 What we really need is neural search.
## What is neural search?
Exa is a fully neural search engine built using a foundational embeddings model trained for webpage retrieval. It's capable of understanding entity types (company, blog post, Github repo), descriptors (funny, scholastic, authoritative), and any other semantic qualities inside of a query. Neural search can be far more useful than traditional searches for these complex queries.
## Finding companies with Exa link similarity search
Let's try Exa, using the Python SDK! We can use the`find_similar_and_contents` function to find similar links and get contents from each link. The input is simply a URL, [https://thrift.house](https://thrift.house) and we set `num_results=10`(this is customizable up to thousands of results in Exa).
By specifying `highlights={"max_characters":2000}` for each search result, Exa will also identify and return relevant excerpts from the content. This will allow us to quickly understand each website that we find.
```Python Python theme={null}
!pip install exa_py
from exa_py import Exa
import os
EXA_API_KEY= os.environ.get("EXA_API_KEY")
exa = Exa(api_key=EXA_API_KEY)
input_url = "https://thrift.house"
search_response = exa.find_similar_and_contents(
input_url,
highlights={"max_characters":2000},
num_results=10)
companies = search_response.results
print(companies[0])
```
This is an example of the full first result:
```
[Result(url='https://www.mystorestash.com/',
id='lMTt0MBzc8ztb6Az3OGKPA',
title='The Airbnb of Storage',
published_date='2023-01-01',
author=None,
text=None,
highlights=["I got my suitcase picked up right from my dorm and didn't have to worry for the whole summer.Angela Scaria /Still have questions?Where are my items stored?"],
highlight_scores=[0.23423566609247845])]
```
And here are the 10 titles and URLs I got:
```Python Python theme={null}
# to just see the 10 titles and urls
urls = {}
for c in companies:
print(c.title + ':' + c.url)
```
```rumie - College Marketplace:https://www.rumieapp.com/ theme={null}
The Airbnb of Storage:https://www.mystorestash.com/
Bunction.net:https://bunction.net/
Home - Community Gearbox:https://communitygearbox.com/
NOVA SHOPPING:https://www.novashoppingapp.com/
Re-Fridge: Buy, sell, or store your college fridge - Re-Fridge:https://www.refridge.com/
Jamble: Social Fashion Resale:https://www.jambleapp.com/
Branded Resale | Treet:https://www.treet.co/
Swapskis:https://www.swapskis.co/
Earn Money for Used Clothing:https://www.thredup.com/cleanout?redirectPath=%2Fcleanout%2Fsell
```
Looks pretty darn good! As a bonus specifically for companies data, specifying `category="company"` in the SDK will search across a curated, larger companies dataset - if you're interested in this, let us know at [hello@exa.ai](mailto:hello@exa.ai)!
Now that we have 10 companies we want to dig into further, let’s do some research on each of these companies.
## Finding additional info for each company
Now let's get more information by finding additional webpages about each company. To do this, we're going to search for each company's URL. We can do this with the `search_and_contents` function, and specify `num_results=5`. This will give me 5 websites about each company.
```python Python theme={null}
# doing an example with the first companies
c = companies[0]
all_contents = ""
search_response = exa.search_and_contents(
c.url, # input the company's URL
num_results=5
)
research_response = search_response.results
for r in research_response:
all_contents += r.text
```
Here's an example of the first result for the first company, Rumie App. You can see the first result is the actual link contents itself.
```
What we really need is neural search.
## What is neural search?
Exa is a fully neural search engine built using a foundational embeddings model trained for webpage retrieval. It's capable of understanding entity types (company, blog post, Github repo), descriptors (funny, scholastic, authoritative), and any other semantic qualities inside of a query. Neural search can be far more useful than traditional searches for these complex queries.
## Finding companies with Exa link similarity search
Let's try Exa, using the Python SDK! We can use the`find_similar_and_contents` function to find similar links and get contents from each link. The input is simply a URL, [https://thrift.house](https://thrift.house) and we set `num_results=10`(this is customizable up to thousands of results in Exa).
By specifying `highlights={"max_characters":2000}` for each search result, Exa will also identify and return relevant excerpts from the content. This will allow us to quickly understand each website that we find.
```Python Python theme={null}
!pip install exa_py
from exa_py import Exa
import os
EXA_API_KEY= os.environ.get("EXA_API_KEY")
exa = Exa(api_key=EXA_API_KEY)
input_url = "https://thrift.house"
search_response = exa.find_similar_and_contents(
input_url,
highlights={"max_characters":2000},
num_results=10)
companies = search_response.results
print(companies[0])
```
This is an example of the full first result:
```
[Result(url='https://www.mystorestash.com/',
id='lMTt0MBzc8ztb6Az3OGKPA',
title='The Airbnb of Storage',
published_date='2023-01-01',
author=None,
text=None,
highlights=["I got my suitcase picked up right from my dorm and didn't have to worry for the whole summer.Angela Scaria /Still have questions?Where are my items stored?"],
highlight_scores=[0.23423566609247845])]
```
And here are the 10 titles and URLs I got:
```Python Python theme={null}
# to just see the 10 titles and urls
urls = {}
for c in companies:
print(c.title + ':' + c.url)
```
```rumie - College Marketplace:https://www.rumieapp.com/ theme={null}
The Airbnb of Storage:https://www.mystorestash.com/
Bunction.net:https://bunction.net/
Home - Community Gearbox:https://communitygearbox.com/
NOVA SHOPPING:https://www.novashoppingapp.com/
Re-Fridge: Buy, sell, or store your college fridge - Re-Fridge:https://www.refridge.com/
Jamble: Social Fashion Resale:https://www.jambleapp.com/
Branded Resale | Treet:https://www.treet.co/
Swapskis:https://www.swapskis.co/
Earn Money for Used Clothing:https://www.thredup.com/cleanout?redirectPath=%2Fcleanout%2Fsell
```
Looks pretty darn good! As a bonus specifically for companies data, specifying `category="company"` in the SDK will search across a curated, larger companies dataset - if you're interested in this, let us know at [hello@exa.ai](mailto:hello@exa.ai)!
Now that we have 10 companies we want to dig into further, let’s do some research on each of these companies.
## Finding additional info for each company
Now let's get more information by finding additional webpages about each company. To do this, we're going to search for each company's URL. We can do this with the `search_and_contents` function, and specify `num_results=5`. This will give me 5 websites about each company.
```python Python theme={null}
# doing an example with the first companies
c = companies[0]
all_contents = ""
search_response = exa.search_and_contents(
c.url, # input the company's URL
num_results=5
)
research_response = search_response.results
for r in research_response:
all_contents += r.text
```
Here's an example of the first result for the first company, Rumie App. You can see the first result is the actual link contents itself.
```
The key to your college experience.
Access the largest college exclusive marketplace to buy, sell, and rent with other students.
Users in Our Network
Snap a pic, post a listing, and message buyers all from one intuitive app.
Quick setup and .edu verification
Sell locally or ship to other campuses
Trade with other students like you
rumie students get access to student exclusive discounts from local and national businesses around their campus.
Wear a new dress every weekend! Just rent it directly from a student on your campus.
Make money off of the dresses you've already worn
rumie rental guarantee ensures your dress won't be damaged
Find a new dress every weekend and save money
rumie students get access to the first-ever student ticket marketplace. No more getting scammed trying to buy tickets from strangers on the internet.
.edu authentication and buyer protection on purchases.
Post your first listing in under a minute.
Trade with other students, not strangers.
List an item in a few simple steps. Message sellers with ease.
Saves me money
Facebook Marketplace and Amazon are great but often times you have to drive a long way to meet up or pay for shipping. rumie let’s me know what is available at my school… literally at walking distance.
5 stars!
Having this app as a freshman is great! It makes buying and selling things so safe and easy! Much more efficient than other buy/sell platforms!
Amazing!
5 stars for being simple, organized, safe, and a great way to buy and sell in your college community.. much more effective than posting on Facebook or Instagram!
The BEST marketplace for college students!!!
Once rumie got to my campus, I was excited to see what is has to offer! Not only is it safe for students like me, but the app just has a great feel and is really easy to use. The ONLY place I’ll be buying and selling while I’m a student.
Forget clothing instas, selling groupme's, and stress when buying and selling. Do it all from the rumie app.
Install the Python SDK with pip.
```bash theme={null} pip install exa-py ```Get your API key from the Exa Dashboard, create a file called `exa.py`, and add the code below.
```python python theme={null} from exa_py import Exa exa = Exa(api_key="your-api-key") result = exa.get_contents( ["tesla.com"], text=True ) ```Install the JavaScript SDK with npm.
```bash theme={null} npm install exa-js ```Get your API key from the Exa Dashboard, create a file called `exa.ts`, and add the code below.
```javascript javascript theme={null} import Exa from "exa-js"; const exa = new Exa("your-api-key"); const result = await exa.getContents(["tesla.com"], { text: true, }); ```Get your API key from the Exa Dashboard and pass the following command to your terminal.
```bash bash theme={null} curl -X POST https://api.exa.ai/contents \ --header "content-type: application/json" \ --header "x-api-key: your-api-key" \ --data ' { "ids": ["tesla.com"], "text": true }' ```You clicked {count} times
\n \n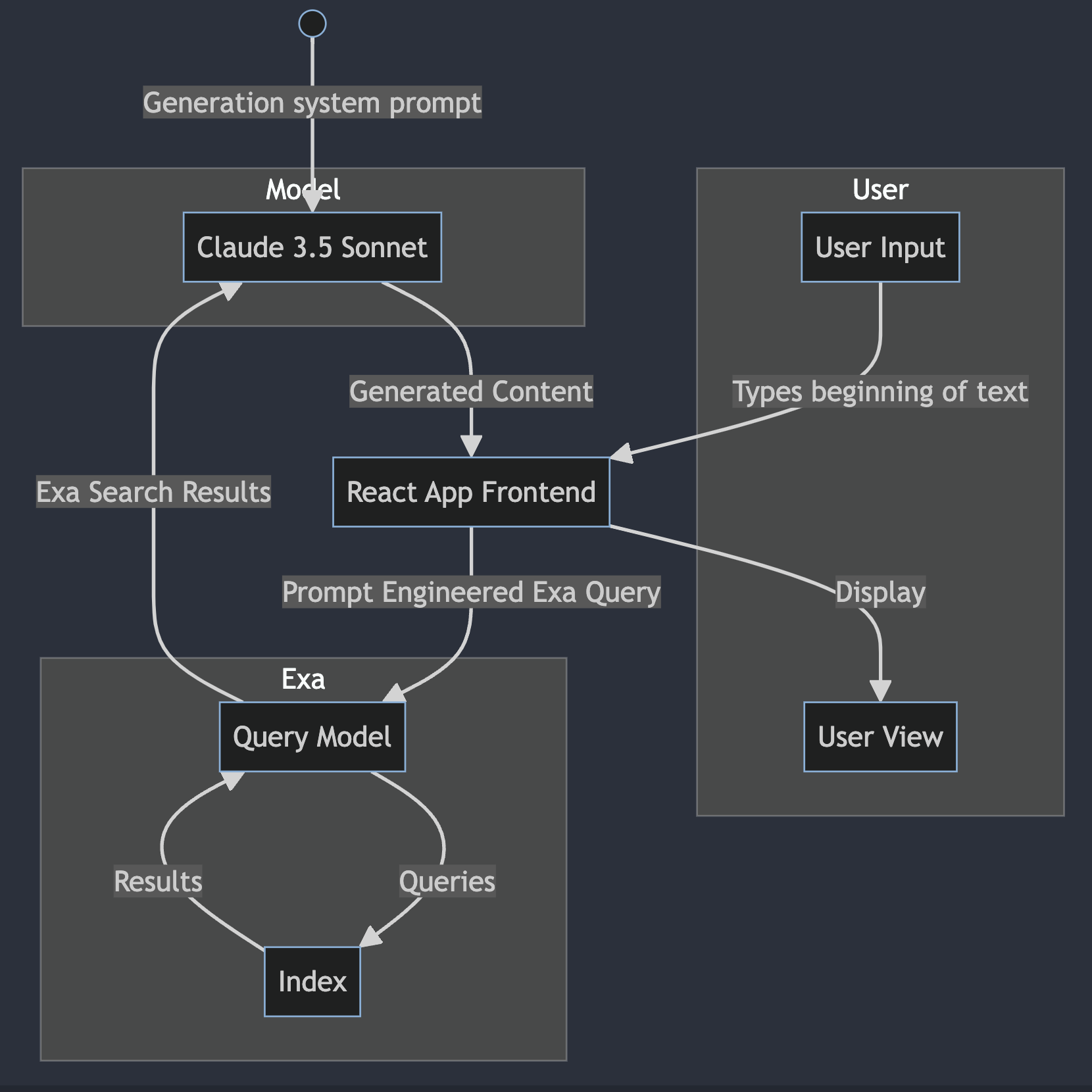 Conceptual block diagram of how the writing assistant works
## Exa prompting and query style
The Exa search is performed using a unique query style that appends the user's input with a prompt for continuation. Here's the relevant code snippet:
```JavaScript JavaScript theme={null}
let exaQuery = conversationState.length > 1000
? (conversationState.slice(-1000))+"\n\nIf you found the above interesting, here's another useful resource to read:"
: conversationState+"\n\nIf you found the above interesting, here's another useful resource to read:"
let exaReturnedResults = await exa.searchAndContents(
exaQuery,
{
type: "neural",
numResults: 10,
highlights: {
maxCharacters: 500
}
}
)
```
**Key aspects of this query style:**
* **Continuation prompt:** The crucial post-pend "A helpful source to read so you can continue writing the above:"
* This prompt is designed to find sources that can logically continue the user's writing when passed to an LLM to generate content.
* It leverages Exa's ability to understand context and find semantically relevant results.
* By framing the query as a request for continuation, it aligns with how people naturally share helpful links.
* **Length limitation:** It caps the query at 1000 characters to maintain relevance and continue writing just based on the last section of the text.
Note this prompt is not a hard and fast rule for this use-case - we encourage experimentation with query styles to get the best results for your specific use case. For instance, you could further constrain down to just research papers.
## Prompting Claude with Exa results
The Claude AI model is prompted with a carefully crafted system message and passed the above formatted Exa results. Here is an example system prompt:
```typescript TypeScript theme={null}
const systemPrompt = `You are an essay-completion bot that continues/completes a sentence given some input stub of an essay/prose. You only complete 1-2 SHORT sentence MAX. If you get an input of a half sentence or similar, DO NOT repeat any of the preceding text of the prose. THIS MEANS DO NOT INCLUDE THE STARTS OF INCOMPLETE SENTENCES IN YOUR RESPONSE. This is also the case when there is a spelling, punctuation, capitalization or other error in the starter stub - e.g.:
USER INPUT: pokemon is a
YOUR CORRECT OUTPUT: Japanese franchise created by Satoshi Tajiri.
NEVER/INCORRECT: Pokémon is a Japanese franchise created by Satoshi Tajiri.
USER INPUT: Once upon a time there
YOUR CORRECT OUTPUT: was a princess.
NEVER/INCORRECT: Once upon a time, there was a princess.
USER INPUT: Colonial england was a
YOUR CORRECT OUTPUT: time of great change and upheaval.
NEVER/INCORRECT: Colonial England was a time of great change and upheaval.
USER INPUT: The fog in san francisco
YOUR CORRECT OUTPUT: is a defining characteristic of the city's climate.
NEVER/INCORRECT: The fog in San Francisco is a defining characteristic of the city's climate.
USER INPUT: The fog in san francisco
YOUR CORRECT OUTPUT: is a defining characteristic of the city's climate.
NEVER/INCORRECT: The fog in San Francisco is a defining characteristic of the city's climate.
Once you have made one citation, stop generating. BE PITHY. Where there is a full sentence fed in,
you should continue on the next sentence as a generally good flowing essay would. You have a
specialty in including content that is cited. Given the following two items, (1) citation context and
(2) current essay writing, continue on the essay or prose inputting in-line citations in
parentheses with the author's name, right after that followed by the relevant URL in square brackets.
THEN put a parentheses around all of the above. If you cannot find an author (sometimes it is empty), use the generic name 'Source'.
ample citation for you to follow the structure of: ((AUTHOR_X, 2021)[URL_X]).
If there are more than 3 author names to include, use the first author name plus 'et al'`
```
This prompt ensures that:
* Claude will only do completions, not parrot back the user query like in a typical chat based scenario. Note the inclusion of multiple examples that demonstrate Claude should not reply back with the stub even if there are errors, like spelling or grammar, in the input text (which we found to be a common issue)
* We define the citation style and formatting. We also tell the bot went to collapse authors into 'et al' style citations, as some webpages have many authors
Once again, experimenting with this prompt is crucial to getting best results for your particular use case.
## Conclusion
This demo illustrates the power of combining Exa's advanced search capabilities with generative AI to create a writing assistant. By leveraging Exa's neural search and content retrieval features, the system can provide relevant, up-to-date information to any AI model, resulting in contextually appropriate content generation with citations.
This approach showcases how Exa can be integrated into AI-powered applications to enhance user experiences and productivity.
[Click here to try the Exa-powered Writing Assistant](https://demo.exa.ai/writing)
---
# Source: https://exa.ai/docs/examples/demo-hallucination-detector.md
> ## Documentation Index
> Fetch the complete documentation index at: https://exa.ai/docs/llms.txt
> Use this file to discover all available pages before exploring further.
# Hallucination Detector
> A live demo that detects hallucinations in content using Exa's search.
***
We built a live hallucination detector that uses Exa to verify LLM-generated content. When you input text, the app breaks it into individual claims, searches for evidence to verify each one, and returns relevant sources with a verification confidence score.
A claim is a single, verifiable statement that can be proven true or false - like "The Eiffel Tower is in Paris" or "It was built in 1822."
Conceptual block diagram of how the writing assistant works
## Exa prompting and query style
The Exa search is performed using a unique query style that appends the user's input with a prompt for continuation. Here's the relevant code snippet:
```JavaScript JavaScript theme={null}
let exaQuery = conversationState.length > 1000
? (conversationState.slice(-1000))+"\n\nIf you found the above interesting, here's another useful resource to read:"
: conversationState+"\n\nIf you found the above interesting, here's another useful resource to read:"
let exaReturnedResults = await exa.searchAndContents(
exaQuery,
{
type: "neural",
numResults: 10,
highlights: {
maxCharacters: 500
}
}
)
```
**Key aspects of this query style:**
* **Continuation prompt:** The crucial post-pend "A helpful source to read so you can continue writing the above:"
* This prompt is designed to find sources that can logically continue the user's writing when passed to an LLM to generate content.
* It leverages Exa's ability to understand context and find semantically relevant results.
* By framing the query as a request for continuation, it aligns with how people naturally share helpful links.
* **Length limitation:** It caps the query at 1000 characters to maintain relevance and continue writing just based on the last section of the text.
Note this prompt is not a hard and fast rule for this use-case - we encourage experimentation with query styles to get the best results for your specific use case. For instance, you could further constrain down to just research papers.
## Prompting Claude with Exa results
The Claude AI model is prompted with a carefully crafted system message and passed the above formatted Exa results. Here is an example system prompt:
```typescript TypeScript theme={null}
const systemPrompt = `You are an essay-completion bot that continues/completes a sentence given some input stub of an essay/prose. You only complete 1-2 SHORT sentence MAX. If you get an input of a half sentence or similar, DO NOT repeat any of the preceding text of the prose. THIS MEANS DO NOT INCLUDE THE STARTS OF INCOMPLETE SENTENCES IN YOUR RESPONSE. This is also the case when there is a spelling, punctuation, capitalization or other error in the starter stub - e.g.:
USER INPUT: pokemon is a
YOUR CORRECT OUTPUT: Japanese franchise created by Satoshi Tajiri.
NEVER/INCORRECT: Pokémon is a Japanese franchise created by Satoshi Tajiri.
USER INPUT: Once upon a time there
YOUR CORRECT OUTPUT: was a princess.
NEVER/INCORRECT: Once upon a time, there was a princess.
USER INPUT: Colonial england was a
YOUR CORRECT OUTPUT: time of great change and upheaval.
NEVER/INCORRECT: Colonial England was a time of great change and upheaval.
USER INPUT: The fog in san francisco
YOUR CORRECT OUTPUT: is a defining characteristic of the city's climate.
NEVER/INCORRECT: The fog in San Francisco is a defining characteristic of the city's climate.
USER INPUT: The fog in san francisco
YOUR CORRECT OUTPUT: is a defining characteristic of the city's climate.
NEVER/INCORRECT: The fog in San Francisco is a defining characteristic of the city's climate.
Once you have made one citation, stop generating. BE PITHY. Where there is a full sentence fed in,
you should continue on the next sentence as a generally good flowing essay would. You have a
specialty in including content that is cited. Given the following two items, (1) citation context and
(2) current essay writing, continue on the essay or prose inputting in-line citations in
parentheses with the author's name, right after that followed by the relevant URL in square brackets.
THEN put a parentheses around all of the above. If you cannot find an author (sometimes it is empty), use the generic name 'Source'.
ample citation for you to follow the structure of: ((AUTHOR_X, 2021)[URL_X]).
If there are more than 3 author names to include, use the first author name plus 'et al'`
```
This prompt ensures that:
* Claude will only do completions, not parrot back the user query like in a typical chat based scenario. Note the inclusion of multiple examples that demonstrate Claude should not reply back with the stub even if there are errors, like spelling or grammar, in the input text (which we found to be a common issue)
* We define the citation style and formatting. We also tell the bot went to collapse authors into 'et al' style citations, as some webpages have many authors
Once again, experimenting with this prompt is crucial to getting best results for your particular use case.
## Conclusion
This demo illustrates the power of combining Exa's advanced search capabilities with generative AI to create a writing assistant. By leveraging Exa's neural search and content retrieval features, the system can provide relevant, up-to-date information to any AI model, resulting in contextually appropriate content generation with citations.
This approach showcases how Exa can be integrated into AI-powered applications to enhance user experiences and productivity.
[Click here to try the Exa-powered Writing Assistant](https://demo.exa.ai/writing)
---
# Source: https://exa.ai/docs/examples/demo-hallucination-detector.md
> ## Documentation Index
> Fetch the complete documentation index at: https://exa.ai/docs/llms.txt
> Use this file to discover all available pages before exploring further.
# Hallucination Detector
> A live demo that detects hallucinations in content using Exa's search.
***
We built a live hallucination detector that uses Exa to verify LLM-generated content. When you input text, the app breaks it into individual claims, searches for evidence to verify each one, and returns relevant sources with a verification confidence score.
A claim is a single, verifiable statement that can be proven true or false - like "The Eiffel Tower is in Paris" or "It was built in 1822."
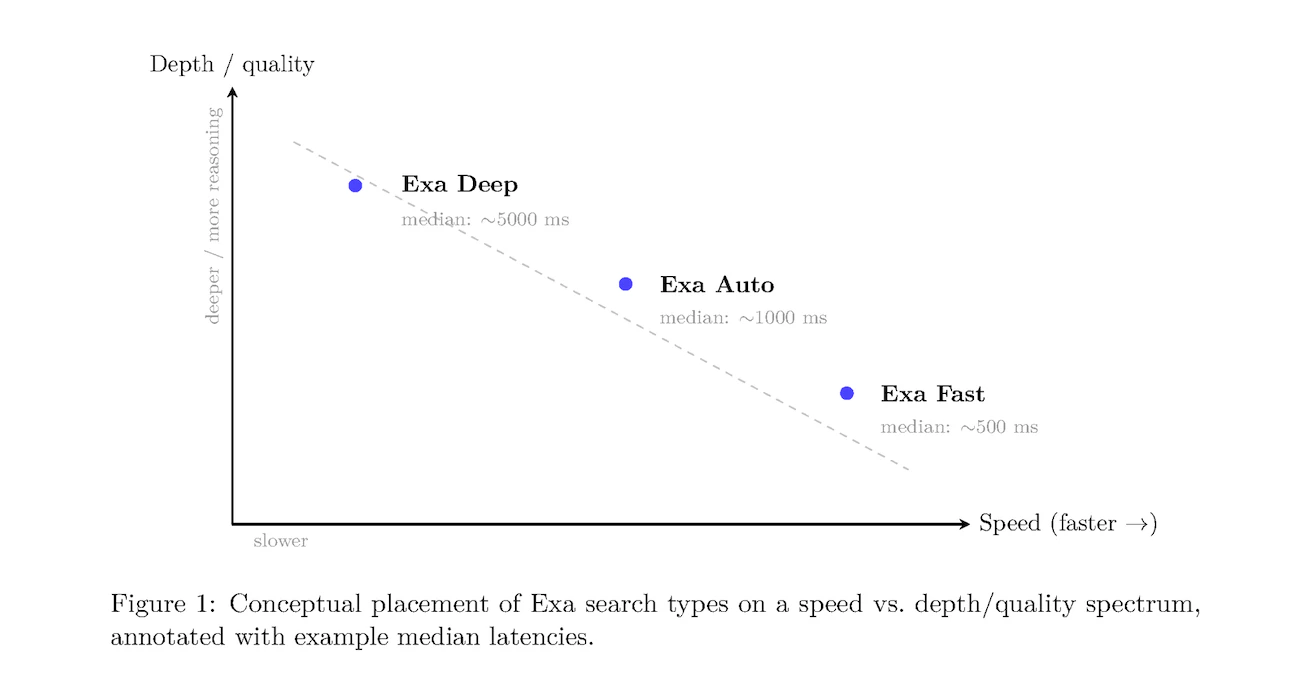 ### Fast Search
**Optimized for**: Speed-critical applications
**Characteristics**:
* Median latency: \~500ms (excluding network and optional features)
* Streamlined neural and reranking models
* Best for single-step factual queries
**When to benchmark with Fast**:
* Low-latency QA datasets (SimpleQA, WebWalkerQA)
* Real-time applications (voice agents, autocomplete)
* High-volume agentic workflows where latency accumulates
**Example configuration**:
```python theme={null}
result = exa.search_and_contents(
"latest AI breakthroughs in 2025",
type="fast",
num_results=10,
text={"max_characters": 15000}
)
```
### Auto Search (Default)
**Optimized for**: Balanced performance without manual tuning
**Characteristics**:
* Median latency: \~1000ms
* Intelligently combines multiple search methods
* Reranker model adapts to query type
**When to benchmark with Auto**:
* General-purpose search evaluations
* When query types vary significantly
* Production workloads requiring versatility
**Example configuration**:
```python theme={null}
result = exa.search_and_contents(
"companies building climate tech solutions",
type="auto", # or omit - auto is default
num_results=10,
text={"max_characters": 15000}
)
```
### Deep Search
### Fast Search
**Optimized for**: Speed-critical applications
**Characteristics**:
* Median latency: \~500ms (excluding network and optional features)
* Streamlined neural and reranking models
* Best for single-step factual queries
**When to benchmark with Fast**:
* Low-latency QA datasets (SimpleQA, WebWalkerQA)
* Real-time applications (voice agents, autocomplete)
* High-volume agentic workflows where latency accumulates
**Example configuration**:
```python theme={null}
result = exa.search_and_contents(
"latest AI breakthroughs in 2025",
type="fast",
num_results=10,
text={"max_characters": 15000}
)
```
### Auto Search (Default)
**Optimized for**: Balanced performance without manual tuning
**Characteristics**:
* Median latency: \~1000ms
* Intelligently combines multiple search methods
* Reranker model adapts to query type
**When to benchmark with Auto**:
* General-purpose search evaluations
* When query types vary significantly
* Production workloads requiring versatility
**Example configuration**:
```python theme={null}
result = exa.search_and_contents(
"companies building climate tech solutions",
type="auto", # or omit - auto is default
num_results=10,
text={"max_characters": 15000}
)
```
### Deep Search
 **Key findings**:
* Exa Fast achieves 94% accuracy on SimpleQA with median latency \<500ms
* Strong performance across multiple benchmarks while maintaining speed advantage
* Ideal for real-time applications and high-volume agent workflows
### Agentic Search APIs
Performance on complex, multi-step tasks (latency >2s):
**Key findings**:
* Exa Fast achieves 94% accuracy on SimpleQA with median latency \<500ms
* Strong performance across multiple benchmarks while maintaining speed advantage
* Ideal for real-time applications and high-volume agent workflows
### Agentic Search APIs
Performance on complex, multi-step tasks (latency >2s):
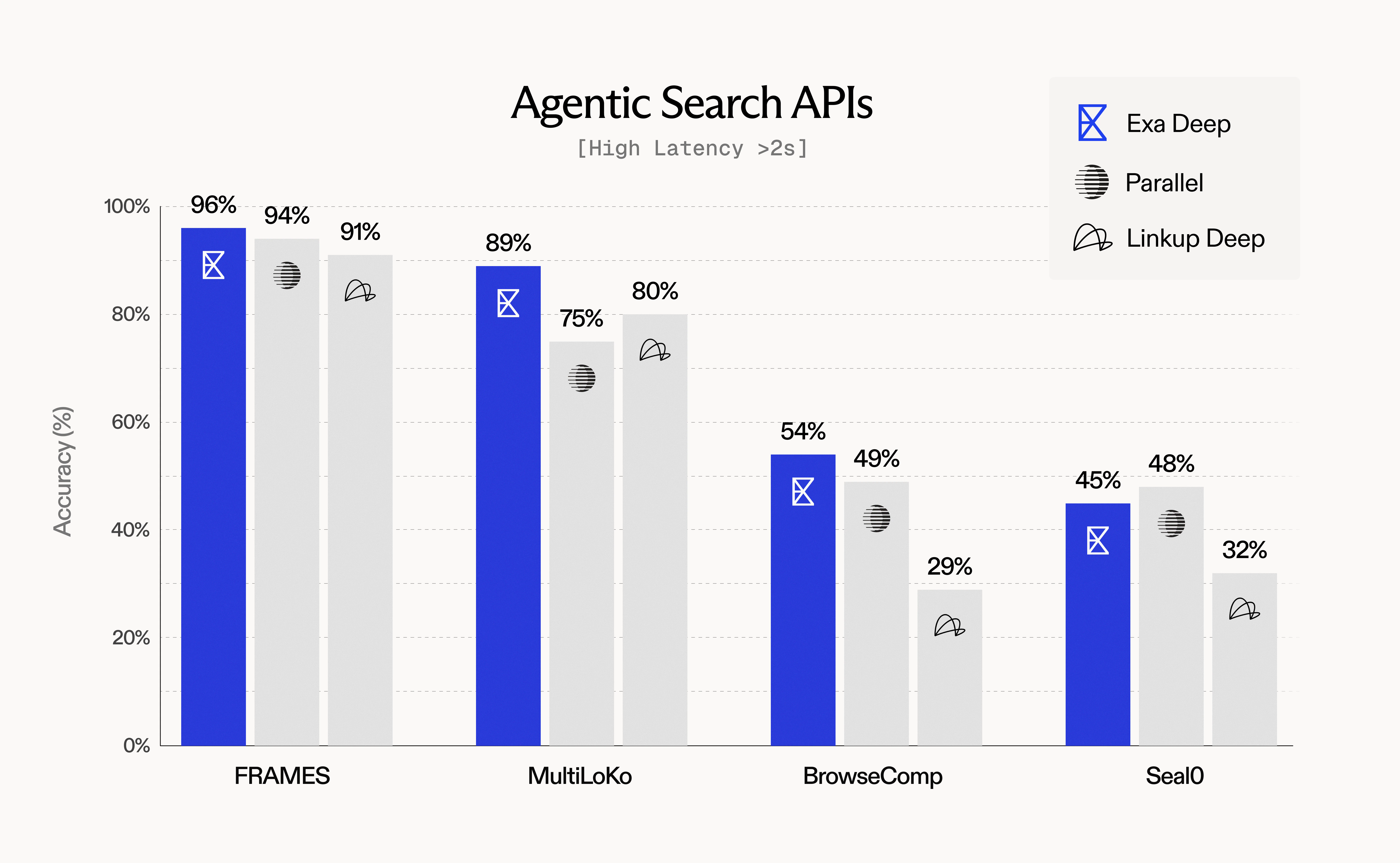 **Key findings**:
* Exa Deep leads on FRAMES (96%) and MultiLoKo (89%) benchmarks
* Query expansion and rich context enable superior agentic performance
* Higher latency justified by comprehensive, high-quality results
## Quality-Latency Tradeoffs
### Understanding the Spectrum
Different use cases require different points on the quality-latency spectrum:
| Use Case | Priority | Recommended Type | Expected Latency | Quality Characteristics |
| ---------------------- | -------- | ---------------- | ---------------- | ---------------------------- |
| Voice agents | Speed | `Fast` | \<500ms | Good factual accuracy |
| Chatbot grounding | Balanced | `Auto` | \~1000ms | Versatile, high quality |
| Research assistant | Depth | `Deep` | \~5000ms | Comprehensive, multi-faceted |
| Batch enrichment | Quality | `Deep` | \~5000ms | Maximum coverage |
| Real-time autocomplete | Speed | `Fast` | \<500ms | Relevant suggestions |
### Interpreting Tradeoffs
When analyzing evaluation results:
1. **Don't compare across latency classes**: `Fast` search at 500ms vs `Deep` search at 5000ms serve different purposes. **Always find the closest competitor in terms of latency for meaningful comparisons** — compare systems with similar P50 latency ranges.
2. **Benchmark within peer groups**:
* Compare Exa Fast (\<500ms) to other sub-1s APIs
* Compare Exa Auto (\~1s) to similar mid-latency systems
* Compare Exa Deep (>2s) to other agentic/research-oriented systems
3. **Consider total workflow time**: For multi-step agents, `Fast` search may complete the entire workflow faster than `Deep` search on a single query
4. **Account for quality requirements**: If accuracy >90% is required, accept higher latency; if \<1s is required, accept some quality tradeoff
### Factors That Impact Latency
Beyond search type selection, several parameters affect response time:
| Parameter | Latency Impact | Recommendation |
| ----------------------------------------------- | -------------- | ----------------------------------- |
| `livecrawl="preferred"` | +500-2000ms | Use only when freshness is critical |
| `livecrawl="fallback"` | Variable | Balanced freshness/speed (default) |
| AI-generated summaries | +300-800ms | Evaluate necessity vs speed |
| `num_results > 10` | +50-200ms | Keep at 10 for fair comparisons |
| Complex date filters | +100-300ms | Simplify when possible |
| Text filtering (`include_text`, `exclude_text`) | +100-500ms | Use sparingly |
## Running Production-Grade Evaluations
### Example: SimpleQA Evaluation Script
**Key findings**:
* Exa Deep leads on FRAMES (96%) and MultiLoKo (89%) benchmarks
* Query expansion and rich context enable superior agentic performance
* Higher latency justified by comprehensive, high-quality results
## Quality-Latency Tradeoffs
### Understanding the Spectrum
Different use cases require different points on the quality-latency spectrum:
| Use Case | Priority | Recommended Type | Expected Latency | Quality Characteristics |
| ---------------------- | -------- | ---------------- | ---------------- | ---------------------------- |
| Voice agents | Speed | `Fast` | \<500ms | Good factual accuracy |
| Chatbot grounding | Balanced | `Auto` | \~1000ms | Versatile, high quality |
| Research assistant | Depth | `Deep` | \~5000ms | Comprehensive, multi-faceted |
| Batch enrichment | Quality | `Deep` | \~5000ms | Maximum coverage |
| Real-time autocomplete | Speed | `Fast` | \<500ms | Relevant suggestions |
### Interpreting Tradeoffs
When analyzing evaluation results:
1. **Don't compare across latency classes**: `Fast` search at 500ms vs `Deep` search at 5000ms serve different purposes. **Always find the closest competitor in terms of latency for meaningful comparisons** — compare systems with similar P50 latency ranges.
2. **Benchmark within peer groups**:
* Compare Exa Fast (\<500ms) to other sub-1s APIs
* Compare Exa Auto (\~1s) to similar mid-latency systems
* Compare Exa Deep (>2s) to other agentic/research-oriented systems
3. **Consider total workflow time**: For multi-step agents, `Fast` search may complete the entire workflow faster than `Deep` search on a single query
4. **Account for quality requirements**: If accuracy >90% is required, accept higher latency; if \<1s is required, accept some quality tradeoff
### Factors That Impact Latency
Beyond search type selection, several parameters affect response time:
| Parameter | Latency Impact | Recommendation |
| ----------------------------------------------- | -------------- | ----------------------------------- |
| `livecrawl="preferred"` | +500-2000ms | Use only when freshness is critical |
| `livecrawl="fallback"` | Variable | Balanced freshness/speed (default) |
| AI-generated summaries | +300-800ms | Evaluate necessity vs speed |
| `num_results > 10` | +50-200ms | Keep at 10 for fair comparisons |
| Complex date filters | +100-300ms | Simplify when possible |
| Text filtering (`include_text`, `exclude_text`) | +100-500ms | Use sparingly |
## Running Production-Grade Evaluations
### Example: SimpleQA Evaluation Script
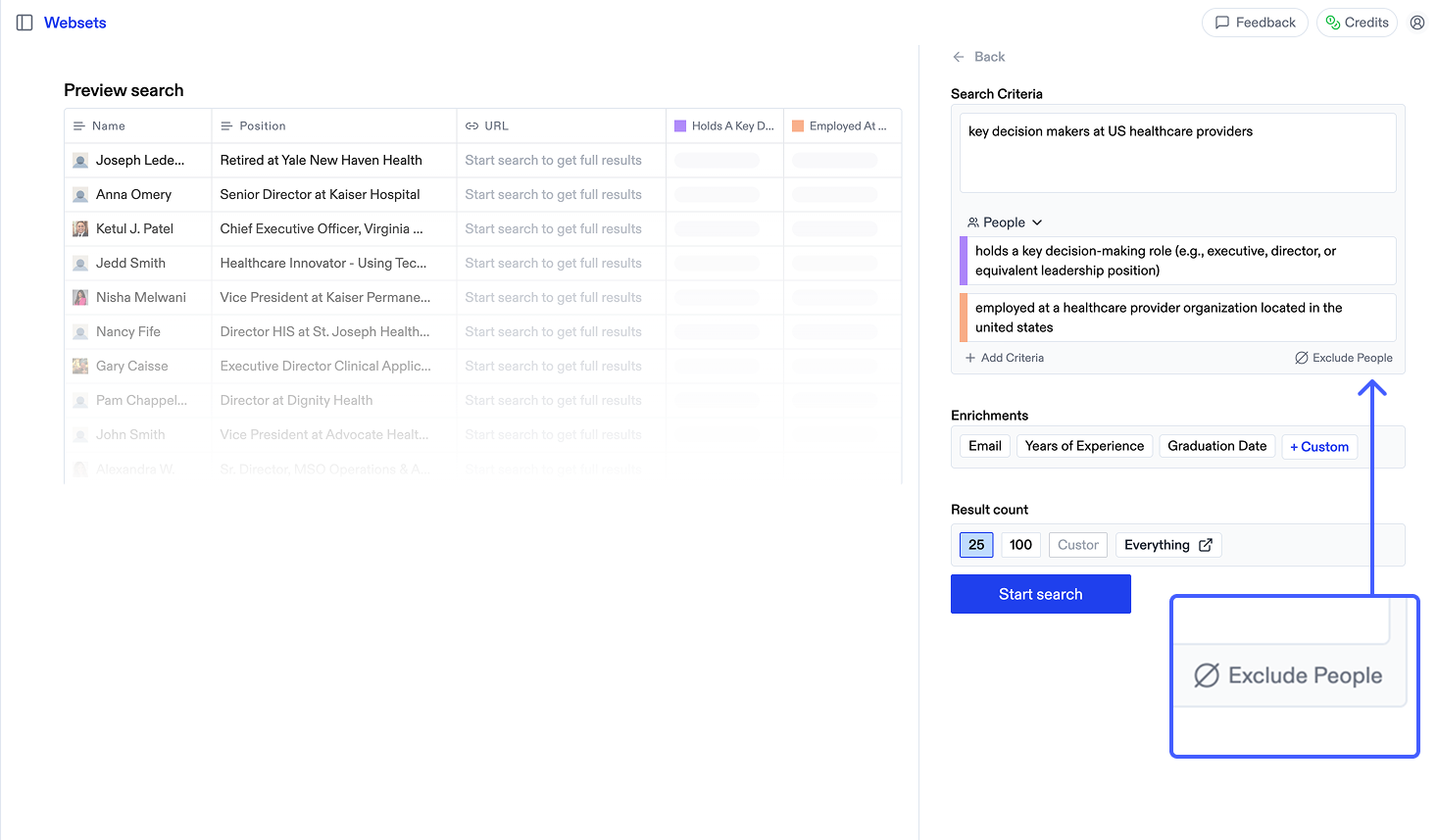 1. Begin creating a new Webset
2. Below the criteria in the sidepanel, click "Exclude"
3. Select from past Websets or upload a CSV with URLs to exclude. You can select multiple sources to exclude from.
4. Start your search, with only new results that don't match your exclusions
The maximum number of results you can exclude is determined by your plan.
1. Begin creating a new Webset
2. Below the criteria in the sidepanel, click "Exclude"
3. Select from past Websets or upload a CSV with URLs to exclude. You can select multiple sources to exclude from.
4. Start your search, with only new results that don't match your exclusions
The maximum number of results you can exclude is determined by your plan.
 ---
# Source: https://exa.ai/docs/integrations/google-adk.md
> ## Documentation Index
> Fetch the complete documentation index at: https://exa.ai/docs/llms.txt
> Use this file to discover all available pages before exploring further.
# Google ADK
Learn how to use Exa's search API with Google's Agent Development Kit (ADK). Google ADK works with Exa through our MCP (Model Context Protocol) server.
For the official Google ADK documentation about Exa integration, visit the [Google ADK Exa integration page](https://google.github.io/adk-docs/tools/third-party/exa/).
## What is Google ADK?
Google's Agent Development Kit (ADK) is a simple framework for building AI agents. It helps developers create and run AI agents that can do different tasks. ADK works with Google's Gemini models and other AI systems. It makes building agents feel more like regular software development.
## Exa MCP Integration
Exa has an MCP server that works with Google ADK. This lets your ADK agents search the web, find similar content, get clean text from web pages, and do research - all using Exa websearch.
## Prerequisites
* Create an [API Key](https://dashboard.exa.ai/api-keys) in Exa.
## Use with Google ADK
You can use Exa with Google ADK in two ways: with a local MCP server or a remote MCP server.
### Local MCP Server
```python theme={null}
from google.adk.agents import Agent
from google.adk.tools.mcp_tool.mcp_session_manager import StdioConnectionParams
from google.adk.tools.mcp_tool.mcp_toolset import MCPToolset
from mcp import StdioServerParameters
EXA_API_KEY = "YOUR_EXA_API_KEY"
root_agent = Agent(
model="gemini-2.5-pro",
name="exa_agent",
instruction="Help users get information from Exa",
tools=[
MCPToolset(
connection_params=StdioConnectionParams(
server_params = StdioServerParameters(
command="npx",
args=[
"-y",
"exa-mcp-server",
# (Optional) Choose which tools to use
# If you don't pick any tools, all tools will be used by default
# "--tools=get_code_context_exa,web_search_exa",
],
env={
"EXA_API_KEY": EXA_API_KEY,
}
),
timeout=30,
),
)
],
)
```
### Remote MCP Server
```python theme={null}
from google.adk.agents import Agent
from google.adk.tools.mcp_tool.mcp_session_manager import StreamableHTTPServerParams
from google.adk.tools.mcp_tool.mcp_toolset import MCPToolset
EXA_API_KEY = "YOUR_EXA_API_KEY"
root_agent = Agent(
model="gemini-2.5-pro",
name="exa_agent",
instruction="""Help users get information from Exa""",
tools=[
MCPToolset(
connection_params=StreamableHTTPServerParams(
url="https://mcp.exa.ai/mcp?exaApiKey=" + EXA_API_KEY,
# (Optional) Choose which tools to use
# If you don't pick any tools, all tools will be used by default
# url="https://mcp.exa.ai/mcp?exaApiKey=" + EXA_API_KEY + "&enabledTools=%5B%22crawling_exa%22%5D",
),
)
],
)
```
## More Resources
* [Exa MCP Server Documentation](https://docs.exa.ai/reference/exa-mcp)
* [Exa MCP Server Repository](https://github.com/exa-labs/exa-mcp-server)
---
# Source: https://exa.ai/docs/changelog/highlights-restored-js-sdk.md
> ## Documentation Index
> Fetch the complete documentation index at: https://exa.ai/docs/llms.txt
> Use this file to discover all available pages before exploring further.
# JS SDK: highlights restored
> The highlights feature has been reintroduced in the JavaScript SDK (exa-js) as of version 2.0.11.
***
**Date: November 26, 2025**
The highlights feature is back in the JavaScript SDK. Following user feedback, we've reintroduced highlights in `exa-js` v2.0.11, allowing you to extract key sentences from search results with relevance scores.
## What's Back
The `highlights` option is now available in search and contents operations:
* `highlights: true` - Returns highlighted sentences with default settings
* `highlights: { maxCharacters, query }` - Customize extraction behavior
Results include:
* `highlights: string[]` - Array of extracted key sentences
* `highlightScores: number[]` - Relevance scores for each highlight
## Usage Examples
**Basic highlights:**
```javascript theme={null}
const results = await exa.searchAndContents("latest AI research", {
highlights: true
});
console.log(results.results[0].highlights);
// ["Key sentence from the article...", "Another relevant excerpt..."]
```
**With options:**
```javascript theme={null}
const results = await exa.searchAndContents("machine learning tutorials", {
highlights: {
maxCharacters: 2000,
query: "beginner friendly"
}
});
```
**Combined with text:**
```javascript theme={null}
const results = await exa.searchAndContents("climate news", {
text: true,
highlights: true
});
// Returns both full text and highlighted excerpts
```
## Scope
This update applies only to the JavaScript SDK (`exa-js`). Other SDKs can access highlights via direct API calls.
## Installation
```bash theme={null}
npm install exa-js@latest
```
---
# Source: https://exa.ai/docs/home.md
> ## Documentation Index
> Fetch the complete documentation index at: https://exa.ai/docs/llms.txt
> Use this file to discover all available pages before exploring further.
# Home
## Build with Exa
---
# Source: https://exa.ai/docs/integrations/google-adk.md
> ## Documentation Index
> Fetch the complete documentation index at: https://exa.ai/docs/llms.txt
> Use this file to discover all available pages before exploring further.
# Google ADK
Learn how to use Exa's search API with Google's Agent Development Kit (ADK). Google ADK works with Exa through our MCP (Model Context Protocol) server.
For the official Google ADK documentation about Exa integration, visit the [Google ADK Exa integration page](https://google.github.io/adk-docs/tools/third-party/exa/).
## What is Google ADK?
Google's Agent Development Kit (ADK) is a simple framework for building AI agents. It helps developers create and run AI agents that can do different tasks. ADK works with Google's Gemini models and other AI systems. It makes building agents feel more like regular software development.
## Exa MCP Integration
Exa has an MCP server that works with Google ADK. This lets your ADK agents search the web, find similar content, get clean text from web pages, and do research - all using Exa websearch.
## Prerequisites
* Create an [API Key](https://dashboard.exa.ai/api-keys) in Exa.
## Use with Google ADK
You can use Exa with Google ADK in two ways: with a local MCP server or a remote MCP server.
### Local MCP Server
```python theme={null}
from google.adk.agents import Agent
from google.adk.tools.mcp_tool.mcp_session_manager import StdioConnectionParams
from google.adk.tools.mcp_tool.mcp_toolset import MCPToolset
from mcp import StdioServerParameters
EXA_API_KEY = "YOUR_EXA_API_KEY"
root_agent = Agent(
model="gemini-2.5-pro",
name="exa_agent",
instruction="Help users get information from Exa",
tools=[
MCPToolset(
connection_params=StdioConnectionParams(
server_params = StdioServerParameters(
command="npx",
args=[
"-y",
"exa-mcp-server",
# (Optional) Choose which tools to use
# If you don't pick any tools, all tools will be used by default
# "--tools=get_code_context_exa,web_search_exa",
],
env={
"EXA_API_KEY": EXA_API_KEY,
}
),
timeout=30,
),
)
],
)
```
### Remote MCP Server
```python theme={null}
from google.adk.agents import Agent
from google.adk.tools.mcp_tool.mcp_session_manager import StreamableHTTPServerParams
from google.adk.tools.mcp_tool.mcp_toolset import MCPToolset
EXA_API_KEY = "YOUR_EXA_API_KEY"
root_agent = Agent(
model="gemini-2.5-pro",
name="exa_agent",
instruction="""Help users get information from Exa""",
tools=[
MCPToolset(
connection_params=StreamableHTTPServerParams(
url="https://mcp.exa.ai/mcp?exaApiKey=" + EXA_API_KEY,
# (Optional) Choose which tools to use
# If you don't pick any tools, all tools will be used by default
# url="https://mcp.exa.ai/mcp?exaApiKey=" + EXA_API_KEY + "&enabledTools=%5B%22crawling_exa%22%5D",
),
)
],
)
```
## More Resources
* [Exa MCP Server Documentation](https://docs.exa.ai/reference/exa-mcp)
* [Exa MCP Server Repository](https://github.com/exa-labs/exa-mcp-server)
---
# Source: https://exa.ai/docs/changelog/highlights-restored-js-sdk.md
> ## Documentation Index
> Fetch the complete documentation index at: https://exa.ai/docs/llms.txt
> Use this file to discover all available pages before exploring further.
# JS SDK: highlights restored
> The highlights feature has been reintroduced in the JavaScript SDK (exa-js) as of version 2.0.11.
***
**Date: November 26, 2025**
The highlights feature is back in the JavaScript SDK. Following user feedback, we've reintroduced highlights in `exa-js` v2.0.11, allowing you to extract key sentences from search results with relevance scores.
## What's Back
The `highlights` option is now available in search and contents operations:
* `highlights: true` - Returns highlighted sentences with default settings
* `highlights: { maxCharacters, query }` - Customize extraction behavior
Results include:
* `highlights: string[]` - Array of extracted key sentences
* `highlightScores: number[]` - Relevance scores for each highlight
## Usage Examples
**Basic highlights:**
```javascript theme={null}
const results = await exa.searchAndContents("latest AI research", {
highlights: true
});
console.log(results.results[0].highlights);
// ["Key sentence from the article...", "Another relevant excerpt..."]
```
**With options:**
```javascript theme={null}
const results = await exa.searchAndContents("machine learning tutorials", {
highlights: {
maxCharacters: 2000,
query: "beginner friendly"
}
});
```
**Combined with text:**
```javascript theme={null}
const results = await exa.searchAndContents("climate news", {
text: true,
highlights: true
});
// Returns both full text and highlighted excerpts
```
## Scope
This update applies only to the JavaScript SDK (`exa-js`). Other SDKs can access highlights via direct API calls.
## Installation
```bash theme={null}
npm install exa-js@latest
```
---
# Source: https://exa.ai/docs/home.md
> ## Documentation Index
> Fetch the complete documentation index at: https://exa.ai/docs/llms.txt
> Use this file to discover all available pages before exploring further.
# Home
## Build with Exa
Get started with Exa's web search and contents APIs
## Make your first API call in minutes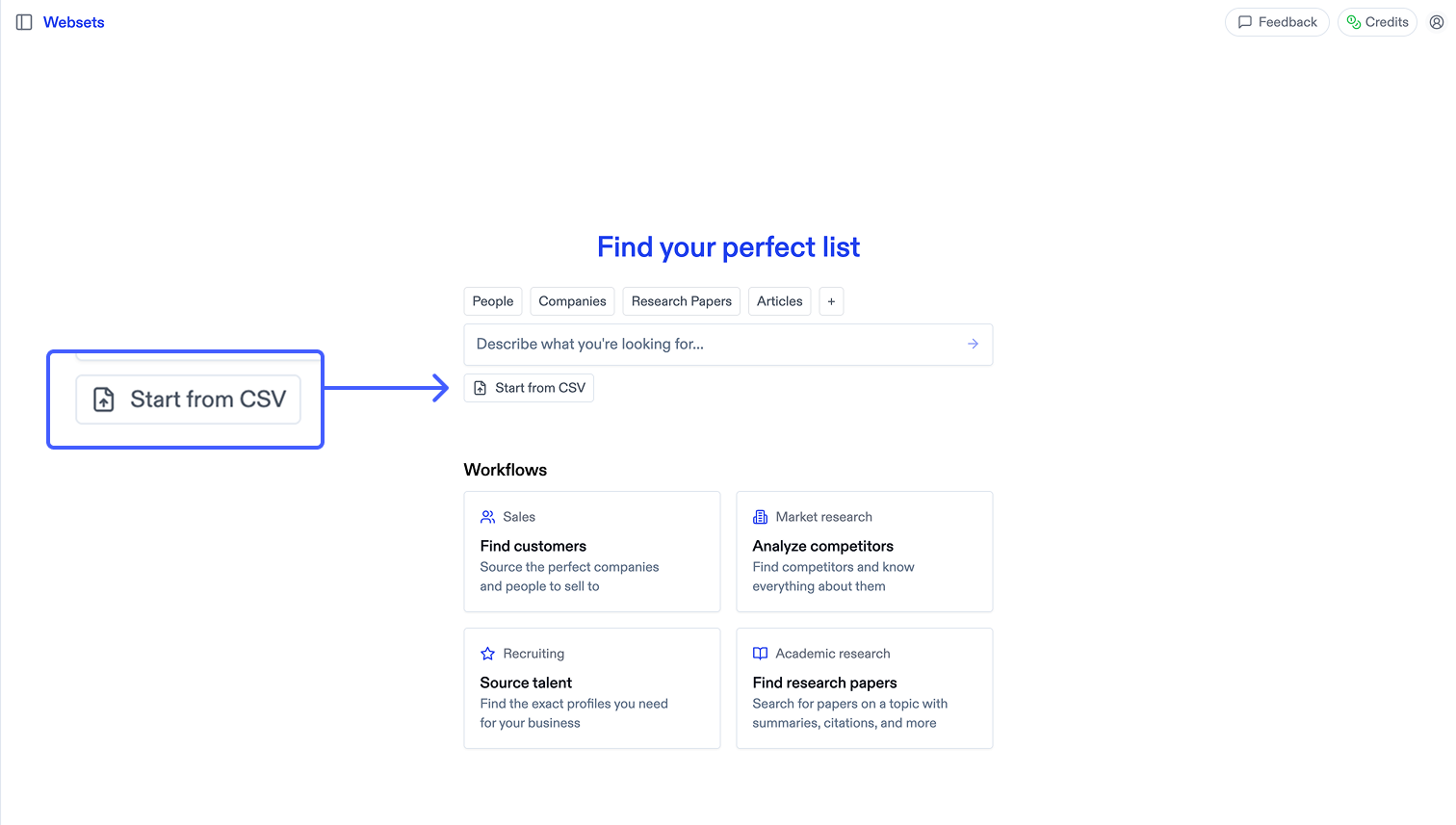 1. Click "Start from CSV" to select your CSV file
2. Select which column contains the URLs you want to analyze
3. Review how your data will be imported before proceeding
4. Your URLs are transformed into a Webset with enrichments and metadata
1. Click "Start from CSV" to select your CSV file
2. Select which column contains the URLs you want to analyze
3. Review how your data will be imported before proceeding
4. Your URLs are transformed into a Webset with enrichments and metadata
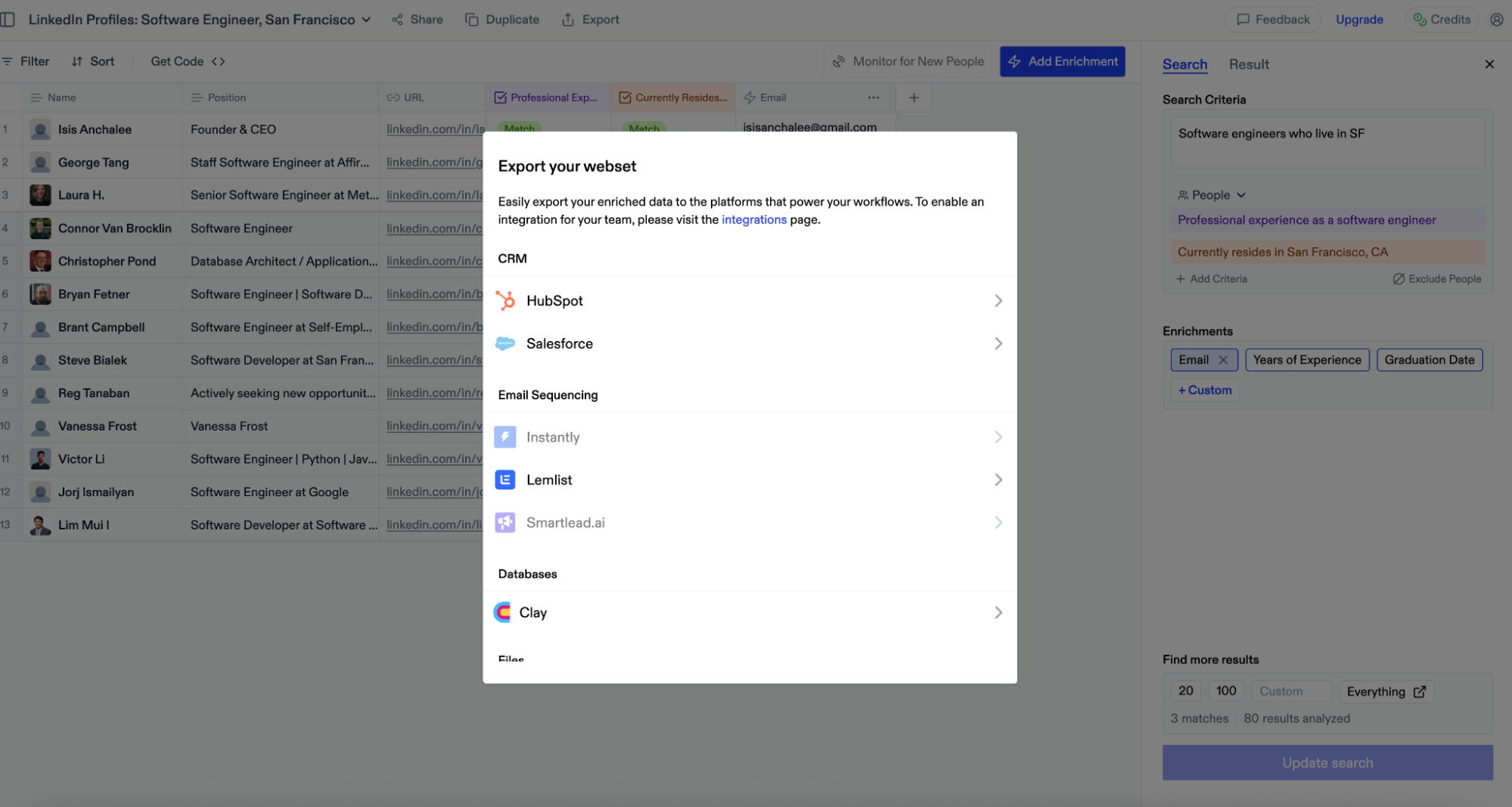
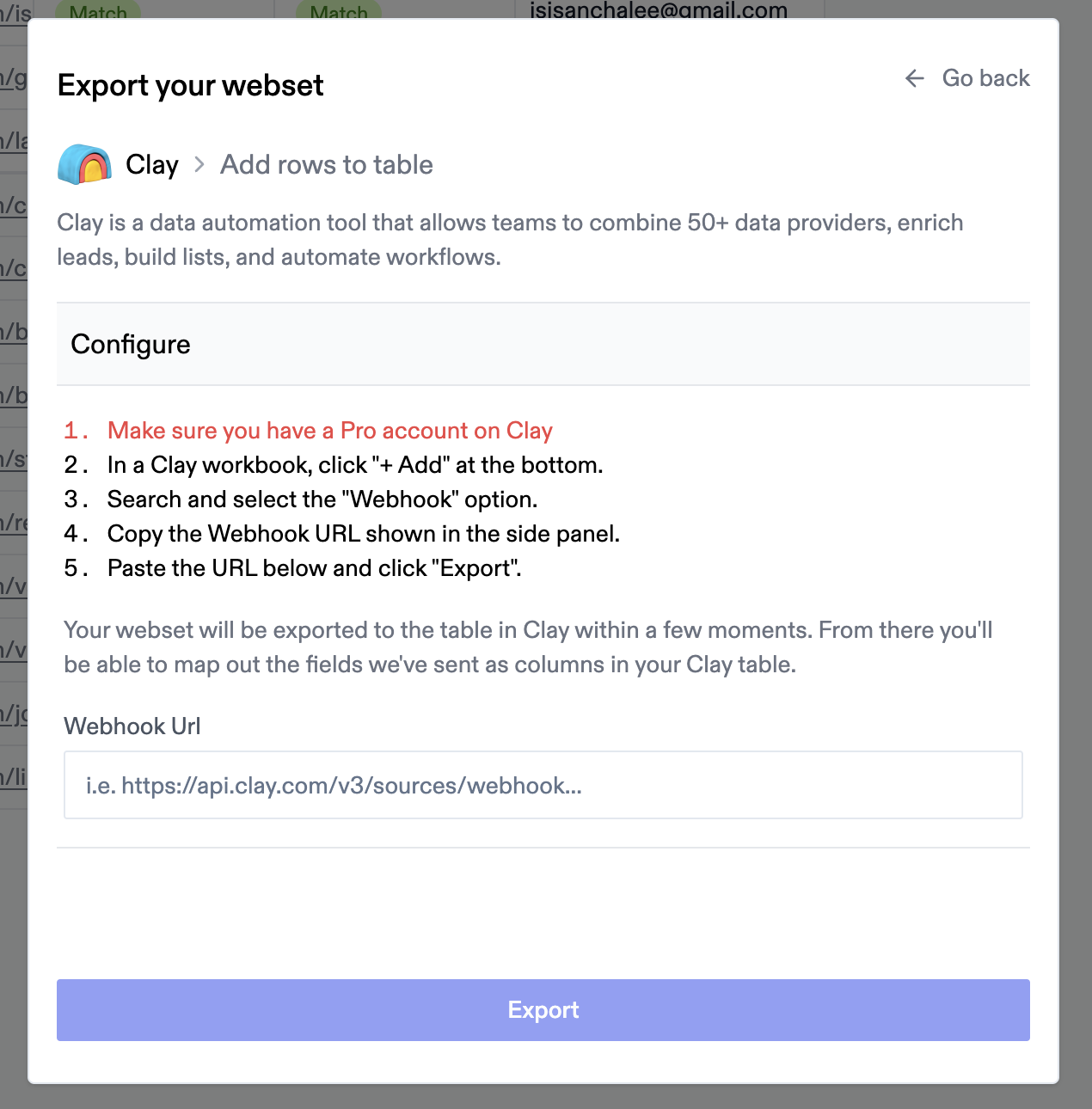
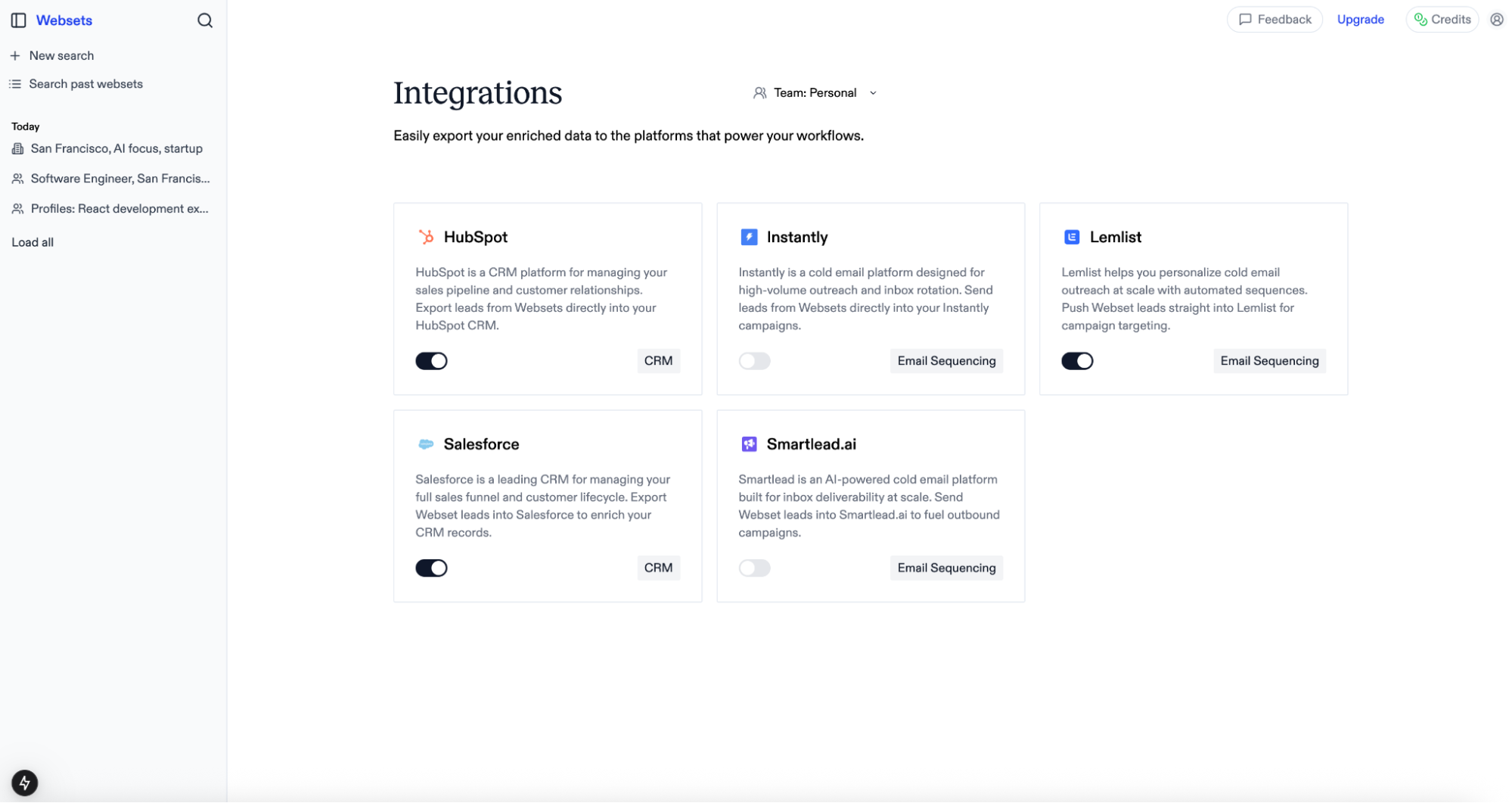 To enable an integration:
1. Visit [https://websets.exa.ai/integrations](https://websets.exa.ai/integrations)
2. Toggle the integration you want to connect
3. Provide your account credentials
4. The integration will be scoped to your currently selected team
To enable an integration:
1. Visit [https://websets.exa.ai/integrations](https://websets.exa.ai/integrations)
2. Toggle the integration you want to connect
3. Provide your account credentials
4. The integration will be scoped to your currently selected team
 ---
# Source: https://exa.ai/docs/introduction.md
> ## Documentation Index
> Fetch the complete documentation index at: https://exa.ai/docs/llms.txt
> Use this file to discover all available pages before exploring further.
# Home
---
# Source: https://exa.ai/docs/introduction.md
> ## Documentation Index
> Fetch the complete documentation index at: https://exa.ai/docs/llms.txt
> Use this file to discover all available pages before exploring further.
# Home
 And, by filtering for only things that were posted recently, you can make sure that the positions were new and not-filled.
But, there's actually an even better way to take advantage of Exa. You can just paste a job posting and get similar ones:
And, by filtering for only things that were posted recently, you can make sure that the positions were new and not-filled.
But, there's actually an even better way to take advantage of Exa. You can just paste a job posting and get similar ones:
 ## More than just jobs
Job search is really just one use case of Exa. Exa is a search engine built using novel representation learning techniques.
For example, Exa excels at finding similar things.
* **Shopping**: if you want a similar (but cheaper) shirt, paste a link to your shirt and it'll give you hundreds like it
* **Research**: paste a link to a research paper to find hundreds of other relevant papers
* **Startups**: if you're building a startup, find your competitors by searching a link to your startup
---
# Source: https://exa.ai/docs/integrations/langchain-docs.md
> ## Documentation Index
> Fetch the complete documentation index at: https://exa.ai/docs/llms.txt
> Use this file to discover all available pages before exploring further.
# LangChain Docs
Learn how to use Exa's search API with LangChain. LangChain has a dedicated Exa tool. This enables AI agents to perform web search.
For detailed instructions on using Exa with LangChain, visit the [LangChain documentation](https://python.langchain.com/v0.2/docs/integrations/tools/exa_search/#using-the-exa-sdk-as-langchain-agent-tools).
---
# Source: https://exa.ai/docs/reference/langchain.md
> ## Documentation Index
> Fetch the complete documentation index at: https://exa.ai/docs/llms.txt
> Use this file to discover all available pages before exploring further.
# LangChain
> How to use Exa's integration with LangChain to perform RAG.
***
LangChain is a framework for building applications that combine LLMs with data, APIs and other tools. In this guide, we'll go over how to use Exa's LangChain integration to perform RAG with the following steps:
1. Set up Exa's LangChain integration and use Exa to retrieve relevant content
2. Connect this content to a toolchain that uses OpenAI's LLM for generation
## More than just jobs
Job search is really just one use case of Exa. Exa is a search engine built using novel representation learning techniques.
For example, Exa excels at finding similar things.
* **Shopping**: if you want a similar (but cheaper) shirt, paste a link to your shirt and it'll give you hundreds like it
* **Research**: paste a link to a research paper to find hundreds of other relevant papers
* **Startups**: if you're building a startup, find your competitors by searching a link to your startup
---
# Source: https://exa.ai/docs/integrations/langchain-docs.md
> ## Documentation Index
> Fetch the complete documentation index at: https://exa.ai/docs/llms.txt
> Use this file to discover all available pages before exploring further.
# LangChain Docs
Learn how to use Exa's search API with LangChain. LangChain has a dedicated Exa tool. This enables AI agents to perform web search.
For detailed instructions on using Exa with LangChain, visit the [LangChain documentation](https://python.langchain.com/v0.2/docs/integrations/tools/exa_search/#using-the-exa-sdk-as-langchain-agent-tools).
---
# Source: https://exa.ai/docs/reference/langchain.md
> ## Documentation Index
> Fetch the complete documentation index at: https://exa.ai/docs/llms.txt
> Use this file to discover all available pages before exploring further.
# LangChain
> How to use Exa's integration with LangChain to perform RAG.
***
LangChain is a framework for building applications that combine LLMs with data, APIs and other tools. In this guide, we'll go over how to use Exa's LangChain integration to perform RAG with the following steps:
1. Set up Exa's LangChain integration and use Exa to retrieve relevant content
2. Connect this content to a toolchain that uses OpenAI's LLM for generation
 ## Getting Started
First, grab a free Exa API key by signing up [here](https://exa.ai/). You get 1000 free queries a month.
Next, fork (clone) our [template](https://replit.com/@olafblitz/exa-hackernews-demo-nodejs?v=1) on Replit.
Once you've forked the template, go to the lower left corner of the screen and scroll through the options until you see "Secrets" (where you manage environment variables like API keys).
## Getting Started
First, grab a free Exa API key by signing up [here](https://exa.ai/). You get 1000 free queries a month.
Next, fork (clone) our [template](https://replit.com/@olafblitz/exa-hackernews-demo-nodejs?v=1) on Replit.
Once you've forked the template, go to the lower left corner of the screen and scroll through the options until you see "Secrets" (where you manage environment variables like API keys).
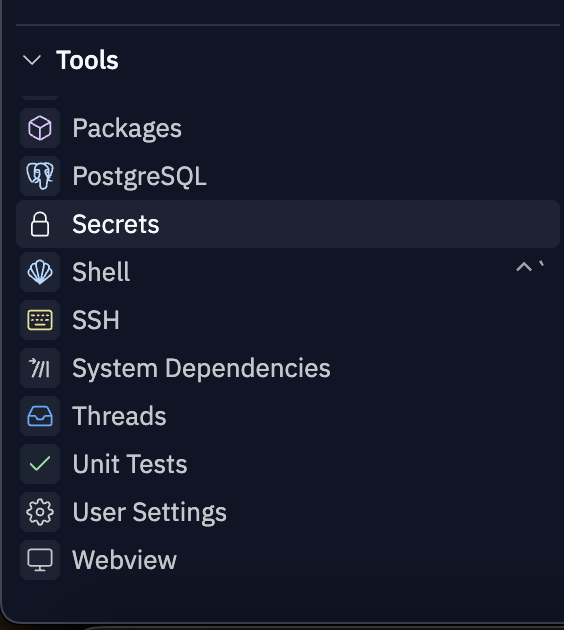 Add your Exa API key as a secret named "EXA\_API\_KEY" (original, we know).
Add your Exa API key as a secret named "EXA\_API\_KEY" (original, we know).
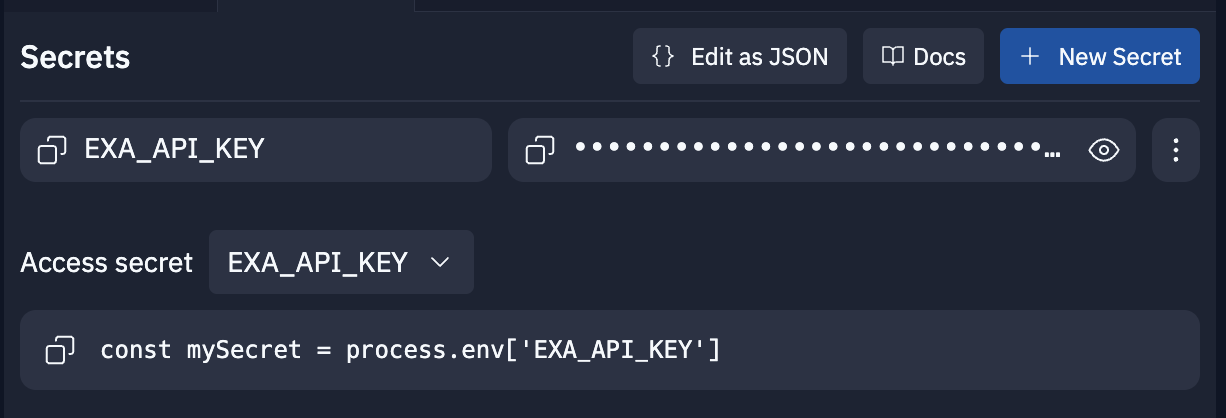 After you've added your API key, click the green Run button in the top center of the window.
After you've added your API key, click the green Run button in the top center of the window.
 After a few seconds, a Webview window will pop up with your website. You'll see a website that vaguely resembles Hacker News. It's a basic Express.js app with some CSS styling.
After a few seconds, a Webview window will pop up with your website. You'll see a website that vaguely resembles Hacker News. It's a basic Express.js app with some CSS styling.
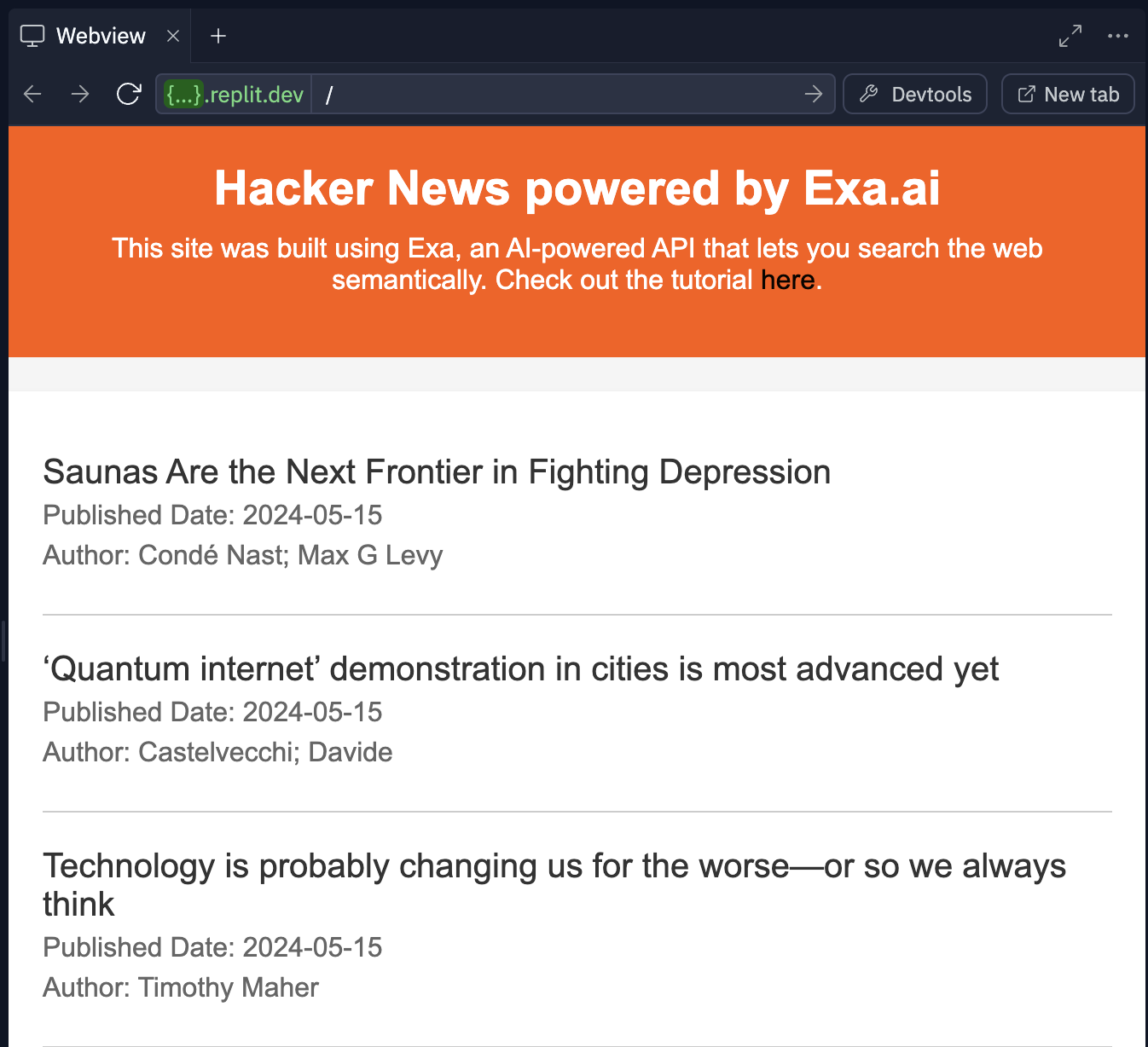 ## How Exa works
In the index.js file (should be open by default), scroll to **line 19**. This is the brains of the site. It's where we call the Exa API with a custom prompt to get back Hacker News-style content.
```
const response = await fetch('https://api.exa.ai/search', {
method: 'POST',
headers: {
'Content-Type': 'application/json',
// Add your API key named "EXA_API_KEY" to Repl.it Secrets
'x-api-key': process.env.EXA_API_KEY,
},
body: JSON.stringify({
// change this prompt!
query: 'here is a really interesting techy article:',
// specify the maximum number of results to retrieve (10 is the limit for free API users)
numResults: 10,
// Set the start date for the article search
startPublishedDate: startPublishedDate,
// Set the end date for the article search
endPublishedDate: endPublishedDate,
}),
});
```
The prompt is set to "here is a really interesting tech article:". This is because of how Exa works behind the scenes. Exa uses embeddings to help predict which links would naturally follow a query. For example, on the Internet, you'll frequently see people recommend great content like this: "this tutorial really helped me understand linked lists: linkedlisttutorial.com". When you prompt Exa, you pretend to be someone recommending what you're looking for. In this case, our prompt nudges Exa to find links that someone would share when discussing a "really interesting tech article".
Check out the [results](https://exa.ai/search?q=here%20is%20a%20really%20interesting%20tech%20article%3A\&filters=%7B%22numResults%22%3A30%2C%22useAutoprompt%22%3Afalse%2C%22domainFilterType%22%3A%22include%22%7D) Exa returns for our prompt. Aren't they nice?
More example prompts to help you get a sense of prompting with Exa:
* [this gadget saves me so much time:](https://exa.ai/search?c=all\&q=this%20gadget%20saves%20me%20so%20much%20time%3A\&filters=%7B%22domainFilterType%22%3A%22include%22%2C%22timeFilterOption%22%3A%22any%5Ftime%22%2C%22activeTabFilter%22%3A%22all%22%7D)
* [i loved my wedding dress from this boutique:](https://exa.ai/search?c=all\&q=i%20loved%20my%20wedding%20dress%20from%20this%20boutique%3A\&filters=%7B%22domainFilterType%22%3A%22include%22%2C%22timeFilterOption%22%3A%22any%5Ftime%22%2C%22activeTabFilter%22%3A%22all%22%7D)
* [this video helped me understand attention mechanisms:](https://exa.ai/search?c=all\&q=this%20video%20helped%20me%20understand%20attention%20mechanisms%3A\&filters=%7B%22domainFilterType%22%3A%22include%22%2C%22timeFilterOption%22%3A%22any%5Ftime%22%2C%22activeTabFilter%22%3A%22all%22%7D)
More examples in the Exa [docs](/reference/the-exa-index).
At this point, please craft your own Exa prompt for your Hacker News site. It can be about anything you find interesting.
Example ideas:
* [this is a really exciting machine learning paper:](https://exa.ai/search?c=all\&q=this%20is%20a%20really%20exciting%20machine%20learning%20paper%3A\&filters=%7B%22domainFilterType%22%3A%22include%22%2C%22timeFilterOption%22%3A%22past%5Fday%22%2C%22activeTabFilter%22%3A%22all%22%7D)
* [here's a delicious new recipe:](https://exa.ai/search?c=all\&q=here%27s%20a%20delicious%20new%20recipe%3A\&filters=%7B%22domainFilterType%22%3A%22include%22%2C%22timeFilterOption%22%3A%22any%5Ftime%22%2C%22activeTabFilter%22%3A%22all%22%7D)
* [this company just got acquired:](https://exa.ai/search?c=all\&q=this%20company%20just%20got%20acquired%3A\&filters=%7B%22domainFilterType%22%3A%22include%22%2C%22timeFilterOption%22%3A%22past%5Fday%22%2C%22activeTabFilter%22%3A%22all%22%7D)
* [here's how the basketball game went:](https://exa.ai/search?c=all\&q=here%27s%20how%20the%20basketball%20game%20went%3A\&filters=%7B%22domainFilterType%22%3A%22include%22%2C%22timeFilterOption%22%3A%22past%5Fday%22%2C%22activeTabFilter%22%3A%22all%22%7D)
Once you have your prompt, replace the old one (line 28 of index.js). Hit the Stop button (where the Run button was) and hit Run again to restart your site with the new prompt.
Feel free to keep tweaking your prompt until you get results you like.
## Customize your site
Now, other things you can modify in the site template include the time window to search over, the number of results to return, the text on the site (title, description, footer), and styling (colors, fonts, etc.).
By default, the site asks the Exa API to get the ten most relevant results from the last 24 hours every time you visit the site. On the free plan, you can only get up to ten results, so you'll have to sign up for an Exa plan to increase this. You *can* tweak the time window though. Lines 12 to 17 in index.js is where we set the time window. You can adjust this as you like to get results from the last week, month, year, etc. Note that you don't have to search starting from the current date. You can search between any arbitrary dates, like October 31, 2015 and January 1, 2018.
To adjust the site title and other text, go to line 51 in index.js where the dynamic HTML starts. You can Ctrl-F "change" to find all the places where you can edit the text.
If orange isn't your vibe, go to the styles.css. To get there, go to the left side panel on Replit and click on the "public" folder.
To keep your site running all the time, you'll need to deploy it on Replit using Deployments. Click Deploy in the top right corner and select Autoscale. You can leave the default settings and click Deploy. This does cost money though. Alternatively you can deploy the site on your own. It's only two files (index.js and public/styles.css).
Well, there you have it! You just made your very own Hacker News-style site using the Exa API. Share it on X and [tag us](https://x.com/ExaAILabs) for a retweet!
---
# Source: https://exa.ai/docs/changelog/livecrawl-preferred-option.md
> ## Documentation Index
> Fetch the complete documentation index at: https://exa.ai/docs/llms.txt
> Use this file to discover all available pages before exploring further.
# New Livecrawl Option: Preferred
> Introducing the 'preferred' livecrawl option that tries to fetch fresh content but gracefully falls back to cached results when crawling fails, providing the best of both worlds.
***
**Date: 7 June 2025**
We've added a new `livecrawl` option called `"preferred"` that provides a more resilient approach to content fetching. This option attempts to crawl fresh content but gracefully falls back to cached results when live crawling fails.
## How Exa works
In the index.js file (should be open by default), scroll to **line 19**. This is the brains of the site. It's where we call the Exa API with a custom prompt to get back Hacker News-style content.
```
const response = await fetch('https://api.exa.ai/search', {
method: 'POST',
headers: {
'Content-Type': 'application/json',
// Add your API key named "EXA_API_KEY" to Repl.it Secrets
'x-api-key': process.env.EXA_API_KEY,
},
body: JSON.stringify({
// change this prompt!
query: 'here is a really interesting techy article:',
// specify the maximum number of results to retrieve (10 is the limit for free API users)
numResults: 10,
// Set the start date for the article search
startPublishedDate: startPublishedDate,
// Set the end date for the article search
endPublishedDate: endPublishedDate,
}),
});
```
The prompt is set to "here is a really interesting tech article:". This is because of how Exa works behind the scenes. Exa uses embeddings to help predict which links would naturally follow a query. For example, on the Internet, you'll frequently see people recommend great content like this: "this tutorial really helped me understand linked lists: linkedlisttutorial.com". When you prompt Exa, you pretend to be someone recommending what you're looking for. In this case, our prompt nudges Exa to find links that someone would share when discussing a "really interesting tech article".
Check out the [results](https://exa.ai/search?q=here%20is%20a%20really%20interesting%20tech%20article%3A\&filters=%7B%22numResults%22%3A30%2C%22useAutoprompt%22%3Afalse%2C%22domainFilterType%22%3A%22include%22%7D) Exa returns for our prompt. Aren't they nice?
More example prompts to help you get a sense of prompting with Exa:
* [this gadget saves me so much time:](https://exa.ai/search?c=all\&q=this%20gadget%20saves%20me%20so%20much%20time%3A\&filters=%7B%22domainFilterType%22%3A%22include%22%2C%22timeFilterOption%22%3A%22any%5Ftime%22%2C%22activeTabFilter%22%3A%22all%22%7D)
* [i loved my wedding dress from this boutique:](https://exa.ai/search?c=all\&q=i%20loved%20my%20wedding%20dress%20from%20this%20boutique%3A\&filters=%7B%22domainFilterType%22%3A%22include%22%2C%22timeFilterOption%22%3A%22any%5Ftime%22%2C%22activeTabFilter%22%3A%22all%22%7D)
* [this video helped me understand attention mechanisms:](https://exa.ai/search?c=all\&q=this%20video%20helped%20me%20understand%20attention%20mechanisms%3A\&filters=%7B%22domainFilterType%22%3A%22include%22%2C%22timeFilterOption%22%3A%22any%5Ftime%22%2C%22activeTabFilter%22%3A%22all%22%7D)
More examples in the Exa [docs](/reference/the-exa-index).
At this point, please craft your own Exa prompt for your Hacker News site. It can be about anything you find interesting.
Example ideas:
* [this is a really exciting machine learning paper:](https://exa.ai/search?c=all\&q=this%20is%20a%20really%20exciting%20machine%20learning%20paper%3A\&filters=%7B%22domainFilterType%22%3A%22include%22%2C%22timeFilterOption%22%3A%22past%5Fday%22%2C%22activeTabFilter%22%3A%22all%22%7D)
* [here's a delicious new recipe:](https://exa.ai/search?c=all\&q=here%27s%20a%20delicious%20new%20recipe%3A\&filters=%7B%22domainFilterType%22%3A%22include%22%2C%22timeFilterOption%22%3A%22any%5Ftime%22%2C%22activeTabFilter%22%3A%22all%22%7D)
* [this company just got acquired:](https://exa.ai/search?c=all\&q=this%20company%20just%20got%20acquired%3A\&filters=%7B%22domainFilterType%22%3A%22include%22%2C%22timeFilterOption%22%3A%22past%5Fday%22%2C%22activeTabFilter%22%3A%22all%22%7D)
* [here's how the basketball game went:](https://exa.ai/search?c=all\&q=here%27s%20how%20the%20basketball%20game%20went%3A\&filters=%7B%22domainFilterType%22%3A%22include%22%2C%22timeFilterOption%22%3A%22past%5Fday%22%2C%22activeTabFilter%22%3A%22all%22%7D)
Once you have your prompt, replace the old one (line 28 of index.js). Hit the Stop button (where the Run button was) and hit Run again to restart your site with the new prompt.
Feel free to keep tweaking your prompt until you get results you like.
## Customize your site
Now, other things you can modify in the site template include the time window to search over, the number of results to return, the text on the site (title, description, footer), and styling (colors, fonts, etc.).
By default, the site asks the Exa API to get the ten most relevant results from the last 24 hours every time you visit the site. On the free plan, you can only get up to ten results, so you'll have to sign up for an Exa plan to increase this. You *can* tweak the time window though. Lines 12 to 17 in index.js is where we set the time window. You can adjust this as you like to get results from the last week, month, year, etc. Note that you don't have to search starting from the current date. You can search between any arbitrary dates, like October 31, 2015 and January 1, 2018.
To adjust the site title and other text, go to line 51 in index.js where the dynamic HTML starts. You can Ctrl-F "change" to find all the places where you can edit the text.
If orange isn't your vibe, go to the styles.css. To get there, go to the left side panel on Replit and click on the "public" folder.
To keep your site running all the time, you'll need to deploy it on Replit using Deployments. Click Deploy in the top right corner and select Autoscale. You can leave the default settings and click Deploy. This does cost money though. Alternatively you can deploy the site on your own. It's only two files (index.js and public/styles.css).
Well, there you have it! You just made your very own Hacker News-style site using the Exa API. Share it on X and [tag us](https://x.com/ExaAILabs) for a retweet!
---
# Source: https://exa.ai/docs/changelog/livecrawl-preferred-option.md
> ## Documentation Index
> Fetch the complete documentation index at: https://exa.ai/docs/llms.txt
> Use this file to discover all available pages before exploring further.
# New Livecrawl Option: Preferred
> Introducing the 'preferred' livecrawl option that tries to fetch fresh content but gracefully falls back to cached results when crawling fails, providing the best of both worlds.
***
**Date: 7 June 2025**
We've added a new `livecrawl` option called `"preferred"` that provides a more resilient approach to content fetching. This option attempts to crawl fresh content but gracefully falls back to cached results when live crawling fails.
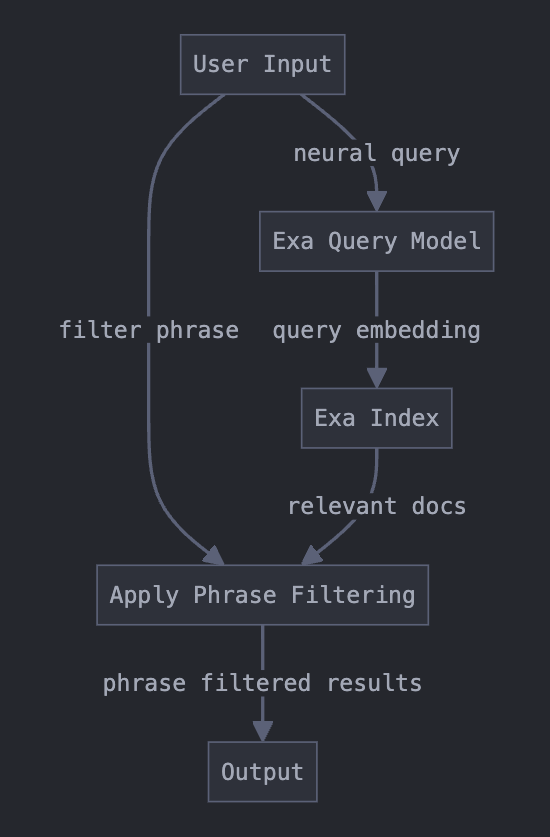 ## Running a query with phrase filter
Using Phrase Filters is super simple. As usual, install the `exa_py` library with `pip install exa_py`. Then instantiate the library:
```Python Python theme={null}
# Now, import the Exa class and pass your API key to it.
from exa_py import Exa
my_exa_api_key = "YOUR_API_KEY_HERE"
exa = Exa(my_exa_api_key)
```
Make a query, in this example searching for the most innovative climate tech companies. To use Phrase Filters, specify a string corresponding to the `includeText` input parameter
```Python Python theme={null}
result = exa.search_and_contents(
"Here is an innovative climate technology company",
type="neural",
num_results=10,
text=True,
include_text=["GmbH"]
)
print(result)
```
Which outputs:
```
{
"results": [
{
"title": "Sorption Technologies |",
"id": "https://sorption-technologies.com/",
"url": "https://sorption-technologies.com/",
"publishedDate": "2024-02-10",
"author": null,
"text": ""
},
{
"title": "FenX | VentureRadar",
"id": "https://www.ventureradar.com/organisation/FenX/364b6fb7-0033-4c88-a4e9-9c3b1f530d72",
"url": "https://www.ventureradar.com/organisation/FenX/364b6fb7-0033-4c88-a4e9-9c3b1f530d72",
"publishedDate": "2023-03-28",
"author": null,
"text": "Follow\n\nFollowing\n\nLocation: Switzerland\n\nFounded in 2019\n\nPrivate Company\n\n\"FenX is a Spinoff of ETH Zurich tackling the world’s energy and greenhouse gas challenges by disrupting the building insulation market. Based on a innovative foaming technique, the company produces high-performance insulation foams made from abandoned waste materials such as fly ash from coal power stations. The final products are fully recyclable, emit low CO2 emissions and are economically competitive.\"\n Description Source: VentureRadar Research / Company Website\n\nExport Similar Companies Similar Companies\n\nCompany \n Country\n Status\n Description\n\nVecor Australia Australia n/a Every year the world’s coal-fired power stations produce approximately 1 billion tonnes of a very fine ash called fly ash. This nuisance ash, which resembles smoke, can be... MCC Technologies USA Private MCC Technologies builds, owns and operates processing plants utilizing coal fly ash waste from landfills and ash ponds. The company processes large volumes of low-quality Class F... Climeworks GmbH Switzerland Private Climeworks has developed an ecologically and economically attractive method to extract CO2 from ambient air. Our goal is to deliver CO2 for the production of synthetic liquid... Errcive Inc USA Private The company is involved in developing a novel fly ash based material to mitigate exhaust pollution. The commercial impact of the work is to allow: the reduction of exhaust fumes... 4 Envi Denmark n/a Danish 4 Envi develops a system for the cleaning and re-use of biomass-fuelled plant’s fly ash. After cleaning, the ash and some of its components can be reused as fertilizers,... Neolithe France n/a Néolithe wants to reduce global greenhouse gas emissions by 5% by tackling a problem that concerns us all: waste treatment! They transform non-recyclable waste into aggregates...\n\nShow all\n\nWebsite Archive\n\nInternet Archive snapshots for |\n\nhttps://fenx.ch/\n\nThe archive allows you to go back in time and view historical versions of the company website\n\nThe site\n\nhttps://fenx.ch/\n\nwas first archived on\n\n4th Jul 2019\n\nIs this your company? Claim this profile andupdate details for free\n\nSub-Scores\n\nPopularity on VentureRadar\n\nWebsite Popularity\n\nLow Traffic Sites\n Low\n\nHigh Traffic Sites\n High\n\nAlexa Global Rank:\n\n3,478,846 | \n fenx.ch\n\nAuto Analyst Score\n\n68\n\nAuto Analyst Score:\n 68 | \n fenx.ch\n\nVentureRadar Popularity\n\nHigh\n\nVentureRadar Popularity:\n High The popularity score combines profile views, clicks and the number of times the company appears in search results.\n\nor\n\nTo continue, please confirm you\n are not a robot"
},
{
"title": "intelligent fluids | LinkedIn",
"id": "https://www.linkedin.com/company/intelligentfluids",
"url": "https://www.linkedin.com/company/intelligentfluids",
"publishedDate": "2023-06-08",
"author": null,
"text": "Sign in to see who you already know at intelligent fluids GmbH (SMARTCHEM)\n\nWelcome back\n\nEmail or phone\n\nPassword\n\nForgot password?\n\nor\n\nNew to LinkedIn? Join now\n\nor\n\nNew to LinkedIn? Join now"
},
{
"title": "justairtech GmbH – Umweltfreundliche Kühlsysteme mit Luft als Kältemittel",
"id": "https://www.justairtech.de/",
"url": "https://www.justairtech.de/",
"publishedDate": "2024-06-13",
"author": null,
"text": "decouple cooling from climate change with air as refrigerant.\n\nWir entwickeln eine hocheffziente Kühlanlage, die Luft als Kältemittel verwendet. Wieso? Die Welt verändert sich tiefgreifender und schneller als in allen Generationen vor uns. Wir sehen darin nicht nur eine Bedrohung, sondern begreifen dies auch als Chance, Prozesse nachhaltig zu gestalten.\n\nUnsere Arbeit konzentriert sich auf die Revolutionierung der Kühlung für Zieltemperaturen von 0–40 °C bei beliebiger Umwelttemperatur. Dabei verwenden wir Luft als Kältemittel.\n\nzielgruppe\n\nDer globale Kühlbedarf macht aktuell 10% des weltweiten Strombedarfs aus und steigt rasant an. Es werden zwischen 2020 und 2070 knapp 10 Klimaanlagen pro Sekunde verkauft (viele weitere Zahlen und Statistiken rund um das Thema Kühlung findest Du bei der International Energy Agency ) . Mit unserer Technologie können wir verhindern, dass der Stromverbrauch und die CO2-Emissionen proportional mit der Anzahl der verkauften Anlagen wächst.\n\nWir entwickeln eine Technologie, die 4–5 mal so effizient wie konventionelle Kühlanlagen arbeitet. Außerdem verwendet sie Luft als Kühlmittel. Luft ist ein natürliches Kältemittel, ist unbegrenzt frei verfügbar und hat ein Global Warming Potential von 0 (mehr zu natürlichen Kältemittel bei der Green Cooling Initiative) . Der Einsatz von Luft als Kältemittel ist nicht neu, aber mit konventionellen Anlagen im Zieltemperaturbereich nicht wettbewerbsfähig umsetzbar. Unser erstes Produkt wird für die Kühlung von Rechenzentren ausgelegt. Weitere Produkte im Bereich der gewerblichen und industriellen Kälteerzeugung werden folgen.\n\nroadmap\n\n06/2020 \n Q4 2020 erste Seed-Finanzierungsrunde Q4 2020 \n 10/2020 erste Patentanmeldungen 10/2020 \n Q4 2021 zweite Seed-Finanzierungsrunde Q4 2021 \n Q4 2021 erste Patenterteilungen beantragt Q4 2021 \n 05/2022 Prototyp des fraktalen Wärmetauschers 05/2022 \n Q3 2022 Start-Up-Finanzierungsrunde Q3 2022\n\nQ4 2023 per CCS ausgeblendet Q4 2023 \n Q4 2023 physischer Anlagenprototyp Q4 2023 \n Q3 2024 Serienüberleitung und Beta-Tests Q3 2024 \n Q3 2025 \n ab 2025\n\nour core values\n\nWe love innovation. And disruption is even better! Failing is part of the game, but we are curious and continuous learners. \n We help and enable each other. Cooperative interaction with our clients, our partners and our colleagues is central. \n We are pragmatic. Our goals always remain our focus. We are dedicated team players. \n We interact respectfully. With each other and our environment.\n\nteam\n\nGerrit Barth Product Development & Technology \n Anna Herzog Head of Sales & Marketing, PR \n Bikbulat Khabibullin Product Development & Technology\n\nJohannes Lampl Product Development & Technology \n Anne Murmann Product Development & Technology \n Jens Schäfer Co-Founder and CEO\n\nHolger Sedlak Inventor, Co-Founder and CTO \n Adrian Zajac Product Development & Technology\n\nstellenangebote\n\npartner & förderungen"
},
{
"title": "Let’s capture CO2 and tackle climate change",
"id": "https://blancair.com/",
"url": "https://blancair.com/",
"publishedDate": "2023-03-01",
"author": null,
"text": "Let’s capture CO2 and tackle climate change\n\nWe need to keep global warming below 1.5°C. This requires a deployment of Negative Emission Technologies (NETs) of around 8 Gt of CO2 in 2050. Natural Climate solutions cannot do it alone.Technology has to give support. BLANCAIR can turn back human-emitted carbon dioxide from our atmosphere by capturing it and sequestering it back into the planet.\n\nGet to know us, our Hamburg team, partnerships and network\n\nTake a look at the BLANCAIR technology, our milestones & our next goals\n\nJoin our BLANCAIR team & help us to fight climate change!"
},
{
"title": "bionero - Der Erde zuliebe. Carbon Removal | Terra Preta",
"id": "https://www.bionero.de/",
"url": "https://www.bionero.de/",
"publishedDate": "2023-10-28",
"author": null,
"text": "Mehr Wachstum. Echter Klimaschutz. bionero ist eines der ersten Unternehmen weltweit, das zertifiziert klimapositiv arbeitet. Das Familienunternehmen, das in der Nähe von Bayreuth beheimatet ist, stellt qualitativ höchstwertige Erden und Substrate her, die durch das einzigartige Produktionsverfahren aktiv CO2 aus der Atmosphäre entziehen und gleichzeitig enorm fruchtbar sind. Aus Liebe und der Ehrfurcht zur Natur entwickelte bionero ein hochmodernes, industrialisiertes Verfahren, das aus biogenen Reststoffen eine höchstwertige Pflanzenkohle herstellt und zu fruchtbaren Schwarzerden made in Germany verwandelt. Hier kannst du bionero im Einzelhandel finden Wir liefern Gutes aus der Natur, für die Natur. Terra Preta (portugiesisch für \"Schwarze Erde\") gilt als \"wiederentdeckte Wundererde\". Sie wurde vor circa 40 Jahren in den Tiefen des Amazonasgebiets entdeckt und intensiv erforscht. Das Besondere an ihr ist ihre Fruchtbarkeit. Tatsächlich gilt dieser Boden als der fruchtbarste unseres Planeten. bionero hat gemeinsam mit Professor Bruno Glaser, einem weltweit anerkannten Experten für Terra Preta, das Herstellungsverfahren dieser besonderen Erde transformiert, optimiert und industrialisiert. Der wesentliche Wirk- und Inhaltsstoff ist eine sog. Pflanzenkohle. Sie sorgt dank ihrer enorm großen spezifischen Oberfläche für optimale Nährstoff- und Wasserspeicherfähigkeiten im Boden und bietet zusätzlich Lebensraum für wertvolle Mikroorganismen. Das Ergebnis ist ein stetiger Humusaufbau und eine dauerhafte Bodenfruchtbarkeit. Das Einzigartige an bionero? Die bionero Wertschöpfungskette ist vollständig klimapositiv! bioneros Produkte bieten einer Branche, die stark in die Kritik geraten ist, einen Weg in eine nachhaltige Zukunft. Während der Herstellung unserer hochwertigen Terra Preta leisten wir einen aktiven Beitrag zum Klimaschutz. Durch die Produktion unserer wichtigsten Zutat, der Pflanzenkohle, wird dem atmosphärischen Kohlenstoffkreislauf aktiv Kohlenstoff entzogen. Der Kohlenstoff, welcher anfangs in den biogenen Reststoffen gespeichert war, wird während des Pyrolyseprozesses für mehrere Jahrtausende in der Pflanzenkohle fixiert und gelangt somit nicht als Kohlenstoffdioxid zurück in unsere Atmosphäre. Das Erstaunliche: Die Pflanzenkohle entzieht der Atmosphäre das bis zu dreieinhalbfache ihres Eigengewichts an CO2! Die entstandenen Kohlenstoffsenken sind dabei transparent quantifizierbar und zertifiziert. Tatsächlich vereint bionero als erstes Unternehmen weltweit alle notwendigen Verfahrensschritte zu einer echten Kohlenstoffsenke gemäß EBC. Der Kohlenstoff ist am Ende der bionero Wertschöpfungskette in einer stabilen Matrix fixiert. Torf ist bis heute der meistgenutzte Rohstoff bei der Herstellung von Pflanzsubstraten. Schon beim Abbau werden Unmengen an CO2 freigesetzt. Moore sind einer der wichtigsten Kohlenstoff-Speicher unseres Planeten. Moore speichern 700 Tonnen Kohlenstoff je Hektar, sechsmal mehr als ein Hektar Wald! Durch die Trockenlegung und den Abbau für die Gewinnung von Torf können diese gewaltigen Mengen Kohlenstoff wieder zu CO2-reagieren und gelangen in die Atmosphäre. Hinzu kommen enorm weite Transportwege. Der Torfabbau findet zu großen Teilen in Osteuropa statt. Um einerseits die natürlichen Ökosysteme zu schützen und andererseits lange Transportwege zu vermeiden, setzen wir auf regional anfallende Roh- und Reststoffe. In langen Reifeprozessen verarbeiten wir natürliche Reststoffe zu hochwertigen Ausgangsstoffen für unsere Produkte. Bei der Auswahl aller Inputstoffe schauen wir genau hin und arbeiten nach dem Prinzip “regional, nachhaltig, umwelt- und klimaschonend“. Nur, wenn diese Voraussetzungen ausnahmslos gewährleistet sind, findet ein Rohstoff letztlich seinen Weg in unsere Produkte. bionero - Mehr Wachstum. Echter Klimaschutz. Erhalte spannende Einblicke in die Abläufe unseres Start-Ups und unsere hochmodernen Verfahren. Hier gibt es die neuesten Trends, aktuelle Tipps, hilfreiche Pflanz- und Pflegeanleitungen und interessante Videos."
},
{
"title": "Green City Solutions",
"id": "https://www.greentalents.de/green-city-solutions.php",
"url": "https://www.greentalents.de/green-city-solutions.php",
"publishedDate": "2022-04-12",
"author": null,
"text": "In their devices, called CityTrees, they combine the natural ability of moss to clean and cool the air with Internet of Things technology to control irrigation and ventilation. In March 2014, Green City Solutions GmbH was founded by Peter Sänger and his friend Liang Wu in Dresden. They set up a team of young experts from the fields of horticulture/biology, computer science, architecture, and mechanical engineering. The knowledge of the individuals was bundled to realise a device that combines nature and technology: the CityTree.\n\nThe living heart of CityTrees is moss cultivated on hanging textile mats. The moss mats are hidden behind wooden bars that provide sufficient shade for these plants, which naturally grow mainly in forests. Sensors are measuring various parameters such as temperature, humidity, and concentration of particulates. This data is used to regulate ventilation and irrigation. Behind the moss mats are large vents that create an airflow through the moss. In this way, the amount of air cleaned by the device can be increased when pollution levels are high, such as during rush hours.\n\nGreen City Solutions collaborates with several partners in Germany and abroad. Scientific partners include the Leibniz Institute for Tropospheric Research (TROPOS) and the Dresden University of Applied Sciences (HTW Dresden), both located in Germany. Green City Solutions has been awarded the Seal of Excellence by the European Commission. This is a European Union quality label for outstanding ideas worthy of funding.\n\nThe work of Green City Solutions mainly contributes to the Sustainable Development Goals 3, 11, 13, and 15:"
},
{
"title": "No.1 DAC manufacturer from Germany - DACMA GmbH",
"id": "https://dacma.com/",
"url": "https://dacma.com/",
"publishedDate": "2024-03-02",
"author": null,
"text": "Reach net zero goal with BLANCAIR by DACMA – a proven direct air capture technology with maximum CO2 uptake and minimal energy demand.\n\nDACMA GmbH, headquartered in Hamburg, Germany, is a pioneering DAC manufacturer with cutting-edge technology. With a proven track record, our first machines were delivered in 2023. Our scalable design reaches gigaton capacities, ensuring high CO2 uptake with minimal energy demand.\n\nGet to know us, our team, partnerships and network\n\nLearn more about the status quo of DAC technologies and our BLANCAIR solution\n\nJoin our DACMA team – help us to reach net zero and fight climate change!\n\nWhy BLANCAIR by DACMA:\n\nNo.1 DAC manufacturer from Germany – leveraging decades of aerospace – innovation\n\nDeliverable: proven technology in the market\n\nInterchangeable adsorbents for continuous performance improvement\n\nPatented reactor design with optimized air flow\n\nUniversal application for different climate conditions\n\n“In just one year, DACMA GmbH have achieved an exponential progress in the atmospheric carbon capture journey. The strategic alliance with Repsol (both in Venturing Capital and projects) will boost the pace of this highly focused group of outstanding engineers that are persistently looking for every angle of the technology improvement. Take the time to celebrate, acknowledge your success and keep going!!!”\n\n“One of the most relevant projects related to the development of technologies with a negative CO2 effect, the ONLY project in Brazil on Direct Air Capture multi-country Spain, Brazil Germany in Open Innovation. Repsol Sinopec Brazil Corporation, Start Up DACMA and PUC Rio Grande do Sul University. A disruptive commitment to a more decarbonized world. Being part of this project is a privilege and a unique opportunity to add value to society.”\n\n“In collaboration with Phoenix Contact, DACMA has developed an application that contributes to CO2 decarbonization. This technology makes a significant contribution to sector coupling in the All Electric Society and to the sustainable use of energy. I am delighted that two technology-driven companies are working together so efficiently.”\n\n“The DACMA GmbH with Jörg Spitzner and his team are not only valuable partners in our network, but also key initiators and innovators who, with BLANCAIR, are driving forward DAC system engineering in the Hamburg metropolitan region – an essential future climate change mitigation technology.”\n\n“Together with our partner DACMA GmbH, we are delighted to be building the first DAC machine on the HAMBURG BLUE HUB site in the Port of Hamburg. The 30-60 tons output of CO2 annually of the BLANCAIR machine can later be used to produce e-methanol for the Port of Hamburg, for example. This is a joint milestone, as it fits in with the plan to purchase large volumes of synthetic fuels from Power-to-X plants in Africa and South America for Germany through the HAMBURG BLUE HUB”.\n\nBacked by strong investors & partners:\n\nassociations & supporters:"
},
{
"title": "Heatrix GmbH Decarbonizing Industry – We decarbonize high temperature industrial heat.",
"id": "https://heatrix.de/",
"url": "https://heatrix.de/",
"publishedDate": "2024-02-28",
"author": null,
"text": "Our mission\n\nis to competitively replace fossil fuels in energy intensive industriesby converting renewable electricity into storable, high-temperature process heat.\n\n11% of global CO2 emissions is caused byhigh-temperature industrial heat.\n\nNo carbon-neutral, cost-competitive and easy\nto\nintegrate solution exists yet.\n\n11%\nof global CO2 emissions is caused by\nhigh-temperature industrial heat.\n\nNo carbon-neutral, cost-competitive and easy\nto integrate solution exists yet.\n\nOur solution\n\nThe Heatrix system combines an electric heater, utilizing off-grid solar or wind \nelectricity, with a thermal energy storage to provide continuous high-temperature \nprocess heat. With an outlet temperature of up to 1500 °C, Heatrix has the potential to \ndecarbonize the majority of high emission industries.\n\nHeatrix technology perfectly fulfils customers' \nrequirements – CO2 free continuous and easily integrated process heat at competitive cost.\n\nCarbon-free green heat, \nreducing CO2 emissions \n up to 100%\n\nProcess heat (hot air) \nup to 1500 °C\n\nThermal storage up\n to 20 hours to \ndeliver green heat 24/7\n\nHigh efficiency up \nto 90% based on \nresistance heating\n\nCost competitive vs. \nfossil fuels and substantially \ncheaper than green hydrogen\n\nModular container\nsystem enables \neasy scalability\n\nEasy integration \nwith minimal \nretrofitting needs\n\nApplications for Heatrix\n\nCalcination\n\nReplacing fossil fuel burners and reducing fuel consumption in calcination processes by integrating Heatrix heat to shaft calciners or precalciners of rotary kilns.\n\nHeat Treatment\n\nInducing required process temperatures via hot air flow from Heatrix replacing fossil fuel burners in heat treatment ovens.\n\nSintering & Pelletization\n\nReduced fuel gas & coke usage by providing Heatrix heat to sintering or pelletization plants.\n\nPreheating\n\nCombined with existing burner system, Heatrix technology can be used to preheat materials and reduce fuel consumption in the actual process.\n\nThis is us\n\nStrategy & Operations\n\nInnovator / Inventor / Sold first tech start-up in 2021 / Ph.D. from RWTH Aachen\n\nTechnology & Product\n\nTech Lead / Fluid dynamics expert / Energy technologies / Ph.D. from University Bremen\n\nBusiness & Finance\n\n2nd-time Founder / former VC-Investor / MBA from Tsinghua, MIT & HEC Paris\n\nContact us\n\nLooking for more information about Heatrix and our technology? We’d love to get in touch!\n\nHeatrix ensures defensibility through modular product, ease of integration, technological advantages and compelling business model.\n\nModular Product\n\n• Avoids individual design process – fits in standard containers• Industry-agnostic solution• Modular configuration to meet customer needs\n\nEasy Interaction\n\n• Rapid deployment• Focus on minimal plant downtime• Compatible to back-up for guaranteed production\n\nBusiness Model\n\n• Ongoing customer relationship and revenue \n• Large growth potential\n• Maximal impact on CO2\nreduction\n\nTechnical Advantage\n\n• Unique system design integrating electric heater and thermal storage \n• IP application in preparation for unique heater and storage design"
},
{
"title": "vabeck® GmbH - Grüne Prozesstechnik für den Umweltschutz",
"id": "https://www.vabeck.com/en",
"url": "https://www.vabeck.com/en",
"publishedDate": "2022-01-01",
"author": null,
"text": ""
}
],
"requestId": "a02fd414d9ca16454089e8720cd6ed2b"
}
```
Nice! On inspection, these results include companies located in Hamburg, Munich and other close by European locations. This example can be extended to any key phrase - have a play with filtering via [other company suffixes - ](https://en.wikipedia.org/wiki/List%5Fof%5Flegal%5Fentity%5Ftypes%5Fby%5Fcountry) and see what interesting results you get back!
---
# Source: https://exa.ai/docs/reference/openai-responses-api-with-exa.md
> ## Documentation Index
> Fetch the complete documentation index at: https://exa.ai/docs/llms.txt
> Use this file to discover all available pages before exploring further.
# OpenAI Responses API
> Use Exa with OpenAI's Responses API - both as a web search tool and for direct research capabilities.
## What is Exa?
Exa is the search engine built for AI. It finds information from across the web and delivers both links and the actual content from pages, making it easy to use with AI models.
Exa uses neural search technology to understand the meaning of queries, not just exact matches. The API works with semantic search and other intelligent methods.
***
## Get Started
First, you'll need API keys from both OpenAI and Exa:
* Get your Exa API key from the [Exa Dashboard](https://dashboard.exa.ai/api-keys)
* Get your OpenAI API key from the [OpenAI Dashboard](https://platform.openai.com/api-keys)
## Complete Example
## Running a query with phrase filter
Using Phrase Filters is super simple. As usual, install the `exa_py` library with `pip install exa_py`. Then instantiate the library:
```Python Python theme={null}
# Now, import the Exa class and pass your API key to it.
from exa_py import Exa
my_exa_api_key = "YOUR_API_KEY_HERE"
exa = Exa(my_exa_api_key)
```
Make a query, in this example searching for the most innovative climate tech companies. To use Phrase Filters, specify a string corresponding to the `includeText` input parameter
```Python Python theme={null}
result = exa.search_and_contents(
"Here is an innovative climate technology company",
type="neural",
num_results=10,
text=True,
include_text=["GmbH"]
)
print(result)
```
Which outputs:
```
{
"results": [
{
"title": "Sorption Technologies |",
"id": "https://sorption-technologies.com/",
"url": "https://sorption-technologies.com/",
"publishedDate": "2024-02-10",
"author": null,
"text": ""
},
{
"title": "FenX | VentureRadar",
"id": "https://www.ventureradar.com/organisation/FenX/364b6fb7-0033-4c88-a4e9-9c3b1f530d72",
"url": "https://www.ventureradar.com/organisation/FenX/364b6fb7-0033-4c88-a4e9-9c3b1f530d72",
"publishedDate": "2023-03-28",
"author": null,
"text": "Follow\n\nFollowing\n\nLocation: Switzerland\n\nFounded in 2019\n\nPrivate Company\n\n\"FenX is a Spinoff of ETH Zurich tackling the world’s energy and greenhouse gas challenges by disrupting the building insulation market. Based on a innovative foaming technique, the company produces high-performance insulation foams made from abandoned waste materials such as fly ash from coal power stations. The final products are fully recyclable, emit low CO2 emissions and are economically competitive.\"\n Description Source: VentureRadar Research / Company Website\n\nExport Similar Companies Similar Companies\n\nCompany \n Country\n Status\n Description\n\nVecor Australia Australia n/a Every year the world’s coal-fired power stations produce approximately 1 billion tonnes of a very fine ash called fly ash. This nuisance ash, which resembles smoke, can be... MCC Technologies USA Private MCC Technologies builds, owns and operates processing plants utilizing coal fly ash waste from landfills and ash ponds. The company processes large volumes of low-quality Class F... Climeworks GmbH Switzerland Private Climeworks has developed an ecologically and economically attractive method to extract CO2 from ambient air. Our goal is to deliver CO2 for the production of synthetic liquid... Errcive Inc USA Private The company is involved in developing a novel fly ash based material to mitigate exhaust pollution. The commercial impact of the work is to allow: the reduction of exhaust fumes... 4 Envi Denmark n/a Danish 4 Envi develops a system for the cleaning and re-use of biomass-fuelled plant’s fly ash. After cleaning, the ash and some of its components can be reused as fertilizers,... Neolithe France n/a Néolithe wants to reduce global greenhouse gas emissions by 5% by tackling a problem that concerns us all: waste treatment! They transform non-recyclable waste into aggregates...\n\nShow all\n\nWebsite Archive\n\nInternet Archive snapshots for |\n\nhttps://fenx.ch/\n\nThe archive allows you to go back in time and view historical versions of the company website\n\nThe site\n\nhttps://fenx.ch/\n\nwas first archived on\n\n4th Jul 2019\n\nIs this your company? Claim this profile andupdate details for free\n\nSub-Scores\n\nPopularity on VentureRadar\n\nWebsite Popularity\n\nLow Traffic Sites\n Low\n\nHigh Traffic Sites\n High\n\nAlexa Global Rank:\n\n3,478,846 | \n fenx.ch\n\nAuto Analyst Score\n\n68\n\nAuto Analyst Score:\n 68 | \n fenx.ch\n\nVentureRadar Popularity\n\nHigh\n\nVentureRadar Popularity:\n High The popularity score combines profile views, clicks and the number of times the company appears in search results.\n\nor\n\nTo continue, please confirm you\n are not a robot"
},
{
"title": "intelligent fluids | LinkedIn",
"id": "https://www.linkedin.com/company/intelligentfluids",
"url": "https://www.linkedin.com/company/intelligentfluids",
"publishedDate": "2023-06-08",
"author": null,
"text": "Sign in to see who you already know at intelligent fluids GmbH (SMARTCHEM)\n\nWelcome back\n\nEmail or phone\n\nPassword\n\nForgot password?\n\nor\n\nNew to LinkedIn? Join now\n\nor\n\nNew to LinkedIn? Join now"
},
{
"title": "justairtech GmbH – Umweltfreundliche Kühlsysteme mit Luft als Kältemittel",
"id": "https://www.justairtech.de/",
"url": "https://www.justairtech.de/",
"publishedDate": "2024-06-13",
"author": null,
"text": "decouple cooling from climate change with air as refrigerant.\n\nWir entwickeln eine hocheffziente Kühlanlage, die Luft als Kältemittel verwendet. Wieso? Die Welt verändert sich tiefgreifender und schneller als in allen Generationen vor uns. Wir sehen darin nicht nur eine Bedrohung, sondern begreifen dies auch als Chance, Prozesse nachhaltig zu gestalten.\n\nUnsere Arbeit konzentriert sich auf die Revolutionierung der Kühlung für Zieltemperaturen von 0–40 °C bei beliebiger Umwelttemperatur. Dabei verwenden wir Luft als Kältemittel.\n\nzielgruppe\n\nDer globale Kühlbedarf macht aktuell 10% des weltweiten Strombedarfs aus und steigt rasant an. Es werden zwischen 2020 und 2070 knapp 10 Klimaanlagen pro Sekunde verkauft (viele weitere Zahlen und Statistiken rund um das Thema Kühlung findest Du bei der International Energy Agency ) . Mit unserer Technologie können wir verhindern, dass der Stromverbrauch und die CO2-Emissionen proportional mit der Anzahl der verkauften Anlagen wächst.\n\nWir entwickeln eine Technologie, die 4–5 mal so effizient wie konventionelle Kühlanlagen arbeitet. Außerdem verwendet sie Luft als Kühlmittel. Luft ist ein natürliches Kältemittel, ist unbegrenzt frei verfügbar und hat ein Global Warming Potential von 0 (mehr zu natürlichen Kältemittel bei der Green Cooling Initiative) . Der Einsatz von Luft als Kältemittel ist nicht neu, aber mit konventionellen Anlagen im Zieltemperaturbereich nicht wettbewerbsfähig umsetzbar. Unser erstes Produkt wird für die Kühlung von Rechenzentren ausgelegt. Weitere Produkte im Bereich der gewerblichen und industriellen Kälteerzeugung werden folgen.\n\nroadmap\n\n06/2020 \n Q4 2020 erste Seed-Finanzierungsrunde Q4 2020 \n 10/2020 erste Patentanmeldungen 10/2020 \n Q4 2021 zweite Seed-Finanzierungsrunde Q4 2021 \n Q4 2021 erste Patenterteilungen beantragt Q4 2021 \n 05/2022 Prototyp des fraktalen Wärmetauschers 05/2022 \n Q3 2022 Start-Up-Finanzierungsrunde Q3 2022\n\nQ4 2023 per CCS ausgeblendet Q4 2023 \n Q4 2023 physischer Anlagenprototyp Q4 2023 \n Q3 2024 Serienüberleitung und Beta-Tests Q3 2024 \n Q3 2025 \n ab 2025\n\nour core values\n\nWe love innovation. And disruption is even better! Failing is part of the game, but we are curious and continuous learners. \n We help and enable each other. Cooperative interaction with our clients, our partners and our colleagues is central. \n We are pragmatic. Our goals always remain our focus. We are dedicated team players. \n We interact respectfully. With each other and our environment.\n\nteam\n\nGerrit Barth Product Development & Technology \n Anna Herzog Head of Sales & Marketing, PR \n Bikbulat Khabibullin Product Development & Technology\n\nJohannes Lampl Product Development & Technology \n Anne Murmann Product Development & Technology \n Jens Schäfer Co-Founder and CEO\n\nHolger Sedlak Inventor, Co-Founder and CTO \n Adrian Zajac Product Development & Technology\n\nstellenangebote\n\npartner & förderungen"
},
{
"title": "Let’s capture CO2 and tackle climate change",
"id": "https://blancair.com/",
"url": "https://blancair.com/",
"publishedDate": "2023-03-01",
"author": null,
"text": "Let’s capture CO2 and tackle climate change\n\nWe need to keep global warming below 1.5°C. This requires a deployment of Negative Emission Technologies (NETs) of around 8 Gt of CO2 in 2050. Natural Climate solutions cannot do it alone.Technology has to give support. BLANCAIR can turn back human-emitted carbon dioxide from our atmosphere by capturing it and sequestering it back into the planet.\n\nGet to know us, our Hamburg team, partnerships and network\n\nTake a look at the BLANCAIR technology, our milestones & our next goals\n\nJoin our BLANCAIR team & help us to fight climate change!"
},
{
"title": "bionero - Der Erde zuliebe. Carbon Removal | Terra Preta",
"id": "https://www.bionero.de/",
"url": "https://www.bionero.de/",
"publishedDate": "2023-10-28",
"author": null,
"text": "Mehr Wachstum. Echter Klimaschutz. bionero ist eines der ersten Unternehmen weltweit, das zertifiziert klimapositiv arbeitet. Das Familienunternehmen, das in der Nähe von Bayreuth beheimatet ist, stellt qualitativ höchstwertige Erden und Substrate her, die durch das einzigartige Produktionsverfahren aktiv CO2 aus der Atmosphäre entziehen und gleichzeitig enorm fruchtbar sind. Aus Liebe und der Ehrfurcht zur Natur entwickelte bionero ein hochmodernes, industrialisiertes Verfahren, das aus biogenen Reststoffen eine höchstwertige Pflanzenkohle herstellt und zu fruchtbaren Schwarzerden made in Germany verwandelt. Hier kannst du bionero im Einzelhandel finden Wir liefern Gutes aus der Natur, für die Natur. Terra Preta (portugiesisch für \"Schwarze Erde\") gilt als \"wiederentdeckte Wundererde\". Sie wurde vor circa 40 Jahren in den Tiefen des Amazonasgebiets entdeckt und intensiv erforscht. Das Besondere an ihr ist ihre Fruchtbarkeit. Tatsächlich gilt dieser Boden als der fruchtbarste unseres Planeten. bionero hat gemeinsam mit Professor Bruno Glaser, einem weltweit anerkannten Experten für Terra Preta, das Herstellungsverfahren dieser besonderen Erde transformiert, optimiert und industrialisiert. Der wesentliche Wirk- und Inhaltsstoff ist eine sog. Pflanzenkohle. Sie sorgt dank ihrer enorm großen spezifischen Oberfläche für optimale Nährstoff- und Wasserspeicherfähigkeiten im Boden und bietet zusätzlich Lebensraum für wertvolle Mikroorganismen. Das Ergebnis ist ein stetiger Humusaufbau und eine dauerhafte Bodenfruchtbarkeit. Das Einzigartige an bionero? Die bionero Wertschöpfungskette ist vollständig klimapositiv! bioneros Produkte bieten einer Branche, die stark in die Kritik geraten ist, einen Weg in eine nachhaltige Zukunft. Während der Herstellung unserer hochwertigen Terra Preta leisten wir einen aktiven Beitrag zum Klimaschutz. Durch die Produktion unserer wichtigsten Zutat, der Pflanzenkohle, wird dem atmosphärischen Kohlenstoffkreislauf aktiv Kohlenstoff entzogen. Der Kohlenstoff, welcher anfangs in den biogenen Reststoffen gespeichert war, wird während des Pyrolyseprozesses für mehrere Jahrtausende in der Pflanzenkohle fixiert und gelangt somit nicht als Kohlenstoffdioxid zurück in unsere Atmosphäre. Das Erstaunliche: Die Pflanzenkohle entzieht der Atmosphäre das bis zu dreieinhalbfache ihres Eigengewichts an CO2! Die entstandenen Kohlenstoffsenken sind dabei transparent quantifizierbar und zertifiziert. Tatsächlich vereint bionero als erstes Unternehmen weltweit alle notwendigen Verfahrensschritte zu einer echten Kohlenstoffsenke gemäß EBC. Der Kohlenstoff ist am Ende der bionero Wertschöpfungskette in einer stabilen Matrix fixiert. Torf ist bis heute der meistgenutzte Rohstoff bei der Herstellung von Pflanzsubstraten. Schon beim Abbau werden Unmengen an CO2 freigesetzt. Moore sind einer der wichtigsten Kohlenstoff-Speicher unseres Planeten. Moore speichern 700 Tonnen Kohlenstoff je Hektar, sechsmal mehr als ein Hektar Wald! Durch die Trockenlegung und den Abbau für die Gewinnung von Torf können diese gewaltigen Mengen Kohlenstoff wieder zu CO2-reagieren und gelangen in die Atmosphäre. Hinzu kommen enorm weite Transportwege. Der Torfabbau findet zu großen Teilen in Osteuropa statt. Um einerseits die natürlichen Ökosysteme zu schützen und andererseits lange Transportwege zu vermeiden, setzen wir auf regional anfallende Roh- und Reststoffe. In langen Reifeprozessen verarbeiten wir natürliche Reststoffe zu hochwertigen Ausgangsstoffen für unsere Produkte. Bei der Auswahl aller Inputstoffe schauen wir genau hin und arbeiten nach dem Prinzip “regional, nachhaltig, umwelt- und klimaschonend“. Nur, wenn diese Voraussetzungen ausnahmslos gewährleistet sind, findet ein Rohstoff letztlich seinen Weg in unsere Produkte. bionero - Mehr Wachstum. Echter Klimaschutz. Erhalte spannende Einblicke in die Abläufe unseres Start-Ups und unsere hochmodernen Verfahren. Hier gibt es die neuesten Trends, aktuelle Tipps, hilfreiche Pflanz- und Pflegeanleitungen und interessante Videos."
},
{
"title": "Green City Solutions",
"id": "https://www.greentalents.de/green-city-solutions.php",
"url": "https://www.greentalents.de/green-city-solutions.php",
"publishedDate": "2022-04-12",
"author": null,
"text": "In their devices, called CityTrees, they combine the natural ability of moss to clean and cool the air with Internet of Things technology to control irrigation and ventilation. In March 2014, Green City Solutions GmbH was founded by Peter Sänger and his friend Liang Wu in Dresden. They set up a team of young experts from the fields of horticulture/biology, computer science, architecture, and mechanical engineering. The knowledge of the individuals was bundled to realise a device that combines nature and technology: the CityTree.\n\nThe living heart of CityTrees is moss cultivated on hanging textile mats. The moss mats are hidden behind wooden bars that provide sufficient shade for these plants, which naturally grow mainly in forests. Sensors are measuring various parameters such as temperature, humidity, and concentration of particulates. This data is used to regulate ventilation and irrigation. Behind the moss mats are large vents that create an airflow through the moss. In this way, the amount of air cleaned by the device can be increased when pollution levels are high, such as during rush hours.\n\nGreen City Solutions collaborates with several partners in Germany and abroad. Scientific partners include the Leibniz Institute for Tropospheric Research (TROPOS) and the Dresden University of Applied Sciences (HTW Dresden), both located in Germany. Green City Solutions has been awarded the Seal of Excellence by the European Commission. This is a European Union quality label for outstanding ideas worthy of funding.\n\nThe work of Green City Solutions mainly contributes to the Sustainable Development Goals 3, 11, 13, and 15:"
},
{
"title": "No.1 DAC manufacturer from Germany - DACMA GmbH",
"id": "https://dacma.com/",
"url": "https://dacma.com/",
"publishedDate": "2024-03-02",
"author": null,
"text": "Reach net zero goal with BLANCAIR by DACMA – a proven direct air capture technology with maximum CO2 uptake and minimal energy demand.\n\nDACMA GmbH, headquartered in Hamburg, Germany, is a pioneering DAC manufacturer with cutting-edge technology. With a proven track record, our first machines were delivered in 2023. Our scalable design reaches gigaton capacities, ensuring high CO2 uptake with minimal energy demand.\n\nGet to know us, our team, partnerships and network\n\nLearn more about the status quo of DAC technologies and our BLANCAIR solution\n\nJoin our DACMA team – help us to reach net zero and fight climate change!\n\nWhy BLANCAIR by DACMA:\n\nNo.1 DAC manufacturer from Germany – leveraging decades of aerospace – innovation\n\nDeliverable: proven technology in the market\n\nInterchangeable adsorbents for continuous performance improvement\n\nPatented reactor design with optimized air flow\n\nUniversal application for different climate conditions\n\n“In just one year, DACMA GmbH have achieved an exponential progress in the atmospheric carbon capture journey. The strategic alliance with Repsol (both in Venturing Capital and projects) will boost the pace of this highly focused group of outstanding engineers that are persistently looking for every angle of the technology improvement. Take the time to celebrate, acknowledge your success and keep going!!!”\n\n“One of the most relevant projects related to the development of technologies with a negative CO2 effect, the ONLY project in Brazil on Direct Air Capture multi-country Spain, Brazil Germany in Open Innovation. Repsol Sinopec Brazil Corporation, Start Up DACMA and PUC Rio Grande do Sul University. A disruptive commitment to a more decarbonized world. Being part of this project is a privilege and a unique opportunity to add value to society.”\n\n“In collaboration with Phoenix Contact, DACMA has developed an application that contributes to CO2 decarbonization. This technology makes a significant contribution to sector coupling in the All Electric Society and to the sustainable use of energy. I am delighted that two technology-driven companies are working together so efficiently.”\n\n“The DACMA GmbH with Jörg Spitzner and his team are not only valuable partners in our network, but also key initiators and innovators who, with BLANCAIR, are driving forward DAC system engineering in the Hamburg metropolitan region – an essential future climate change mitigation technology.”\n\n“Together with our partner DACMA GmbH, we are delighted to be building the first DAC machine on the HAMBURG BLUE HUB site in the Port of Hamburg. The 30-60 tons output of CO2 annually of the BLANCAIR machine can later be used to produce e-methanol for the Port of Hamburg, for example. This is a joint milestone, as it fits in with the plan to purchase large volumes of synthetic fuels from Power-to-X plants in Africa and South America for Germany through the HAMBURG BLUE HUB”.\n\nBacked by strong investors & partners:\n\nassociations & supporters:"
},
{
"title": "Heatrix GmbH Decarbonizing Industry – We decarbonize high temperature industrial heat.",
"id": "https://heatrix.de/",
"url": "https://heatrix.de/",
"publishedDate": "2024-02-28",
"author": null,
"text": "Our mission\n\nis to competitively replace fossil fuels in energy intensive industriesby converting renewable electricity into storable, high-temperature process heat.\n\n11% of global CO2 emissions is caused byhigh-temperature industrial heat.\n\nNo carbon-neutral, cost-competitive and easy\nto\nintegrate solution exists yet.\n\n11%\nof global CO2 emissions is caused by\nhigh-temperature industrial heat.\n\nNo carbon-neutral, cost-competitive and easy\nto integrate solution exists yet.\n\nOur solution\n\nThe Heatrix system combines an electric heater, utilizing off-grid solar or wind \nelectricity, with a thermal energy storage to provide continuous high-temperature \nprocess heat. With an outlet temperature of up to 1500 °C, Heatrix has the potential to \ndecarbonize the majority of high emission industries.\n\nHeatrix technology perfectly fulfils customers' \nrequirements – CO2 free continuous and easily integrated process heat at competitive cost.\n\nCarbon-free green heat, \nreducing CO2 emissions \n up to 100%\n\nProcess heat (hot air) \nup to 1500 °C\n\nThermal storage up\n to 20 hours to \ndeliver green heat 24/7\n\nHigh efficiency up \nto 90% based on \nresistance heating\n\nCost competitive vs. \nfossil fuels and substantially \ncheaper than green hydrogen\n\nModular container\nsystem enables \neasy scalability\n\nEasy integration \nwith minimal \nretrofitting needs\n\nApplications for Heatrix\n\nCalcination\n\nReplacing fossil fuel burners and reducing fuel consumption in calcination processes by integrating Heatrix heat to shaft calciners or precalciners of rotary kilns.\n\nHeat Treatment\n\nInducing required process temperatures via hot air flow from Heatrix replacing fossil fuel burners in heat treatment ovens.\n\nSintering & Pelletization\n\nReduced fuel gas & coke usage by providing Heatrix heat to sintering or pelletization plants.\n\nPreheating\n\nCombined with existing burner system, Heatrix technology can be used to preheat materials and reduce fuel consumption in the actual process.\n\nThis is us\n\nStrategy & Operations\n\nInnovator / Inventor / Sold first tech start-up in 2021 / Ph.D. from RWTH Aachen\n\nTechnology & Product\n\nTech Lead / Fluid dynamics expert / Energy technologies / Ph.D. from University Bremen\n\nBusiness & Finance\n\n2nd-time Founder / former VC-Investor / MBA from Tsinghua, MIT & HEC Paris\n\nContact us\n\nLooking for more information about Heatrix and our technology? We’d love to get in touch!\n\nHeatrix ensures defensibility through modular product, ease of integration, technological advantages and compelling business model.\n\nModular Product\n\n• Avoids individual design process – fits in standard containers• Industry-agnostic solution• Modular configuration to meet customer needs\n\nEasy Interaction\n\n• Rapid deployment• Focus on minimal plant downtime• Compatible to back-up for guaranteed production\n\nBusiness Model\n\n• Ongoing customer relationship and revenue \n• Large growth potential\n• Maximal impact on CO2\nreduction\n\nTechnical Advantage\n\n• Unique system design integrating electric heater and thermal storage \n• IP application in preparation for unique heater and storage design"
},
{
"title": "vabeck® GmbH - Grüne Prozesstechnik für den Umweltschutz",
"id": "https://www.vabeck.com/en",
"url": "https://www.vabeck.com/en",
"publishedDate": "2022-01-01",
"author": null,
"text": ""
}
],
"requestId": "a02fd414d9ca16454089e8720cd6ed2b"
}
```
Nice! On inspection, these results include companies located in Hamburg, Munich and other close by European locations. This example can be extended to any key phrase - have a play with filtering via [other company suffixes - ](https://en.wikipedia.org/wiki/List%5Fof%5Flegal%5Fentity%5Ftypes%5Fby%5Fcountry) and see what interesting results you get back!
---
# Source: https://exa.ai/docs/reference/openai-responses-api-with-exa.md
> ## Documentation Index
> Fetch the complete documentation index at: https://exa.ai/docs/llms.txt
> Use this file to discover all available pages before exploring further.
# OpenAI Responses API
> Use Exa with OpenAI's Responses API - both as a web search tool and for direct research capabilities.
## What is Exa?
Exa is the search engine built for AI. It finds information from across the web and delivers both links and the actual content from pages, making it easy to use with AI models.
Exa uses neural search technology to understand the meaning of queries, not just exact matches. The API works with semantic search and other intelligent methods.
***
## Get Started
First, you'll need API keys from both OpenAI and Exa:
* Get your Exa API key from the [Exa Dashboard](https://dashboard.exa.ai/api-keys)
* Get your OpenAI API key from the [OpenAI Dashboard](https://platform.openai.com/api-keys)
## Complete Example
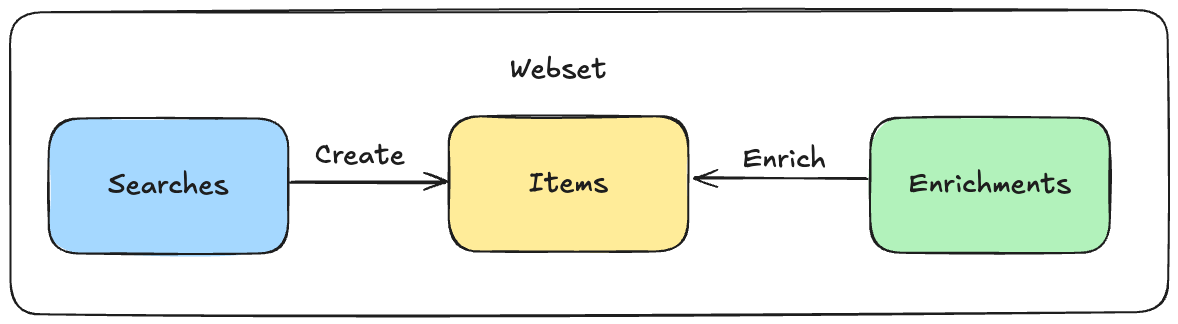 * **Webset**: Container that organizes your unique collection of web content and its related searches
* **Search**: An agent that searches and crawls the web to find precise entities matching your criteria, adding them to your Webset as structured WebsetItems
* **Item**: A structured result with source content, verification status, and type-specific fields (company, person, research paper, etc.)
* **Enrichment**: An agent that searches the web to enhance existing WebsetItems with additional structured data
## Next Steps
* Follow our [quickstart guide](/websets/api/get-started)
* Learn more about [how it works](/websets/api/how-it-works)
* Browse the [API reference](/websets/api/websets/create-a-webset)
---
# Source: https://exa.ai/docs/changelog/people-search-launch.md
> ## Documentation Index
> Fetch the complete documentation index at: https://exa.ai/docs/llms.txt
> Use this file to discover all available pages before exploring further.
# Introducing Exa People Search
> We're launching state-of-the-art people search with 1B+ indexed profiles. The 'linkedin' category is now replaced with 'people' for better results.
***
**Date: December 19, 2025**
We're launching **Exa People Search**, a new way to find and discover people on the web, designed for real production use across sales, recruiting, research, and more.
* **Webset**: Container that organizes your unique collection of web content and its related searches
* **Search**: An agent that searches and crawls the web to find precise entities matching your criteria, adding them to your Webset as structured WebsetItems
* **Item**: A structured result with source content, verification status, and type-specific fields (company, person, research paper, etc.)
* **Enrichment**: An agent that searches the web to enhance existing WebsetItems with additional structured data
## Next Steps
* Follow our [quickstart guide](/websets/api/get-started)
* Learn more about [how it works](/websets/api/how-it-works)
* Browse the [API reference](/websets/api/websets/create-a-webset)
---
# Source: https://exa.ai/docs/changelog/people-search-launch.md
> ## Documentation Index
> Fetch the complete documentation index at: https://exa.ai/docs/llms.txt
> Use this file to discover all available pages before exploring further.
# Introducing Exa People Search
> We're launching state-of-the-art people search with 1B+ indexed profiles. The 'linkedin' category is now replaced with 'people' for better results.
***
**Date: December 19, 2025**
We're launching **Exa People Search**, a new way to find and discover people on the web, designed for real production use across sales, recruiting, research, and more.
Get your API key from the Exa Dashboard and set it as an environment variable.
Create a file called `.env` in the root of your project and add the following line:
```bash theme={null} EXA_API_KEY=your api key without quotes ```Install the Python SDKs with pip. If you want to store your API key in a `.env` file, make sure to install the dotenv library.
```bash theme={null} pip install exa-py pip install openai pip install python-dotenv ```Once you've installed the SDKs, create a file called `exa.py` and add the code below.
Get a list of results and their full text content.
```python python theme={null} from exa_py import Exa from dotenv import load_dotenv import os # Use .env to store your API key or paste it directly into the code load_dotenv() exa = Exa(os.getenv('EXA_API_KEY')) result = exa.search( "An article about the state of AGI", type="auto", contents={ "text": True } ) print(result) ```Get an answer to a question, grounded by citations from exa.
```python python theme={null} from exa_py import Exa from dotenv import load_dotenv import os # Use .env to store your API key or paste it directly into the code load_dotenv() exa = Exa(os.getenv('EXA_API_KEY')) result = exa.stream_answer( "What are the latest findings on gut microbiome's influence on mental health?", text=True, ) for chunk in result: print(chunk, end='', flush=True) ```Get a chat completion from exa.
```python python theme={null} from openai import OpenAI from dotenv import load_dotenv import os # Use .env to store your API key or paste it directly into the code load_dotenv() client = OpenAI( base_url="https://api.exa.ai", api_key=os.getenv('EXA_API_KEY'), ) completion = client.chat.completions.create( model="exa", messages = [ {"role": "system", "content": "You are a helpful assistant."}, {"role": "user", "content": "What are the latest developments in quantum computing?"} ], extra_body={ "text": True } ) print(completion.choices[0].message.content) ```Find similar links to a given URL and get the full text for each link.
```python python theme={null} from exa_py import Exa from dotenv import load_dotenv import os load_dotenv() exa = Exa(os.getenv('EXA_API_KEY')) # get similar links to this post about AGI result = exa.find_similar( "https://amistrongeryet.substack.com/p/are-we-on-the-brink-of-agi", exclude_domains = ["amistrongeryet.substack.com"], num_results = 3 ) urls = [link_data.url for link_data in result.results] # get full text for each url web_pages = exa.get_contents( urls, text=True ) for web_page in web_pages.results: print(f"URL: {web_page.url}") print(f"Text snippet: {web_page.text[:500]} ...") print("-"*100) ```Get your API key from the Exa Dashboard and set it as an environment variable.
Create a file called `.env` in the root of your project and add the following line:
```bash theme={null} EXA_API_KEY=your api key without quotes ```Install the JavaScript SDK with npm. If you want to store your API key in a `.env` file, make sure to install the dotenv library.
```bash theme={null} npm install exa-js npm install openai npm install dotenv ```Once you've installed the SDK, create a file called `exa.ts` and add the code below.
Get a list of results and their full text content.
```javascript javascript theme={null} import dotenv from 'dotenv'; import Exa from 'exa-js'; dotenv.config(); const exa = new Exa(process.env.EXA_API_KEY); const result = await exa.search( "An article about the state of AGI", { type: "auto", contents: { text: true } } ); // print the first result console.log(result.results[0]); ```Get an answer to a question, grounded by citations from exa.
```javascript javascript theme={null} import dotenv from 'dotenv'; import Exa from 'exa-js'; dotenv.config(); const exa = new Exa(process.env.EXA_API_KEY); for await (const chunk of exa.streamAnswer( "What is the population of New York City?", { text: true } )) { if (chunk.content) { process.stdout.write(chunk.content); } if (chunk.citations) { console.log("\nCitations:", chunk.citations); } } ```Get a chat completion from exa.
```javascript javascript theme={null} import OpenAI from "openai"; import dotenv from 'dotenv'; import Exa from 'exa-js'; dotenv.config(); const openai = new OpenAI({ baseURL: "https://api.exa.ai", apiKey: process.env.EXA_API_KEY, }); async function main() { const completion = await openai.chat.completions.create({ model: "exa", messages: [ {"role": "system", "content": "You are a helpful assistant."}, {"role": "user", "content": "What are the latest developments in quantum computing?"} ], store: true, stream: true, extra_body: { text: true // include full text from sources } }); for await (const chunk of completion) { console.log(chunk.choices[0].delta.content); } } main(); ```Find similar links to a given URL and get the full text for each link.
```javascript javascript theme={null} import Exa from 'exa-js'; import dotenv from 'dotenv'; dotenv.config(); const exa = new Exa(process.env.EXA_API_KEY); // Find similar links to this post about AGI const result = await exa.findSimilar( "https://amistrongeryet.substack.com/p/are-we-on-the-brink-of-agi", { excludeDomains: ["amistrongeryet.substack.com"], numResults: 3 } ); const urls = result.results.map(linkData => linkData.url); // Get full text for each URL const webPages = await exa.getContents(urls, { text: true }); webPages.results.forEach(webPage => { console.log(`URL: ${webPage.url}`); console.log(`Text snippet: ${webPage.text.slice(0, 500)} ...`); console.log("-".repeat(100)); }); ```Get your API key from the Exa Dashboard and set it as an environment variable:
```bash theme={null} export EXA_API_KEY='your-api-key-here' ```Pass one of the following commands to your terminal to make an API request.
Get a list of results and their full text content.
```bash bash theme={null} curl --request POST \ --url https://api.exa.ai/search \ --header 'accept: application/json' \ --header 'content-type: application/json' \ --header "x-api-key: ${EXA_API_KEY}" \ --data ' { "query": "An article about the state of AGI", "type": "auto", "contents": { "text": true } }' ```Get an answer to a question, grounded by citations from exa.
```bash bash theme={null} curl --request POST \ --url https://api.exa.ai/answer \ --header 'accept: application/json' \ --header 'content-type: application/json' \ --header "x-api-key: ${EXA_API_KEY}" \ --data "{ \"query\": \"What are the latest findings on gut microbiome's influence on mental health?\", \"text\": true }" ```Get a chat completion from exa.
```bash bash theme={null} curl https://api.exa.ai/chat/completions \ -H "Content-Type: application/json" \ -H "x-api-key: ${EXA_API_KEY}" \ -d '{ "model": "exa", "messages": [ { "role": "system", "content": "You are a helpful assistant." }, { "role": "user", "content": "What are the latest developments in quantum computing?" } ], "extra_body": { "text": true } }' ```Install the Python SDK with pip.
```bash theme={null} pip install exa-py ```Get your API key from the Exa Dashboard, create a file called `exa.py`, and add the code below.
```python python theme={null} from exa_py import Exa exa = Exa(api_key="your-api-key") result = exa.search( "blog post about artificial intelligence", type="auto", contents={ "text": True } ) ```Install the JavaScript SDK with npm.
```bash theme={null} npm install exa-js ```Get your API key from the Exa Dashboard, create a file called `exa.ts`, and add the code below.
```javascript javascript theme={null} import Exa from "exa-js"; const exa = new Exa("your-api-key"); const result = await exa.search( "blog post about artificial intelligence", { type: "auto", contents: { text: true } } ); ```Get your API key from the Exa Dashboard and pass the following command to your terminal.
```bash bash theme={null} curl --request POST \ --url https://api.exa.ai/search \ --header "accept: application/json" \ --header "content-type: application/json" \ --header "x-api-key: your-api-key" \ --data ' { "query": "blog post about artificial intelligence", "type": "auto", "contents": { "text": true } }' ``` Team dropdown (top-left) within the Exa dashboard under Team settings
[Go to API Dashboard](https://dashboard.exa.ai)
## Topping up a Team's balance
With the desired Team selected, you can top up your credit balance in the Billing page.
Team dropdown (top-left) within the Exa dashboard under Team settings
[Go to API Dashboard](https://dashboard.exa.ai)
## Topping up a Team's balance
With the desired Team selected, you can top up your credit balance in the Billing page.
 ## Inviting people to your team
Team admins can add members via the Invite feature in Team settings.
## Inviting people to your team
Team admins can add members via the Invite feature in Team settings.
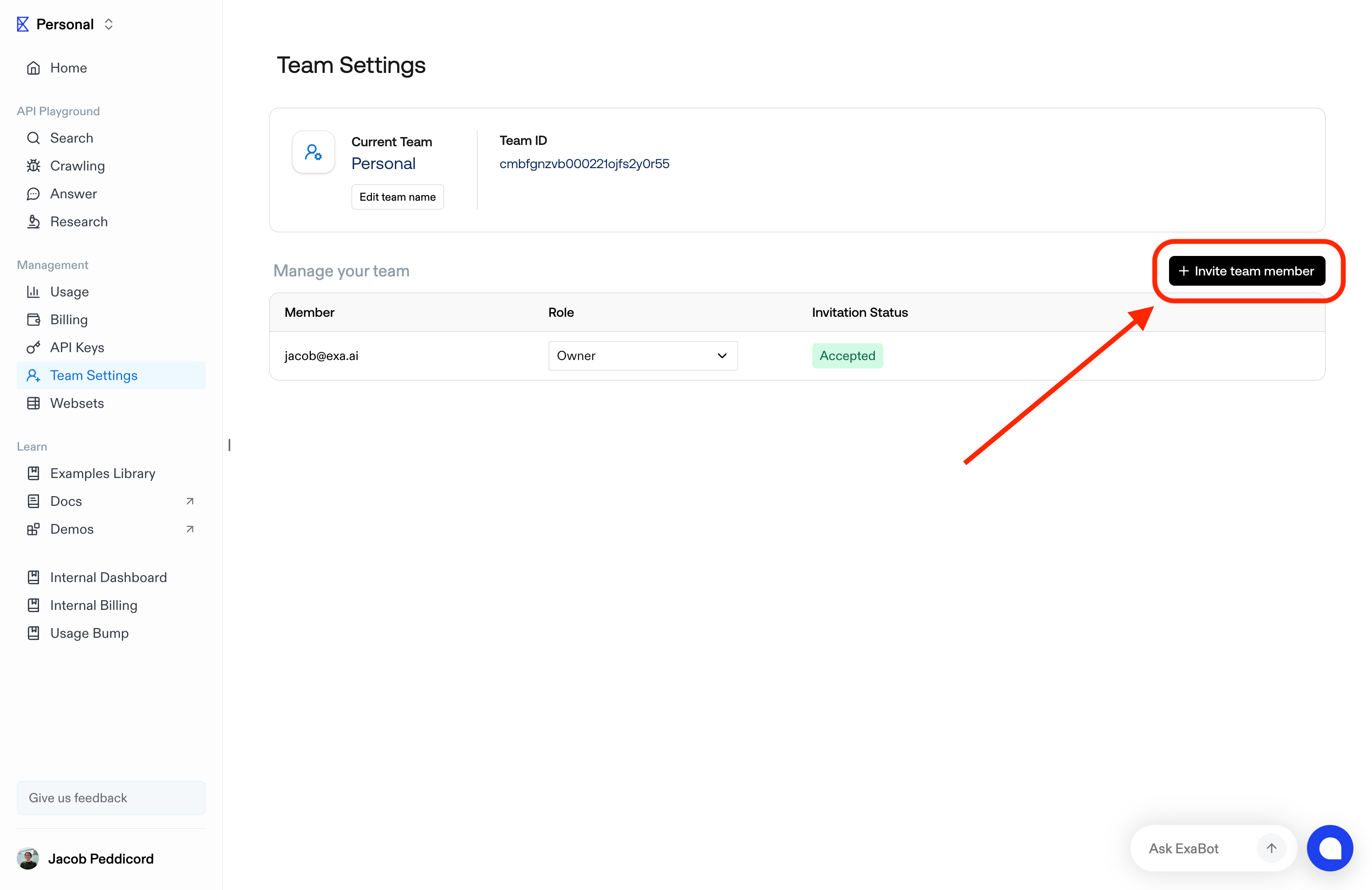 Once a team member is invited, their status will be 'Pending' on the team management menu.
Once a team member is invited, their status will be 'Pending' on the team management menu.
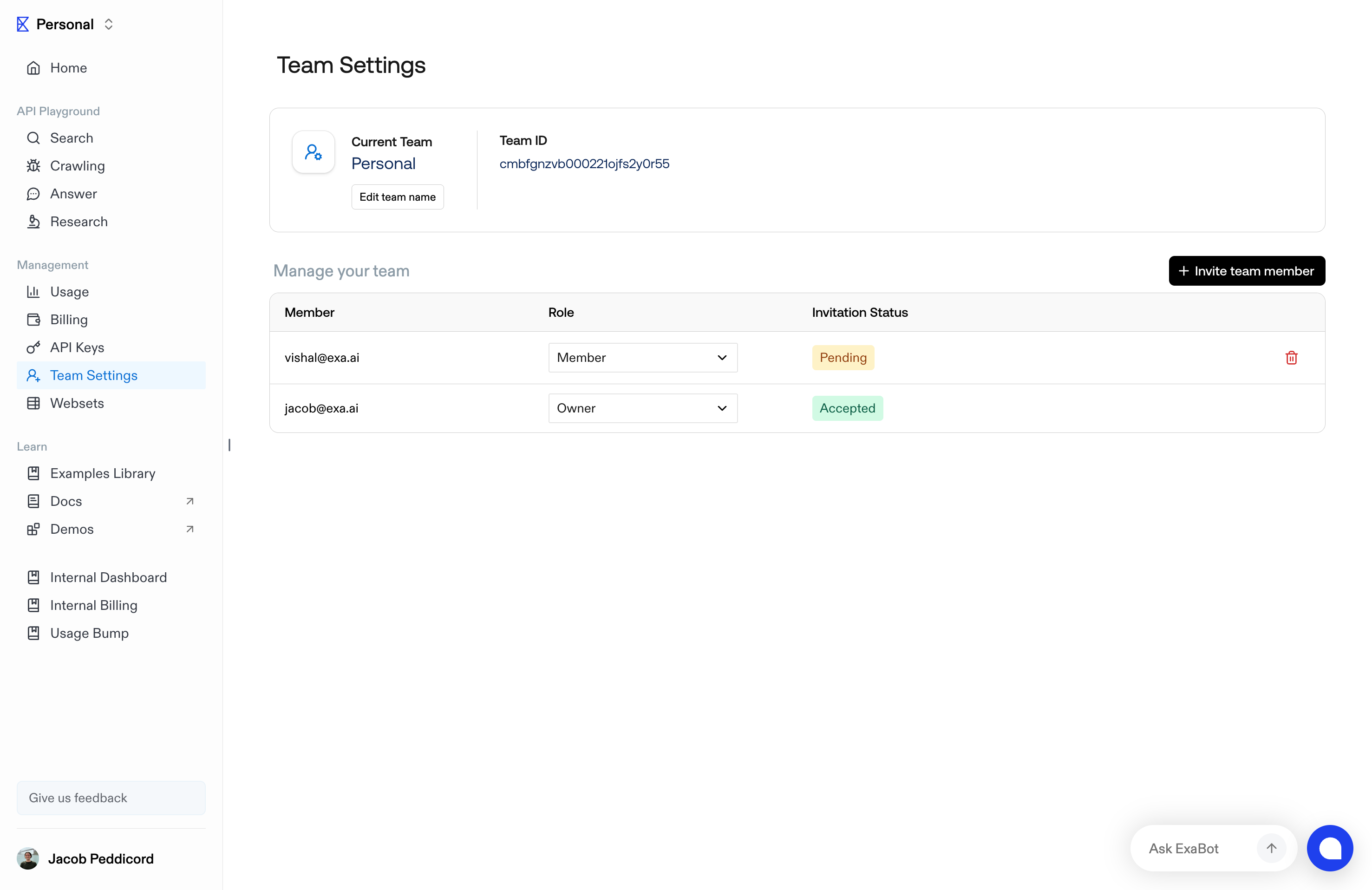 They will receive an email inviting them to join the team.
They will receive an email inviting them to join the team.
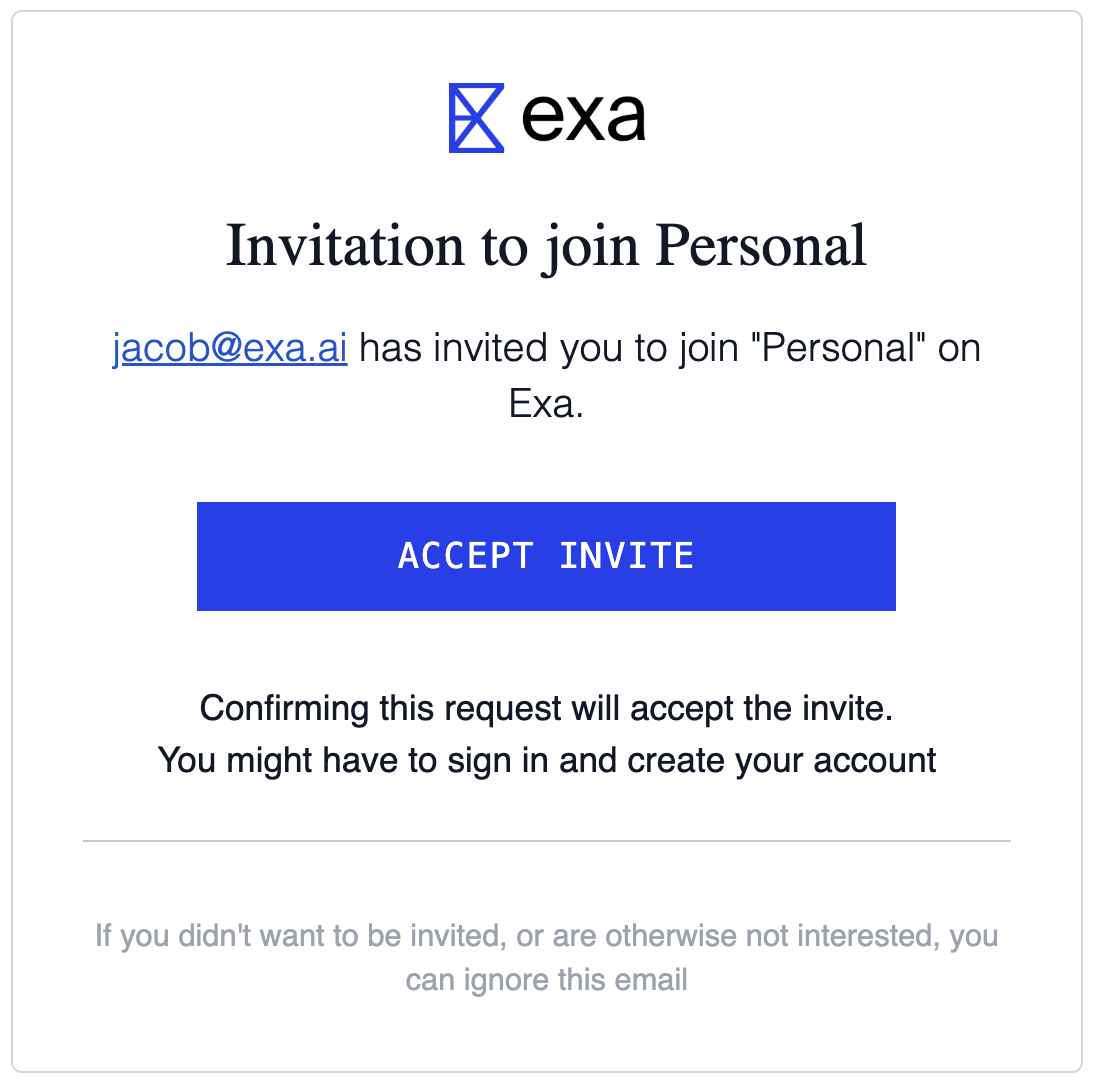 Once accepted, you'll see both members are 'Accepted'. All Team members share the usage limits and features of their respective Team's plan.
Once accepted, you'll see both members are 'Accepted'. All Team members share the usage limits and features of their respective Team's plan.
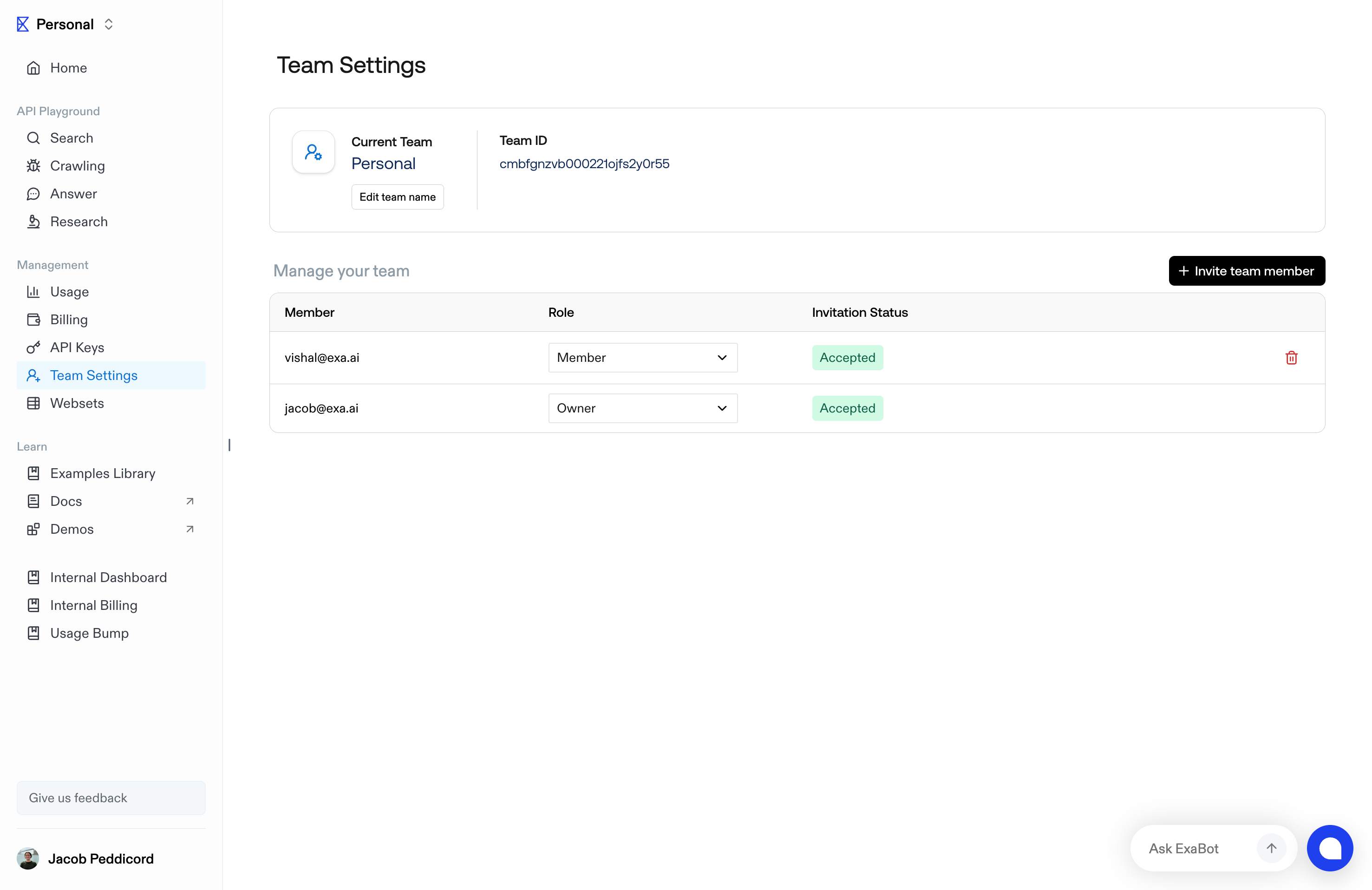 [Go to API Dashboard](https://dashboard.exa.ai)
---
# Source: https://exa.ai/docs/reference/the-exa-index.md
> ## Documentation Index
> Fetch the complete documentation index at: https://exa.ai/docs/llms.txt
> Use this file to discover all available pages before exploring further.
# The Exa Index
> We spend a lot of time and energy creating a high quality, curated index.
***
There are many types of content, and we're constantly discovering new things to search for as well. If there's anything you want to be more highly covered, just reach out to [hello@exa.ai](mailto:hello@exa.ai). See the following table for a high level overview of what is available in our index:
| Category | Availability in Exa Index | Description | Example prompt link |
| :-----------------------------------------------: | :-----------------------: | :-----------------------------------------------------------------------------------------------------------------------------: | :----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------: |
| Research papers | Very High | Offer semantic search over a very vast index of papers, enabling sophisticated, multi-layer and complex filtering for use cases | [If you're looking for the most helpful academic paper on "embeddings for document retrieval", check this out (pdf:](https://search.exa.ai/search?q=If+you%27re+looking+for+the+most+helpful+academic+paper+on+%22embeddings+for+document+retrieval%22\&filters=%7B%22numResults%22%3A30%2C%22domainFilterType%22%3A%22include%22%2C%22type%22%3A%22neural%22%2C%22resolvedSearchType%22%3A%22neural%22%2C%22useAutoprompt%22%3Afalse%7D\&resolvedSearchType=neural) |
| Personal pages | Very High | Excels at finding personal pages, which are often extremely hard/impossible to find on traditional search engines | [Here is a link to the best life coach for when you're unhappy at work:](https://exa.ai/search?q=Here%20is%20a%20link%20to%20the%20best%20life%20coach%20for%20when%20you%27re%20unhappy%20at%20work%3A\&c=personal%20site\&filters=%7B%22numResults%22%3A30%2C%22useAutoprompt%22%3Afalse%2C%22domainFilterType%22%3A%22include%22%7D) |
| Wikipedia | Very High | Covers all of Wikipedia, providing comprehensive access to this vast knowledge base via semantic search | [Here is a Wikipedia page about a Roman emperor:](https://search.exa.ai/search?q=Here+is+a+Wikipedia+page+about+a+Roman+emperor%3A\&filters=%7B%22numResults%22%3A30%2C%22domainFilterType%22%3A%22include%22%2C%22type%22%3A%22neural%22%2C%22useAutoprompt%22%3Afalse%2C%22resolvedSearchType%22%3A%22neural%22%7D\&resolvedSearchType=neurall) |
| News | Very High | Includes a wide, robust index of web news sources, providing coverage of current events | [Here is news about war in the Middle East:](https://exa.ai/search?q=Here+is+news+about+war+in+the+Middle+East%3A\&c=personal+site\&filters=%7B%22numResults%22%3A30%2C%22domainFilterType%22%3A%22include%22%2C%22type%22%3A%22auto%22%2C%22useAutoprompt%22%3Afalse%2C%22resolvedSearchType%22%3A%22neural%22%2C%22startPublishedDate%22%3A%222024-10-29T01%3A45%3A46.055Z%22%7D\&resolvedSearchType=neural) |
| People (LinkedIn profiles) | *Very High (US+EU)* | Use `category="people"` to search for individual profiles. Has improved quality for finding LinkedIn profiles of individuals. | [best theoretical computer scientist at uc berkeley](https://exa.ai/search?q=best+theoretical+computer+scientist+at+uc+berkeley\&filters=%7B%22numResults%22%3A30%2C%22domainFilterType%22%3A%22include%22%2C%22type%22%3A%22neural%22%2C%22category%22%3A%22people%22%2C%22useAutoprompt%22%3Atrue%2C%22resolvedSearchType%22%3A%22neural%22%7D\&autopromptString=A+leading+theoretical+computer+scientist+at+UC+Berkeley.\&resolvedSearchType=neural) |
| Companies (LinkedIn company pages) | *Very High* | Use `category="company"` to search for company pages. Has improved quality for finding LinkedIn company pages. | [AI startups in San Francisco](https://exa.ai/search?q=AI+startups+in+San+Francisco\&filters=%7B%22numResults%22%3A30%2C%22domainFilterType%22%3A%22include%22%2C%22type%22%3A%22neural%22%2C%22category%22%3A%22company%22%2C%22useAutoprompt%22%3Afalse%2C%22resolvedSearchType%22%3A%22neural%22%7D\&resolvedSearchType=neural) |
| Company home-pages | Very High | Wide index of companies covered; also available are curated, customized company datasets - reach out to learn more | [Here is the homepage of a company working on making space travel cheaper:](https://search.exa.ai/search?q=Here+is+the+homepage+of+a+company+working+on+making+space+travel+cheaper%3A\&filters=%7B%22numResults%22%3A30%2C%22domainFilterType%22%3A%22include%22%2C%22type%22%3A%22neural%22%2C%22useAutoprompt%22%3Afalse%2C%22resolvedSearchType%22%3A%22neural%22%7D\&resolvedSearchType=neural) |
| Financial Reports | Very High | Includes SEC 10k financial reports and information from other finance sources like Yahoo Finance. | [Here is a source on Apple's revenue growth rate over the past years:](https://exa.ai/search?q=Here+is+a+source+on+Apple%27s+revenue+growth+rate+over+the+past+years%3A\&filters=%7B%22numResults%22%3A30%2C%22domainFilterType%22%3A%22include%22%2C%22type%22%3A%22neural%22%2C%22startPublishedDate%22%3A%222023-11-18T22%3A35%3A50.022Z%22%2C%22useAutoprompt%22%3Afalse%2C%22resolvedSearchType%22%3A%22neural%22%7D\&resolvedSearchType=neural) |
| GitHub repos | High | Indexes open source code (which the Exa team use frequently!) | [Here's a Github repo if you want to convert OpenAPI specs to Rust code:](https://exa.ai/search?q=Here%27s+a+Github+repo+if+you+want+to+convert+OpenAPI+specs+to+Rust+code%3A\&filters=%7B%22numResults%22%3A30%2C%22domainFilterType%22%3A%22include%22%2C%22type%22%3A%22neural%22%2C%22useAutoprompt%22%3Afalse%2C%22resolvedSearchType%22%3A%22neural%22%7D\&resolvedSearchType=neural) |
| Blogs | High | Excels at finding high quality reading material, particularly useful for niche topics | [If you're a huge fan of Japandi decor, you'd love this blog:](https://exa.ai/search?q=If+you%27re+a+huge+fan+of+Japandi+decor%2C+you%27d+love+this+blog%3A\&filters=%7B%22numResults%22%3A30%2C%22domainFilterType%22%3A%22include%22%2C%22type%22%3A%22neural%22%2C%22useAutoprompt%22%3Afalse%2C%22resolvedSearchType%22%3A%22neural%22%7D\&resolvedSearchType=neural) |
| Places and things | High | Covers a wide range of entities including hospitals, schools, restaurants, appliances, and electronics | [Here is a high-rated Italian restaurant in downtown Chicago:](https://exa.ai/search?q=Here+is+a+high-rated+Italian+restaurant+in+downtown+Chicago%3A\&filters=%7B%22numResults%22%3A30%2C%22domainFilterType%22%3A%22include%22%2C%22type%22%3A%22neural%22%2C%22useAutoprompt%22%3Afalse%2C%22resolvedSearchType%22%3A%22neural%22%7D\&resolvedSearchType=neural) |
| Legal and policy sources | High | Strong coverage of legal and policy information, (e.g., including sources like CPUC, Justia, Findlaw, etc.) | [Here is a common law case in california on marital property rights:](https://search.exa.ai/search?q=Here+is+a+common+law+case+in+california+on+marital+property+rights%3A\&filters=%7B%22numResults%22%3A30%2C%22domainFilterType%22%3A%22include%22%2C%22type%22%3A%22neural%22%2C%22useAutoprompt%22%3Afalse%2C%22includeDomains%22%3A%5B%22law.justia.com%22%5D%2C%22resolvedSearchType%22%3A%22neural%22%7D\&resolvedSearchType=neural) |
| Government and international organization sources | High | Includes content from sources like the IMF and CDC amongst others | [Here is a recent World Health Organization site on global vaccination rates:](https://exa.ai/search?q=Here+is+a+recent+World+Health+Organization+site+on+global+vaccination+rates%3A\&filters=%7B%22numResults%22%3A30%2C%22domainFilterType%22%3A%22include%22%2C%22type%22%3A%22neural%22%2C%22startPublishedDate%22%3A%222023-11-18T22%3A35%3A50.022Z%22%2C%22useAutoprompt%22%3Afalse%2C%22resolvedSearchType%22%3A%22neural%22%7D\&resolvedSearchType=neural) |
| Events | Moderate | Reasonable coverage of events in major municipalities, suggesting room for improvement | [Here is an AI hackathon in SF:](https://search.exa.ai/search?q=Here+is+an+AI+hackathon+in+SF\&filters=%7B%22numResults%22%3A30%2C%22domainFilterType%22%3A%22exclude%22%2C%22type%22%3A%22neural%22%2C%22startPublishedDate%22%3A%222024-07-02T23%3A36%3A15.511Z%22%2C%22useAutoprompt%22%3Afalse%2C%22endPublishedDate%22%3A%222024-07-09T23%3A36%3A15.511Z%22%2C%22excludeDomains%22%3A%5B%22twitter.com%22%5D%2C%22resolvedSearchType%22%3A%22neural%22%7D\&resolvedSearchType=neural) |
| Jobs | Moderate | Can find some job listings | [If you're looking for a software engineering job at a small startup working on an important mission, check out](https://search.exa.ai/search?q=If+you%27re+looking+for+a+software+engineering+job+at+a+small+startup+working+on+an+important+mission%2C+check+out\&filters=%7B%22numResults%22%3A30%2C%22domainFilterType%22%3A%22include%22%2C%22type%22%3A%22neural%22%2C%22useAutoprompt%22%3Afalse%2C%22resolvedSearchType%22%3A%22neural%22%7D\&resolvedSearchType=neural) |
---
# Source: https://exa.ai/docs/websets/api/events/types.md
> ## Documentation Index
> Fetch the complete documentation index at: https://exa.ai/docs/llms.txt
> Use this file to discover all available pages before exploring further.
# Event Types
> Learn about the events that occur within the Webset API
The Websets API uses events to notify you about changes in your Websets. You can monitor these events through our [events endpoint](/websets/api/events/list-all-events) or by setting up [webhooks](/websets/api/webhooks/create-a-webhook).
Events are retained for 60 days before being automatically deleted.
## Webset
* `webset.created` - Emitted when a new Webset is created.
* `webset.deleted` - Emitted when a Webset is deleted.
* `webset.paused` - Emitted when a Webset's operations are paused.
* `webset.idle` - Emitted when a Webset has no running operations.
## Search
* `webset.search.created` - Emitted when a new search is initiated.
* `webset.search.updated` - Emitted when search progress is updated.
* `webset.search.completed` - Emitted when a search finishes finding all items.
* `webset.search.canceled` - Emitted when a search is manually canceled.
## Item
* `webset.item.created` - Emitted when a new item has been added to the Webset.
* `webset.item.enriched` - Emitted when an item's enrichment is completed.
## Import
* `import.created` - Emitted when a new import is initiated.
* `import.completed` - Emitted when an import has been completed.
## Monitor
* `monitor.created` - Emitted when a new monitor is created.
* `monitor.updated` - Emitted when a monitor's configuration is updated.
* `monitor.deleted` - Emitted when a monitor is deleted.
* `monitor.run.created` - Emitted when a monitor run starts.
* `monitor.run.completed` - Emitted when a monitor run finishes.
Each event includes:
* A unique `id`
* The event `type`
* A `data` object containing the full resource that triggered the event
* A `createdAt` timestamp
You can use these events to:
* Track the progress of searches and enrichments
* Build real-time dashboards
* Trigger workflows when new items are found
* Monitor the status of your exports
---
# Source: https://exa.ai/docs/sdks/typescript-sdk-specification.md
> ## Documentation Index
> Fetch the complete documentation index at: https://exa.ai/docs/llms.txt
> Use this file to discover all available pages before exploring further.
# TypeScript SDK Specification
> Enumeration of methods and types in the Exa TypeScript SDK (exa-js).
## Getting started
Install the [exa-js](https://github.com/exa-labs/exa-js) SDK
[Go to API Dashboard](https://dashboard.exa.ai)
---
# Source: https://exa.ai/docs/reference/the-exa-index.md
> ## Documentation Index
> Fetch the complete documentation index at: https://exa.ai/docs/llms.txt
> Use this file to discover all available pages before exploring further.
# The Exa Index
> We spend a lot of time and energy creating a high quality, curated index.
***
There are many types of content, and we're constantly discovering new things to search for as well. If there's anything you want to be more highly covered, just reach out to [hello@exa.ai](mailto:hello@exa.ai). See the following table for a high level overview of what is available in our index:
| Category | Availability in Exa Index | Description | Example prompt link |
| :-----------------------------------------------: | :-----------------------: | :-----------------------------------------------------------------------------------------------------------------------------: | :----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------: |
| Research papers | Very High | Offer semantic search over a very vast index of papers, enabling sophisticated, multi-layer and complex filtering for use cases | [If you're looking for the most helpful academic paper on "embeddings for document retrieval", check this out (pdf:](https://search.exa.ai/search?q=If+you%27re+looking+for+the+most+helpful+academic+paper+on+%22embeddings+for+document+retrieval%22\&filters=%7B%22numResults%22%3A30%2C%22domainFilterType%22%3A%22include%22%2C%22type%22%3A%22neural%22%2C%22resolvedSearchType%22%3A%22neural%22%2C%22useAutoprompt%22%3Afalse%7D\&resolvedSearchType=neural) |
| Personal pages | Very High | Excels at finding personal pages, which are often extremely hard/impossible to find on traditional search engines | [Here is a link to the best life coach for when you're unhappy at work:](https://exa.ai/search?q=Here%20is%20a%20link%20to%20the%20best%20life%20coach%20for%20when%20you%27re%20unhappy%20at%20work%3A\&c=personal%20site\&filters=%7B%22numResults%22%3A30%2C%22useAutoprompt%22%3Afalse%2C%22domainFilterType%22%3A%22include%22%7D) |
| Wikipedia | Very High | Covers all of Wikipedia, providing comprehensive access to this vast knowledge base via semantic search | [Here is a Wikipedia page about a Roman emperor:](https://search.exa.ai/search?q=Here+is+a+Wikipedia+page+about+a+Roman+emperor%3A\&filters=%7B%22numResults%22%3A30%2C%22domainFilterType%22%3A%22include%22%2C%22type%22%3A%22neural%22%2C%22useAutoprompt%22%3Afalse%2C%22resolvedSearchType%22%3A%22neural%22%7D\&resolvedSearchType=neurall) |
| News | Very High | Includes a wide, robust index of web news sources, providing coverage of current events | [Here is news about war in the Middle East:](https://exa.ai/search?q=Here+is+news+about+war+in+the+Middle+East%3A\&c=personal+site\&filters=%7B%22numResults%22%3A30%2C%22domainFilterType%22%3A%22include%22%2C%22type%22%3A%22auto%22%2C%22useAutoprompt%22%3Afalse%2C%22resolvedSearchType%22%3A%22neural%22%2C%22startPublishedDate%22%3A%222024-10-29T01%3A45%3A46.055Z%22%7D\&resolvedSearchType=neural) |
| People (LinkedIn profiles) | *Very High (US+EU)* | Use `category="people"` to search for individual profiles. Has improved quality for finding LinkedIn profiles of individuals. | [best theoretical computer scientist at uc berkeley](https://exa.ai/search?q=best+theoretical+computer+scientist+at+uc+berkeley\&filters=%7B%22numResults%22%3A30%2C%22domainFilterType%22%3A%22include%22%2C%22type%22%3A%22neural%22%2C%22category%22%3A%22people%22%2C%22useAutoprompt%22%3Atrue%2C%22resolvedSearchType%22%3A%22neural%22%7D\&autopromptString=A+leading+theoretical+computer+scientist+at+UC+Berkeley.\&resolvedSearchType=neural) |
| Companies (LinkedIn company pages) | *Very High* | Use `category="company"` to search for company pages. Has improved quality for finding LinkedIn company pages. | [AI startups in San Francisco](https://exa.ai/search?q=AI+startups+in+San+Francisco\&filters=%7B%22numResults%22%3A30%2C%22domainFilterType%22%3A%22include%22%2C%22type%22%3A%22neural%22%2C%22category%22%3A%22company%22%2C%22useAutoprompt%22%3Afalse%2C%22resolvedSearchType%22%3A%22neural%22%7D\&resolvedSearchType=neural) |
| Company home-pages | Very High | Wide index of companies covered; also available are curated, customized company datasets - reach out to learn more | [Here is the homepage of a company working on making space travel cheaper:](https://search.exa.ai/search?q=Here+is+the+homepage+of+a+company+working+on+making+space+travel+cheaper%3A\&filters=%7B%22numResults%22%3A30%2C%22domainFilterType%22%3A%22include%22%2C%22type%22%3A%22neural%22%2C%22useAutoprompt%22%3Afalse%2C%22resolvedSearchType%22%3A%22neural%22%7D\&resolvedSearchType=neural) |
| Financial Reports | Very High | Includes SEC 10k financial reports and information from other finance sources like Yahoo Finance. | [Here is a source on Apple's revenue growth rate over the past years:](https://exa.ai/search?q=Here+is+a+source+on+Apple%27s+revenue+growth+rate+over+the+past+years%3A\&filters=%7B%22numResults%22%3A30%2C%22domainFilterType%22%3A%22include%22%2C%22type%22%3A%22neural%22%2C%22startPublishedDate%22%3A%222023-11-18T22%3A35%3A50.022Z%22%2C%22useAutoprompt%22%3Afalse%2C%22resolvedSearchType%22%3A%22neural%22%7D\&resolvedSearchType=neural) |
| GitHub repos | High | Indexes open source code (which the Exa team use frequently!) | [Here's a Github repo if you want to convert OpenAPI specs to Rust code:](https://exa.ai/search?q=Here%27s+a+Github+repo+if+you+want+to+convert+OpenAPI+specs+to+Rust+code%3A\&filters=%7B%22numResults%22%3A30%2C%22domainFilterType%22%3A%22include%22%2C%22type%22%3A%22neural%22%2C%22useAutoprompt%22%3Afalse%2C%22resolvedSearchType%22%3A%22neural%22%7D\&resolvedSearchType=neural) |
| Blogs | High | Excels at finding high quality reading material, particularly useful for niche topics | [If you're a huge fan of Japandi decor, you'd love this blog:](https://exa.ai/search?q=If+you%27re+a+huge+fan+of+Japandi+decor%2C+you%27d+love+this+blog%3A\&filters=%7B%22numResults%22%3A30%2C%22domainFilterType%22%3A%22include%22%2C%22type%22%3A%22neural%22%2C%22useAutoprompt%22%3Afalse%2C%22resolvedSearchType%22%3A%22neural%22%7D\&resolvedSearchType=neural) |
| Places and things | High | Covers a wide range of entities including hospitals, schools, restaurants, appliances, and electronics | [Here is a high-rated Italian restaurant in downtown Chicago:](https://exa.ai/search?q=Here+is+a+high-rated+Italian+restaurant+in+downtown+Chicago%3A\&filters=%7B%22numResults%22%3A30%2C%22domainFilterType%22%3A%22include%22%2C%22type%22%3A%22neural%22%2C%22useAutoprompt%22%3Afalse%2C%22resolvedSearchType%22%3A%22neural%22%7D\&resolvedSearchType=neural) |
| Legal and policy sources | High | Strong coverage of legal and policy information, (e.g., including sources like CPUC, Justia, Findlaw, etc.) | [Here is a common law case in california on marital property rights:](https://search.exa.ai/search?q=Here+is+a+common+law+case+in+california+on+marital+property+rights%3A\&filters=%7B%22numResults%22%3A30%2C%22domainFilterType%22%3A%22include%22%2C%22type%22%3A%22neural%22%2C%22useAutoprompt%22%3Afalse%2C%22includeDomains%22%3A%5B%22law.justia.com%22%5D%2C%22resolvedSearchType%22%3A%22neural%22%7D\&resolvedSearchType=neural) |
| Government and international organization sources | High | Includes content from sources like the IMF and CDC amongst others | [Here is a recent World Health Organization site on global vaccination rates:](https://exa.ai/search?q=Here+is+a+recent+World+Health+Organization+site+on+global+vaccination+rates%3A\&filters=%7B%22numResults%22%3A30%2C%22domainFilterType%22%3A%22include%22%2C%22type%22%3A%22neural%22%2C%22startPublishedDate%22%3A%222023-11-18T22%3A35%3A50.022Z%22%2C%22useAutoprompt%22%3Afalse%2C%22resolvedSearchType%22%3A%22neural%22%7D\&resolvedSearchType=neural) |
| Events | Moderate | Reasonable coverage of events in major municipalities, suggesting room for improvement | [Here is an AI hackathon in SF:](https://search.exa.ai/search?q=Here+is+an+AI+hackathon+in+SF\&filters=%7B%22numResults%22%3A30%2C%22domainFilterType%22%3A%22exclude%22%2C%22type%22%3A%22neural%22%2C%22startPublishedDate%22%3A%222024-07-02T23%3A36%3A15.511Z%22%2C%22useAutoprompt%22%3Afalse%2C%22endPublishedDate%22%3A%222024-07-09T23%3A36%3A15.511Z%22%2C%22excludeDomains%22%3A%5B%22twitter.com%22%5D%2C%22resolvedSearchType%22%3A%22neural%22%7D\&resolvedSearchType=neural) |
| Jobs | Moderate | Can find some job listings | [If you're looking for a software engineering job at a small startup working on an important mission, check out](https://search.exa.ai/search?q=If+you%27re+looking+for+a+software+engineering+job+at+a+small+startup+working+on+an+important+mission%2C+check+out\&filters=%7B%22numResults%22%3A30%2C%22domainFilterType%22%3A%22include%22%2C%22type%22%3A%22neural%22%2C%22useAutoprompt%22%3Afalse%2C%22resolvedSearchType%22%3A%22neural%22%7D\&resolvedSearchType=neural) |
---
# Source: https://exa.ai/docs/websets/api/events/types.md
> ## Documentation Index
> Fetch the complete documentation index at: https://exa.ai/docs/llms.txt
> Use this file to discover all available pages before exploring further.
# Event Types
> Learn about the events that occur within the Webset API
The Websets API uses events to notify you about changes in your Websets. You can monitor these events through our [events endpoint](/websets/api/events/list-all-events) or by setting up [webhooks](/websets/api/webhooks/create-a-webhook).
Events are retained for 60 days before being automatically deleted.
## Webset
* `webset.created` - Emitted when a new Webset is created.
* `webset.deleted` - Emitted when a Webset is deleted.
* `webset.paused` - Emitted when a Webset's operations are paused.
* `webset.idle` - Emitted when a Webset has no running operations.
## Search
* `webset.search.created` - Emitted when a new search is initiated.
* `webset.search.updated` - Emitted when search progress is updated.
* `webset.search.completed` - Emitted when a search finishes finding all items.
* `webset.search.canceled` - Emitted when a search is manually canceled.
## Item
* `webset.item.created` - Emitted when a new item has been added to the Webset.
* `webset.item.enriched` - Emitted when an item's enrichment is completed.
## Import
* `import.created` - Emitted when a new import is initiated.
* `import.completed` - Emitted when an import has been completed.
## Monitor
* `monitor.created` - Emitted when a new monitor is created.
* `monitor.updated` - Emitted when a monitor's configuration is updated.
* `monitor.deleted` - Emitted when a monitor is deleted.
* `monitor.run.created` - Emitted when a monitor run starts.
* `monitor.run.completed` - Emitted when a monitor run finishes.
Each event includes:
* A unique `id`
* The event `type`
* A `data` object containing the full resource that triggered the event
* A `createdAt` timestamp
You can use these events to:
* Track the progress of searches and enrichments
* Build real-time dashboards
* Trigger workflows when new items are found
* Monitor the status of your exports
---
# Source: https://exa.ai/docs/sdks/typescript-sdk-specification.md
> ## Documentation Index
> Fetch the complete documentation index at: https://exa.ai/docs/llms.txt
> Use this file to discover all available pages before exploring further.
# TypeScript SDK Specification
> Enumeration of methods and types in the Exa TypeScript SDK (exa-js).
## Getting started
Install the [exa-js](https://github.com/exa-labs/exa-js) SDK