.md
# Cookbooks
> Interactive Jupyter notebooks demonstrating advanced use cases and best practices with Fireworks AI
Explore our collection of notebooks that showcase real-world applications, best practices, and advanced techniques for building with Fireworks AI.
## Fine-Tuning & Training
Transfer large model capabilities to efficient models using a two-stage SFT + RFT approach.
**Techniques:** Supervised Fine-Tuning (SFT) + Reinforcement Fine-Tuning (RFT)
**Results:** 52% → 70% accuracy on GSM8K mathematical reasoning
Beat frontier closed-source models for product catalog cleansing with vision-language model fine-tuning.
**Techniques:** Supervised Fine-Tuning (SFT)
**Results:** 48% increase in quality from base model
## Multimodal AI
Extract structured data from invoices, forms, and financial documents using state-of-the-art OCR and document understanding.
**Use Cases:** Forms, invoices, financial documents, product catalogs
**Results:** 90.8% accuracy on invoice extraction (100% on invoice numbers and dates)
Real-time audio transcription with streaming support and low latency.
**Features:** Streaming support, low-latency transcription, production-ready
## API Features
Leverage Model Context Protocol (MCP) for GitHub repository analysis, code search, and documentation Q\&A.
**Features:** Repository analysis, code search, documentation Q\&A, GitMCP integration
**Models:** Qwen 3 235B with external tool support
---
# Source: https://docs.fireworks.ai/tools-sdks/firectl/commands/create-api-key.md
# Source: https://docs.fireworks.ai/api-reference/create-api-key.md
# Source: https://docs.fireworks.ai/tools-sdks/firectl/commands/create-api-key.md
# Source: https://docs.fireworks.ai/api-reference/create-api-key.md
# Source: https://docs.fireworks.ai/tools-sdks/firectl/commands/create-api-key.md
# Source: https://docs.fireworks.ai/api-reference/create-api-key.md
# Create API Key
## OpenAPI
````yaml post /v1/accounts/{account_id}/users/{user_id}/apiKeys
paths:
path: /v1/accounts/{account_id}/users/{user_id}/apiKeys
method: post
servers:
- url: https://api.fireworks.ai
request:
security:
- title: BearerAuth
parameters:
query: {}
header:
Authorization:
type: http
scheme: bearer
description: >-
Bearer authentication using your Fireworks API key. Format:
Bearer
cookie: {}
parameters:
path:
account_id:
schema:
- type: string
required: true
description: The Account Id
user_id:
schema:
- type: string
required: true
description: The User Id
query: {}
header: {}
cookie: {}
body:
application/json:
schemaArray:
- type: object
properties:
apiKey:
allOf:
- $ref: '#/components/schemas/gatewayApiKey'
description: The API key to be created.
required: true
refIdentifier: '#/components/schemas/GatewayCreateApiKeyBody'
requiredProperties:
- apiKey
examples:
example:
value:
apiKey:
displayName:
expireTime: '2023-11-07T05:31:56Z'
response:
'200':
application/json:
schemaArray:
- type: object
properties:
keyId:
allOf:
- &ref_0
type: string
description: >-
Unique identifier (Key ID) for the API key, used primarily
for deletion.
readOnly: true
displayName:
allOf:
- &ref_1
type: string
description: >-
Display name for the API key, defaults to "default" if not
specified.
key:
allOf:
- &ref_2
type: string
description: >-
The actual API key value, only available upon creation and
not stored thereafter.
readOnly: true
createTime:
allOf:
- &ref_3
type: string
format: date-time
description: Timestamp indicating when the API key was created.
readOnly: true
secure:
allOf:
- &ref_4
type: boolean
description: >-
Indicates whether the plaintext value of the API key is
unknown to Fireworks.
If true, Fireworks does not know this API key's plaintext
value. If false, Fireworks does
know the plaintext value.
readOnly: true
email:
allOf:
- &ref_5
type: string
description: Email of the user who owns this API key.
readOnly: true
prefix:
allOf:
- &ref_6
type: string
title: >-
The first few characters of the API key to visually
identify it
readOnly: true
expireTime:
allOf:
- &ref_7
type: string
format: date-time
description: >-
Timestamp indicating when the API key will expire. If not
set, the key never expires.
refIdentifier: '#/components/schemas/gatewayApiKey'
examples:
example:
value:
keyId:
displayName:
key:
createTime: '2023-11-07T05:31:56Z'
secure: true
email:
prefix:
expireTime: '2023-11-07T05:31:56Z'
description: A successful response.
deprecated: false
type: path
components:
schemas:
gatewayApiKey:
type: object
properties:
keyId: *ref_0
displayName: *ref_1
key: *ref_2
createTime: *ref_3
secure: *ref_4
email: *ref_5
prefix: *ref_6
expireTime: *ref_7
````
---
# Source: https://docs.fireworks.ai/api-reference-dlde/create-aws-iam-role-binding.md
# Create Aws Iam Role Binding
## OpenAPI
````yaml post /v1/accounts/{account_id}/awsIamRoleBindings
paths:
path: /v1/accounts/{account_id}/awsIamRoleBindings
method: post
servers:
- url: https://api.fireworks.ai
request:
security:
- title: BearerAuth
parameters:
query: {}
header:
Authorization:
type: http
scheme: bearer
description: >-
Bearer authentication using your Fireworks API key. Format:
Bearer
cookie: {}
parameters:
path:
account_id:
schema:
- type: string
required: true
description: The Account Id
query: {}
header: {}
cookie: {}
body:
application/json:
schemaArray:
- type: object
properties:
principal:
allOf:
- &ref_0
type: string
description: >-
The principal that is allowed to assume the AWS IAM role.
This must be
the email address of the user.
role:
allOf:
- &ref_1
type: string
description: >-
The AWS IAM role ARN that is allowed to be assumed by the
principal.
required: true
refIdentifier: '#/components/schemas/gatewayAwsIamRoleBinding'
requiredProperties: &ref_2
- principal
- role
examples:
example:
value:
principal:
role:
description: The properties of the AWS IAM role binding being created.
response:
'200':
application/json:
schemaArray:
- type: object
properties:
accountId:
allOf:
- type: string
description: The account ID that this binding is associated with.
readOnly: true
createTime:
allOf:
- type: string
format: date-time
description: The creation time of the AWS IAM role binding.
readOnly: true
principal:
allOf:
- *ref_0
role:
allOf:
- *ref_1
refIdentifier: '#/components/schemas/gatewayAwsIamRoleBinding'
requiredProperties: *ref_2
examples:
example:
value:
accountId:
createTime: '2023-11-07T05:31:56Z'
principal:
role:
description: A successful response.
deprecated: false
type: path
components:
schemas: {}
````
---
# Source: https://docs.fireworks.ai/tools-sdks/firectl/commands/create-batch-inference-job.md
# Source: https://docs.fireworks.ai/api-reference/create-batch-inference-job.md
# Source: https://docs.fireworks.ai/tools-sdks/firectl/commands/create-batch-inference-job.md
# Source: https://docs.fireworks.ai/api-reference/create-batch-inference-job.md
# Source: https://docs.fireworks.ai/tools-sdks/firectl/commands/create-batch-inference-job.md
# Source: https://docs.fireworks.ai/api-reference/create-batch-inference-job.md
# Create Batch Inference Job
## OpenAPI
````yaml post /v1/accounts/{account_id}/batchInferenceJobs
paths:
path: /v1/accounts/{account_id}/batchInferenceJobs
method: post
servers:
- url: https://api.fireworks.ai
request:
security:
- title: BearerAuth
parameters:
query: {}
header:
Authorization:
type: http
scheme: bearer
description: >-
Bearer authentication using your Fireworks API key. Format:
Bearer
cookie: {}
parameters:
path:
account_id:
schema:
- type: string
required: true
description: The Account Id
query:
batchInferenceJobId:
schema:
- type: string
required: false
description: ID of the batch inference job.
header: {}
cookie: {}
body:
application/json:
schemaArray:
- type: object
properties:
displayName:
allOf:
- &ref_0
type: string
title: >-
Human-readable display name of the batch inference job.
e.g. "My Batch Inference Job"
state:
allOf:
- &ref_1
$ref: '#/components/schemas/gatewayJobState'
description: >-
JobState represents the state an asynchronous job can be
in.
readOnly: true
status:
allOf:
- &ref_2
$ref: '#/components/schemas/gatewayStatus'
readOnly: true
model:
allOf:
- &ref_3
type: string
description: >-
The name of the model to use for inference. This is
required, except when continued_from_job_name is
specified.
inputDatasetId:
allOf:
- &ref_4
type: string
description: >-
The name of the dataset used for inference. This is
required, except when continued_from_job_name is
specified.
outputDatasetId:
allOf:
- &ref_5
type: string
description: >-
The name of the dataset used for storing the results. This
will also contain the error file.
inferenceParameters:
allOf:
- &ref_6
$ref: '#/components/schemas/gatewayInferenceParameters'
description: Parameters controlling the inference process.
precision:
allOf:
- &ref_7
$ref: '#/components/schemas/DeploymentPrecision'
description: >-
The precision with which the model should be served.
If PRECISION_UNSPECIFIED, a default will be chosen based
on the model.
jobProgress:
allOf:
- &ref_8
$ref: '#/components/schemas/gatewayJobProgress'
description: Job progress.
readOnly: true
continuedFromJobName:
allOf:
- &ref_9
type: string
description: >-
The resource name of the batch inference job that this job
continues from.
Used for lineage tracking to understand job continuation
chains.
required: true
title: 'Next ID: 31'
refIdentifier: '#/components/schemas/gatewayBatchInferenceJob'
examples:
example:
value:
displayName:
model:
inputDatasetId:
outputDatasetId:
inferenceParameters:
maxTokens: 123
temperature: 123
topP: 123
'n': 123
extraBody:
topK: 123
precision: PRECISION_UNSPECIFIED
continuedFromJobName:
response:
'200':
application/json:
schemaArray:
- type: object
properties:
name:
allOf:
- type: string
title: >-
The resource name of the batch inference job. e.g.
accounts/my-account/batchInferenceJobs/my-batch-inference-job
readOnly: true
displayName:
allOf:
- *ref_0
createTime:
allOf:
- type: string
format: date-time
description: The creation time of the batch inference job.
readOnly: true
createdBy:
allOf:
- type: string
description: >-
The email address of the user who initiated this batch
inference job.
readOnly: true
state:
allOf:
- *ref_1
status:
allOf:
- *ref_2
model:
allOf:
- *ref_3
inputDatasetId:
allOf:
- *ref_4
outputDatasetId:
allOf:
- *ref_5
inferenceParameters:
allOf:
- *ref_6
updateTime:
allOf:
- type: string
format: date-time
description: The update time for the batch inference job.
readOnly: true
precision:
allOf:
- *ref_7
jobProgress:
allOf:
- *ref_8
continuedFromJobName:
allOf:
- *ref_9
title: 'Next ID: 31'
refIdentifier: '#/components/schemas/gatewayBatchInferenceJob'
examples:
example:
value:
name:
displayName:
createTime: '2023-11-07T05:31:56Z'
createdBy:
state: JOB_STATE_UNSPECIFIED
status:
code: OK
message:
model:
inputDatasetId:
outputDatasetId:
inferenceParameters:
maxTokens: 123
temperature: 123
topP: 123
'n': 123
extraBody:
topK: 123
updateTime: '2023-11-07T05:31:56Z'
precision: PRECISION_UNSPECIFIED
jobProgress:
percent: 123
epoch: 123
totalInputRequests: 123
totalProcessedRequests: 123
successfullyProcessedRequests: 123
failedRequests: 123
outputRows: 123
inputTokens: 123
outputTokens: 123
cachedInputTokenCount: 123
continuedFromJobName:
description: A successful response.
deprecated: false
type: path
components:
schemas:
DeploymentPrecision:
type: string
enum:
- PRECISION_UNSPECIFIED
- FP16
- FP8
- FP8_MM
- FP8_AR
- FP8_MM_KV_ATTN
- FP8_KV
- FP8_MM_V2
- FP8_V2
- FP8_MM_KV_ATTN_V2
- NF4
- FP4
- BF16
- FP4_BLOCKSCALED_MM
- FP4_MX_MOE
default: PRECISION_UNSPECIFIED
title: >-
- PRECISION_UNSPECIFIED: if left unspecified we will treat this as a
legacy model created before
self serve
gatewayCode:
type: string
enum:
- OK
- CANCELLED
- UNKNOWN
- INVALID_ARGUMENT
- DEADLINE_EXCEEDED
- NOT_FOUND
- ALREADY_EXISTS
- PERMISSION_DENIED
- UNAUTHENTICATED
- RESOURCE_EXHAUSTED
- FAILED_PRECONDITION
- ABORTED
- OUT_OF_RANGE
- UNIMPLEMENTED
- INTERNAL
- UNAVAILABLE
- DATA_LOSS
default: OK
description: |-
- OK: Not an error; returned on success.
HTTP Mapping: 200 OK
- CANCELLED: The operation was cancelled, typically by the caller.
HTTP Mapping: 499 Client Closed Request
- UNKNOWN: Unknown error. For example, this error may be returned when
a `Status` value received from another address space belongs to
an error space that is not known in this address space. Also
errors raised by APIs that do not return enough error information
may be converted to this error.
HTTP Mapping: 500 Internal Server Error
- INVALID_ARGUMENT: The client specified an invalid argument. Note that this differs
from `FAILED_PRECONDITION`. `INVALID_ARGUMENT` indicates arguments
that are problematic regardless of the state of the system
(e.g., a malformed file name).
HTTP Mapping: 400 Bad Request
- DEADLINE_EXCEEDED: The deadline expired before the operation could complete. For operations
that change the state of the system, this error may be returned
even if the operation has completed successfully. For example, a
successful response from a server could have been delayed long
enough for the deadline to expire.
HTTP Mapping: 504 Gateway Timeout
- NOT_FOUND: Some requested entity (e.g., file or directory) was not found.
Note to server developers: if a request is denied for an entire class
of users, such as gradual feature rollout or undocumented allowlist,
`NOT_FOUND` may be used. If a request is denied for some users within
a class of users, such as user-based access control, `PERMISSION_DENIED`
must be used.
HTTP Mapping: 404 Not Found
- ALREADY_EXISTS: The entity that a client attempted to create (e.g., file or directory)
already exists.
HTTP Mapping: 409 Conflict
- PERMISSION_DENIED: The caller does not have permission to execute the specified
operation. `PERMISSION_DENIED` must not be used for rejections
caused by exhausting some resource (use `RESOURCE_EXHAUSTED`
instead for those errors). `PERMISSION_DENIED` must not be
used if the caller can not be identified (use `UNAUTHENTICATED`
instead for those errors). This error code does not imply the
request is valid or the requested entity exists or satisfies
other pre-conditions.
HTTP Mapping: 403 Forbidden
- UNAUTHENTICATED: The request does not have valid authentication credentials for the
operation.
HTTP Mapping: 401 Unauthorized
- RESOURCE_EXHAUSTED: Some resource has been exhausted, perhaps a per-user quota, or
perhaps the entire file system is out of space.
HTTP Mapping: 429 Too Many Requests
- FAILED_PRECONDITION: The operation was rejected because the system is not in a state
required for the operation's execution. For example, the directory
to be deleted is non-empty, an rmdir operation is applied to
a non-directory, etc.
Service implementors can use the following guidelines to decide
between `FAILED_PRECONDITION`, `ABORTED`, and `UNAVAILABLE`:
(a) Use `UNAVAILABLE` if the client can retry just the failing call.
(b) Use `ABORTED` if the client should retry at a higher level. For
example, when a client-specified test-and-set fails, indicating the
client should restart a read-modify-write sequence.
(c) Use `FAILED_PRECONDITION` if the client should not retry until
the system state has been explicitly fixed. For example, if an "rmdir"
fails because the directory is non-empty, `FAILED_PRECONDITION`
should be returned since the client should not retry unless
the files are deleted from the directory.
HTTP Mapping: 400 Bad Request
- ABORTED: The operation was aborted, typically due to a concurrency issue such as
a sequencer check failure or transaction abort.
See the guidelines above for deciding between `FAILED_PRECONDITION`,
`ABORTED`, and `UNAVAILABLE`.
HTTP Mapping: 409 Conflict
- OUT_OF_RANGE: The operation was attempted past the valid range. E.g., seeking or
reading past end-of-file.
Unlike `INVALID_ARGUMENT`, this error indicates a problem that may
be fixed if the system state changes. For example, a 32-bit file
system will generate `INVALID_ARGUMENT` if asked to read at an
offset that is not in the range [0,2^32-1], but it will generate
`OUT_OF_RANGE` if asked to read from an offset past the current
file size.
There is a fair bit of overlap between `FAILED_PRECONDITION` and
`OUT_OF_RANGE`. We recommend using `OUT_OF_RANGE` (the more specific
error) when it applies so that callers who are iterating through
a space can easily look for an `OUT_OF_RANGE` error to detect when
they are done.
HTTP Mapping: 400 Bad Request
- UNIMPLEMENTED: The operation is not implemented or is not supported/enabled in this
service.
HTTP Mapping: 501 Not Implemented
- INTERNAL: Internal errors. This means that some invariants expected by the
underlying system have been broken. This error code is reserved
for serious errors.
HTTP Mapping: 500 Internal Server Error
- UNAVAILABLE: The service is currently unavailable. This is most likely a
transient condition, which can be corrected by retrying with
a backoff. Note that it is not always safe to retry
non-idempotent operations.
See the guidelines above for deciding between `FAILED_PRECONDITION`,
`ABORTED`, and `UNAVAILABLE`.
HTTP Mapping: 503 Service Unavailable
- DATA_LOSS: Unrecoverable data loss or corruption.
HTTP Mapping: 500 Internal Server Error
title: >-
Mimics
[https://github.com/googleapis/googleapis/blob/master/google/rpc/code.proto]
gatewayInferenceParameters:
type: object
properties:
maxTokens:
type: integer
format: int32
description: Maximum number of tokens to generate per response.
temperature:
type: number
format: float
description: Sampling temperature, typically between 0 and 2.
topP:
type: number
format: float
description: Top-p sampling parameter, typically between 0 and 1.
'n':
type: integer
format: int32
description: Number of response candidates to generate per input.
extraBody:
type: string
description: |-
Additional parameters for the inference request as a JSON string.
For example: "{\"stop\": [\"\\n\"]}".
topK:
type: integer
format: int32
description: >-
Top-k sampling parameter, limits the token selection to the top k
tokens.
description: Parameters for the inference requests.
gatewayJobProgress:
type: object
properties:
percent:
type: integer
format: int32
description: Progress percent, within the range from 0 to 100.
epoch:
type: integer
format: int32
description: >-
The epoch for which the progress percent is reported, usually
starting from 0.
This is optional for jobs that don't run in an epoch fasion, e.g.
BIJ, EVJ.
totalInputRequests:
type: integer
format: int32
description: Total number of input requests/rows in the job.
totalProcessedRequests:
type: integer
format: int32
description: >-
Total number of requests that have been processed (successfully or
failed).
successfullyProcessedRequests:
type: integer
format: int32
description: Number of requests that were processed successfully.
failedRequests:
type: integer
format: int32
description: Number of requests that failed to process.
outputRows:
type: integer
format: int32
description: Number of output rows generated.
inputTokens:
type: integer
format: int32
description: Total number of input tokens processed.
outputTokens:
type: integer
format: int32
description: Total number of output tokens generated.
cachedInputTokenCount:
type: integer
format: int32
description: The number of input tokens that hit the prompt cache.
description: Progress of a job, e.g. RLOR, EVJ, BIJ etc.
gatewayJobState:
type: string
enum:
- JOB_STATE_UNSPECIFIED
- JOB_STATE_CREATING
- JOB_STATE_RUNNING
- JOB_STATE_COMPLETED
- JOB_STATE_FAILED
- JOB_STATE_CANCELLED
- JOB_STATE_DELETING
- JOB_STATE_WRITING_RESULTS
- JOB_STATE_VALIDATING
- JOB_STATE_DELETING_CLEANING_UP
- JOB_STATE_PENDING
- JOB_STATE_EXPIRED
- JOB_STATE_RE_QUEUEING
- JOB_STATE_CREATING_INPUT_DATASET
- JOB_STATE_IDLE
- JOB_STATE_CANCELLING
- JOB_STATE_EARLY_STOPPED
default: JOB_STATE_UNSPECIFIED
description: JobState represents the state an asynchronous job can be in.
gatewayStatus:
type: object
properties:
code:
$ref: '#/components/schemas/gatewayCode'
description: The status code.
message:
type: string
description: A developer-facing error message in English.
title: >-
Mimics
[https://github.com/googleapis/googleapis/blob/master/google/rpc/status.proto]
````
---
# Source: https://docs.fireworks.ai/api-reference-dlde/create-batch-job.md
# Create Batch Job
## OpenAPI
````yaml post /v1/accounts/{account_id}/batchJobs
paths:
path: /v1/accounts/{account_id}/batchJobs
method: post
servers:
- url: https://api.fireworks.ai
request:
security:
- title: BearerAuth
parameters:
query: {}
header:
Authorization:
type: http
scheme: bearer
description: >-
Bearer authentication using your Fireworks API key. Format:
Bearer
cookie: {}
parameters:
path:
account_id:
schema:
- type: string
required: true
description: The Account Id
query: {}
header: {}
cookie: {}
body:
application/json:
schemaArray:
- type: object
properties:
displayName:
allOf:
- &ref_0
type: string
description: >-
Human-readable display name of the batch job. e.g. "My
Batch Job"
Must be fewer than 64 characters long.
nodePoolId:
allOf:
- &ref_1
type: string
title: >-
The ID of the node pool that this batch job should use.
e.g. my-node-pool
environmentId:
allOf:
- &ref_2
type: string
description: >-
The ID of the environment that this batch job should use.
e.g. my-env
If specified, image_ref must not be specified.
snapshotId:
allOf:
- &ref_3
type: string
description: >-
The ID of the snapshot used by this batch job.
If specified, environment_id must be specified and
image_ref must not be
specified.
numRanks:
allOf:
- &ref_4
type: integer
format: int32
description: |-
For GPU node pools: one GPU per rank w/ host packing,
for CPU node pools: one host per rank.
envVars:
allOf:
- &ref_5
type: object
additionalProperties:
type: string
description: >-
Environment variables to be passed during this job's
execution.
role:
allOf:
- &ref_6
type: string
description: >-
The ARN of the AWS IAM role that the batch job should
assume.
If not specified, the connection will fall back to the
node
pool's node_role.
pythonExecutor:
allOf:
- &ref_7
$ref: '#/components/schemas/gatewayPythonExecutor'
notebookExecutor:
allOf:
- &ref_8
$ref: '#/components/schemas/gatewayNotebookExecutor'
shellExecutor:
allOf:
- &ref_9
$ref: '#/components/schemas/gatewayShellExecutor'
imageRef:
allOf:
- &ref_10
type: string
description: >-
The container image used by this job. If specified,
environment_id and
snapshot_id must not be specified.
annotations:
allOf:
- &ref_11
type: object
additionalProperties:
type: string
description: >-
Arbitrary, user-specified metadata.
Keys and values must adhere to Kubernetes constraints:
https://kubernetes.io/docs/concepts/overview/working-with-objects/annotations/#syntax-and-character-set
Additionally, the "fireworks.ai/" prefix is reserved.
state:
allOf:
- &ref_12
$ref: '#/components/schemas/gatewayBatchJobState'
description: The current state of the batch job.
readOnly: true
shared:
allOf:
- &ref_13
type: boolean
description: >-
Whether the batch job is shared with all users in the
account.
This allows all users to update, delete, clone, and create
environments
using the batch job.
required: true
title: 'Next ID: 22'
refIdentifier: '#/components/schemas/gatewayBatchJob'
requiredProperties: &ref_14
- nodePoolId
examples:
example:
value:
displayName:
nodePoolId:
environmentId:
snapshotId:
numRanks: 123
envVars: {}
role:
pythonExecutor:
targetType: TARGET_TYPE_UNSPECIFIED
target:
args:
-
notebookExecutor:
notebookFilename:
shellExecutor:
command:
imageRef:
annotations: {}
shared: true
description: The properties of the batch job being created.
response:
'200':
application/json:
schemaArray:
- type: object
properties:
name:
allOf:
- type: string
title: >-
The resource name of the batch job.
e.g.
accounts/my-account/clusters/my-cluster/batchJobs/123456789
readOnly: true
displayName:
allOf:
- *ref_0
createTime:
allOf:
- type: string
format: date-time
description: The creation time of the batch job.
readOnly: true
startTime:
allOf:
- type: string
format: date-time
description: The time when the batch job started running.
readOnly: true
endTime:
allOf:
- type: string
format: date-time
description: >-
The time when the batch job completed, failed, or was
cancelled.
readOnly: true
createdBy:
allOf:
- type: string
description: The email address of the user who created this batch job.
readOnly: true
nodePoolId:
allOf:
- *ref_1
environmentId:
allOf:
- *ref_2
snapshotId:
allOf:
- *ref_3
numRanks:
allOf:
- *ref_4
envVars:
allOf:
- *ref_5
role:
allOf:
- *ref_6
pythonExecutor:
allOf:
- *ref_7
notebookExecutor:
allOf:
- *ref_8
shellExecutor:
allOf:
- *ref_9
imageRef:
allOf:
- *ref_10
annotations:
allOf:
- *ref_11
state:
allOf:
- *ref_12
status:
allOf:
- type: string
description: >-
Detailed information about the current status of the batch
job.
readOnly: true
shared:
allOf:
- *ref_13
updateTime:
allOf:
- type: string
format: date-time
description: The update time for the batch job.
readOnly: true
title: 'Next ID: 22'
refIdentifier: '#/components/schemas/gatewayBatchJob'
requiredProperties: *ref_14
examples:
example:
value:
name:
displayName:
createTime: '2023-11-07T05:31:56Z'
startTime: '2023-11-07T05:31:56Z'
endTime: '2023-11-07T05:31:56Z'
createdBy:
nodePoolId:
environmentId:
snapshotId:
numRanks: 123
envVars: {}
role:
pythonExecutor:
targetType: TARGET_TYPE_UNSPECIFIED
target:
args:
-
notebookExecutor:
notebookFilename:
shellExecutor:
command:
imageRef:
annotations: {}
state: STATE_UNSPECIFIED
status:
shared: true
updateTime: '2023-11-07T05:31:56Z'
description: A successful response.
deprecated: false
type: path
components:
schemas:
PythonExecutorTargetType:
type: string
enum:
- TARGET_TYPE_UNSPECIFIED
- MODULE
- FILENAME
default: TARGET_TYPE_UNSPECIFIED
description: |2-
- MODULE: Runs a python module, i.e. passed as -m argument.
- FILENAME: Runs a python file.
gatewayBatchJobState:
type: string
enum:
- STATE_UNSPECIFIED
- CREATING
- QUEUED
- PENDING
- RUNNING
- COMPLETED
- FAILED
- CANCELLING
- CANCELLED
- DELETING
default: STATE_UNSPECIFIED
description: |-
- CREATING: The batch job is being created.
- QUEUED: The batch job is in the queue and waiting to be scheduled.
Currently unused.
- PENDING: The batch job scheduled and is waiting for resource allocation.
- RUNNING: The batch job is running.
- COMPLETED: The batch job has finished successfully.
- FAILED: The batch job has failed.
- CANCELLING: The batch job is being cancelled.
- CANCELLED: The batch job was cancelled.
- DELETING: The batch job is being deleted.
title: 'Next ID: 10'
gatewayNotebookExecutor:
type: object
properties:
notebookFilename:
type: string
description: Path to a notebook file to be executed.
description: Execute a notebook file.
required:
- notebookFilename
gatewayPythonExecutor:
type: object
properties:
targetType:
$ref: '#/components/schemas/PythonExecutorTargetType'
description: The type of Python target to run.
target:
type: string
description: A Python module or filename depending on TargetType.
args:
type: array
items:
type: string
description: Command line arguments to pass to the Python process.
description: Execute a Python process.
required:
- targetType
- target
gatewayShellExecutor:
type: object
properties:
command:
type: string
title: Command we want to run for the shell script
description: Execute a shell script.
required:
- command
````
---
# Source: https://docs.fireworks.ai/api-reference/create-batch-request.md
# Create Batch Request
Create a batch request for our audio transcription service
### Headers
Your Fireworks API key, e.g. `Authorization=FIREWORKS_API_KEY`. Alternatively, can be provided as a query param.
### Path Parameters
The relative route of the target API operation (e.g. `"v1/audio/transcriptions"`, `"v1/audio/translations"`). This should correspond to a valid route supported by the backend service.
### Query Parameters
Identifies the target backend service or model to handle the request. Currently supported:
* `audio-prod`: [https://audio-prod.api.fireworks.ai](https://audio-prod.api.fireworks.ai)
* `audio-turbo`: [https://audio-turbo.api.fireworks.ai](https://audio-turbo.api.fireworks.ai)
### Body
Request body fields vary depending on the selected `endpoint_id` and `path`.
The request body must conform to the schema defined by the corresponding synchronous API.\
For example, transcription requests typically accept fields such as `model`, `diarize`, and `response_format`.\
Refer to the relevant synchronous API for required fields:
* [Transcribe audio](https://docs.fireworks.ai/api-reference/audio-transcriptions)
* [Translate audio](https://docs.fireworks.ai/api-reference/audio-translations)
### Response
The status of the batch request submission.\
A value of `"submitted"` indicates the batch request was accepted and queued for processing.
A unique identifier assigned to the batch job.
This ID can be used to check job status or retrieve results later.
The unique identifier of the account associated with the batch job.
The backend service selected to process the request.\
This typically matches the `endpoint_id` used during submission.
A human-readable message describing the result of the submission.\
Typically `"Request submitted successfully"` if accepted.
```curl curl theme={null}
# Download audio file
curl -L -o "audio.flac" "https://tinyurl.com/4997djsh"
# Make request
curl -X POST "https://audio-batch.api.fireworks.ai/v1/audio/transcriptions?endpoint_id=audio-prod" \
-H "Authorization: " \
-F "file=@audio.flac"
```
```python python theme={null}
!pip install requests
import os
import requests
# input API key and download audio
api_key = ""
audio = requests.get("https://tinyurl.com/4cb74vas").content
# Prepare request data
url = "https://audio-batch.api.fireworks.ai/v1/audio/transcriptions?endpoint_id=audio-prod"
headers = {"Authorization": api_key}
payload = {
"model": "whisper-v3",
"response_format": "json"
}
files = {"file": ("audio.flac", audio, "audio/flac")}
# Send request
response = requests.post(url, headers=headers, data=payload, files=files)
print(response.text)
```
To check the status of your batch request, use the [Check Batch Status](https://docs.fireworks.ai/api-reference/get-batch-status) endpoint with the returned `batch_id`.
---
# Source: https://docs.fireworks.ai/api-reference-dlde/create-cluster.md
# Create Cluster
## OpenAPI
````yaml post /v1/accounts/{account_id}/clusters
paths:
path: /v1/accounts/{account_id}/clusters
method: post
servers:
- url: https://api.fireworks.ai
request:
security:
- title: BearerAuth
parameters:
query: {}
header:
Authorization:
type: http
scheme: bearer
description: >-
Bearer authentication using your Fireworks API key. Format:
Bearer
cookie: {}
parameters:
path:
account_id:
schema:
- type: string
required: true
description: The Account Id
query: {}
header: {}
cookie: {}
body:
application/json:
schemaArray:
- type: object
properties:
cluster:
allOf:
- $ref: '#/components/schemas/gatewayCluster'
description: The properties of the cluster being created.
clusterId:
allOf:
- type: string
title: The cluster ID to use in the cluster name. e.g. my-cluster
required: true
refIdentifier: '#/components/schemas/GatewayCreateClusterBody'
requiredProperties:
- cluster
- clusterId
examples:
example:
value:
cluster:
displayName:
eksCluster:
awsAccountId:
fireworksManagerRole:
region:
clusterName:
storageBucketName:
metricWriterRole:
loadBalancerControllerRole:
workloadIdentityPoolProviderId:
inferenceRole:
fakeCluster:
projectId:
location:
clusterName:
clusterId:
response:
'200':
application/json:
schemaArray:
- type: object
properties:
name:
allOf:
- &ref_0
type: string
title: >-
The resource name of the cluster. e.g.
accounts/my-account/clusters/my-cluster
readOnly: true
displayName:
allOf:
- &ref_1
type: string
description: >-
Human-readable display name of the cluster. e.g. "My
Cluster"
Must be fewer than 64 characters long.
createTime:
allOf:
- &ref_2
type: string
format: date-time
description: The creation time of the cluster.
readOnly: true
eksCluster:
allOf:
- &ref_3
$ref: '#/components/schemas/gatewayEksCluster'
fakeCluster:
allOf:
- &ref_4
$ref: '#/components/schemas/gatewayFakeCluster'
state:
allOf:
- &ref_5
$ref: '#/components/schemas/gatewayClusterState'
description: The current state of the cluster.
readOnly: true
status:
allOf:
- &ref_6
$ref: '#/components/schemas/gatewayStatus'
description: >-
Detailed information about the current status of the
cluster.
readOnly: true
updateTime:
allOf:
- &ref_7
type: string
format: date-time
description: The update time for the cluster.
readOnly: true
title: 'Next ID: 15'
refIdentifier: '#/components/schemas/gatewayCluster'
examples:
example:
value:
name:
displayName:
createTime: '2023-11-07T05:31:56Z'
eksCluster:
awsAccountId:
fireworksManagerRole:
region:
clusterName:
storageBucketName:
metricWriterRole:
loadBalancerControllerRole:
workloadIdentityPoolProviderId:
inferenceRole:
fakeCluster:
projectId:
location:
clusterName:
state: STATE_UNSPECIFIED
status:
code: OK
message:
updateTime: '2023-11-07T05:31:56Z'
description: A successful response.
deprecated: false
type: path
components:
schemas:
gatewayCluster:
type: object
properties:
name: *ref_0
displayName: *ref_1
createTime: *ref_2
eksCluster: *ref_3
fakeCluster: *ref_4
state: *ref_5
status: *ref_6
updateTime: *ref_7
title: 'Next ID: 15'
gatewayClusterState:
type: string
enum:
- STATE_UNSPECIFIED
- CREATING
- READY
- DELETING
- FAILED
default: STATE_UNSPECIFIED
description: |2-
- CREATING: The cluster is still being created.
- READY: The cluster is ready to be used.
- DELETING: The cluster is being deleted.
- FAILED: Cluster is not operational.
Consult 'status' for detailed messaging.
Cluster needs to be deleted and re-created.
gatewayCode:
type: string
enum:
- OK
- CANCELLED
- UNKNOWN
- INVALID_ARGUMENT
- DEADLINE_EXCEEDED
- NOT_FOUND
- ALREADY_EXISTS
- PERMISSION_DENIED
- UNAUTHENTICATED
- RESOURCE_EXHAUSTED
- FAILED_PRECONDITION
- ABORTED
- OUT_OF_RANGE
- UNIMPLEMENTED
- INTERNAL
- UNAVAILABLE
- DATA_LOSS
default: OK
description: |-
- OK: Not an error; returned on success.
HTTP Mapping: 200 OK
- CANCELLED: The operation was cancelled, typically by the caller.
HTTP Mapping: 499 Client Closed Request
- UNKNOWN: Unknown error. For example, this error may be returned when
a `Status` value received from another address space belongs to
an error space that is not known in this address space. Also
errors raised by APIs that do not return enough error information
may be converted to this error.
HTTP Mapping: 500 Internal Server Error
- INVALID_ARGUMENT: The client specified an invalid argument. Note that this differs
from `FAILED_PRECONDITION`. `INVALID_ARGUMENT` indicates arguments
that are problematic regardless of the state of the system
(e.g., a malformed file name).
HTTP Mapping: 400 Bad Request
- DEADLINE_EXCEEDED: The deadline expired before the operation could complete. For operations
that change the state of the system, this error may be returned
even if the operation has completed successfully. For example, a
successful response from a server could have been delayed long
enough for the deadline to expire.
HTTP Mapping: 504 Gateway Timeout
- NOT_FOUND: Some requested entity (e.g., file or directory) was not found.
Note to server developers: if a request is denied for an entire class
of users, such as gradual feature rollout or undocumented allowlist,
`NOT_FOUND` may be used. If a request is denied for some users within
a class of users, such as user-based access control, `PERMISSION_DENIED`
must be used.
HTTP Mapping: 404 Not Found
- ALREADY_EXISTS: The entity that a client attempted to create (e.g., file or directory)
already exists.
HTTP Mapping: 409 Conflict
- PERMISSION_DENIED: The caller does not have permission to execute the specified
operation. `PERMISSION_DENIED` must not be used for rejections
caused by exhausting some resource (use `RESOURCE_EXHAUSTED`
instead for those errors). `PERMISSION_DENIED` must not be
used if the caller can not be identified (use `UNAUTHENTICATED`
instead for those errors). This error code does not imply the
request is valid or the requested entity exists or satisfies
other pre-conditions.
HTTP Mapping: 403 Forbidden
- UNAUTHENTICATED: The request does not have valid authentication credentials for the
operation.
HTTP Mapping: 401 Unauthorized
- RESOURCE_EXHAUSTED: Some resource has been exhausted, perhaps a per-user quota, or
perhaps the entire file system is out of space.
HTTP Mapping: 429 Too Many Requests
- FAILED_PRECONDITION: The operation was rejected because the system is not in a state
required for the operation's execution. For example, the directory
to be deleted is non-empty, an rmdir operation is applied to
a non-directory, etc.
Service implementors can use the following guidelines to decide
between `FAILED_PRECONDITION`, `ABORTED`, and `UNAVAILABLE`:
(a) Use `UNAVAILABLE` if the client can retry just the failing call.
(b) Use `ABORTED` if the client should retry at a higher level. For
example, when a client-specified test-and-set fails, indicating the
client should restart a read-modify-write sequence.
(c) Use `FAILED_PRECONDITION` if the client should not retry until
the system state has been explicitly fixed. For example, if an "rmdir"
fails because the directory is non-empty, `FAILED_PRECONDITION`
should be returned since the client should not retry unless
the files are deleted from the directory.
HTTP Mapping: 400 Bad Request
- ABORTED: The operation was aborted, typically due to a concurrency issue such as
a sequencer check failure or transaction abort.
See the guidelines above for deciding between `FAILED_PRECONDITION`,
`ABORTED`, and `UNAVAILABLE`.
HTTP Mapping: 409 Conflict
- OUT_OF_RANGE: The operation was attempted past the valid range. E.g., seeking or
reading past end-of-file.
Unlike `INVALID_ARGUMENT`, this error indicates a problem that may
be fixed if the system state changes. For example, a 32-bit file
system will generate `INVALID_ARGUMENT` if asked to read at an
offset that is not in the range [0,2^32-1], but it will generate
`OUT_OF_RANGE` if asked to read from an offset past the current
file size.
There is a fair bit of overlap between `FAILED_PRECONDITION` and
`OUT_OF_RANGE`. We recommend using `OUT_OF_RANGE` (the more specific
error) when it applies so that callers who are iterating through
a space can easily look for an `OUT_OF_RANGE` error to detect when
they are done.
HTTP Mapping: 400 Bad Request
- UNIMPLEMENTED: The operation is not implemented or is not supported/enabled in this
service.
HTTP Mapping: 501 Not Implemented
- INTERNAL: Internal errors. This means that some invariants expected by the
underlying system have been broken. This error code is reserved
for serious errors.
HTTP Mapping: 500 Internal Server Error
- UNAVAILABLE: The service is currently unavailable. This is most likely a
transient condition, which can be corrected by retrying with
a backoff. Note that it is not always safe to retry
non-idempotent operations.
See the guidelines above for deciding between `FAILED_PRECONDITION`,
`ABORTED`, and `UNAVAILABLE`.
HTTP Mapping: 503 Service Unavailable
- DATA_LOSS: Unrecoverable data loss or corruption.
HTTP Mapping: 500 Internal Server Error
title: >-
Mimics
[https://github.com/googleapis/googleapis/blob/master/google/rpc/code.proto]
gatewayEksCluster:
type: object
properties:
awsAccountId:
type: string
description: The 12-digit AWS account ID where this cluster lives.
fireworksManagerRole:
type: string
title: >-
The IAM role ARN used to manage Fireworks resources on AWS.
If not specified, the default is
arn:aws:iam:::role/FireworksManagerRole
region:
type: string
description: >-
The AWS region where this cluster lives. See
https://docs.aws.amazon.com/AmazonRDS/latest/UserGuide/Concepts.RegionsAndAvailabilityZones.html
for a list of available regions.
clusterName:
type: string
description: The EKS cluster name.
storageBucketName:
type: string
description: The S3 bucket name.
metricWriterRole:
type: string
description: >-
The IAM role ARN used by Google Managed Prometheus role that will
write metrics
to Fireworks managed Prometheus. The role must be assumable by the
`system:serviceaccount:gmp-system:collector` service account on the
EKS cluster.
If not specified, no metrics will be written to GCP.
loadBalancerControllerRole:
type: string
description: >-
The IAM role ARN used by the EKS load balancer controller (i.e. the
load balancer
automatically created for the k8s gateway resource). If not
specified, no gateway
will be created.
workloadIdentityPoolProviderId:
type: string
title: |-
The ID of the GCP workload identity pool provider in the Fireworks
project for this cluster. The pool ID is assumed to be "byoc-pool"
inferenceRole:
type: string
description: The IAM role ARN used by the inference pods on the cluster.
title: |-
An Amazon Elastic Kubernetes Service cluster.
Next ID: 16
required:
- awsAccountId
- region
gatewayFakeCluster:
type: object
properties:
projectId:
type: string
location:
type: string
clusterName:
type: string
title: A fake cluster using https://pkg.go.dev/k8s.io/client-go/kubernetes/fake
gatewayStatus:
type: object
properties:
code:
$ref: '#/components/schemas/gatewayCode'
description: The status code.
message:
type: string
description: A developer-facing error message in English.
title: >-
Mimics
[https://github.com/googleapis/googleapis/blob/master/google/rpc/status.proto]
````
---
# Source: https://docs.fireworks.ai/tools-sdks/firectl/commands/create-dataset.md
# Source: https://docs.fireworks.ai/api-reference/create-dataset.md
# Source: https://docs.fireworks.ai/tools-sdks/firectl/commands/create-dataset.md
# Source: https://docs.fireworks.ai/api-reference/create-dataset.md
# Source: https://docs.fireworks.ai/tools-sdks/firectl/commands/create-dataset.md
# Source: https://docs.fireworks.ai/api-reference/create-dataset.md
# Create Dataset
## OpenAPI
````yaml post /v1/accounts/{account_id}/datasets
paths:
path: /v1/accounts/{account_id}/datasets
method: post
servers:
- url: https://api.fireworks.ai
request:
security:
- title: BearerAuth
parameters:
query: {}
header:
Authorization:
type: http
scheme: bearer
description: >-
Bearer authentication using your Fireworks API key. Format:
Bearer
cookie: {}
parameters:
path:
account_id:
schema:
- type: string
required: true
description: The Account Id
query: {}
header: {}
cookie: {}
body:
application/json:
schemaArray:
- type: object
properties:
dataset:
allOf:
- $ref: '#/components/schemas/gatewayDataset'
datasetId:
allOf:
- type: string
sourceDatasetId:
allOf:
- type: string
title: >-
If set, indicates we are creating a new dataset by
filtering this existing dataset ID
filter:
allOf:
- type: string
title: >-
Filter condition (SQL-like WHERE clause) to apply to the
source dataset
required: true
refIdentifier: '#/components/schemas/GatewayCreateDatasetBody'
requiredProperties:
- dataset
- datasetId
examples:
example:
value:
dataset:
displayName:
exampleCount:
userUploaded: {}
evaluationResult:
evaluationJobId:
transformed:
sourceDatasetId:
filter:
originalFormat: FORMAT_UNSPECIFIED
splitted:
sourceDatasetId:
evalProtocol: {}
externalUrl:
format: FORMAT_UNSPECIFIED
sourceJobName:
datasetId:
sourceDatasetId:
filter:
response:
'200':
application/json:
schemaArray:
- type: object
properties:
name:
allOf:
- &ref_0
type: string
readOnly: true
displayName:
allOf:
- &ref_1
type: string
createTime:
allOf:
- &ref_2
type: string
format: date-time
readOnly: true
state:
allOf:
- &ref_3
$ref: '#/components/schemas/gatewayDatasetState'
readOnly: true
status:
allOf:
- &ref_4
$ref: '#/components/schemas/gatewayStatus'
readOnly: true
exampleCount:
allOf:
- &ref_5
type: string
format: int64
userUploaded:
allOf:
- &ref_6
$ref: '#/components/schemas/gatewayUserUploaded'
evaluationResult:
allOf:
- &ref_7
$ref: '#/components/schemas/gatewayEvaluationResult'
transformed:
allOf:
- &ref_8
$ref: '#/components/schemas/gatewayTransformed'
splitted:
allOf:
- &ref_9
$ref: '#/components/schemas/gatewaySplitted'
evalProtocol:
allOf:
- &ref_10
$ref: '#/components/schemas/gatewayEvalProtocol'
externalUrl:
allOf:
- &ref_11
type: string
title: >-
The external URI of the dataset. e.g.
gs://foo/bar/baz.jsonl
format:
allOf:
- &ref_12
$ref: '#/components/schemas/DatasetFormat'
createdBy:
allOf:
- &ref_13
type: string
description: >-
The email address of the user who initiated this
fine-tuning job.
readOnly: true
updateTime:
allOf:
- &ref_14
type: string
format: date-time
description: The update time for the dataset.
readOnly: true
sourceJobName:
allOf:
- &ref_15
type: string
description: >-
The resource name of the job that created this dataset
(e.g., batch inference job).
Used for lineage tracking to understand dataset
provenance.
estimatedTokenCount:
allOf:
- &ref_16
type: string
format: int64
description: The estimated number of tokens in the dataset.
readOnly: true
title: 'Next ID: 23'
refIdentifier: '#/components/schemas/gatewayDataset'
examples:
example:
value:
name:
displayName:
createTime: '2023-11-07T05:31:56Z'
state: STATE_UNSPECIFIED
status:
code: OK
message:
exampleCount:
userUploaded: {}
evaluationResult:
evaluationJobId:
transformed:
sourceDatasetId:
filter:
originalFormat: FORMAT_UNSPECIFIED
splitted:
sourceDatasetId:
evalProtocol: {}
externalUrl:
format: FORMAT_UNSPECIFIED
createdBy:
updateTime: '2023-11-07T05:31:56Z'
sourceJobName:
estimatedTokenCount:
description: A successful response.
deprecated: false
type: path
components:
schemas:
DatasetFormat:
type: string
enum:
- FORMAT_UNSPECIFIED
- CHAT
- COMPLETION
- RL
default: FORMAT_UNSPECIFIED
gatewayCode:
type: string
enum:
- OK
- CANCELLED
- UNKNOWN
- INVALID_ARGUMENT
- DEADLINE_EXCEEDED
- NOT_FOUND
- ALREADY_EXISTS
- PERMISSION_DENIED
- UNAUTHENTICATED
- RESOURCE_EXHAUSTED
- FAILED_PRECONDITION
- ABORTED
- OUT_OF_RANGE
- UNIMPLEMENTED
- INTERNAL
- UNAVAILABLE
- DATA_LOSS
default: OK
description: |-
- OK: Not an error; returned on success.
HTTP Mapping: 200 OK
- CANCELLED: The operation was cancelled, typically by the caller.
HTTP Mapping: 499 Client Closed Request
- UNKNOWN: Unknown error. For example, this error may be returned when
a `Status` value received from another address space belongs to
an error space that is not known in this address space. Also
errors raised by APIs that do not return enough error information
may be converted to this error.
HTTP Mapping: 500 Internal Server Error
- INVALID_ARGUMENT: The client specified an invalid argument. Note that this differs
from `FAILED_PRECONDITION`. `INVALID_ARGUMENT` indicates arguments
that are problematic regardless of the state of the system
(e.g., a malformed file name).
HTTP Mapping: 400 Bad Request
- DEADLINE_EXCEEDED: The deadline expired before the operation could complete. For operations
that change the state of the system, this error may be returned
even if the operation has completed successfully. For example, a
successful response from a server could have been delayed long
enough for the deadline to expire.
HTTP Mapping: 504 Gateway Timeout
- NOT_FOUND: Some requested entity (e.g., file or directory) was not found.
Note to server developers: if a request is denied for an entire class
of users, such as gradual feature rollout or undocumented allowlist,
`NOT_FOUND` may be used. If a request is denied for some users within
a class of users, such as user-based access control, `PERMISSION_DENIED`
must be used.
HTTP Mapping: 404 Not Found
- ALREADY_EXISTS: The entity that a client attempted to create (e.g., file or directory)
already exists.
HTTP Mapping: 409 Conflict
- PERMISSION_DENIED: The caller does not have permission to execute the specified
operation. `PERMISSION_DENIED` must not be used for rejections
caused by exhausting some resource (use `RESOURCE_EXHAUSTED`
instead for those errors). `PERMISSION_DENIED` must not be
used if the caller can not be identified (use `UNAUTHENTICATED`
instead for those errors). This error code does not imply the
request is valid or the requested entity exists or satisfies
other pre-conditions.
HTTP Mapping: 403 Forbidden
- UNAUTHENTICATED: The request does not have valid authentication credentials for the
operation.
HTTP Mapping: 401 Unauthorized
- RESOURCE_EXHAUSTED: Some resource has been exhausted, perhaps a per-user quota, or
perhaps the entire file system is out of space.
HTTP Mapping: 429 Too Many Requests
- FAILED_PRECONDITION: The operation was rejected because the system is not in a state
required for the operation's execution. For example, the directory
to be deleted is non-empty, an rmdir operation is applied to
a non-directory, etc.
Service implementors can use the following guidelines to decide
between `FAILED_PRECONDITION`, `ABORTED`, and `UNAVAILABLE`:
(a) Use `UNAVAILABLE` if the client can retry just the failing call.
(b) Use `ABORTED` if the client should retry at a higher level. For
example, when a client-specified test-and-set fails, indicating the
client should restart a read-modify-write sequence.
(c) Use `FAILED_PRECONDITION` if the client should not retry until
the system state has been explicitly fixed. For example, if an "rmdir"
fails because the directory is non-empty, `FAILED_PRECONDITION`
should be returned since the client should not retry unless
the files are deleted from the directory.
HTTP Mapping: 400 Bad Request
- ABORTED: The operation was aborted, typically due to a concurrency issue such as
a sequencer check failure or transaction abort.
See the guidelines above for deciding between `FAILED_PRECONDITION`,
`ABORTED`, and `UNAVAILABLE`.
HTTP Mapping: 409 Conflict
- OUT_OF_RANGE: The operation was attempted past the valid range. E.g., seeking or
reading past end-of-file.
Unlike `INVALID_ARGUMENT`, this error indicates a problem that may
be fixed if the system state changes. For example, a 32-bit file
system will generate `INVALID_ARGUMENT` if asked to read at an
offset that is not in the range [0,2^32-1], but it will generate
`OUT_OF_RANGE` if asked to read from an offset past the current
file size.
There is a fair bit of overlap between `FAILED_PRECONDITION` and
`OUT_OF_RANGE`. We recommend using `OUT_OF_RANGE` (the more specific
error) when it applies so that callers who are iterating through
a space can easily look for an `OUT_OF_RANGE` error to detect when
they are done.
HTTP Mapping: 400 Bad Request
- UNIMPLEMENTED: The operation is not implemented or is not supported/enabled in this
service.
HTTP Mapping: 501 Not Implemented
- INTERNAL: Internal errors. This means that some invariants expected by the
underlying system have been broken. This error code is reserved
for serious errors.
HTTP Mapping: 500 Internal Server Error
- UNAVAILABLE: The service is currently unavailable. This is most likely a
transient condition, which can be corrected by retrying with
a backoff. Note that it is not always safe to retry
non-idempotent operations.
See the guidelines above for deciding between `FAILED_PRECONDITION`,
`ABORTED`, and `UNAVAILABLE`.
HTTP Mapping: 503 Service Unavailable
- DATA_LOSS: Unrecoverable data loss or corruption.
HTTP Mapping: 500 Internal Server Error
title: >-
Mimics
[https://github.com/googleapis/googleapis/blob/master/google/rpc/code.proto]
gatewayDataset:
type: object
properties:
name: *ref_0
displayName: *ref_1
createTime: *ref_2
state: *ref_3
status: *ref_4
exampleCount: *ref_5
userUploaded: *ref_6
evaluationResult: *ref_7
transformed: *ref_8
splitted: *ref_9
evalProtocol: *ref_10
externalUrl: *ref_11
format: *ref_12
createdBy: *ref_13
updateTime: *ref_14
sourceJobName: *ref_15
estimatedTokenCount: *ref_16
title: 'Next ID: 23'
gatewayDatasetState:
type: string
enum:
- STATE_UNSPECIFIED
- UPLOADING
- READY
default: STATE_UNSPECIFIED
gatewayEvalProtocol:
type: object
gatewayEvaluationResult:
type: object
properties:
evaluationJobId:
type: string
required:
- evaluationJobId
gatewaySplitted:
type: object
properties:
sourceDatasetId:
type: string
required:
- sourceDatasetId
gatewayStatus:
type: object
properties:
code:
$ref: '#/components/schemas/gatewayCode'
description: The status code.
message:
type: string
description: A developer-facing error message in English.
title: >-
Mimics
[https://github.com/googleapis/googleapis/blob/master/google/rpc/status.proto]
gatewayTransformed:
type: object
properties:
sourceDatasetId:
type: string
filter:
type: string
originalFormat:
$ref: '#/components/schemas/DatasetFormat'
required:
- sourceDatasetId
gatewayUserUploaded:
type: object
````
---
# Source: https://docs.fireworks.ai/api-reference/create-deployed-model.md
# Load LoRA
## OpenAPI
````yaml post /v1/accounts/{account_id}/deployedModels
paths:
path: /v1/accounts/{account_id}/deployedModels
method: post
servers:
- url: https://api.fireworks.ai
request:
security:
- title: BearerAuth
parameters:
query: {}
header:
Authorization:
type: http
scheme: bearer
description: >-
Bearer authentication using your Fireworks API key. Format:
Bearer
cookie: {}
parameters:
path:
account_id:
schema:
- type: string
required: true
description: The Account Id
query:
replaceMergedAddon:
schema:
- type: boolean
required: false
description: >-
Merges new addon to the base model, while unmerging/deleting any
existing addon in the deployment. Must be specified for hot
reload deployments
header: {}
cookie: {}
body:
application/json:
schemaArray:
- type: object
properties:
displayName:
allOf:
- &ref_0
type: string
description:
allOf:
- &ref_1
type: string
description: Description of the resource.
model:
allOf:
- &ref_2
type: string
title: |-
The resource name of the model to be deployed.
e.g. accounts/my-account/models/my-model
deployment:
allOf:
- &ref_3
type: string
description: >-
The resource name of the base deployment the model is
deployed to.
default:
allOf:
- &ref_4
type: boolean
description: >-
If true, this is the default target when querying this
model without
the `#` suffix.
The first deployment a model is deployed to will have this
field set to true.
state:
allOf:
- &ref_5
$ref: '#/components/schemas/gatewayDeployedModelState'
description: The state of the deployed model.
readOnly: true
serverless:
allOf:
- &ref_6
type: boolean
title: True if the underlying deployment is managed by Fireworks
status:
allOf:
- &ref_7
$ref: '#/components/schemas/gatewayStatus'
description: Contains model deploy/undeploy details.
readOnly: true
public:
allOf:
- &ref_8
type: boolean
description: If true, the deployed model will be publicly reachable.
required: true
title: 'Next ID: 20'
refIdentifier: '#/components/schemas/gatewayDeployedModel'
examples:
example:
value:
displayName:
description:
model:
deployment:
default: true
serverless: true
public: true
response:
'200':
application/json:
schemaArray:
- type: object
properties:
name:
allOf:
- type: string
title: >-
The resource name. e.g.
accounts/my-account/deployedModels/my-deployed-model
readOnly: true
displayName:
allOf:
- *ref_0
description:
allOf:
- *ref_1
createTime:
allOf:
- type: string
format: date-time
description: The creation time of the resource.
readOnly: true
model:
allOf:
- *ref_2
deployment:
allOf:
- *ref_3
default:
allOf:
- *ref_4
state:
allOf:
- *ref_5
serverless:
allOf:
- *ref_6
status:
allOf:
- *ref_7
public:
allOf:
- *ref_8
updateTime:
allOf:
- type: string
format: date-time
description: The update time for the deployed model.
readOnly: true
title: 'Next ID: 20'
refIdentifier: '#/components/schemas/gatewayDeployedModel'
examples:
example:
value:
name:
displayName:
description:
createTime: '2023-11-07T05:31:56Z'
model:
deployment:
default: true
state: STATE_UNSPECIFIED
serverless: true
status:
code: OK
message:
public: true
updateTime: '2023-11-07T05:31:56Z'
description: A successful response.
deprecated: false
type: path
components:
schemas:
gatewayCode:
type: string
enum:
- OK
- CANCELLED
- UNKNOWN
- INVALID_ARGUMENT
- DEADLINE_EXCEEDED
- NOT_FOUND
- ALREADY_EXISTS
- PERMISSION_DENIED
- UNAUTHENTICATED
- RESOURCE_EXHAUSTED
- FAILED_PRECONDITION
- ABORTED
- OUT_OF_RANGE
- UNIMPLEMENTED
- INTERNAL
- UNAVAILABLE
- DATA_LOSS
default: OK
description: |-
- OK: Not an error; returned on success.
HTTP Mapping: 200 OK
- CANCELLED: The operation was cancelled, typically by the caller.
HTTP Mapping: 499 Client Closed Request
- UNKNOWN: Unknown error. For example, this error may be returned when
a `Status` value received from another address space belongs to
an error space that is not known in this address space. Also
errors raised by APIs that do not return enough error information
may be converted to this error.
HTTP Mapping: 500 Internal Server Error
- INVALID_ARGUMENT: The client specified an invalid argument. Note that this differs
from `FAILED_PRECONDITION`. `INVALID_ARGUMENT` indicates arguments
that are problematic regardless of the state of the system
(e.g., a malformed file name).
HTTP Mapping: 400 Bad Request
- DEADLINE_EXCEEDED: The deadline expired before the operation could complete. For operations
that change the state of the system, this error may be returned
even if the operation has completed successfully. For example, a
successful response from a server could have been delayed long
enough for the deadline to expire.
HTTP Mapping: 504 Gateway Timeout
- NOT_FOUND: Some requested entity (e.g., file or directory) was not found.
Note to server developers: if a request is denied for an entire class
of users, such as gradual feature rollout or undocumented allowlist,
`NOT_FOUND` may be used. If a request is denied for some users within
a class of users, such as user-based access control, `PERMISSION_DENIED`
must be used.
HTTP Mapping: 404 Not Found
- ALREADY_EXISTS: The entity that a client attempted to create (e.g., file or directory)
already exists.
HTTP Mapping: 409 Conflict
- PERMISSION_DENIED: The caller does not have permission to execute the specified
operation. `PERMISSION_DENIED` must not be used for rejections
caused by exhausting some resource (use `RESOURCE_EXHAUSTED`
instead for those errors). `PERMISSION_DENIED` must not be
used if the caller can not be identified (use `UNAUTHENTICATED`
instead for those errors). This error code does not imply the
request is valid or the requested entity exists or satisfies
other pre-conditions.
HTTP Mapping: 403 Forbidden
- UNAUTHENTICATED: The request does not have valid authentication credentials for the
operation.
HTTP Mapping: 401 Unauthorized
- RESOURCE_EXHAUSTED: Some resource has been exhausted, perhaps a per-user quota, or
perhaps the entire file system is out of space.
HTTP Mapping: 429 Too Many Requests
- FAILED_PRECONDITION: The operation was rejected because the system is not in a state
required for the operation's execution. For example, the directory
to be deleted is non-empty, an rmdir operation is applied to
a non-directory, etc.
Service implementors can use the following guidelines to decide
between `FAILED_PRECONDITION`, `ABORTED`, and `UNAVAILABLE`:
(a) Use `UNAVAILABLE` if the client can retry just the failing call.
(b) Use `ABORTED` if the client should retry at a higher level. For
example, when a client-specified test-and-set fails, indicating the
client should restart a read-modify-write sequence.
(c) Use `FAILED_PRECONDITION` if the client should not retry until
the system state has been explicitly fixed. For example, if an "rmdir"
fails because the directory is non-empty, `FAILED_PRECONDITION`
should be returned since the client should not retry unless
the files are deleted from the directory.
HTTP Mapping: 400 Bad Request
- ABORTED: The operation was aborted, typically due to a concurrency issue such as
a sequencer check failure or transaction abort.
See the guidelines above for deciding between `FAILED_PRECONDITION`,
`ABORTED`, and `UNAVAILABLE`.
HTTP Mapping: 409 Conflict
- OUT_OF_RANGE: The operation was attempted past the valid range. E.g., seeking or
reading past end-of-file.
Unlike `INVALID_ARGUMENT`, this error indicates a problem that may
be fixed if the system state changes. For example, a 32-bit file
system will generate `INVALID_ARGUMENT` if asked to read at an
offset that is not in the range [0,2^32-1], but it will generate
`OUT_OF_RANGE` if asked to read from an offset past the current
file size.
There is a fair bit of overlap between `FAILED_PRECONDITION` and
`OUT_OF_RANGE`. We recommend using `OUT_OF_RANGE` (the more specific
error) when it applies so that callers who are iterating through
a space can easily look for an `OUT_OF_RANGE` error to detect when
they are done.
HTTP Mapping: 400 Bad Request
- UNIMPLEMENTED: The operation is not implemented or is not supported/enabled in this
service.
HTTP Mapping: 501 Not Implemented
- INTERNAL: Internal errors. This means that some invariants expected by the
underlying system have been broken. This error code is reserved
for serious errors.
HTTP Mapping: 500 Internal Server Error
- UNAVAILABLE: The service is currently unavailable. This is most likely a
transient condition, which can be corrected by retrying with
a backoff. Note that it is not always safe to retry
non-idempotent operations.
See the guidelines above for deciding between `FAILED_PRECONDITION`,
`ABORTED`, and `UNAVAILABLE`.
HTTP Mapping: 503 Service Unavailable
- DATA_LOSS: Unrecoverable data loss or corruption.
HTTP Mapping: 500 Internal Server Error
title: >-
Mimics
[https://github.com/googleapis/googleapis/blob/master/google/rpc/code.proto]
gatewayDeployedModelState:
type: string
enum:
- STATE_UNSPECIFIED
- UNDEPLOYING
- DEPLOYING
- DEPLOYED
- UPDATING
default: STATE_UNSPECIFIED
description: |-
- UNDEPLOYING: The model is being undeployed.
- DEPLOYING: The model is being deployed.
- DEPLOYED: The model is deployed and ready for inference.
- UPDATING: there are updates happening with the deployed model
title: 'Next ID: 6'
gatewayStatus:
type: object
properties:
code:
$ref: '#/components/schemas/gatewayCode'
description: The status code.
message:
type: string
description: A developer-facing error message in English.
title: >-
Mimics
[https://github.com/googleapis/googleapis/blob/master/google/rpc/status.proto]
````
---
# Source: https://docs.fireworks.ai/tools-sdks/firectl/commands/create-deployment.md
# Source: https://docs.fireworks.ai/api-reference/create-deployment.md
# Source: https://docs.fireworks.ai/tools-sdks/firectl/commands/create-deployment.md
# Source: https://docs.fireworks.ai/api-reference/create-deployment.md
# Source: https://docs.fireworks.ai/tools-sdks/firectl/commands/create-deployment.md
# Source: https://docs.fireworks.ai/api-reference/create-deployment.md
# Create Deployment
## OpenAPI
````yaml post /v1/accounts/{account_id}/deployments
paths:
path: /v1/accounts/{account_id}/deployments
method: post
servers:
- url: https://api.fireworks.ai
request:
security:
- title: BearerAuth
parameters:
query: {}
header:
Authorization:
type: http
scheme: bearer
description: >-
Bearer authentication using your Fireworks API key. Format:
Bearer
cookie: {}
parameters:
path:
account_id:
schema:
- type: string
required: true
description: The Account Id
query:
disableAutoDeploy:
schema:
- type: boolean
required: false
description: >-
By default, a deployment created with a currently undeployed
base model
will be deployed to this deployment. If true, this auto-deploy
function
is disabled.
disableSpeculativeDecoding:
schema:
- type: boolean
required: false
description: >-
By default, a deployment will use the speculative decoding
settings from
the base model. If true, this will disable speculative decoding.
deploymentId:
schema:
- type: string
required: false
description: >-
The ID of the deployment. If not specified, a random ID will be
generated.
validateOnly:
schema:
- type: boolean
required: false
description: >-
If true, this will not create the deployment, but will return
the deployment
that would be created.
skipShapeValidation:
schema:
- type: boolean
required: false
description: >-
By default, a deployment will ensure the deployment shape
provided is validated.
If true, we will not require the deployment shape to be
validated.
header: {}
cookie: {}
body:
application/json:
schemaArray:
- type: object
properties:
displayName:
allOf:
- &ref_0
type: string
description: >-
Human-readable display name of the deployment. e.g. "My
Deployment"
Must be fewer than 64 characters long.
description:
allOf:
- &ref_1
type: string
description: Description of the deployment.
expireTime:
allOf:
- &ref_2
type: string
format: date-time
description: >-
The time at which this deployment will automatically be
deleted.
state:
allOf:
- &ref_3
$ref: '#/components/schemas/gatewayDeploymentState'
description: The state of the deployment.
readOnly: true
status:
allOf:
- &ref_4
$ref: '#/components/schemas/gatewayStatus'
description: >-
Detailed status information regarding the most recent
operation.
readOnly: true
minReplicaCount:
allOf:
- &ref_5
type: integer
format: int32
description: |-
The minimum number of replicas.
If not specified, the default is 0.
maxReplicaCount:
allOf:
- &ref_6
type: integer
format: int32
description: >-
The maximum number of replicas.
If not specified, the default is max(min_replica_count,
1).
May be set to 0 to downscale the deployment to 0.
autoscalingPolicy:
allOf:
- &ref_7
$ref: '#/components/schemas/gatewayAutoscalingPolicy'
baseModel:
allOf:
- &ref_8
type: string
title: >-
The base model name. e.g.
accounts/fireworks/models/falcon-7b
acceleratorCount:
allOf:
- &ref_9
type: integer
format: int32
description: >-
The number of accelerators used per replica.
If not specified, the default is the estimated minimum
required by the
base model.
acceleratorType:
allOf:
- &ref_10
$ref: '#/components/schemas/gatewayAcceleratorType'
description: |-
The type of accelerator to use.
If not specified, the default is NVIDIA_A100_80GB.
precision:
allOf:
- &ref_11
$ref: '#/components/schemas/DeploymentPrecision'
description: The precision with which the model should be served.
enableAddons:
allOf:
- &ref_12
type: boolean
description: If true, PEFT addons are enabled for this deployment.
draftTokenCount:
allOf:
- &ref_13
type: integer
format: int32
description: >-
The number of candidate tokens to generate per step for
speculative
decoding.
Default is the base model's draft_token_count. Set
CreateDeploymentRequest.disable_speculative_decoding to
false to disable
this behavior.
draftModel:
allOf:
- &ref_14
type: string
description: >-
The draft model name for speculative decoding. e.g.
accounts/fireworks/models/my-draft-model
If empty, speculative decoding using a draft model is
disabled.
Default is the base model's default_draft_model. Set
CreateDeploymentRequest.disable_speculative_decoding to
false to disable
this behavior.
ngramSpeculationLength:
allOf:
- &ref_15
type: integer
format: int32
description: >-
The length of previous input sequence to be considered for
N-gram speculation.
enableSessionAffinity:
allOf:
- &ref_16
type: boolean
description: Whether to apply sticky routing based on `user` field.
directRouteApiKeys:
allOf:
- &ref_17
type: array
items:
type: string
description: >-
The set of API keys used to access the direct route
deployment. If direct routing is not enabled, this field
is unused.
directRouteType:
allOf:
- &ref_18
$ref: '#/components/schemas/gatewayDirectRouteType'
description: >-
If set, this deployment will expose an endpoint that
bypasses the Fireworks API gateway.
deploymentTemplate:
allOf:
- &ref_19
type: string
description: >-
The name of the deployment template to use for this
deployment. Only
available to enterprise accounts.
autoTune:
allOf:
- &ref_20
$ref: '#/components/schemas/gatewayAutoTune'
description: The performance profile to use for this deployment.
placement:
allOf:
- &ref_21
$ref: '#/components/schemas/gatewayPlacement'
description: >-
The desired geographic region where the deployment must be
placed.
If unspecified, the default is the GLOBAL multi-region.
region:
allOf:
- &ref_22
$ref: '#/components/schemas/gatewayRegion'
description: >-
The geographic region where the deployment is presently
located. This region may change
over time, but within the `placement` constraint.
readOnly: true
disableDeploymentSizeValidation:
allOf:
- &ref_23
type: boolean
description: Whether the deployment size validation is disabled.
enableMtp:
allOf:
- &ref_24
type: boolean
description: If true, MTP is enabled for this deployment.
enableHotReloadLatestAddon:
allOf:
- &ref_25
type: boolean
description: >-
Allows up to 1 addon at a time to be loaded, and will
merge it into the base model.
deploymentShape:
allOf:
- &ref_26
type: string
description: >-
The name of the deployment shape that this deployment is
using.
On the server side, this will be replaced with the
deployment shape version name.
activeModelVersion:
allOf:
- &ref_27
type: string
description: >-
The model version that is currently active and applied to
running replicas of a deployment.
targetModelVersion:
allOf:
- &ref_28
type: string
description: >-
The target model version that is being rolled out to the
deployment.
In a ready steady state, the target model version is the
same as the active model version.
required: true
title: 'Next ID: 82'
refIdentifier: '#/components/schemas/gatewayDeployment'
requiredProperties: &ref_29
- baseModel
examples:
example:
value:
displayName:
description:
expireTime: '2023-11-07T05:31:56Z'
minReplicaCount: 123
maxReplicaCount: 123
autoscalingPolicy:
scaleUpWindow:
scaleDownWindow:
scaleToZeroWindow:
loadTargets: {}
baseModel:
acceleratorCount: 123
acceleratorType: ACCELERATOR_TYPE_UNSPECIFIED
precision: PRECISION_UNSPECIFIED
enableAddons: true
draftTokenCount: 123
draftModel:
ngramSpeculationLength: 123
enableSessionAffinity: true
directRouteApiKeys:
-
directRouteType: DIRECT_ROUTE_TYPE_UNSPECIFIED
deploymentTemplate:
autoTune:
longPrompt: true
placement:
region: REGION_UNSPECIFIED
multiRegion: MULTI_REGION_UNSPECIFIED
regions:
- REGION_UNSPECIFIED
disableDeploymentSizeValidation: true
enableMtp: true
enableHotReloadLatestAddon: true
deploymentShape:
activeModelVersion:
targetModelVersion:
description: The properties of the deployment being created.
response:
'200':
application/json:
schemaArray:
- type: object
properties:
name:
allOf:
- type: string
title: >-
The resource name of the deployment. e.g.
accounts/my-account/deployments/my-deployment
readOnly: true
displayName:
allOf:
- *ref_0
description:
allOf:
- *ref_1
createTime:
allOf:
- type: string
format: date-time
description: The creation time of the deployment.
readOnly: true
expireTime:
allOf:
- *ref_2
purgeTime:
allOf:
- type: string
format: date-time
description: The time at which the resource will be hard deleted.
readOnly: true
deleteTime:
allOf:
- type: string
format: date-time
description: The time at which the resource will be soft deleted.
readOnly: true
state:
allOf:
- *ref_3
status:
allOf:
- *ref_4
minReplicaCount:
allOf:
- *ref_5
maxReplicaCount:
allOf:
- *ref_6
desiredReplicaCount:
allOf:
- type: integer
format: int32
description: >-
The desired number of replicas for this deployment. This
represents the target
replica count that the system is trying to achieve.
readOnly: true
replicaCount:
allOf:
- type: integer
format: int32
readOnly: true
autoscalingPolicy:
allOf:
- *ref_7
baseModel:
allOf:
- *ref_8
acceleratorCount:
allOf:
- *ref_9
acceleratorType:
allOf:
- *ref_10
precision:
allOf:
- *ref_11
cluster:
allOf:
- type: string
description: >-
If set, this deployment is deployed to a cloud-premise
cluster.
readOnly: true
enableAddons:
allOf:
- *ref_12
draftTokenCount:
allOf:
- *ref_13
draftModel:
allOf:
- *ref_14
ngramSpeculationLength:
allOf:
- *ref_15
enableSessionAffinity:
allOf:
- *ref_16
directRouteApiKeys:
allOf:
- *ref_17
numPeftDeviceCached:
allOf:
- type: integer
format: int32
title: How many peft adapters to keep on gpu side for caching
readOnly: true
directRouteType:
allOf:
- *ref_18
directRouteHandle:
allOf:
- type: string
description: >-
The handle for calling a direct route. The meaning of the
handle depends on the
direct route type of the deployment:
INTERNET -> The host name for accessing the deployment
GCP_PRIVATE_SERVICE_CONNECT -> The service attachment name used to create the PSC endpoint.
AWS_PRIVATELINK -> The service name used to create the VPC endpoint.
readOnly: true
deploymentTemplate:
allOf:
- *ref_19
autoTune:
allOf:
- *ref_20
placement:
allOf:
- *ref_21
region:
allOf:
- *ref_22
updateTime:
allOf:
- type: string
format: date-time
description: The update time for the deployment.
readOnly: true
disableDeploymentSizeValidation:
allOf:
- *ref_23
enableMtp:
allOf:
- *ref_24
enableHotReloadLatestAddon:
allOf:
- *ref_25
deploymentShape:
allOf:
- *ref_26
activeModelVersion:
allOf:
- *ref_27
targetModelVersion:
allOf:
- *ref_28
title: 'Next ID: 82'
refIdentifier: '#/components/schemas/gatewayDeployment'
requiredProperties: *ref_29
examples:
example:
value:
name:
displayName:
description:
createTime: '2023-11-07T05:31:56Z'
expireTime: '2023-11-07T05:31:56Z'
purgeTime: '2023-11-07T05:31:56Z'
deleteTime: '2023-11-07T05:31:56Z'
state: STATE_UNSPECIFIED
status:
code: OK
message:
minReplicaCount: 123
maxReplicaCount: 123
desiredReplicaCount: 123
replicaCount: 123
autoscalingPolicy:
scaleUpWindow:
scaleDownWindow:
scaleToZeroWindow:
loadTargets: {}
baseModel:
acceleratorCount: 123
acceleratorType: ACCELERATOR_TYPE_UNSPECIFIED
precision: PRECISION_UNSPECIFIED
cluster:
enableAddons: true
draftTokenCount: 123
draftModel:
ngramSpeculationLength: 123
enableSessionAffinity: true
directRouteApiKeys:
-
numPeftDeviceCached: 123
directRouteType: DIRECT_ROUTE_TYPE_UNSPECIFIED
directRouteHandle:
deploymentTemplate:
autoTune:
longPrompt: true
placement:
region: REGION_UNSPECIFIED
multiRegion: MULTI_REGION_UNSPECIFIED
regions:
- REGION_UNSPECIFIED
region: REGION_UNSPECIFIED
updateTime: '2023-11-07T05:31:56Z'
disableDeploymentSizeValidation: true
enableMtp: true
enableHotReloadLatestAddon: true
deploymentShape:
activeModelVersion:
targetModelVersion:
description: A successful response.
deprecated: false
type: path
components:
schemas:
DeploymentPrecision:
type: string
enum:
- PRECISION_UNSPECIFIED
- FP16
- FP8
- FP8_MM
- FP8_AR
- FP8_MM_KV_ATTN
- FP8_KV
- FP8_MM_V2
- FP8_V2
- FP8_MM_KV_ATTN_V2
- NF4
- FP4
- BF16
- FP4_BLOCKSCALED_MM
- FP4_MX_MOE
default: PRECISION_UNSPECIFIED
title: >-
- PRECISION_UNSPECIFIED: if left unspecified we will treat this as a
legacy model created before
self serve
gatewayAcceleratorType:
type: string
enum:
- ACCELERATOR_TYPE_UNSPECIFIED
- NVIDIA_A100_80GB
- NVIDIA_H100_80GB
- AMD_MI300X_192GB
- NVIDIA_A10G_24GB
- NVIDIA_A100_40GB
- NVIDIA_L4_24GB
- NVIDIA_H200_141GB
- NVIDIA_B200_180GB
- AMD_MI325X_256GB
default: ACCELERATOR_TYPE_UNSPECIFIED
gatewayAutoTune:
type: object
properties:
longPrompt:
type: boolean
description: If true, this deployment is optimized for long prompt lengths.
gatewayAutoscalingPolicy:
type: object
properties:
scaleUpWindow:
type: string
description: >-
The duration the autoscaler will wait before scaling up a deployment
after observing
increased load. Default is 30s.
scaleDownWindow:
type: string
description: >-
The duration the autoscaler will wait before scaling down a
deployment after observing
decreased load. Default is 10m.
scaleToZeroWindow:
type: string
description: >-
The duration after which there are no requests that the deployment
will be scaled down
to zero replicas, if min_replica_count==0. Default is 1h.
This must be at least 5 minutes.
loadTargets:
type: object
additionalProperties:
type: number
format: float
title: >-
Map of load metric names to their target utilization factors.
Currently only the "default" key is supported, which specifies the
default target for all metrics.
If not specified, the default target is 0.8
gatewayCode:
type: string
enum:
- OK
- CANCELLED
- UNKNOWN
- INVALID_ARGUMENT
- DEADLINE_EXCEEDED
- NOT_FOUND
- ALREADY_EXISTS
- PERMISSION_DENIED
- UNAUTHENTICATED
- RESOURCE_EXHAUSTED
- FAILED_PRECONDITION
- ABORTED
- OUT_OF_RANGE
- UNIMPLEMENTED
- INTERNAL
- UNAVAILABLE
- DATA_LOSS
default: OK
description: |-
- OK: Not an error; returned on success.
HTTP Mapping: 200 OK
- CANCELLED: The operation was cancelled, typically by the caller.
HTTP Mapping: 499 Client Closed Request
- UNKNOWN: Unknown error. For example, this error may be returned when
a `Status` value received from another address space belongs to
an error space that is not known in this address space. Also
errors raised by APIs that do not return enough error information
may be converted to this error.
HTTP Mapping: 500 Internal Server Error
- INVALID_ARGUMENT: The client specified an invalid argument. Note that this differs
from `FAILED_PRECONDITION`. `INVALID_ARGUMENT` indicates arguments
that are problematic regardless of the state of the system
(e.g., a malformed file name).
HTTP Mapping: 400 Bad Request
- DEADLINE_EXCEEDED: The deadline expired before the operation could complete. For operations
that change the state of the system, this error may be returned
even if the operation has completed successfully. For example, a
successful response from a server could have been delayed long
enough for the deadline to expire.
HTTP Mapping: 504 Gateway Timeout
- NOT_FOUND: Some requested entity (e.g., file or directory) was not found.
Note to server developers: if a request is denied for an entire class
of users, such as gradual feature rollout or undocumented allowlist,
`NOT_FOUND` may be used. If a request is denied for some users within
a class of users, such as user-based access control, `PERMISSION_DENIED`
must be used.
HTTP Mapping: 404 Not Found
- ALREADY_EXISTS: The entity that a client attempted to create (e.g., file or directory)
already exists.
HTTP Mapping: 409 Conflict
- PERMISSION_DENIED: The caller does not have permission to execute the specified
operation. `PERMISSION_DENIED` must not be used for rejections
caused by exhausting some resource (use `RESOURCE_EXHAUSTED`
instead for those errors). `PERMISSION_DENIED` must not be
used if the caller can not be identified (use `UNAUTHENTICATED`
instead for those errors). This error code does not imply the
request is valid or the requested entity exists or satisfies
other pre-conditions.
HTTP Mapping: 403 Forbidden
- UNAUTHENTICATED: The request does not have valid authentication credentials for the
operation.
HTTP Mapping: 401 Unauthorized
- RESOURCE_EXHAUSTED: Some resource has been exhausted, perhaps a per-user quota, or
perhaps the entire file system is out of space.
HTTP Mapping: 429 Too Many Requests
- FAILED_PRECONDITION: The operation was rejected because the system is not in a state
required for the operation's execution. For example, the directory
to be deleted is non-empty, an rmdir operation is applied to
a non-directory, etc.
Service implementors can use the following guidelines to decide
between `FAILED_PRECONDITION`, `ABORTED`, and `UNAVAILABLE`:
(a) Use `UNAVAILABLE` if the client can retry just the failing call.
(b) Use `ABORTED` if the client should retry at a higher level. For
example, when a client-specified test-and-set fails, indicating the
client should restart a read-modify-write sequence.
(c) Use `FAILED_PRECONDITION` if the client should not retry until
the system state has been explicitly fixed. For example, if an "rmdir"
fails because the directory is non-empty, `FAILED_PRECONDITION`
should be returned since the client should not retry unless
the files are deleted from the directory.
HTTP Mapping: 400 Bad Request
- ABORTED: The operation was aborted, typically due to a concurrency issue such as
a sequencer check failure or transaction abort.
See the guidelines above for deciding between `FAILED_PRECONDITION`,
`ABORTED`, and `UNAVAILABLE`.
HTTP Mapping: 409 Conflict
- OUT_OF_RANGE: The operation was attempted past the valid range. E.g., seeking or
reading past end-of-file.
Unlike `INVALID_ARGUMENT`, this error indicates a problem that may
be fixed if the system state changes. For example, a 32-bit file
system will generate `INVALID_ARGUMENT` if asked to read at an
offset that is not in the range [0,2^32-1], but it will generate
`OUT_OF_RANGE` if asked to read from an offset past the current
file size.
There is a fair bit of overlap between `FAILED_PRECONDITION` and
`OUT_OF_RANGE`. We recommend using `OUT_OF_RANGE` (the more specific
error) when it applies so that callers who are iterating through
a space can easily look for an `OUT_OF_RANGE` error to detect when
they are done.
HTTP Mapping: 400 Bad Request
- UNIMPLEMENTED: The operation is not implemented or is not supported/enabled in this
service.
HTTP Mapping: 501 Not Implemented
- INTERNAL: Internal errors. This means that some invariants expected by the
underlying system have been broken. This error code is reserved
for serious errors.
HTTP Mapping: 500 Internal Server Error
- UNAVAILABLE: The service is currently unavailable. This is most likely a
transient condition, which can be corrected by retrying with
a backoff. Note that it is not always safe to retry
non-idempotent operations.
See the guidelines above for deciding between `FAILED_PRECONDITION`,
`ABORTED`, and `UNAVAILABLE`.
HTTP Mapping: 503 Service Unavailable
- DATA_LOSS: Unrecoverable data loss or corruption.
HTTP Mapping: 500 Internal Server Error
title: >-
Mimics
[https://github.com/googleapis/googleapis/blob/master/google/rpc/code.proto]
gatewayDeploymentState:
type: string
enum:
- STATE_UNSPECIFIED
- CREATING
- READY
- DELETING
- FAILED
- UPDATING
- DELETED
default: STATE_UNSPECIFIED
description: |2-
- CREATING: The deployment is still being created.
- READY: The deployment is ready to be used.
- DELETING: The deployment is being deleted.
- FAILED: The deployment failed to be created. See the `status` field for
additional details on why it failed.
- UPDATING: There are in-progress updates happening with the deployment.
- DELETED: The deployment is soft-deleted.
gatewayDirectRouteType:
type: string
enum:
- DIRECT_ROUTE_TYPE_UNSPECIFIED
- INTERNET
- GCP_PRIVATE_SERVICE_CONNECT
- AWS_PRIVATELINK
default: DIRECT_ROUTE_TYPE_UNSPECIFIED
title: |-
- DIRECT_ROUTE_TYPE_UNSPECIFIED: No direct routing
- INTERNET: The direct route is exposed via the public internet
- GCP_PRIVATE_SERVICE_CONNECT: The direct route is exposed via GCP Private Service Connect
- AWS_PRIVATELINK: The direct route is exposed via AWS PrivateLink
gatewayMultiRegion:
type: string
enum:
- MULTI_REGION_UNSPECIFIED
- GLOBAL
- US
default: MULTI_REGION_UNSPECIFIED
gatewayPlacement:
type: object
properties:
region:
$ref: '#/components/schemas/gatewayRegion'
description: The region where the deployment must be placed.
multiRegion:
$ref: '#/components/schemas/gatewayMultiRegion'
description: The multi-region where the deployment must be placed.
regions:
type: array
items:
$ref: '#/components/schemas/gatewayRegion'
title: The list of regions where the deployment must be placed
description: >-
The desired geographic region where the deployment must be placed.
Exactly one field will be
specified.
gatewayRegion:
type: string
enum:
- REGION_UNSPECIFIED
- US_IOWA_1
- US_VIRGINIA_1
- US_ILLINOIS_1
- AP_TOKYO_1
- US_ARIZONA_1
- US_TEXAS_1
- US_ILLINOIS_2
- EU_FRANKFURT_1
- US_TEXAS_2
- EU_ICELAND_1
- EU_ICELAND_2
- US_WASHINGTON_1
- US_WASHINGTON_2
- US_WASHINGTON_3
- AP_TOKYO_2
- US_CALIFORNIA_1
- US_UTAH_1
- US_TEXAS_3
- US_GEORGIA_1
- US_GEORGIA_2
- US_WASHINGTON_4
- US_GEORGIA_3
default: REGION_UNSPECIFIED
title: |-
- US_IOWA_1: GCP us-central1 (Iowa)
- US_VIRGINIA_1: AWS us-east-1 (N. Virginia)
- US_ILLINOIS_1: OCI us-chicago-1
- AP_TOKYO_1: OCI ap-tokyo-1
- US_ARIZONA_1: OCI us-phoenix-1
- US_TEXAS_1: Lambda us-south-3 (C. Texas)
- US_ILLINOIS_2: Lambda us-midwest-1 (Illinois)
- EU_FRANKFURT_1: OCI eu-frankfurt-1
- US_TEXAS_2: Lambda us-south-2 (N. Texas)
- EU_ICELAND_1: Crusoe eu-iceland1
- EU_ICELAND_2: Crusoe eu-iceland1 (network1)
- US_WASHINGTON_1: Voltage Park us-pyl-1 (Detach audio cluster from control_plane)
- US_WASHINGTON_2: Voltage Park us-seattle-2
- US_WASHINGTON_3: Vultr Seattle 1
- AP_TOKYO_2: AWS ap-northeast-1
- US_CALIFORNIA_1: AWS us-west-1 (N. California)
- US_UTAH_1: GCP us-west3 (Utah)
- US_TEXAS_3: Crusoe us-southcentral1
- US_GEORGIA_1: DigitalOcean us-atl1
- US_GEORGIA_2: Vultr Atlanta 1
- US_WASHINGTON_4: Coreweave us-west-09b-1
- US_GEORGIA_3: Alicloud us-southeast-1
gatewayStatus:
type: object
properties:
code:
$ref: '#/components/schemas/gatewayCode'
description: The status code.
message:
type: string
description: A developer-facing error message in English.
title: >-
Mimics
[https://github.com/googleapis/googleapis/blob/master/google/rpc/status.proto]
````
---
# Source: https://docs.fireworks.ai/tools-sdks/firectl/commands/create-dpo-job.md
# Source: https://docs.fireworks.ai/api-reference/create-dpo-job.md
# Source: https://docs.fireworks.ai/tools-sdks/firectl/commands/create-dpo-job.md
# Source: https://docs.fireworks.ai/api-reference/create-dpo-job.md
# Source: https://docs.fireworks.ai/tools-sdks/firectl/commands/create-dpo-job.md
# Source: https://docs.fireworks.ai/api-reference/create-dpo-job.md
# null
## OpenAPI
````yaml post /v1/accounts/{account_id}/dpoJobs
paths:
path: /v1/accounts/{account_id}/dpoJobs
method: post
servers:
- url: https://api.fireworks.ai
request:
security:
- title: BearerAuth
parameters:
query: {}
header:
Authorization:
type: http
scheme: bearer
description: >-
Bearer authentication using your Fireworks API key. Format:
Bearer
cookie: {}
parameters:
path:
account_id:
schema:
- type: string
required: true
description: The Account Id
query:
dpoJobId:
schema:
- type: string
required: false
description: >-
ID of the DPO job, a random ID will be generated if not
specified.
header: {}
cookie: {}
body:
application/json:
schemaArray:
- type: object
properties:
displayName:
allOf:
- &ref_0
type: string
dataset:
allOf:
- &ref_1
type: string
description: The name of the dataset used for training.
state:
allOf:
- &ref_2
$ref: '#/components/schemas/gatewayJobState'
readOnly: true
status:
allOf:
- &ref_3
$ref: '#/components/schemas/gatewayStatus'
readOnly: true
trainingConfig:
allOf:
- &ref_4
$ref: '#/components/schemas/gatewayBaseTrainingConfig'
description: Common training configurations.
wandbConfig:
allOf:
- &ref_5
$ref: '#/components/schemas/gatewayWandbConfig'
description: >-
The Weights & Biases team/user account for logging job
progress.
required: true
title: 'Next ID: 13'
refIdentifier: '#/components/schemas/gatewayDpoJob'
requiredProperties: &ref_6
- dataset
examples:
example:
value:
displayName:
dataset:
trainingConfig:
outputModel:
baseModel:
warmStartFrom:
jinjaTemplate:
learningRate: 123
maxContextLength: 123
loraRank: 123
region: REGION_UNSPECIFIED
epochs: 123
batchSize: 123
gradientAccumulationSteps: 123
learningRateWarmupSteps: 123
wandbConfig:
enabled: true
apiKey:
project:
entity:
runId:
response:
'200':
application/json:
schemaArray:
- type: object
properties:
name:
allOf:
- type: string
readOnly: true
displayName:
allOf:
- *ref_0
createTime:
allOf:
- type: string
format: date-time
readOnly: true
completedTime:
allOf:
- type: string
format: date-time
readOnly: true
dataset:
allOf:
- *ref_1
state:
allOf:
- *ref_2
status:
allOf:
- *ref_3
createdBy:
allOf:
- type: string
description: The email address of the user who initiated this dpo job.
readOnly: true
trainingConfig:
allOf:
- *ref_4
wandbConfig:
allOf:
- *ref_5
title: 'Next ID: 13'
refIdentifier: '#/components/schemas/gatewayDpoJob'
requiredProperties: *ref_6
examples:
example:
value:
name:
displayName:
createTime: '2023-11-07T05:31:56Z'
completedTime: '2023-11-07T05:31:56Z'
dataset:
state: JOB_STATE_UNSPECIFIED
status:
code: OK
message:
createdBy:
trainingConfig:
outputModel:
baseModel:
warmStartFrom:
jinjaTemplate:
learningRate: 123
maxContextLength: 123
loraRank: 123
region: REGION_UNSPECIFIED
epochs: 123
batchSize: 123
gradientAccumulationSteps: 123
learningRateWarmupSteps: 123
wandbConfig:
enabled: true
apiKey:
project:
entity:
runId:
url:
description: A successful response.
deprecated: false
type: path
components:
schemas:
gatewayBaseTrainingConfig:
type: object
properties:
outputModel:
type: string
description: >-
The model ID to be assigned to the resulting fine-tuned model. If
not specified, the job ID will be used.
baseModel:
type: string
description: |-
The name of the base model to be fine-tuned
Only one of 'base_model' or 'warm_start_from' should be specified.
warmStartFrom:
type: string
description: |-
The PEFT addon model in Fireworks format to be fine-tuned from
Only one of 'base_model' or 'warm_start_from' should be specified.
jinjaTemplate:
type: string
title: >-
The Jinja template for conversation formatting. If not specified,
defaults to the base model's conversation template configuration
learningRate:
type: number
format: float
description: The learning rate used for training.
maxContextLength:
type: integer
format: int32
description: The maximum context length to use with the model.
loraRank:
type: integer
format: int32
description: The rank of the LoRA layers.
region:
$ref: '#/components/schemas/gatewayRegion'
description: The region where the fine-tuning job is located.
epochs:
type: integer
format: int32
description: The number of epochs to train for.
batchSize:
type: integer
format: int32
description: >-
The maximum packed number of tokens per batch for training in
sequence packing.
gradientAccumulationSteps:
type: integer
format: int32
title: Number of gradient accumulation steps
learningRateWarmupSteps:
type: integer
format: int32
title: Number of steps for learning rate warm up
title: |-
BaseTrainingConfig contains common configuration fields shared across
different training job types.
Next ID: 19
gatewayCode:
type: string
enum:
- OK
- CANCELLED
- UNKNOWN
- INVALID_ARGUMENT
- DEADLINE_EXCEEDED
- NOT_FOUND
- ALREADY_EXISTS
- PERMISSION_DENIED
- UNAUTHENTICATED
- RESOURCE_EXHAUSTED
- FAILED_PRECONDITION
- ABORTED
- OUT_OF_RANGE
- UNIMPLEMENTED
- INTERNAL
- UNAVAILABLE
- DATA_LOSS
default: OK
description: |-
- OK: Not an error; returned on success.
HTTP Mapping: 200 OK
- CANCELLED: The operation was cancelled, typically by the caller.
HTTP Mapping: 499 Client Closed Request
- UNKNOWN: Unknown error. For example, this error may be returned when
a `Status` value received from another address space belongs to
an error space that is not known in this address space. Also
errors raised by APIs that do not return enough error information
may be converted to this error.
HTTP Mapping: 500 Internal Server Error
- INVALID_ARGUMENT: The client specified an invalid argument. Note that this differs
from `FAILED_PRECONDITION`. `INVALID_ARGUMENT` indicates arguments
that are problematic regardless of the state of the system
(e.g., a malformed file name).
HTTP Mapping: 400 Bad Request
- DEADLINE_EXCEEDED: The deadline expired before the operation could complete. For operations
that change the state of the system, this error may be returned
even if the operation has completed successfully. For example, a
successful response from a server could have been delayed long
enough for the deadline to expire.
HTTP Mapping: 504 Gateway Timeout
- NOT_FOUND: Some requested entity (e.g., file or directory) was not found.
Note to server developers: if a request is denied for an entire class
of users, such as gradual feature rollout or undocumented allowlist,
`NOT_FOUND` may be used. If a request is denied for some users within
a class of users, such as user-based access control, `PERMISSION_DENIED`
must be used.
HTTP Mapping: 404 Not Found
- ALREADY_EXISTS: The entity that a client attempted to create (e.g., file or directory)
already exists.
HTTP Mapping: 409 Conflict
- PERMISSION_DENIED: The caller does not have permission to execute the specified
operation. `PERMISSION_DENIED` must not be used for rejections
caused by exhausting some resource (use `RESOURCE_EXHAUSTED`
instead for those errors). `PERMISSION_DENIED` must not be
used if the caller can not be identified (use `UNAUTHENTICATED`
instead for those errors). This error code does not imply the
request is valid or the requested entity exists or satisfies
other pre-conditions.
HTTP Mapping: 403 Forbidden
- UNAUTHENTICATED: The request does not have valid authentication credentials for the
operation.
HTTP Mapping: 401 Unauthorized
- RESOURCE_EXHAUSTED: Some resource has been exhausted, perhaps a per-user quota, or
perhaps the entire file system is out of space.
HTTP Mapping: 429 Too Many Requests
- FAILED_PRECONDITION: The operation was rejected because the system is not in a state
required for the operation's execution. For example, the directory
to be deleted is non-empty, an rmdir operation is applied to
a non-directory, etc.
Service implementors can use the following guidelines to decide
between `FAILED_PRECONDITION`, `ABORTED`, and `UNAVAILABLE`:
(a) Use `UNAVAILABLE` if the client can retry just the failing call.
(b) Use `ABORTED` if the client should retry at a higher level. For
example, when a client-specified test-and-set fails, indicating the
client should restart a read-modify-write sequence.
(c) Use `FAILED_PRECONDITION` if the client should not retry until
the system state has been explicitly fixed. For example, if an "rmdir"
fails because the directory is non-empty, `FAILED_PRECONDITION`
should be returned since the client should not retry unless
the files are deleted from the directory.
HTTP Mapping: 400 Bad Request
- ABORTED: The operation was aborted, typically due to a concurrency issue such as
a sequencer check failure or transaction abort.
See the guidelines above for deciding between `FAILED_PRECONDITION`,
`ABORTED`, and `UNAVAILABLE`.
HTTP Mapping: 409 Conflict
- OUT_OF_RANGE: The operation was attempted past the valid range. E.g., seeking or
reading past end-of-file.
Unlike `INVALID_ARGUMENT`, this error indicates a problem that may
be fixed if the system state changes. For example, a 32-bit file
system will generate `INVALID_ARGUMENT` if asked to read at an
offset that is not in the range [0,2^32-1], but it will generate
`OUT_OF_RANGE` if asked to read from an offset past the current
file size.
There is a fair bit of overlap between `FAILED_PRECONDITION` and
`OUT_OF_RANGE`. We recommend using `OUT_OF_RANGE` (the more specific
error) when it applies so that callers who are iterating through
a space can easily look for an `OUT_OF_RANGE` error to detect when
they are done.
HTTP Mapping: 400 Bad Request
- UNIMPLEMENTED: The operation is not implemented or is not supported/enabled in this
service.
HTTP Mapping: 501 Not Implemented
- INTERNAL: Internal errors. This means that some invariants expected by the
underlying system have been broken. This error code is reserved
for serious errors.
HTTP Mapping: 500 Internal Server Error
- UNAVAILABLE: The service is currently unavailable. This is most likely a
transient condition, which can be corrected by retrying with
a backoff. Note that it is not always safe to retry
non-idempotent operations.
See the guidelines above for deciding between `FAILED_PRECONDITION`,
`ABORTED`, and `UNAVAILABLE`.
HTTP Mapping: 503 Service Unavailable
- DATA_LOSS: Unrecoverable data loss or corruption.
HTTP Mapping: 500 Internal Server Error
title: >-
Mimics
[https://github.com/googleapis/googleapis/blob/master/google/rpc/code.proto]
gatewayJobState:
type: string
enum:
- JOB_STATE_UNSPECIFIED
- JOB_STATE_CREATING
- JOB_STATE_RUNNING
- JOB_STATE_COMPLETED
- JOB_STATE_FAILED
- JOB_STATE_CANCELLED
- JOB_STATE_DELETING
- JOB_STATE_WRITING_RESULTS
- JOB_STATE_VALIDATING
- JOB_STATE_DELETING_CLEANING_UP
- JOB_STATE_PENDING
- JOB_STATE_EXPIRED
- JOB_STATE_RE_QUEUEING
- JOB_STATE_CREATING_INPUT_DATASET
- JOB_STATE_IDLE
- JOB_STATE_CANCELLING
- JOB_STATE_EARLY_STOPPED
default: JOB_STATE_UNSPECIFIED
description: JobState represents the state an asynchronous job can be in.
gatewayRegion:
type: string
enum:
- REGION_UNSPECIFIED
- US_IOWA_1
- US_VIRGINIA_1
- US_ILLINOIS_1
- AP_TOKYO_1
- US_ARIZONA_1
- US_TEXAS_1
- US_ILLINOIS_2
- EU_FRANKFURT_1
- US_TEXAS_2
- EU_ICELAND_1
- EU_ICELAND_2
- US_WASHINGTON_1
- US_WASHINGTON_2
- US_WASHINGTON_3
- AP_TOKYO_2
- US_CALIFORNIA_1
- US_UTAH_1
- US_TEXAS_3
- US_GEORGIA_1
- US_GEORGIA_2
- US_WASHINGTON_4
- US_GEORGIA_3
default: REGION_UNSPECIFIED
title: |-
- US_IOWA_1: GCP us-central1 (Iowa)
- US_VIRGINIA_1: AWS us-east-1 (N. Virginia)
- US_ILLINOIS_1: OCI us-chicago-1
- AP_TOKYO_1: OCI ap-tokyo-1
- US_ARIZONA_1: OCI us-phoenix-1
- US_TEXAS_1: Lambda us-south-3 (C. Texas)
- US_ILLINOIS_2: Lambda us-midwest-1 (Illinois)
- EU_FRANKFURT_1: OCI eu-frankfurt-1
- US_TEXAS_2: Lambda us-south-2 (N. Texas)
- EU_ICELAND_1: Crusoe eu-iceland1
- EU_ICELAND_2: Crusoe eu-iceland1 (network1)
- US_WASHINGTON_1: Voltage Park us-pyl-1 (Detach audio cluster from control_plane)
- US_WASHINGTON_2: Voltage Park us-seattle-2
- US_WASHINGTON_3: Vultr Seattle 1
- AP_TOKYO_2: AWS ap-northeast-1
- US_CALIFORNIA_1: AWS us-west-1 (N. California)
- US_UTAH_1: GCP us-west3 (Utah)
- US_TEXAS_3: Crusoe us-southcentral1
- US_GEORGIA_1: DigitalOcean us-atl1
- US_GEORGIA_2: Vultr Atlanta 1
- US_WASHINGTON_4: Coreweave us-west-09b-1
- US_GEORGIA_3: Alicloud us-southeast-1
gatewayStatus:
type: object
properties:
code:
$ref: '#/components/schemas/gatewayCode'
description: The status code.
message:
type: string
description: A developer-facing error message in English.
title: >-
Mimics
[https://github.com/googleapis/googleapis/blob/master/google/rpc/status.proto]
gatewayWandbConfig:
type: object
properties:
enabled:
type: boolean
description: Whether to enable wandb logging.
apiKey:
type: string
description: The API key for the wandb service.
project:
type: string
description: The project name for the wandb service.
entity:
type: string
description: The entity name for the wandb service.
runId:
type: string
description: The run ID for the wandb service.
url:
type: string
description: The URL for the wandb service.
readOnly: true
description: >-
WandbConfig is the configuration for the Weights & Biases (wandb)
logging which
will be used by a training job.
````
---
# Source: https://docs.fireworks.ai/api-reference-dlde/create-environment.md
# Create Environment
## OpenAPI
````yaml post /v1/accounts/{account_id}/environments
paths:
path: /v1/accounts/{account_id}/environments
method: post
servers:
- url: https://api.fireworks.ai
request:
security:
- title: BearerAuth
parameters:
query: {}
header:
Authorization:
type: http
scheme: bearer
description: >-
Bearer authentication using your Fireworks API key. Format:
Bearer
cookie: {}
parameters:
path:
account_id:
schema:
- type: string
required: true
description: The Account Id
query: {}
header: {}
cookie: {}
body:
application/json:
schemaArray:
- type: object
properties:
environment:
allOf:
- $ref: '#/components/schemas/gatewayEnvironment'
description: The properties of the Environment being created.
environmentId:
allOf:
- type: string
title: >-
The environment ID to use in the environment name. e.g.
my-env
required: true
refIdentifier: '#/components/schemas/GatewayCreateEnvironmentBody'
requiredProperties:
- environment
- environmentId
examples:
example:
value:
environment:
displayName:
baseImageRef:
shared: true
annotations: {}
environmentId:
response:
'200':
application/json:
schemaArray:
- type: object
properties:
name:
allOf:
- &ref_0
type: string
title: >-
The resource name of the environment. e.g.
accounts/my-account/clusters/my-cluster/environments/my-env
readOnly: true
displayName:
allOf:
- &ref_1
type: string
title: >-
Human-readable display name of the environment. e.g. "My
Environment"
createTime:
allOf:
- &ref_2
type: string
format: date-time
description: The creation time of the environment.
readOnly: true
createdBy:
allOf:
- &ref_3
type: string
description: >-
The email address of the user who created this
environment.
readOnly: true
state:
allOf:
- &ref_4
$ref: '#/components/schemas/gatewayEnvironmentState'
description: The current state of the environment.
readOnly: true
status:
allOf:
- &ref_5
$ref: '#/components/schemas/gatewayStatus'
description: The current error status of the environment.
readOnly: true
connection:
allOf:
- &ref_6
$ref: '#/components/schemas/gatewayEnvironmentConnection'
description: Information about the current environment connection.
readOnly: true
baseImageRef:
allOf:
- &ref_7
type: string
description: >-
The URI of the base container image used for this
environment.
imageRef:
allOf:
- &ref_8
type: string
description: >-
The URI of the container image used for this environment.
This is a
image is an immutable snapshot of the base_image_ref when
the environment
was created.
readOnly: true
snapshotImageRef:
allOf:
- &ref_9
type: string
description: >-
The URI of the latest container image snapshot for this
environment.
readOnly: true
shared:
allOf:
- &ref_10
type: boolean
description: >-
Whether the environment is shared with all users in the
account.
This allows all users to connect, disconnect, update,
delete, clone, and
create batch jobs using the environment.
annotations:
allOf:
- &ref_11
type: object
additionalProperties:
type: string
description: >-
Arbitrary, user-specified metadata.
Keys and values must adhere to Kubernetes constraints:
https://kubernetes.io/docs/concepts/overview/working-with-objects/annotations/#syntax-and-character-set
Additionally, the "fireworks.ai/" prefix is reserved.
updateTime:
allOf:
- &ref_12
type: string
format: date-time
description: The update time for the environment.
readOnly: true
title: 'Next ID: 14'
refIdentifier: '#/components/schemas/gatewayEnvironment'
examples:
example:
value:
name:
displayName:
createTime: '2023-11-07T05:31:56Z'
createdBy:
state: STATE_UNSPECIFIED
status:
code: OK
message:
connection:
nodePoolId:
numRanks: 123
role:
zone:
useLocalStorage: true
baseImageRef:
imageRef:
snapshotImageRef:
shared: true
annotations: {}
updateTime: '2023-11-07T05:31:56Z'
description: A successful response.
deprecated: false
type: path
components:
schemas:
gatewayCode:
type: string
enum:
- OK
- CANCELLED
- UNKNOWN
- INVALID_ARGUMENT
- DEADLINE_EXCEEDED
- NOT_FOUND
- ALREADY_EXISTS
- PERMISSION_DENIED
- UNAUTHENTICATED
- RESOURCE_EXHAUSTED
- FAILED_PRECONDITION
- ABORTED
- OUT_OF_RANGE
- UNIMPLEMENTED
- INTERNAL
- UNAVAILABLE
- DATA_LOSS
default: OK
description: |-
- OK: Not an error; returned on success.
HTTP Mapping: 200 OK
- CANCELLED: The operation was cancelled, typically by the caller.
HTTP Mapping: 499 Client Closed Request
- UNKNOWN: Unknown error. For example, this error may be returned when
a `Status` value received from another address space belongs to
an error space that is not known in this address space. Also
errors raised by APIs that do not return enough error information
may be converted to this error.
HTTP Mapping: 500 Internal Server Error
- INVALID_ARGUMENT: The client specified an invalid argument. Note that this differs
from `FAILED_PRECONDITION`. `INVALID_ARGUMENT` indicates arguments
that are problematic regardless of the state of the system
(e.g., a malformed file name).
HTTP Mapping: 400 Bad Request
- DEADLINE_EXCEEDED: The deadline expired before the operation could complete. For operations
that change the state of the system, this error may be returned
even if the operation has completed successfully. For example, a
successful response from a server could have been delayed long
enough for the deadline to expire.
HTTP Mapping: 504 Gateway Timeout
- NOT_FOUND: Some requested entity (e.g., file or directory) was not found.
Note to server developers: if a request is denied for an entire class
of users, such as gradual feature rollout or undocumented allowlist,
`NOT_FOUND` may be used. If a request is denied for some users within
a class of users, such as user-based access control, `PERMISSION_DENIED`
must be used.
HTTP Mapping: 404 Not Found
- ALREADY_EXISTS: The entity that a client attempted to create (e.g., file or directory)
already exists.
HTTP Mapping: 409 Conflict
- PERMISSION_DENIED: The caller does not have permission to execute the specified
operation. `PERMISSION_DENIED` must not be used for rejections
caused by exhausting some resource (use `RESOURCE_EXHAUSTED`
instead for those errors). `PERMISSION_DENIED` must not be
used if the caller can not be identified (use `UNAUTHENTICATED`
instead for those errors). This error code does not imply the
request is valid or the requested entity exists or satisfies
other pre-conditions.
HTTP Mapping: 403 Forbidden
- UNAUTHENTICATED: The request does not have valid authentication credentials for the
operation.
HTTP Mapping: 401 Unauthorized
- RESOURCE_EXHAUSTED: Some resource has been exhausted, perhaps a per-user quota, or
perhaps the entire file system is out of space.
HTTP Mapping: 429 Too Many Requests
- FAILED_PRECONDITION: The operation was rejected because the system is not in a state
required for the operation's execution. For example, the directory
to be deleted is non-empty, an rmdir operation is applied to
a non-directory, etc.
Service implementors can use the following guidelines to decide
between `FAILED_PRECONDITION`, `ABORTED`, and `UNAVAILABLE`:
(a) Use `UNAVAILABLE` if the client can retry just the failing call.
(b) Use `ABORTED` if the client should retry at a higher level. For
example, when a client-specified test-and-set fails, indicating the
client should restart a read-modify-write sequence.
(c) Use `FAILED_PRECONDITION` if the client should not retry until
the system state has been explicitly fixed. For example, if an "rmdir"
fails because the directory is non-empty, `FAILED_PRECONDITION`
should be returned since the client should not retry unless
the files are deleted from the directory.
HTTP Mapping: 400 Bad Request
- ABORTED: The operation was aborted, typically due to a concurrency issue such as
a sequencer check failure or transaction abort.
See the guidelines above for deciding between `FAILED_PRECONDITION`,
`ABORTED`, and `UNAVAILABLE`.
HTTP Mapping: 409 Conflict
- OUT_OF_RANGE: The operation was attempted past the valid range. E.g., seeking or
reading past end-of-file.
Unlike `INVALID_ARGUMENT`, this error indicates a problem that may
be fixed if the system state changes. For example, a 32-bit file
system will generate `INVALID_ARGUMENT` if asked to read at an
offset that is not in the range [0,2^32-1], but it will generate
`OUT_OF_RANGE` if asked to read from an offset past the current
file size.
There is a fair bit of overlap between `FAILED_PRECONDITION` and
`OUT_OF_RANGE`. We recommend using `OUT_OF_RANGE` (the more specific
error) when it applies so that callers who are iterating through
a space can easily look for an `OUT_OF_RANGE` error to detect when
they are done.
HTTP Mapping: 400 Bad Request
- UNIMPLEMENTED: The operation is not implemented or is not supported/enabled in this
service.
HTTP Mapping: 501 Not Implemented
- INTERNAL: Internal errors. This means that some invariants expected by the
underlying system have been broken. This error code is reserved
for serious errors.
HTTP Mapping: 500 Internal Server Error
- UNAVAILABLE: The service is currently unavailable. This is most likely a
transient condition, which can be corrected by retrying with
a backoff. Note that it is not always safe to retry
non-idempotent operations.
See the guidelines above for deciding between `FAILED_PRECONDITION`,
`ABORTED`, and `UNAVAILABLE`.
HTTP Mapping: 503 Service Unavailable
- DATA_LOSS: Unrecoverable data loss or corruption.
HTTP Mapping: 500 Internal Server Error
title: >-
Mimics
[https://github.com/googleapis/googleapis/blob/master/google/rpc/code.proto]
gatewayEnvironment:
type: object
properties:
name: *ref_0
displayName: *ref_1
createTime: *ref_2
createdBy: *ref_3
state: *ref_4
status: *ref_5
connection: *ref_6
baseImageRef: *ref_7
imageRef: *ref_8
snapshotImageRef: *ref_9
shared: *ref_10
annotations: *ref_11
updateTime: *ref_12
title: 'Next ID: 14'
gatewayEnvironmentConnection:
type: object
properties:
nodePoolId:
type: string
description: The resource id of the node pool the environment is connected to.
numRanks:
type: integer
format: int32
description: |-
For GPU node pools: one GPU per rank w/ host packing,
for CPU node pools: one host per rank.
If not specified, the default is 1.
role:
type: string
description: |-
The ARN of the AWS IAM role that the connection should assume.
If not specified, the connection will fall back to the node
pool's node_role.
zone:
type: string
description: >-
Current for the last zone that this environment is connected to. We
want to warn the users about cross zone migration latency when they
are
connecting to node pool in a different zone as their persistent
volume.
readOnly: true
useLocalStorage:
type: boolean
description: >-
If true, the node's local storage will be mounted on /tmp. This flag
has
no effect if the node does not have local storage.
title: 'Next ID: 8'
required:
- nodePoolId
gatewayEnvironmentState:
type: string
enum:
- STATE_UNSPECIFIED
- CREATING
- DISCONNECTED
- CONNECTING
- CONNECTED
- DISCONNECTING
- RECONNECTING
- DELETING
default: STATE_UNSPECIFIED
description: |-
- CREATING: The environment is being created.
- DISCONNECTED: The environment is not connected.
- CONNECTING: The environment is being connected to a node.
- CONNECTED: The environment is connected to a node.
- DISCONNECTING: The environment is being disconnected from a node.
- RECONNECTING: The environment is reconnecting with new connection parameters.
- DELETING: The environment is being deleted.
title: 'Next ID: 8'
gatewayStatus:
type: object
properties:
code:
$ref: '#/components/schemas/gatewayCode'
description: The status code.
message:
type: string
description: A developer-facing error message in English.
title: >-
Mimics
[https://github.com/googleapis/googleapis/blob/master/google/rpc/status.proto]
````
---
# Source: https://docs.fireworks.ai/api-reference/create-evaluation-job.md
# Create Evaluation Job
## OpenAPI
````yaml post /v1/accounts/{account_id}/evaluationJobs
openapi: 3.1.0
info:
title: Gateway REST API
version: 4.15.25
servers:
- url: https://api.fireworks.ai
security:
- BearerAuth: []
tags:
- name: Gateway
paths:
/v1/accounts/{account_id}/evaluationJobs:
post:
tags:
- Gateway
summary: Create Evaluation Job
operationId: Gateway_CreateEvaluationJob
parameters:
- name: account_id
in: path
required: true
description: The Account Id
schema:
type: string
requestBody:
content:
application/json:
schema:
$ref: '#/components/schemas/GatewayCreateEvaluationJobBody'
required: true
responses:
'200':
description: A successful response.
content:
application/json:
schema:
$ref: '#/components/schemas/gatewayEvaluationJob'
components:
schemas:
GatewayCreateEvaluationJobBody:
type: object
properties:
evaluationJob:
$ref: '#/components/schemas/gatewayEvaluationJob'
evaluationJobId:
type: string
leaderboardIds:
type: array
items:
type: string
description: Optional leaderboards to attach this job to upon creation.
required:
- evaluationJob
gatewayEvaluationJob:
type: object
properties:
name:
type: string
readOnly: true
displayName:
type: string
createTime:
type: string
format: date-time
readOnly: true
createdBy:
type: string
readOnly: true
state:
$ref: '#/components/schemas/gatewayJobState'
readOnly: true
status:
$ref: '#/components/schemas/gatewayStatus'
readOnly: true
evaluator:
type: string
description: >-
The fully-qualified resource name of the Evaluation used by this
job.
Format: accounts/{account_id}/evaluators/{evaluator_id}
inputDataset:
type: string
description: >-
The fully-qualified resource name of the input Dataset used by this
job.
Format: accounts/{account_id}/datasets/{dataset_id}
outputDataset:
type: string
description: >-
The fully-qualified resource name of the output Dataset created by
this job.
Format: accounts/{account_id}/datasets/{output_dataset_id}
metrics:
type: object
additionalProperties:
type: number
format: double
readOnly: true
outputStats:
type: string
description: The output dataset's aggregated stats for the evaluation job.
updateTime:
type: string
format: date-time
description: The update time for the evaluation job.
readOnly: true
title: 'Next ID: 18'
required:
- evaluator
- inputDataset
- outputDataset
gatewayJobState:
type: string
enum:
- JOB_STATE_UNSPECIFIED
- JOB_STATE_CREATING
- JOB_STATE_RUNNING
- JOB_STATE_COMPLETED
- JOB_STATE_FAILED
- JOB_STATE_CANCELLED
- JOB_STATE_DELETING
- JOB_STATE_WRITING_RESULTS
- JOB_STATE_VALIDATING
- JOB_STATE_DELETING_CLEANING_UP
- JOB_STATE_PENDING
- JOB_STATE_EXPIRED
- JOB_STATE_RE_QUEUEING
- JOB_STATE_CREATING_INPUT_DATASET
- JOB_STATE_IDLE
- JOB_STATE_CANCELLING
- JOB_STATE_EARLY_STOPPED
- JOB_STATE_PAUSED
default: JOB_STATE_UNSPECIFIED
description: |-
JobState represents the state an asynchronous job can be in.
- JOB_STATE_PAUSED: Job is paused, typically due to account suspension or manual intervention.
gatewayStatus:
type: object
properties:
code:
$ref: '#/components/schemas/gatewayCode'
description: The status code.
message:
type: string
description: A developer-facing error message in English.
title: >-
Mimics
[https://github.com/googleapis/googleapis/blob/master/google/rpc/status.proto]
gatewayCode:
type: string
enum:
- OK
- CANCELLED
- UNKNOWN
- INVALID_ARGUMENT
- DEADLINE_EXCEEDED
- NOT_FOUND
- ALREADY_EXISTS
- PERMISSION_DENIED
- UNAUTHENTICATED
- RESOURCE_EXHAUSTED
- FAILED_PRECONDITION
- ABORTED
- OUT_OF_RANGE
- UNIMPLEMENTED
- INTERNAL
- UNAVAILABLE
- DATA_LOSS
default: OK
description: |-
- OK: Not an error; returned on success.
HTTP Mapping: 200 OK
- CANCELLED: The operation was cancelled, typically by the caller.
HTTP Mapping: 499 Client Closed Request
- UNKNOWN: Unknown error. For example, this error may be returned when
a `Status` value received from another address space belongs to
an error space that is not known in this address space. Also
errors raised by APIs that do not return enough error information
may be converted to this error.
HTTP Mapping: 500 Internal Server Error
- INVALID_ARGUMENT: The client specified an invalid argument. Note that this differs
from `FAILED_PRECONDITION`. `INVALID_ARGUMENT` indicates arguments
that are problematic regardless of the state of the system
(e.g., a malformed file name).
HTTP Mapping: 400 Bad Request
- DEADLINE_EXCEEDED: The deadline expired before the operation could complete. For operations
that change the state of the system, this error may be returned
even if the operation has completed successfully. For example, a
successful response from a server could have been delayed long
enough for the deadline to expire.
HTTP Mapping: 504 Gateway Timeout
- NOT_FOUND: Some requested entity (e.g., file or directory) was not found.
Note to server developers: if a request is denied for an entire class
of users, such as gradual feature rollout or undocumented allowlist,
`NOT_FOUND` may be used. If a request is denied for some users within
a class of users, such as user-based access control, `PERMISSION_DENIED`
must be used.
HTTP Mapping: 404 Not Found
- ALREADY_EXISTS: The entity that a client attempted to create (e.g., file or directory)
already exists.
HTTP Mapping: 409 Conflict
- PERMISSION_DENIED: The caller does not have permission to execute the specified
operation. `PERMISSION_DENIED` must not be used for rejections
caused by exhausting some resource (use `RESOURCE_EXHAUSTED`
instead for those errors). `PERMISSION_DENIED` must not be
used if the caller can not be identified (use `UNAUTHENTICATED`
instead for those errors). This error code does not imply the
request is valid or the requested entity exists or satisfies
other pre-conditions.
HTTP Mapping: 403 Forbidden
- UNAUTHENTICATED: The request does not have valid authentication credentials for the
operation.
HTTP Mapping: 401 Unauthorized
- RESOURCE_EXHAUSTED: Some resource has been exhausted, perhaps a per-user quota, or
perhaps the entire file system is out of space.
HTTP Mapping: 429 Too Many Requests
- FAILED_PRECONDITION: The operation was rejected because the system is not in a state
required for the operation's execution. For example, the directory
to be deleted is non-empty, an rmdir operation is applied to
a non-directory, etc.
Service implementors can use the following guidelines to decide
between `FAILED_PRECONDITION`, `ABORTED`, and `UNAVAILABLE`:
(a) Use `UNAVAILABLE` if the client can retry just the failing call.
(b) Use `ABORTED` if the client should retry at a higher level. For
example, when a client-specified test-and-set fails, indicating the
client should restart a read-modify-write sequence.
(c) Use `FAILED_PRECONDITION` if the client should not retry until
the system state has been explicitly fixed. For example, if an "rmdir"
fails because the directory is non-empty, `FAILED_PRECONDITION`
should be returned since the client should not retry unless
the files are deleted from the directory.
HTTP Mapping: 400 Bad Request
- ABORTED: The operation was aborted, typically due to a concurrency issue such as
a sequencer check failure or transaction abort.
See the guidelines above for deciding between `FAILED_PRECONDITION`,
`ABORTED`, and `UNAVAILABLE`.
HTTP Mapping: 409 Conflict
- OUT_OF_RANGE: The operation was attempted past the valid range. E.g., seeking or
reading past end-of-file.
Unlike `INVALID_ARGUMENT`, this error indicates a problem that may
be fixed if the system state changes. For example, a 32-bit file
system will generate `INVALID_ARGUMENT` if asked to read at an
offset that is not in the range [0,2^32-1], but it will generate
`OUT_OF_RANGE` if asked to read from an offset past the current
file size.
There is a fair bit of overlap between `FAILED_PRECONDITION` and
`OUT_OF_RANGE`. We recommend using `OUT_OF_RANGE` (the more specific
error) when it applies so that callers who are iterating through
a space can easily look for an `OUT_OF_RANGE` error to detect when
they are done.
HTTP Mapping: 400 Bad Request
- UNIMPLEMENTED: The operation is not implemented or is not supported/enabled in this
service.
HTTP Mapping: 501 Not Implemented
- INTERNAL: Internal errors. This means that some invariants expected by the
underlying system have been broken. This error code is reserved
for serious errors.
HTTP Mapping: 500 Internal Server Error
- UNAVAILABLE: The service is currently unavailable. This is most likely a
transient condition, which can be corrected by retrying with
a backoff. Note that it is not always safe to retry
non-idempotent operations.
See the guidelines above for deciding between `FAILED_PRECONDITION`,
`ABORTED`, and `UNAVAILABLE`.
HTTP Mapping: 503 Service Unavailable
- DATA_LOSS: Unrecoverable data loss or corruption.
HTTP Mapping: 500 Internal Server Error
title: >-
Mimics
[https://github.com/googleapis/googleapis/blob/master/google/rpc/code.proto]
securitySchemes:
BearerAuth:
type: http
scheme: bearer
description: >-
Bearer authentication using your Fireworks API key. Format: Bearer
bearerFormat: API_KEY
````
---
> To find navigation and other pages in this documentation, fetch the llms.txt file at: https://docs.fireworks.ai/llms.txt
---
# Source: https://docs.fireworks.ai/api-reference/create-evaluator.md
# Create Evaluator
> Creates a custom evaluator for scoring model outputs. Evaluators use the
[Eval Protocol](https://evalprotocol.io) to define test cases, run model
inference, and score responses. They are used with evaluation jobs and
Reinforcement Fine-Tuning (RFT).
## Source Code Requirements
Your project should contain:
- `requirements.txt` - Python dependencies for your evaluator
- `test_*.py` - Pytest test file(s) with
[`@evaluation_test`](https://evalprotocol.io/reference/evaluation-test)
decorated functions
- Any additional code/modules your evaluator needs
## Workflow
**Recommended:** Use the [`ep upload`](https://evalprotocol.io/reference/cli#ep-upload)
CLI command to handle all these steps automatically.
If using the API directly:
1. Call this endpoint to create the evaluator resource
2. Package your source directory as a `.tar.gz` (respecting `.gitignore`)
3. Call [Get Evaluator Upload Endpoint](/api-reference/get-evaluator-upload-endpoint) to get a signed upload URL
4. `PUT` the tar.gz file to the signed URL
5. Call [Validate Evaluator Upload](/api-reference/validate-evaluator-upload) to trigger server-side validation
6. Poll [Get Evaluator](/api-reference/get-evaluator) until ready
Once active, reference the evaluator in [Create Evaluation Job](/api-reference/create-evaluation-job) or [Create Reinforcement Fine-tuning Job](/api-reference/create-reinforcement-fine-tuning-job).
## OpenAPI
````yaml post /v1/accounts/{account_id}/evaluatorsV2
openapi: 3.1.0
info:
title: Gateway REST API
version: 4.15.25
servers:
- url: https://api.fireworks.ai
security:
- BearerAuth: []
tags:
- name: Gateway
paths:
/v1/accounts/{account_id}/evaluatorsV2:
post:
tags:
- Gateway
summary: Create Evaluator
description: >-
Creates a custom evaluator for scoring model outputs. Evaluators use the
[Eval Protocol](https://evalprotocol.io) to define test cases, run model
inference, and score responses. They are used with evaluation jobs and
Reinforcement Fine-Tuning (RFT).
## Source Code Requirements
Your project should contain:
- `requirements.txt` - Python dependencies for your evaluator
- `test_*.py` - Pytest test file(s) with
[`@evaluation_test`](https://evalprotocol.io/reference/evaluation-test)
decorated functions
- Any additional code/modules your evaluator needs
## Workflow
**Recommended:** Use the [`ep
upload`](https://evalprotocol.io/reference/cli#ep-upload)
CLI command to handle all these steps automatically.
If using the API directly:
1. Call this endpoint to create the evaluator resource
2. Package your source directory as a `.tar.gz` (respecting
`.gitignore`)
3. Call [Get Evaluator Upload
Endpoint](/api-reference/get-evaluator-upload-endpoint) to get a signed
upload URL
4. `PUT` the tar.gz file to the signed URL
5. Call [Validate Evaluator
Upload](/api-reference/validate-evaluator-upload) to trigger server-side
validation
6. Poll [Get Evaluator](/api-reference/get-evaluator) until ready
Once active, reference the evaluator in [Create Evaluation
Job](/api-reference/create-evaluation-job) or [Create Reinforcement
Fine-tuning Job](/api-reference/create-reinforcement-fine-tuning-job).
operationId: Gateway_CreateEvaluatorV2
parameters:
- name: account_id
in: path
required: true
description: The Account Id
schema:
type: string
requestBody:
content:
application/json:
schema:
$ref: '#/components/schemas/GatewayCreateEvaluatorV2Body'
required: true
responses:
'200':
description: A successful response.
content:
application/json:
schema:
$ref: '#/components/schemas/gatewayEvaluator'
components:
schemas:
GatewayCreateEvaluatorV2Body:
type: object
properties:
evaluator:
$ref: '#/components/schemas/gatewayEvaluator'
evaluatorId:
type: string
required:
- evaluator
gatewayEvaluator:
type: object
properties:
name:
type: string
readOnly: true
displayName:
type: string
description:
type: string
createTime:
type: string
format: date-time
readOnly: true
createdBy:
type: string
readOnly: true
updateTime:
type: string
format: date-time
readOnly: true
state:
$ref: '#/components/schemas/gatewayEvaluatorState'
readOnly: true
requirements:
type: string
title: Content for the requirements.txt for package installation
entryPoint:
type: string
title: >-
entry point of the evaluator inside the codebase. In
module::function or path::function format
status:
$ref: '#/components/schemas/gatewayStatus'
title: Status of the evaluator, used to expose build status to the user
readOnly: true
commitHash:
type: string
title: Commit hash of this evaluator from the user's original codebase
source:
$ref: '#/components/schemas/gatewayEvaluatorSource'
description: Source information for the evaluator codebase.
defaultDataset:
type: string
title: Default dataset that is associated with the evaluator
title: 'Next ID: 17'
gatewayEvaluatorState:
type: string
enum:
- STATE_UNSPECIFIED
- ACTIVE
- BUILDING
- BUILD_FAILED
default: STATE_UNSPECIFIED
title: |-
- ACTIVE: The evaluator is ready to use for evaluation
- BUILDING: The evaluator is being built, i.e. building the e2b template
- BUILD_FAILED: The evaluator build failed, and it cannot be used for evaluation
gatewayStatus:
type: object
properties:
code:
$ref: '#/components/schemas/gatewayCode'
description: The status code.
message:
type: string
description: A developer-facing error message in English.
title: >-
Mimics
[https://github.com/googleapis/googleapis/blob/master/google/rpc/status.proto]
gatewayEvaluatorSource:
type: object
properties:
type:
$ref: '#/components/schemas/EvaluatorSourceType'
description: Identifies how the evaluator source code is provided.
githubRepositoryName:
type: string
description: >-
Normalized GitHub repository name (e.g. owner/repository) when the
source is GitHub.
gatewayCode:
type: string
enum:
- OK
- CANCELLED
- UNKNOWN
- INVALID_ARGUMENT
- DEADLINE_EXCEEDED
- NOT_FOUND
- ALREADY_EXISTS
- PERMISSION_DENIED
- UNAUTHENTICATED
- RESOURCE_EXHAUSTED
- FAILED_PRECONDITION
- ABORTED
- OUT_OF_RANGE
- UNIMPLEMENTED
- INTERNAL
- UNAVAILABLE
- DATA_LOSS
default: OK
description: |-
- OK: Not an error; returned on success.
HTTP Mapping: 200 OK
- CANCELLED: The operation was cancelled, typically by the caller.
HTTP Mapping: 499 Client Closed Request
- UNKNOWN: Unknown error. For example, this error may be returned when
a `Status` value received from another address space belongs to
an error space that is not known in this address space. Also
errors raised by APIs that do not return enough error information
may be converted to this error.
HTTP Mapping: 500 Internal Server Error
- INVALID_ARGUMENT: The client specified an invalid argument. Note that this differs
from `FAILED_PRECONDITION`. `INVALID_ARGUMENT` indicates arguments
that are problematic regardless of the state of the system
(e.g., a malformed file name).
HTTP Mapping: 400 Bad Request
- DEADLINE_EXCEEDED: The deadline expired before the operation could complete. For operations
that change the state of the system, this error may be returned
even if the operation has completed successfully. For example, a
successful response from a server could have been delayed long
enough for the deadline to expire.
HTTP Mapping: 504 Gateway Timeout
- NOT_FOUND: Some requested entity (e.g., file or directory) was not found.
Note to server developers: if a request is denied for an entire class
of users, such as gradual feature rollout or undocumented allowlist,
`NOT_FOUND` may be used. If a request is denied for some users within
a class of users, such as user-based access control, `PERMISSION_DENIED`
must be used.
HTTP Mapping: 404 Not Found
- ALREADY_EXISTS: The entity that a client attempted to create (e.g., file or directory)
already exists.
HTTP Mapping: 409 Conflict
- PERMISSION_DENIED: The caller does not have permission to execute the specified
operation. `PERMISSION_DENIED` must not be used for rejections
caused by exhausting some resource (use `RESOURCE_EXHAUSTED`
instead for those errors). `PERMISSION_DENIED` must not be
used if the caller can not be identified (use `UNAUTHENTICATED`
instead for those errors). This error code does not imply the
request is valid or the requested entity exists or satisfies
other pre-conditions.
HTTP Mapping: 403 Forbidden
- UNAUTHENTICATED: The request does not have valid authentication credentials for the
operation.
HTTP Mapping: 401 Unauthorized
- RESOURCE_EXHAUSTED: Some resource has been exhausted, perhaps a per-user quota, or
perhaps the entire file system is out of space.
HTTP Mapping: 429 Too Many Requests
- FAILED_PRECONDITION: The operation was rejected because the system is not in a state
required for the operation's execution. For example, the directory
to be deleted is non-empty, an rmdir operation is applied to
a non-directory, etc.
Service implementors can use the following guidelines to decide
between `FAILED_PRECONDITION`, `ABORTED`, and `UNAVAILABLE`:
(a) Use `UNAVAILABLE` if the client can retry just the failing call.
(b) Use `ABORTED` if the client should retry at a higher level. For
example, when a client-specified test-and-set fails, indicating the
client should restart a read-modify-write sequence.
(c) Use `FAILED_PRECONDITION` if the client should not retry until
the system state has been explicitly fixed. For example, if an "rmdir"
fails because the directory is non-empty, `FAILED_PRECONDITION`
should be returned since the client should not retry unless
the files are deleted from the directory.
HTTP Mapping: 400 Bad Request
- ABORTED: The operation was aborted, typically due to a concurrency issue such as
a sequencer check failure or transaction abort.
See the guidelines above for deciding between `FAILED_PRECONDITION`,
`ABORTED`, and `UNAVAILABLE`.
HTTP Mapping: 409 Conflict
- OUT_OF_RANGE: The operation was attempted past the valid range. E.g., seeking or
reading past end-of-file.
Unlike `INVALID_ARGUMENT`, this error indicates a problem that may
be fixed if the system state changes. For example, a 32-bit file
system will generate `INVALID_ARGUMENT` if asked to read at an
offset that is not in the range [0,2^32-1], but it will generate
`OUT_OF_RANGE` if asked to read from an offset past the current
file size.
There is a fair bit of overlap between `FAILED_PRECONDITION` and
`OUT_OF_RANGE`. We recommend using `OUT_OF_RANGE` (the more specific
error) when it applies so that callers who are iterating through
a space can easily look for an `OUT_OF_RANGE` error to detect when
they are done.
HTTP Mapping: 400 Bad Request
- UNIMPLEMENTED: The operation is not implemented or is not supported/enabled in this
service.
HTTP Mapping: 501 Not Implemented
- INTERNAL: Internal errors. This means that some invariants expected by the
underlying system have been broken. This error code is reserved
for serious errors.
HTTP Mapping: 500 Internal Server Error
- UNAVAILABLE: The service is currently unavailable. This is most likely a
transient condition, which can be corrected by retrying with
a backoff. Note that it is not always safe to retry
non-idempotent operations.
See the guidelines above for deciding between `FAILED_PRECONDITION`,
`ABORTED`, and `UNAVAILABLE`.
HTTP Mapping: 503 Service Unavailable
- DATA_LOSS: Unrecoverable data loss or corruption.
HTTP Mapping: 500 Internal Server Error
title: >-
Mimics
[https://github.com/googleapis/googleapis/blob/master/google/rpc/code.proto]
EvaluatorSourceType:
type: string
enum:
- TYPE_UNSPECIFIED
- TYPE_UPLOAD
- TYPE_GITHUB
- TYPE_TEMPORARY
default: TYPE_UNSPECIFIED
title: |-
- TYPE_UPLOAD: Source code is uploaded by the user
- TYPE_GITHUB: Source code is from a GitHub repository
- TYPE_TEMPORARY: Source code is a temporary UI uploaded code
securitySchemes:
BearerAuth:
type: http
scheme: bearer
description: >-
Bearer authentication using your Fireworks API key. Format: Bearer
bearerFormat: API_KEY
````
---
> To find navigation and other pages in this documentation, fetch the llms.txt file at: https://docs.fireworks.ai/llms.txt
---
# Source: https://docs.fireworks.ai/tools-sdks/firectl/commands/create-identity-provider.md
# firectl create identity-provider
> Creates a new identity provider.
```
firectl create identity-provider [flags]
```
### Examples
```
# Create SAML identity provider
firectl create identity-provider --display-name="Company SAML" \
--saml-metadata-url="https://company.okta.com/app/xyz/sso/saml/metadata"
# Create OIDC identity provider
firectl create identity-provider --display-name="Company OIDC" \
--oidc-issuer="https://auth.company.com" \
--oidc-client-id="abc123" \
--oidc-client-secret="secret456"
# Create OIDC identity provider with multiple domains
firectl create identity-provider --display-name="Example OIDC" \
--oidc-issuer="https://accounts.google.com" \
--oidc-client-id="client123" \
--oidc-client-secret="secret456" \
--tenant-domains="example.com,example.co.uk"
```
### Flags
```
--display-name string The display name of the identity provider (required)
-h, --help help for identity-provider
--oidc-client-id string The OIDC client ID for OIDC providers
--oidc-client-secret string The OIDC client secret for OIDC providers
--oidc-issuer string The OIDC issuer URL for OIDC providers
--saml-metadata-url string The SAML metadata URL for SAML providers
--tenant-domains string Comma-separated list of allowed domains for the organization (e.g., 'example.com,example.co.uk'). If not provided, domain will be derived from account email.
```
### Global flags
```
-a, --account-id string The Fireworks account ID. If not specified, reads account_id from ~/.fireworks/auth.ini.
--api-key string An API key used to authenticate with Fireworks.
--dry-run Print the request proto without running it.
-o, --output Output Set the output format to "text", "json", or "flag". (default text)
-p, --profile string fireworks auth and settings profile to use.
```
---
# Source: https://docs.fireworks.ai/tools-sdks/firectl/commands/create-model.md
# Source: https://docs.fireworks.ai/api-reference/create-model.md
# Source: https://docs.fireworks.ai/tools-sdks/firectl/commands/create-model.md
# Source: https://docs.fireworks.ai/api-reference/create-model.md
# Source: https://docs.fireworks.ai/tools-sdks/firectl/commands/create-model.md
# Source: https://docs.fireworks.ai/api-reference/create-model.md
# Create Model
## OpenAPI
````yaml post /v1/accounts/{account_id}/models
paths:
path: /v1/accounts/{account_id}/models
method: post
servers:
- url: https://api.fireworks.ai
request:
security:
- title: BearerAuth
parameters:
query: {}
header:
Authorization:
type: http
scheme: bearer
description: >-
Bearer authentication using your Fireworks API key. Format:
Bearer
cookie: {}
parameters:
path:
account_id:
schema:
- type: string
required: true
description: The Account Id
query: {}
header: {}
cookie: {}
body:
application/json:
schemaArray:
- type: object
properties:
model:
allOf:
- $ref: '#/components/schemas/gatewayModel'
description: The properties of the Model being created.
modelId:
allOf:
- type: string
description: ID of the model.
cluster:
allOf:
- type: string
description: >-
The resource name of the BYOC cluster to which this model
belongs.
e.g. accounts/my-account/clusters/my-cluster. Empty if it
belongs to
a Fireworks cluster.
required: true
refIdentifier: '#/components/schemas/GatewayCreateModelBody'
requiredProperties:
- modelId
examples:
example:
value:
model:
displayName:
description:
kind: KIND_UNSPECIFIED
githubUrl:
huggingFaceUrl:
baseModelDetails:
worldSize: 123
checkpointFormat: CHECKPOINT_FORMAT_UNSPECIFIED
parameterCount:
moe: true
tunable: true
modelType:
supportsFireattention: true
supportsMtp: true
peftDetails:
baseModel:
r: 123
targetModules:
-
mergeAddonModelName:
teftDetails: {}
public: true
conversationConfig:
style:
system:
template:
contextLength: 123
supportsImageInput: true
supportsTools: true
defaultDraftModel:
defaultDraftTokenCount: 123
deprecationDate:
year: 123
month: 123
day: 123
supportsLora: true
useHfApplyChatTemplate: true
trainingContextLength: 123
snapshotType: FULL_SNAPSHOT
modelId:
cluster:
response:
'200':
application/json:
schemaArray:
- type: object
properties:
name:
allOf:
- &ref_0
type: string
title: >-
The resource name of the model. e.g.
accounts/my-account/models/my-model
readOnly: true
displayName:
allOf:
- &ref_1
type: string
description: |-
Human-readable display name of the model. e.g. "My Model"
Must be fewer than 64 characters long.
description:
allOf:
- &ref_2
type: string
description: >-
The description of the model. Must be fewer than 1000
characters long.
createTime:
allOf:
- &ref_3
type: string
format: date-time
description: The creation time of the model.
readOnly: true
state:
allOf:
- &ref_4
$ref: '#/components/schemas/gatewayModelState'
description: The state of the model.
readOnly: true
status:
allOf:
- &ref_5
$ref: '#/components/schemas/gatewayStatus'
description: >-
Contains detailed message when the last model operation
fails.
readOnly: true
kind:
allOf:
- &ref_6
$ref: '#/components/schemas/gatewayModelKind'
description: |-
The kind of model.
If not specified, the default is HF_PEFT_ADDON.
githubUrl:
allOf:
- &ref_7
type: string
description: The URL to GitHub repository of the model.
huggingFaceUrl:
allOf:
- &ref_8
type: string
description: The URL to the Hugging Face model.
baseModelDetails:
allOf:
- &ref_9
$ref: '#/components/schemas/gatewayBaseModelDetails'
description: >-
Base model details.
Required if kind is HF_BASE_MODEL. Must not be set
otherwise.
peftDetails:
allOf:
- &ref_10
$ref: '#/components/schemas/gatewayPEFTDetails'
description: |-
PEFT addon details.
Required if kind is HF_PEFT_ADDON or HF_TEFT_ADDON.
teftDetails:
allOf:
- &ref_11
$ref: '#/components/schemas/gatewayTEFTDetails'
description: >-
TEFT addon details.
Required if kind is HF_TEFT_ADDON. Must not be set
otherwise.
public:
allOf:
- &ref_12
type: boolean
description: If true, the model will be publicly readable.
conversationConfig:
allOf:
- &ref_13
$ref: '#/components/schemas/gatewayConversationConfig'
description: >-
If set, the Chat Completions API will be enabled for this
model.
contextLength:
allOf:
- &ref_14
type: integer
format: int32
description: The maximum context length supported by the model.
supportsImageInput:
allOf:
- &ref_15
type: boolean
description: If set, images can be provided as input to the model.
supportsTools:
allOf:
- &ref_16
type: boolean
description: >-
If set, tools (i.e. functions) can be provided as input to
the model,
and the model may respond with one or more tool calls.
importedFrom:
allOf:
- &ref_17
type: string
description: >-
The name of the the model from which this was imported.
This field is empty
if the model was not imported.
readOnly: true
fineTuningJob:
allOf:
- &ref_18
type: string
description: >-
If the model was created from a fine-tuning job, this is
the fine-tuning
job name.
readOnly: true
defaultDraftModel:
allOf:
- &ref_19
type: string
description: >-
The default draft model to use when creating a deployment.
If empty,
speculative decoding is disabled by default.
defaultDraftTokenCount:
allOf:
- &ref_20
type: integer
format: int32
description: >-
The default draft token count to use when creating a
deployment.
Must be specified if default_draft_model is specified.
deployedModelRefs:
allOf:
- &ref_21
type: array
items:
type: object
$ref: '#/components/schemas/gatewayDeployedModelRef'
description: Populated from GetModel API call only.
readOnly: true
cluster:
allOf:
- &ref_22
type: string
description: >-
The resource name of the BYOC cluster to which this model
belongs.
e.g. accounts/my-account/clusters/my-cluster. Empty if it
belongs to
a Fireworks cluster.
readOnly: true
deprecationDate:
allOf:
- &ref_23
$ref: '#/components/schemas/typeDate'
description: >-
If specified, this is the date when the serverless
deployment of the model will be taken down.
calibrated:
allOf:
- &ref_24
type: boolean
description: >-
If true, the model is calibrated and can be deployed to
non-FP16 precisions.
readOnly: true
tunable:
allOf:
- &ref_25
type: boolean
description: >-
If true, the model can be fine-tuned. The value will be
true if the tunable field is true, and
the model is validated against the model_type field.
readOnly: true
supportsLora:
allOf:
- &ref_26
type: boolean
description: Whether this model supports LoRA.
useHfApplyChatTemplate:
allOf:
- &ref_27
type: boolean
description: >-
If true, the model will use the Hugging Face
apply_chat_template API to apply the chat template.
updateTime:
allOf:
- &ref_28
type: string
format: date-time
description: The update time for the model.
readOnly: true
defaultSamplingParams:
allOf:
- &ref_29
type: object
additionalProperties:
type: number
format: float
description: >-
A json object that contains the default sampling
parameters for the model.
readOnly: true
rlTunable:
allOf:
- &ref_30
type: boolean
description: If true, the model is RL tunable.
readOnly: true
supportedPrecisions:
allOf:
- &ref_31
type: array
items:
$ref: '#/components/schemas/DeploymentPrecision'
title: Supported precisions
readOnly: true
supportedPrecisionsWithCalibration:
allOf:
- &ref_32
type: array
items:
$ref: '#/components/schemas/DeploymentPrecision'
title: Supported precisions if calibrated
readOnly: true
trainingContextLength:
allOf:
- &ref_33
type: integer
format: int32
description: The maximum context length supported by the model.
snapshotType:
allOf:
- &ref_34
$ref: '#/components/schemas/ModelSnapshotType'
title: 'Next ID: 56'
refIdentifier: '#/components/schemas/gatewayModel'
examples:
example:
value:
name:
displayName:
description:
createTime: '2023-11-07T05:31:56Z'
state: STATE_UNSPECIFIED
status:
code: OK
message:
kind: KIND_UNSPECIFIED
githubUrl:
huggingFaceUrl:
baseModelDetails:
worldSize: 123
checkpointFormat: CHECKPOINT_FORMAT_UNSPECIFIED
parameterCount:
moe: true
tunable: true
modelType:
supportsFireattention: true
defaultPrecision: PRECISION_UNSPECIFIED
supportsMtp: true
peftDetails:
baseModel:
r: 123
targetModules:
-
baseModelType:
mergeAddonModelName:
teftDetails: {}
public: true
conversationConfig:
style:
system:
template:
contextLength: 123
supportsImageInput: true
supportsTools: true
importedFrom:
fineTuningJob:
defaultDraftModel:
defaultDraftTokenCount: 123
deployedModelRefs:
- name:
deployment:
state: STATE_UNSPECIFIED
default: true
public: true
cluster:
deprecationDate:
year: 123
month: 123
day: 123
calibrated: true
tunable: true
supportsLora: true
useHfApplyChatTemplate: true
updateTime: '2023-11-07T05:31:56Z'
defaultSamplingParams: {}
rlTunable: true
supportedPrecisions:
- PRECISION_UNSPECIFIED
supportedPrecisionsWithCalibration:
- PRECISION_UNSPECIFIED
trainingContextLength: 123
snapshotType: FULL_SNAPSHOT
description: A successful response.
deprecated: false
type: path
components:
schemas:
BaseModelDetailsCheckpointFormat:
type: string
enum:
- CHECKPOINT_FORMAT_UNSPECIFIED
- NATIVE
- HUGGINGFACE
default: CHECKPOINT_FORMAT_UNSPECIFIED
DeploymentPrecision:
type: string
enum:
- PRECISION_UNSPECIFIED
- FP16
- FP8
- FP8_MM
- FP8_AR
- FP8_MM_KV_ATTN
- FP8_KV
- FP8_MM_V2
- FP8_V2
- FP8_MM_KV_ATTN_V2
- NF4
- FP4
- BF16
- FP4_BLOCKSCALED_MM
- FP4_MX_MOE
default: PRECISION_UNSPECIFIED
title: >-
- PRECISION_UNSPECIFIED: if left unspecified we will treat this as a
legacy model created before
self serve
ModelSnapshotType:
type: string
enum:
- FULL_SNAPSHOT
- INCREMENTAL_SNAPSHOT
default: FULL_SNAPSHOT
gatewayBaseModelDetails:
type: object
properties:
worldSize:
type: integer
format: int32
description: |-
The default number of GPUs the model is served with.
If not specified, the default is 1.
checkpointFormat:
$ref: '#/components/schemas/BaseModelDetailsCheckpointFormat'
parameterCount:
type: string
format: int64
description: >-
The number of model parameters. For serverless models, this
determines the
price per token.
moe:
type: boolean
description: >-
If true, this is a Mixture of Experts (MoE) model. For serverless
models,
this affects the price per token.
tunable:
type: boolean
description: If true, this model is available for fine-tuning.
modelType:
type: string
description: The type of the model.
supportsFireattention:
type: boolean
description: Whether this model supports fireattention.
defaultPrecision:
$ref: '#/components/schemas/DeploymentPrecision'
description: Default precision of the model.
readOnly: true
supportsMtp:
type: boolean
description: If true, this model supports MTP.
title: 'Next ID: 11'
gatewayCode:
type: string
enum:
- OK
- CANCELLED
- UNKNOWN
- INVALID_ARGUMENT
- DEADLINE_EXCEEDED
- NOT_FOUND
- ALREADY_EXISTS
- PERMISSION_DENIED
- UNAUTHENTICATED
- RESOURCE_EXHAUSTED
- FAILED_PRECONDITION
- ABORTED
- OUT_OF_RANGE
- UNIMPLEMENTED
- INTERNAL
- UNAVAILABLE
- DATA_LOSS
default: OK
description: |-
- OK: Not an error; returned on success.
HTTP Mapping: 200 OK
- CANCELLED: The operation was cancelled, typically by the caller.
HTTP Mapping: 499 Client Closed Request
- UNKNOWN: Unknown error. For example, this error may be returned when
a `Status` value received from another address space belongs to
an error space that is not known in this address space. Also
errors raised by APIs that do not return enough error information
may be converted to this error.
HTTP Mapping: 500 Internal Server Error
- INVALID_ARGUMENT: The client specified an invalid argument. Note that this differs
from `FAILED_PRECONDITION`. `INVALID_ARGUMENT` indicates arguments
that are problematic regardless of the state of the system
(e.g., a malformed file name).
HTTP Mapping: 400 Bad Request
- DEADLINE_EXCEEDED: The deadline expired before the operation could complete. For operations
that change the state of the system, this error may be returned
even if the operation has completed successfully. For example, a
successful response from a server could have been delayed long
enough for the deadline to expire.
HTTP Mapping: 504 Gateway Timeout
- NOT_FOUND: Some requested entity (e.g., file or directory) was not found.
Note to server developers: if a request is denied for an entire class
of users, such as gradual feature rollout or undocumented allowlist,
`NOT_FOUND` may be used. If a request is denied for some users within
a class of users, such as user-based access control, `PERMISSION_DENIED`
must be used.
HTTP Mapping: 404 Not Found
- ALREADY_EXISTS: The entity that a client attempted to create (e.g., file or directory)
already exists.
HTTP Mapping: 409 Conflict
- PERMISSION_DENIED: The caller does not have permission to execute the specified
operation. `PERMISSION_DENIED` must not be used for rejections
caused by exhausting some resource (use `RESOURCE_EXHAUSTED`
instead for those errors). `PERMISSION_DENIED` must not be
used if the caller can not be identified (use `UNAUTHENTICATED`
instead for those errors). This error code does not imply the
request is valid or the requested entity exists or satisfies
other pre-conditions.
HTTP Mapping: 403 Forbidden
- UNAUTHENTICATED: The request does not have valid authentication credentials for the
operation.
HTTP Mapping: 401 Unauthorized
- RESOURCE_EXHAUSTED: Some resource has been exhausted, perhaps a per-user quota, or
perhaps the entire file system is out of space.
HTTP Mapping: 429 Too Many Requests
- FAILED_PRECONDITION: The operation was rejected because the system is not in a state
required for the operation's execution. For example, the directory
to be deleted is non-empty, an rmdir operation is applied to
a non-directory, etc.
Service implementors can use the following guidelines to decide
between `FAILED_PRECONDITION`, `ABORTED`, and `UNAVAILABLE`:
(a) Use `UNAVAILABLE` if the client can retry just the failing call.
(b) Use `ABORTED` if the client should retry at a higher level. For
example, when a client-specified test-and-set fails, indicating the
client should restart a read-modify-write sequence.
(c) Use `FAILED_PRECONDITION` if the client should not retry until
the system state has been explicitly fixed. For example, if an "rmdir"
fails because the directory is non-empty, `FAILED_PRECONDITION`
should be returned since the client should not retry unless
the files are deleted from the directory.
HTTP Mapping: 400 Bad Request
- ABORTED: The operation was aborted, typically due to a concurrency issue such as
a sequencer check failure or transaction abort.
See the guidelines above for deciding between `FAILED_PRECONDITION`,
`ABORTED`, and `UNAVAILABLE`.
HTTP Mapping: 409 Conflict
- OUT_OF_RANGE: The operation was attempted past the valid range. E.g., seeking or
reading past end-of-file.
Unlike `INVALID_ARGUMENT`, this error indicates a problem that may
be fixed if the system state changes. For example, a 32-bit file
system will generate `INVALID_ARGUMENT` if asked to read at an
offset that is not in the range [0,2^32-1], but it will generate
`OUT_OF_RANGE` if asked to read from an offset past the current
file size.
There is a fair bit of overlap between `FAILED_PRECONDITION` and
`OUT_OF_RANGE`. We recommend using `OUT_OF_RANGE` (the more specific
error) when it applies so that callers who are iterating through
a space can easily look for an `OUT_OF_RANGE` error to detect when
they are done.
HTTP Mapping: 400 Bad Request
- UNIMPLEMENTED: The operation is not implemented or is not supported/enabled in this
service.
HTTP Mapping: 501 Not Implemented
- INTERNAL: Internal errors. This means that some invariants expected by the
underlying system have been broken. This error code is reserved
for serious errors.
HTTP Mapping: 500 Internal Server Error
- UNAVAILABLE: The service is currently unavailable. This is most likely a
transient condition, which can be corrected by retrying with
a backoff. Note that it is not always safe to retry
non-idempotent operations.
See the guidelines above for deciding between `FAILED_PRECONDITION`,
`ABORTED`, and `UNAVAILABLE`.
HTTP Mapping: 503 Service Unavailable
- DATA_LOSS: Unrecoverable data loss or corruption.
HTTP Mapping: 500 Internal Server Error
title: >-
Mimics
[https://github.com/googleapis/googleapis/blob/master/google/rpc/code.proto]
gatewayConversationConfig:
type: object
properties:
style:
type: string
description: The chat template to use.
system:
type: string
description: The system prompt (if the chat style supports it).
template:
type: string
description: The Jinja template (if style is "jinja").
required:
- style
gatewayDeployedModelRef:
type: object
properties:
name:
type: string
title: >-
The resource name. e.g.
accounts/my-account/deployedModels/my-deployed-model
readOnly: true
deployment:
type: string
description: The resource name of the base deployment the model is deployed to.
readOnly: true
state:
$ref: '#/components/schemas/gatewayDeployedModelState'
description: The state of the deployed model.
readOnly: true
default:
type: boolean
description: >-
If true, this is the default target when querying this model without
the `#` suffix.
The first deployment a model is deployed to will have this field set
to
true automatically.
readOnly: true
public:
type: boolean
description: If true, the deployed model will be publicly reachable.
readOnly: true
title: 'Next ID: 6'
gatewayDeployedModelState:
type: string
enum:
- STATE_UNSPECIFIED
- UNDEPLOYING
- DEPLOYING
- DEPLOYED
- UPDATING
default: STATE_UNSPECIFIED
description: |-
- UNDEPLOYING: The model is being undeployed.
- DEPLOYING: The model is being deployed.
- DEPLOYED: The model is deployed and ready for inference.
- UPDATING: there are updates happening with the deployed model
title: 'Next ID: 6'
gatewayModel:
type: object
properties:
name: *ref_0
displayName: *ref_1
description: *ref_2
createTime: *ref_3
state: *ref_4
status: *ref_5
kind: *ref_6
githubUrl: *ref_7
huggingFaceUrl: *ref_8
baseModelDetails: *ref_9
peftDetails: *ref_10
teftDetails: *ref_11
public: *ref_12
conversationConfig: *ref_13
contextLength: *ref_14
supportsImageInput: *ref_15
supportsTools: *ref_16
importedFrom: *ref_17
fineTuningJob: *ref_18
defaultDraftModel: *ref_19
defaultDraftTokenCount: *ref_20
deployedModelRefs: *ref_21
cluster: *ref_22
deprecationDate: *ref_23
calibrated: *ref_24
tunable: *ref_25
supportsLora: *ref_26
useHfApplyChatTemplate: *ref_27
updateTime: *ref_28
defaultSamplingParams: *ref_29
rlTunable: *ref_30
supportedPrecisions: *ref_31
supportedPrecisionsWithCalibration: *ref_32
trainingContextLength: *ref_33
snapshotType: *ref_34
title: 'Next ID: 56'
gatewayModelKind:
type: string
enum:
- KIND_UNSPECIFIED
- HF_BASE_MODEL
- HF_PEFT_ADDON
- HF_TEFT_ADDON
- FLUMINA_BASE_MODEL
- FLUMINA_ADDON
- DRAFT_ADDON
- FIRE_AGENT
- LIVE_MERGE
- CUSTOM_MODEL
- EMBEDDING_MODEL
- SNAPSHOT_MODEL
default: KIND_UNSPECIFIED
description: |2-
- HF_BASE_MODEL: An LLM base model.
- HF_PEFT_ADDON: A parameter-efficent fine-tuned addon.
- HF_TEFT_ADDON: A token-eficient fine-tuned addon.
- FLUMINA_BASE_MODEL: A Flumina base model.
- FLUMINA_ADDON: A Flumina addon.
- DRAFT_ADDON: A draft model used for speculative decoding in a deployment.
- FIRE_AGENT: A FireAgent model.
- LIVE_MERGE: A live-merge model.
- CUSTOM_MODEL: A customized model
- EMBEDDING_MODEL: An Embedding model.
- SNAPSHOT_MODEL: A snapshot model.
gatewayModelState:
type: string
enum:
- STATE_UNSPECIFIED
- UPLOADING
- READY
default: STATE_UNSPECIFIED
description: |-
- UPLOADING: The model is still being uploaded (upload is asynchronous).
- READY: The model is ready to be used.
title: 'Next ID: 7'
gatewayPEFTDetails:
type: object
properties:
baseModel:
type: string
title: The base model name. e.g. accounts/fireworks/models/falcon-7b
r:
type: integer
format: int32
description: |-
The rank of the update matrices.
Must be between 4 and 64, inclusive.
targetModules:
type: array
items:
type: string
title: >-
This is the target modules for an adapter that we extract from
for more information what target module means, check out
https://huggingface.co/docs/peft/conceptual_guides/lora#common-lora-parameters-in-peft
baseModelType:
type: string
description: The type of the model.
readOnly: true
mergeAddonModelName:
type: string
title: >-
The resource name of the model to merge with base model, e.g
accounts/fireworks/models/falcon-7b-lora
title: |-
PEFT addon details.
Next ID: 6
required:
- baseModel
- r
- targetModules
gatewayStatus:
type: object
properties:
code:
$ref: '#/components/schemas/gatewayCode'
description: The status code.
message:
type: string
description: A developer-facing error message in English.
title: >-
Mimics
[https://github.com/googleapis/googleapis/blob/master/google/rpc/status.proto]
gatewayTEFTDetails:
type: object
typeDate:
type: object
properties:
year:
type: integer
format: int32
description: >-
Year of the date. Must be from 1 to 9999, or 0 to specify a date
without
a year.
month:
type: integer
format: int32
description: >-
Month of a year. Must be from 1 to 12, or 0 to specify a year
without a
month and day.
day:
type: integer
format: int32
description: >-
Day of a month. Must be from 1 to 31 and valid for the year and
month, or 0
to specify a year by itself or a year and month where the day isn't
significant.
description: >-
* A full date, with non-zero year, month, and day values
* A month and day value, with a zero year, such as an anniversary
* A year on its own, with zero month and day values
* A year and month value, with a zero day, such as a credit card
expiration
date
Related types are [google.type.TimeOfDay][google.type.TimeOfDay] and
`google.protobuf.Timestamp`.
title: >-
Represents a whole or partial calendar date, such as a birthday. The
time of
day and time zone are either specified elsewhere or are insignificant.
The
date is relative to the Gregorian Calendar. This can represent one of
the
following:
````
---
# Source: https://docs.fireworks.ai/api-reference-dlde/create-node-pool-binding.md
# Create Node Pool Binding
## OpenAPI
````yaml post /v1/accounts/{account_id}/nodePoolBindings
paths:
path: /v1/accounts/{account_id}/nodePoolBindings
method: post
servers:
- url: https://api.fireworks.ai
request:
security:
- title: BearerAuth
parameters:
query: {}
header:
Authorization:
type: http
scheme: bearer
description: >-
Bearer authentication using your Fireworks API key. Format:
Bearer